A Size-Controlled AFGAN Model for Ship Acoustic Fault Expansion


Abstract
1. Introduction
2. GAN for Acoustic Fault Sample Expansion
2.1. GAN
2.2. AFGAN Network Architecture
3. The Size-Controlled AFGAN
3.1. The Information Entropy Equivalence Principle
3.2. The Generator Objective Function
4. Experimental Setup
4.1. The Measured Noise Source Data Set
4.2. Network Configuration
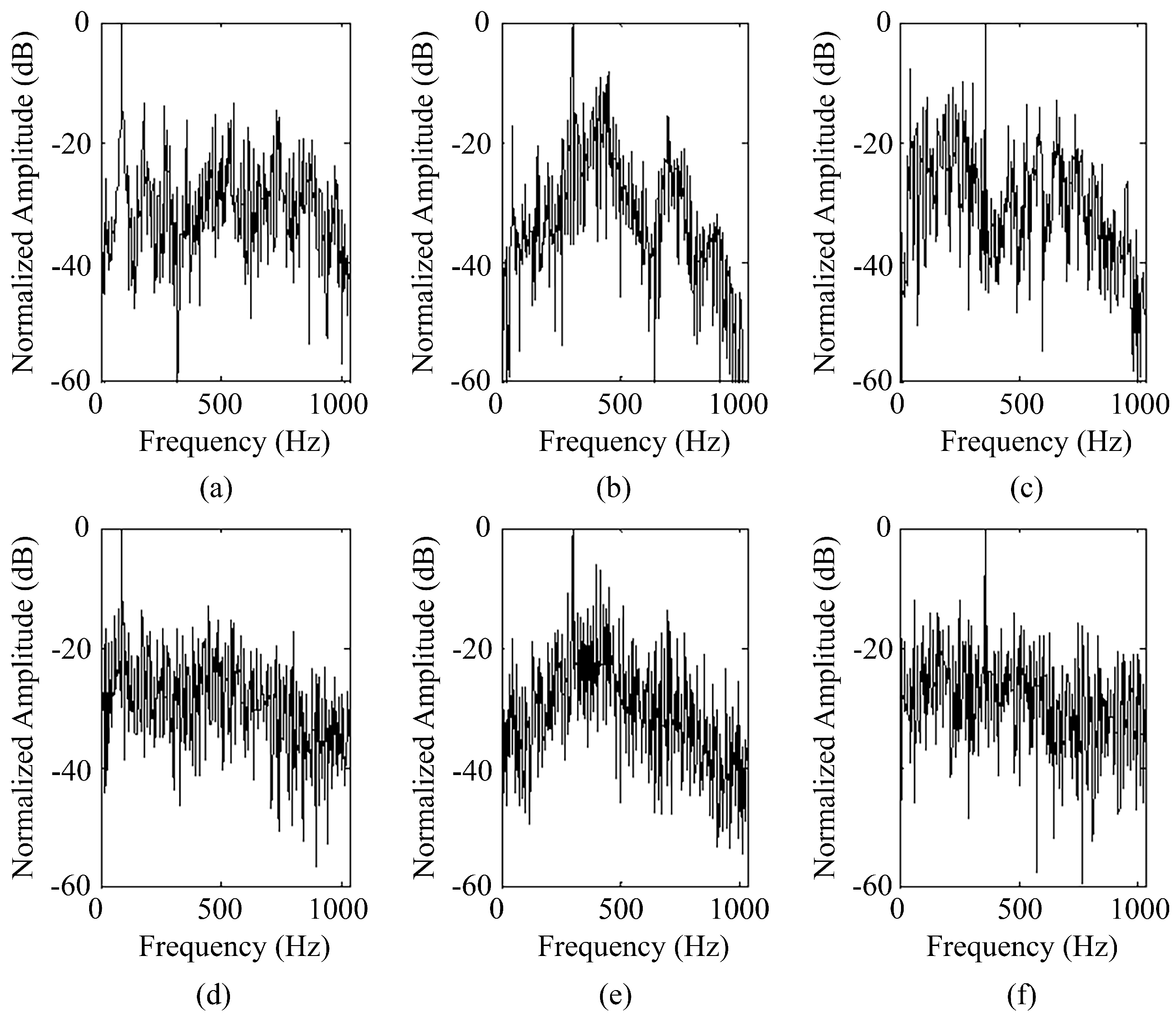
4.3. Sample Expansion
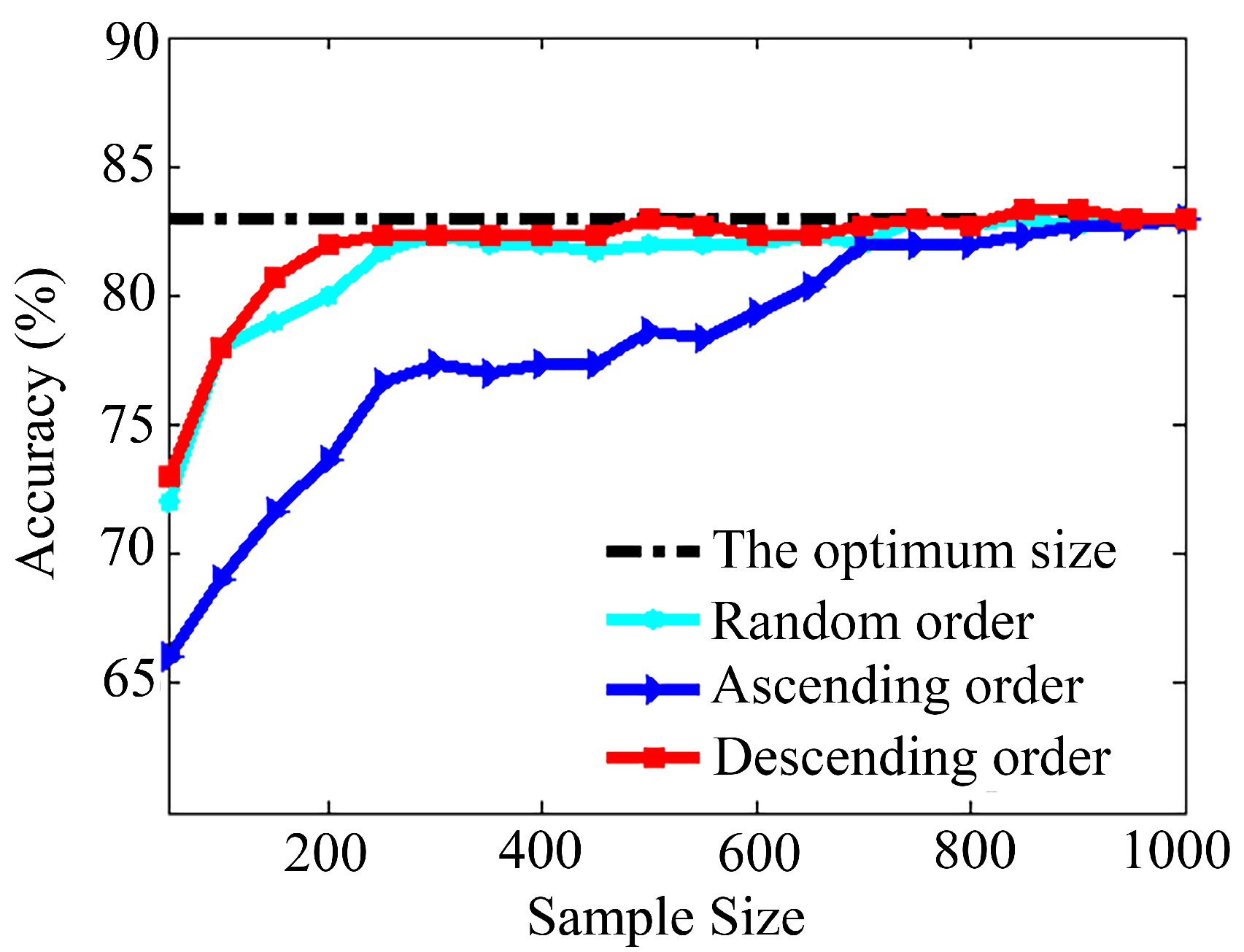
4.4. Recognition Accuracy with Different Expanded Sample Sizes
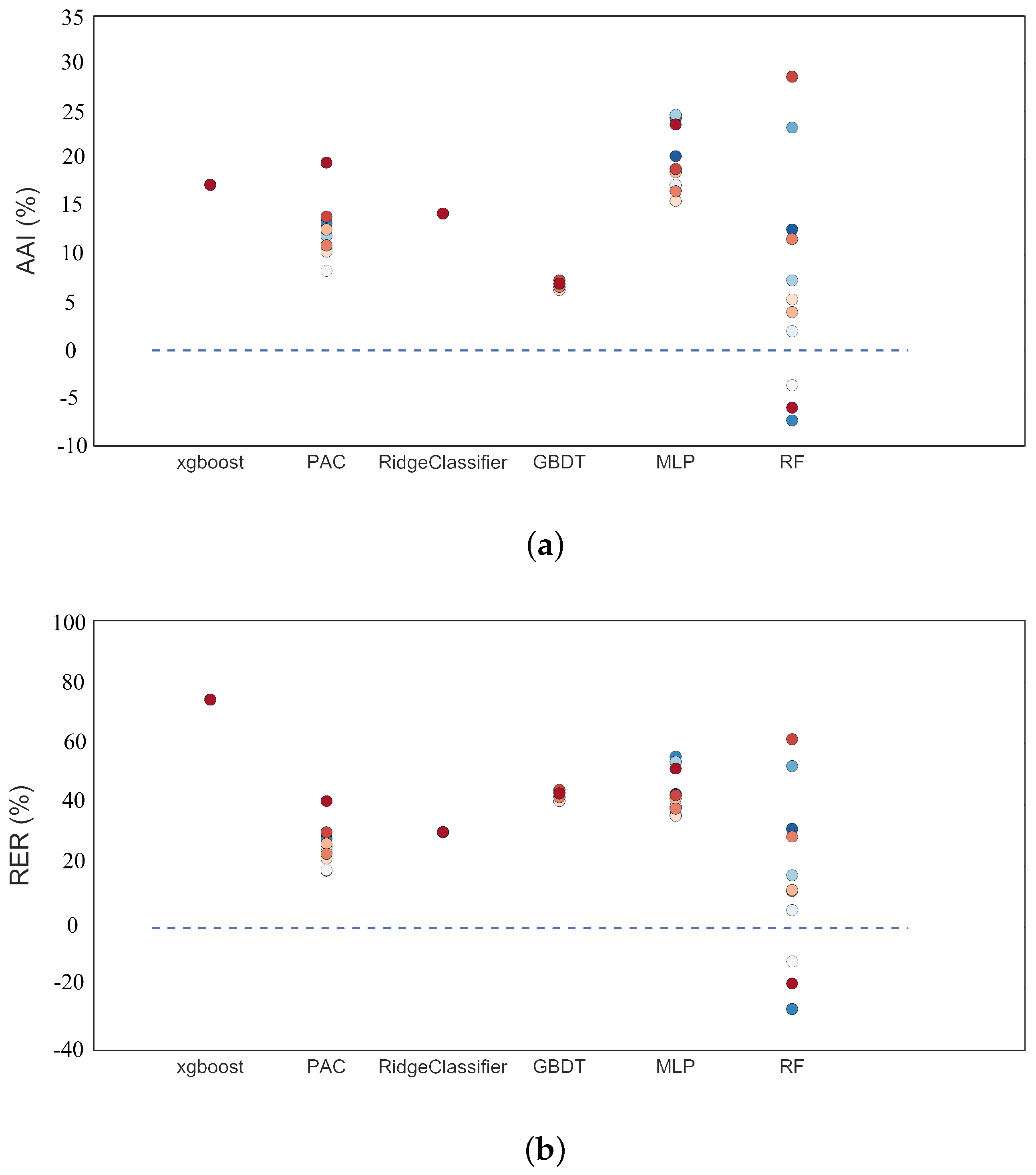
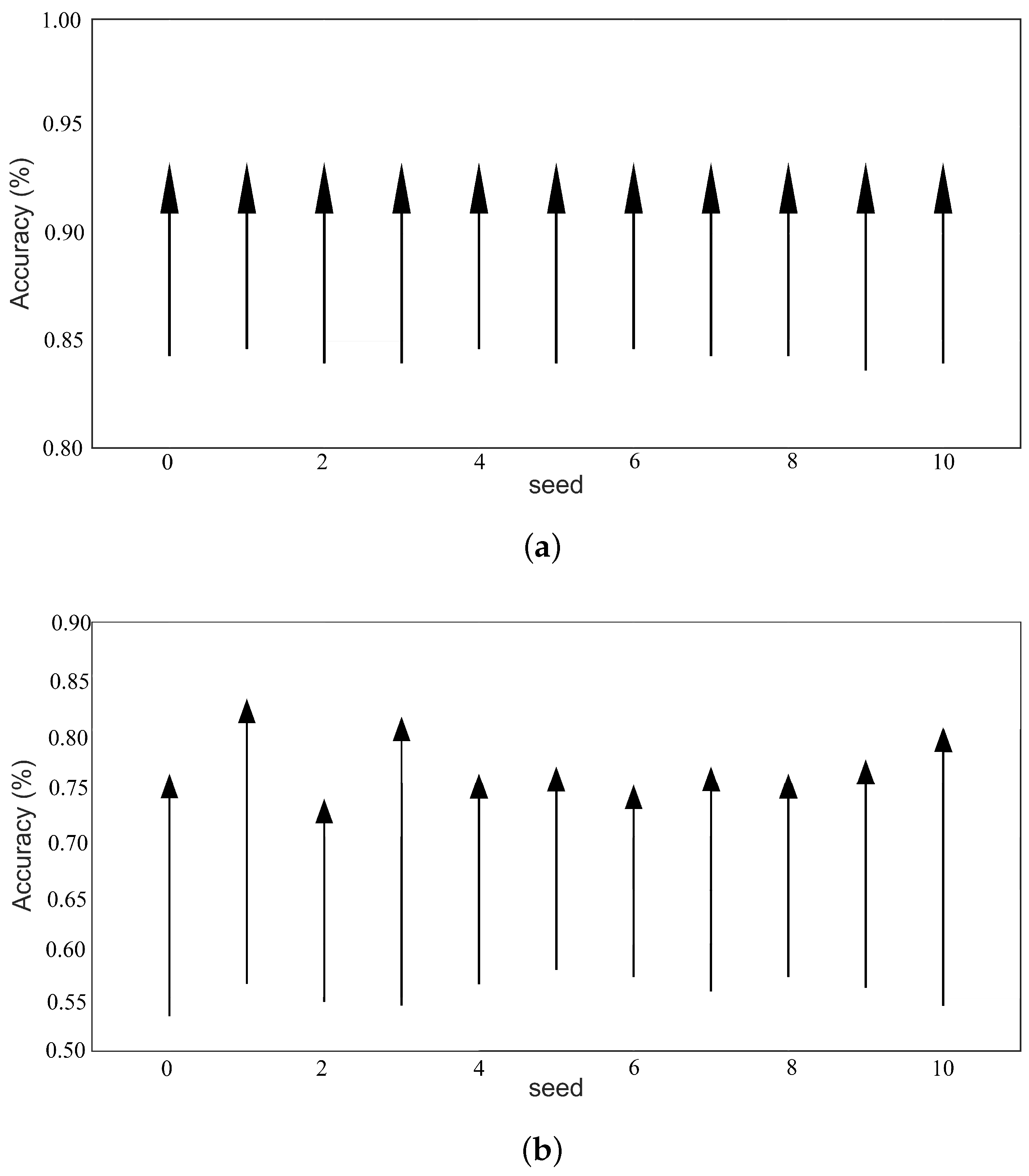
4.5. Sample Expansion Performance on Other Machine Learning Algorithms
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| GAN | Generative Adversarial Network |
| AFGAN | Acoustic Fault Generative Adversarial Network |
| DCGAN | Deep Convolutional Generative Adversarial Network |
| MLP | Multi-Layer Perceptron |
| PAC | Passive Aggressive Classifier |
| Xgboost | Extreme Gradient Boosting Classifier |
| GBDT | Gradient Boosting Decision Tree |
| RF | Random Forest |
| AAI | Absolute Accuracy Increase |
| RER | Relative Error Reduction |
References
- Kouremenos, D.; Hountalas, D. Diagnosis and condition monitoring of medium-speed marine diesel engines. Tribotest 1997, 4, 63–91. [Google Scholar] [CrossRef]
- Zhang, L. Study on the Technique of Acoustic Fault Identification and Its Application. Ph.D. Thesis, Naval University of Engineering, Wuhan, China, 2006. [Google Scholar]
- Zheng, H.; Liu, G.; Tao, J.; Lam, K. FEM/BEM analysis of diesel piston-slap induced ship hull vibration and underwater noise. Appl. Acoust. 2001, 62, 341–358. [Google Scholar] [CrossRef]
- Zhan, Y.L.; Shi, Z.B.; Shwe, T.; Wang, X.Z. Fault diagnosis of marine main engine cylinder cover based on vibration signal. In Proceedings of the IEEE 2007 International Conference on Machine Learning and Cybernetics, Hong Kong, China, 19–22 Augest 2007; pp. 1126–1130. [Google Scholar]
- Li, Z.; Yan, X.; Yuan, C.; Peng, Z. Intelligent fault diagnosis method for marine diesel engines using instantaneous angular speed. J. Mech. Sci. Technol. 2012, 26, 2413–2423. [Google Scholar] [CrossRef]
- Li, Z.; Yan, X.; Guo, Z.; Zhang, Y.; Yuan, C.; Peng, Z. Condition monitoring and fault diagnosis for marine diesel engines using information fusion techniques. Elektron. Elektrotech. 2012, 123, 109–112. [Google Scholar] [CrossRef]
- Niyogi, P.; Girosi, F.; Poggio, T. Incorporating prior information in machine learning by creating virtual examples. Proc. IEEE 1998, 86, 2196–2209. [Google Scholar] [CrossRef]
- Xu, R.; He, L.; Zhang, L.; Tang, Z.; Tu, S. Research on virtual sample based identification of noise sources in ribbed cylindrical double-shells. J. Vib. Shock 2008, 27, 32–35. [Google Scholar]
- Hu, Z.D.; Cao, Y.; Zhang, S.F.; Cai, H. Bootstrap method for missile precision evaluation under extreme small sample test. Syst. Eng. Electron. 2008, 8, 1493–1497. [Google Scholar]
- Wei, N.; Zhang, L.; Qiu, X. An acoustic fault sample expansion method based on noise disturbance. In Proceedings of the 24th International Congress on Sound and Vibration, ICSV 2017, London, UK, 23–27 July 2017. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Curran Associates, Inc.: Montreal, QC, Canada, 2014; pp. 2672–2680. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Pascual, S.; Bonafonte, A.; Serrà, J. SEGAN: Speech enhancement generative adversarial network. arXiv 2017, arXiv:1703.09452. [Google Scholar]
- Saito, M.; Matsumoto, E.; Saito, S. Temporal generative adversarial nets with singular value clipping. In Proceedings of the IEEE International Conference on Computer Vision, Tampa, FL, USA, 5–8 December 2017; pp. 2830–2839. [Google Scholar]
- Hu, W.; Tan, Y. Generating adversarial malware examples for black-box attacks based on GAN. arXiv 2017, arXiv:1702.05983. [Google Scholar]
- Wolterink, J.M.; Leiner, T.; Viergever, M.A.; Išgum, I. Generative adversarial networks for noise reduction in low-dose CT. IEEE Trans. Med. Imaging 2017, 36, 2536–2545. [Google Scholar] [CrossRef] [PubMed]
- Zhao, C.; Shi, M.; Cai, Z.; Chen, C. Research on the Open-Categorical Classification of the Internet-of-Things Based on Generative Adversarial Networks. Appl. Sci. 2018, 8, 2351. [Google Scholar] [CrossRef]
- Zhao, C.; Chen, C.; He, Z.; Wu, Z. Application of Auxiliary Classifier Wasserstein Generative Adversarial Networks in Wireless Signal Classification of Illegal Unmanned Aerial Vehicles. Appl. Sci. 2018, 8, 2664. [Google Scholar] [CrossRef]
- Spyridon, P.; Boutalis, Y.S. Generative Adversarial Networks for Unsupervised Fault Detection. In Proceedings of the 2018 European Control Conference (ECC), Limassol, Cyprus, 12–15 June 2018; pp. 691–696. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Fu, Z. Informatics-Basic Theory and Application; Publishing House of Electronics Industry: Beijing, China, 2011. [Google Scholar]
- Gaudart, J.; Giusiano, B.; Huiart, L. Comparison of the performance of multi-layer perceptron and linear regression for epidemiological data. Comput. Stat. Data Anal. 2004, 44, 547–570. [Google Scholar] [CrossRef]
- Crammer, K.; Dekel, O.; Keshet, J.; Shalev-Shwartz, S.; Singer, Y. Online passive-aggressive algorithms. J. Mach. Learn. Res. 2006, 7, 551–585. [Google Scholar]
- Aswolinskiy, W.; Reinhart, F.; Steil, J.J. Impact of regularization on the model space for time series classification. In Proceedings of the New Challenges in Neural Computation, Bruges, Belgium, 27–29 April 2015; pp. 49–56. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Statist. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experiment | Sample Size per Typical Fault Source | Accuracy | ||
|---|---|---|---|---|
| 90 Hz | 296 Hz | 360 Hz | ||
| E: the optimum size | 831 | 538 | 282 | 83.00% |
| E: half the optimum size | 416 | 269 | 141 | 82.67% |
| E: double the optimum size | 1000 | 1000 | 564 | 81.67% |
| E: all 1000 samples | 1000 | 1000 | 1000 | 83.00% |
| E: none | 0 | 0 | 0 | 61.76% |
| Algorithm | Mean Absolute Accuracy Increase | Improved Models Percentage |
|---|---|---|
| MLP | 19.4% (43.8%) | 100% |
| Passive Aggressive Classifier | 12.2% (26.6%) | 100% |
| Ridge Classifier | 14.3% (31.2%) | 100% |
| Extreme Gradient Boosting Classifier | 17.3% (74.3%) | 100% |
| Random Forest | 7.1% (15.2%) | 72.7% |
| Gradient Boosting Decision Tree | 6.8% (42.8%) | 100% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, L.; Wei, N.; Du, X.; Wang, S. A Size-Controlled AFGAN Model for Ship Acoustic Fault Expansion. Appl. Sci. 2019, 9, 2292. https://doi.org/10.3390/app9112292
Zhang L, Wei N, Du X, Wang S. A Size-Controlled AFGAN Model for Ship Acoustic Fault Expansion. Applied Sciences. 2019; 9(11):2292. https://doi.org/10.3390/app9112292
Chicago/Turabian StyleZhang, Linke, Na Wei, Xuhao Du, and Shuping Wang. 2019. "A Size-Controlled AFGAN Model for Ship Acoustic Fault Expansion" Applied Sciences 9, no. 11: 2292. https://doi.org/10.3390/app9112292
APA StyleZhang, L., Wei, N., Du, X., & Wang, S. (2019). A Size-Controlled AFGAN Model for Ship Acoustic Fault Expansion. Applied Sciences, 9(11), 2292. https://doi.org/10.3390/app9112292