1. Introduction
Wind power is one of the most rapidly growing renewable energies and is regarded as an appealing alternative to conventional power generated from fossil fuel. However, due to the intermittency of wind speed, large-scale wind power penetration will affect the quality of an electric grid, which makes the safe and stable operation of an electric power system a great challenge. In order to reduce the impact of large-scale wind power integration, accurate and effective wind power prediction is necessary to improve the limitations of wind power penetration [
1]. As the wind power mainly depends on wind speed, most wind power prediction models will at first forecast wind speed and then convert wind speed to wind power according to certain power curves.
Over the years, many methods have emerged that utilize statistical processing via local or numerical wind prediction (NWP) data for wind speed forecasts. For example, a hybrid methodology based on support vector regression is proposed for wind forecasting in [
2], which shows more accurate results than those from NWP. Wind field accuracy can also be substantially improved by using the Kalman filter as a post-processing procedure [
3]. With the advance of modern intelligent algorithms, statistical forecast methods have been growing strongly, as they have the advantage of suiting different topographical and historical data. However, since the majority of statistical prediction models are essentially based on local historical data, these methods may intrinsically be prone to significant uncertainty in predicting future conditions. It is desirable to establish models that can provide more assurance for forecasting.
In contrast to statistical methods, physical approaches apply mechanical and thermal principles and numerical methods, such as computational fluid dynamics (CFD), to produce wind speed forecasts. Forecast methods based on physical approaches can usually provide wind speed and its associated parameters such as pressure, humidity, and temperature. Their upscaling algorithm can be based on the correlation between the representative wind farm power generation and the total power data over a certain period of measurements. There are several studies about upscaling algorithms. For example, in [
4] it is proven that rough set theory is a useful tool for short-term multistep wind power prediction when combined with multiposition NWP data. A downscaled simulation framework can also be applied to carry out a multi-scale simulation of time-varying wind fields [
5]. However, the calculation capacity of physical models is restricted by the complexity of its conditions as indicated by earlier studies [
6], as the high number of computational grid points requires enormous computational resources and time. Therefore, any physical method will be welcome if it can yield rapid predictions based on meteorological data or real time data from other sources.
Recently, a new methodology for reconstruction that employs CFD generated data and a limited number of real time measurements at distributed locations has emerged. In this methodology, CFD is used to calculate the distribution of a data set in the field so that the data set can be obtained before the prediction, which facilitates the process of reconstruction. Proper orthogonal decomposition (POD) is then used to capture dominant features of the data set and subsequent POD modes can be used to reconstruct the whole field. This methodology can meet the requirements of real-time field prediction in many situations such as underwater acoustics [
7] and aerodynamic design [
8].
In our previous study, we applied this method to the reconstruction of wind fields and obtained comparatively satisfactory results [
9]. This method, which very often involves an inverse process, can drastically reduce the quantity of the computational work, e.g., by three or four orders of magnitude, and reconstruct velocity fields at a very fast speed, which effectively enables onsite short-term wind forecasts.
However, the POD method still needs a large number of samples of the velocity fields, i.e., “snapshots,” to extract the basis vectors of very small matrix dimensions. Although the POD method enables the fast reconstruction of wind fields by using small matrix dimension basis vectors, the extraction of the basis vectors itself will cost immense computational work when the snapshots correspond to large areas and the spatial resolution for these areas is high.
In view of the above discussion, it is therefore the purpose of this study to establish a new approach to tackle the problems facing the POD method. This new approach will be a physical approach based on CFD simulations to minimize the uncertainty of the forecasts in the wind field. More importantly, the new approach aims to help the POD procedure extract its basis vectors, even for very large areas with high spatial resolutions, so that it can be applied to large-area wind field reconstructions.
2. Methods
2.1. Trodational POD and Gappy POD
POD (proper orthogonal decomposition) is an effective way to reduce the data dimensions and rapidly reconstruct a large area. It already has many successful applications in data processing such as the derivation of the dynamic mode [
10] and the stability analysis and the design of airfoil profiles [
11]. POD satisfies the requirement of a low computing cost while in many circumstances having acceptable accuracies, which may be an effective tool to rapidly reconstruct a wind field with acceptable accuracy, where a large amount of data is processed [
12].
POD uses “snapshots” to extract its basis vectors. The snapshots of the POD method can be obtained from either experimental measurements or from numerical simulations. The POD snapshots in this paper come from CFD simulations. For a given area, a CFD calculation is performed to generate the velocity distributions. A series of snapshots of the velocity distributions are then collected and denoted as , where the superscript indicates the snapshot.
Consider the collection of m snapshots,
. The correlation matrix
is formed by computing the inner product for every pair of snapshots.
where
denotes the inner product of
and
. The eigenvalues
and eigenvectors
of
are computed by singular value decomposition (SVD). The
POD basis vector
is given by a linear combination of snapshots.
where
denotes the
element of the
eigenvector. The magnitude of the
eigenvalue describes the relative importance of the
POD basis vector. For each basis vector, the importance is quantified by defining the relative energy
, which means the percentage of the
eigenvalue in the sum of the whole eigenvalues.
The POD method can also be employed to reconstruct the missing or gappy data from the partial measurement data. To do this, the first step is to define a mask vector that describes a particular field vector to identify where the data are available and where the data are missing.
For the solution
, the corresponding mask vector
is defined as
if
is missing;
if
is known, where
denotes the
element of the vector
; the dot product is defined as
; the induced norm is defined as
is set to be a solution vector that has some missing elements and is associated with the mask vector
, so the repaired vector
, i.e.,
, with all the missing data “recovered,” can be approximated by
The coefficients
in the POD method can be acquired by solving the following minimization function:
where
defines the
L-2 norm. It is worth mentioning that in Equation (4) only the elements with existing data in
are compared with
.
In order to obtain the solution for the minimum error, one can let the partial derivative with respect to
equal to zero. Therefore, matrix
can be obtained by a series of calculations:
where
,
, and
contains the solution vectors of
. The specific mathematical derivation process of POD can be referred to [
13].
2.2. The New Algorithm
To realize the POD method for a physical-approach-based wind forecast, samples, or snapshots, of the wind velocities will be calculated using certain numerical methods—very often CFD.
A problem pertaining to this POD procedure tends to occur during the extraction of the basis vectors when the snapshots contain large amounts of data, resulting in unbearably high demands on computing resources and time. This problem will inevitably happen if the number of computational grid points is very high, as it is the result of the large computation domain and fine grids/high-spatial resolution. This problem will be more pronounced in the cases of short-term wind forecasts because time is crucial for such forecasts.
To solve the problem of extracting the basis vectors of the POD matrix, a subset of the wind field is defined in the procedure. This approach is based on the capability of the gappy POD method in recovering missing data during the reconstruction process, with the consideration that the missing data are outside the original domain. The new algorithm is formed by the following sequence:
A series of velocity distribution profiles for a large area is generated by offsite CFD simulations .
A sub-domain , i.e., a small area such as a wind farm within the large area, is selected, and a group of snapshots of wind velocities over this subset of the large area is obtained. A group of basis vectors of the snapshots is extracted from the subset domain by Equation (2).
Wind speed is measured at a small number of selected locations as the real time input for the wind field reconstruction in the next step.
The wind velocity profile for the larger area is reconstructed with a refined mesh via gappy data reconstruction methods, using Equation (3) with the limited amount of real time data from the above step.
The first and second steps of the above algorithm can be performed offsite, as wind forecasting is not involved. Therefore, the time consumption is not a concern, since no real time data are needed during these steps. The wind forecast is made in the third step. In the third step, only a single step matrix calculation is needed to obtain the velocity distribution. One of the essences of this method is that the dimension of the matrix can be several orders of magnitude lower than those used in the CFD calculations. This allows the wind velocity to be reconstructed very quickly, virtually in real time.
In addition, there is no restriction in selecting the subset of the full area. The choice can be very flexible or specified by the operators of the windfarm. For example, if a wind forecast is to be made, the subset domain can be chosen at the wind farm itself. One way of doing so is to calculate the wind velocity distribution for the large area and then draw the velocity profile at the mesh points within this subset domain. This is, however, at this moment an intuition, and its performance will be examined in the following sections.
4. Experiment
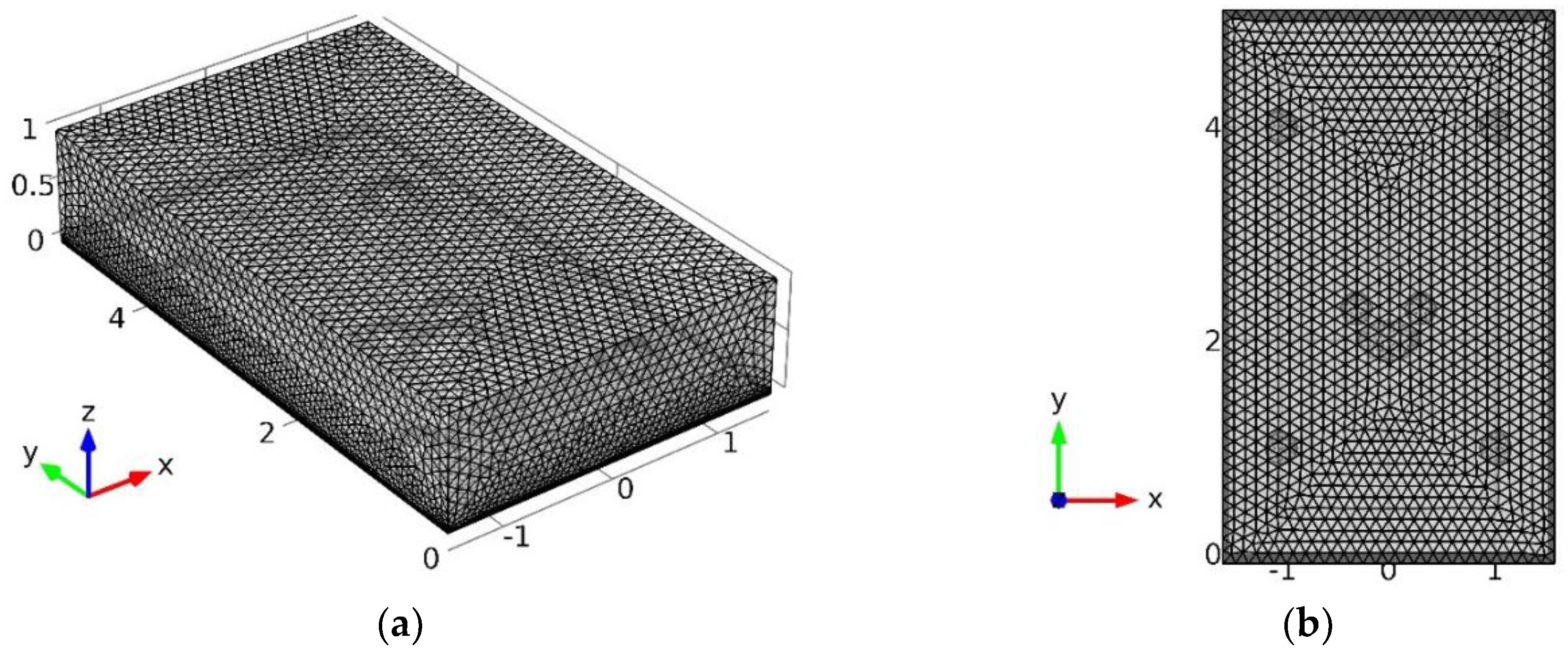
According to the reconstruction method and the simulation results, we used our existing test platform to perform the verification test with an equal scale reduction of simulation.
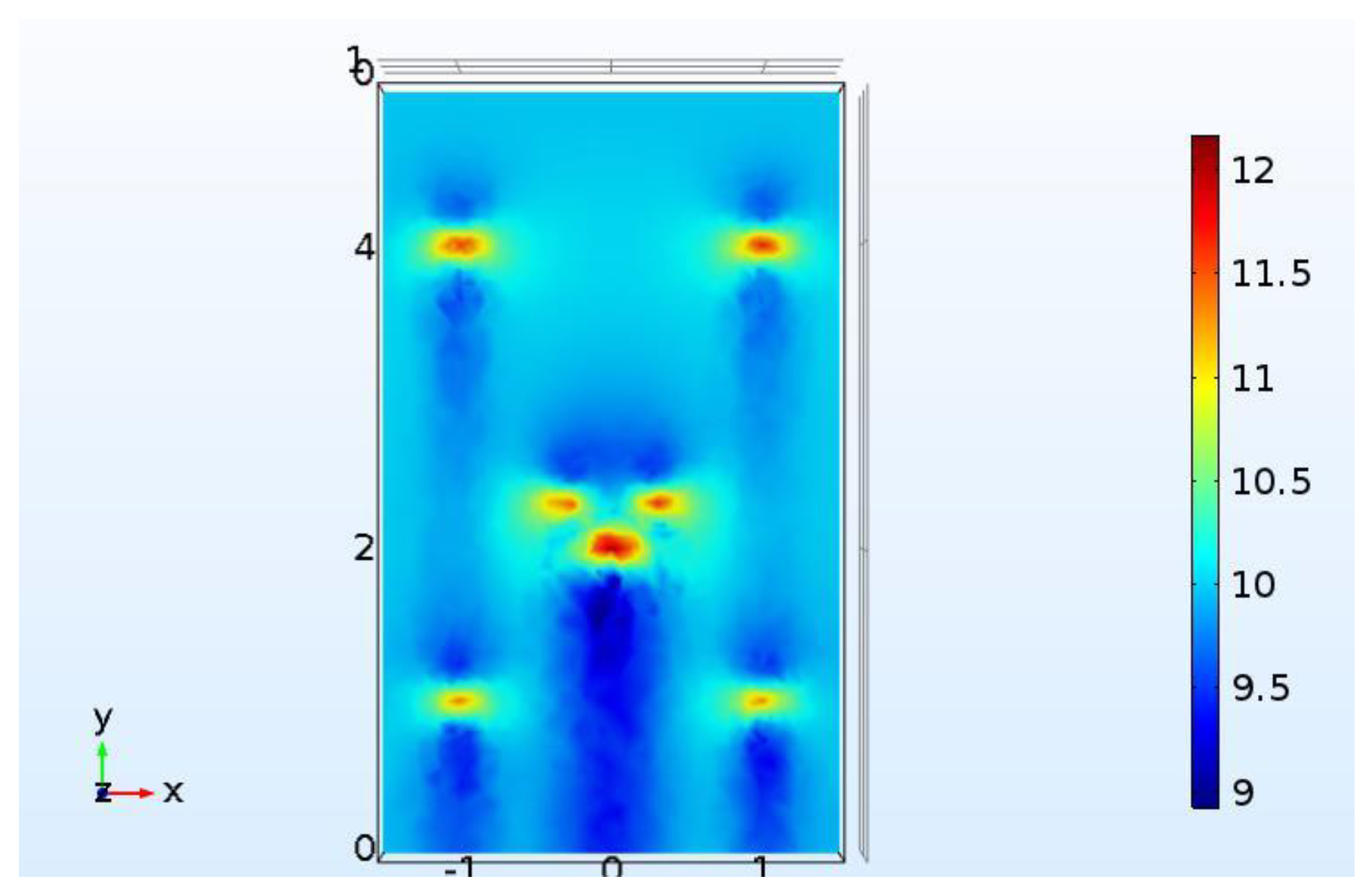
The wind tunnel, which was 10 m in length, was built and made up of a mixed-up air blower and a contraction segment, which was used to adapt to the downstream experimental section, and final diffuser section. The central experimental section had a 3 × 5 × 1 m cuboid area, which was constructed with Plexiglas plates. Models were put in the experimental section, and hot-wire anemometers were installed on top of Plexiglas surrounding the models. The experiment facilities are shown is
Figure 9.
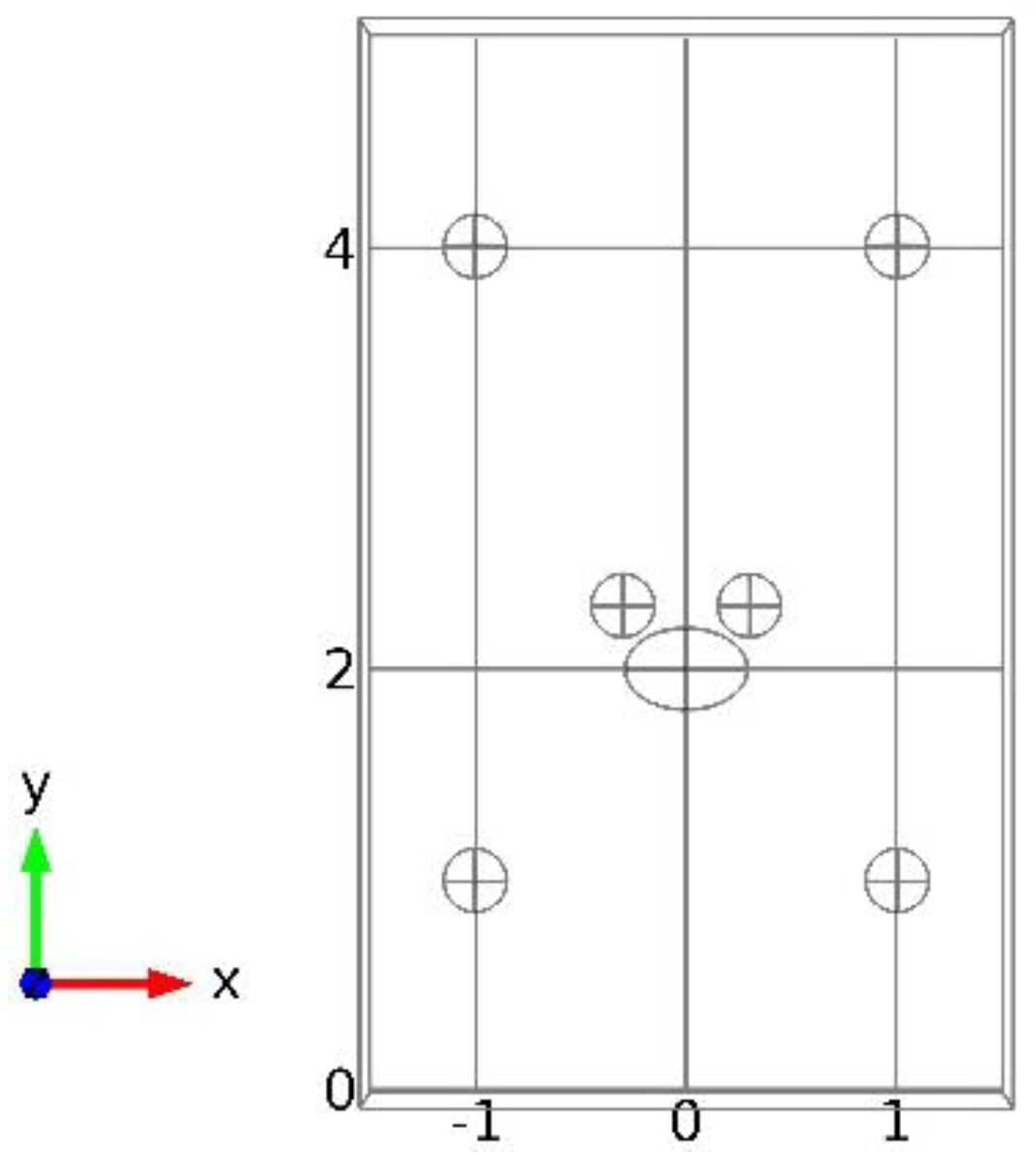
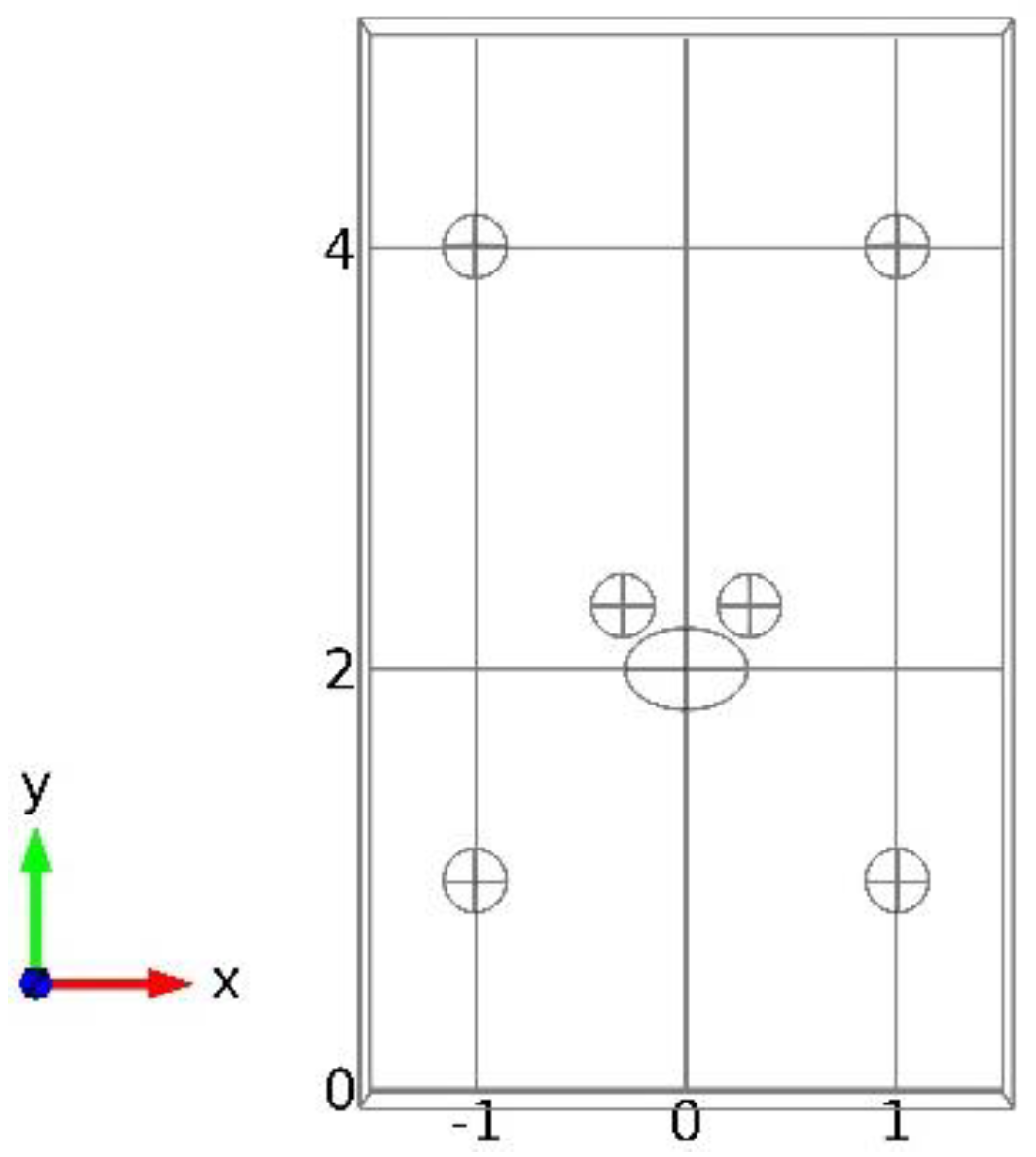
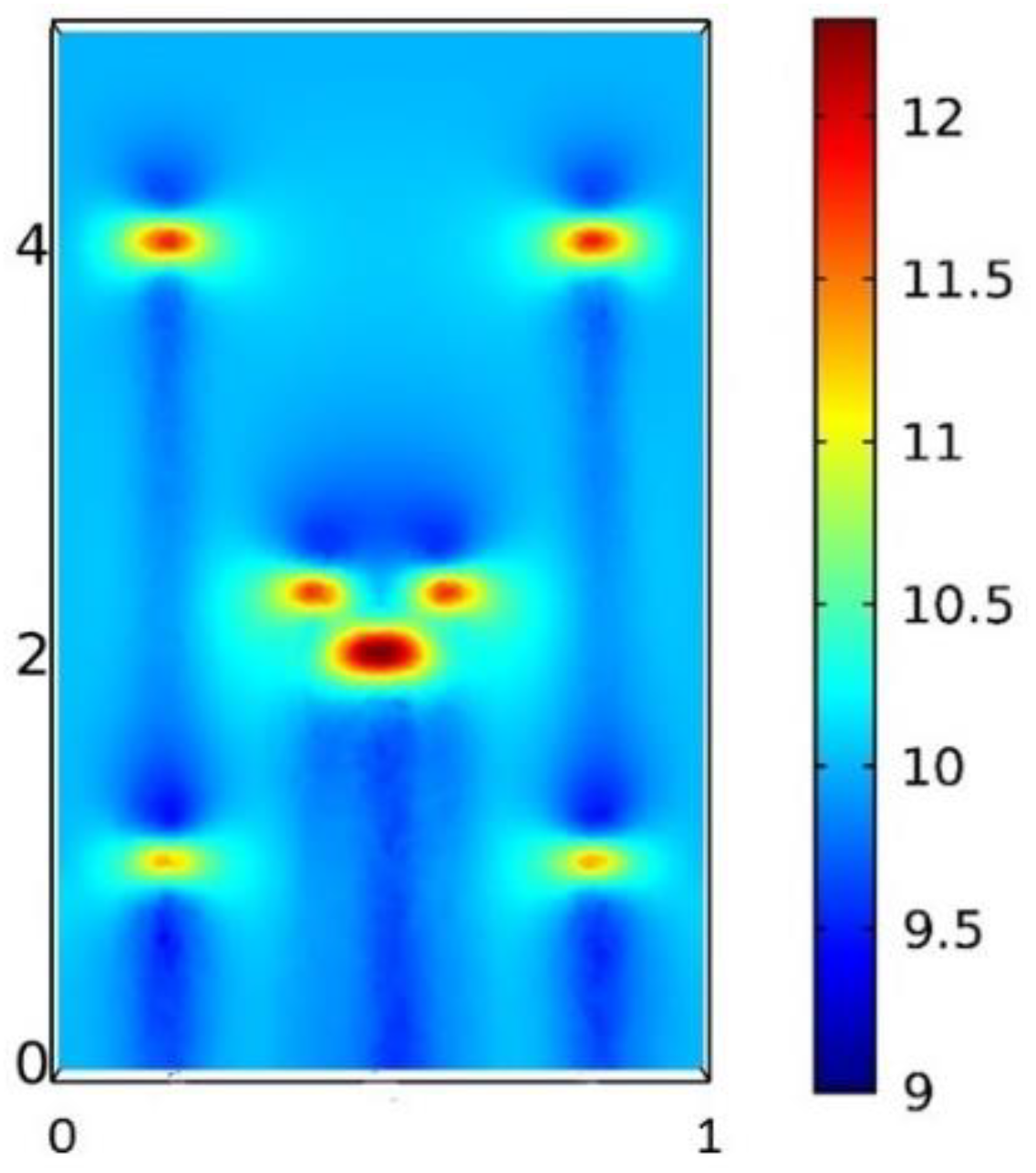
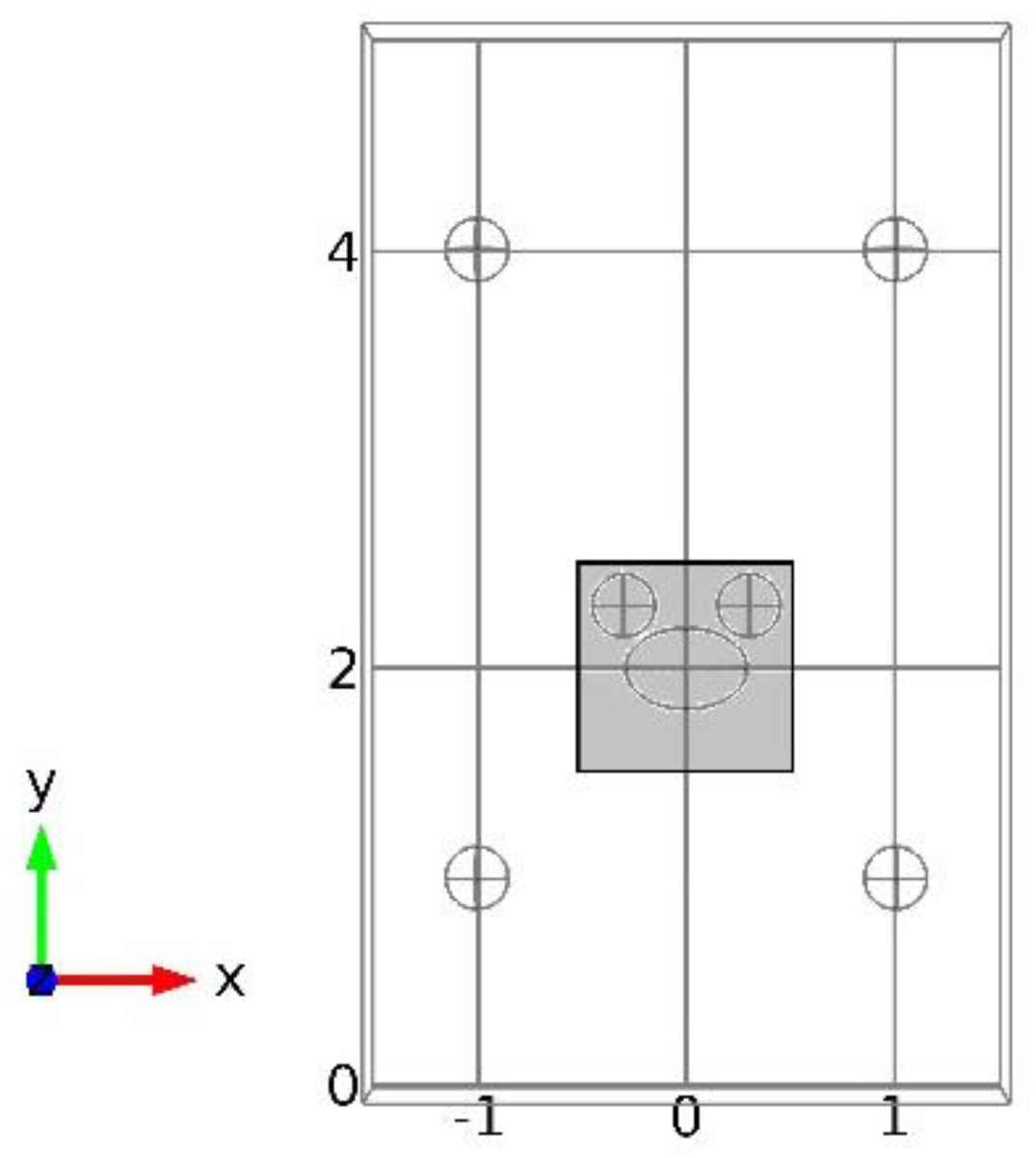
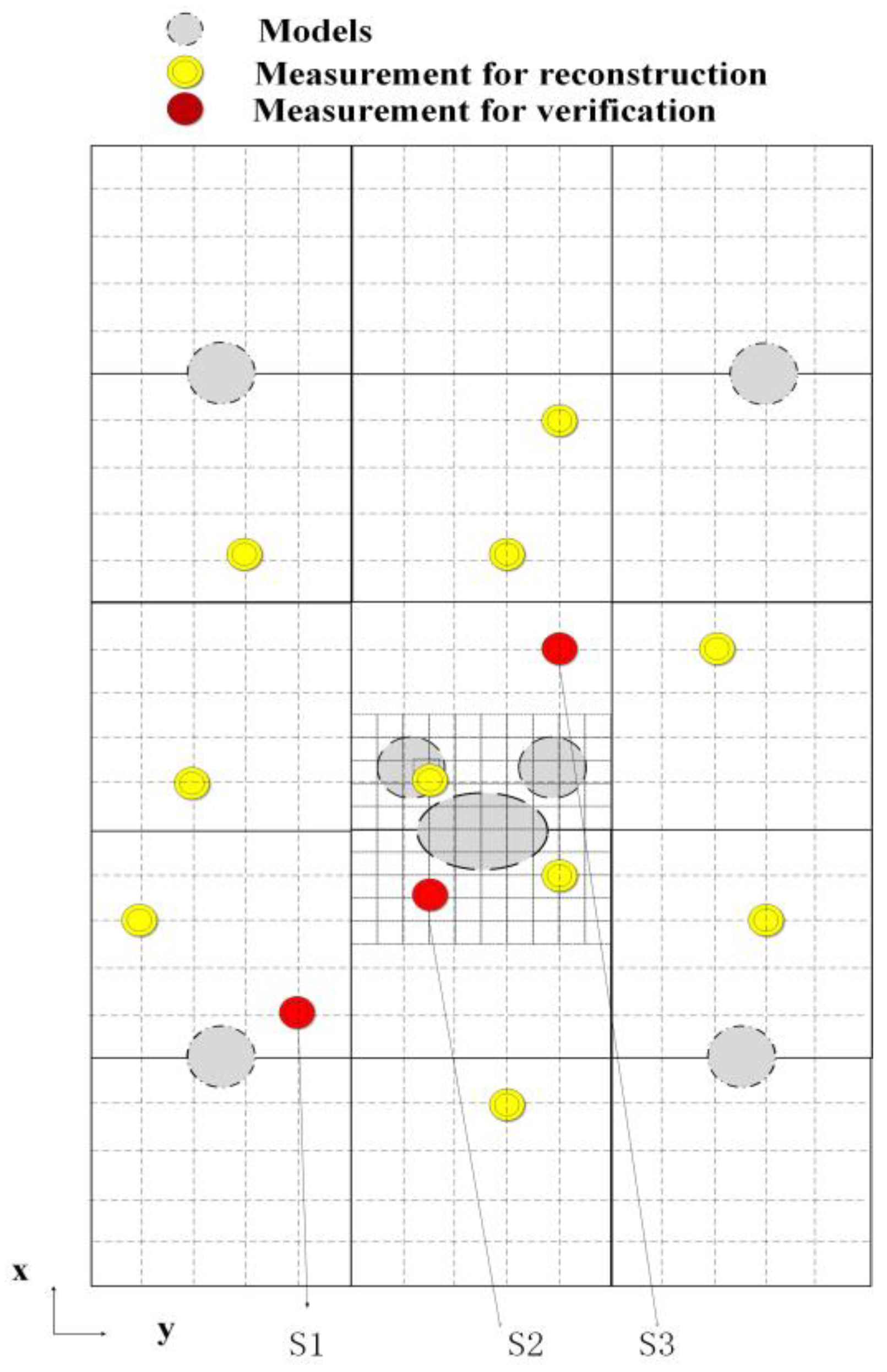
According to simulation, we conducted the experiment at a 2D level and selected the meshed experimental plane to be 20 cm away from the ground, as shown in
Figure 10. A subset of the whole space of
was meshed with a size of
, while another area was meshed with a size of
.
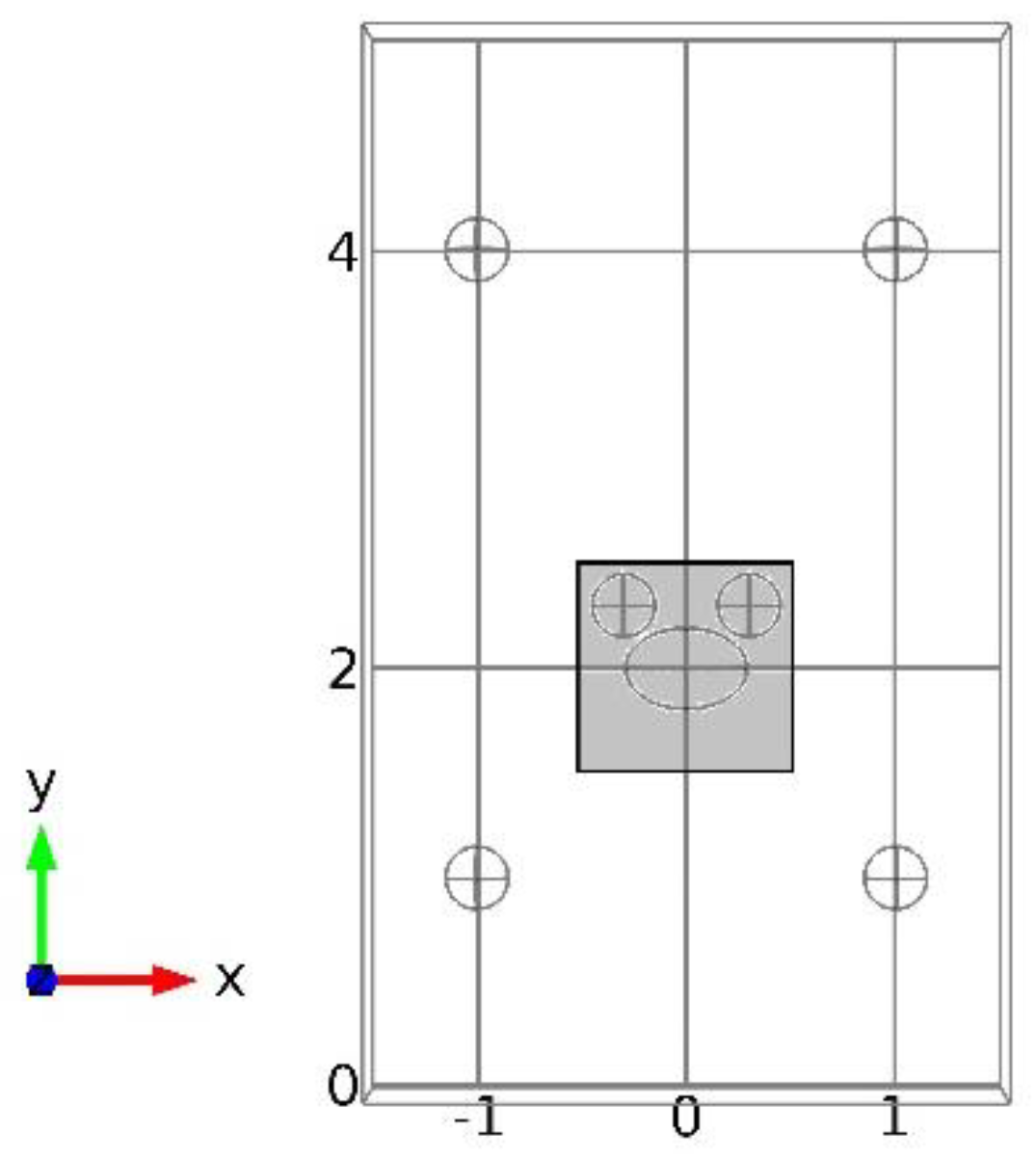
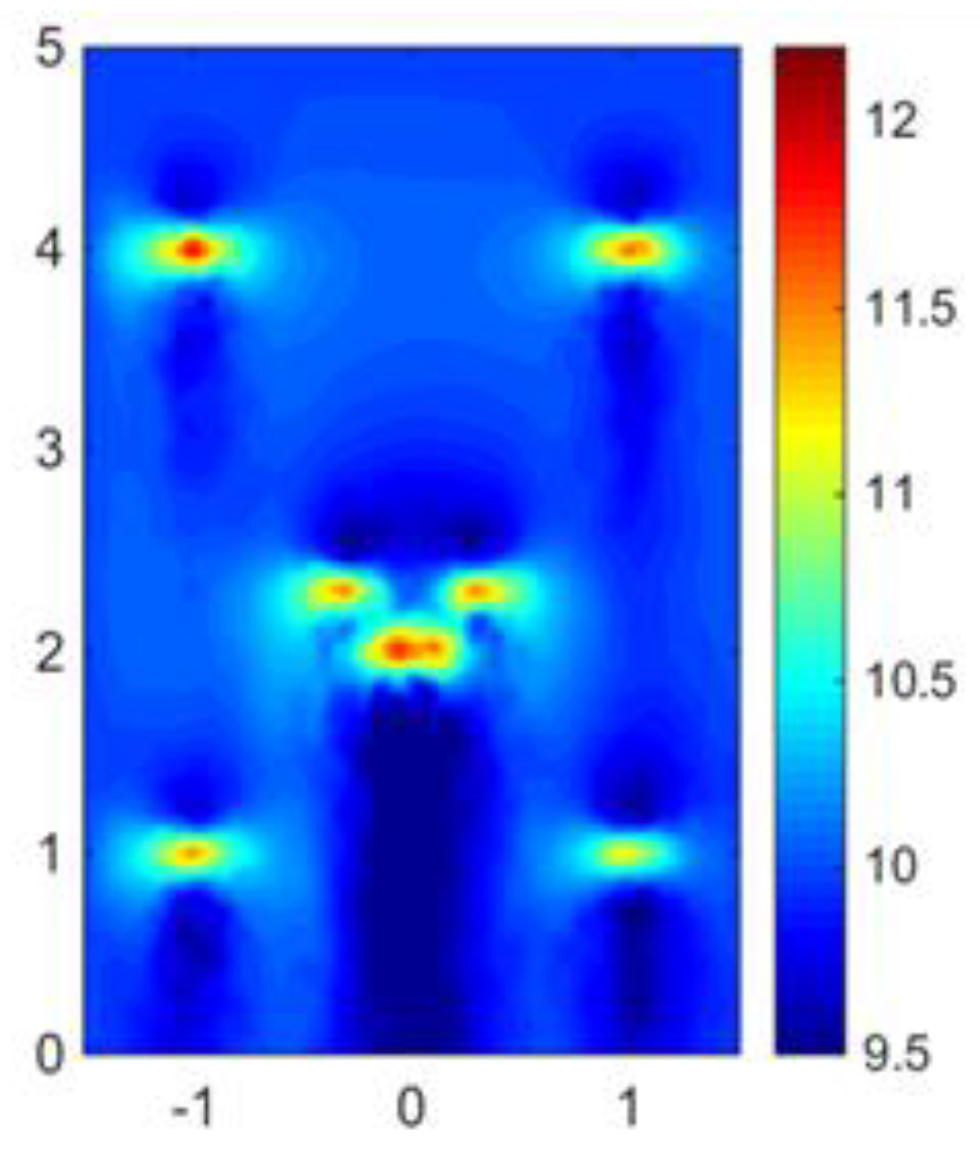
First, offset CFD simulations were done in a sub-domain of
by refined meshes, and a group of basis vectors was extracted. Since the test bed was scaled down by simulation, the specific software settings are the same as in
Section 3.
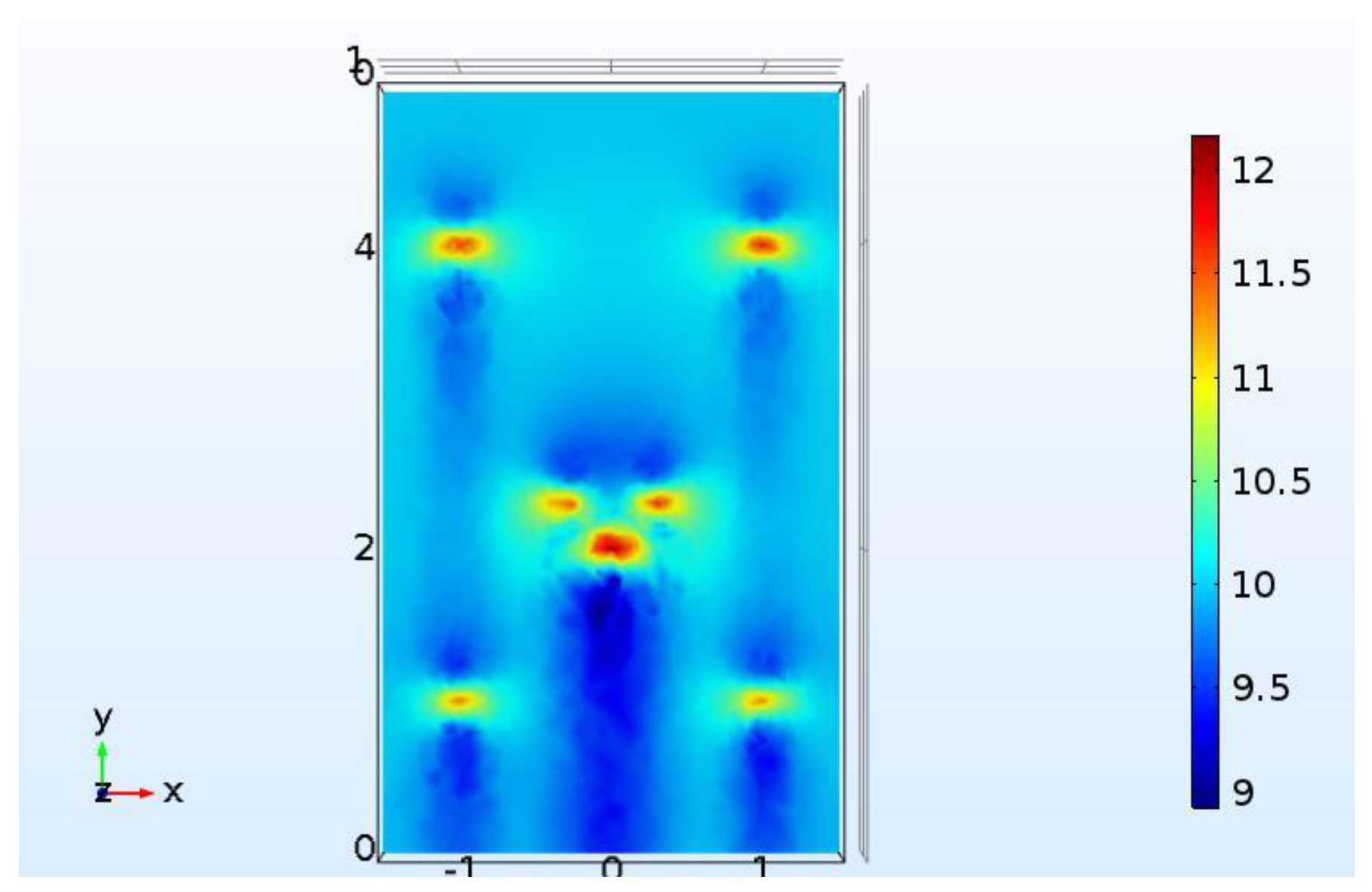
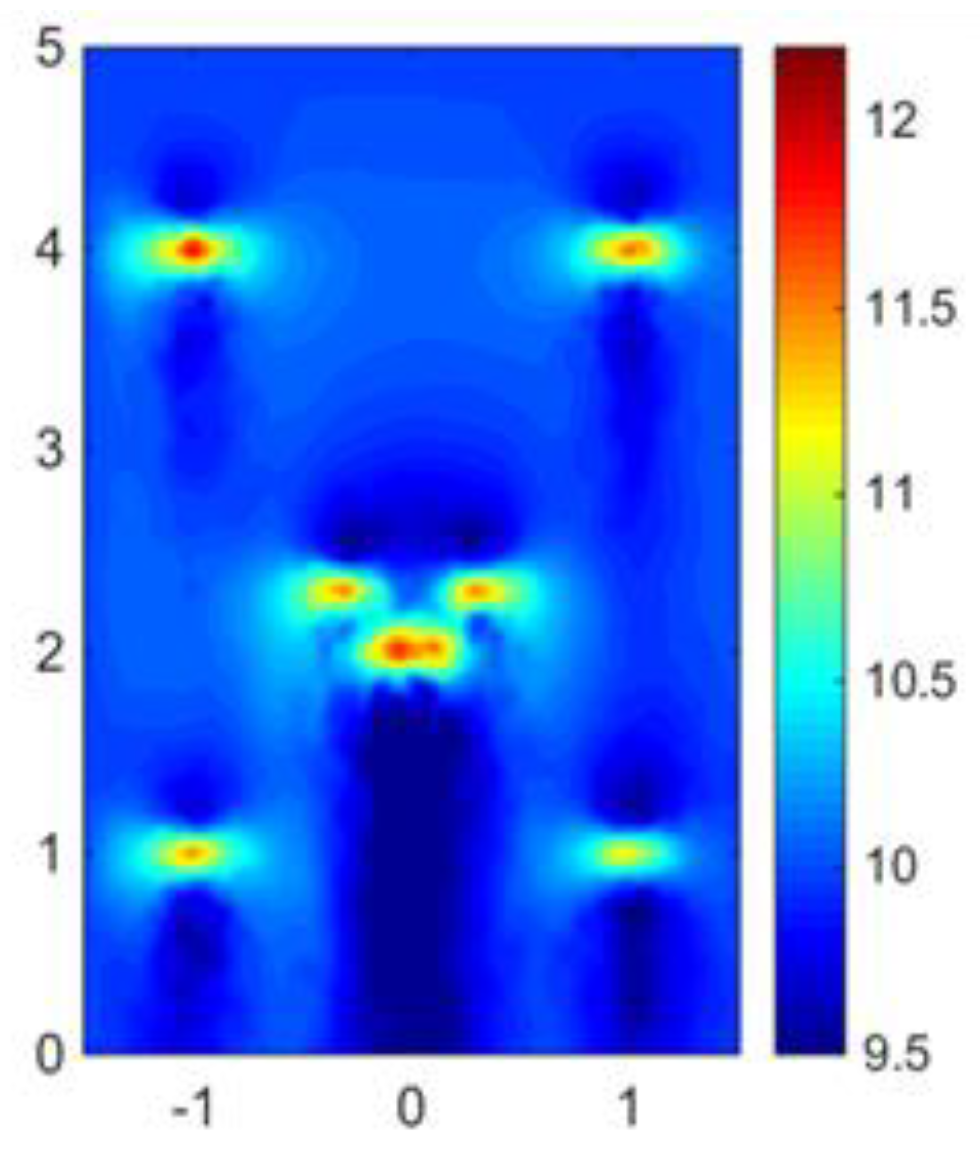
Online measurements were made in the whole plane in the coarse grid points when the inlet velocity was set to 6 m/s. Ten sensors were installed randomly in the coarse grid points, as shown by the yellow dots in
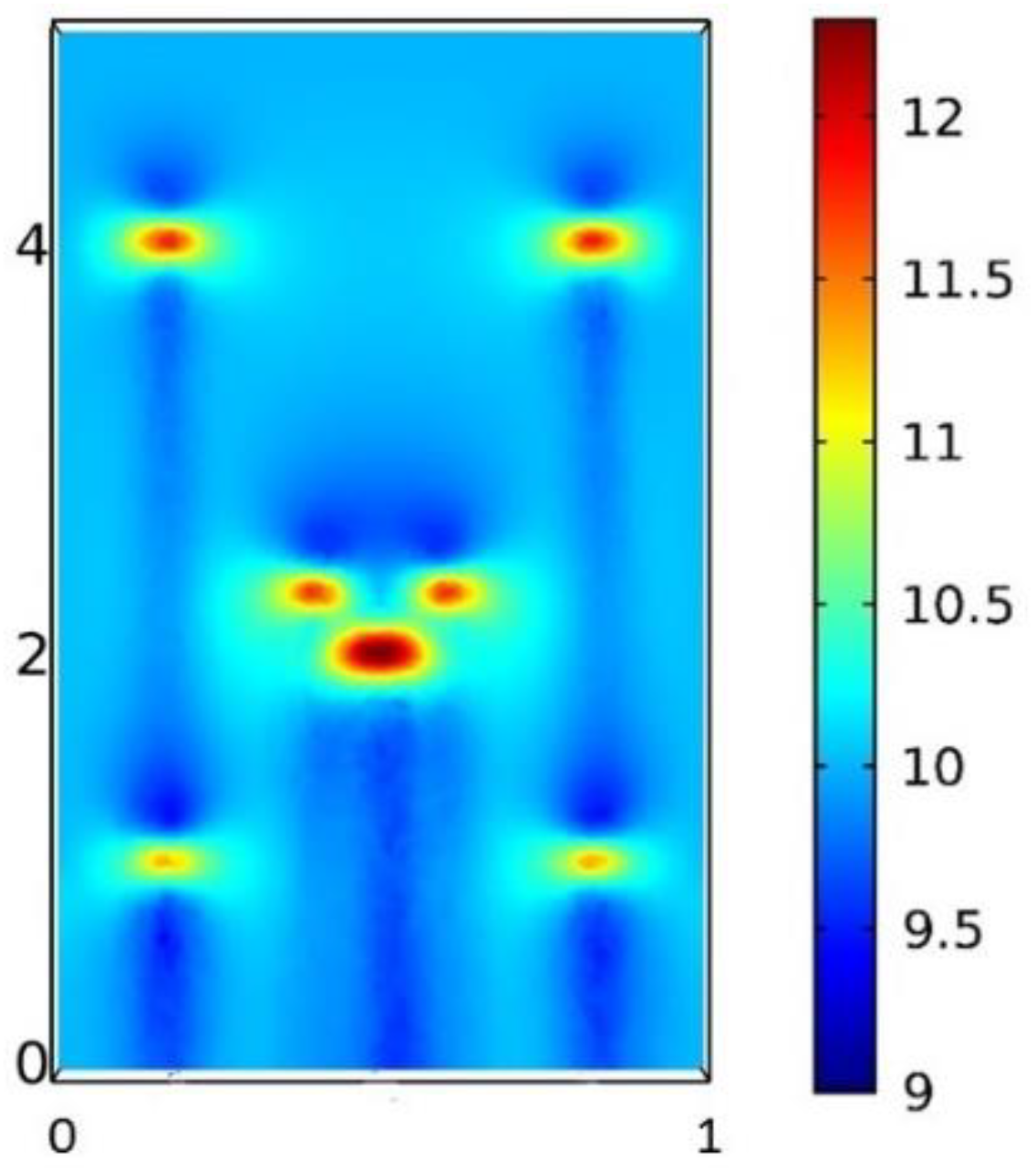
Figure 10. The whole wind field can be reconstructed via gappy data reconstruction methods.
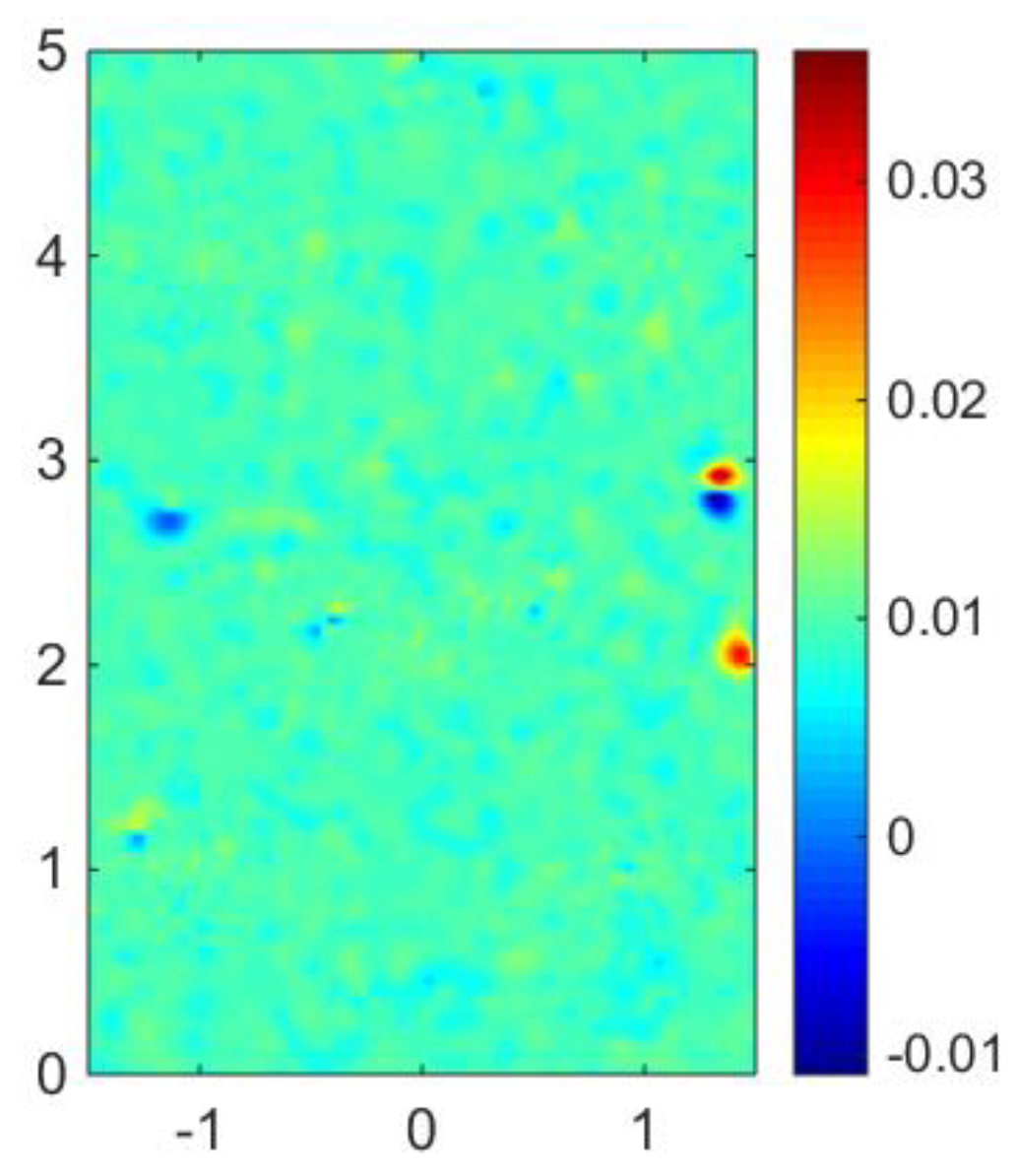
Three extra sensors were installed as a validation group to verify the results of reconstruction. One control group was set: data were reconstructed by POD basis vectors at these points. The other group consisted of data by CFD simulation with the coarse meshes when the inlet velocity was set to 6 m/s. The results are shown in
Table 2. The relative error represents the error between the sensor measurement and the reconstructed data.
It can be seen visually in
Table 2 that all errors of the three points is less than 5%. Since sensors also exhibit some measurement error, 5% is an acceptable result. In addition, three validation points were selected, respectively, at locations far away from the sub-domain, in the sub-domain, and near the sub-domain, and the reconstruction errors were similar. We can conclude that the method we put forward can correctly reconstruct wind field.
5. Conclusions
An efficient wind field reconstruction method was studied that combines the POD method and the CFD method. As a new approach, a subset of the large area was defined to extract basis vectors for POD reconstruction. The new approach allows the POD method to be applied to reconstruct a wind field for large areas with high spatial resolutions. The simulation and experiments showed good results, as we expected.
Compared with previous methods, this method reduces the amount of offline work. POD basis vectors are only obtained by CFD simulation in the sub-domain area. In addition, measurements can be obtained by sensors in coarse meshes in large areas. Both the simulation and experiments showed good results.
This new approach can find applications with respect to problems of a similar nature, such as compressed sensing and process tomography.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}