Competition Among the World’s Main Technological Powers to Develop IPs: Cross-National Longitudinal Patentography Over a 9-Year Time Span



Abstract
1. Introduction
2. A Review of the Methods
2.1. The Initial Patent Analysis System Proposed by CHI Research
2.2. The Patent Indicator Framework Proposed by Ernst
2.3. The PCA Model
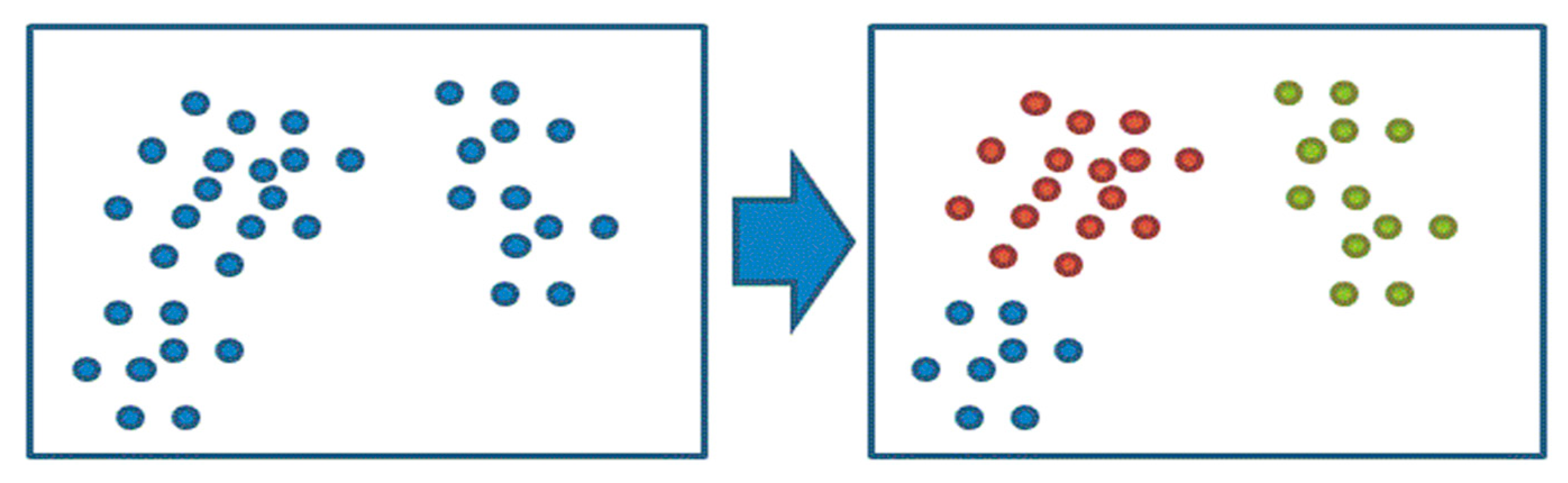
2.4. The K-means Technique
3. Results from Patent Data Mining across the Countries
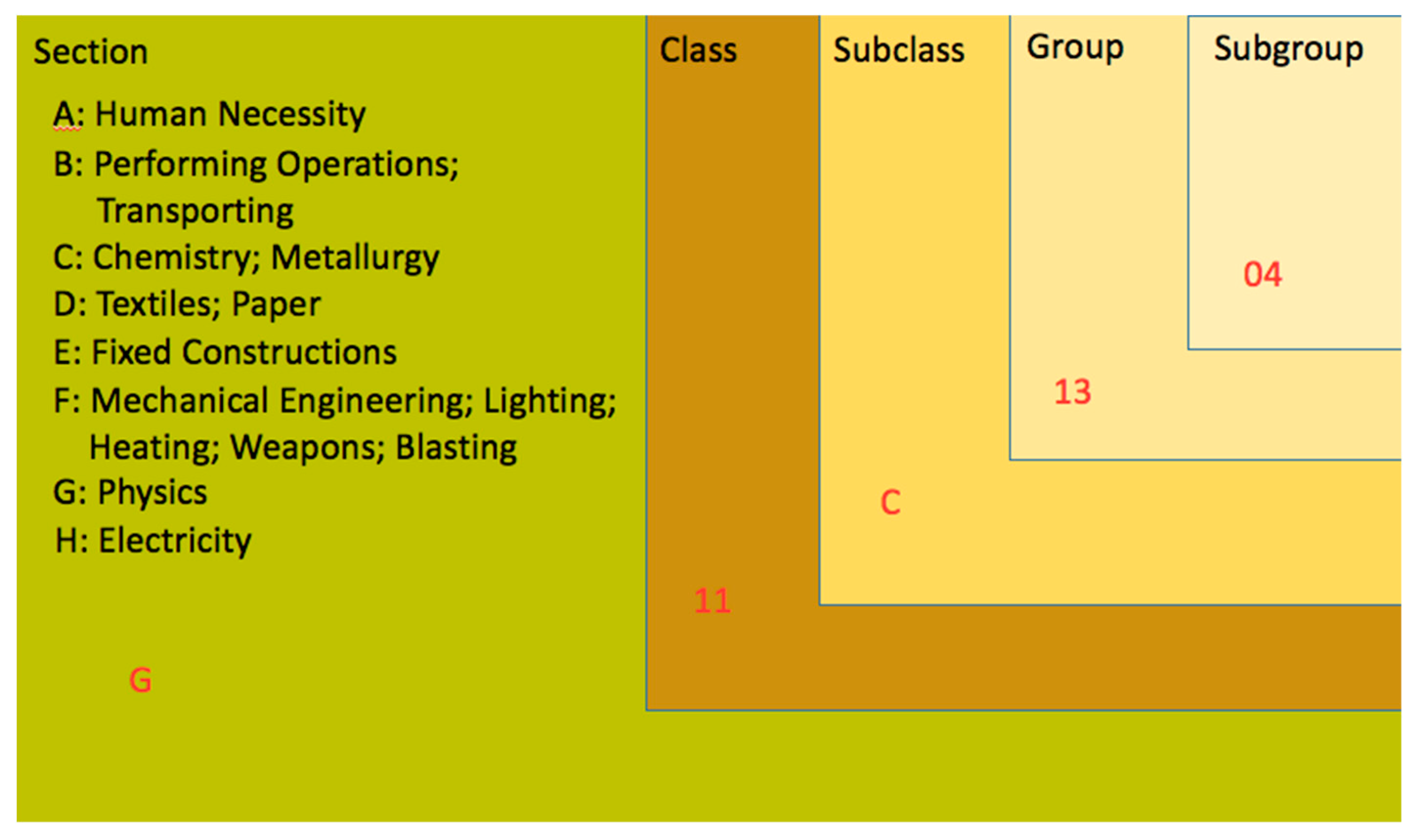
3.1. IPCs and the Patent Data Pre-processing: The Basis
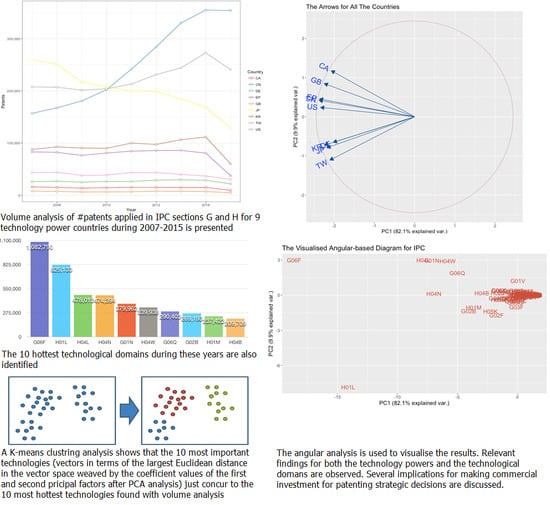
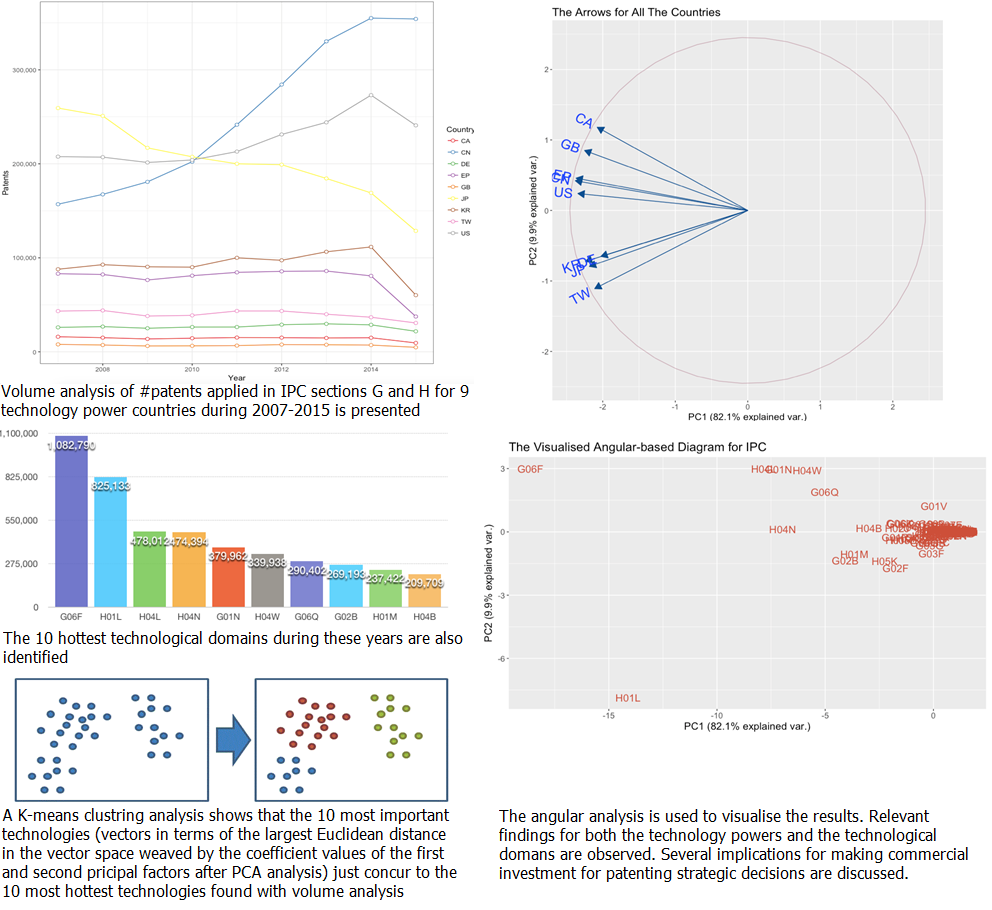
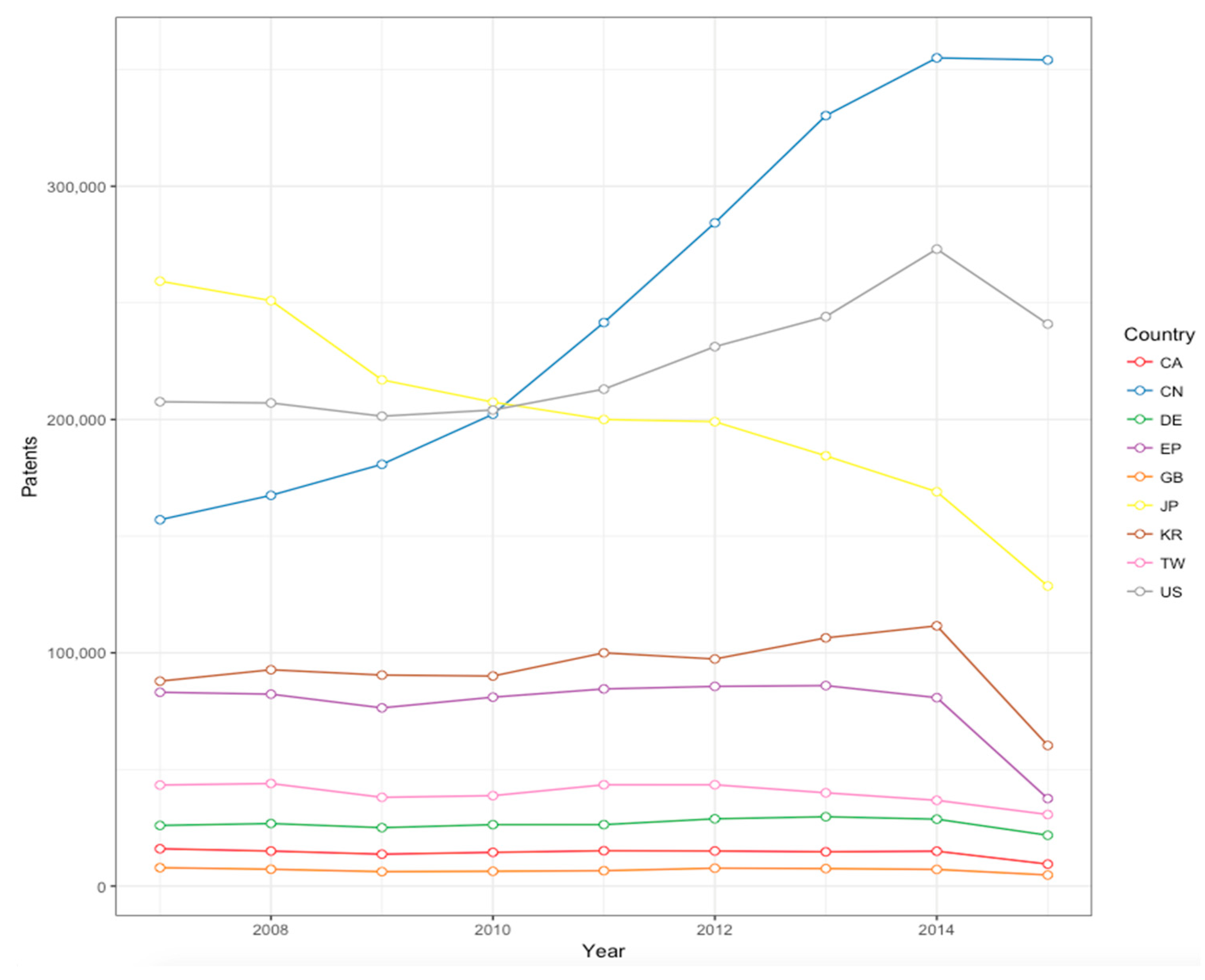
3.2. Patenting Activities in the Main ‘Technological Power’ Countries
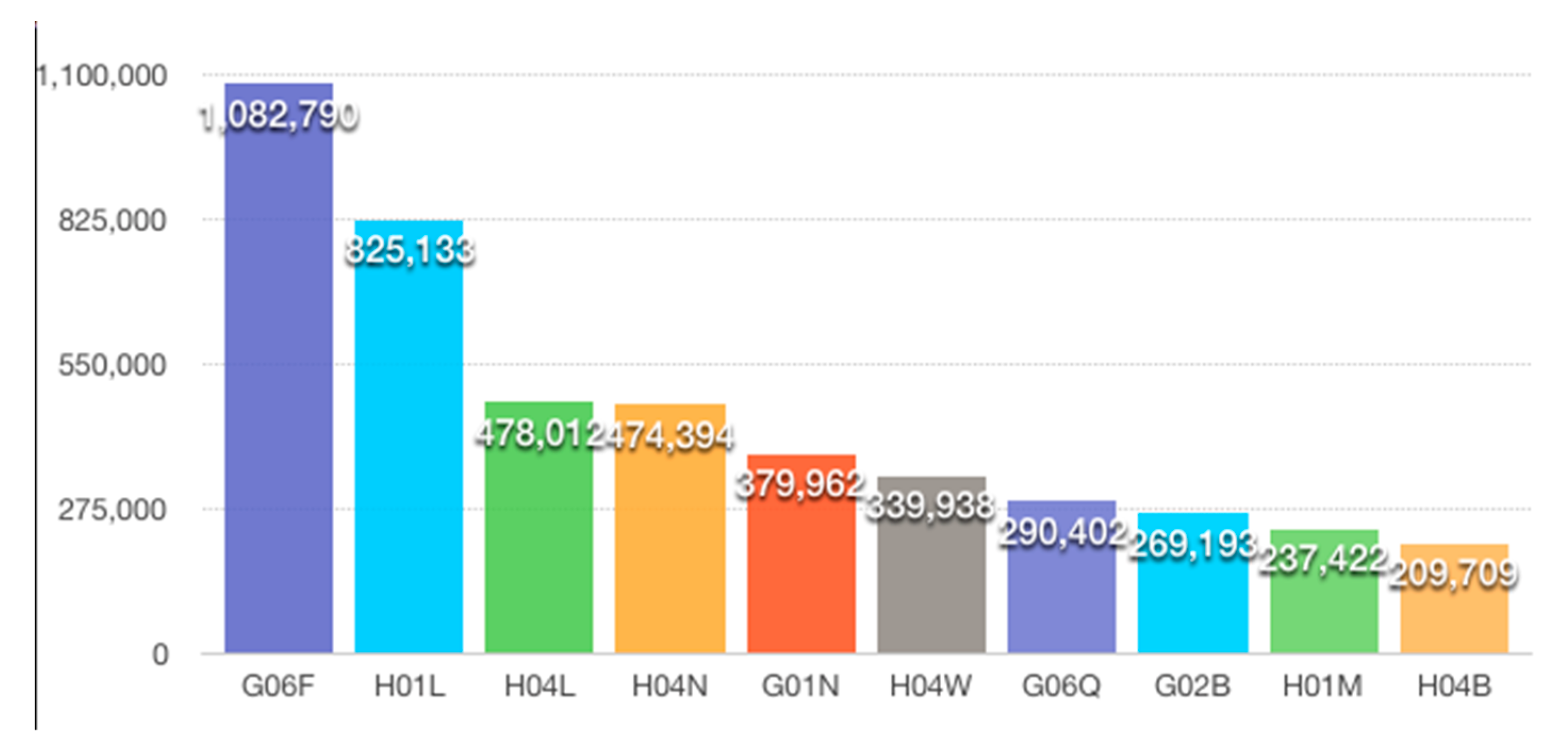
3.3. Hottest Technologies around the World
3.4. Total Correlation Matrix of the Patenting Activities among the Countries
- Among the correlational numbers that involve the STS of TWN, the highest one is 0.925, i.e., TWN’s STS correlates with KOR’s STS to a high degree. This not only implies that the markets for technological products in these two countries are almost identical, but also indicates that the patenting strategies of the high-tech companies are very similar in these two countries. Relatedly, many industrial analysts have claimed that “if North Korea launches a missile, the largest beneficiary would be TWN because it will receive an economy of scale due to the shifts in orders of technological products from KOR to TWN”. This claim is supported by the patent-based analysis here. This analysis provides evidence that the intrinsic structures of the technology industry are very similar in these two countries.
- The second highest correlation number for TWN (0.879) is between it and JPN. This is because a high volume of trade occurs between TWN and JPN, i.e., the high-tech industry in JPN submits a considerable amount of OEM (Original Equipment Manufacturing) orders to TWN for component-making. An extended observation from this point is that the correlation number for (JPN, CHN) is 0.796, which is lower than those for (JPN, KOR), (JPN, TWN), (JPN, USA) and (JPN, EU), despite the fact that CHN has increased its impact in recent years and become one of the most important markets. In other words, the relatively low number could thus be read as indicating either that the technological strengths of these two countries do not overlap so much or that Japan is relatively uninterested in the Chinese market (and/or vice versa), in spite of Japan and China being neighbouring countries. That said, the underlying reasons for the number are outside of the scope of this study.
- The third highest correlation number for TWN (0.818) is between it and the USA. A common situation is that companies in the USA also submit OEM orders to manufacturers in TWN, and many of these products are then shipped back to the America or shipped to other countries in Asia. Therefore, the wafer foundries in TWN have become the partners of the R&D companies in the USA, and this co-dependency has increased their technological correlation. With respect to what they have patented in the USA, the USA companies will try to protect their IPs in Taiwan before making an order. Of course, given that economic data indicates that TWN usually has a trade surplus with the USA, and that this is usually due to exports of technology products resulting from mutually beneficial partnerships, the observation of technological correlation between the two countries is common; however, it is worth noting, then, that this finding derived from the cross-national patent databases once again reflects the facts.
- Surprisingly, in terms of the STSs, the technological (and also the market) relevance between TWN and CHN is relatively low (0.757) and is only middle ranked (i.e., 5 of 8). This is because although TWN companies addressed the market in CHN, moved many factories over there and applied for a considerable number of patents in CHN during the study period, the opposite did not also occur. Setting aside the possible reasons for it, companies in CHN bypassed the market in TWN and applied for patents in other technological power countries which were deemed more important during the study period. In the table, the (CHN, TWN) pair is ranked the lowest (8 of 8) among all of the (CHN, *) correlation pairs.
- Finally, the correlation between the technology industries of CAN and TWN is very low at only 0.495. This is the smallest number in the entire table. The reason for this observation is presumably that the two countries are the least populated countries in the list of technological powers (i.e., there are 37.281 and 23.589 million people in CAN and TWN, respectively). Given the resulting smaller sizes of their domestic markets, patent applications are only necessary when there is technological conflict between companies from the two countries.
4. Further Analysis with Discussions and Implications
4.1. The Principal Factors Affecting High-tech Companies’ Global Patenting Strategies
4.2. Angular Analysis and the Inferences of Fact
4.2.1. Classifying the Technological Powers with the Angular Analysis Method
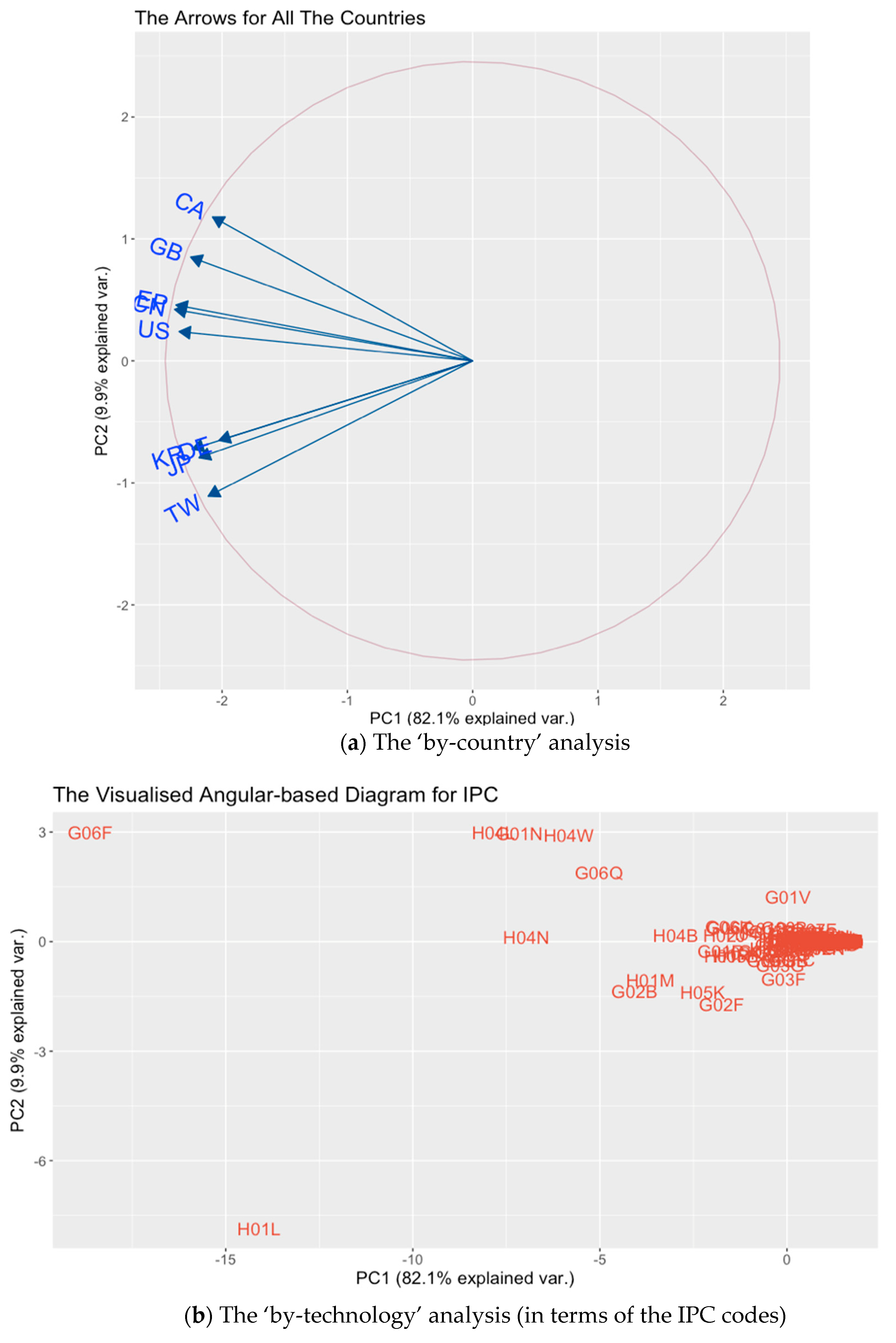
- Two groups of technological powers are classified naturally. The destinations of the arrows for the USA, CHN, EU, GBR and CAN fall in quadrant II, while those for GER, JPN, TWN and KOR fall in quadrant III. As such, these countries are roughly classified into two distinct groups due to the divergence in the STS in each country.
- The high-tech industries and markets in Japan and Germany are very similar. Based on the direction in which the arrows are pointing, it can be concluded that the industries and markets in JPN and GER are very similar (correlated): “There are well-known similarities between Japan and Germany - they are both manufacturers of exports which are in demand across the world, they have excellent engineering skills and leadership in manufacturing and craftsmanship” [30]. This is indeed a surprising finding. According to statements made by experienced patent attorneys and historians who are familiar with the world’s industrial history, this is perhaps because these two countries are the two leading experts in the field of precision machinery, e.g., in the machine tool and automobile industries. In addition, the collaborations between them is quite strong, so technology company patenting strategies in these two countries are extremely correlated with each other.
- Germany plays a special role in Europe. Another surprising fact is that GER and the EU are located in different quadrants (i.e., they are classified into two different groups). This implies that the market and industrial properties of GER are totally isolated from the rest of the EU. So, many overseas technology companies would thus be interested in applying for patents in GER in order to protect their IP directly there, rather than in applying for patents first via the EU’s official patent office and then claiming their IP rights in GER later (an approach which would be more time-consuming).
4.2.2. Results from Using Angular Similarity as the Classification Basis
4.2.3. Analysing the Technological Domains Addressed by the Technological Powers
- The market or industry in the USA addresses technologies related to communications and software. In Figure 7b, the arrow for the USA points to many IPC codes, including H04N (pictorial communication, e.g., TV or smartphone screens), H04B (transmission technologies, e.g., wireless transceivers), H02J (circuit arrangements or systems for supplying or distributing electric power; systems for Storing Electric Energy, e.g., batteries) and G06F (electrical digital data processing and peripherals, e.g., CPUs). This implies that the market or industry in the USA is biased toward communications and software technologies, and that the USA is the battleground for products in these areas.
- The markets or industries in CHN and the EU are similar, and they differ from the USA from the subclass level. In the figure, it can also be observed that for the other countries in group (i), the arrows of CHN and the EU almost overlap. This implies that the technological markets or industrial properties in these two economies are almost identical. In addition to this, the IPC codes being pointed to by these two arrows are as follows: G06K (recognition/presentation of data; record carriers; handling record carriers, e.g., OCR devices), G06T (image data processing or generation, in general, e.g., computer graphics) and H04M (telephonic communications, e.g., switches or PBX). So, as can be seen, although the three countries in group (i) all exhibit a general interest in the G06 and the H04 classes, their real interests are varied because the subclasses that are focused on are different. In other words, within group (i), in general, the main interests of the technology industries vary at the subclass level.
- Technologies pertaining to smartphone design are the main focus. If the above two findings for the group (i) countries are combined to state something other than their differences, it reflects the remarkable technological developments for smartphones during the study period. Over that time span, these countries have, coincidentally, targeted the technologies making up the market for ‘touchable mobile device with panels’, which is, in other words, the smartphone market.
- Industries and markets for countries in group (ii) are more homogeneous, but JPN and KOR address more areas in similar fields. JPN, GER and KOR form group (ii). Unlike in group (i), in which the arrows of the EU and CHN overlap but that of the USA is somewhat farther away, the vectors of JPN, GER and KOR all almost overlap with each other in Figure 7b. This not only indicates the homogeneity of the market/industrial properties among them, but also facilitates the ‘by-IPC analysis’, because they point in an almost uniform direction. After identifying the subclasses along with the directions of these three arrows, it can be seen that the main technologies in these countries include those in the following categories: G01R (measuring electric variables; measuring magnetic variables, e.g., filters), G02B (optical elements, systems, or apparatuses, e.g., fibres), H01L (semiconductor devices; electric solid state devices not otherwise specified, e.g., LEDs), H01M (processes or means for the direct conversion of chemical into electrical energy, e.g., fuel cells), H02K (dynamo-electric machines, e.g., clutches) and H05B (electric heating; electric lighting not otherwise specified, e.g., electric heating elements). These IPCs reveal the background business logics of the high-tech industries in these countries. Without exception, all of them address the manufacturing and testing technologies for semiconductors as well as those for large dynamo-electric (motor) units. However, as both JPN and KOR have larger variances than GER (see the magnitudes instead of the directions of the arrows), it is reasonable to assume that they are focused on a larger number of other fields at the subclass level for, e.g., the optical, semiconductor and motor technologies.
- Analysing the industrial properties for the countries in group (iii): using TWN as an example. For the rest of the countries in group (iii), as discussed previously, their high-tech industrial interests are quite diversified. As an example, the market and industry in TWN are studied. For this analytical purpose, some main IPC codes can also be identified along with the direction of the arrow for TWN. These main IPC codes include the following: H05K (printed circuits; casings or construction details of electric apparatuses; manufacture of assemblages of electrical components, e.g., mother boards), G02F (devices or arrangements, the optical operation of which is modified by changing the optical properties of the medium of the devices or arrangements for the control of the intensity, color, phase, polarization or direction of light, e.g., optical logic elements or LCD manufacturing) and H01L (as stated previously). In other words, TWN addresses its technological niches in some hardware manufacturing fields and the manufacturing processes of, e.g., PCB, optical elements and semiconductors. This observation also applies to the other two countries in this outlier group (i.e., CAN and GBR).
4.3. The Most Important Technologies and the Associated Implications
- The most important (influencing) technologies are identified. As can be imagined, the farther a point is from the origin, the more important the technology should be (this is again indicated by the magnitude of the vector). So, the top 10 ‘most important technologies’ during the study period, at the ‘subclass’ level, are (ranked by vector length): G06F, H01L, H04L, H04N, G01N, H04W, G06Q, G02B, G06Q, H01M and H04B. As a supplementary material, the coordinate and the magnitude (Euclidean distance toward the origin) of the vectors of all IPCs are also listed and ranked in Table 3, while the abovementioned most important technologies are highlighted.
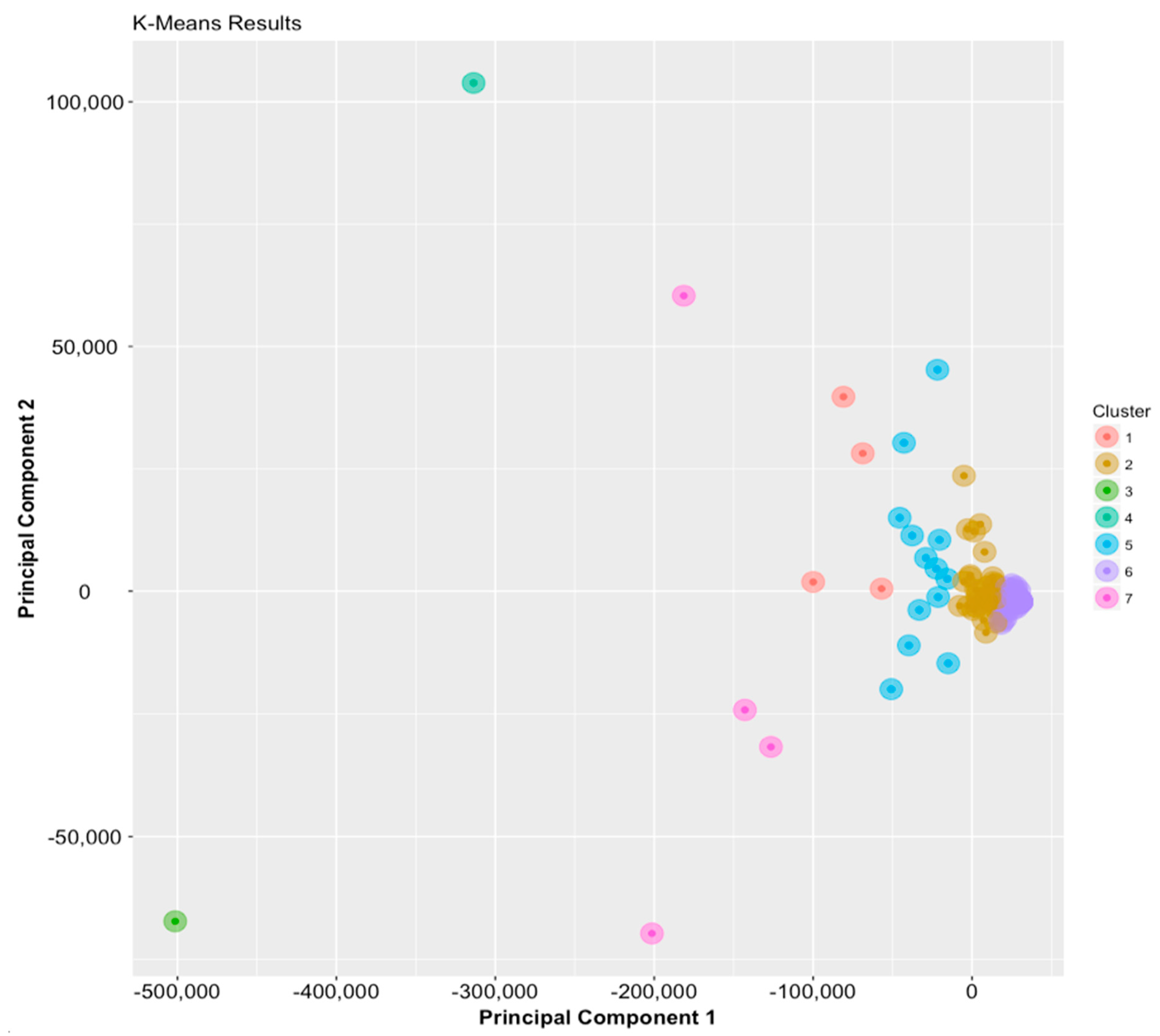
- The set of most important technologies identified above is identical to the set of most popular (hottest) technologies, when the top 10 in either case are considered. When the order in the ‘most important technologies list’ above is ignored, it becomes a set of elements, i.e., the ‘most important technologies set’ (see the highlighted entries for the domains in Table 3). As the patterns in Table 4 are extensively analysed (and also mapped to Figure 8), these 10 technologies fall in (and perfectly match) the four clusters (i.e., CID = 1, 3, 4 and 7) that not only have the centres that are the farthest from the origin O (see the ‘Dist. to O’ column in Table 4; 505,921 for CID = 3, 330,414 for CID = 4, 163,899 for CID = 4 and 78,659 for CID = 7) but also the highest average within-group variances for the IPC codes (i.e., 51468.61 for CID = 7 and 22483.96 for CID=1, except that 0 was observed for both CID = 3 and CID = 4 since for these clusters, each contains only one technological domain). These observations of the patterns rendered by the four clusters (which consists of a few very diversified points and at the same time are very far away from the origin) may help ascertain the importance of the 10 technologies in the set. Going back to Figure 6 in Section 3.3, the ‘hottest technologies list’ also implies another ‘hottest technologies set’ regardless of the rank order. Comparing these two non-ordered sets, it is found that the ‘most important technologies set’ obtained by the K-means machine learning technique is exactly identical to the ‘hottest technologies set’ identified before by the descriptive statistical method. This is perhaps the most surprising finding of this study, and one which leads to further implications.
- The popularity of a technology may connote its importance, and vice versa. From the fact that “in patent databases, those hottest technologies are also the most important technologies”, it can be concluded that “a technology’s importance can be roughly estimated based on its popularity because they are strongly correlated” and that “a technology’s volume of patents, when observed from the patent databases, may indicate the importance of this technology”. In other words, through this analysis, the longstanding missing link between importance and popularity (of a technology) is established and supported.
- The ten hottest and most important technologies are, in fact, closely related to our daily lives. These technologies cover several areas that are generally relevant to our daily lives nowadays, i.e., wireless communications and networking, digital image transmission, cellular battery modules, optical lenses and fin-tech products (including data-driven decision models). The angular-based analysis in Section 4.2 also reflects the following conclusion: these areas concur with the main areas addressed by the countries in group (i) (i.e., the USA, EUR and CHN). In the PCA model established in 4.1, the estimated loading factors indicated that the USA, EUR and CHN are the most influential technological powers around the world. The set of the ten hottest and most important technological fields are exactly the IPC subclasses that these economies emphasised during the study period and in which they have applied for a considerable number of patents (indicating that the popularity of these subclasses increased).
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
Appendix B
Appendix C
Appendix D
Appendix E
References
- Kucharavy, D.; De Guio, R. Application of S-shaped curves. Procedia Eng. 2011, 9, 559–572. [Google Scholar] [CrossRef]
- Forster, R.N. Assessing technological threats. Res. Manag. 1986, 29, 17–20. [Google Scholar]
- Breitzman, A.F.; Narin, F. Method and apparatus for choosing a stock portfolio, based on patent indicators. U.S. Patent 6,175,824, 16 January 2001. [Google Scholar]
- Thomas, P.; Narin, F. System and method for producing technology-based price targets for a company stock. U.S. Patent 6,832,211, 14 December 2004. [Google Scholar]
- Lin, H.-Y. A Model and Platform for Patent Search/Valuation. Master’s Thesis, Department of Industrial Engineering and Engineering Management, National Tsing-Hua University, Hsinchu City, Taiwan, 2005. [Google Scholar]
- Narin, F.; Albert, M.; Kroll, P.; Hicks, D. Inventing Our Future—The Link between Australian Patenting and basic Science; CHI Report; Australian Government: Canberra, ACT, Australia, 2000.
- Ernst, H. Patent portfolios for strategic R&D planning. J. Eng. Technol. Manag. 1998, 15, 279–308. [Google Scholar]
- Ernst, H. Patent information for strategic technology management. World Pat. Inf. 2003, 25, 233–242. [Google Scholar] [CrossRef]
- Allison, J.R.; Lemley, M.A.; Moore, K.A.; Trunkey, R.D. Valuable Patents. Georget. Law. J. 2003, 92, 435. [Google Scholar] [CrossRef]
- Pearson, K. On lines and planes of closest fit to systems of points in space. Philos. Mag. 1901, 2, 559–572. [Google Scholar] [CrossRef]
- Hotelling, H. Analysis of a complex of statistical variables into principal components. J. Educ. Psychol. 1933, 24, 417–441. [Google Scholar] [CrossRef]
- Zhuang, Z.Y.; Ouhyoung, M. Novel multiresolution metrics for content-based image retrieval. In Proceedings of the Pacific Conference on Computer Graphics and Applications, In pg (Pacific Graphics), Seoul, KOREA, 13–16 October 1997; IEEE: Piscataway, NJ, USA, 1997; p. 105. [Google Scholar]
- Ho, N.; Jarvis, R. Vision based global localisation using a 3D environmental model created by a laser range scanner. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2008, Nice, France, 22–26 September 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 2964–2969. [Google Scholar]
- Lee, S.; Yoon, B.; Park, Y. An approach to discovering new technology opportunities: Keyword-based patent map approach. Technovation 2009, 29, 481–497. [Google Scholar] [CrossRef]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A k-means clustering algorithm. J. R. Stat. Soc. Ser. C (Appl. Stat.) 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Celebi, M.E.; Kingravi, H.A.; Vela, P.A. A comparative study of efficient initialization methods for the k-means clustering algorithm. Expert Syst. Appl. 2013, 40, 200–210. [Google Scholar] [CrossRef]
- Injadat, M.; Salo, F.; Nassif, A.B. Data mining techniques in social media: A survey. Neurocomputing 2016, 214, 654–670. [Google Scholar] [CrossRef]
- Kim, G.J.; Park, S.S.; Jang, D.S. Technology forecasting using topic-based patent analysis. J. Sci. Ind. Res. 2015, 74, 265–270. [Google Scholar]
- Oliveira, G.V.; Coutinho, F.P.; Campello, R.J.; Naldi, M.C. Improving k-means through distributed scalable metaheuristics. Neurocomputing 2017, 246, 45–57. [Google Scholar] [CrossRef]
- Raschka, S. Python Machine Learning; Packt Publishing Ltd.: Birmingham, UK, 2015. [Google Scholar]
- Kassambara, A. Practical Guide to Cluster Analysis in R; CreateSpace: North Charleston, SC, USA, 2017. [Google Scholar]
- World Intellectual Property Organization. International Patent Classification. Available online: http://www.wipo.int/classifications/ipc/en/ (accessed on 4 November 2017).
- Wittstruck, D.; Teuteberg, F. Understanding the success factors of sustainable supply chain management: empirical evidence from the electrics and electronics industry. Corp. Soc. Responsib. Environ. Manag. 2012, 19, 141–158. [Google Scholar] [CrossRef]
- Merritt, R. Smartphone, Samsung in Trouble. 2016. Available online: https://www.eetimes.com/author.asp?section_id=36&doc_id=1325927 (accessed on 16 December 2017).
- Kim, W.C.; Mauborgne, R. Blue Ocean Strategy: How to Create Uncontested Market Space and Make the Competition Irrelevant; Harvard Business School Press: Boston, MA, USA, 2004. [Google Scholar]
- Chi, L.-P.; Zhuang, Z.-Y.; Fu, C.-H.; Huang, J.-H. A Knowledge Discovery Education Framework Targeting the Effective Budget Use and Opinion Explorations in Designing Specific High Cost Product. Sustainability 2018, 10, 2742. [Google Scholar] [CrossRef]
- Zhuang, Z.-Y.; Lin, C.-C.; Chen, C.-Y.; Su, C.-R. Rank-Based Comparative Research Flow Benchmarking the Effectiveness of AHP–GTMA on Aiding Decisions of Shredder Selection by Reference to AHP–TOPSIS. Appl. Sci. 2018, 8, 1974. [Google Scholar] [CrossRef]
- Husson, F.; Lê, S.; Pagès, J. Exploratory Multivariate Analysis by Example Using R; Chapman and Hall/CRC: Boca Raton, FL, USA, 2017; pp. 11–51. [Google Scholar]
- Everitt, B.; Hothorn, T. An Introduction to Applied Multivariate Analysis with R; Springer Science & Business Media: Berlin, Germany, 2011; pp. 71–72. [Google Scholar]
- Rudlin, P.; 4 Differences between Japanese and German Approaches to Work, Communication and Customer Service. Official Website of Japan Intercultural Consulting. 2014. Available online: https://www.japanintercultural.com/en/blogs/default.aspx?blogid=240 (accessed on 6 May 2018).
- Bai, C.; Sarkis, J. Integrating sustainability into supplier selection: A grey-based TOPSIS analysis. Technol. Econ. Dev. Econ. 2018, 24, 2202–2224. [Google Scholar] [CrossRef]
- Ignatius, J.; Tan, T.S.; Dhamotharan, L.; Goh, M. Deregulation control by mergers and acquisitions: A game theoretic analysis of the Chinese airline industry. Technol. Econ. Dev. Econ. 2018, 24, 2277–2294. [Google Scholar] [CrossRef]
- Gunduz, M.; Yahya, A.M.A. Analysis of project success factors in construction industry. Technol. Econ. Dev. Econ. 2018, 24, 67–80. [Google Scholar] [CrossRef]
- Zhuang, Z.-Y.; Su, C.-R.; Chang, S.-C. The effectiveness of IF-MADM (intuitionistic-fuzzy multi-attribute decision-making) for group decisions: Methods and an empirical assessment for the selection of a senior centre. Technol. Econ. Dev. Econ. 2019, 25, 322–364. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indicator | Definition | Meaning |
|---|---|---|
| Patent Activity | The number of patent applications | The level of R&D activities |
| Share of Granted Patents | Granted patents/patent activity | Higher technological capacity |
| Technological Scope | Diversity and number of IPC classes a | Technological quality of patent applications |
| International Scope | Size of patent family and share of triad (US, JP and EPO) patents of patent activities | Economic quality of patent applications |
| Technology Share | The ratio of patent activity to patent applications of all competitors in technological field | Competitive technological position in technological field |
| Relative Technology Share | Patent strength/maximum patent strength in technological field | Distance of firm i from the technological leader in technological field |
| Citation Ratio | The number of patent citations against the number of patent applications | The number of citations received by a patent in subsequent patent documents can also be viewed as a sign for an economically important invention |
| Patent Growth Rate | Average growth of patent applications per technological field/average growth of patent applications in all technological fields | Measures the average growth of patent applications in a technological field relative to the average growth of total patent applications |
| Country vs. Country a | CAN | CHN | GER | EU | GBR | JPN | KOR | TWN | USA |
|---|---|---|---|---|---|---|---|---|---|
| CAN | 1.000 | 0.892 | 0.607 | 0.900 | 0.921 | 0.602 | 0.651 | 0.495 | 0.812 |
| CHN | 0.892 | 1.000 | 0.778 | 0.981 | 0.934 | 0.796 | 0.814 | 0.757 | 0.939 |
| GER | 0.607 | 0.778 | 1.000 | 0.750 | 0.636 | 0.775 | 0.765 | 0.770 | 0.683 |
| EU | 0.900 | 0.981 | 0.750 | 1.000 | 0.932 | 0.801 | 0.825 | 0.737 | 0.924 |
| GBR | 0.921 | 0.934 | 0.636 | 0.932 | 1.000 | 0.711 | 0.732 | 0.646 | 0.940 |
| JPN | 0.602 | 0.796 | 0.775 | 0.801 | 0.711 | 1.000 | 0.895 | 0.879 | 0.810 |
| KOR | 0.651 | 0.814 | 0.765 | 0.825 | 0.732 | 0.895 | 1.000 | 0.925 | 0.839 |
| TWN | 0.495 | 0.757 | 0.770 | 0.737 | 0.646 | 0.879 | 0.925 | 1.000 | 0.818 |
| USA | 0.812 | 0.939 | 0.683 | 0.924 | 0.940 | 0.810 | 0.839 | 0.818 | 1.000 |
| IPC | X | Y | Magnitude | Rank | CID | IPC | X | Y | Magnitude | Rank | CID | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| G01B | ( | −7739.54249 | , | −2990.0055 | ) | 8297.026633 | 117 | 2 | G10H | ( | 27655.8573 | , | −587.916233 | ) | 27662.10561 | 61 | 6 |
| G01C | ( | −1329.38785 | , | 2868.29038 | ) | 3161.386051 | 127 | 2 | G10K | ( | 25965.5279 | , | 659.5932016 | ) | 25973.9043 | 70 | 6 |
| G01D | ( | 15437.23071 | , | −1385.6492 | ) | 15499.29404 | 101 | 2 | G10L | ( | 11396.9956 | , | −1763.38027 | ) | 11532.60674 | 110 | 2 |
| G01F | ( | 16599.97106 | , | −3330.2129 | ) | 16930.72228 | 95 | 2 | G11B | ( | −2718.9937 | , | 12657.45776 | ) | 12946.20267 | 107 | 2 |
| G01G | ( | 25998.48537 | , | −2635.8023 | ) | 26131.75645 | 69 | 6 | G11C | ( | −2496.9105 | , | −3048.66589 | ) | 3940.675811 | 122 | 2 |
| G01H | ( | 27305.67738 | , | −2518.2019 | ) | 27421.54915 | 64 | 6 | G12B | ( | 30075.1376 | , | −2430.79408 | ) | 30173.21094 | 39 | 6 |
| G01J | ( | 15634.0645 | , | −3716.5686 | ) | 16069.74969 | 97 | 2 | G21B | ( | 30670.9816 | , | −2242.13112 | ) | 30752.82532 | 30 | 6 |
| G01K | ( | 20725.58222 | , | −3920.1657 | ) | 21093.06657 | 87 | 6 | G21C | ( | 26149.9783 | , | −451.100656 | ) | 26153.8689 | 68 | 6 |
| G01L | ( | 15842.32504 | , | −2556.2687 | ) | 16047.23566 | 98 | 2 | G21D | ( | 30183.0829 | , | −1602.49796 | ) | 30225.59331 | 37 | 6 |
| G01M | ( | 7216.719486 | , | −5916.9472 | ) | 9332.272166 | 116 | 2 | G21F | ( | 27961.3409 | , | 19.06400515 | ) | 27961.34738 | 58 | 6 |
| G01N | ( | -142953.398 | , | -24215.979 | ) | 144989.9572 | 5 | 7 | G21G | ( | 30504.227 | , | −2259.45869 | ) | 30587.792 | 33 | 6 |
| G01P | ( | 22347.27428 | , | −1413.0689 | ) | 22391.90549 | 82 | 6 | G21H | ( | 30908.8917 | , | −2227.95374 | ) | 30989.08454 | 26 | 6 |
| G01R | ( | −39770.4633 | , | −11076.975 | ) | 41284.2478 | 15 | 5 | G21J | ( | 31065.8187 | , | −2193.79868 | ) | 31143.18296 | 19 | 6 |
| G01S | ( | 845.8445049 | , | −3838.6185 | ) | 3930.705426 | 123 | 2 | G21K | ( | 28106.4215 | , | −2034.36734 | ) | 28179.94992 | 56 | 6 |
| G01T | ( | 23754.57091 | , | −176.0965 | ) | 23755.22361 | 77 | 6 | H01B | ( | −1109.918 | , | 3266.971376 | ) | 3450.365188 | 126 | 2 |
| G01V | ( | 17561.41426 | , | −6018.3175 | ) | 18564.03556 | 94 | 6 | H01C | ( | 27703.4148 | , | −1911.98168 | ) | 27769.31515 | 60 | 6 |
| G01W | ( | 29451.13564 | , | −2092.9604 | ) | 29525.41065 | 48 | 6 | H01F | ( | 2603.68973 | , | 279.855573 | ) | 2618.686566 | 128 | 2 |
| G02B | ( | -80948.5454 | , | 39723.398 | ) | 90169.92489 | 8 | 1 | H01G | ( | 13015.1155 | , | 2843.146727 | ) | 13322.03869 | 106 | 2 |
| G02C | ( | 24583.91924 | , | −1604.1999 | ) | 24636.2039 | 74 | 6 | H01H | ( | 3396.75559 | , | −1382.2747 | ) | 3667.237639 | 125 | 2 |
| G02F | ( | −42838.6842 | , | 30314.3612 | ) | 52479.64707 | 12 | 5 | H01J | ( | 3896.68445 | , | −159.214022 | ) | 3899.935743 | 124 | 2 |
| G03B | ( | −5103.82769 | , | 23594.534 | ) | 24140.23798 | 76 | 2 | H01K | ( | 30238.2249 | , | −2271.73426 | ) | 30323.4401 | 36 | 6 |
| G03C | ( | 30059.34145 | , | −2309.5555 | ) | 30147.93617 | 40 | 6 | H01L | ( | -313673.11 | , | 103838.8805 | ) | 330413.8816 | 2 | 4 |
| G03D | ( | 30951.59551 | , | −2197.8116 | ) | 31029.52852 | 25 | 6 | H01M | ( | -68784.185 | , | 28167.24428 | ) | 74328.04118 | 9 | 1 |
| G03F | ( | 1316.855449 | , | 12186.4598 | ) | 12257.40228 | 108 | 2 | H01P | ( | 23203.034 | , | −2615.67061 | ) | 23350.00037 | 78 | 6 |
| G03G | ( | −21771.1333 | , | 45247.0651 | ) | 50212.34059 | 13 | 5 | H01Q | ( | 5988.77812 | , | −2998.48249 | ) | 6697.489126 | 118 | 2 |
| G03H | ( | 28890.25315 | , | −1338.5879 | ) | 28921.24729 | 52 | 6 | H01R | ( | −21337.623 | , | −1185.65121 | ) | 21370.53891 | 85 | 5 |
| G04B | ( | 27321.28884 | , | −2155.2885 | ) | 27406.16888 | 65 | 6 | H01S | ( | 14456.6571 | , | 1431.728887 | ) | 14527.38046 | 103 | 2 |
| G04C | ( | 29854.03698 | , | −1650.9209 | ) | 29899.6499 | 42 | 6 | H01T | ( | 27952.3944 | , | −1107.39024 | ) | 27974.32157 | 57 | 6 |
| G04F | ( | 30279.31421 | , | −2218.722 | ) | 30360.49401 | 34 | 6 | H02B | ( | 22552.7739 | , | −4013.51932 | ) | 22907.11568 | 81 | 6 |
| G04G | ( | 28699.14613 | , | −1290.8128 | ) | 28728.16016 | 53 | 6 | H02G | ( | 14084.7727 | , | 1053.909753 | ) | 14124.14769 | 104 | 2 |
| G04R | ( | 30519.86049 | , | −2181.7256 | ) | 30597.74192 | 32 | 6 | H02H | ( | 14847.1336 | , | −6422.81194 | ) | 16176.83183 | 96 | 2 |
| G05B | ( | −14983.9822 | , | −14732.006 | ) | 21013.13245 | 88 | 5 | H02J | ( | −33190.604 | , | −3833.12746 | ) | 33411.21123 | 17 | 5 |
| G05D | ( | 8775.493132 | , | −8464.6522 | ) | 12192.60497 | 109 | 2 | H02K | ( | −15602.097 | , | 2510.887033 | ) | 15802.84686 | 99 | 5 |
| G05F | ( | 19939.99616 | , | −3849.2202 | ) | 20308.12506 | 91 | 6 | H02M | ( | −5010.0528 | , | 1986.169001 | ) | 5389.387361 | 119 | 2 |
| G05G | ( | 28611.20497 | , | −1747.9788 | ) | 28664.55093 | 54 | 6 | H02N | ( | 21092.2218 | , | −1461.87299 | ) | 21142.82134 | 86 | 6 |
| G06C | ( | 30976.91704 | , | −2212.0533 | ) | 31055.79767 | 23 | 6 | H02P | ( | 9742.49238 | , | 934.3646014 | ) | 9787.195459 | 114 | 2 |
| G06D | ( | 31066.92244 | , | −2194.2993 | ) | 31144.31922 | 18 | 6 | H02S | ( | 25492.8284 | , | −3810.22962 | ) | 25775.99949 | 71 | 6 |
| G06E | ( | 30995.94442 | , | −2220.3759 | ) | 31075.3703 | 22 | 6 | H03B | ( | 27477.4262 | , | −797.302724 | ) | 27488.99133 | 63 | 6 |
| G06F | ( | -501431.002 | , | -67253.564 | ) | 505921.0332 | 1 | 3 | H03C | ( | 30730.0124 | , | −2220.73809 | ) | 30810.14995 | 29 | 6 |
| G06G | ( | 28351.70914 | , | −3296.0209 | ) | 28542.65518 | 55 | 6 | H03D | ( | 29646.9243 | , | −2314.25207 | ) | 29737.11288 | 46 | 6 |
| G06J | ( | 31057.26691 | , | −2196.731 | ) | 31134.85916 | 20 | 6 | H03F | ( | 20536.6451 | , | −1522.00491 | ) | 20592.96705 | 89 | 6 |
| G06K | ( | −50830.7843 | , | −20024.291 | ) | 54632.78193 | 11 | 5 | H03G | ( | 26913.6299 | , | −1807.49597 | ) | 26974.25659 | 66 | 6 |
| G06M | ( | 30119.74722 | , | −2198.19 | ) | 30199.8545 | 38 | 6 | H03H | ( | 21805.3697 | , | 739.1366687 | ) | 21817.89337 | 83 | 6 |
| G06N | ( | 19653.48715 | , | −6106.7052 | ) | 20580.36456 | 90 | 6 | H03J | ( | 29704.2662 | , | −1596.50929 | ) | 29747.13885 | 45 | 6 |
| G06Q | ( | -99988.7346 | , | 1882.52409 | ) | 100006.4545 | 7 | 1 | H03K | ( | 9430.22879 | , | −2250.98438 | ) | 9695.160945 | 115 | 2 |
| G06T | ( | −37689.9297 | , | 11381.8023 | ) | 39371.00743 | 16 | 5 | H03L | ( | 24158.6062 | , | −3020.41433 | ) | 24346.68677 | 75 | 6 |
| G07B | ( | 27895.48698 | , | −1232.4205 | ) | 27922.69783 | 59 | 6 | H03M | ( | 15447.5895 | , | −1489.45239 | ) | 15519.22963 | 100 | 2 |
| G07C | ( | 21029.44645 | , | −5576.1675 | ) | 21756.17756 | 84 | 6 | H04B | ( | -56960.215 | , | 520.0938859 | ) | 56962.58903 | 10 | 1 |
| G07D | ( | 25037.33654 | , | 1375.3137 | ) | 25075.08143 | 73 | 6 | H04H | ( | 26124.715 | , | −1583.5866 | ) | 26172.66668 | 67 | 6 |
| G07F | ( | 19790.65504 | , | −3016.2309 | ) | 20019.18269 | 92 | 6 | H04J | ( | 13309.7489 | , | 1900.397057 | ) | 13444.73593 | 105 | 2 |
| G07G | ( | 27592.59151 | , | 930.538057 | ) | 27608.27787 | 62 | 6 | H04K | ( | 29667.1677 | , | −2686.66189 | ) | 29788.57146 | 44 | 6 |
| G08B | ( | 2872.401218 | , | −3253.925 | ) | 4340.359037 | 121 | 2 | H04L | ( | -201428.8 | , | -69740.2774 | ) | 213160.1915 | 3 | 7 |
| G08C | ( | 18398.70175 | , | −6673.6675 | ) | 19571.66483 | 93 | 6 | H04M | ( | −29050.345 | , | 6799.674282 | ) | 29835.51771 | 43 | 5 |
| G08G | ( | 7877.307342 | , | 8033.669 | ) | 11251.30253 | 111 | 2 | H04N | ( | -181399.73 | , | 60377.27726 | ) | 191183.8865 | 4 | 7 |
| G09B | ( | 10492.86486 | , | −889.15004 | ) | 10530.47011 | 113 | 2 | H04Q | ( | 10765.7121 | , | −1232.87073 | ) | 10836.07527 | 112 | 2 |
| G09C | ( | 29673.65858 | , | 86.0808862 | ) | 29673.78343 | 47 | 6 | H04R | ( | 5017.21898 | , | −1525.89996 | ) | 5244.125949 | 120 | 2 |
| G09D | ( | 30953.4895 | , | −2213.0528 | ) | 31032.50094 | 24 | 6 | H04S | ( | 28966.8208 | , | −1489.58758 | ) | 29005.09572 | 51 | 6 |
| G09F | ( | 5201.062408 | , | 13671.5278 | ) | 14627.43047 | 102 | 2 | H04W | ( | -126554.54 | , | -31715.9776 | ) | 130468.2126 | 6 | 7 |
| G09G | ( | −22441.5606 | , | 4603.9677 | ) | 22908.95372 | 80 | 5 | H05B | ( | −20516.906 | , | 10493.45439 | ) | 23044.65253 | 79 | 5 |
| G10B | ( | 30840.35251 | , | −1786.3533 | ) | 30892.0443 | 28 | 6 | H05C | ( | 30999.2393 | , | −2213.05014 | ) | 31078.13425 | 21 | 6 |
| G10C | ( | 30599.31248 | , | −2126.8488 | ) | 30673.13825 | 31 | 6 | H05F | ( | 29861.1899 | , | −1980.35381 | ) | 29926.78501 | 41 | 6 |
| G10D | ( | 28896.50376 | , | −2530.903 | ) | 29007.12671 | 50 | 6 | H05G | ( | 28961.9364 | , | −2162.02998 | ) | 29042.52287 | 49 | 6 |
| G10F | ( | 30889.52961 | , | −2095.7007 | ) | 30960.53942 | 27 | 6 | H05H | ( | 25685.3922 | , | 377.4390402 | ) | 25688.16521 | 72 | 6 |
| G10G | ( | 30291.8942 | , | -1748.4749 | ) | 30342.314 | 35 | 6 | H05K | ( | -45543.258 | , | 14997.64323 | ) | 47949.11498 | 14 | 5 |
| CID | IPC Cnt | Center X | Center Y | Dist. To O | Tan−1 (°) | Within GRP. VAR. | Avg. VAR. | IPC Codes |
|---|---|---|---|---|---|---|---|---|
| 5 | 13 | −30428.3 | 5807.446 | 30977.5 | −10.8054 | 230028.9 | 17694.53 | {"G01R", "G02F", "G03G", "G05B", "G06K", "G06T", "G09G", "H01R", "H02J", "H02K", "H04M", "H05B", "H05K"} |
| 7 | 4 | −163084 | −16323.7 | 163899 | 5.715925 | 205874.5 | 51468.61 | {"G01N", "H04L", "H04N", "H04W"} |
| 4 | 1 | −313673 | 103838.9 | 330413.9 | −18.3167 | 0 | 0 | {"H01L"} |
| 3 | 1 | −501431 | −67253.6 | 505921 | 7.639108 | 0 | 0 | {"G06F"} |
| 2 | 34 | 6764.796 | 826.2484 | 6815.068 | 6.963583 | 282985.6 | 8323.107 | {"G01B", "G01C", "G01D", "G01F", "G01J", "G01L", "G01M", "G01S", "G03B", "G03F", "G05D", "G08B", "G08G", "G09B", "G09F", "G10L", "G11B", "G11C", "H01B", "H01F", "H01G", "H01H", "H01J", "H01Q", "H01S", "H02G", "H02H", "H02M", "H02P", "H03K", "H03M", "H04J", "H04Q", "H04R "} |
| 6 | 71 | 27319.53 | −2044.69 | 27395.94 | −4.28023 | 237455.4 | 3344.442 | {"G01G", "G01H", "G01K", "G01P", "G01T", "G01V", "G01W", "G02C", "G03C", "G03D", "G03H", "G04B", "G04C", "G04F", "G04G", "G04R", "G05F", "G05G", "G06C", "G06D", "G06E", "G06G", "G06J", "G06M", "G06N", "G07B", "G07C", "G07D", "G07F", "G07G", "G08C", "G09C", "G09D", "G10B", "G10C", "G10D", "G10F", "G10G", "G10H", "G10K", "G12B", "G21B", "G21C", "G21D", "G21F", "G21G", "G21H", "G21J", "G21K", "H01C", "H01K", "H01P", "H01T", "H02B", "H02N", "H02S", "H03B", "H03C", "H03D", "H03F", "H03G", "H03H", "H03J", "H03L", "H04H", "H04K", "H04S", "H05C", "H05F", "H05G", "H05H"} |
| 1 | 4 | −76670.4 | 17573.32 | 78658.6 | −12.9095 | 89935.84 | 22483.96 | {"G02B", "G06Q", "H01M", "H04B"} |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hsu, C.-C.; Zhuang, Z.-Y. Competition Among the World’s Main Technological Powers to Develop IPs: Cross-National Longitudinal Patentography Over a 9-Year Time Span. Appl. Sci. 2019, 9, 2432. https://doi.org/10.3390/app9122432
Hsu C-C, Zhuang Z-Y. Competition Among the World’s Main Technological Powers to Develop IPs: Cross-National Longitudinal Patentography Over a 9-Year Time Span. Applied Sciences. 2019; 9(12):2432. https://doi.org/10.3390/app9122432
Chicago/Turabian StyleHsu, Cheng-Chien, and Zheng-Yun Zhuang. 2019. "Competition Among the World’s Main Technological Powers to Develop IPs: Cross-National Longitudinal Patentography Over a 9-Year Time Span" Applied Sciences 9, no. 12: 2432. https://doi.org/10.3390/app9122432
APA StyleHsu, C.-C., & Zhuang, Z.-Y. (2019). Competition Among the World’s Main Technological Powers to Develop IPs: Cross-National Longitudinal Patentography Over a 9-Year Time Span. Applied Sciences, 9(12), 2432. https://doi.org/10.3390/app9122432