A Model-Based Approach of Foreground Region of Interest Detection for Video Codecs

Abstract
1. Introduction
1.1. Related Work
1.2. Overview and Contributions
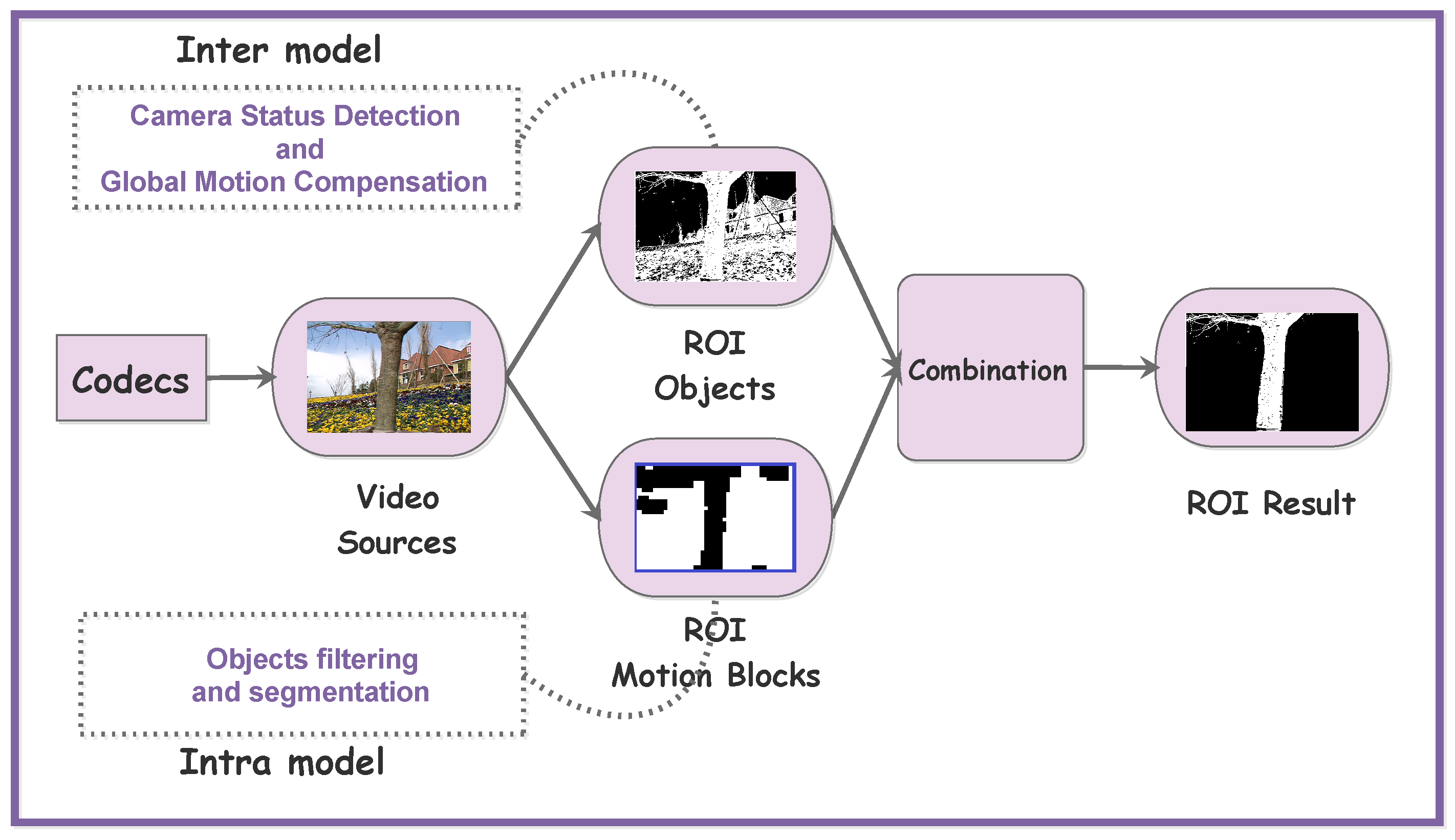
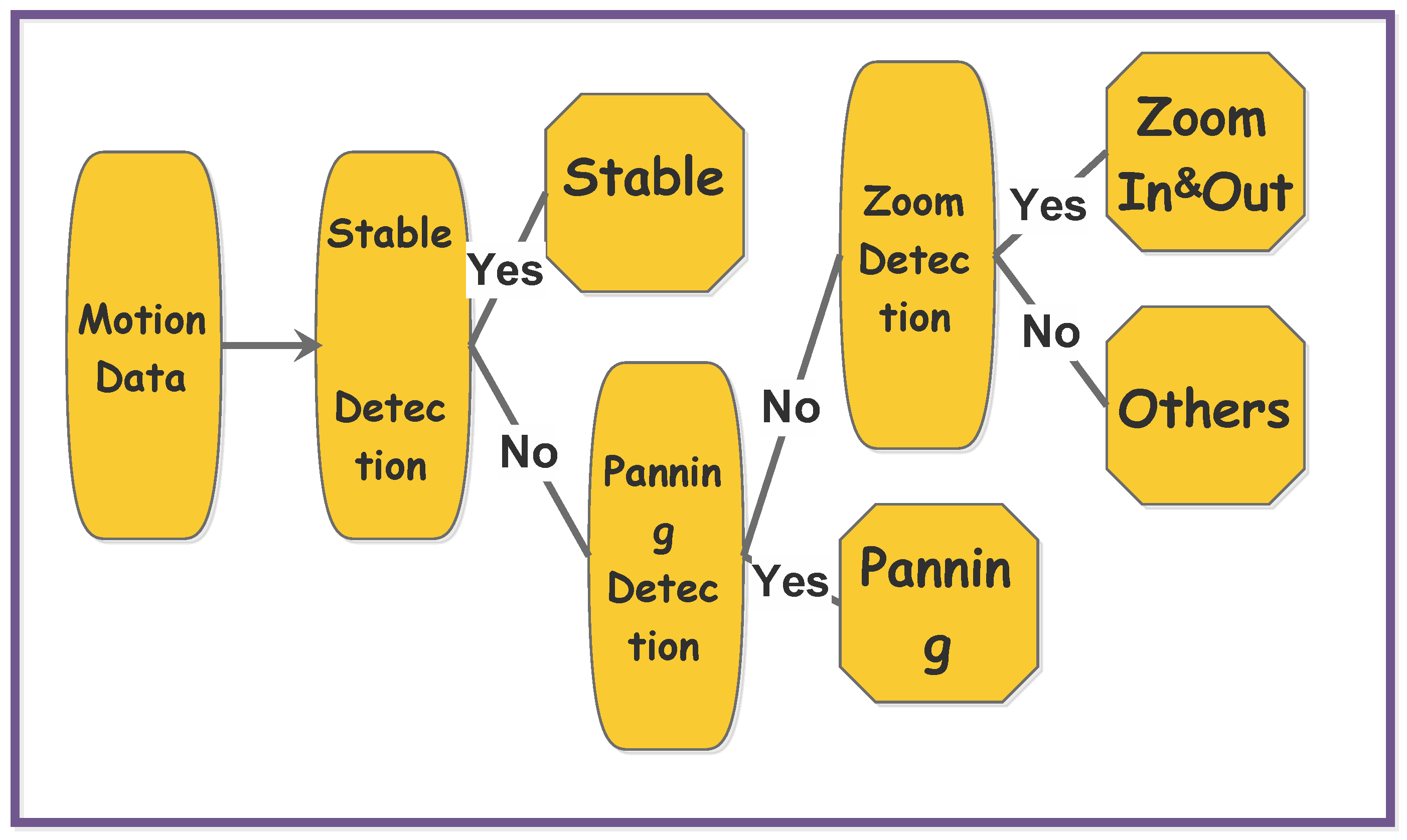
2. Detection Model
2.1. Foreground Motion Blocks Extraction
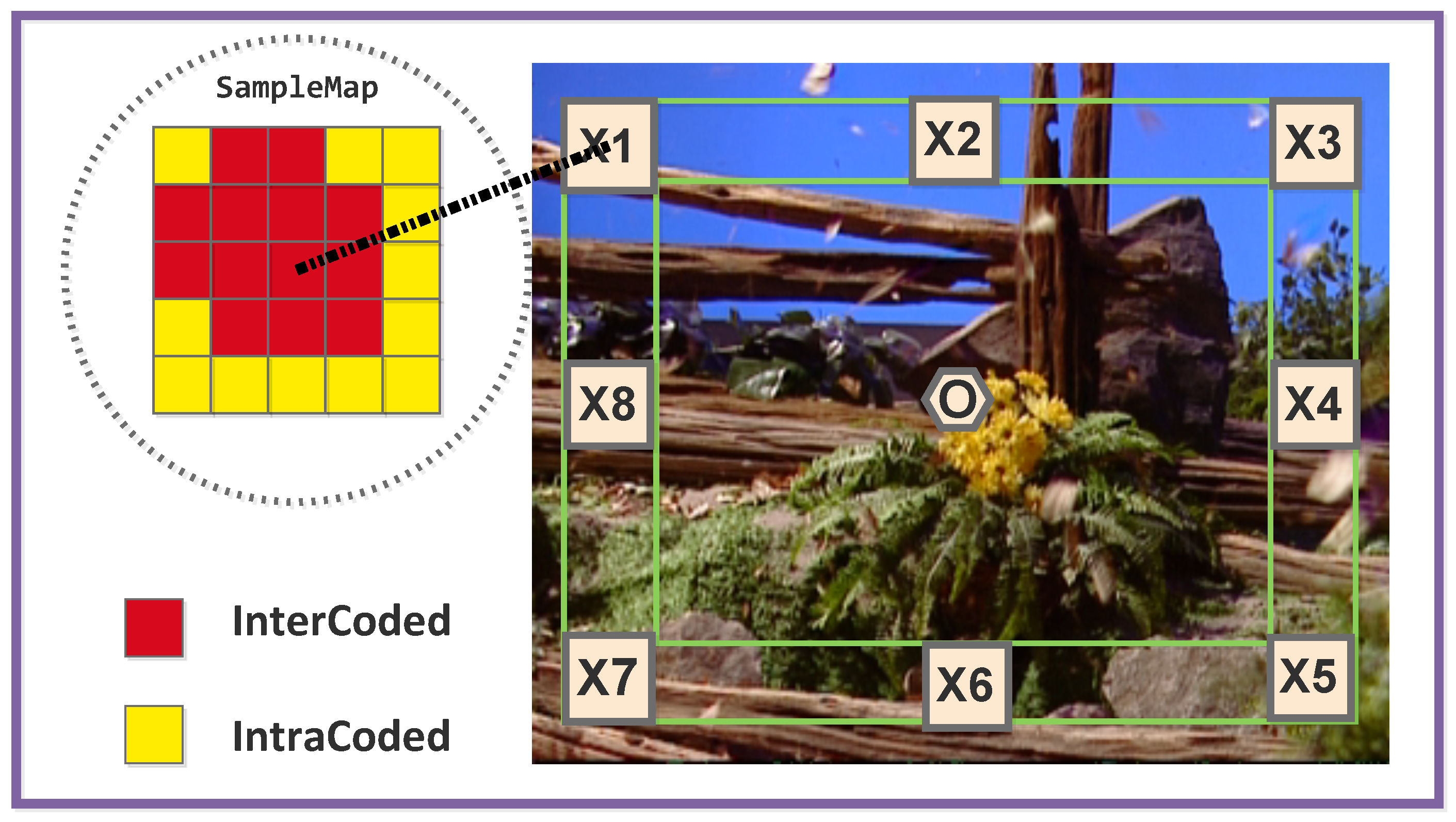
2.1.1. Sampling Areas Determination
| Algorithm 1 Sampling block filter algorithm |
|
2.1.2. Camera Status Detection
- PanningTo determine Camera Panning, an intuitive approach is to compare the norm and direction of MVs among different sampling areas. For each area , its average MV value is computed as follows:We define MV set . For normalization, we have:and their variance without the minimum and maximum values are listed below:Please note that denotes the average values of , and N equals to the size of . Meanwhile, the angle components of are taken into consideration as well. Let be the angle component for :and its variance is followed by:Then, a score parameter for judging camera panning is formed as:is within a range of (0,1) since normalization process is done before calculation, and is treated as the penalty function. When , since we attempt to put more weight on the variance of to decide the camera panning circumstance.
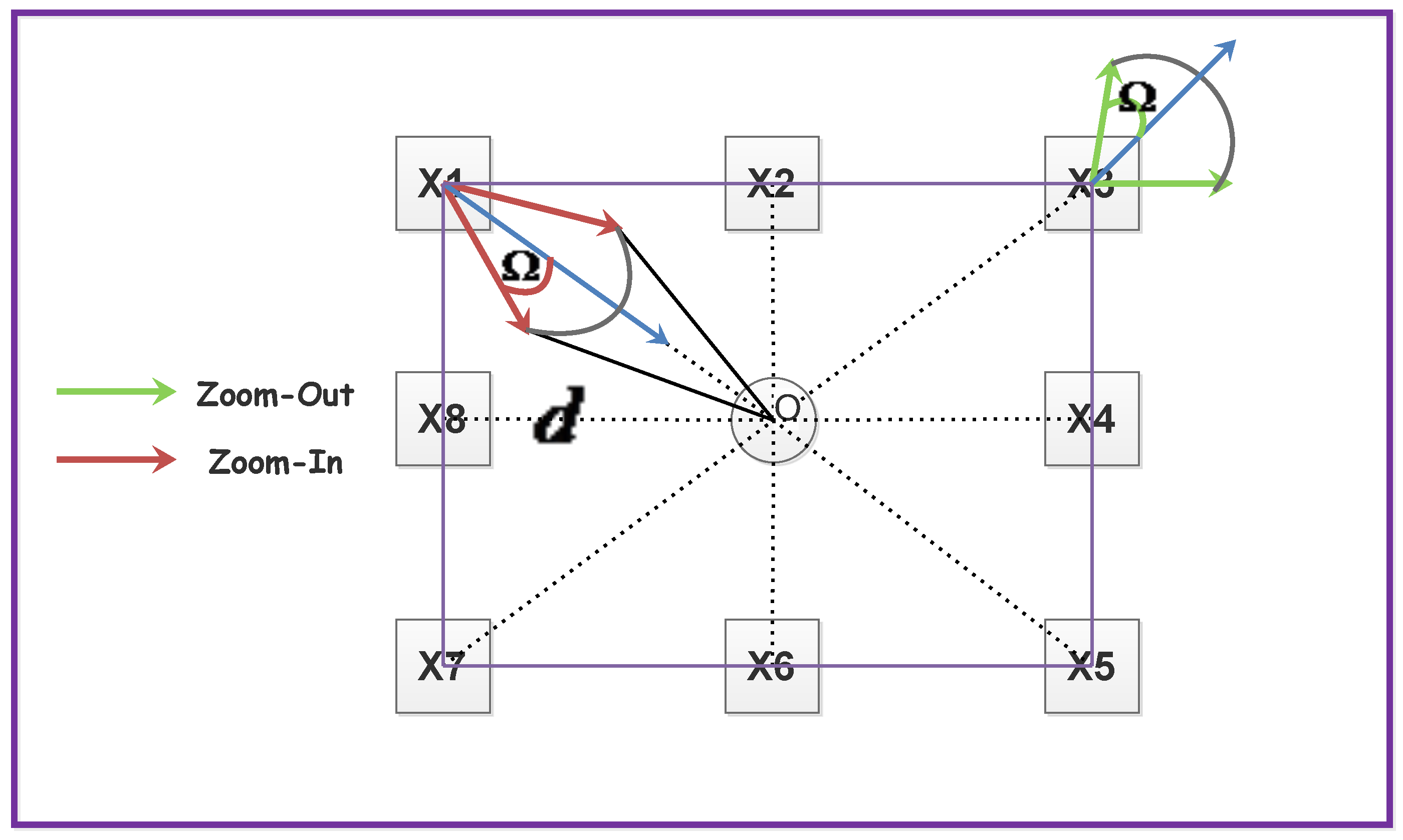
- Zoom-In and Out:In this status, each sampling area has a different direction of motion vector. An illustration for the zooming model is displayed in Figure 3.Obviously, the directions of motion vectors for these sampling areas can be regarded as a factor to determine the zooming in and out situation. Also, the norm of motion vectors is relevant with the distance between the anchor point and each center of the character block. To be specific, we categorize into two groups: and . Also, define a set of vectors that:where is the coordinate of the anchor point o, and is the mean coordinate of . For camera zoom-in status, the inner product of and is a positive value while it is negative in zoom-out status. We can compute the offset angle for zoom in and out by:Apparently, means is in the direction of zoom-in, otherwise zoom-out. We keep in a belief range , in which the max difference between and is set assigned with a constant value (marked in Figure 3 as gray solid arcs). Suppose obeys the normal distribution: . Then, the likelihood factor is given as:Please note that is normalized to unify the range. Besides, a ’hit and miss’ voting scheme is induced: for the zoom-in situation, if , we say that sampling area i misses the zoom-in contribution, otherwise hit; for the zoom-out situation, if , we say miss, otherwise hit. Now, the voting rate for zooming situation is declared as:where is also an indicator function:When , the voting rate’s error is given as . It can be seen that the sampling areas with opposite motion directions show more negative contributions on than ones with higher variances, which is reasonable since motion direction plays an important role in zoom judging. Another factor that influences zoom judging is the norm of , it satisfies:where w and h are width and height of a frame, stands for the average norm of MVs in . Observe that this equation is the approximate one, and its relative error can be defined as:Finally, the score for deciding camera zooming is given below:When is negative, it is inclined to zoom-out situation, otherwise zoom-in. In addition, we have to set a threshold that must satisfy for the zooming circumstances.
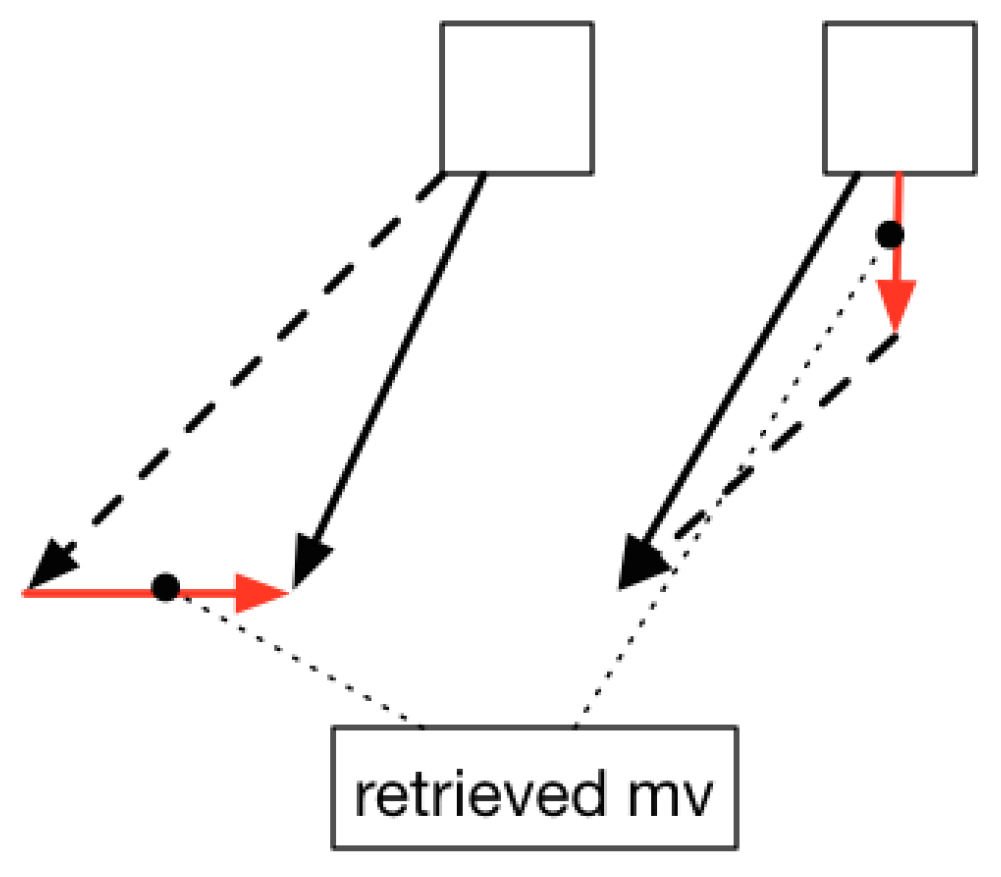
- Stable and Others:For a stable situation, it is easy to judge by checking whether or . Besides, the sampling set contains most of intracoded blocks (), which indicates the stable situation as well. The last circumstances is named as “rest” when it does not satisfy any of the above circumstances. Please note that may consist some important situations that we have ignored in previous detection steps. For example, the combination of panning and zooming, which occurs frequently in video recording. It is hard to decompose both panning and zooming motion vector component since the panning component can have any directions and norms. An alternative way is to simplify this problem by extracting the horizontal and vertical panning motion vectors from the composed one separately. We consider the upper-right corner sampling area in Figure 4 for instance, solid lines represent the extracted motion vectors, and they can be forced to decompose into the zoom-in and the retrieved horizontal/vertical components (dotted lines and red solid lines). The norm of the zoom-in component is set as a fixed value to make sure the retrieved motion vector is horizontal or vertical. We re-compare the retrieved horizontal and vertical components for the sampling areas using the camera panning model; if it satisfies the conditions, the status of camera is both panning and zooming. On the other hand, the zoom-out situation follows the same rule as the zoom-in.
| Algorithm 2 Global motion decision algorithm |
2.1.3. Global Motion Compensation
2.1.4. Discussion
- Gradient-Descent (GD) [63]: It aims to compute the gradient by Newton-Raphson method for the error distance between the true and the estimated MVs, then it updates parameters based on the gradient descend direction so that the error distance is reduced.
- Least-Sum-Square M-Estimator (LSS-ME) [64]: It involves formulating the error distance by an over-determined regression: , where , is a vector of transformed coordinates , and N is the total number of MVs. It also uses iterative outlier rejection through a robust M-Estimator to estimate motion components .
- RANSAC [65]: This method induces a statistical method for GME in different computer vision problems. It computes the homography matrix via a large number of iterations to achieve the maximum transformed matching points between the current and the reference frames.
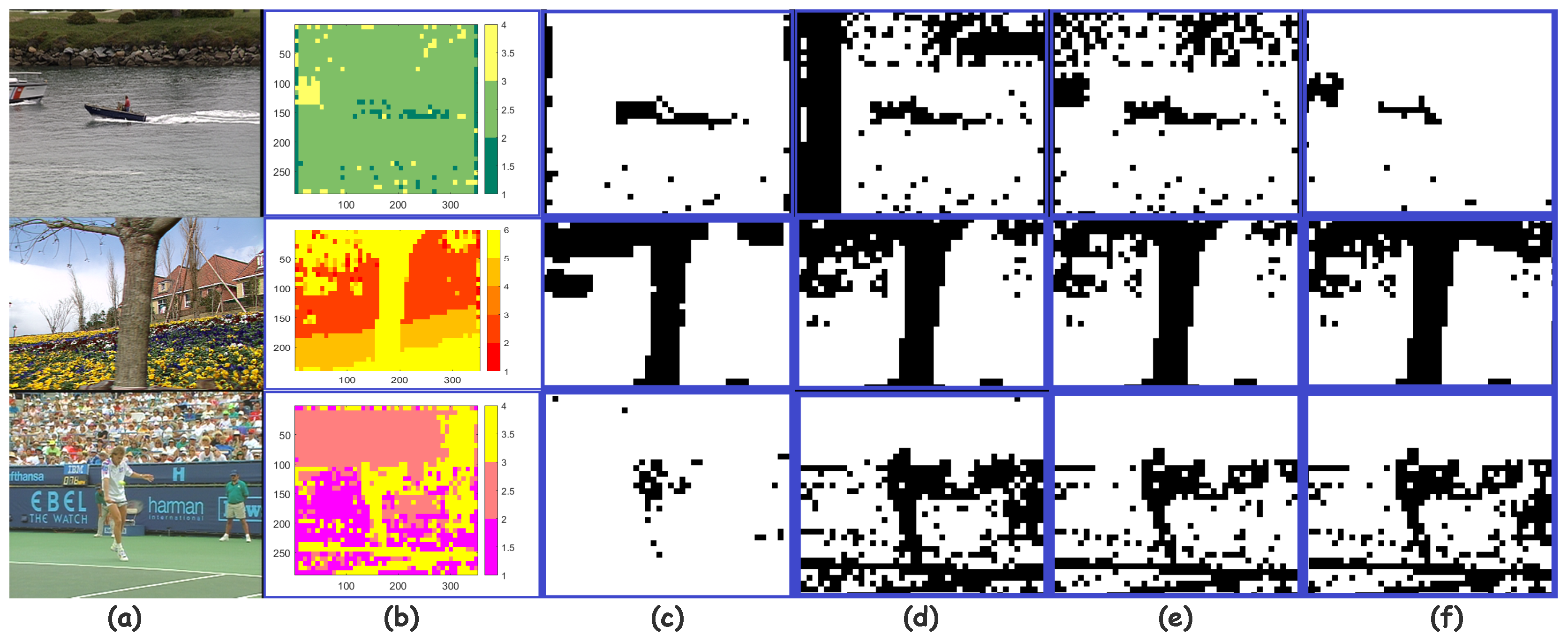
2.1.5. Marking Motion Areas
| Algorithm 3 KFCM Motion Areas Clustering Algorithm |
|
| Algorithm 4 Motion Area Pruning Algorithm |
| : |
Input:b: The current processing block; : Whether the block is visited; : Temp block lists; Search range r and step s.
|
| : |
Input: : Margin block set ; Original block set . Pruned block set ().
|
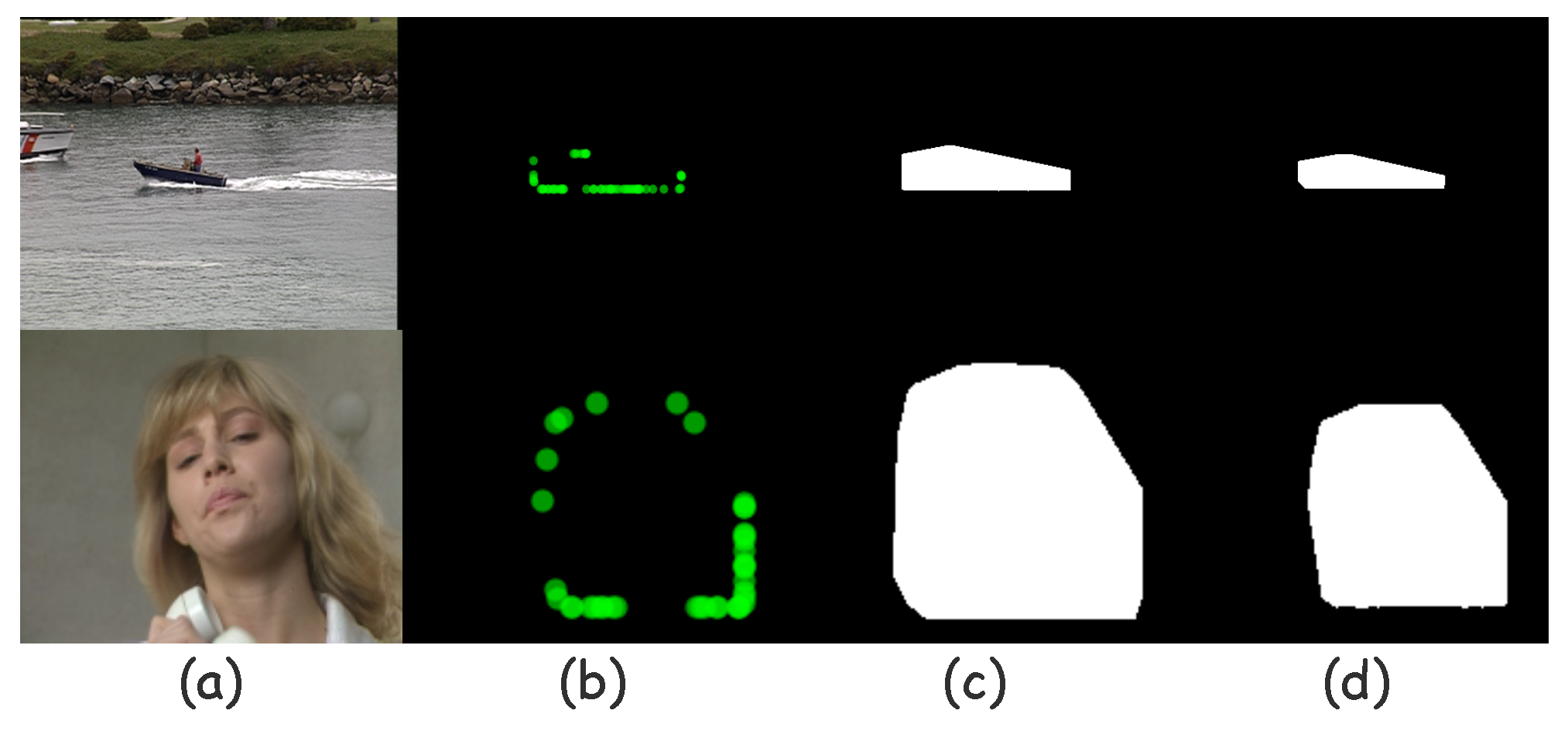
2.1.6. Mask Drawing and ROI Extracting
3. Experiments
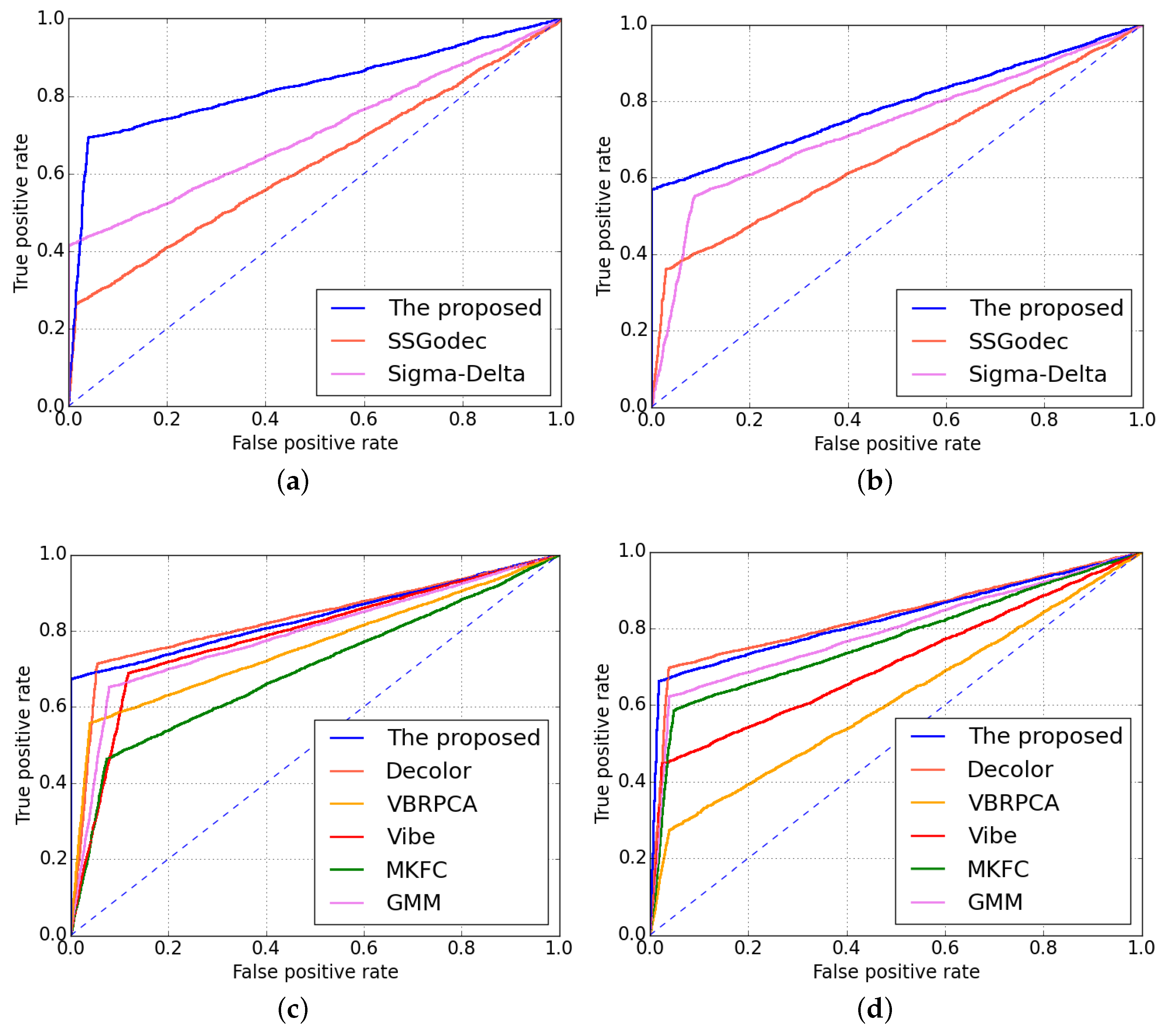
3.1. Visual Effect Analysis Experiments
3.1.1. Parameters Settings
3.1.2. Visual Comparisons on CDNet Dataset
3.1.3. Visual Comparisons On AVC/HEVC Sequences
3.1.4. Miscellaneous Analysis
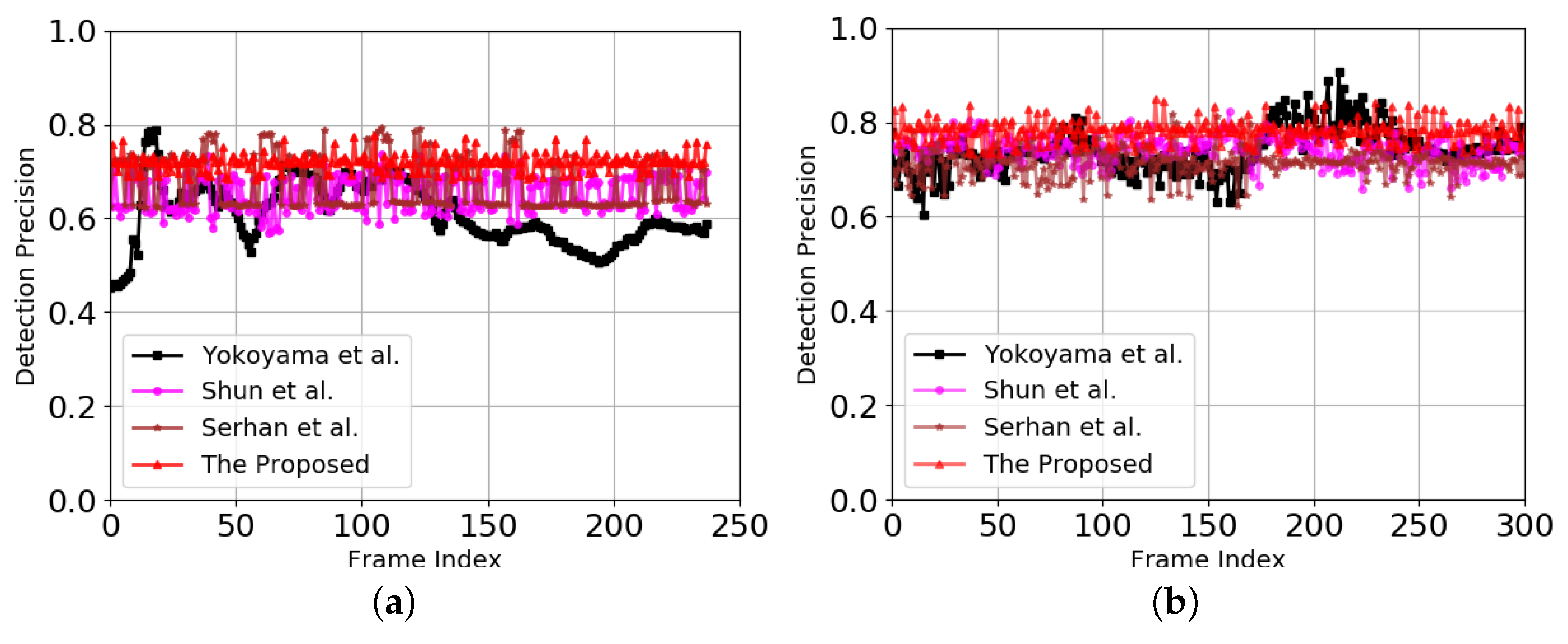
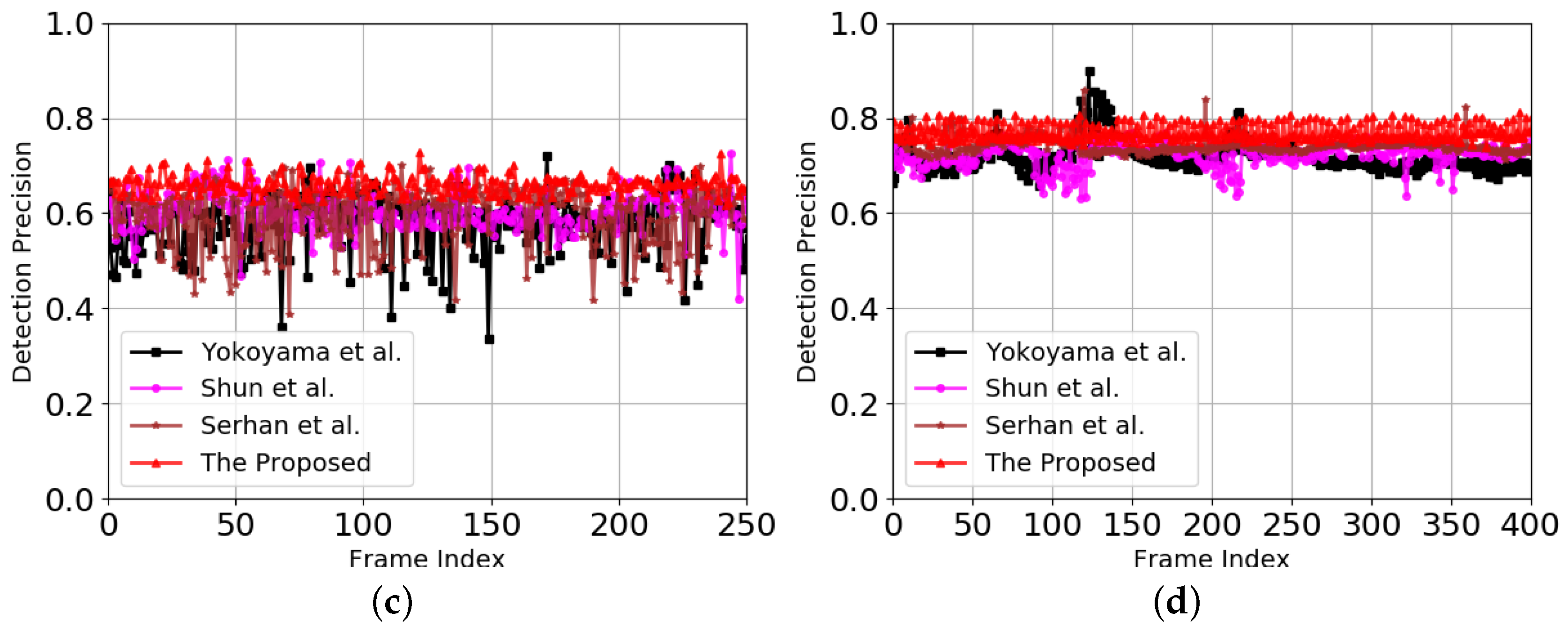
3.1.5. Performance Comparisons with Motion Vector Extraction Methods
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Faugeras, O.D. Digital color image processing within the framework of a human visual model. IEEE Trans. Acoust. Speech Signal Process. 1979, 27, 380–393. [Google Scholar] [CrossRef]
- Song, H.; Kuo, C.C. A region-based H.263+ codec and its rate control for low VBR video. IEEE Trans. Multimed. 2004, 6, 489–500. [Google Scholar] [CrossRef]
- Tong, L.; Rao, K. Region of interest based H.263 compatible codec and its rate control for low bit rate video conferencing. In Proceedings of the 2005 International Symposium on Intelligent Signal Processing and Communication Systems, Hong Kong, China, 13–16 December 2005; pp. 249–252. [Google Scholar] [CrossRef]
- Mukherjee, D.; Bankoski, J.; Grange, A.; Han, J.; Koleszar, J.; Wilkins, P.; Xu, Y.; Bultje, R. The latest open-source video codec VP9 - An overview and preliminary results. In Proceedings of the Picture Coding Symposium (PCS), San Jose, CA, USA, 8–11 December 2013; pp. 390–393. [Google Scholar] [CrossRef]
- Sullivan, G.; Ohm, J.; Han, W.J.; Wiegand, T. Overview of the High Efficiency Video Coding (HEVC) Standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Wang, H.; Chang, S.F. A highly efficient system for automatic face region detection in MPEG video. IEEE Trans. Circuits Syst. Video Technol. 1997, 7, 615–628. [Google Scholar] [CrossRef]
- Hartung, J.; Jacquin, A.; Pawlyk, J.; Rosenberg, J.; Okada, H.; Crouch, P. Object-oriented H.263 compatible video coding platform for conferencing applications. IEEE J. Sel. Areas Commun. 1998, 16, 42–55. [Google Scholar] [CrossRef]
- Doulamis, N.; Doulamis, A.; Kalogeras, D.; Kollias, S. Low bit-rate coding of image sequences using adaptive regions of interest. IEEE Trans. Circuits Syst. Video Technol. 1998, 8, 928–934. [Google Scholar] [CrossRef]
- Lam, C.F.; Lee, M. Video segmentation using color difference histogram. In Multimedia Information Analysis and Retrieval, Proceedings of the IAPR International Workshop, MINAR’ 98, Hong Kong, China, 13–14 August 1998; Springer: Berlin/Heidelberg, Germany, 1998; pp. 159–174. [Google Scholar] [CrossRef]
- Schafer, R. MPEG-4: A multimedia compression standard for interactive applications and services. Electron. Commun. Eng. J. 1998, 10, 253–262. [Google Scholar] [CrossRef]
- Zhou, X.; Yang, C.; Zhao, H.; Yu, W. Low-Rank Modeling and Its Applications in Image Analysis. CoRR 2014, arXiv:1401.3409. [Google Scholar] [CrossRef]
- Gupta, S.; Davidson, J.; Levine, S.; Sukthankar, R.; Malik, J. Cognitive Mapping and Planning for Visual Navigation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhang, Z.; Jing, T.; Han, J.; Xu, Y.; Zhang, F. A New Rate Control Scheme For Video Coding Based On Region Of Interest. IEEE Access 2017, 5, 13677–13688. [Google Scholar] [CrossRef]
- Zhang, Z.; Jing, T.; Han, J.; Xu, Y.; Li, X. Flow-Process Foreground Region of Interest Detection Method for Video Codecs. IEEE Access 2017, 5, 16263–16276. [Google Scholar] [CrossRef]
- Zhang, Z.; Jing, T.; Han, J.; Xu, Y.; Li, X.; Gao, M. ROI-Based Video Transmission in Heterogeneous Wireless Networks With Multi-Homed Terminals. IEEE Access 2017, 5, 26328–26339. [Google Scholar] [CrossRef]
- Gonzalez, D.; Botella, G.; Meyer-Baese, U.; Garcia, C.; Sanz, C.; Prieto-Matas, M.; Tirado, F. A low cost matching motion estimation sensor based on the NIOS II microprocessor. Sensors 2012, 12, 13126–13149. [Google Scholar] [CrossRef] [PubMed]
- Gonzalez, D.; Botella, G.; Garcia, C.; Prieto, M.; Tirado, F. Acceleration of block-matching algorithms using a custom instruction-based paradigm on a Nios II microprocessor. EURASIP J. Adv. Signal Process. 2013, 2013, 118. [Google Scholar] [CrossRef]
- Nunez-Yanez, J.L.; Nabina, A.; Hung, E.; Vafiadis, G. Cogeneration of Fast Motion Estimation Processors and Algorithms for Advanced Video Coding. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2012, 20, 437–448. [Google Scholar] [CrossRef]
- Stauffer, C.; Grimson, W.E.L. Adaptive background mixture models for real-time tracking. In Proceedings of the 1999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (Cat. No PR00149), Fort Collins, CO, USA, 23–25 June 1999; Volume 2, p. 252. [Google Scholar] [CrossRef]
- Stauffer, C.; Grimson, W.E.L. Learning Patterns of Activity Using Real-Time Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 747–757. [Google Scholar] [CrossRef]
- Zivkovic, Z. Improved adaptive Gaussian mixture model for background subtraction. In Proceedings of the 17th International Conference on Pattern Recognition, Cambridge, UK, 26–26 August 2004; Volume 2, pp. 28–31. [Google Scholar] [CrossRef]
- Cand, E.; Li, X.; Ma, Y.; Wright, J. Robust principal component analysis?: Recovering low-rank matrices from sparse errors. In Proceedings of the 2010 IEEE Sensor Array and Multichannel Signal Processing Workshop, Jerusalem, Israel, 4–7 October 2010; pp. 201–204. [Google Scholar] [CrossRef]
- Gao, Z.; Cheong, L.F.; Wang, Y.X. Block-Sparse RPCA for Salient Motion Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1975–1987. [Google Scholar] [CrossRef] [PubMed]
- Guyon, C.; Bouwmans, T.; Zahzah, E.H. Foreground detection based on low-rank and block-sparse matrix decomposition. In Proceedings of the 2012 19th IEEE International Conference on Image Processing (ICIP), Orlando, FL, USA, 30 September–3 October 2012; pp. 1225–1228. [Google Scholar] [CrossRef]
- Xu, H.; Caramanis, C.; Sanghavi, S. Robust PCA via Outlier Pursuit. IEEE Trans. Inf. Theory 2012, 58, 3047–3064. [Google Scholar] [CrossRef]
- Derin Babacan, S.; Luessi, M.; Molina, R.; Katsaggelos, A.K. Sparse Bayesian Methods for Low-Rank Matrix Estimation. IEEE Trans. Signal Process. 2012, 60, 3964–3977. [Google Scholar] [CrossRef]
- Balzano, L.; Nowak, R.; Recht, B. Online identification and tracking of subspaces from highly incomplete information. In Proceedings of the 2010 48th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, VA, USA, 29 September–1 October 2010; pp. 704–711. [Google Scholar] [CrossRef]
- Peng, Y.; Ganesh, A.; Wright, J.; Xu, W.; Ma, Y. RASL: Robust Alignment by Sparse and Low-Rank Decomposition for Linearly Correlated Images. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2233–2246. [Google Scholar] [CrossRef]
- Zhou, T.; Tao, D. GoDec: Randomized Low-rank and Sparse Matrix Decomposition in Noisy Case. In Proceedings of the 28th ICML, Bellevue, WA, USA, 28 June–2 July 2011; pp. 33–40. [Google Scholar]
- Chan, A.B.; Vasconcelos, N. Layered Dynamic Textures. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 1862–1879. [Google Scholar] [CrossRef]
- Chan, A.B.; Vasconcelos, N. Modeling, Clustering, and Segmenting Video with Mixtures of Dynamic Textures. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 909–926. [Google Scholar] [CrossRef] [PubMed]
- Mumtaz, A.; Coviello, E.; Lanckriet, G.R.G.; Chan, A.B. Clustering Dynamic Textures with the Hierarchical EM Algorithm for Modeling Video. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1606–1621. [Google Scholar] [CrossRef]
- Chan, A.B.; Mahadevan, V.; Vasconcelos, N. Generalized Stauffer–Grimson background subtraction for dynamic scenes. Mach. Vis. Appl. 2011, 22, 751–766. [Google Scholar] [CrossRef]
- Barnich, O.; Droogenbroeck, M.V. ViBe: A Universal Background Subtraction Algorithm for Video Sequences. IEEE Trans. Image Process. 2011, 20, 1709–1724. [Google Scholar] [CrossRef] [PubMed]
- Yao, J.; Odobez, J.M. Multi-Layer Background Subtraction Based on Color and Texture. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar] [CrossRef]
- Maddalena, L.; Petrosino, A. A Self-Organizing Approach to Background Subtraction for Visual Surveillance Applications. IEEE Trans. Image Process. 2008, 17, 1168–1177. [Google Scholar] [CrossRef] [PubMed]
- Panda, D.K.; Meher, S. Detection of Moving Objects Using Fuzzy Color Difference Histogram Based Background Subtraction. IEEE Signal Process. Lett. 2016, 23, 45–49. [Google Scholar] [CrossRef]
- Chiranjeevi, P.; Sengupta, S. Detection of Moving Objects Using Multi-channel Kernel Fuzzy Correlogram Based Background Subtraction. IEEE Trans. Cybern. 2014, 44, 870–881. [Google Scholar] [CrossRef]
- Boykov, Y.; Veksler, O.; Zabih, R. Fast approximate energy minimization via graph cuts. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 1222–1239. [Google Scholar] [CrossRef]
- Kolmogorov, V.; Zabin, R. What energy functions can be minimized via graph cuts? IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 147–159. [Google Scholar] [CrossRef]
- Boykov, Y.; Kolmogorov, V. An experimental comparison of min-cut/max- flow algorithms for energy minimization in vision. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 1124–1137. [Google Scholar] [CrossRef]
- Tang, M.; Gorelick, L.; Veksler, O.; Boykov, Y. GrabCut in One Cut. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1769–1776. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 346–361. [Google Scholar]
- Szegedy, C.; Toshev, A.; Erhan, D. Deep Neural Networks for Object Detection. Adv. Neural Inf. Process. Syst. 2013, 26, 2553–2561. [Google Scholar]
- Erhan, D.; Szegedy, C.; Toshev, A.; Anguelov, D. Scalable Object Detection Using Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 2155–2162. [Google Scholar]
- Szegedy, C.; Reed, S.E.; Erhan, D.; Anguelov, D. Scalable, High-Quality Object Detection. CoRR 2014, arXiv:1412.1441. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. CoRR 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. CoRR 2015, arXiv:1512.02325. [Google Scholar]
- Huang, G.; Liu, Z.; Weinberger, K.Q. Densely Connected Convolutional Networks. CoRR 2016, arXiv:1608.06993. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. CoRR 2016, arXiv:1605.06409. [Google Scholar]
- Pinheiro, P.H.O.; Collobert, R.; Dollár, P. Learning to Segment Object Candidates. CoRR 2015, arXiv:1506.06204. [Google Scholar]
- Girshick, R.B.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. CoRR 2013, arXiv:1311.2524. [Google Scholar]
- Yuan, J.; Wu, Y. Mining visual collocation patterns via self-supervised subspace learning. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2012, 42, 334–346. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Jing, T.; Tian, C.; Cui, P.; Li, X.; Gao, M. Objects Discovery Based on Co-Occurrence Word Model with Anchor-Box Polishing. IEEE Trans. Circuits Syst. Video Technol. 2019. [Google Scholar] [CrossRef]
- Chen, Y.M.; Bajic, I.V. A Joint Approach to Global Motion Estimation and Motion Segmentation From a Coarsely Sampled Motion Vector Field. IEEE Trans. Circuits Syst. Video Technol. 2011, 21, 1316–1328. [Google Scholar] [CrossRef]
- Unger, M.; Asbach, M.; Hosten, P. Enhanced background subtraction using global motion compensation and mosaicing. In Proceedings of the 2008 15th IEEE International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008; pp. 2708–2711. [Google Scholar] [CrossRef]
- Jin, Y.; Tao, L.; Di, H.; Rao, N.I.; Xu, G. Background modeling from a free-moving camera by Multi-Layer Homography Algorithm. In Proceedings of the 2008 15th IEEE International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008; pp. 1572–1575. [Google Scholar] [CrossRef]
- Guerreiro, R.F.C.; Aguiar, P.M.Q. Global Motion Estimation: Feature-Based, Featureless, or Both?! In Image Analysis and Recognition, Proceedings of the Third International Conference, ICIAR 2006, voa de Varzim, Portugal, 18–20 September 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 721–730. [Google Scholar]
- The Change Detection Dataset. Available online: http://changedetection.net (accessed on 25 March 2019).
- The HEVC/AVC Official Test Sequences, Online. Available online: ftp://hevc@ftp.tnt.uni-hannover.de/testsequences (accessed on 25 March 2019).
- Su, Y.; Sun, M.T.; Hsu, V. Global motion estimation from coarsely sampled motion vector field and the applications. IEEE Trans. Circuits Syst. Video Technol. 2005, 15, 232–242. [Google Scholar] [CrossRef]
- Smolic, A.; Hoeynck, M.; Ohm, J.R. Low-complexity global motion estimation from P-frame motion vectors for MPEG-7 applications. In Proceedings of the 2000 International Conference on Image Processing (Cat. No.00CH37101), Vancouver, BC, Canada, 10–13 September 2000; Volume 2, pp. 271–274. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography. In Readings in Computer Vision: Issues, Problems, Principles, and Paradigms; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1987; pp. 726–740. [Google Scholar] [CrossRef]
- Jarvis, R. On the identification of the convex hull of a finite set of points in the plane. Inf. Process. Lett. 1973, 2, 18–21. [Google Scholar] [CrossRef]
- Zhou, X.; Yang, C.; Yu, W. Moving Object Detection by Detecting Contiguous Outliers in the Low-Rank Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 597–610. [Google Scholar] [CrossRef] [PubMed]
- Rueda, L.; Mery, D.; Kittler, J. Σ-Δ Background Subtraction and the Zipf Law. In Progress in Pattern Recognition, Image Analysis and Applications, Proceedings of the 12th Iberoamericann Congress on Pattern Recognition, CIARP 2007, Valparaiso, Chile, 13–16 November 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 42–51. [Google Scholar] [CrossRef]
- Yokoyama, T.; Iwasaki, T.; Watanabe, T. Motion Vector Based Moving Object Detection and Tracking in the MPEG Compressed Domain. In Proceedings of the 2009 Seventh International Workshop on Content-Based Multimedia Indexing, Chania, Greece, 3–5 June 2009; pp. 201–206. [Google Scholar] [CrossRef]
- Yoneyama, A.; Nakajima, Y.; Yanagihara, H.; Sugano, M. Moving object detection and identification from MPEG coded data. In Proceedings of the 1999 International Conference on Image Processing (Cat. 99CH36348), Kobe, Japan, 24–28 October 1999; Volume 2, pp. 934–938. [Google Scholar] [CrossRef]
- Niu, C.; Liu, Y. Moving Object Segmentation Based on Video Coding Information in H.264 Compressed Domain. In Proceedings of the 2009 2nd International Congress on Image and Signal Processing, Tianjin, China, 17–19 October 2009; pp. 1–5. [Google Scholar] [CrossRef]
- Zhang, S.; Su, X.; Xie, L. Global motion compensation for image sequences and motion object detection. In Proceedings of the 2010 International Conference on Computer Application and System Modeling (ICCASM 2010), Taiyuan, China, 22–24 October 2010; Volume 1, pp. V1–406–V1–409. [Google Scholar] [CrossRef]
- Gul, S.; Meyer, J.T.; Hellge, C.; Schierl, T.; Samek, W. Hybrid video object tracking in H.265/HEVC video streams. In Proceedings of the 2016 IEEE 18th International Workshop on Multimedia Signal Processing (MMSP), Montreal, QC, Canada, 21–23 September 2016; pp. 1–5. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequences | Our Method | GD | LSS-ME | RANSAC |
|---|---|---|---|---|
| Flower | 0.097 s | 0.181 s | 0.466 s | 0.240 s |
| Stefan | 0.293 s | 0.665 s | 0.712 s | 0.497 s |
| CoastGuard | 0.225 s | 0.604 s | 0.811 s | 0.472 s |
| Seq | Status | prec | Recall | F-Score | ||
|---|---|---|---|---|---|---|
| BQTerrace Flower Foreman | panning /rests | 0.1 | 0.3 | 0.818 | 0.901 | 0.857 |
| 0.3 | 0.3 | 0.940 | 0.901 | 0.922 | ||
| 0.5 | 0.3 | 0.846 | 0.880 | 0.863 | ||
| 0.7 | 0.3 | 0.702 | 0.801 | 0.747 | ||
| PartyScene BQSquare Mobile | zooming /rests | 0.3 | 0.1 | 0.649 | 0.740 | 0.692 |
| 0.3 | 0.3 | 0.722 | 0.780 | 0.750 | ||
| 0.3 | 0.5 | 0.773 | 0.820 | 0.796 | ||
| 0.3 | 0.7 | 0.693 | 0.680 | 0.686 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Jing, T.; Ding, B.; Gao, M.; Li, X. A Model-Based Approach of Foreground Region of Interest Detection for Video Codecs. Appl. Sci. 2019, 9, 2670. https://doi.org/10.3390/app9132670
Zhang Z, Jing T, Ding B, Gao M, Li X. A Model-Based Approach of Foreground Region of Interest Detection for Video Codecs. Applied Sciences. 2019; 9(13):2670. https://doi.org/10.3390/app9132670
Chicago/Turabian StyleZhang, Zhewei, Tao Jing, Bowen Ding, Meilin Gao, and Xuejing Li. 2019. "A Model-Based Approach of Foreground Region of Interest Detection for Video Codecs" Applied Sciences 9, no. 13: 2670. https://doi.org/10.3390/app9132670
APA StyleZhang, Z., Jing, T., Ding, B., Gao, M., & Li, X. (2019). A Model-Based Approach of Foreground Region of Interest Detection for Video Codecs. Applied Sciences, 9(13), 2670. https://doi.org/10.3390/app9132670