1. Introduction
Increased public awareness of energy conservation in recent years motivates electricity consumers to participate in energy management actively [
1]. Demand response (DR) is one of the solutions for demand side management, which responds to certain conditions by reducing or shifting loads to a different time period. With the advent of the smart grid, residential DR has great research potential. Since different types of appliances have different opportunities and ways to participate in DR, it is crucial to study detailed appliance-level power consumption. In addition, the visualization of detailed consumption of high-power appliances will help customers to replace some inefficient devices, so as to save energy [
2].
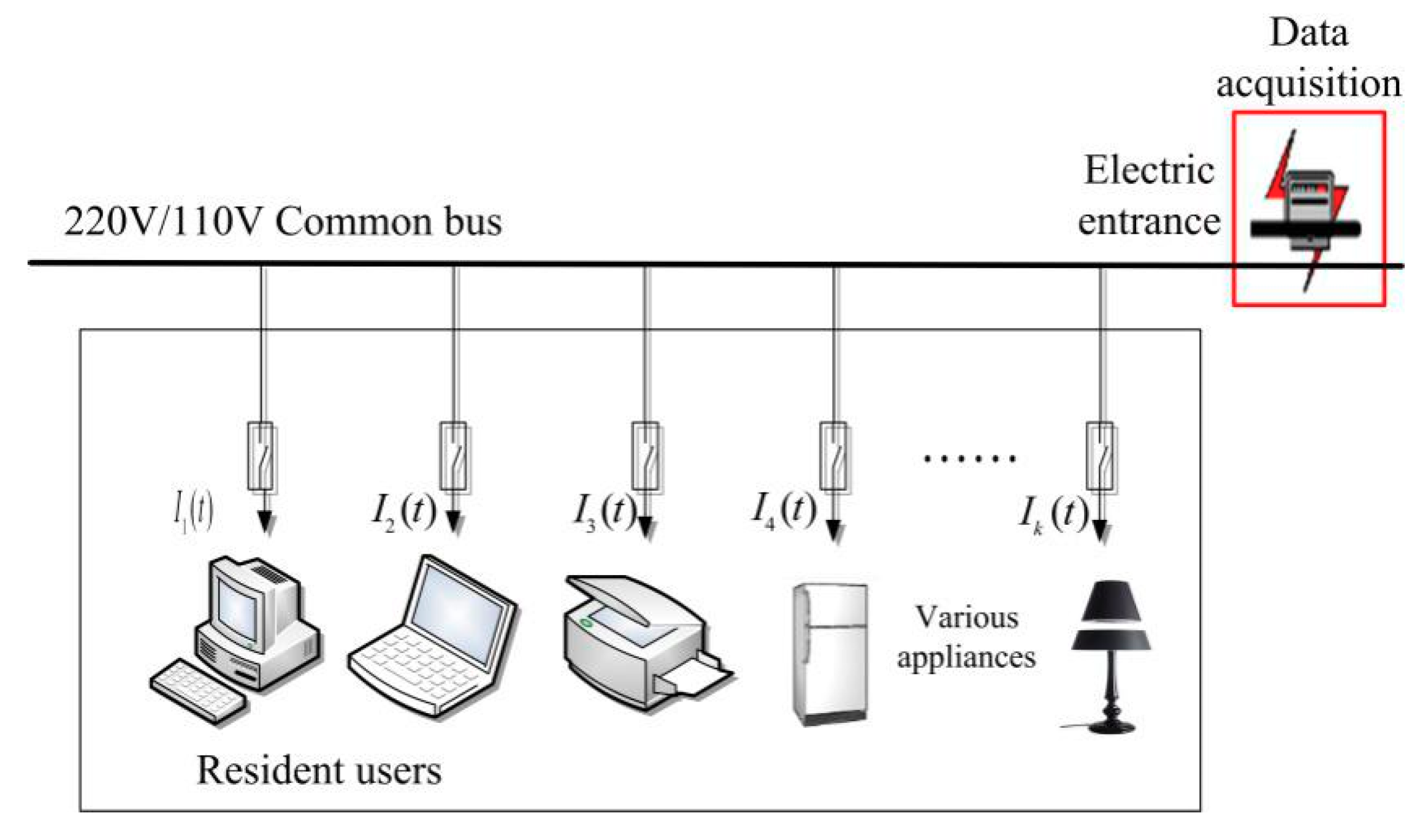
Traditional intrusive load monitoring needs to install lots of sensors to acquire a signal of each appliance. In the process of sensors’ installation and maintenance, the power supply needs to be temporarily interrupted, which causes inconvenience for both the power grid and users. Due to the poor practicability of the intrusive method, Hart proposed the concept of non-intrusive load monitoring (NILM) in the 1980s [
3]. Since it has a lower installation cost and impact for users, NILM is more attractive to customers and utilities. The main idea of NILM is disaggregating mixed electrical signals acquired at power entrance to obtain the working status and detailed power consumption information of individual appliances.
Early studies in NILM focused on detecting state-changing events by identifying distinct electrical features of individual appliances, which are called “load signature” and can be divided into two categories: steady-state and transient state. It is a good idea to complete NILM with unsupervised learning by combining different features [
4]. The most commonly used steady-state signatures are active and reactive power [
2,
5]. They are effective in identifying high-power devices, but it is challenging to separate low-power appliances for them due to the possibility of power overlap. Later works extended the steady-state signature to many aspects, such as harmonics [
6], current and voltage waveforms [
7], voltage-current trajectory [
8,
9,
10], inactive current [
11] etc. All of them can disaggregate certain types of appliances effectively. In order to define more accurate load signatures, features are extracted from the period of two stable operations, called transient signature [
12,
13,
14]. Due to a relatively shorter duration of transient signatures, the probability of feature overlapping is lower. Transient signatures require a high sampling rate. However, it is difficult to achieve high sampling rate in practical applications, which limits the practicability of transient signatures.
With the large-scale deployment of smart meters, NILM approaches that work with a lower sampling rate have drawn increasing attention. Most smart meters installed in practical applications measure and transmit the power signals at a relatively low frequency, generally between 1 Hz and 1/900 Hz [
15]. Consequently, the steady-state signatures become a more suitable choice in applications. Low-rate NILM methods can be divided into two categories. One refers to event-based NILM [
16], which implements load monitoring by classifying the signatures related to load events. The other is state-based NILM [
17], which realizes load disaggregation through pattern recognition.
Most of state-based NILM methods are based on the hidden Markov model (HMM) and its variations [
18,
19,
20,
21] due to the strong ability in modeling the combination of stationary process with continuous valued data over discrete time. Yuan proposes a load disaggregation method based on clustering algorithm and support vector regression optimization, which works very well [
22]. Four different extensions of HMM are presented [
20], but they are likely to converge to a local minimum. To address this problem, the hierarchical Dirichlet process hidden semi-Markov mode (HDP-HSMM) is described [
21]. To extend NILM service to new households without further intrusive monitoring, a model fitting algorithm is designed [
23], which adopts iterative k-means to fit a HMM with only one typical duty cycle of device. However, HMM has heavy dependence on clean transitions from one state to another, especially for continuously varying appliances. To alleviate this problem, a sparse coding method based on structured prediction is developed [
24]. Motivated by the success of deep learning, a deep sparse coding is proposed [
25]. However, a typical shortcoming is that more parameters need to be learned for going deeper. Kelly uses a neural network to complete the load disaggregation problem and gets good results [
26]. But generally, state-based algorithms have a common drawback, i.e., long periods of training and high computational complexity, which makes them difficult to apply to real-time disaggregation.
Event-based algorithms have a relatively fixed processing procedure, including event detection, feature extraction and event classification. To obtain accurate identification results, different classification techniques are tried, including k-means [
27], k-nearest neighbor (k-NN) [
28], naïve Bayes [
29], maximum likelihood [
30] and decision tree (DT) [
31]. In [
30] the maximum likelihood classifier is designed to disaggregate load based on the power profiles, but it only works for single-state loads. Zhao relies on graph signal processing (GSP) to realize the edge detection, clustering, and pattern matching [
31]. However, experimental results show that power fluctuation or a close power range of appliances will influence algorithm performance. Qi adopts graph shift quadratic form constraint to complete low-rate load disaggregation [
32]. A novel combined k-means-SVM-based NILM method is developed [
33]. However, event-based methods face a common challenge, that is, most of the existing algorithms only rely on a two-dimensional feature space of active and reactive power for load identification without considering other additional features, such as time and sequence signatures. Moreover, the same type of appliances in different households have quite different signatures, so it is unsuitable to use a unified model to represent them.
The existing NILM methods are focused on detection of all appliances without considering the applicability of load disaggregation in realistic applications, that is, there is no definition of an accurate load space related to the actual application. Load space refers to the range of load types to be analyzed. In this paper, we define different load types that need to be analyzed. It also describes which loads belong to different types. Because of the complexity of the original load space, it is impractical to identify all devices based on a one-dimensional aggregated signal. So, there is an emerging need to define a suitable load space.
In order to address the difficulty of identifying appliances with similar power, a linear discriminant classifier group considering multidimensional features is designed in this paper. It is an event-based method, which can work seamlessly with smart meter infrastructure without installing additional acquisition devices. Considering the practical application of this study is to provide appliance-level information for DR and energy-saving service, the types of the monitored load can be narrowed down to some controllable and high-power loads.
This work formalizes a load identification technique based on the multi-feature integrated classification (MFIC), where the only input is the time-stamped power readings from the smart meter. The major contributions of this paper are as follows:
- (1)
Considering the different operating habits and inherent electrical characteristics of loads, multidimensional features are used to model each appliance and improve the load discrimination. In addition, due to the great difference of appliances signatures in different households, this paper uses proprietary model database to replace the uniform feature database.
- (2)
Based on steady-state segmentation, a designed event detector in this paper has fewer parameters and no dependence with the detection window.
- (3)
A linear discriminant classifier for each appliance is designed according to the overall similarity of multi-features. Based on the designed discriminant classifiers, a discriminant classifier group can be formed.
The structure of this paper is given as follows.
Section 2 selects multidimensional features for load modeling. In addition, a brief analysis of DR and energy-saving services is made to specify the research objective and narrow down the load space.
Section 3 elaborates on the problem definition and the complete process of proposed MFIC algorithm.
Section 4 presents experiments and their results. The last section concludes the paper and discusses future works.
3. Methodology
3.1. Load Disaggregation Definition
The definition of load disaggregation can be expressed as follows: Given the mixed signal collected at the power entrance of a house, we need to disaggregate the mixed signal into a series of individual components attributed to specific appliances. The mixed signal consists of individual appliance signals which are switched ON at the given moment. It is necessary to design a Boolean coefficient
an,m(
k), which determines whether the mode
m of appliance
n is ON at the
kth sampling point. Mathematically, the mixed signal obtained can be formulated as a linear combination of some unknown appliance power consumption data, which is shown as Equation (1).
where,
P(
k),
k = 1,2,3,…,
L is the aggregated power signal (
L is the number of samples) and
pn,
m(
k) denotes the individual power consumption of appliance
n in mode
m.
N and
M are the number of appliances and modes, respectively.
e(
k) stands for the noise signal and small appliances whose power is very small so that they have little effect on mixed signals, including phone chargers, DVD player and so on. So it can be ignored in load identification. The objective is to decode
P(
k) and obtain the status of each appliances by using a set of appliance models in the house.
In existing research, subjected to some prior information, combination optimization is a common method to solve the Equation (1), which searches the optimum appliance status by minimizing the difference between the actual aggregate power and the sum of disaggregated appliance powers.
3.2. Algorithm Overview
In reality, appliances may not operate at their rated power, because the actual power consumption is proportional to the power of total load. Furthermore, different appliances may operate in similar electrical signature “power”. It is difficult to solve the problem in Equation (2) by combination optimization.
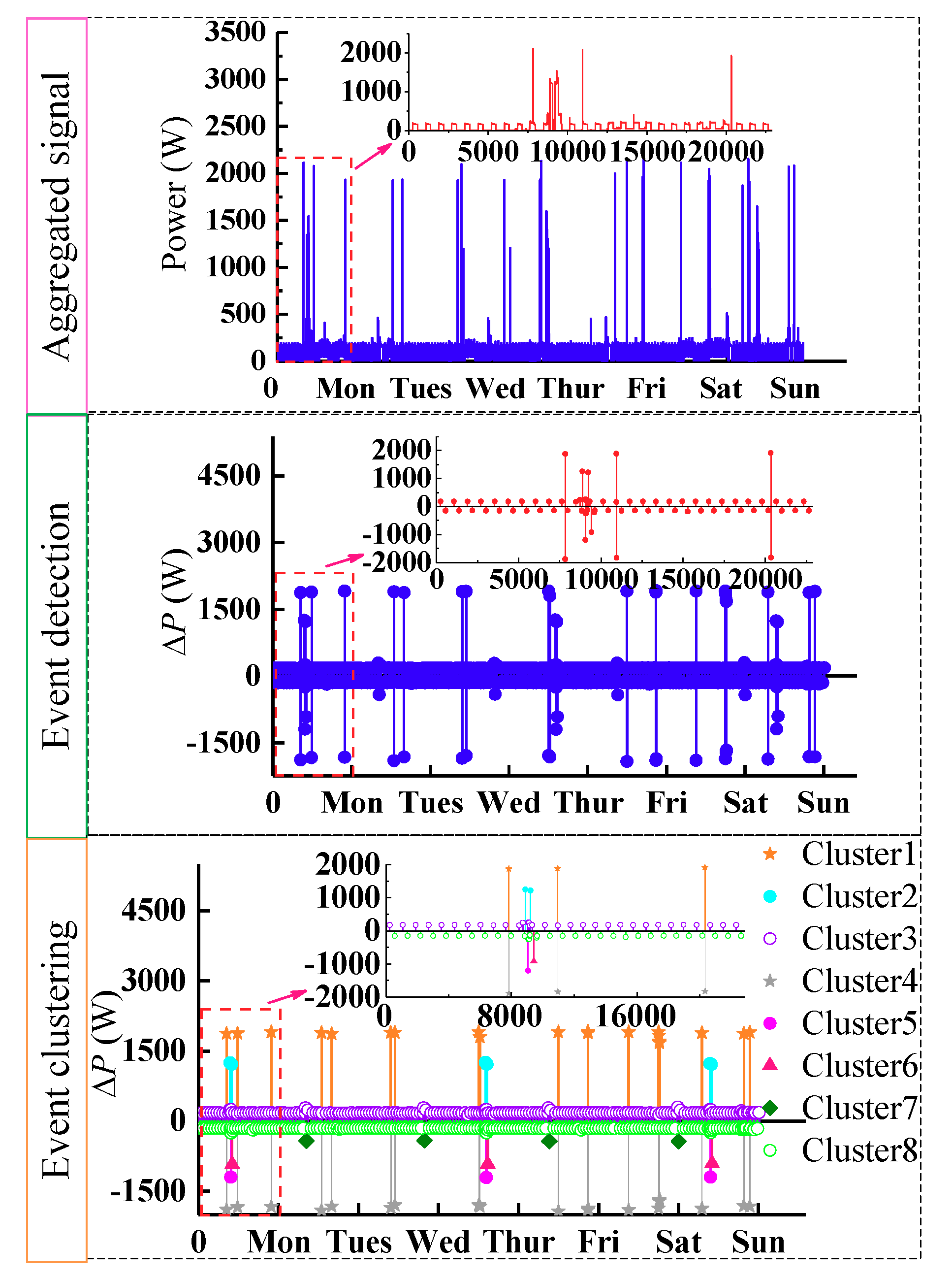
The actual electric data display that it is easy to segment the total signal into some steady-state process by clearly step changes. Therefore, an event-based algorithm is designed to solve the load disaggregation problem, including three steps: (1) event detection and clustering, (2) event paring and electrical feature extraction and (3) feature matching. Firstly, we detect the significant active power changes, which represents that some appliances changed their status. Then, events with similar power should be grouped, i.e., clustering. After the formation of clusters, events in “positive” clusters require to be paired with those in negative clusters. Finally, extract the features from each positive-negative cluster pair, and match them with the appliance models. The flowchart is illustrated in
Figure 4.
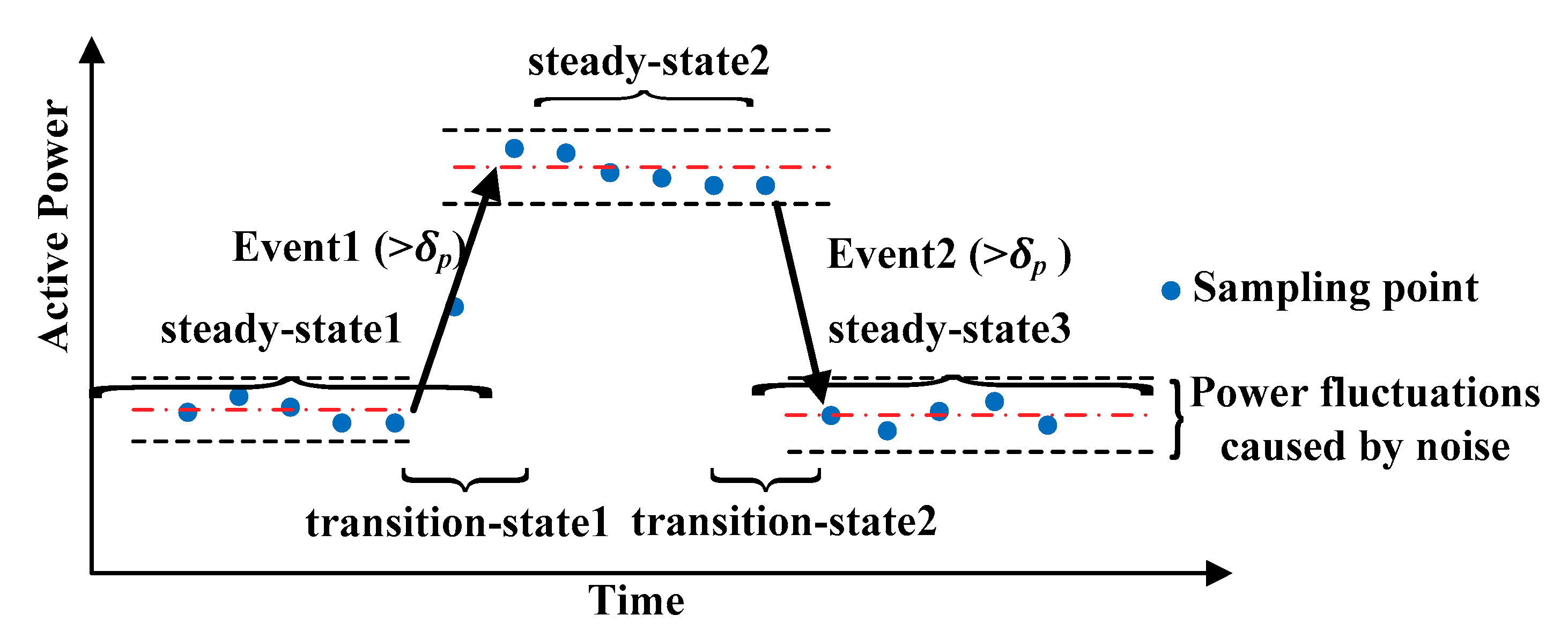
3.3. Steady-State Segment Based Event Detection
One important characteristic of event-based load disaggregation is to detect the significant rising or falling edge in active power, and record the power value and occurrence time of events. This paper presents an event detection method based on steady-state segment. It has two parameters, one is noise threshold
dn, the other is power threshold
dp. The schematic diagram of the event detection is shown in
Figure 5.
Each appliance can be represented by two states: (1) steady state, including ON and OFF state; and (2) transition state, i.e., the process of changing operation state of multi-state appliance. As long as the steady-state segments are identified, the duration of the power-on or power-off processes for different appliances can be determined adaptively. Load switching is successively based on the switch continuity principle [
3], i.e., only one state transition can occur within the sampling time interval. It is feasible to use the step power variation in aggregated signal as the discriminant feature of event occurrence.
The power grid noise exists in the actual electric environment all the time. Low-frequency data can largely avoid noise interference, because the sampling frequency is much less than the noise frequency. In order to further improve the accuracy of the algorithm, the noise threshold is introduced to minimize the possibility of noise impact. Considering the robust to the possible variation of power amplitude caused by the noise, an appropriate event extraction method is designed. The local mean and variance of power are used to capture the load steady state. Assuming
P(
k),
k = 1,2,3,…,
L is a given aggregate power signal and
T(
k),
k = 1,2,3,…,
L is the corresponding timestamp. By calculating the power changes at a certain time point, as well as before and after two time points, we can judge whether the household appliances are running steadily at that time. Two quantities are be calculated by Equations (3) and (4), where the former is the local mean power and the latter is the local variance.
The reason for choosing 1/3 is that it represents the mean and variance of three time points.
Let
δn2 denote the noise variation in power grid. If
σp(
k) <
δn,
P(
k) is considered in a steady state and then two variables
Pstd(
m) and
Tstd(
m) are added to record the
mth steady state, shown as follows.
After all the steady state segments are identified, the power difference between two consecutive steady states is calculated as Equation (7):
Set by users, the value of power threshold
δp depends on the load events they are interested in. For example, if users focus on the events with power change greater than 100 W, they can set
δp = 100. If abs(△
Pstd(
m))>
δp, it indicates that a new event is detected. The power value and timestamp of this event can be obtained as:
where
n represents the
nth event.
Pevt(
n) stands for the power value of the
nth event,
Te_start(
n) and
Te_end(
n) stand for the start time and end time of the event, respectively.
3.4. Event Clustering
The collection of the registered events Pevt(n), n = 1,2,…,Ne is the basis of the event clustering. Ne denotes the number of events detected. Each state of appliances has a unique value and only one appliance may have state transition in one sampling interval, it is reasonable to gather events with similar value into one cluster. Each cluster represents one kind of state transition of appliance.
The proposed clustering algorithm without prior knowledge can adaptively determine the number of clusters. There are two steps:
Step (1): separate the rising and falling edges of the event candidates into two collections of Pevt_up and Pevt_down. Then the rising and falling edges are arranged in descending order according to the absolute value of power, respectively. Set cluster threshold as Thrc. When the difference between two consecutive rising or falling edges is greater than Thrc, a new cluster is generated. The value of Thrc is set small so that the clustering results are more detailed. However, the event caused by the same appliance is also easy to separate some events into different clusters wrongly because of the power fluctuation. In order to solve this problem, we merge some clusters with the similar average power. The detailed process is illustrated in step 2.
Step (2): calculate the mean power of each cluster, and the mean power difference between two adjacent clusters is obtained. If the difference is less than a certain value, it can be considered that these two adjacent clusters belong to the same appliance state. Thus, we will merge them and the new cluster candidates will be formed.
3.5. Building Appliance Candidate Model
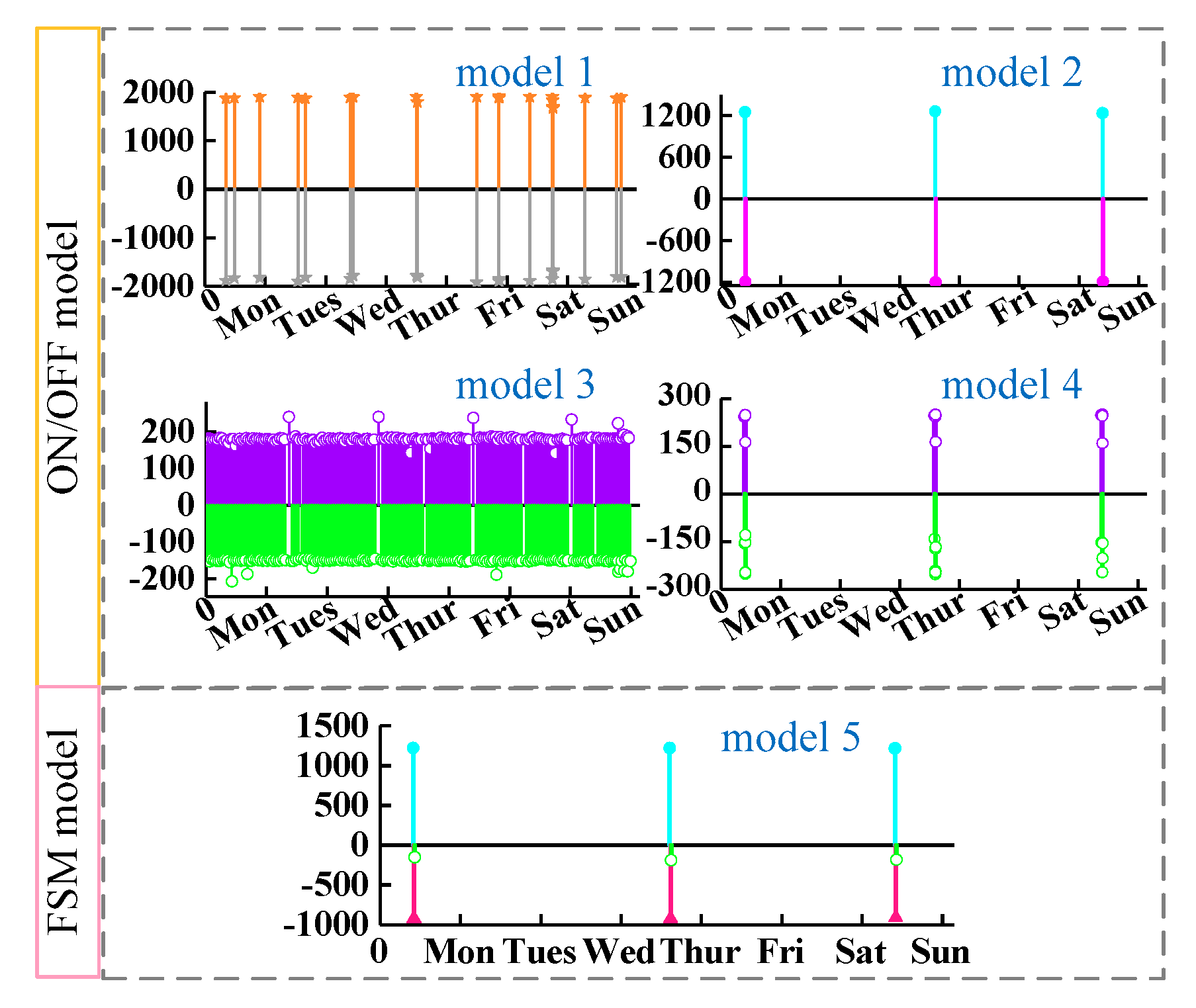
After clustering the events, “positive” clusters containing rising edges and “negative” clusters composed of falling edges are obtained. Then, the pairing method is designed to generate appliance candidate models automatically.
Most of the existing NILM algorithms only consider the single-state appliances, so the identification of multi-state loads is limited. The multi-state appliances are very common which cannot be described by ON/OFF model, so it is necessary to establish an appropriate model for them. The finite state machine (FSM) [
1] is a typical model for these appliances. The sum of power changes in any cycle of state transition is zero, which can be called zero loop-sum constraint (ZLSC) [
1]. Meanwhile, the operating states in an FSM model have different power levels, i.e., uniqueness constraint (UC). The two constraints ensure that it is possible to construct individual FSM from streams of events.
In the following, the method of generating appliance models is introduced. For the single-state appliances, an interruption model is established, and for controllable load, a FSM model is established. It includes two main steps, i.e., cluster pairing and event pairing.
Step (1): to construct ON/OFF models for the single-state appliance candidates, this paper pairs the “positive” cluster and “negative” cluster with similar absolute average power. We take advantage of special algebraic properties of events in a complete transition cycle, i.e., ZLSC and UC, to construct the FSM models. In order to reduce the complexity of cluster pairing, the ON/OFF models are built firstly. After the completion of all positive-negative cluster pairs, they are removed from the total clusters and FSM models are established from the other clusters.
Step (2): after the cluster pairing, some cluster pair candidates for single-state or finite-state appliances will be generated. It is essential to further match the events in each cluster pair. For example, each rising edge in the positive cluster is matched with a falling edge in the paired negative cluster by difference in the pairing features of two events. Then, a specialized forward-backward pairing procedure is designed to realize the effective pairing.
Let Cp and Cn denote two paired clusters, where |Cp| and |Cn| denote their cardinality.
(a) Forward Pairing
For each Cp(i)∈Cp, the forward pairing is to match an optimal falling edge among all elements in Cn according to the order from i = 1 to |Cp|-1. Normally, the ON and OFF events appear alternately, that is, using time stamps to sort events belonging to the same appliance will get an ON/OFF/ON/OFF… sequence. Thus, the falling edge paired with Cp(i) must occur after Cp(i) and before Cp(i+1). Denoted by Ω, the subset of Cn that satisfy the above condition are considered as a set of candidates. Let |Ω| represent the element number in Ω, the values of |Ω| can be divided into three cases. Different pairing processes are designed for these cases. Two vectors Mp and Mt are defined to represent the power difference and time intervals between paired events.
Case 1: When |
Ω| = 1, the absolute power difference
Ωp and time interval
Ωt between
Cp(
i) and the only element in
Ω are calculated. The probability of pairing
Cp(
i) and the element in
Ω can be defined as:
where,
mp stands for the mean value of the elements in
Mp, and
mt denotes the median value of the elements in
Mt.
If ci is larger than a given threshold, the only element in Ω can be considered as the paired falling edge for Cp(i), otherwise they are not matching. Then the Ωp and Ωt between paired events in vector Mp and Mt are recorded.
Case 2: When |
Ω|>1, the
Ωp and
Ωt between
Cp(
i) and each candidate in
Ω are calculated. The probability of pairing
Cp(
i) and the
jth candidate in
Ω can be obtained as:
Falling edge Cn corresponding to the maximum value in vector Ci is searched. If the maximum value is larger than the given threshold, Cn can be judged to the paired falling edge for Cp(i). Then the power difference and time intervals between paired events can be obtained.
Case 3: When |Ω| = 0, there is no appropriate element in Cn pairing with Cp(i). It is not applicable to a special situation, i.e., Cp(i+1) is clustered wrongly. So backward pairing is proposed, in this case of the lower accuracy with forward pairing only.
When the forward pairing is completed, all event pairs are stored in matrix Ef.
(b) Backward Pairing
For each Cn(i)∈Cn, the backward pairing is to match an optimal rising edge among all elements of Cp according to the order from i = |Cn| to 2. According to the analysis in forward pairing, the rising edge paired with Cn(i) must occur before Cn(i) and after Cn(i-1). The subsets of Cp that satisfy the above condition are considered as a set of candidates, denoted by Ψ. Let |Ψ| represent the element number of Ψ. The specific realization process is basically the same with the former pairing. The accuracy obtained by backward pairing is low when |Ψ| = 0, which needs to be analyzed with forward pairing results. When the forward pairing is completed, all event pairs are stored in Eb.
Finally, the optimal matching results can be obtained by comparing Ef and Eb. The event pairs that appear in both Ef and Eb can be considered to be matched correctly. The essence of this situation is that there are multiple falling edges between two successive rising edges, leading to inaccurate results of backward pairing. Moreover, if there are some event pairs in Ef and Eb that have the same falling edges but different corresponding rising edges, then the pairing results in Eb are considered to be optimal. The essence of this situation is that there are multiple rising edges between two successive falling edges, leading to inaccurate results of forward pairing.
3.6. Appliance Identification Based on Multi-Feature Integrated Classification (MFIC)
With the aforementioned process, the raw data recorded by smart meter is disaggregated to a set of appliance candidate models and each model carries unique information corresponding to an appliance footprint. Then, the features are extracted to label each candidate models combined with an existing feature library for the particular house.
3.6.1. Similarity Index of Single Feature
Intrinsic features are determined by the internal structure of appliances, which are not affected by the user’ behavior habits, and relatively stable with slight fluctuations. The similarity indices of these features can be quantified as:
where, (·) denotes the intrinsic feature of detection.
v represents the detected value of certain feature, and
vmean denotes the mean value of certain feature recorded in the feature library. Considering the slight fluctuations in these intrinsic features,
vmax and
vmin are used to represent the limits of upper and lower fluctuation bound.
H(·) is a piecewise function.
k is a calibration parameter to ensure that the similarity index is almost 0 when the detected value
ν exceeds
νmax and
νmin.
k = 1 in this paper.
Statistical features are expressed as a range rather than a fixed value. The similarity calculation of statistical features is defined as:
where, (·) stands for the statistical feature of detection.
x is the statistical value of specific feature.
denotes the range of possible values for a certain feature.
3.6.2. Appliance Recognition Based on Linear Discriminant Classifier Group
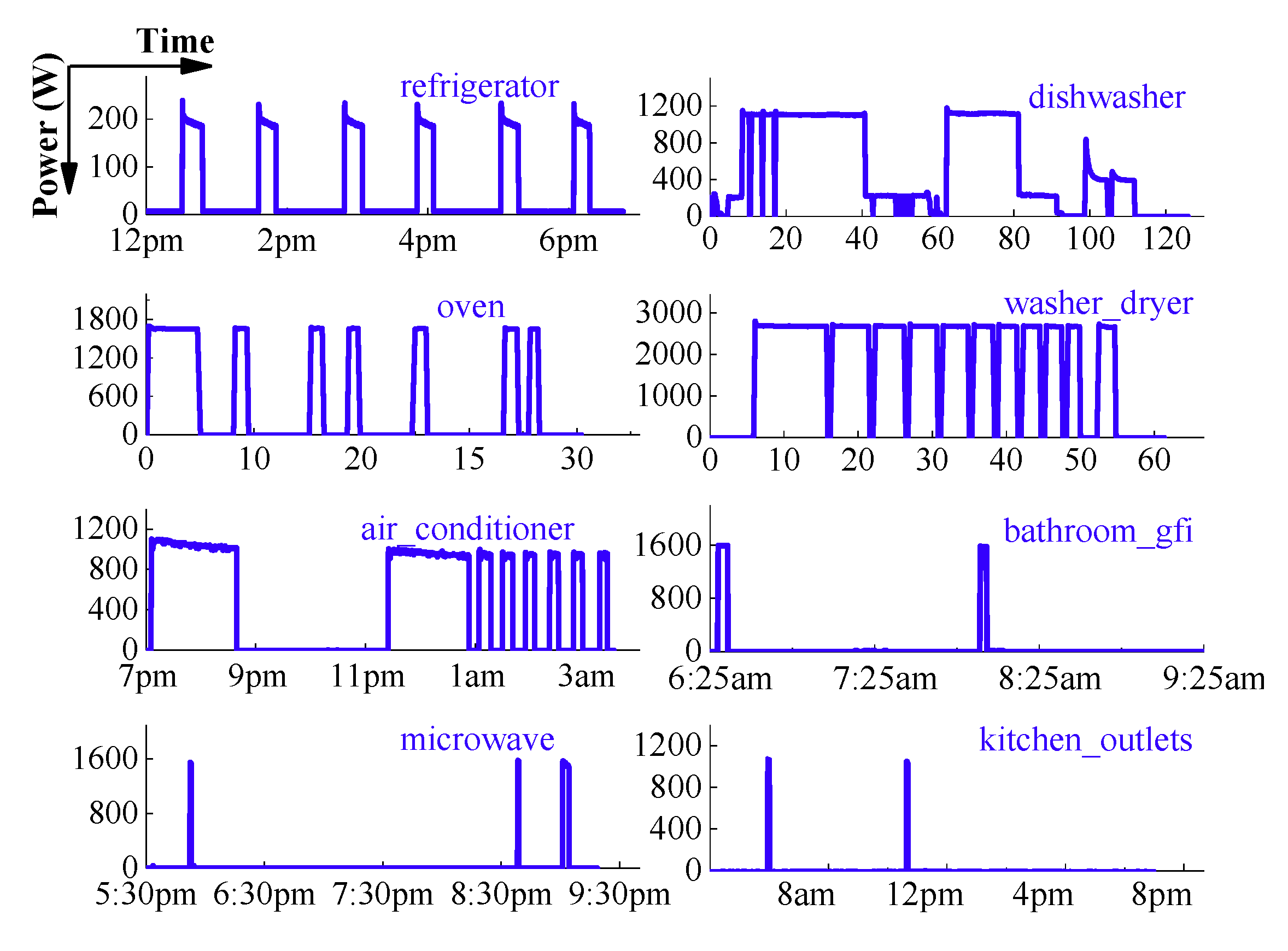
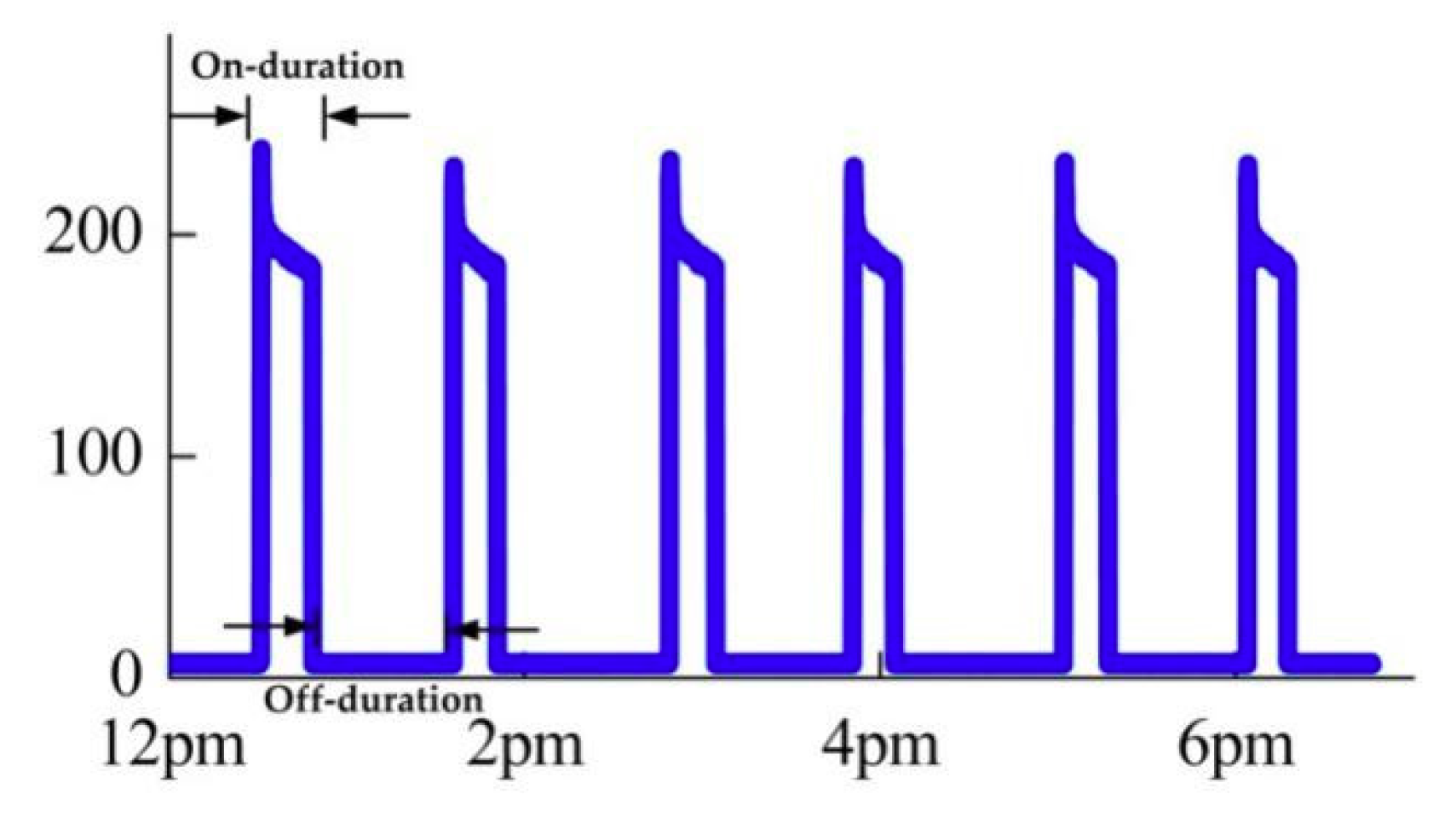
This section aims to label each appliance candidate model based on similarity indices. In order to synthetically consider the effects of various features in appliance identification, a linear discriminant classifier is designed for each appliance based on the similarity of all features. All the classifiers constitute a linear discriminant classifier group. The similarity is calculated by the sum of weighted similarity of different features. Because the feature weights of different appliances are inconsistent, the particular weight vector needs to be set for each linear discriminant classifier separately. It is firstly estimated by observing the difference of different appliances’ features. For instance, a refrigerator has specific ON-duration and OFF-duration, so the two features will be emphasized, while they are not important for light. Generally, the intrinsic features are more important than statistical features since statistical features are easily influenced by the external environment. After the predefinition of weight vectors, it is necessary to adjust their values to exploit the test data in different times and environments, so as to ensure the identification accuracy.
The detailed process of labeling appliance candidate models is described below. At first, the intrinsic and statistical features of each model are extracted. Then each unlabeled model will be classified by the linear discriminant classifier group in this particular house. The classification result of the
jth classifier is calculated as:
where,
ωj stands for the weight vector of the
jth classifier,
Sj includes feature similarity indices between the unlabeled model and the
jth classifier, and
δj represents the judgment threshold of the
jth classifier. If
d(
Sj)> = 0, the unlabeled model is determined as the appliance corresponding to the
jth classifier; otherwise not.
3.6.3. Performance Metrics
In order to evaluate the effects of signals disaggregation and compare with existing implemented algorithms, some indices are needed to evaluate the performance. Since an event-based NILM algorithm is designed in this paper, it is essential to measure the accuracy of this method in predicting which appliance is running in each state. Classification accuracy indices, such as precision, recall, and F-measure, are suitable for evaluation. Precision denotes the positive predictive values, i.e., the correct proportion of samples identified as appliance
c. Recall represents the true positive rate, i.e., the proportion of samples belonging to appliance
c that are recognized correctly. F-measure is harmonic mean of precision and recall. These typical classification metrics can be formulated as follows:
where, the subscript
c is used to mark different appliances or states.
TPc indicates true positive, i.e., the correct judgment that appliance
c is ON;
FPc represents the false positive, i.e., appliance
c is judged to be ON but actually OFF,
FNc denotes false negative, that is, appliance
c is ON but is wrongly judged as OFF.
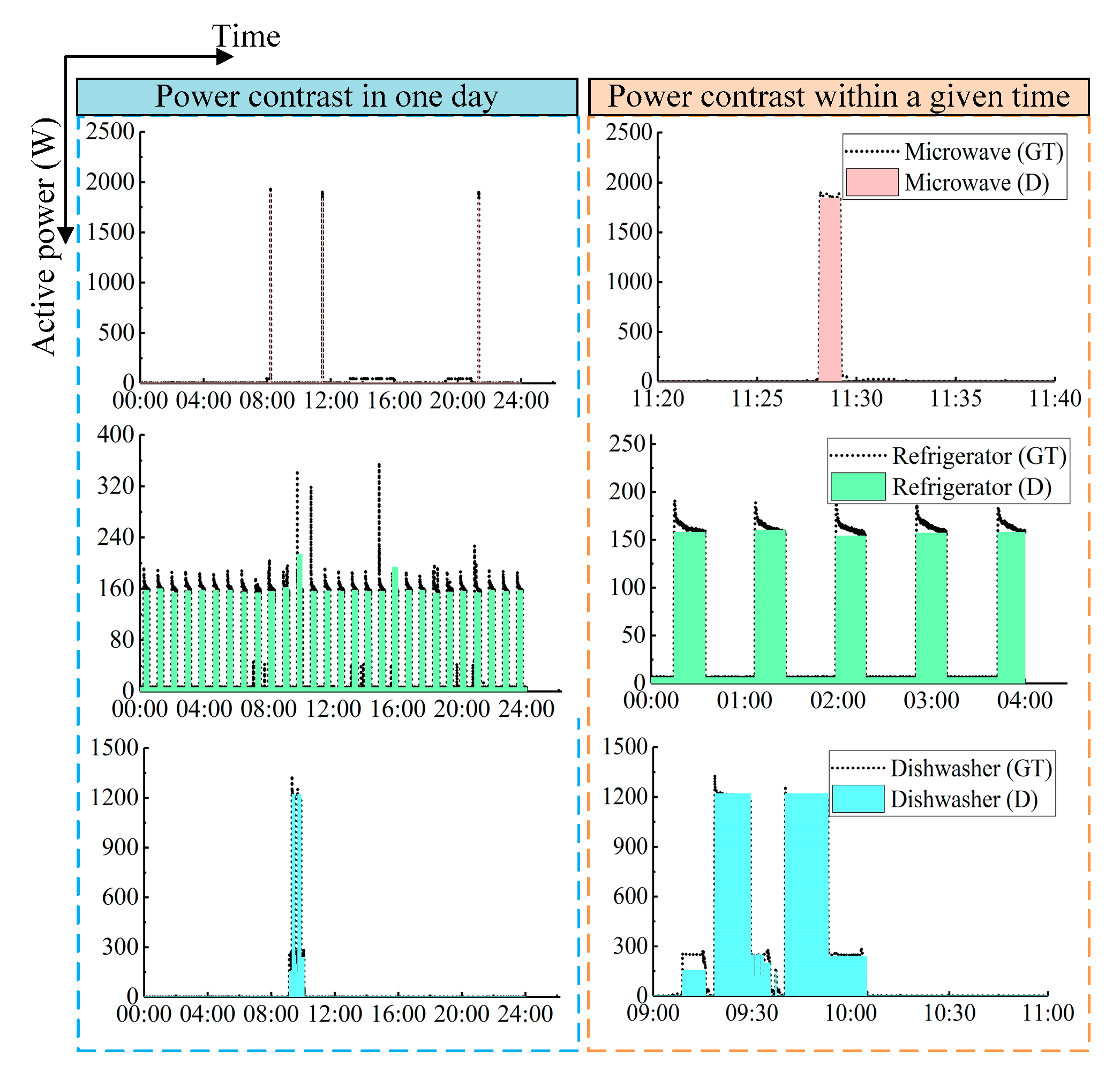
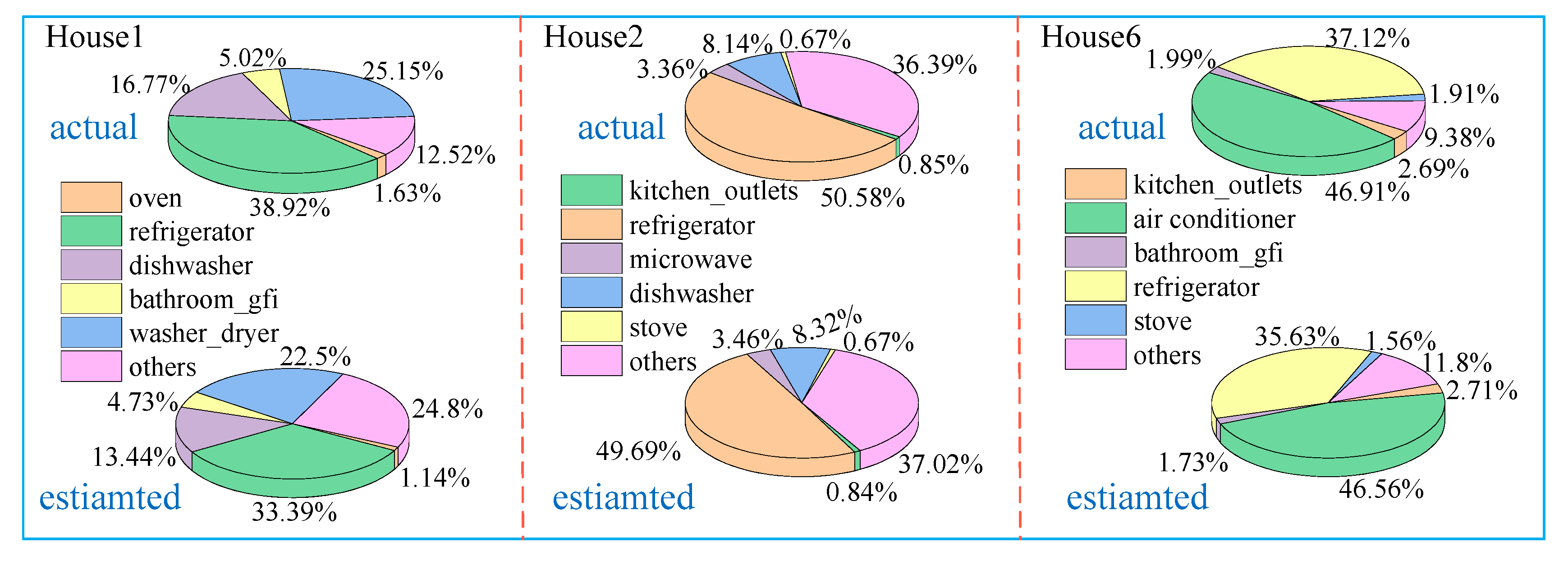
It is important to feedback the detailed power consumption of each appliance to users, so the accuracy of estimated power also needs to be considered. To compare the estimated power with the actual power consumption, disaggregation accuracy (
DA) and percentage of contribution in energy consumption (
PCEC) are used to evaluate the effects of different algorithms for reconstructing power profiles. The
DA provides a global comparison between the estimated power and the ground truth, while the
PCEC is used to calculate the contribution of each appliance in total power consumption. The calculation formulas are shown as Equations (20) and (21).
where,
L is the number of disaggregated readings,
N denotes the number of appliances in the house,
represents the estimated power consumption of appliance
n at the
kth sample,
pn(
k) is the actual power consumed at the
kth sample for appliance
n, and
P(
k) stands for the aggregated power at the
kth sample.
where,
PCECn represents the contribution of appliance
n to total power consumption.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}