Bidirectional Long Short-Term Memory Neural Networks for Linear Sum Assignment Problems


Abstract
1. Introduction
2. Preliminary
2.1. Problem Formulation
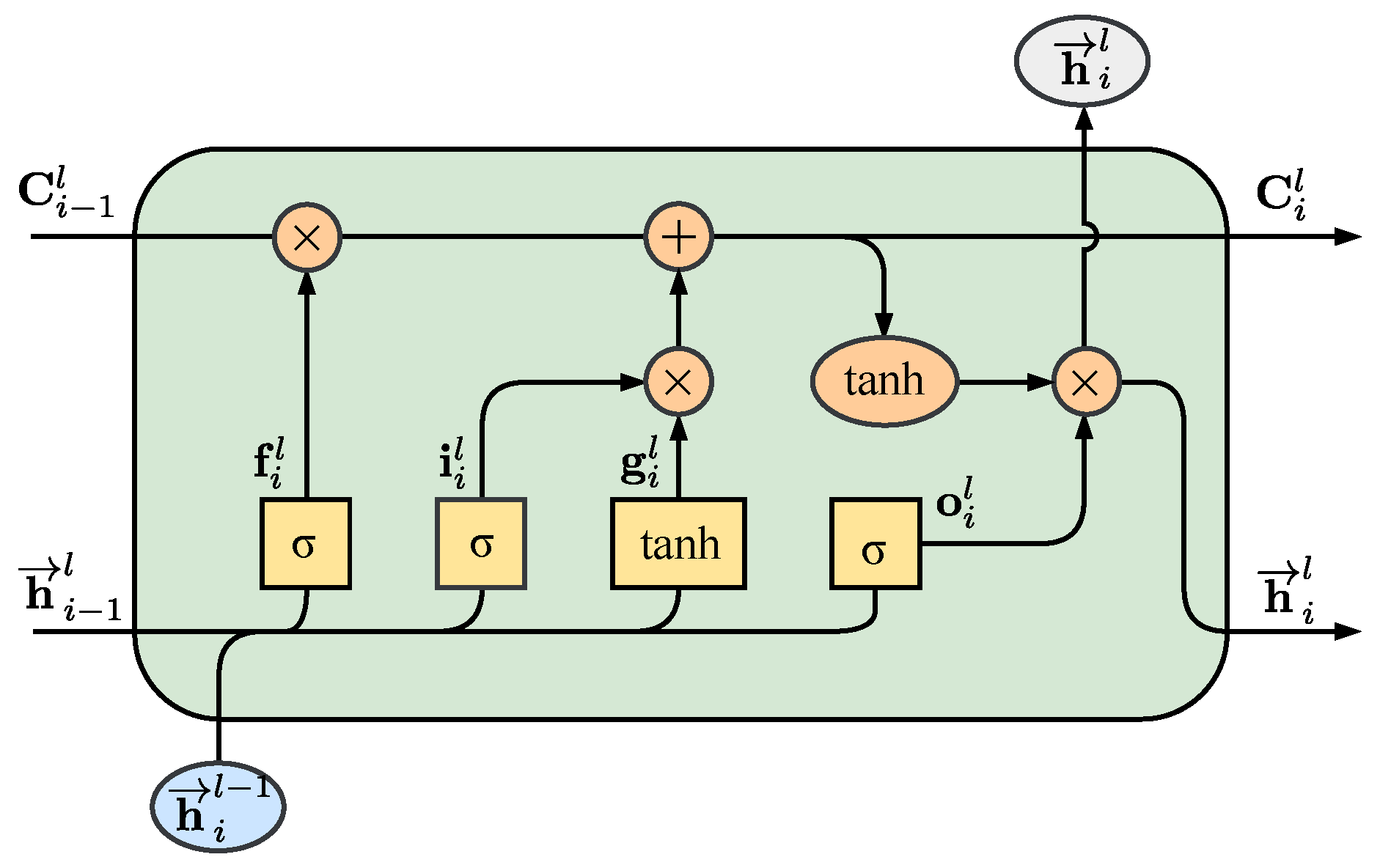
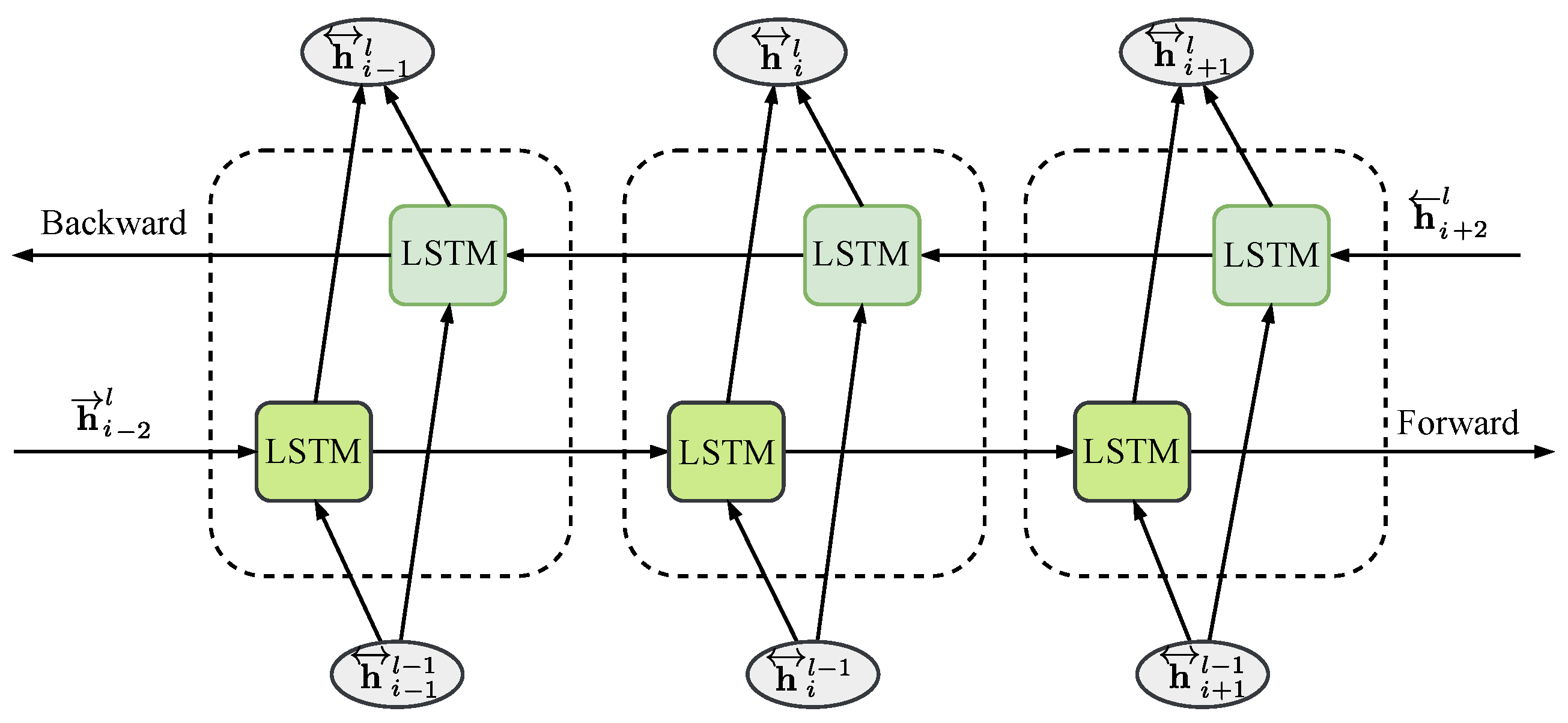
2.2. Bidirectional LSTM
3. Proposed Method
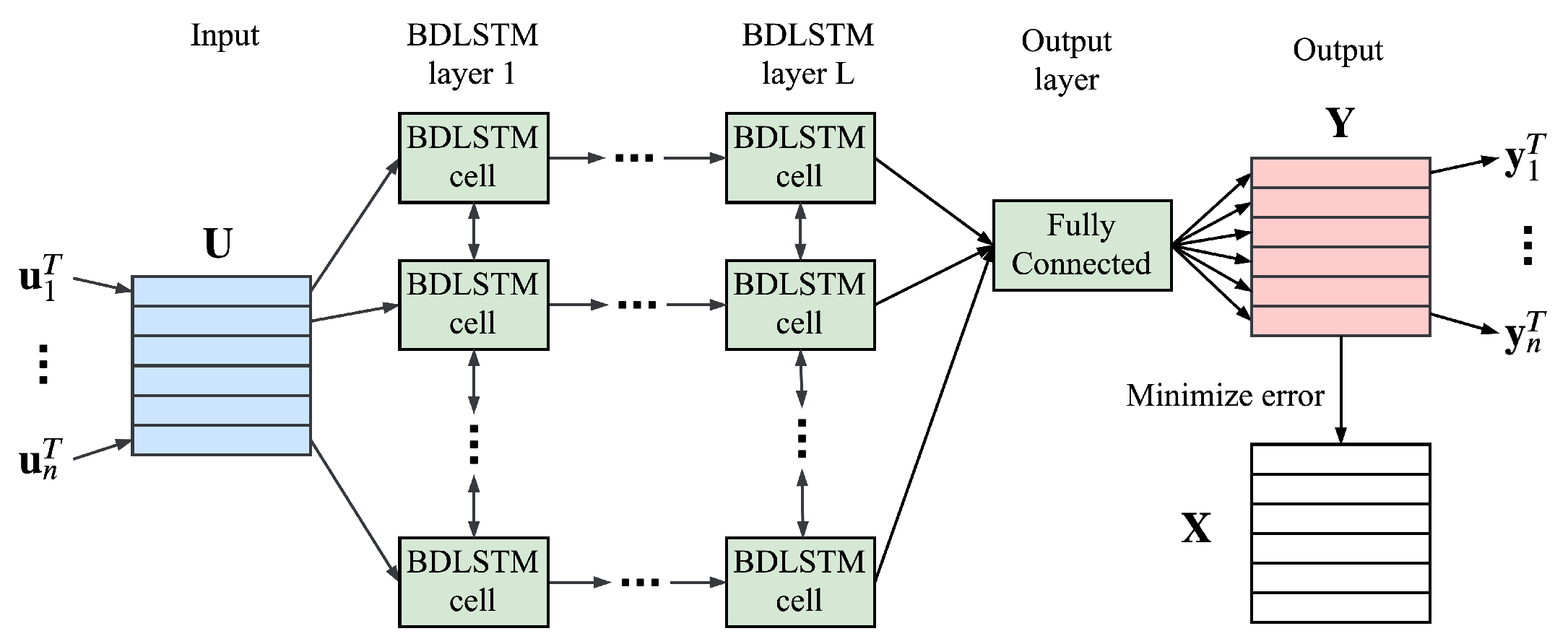
3.1. System Model
- Step 1: Find jobs that are assigned to multiple or no agents.
- Step 2: Extract the cost values of jobs from Step 1 as a small LSAP.
- Step 3: Solve the LSAP from Step 2 using the Hungarian algorithm.
- Step 4: is modified into a decision matrix using Step 3, where is an n by n permutation matrix.
3.2. Training Stage
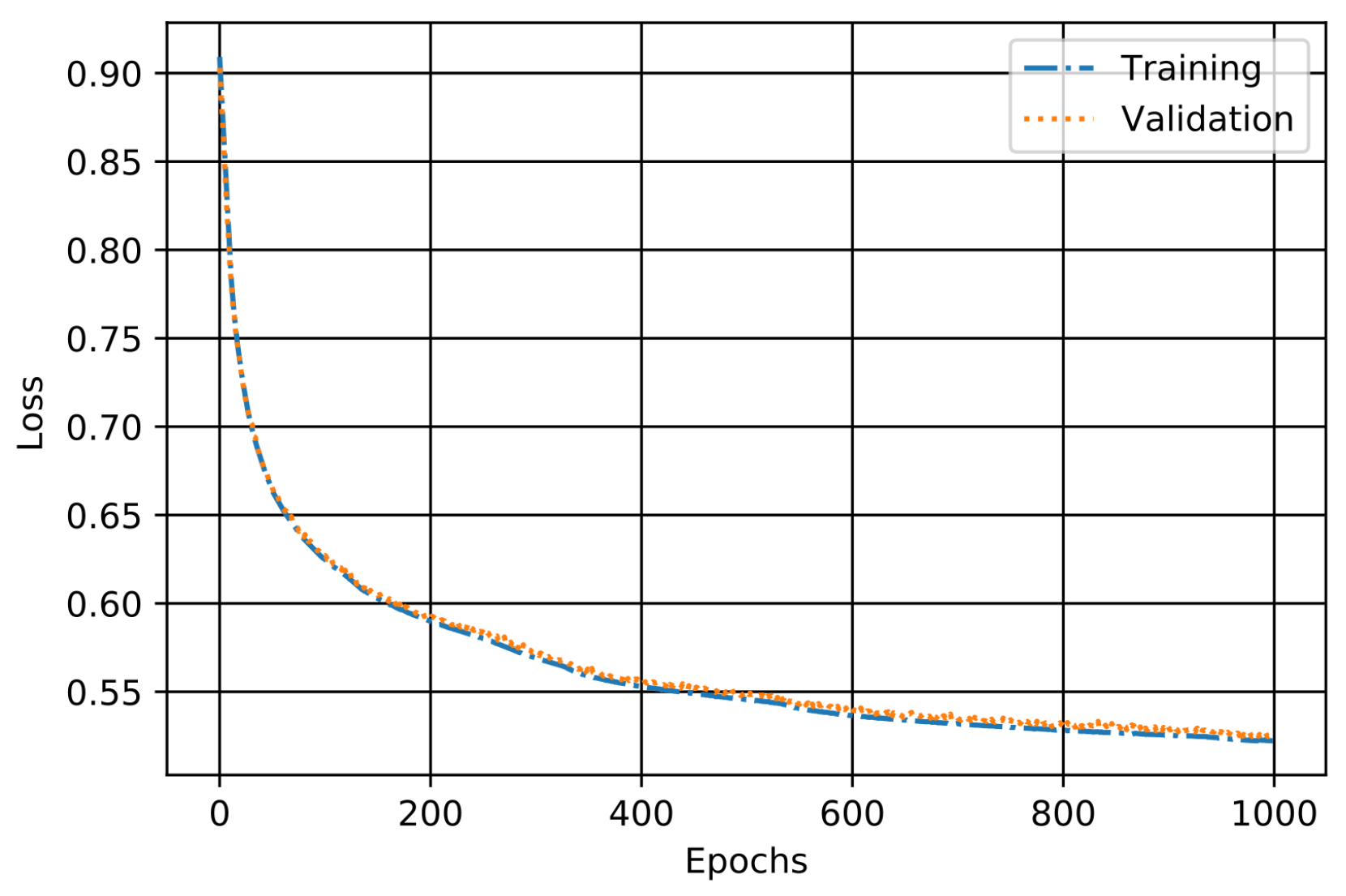
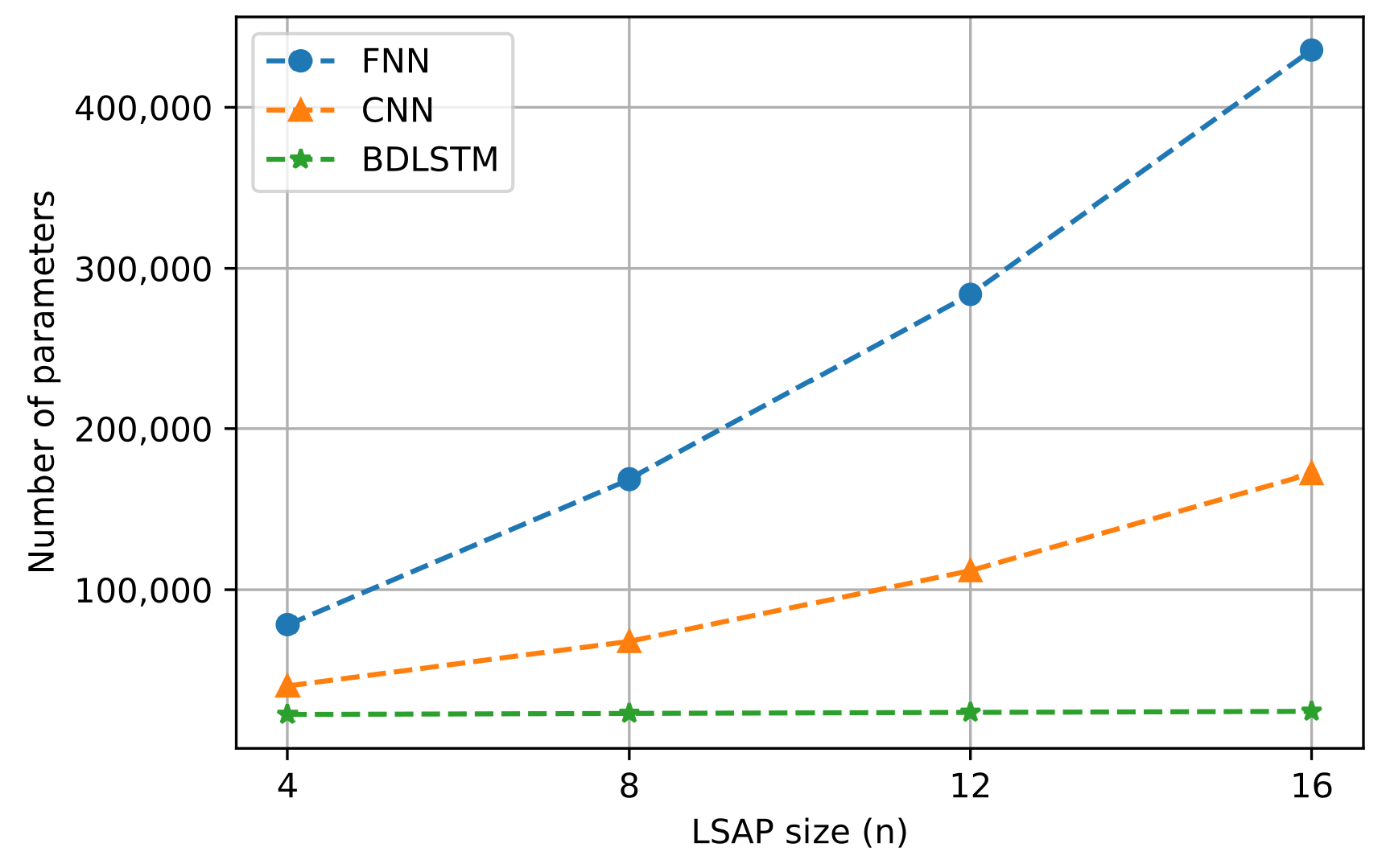
4. Performance Evaluation
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kim, T.; Dong, M. An Iterative Hungarian Method to Joint Relay Selection and Resource Allocation for D2D Communications. IEEE Wirel. Commun. Lett. 2014, 3, 625–628. [Google Scholar] [CrossRef]
- Sun, H.; Chen, X.; Shi, Q.; Hong, M.; Fu, X.; Sidiropoulos, N.D. Learning to Optimize: Training Deep Neural Networks for Interference Management. IEEE Trans. Signal Process. 2018, 66, 5438–5453. [Google Scholar] [CrossRef]
- Song, H.; Fang, X.; Fang, Y. Unlicensed Spectra Fusion and Interference Coordination for LTE Systems. IEEE Trans. Mob. Comput. 2016, 15, 3171–3184. [Google Scholar] [CrossRef]
- Kuhn, H.W. The Hungarian method for the assignment problem. Naval Res. Logist. Q. 1955, 2, 83–97. [Google Scholar] [CrossRef]
- Naiem, A.; El-Beltagy, M.; Ab, P. Deep greedy switching: A fast and simple approach for linear assignment problems. In Proceedings of the 7th International Conference of Numerical Analysis and Applied Mathematics, Thessaloniki, Greece, 25–30 September 2017; pp. 1–6. [Google Scholar]
- Karmarkar, N.K.; Ramakrishnan, K.G. Computational results of an interior point algorithm for large scale linear programming. Math. Programm. 1991, 52, 555–586. [Google Scholar] [CrossRef]
- Akgül, M.; Ekin, O. A dual feasible forest algorithm for the linear assignment problem. RAIRO Oper. Res. 1991, 25, 403–411. [Google Scholar] [CrossRef][Green Version]
- Lee, J.; Kim, K.; Shabestary, T.; Kang, H. Deep bi-directional long short-term memory based speech enhancement for wind noise reduction. In Proceedings of the 2017 Hands-free Speech Communications and Microphone Arrays (HSCMA), San Francisco, CA, USA, 1–3 March 2017; pp. 41–45. [Google Scholar] [CrossRef]
- Graves, A.; Jaitly, N.; Mohamed, A. Hybrid speech recognition with Deep Bidirectional LSTM. In Proceedings of the 2013 IEEE Workshop on Automatic Speech Recognition and Understanding, Olomouc, Czech Republic, 8–12 December 2013; pp. 273–278. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object Detection with Deep Learning: A Review. arXiv 2018, arXiv:1807.05511. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, M.T.; Nguyen, V.H.; Yun, S.J.; Kim, Y.H. Recurrent Neural Network for Partial Discharge Diagnosis in Gas-Insulated Switchgear. Energies 2018, 11, 1202. [Google Scholar] [CrossRef]
- Nguyen, V.H.; Nguyen, M.T.; Choi, J.; Kim, Y.H. NLOS Identification in WLANs Using Deep LSTM with CNN Features. Sensors 2018, 18, 4057. [Google Scholar] [CrossRef] [PubMed]
- Boutaba, R.; Salahuddin, M.A.; Limam, N.; Ayoubi, S.; Shahriar, N.; Estrada-Solano, F.; Caicedo, O.M. A comprehensive survey on machine learning for networking: evolution, applications and research opportunities. J. Internet Serv. Appl. 2018, 9, 16. [Google Scholar] [CrossRef]
- Bennett, K.P.; Parrado-Hernández, E. The Interplay of Optimization and Machine Learning Research. J. Mach. Learn. Res. 2006, 7, 1265–1281. [Google Scholar]
- Gambella, C.; Ghaddar, B.; Naoum-Sawaya, J. Optimization Models for Machine Learning: A Survey. arXiv 2019, arXiv:1901.05331. [Google Scholar]
- Lee, M.; Xiong, Y.; Yu, G.; Li, G.Y. Deep Neural Networks for Linear Sum Assignment Problems. IEEE Wirel. Commun. Lett. 2018, 7, 962–965. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Minh-Tuan, N.; Kim, Y.-H. Bidirectional Long Short-Term Memory Neural Networks for Linear Sum Assignment Problems. Appl. Sci. 2019, 9, 3470. https://doi.org/10.3390/app9173470
Minh-Tuan N, Kim Y-H. Bidirectional Long Short-Term Memory Neural Networks for Linear Sum Assignment Problems. Applied Sciences. 2019; 9(17):3470. https://doi.org/10.3390/app9173470
Chicago/Turabian StyleMinh-Tuan, Nguyen, and Yong-Hwa Kim. 2019. "Bidirectional Long Short-Term Memory Neural Networks for Linear Sum Assignment Problems" Applied Sciences 9, no. 17: 3470. https://doi.org/10.3390/app9173470
APA StyleMinh-Tuan, N., & Kim, Y.-H. (2019). Bidirectional Long Short-Term Memory Neural Networks for Linear Sum Assignment Problems. Applied Sciences, 9(17), 3470. https://doi.org/10.3390/app9173470