1. Introduction
Due to the rapid advance of mobile communication technologies and modern smart mobiles, location-based service (LBS) has become ubiquitous in recent years. With positioning technologies and applications loaded on smart mobiles, users could query location-based service providers (LBSP) for personalized services according to their locations, such as finding the nearest restaurant, getting a travel guide, or searching for a nearby market, etc.
Although location-based service brings convenience to users and plays an increasingly important role in daily life, people are also aware that their private information may be revealed along with the services provided by LBSP. Hence, the problem of privacy leakage has become a main factor that hinders the further development of LBS. Therefore, how to protect users’ privacy information while providing conventional services to users has become a topic of major interest.
Generally speaking, current popular applications on smart phones can be roughly divided into two categories. One is to hide the “who” aspect completely for LBSP, and just uses the service with “what” and “where”, such as AMAP. Another is not to hide the “who” for LBSP, and uses the service with “who”, “what”, and “where”, such as Dianping. Here, “who” means the identity of a user, “where” means the location of a user, and “what” means the preference of a user. For the wide application of LBS, users’ sensitive information (i.e., “who”, “where”, “what”) should be protected well while interacting with LBSP. For the aspect of “who”, security techniques such as pseudo-ID [
1] and pseudonym are usually used to make users’ real identity indistinguishable, but it is insufficient to protect users’ sensitive information [
2]. For the aspect of “what”, exposure of a user’s preference may result in the leakage of his sensitive information. For example, if Bob often sends some requests about the knowledge of coronary disease to LBSP, then LBSP or adversary could infer that Bob or his family members may have a health problem of coronary disease. For the aspect of “where”, if Bob often reveals his locations close to a hospital when sending his requests to LBSP, adversary or LBSP may also infer that Bob may have some health problems. If this sensitive information is leaked, some commercial organizations or adversary may send drug ads to Bob frequently. To address the problem of leaking users’ privacy caused by location information, k-anonymity as a classic scheme was proposed. k-anonymity is an anonymity set which is composed of users with different locations, and makes one user’s location indistinguishable from the locations of at least k-1 other users at some point [
3]. For example, there are
k users simultaneously requesting LBSP.
But k-anonymity is insufficient to guarantee users’ preference privacy when they request the same preference service in LBS query. There are at least two attacks, the Homogeneity Attack and Background Knowledge Attack, that can be used to compromise a anonymity set [
4]. In order to overcome this deficiency, the concept of
l-diversity, which ensures at least
l well-represented values in each equivalence class, was proposed to protect users’ privacy.
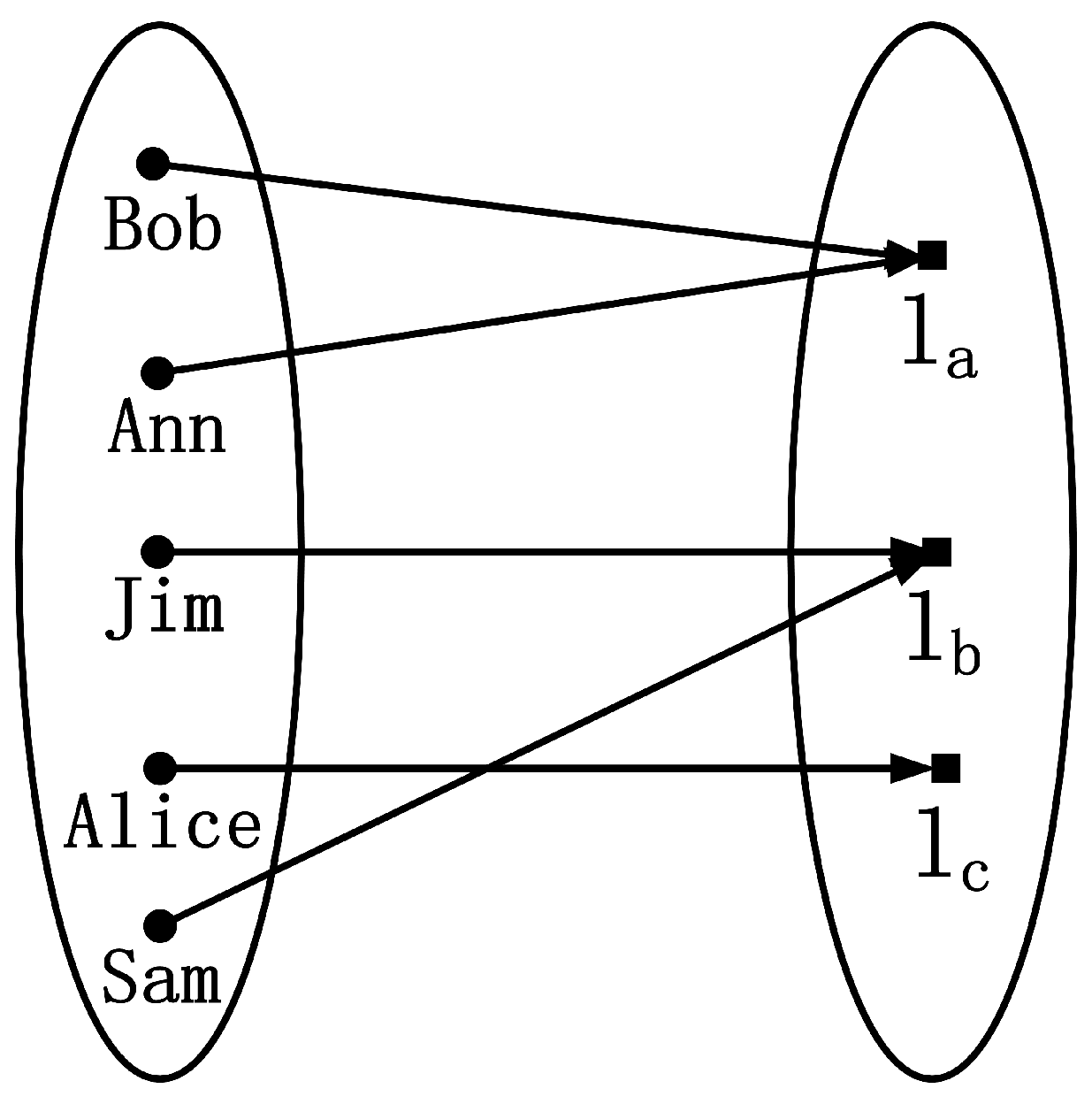
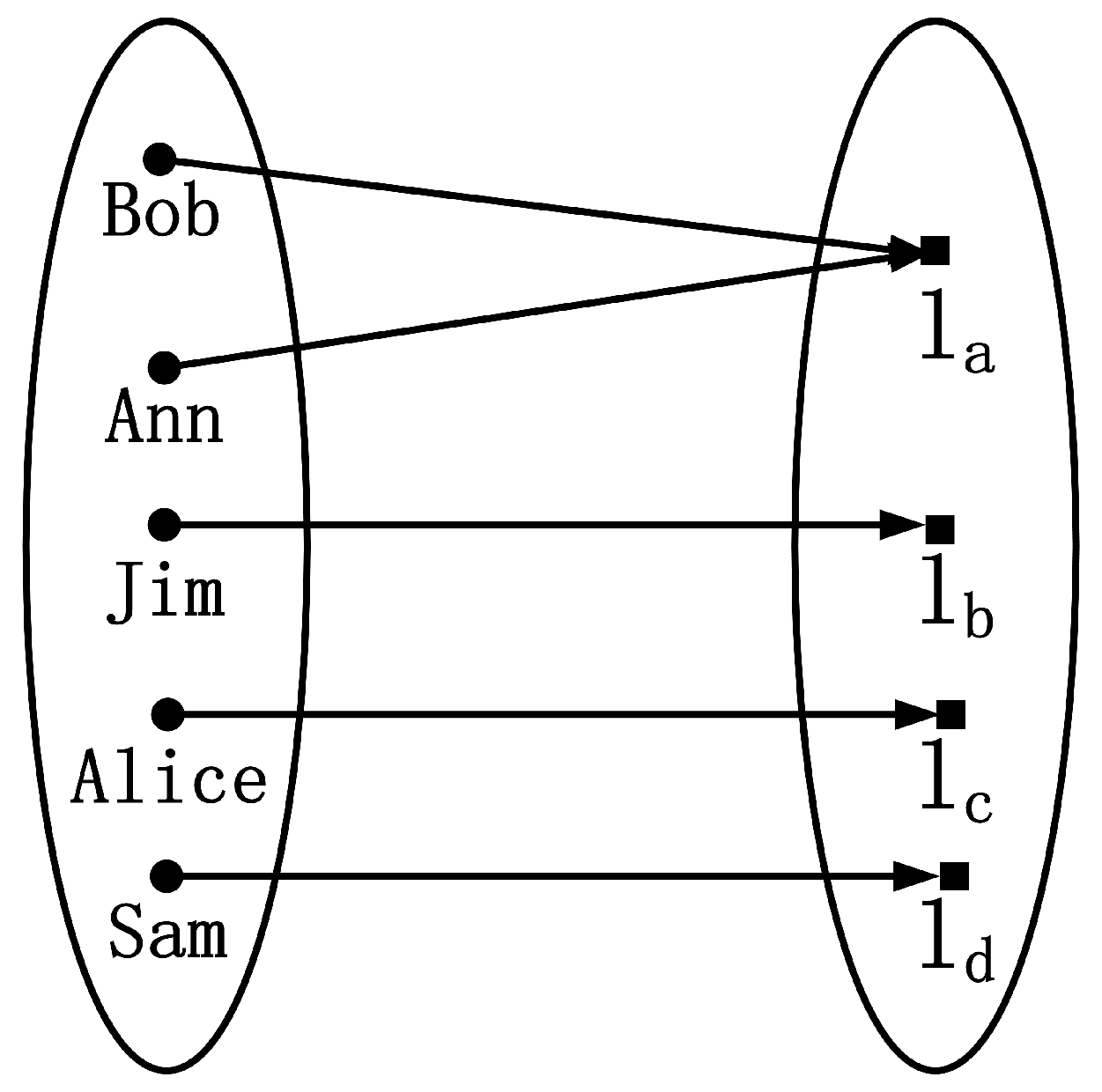
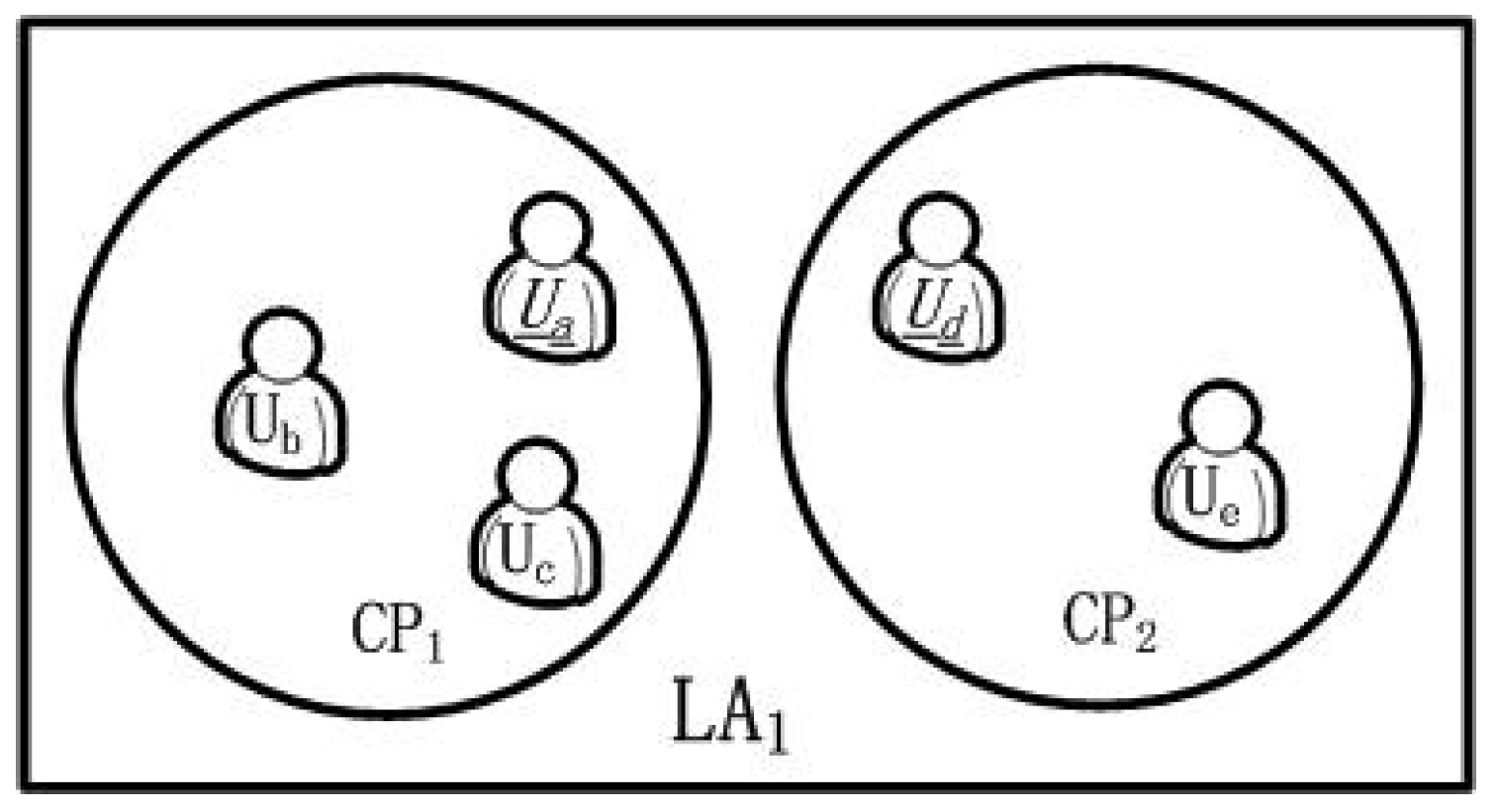
Figure 1 shows the way to protect users’ privacy by k-anonymity and
l-diversity. There are 6 users (i.e.,
k = 6) who are distributed in different locations requesting 4 different services (i.e.,
l = 4), and LBSP cannot link a specific service to a specific user. There are many studies adopt both k-anonymity and l-diversity to protect personal privacy in LBS query. For example, the authors [
5] proposed a Dummy-Location-Selection (DLS) algorithm to protect location privacy and preference privacy. The paper [
6] used Snet-Hierarchy to protect personal privacy by k-anonymity and l-diversity. A personalized spatial cloaking scheme named TTcloak was proposed in paper [
7], users’ location privacy and preference privacy were protected by k-anonymity and l-diversity respectively in Mobile Social Networks.
Currently, most of the existing works concerning the LBS query mainly focus on the security of users’ privacy with little consideration of service efficiency. Based on k-anonymity and l-diversity, some current research work, such as paper [
8], solved the problem that how to calculate the number of l-diversity without a trusted anonymizer server under a distributed architecture. But the algorithm, proposed to protect preference privacy in the clustering process, has a high degree of complexity. The authors [
9] mentioned that users’ service should be classified to different service categories, but did not consider how to identify the classified service categories, and it is inevitable to incur a huge time cost if using the way of semantic recognition. Therefore, under the system of distributed architecture, how to identify and calculate l-diversity securely and efficiently in the clustering process is still a challenge. As far as we know, there is no research on this problem. Furthermore, in real applications, it is unreasonable to judge the attribute of a user’s location in LBS query from a traditional and static viewpoint. For example, restaurants and schools are often seen as sensitive or dense locations because of the dense population from the traditional point of view [
5,
9]. However, as we all know, if the time is not for meal or school day, it is unreasonable for restaurants and schools to be classified as sensitive or dense locations. Thus, the schemes based on the static viewpoint are not very practical.
In this paper, aiming at addressing the above challenges, we propose service category table based (SCTB) algorithm to improve clustering efficiency while protecting users’ preference privacy. Therefore, under the system of distributed architecture, we rigorously explore the calculation procedure of l-diversity in LBS query, and introduce the service category table into our SCTB algorithm to make SCTB algorithm not only suitable for a single request but also for continuous request. Different from previous solutions based on the straightforward static scenario (e.g., a restaurant is unified as sensitive or dense locations), the scheme in this paper focuses on the process of security and efficient clustering from a dynamic and global perspective. The main contributions of this paper are as follows.
1. To overcome the vulnerabilities of preference privacy in LBS query, we introduce the service category table to represent different kinds of preference privacy so that the process of identifying the kinds of l-diversity can be fast, secure, and computationally inexpensive.
2. Unlike previous works that focus on location privacy and preference privacy independently, we firstly study the relationships between k and l in the clustering process. Then based on the relationships, the concepts of relatively dense scenario and relatively sparse scenario from a dynamic perspective are proposed. Finally, according to different scenarios mentioned above, we give the corresponding algorithm to improve the success rate of clustering from a global perspective.
3. We propose service category table based (SCTB) algorithm which includes request aggregation protocol, variety judgment protocol, filtering aggregation protocol, and representative aggregation protocol to reduce the time cost of clustering process and improve the success rate of clustering groups while protecting preference privacy of users. We also study the circumstance when users’ preferences in the clustering process have similarities.
4. We carry out extensive simulations to evaluate the performance of our SCTB algorithm.
5. Algorithm Design
In this section, we firstly describe the scheme of SCTB. Then SCTB proposed in this paper is explained, which includes request aggregation protocol, variety judgment protocol, filtering aggregation protocol, and representative aggregation protocol. Lastly, we make a summary of our service category table based (SCTB) algorithm.
5.1. The Algorithm Scheme
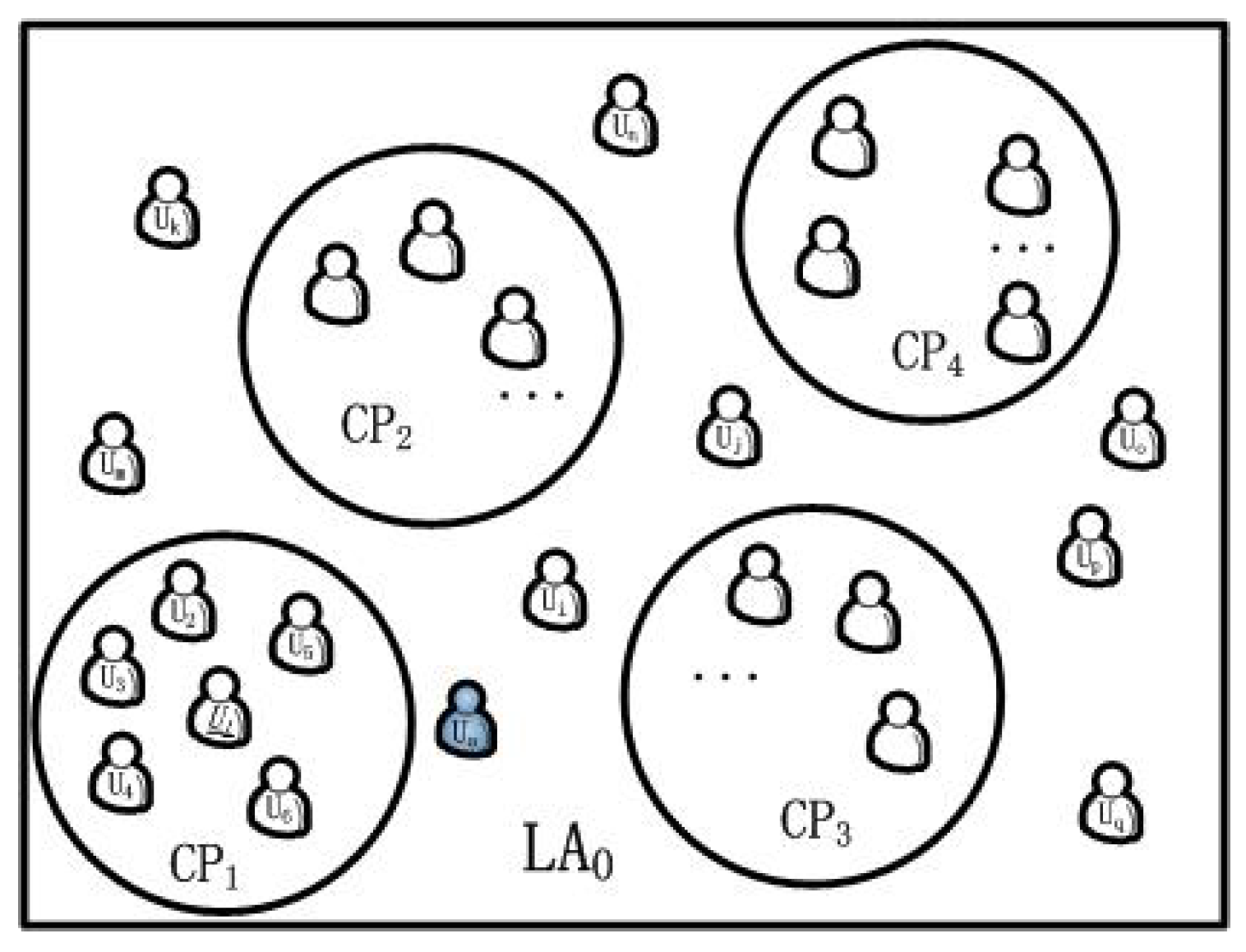
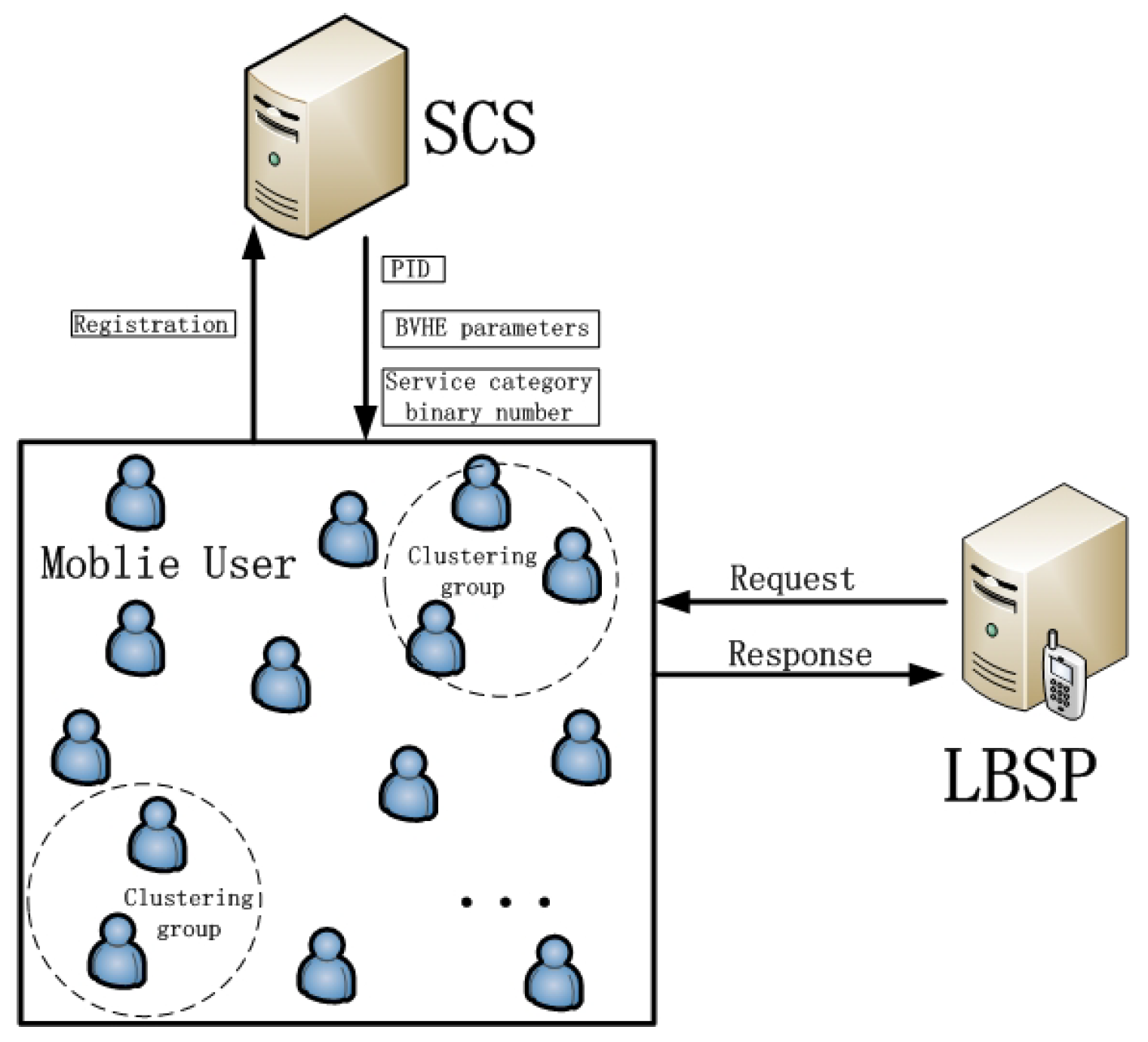
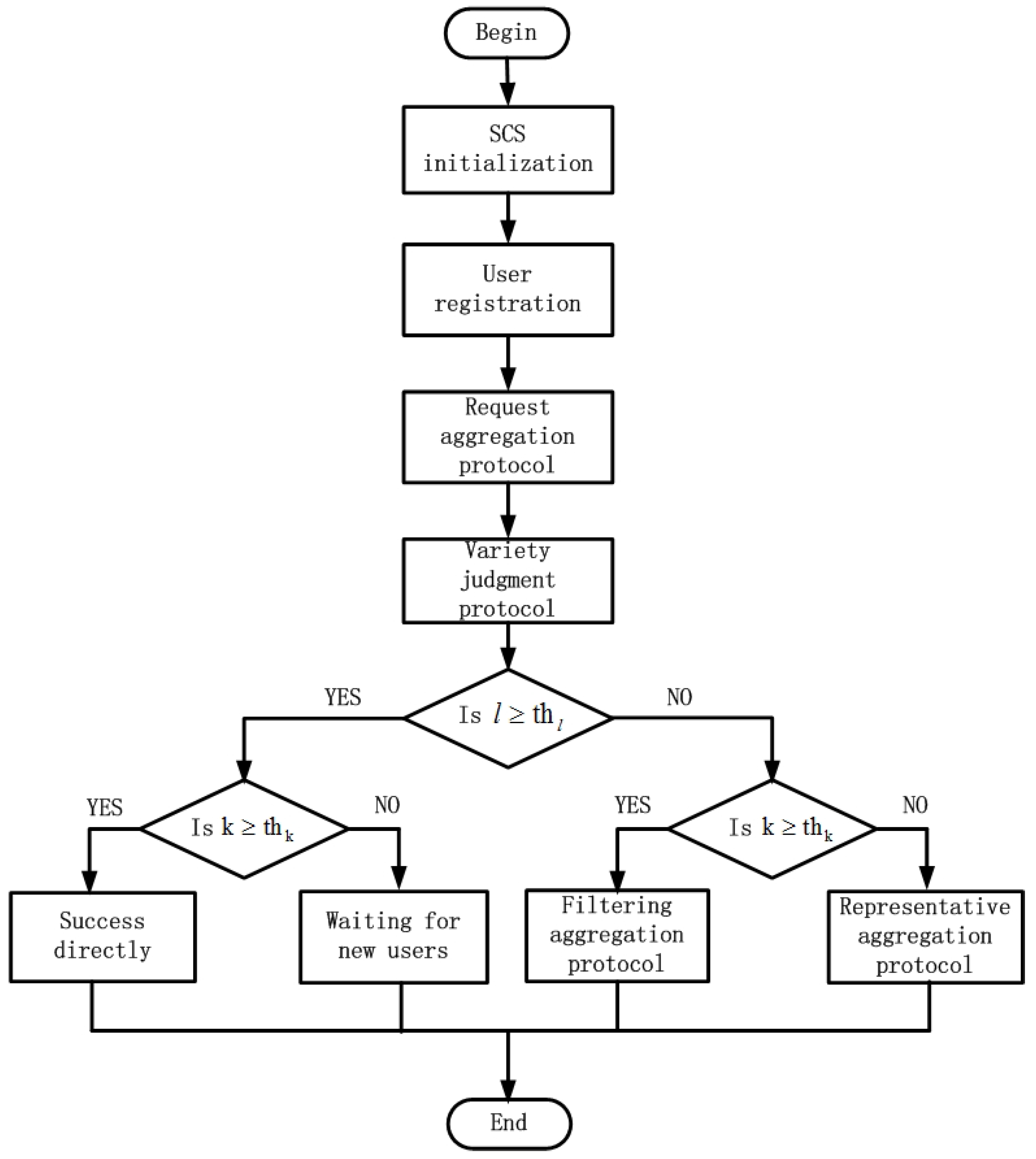
For the security parameters
and
in a region, the service category server bootstraps the LBS system and initializes it. If a user wants to obtain service from the LBS system, he must register himself to the LBS system. Before sending a request to the LBSP, he should firstly unite with other
k − 1 users to become a clustering group by using the request aggregation protocol. Then the kinds of service category
l in the clustering group can be calculated by the variety judgment protocol. The representative user of the clustering group firstly should judge the relationship between
l and
. If
, the representative user will judge the relationship between
k and
. Then there will be two results: If
, which means the clustering group has met the conditions of clustering success, the clustering process is ended. If
, which means the clustering group has not met the condition of clustering success, the clustering group will wait for new users to join to meet the condition (i.e.,
) until timeout. If
, which means the clustering group has not met the condition of clustering success, the representative user will choose filtering aggregation protocol or representative aggregation protocol by judging the relationship between
k and
for improving the success rate of clustering. Note that, if a clustering group does not meet the conditions (i.e.,
and
) and runs into a timeout, the clustering process of this group is a failure, and no service request will be sent to LBSP. The scheme of our SCTB algorithm is shown as
Figure 10.
5.2. Request Aggregation Protocol
Generally speaking, assume that a user is not in a clustering group of other users and wants to launch a request to the LBSP in his region. should unite with other users to form a clustering group. Algorithm 1 describes the pseudo code of the request aggregation protocol. The detailed explanation is as follows.
User firstly broadcasts the request aggregating message and sets the termination time T, and T starts counting down. If there are some users who want to join in the clustering process of , these users should return their pseudo-IDs to . Then will count the number k of users who have responded. If the number (include himself) , takes himself as the representative of the clustering group, which is symbolized by , he names the clustering group as . When the number of sums is obtained by one clustering group (i.e., this sum is obtained only from ), the number of groups . After the setting above, firstly uses his public key to encrypt his kind of service category . Then gives his and to members of this clustering group. Finally, the members use to encrypt their kinds of service category and return the result = = to , where , . names this result of the clustering group as , which is the encrypted sum of kinds of service category in . firstly uses his private key to decrypt and gets . Then uses variety judgment protocol to calculate the kinds of service category l in . Note that here the kinds of service category . Otherwise, would know other users’ kinds of service category in the current clustering group. There will be four cases as follows, and here assume that .
Case 1: and . firstly notifies the members in to prepare their inputs based on their kinds of service category. Then he repackages their packets and gets an aggregated package, which is symbolized by . As the respective, sends to the LBSP.
Case 2:
and
. As explained in
Section 3.4, k-anonymity is easier to be satisfied than l-diversity. So waiting for new users to join is a better choice for
. Under this situation,
does not need to judge new users’ kinds of service category, and just wait for new users’ joining to meet the condition
.
Case 3: and . We know this case is the same as scenario 1, the filtering aggregation protocol will be carried out. The reasons why we choose it will be explained when we describe it.
Case 4: and . We know this case is the same as scenario 2, the representative aggregation protocol will be carried out. The reasons why we choose it will be also explained when we describe it.
| Algorithm 1 Requests aggregation |
| Input: Initiator, Service category table, Users |
| Output: Representative, l, k |
| 1: Initiator broadcasts the request aggregating message, and sets the termination time T; |
| 2: if then |
| 3: {,,…,} → ; |
| 4: gets the number of users k; |
| 5: if then |
| 6: The representative = , the group name = , ; |
| 7: else |
| 8: The clustering process is a failure; |
| 9: end if |
| 10: and → |
| and → |
| … |
| finally → ; |
| 11: names as , and uses to get ; |
| 12: uses variety judgment protocol, and gets l; |
| 13: if then |
| 14: if and then |
| 15: The clustering process is a success, the remaining work will be performed; |
| 16: end if |
| 17: if and then |
| 18: Waiting for new users to join; |
| 19: end if |
| 20: if and then |
| 21: Filtering aggregation protocol is adopted; |
| 22: end if |
| 23: if and then |
| 24: Representative aggregation protocol is adopted; |
| 25: end if |
| 26: else |
| 27: The clustering process is a failure; |
| 28: end if |
| 29: end if |
5.3. Variety Judgment Protocol
The purpose of this variety judgment protocol is to figure out the kinds of service category
l in the clustering process. When there is only one sum
in a clustering group, we know the
just as the illustration in request aggregation protocol. After
gets
from
, he would use the way as explained in
Section 3.3 to figure out the result of
, which represents the kinds of service category
l in the clustering process of
at this moment. When there is not only one sum
in this clustering group, such as two sums, then the representative sets
, and this case will be explained in representative aggregation protocol. After
gets the combined sum
from two clustering groups, he also uses the way as explained in
Section 3.3 to figure out the result of
. Algorithm 2 describes the pseudo code of the variety judgment protocol.
| Algorithm 2 Variety judgment |
| Input:, , , , |
| Output:l |
| 1: if then |
| 2: figures out the result of from in ; |
| 3: end if |
| 4: if then |
| 5: figures out the result of from combined sum ; |
| 6: end if |
5.4. Filtering Aggregation Protocol
According to the given security parameters
and
in a region, when a clustering group has already met the condition
but not met
. If the success of this clustering group (i.e., meet the conditions
and
) needs to be promoted, the clustering group should make the new users who want to join in the clustering group have different kinds of service category rather than those kinds of service category that the clustering group already has. Therefore, the purpose of our filtering aggregation protocol is to choose new users selectively. There are two reasons for adopting this method: Firstly, it is no use for increasing the success probability of the clustering group when the new users have the same kinds of service category as the clustering group already has, on the contrary, it just increases the load of the clustering group. For example, suppose that the
and
in a region, and a clustering group now under the conditions that
k = 8 and
l = 3. Assume that the clustering group meets the conditions
and
finally,
k = 15 and
l = 5 may be the final result of the clustering group, which obviously generates more traffic and computation load than the result
k = 10 and
l = 5 by using our filtering aggregation protocol. And it is more effective especially when users’ kinds of service category in LBS query are similar or even identical under a certain time and space, which will be proved in the
Section 6. Secondly, it will influence the global success rate of clustering groups in this region. In the condition of the same
and
, if a clustering group contains too many users, obviously, other clustering groups cannot cluster successfully due to lack of users.
From the variety judgment protocol, we can know the number of l and k in . Assume that the case is and , when a new user wants to join in . The representative firstly gives his and to . Then uses to encrypt his kind of service category and obtains the intermediate result = + . Finally, returns to , and recalculates the current value of , which is symbolized by . If , we know the new user’s kind of service category is different from the kinds of service category that already has, and it is helpful to promote the success of . Therefore, the representative allows the new user to join. Otherwise, refuses . Finally, if the current , the clustering process is a success, or else waits for more new users to join. Algorithm 3 describes the pseudo code of the filtering aggregation protocol.
Security analysis: It will be explained from two sides in the clustering process.
From the perspective of the single newly-joining user who wants to join in : Because sends the encrypted result to the single newly-joining user , cannot infer the existing kinds of service category contained in unless he can decrypt .
From the perspective of the clustering group: If the user submits the kind of service category which is different from those kinds of service category that already has (i.e., ), the representative cannot know the exact kind of service category because of the different .
If the user submits the kind of service category which is the same as one of these kinds of service category that the already has (i.e., ), there will be two cases as follows.
- (a)
If the kind of service category of user is same as the representative , will know the kind of service category of user because of the same ;
- (b)
If the kind of service category of user is not the same as the representative , which means it is the same as one of other users in , the representative cannot know the exact kind of service category of user because of the different .
But due to the regulation of the filtering aggregation protocol, if , the representative has to refuse . Therefore, he cannot do further exploration for user . Because the corresponding relationship between the kind of service category and binary number is not unchangeable, although the representative has deduced the meaning of of in this clustering process, he cannot make sure that the meaning of is the same as previous or subsequent clustering process.
| Algorithm 3 Filtering aggregation |
| Input: New users, |
| Output: New l |
| 1: while and do |
| 2: continue broadcasting the request aggregating message, the new user wants to join; |
| 3: and → |
| → ; |
| 4: if then |
| 5: The join of is agreed; |
| 6: else |
| 7: The join of is refused; |
| 8: end if |
| 9: end while |
5.5. Representative Aggregation Protocol
According to the given security parameters and in a region, both and are not met in an original clustering group. If the success of this clustering group needs to be promoted, the method is to combine with other clustering groups that have the same conditions (i.e., , ). The reason is that the cooperation among clustering groups could have a higher success probability to promote the success of the original clustering group than just waiting for new users to join. Besides, if other clustering groups nearby are found finally, the time cost of clustering will also be reduced. When the users’ kinds of service category are similar or even identical in a certain time and space, for the original clustering group, newly-joining users are more likely to contribute to the value of k rather than the value of l. Note that our method is not to prevent new users from joining, but to find other clustering groups as the first choice.
From the variety judgment protocol, we can know the number of l and k in . Assume that the case is and . begins to broadcast the representative aggregating message, but different from request aggregating message, the representative aggregating message can only be responded by representatives. Suppose that there is a clustering group with the same conditions (i.e., , ) as , and its representative responds to . Firstly, will send his to , then sends his current set of pseudo-IDs and encrypted sum back to . Note that this is from decrypted . Then, will set and recalculate the value of . Finally, the current is figured out by the combined sum which is obtained by adding of and of . According to the relationship of current k and l between and , chooses the different protocol mentioned above to finish the subsequent process. Algorithm 4 describes the pseudo code of the representative aggregation protocol.
| Algorithm 4 Representative aggregation |
| Input: New clustering groups, |
| Output: New l, New k |
| 1: while , and do |
| 2: broadcasts the representative aggregating message, then the responds; |
| 3: → |
| 4: The pseudo-IDs set of and → ; |
| 5: , and gets current k and l from combined sum ; |
| 6: if and then |
| 7: The clustering process is a success, the remaining work will be performed; |
| 8: end if |
| 9: if and then |
| 10: Waiting for new users to join; |
| 11: end if |
| 12: if and then |
| 13: Filtering aggregation protocol is adopted; |
| 14: end if |
| 15: if and then |
| 16: Representative aggregation protocol is adopted; |
| 17: end if |
| 18: end while |
5.6. Service Category Table Based Algorithm
Algorithm 5 summarizes the strategies of the service category table based (SCTB) algorithm in this paper. If the user wants to send a request to the LBSP. Firstly, he should aggregate other users by using the request aggregation protocol. If there are some users who agree to form a clustering group together with the user , he will become the representative. Secondly, the representative uses variety judgment protocol to figure out the kinds of service category in the clustering group. Finally, from the comparison between (k,l) and (,), chooses different strategies according to the following four kinds of situations:
- (i)
and , the clustering process is a success;
- (ii)
and , waiting for new users to join;
- (iii)
and ; using filtering aggregation protocol for the subsequent processing;
- (iv)
and , using representative aggregation protocol for the subsequent processing.
| Algorithm 5 Service Category Table Based (SCTB) algorithm |
| 1: Broadcast the aggregating message; |
| 2: Aggregate uers’ requests by using request aggregation protocol; |
| 3: Figure out the current k and l by using variety judgment protocol; |
| 4: if and then |
| 5: The clustering process is a a success, the remaining work will be performed; |
| 6: end if |
| 7: while do |
| 8: if and then |
| 9: Waiting for new users to join; |
| 10: end if |
| 11: if and then |
| 12: Filtering aggregation protocol is adopted; |
| 13: end if |
| 14: if and then |
| 15: Representative aggregation protocol is adopted; |
| 16: end if |
| 17: end while |
6. Evaluation
In this section, the efficiency and effectiveness of our SCTB algorithm are experimentally evaluated. Firstly, we analyze the computational cost of the PLAM [
8] and our SCTB on figuring out the kinds of service category in the clustering process. Then we describe the simulation environment and give the simulation results.
6.1. Performance Analysis
Assume that there is a clustering process which contains users and a data-pool which contains different kinds of service category, and are both random constant. Because PLAM, LLB, and our SCTB adopt the system architecture of TTP-free, and the kinds of service category in a clustering group are both figured out by the representative of the clustering group, the two algorithms (i.e., PLAM and LLB algorithm) are used for comparison. We assume that all conditions are the same and meet the premise that one user sends one kind of service category in a clustering process. For example, user Bob only sends one request about finding a restaurant in one clustering process, but he cannot send the request that contains both finding a restaurant and a hospital at the same time. We now give the computational cost of our SCTB and PLAM about the process of identifying and calculating l-diversity.
Claim 1. In a clustering process, ignoring the computational complexity of decryption, the computational complexity of SCTB on figuring out l-diversity is .
Proof of Claim 1. Firstly, the
users should add together to form
, and
is the public key of the representative. We can know the computational complexity is
[
32]. Then we decrypt
and get
, the
can be figured out by
. Because the number of
is equal to
, and
is the total kinds of service category that can be represented. Therefore, the computational complexity is
. Ignoring the computational complexity of decryption, the computational complexity of this process is
. □
Claim 2. In a clustering process, ignoring the computational complexity of decryption, the computational complexity of PLAM on figuring out l-diversity is .
Proof of Claim 2. Under the same settings as above. PLAM adopts a set to denote different kinds of service category that available to a , and the set also means the total kinds of service category that can be represented is n, where the number n is equivalent to . Firstly, the representative should calculate , and we know the computational complexity is . Then users cooperatively exchange and calculate , and we know the computational complexity of is . Therefore, the computational complexity of is . Ignoring the computational complexity of decryption, the computational complexity of this process is . □
According to above-mentioned analysis, we can know that the computational complexity of our SCTB is smaller than the PLAM. Therefore, it is helpful to finish the clustering process as well as reduce the communication overhead among users.
6.2. Performance Metrics
In order to evaluate the performance and effectiveness of the proposed algorithm, some metrics of this paper are explained in this subsection.
is a comprehensive evaluation for clustering groups in a region, and it is mainly composed of and in this paper.
is used to measure the time taken for a clustering group from initiating clustering to meet the conditions of k-anonymity and l-diversity (i.e., and ) in a region. The smaller the response time, the more efficiency of a clustering group. It also means the faster a clustering group can send the aggregated package to LBSP.
is used to measure the ratio of the number of clustering groups that meet the conditions
and
to the number of all clustering groups in a region [
3]. The higher the success rate, the more efficiency of cluster groups. It also means more users’ requests can be sent to LBSP.
6.3. Simulation and Results
The essence of the SCTB algorithm is to improve clustering efficiency while protecting privacy. Therefore, the extensive simulations are conducted for evaluating the performance of our algorithm. In this section, we describe the details of our simulation environment, then give the simulation results and analysis.
6.3.1. Simulation Setup
We use Matlab R2018a to conduct our simulations, and run all algorithms on a local machine with an Intel Core-i5 2.5 GHz, 6 GB RAM, and Microsoft Windows 7 OS. Assume that there is a region A of size 10 km × 10 km with 100 × 100 locations. We construct a full-mesh network consisting of 100 × 100 nodes to simulate the locations in region A. To evaluate the effectiveness of our SCTB algorithm, we introduce the concept of service category similarity, which is symbolized by in this paper. Suppose that under normal circumstances, the kind of service category of user A is not related to the kind of service category of user B, then the service category similarity between user A and user B is . Assume that under certain space-time conditions, the probability of user A’s kind of service category is half the same as user B’s, then we denote the service category similarity between user A and user B is . We perform the simulation in the following four different scenarios and average performance results were obtained for running each scenario for 30 min.
Scenario-1: There are users with transmission radius of = 50 m randomly distributed in region A. Assume that the total kinds of service category in the data-pool are 16. All users should join in the clustering process, if a user receives a request aggregating massage when he wants a LBS query, he will response for it and join in that clustering group. Otherwise, will broadcast the request aggregating message as an initiator, and wait for other users to join. A certain number of users who send requests at a time interval. The ratio of the certain number of users to the total number of users is 1/10, and the time interval is . The rate of to is . We set the service category similarity , which means the probability of service category similarity among users is 0%.
Scenario-2: We set the service category similarity , which means the probability of service category similarity among users is 50%. The rest of the conditions are the same as Scenario-1.
Scenario-3: We set the service category similarity , which means the probability of service category similarity among users is 75%. The rest of the conditions are the same as Scenario-1.
Scenario-4: Users move independently with the same velocity , and a representative sends clustering requests continuously in the under different . The rest of the conditions are the same as Scenario-1.
6.3.2. Simulation Results
We compare the other two algorithms (i.e., PLAM algorithm and LLB algorithm) with our SCTB algorithm.
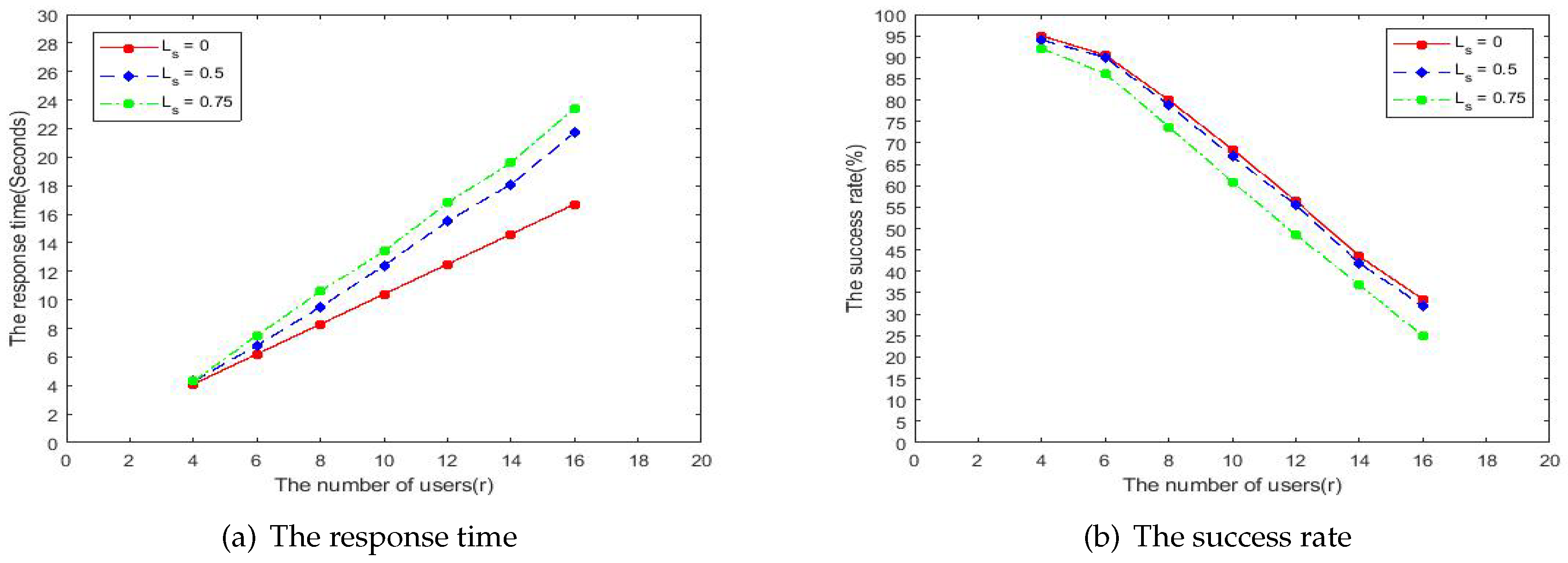
Figure 11a shows the simulation results of response time under Scenario-1. It can be seen that with the number of users in a clustering group increases, the response time increases no matter which kind of algorithm is used. It is because more user leads more time to be spent. It can also be known that the response time of our SCTB is less than PLAM and LLB. That is because the computational complexity of our SCTB is smaller than PLAM and LLB. The reason why the response time of LLB is less than PLAM is the combination of some clustering groups when some certain condition is satisfied. And the condition is as follows: When the number of users in clustering group A is less than
, the clustering group A can join in another clustering group B if and only if the clustering group B is within the communication range of A and the number of users in B is bigger than
[
9].
Figure 11b presents the relationship between the number of users and the success rate under Scenario-1. It can be seen that the success rate of our SCTB algorithm is higher than PLAM and LLB. That is because our SCTB algorithm leads the clustering process to choose new users selectively, and makes the clustering groups more reasonable by using the filtering aggregation protocol as analyzed in
Section 5.4. Besides, the representative aggregation protocol promotes the success of clustering groups as well. The reason why the success rate of LLB is higher than PLAM is also the combination of some clustering groups. From
Figure 11b, it also can be known that no matter which kind of algorithm mentioned above is used in the clustering process, the success rate decreases as the number of users in a clustering group increases. The reason is that with the number of users in a clustering group increases (i.e.,
), the clustering group has to spend more time to find users to meet the condition
, which leads to the decrease of the success rate.
Figure 12 and
Figure 13 show the simulation results under Scenario-2 and Scenario-3 respectively.
Figure 12a and
Figure 13a present the response time under Scenario-2 and Scenario-3 respectively. It can be seen that
Figure 12a and
Figure 13a reflect a trend similar to
Figure 11a, that is, the response time increases with the number of users in a clustering group increases. The response time of PLAM algorithm and LLB algorithm have almost the same performance in Scenario-1 and Scenario-2, which is influenced by the set ratio
. However, in
Figure 13a, with the number of users in a clustering group increases, the response time of PLAM and LLB increases faster than
Figure 11a and
Figure 12a. The reason is, for a clustering group, the higher service category similarity of users leads a clustering group has to find more users to meet the condition
, which will lead more time to be spent.
Figure 12b and
Figure 13b present the success rate under Scenario-2 and Scenario-3 respectively. It can be seen that
Figure 12b and
Figure 13b show a trend similar to
Figure 11b, that is, the success rate decreases as the number of users in a clustering group increases. The success rate of PLAM algorithm and LLB algorithm nearly has the same performance in Scenario-1 and Scenario-2 due to the ratio
. However, as can be seen from
Figure 13b, with the higher service category similarity of users, our SCTB still has a better performance than PLAM and LLB. This is because our SCTB chooses new users selectively during the clustering process, and makes the clustering groups more reasonable in a region.
Figure 14 shows the performance of the SCTB under Scenario-1, Scenario-2, and Scenario-3.
Figure 14a shows the response time of SCTB under different scenarios. It can be seen that the response time increases with the number of users in a clustering group increases. In the case of the same
, the higher the service category similarity, the longer the response time.
Figure 14b presents the success rate of SCTB algorithm under different scenarios. It can be seen that the success rate decreases with the number of users in a clustering group increases. In the case of the same
, the higher the service category similarity, the lower the success rate.
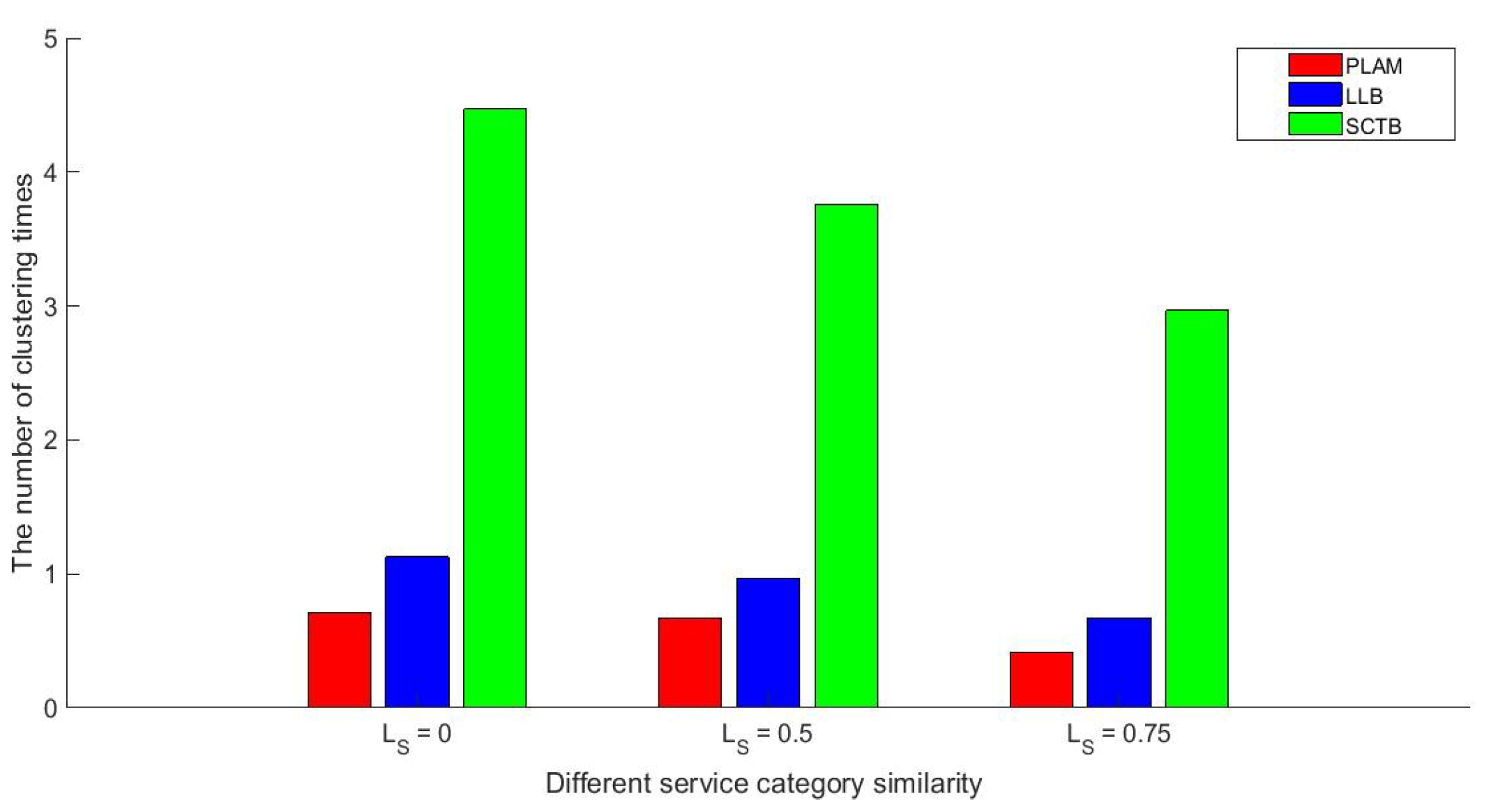
Figure 15 shows the number of clustering times when
under Scenario-4. It can be seen that the representative
could complete more number of clustering times by using our SCTB than PLAM and LLB. The reason is that the computational complexity of our SCTB is smaller than PLAM and LLB when
calculates the kinds of service category (i.e.,
l) in a clustering group. Therefore, it can allow
to spend less time to complete more clustering times.
Figure 15 also shows that with the increase of service category similarity, no matter which algorithm mentioned above is used, the number of clustering times decreases. This is because the higher service category similarity means more users are needed to meet the condition
. Therefore, more time will be spent. However, we can see that our SCTB algorithm is still has a better performance than other two algorithms, so it is also useful in the scenario of a continuous request.
6.4. Limitations of Current Work
There are some limitations of our current work. Firstly, limitations of our simulation. We assume that the mobile devices of users have sufficient computing resources to complete calculations and communications, and the factors such as communication delays among devices are not considered as well. Secondly, limitations of our SCTB algorithm. In our paper, we assume that the kinds of service category are distinct and semantically dissimilar, which means they have no semantic relationship. Therefore, how to apply our approach to semantically similar scenarios more practically is still a challenge. However, our simulations prove that our algorithm is useful for the clustering process. Besides, the results match to theoretical development which was presented between
Section 3 and
Section 6. Testing those algorithms (i.e., PLAM, LLB, and our SCTB) in a real environment is still a challenge. That is because there are many uncertain factors, such as the strength of the network, different user habits, and different social conventions may cause different results.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}