PARNet: A Joint Loss Function and Dynamic Weights Network for Pedestrian Semantic Attributes Recognition of Smart Surveillance Image


Abstract
:1. Introduction
2. Methodology
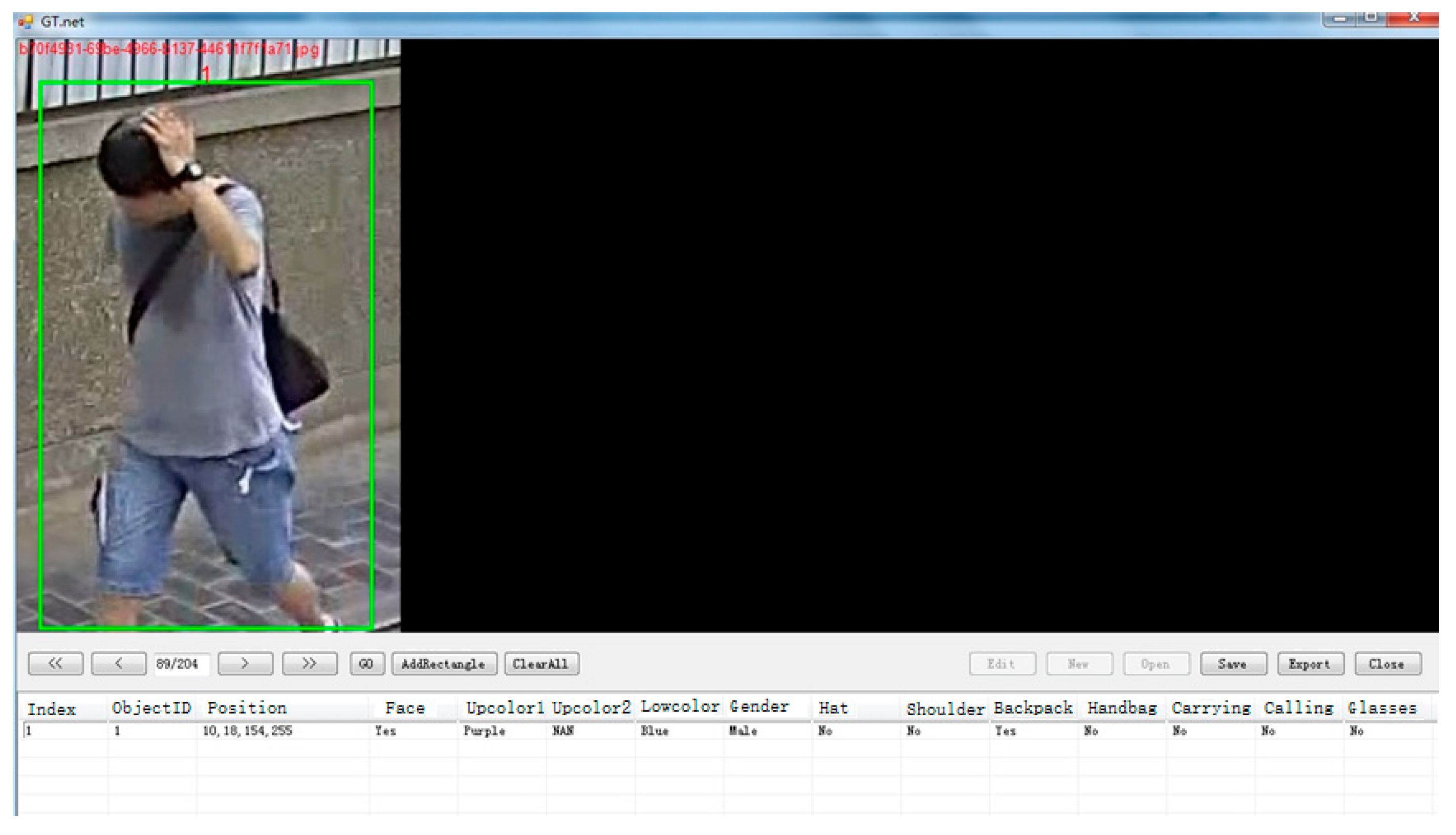
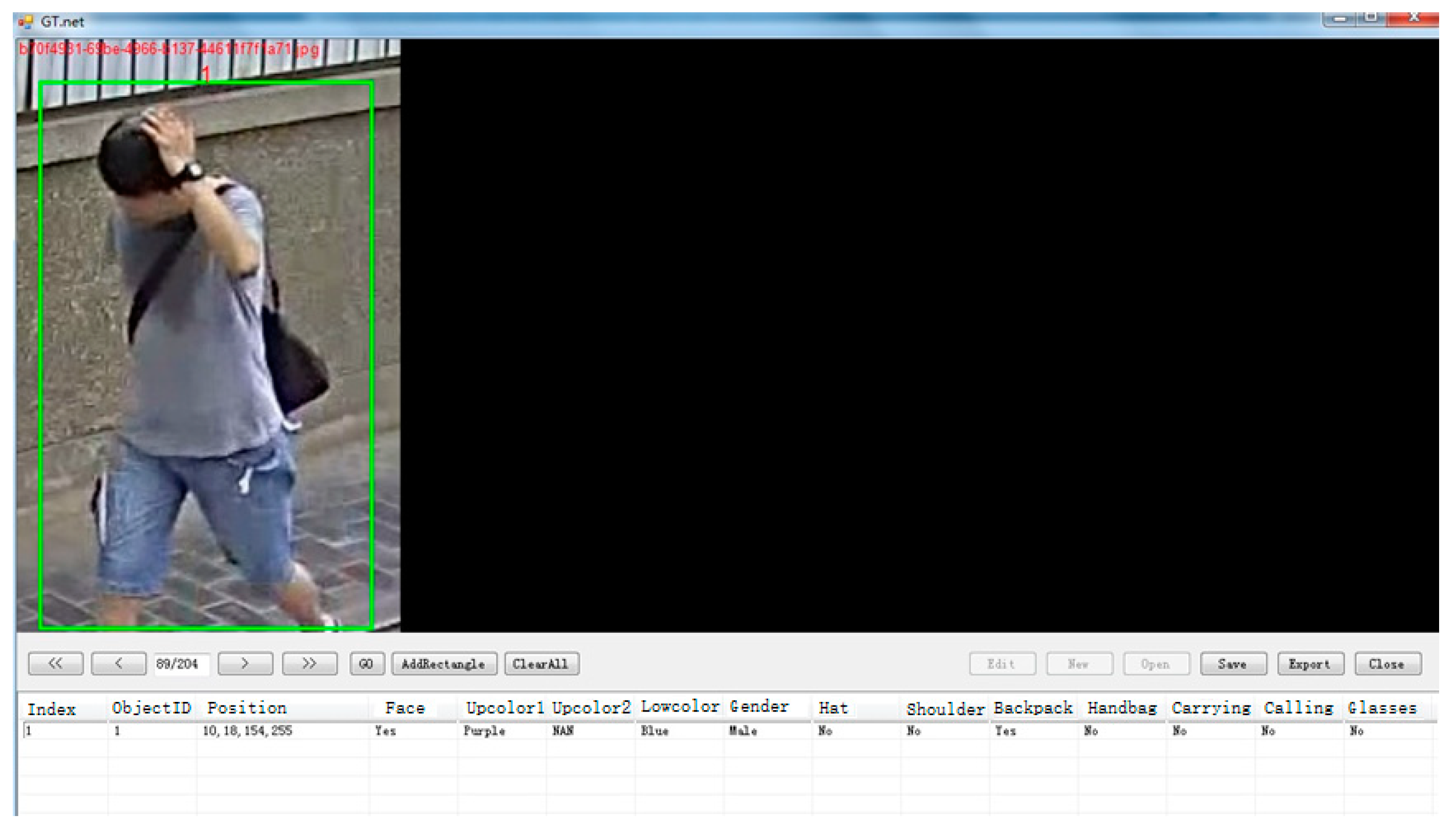
2.1. Pedestrian Attributes Dataset Construction
2.2. Proposed Method
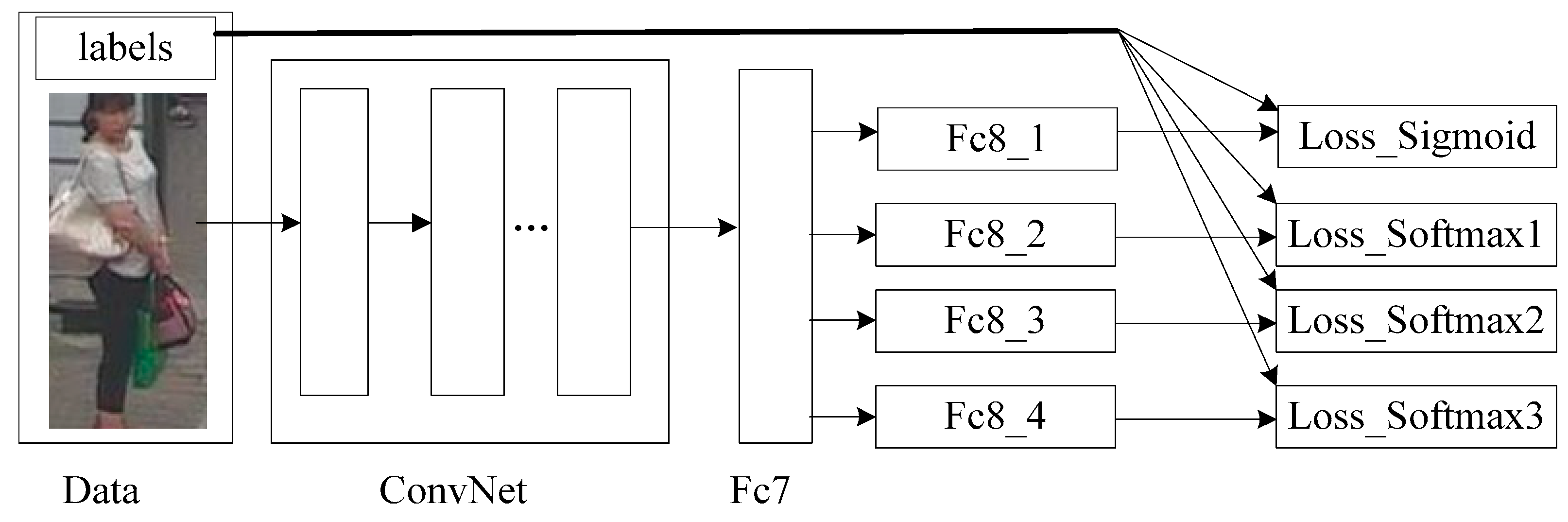
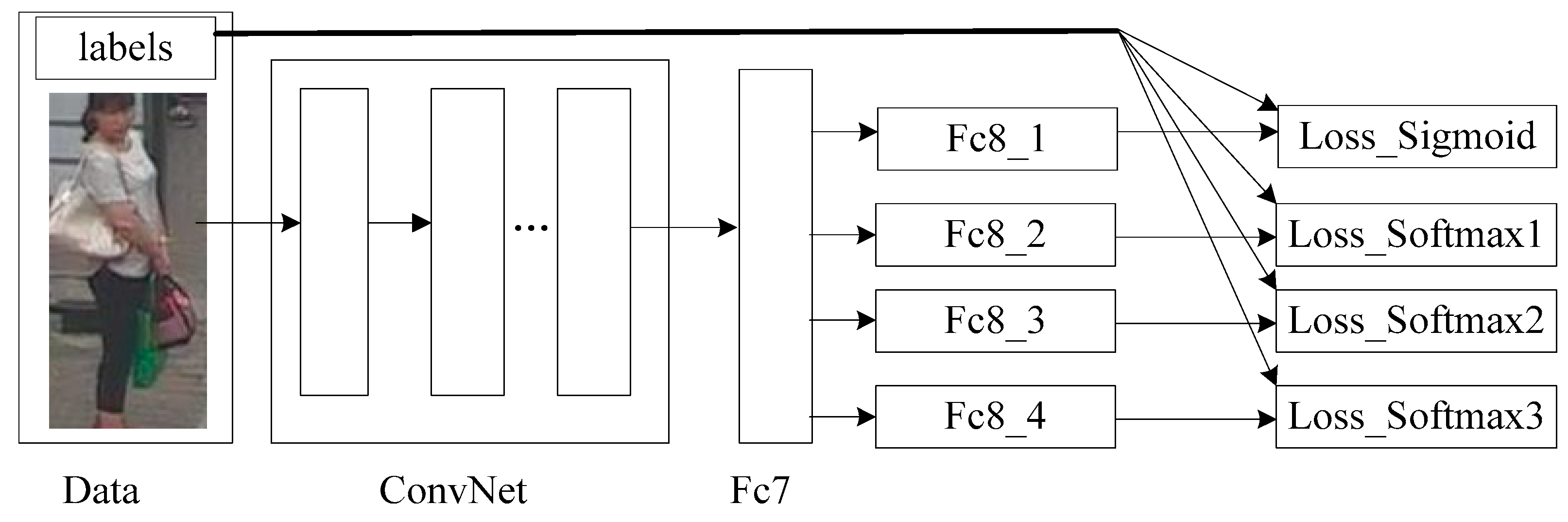
2.2.1. Joint Loss Function
2.2.2. Dynamic Weights for Joint Loss Function
2.2.3. Optimization
3. Results
3.1. Datasets
3.2. Implementation
3.3. Evaluation Metrics
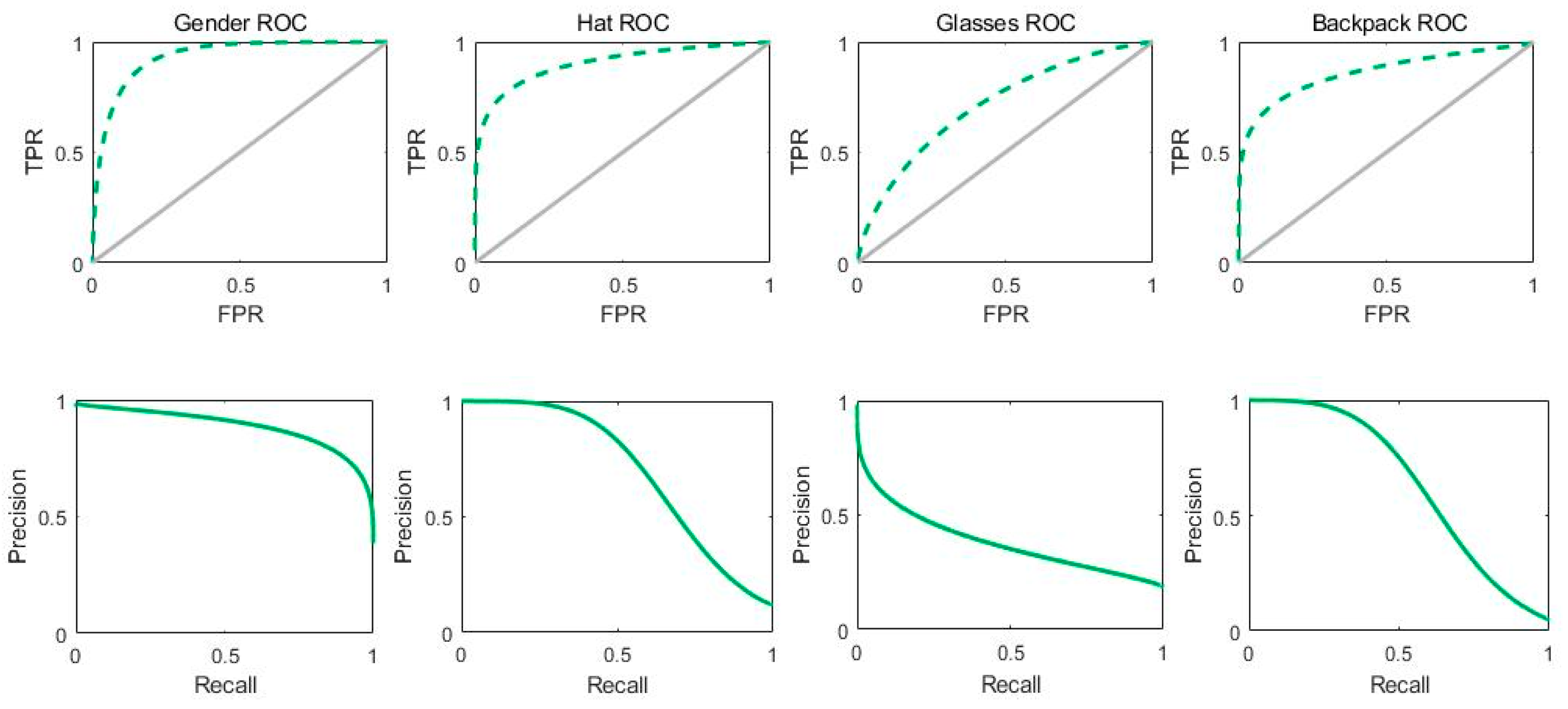
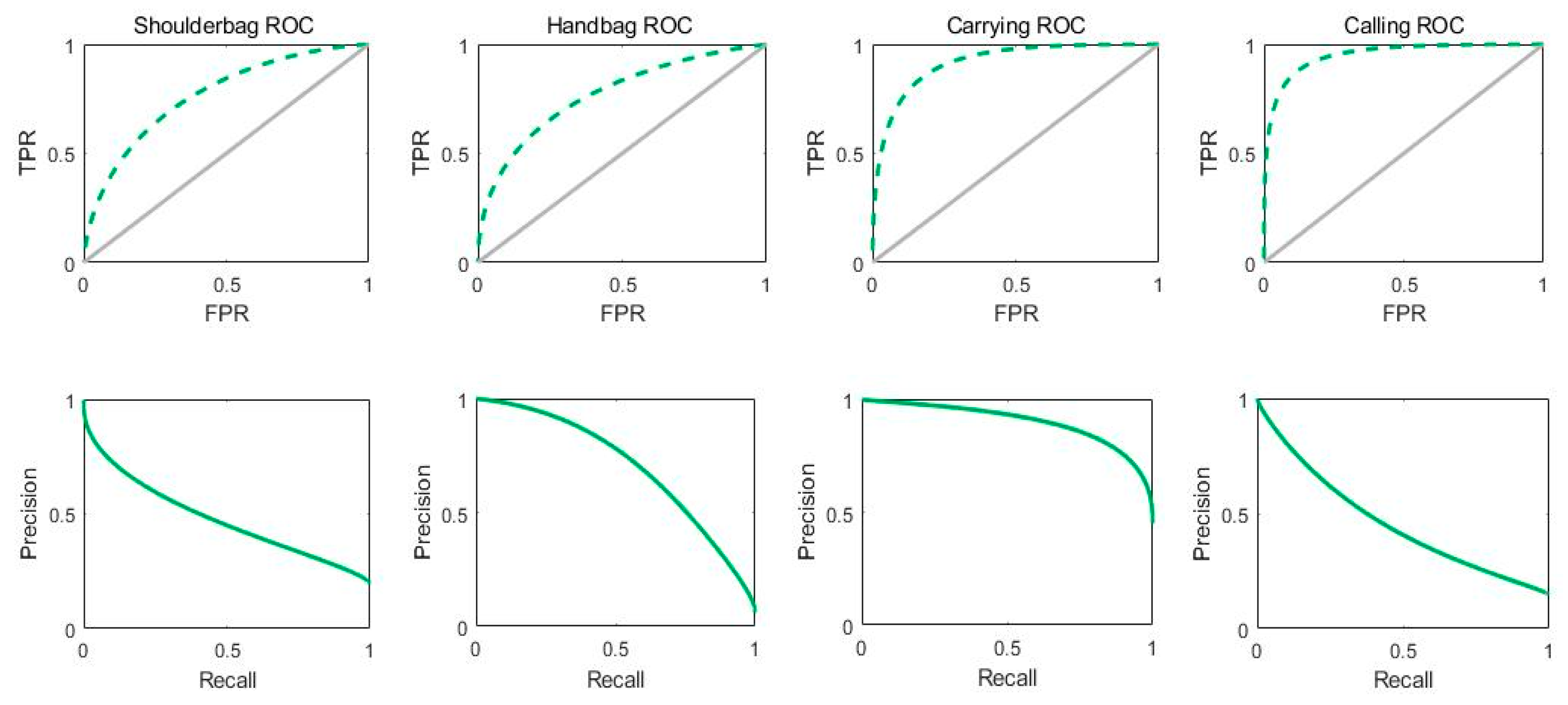
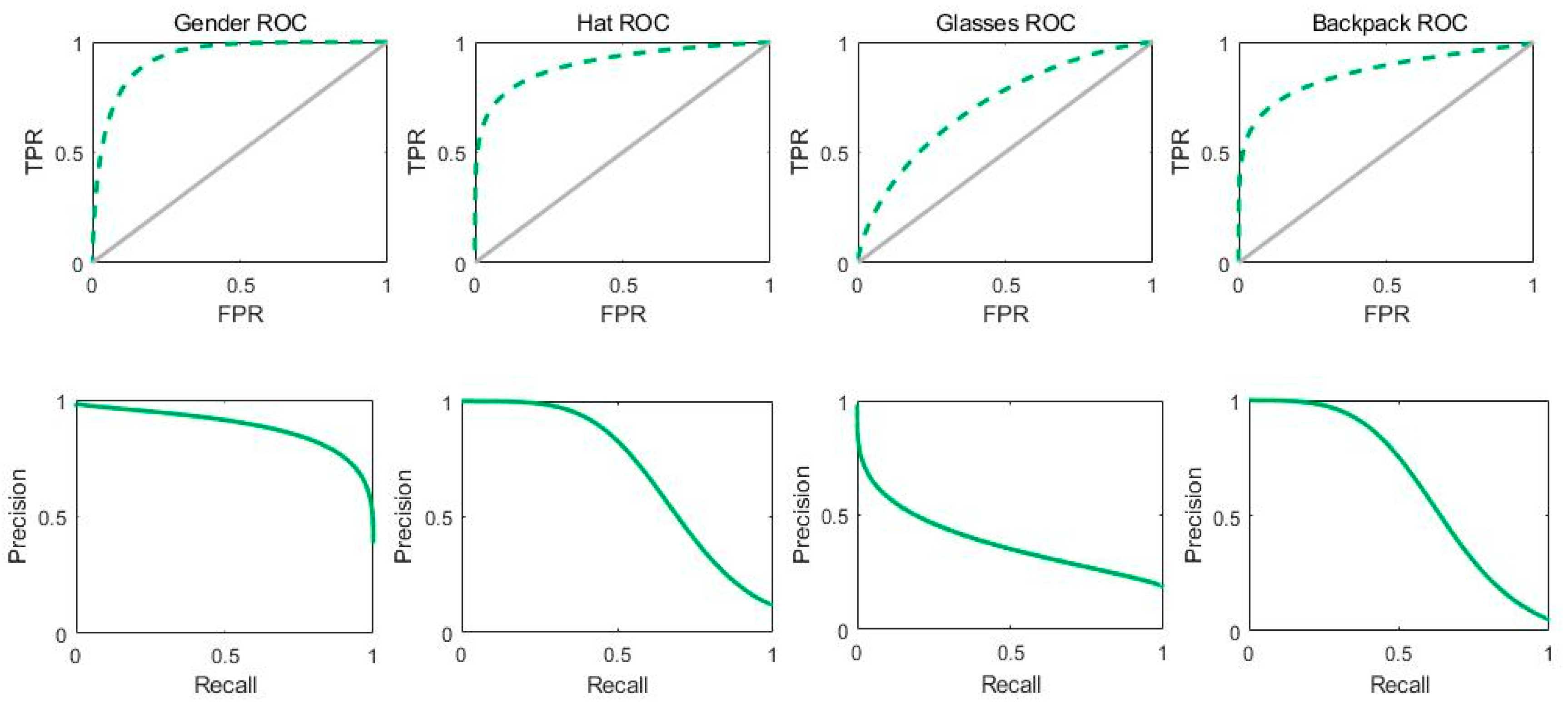
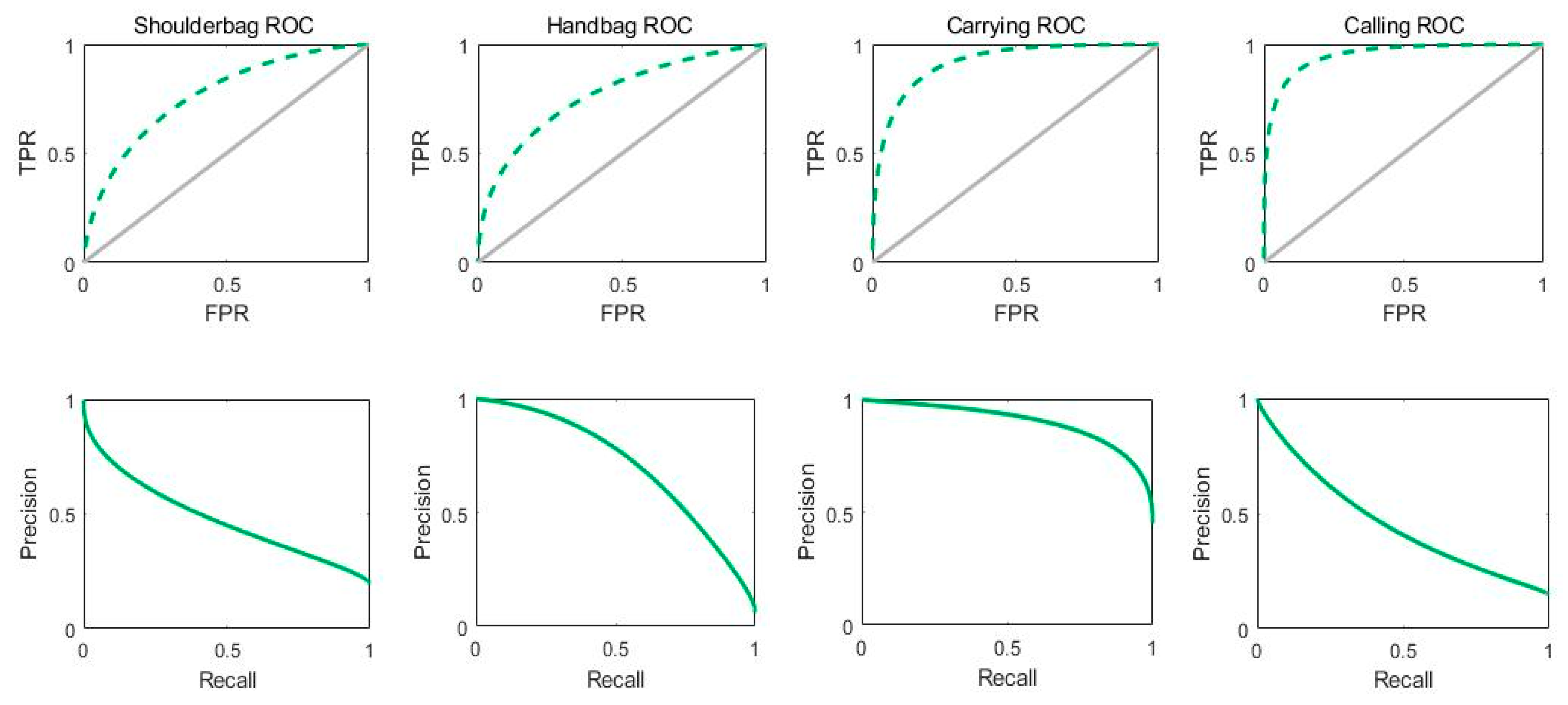
3.4. PARNet Experimental Results on NEU-Dataset
3.5. Comparisons with Related Methods
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Li, D.; Zhang, Z.; Chen, X.; Huang, K. A richly annotated pedestrian dataset for person retrieval in real surveillance scenarios. IEEE Trans. Image Process. 2018, 28, 1575–1590. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Zhu, X.; Gong, S.; Li, W. Attribute recognition by joint recurrent learning of context and correlation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Li, X.; Li, L.; Flohr, F.; Wang, J.; Xiong, H.; Bernhard, M.; Pan, S.; Gavrila, D.M.; Li, K. A unified framework for concurrent pedestrian and cyclist detection. IEEE Trans. Intell. Transp. Syst. 2017, 18, 269–281. [Google Scholar] [CrossRef]
- Deng, Y.; Luo, P.; Loy, C.C.; Tang, X. Pedestrian attribute recognition at far distance. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014. [Google Scholar]
- Layne, R.; Hospedales, T.M.; Gong, S. Towards person identification and re-identification with attributes. In Proceedings of the Computer Vision—ECCV 2012. Workshops and Demonstrations, Florence, Italy, 7–13 October 2012. [Google Scholar]
- Layne, R.; Hospedales, T.M.; Gong, S.; Mary, Q. Person re-identification by attributes. In Proceedings of the British Machine Vision Conference, Surrey, UK, 3–7 September 2012. [Google Scholar]
- Sudowe, P.; Spitzer, H.; Leibe, B. Person attribute recognition with a jointly-trained holistic CNN model. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 87–95. [Google Scholar]
- Tian, Y.; Luo, P.; Wang, X.; Tang, X. Pedestrian detection aided by deep learning semantic tasks. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5079–5087. [Google Scholar] [CrossRef]
- Li, D.; Chen, X.; Huang, K. Multi-attribute learning for pedestrian attribute recognition in surveillance scenarios. In Proceedings of the IAPR Asian Conference on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, 3–6 November 2015. [Google Scholar]
- Georgia, G.; Ross, G.; Jitendra, M. Actions and attributes from wholes and parts. In Proceedings of the International Conference of Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015. [Google Scholar]
- Yu, K.; Leng, B.; Zhang, Z.; Li, D.; Huang, K. Weakly-supervised learning of mid-level features for pedestrian attribute recognition and localization. arXiv 2016, arXiv:1611.05603. [Google Scholar]
- Li, Y.; Huang, C.; Loy, C.C.; Tang, X. Human attribute recognition by deep hierarchical contexts. In Computer Vision—ECCV 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 684–700. [Google Scholar]
- Sarafianos, N.; Xu, X.; Kakadiaris, I.A. Deep imbalanced attribute classification using visual attention aggregation. arXiv 2018, arXiv:1807.03903. [Google Scholar]
- Li, D.; Chen, X.; Zhang, Z.; Huang, K. Pose guided deep model for pedestrian attribute recognition in surveillance scenarios. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME 2018), San Diego, CA, USA, 23–27 July 2018. [Google Scholar]
- Hong, R.; Cheng, W.H.; Yamasaki, T.; Wang, M.; Ngo, C.W. Advances in multimedia information processing—PCM 2018. In Lecture Notes in Computer Science, Proceedings of the 19th Pacific-Rim Conference on Multimedia, Hefei, China, 21–22 September 2018; Part II Pedestrian attributes recognition in surveillance scenarios with hierarchical multi-task CNN models; Springer: Cham, Switzerland, 2018; Chapter 70; Volume 11165, pp. 758–767. [Google Scholar] [CrossRef]
- Hirzer, M.; Beleznai, C.; Roth, P.M.; Bischof, H. Person re-identification by descriptive and discriminative classification. In Image Analysis; Springer: Cham, Switzerland, 2011; pp. 91–102. [Google Scholar]
- Liu, C.; Gong, S.; Loy, C.C.; Lin, X. Person re-identification: What features are important. In Proceedings of the Computer Vision—ECCV 2012. Workshops and Demonstrations, Florence, Italy, 7–13 October 2012. [Google Scholar]
- Zhu, J.; Liao, S.; Lei, Z.; Yi, D.; Li, S.Z. Pedestrian attribute classification in surveillance: Database and evaluation. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013. [Google Scholar]
- Gray, D.; Tao, H. Viewpoint invariant pedestrian recognition with an ensemble of localized features. In Proceedings of the European Conference on Computer Vision, Marseille, France, 12–18 October 2008. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Neural Information Processing Systems Conference, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Li, D.; Zhang, Z.; Chen, X.; Ling, H.; Huang, K. A richly annotated dataset for pedestrian attribute recognition. arXiv 2016, arXiv:1603.07054. [Google Scholar]
- Zhang, M.L.; Zhou, Z.H. A review on multi-label learning algorithms. IEEE Trans. Knowl. Data Eng. 2014, 26, 1819–1837. [Google Scholar] [CrossRef]
- Liu, X.; Zhao, H.; Tian, M.; Sheng, L.; Shao, J.; Yi, S.; Yan, J.; Wang, X. HydraPlus-net: Attentive deep features for pedestrian analysis. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 350–359. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Gender | Hat | Upcolor White | Upcolor Black | Lowercolor White | Lowercolor Black |
|---|---|---|---|---|---|---|
| 1 | 0 (female) | 0 | 1 | 0 | 0 | 1 |
| 2 | 1 (male) | 1 | 0 | 0 | 1 | 0 |
| 3 | 1 (male) | 0 | 1 | 0 | 1 | 0 |
| 4 | 1 (male) | 1 | 0 | 1 | 0 | 1 |
| 5 | 0 (female) | 0 | 1 | 0 | 0 | 1 |
| 6 | 1 (male) | 0 | 0 | 1 | 0 | 0 |
| Number | Attributes | Label Value Range | The Positive Samples Numbers | The Negative Samples Number |
|---|---|---|---|---|
| 1 | Gender | 0-1 | 10,048 | 15,845 |
| 2 | Hat | 0-1 | 1221 | 24,672 |
| 3 | Glasses | 0-1 | 4556 | 21,337 |
| 4 | Backpack | 0-1 | 2995 | 22,898 |
| 5 | Shoulderbag | 0-1 | 5030 | 20,863 |
| 6 | Handbag | 0-1 | 3482 | 22,411 |
| 7 | Carrying Things | 0-1 | 11,297 | 14,596 |
| 8 | Calling | 0-1 | 1468 | 24,425 |
| 9 | Upcolor 1 | 0-10 | - | - |
| 10 | Upcolor 2 | 0-10 | - | - |
| 11 | Lowercolor | 0-10 | - | - |
| Attributes | Acc | PRR | NRR | mA | Prec | Rec | F1 |
|---|---|---|---|---|---|---|---|
| Gender | 85.25 | 90.43 | 82.00 | - | 75.95 | 90.43 | 82.56 |
| Hat | 90.70 | 75.51 | 91.46 | - | 30.66 | 75.51 | 43.62 |
| Glasses | 72.81 | 72.16 | 72.94 | - | 35.51 | 72.16 | 47.60 |
| Backpack | 89.53 | 71.23 | 91.93 | - | 53.68 | 71.23 | 61.23 |
| Shoulderbag | 74.04 | 79.61 | 72.81 | - | 39.31 | 79.61 | 52.63 |
| Handbag | 78.02 | 70.86 | 79.18 | - | 35.47 | 70.86 | 47.28 |
| Carrying | 84.77 | 87.77 | 82.33 | - | 80.12 | 87.77 | 83.77 |
| Calling | 88.33 | 95.95 | 87.88 | - | 31.99 | 95.96 | 47.98 |
| Upcolor 1 | 69.95 | - | - | - | - | - | - |
| Upcolor 2 | 77.76 | - | - | - | - | - | - |
| Lowercolor | 78.90 | - | - | - | - | - | - |
| Average | 80.92 | 78.23 | 81.81 | 75.23 | 47.84 | 80.44 | 58.33 |
| Methods | mA | Acc | Prec | Rec | F1 |
|---|---|---|---|---|---|
| ELF-mm | 69.94 | 29.29 | 32.84 | 71.18 | 44.95 |
| FC7-mm | 72.28 | 31.72 | 35.75 | 71.18 | 47.73 |
| FC6-mm | 73.32 | 33.37 | 37.57 | 73.23 | 49.66 |
| CAN | 69.66 | 62.61 | 80.12 | 72.26 | 75.98 |
| DeepMAR | 73.79 | 62.02 | 74.92 | 76.21 | 75.56 |
| M-Net | 74.44 | 64.99 | 77.83 | 77.89 | 77.86 |
| HP-Net | 76.12 | 65.39 | 77.33 | 78.79 | 78.05 |
| Our method | 89.94 | 88.27 | 52.15 | 95.33 | 65.12 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Tong, G.; Li, X.; Wang, Y.; Zou, B.; Liu, Y. PARNet: A Joint Loss Function and Dynamic Weights Network for Pedestrian Semantic Attributes Recognition of Smart Surveillance Image. Appl. Sci. 2019, 9, 2027. https://doi.org/10.3390/app9102027
Li Y, Tong G, Li X, Wang Y, Zou B, Liu Y. PARNet: A Joint Loss Function and Dynamic Weights Network for Pedestrian Semantic Attributes Recognition of Smart Surveillance Image. Applied Sciences. 2019; 9(10):2027. https://doi.org/10.3390/app9102027
Chicago/Turabian StyleLi, Yong, Guofeng Tong, Xin Li, Yuebin Wang, Bo Zou, and Yujie Liu. 2019. "PARNet: A Joint Loss Function and Dynamic Weights Network for Pedestrian Semantic Attributes Recognition of Smart Surveillance Image" Applied Sciences 9, no. 10: 2027. https://doi.org/10.3390/app9102027
APA StyleLi, Y., Tong, G., Li, X., Wang, Y., Zou, B., & Liu, Y. (2019). PARNet: A Joint Loss Function and Dynamic Weights Network for Pedestrian Semantic Attributes Recognition of Smart Surveillance Image. Applied Sciences, 9(10), 2027. https://doi.org/10.3390/app9102027