A Low Cost Vision-Based Road-Following System for Mobile Robots


Abstract
:1. Introduction
- (1)
- In order to have the ability to detect the road in the majority of cases, the system combines the detection of a color-based road detector and texture line detector. Benefiting from the combination of the two detectors, the proposed road-following system is more suitable with small single lane roads, such as sidewalks, bikeways, parkways, etc.
- (2)
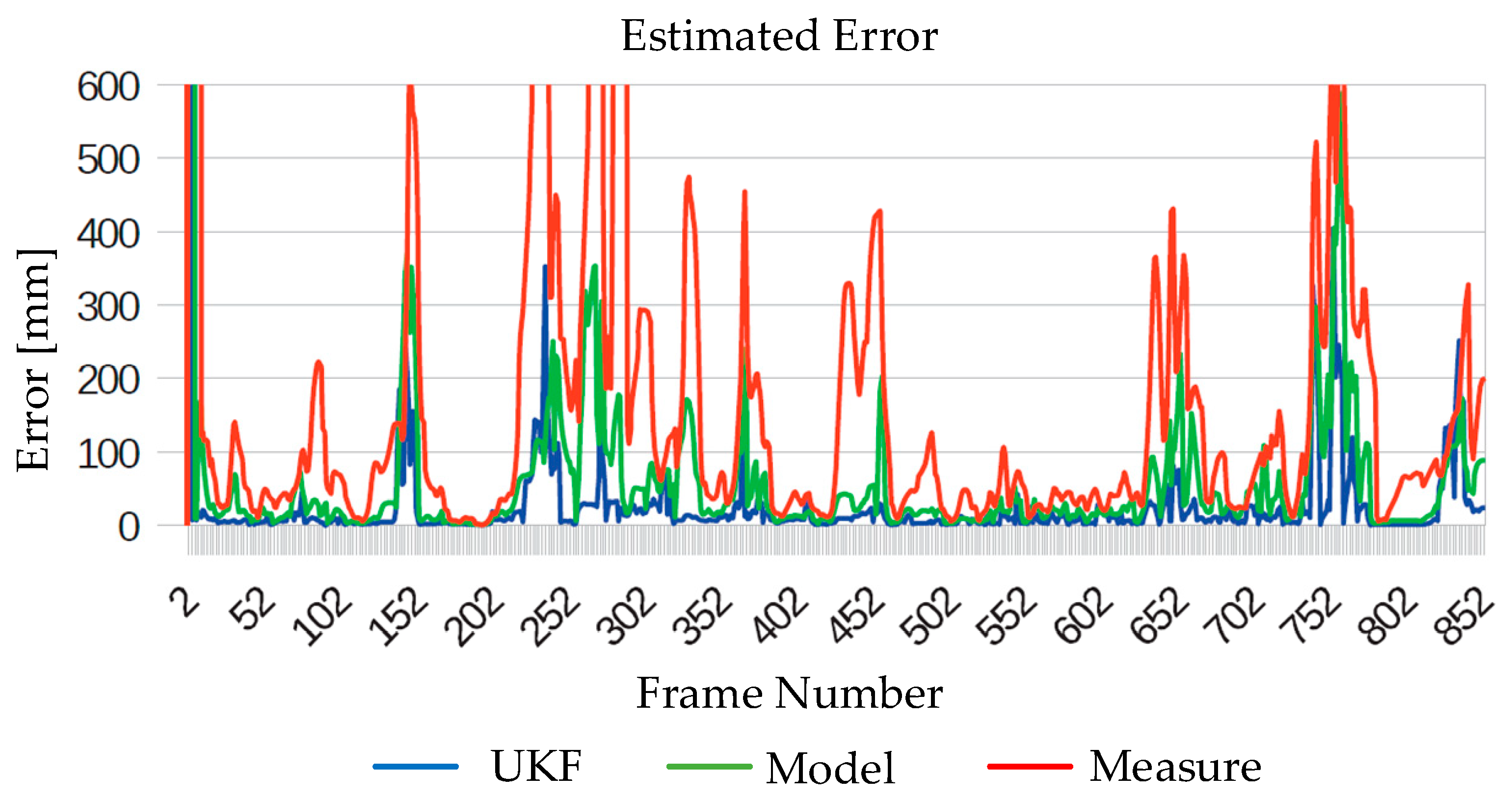
- The UKF is used to enhance the robustness of the system. The UKF estimates the best road borders from the measurements in occlusion or in miss detection and presents a smooth road transition frame to frame.
- (3)
- The proposed system could be easily integrated with a local controller, such as pure pursuit, model predictive control (MPC) or Douglas-Peucker (DP). This will improve the navigation ability of robots in single lane road scenarios.
2. Related Work
3. Mobile Robot System
3.1. Platform Description
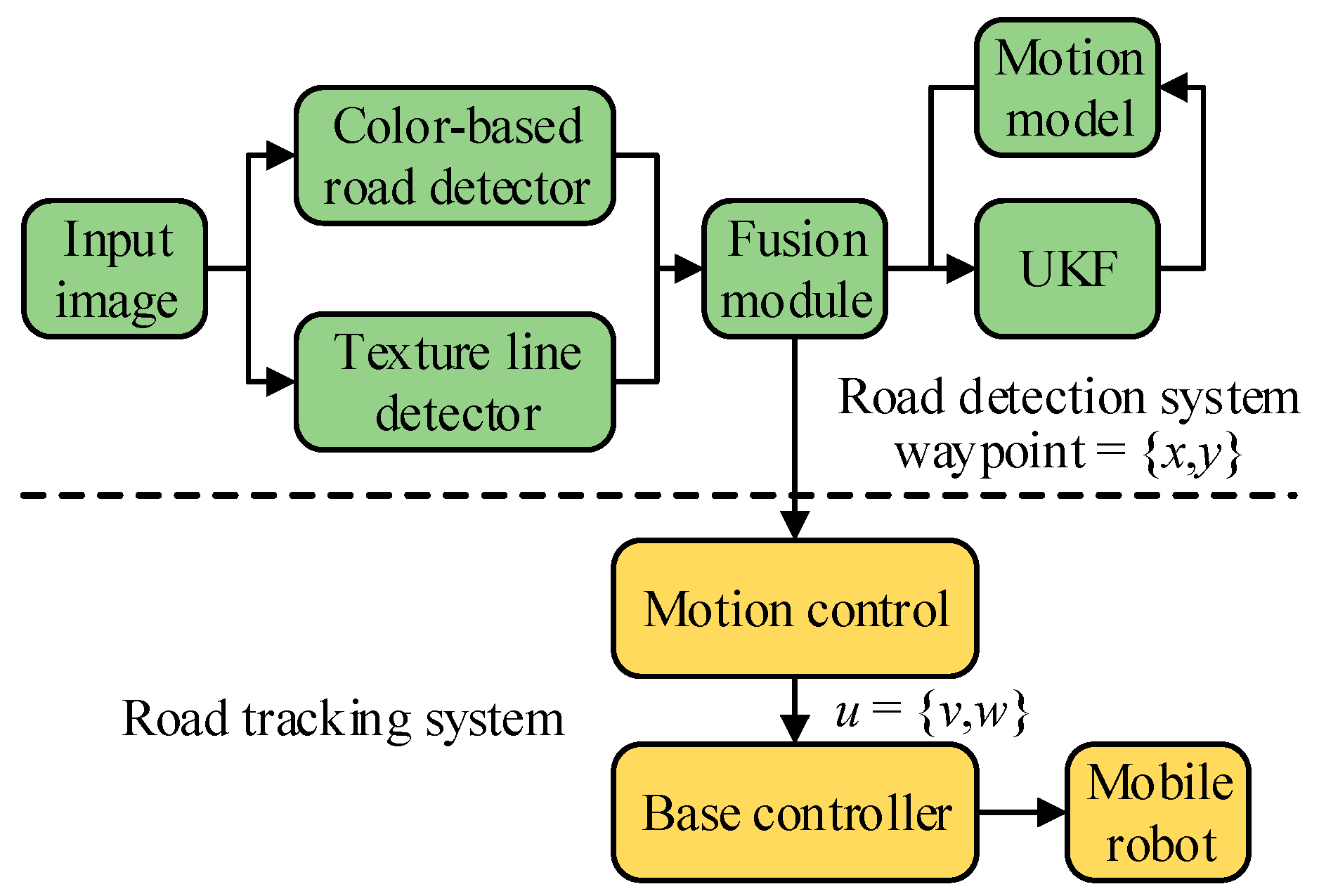
3.2. System Architecture
4. Road Detection System
4.1. Image Processing Module
4.2. Color-Based Road Detector
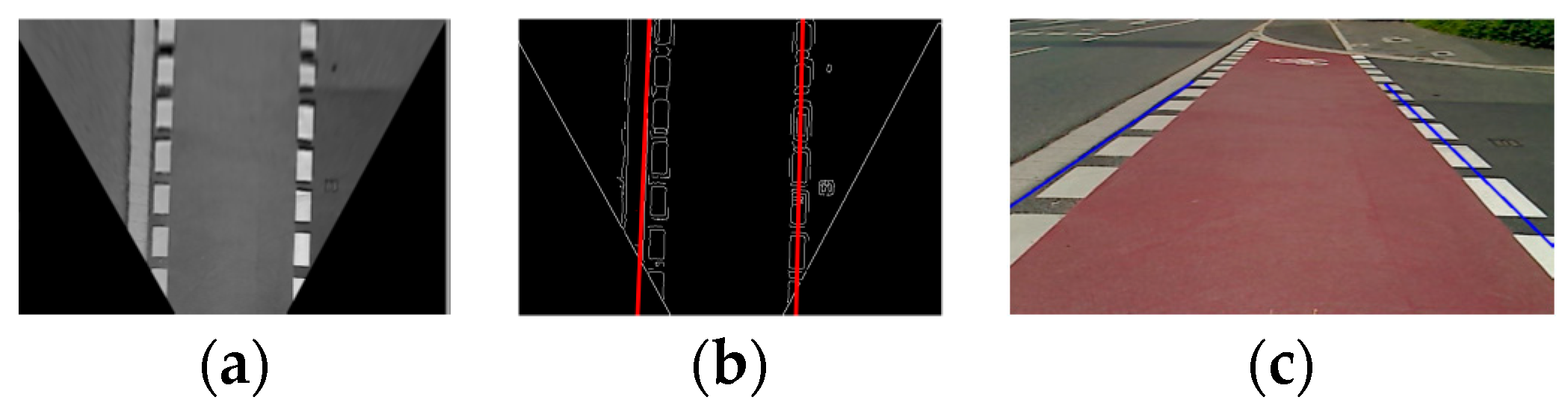
4.3. Texture Line Detector
- Intrinsic parameters are the parameters of the lens and the image sensor. These parameters consist of the camera focal lengths, the optical centers and also the distortion coefficients. The calibration algorithm detects the corners of a chessboard pattern. The chessboard pattern requires at least two snapshots. However, based on experience, more images produce better results. We used 24 images that cover the whole 3D visual area of the camera. The output of the algorithm is an “XML” file with the camera matrix and distortion coefficients.
- Extrinsic parameters are calculated based on the Perspective-n-Point problem or PNP. This problem is used to estimate the position of an object when we have a calibrated camera. The locations of the 3D points on the object and the corresponding 2D projections in the image are known. The corresponding translation and rotation vectors can be estimated based on the 3D points and the corresponding 2D projections.
4.4. Fusion Module with UKF
5. Road Tracking System
6. Experiments
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Wurm, K.M.; Kummerle, R.; Stachniss, C.; Burgard, W. Improving robot navigation in structured outdoor environments by identifying vegetation from laser data. In Proceedings of the 2009 IEEE/RSJ International Conference on Intelligent Robots and System, St. Louis, MO, USA, 11–15 October 2009; pp. 1217–1222. [Google Scholar]
- Gim, S.; Adouane, L.; Lee, S.; Derutin, J.P. Clothoids composition method for smooth path generation of car-like vehicle navigation. J. Intell. Robot. Syst. 2017, 88, 129–146. [Google Scholar] [CrossRef]
- Ort, T.; Paull, L.; Rus, D. Autonomous vehicle navigation in rural environments without detailed prior maps. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation, Brisbane, Australia, 21–25 May 2018; pp. 1–8. [Google Scholar]
- Cervantes, G.A.; Devy, M.; Hernandez, A.M. Lane extraction and tracking for robot navigation in agricultural applications. In Proceedings of the 11th International Conference on Advanced Robotics, Coimbra, Portugal, 30 June–3 July 2003; pp. 816–821. [Google Scholar]
- Jia, B.; Liu, R.; Zhu, M. Real-time obstacle detection with motion features using monocular vision. Vis. Comput. 2015, 31, 281–293. [Google Scholar] [CrossRef]
- Hane, C.; Sattler, T.; Pollefeys, M. Obstacle detection for self-driving cars using only monocular cameras and wheel odometry. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems, Hamburg, Germany, 28 September–2 October 2015; pp. 5101–5108. [Google Scholar]
- Zhang, Z.; Xu, H.; Chao, Z.; Li, X.; Wang, C. A novel vehicle reversing speed control based on obstacle detection and sparse representation. IEEE Trans. Intell. Transp. Syst. 2015, 16, 1321–1334. [Google Scholar] [CrossRef]
- Maier, D.; Hornung, A.; Bennewitz, M. Real-time navigation in 3D environments based on depth camera data. In Proceedings of the 2012 IEEE-RAS International Conference on Humanoid Robots, Osaka, Japan, 29 November–1 December 2012; pp. 692–697. [Google Scholar]
- Xu, W.; Zhuang, Y.; Hu, H.; Zhao, Y. Real-time road detection and description for robot navigation in an unstructured campus environment. In Proceedings of the 11th World Congress on Intelligent Control and Automation, Shenyang, China, 27–30 June 2014; pp. 928–933. [Google Scholar]
- Ulrich, I.; Nourbakhsh, I. Appearance-based obstacle detection with monocular color vision. In Proceedings of the AAAI National Conference on Artificial Intelligence, Austin, TX, USA, 30 July–3 August 2000; pp. 866–871. [Google Scholar]
- Wang, Y.; Cui, D.; Su, C.; Wang, P. Vision-based road detection by Monte Carlo Method. Inf. Technol. J. 2010, 9, 481–487. [Google Scholar] [CrossRef]
- Kong, H.; Audibert, J.Y.; Ponce, J. Vanishing point detection for road detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami Beach, FL, USA, 20–25 June 2009; pp. 96–103. [Google Scholar]
- Zhou, S.; Iagnemma, K. Self-supervised learning method for unstructured road detection using fuzzy support vector machines. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 1183–1189. [Google Scholar]
- Wang, Q.; Fang, J.; Yuan, Y. Adaptive road detection via context-aware label transfer. Neurocomputing 2015, 158, 174–183. [Google Scholar] [CrossRef]
- Ososinski, M.; Labrosse, F. Automatic driving on Ill-defined roads: An adaptive, shape-constrained, color-based method. J. Field Robot. 2013, 32, 504–533. [Google Scholar] [CrossRef]
- Jeong, H.; Oh, Y.; Part, J.H.; Koo, B.S.; Lee, S.W. Vision based adaptive and recursive tracking of unpaved roads. Pattern Recognit. Lett. 2002, 23, 73–82. [Google Scholar] [CrossRef]
- Yuan, Y.; Jiang, Z.; Wang, Q. Video-based road detecting via online structural learning. Neurocomputing 2015, 168, 336–347. [Google Scholar] [CrossRef]
- Li, J.; Mei, X.; Prokhorov, D. Deep neural network for structural prediction and lane detection in traffic scene. IEEE Trans. Neural Netw. Learn. Syst. 2016, 99, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Qiao, Y. Road segmentation via iterative deep analysis. In Proceedings of the IEEE International Conference on Robotics and Biomimetics, Zhuhai, China, 6–9 December 2015; pp. 2640–2645. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for scene segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Kurashiki, K.; Aguilar, M.; Soontornvanichkit, S. Visual navigation of a wheeled mobile robot using front image in semi-structured environment. J. Robot. Mechatron. 2015, 27, 392–400. [Google Scholar] [CrossRef]
- Agrawal, M.; Konolige, K.; Bolles, R. Localization and mapping for autonomous navigation in outdoor terrains: A stereo vision approach. In Proceedings of the IEEE Workshop Applications of Computer Vision, Austin, TX, USA, 21–22 February 2007; p. 7. [Google Scholar]
- Kostavelis, I.; Gasteratos, A. Semantic mapping for mobile robotics tasks: A survey. Robot. Auton. Syst. 2015, 66, 86–103. [Google Scholar] [CrossRef]
- Lezama, J.; Randall, G.; Grompone, R. Vanishing point detection in urban scenes using point alignments. Image Process. On Line 2017, 7, 131–164. [Google Scholar] [CrossRef]
- Julier, S.; Uhlmann, J. A new extension of the kalman filter to nonlinear systems. In Proceedings of the 11th International Symposium on Aerospace/Defence Sensing, Simulation and Controls, Orlando, FL, USA, 11 April 1997; pp. 182–193. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
 | |
|---|---|
| Sensor type | HIK Vision DS-2ZCN2006 (C) |
| Resolution | 1280 × 960 |
| Format | JPEG or BMP |
| Frame rates | 25 fps, 30 fps |
| Signal system | PAL/NTSC |
| Interface | 1 RJ45 10 M/100 M Ethernet interface |
| Voltage requirements | DC12 V ± 10% |
| Power consumption | 2.5 W (static), 4.5 W (dynamic) |
| Gain | 0 to 16 DB |
| Shutter | 1/1 s to 1/30,000 s |
| SNR | 52 dB or better at minimum gain |
| Camera dimensions | 74.3 mm × 81.1 mm × 142 mm |
| Mass | 320 g |
| Operating temperature | −10 °C to 60 °C |
| Focal length | 4.7–94 mm |
| Max CCD format | 1/3″ |
| Aperture | F1.6–F3.5 |
| Maximum field of view | Horizontal: 58.9° |
| Video compression | H.265/H.264 |
| Road Type Number | Characteristic | Number of Frames | Correct Rate |
|---|---|---|---|
| 1 | Bikeway, daylight, cement road | 1912 | 97.8% |
| 2 | Parkway, sunset, cement road | 734 | 97.4% |
| 3 | Parkway, daylight, asphalt road | 3660 | 99.1% |
| 4 | Bikeway, sunset, asphalt road | 1555 | 92.9% |
| 5 | Parkway, sunshine, asphalt road | 951 | 95.7% |
| 6 | Bikeway, daylight, asphalt road | 1645 | 99.39% |
| 7 | Parkway, daylight, dirt road | 2123 | 99.15% |
| 8 | Sidewalk, daylight, brick road | 4366 | 98.35% |
| 9 | Sidewalk, daylight, dirt road | 3069 | 99.24% |
| 10 | Sidewalk, sunset, brick road | 387 | 98.7% |
| 11 | Bikeway, sunshine, asphalt road | 386 | 79.27% |
| 12 | Sidewalk, daylight, cement road | 2066 | 99.61% |
| 13 | Sidewalk, daylight, asphalt road | 1884 | 99.78% |
| Sub-Process | Time (ms) | Percentage (%) |
|---|---|---|
| Extraction of the region of interest | 4.4915 | 6.03% |
| Smooth the image | 0.47 | 0.63% |
| Apply white balance filter | 10.31625 | 13.84% |
| Apply RGB normalization | 5.6225 | 7.55% |
| Convert to HSV color space | 2.70725 | 3.63% |
| Extraction of road window | 0.403 | 0.54% |
| Image color segmentation | 1.4385 | 1.93% |
| Morphological filtering | 3.4315 | 4.61% |
| Border validation | 0.457 | 0.61% |
| Road border estimation | 1.17075 | 1.57% |
| IPM | 11.79625 | 15.83% |
| Extraction of straight lines | 12.57375 | 16.88% |
| Fusion of color-based borders and texture borders | 9.503 | 12.76% |
| UKF computation | 5.16875 | 6.94% |
| Draw IPM lines, 3D points and Kalman borders | 4.951 | 6.65% |
| Total computation time [ms] | 74.5 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Hernandez, D.E.; Su, Z.; Su, B. A Low Cost Vision-Based Road-Following System for Mobile Robots. Appl. Sci. 2018, 8, 1635. https://doi.org/10.3390/app8091635
Zhang H, Hernandez DE, Su Z, Su B. A Low Cost Vision-Based Road-Following System for Mobile Robots. Applied Sciences. 2018; 8(9):1635. https://doi.org/10.3390/app8091635
Chicago/Turabian StyleZhang, Haojie, David E. Hernandez, Zhibao Su, and Bo Su. 2018. "A Low Cost Vision-Based Road-Following System for Mobile Robots" Applied Sciences 8, no. 9: 1635. https://doi.org/10.3390/app8091635
APA StyleZhang, H., Hernandez, D. E., Su, Z., & Su, B. (2018). A Low Cost Vision-Based Road-Following System for Mobile Robots. Applied Sciences, 8(9), 1635. https://doi.org/10.3390/app8091635