Revealing Household Characteristics from Electricity Meter Data with Grade Analysis and Machine Learning Algorithms



Abstract
1. Introduction
- (1)
- Extraction of the comprehensive set of the behavioral features to capture different aspects of household characteristics;
- (2)
- Application of grade cluster analysis to identify important attributes to detect distinct consumption patterns of the customers and further, using only a subset of relevant features for classification, to reveal socio-demographic characteristics of the households;
- (3)
- Classification of households’ properties using three machine learning algorithms and three feature selection techniques.
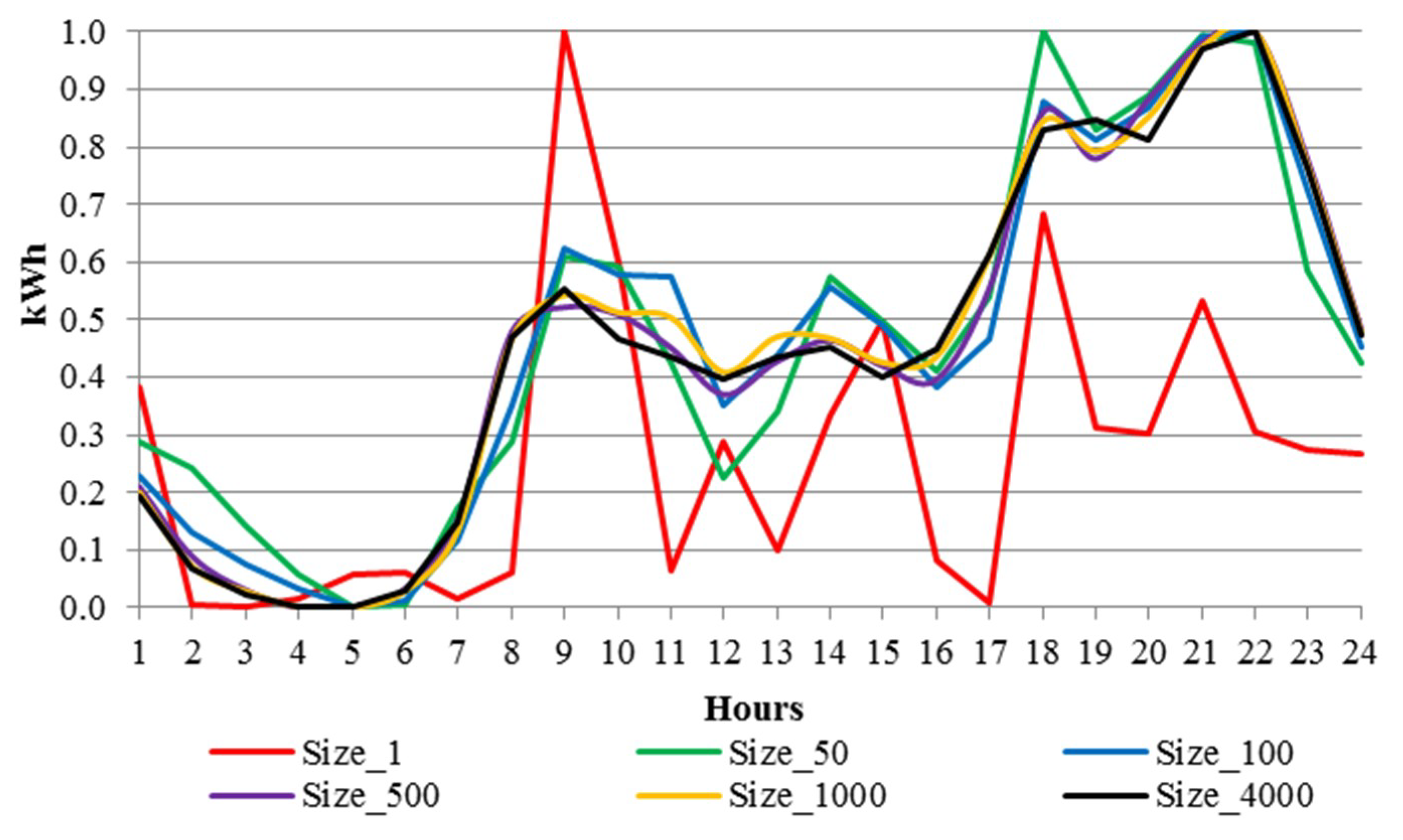
2. Smart Meter Data Used
2.1. The CER Data Set
2.2. Features
3. Grade Data Analysis
4. GCA Clustering Experiments
- gray–the feature for the element (household) is neutral (ranging between the 0.99–1.01) which means that the real value of the feature is equal to its expected value;
- black or dark gray–the feature for the element (household) is over-represented (between 1.01 and 1.5 for weak over-representation and more than 1.5 for strong) which means that the real value of the feature is greater than the expected one;
- light gray or white–the feature for the element (household) is under-represented (between 0.66 and 0.99 for weak under-representation and less than 0.66 for strong under-representation), which means that the real value of feature is less than the expected one.
5. Classification of Selected Household Characteristics
5.1. Problem Statement
- Family type;
- Number of bedrooms;
- Number of appliances;
- Employment;
- Floor area;
- House type;
- House age;
- Householder age.
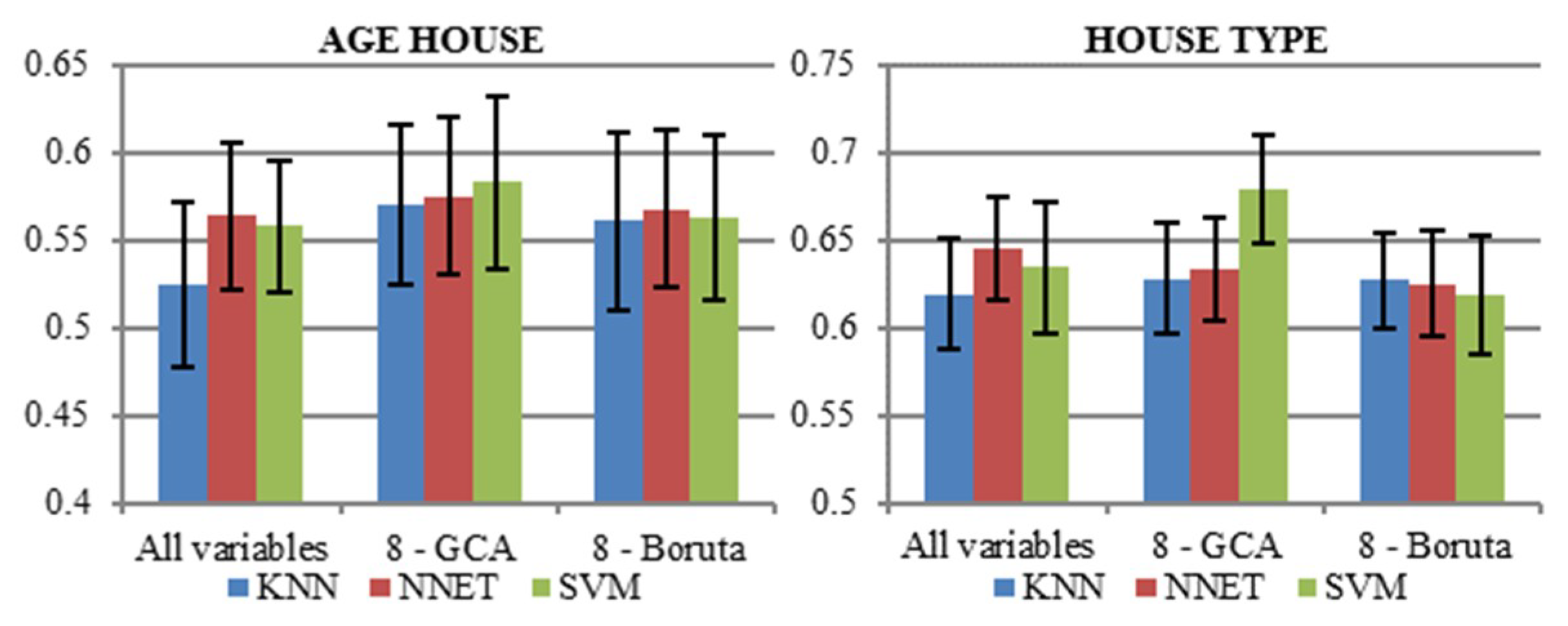
- All the variables (91) were used in the algorithms;
- Eight variables based on GCA and selected as representatives of each cluster having the highest AUC measure (please refer to Appendix A, Table A1);
- Eight variables based on Boruta package which is the feature selection algorithm for finding relevant variables [26].
5.2. Accuracy Measures
5.3. Classification Algorithms
5.3.1. Artificial Neural Networks
5.3.2. K-Nearest Neighbors Classification
5.3.3. Support Vector Classification
5.4. Classification Results
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cluster: 1 | ||||||||
| Variable | Family | Bedrooms | Age_Person | Employ | House_Type | Age_House | Appliances | Floor_Area |
| r_var_wd_we | 0.467 | 0.495 | 0.495 | 0.482 | 0.508 | 0.488 | 0.468 | 0.498 |
| number_zeros | 0.513 | 0.506 | 0.506 | 0.482 | 0.508 | 0.503 | 0.49 | 0.5 |
| r_morning_noon_no_min | 0.566 | 0.539 | 0.539 | 0.509 | 0.485 | 0.517 | 0.538 | 0.555 |
| r_wd_morning_noon | 0.568 | 0.52 | 0.52 | 0.608 | 0.487 | 0.523 | 0.542 | 0.546 |
| r_wd_evening_noon | 0.49 | 0.499 | 0.499 | 0.595 | 0.505 | 0.546 | 0.526 | 0.521 |
| r_evening_noon_no_min | 0.525 | 0.51 | 0.51 | 0.638 | 0.493 | 0.54 | 0.513 | 0.519 |
| r_we_morning_noon | 0.61 | 0.518 | 0.518 | 0.644 | 0.549 | 0.517 | 0.495 | 0.533 |
| width_peaks | 0.514 | 0.538 | 0.538 | 0.521 | 0.577 | 0.47 | 0.419 | 0.514 |
| r_max_wd_we | 0.53 | 0.508 | 0.508 | 0.513 | 0.523 | 0.501 | 0.491 | 0.522 |
| r_morning_noon | 0.589 | 0.52 | 0.52 | 0.494 | 0.527 | 0.521 | 0.538 | 0.552 |
| const_time | 0.547 | 0.542 | 0.542 | 0.562 | 0.511 | 0.541 | 0.557 | 0.537 |
| r_evening_noon | 0.496 | 0.501 | 0.501 | 0.53 | 0.508 | 0.509 | 0.53 | 0.52 |
| r_min_mean | 0.513 | 0.553 | 0.553 | 0.633 | 0.528 | 0.487 | 0.581 | 0.537 |
| r_we_evening_noon | 0.515 | 0.495 | 0.495 | 0.484 | 0.506 | 0.512 | 0.518 | 0.487 |
| r_mean_max_no_min | 0.554 | 0.579 | 0.579 | 0.566 | 0.572 | 0.546 | 0.562 | 0.536 |
| r_wd_night_day | 0.584 | 0.519 | 0.519 | 0.55 | 0.557 | 0.521 | 0.631 | 0.514 |
| value_min_guess | 0.481 | 0.533 | 0.533 | 0.502 | 0.579 | 0.516 | 0.577 | 0.509 |
| first_above_base | 0.535 | 0.515 | 0.515 | 0.531 | 0.524 | 0.568 | 0.552 | 0.522 |
| r_night_day | 0.588 | 0.52 | 0.52 | 0.499 | 0.559 | 0.519 | 0.566 | 0.521 |
| dist_big_v | 0.544 | 0.526 | 0.526 | 0.502 | 0.518 | 0.512 | 0.54 | 0.522 |
| r_noon_wd_we | 0.512 | 0.502 | 0.502 | 0.514 | 0.495 | 0.496 | 0.537 | 0.536 |
| r_we_night_day | 0.574 | 0.518 | 0.518 | 0.565 | 0.55 | 0.515 | 0.569 | 0.542 |
| r_afternoon_wd_we | 0.508 | 0.495 | 0.495 | 0.501 | 0.502 | 0.505 | 0.537 | 0.485 |
| time_above_base2 | 0.51 | 0.523 | 0.523 | 0.557 | 0.551 | 0.538 | 0.567 | 0.547 |
| number_big_peaks | 0.618 | 0.541 | 0.541 | 0.504 | 0.51 | 0.533 | 0.481 | 0.512 |
| r_evening_wd_we | 0.478 | 0.508 | 0.508 | 0.5 | 0.511 | 0.5 | 0.506 | 0.537 |
| r_night_wd_we | 0.504 | 0.5 | 0.5 | 0.508 | 0.533 | 0.503 | 0.488 | 0.554 |
| Cluster: 2 | ||||||||
| Variable | Family | Bedrooms | Age_Person | Employ | House_Type | Age_House | Appliances | Floor_Area |
| number_small_peaks | 0.569 | 0.546 | 0.546 | 0.522 | 0.516 | 0.527 | 0.526 | 0.508 |
| s_num_peaks | 0.569 | 0.546 | 0.546 | 0.522 | 0.516 | 0.527 | 0.526 | 0.508 |
| r_min_wd_we | 0.508 | 0.51 | 0.51 | 0.511 | 0.552 | 0.512 | 0.503 | 0.537 |
| r_morning_wd_we | 0.567 | 0.483 | 0.483 | 0.579 | 0.544 | 0.509 | 0.467 | 0.499 |
| t_daily_max | 0.502 | 0.506 | 0.506 | 0.494 | 0.507 | 0.523 | 0.516 | 0.55 |
| s_cor_we | 0.525 | 0.519 | 0.519 | 0.533 | 0.506 | 0.523 | 0.54 | 0.515 |
| s_cor_wd_we | 0.548 | 0.541 | 0.541 | 0.562 | 0.511 | 0.503 | 0.544 | 0.542 |
| percent_above_base | 0.63 | 0.585 | 0.585 | 0.499 | 0.542 | 0.511 | 0.571 | 0.547 |
| s_cor_wd | 0.549 | 0.545 | 0.545 | 0.55 | 0.522 | 0.521 | 0.584 | 0.517 |
| t_above_mean | 0.569 | 0.556 | 0.556 | 0.558 | 0.523 | 0.541 | 0.542 | 0.516 |
| ts_acf_mean3h | 0.547 | 0.561 | 0.561 | 0.518 | 0.561 | 0.52 | 0.565 | 0.527 |
| t_daily_min | 0.544 | 0.549 | 0.549 | 0.53 | 0.535 | 0.507 | 0.555 | 0.548 |
| ts_acf_mean3h_weekday | 0.589 | 0.565 | 0.565 | 0.497 | 0.52 | 0.51 | 0.574 | 0.526 |
| Cluster: 3 | ||||||||
| Variable | Family | Bedrooms | Age_Person | Employ | House_Type | Age_House | Appliances | Floor_Area |
| r_mean_max | 0.57 | 0.59 | 0.59 | 0.527 | 0.587 | 0.528 | 0.598 | 0.539 |
| t_above_base | 0.718 | 0.584 | 0.584 | 0.519 | 0.502 | 0.516 | 0.552 | 0.528 |
| r_day_night_no_min | 0.582 | 0.529 | 0.529 | 0.553 | 0.512 | 0.539 | 0.568 | 0.506 |
| wide_peaks | 0.457 | 0.541 | 0.541 | 0.497 | 0.577 | 0.508 | 0.588 | 0.515 |
| c_max | 0.758 | 0.635 | 0.635 | 0.636 | 0.545 | 0.546 | 0.634 | 0.557 |
| c_wd_max | 0.757 | 0.63 | 0.63 | 0.642 | 0.538 | 0.557 | 0.629 | 0.544 |
| c_we_max | 0.746 | 0.634 | 0.634 | 0.623 | 0.546 | 0.538 | 0.616 | 0.541 |
| s_max_avg | 0.783 | 0.647 | 0.647 | 0.65 | 0.551 | 0.549 | 0.652 | 0.543 |
| value_above_base | 0.779 | 0.65 | 0.65 | 0.609 | 0.55 | 0.559 | 0.632 | 0.54 |
| c_sm_max | 0.766 | 0.646 | 0.646 | 0.639 | 0.564 | 0.551 | 0.653 | 0.551 |
| c_min | 0.658 | 0.641 | 0.641 | 0.574 | 0.578 | 0.52 | 0.635 | 0.533 |
| sm_variety | 0.731 | 0.631 | 0.631 | 0.584 | 0.575 | 0.517 | 0.612 | 0.56 |
| Cluster: 4 | ||||||||
| Variable | Family | Bedrooms | Age_Person | Employ | House_Type | Age_House | Appliances | Floor_Area |
| c_wd_min | 0.661 | 0.647 | 0.647 | 0.572 | 0.585 | 0.519 | 0.661 | 0.514 |
| c_we_evening | 0.737 | 0.649 | 0.649 | 0.63 | 0.573 | 0.541 | 0.619 | 0.554 |
| c_evening | 0.764 | 0.661 | 0.661 | 0.645 | 0.583 | 0.541 | 0.645 | 0.557 |
| c_wd_evening | 0.765 | 0.657 | 0.657 | 0.645 | 0.581 | 0.541 | 0.641 | 0.553 |
| c_evening_no_min | 0.761 | 0.65 | 0.65 | 0.645 | 0.571 | 0.542 | 0.624 | 0.548 |
| b_day_diff | 0.744 | 0.64 | 0.64 | 0.61 | 0.566 | 0.545 | 0.647 | 0.552 |
| c_wd_night | 0.661 | 0.633 | 0.633 | 0.576 | 0.611 | 0.505 | 0.654 | 0.54 |
| c_afternoon | 0.654 | 0.633 | 0.633 | 0.578 | 0.615 | 0.5 | 0.652 | 0.522 |
| c_night | 0.654 | 0.633 | 0.633 | 0.578 | 0.615 | 0.5 | 0.652 | 0.522 |
| b_day_weak | 0.714 | 0.631 | 0.631 | 0.605 | 0.565 | 0.543 | 0.63 | 0.557 |
| c_wd_morning | 0.684 | 0.628 | 0.628 | 0.599 | 0.587 | 0.498 | 0.622 | 0.55 |
| c_morning | 0.673 | 0.629 | 0.629 | 0.585 | 0.601 | 0.498 | 0.624 | 0.55 |
| c_weekend | 0.742 | 0.657 | 0.657 | 0.603 | 0.597 | 0.489 | 0.641 | 0.528 |
| c_we_morning | 0.627 | 0.617 | 0.617 | 0.541 | 0.615 | 0.504 | 0.612 | 0.535 |
| c_we_min | 0.648 | 0.64 | 0.64 | 0.572 | 0.606 | 0.49 | 0.629 | 0.549 |
| c_we_night | 0.639 | 0.628 | 0.628 | 0.579 | 0.606 | 0.494 | 0.638 | 0.494 |
| c_we_afternoon | 0.749 | 0.635 | 0.635 | 0.603 | 0.559 | 0.535 | 0.611 | 0.529 |
| s_min_avg | 0.665 | 0.655 | 0.655 | 0.575 | 0.617 | 0.492 | 0.659 | 0.526 |
| c_week | 0.761 | 0.669 | 0.669 | 0.603 | 0.599 | 0.496 | 0.67 | 0.555 |
| c_night_no_min | 0.638 | 0.606 | 0.606 | 0.566 | 0.594 | 0.512 | 0.623 | 0.521 |
| s_diff | 0.765 | 0.668 | 0.668 | 0.6 | 0.594 | 0.499 | 0.668 | 0.554 |
| c_weekday | 0.765 | 0.668 | 0.668 | 0.6 | 0.594 | 0.499 | 0.668 | 0.554 |
| bg_variety | 0.806 | 0.657 | 0.657 | 0.603 | 0.561 | 0.525 | 0.631 | 0.546 |
| n_d_diff | 0.636 | 0.603 | 0.603 | 0.567 | 0.59 | 0.507 | 0.624 | 0.512 |
| c_morning_no_min | 0.676 | 0.612 | 0.612 | 0.581 | 0.578 | 0.501 | 0.59 | 0.548 |
| s_q1 | 0.715 | 0.665 | 0.665 | 0.573 | 0.612 | 0.498 | 0.657 | 0.515 |
| c_we_noon | 0.71 | 0.625 | 0.625 | 0.557 | 0.571 | 0.517 | 0.61 | 0.541 |
| c_wd_afternoon | 0.766 | 0.646 | 0.646 | 0.574 | 0.562 | 0.541 | 0.648 | 0.553 |
| s_q3 | 0.743 | 0.662 | 0.662 | 0.588 | 0.6 | 0.494 | 0.66 | 0.554 |
| c_noon | 0.73 | 0.644 | 0.644 | 0.536 | 0.581 | 0.505 | 0.63 | 0.538 |
| s_q2 | 0.759 | 0.662 | 0.662 | 0.565 | 0.589 | 0.486 | 0.651 | 0.532 |
| c_wd_noon | 0.717 | 0.636 | 0.636 | 0.518 | 0.573 | 0.5 | 0.622 | 0.532 |
| c_noon_no_min | 0.715 | 0.624 | 0.624 | 0.513 | 0.557 | 0.498 | 0.604 | 0.528 |
| ts_stl_varRem | 0.748 | 0.632 | 0.632 | 0.646 | 0.556 | 0.494 | 0.616 | 0.541 |
| s_var_we | 0.735 | 0.635 | 0.635 | 0.623 | 0.553 | 0.491 | 0.61 | 0.535 |
| t_above_1kw | 0.74 | 0.655 | 0.655 | 0.605 | 0.595 | 0.499 | 0.668 | 0.549 |
| s_variance | 0.75 | 0.641 | 0.641 | 0.635 | 0.563 | 0.499 | 0.645 | 0.545 |
| s_var_wd | 0.752 | 0.637 | 0.637 | 0.634 | 0.559 | 0.504 | 0.644 | 0.545 |
| t_above_2kw | 0.745 | 0.651 | 0.651 | 0.632 | 0.573 | 0.496 | 0.657 | 0.53 |
Appendix B
| Training/Validation Sample | ||||
| AC | AUC | |||
| Model for family | All variables | ANN (iteration = 17, neurons = 9) | 0.766 (±0.015)/0.731 (±0.025) | 0.854 (±0.016)/0.822 (±0.029) |
| KNN (k = 260) | 0.722 (±0.017)/0.701 (±0.026) | 0.806 (±0.019)/0.787 (±0.031) | ||
| SVM (kernel = polynomial, degree = 1, C = 0.3, gamma = 0.1) | 0.778 (±0.016)/0.735 (±0.026) | 0.825 (±0.017)/0.808 (±0.033) | ||
| 8 best variables based on AUC and GCA | ANN (iteration = 28, neurons = 7) | 0.755 (±0.016)/0.736 (±0.025) | 0.834 (±0.019)/0.812 (±0.031) | |
| KNN (k = 280) | 0.776 (±0.016)/0.759 (±0.025) | 0.831 (±0.019)/0.811 (±0.033) | ||
| SVM (kernel = sigmoid, degree = 1, C = 0.9, gamma = 0.1) | 0.673 (±0.018)/0.668 (±0.027) | 0.798 (±0.019)/0.794 (±0.025) | ||
| 8 best variables based on Boruta | ANN (iteration = 28, neurons = 14) | 0.769 (±0.016)/0.740 (±0.025) | 0.847 (±0.016)/0.817 (±0.031) | |
| KNN (k = 160) | 0.754 (±0.016)/0.737 (±0.025) | 0.833 (±0.017)/0.803 (±0.031) | ||
| SVM (kernel = sigmoid, degree = 1, C = 0.3, gamma = 0.1) | 0.761 (±0.016)/0.750 (±0.025) | 0.826 (±0.018)/0.800 (±0.032) | ||
| Training/Validation Sample | ||||
| AC | AUC | |||
| Model for bedrooms | All variables | ANN (iteration = 2217, neurons = 4) | 0.493 (±0.018)/0.509 (±0.028) | 0.700 (±0.013)/0.674 (±0.024) |
| KNN (k = 250) | 0.494 (±0.019)/0.496 (±0.028) | 0.668 (±0.012)/0.660 (±0.024) | ||
| SVM (kernel = sigmoid, degree = 1, C = 0.1, gamma = 0.1) | 0.494 (±0.018)/0.508 (±0.028) | 0.674 (±0.014)/0.656 (±0.023) | ||
| 8 best variables based on AUC and GCA | ANN (iteration = 19, neurons = 6) | 0.482 (±0.019)/0.492 (±0.028) | 0.683 (±0.013)/0.669 (±0.025) | |
| KNN (k = 300) | 0.491 (±0.018)/0.505 (±0.028) | 0.685 (±0.013)/0.657 (±0.025) | ||
| SVM (kernel = polynomial, degree = 1, C = 0.9, gamma = 0.9) | 0.490 (±0.018)/0.504 (±0.028) | 0.667 (±0.012)/0.664 (±0.025) | ||
| 8 best variables based on Boruta | ANN (iteration = 26, neurons = 9) | 0.494 (±0.018)/0.507 (±0.028) | 0.683 (±0.013)/0.665 (±0.025) | |
| KNN (k = 300) | 0.492 (±0.019)/0.514 (±0.028) | 0.687 (±0.013)/0.667 (±0.024) | ||
| SVM (kernel = polynomial, degree = 3, C = 0.7, gamma = 0.7) | 0.486 (±0.018)/0.512 (±0.028) | 0.679 (±0.011)/0.667 (±0.021) | ||
| Training/Validation Sample | ||||
| AC | AUC | |||
| Model for age_person | All variables | ANN (iteration = 16, neurons = 3) | 0.678 (±0.017)/0.683 (±0.027) | 0.708 (±0.016)/0.690 (±0.026) |
| KNN (k = 90) | 0.670 (±0.017)/0.670 (±0.027) | 0.713 (±0.017)/0.673 (±0.028) | ||
| SVM (kernel = polynomial, degree = 1, C = 0.1, gamma = 0.9) | 0.674 (±0.017)/0.678 (±0.027) | 0.726 (±0.013)/0.691 (±0.023) | ||
| 8 best variables based on AUC and GCA | ANN (iteration = 27, neurons = 4) | 0.666 (±0.017)/0.674 (±0.027) | 0.666 (±0.019)/0.625 (±0.029) | |
| KNN (k = 260) | 0.665 (±0.018)/0.680 (±0.026) | 0.663 (±0.021)/0.614 (±0.030) | ||
| SVM (kernel = polynomial, degree = 2, C = 0.93, gamma = 0.1) | 0.666 (±0.018)/0.680 (±0.027) | 0.639 (±0.023)/0.613 (±0.036) | ||
| 8 best variables based on Boruta | ANN (iteration = 23, neurons = 9) | 0.666 (±0.017)/0.669 (±0.027) | 0.699 (±0.017)/0.670 (±0.028) | |
| KNN (k = 300) | 0.665 (±0.017)/0.671 (±0.027) | 0.698 (±0.019)/0.660 (±0.025) | ||
| SVM (kernel = polynomial, degree = 3, C = 0.5, gamma = 0.1) | 0.662 (±0.017)/0.671 (±0.027) | 0.659 (±0.016)/0.658 (±0.025) | ||
| Training/Validation Sample | ||||
| AC | AUC | |||
| Model for employ | All variables | ANN (iteration = 13, neurons = 8) | 0.696 (±0.017)/0.676 (±0.027) | 0.754 (±0.017)/0.732 (±0.027) |
| KNN (k = 140) | 0.674 (±0.017)/0.655 (±0.027) | 0.734 (±0.017)/0.711 (±0.025) | ||
| SVM (kernel = linear, degree = 1, C = 1, gamma = 1) | 0.703 (±0.017)/0.663 (±0.027) | 0.758 (±0.018)/0.728 (±0.034) | ||
| 8 best variables based on AUC and GCA | ANN (iteration = 6, neurons = 11) | 0.678 (±0.018)/0.671 (±0.027) | 0.713 (±0.018)/0.712 (±0.030) | |
| KNN (k = 260) | 0.682 (±0.018)/0.671 (±0.027) | 0.734 (±0.018)/0.713 (±0.027) | ||
| SVM (kernel = polynomial, degree = 3, C = 0.1, gamma = 0.5) | 0.672 (±0.017)/0.663 (±0.027) | 0.726 (±0.020)/0.713 (±0.031) | ||
| 8 best variables based on Boruta | ANN (iteration = 5, neurons = 13) | 0.652 (±0.018)/0.655 (±0.027) | 0.704 (±0.018)/0.702 (±0.030) | |
| KNN (k = 300) | 0.677 (±0.017)/0.662 (±0.027) | 0.723 (±0.019)/0.703 (±0.031) | ||
| SVM (kernel = sigmoid, degree = 1, C = 0.9, gamma = 0.9) | 0.678 (±0.017)/0.666 (±0.027) | 0.718 (±0.021)/0.704 (±0.030) | ||
| Training/Validation Sample | ||||
| AC | AUC | |||
| Model for floor_area | All variables | ANN (iteration = 17, neurons = 9) | 0.622 (±0.018)/0.587 (±0.028) | 0.604 (±0.033)/0.594 (±0.038) |
| KNN (k = 260) | 0.598 (±0.018)/0.585 (±0.028) | 0.681 (±0.031)/0.573 (±0.055) | ||
| SVM (kernel = sigmoid, degree = 1, C = 0.7, gamma = 0.1) | 0.609 (±0.018)/0.598 (±0.028) | 0.587 (±0.053)/0.627 (±0.057) | ||
| 8 best variables based on AUC and GCA | ANN (iteration = 28, neurons = 7) | 0.613 (±0.018)/0.578 (±0.028) | 0.580 (±0.033)/0.566 (±0.063) | |
| KNN (k = 280) | 0.585 (±0.018)/0.571 (±0.028) | 0.692 (±0.026)/0.560 (±0.064) | ||
| SVM (kernel = polynomial, degree = 1, C = 0.9, gamma = 0.1) | 0.599 (±0.018)/0.583 (±0.028) | 0.574 (±0.044)/0.575 (±0.061) | ||
| 8 best variables based on Boruta | ANN (iteration = 28, neurons = 14) | 0.603 (±0.017)/0.592 (±0.027) | 0.583 (±0.034)/0.583 (±0.049) | |
| KNN (k = 160) | 0.591 (±0.018)/0.571 (±0.028) | 0.625 (±0.032)/0.576 (±0.083) | ||
| SVM (kernel = polynomial, degree = 1, C = 0.9, gamma = 0.5) | 0.593 (±0.018)/0.586 (±0.027) | 0.579 (±0.032)/0.584 (±0.055) | ||
| Training/Validation Sample | ||||
| AC | AUC | |||
| Model for appliances | All variables | ANN (iteration = 19, neurons = 1) | 0.908 (±0.011)/0.905 (±0.017) | 0.686 (±0.048)/0.566 (±0.088) |
| KNN (k = 40) | 0.908 (±0.011)/0.905 (±0.017) | 0.784 (±0.023)/0.591 (±0.126) | ||
| SVM (kernel = polynomial, degree = 1, C = 0.3, gamma = 0.9) | 0.908 (±0.011)/0.905 (±0.017) | 0.596 (±0.060)/0.616 (±0.078) | ||
| 8 best variables based on AUC and GCA | ANN (iteration = 12, neurons = 2) | 0.908 (±0.011)/0.905 (±0.017) | 0.605 (±0.055)/0.566 (±0.111) | |
| KNN (k = 70) | 0.908 (±0.011)/0.905 (±0.017) | 0.766 (±0.022)/0.606 (±0.125) | ||
| SVM (kernel = polynomial, degree = 1, C = 0.5, gamma = 0.3) | 0.908 (±0.011)/0.905 (±0.017) | 0.659 (±0.049)/0.654 (±0.099) | ||
| 8 best variables based on Boruta | ANN (iteration = 11, neurons = 7) | 0.908 (±0.011)/0.905 (±0.017) | 0.650 (±0.056)/0.607 (±0.080) | |
| KNN (k = 120) | 0.908 (±0.011)/0.905 (±0.017) | 0.740 (±0.024)/0.594 (±0.092) | ||
| SVM (kernel = radial, degree = 1, C = 1, gamma = 0.9) | 0.908 (±0.011)/0.905 (±0.017) | 0.666 (±0.068)/0.667 (±0.041) | ||
| Training/Validation Sample | ||||
| AC | AUC | |||
| Model for age_house | All variables | ANN (iteration = 17, neurons = 9) | 0.900 (±0.011)/0.899 (±0.018) | 0.563 (±0.029)/0.564 (±0.042) |
| KNN (k = 260) | 0.876 (±0.012)/0.870 (±0.020) | 0.616 (±0.035)/0.525 (±0.047) | ||
| SVM (kernel = sigmoid, degree = 1, C = 0.3, gamma = 0.5) | 0.900 (±0.011)/0.899 (±0.018) | 0.548 (±0.033)/0.558 (±0.038) | ||
| 8 best variables based on AUC and GCA | ANN (iteration = 28, neurons = 15) | 0.900 (±0.011)/0.899 (±0.018) | 0.593 (±0.032)/0.575 (±0.045) | |
| KNN (k = 280) | 0.871 (±0.013)/0.878 (±0.019) | 0.625 (±0.030)/0.570 (±0.046) | ||
| SVM (kernel = polynomial, degree = 3, C = 0.3, gamma = 0.5) | 0.900 (±0.011)/0.899 (±0.018) | 0.586 (±0.029)/0.583 (±0.049) | ||
| 8 best variables based on Boruta | ANN (iteration = 28, neurons = 2) | 0.900 (±0.011)/0.899 (±0.018) | 0.581 (±0.033)/0.568 (±0.045) | |
| KNN (k = 160) | 0.873 (±0.013)/0.865 (±0.021) | 0.606 (±0.029)/0.561 (±0.051) | ||
| SVM (kernel = polynomial, degree = 1, C = 0.1, gamma = 0.1) | 0.900 (±0.011)/0.899 (±0.018) | 0.558 (±0.028)/0.563 (±0.047) | ||
| Training/Validation Sample | ||||
| AC | AUC | |||
| Model for house_type | All variables | ANN (iteration = 10, neurons = 13) | 0.611 (±0.017)/0.606 (±0.028) | 0.650 (±0.020)/0.616 (±0.029) |
| KNN (k = 300) | 0.598 (±0.018)/0.559 (±0.027) | 0.626 (±0.020)/0.587 (±0.032) | ||
| SVM (kernel = sigmoid, degree = 1, C = 0.1, gamma = 0.5) | 0.590 (±0.018)/0.597 (±0.028) | 0.606 (±0.020)/0.596 (±0.038) | ||
| 8 best variables based on AUC and GCA | ANN (iteration = 13, neurons = 7) | 0.600 (±0.018)/0.596 (±0.028) | 0.632 (±0.019)/0.604 (±0.029) | |
| KNN (k = 210) | 0.602 (±0.018)/0.590 (±0.027) | 0.628 (±0.023)/0.597 (±0.031) | ||
| SVM (kernel = polynomial, degree = 3, C = 0.1, gamma = 0.5) | 0.615 (±0.018)/0.620 (±0.028) | 0.679 (±0.025)/0.648 (±0.031) | ||
| 8 best variables based on Boruta | ANN (iteration = 25, neurons = 2) | 0.603 (±0.018)/0.590 (±0.028) | 0.628 (±0.021)/0.595 (±0.030) | |
| KNN (k = 240) | 0.602 (±0.018)/0.590 (±0.028) | 0.627 (±0.019)/0.600 (±0.027) | ||
| SVM (kernel = sigmoid, degree = 1, C = 0.5, gamma = 0.7) | 0.599 (±0.018)/0.590 (±0.027) | 0.619 (±0.021)/0.585 (±0.034) | ||
Appendix C
| Family | Bedrooms | ||||
| Variable | AUC | Cluster | Variable | AUC | Cluster |
| number_big_peaks | 0.618 | 1 | r_mean_max_no_min | 0.578 | 1 |
| r_we_morning_noon | 0.609 | 1 | r_min_mean | 0.553 | 1 |
| percent_above_base | 0.630 | 2 | percent_above_base | 0.584 | 2 |
| ts_acf_mean3h_weekday | 0.58 | 2 | ts_acf_mean3h_weekday | 0.565 | 2 |
| s_max_avg | 0.782 | 3 | value_above_base | 0.649 | 3 |
| c_min | 0.658 | 3 | c_min | 0.640 | 3 |
| bg_variety | 0.806 | 4 | c_week | 0.668 | 4 |
| c_wd_min | 0.660 | 4 | c_wd_min | 0.646 | 4 |
| Age_Person | Employ | ||||
| Variable | AUC | Cluster | Variable | AUC | Cluster |
| r_mean_max_no_min | 0.578 | 1 | r_evening_noon_no_min | 0.643 | 1 |
| r_min_mean | 0.553 | 1 | r_wd_morning_noon | 0.595 | 1 |
| percent_above_base | 0.584 | 2 | r_morning_wd_we | 0.578 | 2 |
| ts_acf_mean3h_weekday | 0.565 | 2 | s_cor_wd_we | 0.562 | 2 |
| value_above_base | 0.649 | 3 | s_max_avg | 0.649 | 3 |
| c_min | 0.640 | 3 | sm_variety | 0.583 | 3 |
| c_week | 0.668 | 4 | ts_stl_varRem | 0.646 | 4 |
| c_wd_min | 0.646 | 4 | c_wd_morning | 0.598 | 4 |
| House_Type | Age_House | ||||
| Variable | AUC | Cluster | Variable | AUC | Cluster |
| value_min_guess | 0.578 | 1 | first_above_base | 0.567 | 1 |
| width_peaks | 0.577 | 1 | r_wd_evening_noon | 0.546 | 1 |
| ts_acf_mean3h | 0.561 | 2 | t_above_mean | 0.540 | 2 |
| r_min_wd_we | 0.552 | 2 | number_small_peaks | 0.527 | 2 |
| r_mean_max | 0.586 | 3 | value_above_base | 0.559 | 3 |
| c_min | 0.578 | 3 | r_day_night_no_min | 0.539 | 3 |
| s_min_avg | 0.616 | 4 | b_day_diff | 0.544 | 4 |
| s_q3 | 0.600 | 4 | c_we_evening | 0.540 | 4 |
| Appliances | Floor_Area | ||||
| Variable | AUC | Cluster | Variable | AUC | Cluster |
| r_wd_night_day | 0.631 | 1 | r_morning_noon_no_min | 0.55 | 1 |
| r_min_mean | 0.580 | 1 | time_above_base2 | 0.54 | 1 |
| s_cor_wd | 0.584 | 2 | t_daily_max | 0.549 | 2 |
| percent_above_base | 0.571 | 2 | t_daily_min | 0.548 | 2 |
| c_sm_max | 0.653 | 3 | sm_variety | 0.560 | 3 |
| c_min | 0.634 | 3 | c_max | 0.556 | 3 |
| c_week | 0.669 | 4 | c_evening | 0.557 | 4 |
| c_wd_min | 0.661 | 4 | c_wd_morning | 0.549 | 4 |
References
- Chicco, G. Overview and performance assessment of the clustering methods for electrical load pattern grouping. Energy 2012, 421, 68–80. [Google Scholar] [CrossRef]
- Chicco, G.; Napoli, R.; Piglione, F.; Postolache, P.; Scutariu, M.; Toader, C. Load pattern-based classification of electricity customers. IEEE Trans. Power Syst. 2004, 192, 1232–1239. [Google Scholar] [CrossRef]
- Gajowniczek, K.; Ząbkowski, T. Short term electricity forecasting based on user behavior using individual smart meter data. Intell. Fuzzy Syst. 2015, 30, 223–234. [Google Scholar] [CrossRef]
- Haben, S.; Singleton, C.; Grindrod, P. Analysis and clustering of residential customers energy behavioral demand using smart meter data. IEEE Trans. Smart Grid 2016, 7, 136–144. [Google Scholar] [CrossRef]
- Gajowniczek, K.; Ząbkowski, T. Electricity forecasting on the individual household level enhanced based on activity patterns. PLoS ONE 2017, 12, e0174098. [Google Scholar] [CrossRef] [PubMed]
- Sial, A.; Singh, A.; Mahanti, A.; Gong, M. Heuristics-Based Detection of Abnormal Energy Consumption. In International Conference on Smart Grid Inspired Future Technologies; Chong, P., Seet, B.C., Chai, M., Eds.; Springer: Cham, Switzerland, 2018; pp. 21–31. [Google Scholar]
- Batra, N.; Singh, A.; Whitehouse, K. Creating a Detailed Energy Breakdown from just the Monthly Electricity Bill. In Proceedings of the 3rd International NILM Workshop, San Francisco, CA, USA, 14–15 May 2016. [Google Scholar]
- Rashid, H.; Arjunan, P.; Singh, P.; Singh, A. Collect, compare, and score: A generic data-driven anomaly detection method for buildings. In Proceedings of the Seventh International Conference on Future Energy Systems Poster Sessions, Waterloo, ON, Canada, 21–24 June 2016. [Google Scholar]
- Beckel, C.; Sadamori, L.; Santini, S. Automatic socio-economic classification of households using electricity consumption data. In Proceedings of the Fourth International Conference on Future Energy Systems, Waterloo, ON, Canada, 15 January 2013. [Google Scholar]
- Hopf, K.; Sodenkamp, M.; Kozlovkiy, I.; Staake, T. Feature extraction and filtering for household classification based on smart electricity meter data. Comput. Sci. Res. Dev. 2016, 31, 141–148. [Google Scholar] [CrossRef]
- Poortinga, W.; Steg, L.; Vlek, C.; Wiersma, G. Household preferences for energy-saving measures: A conjoint analysis. J. Econ. Psychol. 2003, 24, 49–64. [Google Scholar] [CrossRef]
- Vassileva, I.; Campillo, J. Increasing energy efficiency in low-income households through targeting awareness and behavioral change. Renew. Energy 2014, 67, 59–63. [Google Scholar] [CrossRef]
- Ehrhardt-Martinez, K. Changing habits, lifestyles and choices: The behaviours that drive feedback-induced energy savings. In Proceedings of the 2011 ECEEE Summer Study on Energy Efficiency in Buildings, Toulon, France, 1–6 June 2011. [Google Scholar]
- Chicco, G.; Napoli, R.; Postolache, P.; Scutariu, M.; Toader, C. Customer characterization options for improving the tariff offer. IEEE Trans. Power Syst. 2003, 18, 381–387. [Google Scholar] [CrossRef]
- Carroll, J.; Lyons, S.; Denny, E. Reducing household electricity demand through smart metering: The role of improved information about energy saving. Energy Econ. 2014, 45, 234–243. [Google Scholar] [CrossRef]
- Anda, M.; Temmen, J. Smart metering for residential energy efficiency: The use of community based social marketing for behavioural change and smart grid introduction. Renew. Energy 2014, 67, 119–127. [Google Scholar] [CrossRef]
- Hart, G.W. Nonintrusive Appliance Load Monitoring; IEEE: New York, NY, USA, 1992. [Google Scholar]
- Zeifman, M.; Roth, K. Nonintrusive appliance load monitoring: Review and outlook. IEEE Trans. Consum. Electron. 2011, 57, 76–84. [Google Scholar] [CrossRef]
- Zoha, A.; Gluhak, A.; Imran, M.A.; Rajasegarar, S. Non-intrusive load monitoring approaches for disaggregated energy sensing: A survey. Sensors 2012, 12, 16838–16866. [Google Scholar] [CrossRef] [PubMed]
- Beckel, C.; Sadamori, L.; Staake, T.; Santini, S. Revealing household characteristics from smart meter data. Energy 2014, 78, 397–410. [Google Scholar] [CrossRef]
- Szczesny, W. On the performance of a discriminant function. J. Classif. 1991, 8, 201–215. [Google Scholar] [CrossRef]
- Kowalczyk, T.; Pleszczynska, E.; Ruland, F. Grade Models and Methods for Data Analysis: With Applications for the Analysis of Data Populations; Springer: Berlin/Heidelberg, Germany, 2004; Volume 151. [Google Scholar]
- Ciok, A.; Kowalczyk, T.; Pleszczyńska, E. How a new statistical infrastructure induced a new computing trend in data analysis. In International Conference on Rough Sets and Current Trends in Computing; Springer: Berlin/Heidelberg, Germany, 1998. [Google Scholar]
- Szczesny, W. Grade correspondence analysis applied to contingency tables and questionnaire data. Intell. Data Anal. 2002, 6, 17–51. [Google Scholar]
- Program for Grade Data Analysis. Available online: gradestat.ipipan.waw.pl (accessed on 9 June 2018).
- Kursa, M.B.; Rudnicki, W.R. Feature selection with the Boruta package. J. Stat. Softw. 2010, 36, 1–13. [Google Scholar] [CrossRef]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Gajowniczek, K.; Ząbkowski, T. Simulation study on clustering approaches for short-term electricity forecasting. Complex 2018, 2018, 3683969. [Google Scholar] [CrossRef]
- Gajowniczek, K.; Ząbkowski, T. Two-Stage Electricity Demand Modeling Using Machine Learning Algorithms. Energies 2017, 10, 1547. [Google Scholar] [CrossRef]
- Nguyen, B.; Morell, C.; De Baets, B. Large-scale distance metric learning for k-nearest neighbours regression. Neurocomputing 2016, 214, 805–814. [Google Scholar] [CrossRef]
- Davò, F.; Vespucci, M.T.; Gelmini, A.; Grisi, P.; Ronzio, D. Forecasting Italian electricity market prices using a Neural Network and a Support Vector Regression. In Proceedings of the 2016 AEIT International Annual Conference (AEIT), Capri, Italy, 5–7 October 2016. [Google Scholar]
- Muandet, K.; Fukumizu, K.; Sriperumbudur, B.; Schölkopf, B. Kernel mean embedding of distributions: A review and beyond. Found. Trends Mach. Learn. 2017, 10, 1–141. [Google Scholar] [CrossRef]







| Consumption | Ratios | Statistical | Temporal |
|---|---|---|---|
| c_week | r_night_day | s_variance | t_above_base |
| c_weekday | r_morning_noon | s_cor_wd | t_above_1kw |
| c_weekend | r_evening_noon | s_num_peaks | t_above_2kw |
| c_evening | r_mean_max | s_diff | t_above_mean |
| c_morning | r_min_mean | s_q1 | t_daily_max |
| c_night | r_evening_wd_we | s_q2 | t_daily_min |
| c_noon | r_night_wd_we | s_q3 | ts_acf_mean3h |
| c_min | r_morning_wd_we | s_min_avg | ts_acf_mean3h_weekday |
| c_max | r_noon_wd_we | s_max_avg | ts_stl_varRem |
| c_we_max | r_afternoon_wd_we | s_var_we | b_day_diff |
| c_we_evening | r_min_wd_we | s_var_wd | b_day_weak |
| c_wd_evening | r_max_wd_we | s_cor_wd_we | wide_peaks |
| c_we_night | r_var_wd_we | s_cor_we | width_peaks |
| c_wd_night | r_we_night_day | n_d_diff | sm_variety |
| c_we_morning | r_wd_night_day | number_zeros | bg_variety |
| c_wd_morning | r_we_morning_noon | time_above_base2 | |
| c_we_noon | r_wd_morning_noon | percent_above_base | |
| c_wd_noon | r_we_evening_noon | value_above_base | |
| c_we_afternoon | r_wd_evening_noon | const_time | |
| c_wd_afternoon | r_mean_max_no_min | value_min_guess | |
| c_afternoon | r_evening_noon_no_min | first_above_base | |
| c_we_min | r_morning_noon_no_min | number_big_peaks | |
| c_wd_max | r_day_night_no_min | number_small_peaks | |
| c_wd_min | dist_big_v | ||
| c_sm_max | |||
| c_evening_no_min | |||
| c_morning_no_min | |||
| c_night_no_min | |||
| c_noon_no_min |
| Household | Feature_1 | Feature_2 | … | Feature_91 |
|---|---|---|---|---|
| 1 | 0.23 | 0.57 | … | 0.85 |
| 2 | 0.64 | 0.77 | … | 0.27 |
| … | … | … | … | … |
| 4182 | 0.51 | 0.73 | … | 0.63 |
| Category | Person’s Age | Number of Appliances |
| What Age Were You on Your Last Birthday? | Approximately How Many Appliances Are in Your Home? | |
| 1 | 18–35 | ≤8 appliances |
| 2 | 36–65 | between 9 and 11 |
| 3 | 65+ | >11 appliances |
| Category | Number of Bedrooms | Floor Area |
| How many bedrooms are in your home? | Approximately what is the area of your home? | |
| 1 | ≤2 bedrooms | Not available |
| 2 | 3 bedrooms | <100 m2 |
| 3 | 4 bedrooms | between 100 m2 and 200 m2 |
| 4 | ≥5 bedrooms | >200 m2 |
| Category | Employment | Family type |
| What is the employment status of the chief income earner in your household? | What best describes the people you live with? | |
| 1 | An employee, Self-employed (with employees), Self-employed (with no employees) | I live alone |
| 2 | Unemployed (actively seeking work), Unemployed (not actively seeking work), Retired, Carer: Looking after relative family | All people in my home are over 15 years of age, both adults and children under 15 years of age live in my home |
| Category | House Age | House Type |
| Approximately how old is your home? | Which best describes your home? | |
| 1 | ≤30 years | Semi-detached house, Terraced house |
| 2 | >30 years | Apartment, Detached house, Bungalow |
| Predicted Value | |||
|---|---|---|---|
| Positive (P) | Negative (N) | ||
| Real Value | Positive (P) | True positive (TP) | False negative (FN) |
| Negative (N) | False positive (FP) | True negative (TN) | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gajowniczek, K.; Ząbkowski, T.; Sodenkamp, M. Revealing Household Characteristics from Electricity Meter Data with Grade Analysis and Machine Learning Algorithms. Appl. Sci. 2018, 8, 1654. https://doi.org/10.3390/app8091654
Gajowniczek K, Ząbkowski T, Sodenkamp M. Revealing Household Characteristics from Electricity Meter Data with Grade Analysis and Machine Learning Algorithms. Applied Sciences. 2018; 8(9):1654. https://doi.org/10.3390/app8091654
Chicago/Turabian StyleGajowniczek, Krzysztof, Tomasz Ząbkowski, and Mariya Sodenkamp. 2018. "Revealing Household Characteristics from Electricity Meter Data with Grade Analysis and Machine Learning Algorithms" Applied Sciences 8, no. 9: 1654. https://doi.org/10.3390/app8091654
APA StyleGajowniczek, K., Ząbkowski, T., & Sodenkamp, M. (2018). Revealing Household Characteristics from Electricity Meter Data with Grade Analysis and Machine Learning Algorithms. Applied Sciences, 8(9), 1654. https://doi.org/10.3390/app8091654