Regular Equivalence for Social Networks

Abstract
1. Introduction
2. Background and Context
3. Materials and Methods
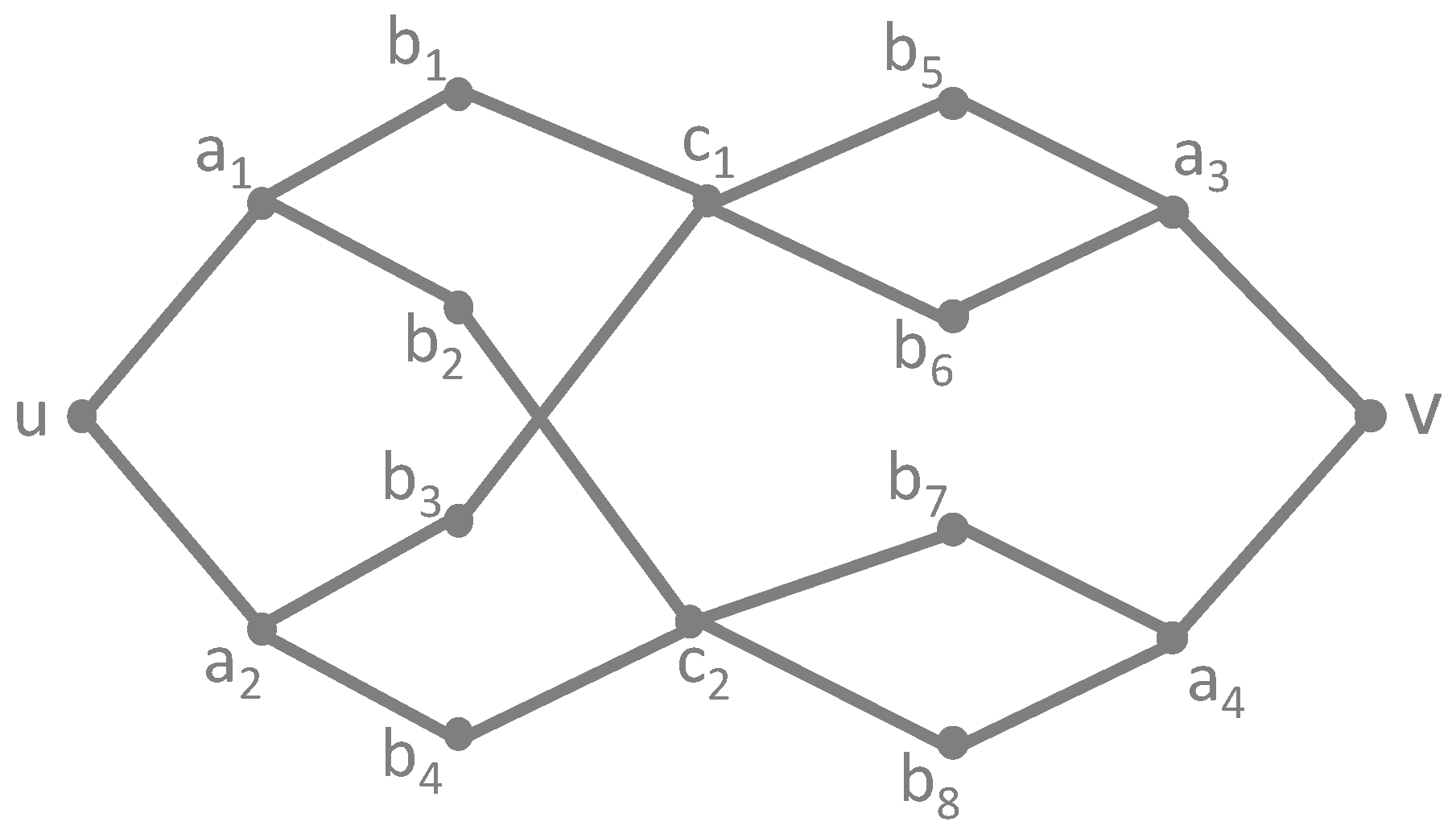
3.1. Graphs and Equivalence Relations
3.2. Regular Equivalence Algorithm
3.2.1. Description of the Algorithm
| Algorithm 1 Regular equivalence. |
Input: Graph G Output: Minimal regular coloring function c 1: for do end for 2: 3: repeat 4: for do end for 5: for do 6: Calculate 7: 8: end for 9: if then 10: break repeat-loop 11: end if 12: 13: 14: for do 15: for do end for 16: 17: end for 18: end repeat 19: return c |
3.2.2. Proof of Correctness
3.3. Computational Complexity
4. Results
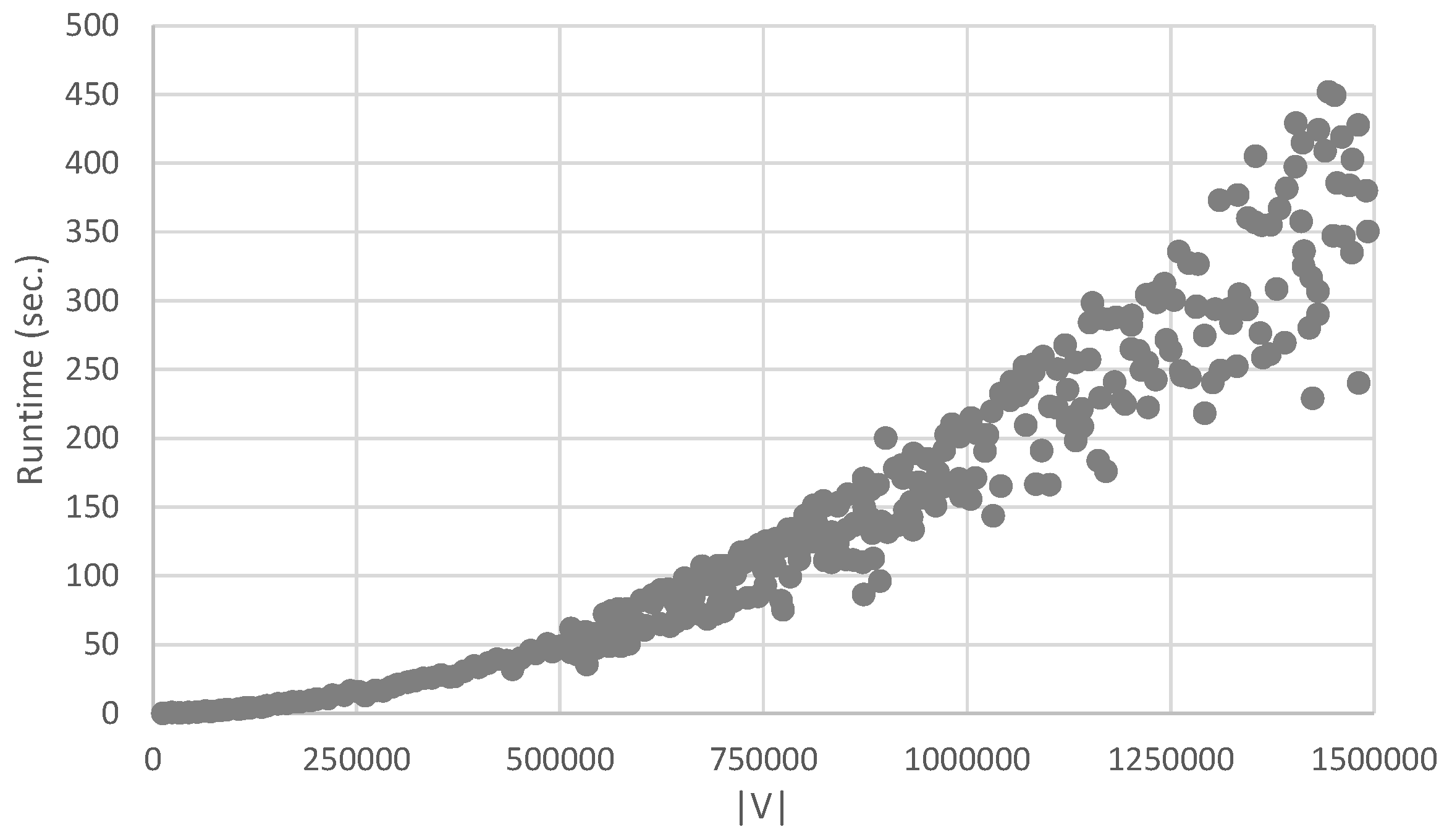
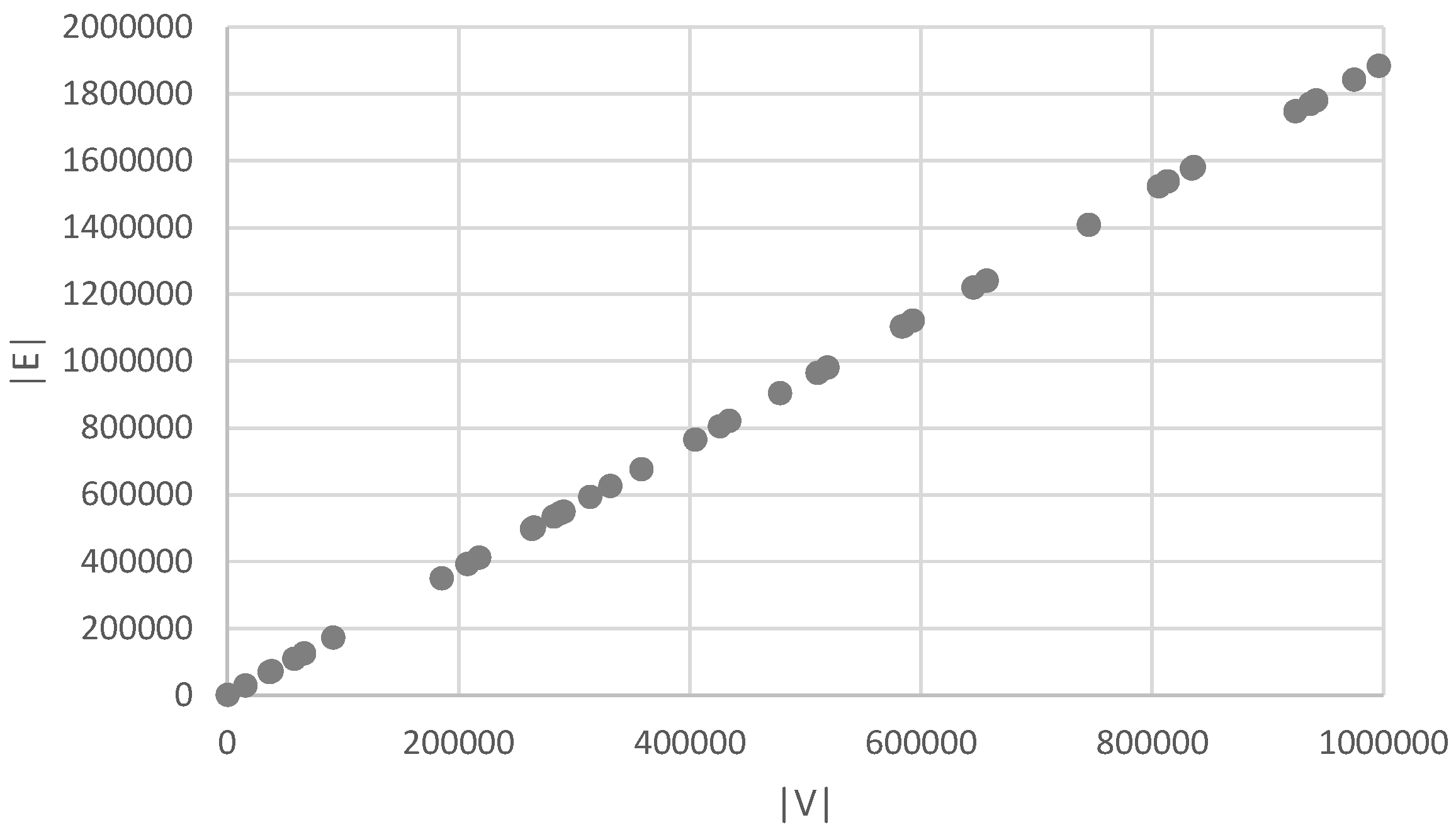
4.1. Runtimes for Calculating Regular Equivalences
4.2. Experiments
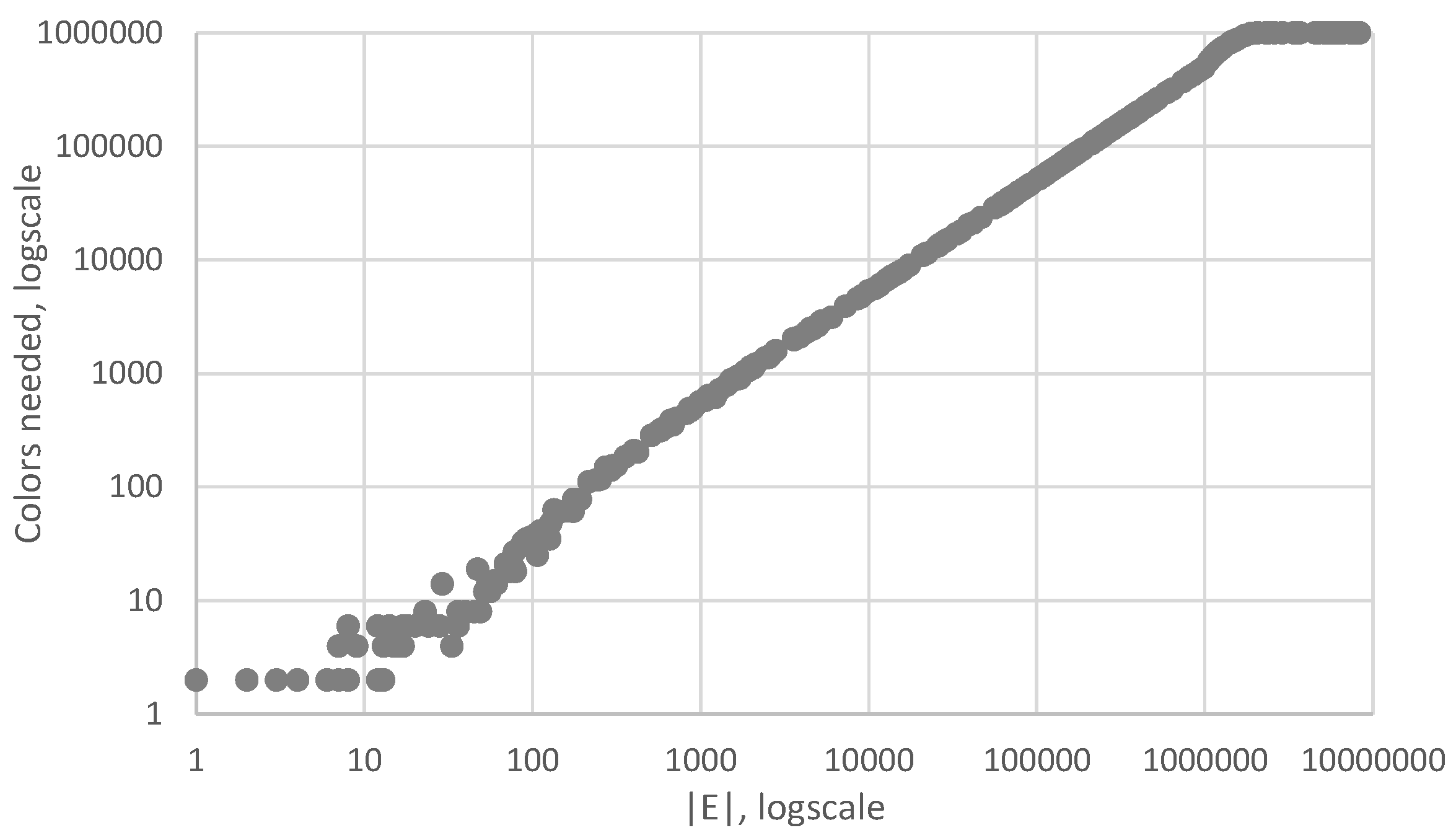
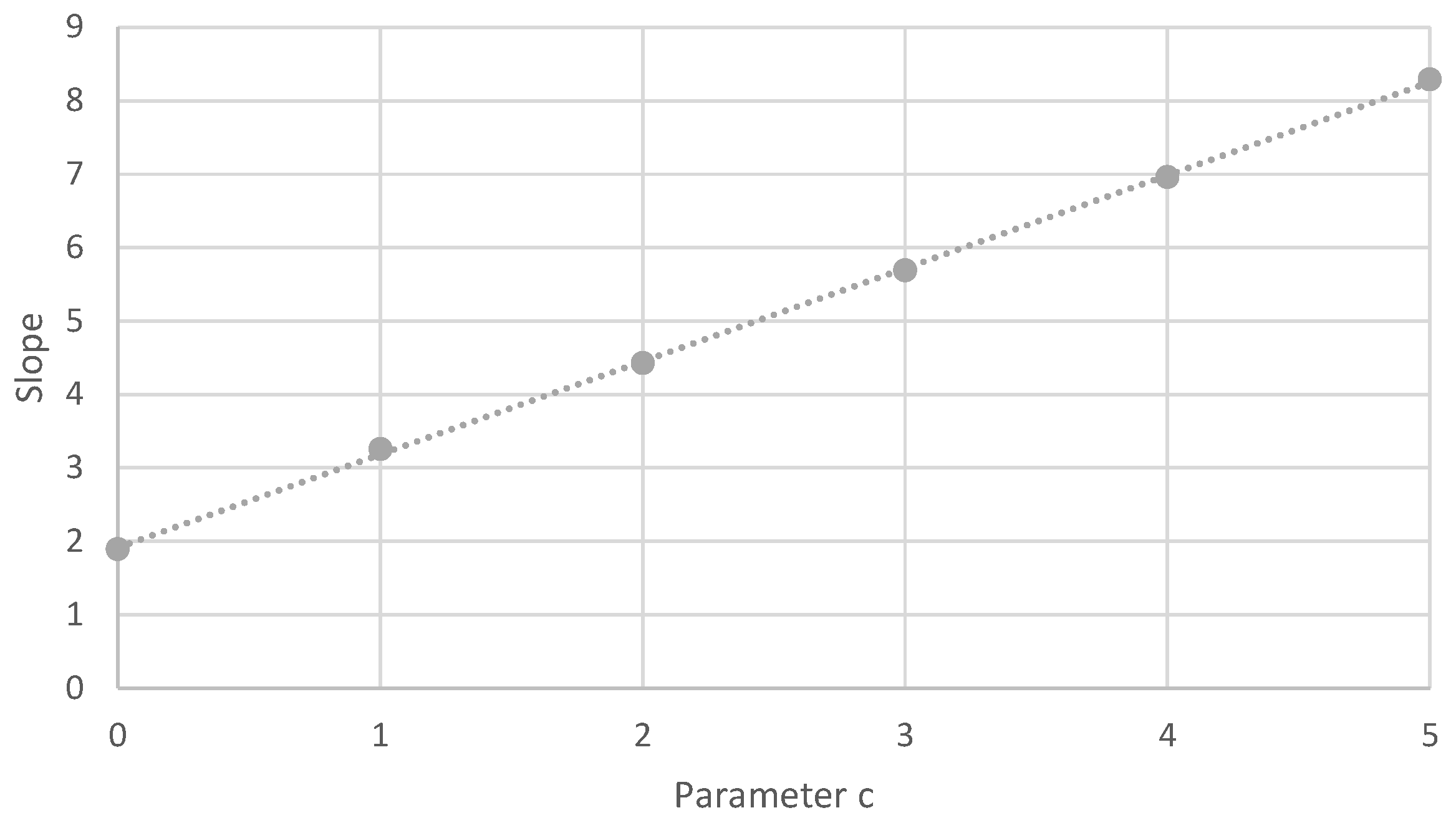
4.2.1. Random Barabási–Albert Graphs
| Algorithm 2 Relation between & to have many colors |
Input: Output: 1: 2: 3: while 4: 5: for 1 to 100 do 6: 7: 8: if then 9: 10: end if 11: end for 12: if then 13: 14: else 15: 16: end if 17: 18: end while 19: return |
4.2.2. Real-Life Social Networks
- CA-AstroPh: This graph represents a collaboration network on astrophysics obtained from arXiv. It covers scientific collaborations between authors that submitted papers within the Astrophysics category. If two authors u and v co-authored a paper, the graph will contain an (undirected) edge . It will thus contain a small complete subgraph for every paper in the database, as all authors on a single paper always induce a complete graph for these authors.
- CA-CondMat: This dataset corresponds to the collaboration network obtained from arXiv within the Condense Matter Physics category. It was derived in a similar way as the CA-AstroPh network. It has about more vertices than CA-AstroPh but only about half the number of edges.
- Email-Enron: This is an email-communication network, covering email communication within the company Enron, and consisting of about half a million emails. It was disclosed to the public by the Federal Energy Regulatory Commission during the investigation into the Enron scandal in 2001. Vertices represent email-addresses, and an undirected edge is added to the graph if either u or v sent at least one email to v or u, respectively. Thus, the original direction of communication is not available in the dataset.
- Slashdot0811: This dataset represents a social network derived from the website Slashdot, which is a news website focusing on technology-related subjects. Users can post messages and tag each other as friend or foe. They are represented by vertices and the tags are represented as undirected edges. No distinction is made between friend-tags and foe-tags, so an edge can have four different meanings. This explains the reduction in compared to the original dataset.
- DBLP: The DBLP-dataset is derived from the DBLP-database maintained by the University of Trier, which contains a computer science bibliography with a comprehensive list of academic research papers in different subjects all related to computer science. The dataset represents a collaboration network where two authors (vertices) are connected through an (undirected) edge if and only if they co-authored at least one paper.
- LiveJournal: This dataset was derived from LiveJournal, a website community allowing free blogs. People can befriend each other and form groups together. We consider being friends/foes a symmetric relation, and represent users as vertices and their friendships as undirected edges.
5. Discussion
Future Work
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| Seq(u,v) | vertices u and v are structurally equivalent |
| Aut(A) | permutation A is an automorphism |
| Aeq(u,v) | vertices u and v are automorphically equivalent |
| Reg(c) | coloring function c is regular |
| Minreg(c) | coloring function c is regular and minimal |
| Req(u,v) | vertices u and v are regularly equivalent |
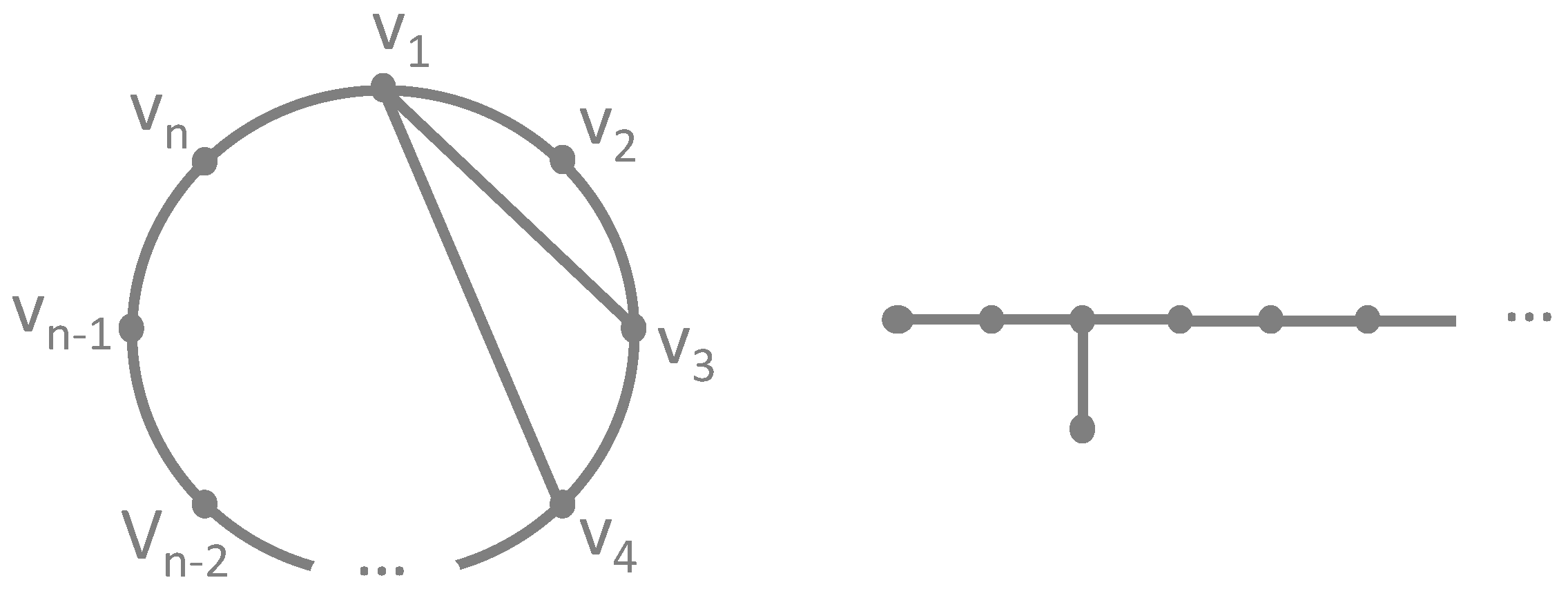
Appendix A. Barabási–Albert Graphs
- Add a new vertex to .
- Add new edges, each one between and some vertex , which is randomly chosen with a probability proportional to its degree.
- Add new edges, each one randomly chosen between vertices and , with a probability proportional to the product of their degrees.
References
- Erdos, P.; Rényi, A. On random graphs. Publ. Math. Debr. 1959, 6, 290–297. [Google Scholar]
- van Steen, M. Graph Theory and Complex Networks: An Introduction; On Demand Publishing, LLC-Create Space: North Charleston, SC, USA, 2010. [Google Scholar]
- Watts, D.J.; Strogatz, S.H. Collective dynamics of’small-world’networks. Nature 1998, 393, 440–442. [Google Scholar] [CrossRef] [PubMed]
- Csermely, P. Weak Links: The Universal Key to the Stability of Networks and Complex Systems; Springer-Verlag: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Barabási, A.; Ravasz, E.; Vicsek, T. Deterministic scale-free networks. Physica A 2001, 299, 559–564. [Google Scholar] [CrossRef]
- Albert, R.; Barabasi, A.L. Statistical mechanics of complex networks. Rev. Mod. Phys. 2002, 74, 47–97. [Google Scholar] [CrossRef]
- Barabási, A.L. Linked: The New Science Of Networks; Perseus Books Group: New York, NY, USA, 2002. [Google Scholar]
- Barabási, A.L.; Albert, R. Emergence of Scaling in Random Networks. Science 1999, 286, 509–512. [Google Scholar]
- Dorogovtsev, S.N.; Mendes, J.F.F. Evolution of Networks; Oxford University Press, Inc.: New York, NY, USA, 2003. [Google Scholar]
- Vega-Redondo, F. Complex Social Networks; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Dorogovtsev, S.N.; Mendes, J.F.F.; Samukhin, A.N. Structure of Growing Networks with Preferential Linking. Phys. Rev. Lett. 2000, 85, 4633–4636. [Google Scholar] [CrossRef]
- Holme, P.; Kim, B.J. Growing scale-free networks with tunable clustering. Phys. Rev. E 2002, 65, 026107. [Google Scholar] [CrossRef]
- Chen, Q.; Shi, D. The modeling of scale-free networks. Physica A 2004, 335, 240–248. [Google Scholar] [CrossRef]
- Wasserman, S.; Faust, K. Social Network Analysis; Cambridge University Press: Cambridge, UK, 1995. [Google Scholar]
- Easley, D.; Kleinberg, J. Networks, Crowds, and Markets; Cambridge University Press: New York, NY, USA, 2010. [Google Scholar]
- Lorrain, F.; White, H.C. Structural equivalence of individuals in social networks. J. Math. Soc. 1971, 1, 49–80. [Google Scholar] [CrossRef]
- Hanneman, R.; Riddle, M. Introduction to Social Network Methods; University of California: Oakland, CA, USA, 2005. [Google Scholar]
- Newman, M. Networks: An Introduction; OUP Oxford: Oxford, UK, 2010. [Google Scholar]
- Borgatti, S.P.; Everett, M.G. Notions of Position in Social Network Analysis. Sociol. Methodol. 1992, 22, 1–35. [Google Scholar] [CrossRef]
- Jin, R.; Lee, V.E.; Li, L. Scalable and Axiomatic Ranking of Network Role Similarity. ACM Trans. Knowl. Discov. Data 2014, 8, 3:1–3:37. [Google Scholar] [CrossRef]
- Fan, T.F.; Liau, C.J. Logical characterizations of regular equivalence. Artif. Intell. 2014, 214, 66–88. [Google Scholar] [CrossRef]
- Marx, M.; Masuch, M. Regular equivalence and dynamic logic. Soc. Netw. 2003, 25, 51–65. [Google Scholar] [CrossRef]
- Brandes, U.; Lerner, J. Structural Similarity: Spectral Methods for Relaxed Blockmodeling. J. Class 2010, 27, 279–306. [Google Scholar] [CrossRef]
- Boyd, J.P.; Jonas, K.J. Are social equivalences ever regular?: Permutation and exact tests. Soc. Netw. 2001, 23, 87–123. [Google Scholar] [CrossRef]
- Casse, J.I.; Shelton, C.R.; Hanneman, R.A. A new criterion function for exploratory blockmodeling for structural and regular equivalence. Soc. Netw. 2013, 35, 31–50. [Google Scholar] [CrossRef]
- Prota, L.; Doreian, P. Finding roles in sparse economic hierarchies: Going beyond regular equivalence. Soc. Netw. 2016, 45, 1–17. [Google Scholar] [CrossRef]
- Barrière, L.; Comellas, F.; Dalfó, C.; Fiol, M.A. Deterministic hierarchical networks. Physica A 2016, 49. [Google Scholar] [CrossRef]
- Fan, T.F.; Liau, C.J.; Lin, T.Y. A theoretical investigation of regular equivalences for fuzzy graphs. Int. J. Approx. Reason. 2008, 49, 678–688. [Google Scholar] [CrossRef]
- Doran, D. On the discovery of social roles in large scale social systems. Soc. Netw. Anal. Min. 2015, 5, 1–18. [Google Scholar] [CrossRef]
- Henderson, K.; Gallagher, B.; Eliassi-Rad, T.; Tong, H.; Basu, S.; Akoglu, L.; Koutra, D.; Faloutsos, C.; Li, L. RolX: Structural Role Extraction and Mining in Large Graphs. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD 2012, Beijing, China, 12–16 August 2012. [Google Scholar]
- Vega, D.; Magnani, M.; Montesi, D.; Meseguer, R.; Freitag, F. A new approach to role and position detection in networks. Soc. Netw. Anal. Min. 2016, 6, 1–23. [Google Scholar] [CrossRef]
- Vega, D.; Meseguer, R.; Freitag, F.; Magnani, M. Role and Position Detection in Networks: Reloaded. In Proceedings of the 2015 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Paris, France, 25–28 August 2015. [Google Scholar]
- Rossi, R.A.; Ahmed, N.K. Role Discovery in Networks. IEEE Trans. Knowl. Data Eng. 2015, 27, 1112–1131. [Google Scholar] [CrossRef]
- Purcell, C.; Rombach, P. On the complexity of role colouring planar graphs, trees and cographs. J. Discr. Alg. 2015, 35, 1–8. [Google Scholar] [CrossRef]
- Chen, J.; Saad, Y. Dense Subgraph Extraction with Application to Community Detection. IEEE Trans. Knowl. Data Eng. 2012, 24, 1216–1230. [Google Scholar] [CrossRef]
- Borgatti, S.; Everett, M. Two algorithms for computing regular equivalence. Soc. Netw. 1993, 15, 361–376. [Google Scholar] [CrossRef]
- Newman, M.E.J. Fast algorithm for detecting community structure in networks. Phys. Rev. E 2004, 69, 066133. [Google Scholar] [CrossRef]
- Boyd, J.P. Finding and testing regular equivalence. Soc. Netw. 2002, 24, 315–331. [Google Scholar] [CrossRef]
- Sedgewick, R.; Wayne, K. Algorithms; Pearson Education: London, UK, 2011. [Google Scholar]
- Leskovec, J.; Krevl, A. SNAP Datasets: Stanford Large Network Dataset Collection. Available online: http://snap.stanford.edu/data (accessed on 30 November 2018).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | |V| | |E| | |E|/|V| |
|---|---|---|---|
| CA-AstroPh | 18,772 | 198,050 | 10.6 |
| CA-CondMat | 23,133 | 93,439 | 4.0 |
| Email-Enron | 36,692 | 183,831 | 5.0 |
| Slashdot0811 | 77,360 | 469,180 | 6.1 |
| DBLP | 317,080 | 1,049,866 | 3.3 |
| LiveJournal | 3,997,962 | 34,681,189 | 8.7 |
| Network | |C| | |C|/|V| | Runtime (s) |
|---|---|---|---|
| CA-AstroPh | 14,734 | 0.9 | |
| CA-CondMat | 17,131 | 0.5 | |
| Email-Enron | 20,417 | 0.4 | |
| Slashdot0811 | 61,457 | 1.4 | |
| DBLP | 233,466 | 14.5 | |
| LiveJournal | 3,703,526 | 1684 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Audenaert, P.; Colle, D.; Pickavet, M. Regular Equivalence for Social Networks. Appl. Sci. 2019, 9, 117. https://doi.org/10.3390/app9010117
Audenaert P, Colle D, Pickavet M. Regular Equivalence for Social Networks. Applied Sciences. 2019; 9(1):117. https://doi.org/10.3390/app9010117
Chicago/Turabian StyleAudenaert, Pieter, Didier Colle, and Mario Pickavet. 2019. "Regular Equivalence for Social Networks" Applied Sciences 9, no. 1: 117. https://doi.org/10.3390/app9010117
APA StyleAudenaert, P., Colle, D., & Pickavet, M. (2019). Regular Equivalence for Social Networks. Applied Sciences, 9(1), 117. https://doi.org/10.3390/app9010117