1. Introduction
Remote sensing images are important data for spatial information processing. Automatic analysis of feature information in images has an important application significance [
1,
2,
3,
4,
5,
6]. Remote sensing image fully exploits geographic information, which is of great significance in the fields of forestry monitoring [
2], water system monitoring [
3] and geological exploration [
4]. Remote sensing technology analysis of ground objects and their changes with time and space have great application significance in the fields of military reconnaissance, economic construction, meteorological forecasting [
5,
6,
7,
8] and earthquake disaster early warning [
9], which are related to the national economy and people’s livelihood. A large amount of urban geographic information contained in remote sensing images, which can be used in many fields, such as digital cities, intelligent transportation, navigation maps, and urban planning [
10,
11]. Therefore, automatic analysis of remote sensing images has become an important research topic for geospatial information detection.
Remote sensing image contains a wealth of feature information. Rich geospatial information can be obtained through automatic classification methods to serve all aspects of human’s life. The multi-objective classification of remote sensing images is to assign a label to each pixel in the image. It divides the image into different semantic regions. The researchers have carried out many explorations.
In the 1980s, the statistical analysis of the features of remote sensing images is the mainstream method, which required different feature extraction methods for different tasks [
12]. The development of digital image processing has promoted the advancement of image analysis, and remote sensing image classification can be realized based on artificial features. Commonly features include color histogram [
13], direction gradient histogram [
14] and scale-invariant feature transform [
15], which contain a large amount of information. The artificial feature-based method can deal with some basic remote sensing image classification problems, but for more complex remote sensing images, it cannot achieve the desired performance.
In recent years, machine learning is developing rapidly, which leads to many remote sensing image classification and semantic segmentation algorithms based on machine learning methods are proposed. For example, Wang et al. [
16] jointly used low-rank representation (LRR), spectral-spatial graph regularization and subspace learning to classify the objects in hyperspectral images, and proposed a self-supervised low-rank representation framework. Ma et al. [
17] used classification and regression tree (CART) to classify remote sensing images, which achieved the accurate classification of different land objects in remote sensing image. However, its performance still needs to be improved. Réjichi S et al. [
18] used principal component analysis to preserve the main information of the image and reduce the feature’s dimension. This method can obtain the invariant features in the classification task, which improves the efficiency of classification. Zhao et al. [
19] used K-means to segment remote sensing image. In this method, the initial class number and centers are determined by the probability density function of the first principal component. The machine learning-based remote sensing image classification methods have achieved good results and strong stability. With the increasing demand for remote sensing image interpretation, the goals are becoming more complex and diverse. The algorithms based on feature engineering and shallow learning model are not suitable to solve the complex multi-class classification of remote sensing image.
Deep learning has been widely used in many fields. This kind of method autonomously learns data features through massive training data, which greatly accelerates the development of image recognition. In 2006, Hinton used the back propagation algorithm to train the deep confidence network [
20], which greatly improved the recognition performance. Common image classification networks include LeNet [
21], AlexNet [
22], ResNet [
23], etc. Later, the proposed Regions with Convolutional Neural Networks (RCNN) [
24] opened up a research boom using the deep learning method for object detection. The object detection network can not only identify the object, but also identify the position of the object in the image. Object detection networks include Faster RCNN [
25], SSD [
26], YOLO [
27], etc.
With the development of image classification and object detection algorithms, scholars have proposed networks for pixel-level classification of images, which can assign a label to each pixel in the image. For example, Shelhamer E et al. [
28] proposed a fully convolutional network (FCN) for semantic segmentation. This network can achieve end-to-end pixel-level classification of images, which greatly improves the efficiency of remote sensing image object classification. In 2015, Vijay et al. [
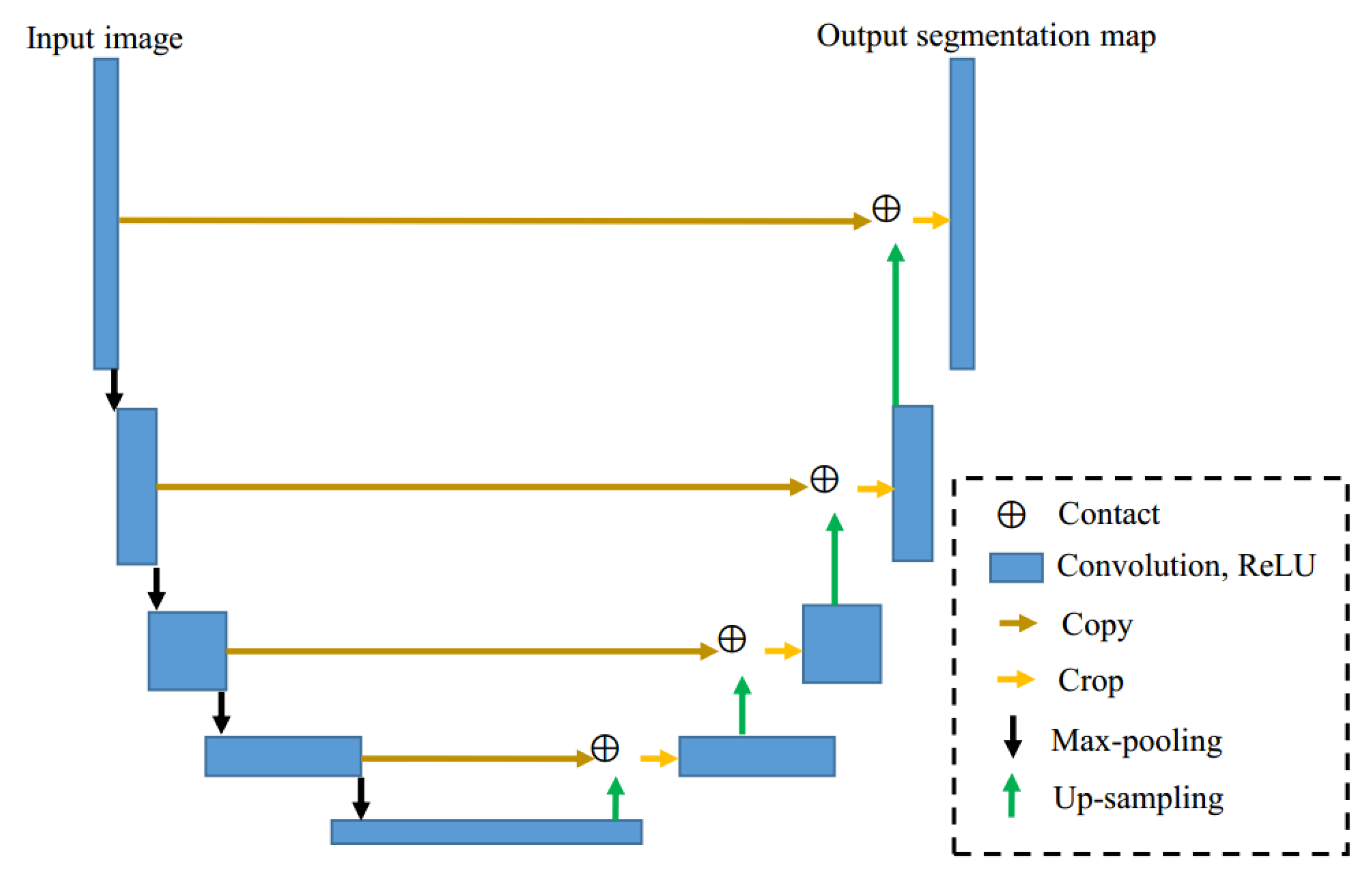
29] proposed a semantic segmentation network, named SegNet. It consists of an encoding structure and a decoding structure, which preserved the details of the image by saving the position index in the pooling process. At the same year, U-Net [
30] is proposed by for semantic segmentation of the image, which makes full use of the low-level semantic information of the image in the up-sampling process. It can achieve good results in image segmentation with fewer samples. Besides, some effective networks (e.g., References [
31,
32,
33,
34]) are proposed for remote sensing image. For example, He et al. [
35] use deep confidence network to analyze remote sensing data. The network training speed is fast, and it is not easy to fall into local optimum. Although it has achieved good classification performance, the accuracy of object recognition still needs to be improved.
To achieve effective semantic segmentation performance of remote sensing image, we design multi-scale feature encoding structure and max-pooling indices decoding structure. In addition, we propose cost-sensitive loss function, and introduce batch normalization layer to accelerate network convergence process.
The main contributions of this paper are as follows:
1. This paper presents a novel multi-scale deep features fusion and cost-sensitive loss function based semantic segmentation network for remote sensing images, named MFCSNet. Combining the advantages of U-Net and SegNet, a multi-scale feature encoding structure and a max-pooling indices decoding structure is designed. The MFCSNet can fully extract the features of the remote sensing image. This network can integrate the low-level semantic information and high-level semantic information. The max-pooling indices up-sampling method retains the details, such as the object edge, which can effectively improve the network classification effect.
2. In order to solve the problem of low classification accuracy of objects with few pixels in complex remote sensing images. This paper designs a cost-sensitive loss function. The MFCSNet obtains a more robust network model by raising the penalty coefficient for the misclassified samples. Besides, the batch normalization layer and standardizing the distribution of neural network output are used to improve the network convergence speed, which can improve the classification performance of the network.
3. Proposed Method
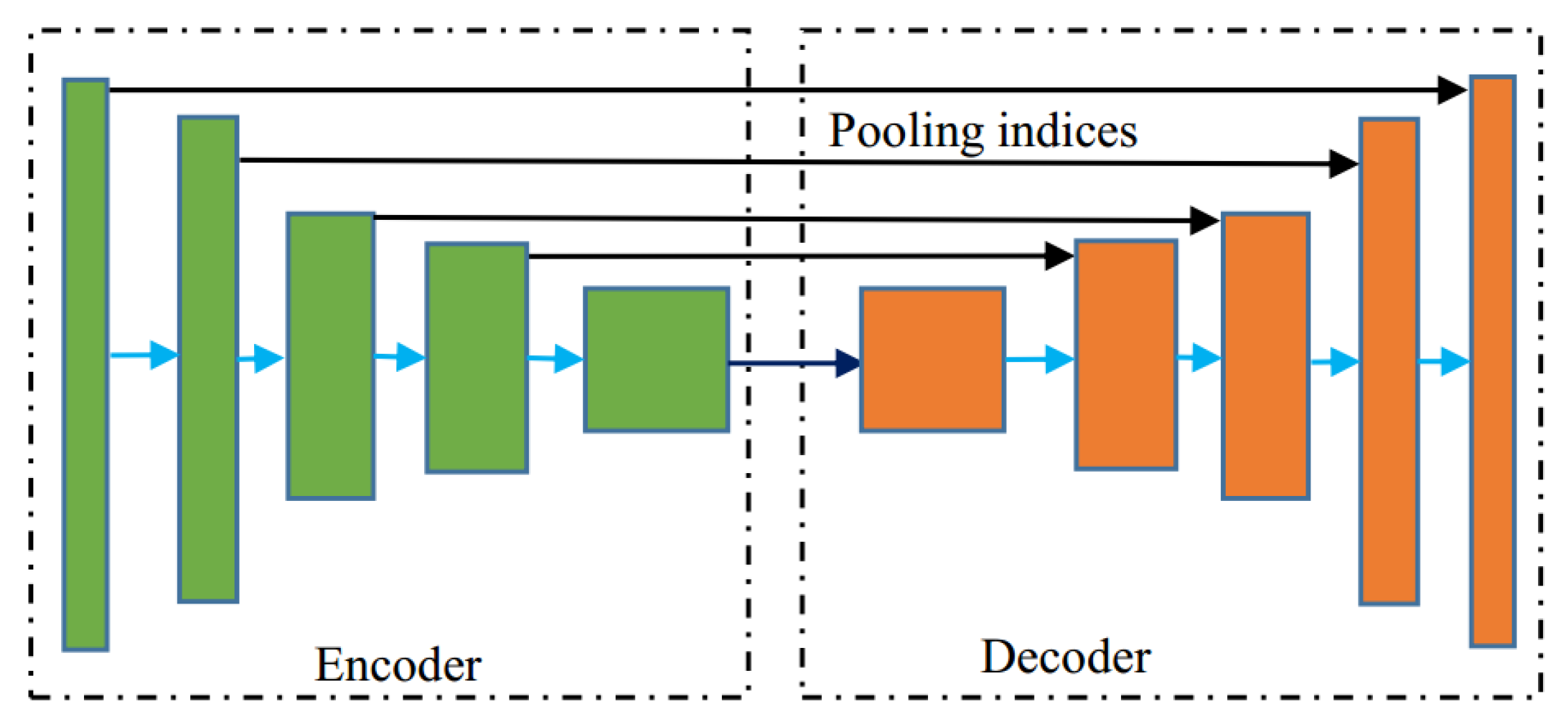
SegNet network retains the location information of the object through the max-pooling indices. The U-Net network realizes the combination of the low-level image features and the high-level image features through the multi-level jump structure, which can extract fuller features and reduce the dependence on the number of samples. Thus, we improve U-Net and SegNet networks to propose a new multi-scale deep features fusion and cost-sensitive loss function based multi-object classification network for remote sensing images, named MFCSNet.
As shown in
Figure 3, the improved network in this paper consists of the encoding part (on the left side) and the decoding part (on the right side). The multi-scale feature encoding structure is used to extract each scale features of the input image continuously. This process includes convolution layers and pooling layers. Then the up-sampling is continuously performed by the decoding structure. To accurately retain the location information of the object features, the up-sampling is achieved by the max-pooling indices structure.
In order to make full use of the shallow features, such as texture and edge of the image, the corresponding feature map in the feature coding structure is continuously combined during up-sampling. Thereby, the overall classification performance of the network can be improved. To improve the classification accuracy for the objects with a small number of samples, we propose a cost-sensitive loss function, which improves the classification performance of the network. The network details of each part will be discussed in the following.
3.1. Multi-Scale Feature Encoding Structure
In order to extract the essential features of different objects in remote sensing images, we design a feature encoding structure consisting of thirteen convolution layers and five pooling layers, as shown in
Figure 3. The convolution kernels of the convolution layers conv1_1, conv1_2 to conv5_3 have the kernel size of 3 × 3. The number of convolution operation channels is shown in
Figure 3. In the first convolution layer, the input color image is convoluted by the convolution kernel, whose number of channels is 64 and kernel size is 3 × 3. The shape of the output feature map is 64 × 256 × 256. After five stages of convolution and pooling operations, features of different scales can be obtained.
The activation function converts the linear mapping of the convolution layer into a non-linear mapping. The activation function used in this paper is ReLU. ReLU has the characteristics of simple calculation and stable gradient value, which can effectively solve the problem of too small gradient or gradient explosion.
There are five pooling layers in the encoding structure, such as MaxPool1, MaxPool2 to MaxPool5. The pooling layer adopts the max-pooling mode, and the size of the pooling kernel is 2 × 2. During the pooling process, the maximum index position of each pooling operation is recorded and released during the decoding process, so that the location information of the object can be retained. The pooling layer can compress the feature map, and reduce the number of network parameters, the calculation time and space complexity. Feature compression can extract key information in the image, which can improve classification performance. During the convolution and pooling operations, if the size of the feature map is halved, the number of channels of the convolution kernel is doubled to obtain a richer feature of the image.
3.2. Max-Pooling Indices Decoding Structure
After feature encoding, image features of different scales are obtained. The sizes of these feature maps are 1/2, 1/4, 1/8, 1/16, and 1/32 of the original image sizes, as shown in
Figure 3. By performing an up-sampling operation on the feature map, the feature map can be gradually restored to the original image size to obtain the class attribution of each pixel.
The size of objects in remote sensing images is generally small. Thus, the sharpness of their outlines is easily affected by factors, e.g., illumination and weather, which brings difficulties to the object classification task. To solve this problem, we fully consider the details of the object area and its location information. We design the decoding network through the max-pooling indices in the up-sampling process. After the up-sampling is completed, the result is merged with the feature map in the encoding process, so that the shallow contour information of the remote sensing image and the deep semantic information are transmitted in the network.
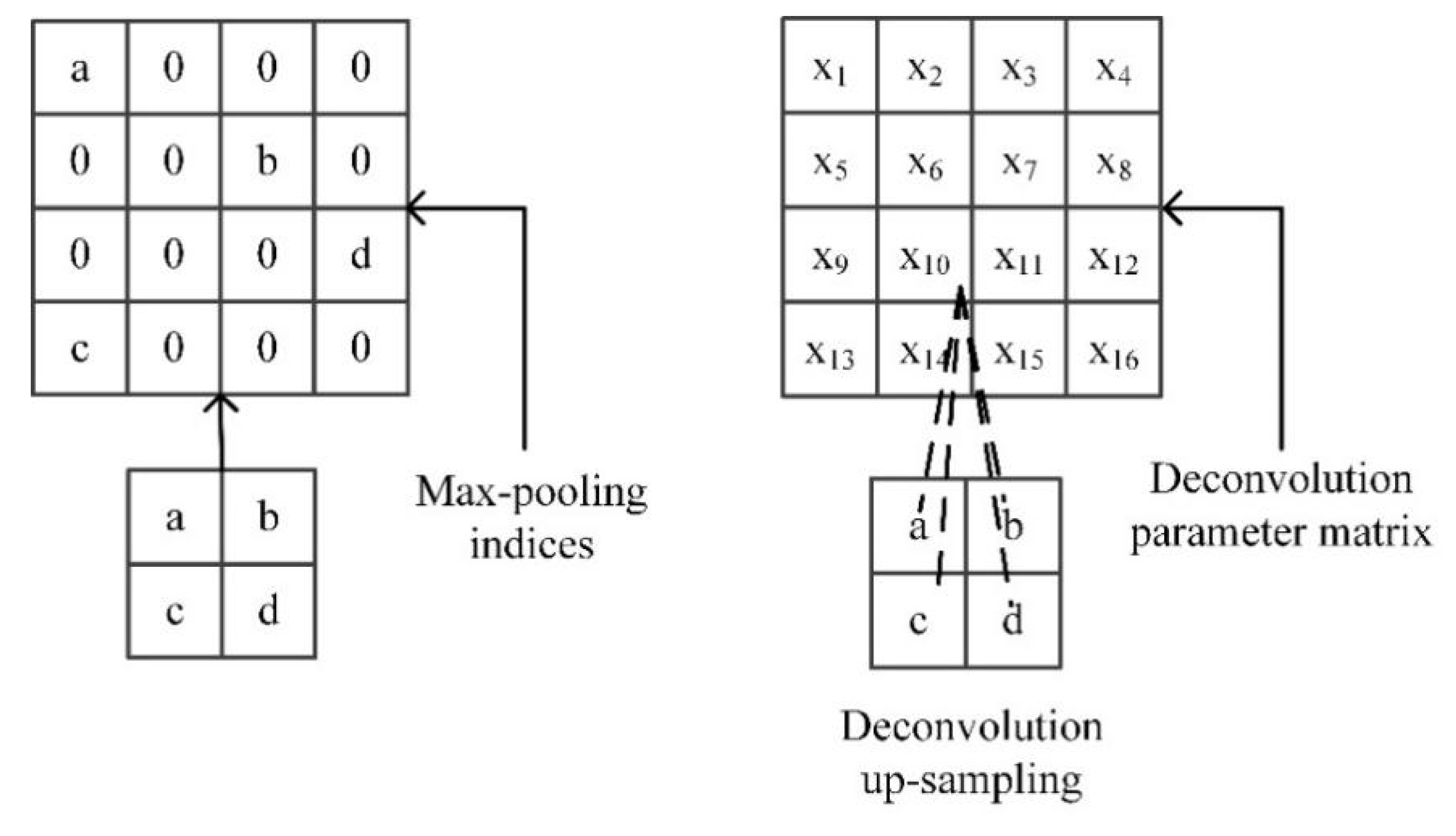
Unlike the method of deconvolution up-sampling. In this paper, the up-sampling method records the max-pooling location during the network encoding process for up-sampling.
As shown in
Figure 4, when the max-pooling indices are up-sampled, the feature map is mapped to the up-sampled result according to the maximum coordinate information recorded in the encoding process, and the other non-indexed locations are supplemented with zero, so that the original information can be accurately retained. The location information of the maximum value avoids the loss of information during the up-sampling process. The deconvolution up-sampling method is to deconvolute the feature map by the deconvolution parameter matrix to obtain the up-sampled feature map. It can be seen that the deconvolution calculation process is essentially the inverse of the convolution calculation. After the up-sampling operation is performed using the max-pooling indices, the obtained feature map size is doubled before the up-sampling. Then the feature map contains key feature information of a scale on the image.
Before the convolution in the decoding structure, the up-sampled feature map obtained from the previous stage is connected to the feature map of the corresponding size in the encoding process, such as the structure shown by Concat1, Conact2 to Concat4. By adding a jump structure during the up-sampling process, the low-level features can be reused. The shallow network can acquire information, such as edges and textures of the image. The deep network can learn the semantic information of the image. This structure has a greater receptive field. Such a structure realizes the fusion of the low-level information and the high-level information, so that the network has a richer feature learning ability. In addition, this jumped connection structure does not introduce excessive computational complexity and model complexity, allowing the gradient to propagate efficiently in the network. After the max-pooling indices operation, the convolution operation smooths the abrupt points caused by zero padding.
The multi-objective classification network of remote sensing images designed in this paper stores the max-pooling location during the encoding process, and releases the information in the decoding process. This method can save the key information of the image and accurately record the location information of the object. The semantic information obtained by up-sampling and the contour, texture and spectrum information obtained by the encoding process. These features are fully exploited to improve the network classification ability and the overall performance of the network.
3.3. Batch Normalization Acceleration Layer
The multi-objective classification network of remote sensing images designed in this paper is depth, which can fully learn the features of the image. However, as the network depth increases, the network convergence becomes more and more difficult, and the training speed becomes worse. Therefore, we design a batch normalization (BN) layer in the full convolution neural network. In this way, the input of each layer satisfies the same distribution, and can accelerate the convergence of the network. As the network deepens, the distribution of the activation input values gradually shifts, which causes the network to converge slowly. Through the batch normalization method, the distribution of the input values is transformed into a normal distribution, which the variance is 0, and the mean is 1. It avoids the gradient disappearance and the gradient dispersion problem. The normalized formula is:
where
x represents the input vector of the network,
E[
x(k)] represents the mean of the input, and
Var[
x(k)] represents variance.
The normalization operation can enhance the flow of backpropagation information and accelerate the convergence of the network. However, such a transformation can also lead to poor expression of the network, which is fatal for networks that need to learn complex features. In order to solve this problem, two adjustment parameters need to be added to each neuron. The inverse transformation of the transformed activation is used to restore the normalized data to a certain extent. The average value
μB and the variance
σB2 are obtained for the batch as follows:
Perform scale and translation transformations:
where
x represents a mini-batch input value, and
B represents the parameters that need to be learned. Then the normalization of the network input during the training process can be completed. After the trained model is obtained, the batch normalization of the test process is to obtain the mean and variance for the entire data set, which is different from the current batch used in the training process. During the training process, it is necessary to record the mean and variance of each batch and perform unbiased estimation as the basis for batch normalization in the testing process.
The network convergence process can be significantly accelerated, followed by the batch normalization. The training time can be reduced. The network can use a large learning rate, and the classification performance of the network is improved to some extent. If the input scales of the layers in the network differ greatly, then the training of the network should be performed using a lower learning rate according to the barrel theory. After introducing the batch normalization layer, data can be normalized to the same scale, which allows for a larger learning rate. This makes the network less sensitive to the learning rate, and makes network parameters optimization easier. This method is convenient to obtain a better remote sensing image classification network.
3.4. Cost-Sensitive Loss Function
For the neural network, the smaller the loss function, the stronger the performance of the network model. Generally, loss functions are square loss function, exponential loss function and cross-entropy loss function. The neural network designed in this paper uses the cross-entropy loss function and improves it for multi-objective classification tasks of remote sensing images.
Remote sensing images contain complex objects and unbalanced samples. For example, vegetation types account for a large proportion of remote sensing images, while roads and other objects often occupy only a small number of pixels in remote sensing images. In the process of neural network learning, the class with a small number of samples is prone to under-fitting. In order to solve this problem, we add a cost-sensitive matrix to the loss function. Thus, the network model has a larger penalty when it misclassifies a few sample categories, and it strengthens the attention of this class sample.
For multi-classification, assuming that the total number of samples in the training data set is N, and the number of classes is M. The size of cost-sensitive matrix
W is M × M, which can be set to balance the penalty weights for different misclassified samples.
where w(
j,
k) represents the penalty when the class
j is misclassified as the class
k. The elements on the diagonal of the matrix
W are 0. The values of the cost-sensitive matrix are set according to the number of samples and the confusion matrix in the classification result. By introducing a cost-sensitive matrix to the loss function, the influence of samples imbalance on the performance of the network can be reduced. Then, the classification performance on a smaller number of categories can be improved.
3.5. Network Training and Optimization
The forward propagation algorithm and the back propagation algorithm are two processes for convolution neural network training. The process of forward propagation is the process of getting the corresponding output based on the input. The backpropagation algorithm reversely transmits the error value according to the error between the output value and the true value. Backpropagation algorithm corrects the connection weight between the neurons to obtain the network model with the smallest error.
For a data set containing m samples {(
x(1),
y(1)),…,(
x(m),
y(m))},
OW,b(
x) represents the output value of the sample (
x,
y) after classified by the network. To perform iterative optimization of the network, define the following cost function:
Considering m samples in the data set, an expression for their overall cost function can be obtained:
In Formula (8), the first term represents the mean square error term, reflecting the deviation between the predicted value and the true value. The second term is a regularization term that prevents overfitting, expressed in terms of the complexity of the hyperparameters.
The backpropagation algorithm uses gradient descent and chain derivation rules to calculate the parameters. It continuously corrects the values of the hyperparameters
W and b in the iteration to gradually reduce the error. The backpropagation training method has the following steps: First, the forward propagation algorithm is used to obtain the output values of the network, the activation values and weights of each layer of the network. Then, the error of each output neuron can be calculated. The error calculation formula is as follows:
Next, the partial derivative of backpropagation can be calculated by the chain derivation rule:
Finally, the following formulas are used to update the network weights:
During the training process, the network weights are iteratively optimized until the termination condition is met. Common methods for judging convergence include setting the maximum number of iterations and determining whether the difference between adjacent errors meets the specified error interval. At the end of the training, parameters W and b are obtained which can correctly classify the samples. In the calculation of the pooling layer, the size transformation of the feature map is performed, and then the propagation and parameters updating are performed.
A larger learning rate is used at the beginning of the network training, which can make the optimization step of the network larger. It can skip the local extreme point in the high-dimensional space. This way can obviously accelerate the convergence speed of the network. After a certain number of iterations, the parameters of the model can be closer to the true values, and the network converges at the optimal values.
5. Conclusions
In this paper, we proposed a novel MFCSNet network for remote sensing image semantic segmentation. MFCSNet uses multi-scale deep features fusion and cost-sensitive loss function to make the segmentation network more effective. For the features extraction and fusion, MFCSNet provides a novel framework with multi-scale feature coding structure and max-pooling indices decoding structure. Instead of using FCN and SegNet, MFCSNet combines the corresponding down-sampling feature maps during up-sampling process to extract the low-level and high-level fusion features. Different U-Net framework, max-pooling indices decoding is used for up-sampling process, which can retain objects location information. This up-sampling structure can improve the recognition rate of the object edge. In MFCSNet, the batch normalization acceleration layer can reduce the sensitivity of the learning rate and improve the network convergence speed, which can make the network parameters optimize easily. To improve the classification performance on the category with a small number of samples, we design a cost-sensitive loss function by increasing the penalty for the misclassification of the object. For the MFCSNet model training, data enhancement and sample equalization processing are performed on the training set, which can suppress network overfitting and improve the generalization ability of the network. Compared with other state-of-the-art methods, i.e., U-Net and SegNet, the classification of all the objects with the proposed method has better classification accuracy. The precision of each category of MFCSNet has achieved the highest value. The OA and Kappa coefficient of MFCSNet is 94.46% and 0.9113, respectively, which are at least 1.92% and 0.0303 higher than U-Net and SegNet. Besides, the integrity of each object segmented by MFCSNet is obviously better than the others, especially road. Thus, the proposed MFCSNet can achieve promising performance in overall classification performance, feature edge recognition, consistency of prediction results, and so on.
Although our algorithm achieves promising semantic segmentation accuracy for the Jiage data set, there are some drawbacks and interesting ideas which can be further explored to extend the research reported in this paper. The segmentation of MFCSNet is based on the single pixel, which makes the contour information of the object not complete and the associated information between the objects lost. Thus, for the proposed method, the segmentation of some small roads is not complete, and there are some noisy pixels. Besides, in the test phase of this method, the large-size image needs to be divided into small blocks for testing. The test results are spliced to obtain the segmentation result of the original image. This can result in unevenness in the splice regions. In the future, the higher-order potentials, which constructed by different constraints based on the object structure information, the adjacency of pixels and topologies of different levels of segmentation regions will be introduced to construct the CRF model to optimize the rendering of the segmentation. In addition, some post-processing methods, such as morphological filtering, will also be used in the optimization of segmentation results.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}