1. Introduction
The global IP traffic forecast provided by Cisco Systems reported that the annual run rate for global IP traffic was 1.5 Zeta bytes per year (122 EB per month) in 2017, and the global IP traffic will reach 4.8 ZB per year by 2022, which means it will increase nearly threefold over the next five years. The rapid growth of traffic has made packet forwarding in routers a bottleneck in constructing high-performance networks.
An IP address is composed of a network part and a host part. The network part indicates a group of hosts included in a network while the host part indicates a specific host [
1]. The network part is called a prefix and hosts connected to the same network have the same prefix. In a class-based addressing scheme, the prefix length is fixed at 8, 16, or 24 bits and routers perform an exact match operation for an IP address lookup. However, because of the excessive address wasting caused by the inflexibility of the prefix lengths under the class-based addressing scheme, a new addressing scheme called classless inter-domain routing (CIDR) has been introduced. In the CIDR scheme, arbitrary prefix lengths are allowed and routers identify the longest prefix among all matching prefixes as the best matching prefix (BMP) for an IP address lookup [
2,
3,
4].
Various IP address lookup algorithms have been researched, including trie-based [
2,
3], hash table-based [
5] and Bloom filter-based algorithms [
6,
7]. Since an access to an off-chip memory is 10-20 times slower than an access to an on-chip memory [
8], reducing the number of off-chip memory accesses required for looking up an IP address is the most effective strategy [
6,
7]. While the trie and the hash table are generally stored in off-chip memories due to their sizes, a Bloom filter is an efficient structure that can be stored in an on-chip memory.
In building a packet forwarding engine, various hardware components, such as application- specific integrated circuits (ASIC), ternary content addressable memory (TCAM) and field-programmable gate arrays (FPGA), are used to satisfy the wire-speed packet forwarding requirement. As a flexible and programmable device, the FPGA has a matrix of configurable logic blocks connected through programmable interconnects. In particular, FPGAs have been widely used to build the prototypes of packet forwarding engines [
9,
10,
11,
12,
13] and intrusion detection systems [
14,
15,
16].
The contribution of this paper is as follows. We propose a vectored-Bloom filter (VBF) architecture, which is a multi-bit vector Bloom filter for the purpose of IP address lookup. The VBF is proposed to obtain lookup results by accessing only an on-chip memory. An off-chip hash table is rarely accessed when the VBF fails to provide the results. We have evaluated our proposed architecture in two steps. The construction procedures of the VBF and the hash table are implemented using C at behavior level, since the construction procedure is not necessarily performed in real-time. The performance at the behavior level has been evaluated in terms of on-chip memory requirement, off-chip memory requirement, the average number and the worst-case number of memory accesses, indeterminable rate and false port return rate. The search procedure that should be performed in real-time is implemented using Verilog with a single FPGA. The performance of the FPGA has been evaluated in terms of block-RAM (BRAM) requirement, resource utilization and throughput.
The remainder of this paper is organized as follows.
Section 2 briefly explains the Bloom filter and previous IP address lookup algorithms utilizing on-chip memories.
Section 3 describes our proposed IP address lookup algorithm using a vectored-Bloom filter including theoretical analysis on the search failure probability of our proposed algorithm.
Section 4 describes the hardware architecture implemented on an FPGA.
Section 5 shows behavior simulation results comparing the performance of the proposed VBF with other structures.
Section 6 shows the hardware implementation details of our proposed structure. Finally,
Section 7 concludes the paper.
3. IP Address Lookup Using a Vectored-Bloom Filter
The basic idea of the proposed vectored-Bloom filter (VBF) structure for IP address lookup was briefly introduced in References [
31] and [
32]. The VBF consists of
m multi-bit vectors and each vector comprised of
l bits contains an output port. The proposed structure completes an IP address lookup by querying only the on-chip VBF without accessing the off-chip hash table. Depending on how output ports are programmed to the VBF, two different structures are possible [
31]. The first structure involves making the
l-bit vector represent up to
output ports, zero and a
conflict value, which is the value of
. The
conflict indicates that the vector is programmed by two or more different output ports.
In programming a prefix, the k vectors pointed by the k hash indexes of the prefix are written with the output port of the prefix. If any of the vectors already have an output port other than the output port, all of the bits in the vector are set to 1 in order to represent the conflict (). In querying an input, if all the k vectors located by the k hash indexes of the input have the conflict values, the VBF cannot return an output port and the result is termed an indeterminable. If any of the k vectors has 0, the input is not a prefix and hence the result is termed a negative. If the vectors other than conflict have the same value, the input is a prefix and the value is the output port of the prefix and hence the result is termed a positive.
The second structure involves making the l-bit vector represent l output ports by assigning each bit in a vector an output port. Hence, two or more different output ports can be represented in a vector by setting the corresponding bits and the conflict value is not necessarily defined.
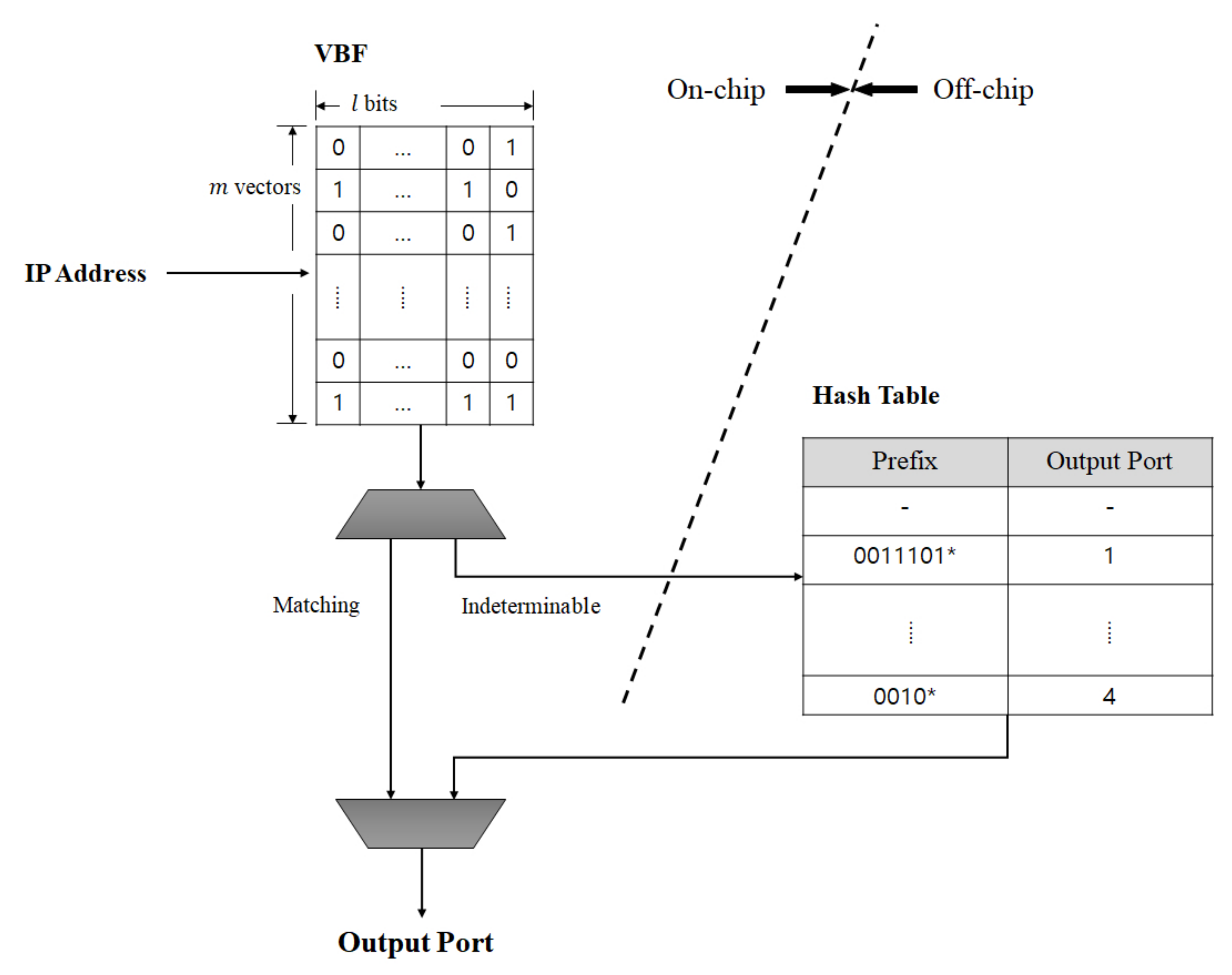
The motivation of the proposed VBF structure is to complete the IP address lookup by only searching the VBF implemented with an on-chip memory, without accessing a hash table implemented with an off-chip memory. The hash table is infrequently accessed only when the VBF fails to provide the output port. The VBF structure is shown in
Figure 1. Assuming that output ports are uniformly distributed, for
n given prefixes, the optimal number of hash functions for the VBF is defined as follows, similarly to Label (
1).
since a VBF can be considered with
lm-bit Bloom filters, each of which is programmed by
prefixes.
In this paper, we describe the second structure in detail including the hardware architecture which was not described in Reference [
31]. Hence,
Section 4 is completely a new section compared with Reference [
31]. In Reference [
32], even though the hardware architecture of the VBF implemented on the FPGA is briefly described, the proposed structure has not been evaluated through a behavior simulation and not been compared with other algorithms. In this paper, we describe our algorithm and the proposed hardware structures in detail and the proposed architecture has been evaluated through both a behavior simulation with C language and a timing simulation with Verilog. In addition, we compare our algorithm with other algorithms with a large scale. Hence. the
Section 5 is completely a new section and
Section 6 is largely extended compared with Reference [
32].
3.1. VBF Programming
Algorithm 1 describes the construction procedure of the VBF. All of the prefixes in a routing set are programmed into the VBF and also stored in a hash table. For prefix x in a routing set with output port , hash indexes are first obtained. In order to program the output port to the vectors pointed by the indexes, each bit location corresponding to is set to 1.
| Algorithm 1: Programming Procedure of VBF |
 |
3.2. VBF Querying
Algorithm 2 describes the querying procedure of the VBF in detail. For a given input key, indexes are first obtained and a bit-wise AND operation is then performed for vectors obtained from the VBF in order to obtain a l-bit result vector, . The querying has three possible results: negative, positive or indeterminable. If all of the bits in the are 0, the input was definitively not programmed to the VBF and the result is termed a negative. If the has a single set bit, the input is considered a member of the routing set and the location of the set bit is returned as the matching output port; the result is then termed a positive. If the has plural set bits, the VBF cannot return a value and the result is termed an indeterminable. In Algorithm 2, outPort is the matching output port and is the number of set bits in the . Therefore, if is 1, it means a positive and outPort is returned as the matching port. If is larger than 1, it means an indeterminable and a matching port cannot be returned from the VBF.
| Algorithm 2: Querying Procedure of VBF |
 |
3.3. Hash Table Implementation
In implementing the hash table, hash collisions should be carefully considered. In order to reduce the number of collisions, we use two hash indexes and a linked list to store a prefix into the hash table. In other words, storing a prefix can have a maximum of three choices of hash entries. The first hash index has the highest priority. If both entries indicated by the two hash indexes have already been filled by other prefixes, the prefix is stored in the entry indicated by the linked list. Each hash table entry stores a prefix, the length of the prefix, a corresponding output port and a linked list.
3.4. IP Address Lookup Using VBF
Algorithm 3 describes the IP address lookup procedure using the VBF in detail. For a given input IP address, the VBF is queried by gradually decreasing the querying length, starting from the longest prefix length.
If the VBF returns a negative at the current length, the querying is continued at a shorter length (if the current length is not already the shortest).
If the result of the VBF is a positive, the VBF returns a matching output port (BMPport) and the IP address lookup procedure is completed. Note that the VBF can generate a false positive for a substring of the given input even though the substring is not included in the routing set and a false output port can be returned for the input. As will be shown in simulation, the false port return rate converges to zero when the sizing factor of the VBF is larger than two.
If the VBF returns an indeterminable, the off-chip hash table should be accessed because the matching output port at the current length of the given input cannot be determined. In searching the hash table, two hash indexes are used for multi-hashing. If the matching entry is found from the entry pointed by the first hash index, the search is complete. If the matching entry is not found, the procedure continues to search the hash entry pointed by the second hash index. If the matching entry is not found, the procedure continues to search the hash entry pointed by the linked list. The search procedure is completed if the matching entry is found. Otherwise, the search procedure should go back to the VBF.
| Algorithm 3: IP Address Lookup Procedure Using VBF |
 |
3.5. Theoretical Analysis on Search Failure Probability
In this section, we present the theoretical probability of search failure of the proposed VBF. The search failure in the VBF occurs in two cases;
false port return and
indeterminable. The theoretical probability of the search failure for the first architecture of the VBF (summarized in the first paragraph of
Section 3) has been provided in Reference [
21] and this section provides the theoretical search failure probability for the second structure of the VBF. The VBF consists of
m multi-bit vectors and each vector comprised of
l bits contains
l different ports. For
n elements included in programming set
S, assuming that the elements are equally distributed to each port, the number of elements in each port set,
, is equal to
.
In querying, while false positives can occur for non-programmed inputs, indeterminables can occur for all inputs including programmed inputs. If the VBF returns a value for a non-programmed input, it is a false positive, which means that a single port is returned among l values. If the VBF returns two or more values, it is an indeterminable, which means that more than one port is returned among l ports in one querying.
Let
p represent the probability that a specific bit in a vector is set at least once by
elements, after programming all elements by
k hash functions. If the hash functions are assumed to be perfectly random,
p can be calculated as
When querying input
x not included in set
S, a
false positive can occur if the same bit locations in each of
k vectors are 1 and other bit locations in each of
k vectors are 0. Hence, the
false port return probability,
, is as follows.
An
indeterminable can occur if there exist more than one port regardless of true or false ports. The
indeterminable probability,
, is defined as follows.
is the
indeterminable probability for the inputs included in
S. In case of inputs included in
S, since one true port must occur, an
indeterminable can occur if the number of false ports is from 1 to
times. Therefore,
is as follows.
is the
indeterminable probability for the inputs not included in
S. In case of inputs not included in
S, an
indeterminable can occur if the number of false ports is from 2 to
l times. Therefore,
is as follows.
From Labels (
7) and (
8), the
indeterminable probability is
From Label (
4), since
p is the function of the size of the Bloom filter,
m, the
false port return probability in Label (
5) and the
indeterminable probability in Label (
9) can be controlled by the size of the Bloom filter.
4. Hardware Architecture
The construction procedures of the VBF and the hash table are implemented at the behavior level using C language, since they are not necessarily performed in real-time. The IP address lookup procedure described in Algorithms 2 and 3 is implemented using Verilog on a single FPGA. In this section, we describe the hardware architecture of the VBF which is implemented on the FPGA.
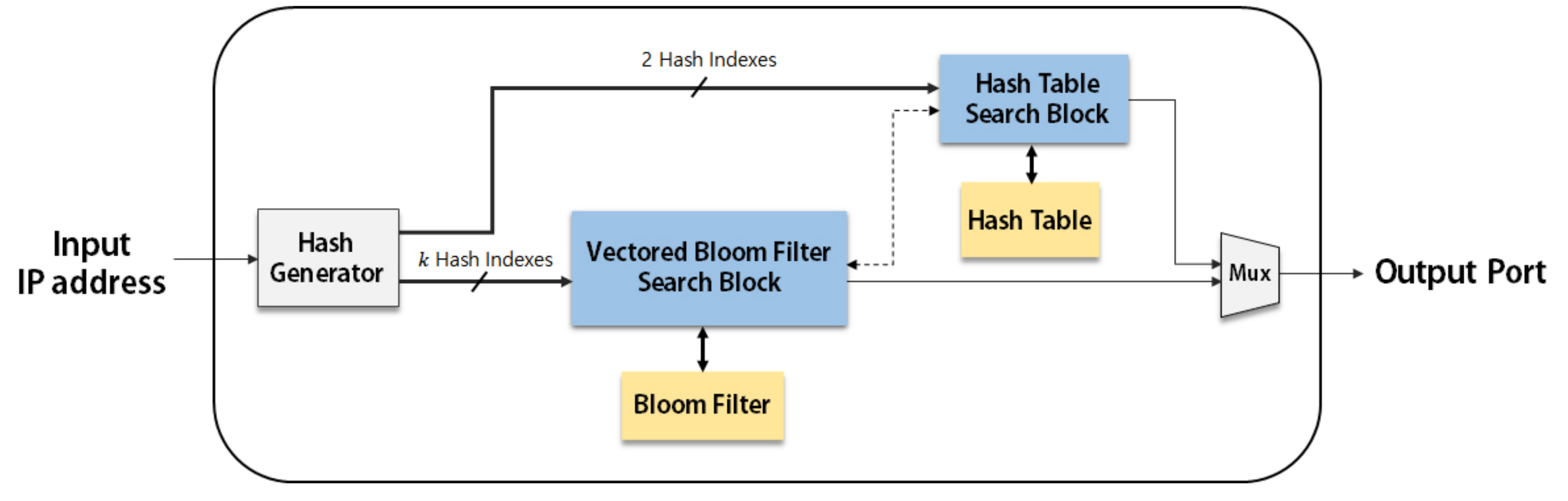
4.1. Basic IP Address Lookup Module
Figure 2 shows the block diagram of our proposed IP address lookup module in its basic form. The basic IP address lookup module contains a hash index generator, a VBF search block and a hash table search block. The hash index generator is realized with a 64-bit cyclic redundancy check (CRC-64) generator. The CRC-64 is implemented with a shift register and few exclusive-OR gates, which is much simpler than MD5 and SHA-256 and hence the CRC-64 is used in our implementation.
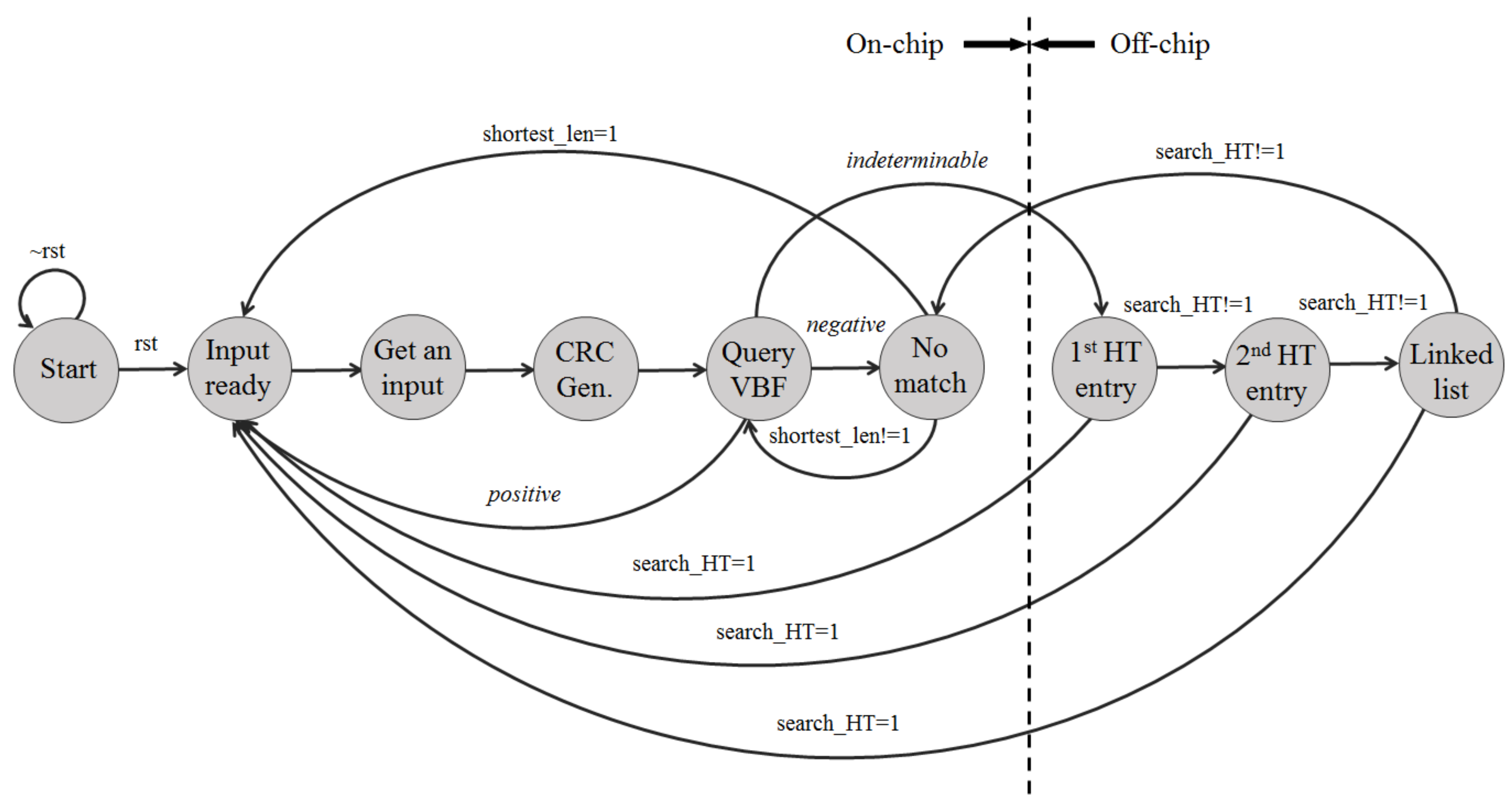
Figure 3 shows the state machine representing the IP address lookup procedure in detail. When the reset signal is given at state
Start, the state machine is ready to accept an input address. When an IP address is given to the module, the lookup procedure starts from the longest prefix length and iterates by decreasing the length until a matching prefix is found.At state
CRC Gen, for a substring of the input IP address, the CRC code is first obtained when the corresponding number of input bits are serially entered into the CRC generator starting from the most significant bit. Multiple hash indexes are obtained by combining multiple bits in the CRC code. In our implementation, to obtain the CRC code within a single cycle, the operations required in the 64-bit CRC generator are implemented in parallel.
The vectors of the VBF pointed by hash indexes are bitwise-ANDed to obtain a result vector at state Query VBF. The vector can produce three different results: negative, positive or indeterminable. The negative result means no matching output port at the current length; the search procedure goes on to state No match and then continues to query the VBF with a shorter length. The positive result means a matching output port from the VBF and hence the search is completed for the current input; in this case, the search procedure goes to state Input ready for the next input. The indeterminable result means that an output port cannot be returned from the VBF and hence the search procedure needs to proceed to the hash table.
At State 1st HT entry, the hash entry pointed by the first hash index is accessed. If the entry does not have a matching prefix, another entry pointed by the second hash index is accessed at state 2nd HT entry. If the entry pointed by the second hash index does not have a matching prefix, the other entry pointed by the linked list of the second entry is accessed at state Linked list. If the output port is not found in any of these hash entries, the matching prefix does not exist in the current length and the search procedure goes back to state No match and continues to query the VBF with a shorter length. If a matching prefix is found from any of these entries, the search is completed for the current input and hence the search procedure goes to state Input ready for the next input.
In terms of time complexity, since the query for the vectored-Bloom filter performs the linear search on the number of bits in an IP address, the on-chip search performance is , where W is the length of the IP address. However, the off-chip hash table access which mainly determines the IP address lookup performance does not occur for a sufficiently large VBF.
4.2. Parallel Architecture
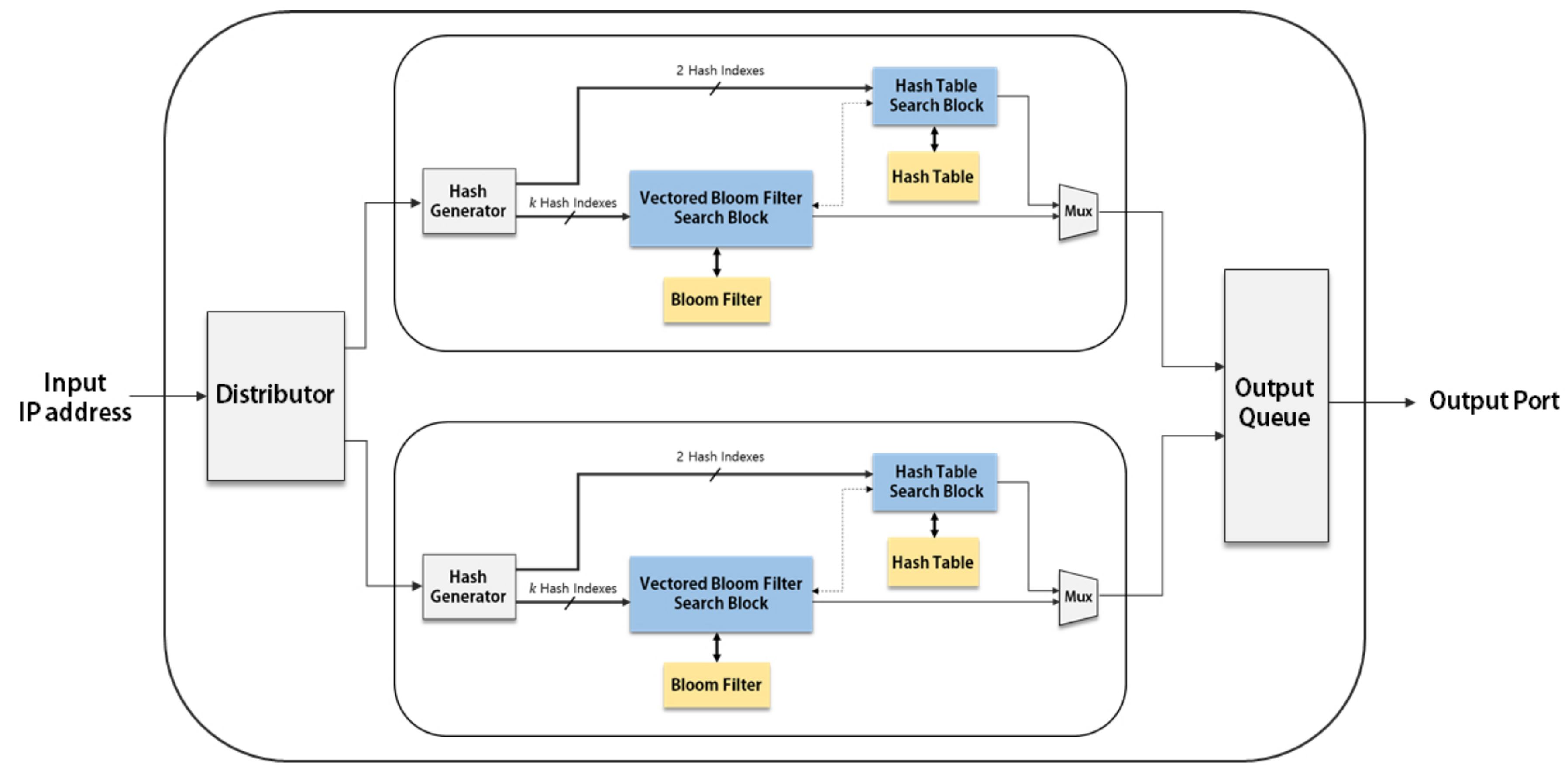
The IP address lookup performance using the VBF can be effectively improved by applying parallelism.
Figure 4 describes the parallel architecture using two basic IP address lookup modules. Two new blocks are implemented for this parallel architecture: a
Distributer and an
Output Queue. The
Distributer provides inputs to each module when the module is ready for a new input, while the
Output Queue provides the output ports according to the order of arrived inputs.
4.3. Parallel Architecture with a Single Hash Table
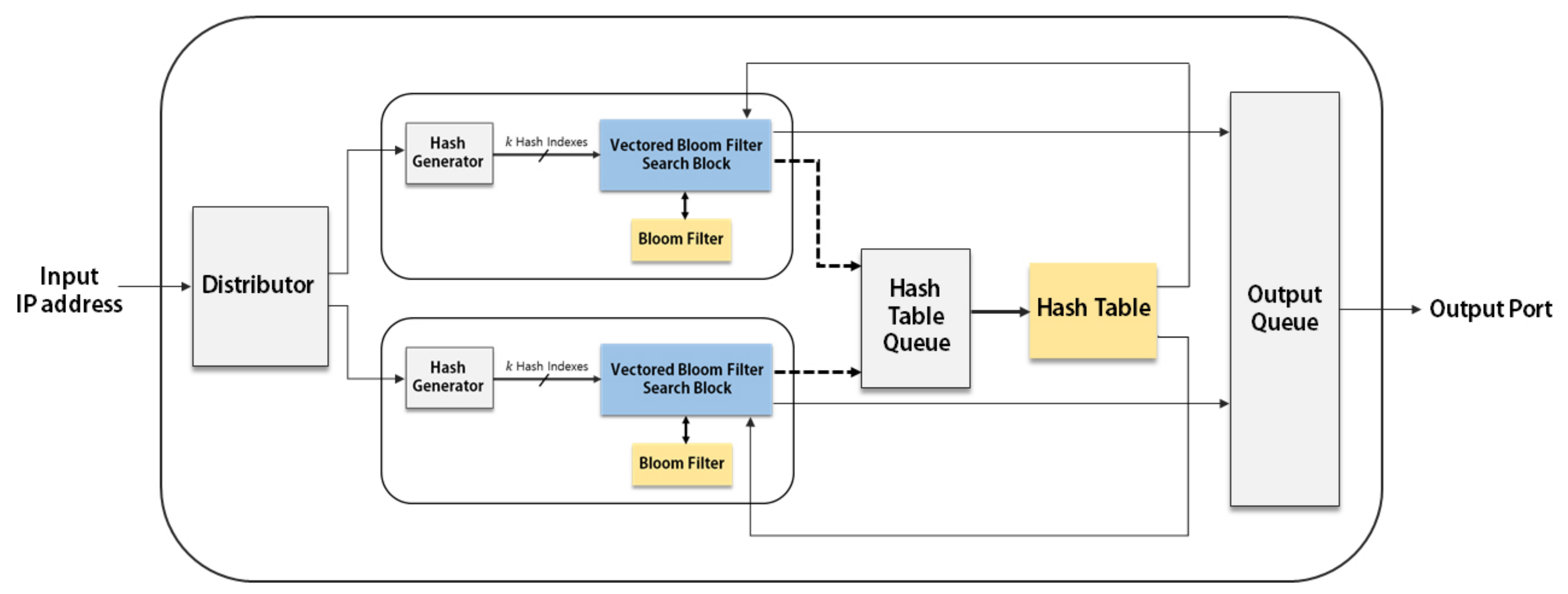
Since the parallel architecture has multiple copies of the basic IP address lookup modules, the block-RAM (BRAM) utilization is rapidly increased when the number of modules is increased. The BRAM thus becomes the bottleneck in increasing the degree of parallelism. Since the hash table is infrequently accessed in our proposed IP address lookup architecture, multiple VBF blocks can share one hash table. In other words, we can separate the hash table from the basic IP address lookup module and make multiple VBF search blocks share a single hash table.
Figure 5 shows the parallel architecture with a single hash table, in which two VBF search blocks share a single hash table. The hash table search block is now composed of a
Hash Table Queue and the hash table.
The Hash Table Queue is a waiting place before accessing the hash table in preparing the case that two or more input addresses need to access the hash table at the same time. If the output port for an input is not determined by the VBF search block, the index of the input and two hash indexes for the hash table are stored in the Hash Table Queue. When the input arrives to the front of the queue, the stored indexes for each input are used to access the shared hash table. The input is removed from the queue after accessing the hash table.
5. Behavior Simulation
Performance evaluation was carried out using routing sets downloaded from backbone routers [
33] at the behavior level with C language and at the hardware level with Verilog on an FPGA. We have created four routing sets and the number of prefixes (
N) in each set is 1000, 5000, 14,553 and 30,000 (called 1 k, 5 k, 14 k and 30 k, respectively). Note that the number of prefixes included in actual backbone routers can be several hundred thousands. The simulation results of our proposed algorithm for large routing sets have been already shown in our previous paper [
31]. This paper focuses on verifying the feasibility of the hardware implementation using an FPGA for our proposed architecture. Since the number of prefixes that can be handled by the FPGA is limited by the size of BRAM, we have used sets with a small number of prefixes in this paper.
The number of inputs to test is three times the number of prefixes in each routing set. Assuming that the number of output ports is eight, 8 bits are allocated for each vector of the vectored-Bloom filter.
5.1. Performance of the Proposed Structure
Table 1 shows the data structures of the VBF and a hash table. Let
N be the number of prefixes in each set. For the
depth of the VBF,
, where
and sizing factor
= 1, 2 and 4. The
width of the VBF is the vector size (
l), which is determined by the number of output ports.
The depth of the hash table, and the width of the hash table is the size of a hash entry. A single hash entry has four fields. In storing a prefix, 32 bits are allocated assuming IPv4. The prefix length has five bits calculated by . The output port uses three bits calculated by because the number of output ports l is assumed to be 8. Since the number of entries in the hash table is , the linked list has bits.
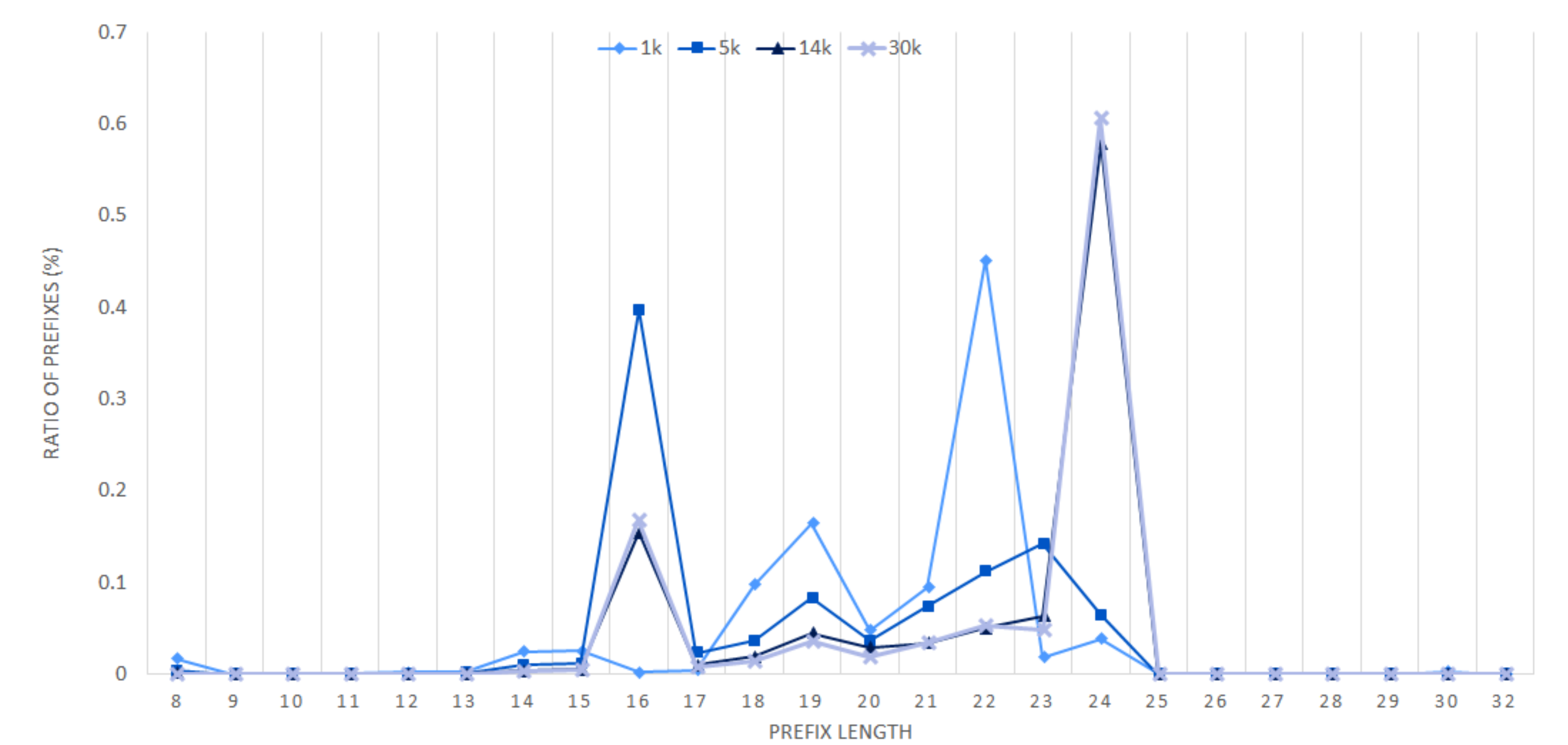
Since the VBF querying procedure starts from the longest length existing in the set and stops when a positive result is returned, the performance is affected by the distribution of the prefix lengths.
Figure 6 shows the distribution of prefixes according to their lengths in each set.
Table 2 shows the on-chip memory requirement (
) for a VBF and the off-chip memory requirement (
) for a hash table. It is shown that the VBF requires less memory than a hash table even when the sizing factor
is 4, since each vector of the VBF only represents an output port while the hash entry stores a prefix, a length, an output port and a linked list. The optimal number of hash functions for the VBF (
) is shown as well.
Table 3 shows the
indeterminable rate and
false port return rate according to the size of the VBF. The
indeterminable rate (
I) is defined as the number of inputs causing
indeterminable over the number of inputs. Since the output ports for these inputs are not identified by the VBF because of multiple set bits in the resulting vector, the search procedure should perform an access to the hash table. The
false port return rate (
F) is defined as the number of inputs having false return over the number of inputs. False ports can be returned by the false positives of the VBF. Note that the
indeterminable rate and the
false port return rate are zero when the sizing factor of the VBF is larger than two as shown in
Table 3.
5.2. Performance Comparison with Other Structures
Table 4 shows the comparison on Bloom filter characteristics of the proposed VBF structure with other structures such as BF-chaining with pre-computation [
20] and PBF [
6]. For fair comparison, the performances of each algorithm should be compared under the same amount of the on-chip memory required for constructing each Bloom filter. Based on the memory amount of the VBF shown in
Table 2, in constructing Bloom filters for the BF-chaining and the PBF, sizing factor
and the number of hash indexes for each structure are calculated, when the same amount of the memory is used. As sizing factor
increases, the number of off-chip hash table accesses decreases because the number of the search failures decreases. Tables should be cited in sequential numerical order. Please confirm if it’s invalid citation, if no, please revise the order. The VBF has the width of 8 but the number of elements for each output port is
and hence the VBF is basically the same as a standard Bloom filter as in the BF-chaining and the PBF structures. Since all nodes of a binary trie are stored in the Bloom filter of the BF-chaining, the
k of the BF-chaining is smaller than
. Since the PBF requires up to
W independent Bloom filters [
6], where
W is the valid lengths of prefixes, the space efficiency is degraded.
Table 5 shows the comparison of off-chip memory requirements. The hash table in the BF-chaining stores all of the nodes (
T) in a binary trie, while the PBF and the VBF only store prefixes (
N) in each routing set. Thus, the off-chip memory requirement of the PBF and the VBF is much smaller than that of the BF-chaining.
Table 6 shows the comparison of the on-chip search performance in terms of the average number and the worst-case number of Bloom filter accesses, represented by
and
, respectively. Since the Bloom filter querying is not performed for lengths not including any prefix,
is the number of valid prefix lengths for each set. Note that the Bloom filter querying of the BF-chaining proceeds from the shortest length, while the querying of the PBF and the VBF proceeds from the longest length. Thus, as the size of each Bloom filter (
) increases, the average number of Bloom filter accesses (
) of the BF-chaining decreases but that of the VBF increases, because the number of
negatives increases. The larger number of
negatives results in the smaller number of hash table accesses in both structures.
In case of the PBF, for the fair comparison with other structures, we assume that all of the BFs in the PBF structure are sequentially queried until the longest prefix is matched as in the VBF. Hence, the
is constant regardless of the size of the Bloom filter because Bloom filter querying always stops at the length of the matching longest prefix. In other words, starting from the longest length, the Bloom filter querying always continues until a true positive occurs and hence the average number of Bloom filter querying is not related to the size of the Bloom filter. The
of the VBF in 5 k is greater than that in other sets, because the 5 k set has many short length prefixes, such as length 16, as shown in
Figure 6. Since the search procedure proceeds from the longest length, if the prefix matching occurs in a short length, the
becomes large.
Table 7 shows the comparison on off-chip search performance in terms of the average number and the worst-case number of hash table accesses, represented by
and
, respectively. The number of off-chip memory accesses is the most important performance criterion in the IP address lookup problem. To improve the IP address lookup performance, the number of off-chip accesses should be minimized. In the BF-chaining and the PBF, even if the size of the Bloom filter (
) increases, the off-chip hash table is accessed at least once in order to obtain the matching output port. However, hash table accesses occur infrequently in our proposed VBF architecture, since the Bloom filter stored in an on-chip memory returns the matching output port in every case except the
indeterminable cases. Only when the VBF produces an
indeterminable result, the hash table is accessed. It is shown that the average number of hash table accesses becomes zero as the size of the Bloom filter (
) increases.
6. Hardware Implementation
This section shows the hardware implementation details of our proposed structure. Especially, the
parallel architecture with a single hash table shown in
Figure 5 has been implemented. The hardware implementation has been carried out with Verilog language using Vivado 2017.4 development tool. Our target device is NetFPGA CML operating at 100 MHz. The size of the VBF is
. The VBF and the hash table implemented with BRAMs are loaded with values obtained from the simulation at the behavior level.
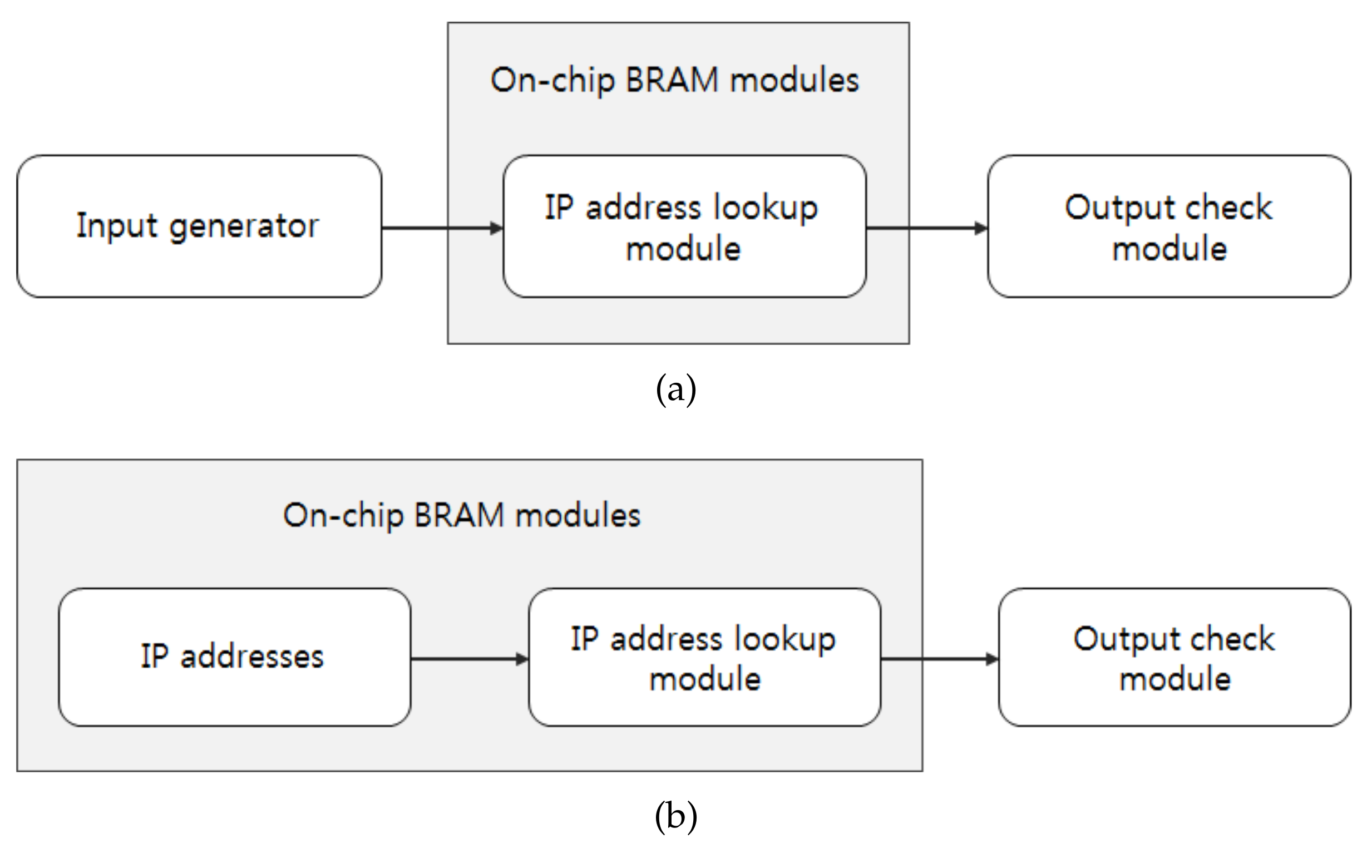
Figure 7 shows the hardware test flow. Generally, the input IP addresses should be provided by an external input generater, as shown in
Figure 7a. However, in our experiment, the input IP addresses are stored in a BRAM, as shown in
Figure 7b, in order to provide the input at the operation rate of the hardware implemented on the FPGA. The input IP addresses are stored in dual-port RAMs and hence the parallel architecture can process two IP addresses in parallel.
Since the VBF search block in the basic IP address lookup module has 11 hash indexes obtained from Label (
3) and a VBF is implemented with a dual-port RAM, six duplicates of the VBF are required. Since the parallel architecture has two basic IP address lookup modules, the VBF duplication should be doubled again and hence the 12 copies of the VBFs are implemented in total.
Table 8 shows the memory requirement in the hardware implementation. The BRAM has 18-Kbit and 36-Kbit blocks and the blocks are automatically allocated for each component. It is shown that a VBF is implemented with a single 18-Kbit block for the 1 k set, with four 36-Kbit blocks for the 5 k set and so on. Since each parallel architecture requires 12 copies of VBFs, the total number of VBFs is multiplied by 12. Similarly, it is shown the number of blocks used to store a hash table and input IP addresses for each routing set.
The values in total BRAMs represent the summation of the BRAM in KBytes. The utilization rate of the BRAM is based on the BRAM capacity of 16,020 Kbits. Since each component is allocated in blocks, the memory requirement of a VBF or a hash table in hardware implementation is greater than that in behavior simulation.
Table 9 shows resource utilization.
Capacity means the amount of available resources and
Used means the amount of resources used in our implementation.
Utilization represents the ratio between
Used and
Capacity. It is shown that the utilization of the BRAM reaches up to 84.0% for the 30 k set.
Table 10 shows the total on-chip power and the worst negative slack reported in Vivado 2017.4 development tool.
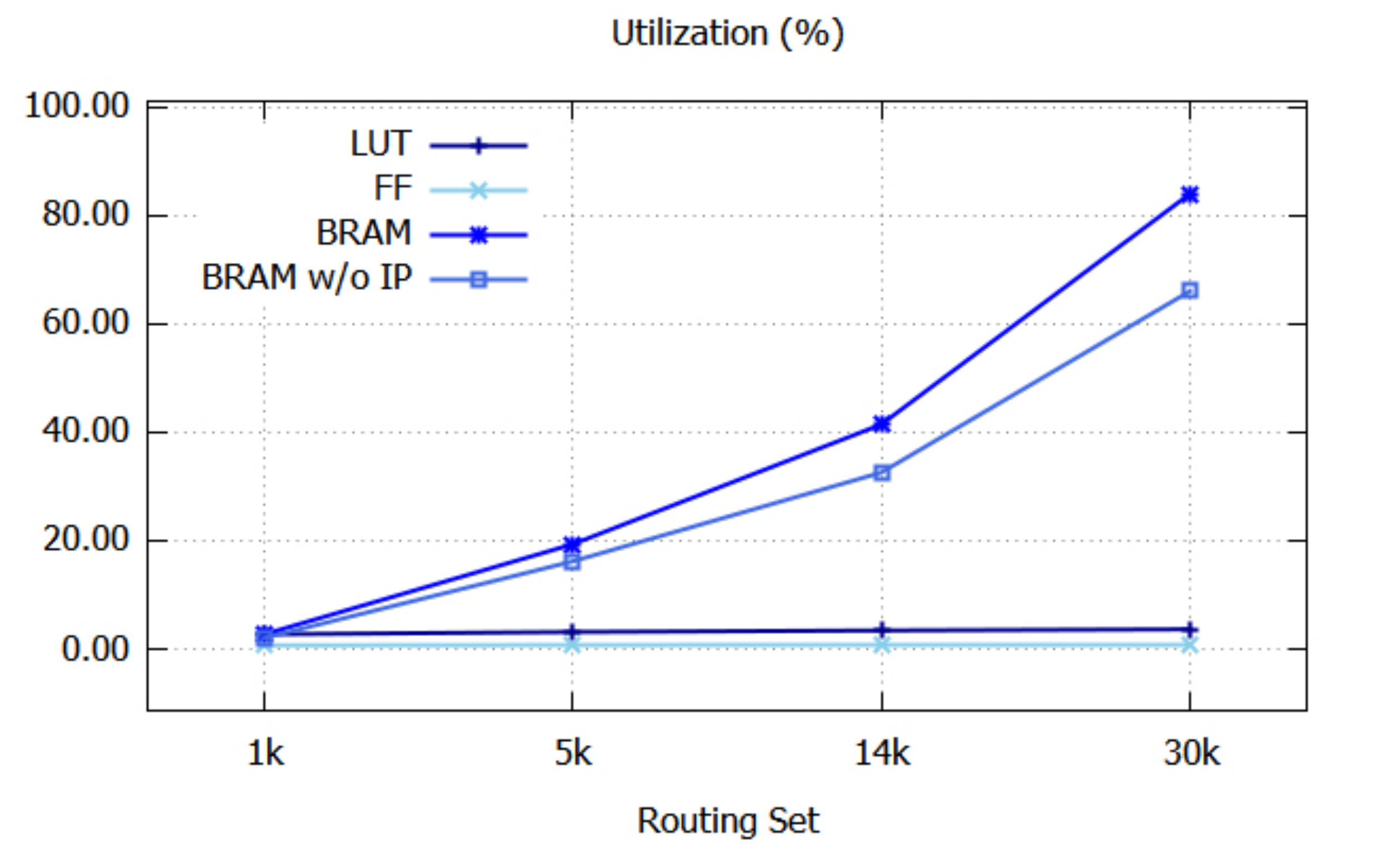
Figure 8 graphically shows the resource utilization. Since the utilizations of IO and BUFG do not depend on the sizes of the routing sets, their utilizations are not shown. The utilizations of LUT and FF are almost constant, even when the size of the routing set increases.
BRAM w/o IP refers to the BRAM utilization when input IP addresses are not stored in BRAMs, as shown in
Figure 7a. In this case, the BRAM utilization reaches up to 66.1%, which is substantially lower than 84.0%.
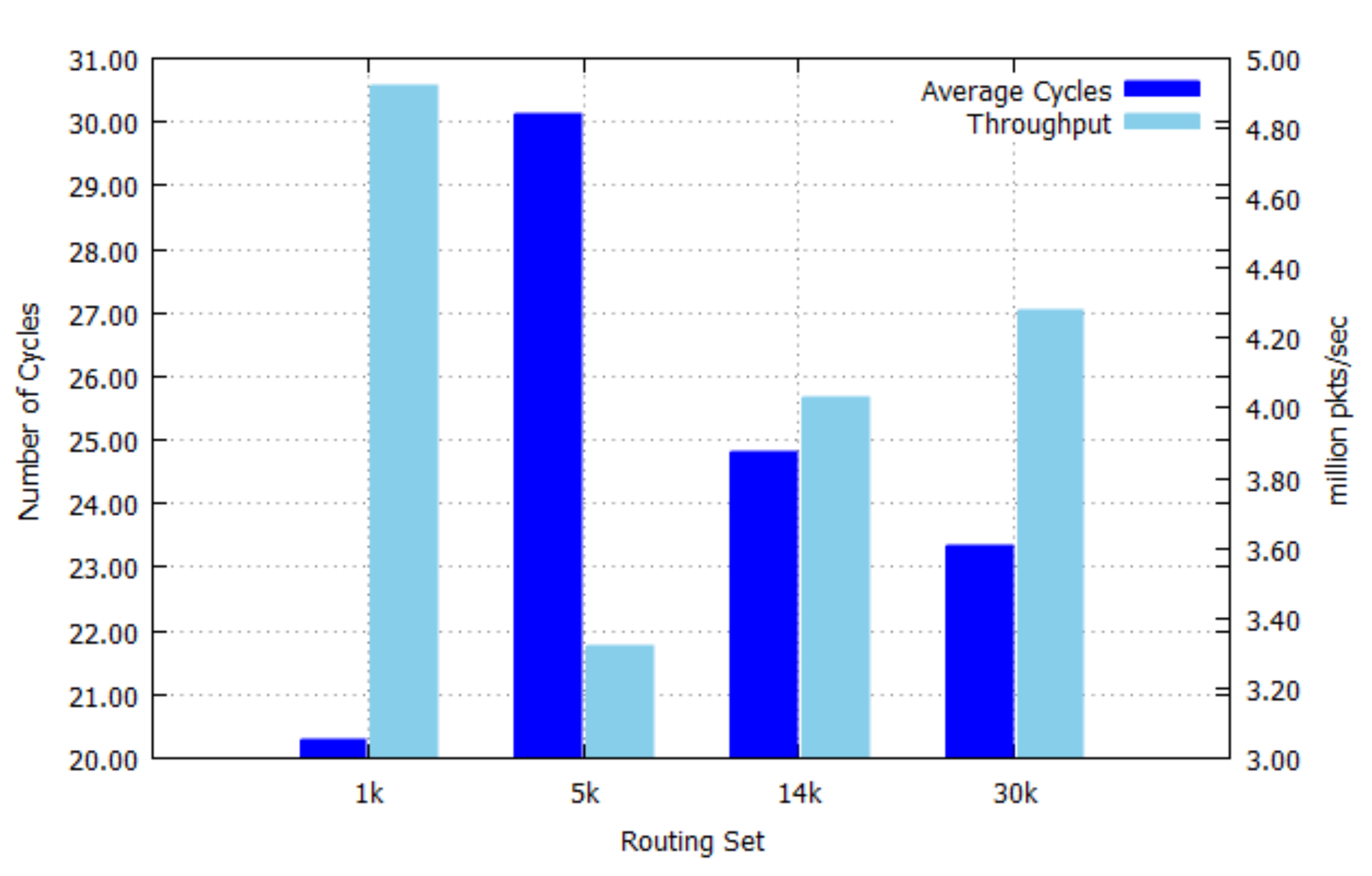
Figure 9 shows the average number of cycles needed to perform an IP address lookup and the throughput of our implementation. The average number of cycles is related to the search performance and the search performance is affected by the prefix length distribution shown in
Figure 6. The throughput is the maximum number of processed packets per second (p/s or pps) and it is inversely related to the average number of cycles. The best-case of the throughput is 4.92 million packets/sec for the 1 k set, while the worst-case of the throughput is 3.32 million packets/sec for the 5 k set, because the 5 k set has more short-length prefixes than other sets as shown in
Figure 6. Note that the throughput performance depends more on the prefix length distribution rather than the number of prefixes. The prefix length distribution is related to the role of routers, whether the router is a backbone router or an edge router. Backbone routers have the more number of short-length prefixes than edge routers, since edge routers connect mostly access networks, which has a more specific (longer-length) prefix.
Considering that the number of prefixes is scaled to several hundred thousands reflecting real backbone routing tables, if the proposed architecture is implemented with an ASIC, which has at least 4 Mbytes on-chip memory operating at 500 MHz [
6], the expected throughput can be improved by 5 times. The proposed architecture can provide the wire-speed IP address lookup at the rate of about 15 to 25 million packets/sec, since the routing sets used in our simulation has the similar characteristics as actual routing sets by being downloaded (and randomly selected) from real backbone routers.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}