1. Introduction
At present, the average natural gas storage in the world is 53 years. There is more coal in storage than oil and natural gas, and the world’s coal storage capacity is 15,980 tons, which can be mined for about 200 years [
1]. It can be seen that a shortage of fossil fuels is imminent. Photovoltaic (PV) power generation has developed rapidly in the world in recent years due to its advantages in meeting energy demands, reducing environmental pollution, and improving energy structure [
2]. As a result of solar radiation and other factors, PV power output has high volatility and randomness, and with the increase of photovoltaic grid-connected capacity, this adverse impact will bring more and more risks to grid operation. Therefore, accurate prediction of photovoltaic power generation will be of great significance to the stability and safety of grid dispatching and power systems [
3].
In many previous studies, the prediction of photovoltaic power generation based on physical models has shown great progress. Zhang et al. [
4] established the basic model of the photovoltaic cell and photoelectric conversion efficiency based on the principle of photovoltaic power generation and photoelectric conversion efficiency model. Then empirical formulas affecting photoelectric conversion efficiency were obtained, and reasonable empirical parameters were selected to predict PV output power. Dolara et al. [
5] proposed the three-parameter, four-parameter, and five-parameter equivalent circuit model comparison method for photovoltaic cells and two thermal models for estimating battery temperature, which can achieve better accuracy with fewer parameter solutions. However, the creation of physical model and parameter solving process are complicated, and the anti-interference ability of the model is poor.
With the development of machine learning technology and computer hardware capabilities, an increasing number of machine learning and statistical regression methods have been applied to the field of photovoltaic power generation prediction. This includes artificial neural network algorithms [
6], support vector machine (SVM) algorithms [
7,
8], the ARMAX algorithm [
9], the Markov chain algorithm [
10], and so on. Chen et al. [
11] proposed a neural network-based photovoltaic power generation prediction model that can predict power generation under different weather conditions one day in advance. Chen et al. [
12] proposed a solar irradiance prediction method based on the support vector machine algorithm. This method uses different kernel functions to predict solar irradiance, which are then compared. Based on the ARMAX algorithm, Li et al. [
13] considered meteorological factors to obtain more-accurate prediction results. A photovoltaic power generation prediction model based on an improved Markov chain was proposed by Ding [
14]. The Markov chain is mainly used to correct the residual of the prediction model to improve accuracy. However, these algorithms have obvious defects. It is easy for the neural network algorithm to fall into the local minimum, and the model is not well explained. The support vector machine has limited processing ability for large samples of data, and the time series method has weak non-stationary processing ability. Many scholars have improved the efficiency of models by improving the algorithm. Eseye et al. [
15] used the particle swarm optimization (PSO) to optimize the normalization parameters and kernel parameters of SVM. The back propagation (BP) neural network algorithm was improved by combining the momentum term with the variable learning rate, so the defects—the traditional BP learning algorithm is liable to fall into local minimum points, and has a slow convergence rate—were remedied. The improved BP neural network is used to improve the predictive performance [
16].
The output of PV generation is restricted by its external environment, and the weather has a greater impact on photovoltaic systems. In order to reduce the impact of weather, data are classified according to the type of the weather. Some results prove that such methods have a better performance [
17,
18]. In most models, only conventional variables such as temperature, humidity, and wind speed are generally considered, so the accuracy of these models will decrease under extreme weather conditions. The aerosol index (AI) can indicate that there is a strong linear relationship between particulate matter in the atmosphere and solar radiation attenuation, which has a potential impact on the energy generated by photovoltaic panels. In [
19], based on the classification of seasons, AI can be used as an additional input parameter to adapt to the complicated environment. The drawback of these methods, then, is that the accuracy of models depends largely on the accuracy of the weather classification.
The accuracy of predictive models based on statistical learning depends mainly on a large amount of historical data. However, historical data contains complex information, and there is redundant information that may not be necessary. Not all weather factors have a significant impact on PV output, so we need to extract or remove information from historical data to reduce the complexity of models. In [
20], it is shown that temperature and insolation are positively correlated with PV power, humidity is negatively correlated with PV power, and wind speed has no obvious correlation with PV power by the correlation analysis. Therefore, air temperature, humidity, insolation, and historical PV power can be selected as inputs to the prediction model to reduce the complexity of the data. Zhu et al. [
21] proposed a PV output prediction method combining wavelet decomposition and the artificial neural network (ANN) algorithm. After separating the useful information and the interference information by wavelet decomposition, the neural network model is used to obtain the predicted power value. Malvoni et al. [
22] combined the quadratic Renyi entropy criteria with principal component analysis (PCA) to reasonably reduce the data dimension and use least squares support vector machines (LSSVM) to predict future PV power. This model can facilitate calculation, while improving accuracy. In addition, it has been found that the introduction of image data can also improve prediction accuracy. Marquez et al. [
23] proposed a method for combining solar cloud image data and artificial neural network models to predict solar irradiance. Zhu Xiang et al. [
24] used cloud information and cloud maps in numerical weather prediction (NWP) to predict the power attenuation caused by cloud clusters blocking photovoltaic power plants over the subsequent 4 hours, then corrected the predicted values to improve the accuracy of model prediction. This type of method requires more advanced experimental equipment, however.
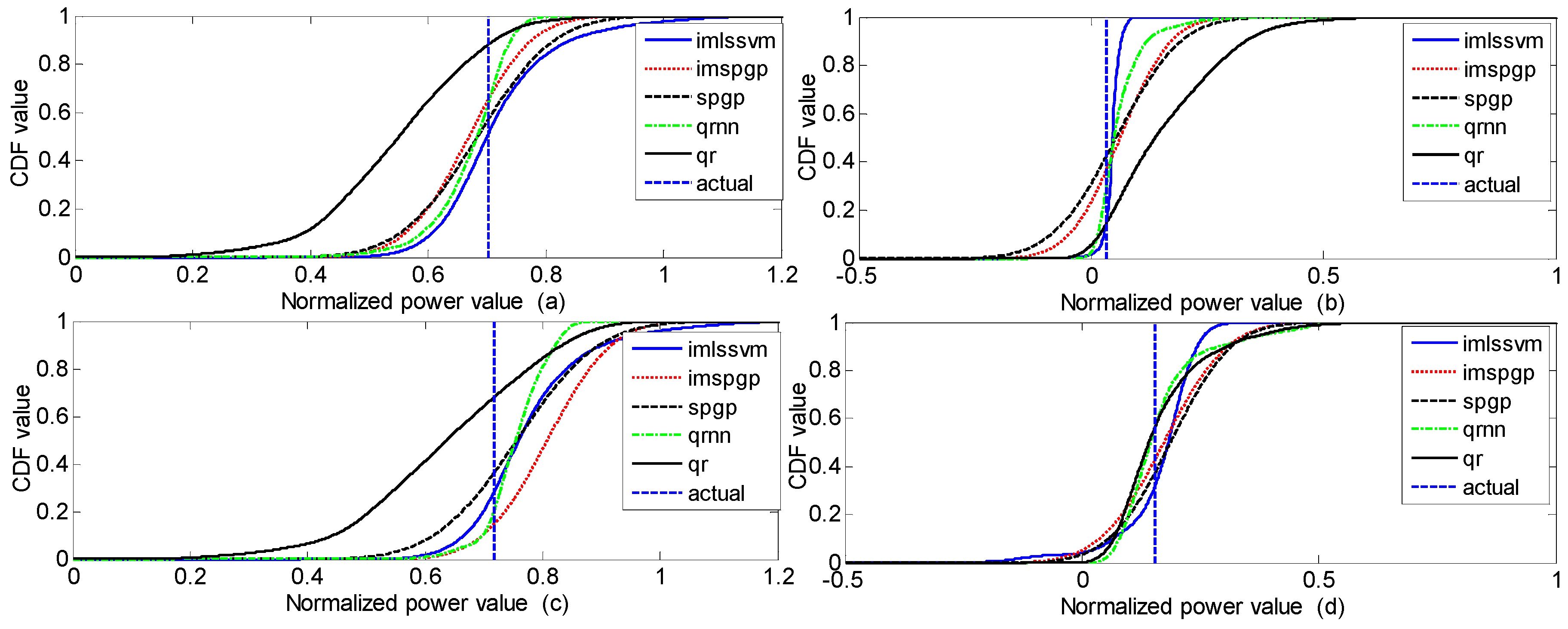
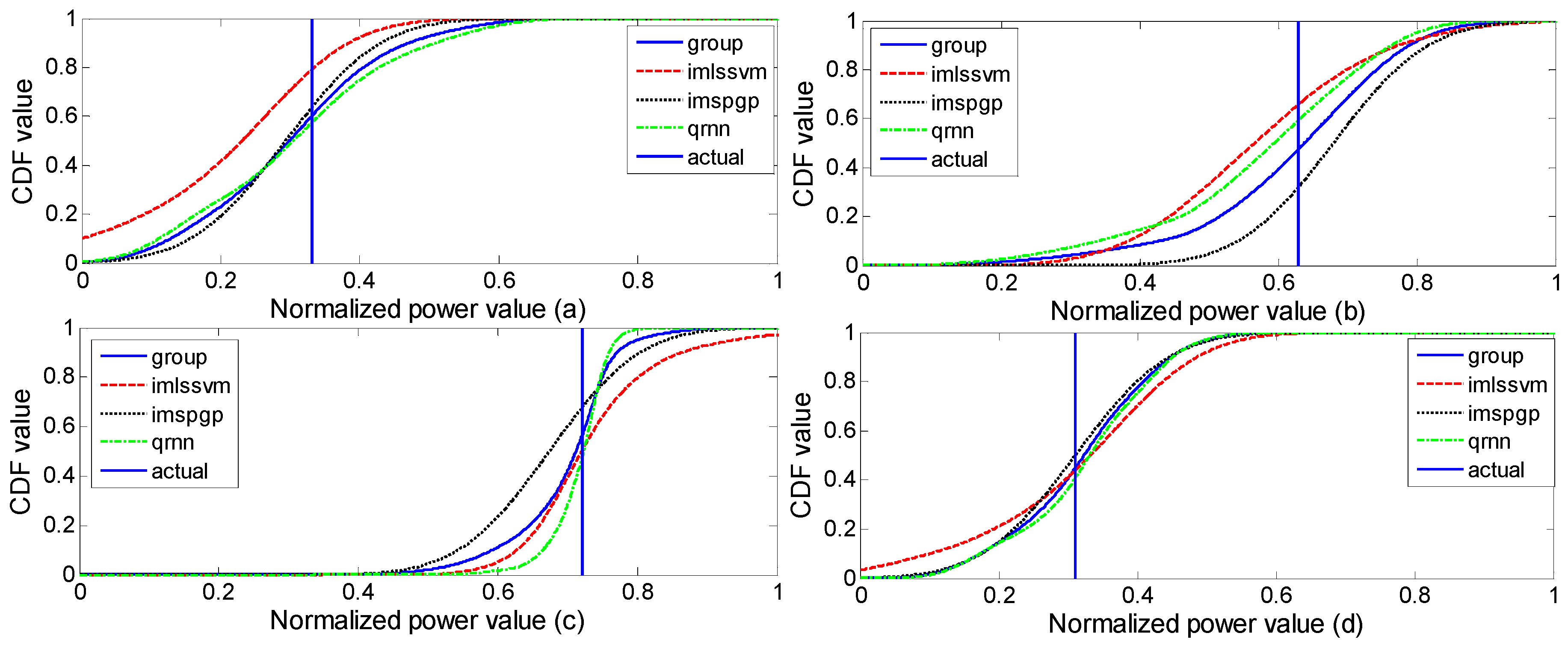
Most of the research has aimed to predict a certain value at a certain moment, but it is difficult for point prediction values to express the uncertainty of the prediction result, which will affect power grid scheduling and the stability of the power system. Compared with point prediction, probabilistic prediction makes up for the shortcoming that point prediction cannot measure the uncertainty of prediction results [
25]. Due to the uncertainty of solar resources and the inherent defects of the prediction model, the point prediction error of solar power cannot be avoided, and the defect that the point prediction result cannot make a quantitative description of the uncertainty of solar power is difficult to overcome. In terms of the application of solar power, there needs to be a relatively accurate estimation of the fluctuation range of solar power, which requires planning, operation, safety, and stability analysis of the power grid (including solar power generation). The probabilistic prediction of solar power generation expands the connotations of solar power generation prediction, and can provide the probability distribution of PV power generation. The diversity of probability distribution at different time points can provide power system policymakers with an abundance of uncertain information, including economic dispatch, rotating standby arrangement, and electricity market price optimization problems. In a word, the probabilistic prediction method can give the possible PV power value and its probability distribution in the next moment, and provide more-comprehensive prediction information [
26]. However, the current research on probability prediction in the field of photovoltaic power generation is still in its infancy. Fatemi et al. [
27] proposed two parametric probability prediction methods for predicting solar irradiance by β-distribution and bilateral power distribution, effectively predicting solar irradiance and accurately describing its stochastic characteristics. Fonseca et al. [
28] assumed the prediction error distribution as the normal distribution and the Laplacian distribution. The probability distribution of the generated power and the confidence interval value at different confidence levels was then obtained by the maximum likelihood estimation method. Almeida et al. [
29] used the meteorological data obtained by NWP as input data, and a probability prediction model based on a quantile regression prediction algorithm was established to study the probability prediction of photovoltaic power generation. Mohammad et al. [
30] combined the probability distribution theory with the Gaussian mixture method, and the prediction results are consistent with the actual probability distribution of photovoltaic power under different weather conditions.
Considering that PV output is affected by many weather factors, and that the complexity of a model will increase if too many variables exist, this paper preprocesses the original data set based on feature selection and similar sample classifications. It is difficult for the point prediction method to express the uncertainty of prediction results. Two improved photovoltaic power generation probabilistic prediction models are proposed in this paper to improve the preliminary prediction performance. The idea of traditional combination methods is to combine different algorithms to optimize a certain prediction model without changing the essential structure of the models. Through analysis, it was found that different models had different advantages during different periods of time. In order to improve the prediction accuracy by contributing to the advantages of the different models, a new probability prediction model with multi-interval and variable weight is proposed. The method is applied to handle the uncertainties of photovoltaic power generation for the first time, to the best of our knowledge.
The major contributions and innovations of this paper are as follows:
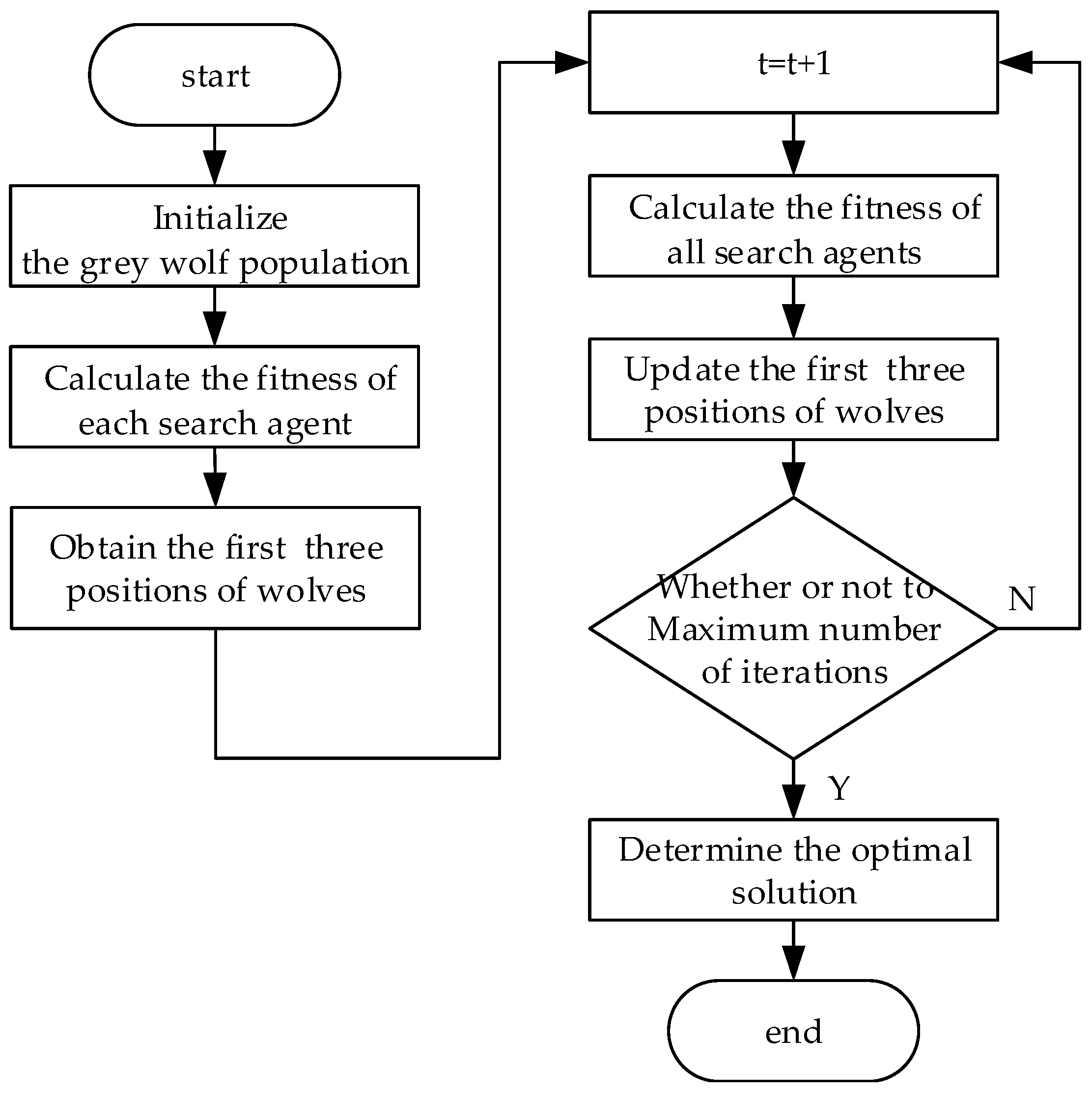
1. The improved grey wolf optimization algorithm is used to optimize the sparse Gaussian process model and the least squares support vector machine model. The better super-parameter values are obtained, which improve accuracy.
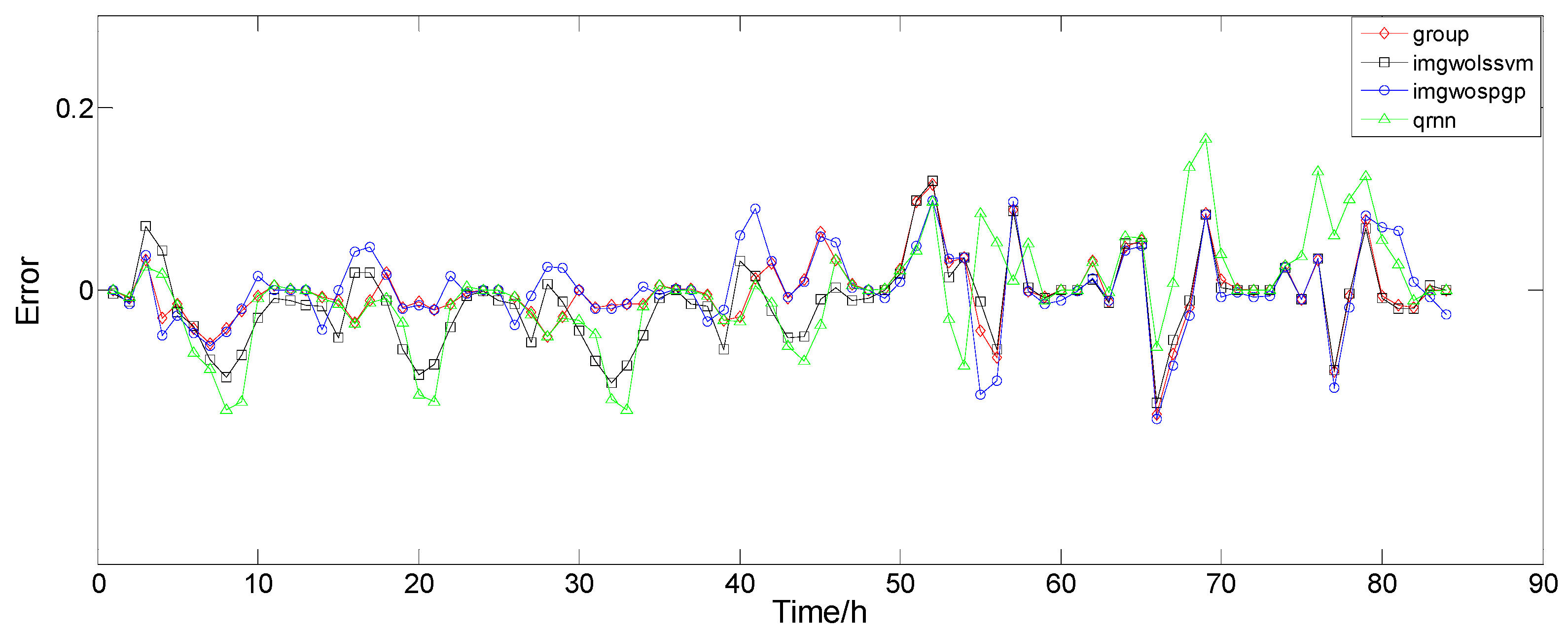
2. An error correction probability prediction model based on improved least squares support vector machine (IMLSSVM) is proposed. The model can be corrected by using the historical error distribution to realize the probability prediction model under the premise of realizing point prediction.
3. A piecewise optimal combination model is proposed that uses different combined weighting coefficients in different periods to make full use of different prediction models.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}