1. Introduction
A speech signal carries information not only connected with the lexical content, but also with the emotional state, age, and gender information of the speaker. Hence, speech signals can be used to recognize the emotional state of the speaker during communication with a machine.
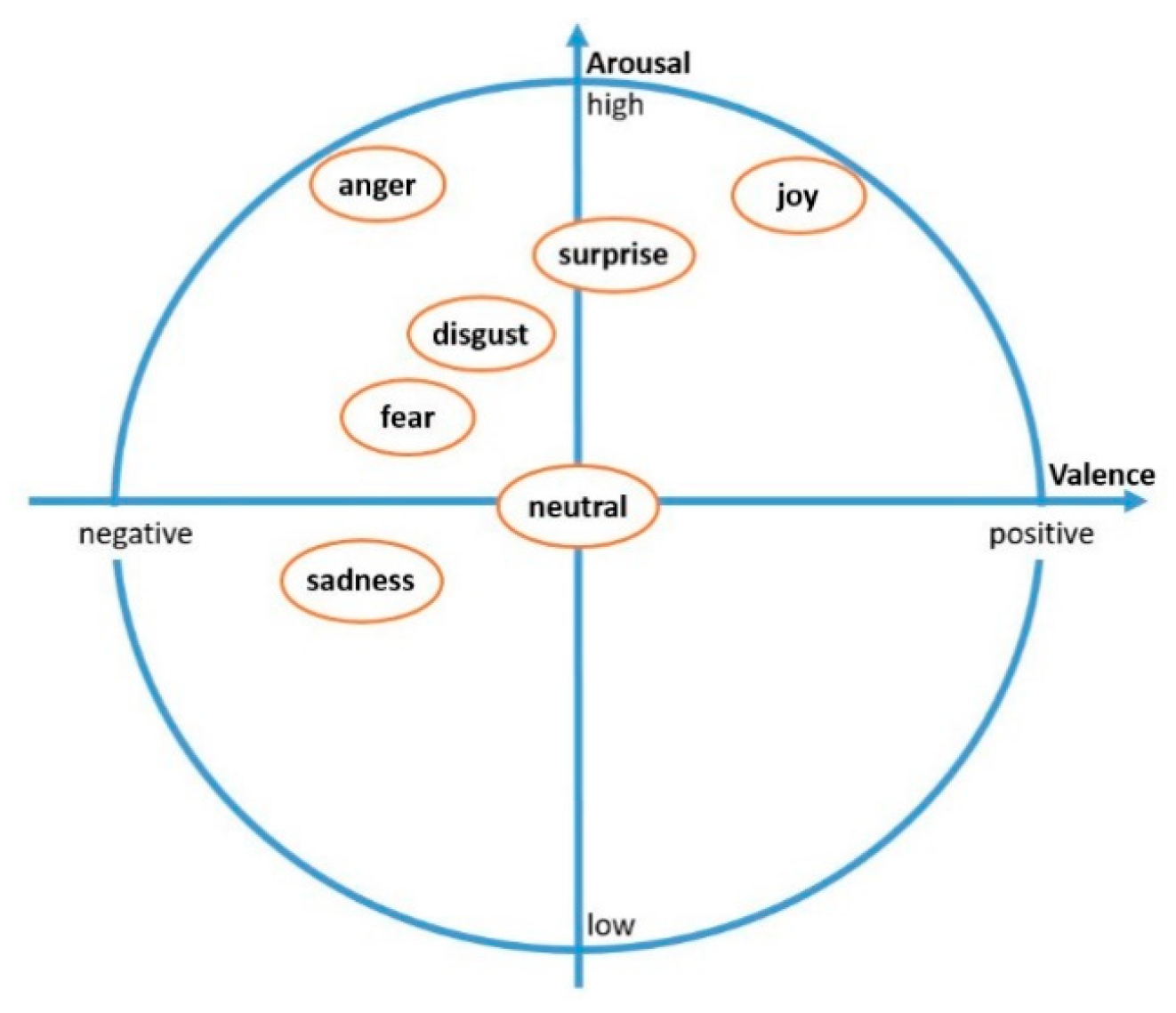
The automatic speech emotion recognition (SER) system needs an appropriate model to represent emotions. Human emotions can be modelled via the categorical approach, dimensional approach, and appraisal-based approach. In the categorical approach, emotions are divided into emotion categories: anger, happiness, fear, sadness, and so on. In the dimensional approach, emotions are represented by three major dimensions: valence (how positive or negative), arousal (how excited or apathetic) and dominance (dominant or submissive) [
1,
2].
Figure 1 illustrates seven basic emotions in arousal-valence dimensions [
2].
The emotional states of the users can be recognized by a machine that uses sensory data, which comes from devices such as smartwatches, in order to detect the stress level of the users [
3,
4], or by extracting useful acoustic features of a speech wave. The acoustic features of emotional speech signal are well established in the arousal dimension and good results have been achieved in distinguishing high- and low-arousal emotions. For instance, Eyben et al. studied acoustic features in detail and proposed the geneva minimalistic acoustic parameter set (GeMAPS) [
5]. In this study, more than ninety percent accuracy was achieved in binary arousal classification, but the accuracy was less than eighty percent with the binary valence classification. Several other studies [
6,
7,
8] reported that discriminating emotions in the valence dimension was the most challenging problem. This problem is not only with the valence dimension but also with the discrimination of discrete emotions.
Communication between acoustic features of emotional speech and music was investigated in [
9].
Table 1 shows acoustic cues for discrete emotions expressed in speech and music performances. From
Table 1, it is clear that most of the acoustic features of anger and happiness expressed in speech and music performances are similar. The prosodic, spectral, and excitation source features of emotional speech signals were analyzed for anger, happiness, neutrality, and sadness, and it was reported that those emotions share similar acoustic patterns [
10,
11,
12]. Hence, there is more confusion in discriminating between those emotions. Busso et al. reported that spectral and fundamental frequency (F0) features discriminate emotions in the valence dimension more accurately [
13].
Moreover, Goudbeek et al. reported that the mean value of the second formant was higher in positive emotions [
14]. As the studies show, acoustic features related to the spectral and frequency of the speech signals can characterize emotions in the valence dimension better than acoustic features related to the intensity and energy of the speech signals.
Nevertheless, these acoustic features are not perfect. Thus, problems remain in discriminating emotions in the valence dimension. There are more than a hundred acoustic features. Hence, they need to be analyzed in order to find the best features that can characterize emotions in the valence dimension.
Timbre is known as a complex set of auditory attributes that describes the quality of a sound. Usually, timbre incorporates spectral and harmonic features of a sound [
15]. It allows us to distinguish sounds even though they have the same pitch and loudness. For instance, when a guitar and a flute play the same note with the same amplitude, each instrument produces a sound that has a unique tone color [
16]. Recently, timbre features have been analyzed for music emotion classification [
17,
18].
Furthermore, the effectiveness of timbre features has been explored for audio classification [
19] and music mood classification [
20], but it has not been analyzed for speech emotion recognition. In this paper, we analyzed timbre features to improve the recognition rate of emotions in a speech in the valence dimension. Furthermore, sequential forward selection (SFS) was applied to find the best feature subset among the timbre acoustic features. The effectiveness of the timbre features for speech emotion recognition was evaluated by compared to well-known MFCC and energy features of the speech signal.
Through the experiments, significant improvement was achieved using the selected best feature subset. Timbre features proved to be effective with the classification of discrete emotions and in the classification of emotions in the valence dimension. Average classification accuracy improvements of 24.06% and 18.77% were achieved with the binary valence classification and the classification of discrete emotions using the combination of baseline and timbre acoustic features on the Berlin Emotional Speech Database.
The rest of this paper is structured as follows:
Section 2 gives information about related works that investigated acoustic features of a speech signal for emotion recognition.
Section 3 describes general speech emotion recognition systems, acoustic feature extraction methods, and classification models. Emotion databases, the experiments, and the results are given in
Section 4. Analysis of the results and discussion is presented in
Section 5. Finally,
Section 6 presents the conclusion of this work and future research directions.
2. Related Works
One of the most critical factors to consider when building an SER system is finding the most effective speech features to discriminate emotions from a speech signal. To solve this challenge, many researchers have investigated a massive number of speech features and achieved considerably good results in the arousal dimension (excited versus calm). For instance, CEICES systematically analyzed the acoustic features of speech to find the best acoustic feature set. They combined the acoustic features which they had and chose the best feature set based on classification accuracy.
In recent studies, the investigation of the acoustic features not only in the arousal dimension (excited versus calm), but also in the valence dimension (positive versus negative) has increased. Goudbeek and Scherer analyzed duration, F0, voice quality, and intensity features of an emotional speech signal to determine the role of those acoustic features regarding the arousal, valence, and potency/control emotional dimensions [
21]. Their study showed that the variation of intensity of positive emotions was less than the variation of intensity of negative emotions. Moreover, positive emotions have a steeper spectral slope compared to negative emotions. Finally, they concluded that spectral shape features, and the speaking rate, which is related to rhythm, are the critical acoustic features for discriminating emotions in the valence dimension.
Eyben et al. [
22] reported the importance of cepstral features (Mel frequency cepstral coefficients—MFCC). MFCC is closely related to spectral shape features. Speech features, such as energy, F0, voice quality, spectral, MFCC, and RASTA style-filtered auditory spectrum features of speech were analyzed to determine the relative effectiveness of these acoustic features in the valence dimension in [
8]. They concluded that MFCC and RASTA style-filtered auditory spectra were the most relevant acoustic features for the valence dimension. Furthermore, the vital role of spectral shape and slope was studied and confirmed by [
23,
24].
Recently, Eyben et al. proposed the GeMAPS for voice research [
5]. They chose acoustic features based on physiological changes in voice production, automatic extractability, and theoretical significance. This acoustic feature set included frequency-related (pitch, jitter), energy/amplitude related (shimmer, loudness), spectral (alpha ratio, spectral slope), and temporal (mean length, a rate of loudness peaks) features. They performed binary classification in the arousal and the valence dimensions using their minimalistic acoustic feature set and achieved 95.3% accuracy in the arousal dimension. Nevertheless, the highest accuracy was 78.1% in the valence dimension. This standard minimalistic acoustic feature set is much more powerful than other large-scale brute-force acoustic feature sets. Moreover, the most effective acoustic feature set in the field of SER so far was reviewed in [
25].
Yildirim et al. reported that the most acoustic features were shared between anger and happiness, and between neutral and sad emotions [
26]. Even though these pairs of emotions have a similar correlation in the arousal dimension, they are different in the valence dimension. Moreover, Juslin and Laukka investigated many acoustic features of speech and music to find the communication of emotions in vocal expressions and music performances, and they reported that most of the acoustic features of anger, happiness, and fear were the same (
Table 1) [
9], but we can differentiate between them in the valence dimension. Therefore, it is crucial to find the acoustic features that can differentiate emotions with similar energy, pitch, loudness, duration, and so on.
In recent years, along with exploring the speech features for SER, deep learning has been applied to various speech-related tasks. A trend in the deep learning community has emerged towards deriving a representation of the input signal directly from raw, unprocessed data. The motivation behind this idea is that the deep learning models learn an intermediate representation of the raw input signal automatically. For instance, in [
27], a raw input signal and a log-mel spectrogram were used as an input to a merged deep convolutional neural network (CNN) to recognize emotion in speech. Furthermore, deep neural networks [
28] and end-to-end multi-task learning for emotion recognition from raw speech signal [
29] are recent examples of this approach. However, these frameworks might suffer from overfitting or from the limited size of the training data. In this work, we aimed to analyze the acoustic features of audio signals, which has not been explored for SER tasks.
The timbre model is used to distinguish two sounds with the same pitch and loudness in research into musical sounds. In general, timbre distinguishes between two sounds that have the same pitch and loudness [
16]. Peeters proposed audio descriptors along with the acoustic feature extraction tool named Timbre Toolbox, which could potentially characterize the timbre of musical signals [
30]. These audio descriptors comprise the temporal energy envelope (attack, decay, release), the spectral (spectral centroid, spread, slope), and the harmonic (harmonic energy, inharmonicity). Based on the theoretical, as well as the practical significance of these acoustic features of an emotionally expressed speech signal, we aimed to analyze them in the valence dimension as well as to classify discrete emotions in this paper.
5. Results and Discussion
One of the primary challenges in pattern recognition is finding the best features that can be correctly discriminated with recognition. In speech recognition, as well as in emotion recognition from speech, MFCC and energy are known to be the most useful acoustic features. Moreover, GeMAPS can be considered a standard acoustic feature set in music classification, speech recognition, and the SER [
5]. However, some emotions are difficult to discriminate using MFCC and energy, such as anger and happiness. In most previous studies [
48,
49,
57], classification accuracy of the happy emotion was low. The best accuracy rate (86.7%) was achieved using a large-scale brute-force acoustic feature set (6373 acoustic features), and 78.1% accuracy was achieved using extended GeMAPS for binary valence classification on EMO-DB [
5]. Although the highest accuracy rate was achieved using a large-scale brute-force acoustic feature set, it is too difficult in terms of extraction time to use those features for real-time speech emotion recognition systems. The numbers of extracted features, along with the extraction time, are also crucial factors to consider when training pattern models and building a real-time speech emotion recognition system.
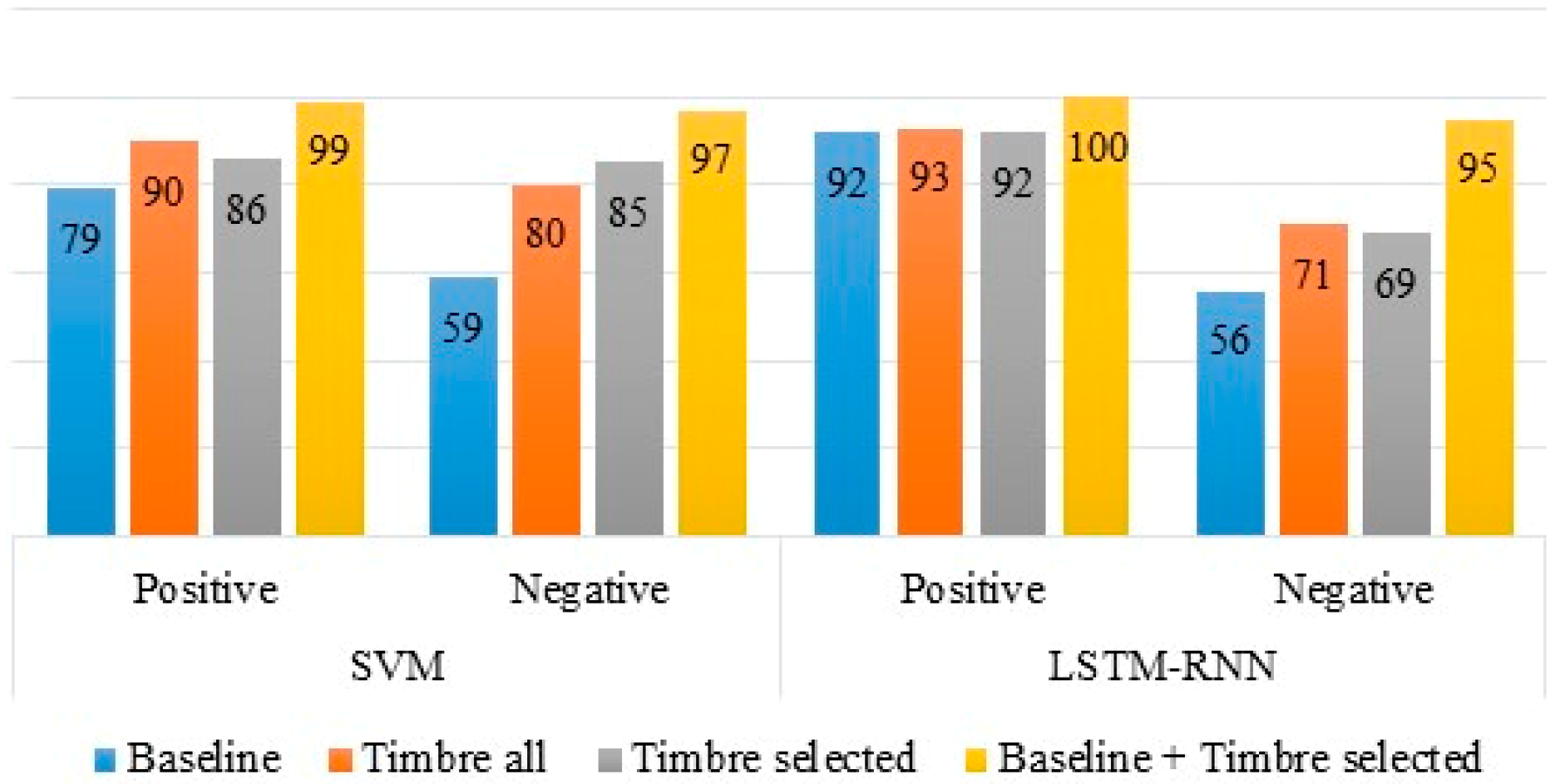
First, we examined the results for the EMO-DB. In our experiment, 97.87%, which was the highest accuracy rate (
Table 4), was obtained using the combination of baseline and timbre selected acoustic features for binary valence classification. The combination of the baseline and timbre selected acoustic features sets also gave the highest accuracy rate for discrete emotions classification. The difference in accuracy rate between the timbre all and timbre selected acoustic feature sets was less than 2%. However, the number of acoustic features in timbre selected was almost two times less than the number of features in the timbre all feature set. This means that irrelevant features in timbre were all removed when the SFS was applied. The results were improved for the combination of the baseline and timbre selected acoustic feature sets compared to the rest of the acoustic feature sets. Consequently, it was clear that baseline and timbre features complemented each other.
Figure 4 shows the recognition rates of positive and negative emotions obtained using all feature sets for binary classification. The recognition rates of both positive and negative emotions improved for the combination of the baseline and timbre selected feature set compared to the rest of feature sets on both SVM and LSTM-RNN.
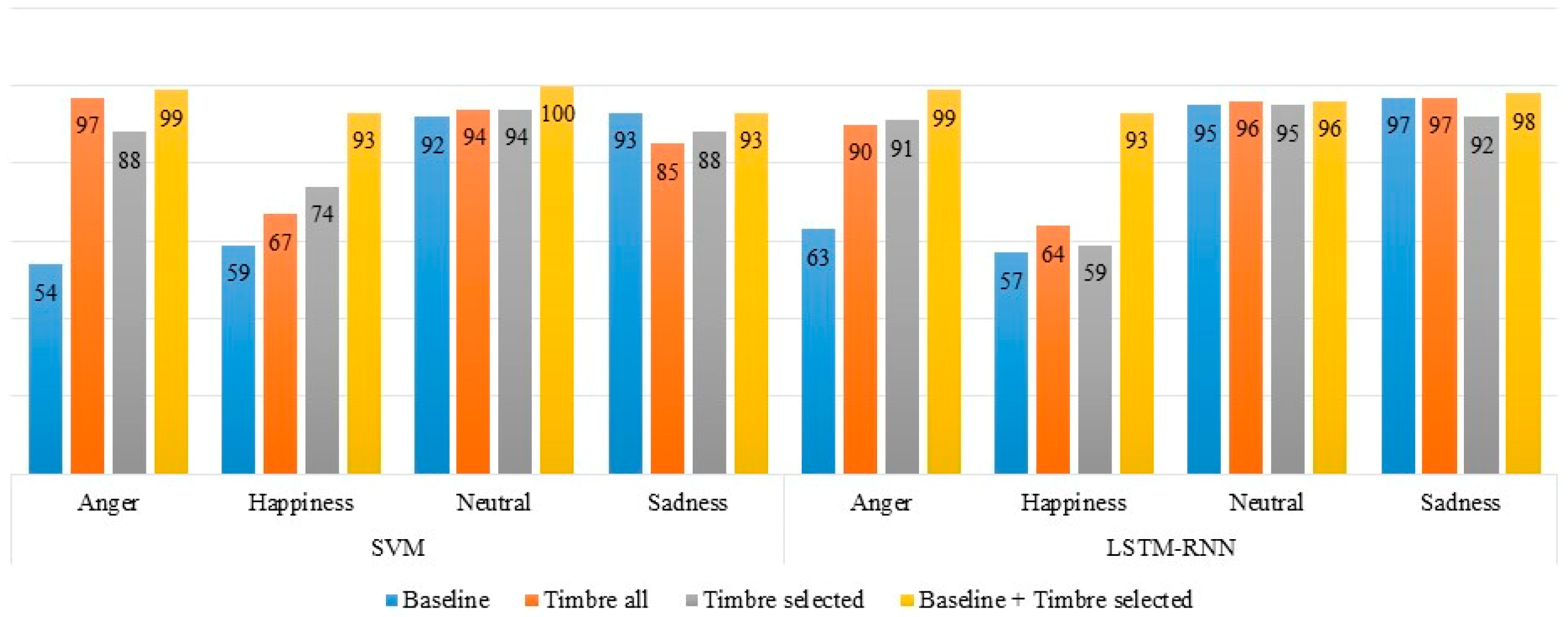
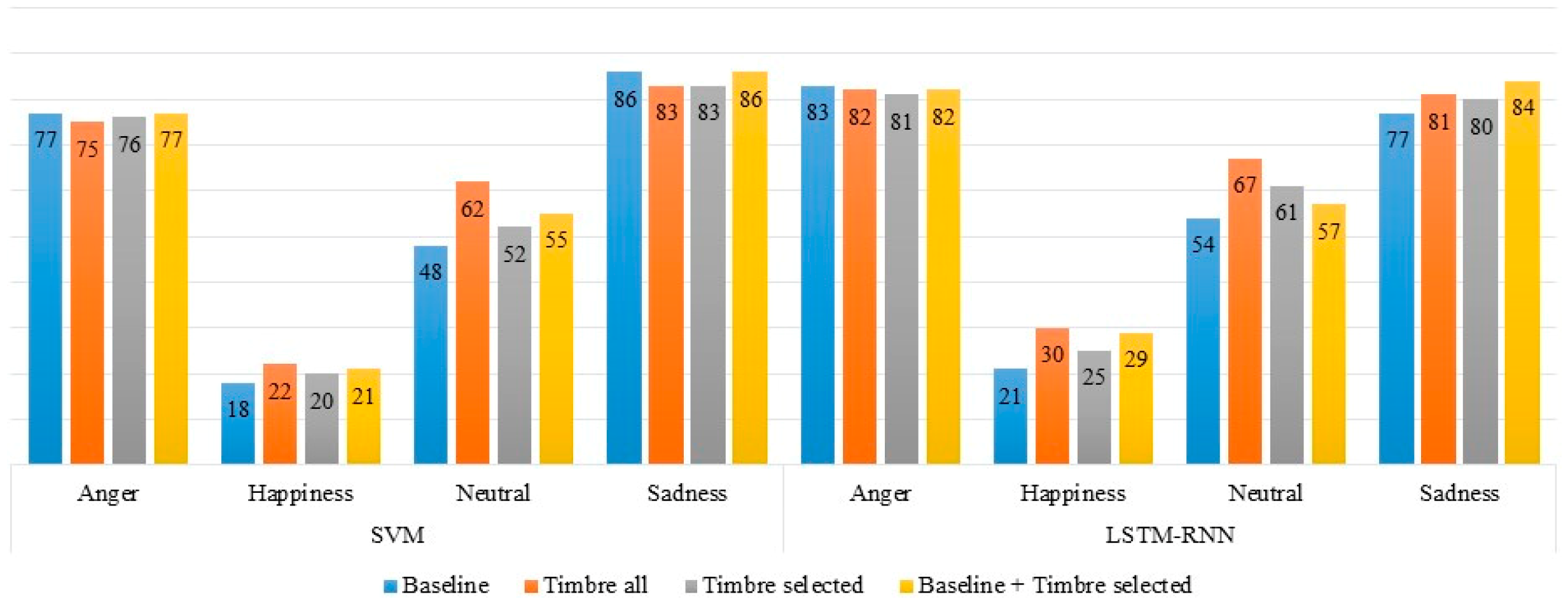
Figure 5 shows the recognition rates of discrete emotions obtained using SVM and LSTM-RNN for different acoustic feature sets. It is clear from
Figure 5 that the recognition rates for all emotions were significantly better for the combination of the baseline and timbre selected acoustic feature sets compared to the recognition rates for the rest of the acoustic feature sets. The recognition rates for angry and happy emotions increased substantially for the timbre all acoustic feature set, but the changes in the results for neutral and sad emotions were not significant. Timbre features improved the discrimination of emotions that have the same level of pitch and loudness. Baseline acoustic features can discriminate emotions when the acoustic features of emotions in speech, such as pitch and loudness, are different. In
Table 6, comparison of the results in the literature with a proposed feature set was given for EMO-DB. From
Table 6, it can be seen that the proposed feature set increased recognition accuracy for both the discrete emotions classification and the binary valence classification.
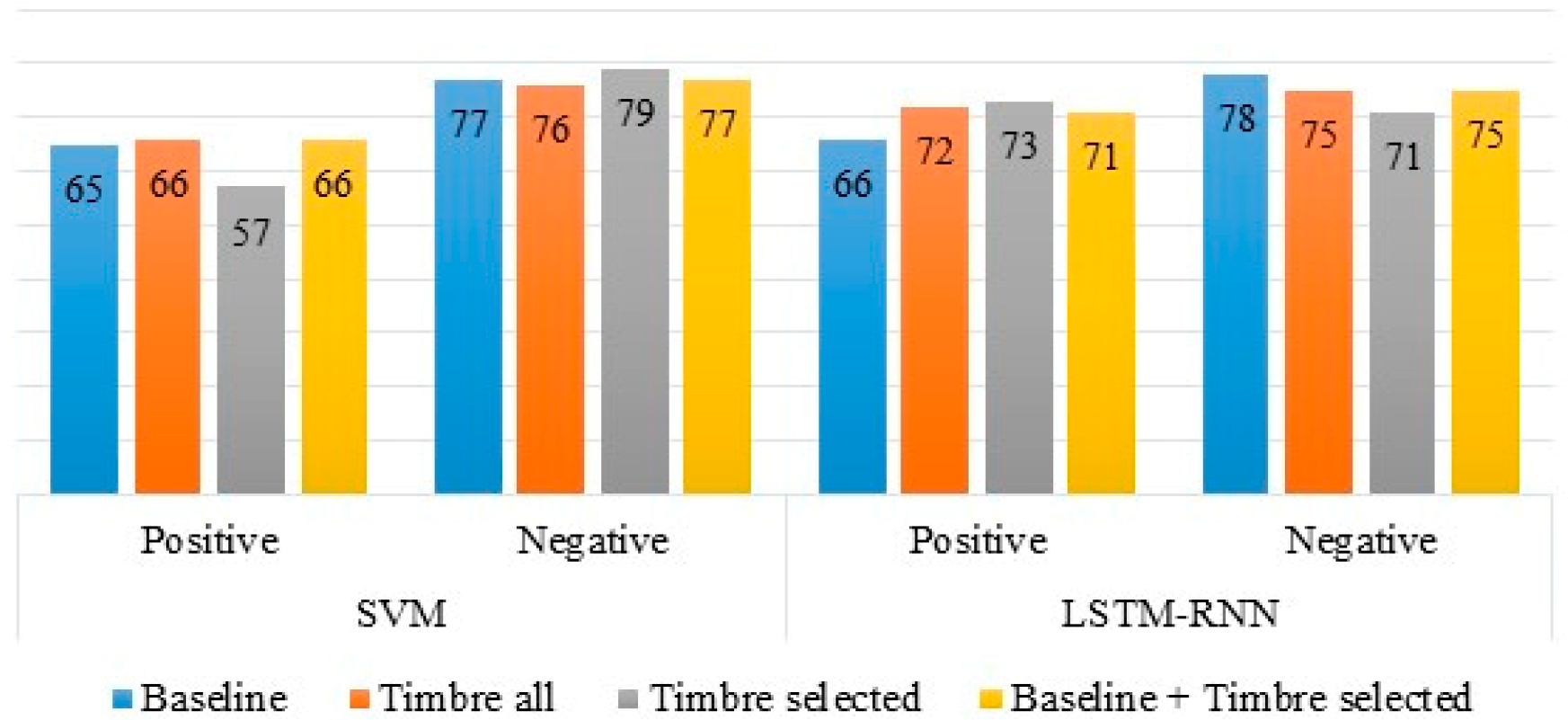
The results on IEMOCAP were different from EMO-DB. As can be seen from
Table 5, the highest recognition rates for binary valence classification (74%) and the classification of discrete emotions (65.06%) were achieved using the timbre all acoustic feature set. The results obtained using the timbre selected acoustic feature set were higher than the baseline feature set and close to the timbre all feature set. Although the recognition rates on a combination of the baseline and the timbre selected feature set were better than the baseline feature set, they were lower than the results on the timbre all feature set. The baseline and timbre selected feature sets complemented each other on the IEMOCAP database.
Figure 6 shows the recognition rates of positive and negative emotions achieved using the baseline, timbre all, timbre selected, and the combination of baseline and timbre selected feature sets for binary valence classification.
The highest recognition rate for positive emotion was obtained using the timbre all feature set increased the recognition rate of positive emotion, but it decreased for the timbre selected feature set when using SVM. The difference between recognition rates of negative emotion in all feature sets was not significant.
Figure 7 presents the recognition rates of anger, happiness, neutrality, and sadness obtained using all feature sets. It is clear from
Figure 7 that the timbre all feature set improved the recognition rate of all emotions except anger compared to the baseline feature set. In both classifiers, the recognition rate of emotions decreased with the timbre selected feature set compared to the timbre all feature set.
Table 7 shows the comparison of the results in literature with the proposed acoustic feature set for IEMOCAP. It is clear from
Table 7 that the accuracy obtained using the timbre all feature set is higher than the other results in the literature. Acoustic features used in the literature is given in
Table 8.
During the experiments that applied the SFS method, it was found that some of the spectral shapes (spectral skewness, kurtosis, slope, decrease, roll-off, flatness) and harmonic (harmonic energy, noise energy, harmonic spectral deviation, and odd-to-even harmonic ratio) features of timbre were all unable to characterize the emotions from speech as well as the features in the timbre that had been selected for the EMO-DB. In addition, the timbre selected consisted of only nine acoustic features, which was very useful in terms of dimensionality compared to a large-scale brute-force acoustic feature set for building an automatic SER system. Furthermore, it can characterize emotions in the valence dimension. For the EMO-DB, overall, the SVM and the LSTM-RNN gave good results for the combination of the baseline and timbre selected acoustic feature sets.
The timbre features also improved the recognition rates of emotions for the IEMOCAP. The improvement was not as high as for EMO-DB. The IEMOCAP database was originally designed to research emotion recognition from multiple modalities, including facial expressions, gesture, and speech. We only used speech to recognize the emotions, and this might not have been enough to achieve higher results for this database. However, the results are comparable to the literature results. We achieved higher results using the LSTM-RNN in terms of classifiers.
The experimental results in this work showed the effectiveness of the timbre features, which consisted of spectral and harmonic features. Timbre features can characterize emotions that share similar acoustic contents in the arousal dimension, but are different in the valence dimensions, such as anger and happiness. Moreover, we investigated whether timbre features can be used not only to discriminate instrument sounds, music emotion recognition [
17,
18], and music mood classification [
20], but also to classify emotions in a speech signals. Spectral shape and harmonic features complement each other to describe the voice quality of a sound. When we combined timbre selected and baseline acoustic features, the results improved significantly compared to the rest of the acoustic feature sets for EMO-DB. The difference between the results of timbre and the combination of the baseline and timbre selected acoustic feature sets was not high (around 3%) for IEMOCAP. Timbre selected and the baseline acoustic features complement each other for both databases.
6. Conclusions
The primary objective of this work was to analyze the timbral acoustic features to improve the classification accuracy of emotions in the valence dimension. To accomplish this, timbre acoustic features that consisted of spectral shape and harmonic features were extracted using a timbre toolbox [
30]. To find the best feature subset among the timbre acoustic features, the SFS was applied. MFCC, energy, and their first-order derivatives were also analyzed in order to compare the results. All acoustic features were divided into four groups, namely baseline (MFCC, energy and their first-order derivatives), timbre all, timbre selected and a combination of baseline and timbre selected acoustic features.
The classification was performed for binary valence and classification of categorical emotions using SVM and LSTM-RNN on the EMO-DB and IEMOCAP emotional speech databases. The average accuracy rates of 24.06% and 18.77% were improved for binary valence and discrete emotions as compared to the results using the baseline acoustic features for the EMO-DB. Although the improvement of the average classification rate for the IEMOCAP database was not high, the classification accuracy of happy and neutral emotions was improved considerably using timbre all acoustic features. The LSTM-RNN gave better results than SVM for the IEMOCAP.
In conclusion, timbre features showed their effectiveness in the classification of positive and negative emotions, as well as the classification accuracy of happy emotion improved considerably. For future work, timbre features should be analyzed for classification of fear and boredom emotions, which are also a challenge to discriminate. Moreover, timbre features need to be analyzed with other types of acoustic features to find an acoustic feature that complements timbre features.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}