A Survey of Handwritten Character Recognition with MNIST and EMNIST



Abstract
1. Introduction
2. MNIST Database
2.1. Acquisition and Data Format
2.2. State of the Art
3. EMNIST Database
3.1. Acquisition and Data Format
- Storing original images in NIST SD 19 as 128 × 128-pixels black and white images.
- Applying a Gaussian blur filter to soften edges.
- Removing empty padding to reduce the image to the region of interest.
- Centering the digit in a square box preserving the aspect ration.
- Adding a blank padding of 2-pixels per side.
- Downsampling the image 28 × 28 pixels using bi-cubic interpolation.
- By_Class: in this schema classes are digits [0–9], lowercase letters [a–z] and uppercase letters [A–Z]. Thus, there are 62 different classes.
- By_Merge: this schema addresses the fact that some letters are quite similar in their lowercase and uppercase variants, thus both classes can be fused. In particular, these letter are ‘c’, ‘i’, ‘j’, ‘k’, ‘l’, ‘m’, ‘o’, ‘p’, ‘s’, ‘u’, ‘v’, ‘w’, ‘x’, ‘y’ and ‘z’. This schema contains 47 classes.
- Balanced: both By_Class and By_Merge datasets are very unbalanced when it comes to letters, a fact that could negatively impact the classification performance. This dataset takes the By_Merge dataset and reduces the number of instances from 814,255 (total number of samples in NIST Special Database 19) to only 131,600, guaranteeing that there is an equal number of samples per each label.
- Digits: similar to MNIST, but from a different source and with 280,000 instances.
- Letters: this dataset contains mixed lowercase and uppercase letteres, thus containing 26 classes and a total of 145,600 samples.
3.2. State of the Art
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| BFGS | Broyden–Fletcher–Goldfarb–Shanno algorithm |
| CG | Conjugate gradient |
| C-SVDD | Centering support vector data description |
| CNN | Convolutional neural network |
| COSFIRE | Combination of shifted filter responses |
| DCT | Discrete cosine transform |
| DWT | Discrete wavelet transform |
| ELM | Extreme learning machine |
| EMNIST | Extended MNIST |
| K-NN | k-nearest neighbors |
| MNIST | Mixed National Institute of Standards and Technology |
| NN | Neural network |
| PCA | Principal component analysis |
| RNN | Recurrent neural network |
| SIFT | Scale-invariant feature transform |
| SVM | Support vector machine |
References
- TensorFlow. MNIST for ML Beginners. 2017. Available online: https://www.tensorflow.org/get_started/mnist/beginners (accessed on 20 April 2018).
- LeCun, Y.; Cortes, C.; Burges, C.J.C. The MNIST Database of Handwritten Digits. 2012. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 25 April 2018).
- Benenson, R. Classification Datasets Results. 2016. Available online: http://rodrigob.github.io/are_we_there_yet/build/classification_datasets_results.html (accessed on 21 May 2018).
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Belongie, S.; Malik, J.; Puzicha, J. Shape matching and object recognition using shape contexts. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 509–522. [Google Scholar] [CrossRef]
- Keysers, D.; Deselaers, T.; Gollan, C.; Ney, H. Deformation models for image recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1422–1435. [Google Scholar] [CrossRef] [PubMed]
- Kégl, B.; Busa-Fekete, R. Boosting products of base classifiers. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 497–504. [Google Scholar]
- Decoste, D.; Schölkopf, B. Training invariant support vector machines. Mach. Learn. 2002, 46, 161–190. [Google Scholar] [CrossRef]
- Simard, P.; Steinkraus, D.; Platt, J.C. Best Practices for Convolutional Neural Networks Applied to Visual Document Analysis. In Proceedings of the 7th International Conference on Document Analysis and Recognition, Edinburgh, UK, 3–6 August 2003; Volume 2, pp. 958–963. [Google Scholar]
- Deng, L.; Yu, D. Deep Convex Net: A Scalable Architecture for Speech Pattern Classification. In Proceedings of the 12th Annual Conference of the International Speech Communication Association, Florence, Italy, 27–31 August 2011; pp. 2285–2288. [Google Scholar]
- Meier, U.; Cireşan, D.C.; Gambardella, L.M.; Schmidhuber, J. Better Digit Recognition with a Committee of Simple Neural Nets. In Proceedings of the 2011 International Conference on Document Analysis and Recognition, Beijing, China, 18–21 September 2011; pp. 1250–1254. [Google Scholar]
- Cireşan, D.C.; Meier, U.; Gambardella, L.M.; Schmidhuber, J. Deep, big, simple neural nets for handwritten digit recognition. Neural Comput. 2010, 22, 3207–3220. [Google Scholar] [CrossRef] [PubMed]
- Martin, C.H. TensorFlow Reproductions: Big Deep Simple MNIST. 2016. Available online: https://calculatedcontent.com/2016/06/08/tensorflow-reproductions-big-deep-simple-mnist/ (accessed on 10 May 2018).
- Lauer, F.; Suen, C.Y.; Bloch, G. A trainable feature extractor for handwritten digit recognition. Pattern Recogn. 2007, 40, 1816–1824. [Google Scholar] [CrossRef]
- Labusch, K.; Barth, E.; Matinetz, T. Simple Method for High-Performance Digit Recognition Based on Sparse Coding. IEEE Trans. Neural Netw. 2008, 19, 1985–1989. [Google Scholar] [CrossRef] [PubMed]
- Ranzato, M.A.; Poultney, C.; Chopra, S.; LeCun, Y. Efficient Learning of Sparse Representations with an Energy-Based Model. In Advances in Neural Information Processing Systems 19, NIPS Proceedings; MIT Press: Cambridge, MA, USA, 2006; pp. 1137–1144. [Google Scholar]
- Jarrett, K.; Kavukcuoglu, K.; Ranzato, M.A.; LeCun, Y. What is the Best Multi-Stage Architecture for Object Recognition? In Proceedings of the 2011 International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2146–2153. [Google Scholar]
- Cireşan, D.C.; Meier, U.; Masci, J.; Gambardella, L.M.; Schmidhuber, J. Flexible, High Performance Convolutional Neural Networks for Image Classification. In Proceedings of the 22nd International Joint Conference on Artificial Intelligence, Barcelona, Spain, 19–22 July 2011; pp. 1237–1242. [Google Scholar]
- Cireşan, D.C.; Meier, U.; Gambardella, L.M.; Schmidhuber, J. Convolutional Neural Network Committees for Handwritten Character Classification. In Proceedings of the 2011 International Conference on Document Analysis and Recognition, Beijing, China, 18–21 September 2011; pp. 1135–1139. [Google Scholar]
- Cireşan, D.C.; Meier, U.; Schmidhuber, J. Multi-column deep neural networks for image classification. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3642–3649. [Google Scholar]
- McDonnell, M.D.; Tissera, M.D.; Vladusich, T.; van Schaik, A.; Tapson, J. Fast, simple and accurate handwritten digit classification by training shallow neural network classifiers with the ‘extreme learning machine’ algorithm. PLoS ONE 2015, 10, e0134254. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Kasun, L.L.C.; Zhou, H.; Huang, G.B.; Vong, C.M. Representational learning with extreme learning machine for big data. IEEE Intell. Syst. 2013, 28, 31–34. [Google Scholar]
- Wan, L.; Zeiler, M.; Zhang, S.; LeCun, Y.; Fergus, R. Regularization of neural networks using DropConnect. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; Volume 28, pp. 3-1058–3-1066. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Stochastic Pooling for Regularization of Deep Convolutional Neural Networks. arXiv 2013, arXiv:1301.3557. [Google Scholar]
- Goodfellow, I.J.; Warde-Farley, D.; Mirza, M.; Courville, A.; Bengio, Y. Maxout networks. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; Volume 28, pp. 3-1319–3-1327. [Google Scholar]
- Lee, C.Y.; Xie, S.; Gallagher, P.W.; Zhang, Z.; Tu, Z. Deeply supervised nets. In Proceedings of the 18th International Conference on Artificial Intelligence and Statistics, San Diego, CA, USA, 9–12 May 2015; Volume 38, pp. 562–570. [Google Scholar]
- Sato, I.; Nishimura, H.; Yokoi, K. APAC: Augmented PAttern Classification with Neural Networks. arXiv 2015, arXiv:1505.03229. [Google Scholar]
- Chang, J.R.; Chen, Y.S. Batch-normalized Maxout Network in Network. arXiv 2015, arXiv:1511.02583. [Google Scholar]
- Lee, C.Y.; Gallagher, P.W.; Tu, Z. Generalizing Pooling Functions in Convolutional Neural Networks: Mixed, Gated, and Tree. In Proceedings of the 19th International Conference on Artificial Intelligence and Statistics, Cadiz, Spain, 9–11 May 2016; Volume 51, pp. 464–472. [Google Scholar]
- Liang, M.; Hu, X. Recurrent convolutional neural network for object recognition. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3367–3375. [Google Scholar]
- Liao, Z.; Carneiro, G. On the Importance of Normalisation Layers in Deep Learning with Piecewise Linear Activation Units. arXiv 2015, arXiv:1508.00330. [Google Scholar]
- Liao, Z.; Carneiro, G. Competitive Multi-scale Convolution. arXiv 2015, arXiv:1511.05635. [Google Scholar]
- Graham, B. Fractional Max-Pooling. arXiv 2015, arXiv:1412.6071. [Google Scholar]
- McFonnell, M.D.; Vladusich, T. Enhanced Image Classification With a Fast-Learning Shallow Convolutional Neural Network. In Proceedings of the 2015 International Joint Conference on Neural Networks, Killarney, Ireland, 12–17 July 2015. [Google Scholar]
- Mairal, J.; Koniusz, P.; Harchaoui, Z.; Schmid, C. Convolutional kernel networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2627–2635. [Google Scholar]
- Xu, C.; Lu, C.; Liang, X.; Gao, J.; Zheng, W.; Wang, T.; Yan, S. Multi-loss Regularized Deep Neural Network. IEEE Trans. Circuits Syst. Video Technol. 2015, 26, 2273–2283. [Google Scholar] [CrossRef]
- Srivastava, R.K.; Greff, K.; Schmidhuber, J. Training Very Deep Networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 2377–2385. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network In Network. In Proceedings of the 2nd International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Ranzato, M.A.; Huang, F.J.; Boureau, Y.L.; LeCun, Y. Unsupervised Learning of Invariant Feature Hierarchies with Applications to Object Recognition. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007. [Google Scholar]
- Bruna, J.; Mallat, S. Invariant Scattering Convolution Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1872–1886. [Google Scholar] [CrossRef]
- Calderón, A.; Roa-Valle, S.; Victorino, J. Handwritten digit recognition using convolutional neural networks and Gabor filters. In Proceedings of the 2003 International Conference on Computational Intelligence, Cancun, Mexico, 19–21 May 2003. [Google Scholar]
- Le, Q.V.; Ngiam, J.; Coates, A.; Prochnow, B.; Ng, A.Y. On Optimization Methods for Deep Learning. In Proceedings of the 28th International Conference on Machine Learning, Washington, DC, USA, 28 June–2 July 2011. [Google Scholar]
- Yang, Z.; Moczulski, M.; Denil, M.; de Freitas, N.; Smola, A.; Song, L.; Wang, Z. Deep Fried Convnets. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Hertel, L.; Barth, E.; Käster, T.; Martinetz, T. Deep convolutional neural networks as generic feature extractors. In Proceedings of the 2015 International Joint Conference on Neural Networks, Killarney, Ireland, 12–16 July 2015. [Google Scholar]
- Wang, D.; Tan, X. Unsupervised feature learning with C-SVDDNet. Pattern Recogn. 2016, 60, 473–485. [Google Scholar] [CrossRef]
- Zhang, S.; Jiang, H.; Dai, L. Hybrid Orthogonal Projection and Estimation (HOPE): A New Framework to Learn Neural Networks. J. Mach. Learn. Res. 2016, 17, 1286–1318. [Google Scholar]
- Visin, F.; Kastner, K.; Cho, K.; Matteucci, M.; Courville, A.; Bengio, Y. ReNet: A Recurrent Neural Network Based Alternative to Convolutional Networks. arXiv 2015, arXiv:1505.00393. [Google Scholar]
- Azzopardi, G.; Petkov, N. Trainable COSFIRE Filters for Keypoint Detection and Pattern Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 490–503. [Google Scholar] [CrossRef]
- Chan, T.H.; Jia, K.; Gao, S.; Lu, J.; Zeng, Z.; Ma, Y. PCANet: A Simple Deep Learning Baseline for Image Classification? IEEE Trans. Image Process. 2015, 24, 5017–5032. [Google Scholar] [CrossRef]
- Mairal, J.; Bach, F.; Ponce, J. Task-Driven Dictionary Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 791–804. [Google Scholar] [CrossRef] [PubMed]
- Jia, Y.; Huang, C.; Darrell, T. Beyond spatial pyramids: Receptive field learning for pooled image features. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3370–3377. [Google Scholar]
- Thom, M.; Palm, G. Sparse Activity and Sparse Connectivity in Supervised Learning. J. Mach. Learn. Res. 2013, 14, 1091–1143. [Google Scholar]
- Lee, H.; Grosse, R.; Ranganath, R.; Ng, A.Y. Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 609–616. [Google Scholar]
- Min, R.; Stanley, D.A.; Yuan, Z.; Bonner, A.; Zhang, Z. A Deep Non-Linear Feature Mapping for Large-Margin kNN Classification. arXiv 2009, arXiv:0906.1814. [Google Scholar]
- Yang, J.; Yu, K.; Huang, T. Supervised translation-invariant sparse coding. In Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3517–3524. [Google Scholar]
- Salakhutdinov, R.; Hinton, G. Deep Boltzmann Machines. In Proceedings of the 12th International Conference on Artificial Intelligence and Statistics, Clearwater Beach, FL, USA, 16–18 April 2009; Volume 5, pp. 448–455. [Google Scholar]
- Goodfellow, I.J.; Mirza, M.; Courville, A.; Bengio, Y. Multi-Prediction Deep Boltzmann Machines. In Advances in Neural Information Processing Systems 26, NIPS Proceedings; Neural Information Processing Systems Foundation, Inc.: San Diego, CA, USA, 2013; pp. 548–556. [Google Scholar]
- Mishkin, D.; Matas, J. All you need is a good init. In Proceedings of the 4th International Conference on Learning Representations, Scottsdale, AZ, USA, 2–4 May 2016. [Google Scholar]
- Alom, M.Z.; Hasan, M.; Yakopcic, C.; Taha, T.M. Inception Recurrent Convolutional Neural Network for Object Recognition. arXiv 2017, arXiv:1704.07709. [Google Scholar]
- Baker, B.; Gupta, O.; Naik, N.; Raskar, R. Designing Neural Network Architectures using Reinforcement Learning. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Davison, J. DEvol: Automated Deep Neural Network Design via Genetic Programming. 2017. Available online: https://github.com/joeddav/devol (accessed on 4 May 2018).
- Baldominos, A.; Saez, Y.; Isasi, P. Evolutionary Convolutional Neural Networks: An Application to Handwriting Recognition. Neurocomputing 2018, 283, 38–52. [Google Scholar] [CrossRef]
- Baldominos, A.; Saez, Y.; Isasi, P. Hybridizing Evolutionary Computation and Deep Neural Networks: An Approach to Handwriting Recognition Using Committees and Transfer Learning. Complexity 2019, 2019, 2952304. [Google Scholar] [CrossRef]
- Bochinski, E.; Senst, T.; Sikora, T. Hyper-parameter optimization for convolutional neural network committees based on evolutionary algorithms. In Proceedings of the 2017 IEEE International Conference on Image Processing, Beijing, China, 17–20 September 2017; pp. 3924–3928. [Google Scholar]
- Baldominos, A.; Saez, Y.; Isasi, P. Model Selection in Committees of Evolved Convolutional Neural Networks Using Genetic Algorithms. In Intelligent Data Engineering and Automated Learning–IDEAL 2018; Lecture Notes in Computer Science; Springer: Berlin, Germany, 2018; Volume 11314, pp. 364–373. [Google Scholar]
- Cohen, G.; Afshar, S.; Tapson, J.; van Schaik, A. EMNIST: An extension of MNIST to handwritten letters. arXiv 2017, arXiv:1702.05373. [Google Scholar]
- NIST. NIST Special Database 19. 2017. Available online: https://www.nist.gov/srd/nist-special-database-19 (accessed on 28 April 2018).
- Grother, P.J.; Hanaoka, K.K. NIST Special Database 19 Handprinted Forms and Characters Database; Technical Report; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2016.
- Van Schaik, A.; Tapson, J. Online and adaptive pseudoinverse solutions for ELM weights. Neurocomputing 2015, 149A, 233–238. [Google Scholar] [CrossRef][Green Version]
- Ghadekar, P.; Ingole, S.; Sonone, D. Handwritten Digit and Letter Recognition Using Hybrid DWT-DCT with KNN and SVM Classifier. In Proceedings of the 4th International Conference on Computing Communication Control and Automation, Pune, India, 16–18 August 2018. [Google Scholar]
- Botalb, A.; Moinuddin, M.; Al-Saggaf, U.M.; Ali, S.S.A. Contrasting Convolutional Neural Network (CNN) with Multi-Layer Perceptron (MLP) for Big Data Analysis. In Proceedings of the 2018 International Conference on Intelligent and Advanced System, Kuala Lumpur, Malaysia, 13–14 August 2018. [Google Scholar]
- Peng, Y.; Yin, H. Markov Random Field Based Convolutional Neuralx Networks for Image Classification. In IDEAL 2017: Intelligent Data Engineering and Automated Learning; Lecture Notes in Computer, Science; Yin, H., Gao, Y., Chen, S., Wen, Y., Cai, G., Gu, T., Du, J., Tallón-Ballesteros, A., Zhang, M., Eds.; Springer: Guilin, China, 2017; Volume 10585, pp. 387–396. [Google Scholar]
- Singh, S.; Paul, A.; Arun, M. Parallelization of digit recognition system using Deep Convolutional Neural Network on CUDA. In Proceedings of the 2017 Third International Conference on Sensing, Signal Processing and Security, Chennai, India, 4–5 May 2017; pp. 379–383. [Google Scholar]
- Mor, S.S.; Solanki, S.; Gupta, S.; Dhingra, S.; Jain, M.; Saxena, R. Handwritten text recognition: With deep learning and Android. Int. J. Eng. Adv. Technol. 2019, 8, 172–178. [Google Scholar]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic Routing Between Capsules. In Advances in Neural Information Processing Systems 30; NIPS Proceedings; Neural Information Processing Systems Foundation, Inc.: San Diego, CA, USA, 2017; pp. 548–556. [Google Scholar]
- Jayasundara, V.; Jayasekara, S.; Jayasekara, N.H.; Rajasegaran, J.; Seneviratne, S.; Rodrigo, R. TextCaps: Handwritten character recognition with very small datasets. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision, Waikoloa Village, HI, USA, 7–11 2019 January. [Google Scholar]
- Dos Santos, M.M.; da Silva Filho, A.G.; dos Santos, W.P. Deep convolutional extreme learning machines: Filters combination and error model validation. Neurocomputing 2019, 329, 359–369. [Google Scholar] [CrossRef]
- Cavalin, P.; Oliveira, L. Confusion Matrix-Based Building of Hierarchical Classification. In Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications; Lecture Notes in Computer Science; Springer: Berlin, Germany, 2019; Volume 11401, pp. 271–278. [Google Scholar]
- Dufourq, E.; Bassett, B.A. EDEN: Evolutionary Deep Networks for Efficient Machine Learning. arXiv 2017, arXiv:1709.09161. [Google Scholar]
- Neftci, E.O.; Augustine, C.; Paul, S.; Detorakis, G. Event-Driven Random Back-Propagation: Enabling Neuromorphic Deep Learning Machines. Front. Neurosci. 2017, 11, 324. [Google Scholar] [CrossRef] [PubMed]
- Shu, L.; Xu, H.; Liu, B. Unseen Class Discovery in Open-world Classification. arXiv 2018, arXiv:1801.05609. [Google Scholar]
- Srivastava, S.; Priyadarshini, J.; Gopal, S.; Gupta, S.; Dayal, H.S. Optical Character Recognition on Bank Cheques Using 2D Convolution Neural Network. In Applications of Artificial Intelligence Techniques in Engineering; Dvances in Intelligent Systems and Computing; Springer: Berlin, Germany, 2019; Volume 697, pp. 589–596. [Google Scholar]
- Sharma, A.S.; Mridul, M.A.; Jannat, M.E.; Islam, M.S. A Deep CNN Model for Student Learning Pedagogy Detection Data Collection Using OCR. In Proceedings of the 2018 International Conference on Bangla Speech and Language Processing, Sylhet, Bangladesh, 21–22 September 2018. [Google Scholar]
- Shawon, A.; Rahman, M.J.U.; Mahmud, F.; Zaman, M.A. Bangla Handwritten Digit Recognition Using Deep CNN for Large and Unbiased Dataset. In Proceedings of the 2018 International Conference on Bangla Speech and Language Processing, Sylhet, Bangladesh, 21–22 September 2018. [Google Scholar]
- Milgram, J.; Cheriet, M.; Sabourin, R. Estimating accurate multi-class probabilities with support vector machines. In Proceedings of the 2005 IEEE International Joint Conference on Neural Networks, Montreal, QC, Canada, 31 July–4 August 2005; pp. 1906–1911. [Google Scholar]
- Granger, E.G.; Henniges, P.; Sabourin, R.; Oliveira, L.S. Supervised Learning of Fuzzy ARTMAP Neural Networks Through Particle Swarm Optimisation. J. Pattern Recogn. Res. 2007, 2, 27–60. [Google Scholar] [CrossRef]
- Oliveira, L.E.S.; Sabourin, R.; Bortolozzi, F.; Suen, C.Y. Automatic Recognition of Handwritten Numerical Strings: A Recognition and Verification Strategy. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 1438–1454. [Google Scholar] [CrossRef]
- Radtke, P.V.W.; Sabourin, R.; Wong, T. Using the RRT algorithm to optimize classification systems for handwritten digits and letters. In Proceedings of the 2008 ACM Symposium on Applied Computing, Fortaleza, Brazil, 16–20 March 2008; pp. 1748–1752. [Google Scholar]
- Koerich, A.L.; Kalva, P.R. Unconstrained handwritten character recognition using metaclasses of characters. In Proceedings of the 2005 IEEE International Conference on Image Processing, Genoa, Italy, 11–14 September 2005; pp. 542–545. [Google Scholar]
- Cavalin, P.R.; Britto, A.S.; Bortolozzi, F.; Sabourin, R.; Oliveira, L.E.S. An implicit segmentation-based method for recognition of handwritten strings of characters. In Proceedings of the 2006 ACM Symposium on Applied Computing, Dijon, France, 23–27 April 2006; pp. 836–840. [Google Scholar]



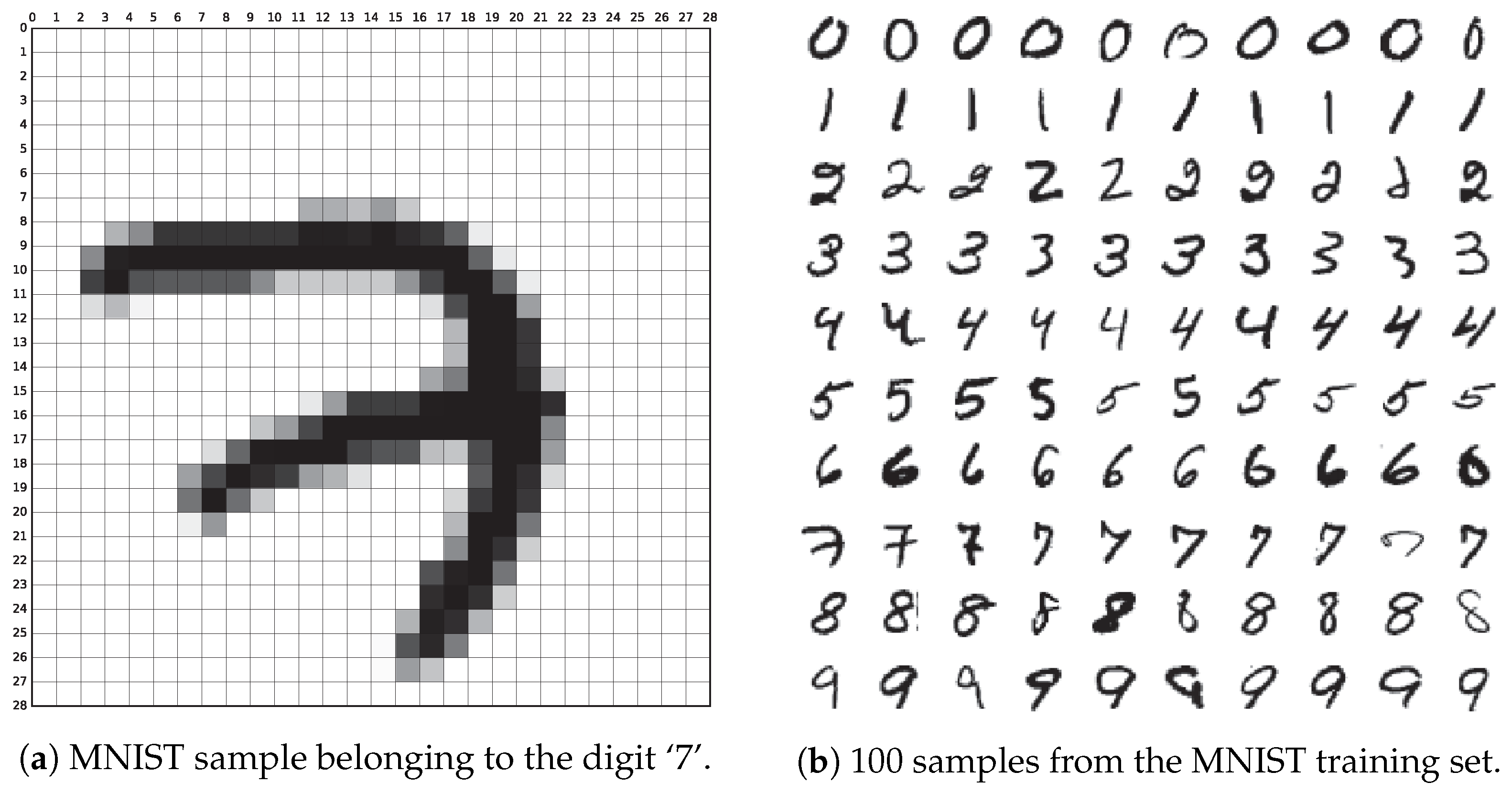{kind=link}
{kind=link}
| Technique | Test Error Rate |
|---|---|
| NN 6-layer 5,700 hidden units [12] | 0.35% |
| MSRV C-SVDDNet [46] | 0.35% |
| Committee of 25 NN 2-layer 800 hidden units [11] | 0.39% |
| RNN [48] | 0.45% |
| K-NN (P2DHMDM) [6] | 0.52% |
| COSFIRE [49] | 0.52% |
| K-NN (IDM) [6] | 0.54% |
| Task-driven dictionary learning [51] | 0.54% |
| Virtual SVM, deg-9 poly, 2-pixel jit [8] | 0.56% |
| RF-C-ELM, 15,000 hidden units [21] | 0.57% |
| PCANet (LDANet-2) [50] | 0.62% |
| K-NN (shape context) [5] | 0.63% |
| Pooling + SVM [52] | 0.64% |
| Virtual SVM, deg-9 poly, 1-pixel jit [8] | 0.68% |
| NN 2-layer 800 hidden units, XE loss [9] | 0.70% |
| SOAE- with sparse connectivity and activity [53] | 0.75% |
| SVM, deg-9 poly [4] | 0.80% |
| Product of stumps on Haar f. [7] | 0.87% |
| NN 2-layer 800 hidden units, MSE loss [9] | 0.90% |
| CNN (2 conv, 1 dense, relu) with DropConnect [24] | 0.21% |
| Committee of 25 CNNs [20] | 0.23% |
| CNN with APAC [28] | 0.23% |
| CNN (2 conv, 1 relu, relu) with dropout [24] | 0.27% |
| Committee of 7 CNNs [19] | 0.27% |
| Deep CNN [18] | 0.35% |
| CNN (2 conv, 1 dense), unsup pretraining [16] | 0.39% |
| CNN, XE loss [9] | 0.40% |
| Scattering convolution networks + SVM [41] | 0.43% |
| Feature Extractor + SVM [14] | 0.54% |
| CNN Boosted LeNet-4 [4] | 0.70% |
| CNN LeNet-5 [4] | 0.80% |
| Technique | Test Error Rate |
|---|---|
| HOPE+DNN with unsupervised learning features [47] | 0.40% |
| Deep convex net [10] | 0.83% |
| CDBN [54] | 0.82% |
| S-SC + linear SVM [56] | 0.84% |
| 2-layer MP-DBM [58] | 0.88% |
| DNet-kNN [55] | 0.94% |
| 2-layer Boltzmann machine [57] | 0.95% |
| Batch-normalized maxout network-in-network [29] | 0.24% |
| Committees of evolved CNNs (CEA-CNN) [65] | 0.24% |
| Genetically evolved committee of CNNs [66] | 0.25% |
| Committees of 7 neuroevolved CNNs [64] | 0.28% |
| CNN with gated pooling function [30] | 0.29% |
| Inception-Recurrent CNN + LSUV + EVE [60] | 0.29% |
| Recurrent CNN [31] | 0.31% |
| CNN with norm. layers and piecewise linear activation units [32] | 0.31% |
| CNN (5 conv, 3 dense) with full training [45] | 0.32% |
| MetaQNN (ensemble) [61] | 0.32% |
| Fractional max-pooling CNN with random overlapping [34] | 0.32% |
| CNN with competitive multi-scale conv. filters [33] | 0.33% |
| CNN neuroevolved with GE [63] | 0.37% |
| Fast-learning shallow CNN [35] | 0.37% |
| CNN FitNet with LSUV initialization and SVM [59] | 0.38% |
| Deeply supervised CNN [27] | 0.39% |
| Convolutional kernel networks [36] | 0.39% |
| CNN with Multi-loss regularization [37] | 0.42% |
| MetaQNN [61] | 0.44% |
| CNN (3 conv maxout, 1 dense) with dropout [17] | 0.45% |
| Convolutional highway networks [38] | 0.45% |
| CNN (5 conv, 3 dense) with retraining [45] | 0.46% |
| Network-in-network [39] | 0.47% |
| CNN (3 conv, 1 dense), stochastic pooling [25] | 0.49% |
| CNN (2 conv, 1 dense, relu) with dropout [24] | 0.52% |
| CNN, unsup pretraining [17] | 0.53% |
| CNN (2 conv, 1 dense, relu) with DropConnect [24] | 0.57% |
| SparseNet + SVM [15] | 0.59% |
| CNN (2 conv, 1 dense), unsup pretraining [16] | 0.60% |
| DEvol [62] | 0.60% |
| CNN (2 conv, 2 dense) [40] | 0.62% |
| Boosted Gabor CNN [42] | 0.68% |
| CNN (2 conv, 1 dense) with L-BFGS [43] | 0.69% |
| Fastfood 1024/2048 CNN [44] | 0.71% |
| Feature Extractor + SVM [14] | 0.83% |
| Dual-hidden Layer Feedforward Network [21] | 0.87% |
| CNN LeNet-5 [4] | 0.95% |
| Technique | By_Class | By_Merge | Balanced | Letters | Digits |
|---|---|---|---|---|---|
| DWT-DCT + SVM [71] | – | – | – | 89.51% | 97.74% |
| Linear classifier [67] | 51.80% | 50.51% | 50.93% | 55.78% | 84.70% |
| OPIUM [67] | 69.71% | 72.57% | 78.02% | 85.15% | 95.90% |
| SVMs (one against all + sigmoid) [86] | – | – | – | – | 98.75% * |
| Multi-layer perceptron [88] | – | – | – | – | 98.39% * |
| Hidden Markov model [91] | – | – | – | 90.00% * | 98.00% * |
| Record-to-record travel [89] | – | – | – | 93.78% * | 96.53% * |
| PSO + fuzzy ARTMAP NNs [87] | – | – | – | – | 96.49% * |
| Multi-layer perceptron [90] | – | – | – | 87.79% * | – |
| CNN (6 conv + 2 dense) [85] | – | – | 90.59% | – | 99.79% |
| Markov random field CNN [73] | 87.77% | 90.94% | 90.29% | 95.44% | 99.75% |
| TextCaps [76] | 90.46% | 95.36% | 99.79% | ||
| CNN (2 conv + 1 dense) [75] | 87.10% | – | – | – | – |
| Committees of neuroevolved CNNs [64] | – | – | – | 95.35% | 99.77% |
| Deep convolutional ELM [78] | – | – | – | – | 99.775% |
| Parallelized CNN [74] | – | – | – | – | 99.62% |
| CNN (flat; 2 conv + 1 dense) [79] | – | – | 87.18% | 93.63% | 99.46% |
| EDEN [80] | – | – | – | 88.30% | 99.30% |
| Committee of 7 CNNs [19] | 88.12% * | – | – | 92.42% * | 99.19% * |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baldominos, A.; Saez, Y.; Isasi, P. A Survey of Handwritten Character Recognition with MNIST and EMNIST. Appl. Sci. 2019, 9, 3169. https://doi.org/10.3390/app9153169
Baldominos A, Saez Y, Isasi P. A Survey of Handwritten Character Recognition with MNIST and EMNIST. Applied Sciences. 2019; 9(15):3169. https://doi.org/10.3390/app9153169
Chicago/Turabian StyleBaldominos, Alejandro, Yago Saez, and Pedro Isasi. 2019. "A Survey of Handwritten Character Recognition with MNIST and EMNIST" Applied Sciences 9, no. 15: 3169. https://doi.org/10.3390/app9153169
APA StyleBaldominos, A., Saez, Y., & Isasi, P. (2019). A Survey of Handwritten Character Recognition with MNIST and EMNIST. Applied Sciences, 9(15), 3169. https://doi.org/10.3390/app9153169