Layer-Level Knowledge Distillation for Deep Neural Network Learning


Abstract
:1. Introduction
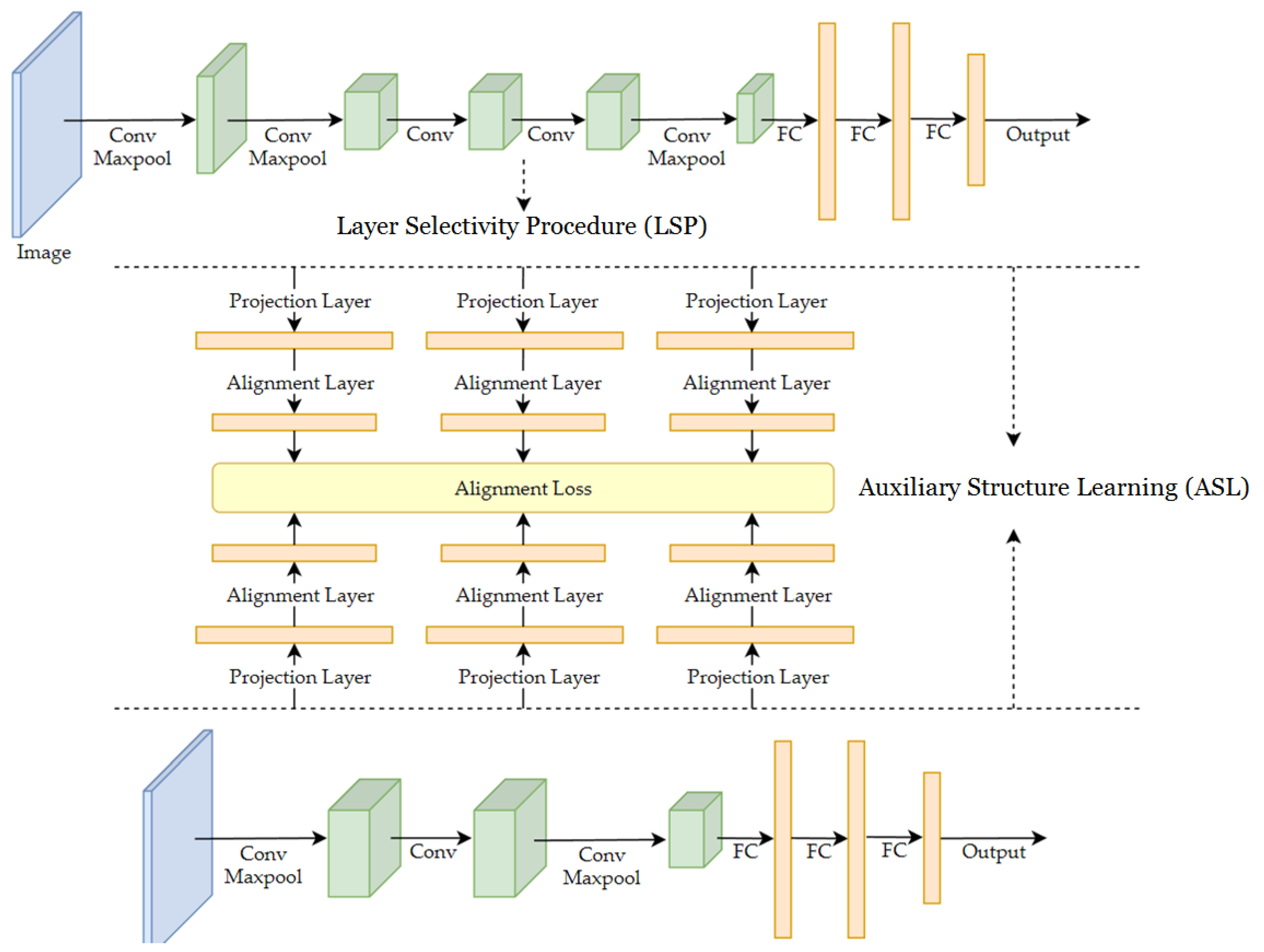
- Auxiliary Structure Learning (ASL) is proposed to improve the performance of a target model by distilling knowledge from a well-trained model;
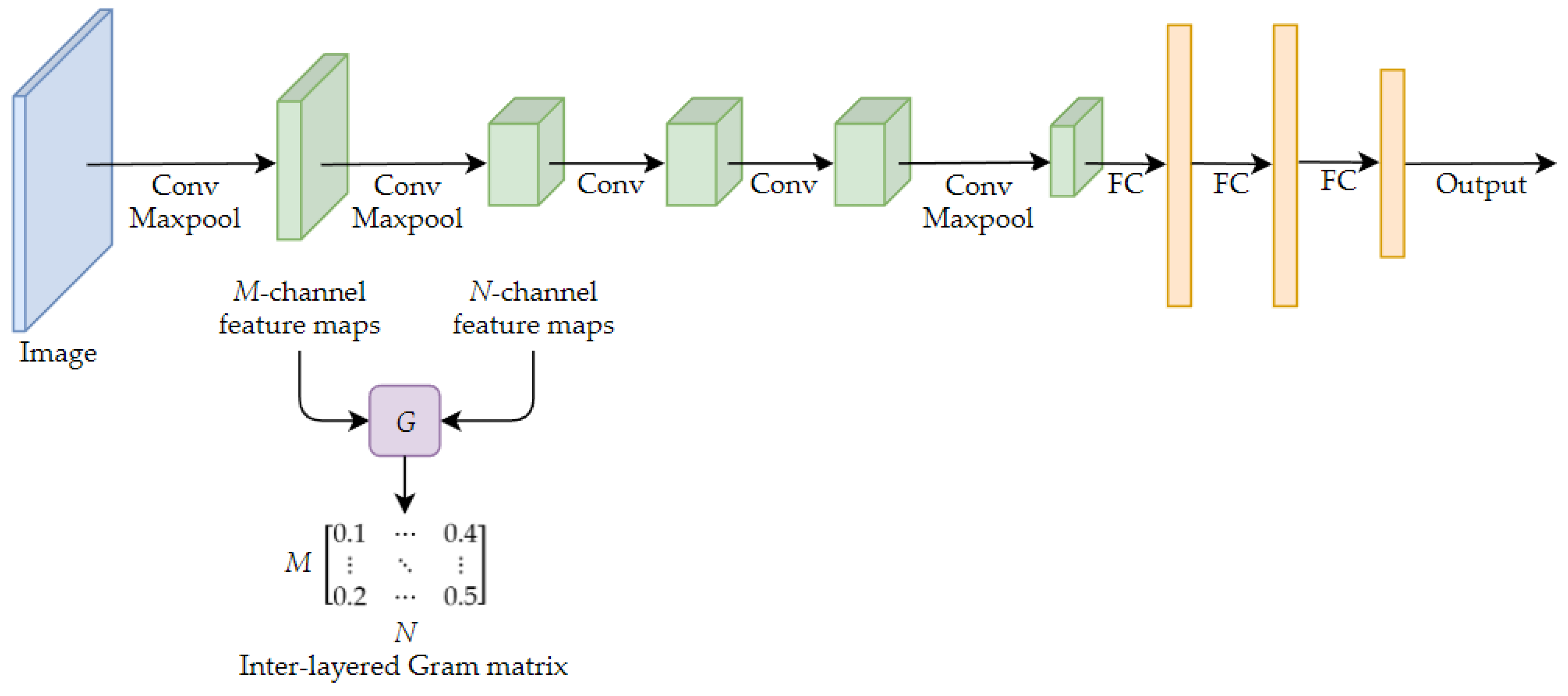
- The Layer Selectivity Procedure (LSP) includes two novel operators, the layered inter-class Gram matrix and the inter-layered Gram matrix, which are proposed for the selection and linkage of the intermediate layers of both target and source models.
2. Related Work
2.1. Model Compression by Network Pruning
2.2. Knowledge Distillation
2.2.1. Knowledge Distillation from Output
2.2.2. Knowledge Distillation from a Single Layer
2.2.3. Knowledge Distillation from Multiple Layers
2.3. Alignment Layers
3. Proposed Method
3.1. Auxiliary Structure Learning (ASL)
- Teacher network. The teacher network is also known as the source network, and is a well-trained deep learning model. In the ASL framework, the teacher network is supplied with pre-trained weights before the student network starts to train.
- Student network. The student network is also known as the target network. A student network is a new deep learning model without pre-trained weights.
- Alignment layer. The alignment layer is used to bridge the dual path deep learning models. It is designed to be the loss function that enforces similarity between two corresponding intermediate layers of both models.
- Projection layer. Since any two intermediate layers of both the teacher and student models are not likely to have the same feature dimensions, they cannot align directly. Before the representation layer connects to the alignment layer, it needs to connect to one additional fully connected layer, which is called the projection layer. This ensures that the two intermediate layers are projected to same dimension.
3.2. Layer Selectivity Procedure (LSP)
3.2.1. Inter-Layered Gram Matrix
3.2.2. Layered Inter-Class Gram Matrix
3.2.3. Layer Selectivity Procedure (LSP)
4. Experimental Results
4.1. Datasets
4.2. Experiment Settings
4.3. Results of ASL Framework and LSP
4.4. Comparison of Knowledge Distillation by Auxiliary Structure Learning
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR09), Miami, FL, USA, 22–24 June 2009. [Google Scholar]
- Girshick, R.B.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv 2013, arXiv:1311.2524. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Huang, Z.; Wang, N. Like What You Like: Knowledge Distill via Neuron Selectivity Transfer. arXiv 2017, arXiv:1707.01219. [Google Scholar]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. FitNets: Hints for Thin Deep Nets. arXiv 2014, arXiv:1412.6550. [Google Scholar]
- Yim, J.; Joo, D.; Bae, J.; Kim, J. A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 7130–7138. [Google Scholar]
- Molchanov, P.; Tyree, S.; Karras, T.; Aila, T.; Kautz, J. Pruning Convolutional Neural Networks for Resource Efficient Transfer Learning. arXiv 2016, arXiv:1611.06440. [Google Scholar]
- Luo, J.-H.; Wu, J.; Lin, W. ThiNet: A Filter Level Pruning Method for Deep Neural Network Compression. In Proceedings of the IEEE International Conference on Computer Vision (ICCV 2017), Venice, Italy, 22–29 October 2017; pp. 5068–5076. [Google Scholar]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning Filters for Efficient ConvNets. arXiv 2016, arXiv:1608.08710. [Google Scholar]
- He, Y.; Zhang, X.; Sun, J. Channel Pruning for Accelerating Very Deep Neural Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV 2017), Venice, Italy, 22–29 October 2017; pp. 1398–1406. [Google Scholar]
- Luo, P.; Zhu, Z.; Liu, Z.; Wang, X.; Tang, X. Face Model Compression by Distilling Knowledge from Neurons. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 3560–3566. [Google Scholar]
- Kim, Y.-D.; Park, E.; Yoo, S.; Choi, T.; Yang, L.; Shin, D. Compression of deep convolutional neural networks for fast and low power mobile applications. arXiv 2015, arXiv:1511.06530. [Google Scholar]
- Tang, R.; Lin, J. Adaptive Pruning of Neural Language Models for Mobile Devices. arXiv 2018, arXiv:1809.10282. [Google Scholar]
- Wang, J.; Cao, B.; Yu, P.; Sun, L.; Bao, W.; Zhu, X. Deep learning towards mobile applications. In Proceedings of the 2018 IEEE 38th International Conference on Distributed Computing Systems (ICDCS), Vienna, Austria, 2–6 July 2018; pp. 1385–1393. [Google Scholar]
- Chen, G.; Choi, W.; Yu, X.; Han, T.; Chandraker, M. Learning efficient object detection models with knowledge distillation. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 742–751. [Google Scholar]
- Yu, R.; Li, A.; Morariu, V.I.; Davis, L.S. Visual relationship detection with internal and external linguistic knowledge distillation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1974–1982. [Google Scholar]
- Plesse, F.; Ginsca, A.; Delezoide, B.; Prêteux, F. Visual Relationship Detection Based on Guided Proposals and Semantic Knowledge Distillation. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), Munich, Germany, 8–14 September 2018; pp. 1–6. [Google Scholar]
- Yang, X.; He, D.; Zhou, Z.; Kifer, D.; Giles, C.L. Improving offline handwritten Chinese character recognition by iterative refinement. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 5–10. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems 2012, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1106–1114. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W.J. Learning both Weights and Connections for Efficient Neural Networks. arXiv 2015, arXiv:1506.02626. [Google Scholar]
- Chen, Q.; Huang, J.; Feris, R.; Brown, L.M.; Dong, J.; Yan, S. Deep domain adaptation for describing people based on fine-grained clothing attributes. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5315–5324. [Google Scholar]
- Yao, B.; Li, F.-F. Grouplet: A structured image representation for recognizing human and object interactions. In Proceedings of the Twenty-Third IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2010), San Francisco, CA, USA, 13–18 June 2010; pp. 9–16. [Google Scholar]
- Delaitre, V.; Laptev, I.; Sivic, J. Recognizing human actions in still images: A study of bag-of-features and part-based representations. In Proceedings of the British Machine Vision Conference (BMVC 2010), Aberystwyth, UK, 31 August–3 September 2010; pp. 1–11. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? arXiv 2014, arXiv:1411.1792. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.B.; Guadarrama, S.; Darrell, T. Caffe: Convolutional Architecture for Fast Feature Embedding. arXiv 2014, arXiv:1408.5093. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| Layer Name | Type | Kernel | Stride | # Channels |
|---|---|---|---|---|
| Conv1 | conv | 11 | 4 | 96 |
| maxpool | 3 | 2 | 96 | |
| Conv2 | conv | 5 | 1 | 256 |
| maxpool | 3 | 2 | 256 | |
| Conv3 | conv | 3 | 1 | 384 |
| Conv4 | conv | 3 | 1 | 384 |
| Conv5 | conv | 3 | 1 | 256 |
| maxpool | 3 | 2 | 256 | |
| FC1 | 4096 | |||
| FC2 | 4096 | |||
| Layer Name | Type | Kernel | Stride | # Channels |
|---|---|---|---|---|
| Conv1 | conv | 3 | 1 | 96 |
| maxpool | 3 | 2 | 96 | |
| Conv2 | conv | 3 | 2 | 384 |
| Conv3 | conv | 3 | 1 | 256 |
| maxpool | 3 | 2 | 256 | |
| FC1 | 512 | |||
| FC2 | 512 | |||
| Layer Name | Teacher Net | Student Net |
|---|---|---|
| Conv2 | 0.00588 | 0.00193 |
| Conv3 | 0.00322 | 0.00143 |
| Conv4 | 0.00316 | N/A |
| Conv5 | 0.00307 | N/A |
| FC1 | 0.00015 | 0.00028 |
| FC2 | 0.00023 | 0.00037 |
| Configuration (X, Conv3) | PPMI | Willow | UIUC-Sports | |||
|---|---|---|---|---|---|---|
| Student Only | -- | 24.1 | -- | 41.0 | -- | 74.6 |
| Teacher Only | 60.7 | -- | 75.5 | -- | 94.2 | -- |
| Conv2 | 38.7 | 36.1 | 48.0 | 41.4 | 80.2 | 79.9 |
| Conv3 | 39.3 | 35.9 | 49.4 | 42.2 | 80.0 | 79.7 |
| Conv4 | 40.1 | 36.3 | 49.1 | 46.1 | 79.1 | 79.0 |
| Conv5 | 40.8 | 36.7 | 47.7 | 43.4 | 80.5 | 81.1 |
| Layer Combination | PPMI | Willow | UIUC-Sports | |||
|---|---|---|---|---|---|---|
| Conv2-Conv3 | 38.4 | 36.4 | 42.5 | 41.1 | 78.2 | 77.8 |
| Conv3-Conv4 | 39.5 | 36.0 | 48.2 | 42.8 | 78.6 | 77.0 |
| Conv4-Conv5 | 38.5 | 36.2 | 46.5 | 43.1 | 79.5 | 80.5 |
| Conv5-FC1 | 40.0 | 37.0 | 48.8 | 45.4 | 80.6 | 81.9 |
| FC1-FC2 | 37.5 | 35.5 | 46.0 | 43.1 | 82.1 | 81.0 |
| Layer Combination | PPMI | Willow | UIUC-Sports | |||
|---|---|---|---|---|---|---|
| Conv2-FC1-FC2 | 41.0 | 36.1 | 48.2 | 42.2 | 82.0 | 80.5 |
| Conv3-FC1-FC2 | 38.5 | 35.7 | 48.0 | 44.8 | 81.5 | 80.8 |
| Conv4-FC1-FC2 | 40.6 | 36.4 | 45.4 | 42.8 | 80.6 | 80.4 |
| Conv5-FC1-FC2 | 39.8 | 37.6 | 47.1 | 46.0 | 82.4 | 82.2 |
| Layer Combination | PPMI | Willow | UIUC-Sports | |||
|---|---|---|---|---|---|---|
| Conv2-Conv3-FC1 | 38.8 | 36.2 | 46.8 | 45.7 | 79.2 | 78.1 |
| Conv2-Conv3-FC2 | 39.0 | 36 | 48.5 | 46.2 | 80.2 | 79.3 |
| Conv3-FC1-FC2 | 39.0 | 36.8 | 48.8 | 46 | 78.4 | 79.8 |
| Methods | Accuracy (%) | ||
|---|---|---|---|
| PPMI | Willow | UIUC-Sports | |
| Teacher Only | 60.7 | 75.5 | 94.2 |
| Student Only | 24.1 | 41.0 | 74.6 |
| Hinton et al. [7] | 27.8 | 42.4 | 77.2 |
| FSP [10] | 37.9 | 44.2 | 85.5 |
| LSL | 41.0 | 48.0 | 87.2 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.-T.; Lin, S.-C.; Chen, C.-Y.; Chiang, C.-K. Layer-Level Knowledge Distillation for Deep Neural Network Learning. Appl. Sci. 2019, 9, 1966. https://doi.org/10.3390/app9101966
Li H-T, Lin S-C, Chen C-Y, Chiang C-K. Layer-Level Knowledge Distillation for Deep Neural Network Learning. Applied Sciences. 2019; 9(10):1966. https://doi.org/10.3390/app9101966
Chicago/Turabian StyleLi, Hao-Ting, Shih-Chieh Lin, Cheng-Yeh Chen, and Chen-Kuo Chiang. 2019. "Layer-Level Knowledge Distillation for Deep Neural Network Learning" Applied Sciences 9, no. 10: 1966. https://doi.org/10.3390/app9101966
APA StyleLi, H.-T., Lin, S.-C., Chen, C.-Y., & Chiang, C.-K. (2019). Layer-Level Knowledge Distillation for Deep Neural Network Learning. Applied Sciences, 9(10), 1966. https://doi.org/10.3390/app9101966