Predicting Heating Load in Energy-Efficient Buildings Through Machine Learning Techniques

 ,
,  ,
, 
Abstract
1. Introduction
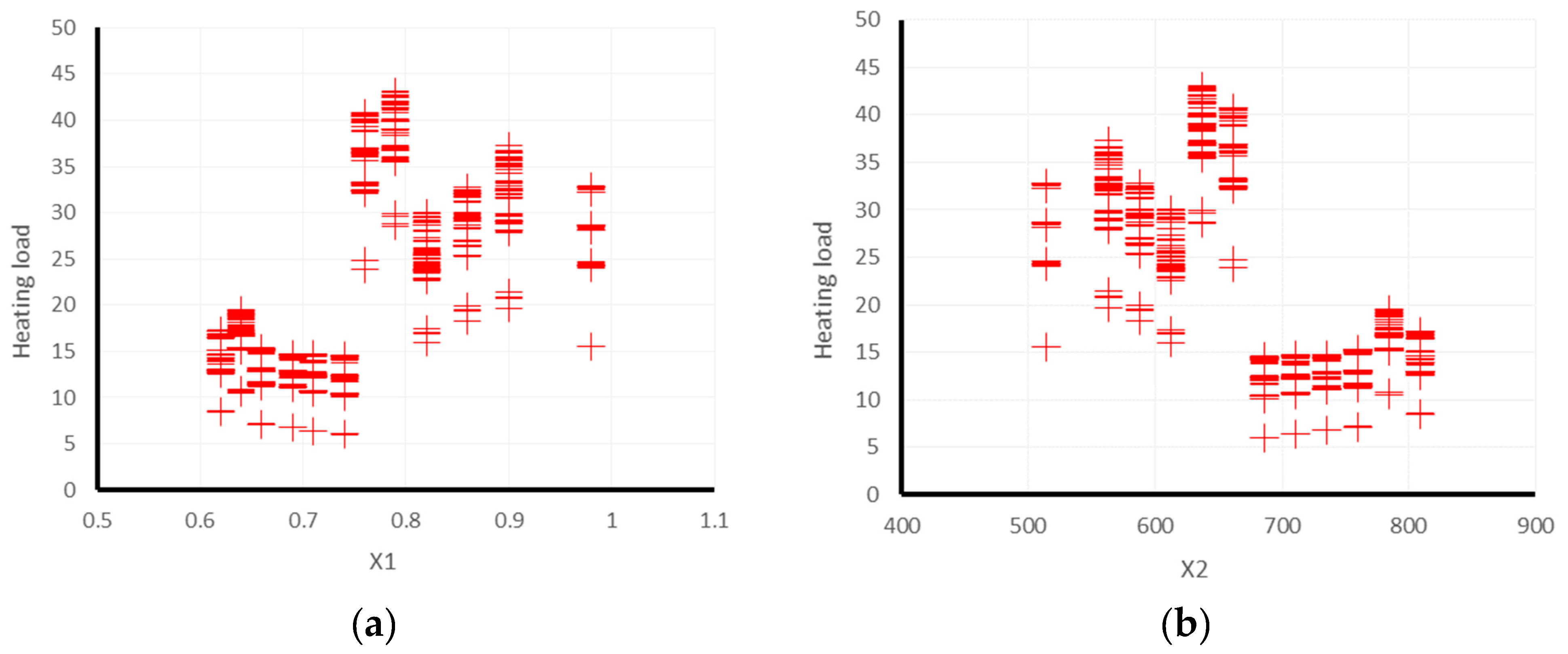
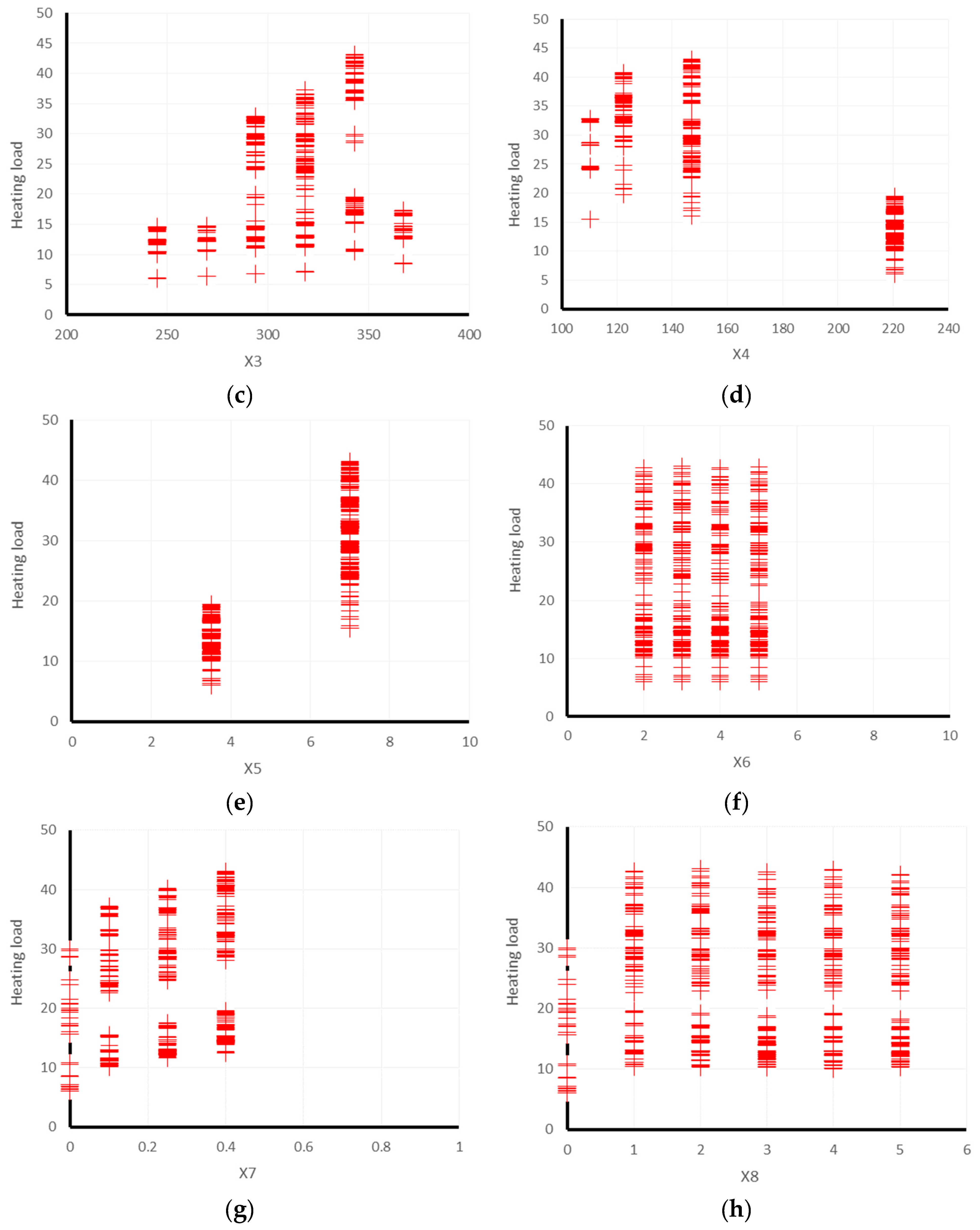
2. Database Collection
Statistical Details of the Dataset
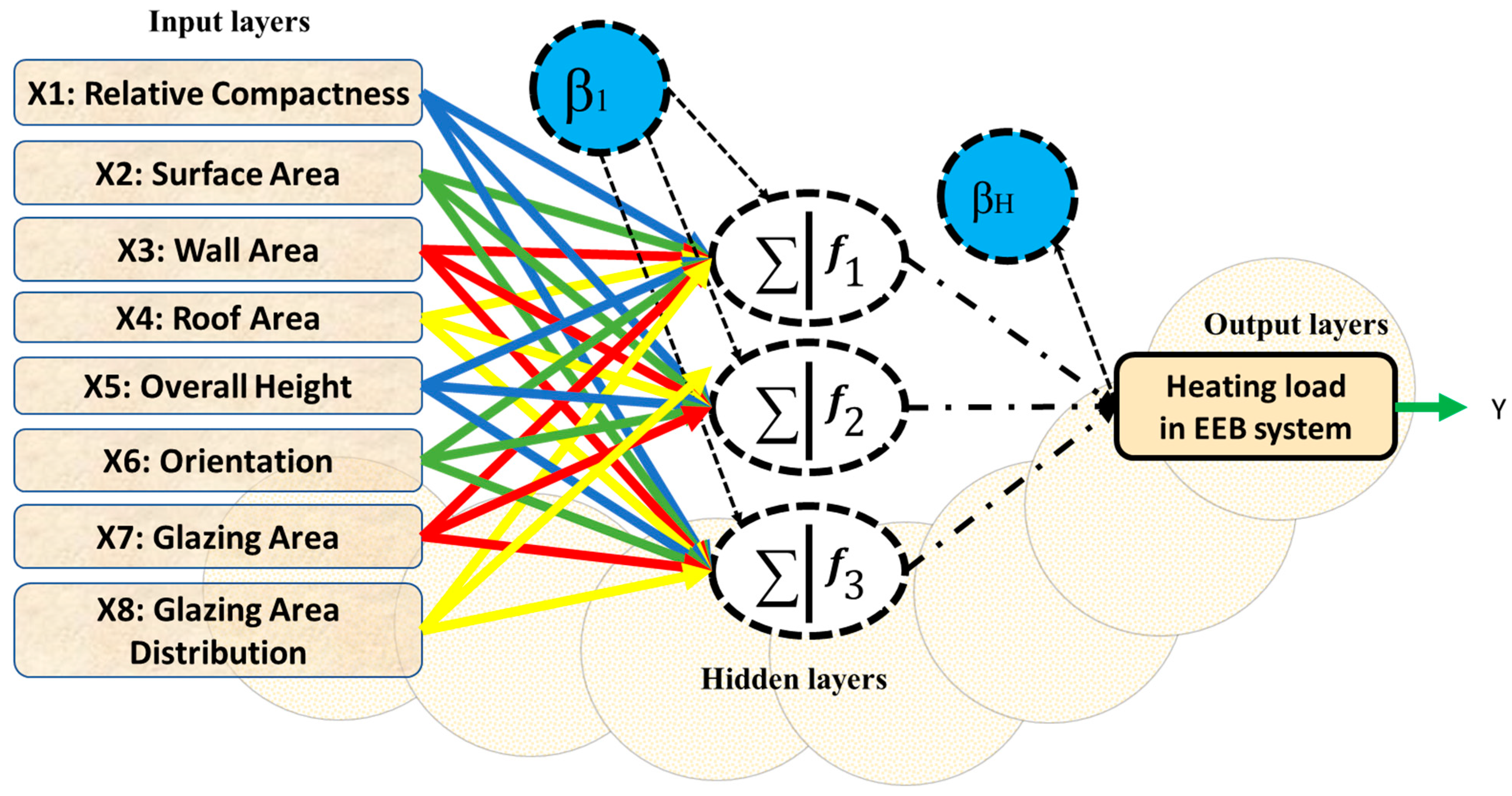
3. Model Development
3.1. Multi-Layer Perceptron Regressor (MLPr)
3.2. Lazy Locally Weighted Learning (LLWL)
- ❖
- numDecimalPlaces—The number of decimal places. This number will be implemented for the output of numbers in the model.
- ❖
- batchSize—The chosen number of cases to process if batch estimation is being completed. A normal value of the batch size is 100. In this example we also consider it to be constant as it did not have significant impact on the outputs.
- ❖
- KNN—The number of neighbors that are employed to set the width of the weighting function (noting that KNN ≤ 0 means all neighbors are considered).
- ❖
- nearestNeighborSearchAlgorithm—The potential nearest neighbor search algorithm to be applied (the default algorithm that was also selected in our study was LinearNN).
- ❖
- weightingKernel—The number that determines the weighting function. (0 = Linear; 1 = Epnechnikov; 2 = Tricube; 3 = Inverse; 4 = Gaussian; and 5 = Constant. (default 0 = Linear)).
3.3. Alternating Model Tree (AMT)
3.4. Random Forest (RF)
3.5. ElasticNet (ENet)
0.161 × X8 + 35.597.
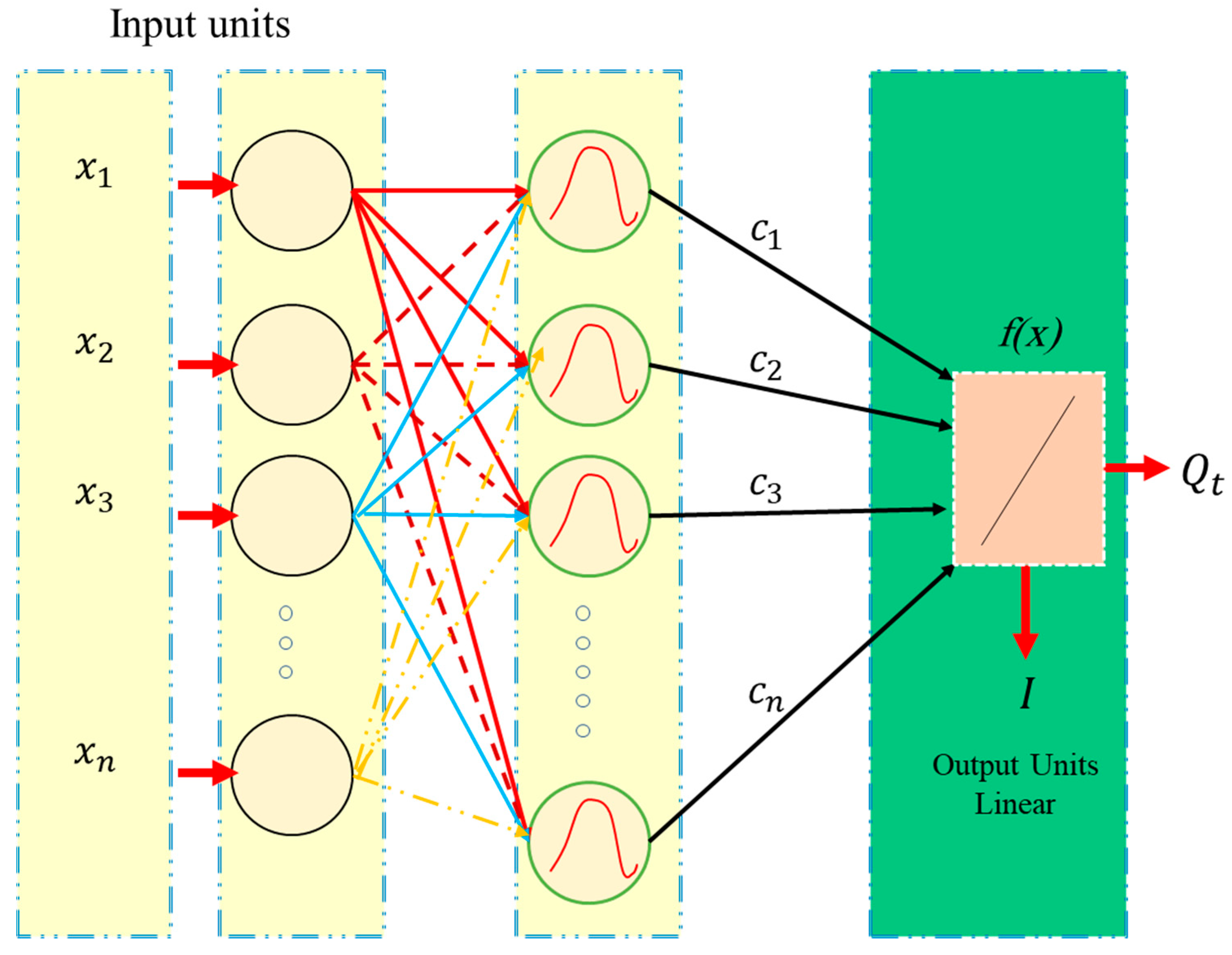
3.6. Radial Basis Function Regression (RBFr)
3.7. Model Assessment Approaches
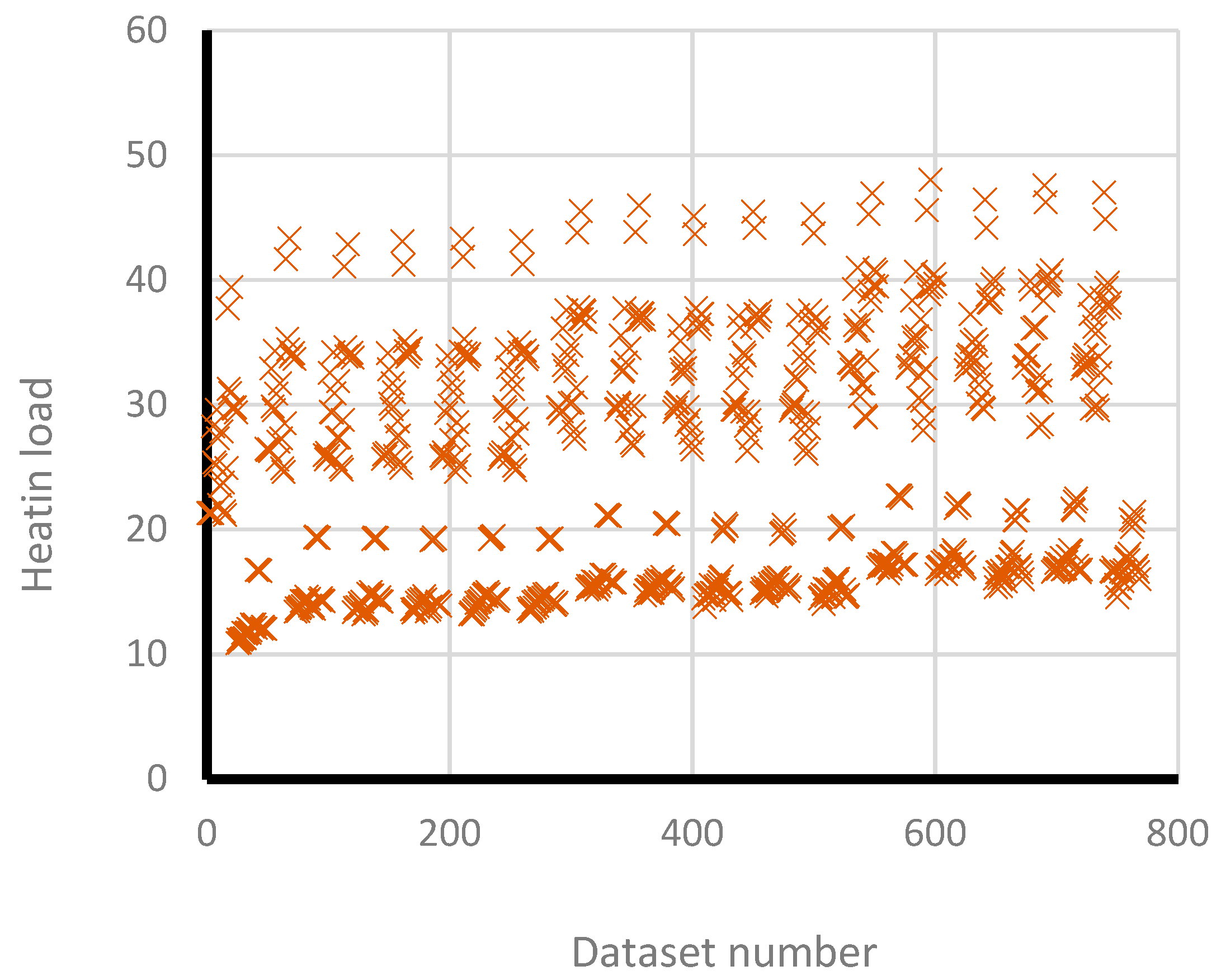
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Nguyen, T.N.; Tran, T.P.; Hung, H.D.; Voznak, M.; Tran, P.T.; Minh, T.; Thanh-Long, N. Hybrid TSR-PSR alternate energy harvesting relay network over Rician fading channels: Outage probability and SER analysis. Sensors 2018, 18, 3839. [Google Scholar] [CrossRef]
- Najafi, B.; Ardabili, S.F.; Mosavi, A.; Shamshirband, S.; Rabczuk, T. An intelligent artificial neural network-response surface methodology method for accessing the optimum biodiesel and diesel fuel blending conditions in a diesel engine from the viewpoint of exergy and energy analysis. Energies 2018, 11, 860. [Google Scholar] [CrossRef]
- Nazir, R.; Ghareh, S.; Mosallanezhad, M.; Moayedi, H. The influence of rainfall intensity on soil loss mass from cellular confined slopes. Measurement 2016, 81, 13–25. [Google Scholar] [CrossRef]
- Mojaddadi, H.; Pradhan, B.; Nampak, H.; Ahmad, N.; Ghazali, A.H.B. Ensemble machine-learning-based geospatial approach for flood risk assessment using multi-sensor remote-sensing data and GIS. Geomat. Nat. Hazards Risk 2017, 8, 1080–1102. [Google Scholar] [CrossRef]
- Rizeei, H.M.; Pradhan, B.; Saharkhiz, M.A. Allocation of emergency response centres in response to pluvial flooding-prone demand points using integrated multiple layer perceptron and maximum coverage location problem models. Int. J. Disaster Risk Reduct. 2019, 101205. [Google Scholar] [CrossRef]
- Rizeei, H.M.; Pradhan, B.; Saharkhiz, M.A. Urban object extraction using Dempster Shafer feature-based image analysis from worldview-3 satellite imagery. Int. J. Remote Sens. 2019, 40, 1092–1119. [Google Scholar] [CrossRef]
- Mezaal, M.; Pradhan, B.; Rizeei, H. Improving landslide detection from airborne laser scanning data using optimized Dempster–Shafer. Remote Sens. 2018, 10, 1029. [Google Scholar] [CrossRef]
- Aal-shamkhi, A.D.S.; Mojaddadi, H.; Pradhan, B.; Abdullahi, S. Extraction and modeling of urban sprawl development in Karbala City using VHR satellite imagery. In Spatial Modeling and Assessment of Urban Form; Springer: Cham, Switzerland, 2017; pp. 281–296. [Google Scholar]
- Gao, W.; Wang, W.; Dimitrov, D.; Wang, Y. Nano properties analysis via fourth multiplicative ABC indicator calculating. Arab. J. Chem. 2018, 11, 793–801. [Google Scholar] [CrossRef]
- Aksoy, H.S.; Gör, M.; İnal, E. A new design chart for estimating friction angle between soil and pile materials. Geomech. Eng. 2016, 10, 315–324. [Google Scholar] [CrossRef]
- Gao, W.; Dimitrov, D.; Abdo, H. Tight independent set neighborhood union condition for fractional critical deleted graphs and ID deleted graphs. Discret. Contin. Dyn. Syst. S 2018, 12, 711–721. [Google Scholar] [CrossRef]
- Bui, D.T.; Moayedi, H.; Gör, M.; Jaafari, A.; Foong, L.K. Predicting slope stability failure through machine learning paradigms. ISPRS Int. Geo-Inf. 2019, 8, 395. [Google Scholar] [CrossRef]
- Gao, W.; Guirao, J.L.G.; Abdel-Aty, M.; Xi, W. An independent set degree condition for fractional critical deleted graphs. Discret. Contin. Dyn. Syst. S 2019, 12, 877–886. [Google Scholar] [CrossRef]
- Moayedi, H.; Bui, D.T.; Gör, M.; Pradhan, B.; Jaafari, A. The feasibility of three prediction techniques of the artificial neural network, adaptive neuro-fuzzy inference system, and hybrid particle swarm optimization for assessing the safety factor of cohesive slopes. ISPRS Int. Geo-Inf. 2019, 8, 391. [Google Scholar] [CrossRef]
- Gao, W.; Guirao, J.L.G.; Basavanagoud, B.; Wu, J. Partial multi-dividing ontology learning algorithm. Inf. Sci. 2018, 467, 35–58. [Google Scholar] [CrossRef]
- Ince, R.; Gör, M.; Alyamaç, K.E.; Eren, M.E. Multi-fractal scaling law for split strength of concrete cubes. Mag. Concr. Res. 2016, 68, 141–150. [Google Scholar] [CrossRef]
- Gao, W.; Wu, H.; Siddiqui, M.K.; Baig, A.Q. Study of biological networks using graph theory. Saudi J. Biol. Sci. 2018, 25, 1212–1219. [Google Scholar] [CrossRef]
- Ngo, N.T. Early predicting cooling loads for energy-efficient design in office buildings by machine learning. Energy Build. 2019, 182, 264–273. [Google Scholar] [CrossRef]
- Jafarinejad, T.; Erfani, A.; Fathi, A.; Shafii, M.B. Bi-level energy-efficient occupancy profile optimization integrated with demand-driven control strategy: University building energy saving. Sustain. Cities Soc. 2019, 48, 101539. [Google Scholar] [CrossRef]
- Kheiri, F. A review on optimization methods applied in energy-efficient building geometry and envelope design. Renew. Sustain. Energy Rev. 2018, 92, 897–920. [Google Scholar] [CrossRef]
- Wang, W.; Chen, J.Y.; Huang, G.S.; Lu, Y.J. Energy efficient HVAC control for an IPS-enabled large space in commercial buildings through dynamic spatial occupancy distribution. Appl. Energy 2017, 207, 305–323. [Google Scholar] [CrossRef]
- Yu, Z.; Haghighat, F.; Fung, B.C.M. Advances and challenges in building engineering and data mining applications for energy-efficient communities. Sustain. Cities Soc. 2016, 25, 33–38. [Google Scholar] [CrossRef]
- Zhang, H.; Yuan, C.; Yang, G.; Wu, L.; Peng, C.; Ye, W.; Shen, Y.; Moayedi, H. A novel constitutive modelling approach measured under simulated freeze–thaw cycles for the rock failure. Eng. Comput. 2019. [Google Scholar] [CrossRef]
- Bui, D.T.; Moayedi, H.; Anastasios, D.; Foong, L.K. Predicting heating and cooling loads in energy-efficient buildings using two hybrid intelligent models. Appl. Sci. 2019, 9, 3543. [Google Scholar]
- Moayedi, H.; Nguyen, H.; Rashid, A.S.A. Comparison of dragonfly algorithm and Harris hawks optimization evolutionary data mining techniques for the assessment of bearing capacity of footings over two-layer foundation soils. Eng. Comput. 2019. [Google Scholar] [CrossRef]
- Moayedi, H.; Aghel, B.; Abdullahi, M.A.M.; Nguyen, H.; Rashid, A.S.A. Applications of rice husk ash as green and sustainable biomass. J. Clean. Prod. 2019, 237, 117851. [Google Scholar] [CrossRef]
- Huang, X.X.; Moayedi, H.; Gong, S.; Gao, W. Application of metaheuristic algorithms for pressure analysis of crude oil pipeline. Energy Sources Part A Recovery Util. Environ. Effects 2019. [Google Scholar] [CrossRef]
- Gao, W.; Alsarraf, J.; Moayedi, H.; Shahsavar, A.; Nguyen, H. Comprehensive preference learning and feature validity for designing energy-efficient residential buildings using machine learning paradigms. Appl. Soft Comput. 2019, 84, 105748. [Google Scholar] [CrossRef]
- Bui, D.T.; Moayedi, H.; Kalantar, B.; Osouli, A.; Pradhan, B.; Nguyen, H.; Rashid, A.S.A. Harris hawks optimization: A novel swarm intelligence technique for spatial assessment of landslide susceptibility. Sensors 2019, 19, 3590. [Google Scholar] [CrossRef]
- Biswas, M.R.; Robinson, M.D.; Fumo, N. Prediction of residential building energy consumption: A neural network approach. Energy 2016, 117, 84–92. [Google Scholar] [CrossRef]
- Fan, C.; Wang, J.; Gang, W.; Li, S. Assessment of deep recurrent neural network-based strategies for short-term building energy predictions. Appl. Energy 2019, 236, 700–710. [Google Scholar] [CrossRef]
- Ince, R.; Gör, M.; Eren, M.E.; Alyamaç, K.E. The effect of size on the splitting strength of cubic concrete members. Strain 2015, 51, 135–146. [Google Scholar] [CrossRef]
- Sayin, E.; Yön, B.; Calayir, Y.; Gör, M. Construction failures of masonry and adobe buildings during the 2011 Van earthquakes in Turkey. Struct. Eng. Mech. 2014, 51, 503–518. [Google Scholar] [CrossRef]
- Zemella, G.; de March, D.; Borrotti, M.; Poli, I. Optimised design of energy efficient building facades via evolutionary neural networks. Energy Build. 2011, 43, 3297–3302. [Google Scholar] [CrossRef]
- Chou, J.S.; Bui, D.K. Modeling heating and cooling loads by artificial intelligence for energy-efficient building design. Energy Build. 2014, 82, 437–446. [Google Scholar] [CrossRef]
- Hidayat, I.; Utami, S.S. Activity based smart lighting control for energy efficient building by neural network model. In Astechnova 2017 International Energy Conference; Sunarno, I., Sasmito, A.P., Hong, L.P., Eds.; EDP Sciences: Les Ulis, France, 2018; Volume 43. [Google Scholar]
- Malik, S.; Kim, D. Prediction-learning algorithm for efficient energy consumption in smart buildings based on particle regeneration and velocity boost in particle swarm optimization neural networks. Energies 2018, 11, 1289. [Google Scholar] [CrossRef]
- Pino-Mejías, R.; Pérez-Fargallo, A.; Rubio-Bellido, C.; Pulido-Arcas, J.A. Comparison of linear regression and artificial neural networks models to predict heating and cooling energy demand, energy consumption and CO2 emissions. Energy 2017, 118, 24–36. [Google Scholar] [CrossRef]
- Deb, C.; Eang, L.S.; Yang, J.; Santamouris, M. Forecasting diurnal cooling energy load for institutional buildings using artificial neural networks. Energy Build. 2016, 121, 284–297. [Google Scholar] [CrossRef]
- Li, Q.; Meng, Q.; Cai, J.; Yoshino, H.; Mochida, A. Predicting hourly cooling load in the building: A comparison of support vector machine and different artificial neural networks. Energy Convers. Manag. 2009, 50, 90–96. [Google Scholar] [CrossRef]
- Kolokotroni, M.; Davies, M.; Croxford, B.; Bhuiyan, S.; Mavrogianni, A. A validated methodology for the prediction of heating and cooling energy demand for buildings within the Urban Heat Island: Case-study of London. Sol. Energy 2010, 84, 2246–2255. [Google Scholar] [CrossRef]
- Nguyen, H.; Moayedi, H.; Foong, L.K.; Al Najjar, H.A.H.; Jusoh, W.A.W.; Rashid, A.S.A.; Jamali, J. Optimizing ANN models with PSO for predicting short building seismic response. Eng. Comput. 2019, 35, 1–15. [Google Scholar] [CrossRef]
- Tsanas, A.; Xifara, A. Accurate quantitative estimation of energy performance of residential buildings using statistical machine learning tools. Energy Build. 2012, 49, 560–567. [Google Scholar] [CrossRef]
- Atkeson, C.G.; Moore, A.W.; Schaal, S. Locally weighted learning for control. In Lazy Learning; Springer: Dordrecht, The Netherlands, 1997; pp. 75–113. [Google Scholar]
- Frank, E.; Mayo, M.; Kramer, S. Alternating model trees. In Proceedings of the 30th Annual ACM Symposium on Applied Computing, Salamanca, Spain, 13–17 April 2015; pp. 871–878. [Google Scholar]
- Hamilton, C.R. Hourly Solar Radiation Forecasting through Neural Networks and Model Trees. Ph.D. Thesis, University of Georgia, Athens, GA, USA, 2016. [Google Scholar]
- Rodrigues, É.O.; Pinheiro, V.; Liatsis, P.; Conci, A. Machine learning in the prediction of cardiac epicardial and mediastinal fat volumes. Comput. Biol. Med. 2017, 89, 520–529. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Wadsworth International Group: Belmont, CA, USA, 1984. [Google Scholar]
- Ho, T.K. The random subspace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar]
- Svetnik, V.; Liaw, A.; Tong, C.; Culberson, J.C.; Sheridan, R.P.; Feuston, B.P. Random forest: A classification and regression tool for compound classification and QSAR modeling. J. Chem. Inf. Comput. Sci. 2003, 43, 1947–1958. [Google Scholar] [CrossRef] [PubMed]
- Diaz-Uriarte, R.; de Andres, S.A. Gene selection and classification of microarray data using random forest. BMC Bioinform. 2006, 7, 3. [Google Scholar] [CrossRef]
- Cutler, D.R.; Edwards, T.C.; Beard, K.H.; Cutler, A.; Hess, K.T. Random forests for classification in ecology. Ecology 2007, 88, 2783–2792. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2005, 67, 301–320. [Google Scholar] [CrossRef]
- Buhmann, M.D. Radial Basis Functions: Theory and Implementations; Cambridge University Press: Cambridge, UK, 2003; Volume 12. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Layers Used as Input | Main Output | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Relative Compactness | Surface Area (m2) | Wall Area (m2) | Roof Area (m2) | Overall Height (m) | Orientation (-) | Glazing Area (m2) | Glazing Area Distribution (m2) | Heating Load (kW/h) | |
| Used label | X1 | X2 | X3 | X4 | X5 | X6 | X7 | X8 | Y1 |
| No. of data | 768 | ||||||||
| Minimum | 0.6 | 514.5 | 245.0 | 110.3 | 3.5 | 2.0 | 0.0 | 0.0 | 6.0 |
| Maximum | 1.0 | 808.5 | 416.5 | 220.5 | 7.0 | 5.0 | 0.4 | 5.0 | 43.1 |
| Average | 0.8 | 671.7 | 318.5 | 176.6 | 5.3 | 3.5 | 0.2 | 2.8 | 22.3 |
| Number of Iterations | |||||
|---|---|---|---|---|---|
| Evaluation metrics | 10 | 20 | 30 | 40 | 50 |
| Correlation coefficient | 0.9984 | 0.9971 | 0.9974 | 0.9975 | 0.9972 |
| Mean absolute error | 0.4349 | 0.7527 | 0.7051 | 0.6464 | 0.6666 |
| Root mean squared error | 0.5752 | 0.9566 | 0.8936 | 0.8495 | 0.8995 |
| Relative absolute error (%) | 4.75 | 7.94 | 7.43 | 6.82 | 7.0341 |
| Root relative squared error (%) | 5.69 | 8.94 | 8.35 | 7.93 | 8.4062 |
| Proposed Models | Network Results | Ranking the Predicted Models | Total Ranking Score | Rank | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R2 | MAE | RMSE | RAE (%) | RRSE (%) | R2 | MAE | RMSE | RAE (%) | RRSE (%) | |||
| lazy.LWL | 0.903 | 3.2838 | 4.3335 | 35.9104 | 42.9757 | 2 | 1 | 2 | 1 | 2 | 8 | 5 |
| Alternating Model Tree | 0.9985 | 0.4096 | 0.5449 | 4.4788 | 5.4036 | 5 | 5 | 5 | 5 | 5 | 25 | 2 |
| Random Forest | 0.9997 | 0.19 | 0.2399 | 2.078 | 2.3795 | 6 | 6 | 6 | 6 | 6 | 30 | 1 |
| ElasticNet | 0.8915 | 3.2332 | 4.5678 | 35.3566 | 45.2993 | 1 | 2 | 1 | 2 | 1 | 7 | 6 |
| MLP Regressor | 0.9915 | 0.9795 | 1.3156 | 10.7117 | 13.0465 | 4 | 4 | 4 | 4 | 4 | 20 | 3 |
| RBF Regressor | 0.9647 | 1.8226 | 2.6555 | 19.9307 | 26.3348 | 3 | 3 | 3 | 3 | 3 | 15 | 4 |
| Proposed Models | Network Results | Ranking the Predicted Models | Total Ranking Score | Rank | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R2 | MAE | RMSE | RAE (%) | RRSE (%) | R2 | MAE | RMSE | RAE (%) | RRSE (%) | |||
| lazy.LWL | 0.9049 | 3.2345 | 4.2752 | 35.1778 | 42.2953 | 2 | 2 | 2 | 2 | 2 | 10 | 5 |
| Alternating Model Tree | 0.9981 | 0.4869 | 0.6236 | 5.2956 | 6.1693 | 5 | 5 | 5 | 5 | 5 | 25 | 2 |
| Random Forest | 0.9989 | 0.3385 | 0.4649 | 3.6813 | 4.5995 | 6 | 6 | 6 | 6 | 6 | 30 | 1 |
| ElasticNet | 0.896 | 3.2585 | 4.4683 | 35.4392 | 44.2052 | 1 | 1 | 1 | 1 | 1 | 5 | 6 |
| MLP Regressor | 0.9868 | 1.12 | 1.6267 | 12.1811 | 16.0934 | 4 | 4 | 4 | 4 | 4 | 20 | 3 |
| RBF Regressor | 0.9693 | 1.9109 | 2.4647 | 20.7827 | 24.3837 | 3 | 3 | 3 | 3 | 3 | 15 | 4 |
| Proposed Models | Training Dataset | Testing Dataset | Total Rank | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| R2 | MAE | RMSE | RAE (%) | RRSE (%) | R2 | MAE | RMSE | RAE | RRSE | ||
| lazy.LWL | 2 | 1 | 2 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 10 |
| Alternating Model Tree | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 25 |
| Random Forest | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 30 |
| ElasticNet | 1 | 2 | 1 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 5 |
| MLP Regressor | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 20 |
| RBF Regressor | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 15 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moayedi, H.; Bui, D.T.; Dounis, A.; Lyu, Z.; Foong, L.K. Predicting Heating Load in Energy-Efficient Buildings Through Machine Learning Techniques. Appl. Sci. 2019, 9, 4338. https://doi.org/10.3390/app9204338
Moayedi H, Bui DT, Dounis A, Lyu Z, Foong LK. Predicting Heating Load in Energy-Efficient Buildings Through Machine Learning Techniques. Applied Sciences. 2019; 9(20):4338. https://doi.org/10.3390/app9204338
Chicago/Turabian StyleMoayedi, Hossein, Dieu Tien Bui, Anastasios Dounis, Zongjie Lyu, and Loke Kok Foong. 2019. "Predicting Heating Load in Energy-Efficient Buildings Through Machine Learning Techniques" Applied Sciences 9, no. 20: 4338. https://doi.org/10.3390/app9204338
APA StyleMoayedi, H., Bui, D. T., Dounis, A., Lyu, Z., & Foong, L. K. (2019). Predicting Heating Load in Energy-Efficient Buildings Through Machine Learning Techniques. Applied Sciences, 9(20), 4338. https://doi.org/10.3390/app9204338