Modeling of CO Emissions from Traffic Vehicles Using Artificial Neural Networks

 ,
, 

 and
and 
Abstract
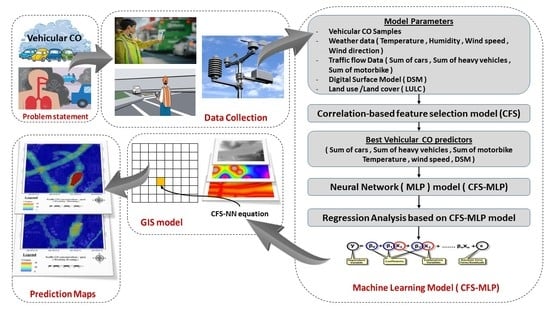
1. Introduction
2. Previous Works
3. Materials and Methods
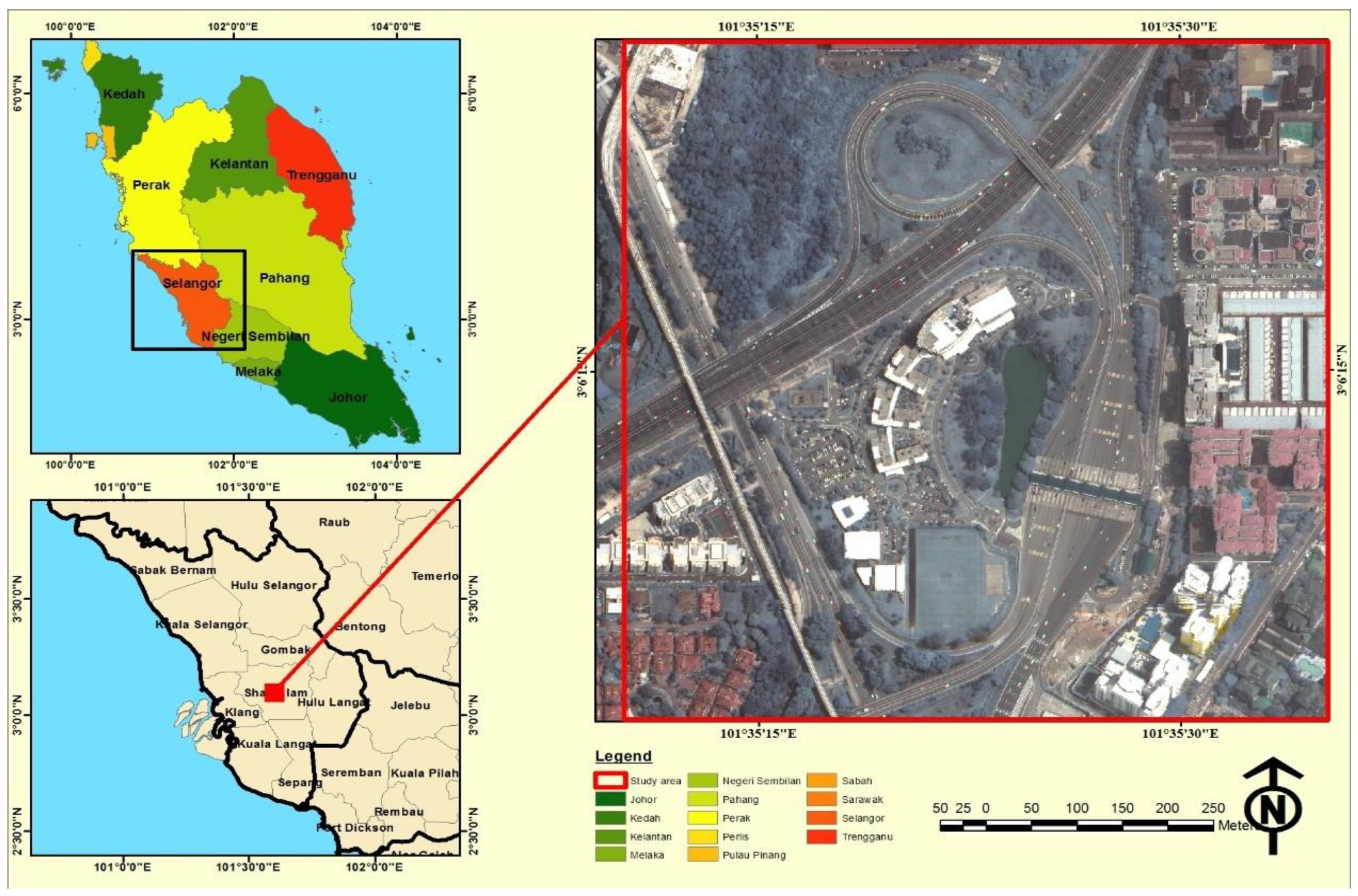
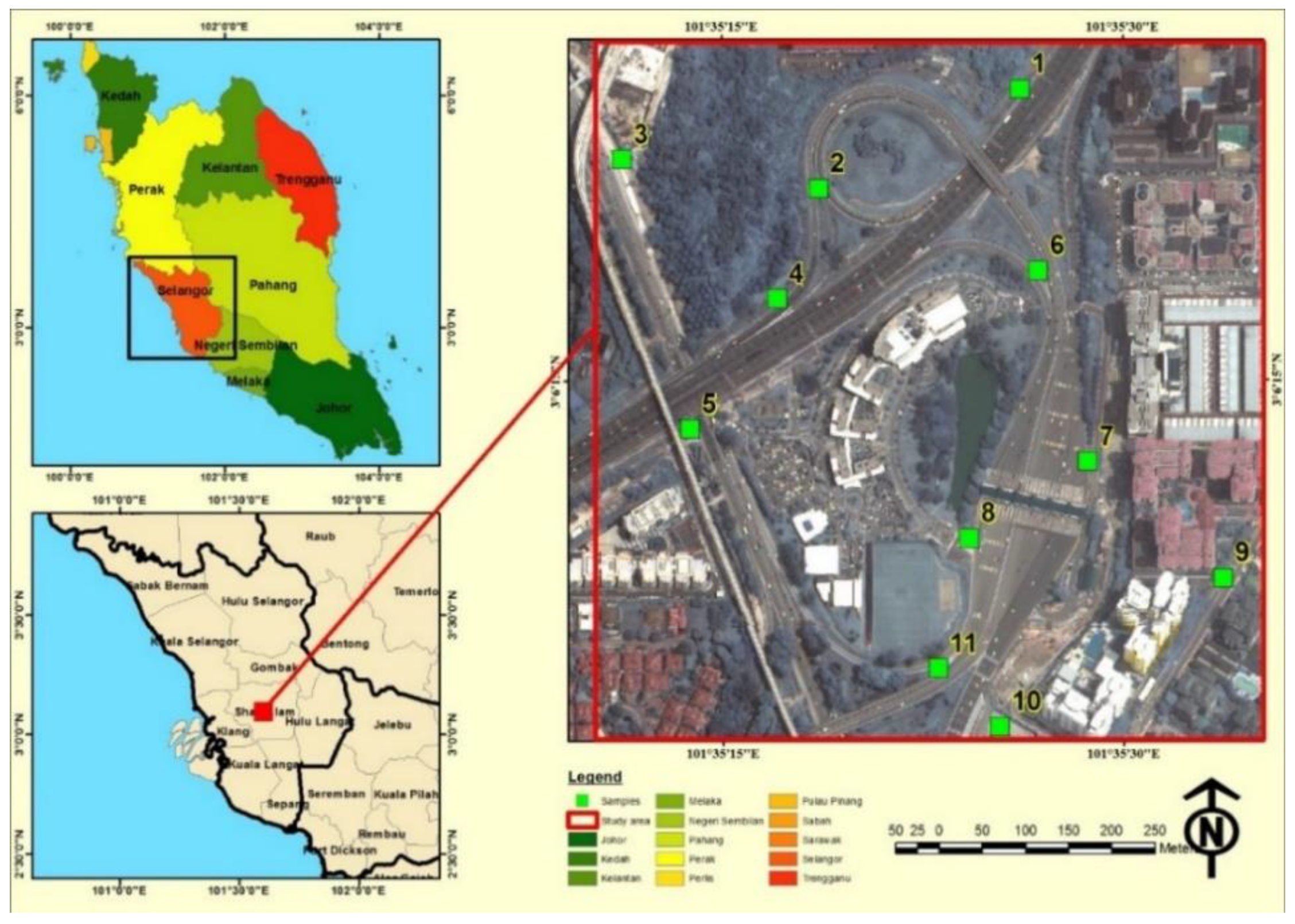
3.1. Study Area
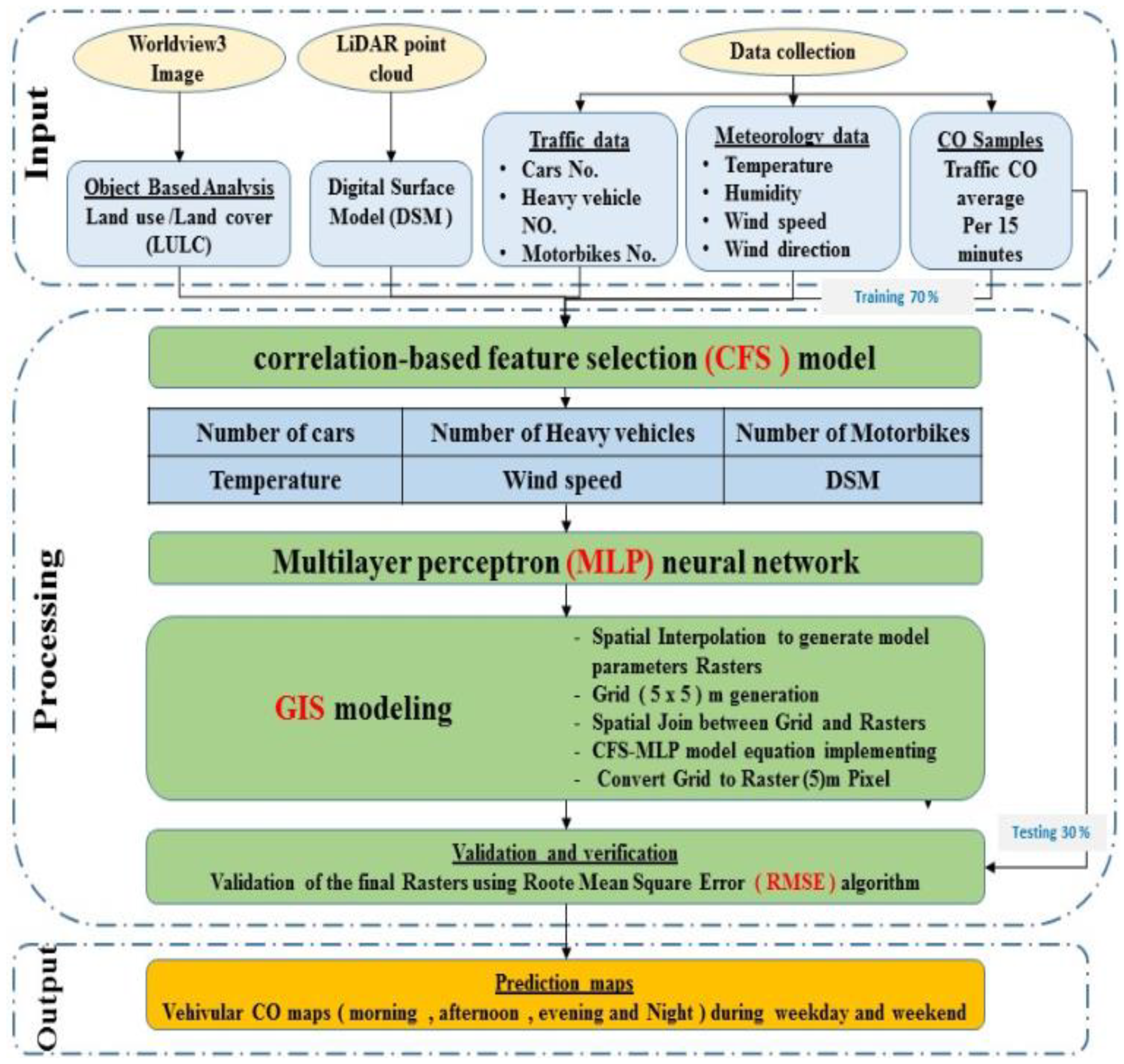
3.2. Data and Method
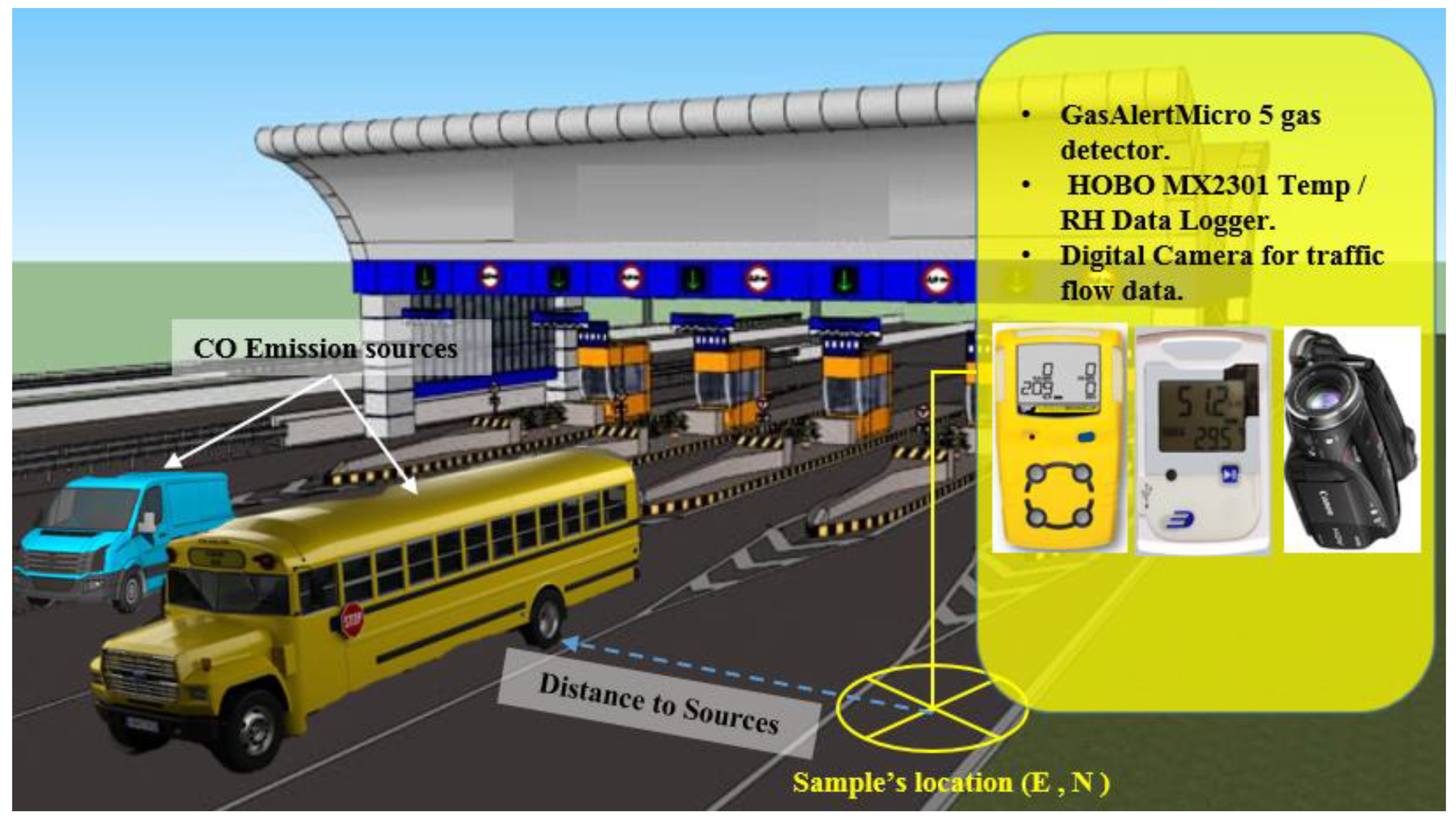
3.3. Field Surveying
3.3.1. Sampling Selection
3.3.2. Data Collection
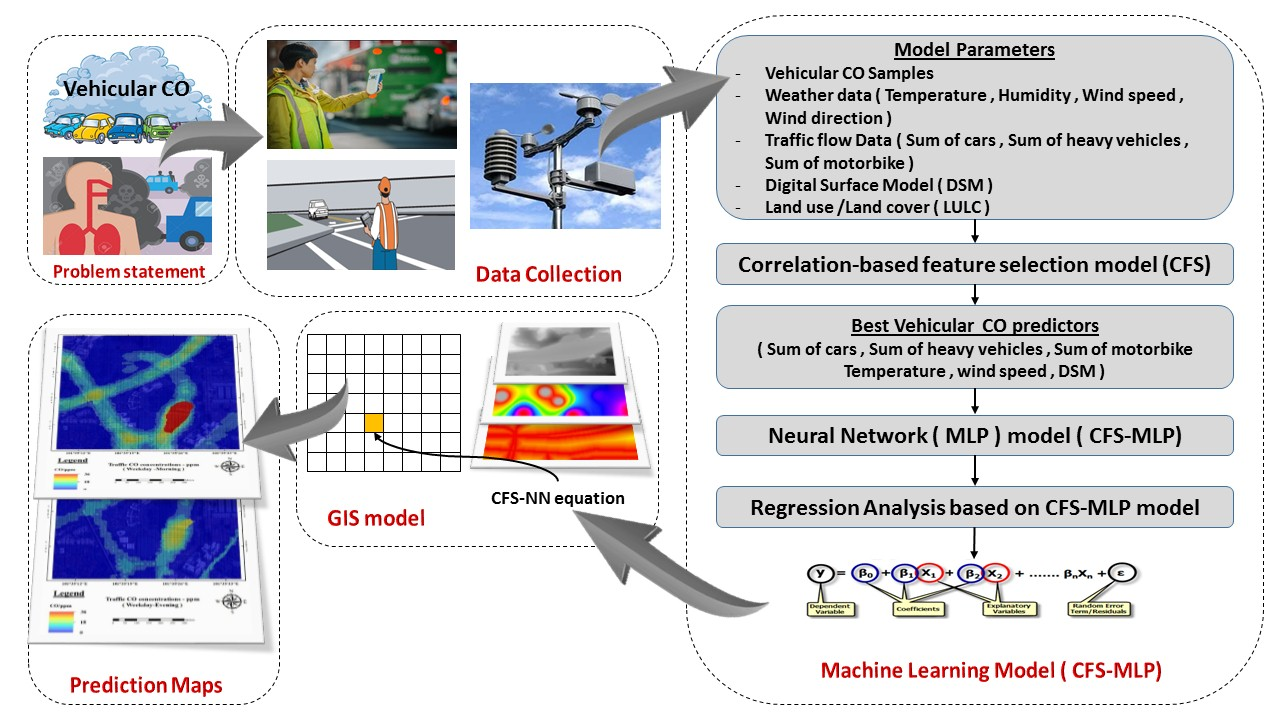
3.4. Vehicular CO Prediction Model
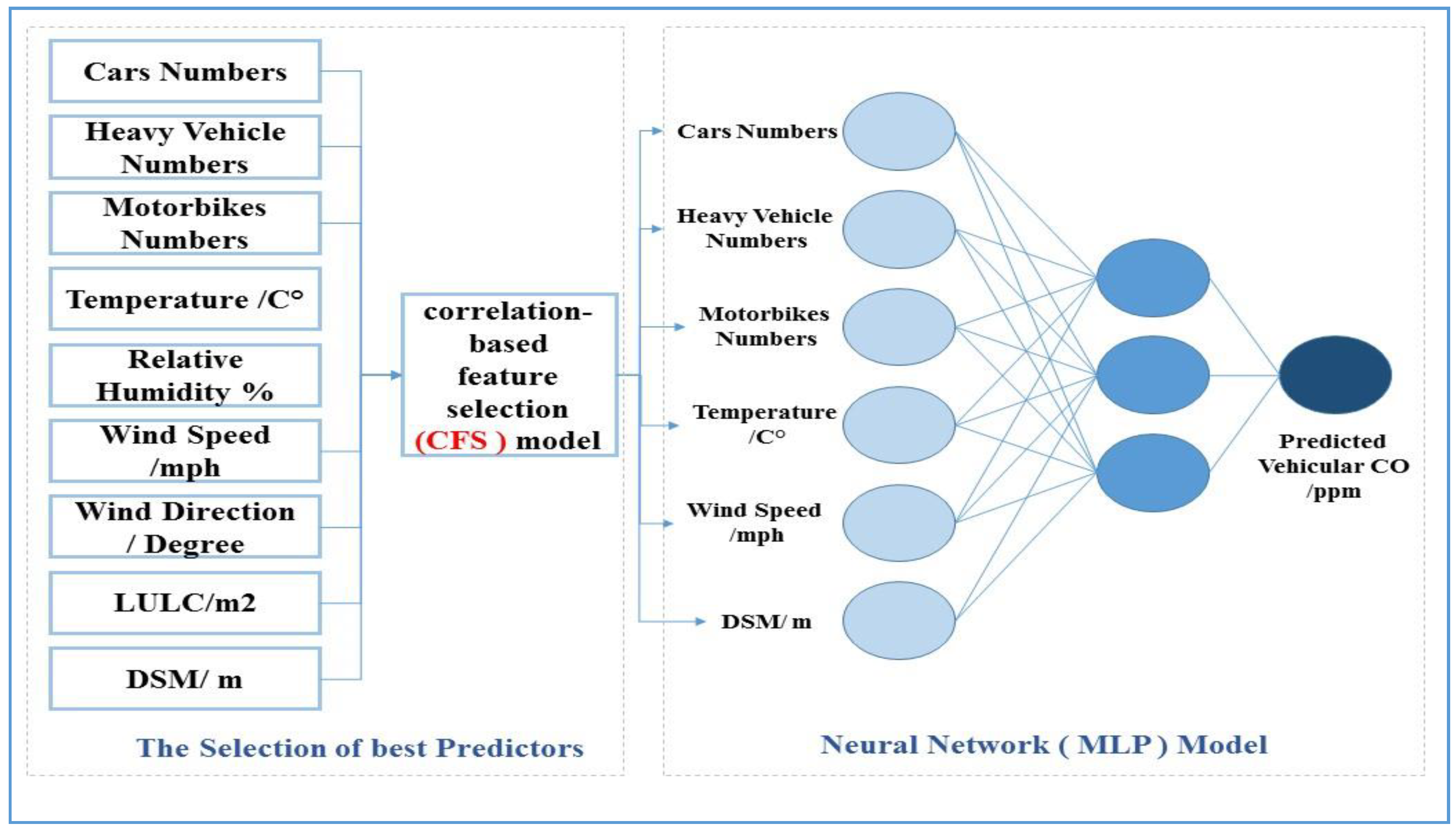
3.4.1. Vehicular CO Model Parameters
3.4.2. Correlation-Based Feature Selection (CFS) Model
3.4.3. Multilayer Perceptron (MLP) Neural Network
3.4.4. Optimization Method
3.4.5. GIS Modelling
4. Results and Discussion
4.1. Contribution of Traffic CO Predictors
4.2. Traffic CO Prediction Results
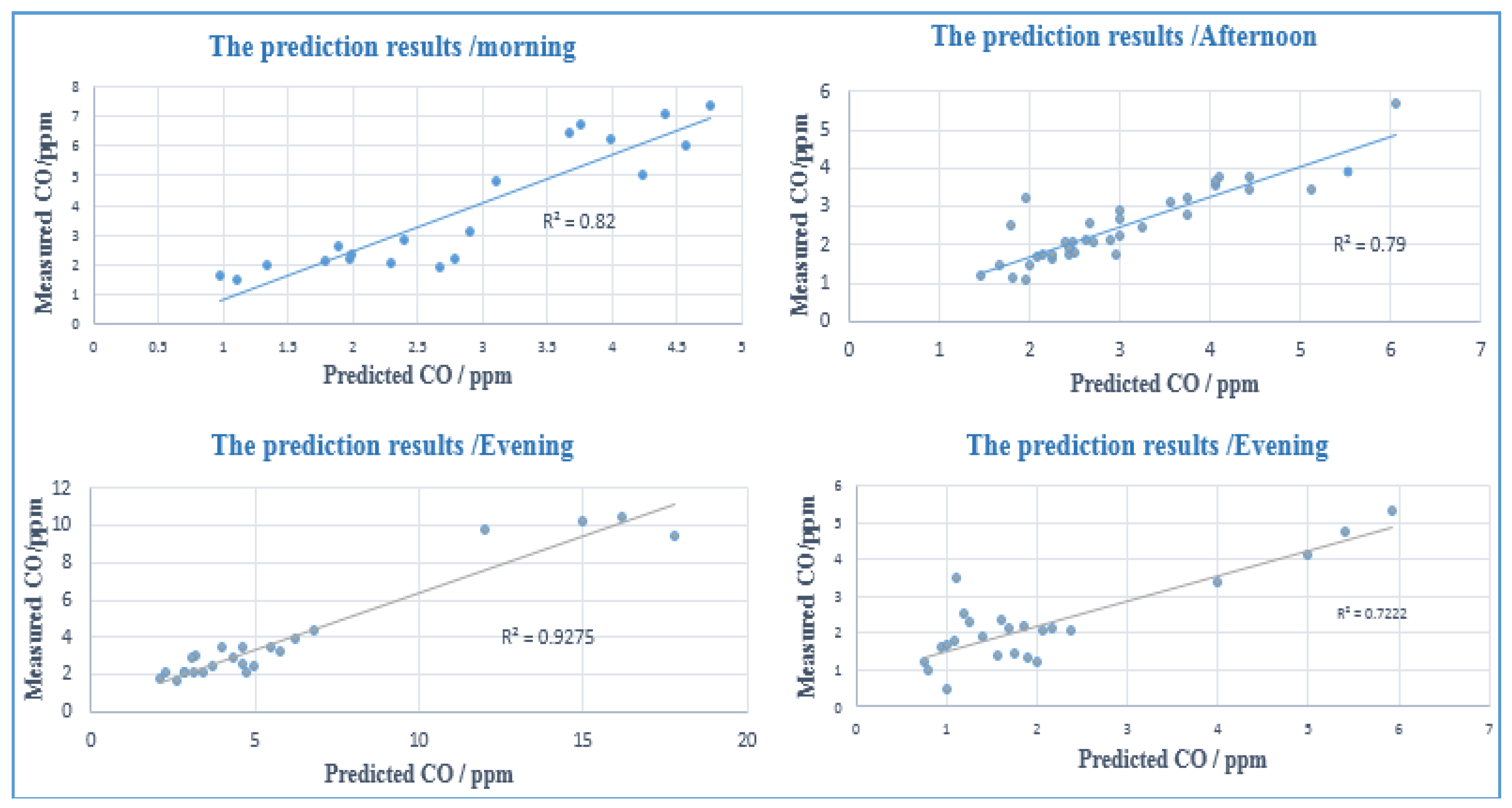
4.3. Traffic CO Prediction at Different Times of Day
4.4. GIS Modelling Results
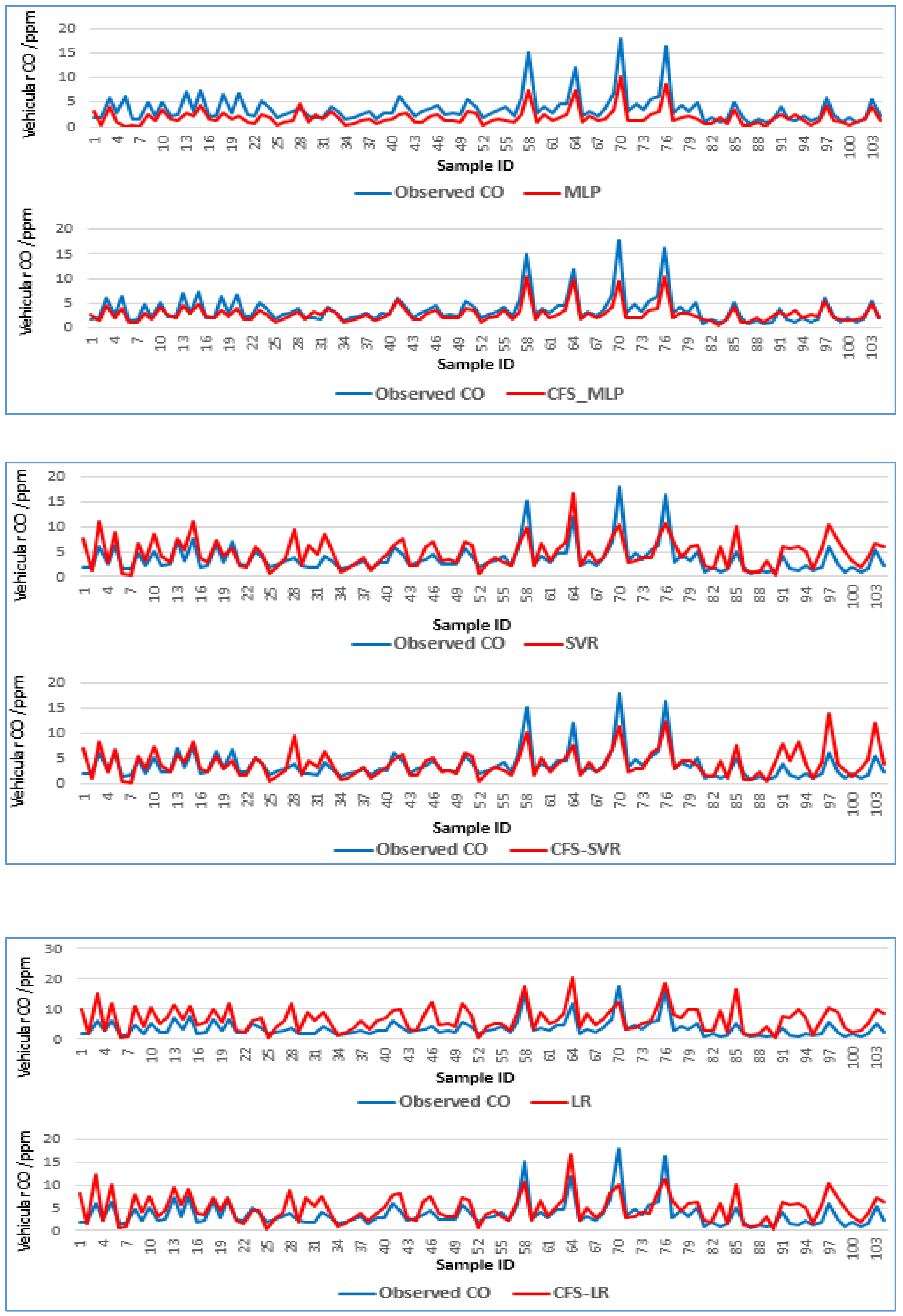
4.5. Comparison with Other Models
4.6. Validation of Traffic CO Prediction Maps
Temp/C + 0.0312 × Relative Humidity − 0.1315 × Wind speed + 0.0018 × Wind
Angle Degree − 0.0232 ∗ DSM + 0.0006 × Builtup area + 0.0064 × Highway −
8.6627.
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| GIS | A Geospatial Information System is a system designed to collect, manage, analyze, store and produce different types of spatial data. |
| CO | Carbon Monoxide is a toxic gas and it has no has no color, taste, or smell, resulting from the incomplete combustion of fuel. |
| RMSE | The algorithm of the root mean square is used to calculate the differences between values estimated by a model and the observed values. |
| VISSIM | Software designed for traffic flow simulation at a micro-scale level, which is designed by Planning Transport Verkehr (PTV), Germany. |
| EPR | The evolutionary polynomial regression, EPR, is one of the data-mining algorithms developed based on evolutionary computing and the integration of numerical regression and genetic algorithm. |
| CFS | A correlation-based feature selection algorithm, which is a type of filter algorithm that selects features based on a heuristic (correlation-based) function. |
| LiDAR | Light Detection and Ranging is an advanced surveying technology usually used to create 3D models by measure the distance between targets and the Laser Sensor. |
| ENVI | Environment for Visualizing Images: professional software used for image analysis and remote sensing applications. |
| MLP | A multilayer perceptron (MLP) is a class of feedforward artificial neural networks. An MLP consists of, at least, three layers of nodes: an input layer, a hidden layer and an output layer. Except for the input nodes, each node is a neuron that uses a nonlinear activation function. |
| LULC | Land Use and Land Cover are data files that describe the land surfaces such as water, vegetation and cultural features. |
| CFS-MLP | The proposed model that is the combination of two models, the correlation based feature selection algorithm and multilayer perceptron Neural Network algorithm. |
| CALINE4 | California Line Source Dispersion is one of the dispersion models used to estimate carbon monoxide emissions near roads based on various parameters related to geographic locations. |
| MAE | Mean Absolute Error, MAE, measures the average magnitude of the errors in a set of predictions, without considering their direction. It is the average over the test sample of the absolute differences between prediction and actual observation where all individual differences have equal weight. |
| RAE | Relative Absolute Error is defined as the absolute error relative to the size of the measurement, and it depends on both the absolute error and the measured value. The relative error is large when the measured value is small, or when the absolute error is large. |
| ANN | An Artificial Neural Network is a computational model based on the structure and functions of biological neural networks. Information that flows through the network affects the structure of the ANN because a neural network changes—or learns, in a sense—based on that input and output. |
References
- Bastien, L.A.; McDonald, B.C.; Brown, N.J.; Harley, R.A. High-resolution mapping of sources contributing to urban air pollution using adjoint sensitivity analysis: Benzene and diesel black carbon. Environ. Sci. Technol. 2015, 49, 7276–7284. [Google Scholar] [CrossRef] [PubMed]
- Fameli, K.M.; Assimakopoulos, V.D. Development of a road transport emission inventory for Greece and the Greater Athens Area: Effects of important parameters. Sci. Total Environ. 2015, 505, 770–786. [Google Scholar] [CrossRef]
- Borge, R.; Narros, A.; Artinano, B.; Yagüe, C.; Gomez-Moreno, F.J.; de la Paz, D.; Quaassdorff, C. Assessment of microscale spatio-temporal variation of air pollution at an urban hotspot in Madrid (Spain) through an extensive field campaign. Atmos. Environ. 2016, 140, 432–445. [Google Scholar] [CrossRef]
- Oftedal, B.; Krog, N.H.; Pyko, A.; Eriksson, C.; Graff-Iversen, S.; Haugen, M.; Aasvang, G.M. Road traffic noise and markers of obesity–a population-based study. Environ. Res. 2015, 138, 144–153. [Google Scholar] [CrossRef]
- Ancona, C.; Badaloni, C.; Mattei, F.; Cesaroni, G.; Stafoggia, M.; Forastiere, F. Health Impact Assessment of Air Pollution, Noise, and Lack of Green in Rome. J. Transp. Health 2017, 5, S42–S43. [Google Scholar] [CrossRef]
- Garshick, E.; Laden, F.; Hart, J.E.; Caron, A. Residence near a major road and respiratory symptoms in US veterans. Epidemiology 2003, 14, 728. [Google Scholar] [CrossRef] [PubMed]
- Delfino, R.J.; Tjoa, T.; Gillen, D.L.; Staimer, N.; Polidori, A.; Arhami, M.; Longhurst, J. Traffic-related air pollution and blood pressure in elderly subjects with coronary artery disease. Epidemiology 2010, 21, 396–404. [Google Scholar] [CrossRef]
- Crouse, D.L.; Goldberg, M.S.; Ross, N.A.; Chen, H.; Labrèche, F. Postmenopausal breast cancer is associated with exposure to traffic-related air pollution in Montreal, Canada: A case–control study. Environ. Health Perspect. 2010, 118, 1578. [Google Scholar] [CrossRef]
- Domene, E.; Lopez, R.; Fauro, B.; Rojas-Rueda, D.; Conill, C.; Alsina, G.; Marull, J. Modelling Impacts of Mobility on Urban Air Quality and Health: Scenario Analysis for the Barcelona Metropolitan Area (Metropolitan Mobility Plan). J. Transp. Health 2017, 5, S60–S61. [Google Scholar] [CrossRef]
- Singh, D.; Kumar, A.; Kumar, K.; Singh, B.; Mina, U.; Singh, B.B.; Jain, V.K. Statistical modeling of O3, NOx, CO, PM2. 5, VOCs and noise levels in commercial complex and associated health risk assessment in an academic institution. Sci. Total Environ. 2016, 572, 586–594. [Google Scholar] [CrossRef] [PubMed]
- Behera, S.N.; Sharma, M.; Mishra, P.K.; Nayak, P.; Damez-Fontaine, B.; Tahon, R. Passive measurement of NO2 and application of GIS to generate spatially-distributed air monitoring network in urban environment. Urban Clim. 2015, 14, 396–413. [Google Scholar] [CrossRef]
- Johnson, M.; Isakov, V.; Touma, J.S.; Mukerjee, S.; Özkaynak, H. Evaluation of land-use regression models used to predict air quality concentrations in an urban area. Atmos. Environ. 2010, 44, 3660–3668. [Google Scholar] [CrossRef]
- Kanaroglou, P.S.; Adams, M.D.; De Luca, P.F.; Corr, D.; Sohel, N. Estimation of sulfur dioxide air pollution concentrations with a spatial autoregressive model. Atmos. Environ. 2013, 79, 421–427. [Google Scholar] [CrossRef]
- Vandaele, N.; Van Woensel, T.; Verbruggen, A. A queueing based traffic flow model. Transp. Res. Part D Transp. Environ. 2000, 5, 121–135. [Google Scholar] [CrossRef]
- Tomić, J.; Bogojević, N.; Pljakić, M.; Šumarac-Pavlović, D. Assessment of traffic noise levels in urban areas using different soft computing techniques. J. Acoust. Soc. Am. 2016, 140, EL340–EL345. [Google Scholar] [CrossRef]
- Hamad, K.; Khalil, M.A.; Shanableh, A. Modeling roadway traffic noise in a hot climate using artificial neural networks. Transp. Res. Part D. Transp. Environ. 2017, 53, 161–177. [Google Scholar] [CrossRef]
- Di Mascio, P.; Di Vito, M.; Loprencipe, G.; Ragnoli, A. Procedure to determine the geometry of road alignment using GPS data. Procedia-Soc. Behav. Sci. 2012, 53, 1202–1215. [Google Scholar] [CrossRef]
- Righini, G.; Cappelletti, A.; Ciucci, A.; Cremona, G.; Piersanti, A.; Vitali, L.; Ciancarella, L. GIS based assessment of the spatial representativeness of air quality monitoring stations using pollutant emissions data. Atmos. Environ. 2014, 97, 121–129. [Google Scholar] [CrossRef]
- Hülsmann, F.; Gerike, R.; Ketzel, M. Modelling traffic and air pollution in an integrated approach–the case of Munich. Urban Clim. 2014, 10, 732–744. [Google Scholar] [CrossRef]
- Kim, Y.; Guldmann, J.M. Land-use regression panel models of NO2 concentrations in Seoul, Korea. Atmos. Environ. 2015, 107, 364–373. [Google Scholar] [CrossRef]
- Zarandi, M.F.; Faraji, M.R.; Karbasian, M. Interval type-2 fuzzy expert system for prediction of carbon monoxide concentration in mega-cities. Appl. Soft Comput. 2012, 12, 291–301. [Google Scholar] [CrossRef]
- Kwok, L.K.; Lam, Y.F.; Tam, C.Y. Developing a statistical based approach for predicting local air quality in complex terrain area. Atmos. Pollut. Res. 2017, 8, 114–126. [Google Scholar] [CrossRef]
- Quaassdorff, C.; Borge, R.; Pérez, J.; Lumbreras, J.; de la Paz, D.; de Andrés, J.M. Microscale traffic simulation and emission estimation in a heavily trafficked roundabout in Madrid (Spain). Sci. Total Environ. 2016, 566, 416–427. [Google Scholar] [CrossRef]
- Shakerkhatibi, M.; Mohammadi, N.; Zoroufchi Benis, K.; Behrooz Sarand, A.; Fatehifar, E.; Asl Hashemi, A. Using ANN and EPR models to predict carbon monoxide concentrations in urban area of Tabriz. Environ. Health Eng. Manag. J. 2015, 2, 117–122. [Google Scholar]
- Cai, M.; Yin, Y.; Xie, M. Prediction of hourly air pollutant concentrations near urban arterials using artificial neural network approach. Transp. Res. Part D Transp. Environ. 2009, 14, 32–41. [Google Scholar] [CrossRef]
- Zheng, Y.; Liu, F.; Hsieh, H.P. U-Air: When urban air quality inference meets big data. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; pp. 1436–1444. [Google Scholar]
- Namdeo, A.; Mitchell, G.; Dixon, R. TEMMS: An integrated package for modelling and mapping urban traffic emissions and air quality. Environ. Model Softw. 2002, 17, 177–188. [Google Scholar] [CrossRef]
- Kho, F.W.L.; Law, P.L.; Ibrahim, S.H.; Sentian, J. Carbon monoxide levels along roadway. Int. J. Environ. Sci. Technol. 2007, 4, 27–34. [Google Scholar] [CrossRef]
- Ranjbar, H.R.; Gharagozlou, A.R.; Nejad, A.R.V. 3D analysis and investigation of traffic noise impact from Hemmat highway located in Tehran on buildings and surrounding areas. J. Geogr. Inf. Syst. 2012, 4, 322. [Google Scholar] [CrossRef]
- Li, F.; Liao, S.S.; Cai, M. A new probability statistical model for traffic noise prediction on free flow roads and control flow roads. Transp. Res. Part D Transp. Environ. 2016, 49, 313–322. [Google Scholar] [CrossRef]
- Ragettli, M.S.; Goudreau, S.; Plante, C.; Fournier, M.; Hatzopoulou, M.; Perron, S.; Smargiassi, A. Statistical modeling of the spatial variability of environmental noise levels in Montreal, Canada, using noise measurements and land use characteristics. J. Expos. Sci. Environ. Epidemiol. 2016, 26, 597. [Google Scholar] [CrossRef]
- Kirchstetter, T.W.; Singer, B.C.; Harley, R.A.; Kendall, G.R.; Chan, W. Impact of oxygenated gasoline use on California light-duty vehicle emissions. Environ. Sci. Technol. 1996, 30, 661–670. [Google Scholar] [CrossRef]
- Goyal, P. Present scenario of air quality in Delhi: A case study of CNG implementation. Atmos. Environ. 2003, 37, 5423–5431. [Google Scholar] [CrossRef]
- Chen, K.S.; Wang, W.C.; Chen, H.M.; Lin, C.F.; Hsu, H.C.; Kao, J.H.; Hu, M.T. Motorcycle emissions and fuel consumption in urban and rural driving conditions. Sci. Total Environ. 2003, 312, 113–122. [Google Scholar] [CrossRef]
- Henderson, S.B.; Beckerman, B.; Jerrett, M.; Brauer, M. Application of land use regression to estimate long-term concentrations of traffic-related nitrogen oxides and fine particulate matter. Environ. Sci. Technol. 2007, 41, 2422–2428. [Google Scholar] [CrossRef]
- Shi, Y.; Lau, K.K.L.; Ng, E. Developing street-level PM2.5 and PM10 land use regression models in high-density Hong Kong with urban morphological factors. Environ. Sci. Technol. 2016, 50, 8178–8187. [Google Scholar] [CrossRef]
- Hall, M.A. Correlation-Based Feature Selection for Machine Learning. Ph.D. Thesis, The University of Waikato, Hamilton, New Zealand, 1999. [Google Scholar]
- Boznar, M.; Lesjak, M.; Mlakar, P. A neural network-based method for short-term predictions of ambient SO2 concentrations in highly polluted industrial areas of complex terrain. Atmos. Environ. Part B Urban Atmos. 1993, 27, 221–230. [Google Scholar] [CrossRef]
- Chaloulakou, A.; Saisana, M.; Spyrellis, N. Comparative assessment of neural networks and regression models for forecasting summertime ozone in Athens. Sci. Total Environ. 2003, 313, 1–13. [Google Scholar] [CrossRef]
- De Cos Juez, F.J.; Nieto, P.G.; Torres, J.M.; Castro, J.T. Analysis of lead times of metallic components in the aerospace industry through a supported vector machine model. Math. Comput. Model. 2010, 52, 1177–1184. [Google Scholar] [CrossRef]
- Gardner, M.W.; Dorling, S.R. Neural network modelling and prediction of hourly NOx and NO2 concentrations in urban air in London. Atmos. Environ. 1999, 33, 709–719. [Google Scholar] [CrossRef]
- Hooyberghs, J.; Mensink, C.; Dumont, G.; Fierens, F.; Brasseur, O. A neural network forecast for daily average PM10 concentrations in Belgium. Atmos. Environ. 2005, 39, 3279–3289. [Google Scholar] [CrossRef]
- Kukkonen, J.; Partanen, L.; Karppinen, A.; Ruuskanen, J.; Junninen, H.; Kolehmainen, M.; Cawley, G. Extensive evaluation of neural network models for the prediction of NO2 and PM10 concentrations, compared with a deterministic modelling system and measurements in central Helsinki. Atmos. Environ. 2003, 37, 4539–4550. [Google Scholar] [CrossRef]
- Nieto, P.G.; Lasheras, F.S.; García-Gonzalo, E.; de Cos Juez, F.J. PM 10 concentration forecasting in the metropolitan area of Oviedo (Northern Spain) using models based on SVM, MLP, VARMA and ARIMA: A case study. Sci. Total Environ. 2018, 621, 753–761. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. The Elements of Statistical Learning; Springer Series in Statistics: New York, NY, USA, 2001; Volume 1. [Google Scholar]
- Rojek, I. Technological process planning by the use of neural networks. AI EDAM 2017, 31, 1–5. [Google Scholar] [CrossRef]
- Mousavi, S.Z.; Kavian, A.; Soleimani, K.; Mousavi, S.R.; Shirzadi, A. GIS-based spatial prediction of landslide susceptibility using logistic regression model. Geomat. Nat. Hazards Risk 2011, 2, 33–50. [Google Scholar] [CrossRef]
- Sharma, N.; Gulia, S.; Dhyani, R.; Singh, A. Performance evaluation of CALINE 4 dispersion model for an urban highway corridor in Delhi. J. Sci. Ind. Res. 2013, 72, 521–530. [Google Scholar]
- Pao, Y.-H.; Phillips, S.M.; Sobajic, D.J. Neural-net computing and the intelligent control of systems. Int. J. Control 1992, 56, 263–289. [Google Scholar] [CrossRef]
- Pao, H.-T.; Fu, H.-C.; Tseng, C.-L. Forecasting of CO2 emissions, energy consumption and economic growth in China using an improved grey model. Energy 2012, 40, 400–409. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Average | Minimum | Maximum |
|---|---|---|---|
| Number of vehicles (per 15 min) | 1172 | 126 | 2762 |
| Number of heavy vehicles (per 15 min) | 78 | 16 | 325 |
| Number of motorbikes (per 15 min) | 112 | 9 | 489 |
| Temperature (°C) | 29.9 | 25.6 | 37.7 |
| Humidity (%) | 73.5 | 54.3 | 94.5 |
| Wind Speed (mph) | 16.87 | 16 | 18.20 |
| Wind Direction (angle) | 247.1 | 0 | 350 |
| DSM (m) | 25.7 | 10.03 | 129.5 |
| Time | Weekend | Weekday | ||||
|---|---|---|---|---|---|---|
| Average CO Concentration (per 15 min) (ppm) | Average CO Concentration (per 15 min) (ppm) | |||||
| Min | Max | Mean | Min | Max | Mean | |
| Morning | 0 | 8 | 2.36 | 0 | 30.5 | 8.5 |
| Afternoon | 0 | 14.5 | 3.5 | 0 | 12.8 | 4.5 |
| Evening | 0 | 9.3 | 3.92 | 0 | 27.3 | 5.84 |
| Night | 0 | 3.6 | 1.47 | 0 | 5.6 | 1.9 |
| Parameter | Search Domain |
|---|---|
| Type of network | MLP, RBF |
| Number of hidden units | (3–40) |
| Training Algorithm | BFGS, RBFT |
| Hidden Activation | Identity, Logistic, Tanh, Exponential, Gaussian |
| Output Activation | Identity, Logistic, Tanh, Exponential, Gaussian |
| Learning rate | (0.1, 0.5) |
| Momentum | (0.1–0.9) |
| Road Traffic CO Predictors | R-Squared | F-Statistic |
|---|---|---|
| Number of heavy vehicles | 0.7546 | 32.784 |
| Number of vehicles | 0.5322 | 18.277 |
| Number of motorbikes | 0.0472 | 1.951 |
| DSM (m) | 0.0168 | 1.231 |
| Wind speed (mph) | 0.0016 | 0.124 |
| Temperature (°C) | 0.0014 | 0.1178 |
| MLP Model | CFS-MLP Model | ||
|---|---|---|---|
| Best structure | 9-4-1 | Best structure | 6-3-1 |
| Correlation coefficient | 0.8657 | Correlation coefficient | 0.980 |
| Mean absolute error (ppm) | 0.991 | Mean absolute error (ppm) | 0.8925 |
| Root mean squared error (ppm) | 1.2862 | Root mean squared error (ppm) | 1.2736 |
| Relative absolute error % | 30.94% | Relative absolute error % | 21.99% |
| Root relative squared error % | 23.48% | Root relative squared error % | 19.40% |
| Total number of instances | 247 | Total number of instances | 247 |
| Traffic CO Predictors | Estimated Coefficient | |||
|---|---|---|---|---|
| Morning | Afternoon | Evening | Night | |
| Number of vehicles | −0.0016 | 0.0142 | 0.0108 | 0.0147 |
| Number of heavy vehicles | 0.0622 | 0.01 | 0.0319 | −0.0216 |
| Number of motorbikes | 0.0135 | −0.0378 | −0.0376 | −0.0093 |
| Temperature °C | −0.4501 | 0.5512 | 0.4888 | −0.0333 |
| Wind speed mph | 0.0752 | −0.194 | −0.4084 | 0.0135 |
| DSM m | −0.2085 | 0.213 | 0.0812 | 0.1116 |
| Intercept | 16.8559 | −22.2525 | −15.8113 | −2.1367 |
| RMSE | 2.914 ppm | 2.0347 ppm | 2.9817 ppm | 0.387 ppm |
| CFS-MLP Model | SVR Model | LR Model | |||
|---|---|---|---|---|---|
| Correlation coefficient | 0.980 | Correlation coefficient | 0.8668 | Correlation coefficient | 0.851 |
| Mean absolute error (ppm) | 0.896 | Mean absolute error (ppm) | 1.640 | Mean absolute error (ppm) | 1.851 |
| Root mean squared error (ppm) | 1.286 | Root mean squared error (ppm) | 2.752 | Root mean squared error (ppm) | 2.849 |
| Relative absolute error (%) | 21.99 | Relative absolute error (%) | 51.646 | Relative absolute error (%) | 55.048 |
| Root relative squared error (%) | 19.40 | Root relative squared error (%) | 49.784 | Root relative squared error (%) | 48.292 |
| Total number of instances | 247 | Total number of instances | 247 | Total number of instances | 247 |
| CFS-MLP Model | CFS-SVR Model | CFS-LR Model | |||
|---|---|---|---|---|---|
| Correlation coefficient | 0.980 | Correlation coefficient | 0.7578 | Correlation coefficient | 0.82 |
| Mean absolute error (ppm) | 0.896 | Mean absolute error (ppm) | 1.972 | Mean absolute error (ppm) | 1.9713 |
| Root mean squared error (ppm) | 1.286 | Root mean squared error (ppm) | 3.7109 | Root mean squared error (ppm) | 3.1057 |
| Relative absolute error (%) | 21.99 | Relative absolute error (%) | 64.3605 | Relative absolute error (%) | 64.333 |
| Root relative squared error (%) | 19.40 | Root relative squared error (%) | 67.2464 | Root relative squared error (%) | 56.2795 |
| Total number of instances | 247 | Total number of instances | 247 | Total number of instances | 247 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Azeez, O.S.; Pradhan, B.; Shafri, H.Z.M.; Shukla, N.; Lee, C.-W.; Rizeei, H.M. Modeling of CO Emissions from Traffic Vehicles Using Artificial Neural Networks. Appl. Sci. 2019, 9, 313. https://doi.org/10.3390/app9020313
Azeez OS, Pradhan B, Shafri HZM, Shukla N, Lee C-W, Rizeei HM. Modeling of CO Emissions from Traffic Vehicles Using Artificial Neural Networks. Applied Sciences. 2019; 9(2):313. https://doi.org/10.3390/app9020313
Chicago/Turabian StyleAzeez, Omer Saud, Biswajeet Pradhan, Helmi Z. M. Shafri, Nagesh Shukla, Chang-Wook Lee, and Hossein Mojaddadi Rizeei. 2019. "Modeling of CO Emissions from Traffic Vehicles Using Artificial Neural Networks" Applied Sciences 9, no. 2: 313. https://doi.org/10.3390/app9020313
APA StyleAzeez, O. S., Pradhan, B., Shafri, H. Z. M., Shukla, N., Lee, C.-W., & Rizeei, H. M. (2019). Modeling of CO Emissions from Traffic Vehicles Using Artificial Neural Networks. Applied Sciences, 9(2), 313. https://doi.org/10.3390/app9020313