Non-Touch Sign Word Recognition Based on Dynamic Hand Gesture Using Hybrid Segmentation and CNN Feature Fusion




Abstract
:1. Introduction
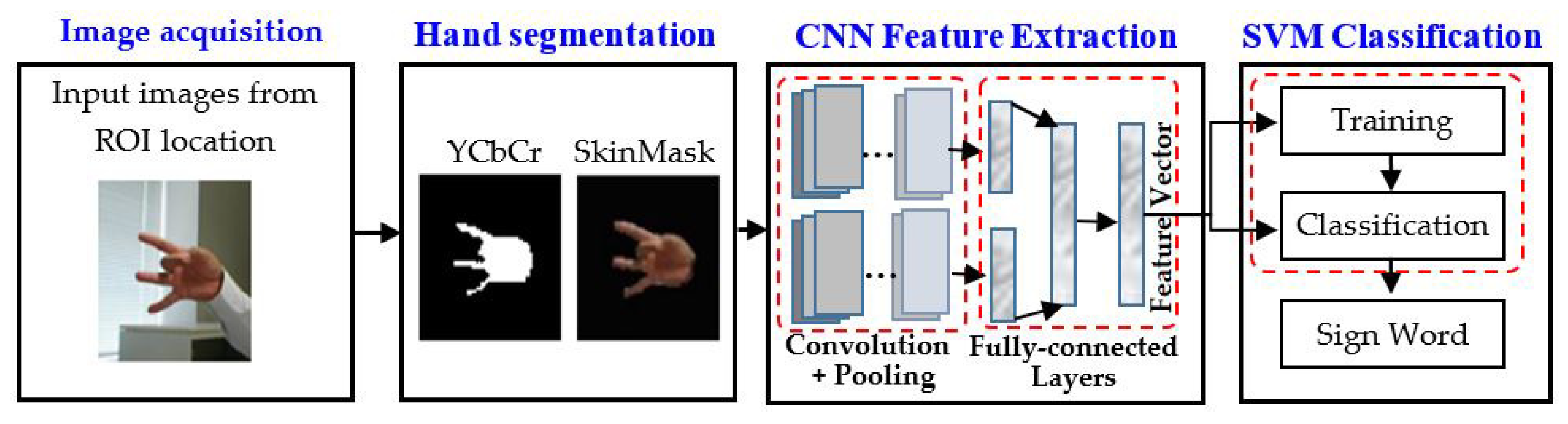
- Hand gesture recognition performance is sub-optimal due to the uncontrolled environment, perspective light diversity, and partial occlusion. Considering the challenges of recognizing the gesture of a sign word, this system proposes a hybrid segmentation strategy that can easily detect the gesture of the hand. Hybrid segmentation can be defined as the coordination of the techniques of two segmentations like YCbCr and SkinMask. YCbCr segmentation converts the input images into YCbCr, then performs binarization, erosion, and fills in the holes. SkinMask segmentation converts the input images into HSV, and the range of H, S, and V values is measured based on the color range of skin. Therefore, the segmented images are provided for feature extraction.
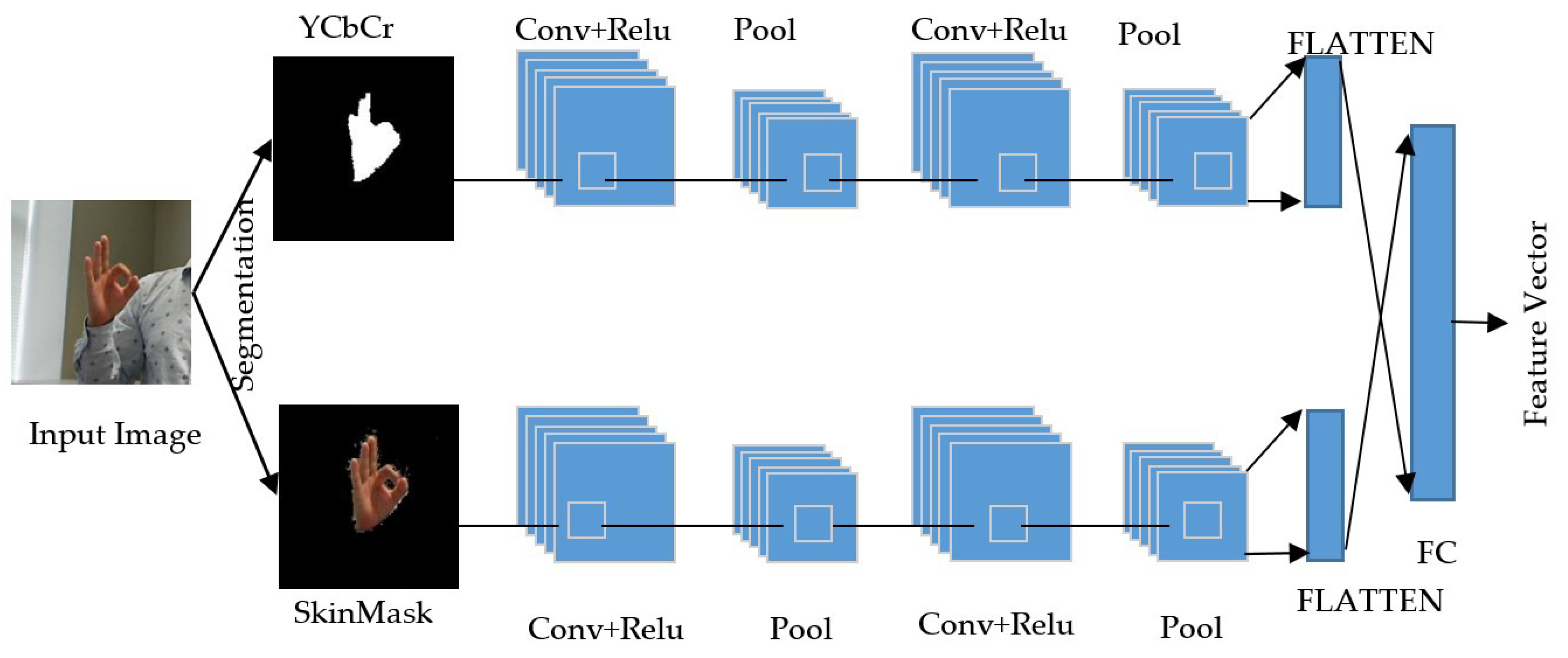
- We propose a two-channel strategy of the convolutional neural network, which would be an input YCbCr, and the other would be SkinMask segmented images. The features of segmented images are extracted using CNN, and then, a fusion is applied in the fully connected layer. Furthermore, the fusion feature is fed into the classification process.
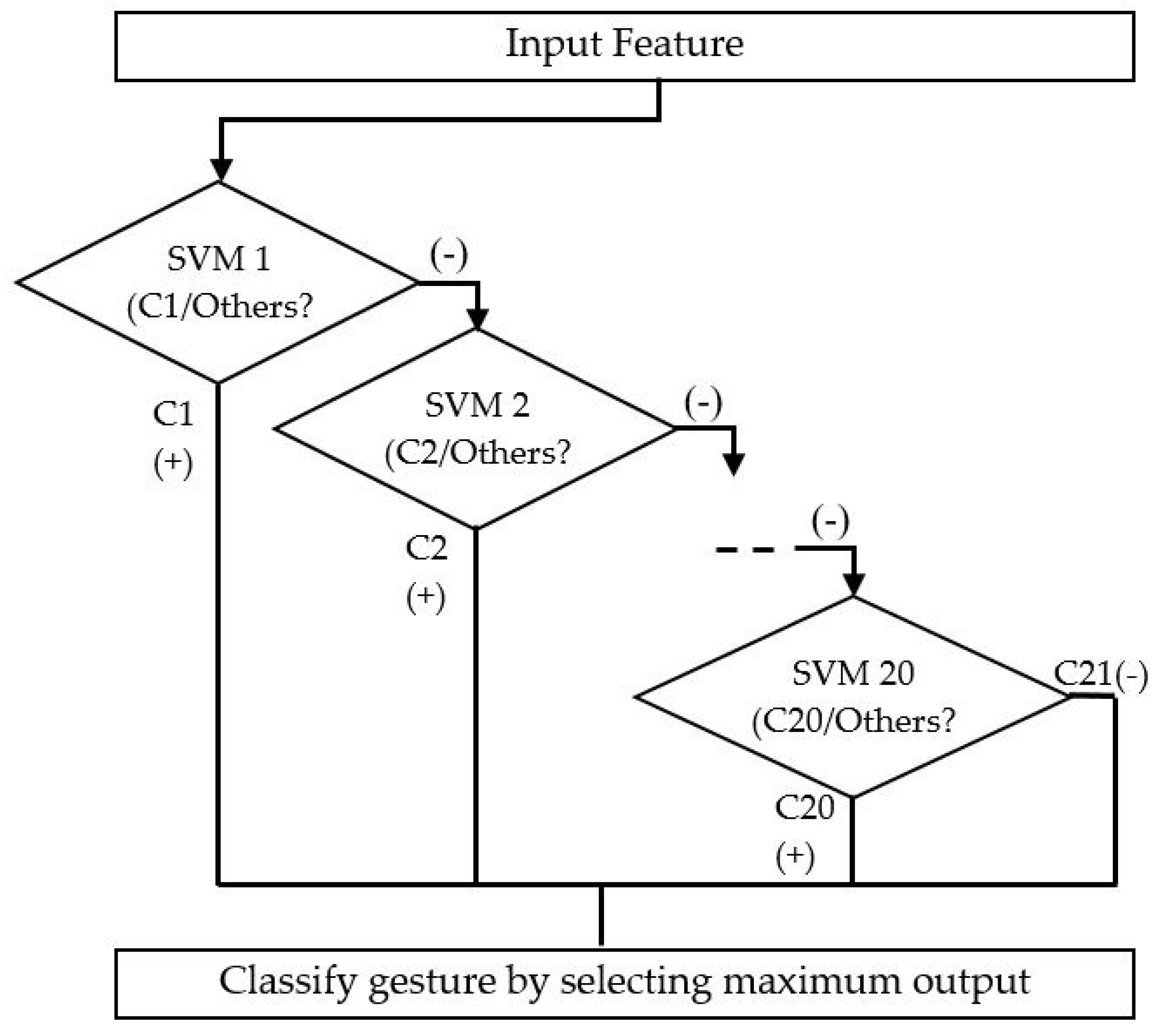
- A multiclass SVM classifier is used to classify the hand gestures, and the system displays related text.
2. Related Work
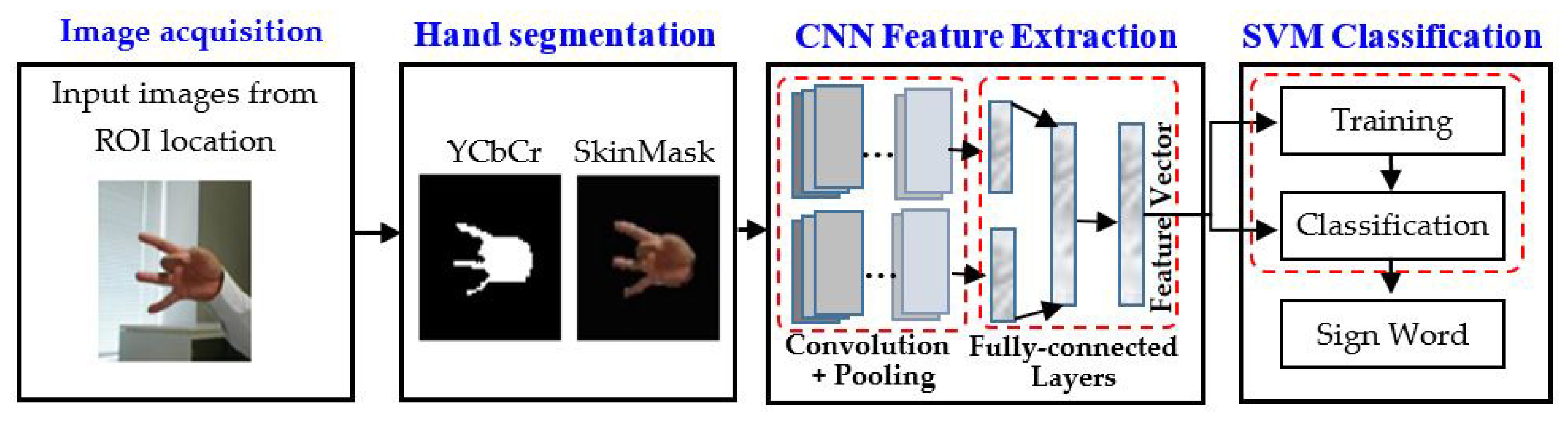
3. Method of Sign Word Recognition System
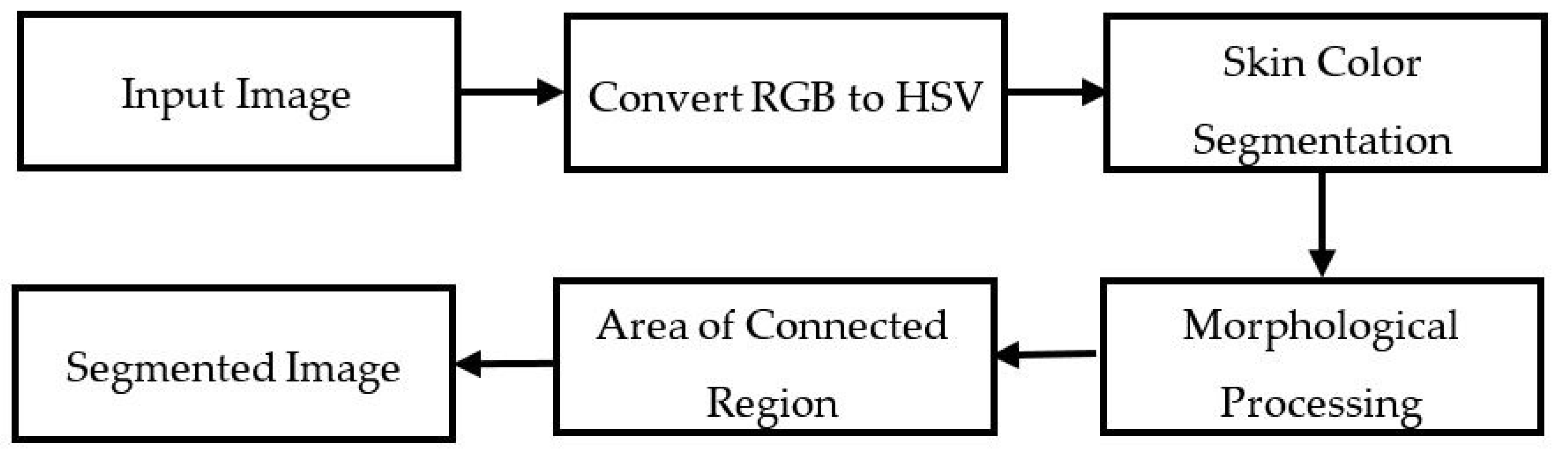
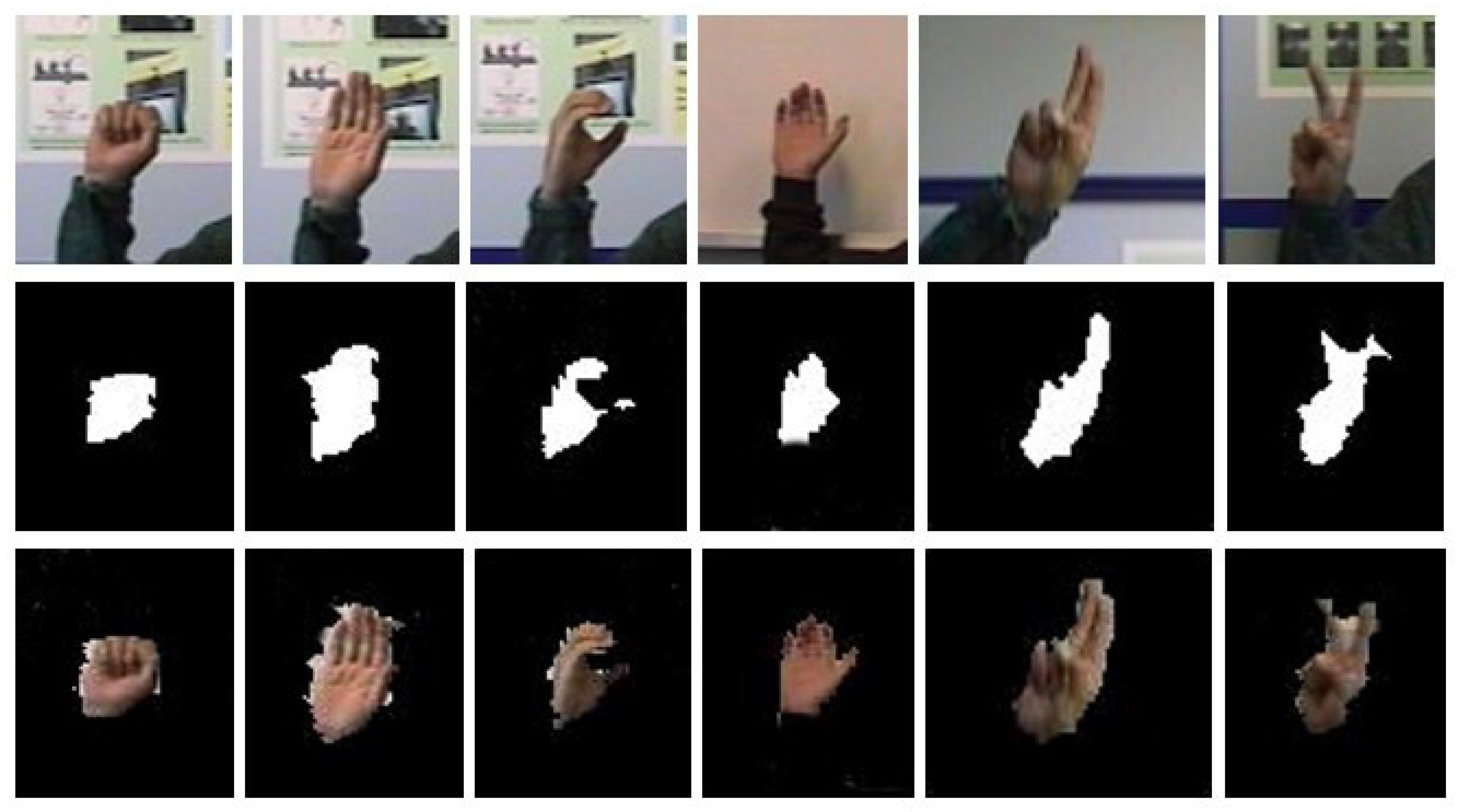
3.1. Hand Segmentation Technique
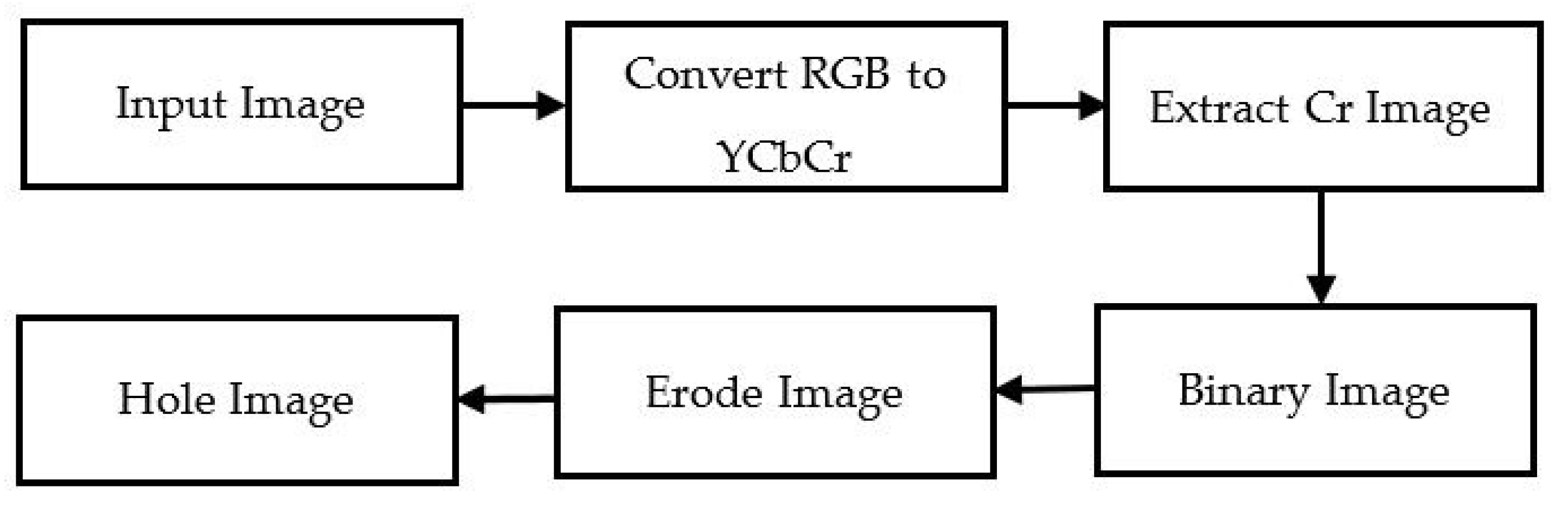
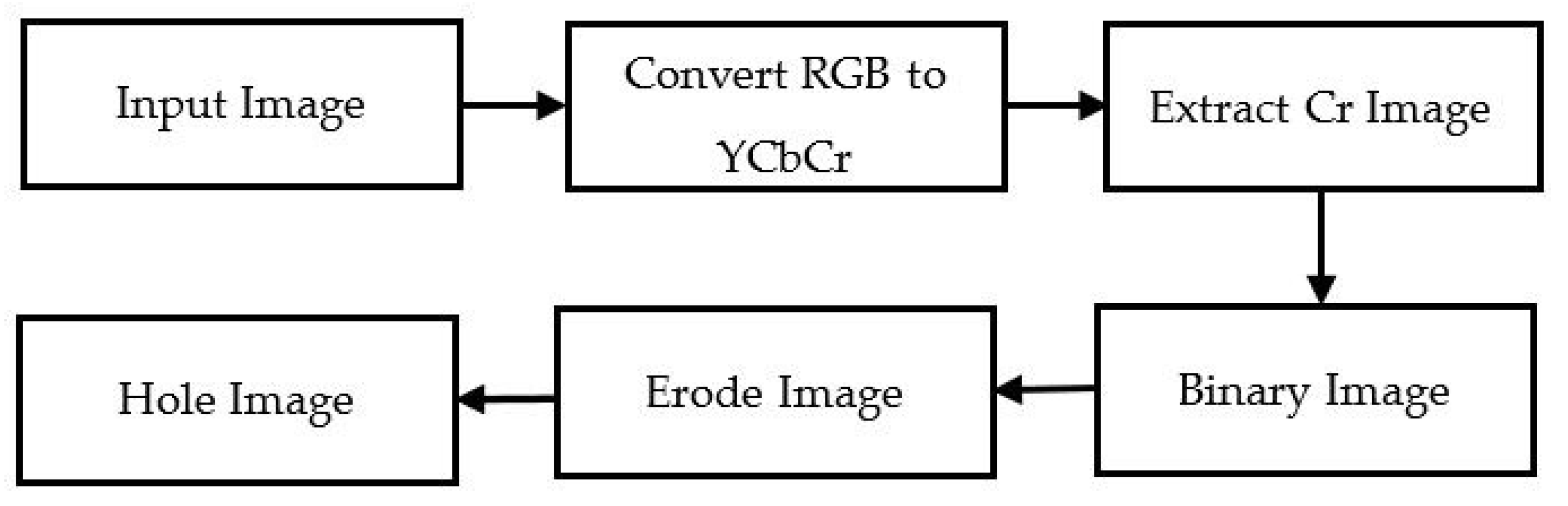
3.1.1. YCbCr Segmentation
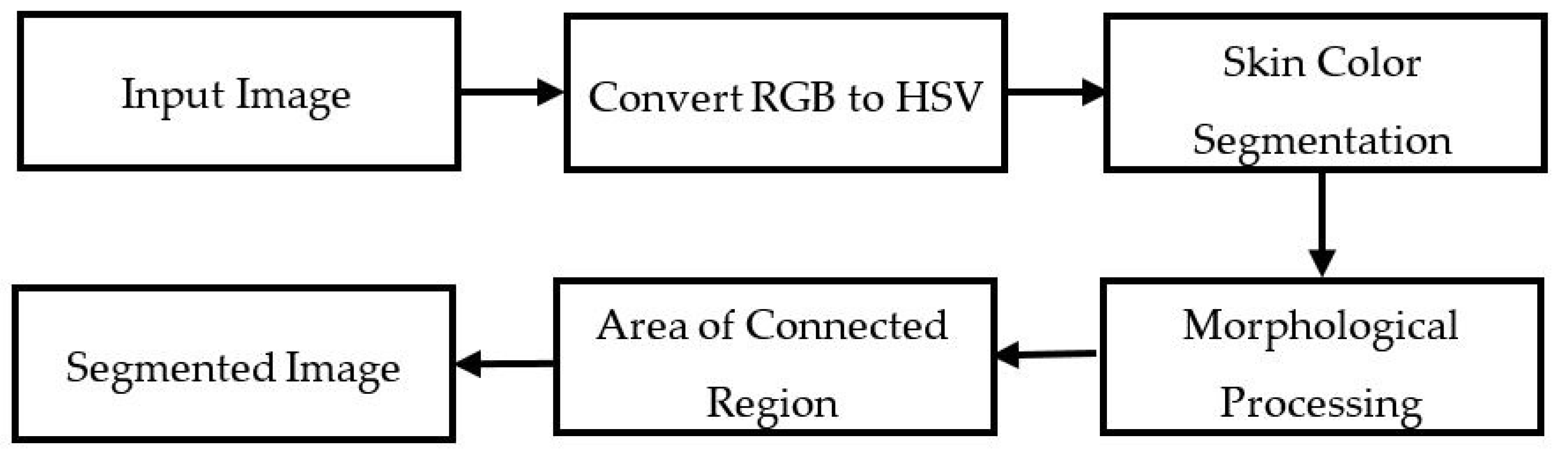
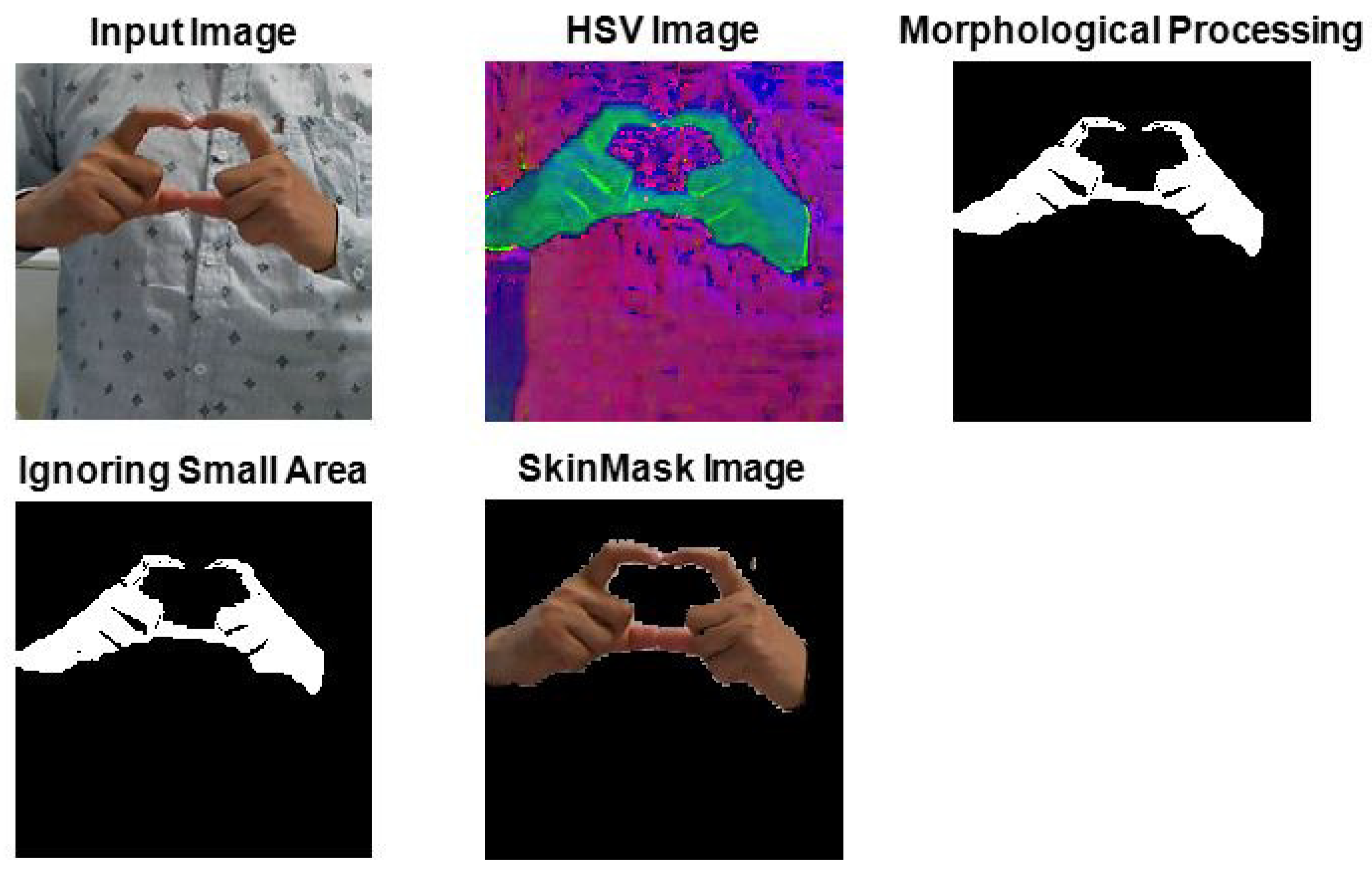
3.1.2. SkinMask Segmentation
3.2. CNN Feature Extraction
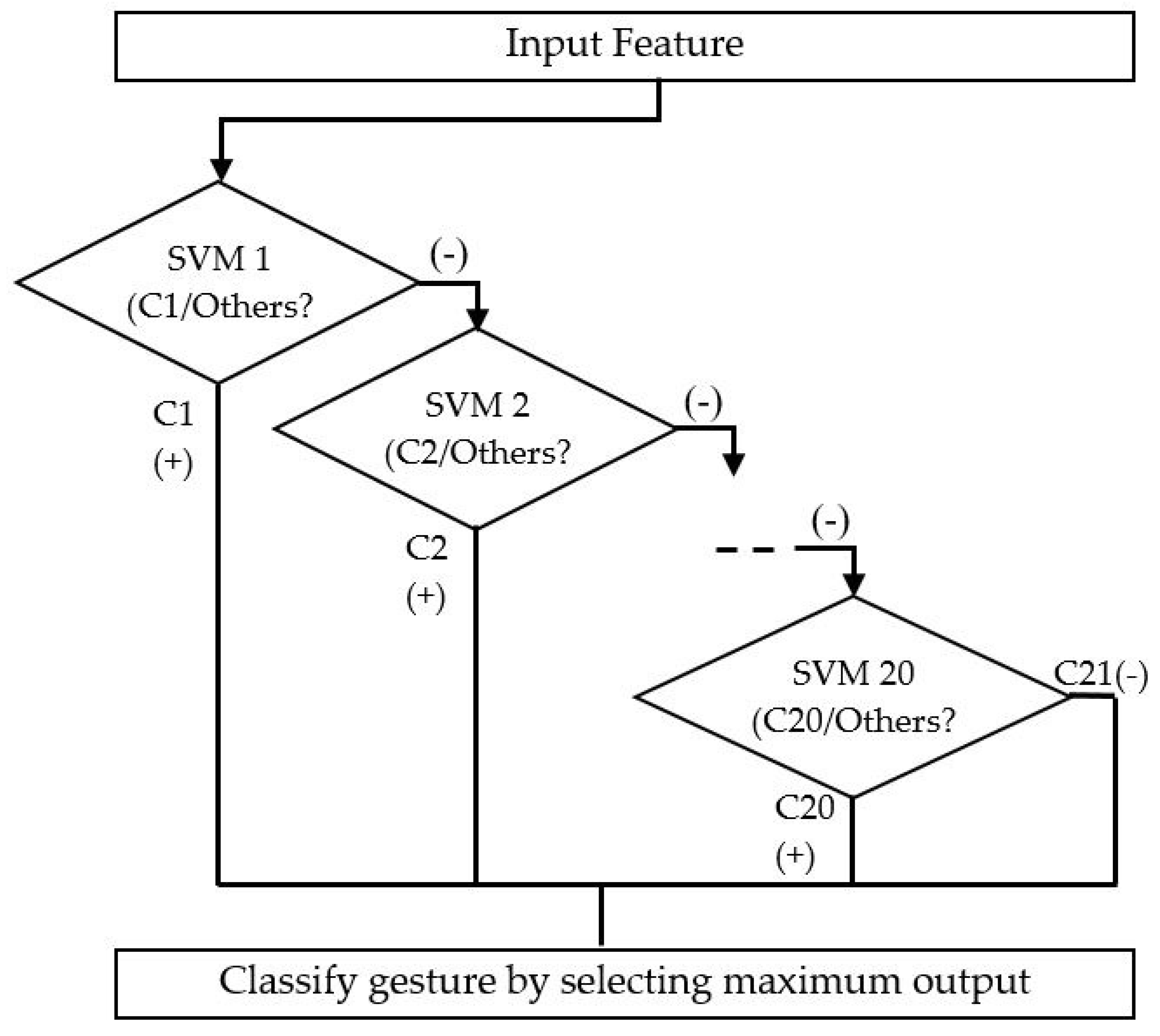
3.3. SVM Classification
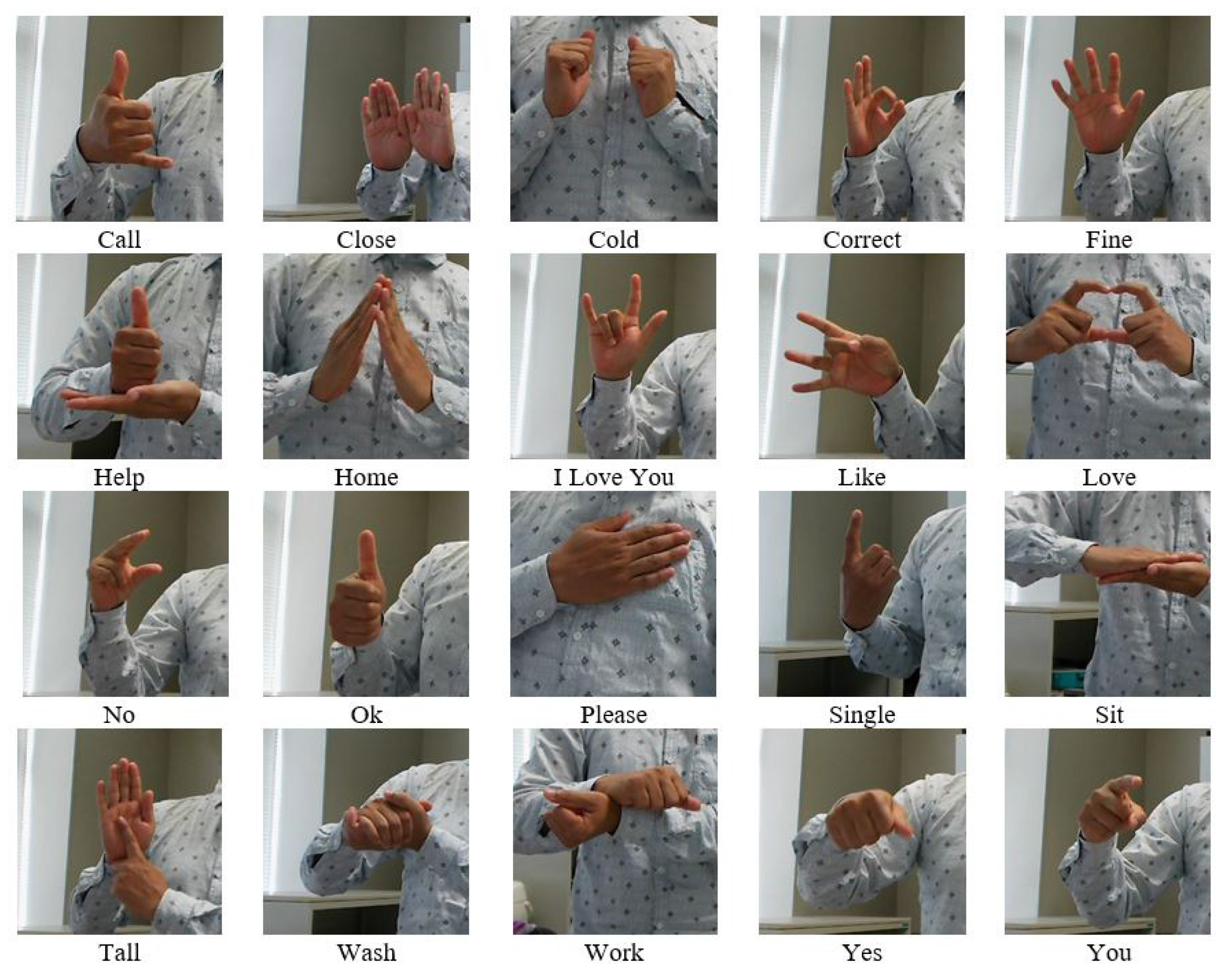
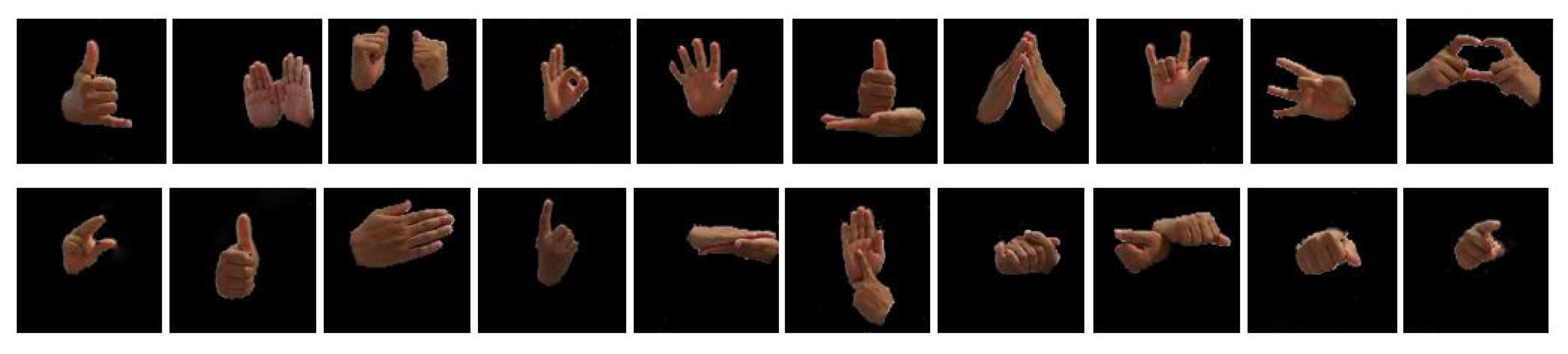
4. Experimental Dataset and Simulation Results
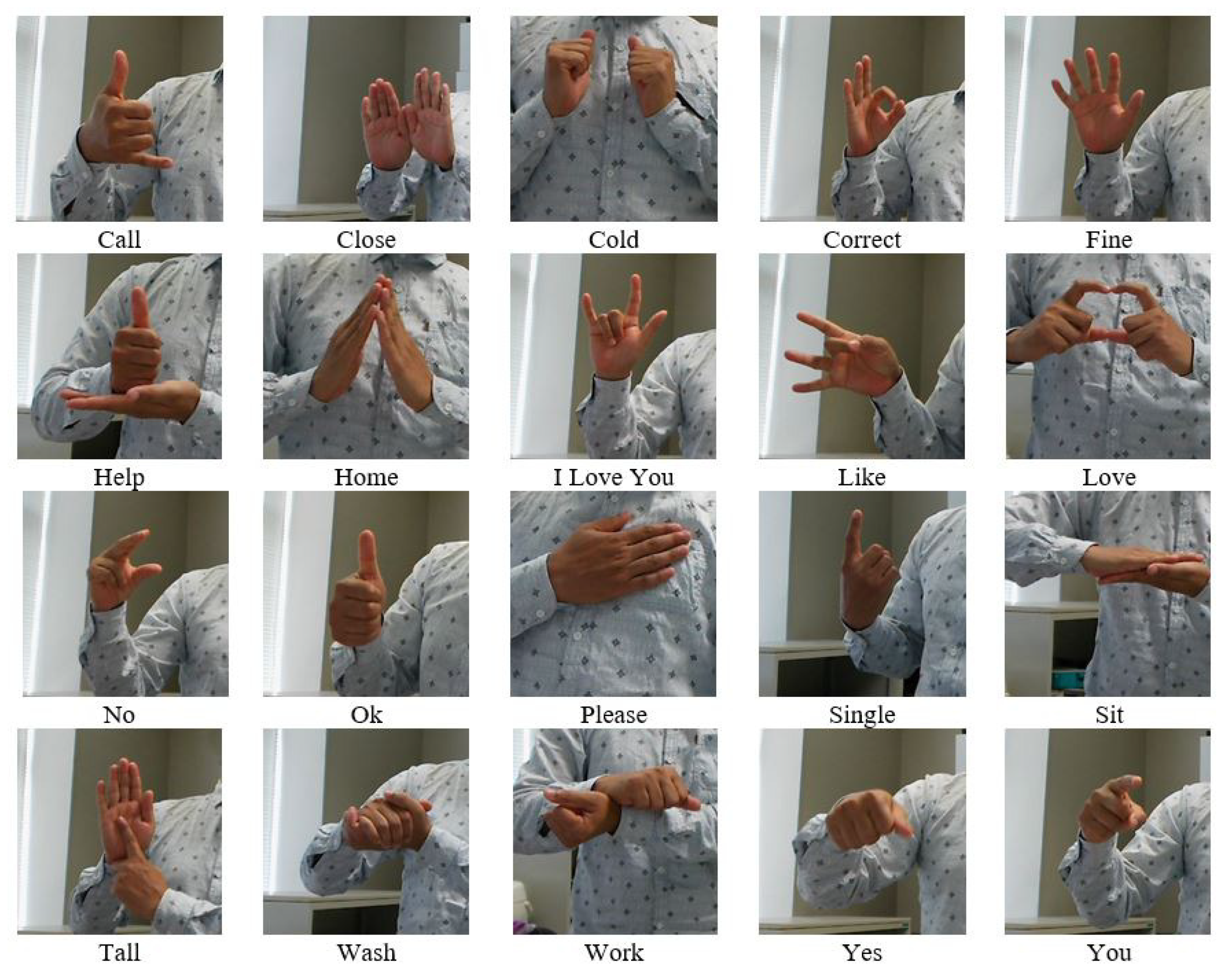
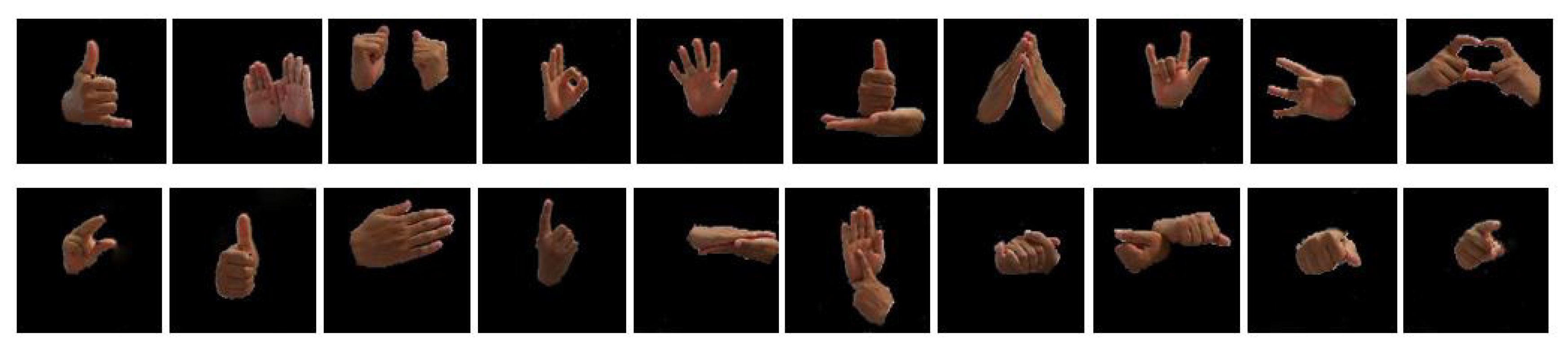
4.1. Dataset Description
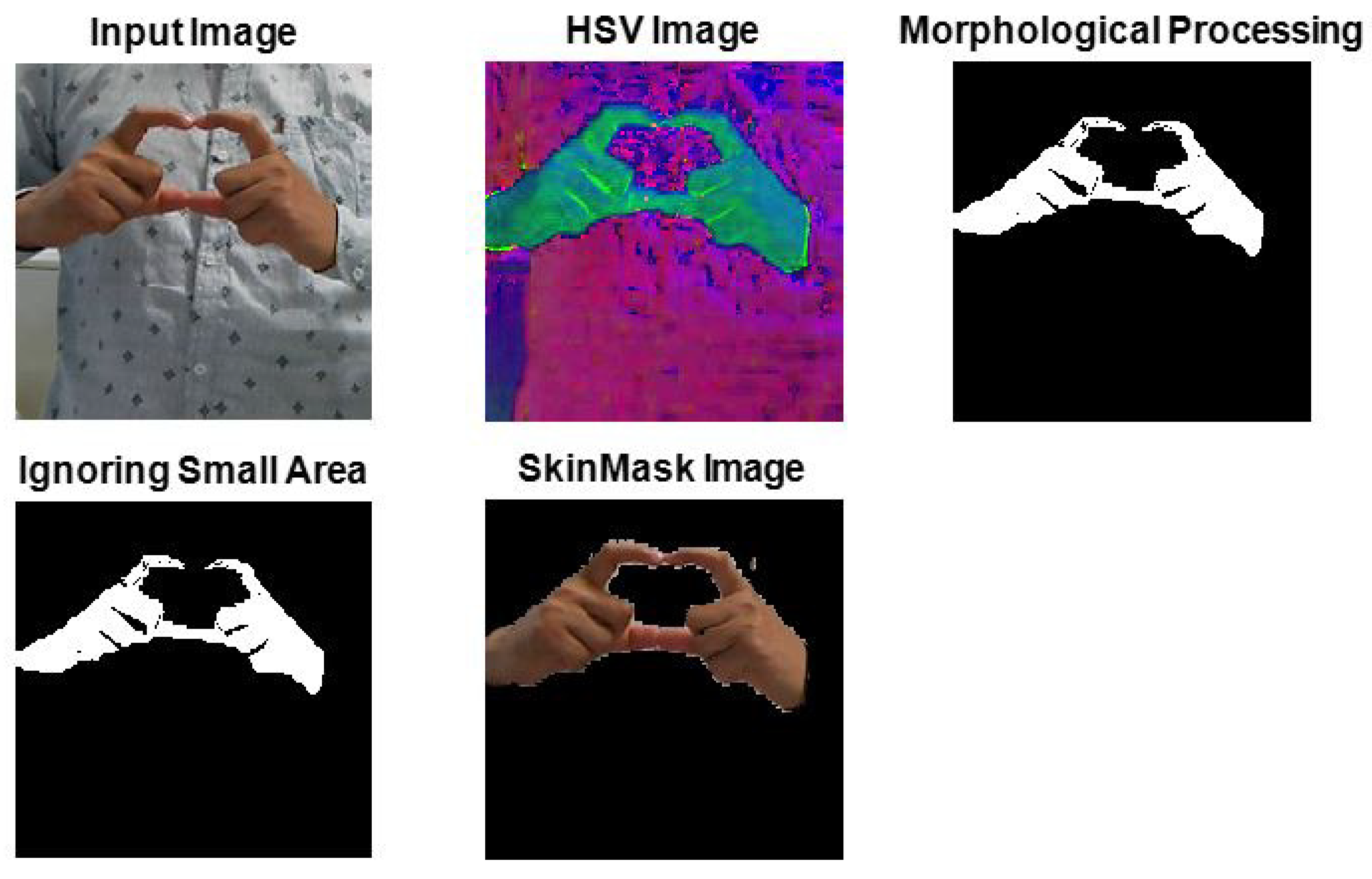
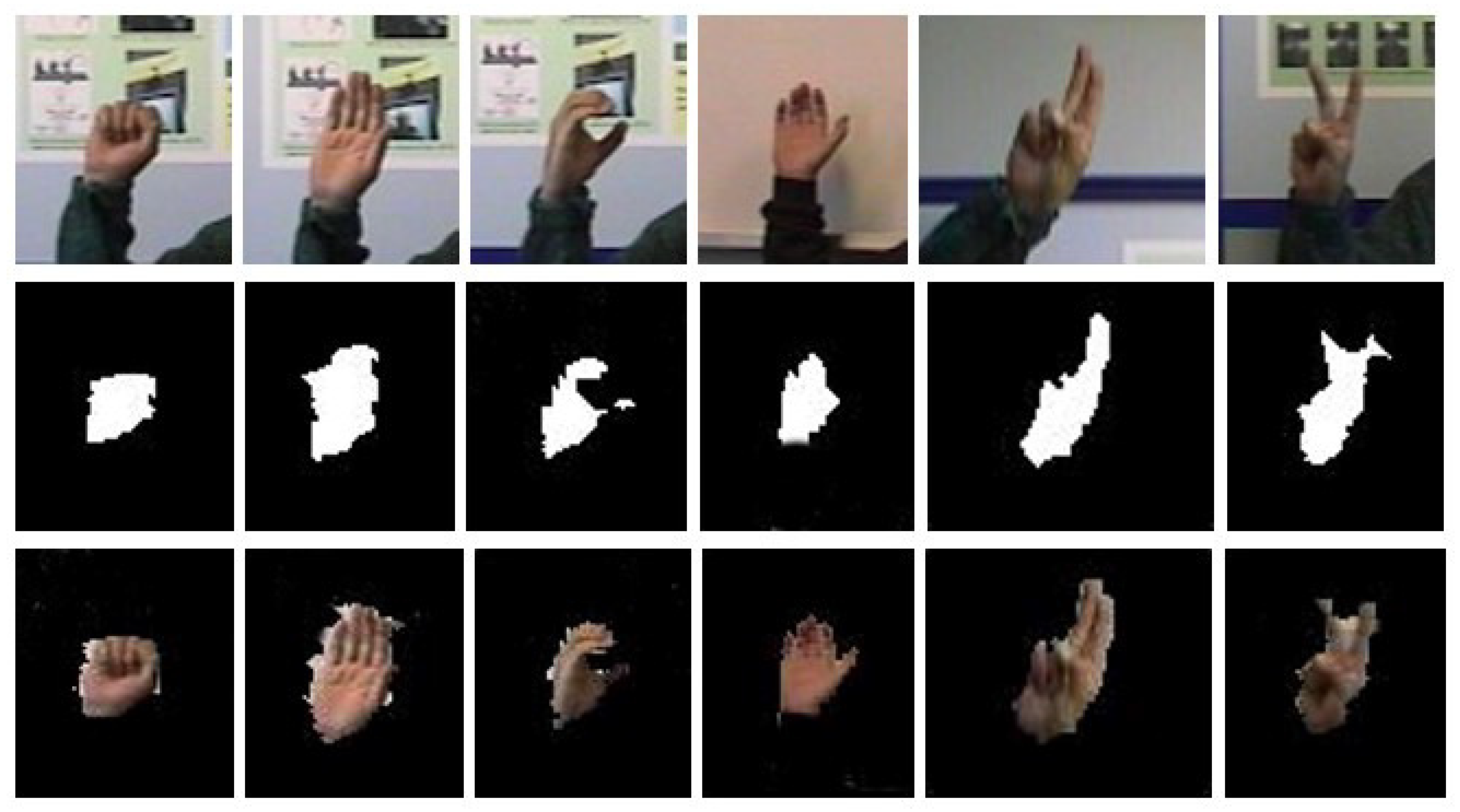
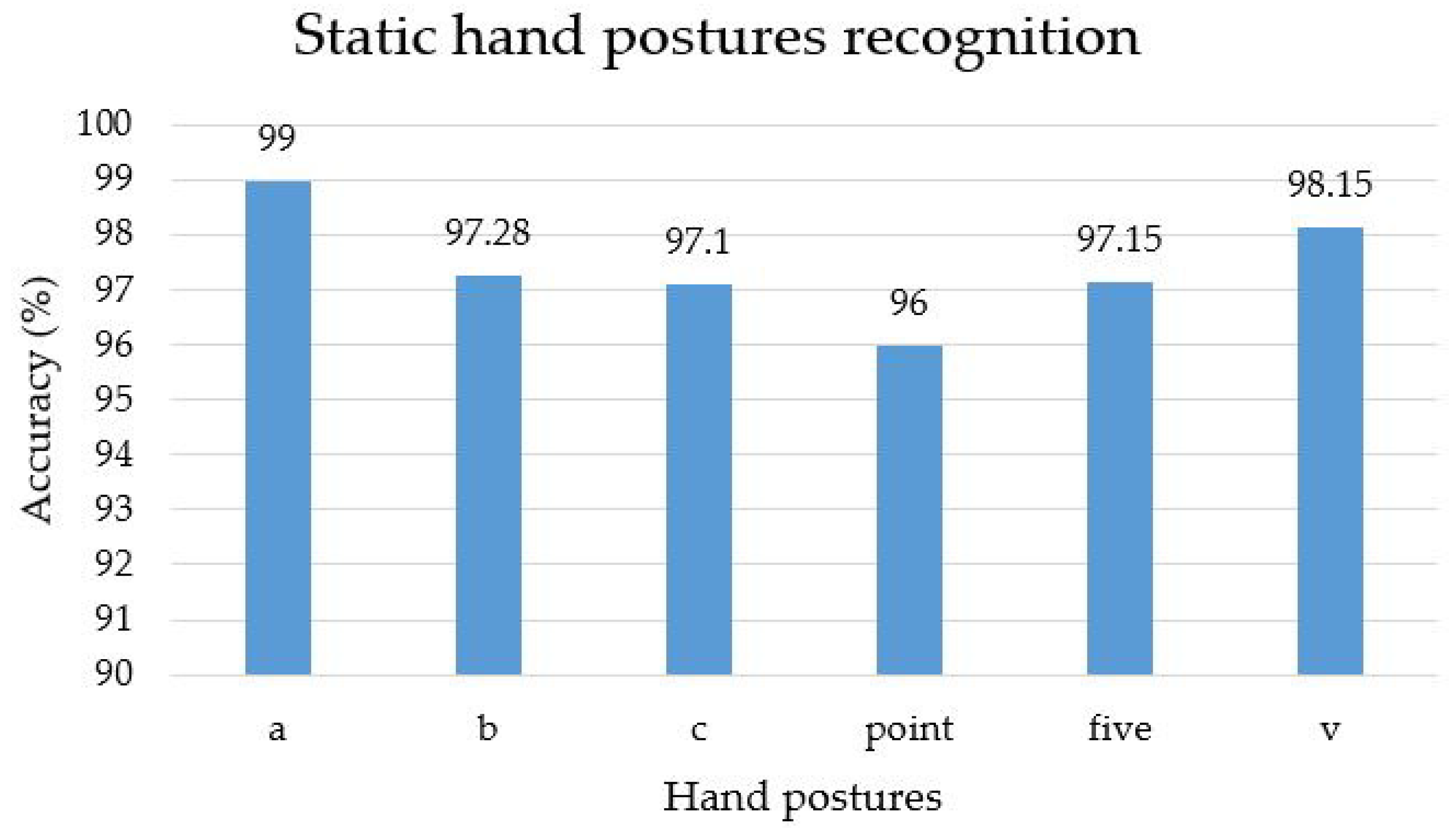
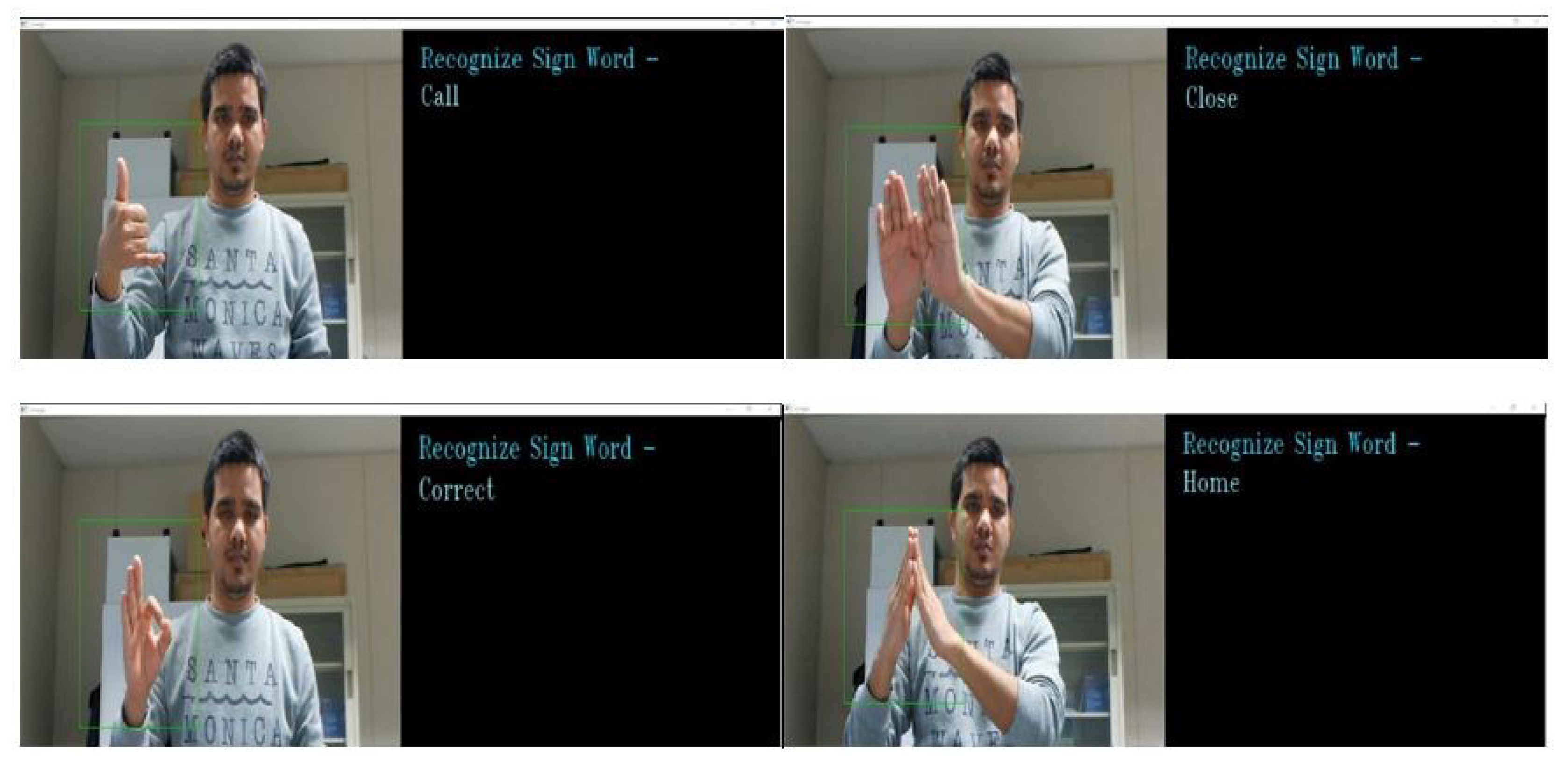
4.2. Hand Gesture Segmentation
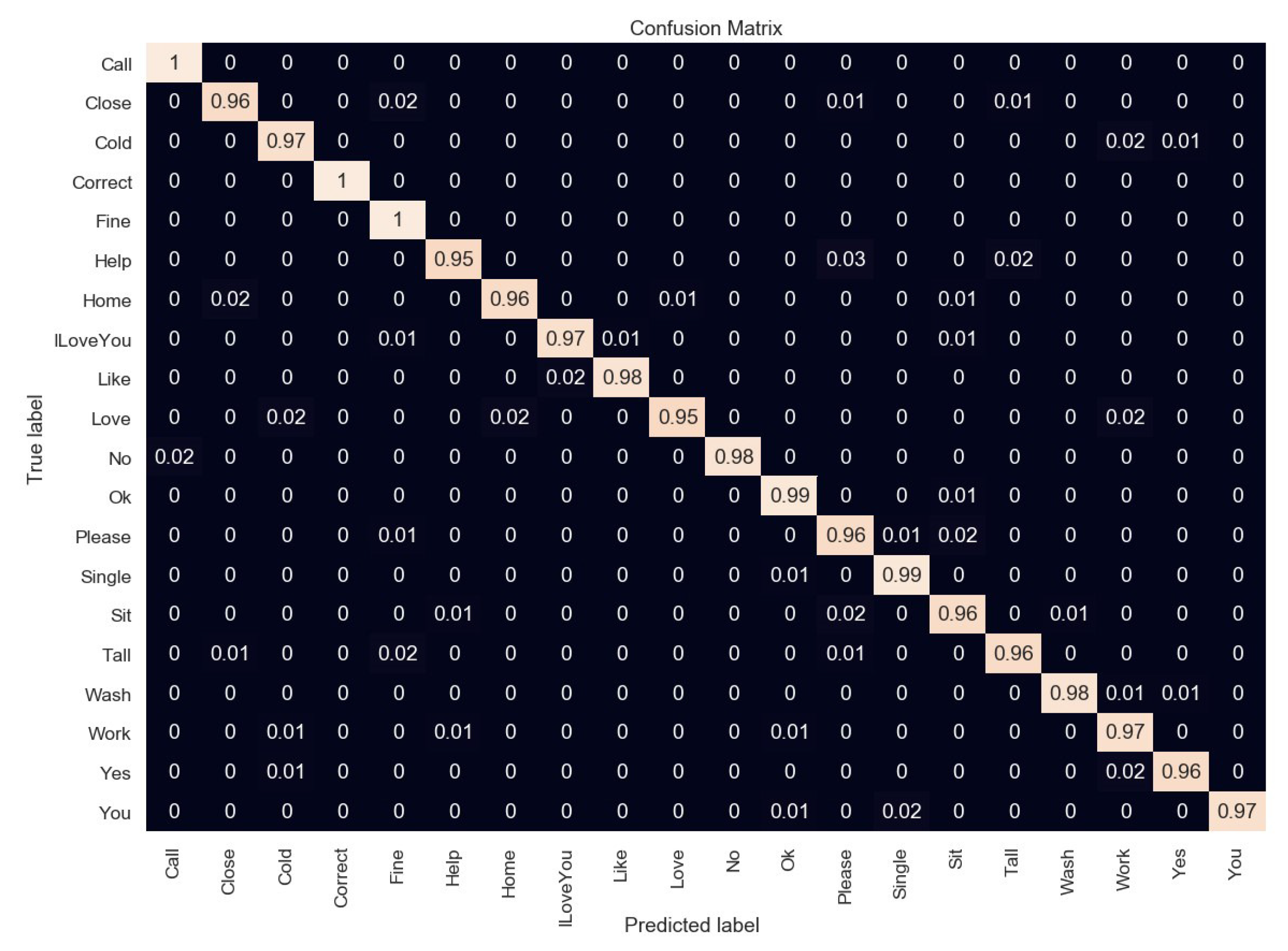
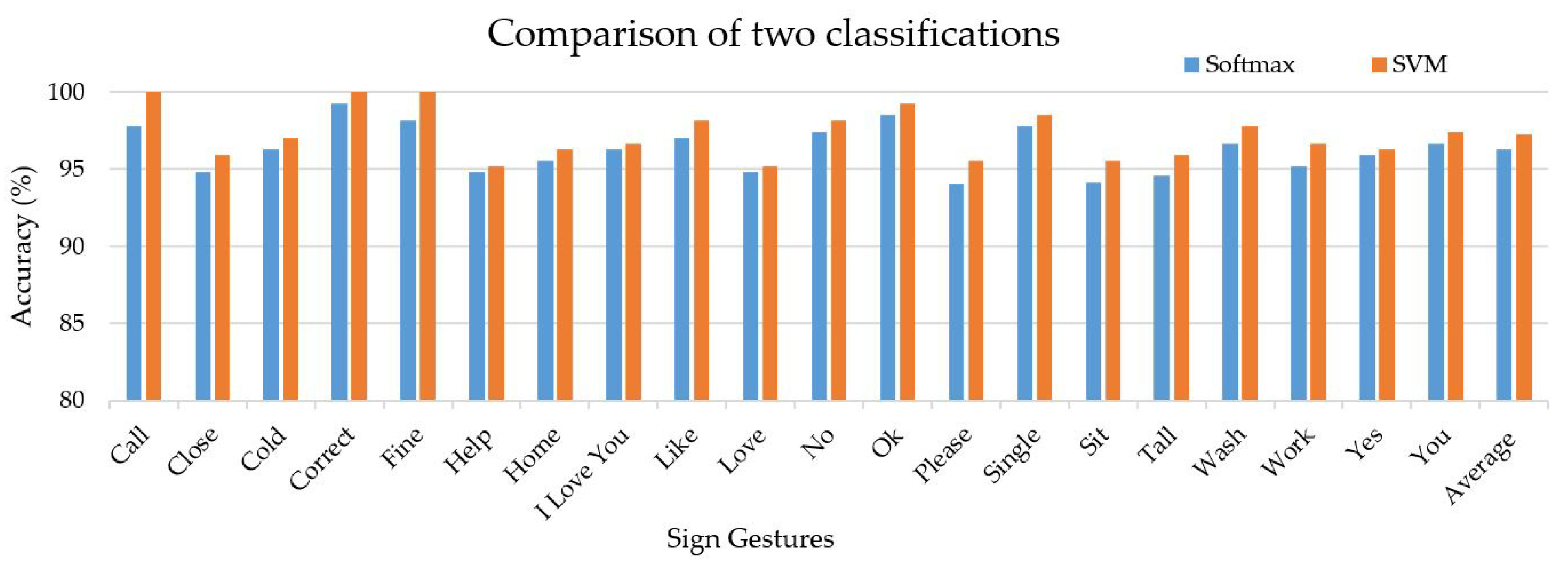
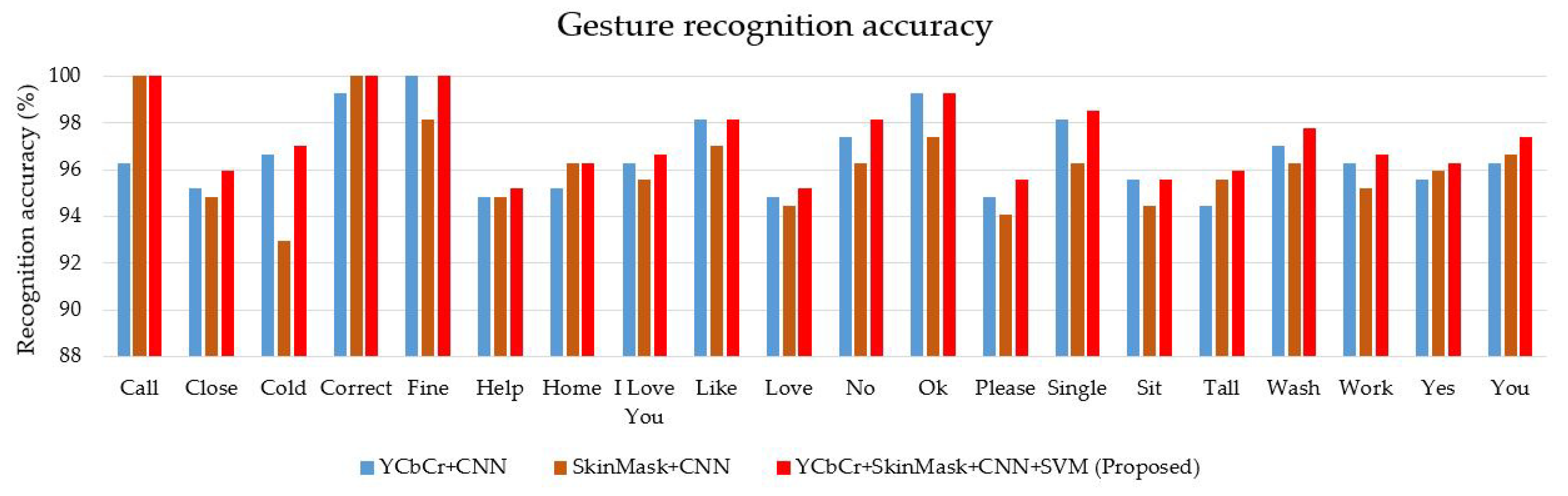
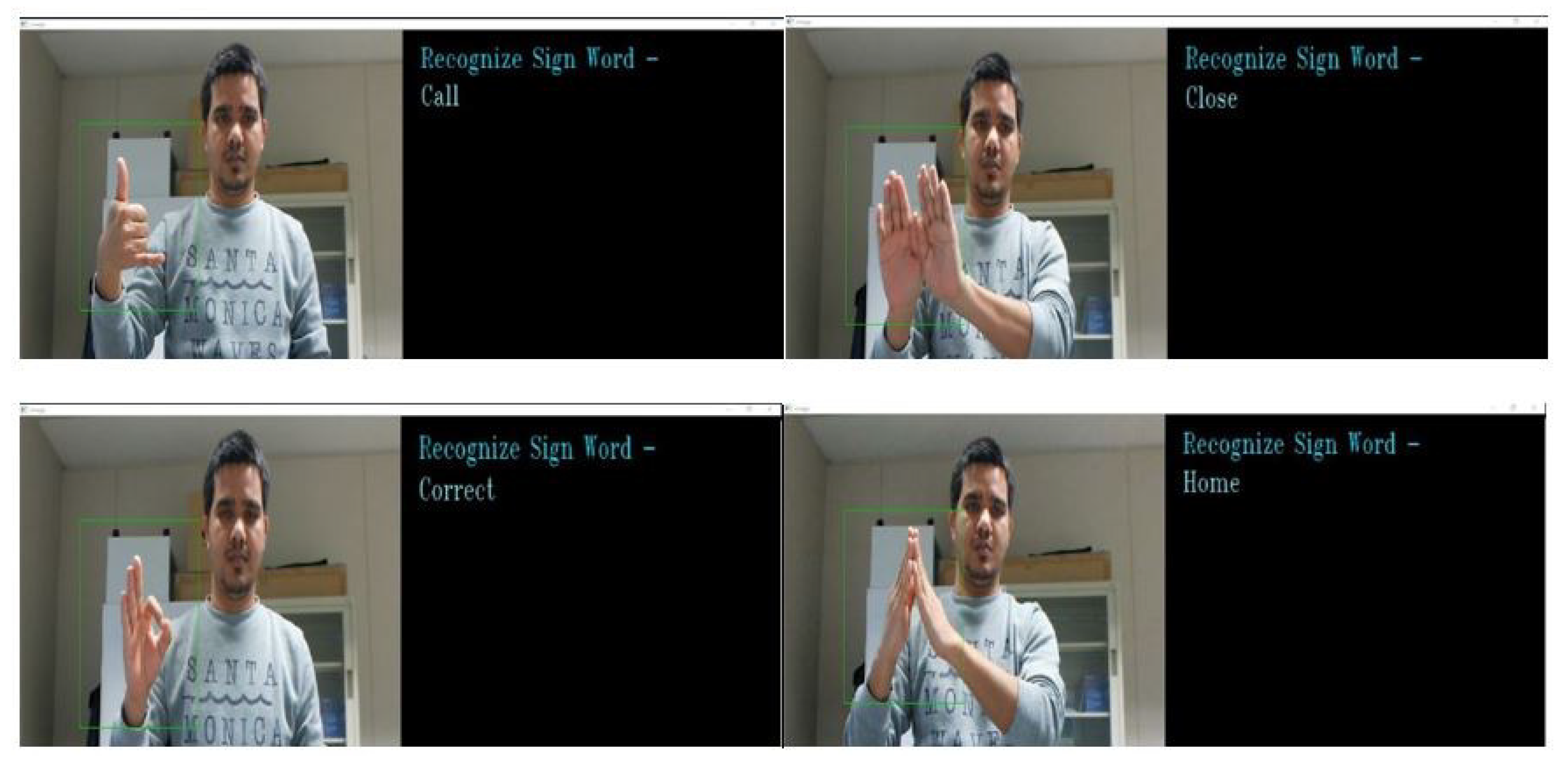
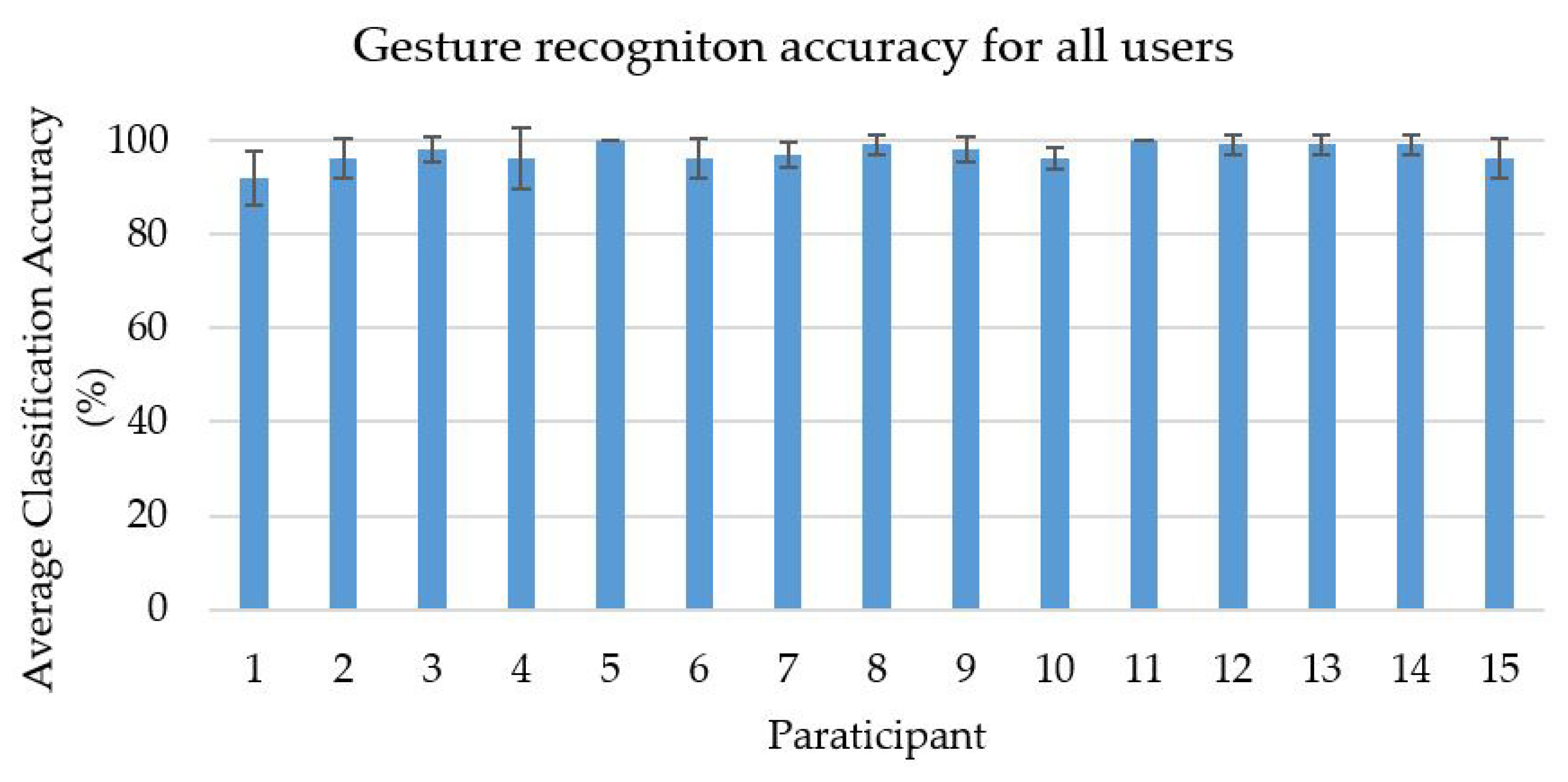
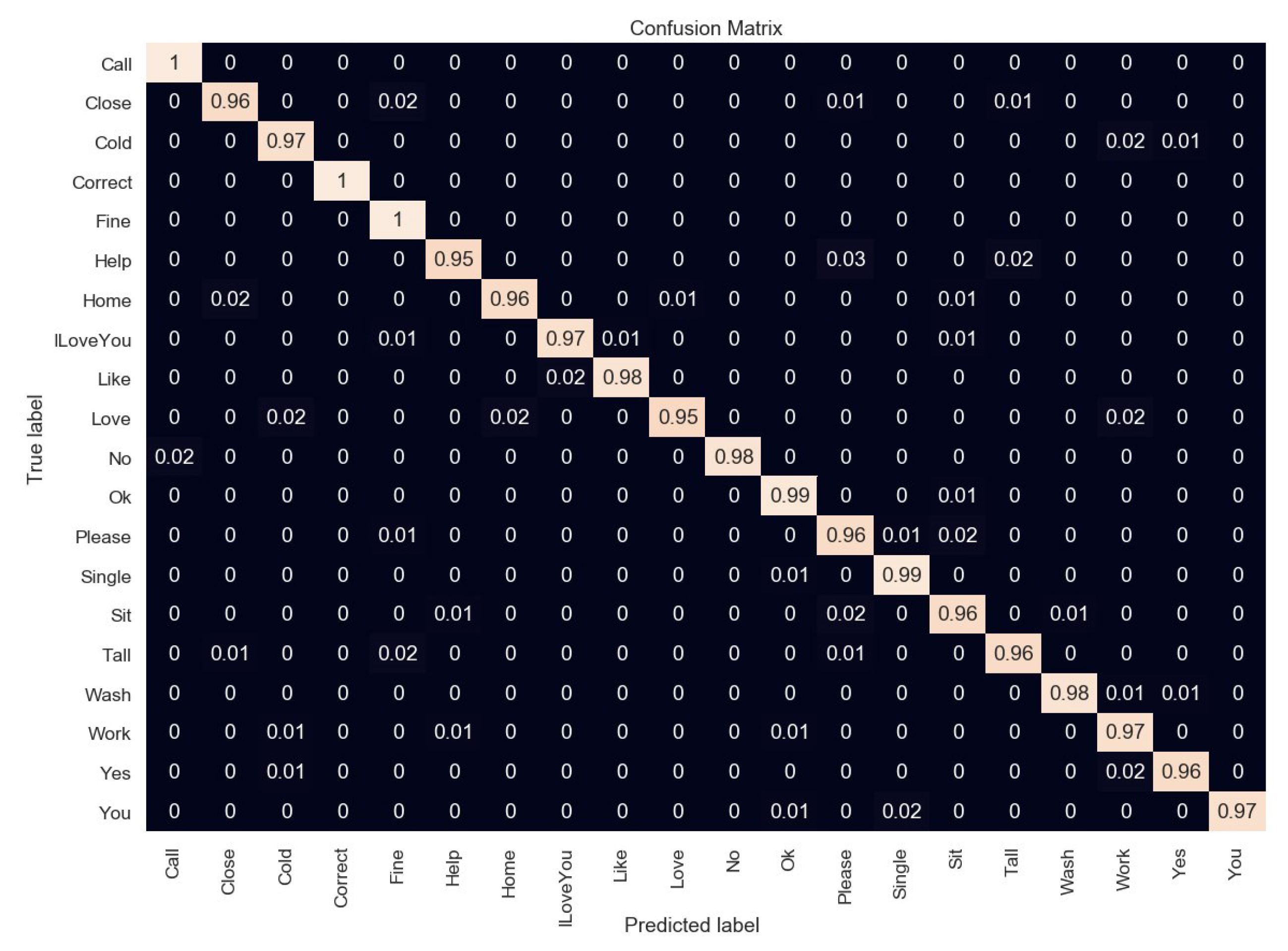
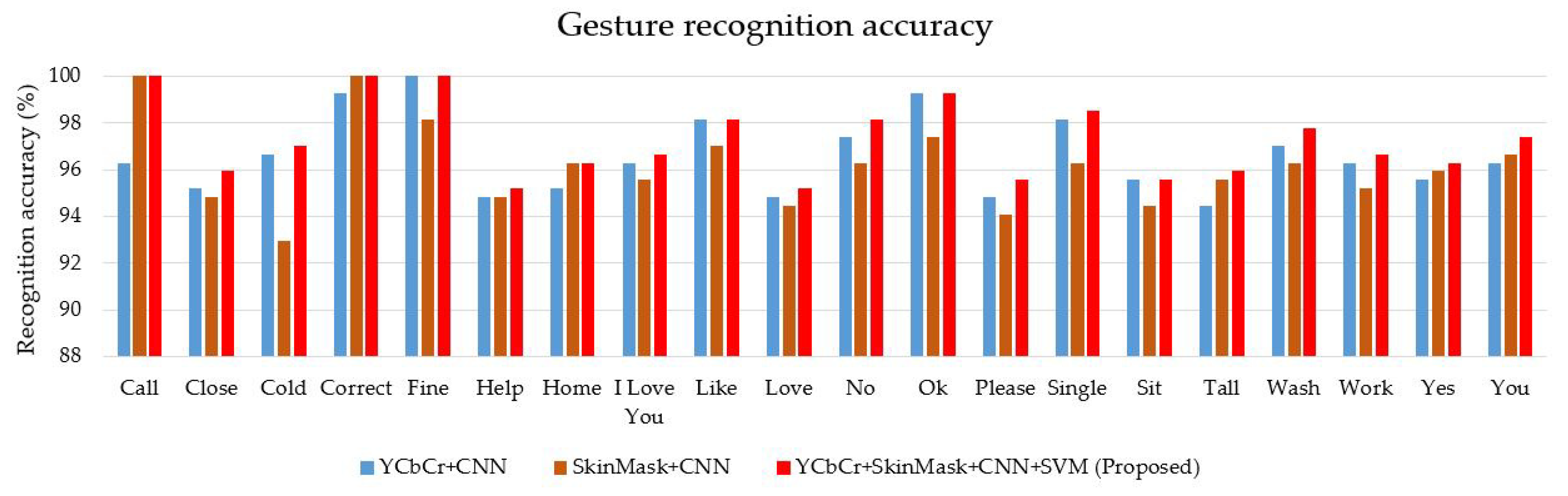
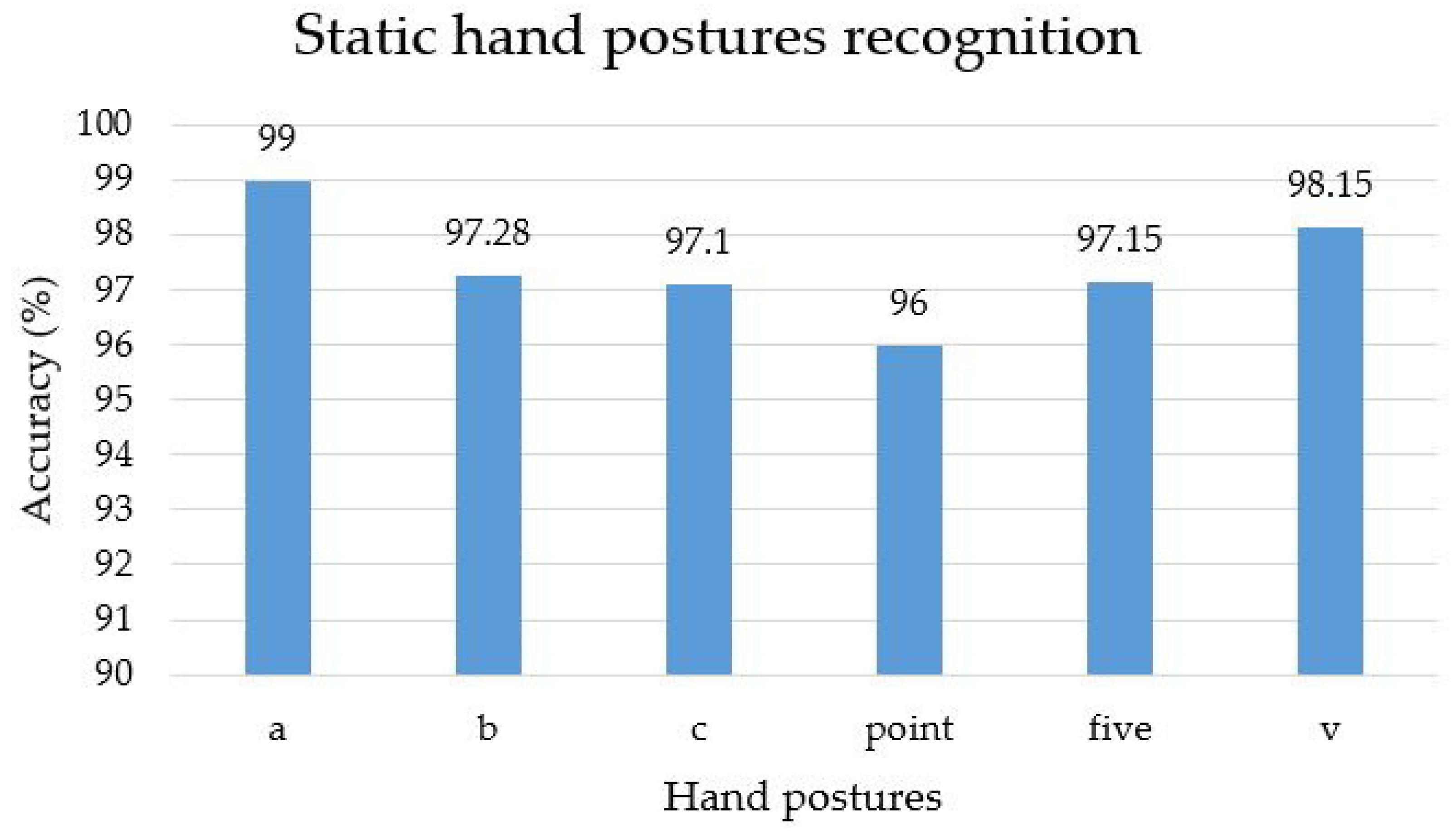
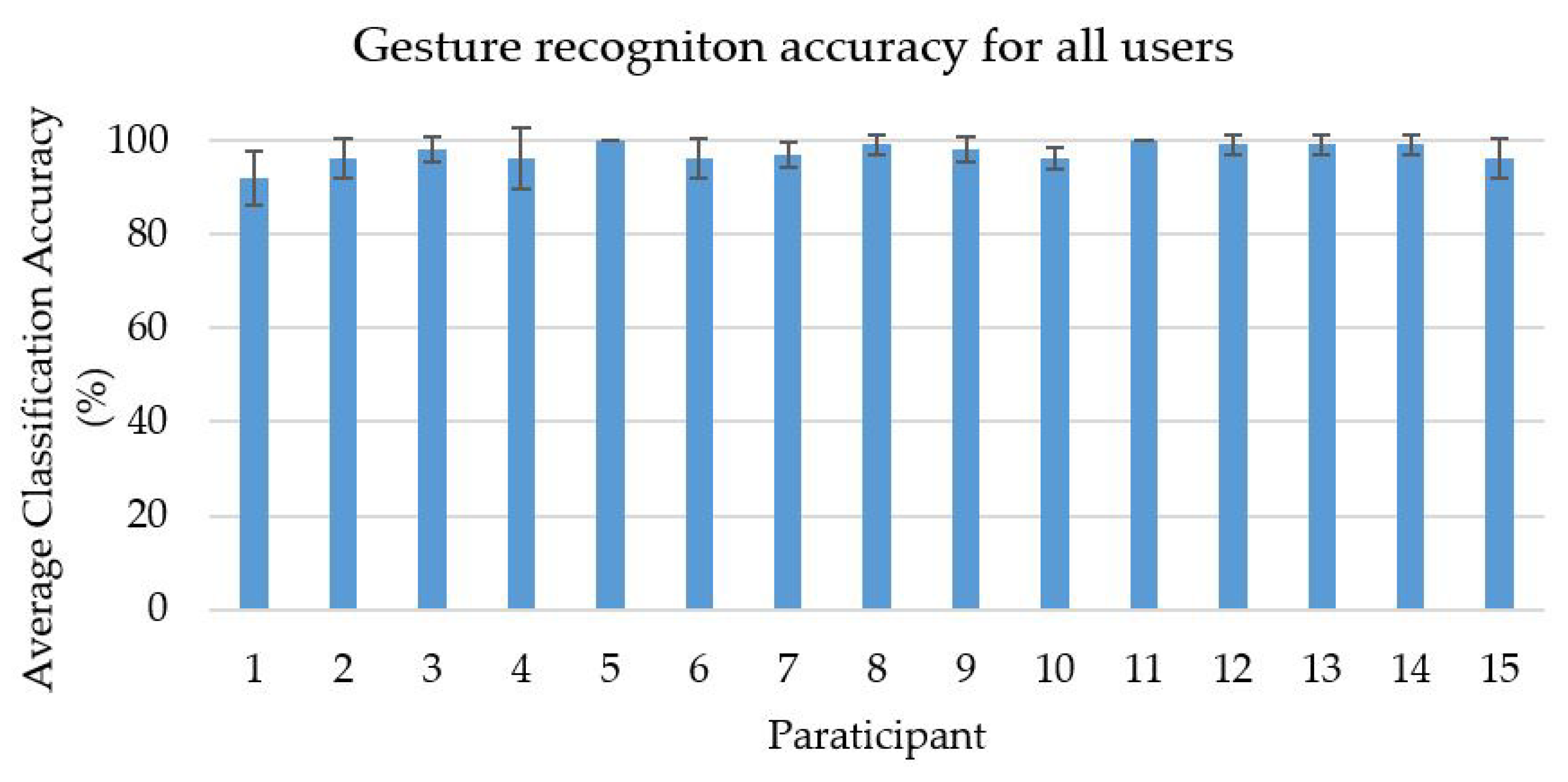
4.3. Feature Extraction and Classification
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- World Health Organization (WHO). Available online: www.who.int/deafness/world-hearing-day/whd-2018/en (accessed on 20 July 2019).
- Ahmed, M.A.; Zaidan, B.B.; Zaidan, A.A.; Salih, M.M.; Lakulu, M.M. A review on systems-based sensory gloves for sign language recognition state of the art between 2007 and 2017. Sensors 2018, 18, 2208. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Sun, L.; Jafari, R. A wearable system for recognizing American sign language in real-time using IMU and surface EMG sensors. IEEE J. Biomed. Health Inform. 2016, 20, 1281–1290. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Chen, X.; Zhang, X.; Wang, K.; Wang, Z.J. A sign-component based framework for Chinese sign language recognition using accelerometer and sEMG data. IEEE Trans. Biomed. Eng. 2012, 59, 2695–2704. [Google Scholar] [PubMed]
- Sun, Y.; Li, C.; Li, G.; Jiang, G.; Jiang, D.; Liu, H.; Zheng, Z.; Shu, W. Gesture recognition based on kinect and sEMG signal fusion. Mob. Netw. Appl. 2018, 1, 1–9. [Google Scholar] [CrossRef]
- Gupta, H.P.; Chudgar, H.S.; Mukherjee, S.; Dutta, T.; Sharma, K. A continuous hand gestures recognition technique for human-machine interaction using accelerometer and gyroscope sensors. IEEE Sens. J. 2016, 16, 6425–6432. [Google Scholar] [CrossRef]
- Tubaiz, N.; Shanableh, T.; Assaleh, K. Glove-based continuous Arabic sign language recognition in user-dependent mode. IEEE Trans. Hum. Mach. Syst. 2015, 45, 526–533. [Google Scholar] [CrossRef]
- Lee, B.G.; Lee, S.M. Smart wearable hand device for sign language interpretation system with sensors fusion. IEEE Sens. J. 2018, 18, 1224–1232. [Google Scholar] [CrossRef]
- Tao, W.; Leu, M.C.; Yin, Z. American Sign Language alphabet recognition using Convolutional Neural Networks with multiview augmentation and inference fusion. Eng. Appl. Artif. Intell. 2018, 76, 202–213. [Google Scholar] [CrossRef]
- Rodriguez, K.O.; Chavez, G.C. Finger spelling recognition from RGB-D information using kernel descriptor. In Proceedings of the IEEE XXVI Conference on Graphics, Patterns and Images, Arequipa, Peru, 5–8 August 2013; pp. 1–7. [Google Scholar]
- Rahim, M.A.; Shin, J.; Islam, M.R. Human-Machine Interaction based on Hand Gesture Recognition using Skeleton Information of Kinect Sensor. In Proceedings of the 3rd International Conference on Applications in Information Technology, Aizu-Wakamatsu, Japan, 1–3 November 2018; pp. 75–79. [Google Scholar]
- Kumar, P.; Saini, R.; Roy, P.P.; Dogra, D.P. A position and rotation invariant framework for sign language recognition (SLR) using Kinect. Multimed. Tools Appl. 2018, 77, 8823–8846. [Google Scholar] [CrossRef]
- Saini, R.; Kumar, P.; Roy, P.P.; Dogra, D.P. A novel framework of continuous human-activity recognition using kinect. Neurocomputing 2018, 311, 99–111. [Google Scholar] [CrossRef]
- Shin, J.; Kim, C.M. Non-touch character input system based on hand tapping gestures using Kinect sensor. IEEE Access 2017, 5, 10496–10505. [Google Scholar] [CrossRef]
- Chuan, C.H.; Regina, E.; Guardino, C. American sign language recognition using leap motion sensor. In Proceedings of the IEEE 13th International Conference on Machine Learning and Applications, Detroit, MI, USA, 3–6 December 2014; pp. 541–544. [Google Scholar]
- Raut, K.S.; Mali, S.; Thepade, S.D.; Sanas, S.P. Recognition of American sign language using LBG vector quantization. In Proceedings of the IEEE International Conference on Computer Communication and Informatics, Coimbatore, India, 3–5 January 2014; pp. 1–5. [Google Scholar]
- Pisharady, P.K.; Saerbeck, M. Recent methods and databases in vision-based hand gesture recognition: A review. Comput. Vis. Image Underst. 2015, 141, 152–165. [Google Scholar] [CrossRef]
- D’Orazio, T.; Marani, R.; Renó, V.; Cicirelli, G. Recent trends in gesture recognition: How depth data has improved classical approaches. Image Vis. Comput. 2016, 52, 56–72. [Google Scholar] [CrossRef]
- Wu, X.Y. A hand gesture recognition algorithm based on DC-CNN. Multimed. Tools Appl. 2019, 1–13. [Google Scholar] [CrossRef]
- Chevtchenko, S.F.; Vale, R.F.; Macario, V.; Cordeiro, F.R. A convolutional neural network with feature fusion for real-time hand posture recognition. Appl. Soft Comput. 2018, 73, 748–766. [Google Scholar] [CrossRef]
- Agrawal, S.C.; Jalal, A.S.; Tripathi, R.K. A survey on manual and non-manual sign language recognition for isolated and continuous sign. Int. J. Appl. Pattern Recognit. 2016, 3, 99–134. [Google Scholar] [CrossRef]
- Gholami, R.; Fakhari, N. Support Vector Machine: Principles, Parameters, and Applications. In Handbook of Neural Computation; Academic Press: Cambridge, MA, USA, 2017; pp. 515–535. [Google Scholar]
- Marcel, S.; Bernier, O. Hand posture recognition in a body-face centered space. In International Gesture Workshop; Springer: Berlin/Heidelberg, Germany, 1999; pp. 97–100. [Google Scholar]
- Flores, C.J.L.; Cutipa, A.G.; Enciso, R.L. Application of convolutional neural networks for static hand gestures recognition under different invariant features. In Proceedings of the 2017 IEEE XXIV International Conference on Electronics, Electrical Engineering and Computing (INTERCON), Cusco, Peru, 15–18 August 2017; pp. 1–4. [Google Scholar]
- Lin, H.I.; Hsu, M.H.; Chen, W.K. Human hand gesture recognition using a convolution neural network. In Proceedings of the IEEE International Conference on Automation Science and Engineering (CASE), Taipei, Taiwan, 18–22 August 2014; pp. 1038–1043. [Google Scholar]
- Pigou, L.; Dieleman, S.; Kindermans, P.J.; Schrauwen, B. Sign language recognition using convolutional neural networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 572–578. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Method | Reported Accuracy (%) | Classification Accuracy (%) | |
|---|---|---|---|---|
| Softmax | SVM | |||
| [25] | Skin Model and CNN | 95.96 | 95.26 | 96.11 |
| [26] | CNN | 91.7 | 93.61 | 94.7 |
| [24] | YCbCr and CNN | 96.2 | 95.37 | 96.58 |
| Proposed | Hybrid segmentation and double channel of CNN | - | 96.29 | 97.28 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rahim, M.A.; Islam, M.R.; Shin, J. Non-Touch Sign Word Recognition Based on Dynamic Hand Gesture Using Hybrid Segmentation and CNN Feature Fusion. Appl. Sci. 2019, 9, 3790. https://doi.org/10.3390/app9183790
Rahim MA, Islam MR, Shin J. Non-Touch Sign Word Recognition Based on Dynamic Hand Gesture Using Hybrid Segmentation and CNN Feature Fusion. Applied Sciences. 2019; 9(18):3790. https://doi.org/10.3390/app9183790
Chicago/Turabian StyleRahim, Md Abdur, Md Rashedul Islam, and Jungpil Shin. 2019. "Non-Touch Sign Word Recognition Based on Dynamic Hand Gesture Using Hybrid Segmentation and CNN Feature Fusion" Applied Sciences 9, no. 18: 3790. https://doi.org/10.3390/app9183790
APA StyleRahim, M. A., Islam, M. R., & Shin, J. (2019). Non-Touch Sign Word Recognition Based on Dynamic Hand Gesture Using Hybrid Segmentation and CNN Feature Fusion. Applied Sciences, 9(18), 3790. https://doi.org/10.3390/app9183790