Understanding Citizen Issues through Reviews: A Step towards Data Informed Planning in Smart Cities

 , ,
, ,  ,
,  and
and 
Abstract
:Featured Application
Abstract
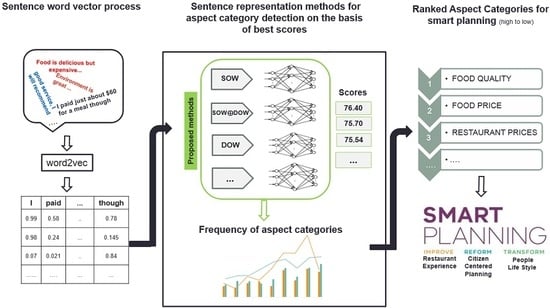
1. Introduction
2. Related Work
2.1. Aspect Category Detection in Sentiment Analysis
2.2. Word Embedding for Sentences and Their Importance in Aspect Category Detection
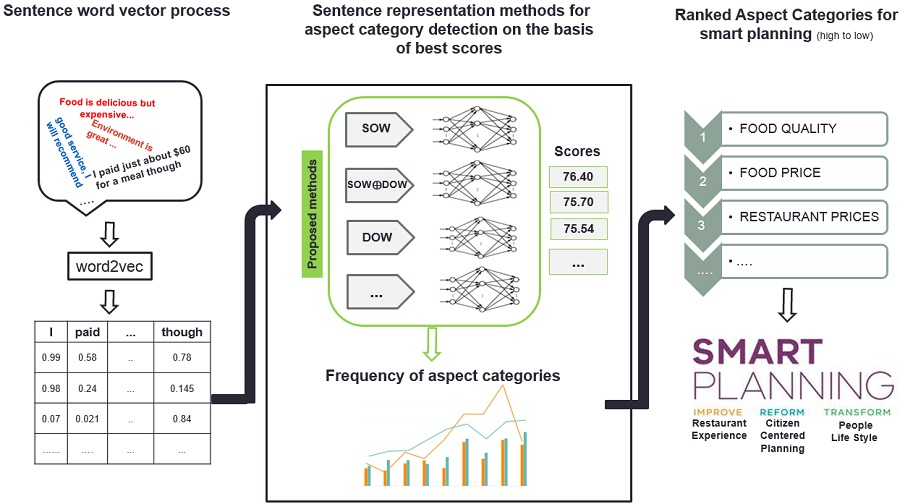
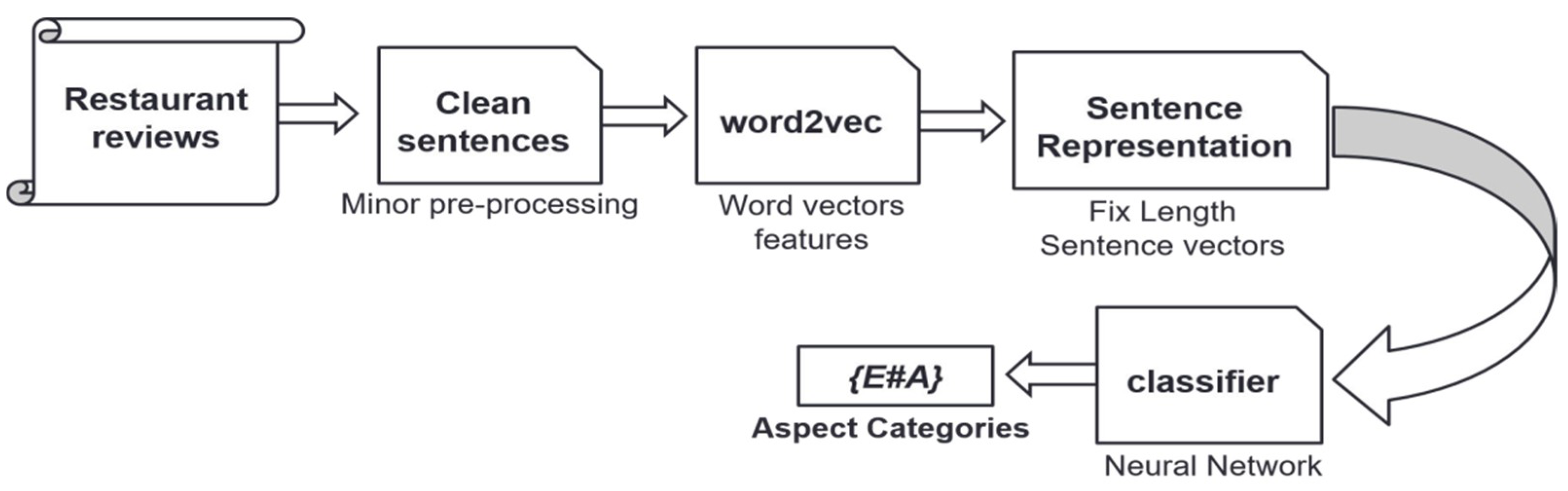
3. Proposed Methodology
3.1. Sentence Representation
3.1.1. Normalized Representation of Sentence Vector
3.1.2. Un-Normalized Representation of Sentence Vectors
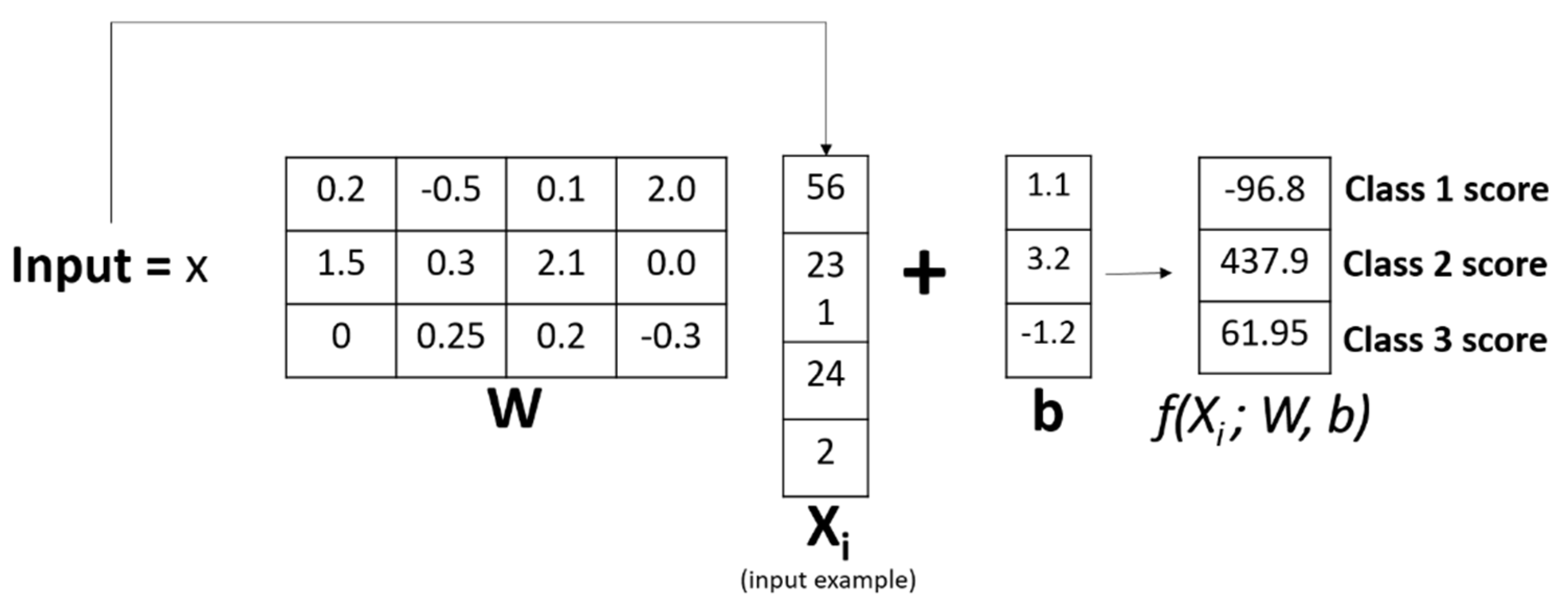
3.2. Details of the Neural Network
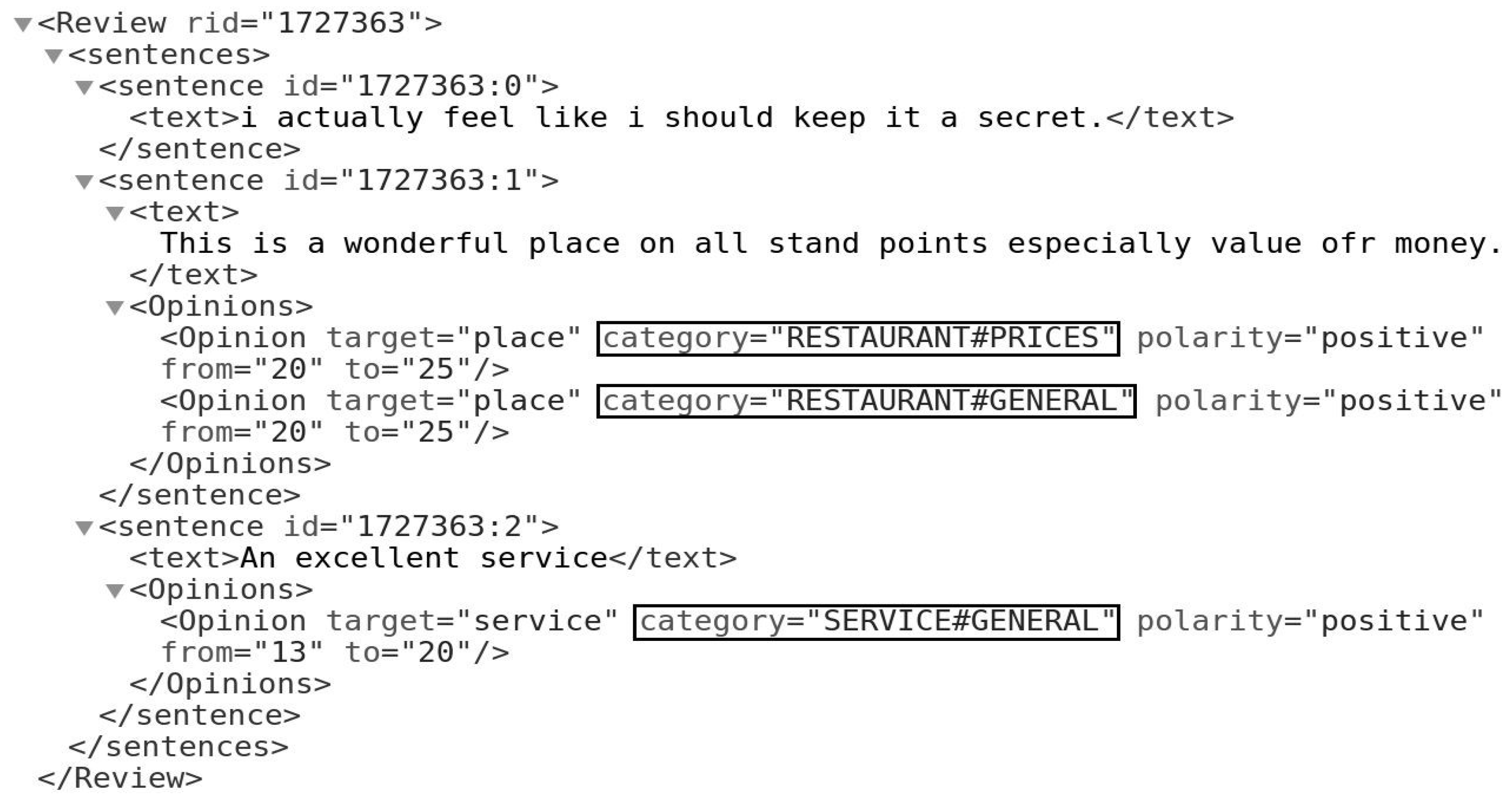
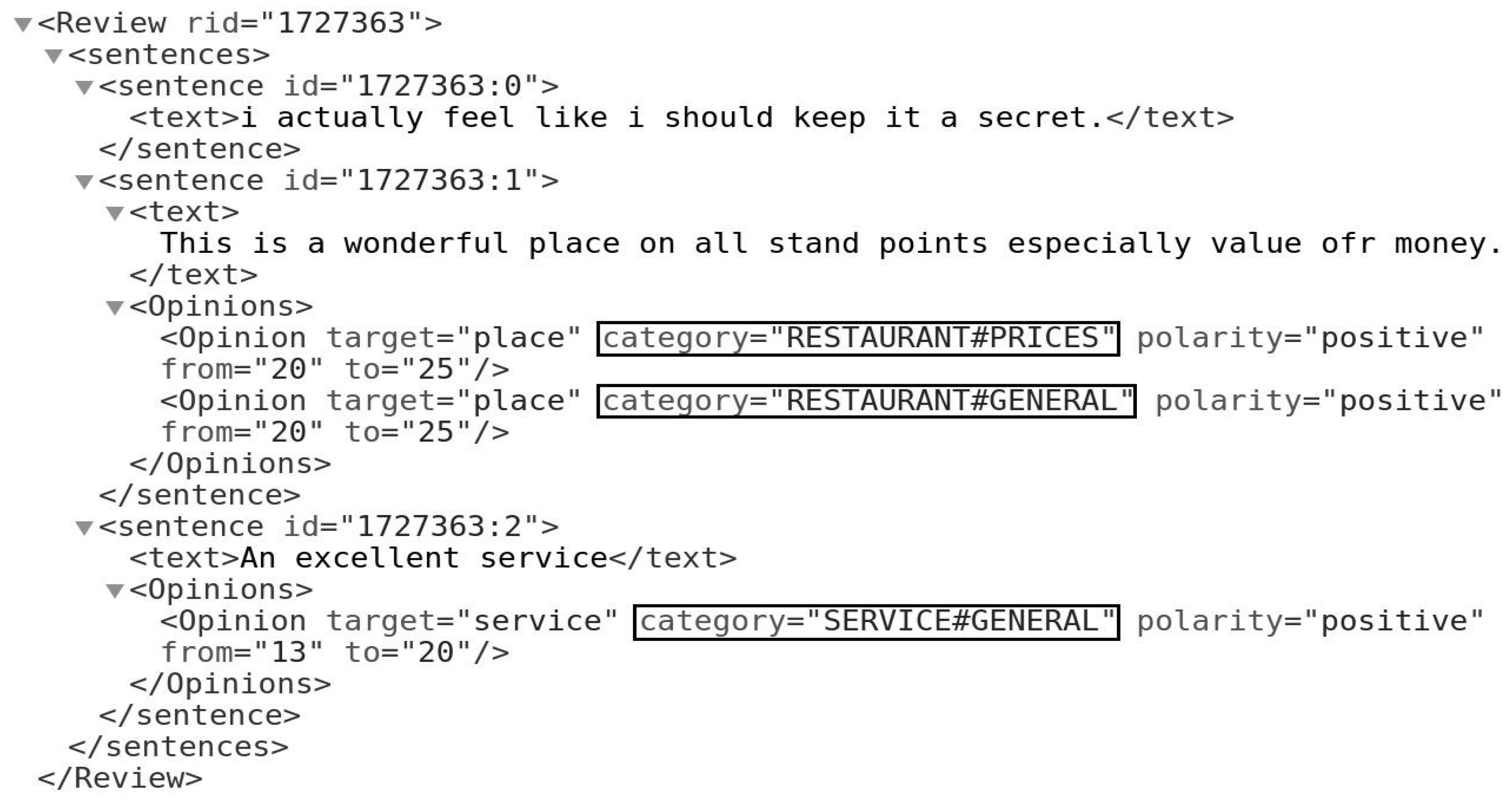
4. Tasks and Datasets
5. Experimental Setup
5.1. Word Vectors
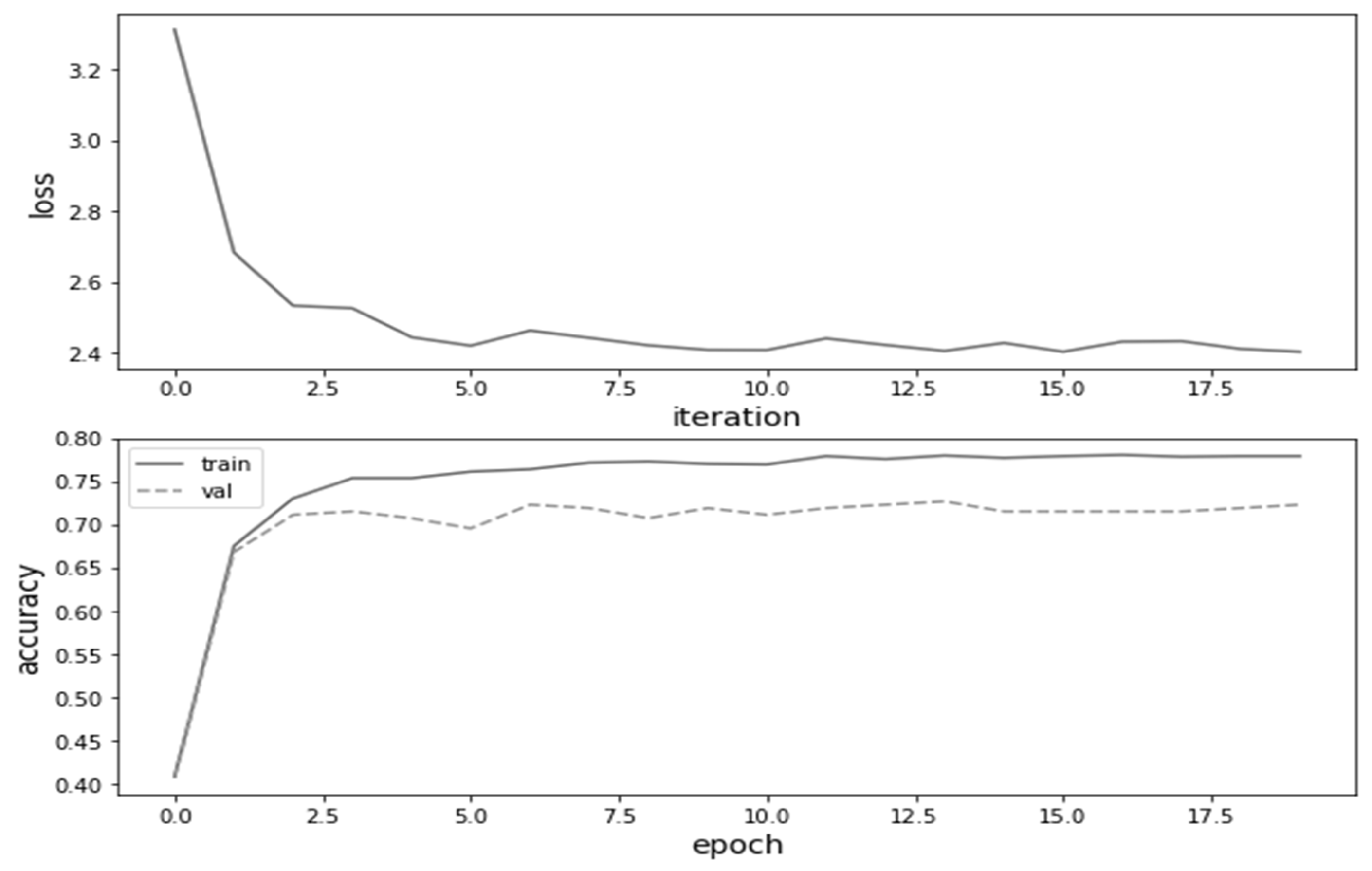
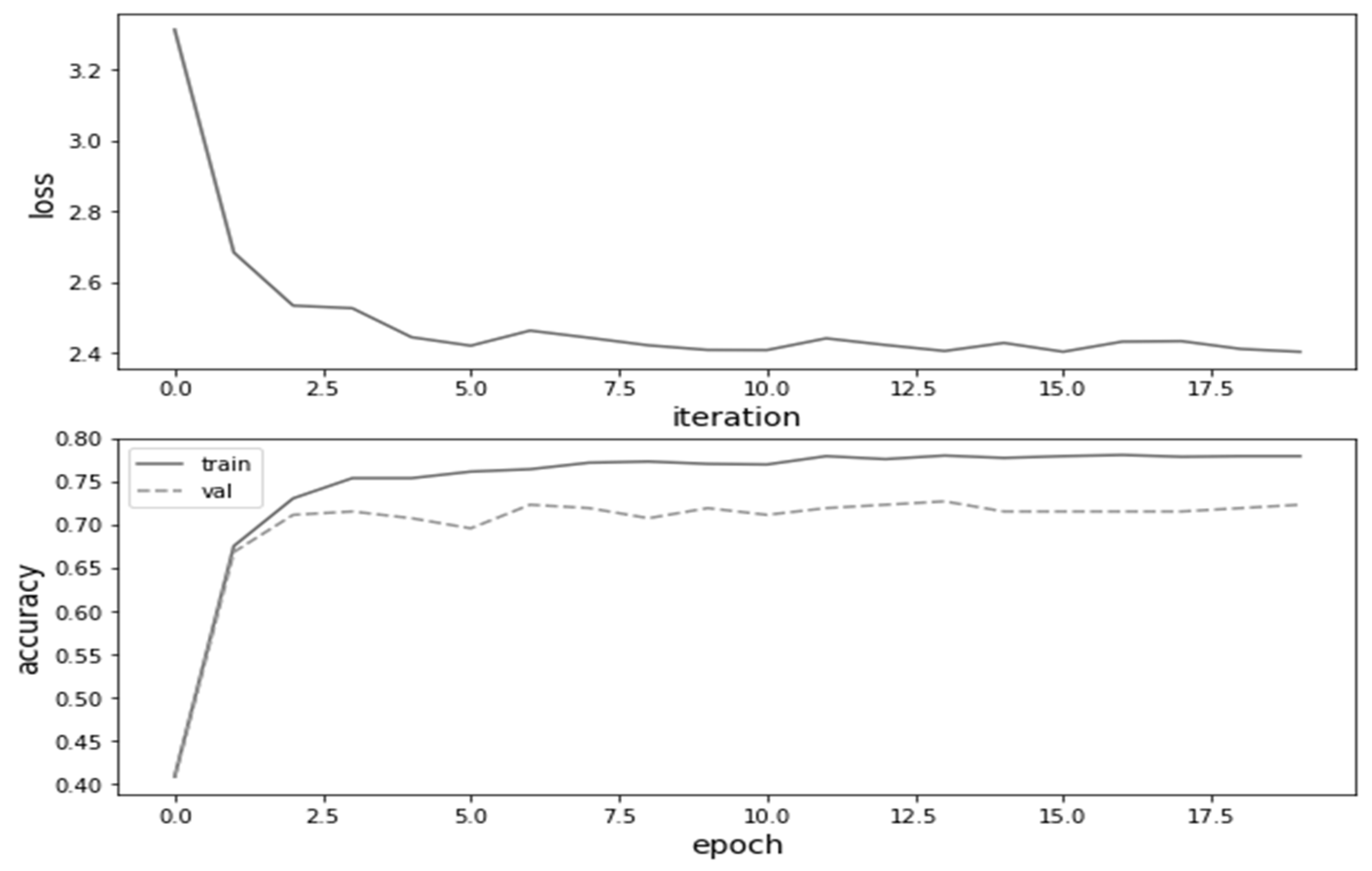
5.2. Classification Model
6. Results and Discussion
6.1. Normalized Representation of Sentence Vectors
6.2. Normalized Representation of Sentence Vectors
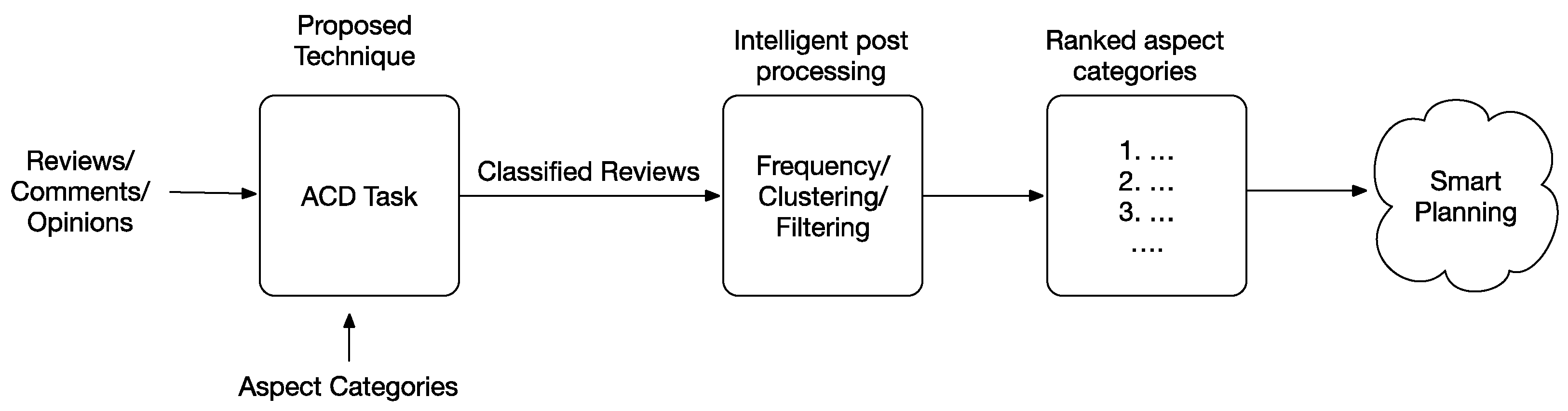
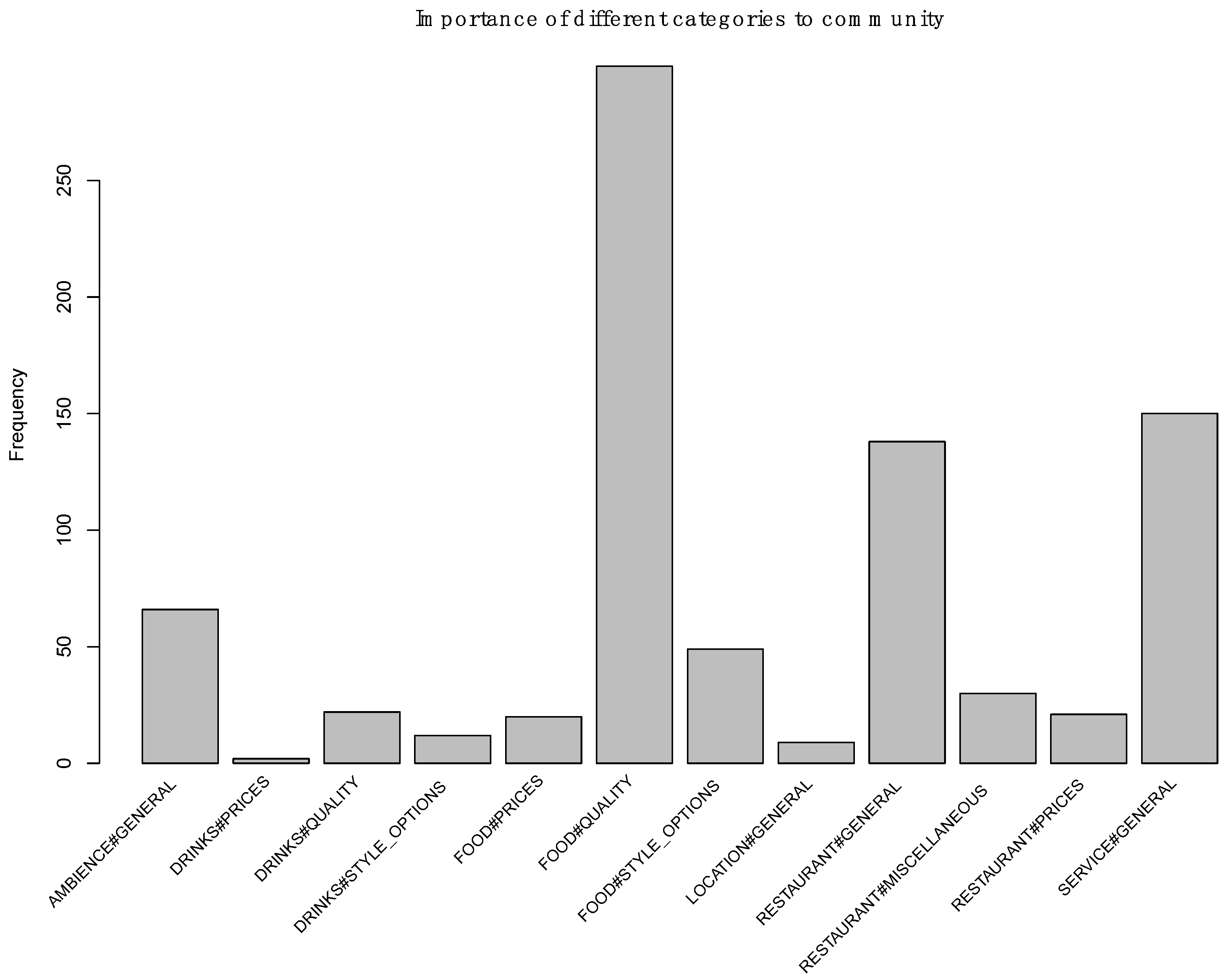
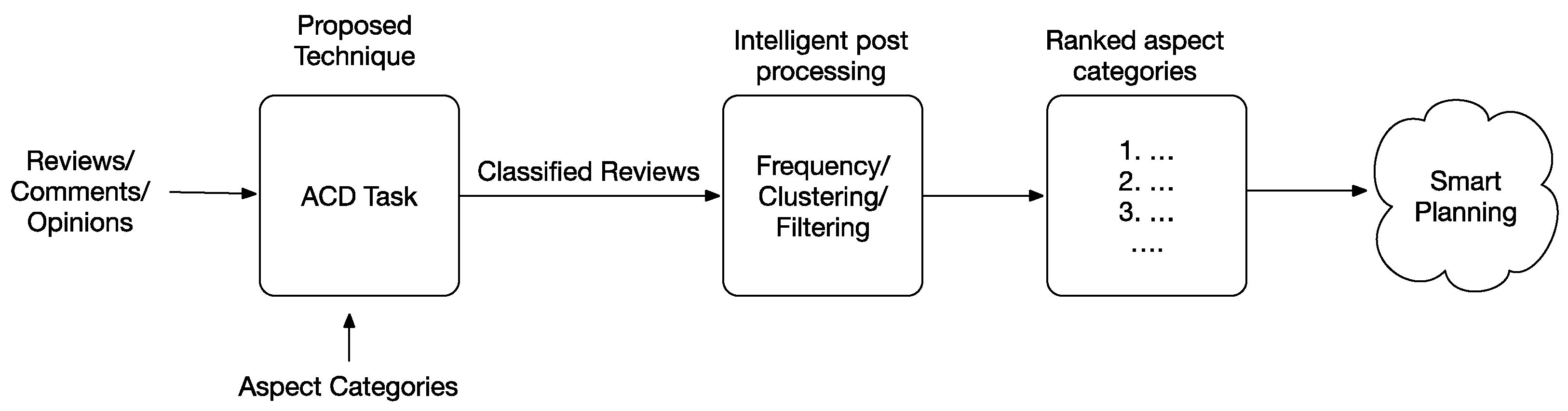
7. Smart Planning Using ACD
8. Limitations of the Proposed Methods
9. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Nam, T.; Pardo, T.A. Conceptualizing smart city with dimensions of technology, people, and institutions. In Proceedings of the 12th Annual International Digital Government Research Conference: Digital Government Innovation in Challenging Times, College Park, MD, USA, 12–15 June 2011; pp. 282–291. [Google Scholar]
- Puron-Cid, G.; Gil-Garcia, J.; Zhang, J. Smart cities, smart governments and smart citizens: A brief introduction. Int. J. E Plan. Res. 2015, 4, iv–vii. [Google Scholar]
- Dameri, R.P.; Camille, R.-S. Smart city and value creation. In Smart City; Dameri, R.P., Camille, R.-S., Eds.; Springer: Cham, Switzerland, 2014; pp. 1–12. [Google Scholar]
- Fahim, M.; Baker, T.; Khattak, A.M.; Alfandi, O. Alert me: Enhancing active lifestyle via observing sedentary behavior using mobile sensing systems. In Proceedings of the 2017 IEEE 19th International Conference on e-Health Networking, Applications and Services (Healthcom), Dalian, China, 12–15 October 2017. [Google Scholar]
- Fahim, M.; Baker, T. Knowledge-Based Decision Support Systems for Personalized u-lifecare Big Data Services. In Current Trends on Knowledge-Based Systems; Giner, A.-H., Rafael, V.-G., Eds.; Springer: Cham, Switzerland, 2017; pp. 187–203. [Google Scholar]
- Arunachalam, R.; Sarkar, S. The new eye of government: Citizen sentiment analysis in social media. In Proceedings of the Sixth International Joint Conference on Natural Language Processing, Nagoya, Japan, 14 October 2013; pp. 23–28. [Google Scholar]
- Liu, B. Sentiment Analysis and Opinion Mining; Morgan & Claypool Publishers: Williston, VT, USA, 2012; Volume 5, pp. 1–167. [Google Scholar]
- Pang, B.; Lee, L. Opinion Mining and Sentiment Analysis; Now Publishers Inc.: Hanover, MA, USA, 2008; Volume 2, pp. 1–135. [Google Scholar]
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up? Sentiment classification using machine learning techniques. In Proceedings of the ACL-02 Conference on Empirical Methods in Natural Language Processing, Stroudsburg, PA, USA, 2002; Volume 10, pp. 79–86. [Google Scholar]
- Lu, B.; Ott, M.; Cardie, C.; Tsou, B.K. Multi-aspect sentiment analysis with topic models. In Proceedings of the 2011 IEEE 11th International Conference on Data Mining Workshops, Vancouver, BC, Canada, 11–14 December 2011; IEEE: New York, NY, USA; pp. 81–88. [Google Scholar]
- Hu, M.; Liu, B. Mining and summarizing customer reviews. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; ACM: New York, NY, USA; pp. 168–177. [Google Scholar]
- Pontiki, M.; Galanis, D.; Papageorgiou, H.; Androutsopoulos, I.; Manandhar, S.; AL-Smadi, M.; Al-Ayyoub, M.; Zhao, Y.; Qin, B.; De Clercq, O.; et al. Semeval-2016 task 5: Aspect based sentiment analysis. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), San Diego, CA, USA, 16–17 June 2016; Association for Computational Linguistics: Stroudsburg, PA, USA, 1962; pp. 19–30. [Google Scholar]
- Pontiki, M.; Galanis, D.; Papageorgiou, H.; Manandhar, S.; Androutsopoulos, I. Semeval-2015 task 12: Aspect based sentiment analysis. In Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015), Denver, CO, USA, 4–5 June 2015; pp. 486–495. [Google Scholar]
- Qiu, G.; Liu, B.; Bu, J.; Chen, C. Opinion word expansion and target extraction through double propagation. Comput. Linguist. 2011, 37, 9–27. [Google Scholar] [CrossRef]
- Alvarez-Lopez, T.; Costa-Montenegro, E.; Gonz´ alez-Castano, F.J. GTI at Semeval-2016 task 5: SVM and CRF for aspect detection and unsupervised aspect-based sentiment analysis. In Proceedings of the 10th International Workshop on Semantic Evaluation, San Diego, CA, USA, 16–17 June 2016; pp. 306–311. [Google Scholar]
- Ganu, G.; Elhadad, N.; Marian, A. Beyond the Stars: Improving Rating Predictions Using Review Text Content. WebDB 2009, 9, 1–6. Available online: http://people.dbmi.columbia.edu/noemie/papers/webdb09.pdf (accessed on 2 January 2016).
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Volume 14, pp. 1532–1543. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems 16; Thrun, S., Saul, L.K., Schölkopf, B., Eds.; MIT Press: Cambridge, MA, USA, 2013; pp. 3111–3119. [Google Scholar]
- Titov, I.; McDonald, R. Modeling online reviews with multi-grain topic models. In Proceedings of the 17th International Conference on World Wide Web, Beijing, China, 21–25 April 2008; ACM: New York, NY, USA, 1947; pp. 111–120. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Hofmann, T. Probabilistic latent semantic indexing. In Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Berkeley, CA, USA, 15–19 August 1999; ACM: New York, NY, USA, 1947; pp. 50–57. [Google Scholar]
- Brody, S.; Elhadad, N. An unsupervised aspect-sentiment model for online reviews. In Proceedings of the Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics (ACL), Los Angeles, CA, USA, 2–4 June 2010; Association for Computational Linguistics: Stroudsburg, PA, USA, 1962; pp. 804–812. [Google Scholar]
- Zhao, W.X.; Jiang, J.; Yan, H.; Li, X. Jointly modeling aspects and opinions with a MaxEnt-LDA hybrid. In Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing, Cambridge, MA, USA, 9–11 October 2010; Association for Computational Linguistics: Stroudsburg, PA, USA, 1962; pp. 56–65. [Google Scholar]
- Joachims, T. A support vector method for multivariate performance measures. In Proceedings of the 22nd International Conference on Machine Learning, Bonn, Germany, 7–11 August 2005; ACM: New York, NY, USA, 1947; pp. 377–384. [Google Scholar]
- Heuer, H. Text Comparison Using Word Vector Representations and Dimensionality Reduction. arXiv, 2016; arXiv:1607.00534. [Google Scholar]
- Socher, R.; Huval, B.; Manning, C.D.; Ng, A.Y. Semantic compositionality through recursive matrix-vector spaces. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Jeju Island, Korea, 12–14 July 2012; Association for Computational Linguistics: Stroudsburg, PA, USA, 1962; pp. 1201–1211. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the 31st International Conference on Machine Learning (ICML-14), Beijing, China, 21–26 June 2014; pp. 1188–1196. [Google Scholar]
- Zhou, X.; Wan, X.; Xiao, J. Representation learning for aspect category detection in online reviews. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Kim, Y. Convolutional neural networks for sentence classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Toh, Z.; Su, J. Nlangp at semeval-2016 task 5: Improving aspect based sentiment analysis using neural network features. In Proceedings of the 10th International Workshop on Semantic Evaluation, San Diego, CA, USA, 16–17 June 2016; pp. 282–288. [Google Scholar]
- Wang, B.; Liu, M. Deep Learning for Aspect-Based Sentiment Analysis. Available online: https://cs224d.stanford.edu/reports/WangBo.pdf (accessed on 2 April 2016).
- Alghunaim, A.; Mohtarami, M.; Cyphers, S.; Glass, J. A vector space approach for aspect-based sentiment analysis. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics—Human Language Technologies (NAACL HLT 2015), Denver, CO, USA, 31 May–5 June 2015; pp. 116–122. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1026–1034. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv, 2014; arXiv:1412.6980. [Google Scholar]
- Rahim, R.; Sojka, P. Software framework for topic modelling with large corpora. In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks, Valletta, Malta, 22 May 2010. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. arXiv, 2016; arXiv:1603.04467. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Opinion | Category | Polarity |
|---|---|---|
| Easy to use and great for online gaming | Ease of use | Positive |
| Liking the graphics, quality, speed | Picture/video | Positive |
| All in all, great value!!! | Value | Positive |
| Great performance with nice design and fun | Design/style | Positive |
| ... that stupid light drains the battery so fast | Battery | Negative |
| The controls are great | Controls | Positive |
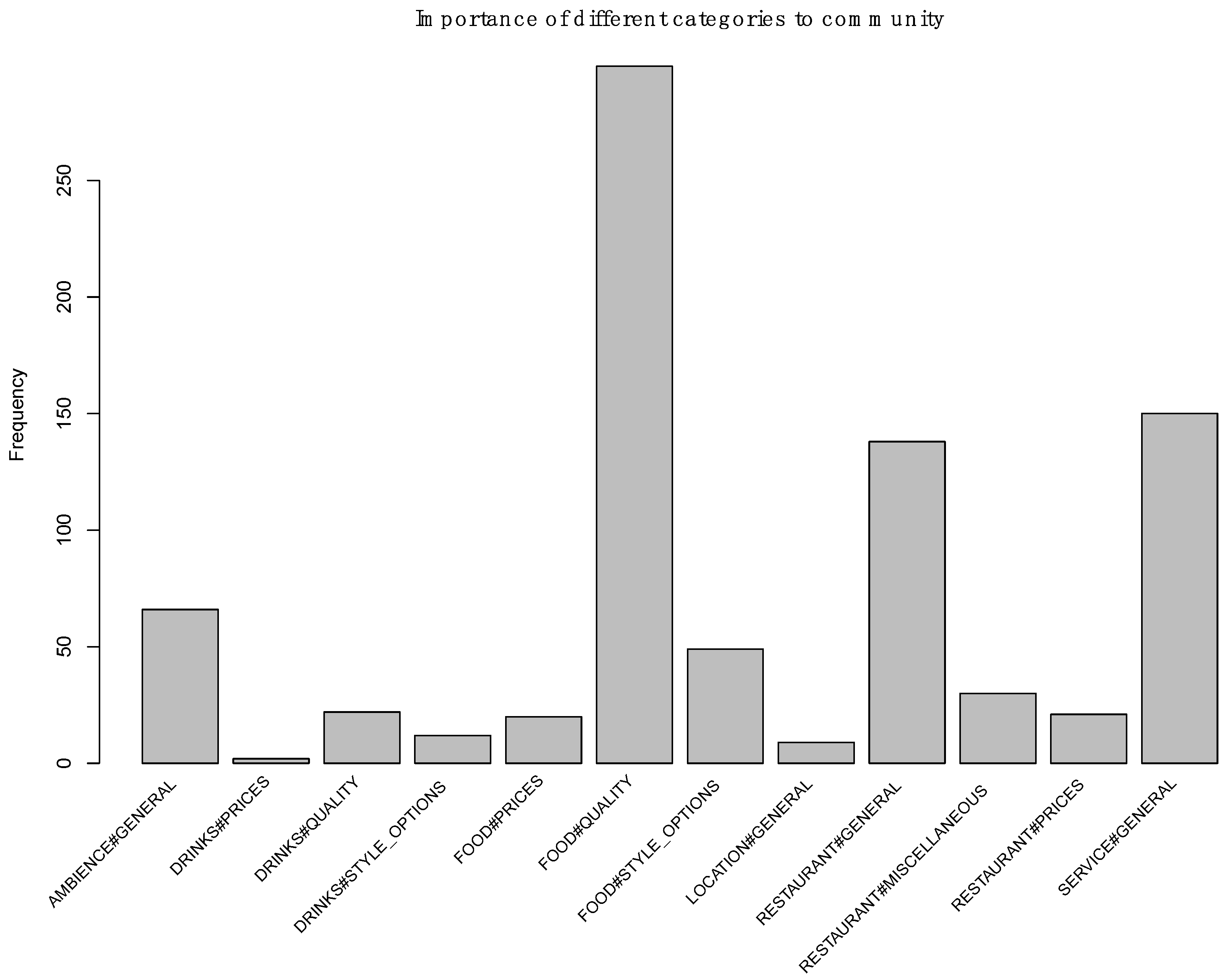
| Categories | Training | Test |
|---|---|---|
| FOOD#QUALITY | 681 | 226 |
| SERVICE#GENERAL | 419 | 145 |
| RESTAURANT#GENERAL | 421 | 142 |
| AMBIENCE#GENERAL | 226 | 57 |
| FOOD#STYLE_OPTIONS | 128 | 48 |
| RESTAURANT#MISCELLANEOUS | 97 | 33 |
| FOOD#PRICES | 82 | 22 |
| RESTAURANT#PRICES | 80 | 21 |
| DRINK#QUALITY | 46 | 21 |
| DRINKS#STYLE_OPTIONS | 30 | 12 |
| LOCATION#GENERAL | 28 | 13 |
| DRINKS#PRICES | 20 | 3 |
| TOTAL: 12 | TOTAL: 2258 | TOTAL: 743 |
| Parameter | Value |
|---|---|
| Word size | 400 |
| Min word count | 1 |
| Number of workers | 5 |
| Context | 5 |
| Down sampling | 1 × 10−3 |
| Parameter | Value |
|---|---|
| Epochs | 100 |
| Hidden layer units | layer 1: 300, layer 2: 250 |
| Batch size | 80 |
| Base learning rate | 0.002 |
| Decay rate | 0.96 |
| Regularization | 0.003 |
| Method | Precision | Recall | F1 Scores |
|---|---|---|---|
| Avg-SUM | 66.66 | 77.79 | 71.80 |
| Avg-DOW | 62.88 | 79.81 | 70.34 |
| L1-AvgSOW | 74.62 | 73.21 | 73.91 |
| L2-AvgSOW | 65.82 | 77.52 | 71.19 |
| L1-AvgDOW | 75.20 | 73.88 | 74.54 |
| L2-AvgDOW | 65.74 | 80.08 | 72.20 |
| L1-SOW | 77.41 | 72.40 | 74.82 |
| L2-SOW | 69.65 | 78.46 | 73.79 |
| L1-DOW | 77.46 | 73.08 | 75.20 |
| L2-DOW | 67.88 | 77.65 | 72.44 |
| Method | Precision | Recall | F1 Scores |
|---|---|---|---|
| Avg-SUM | 79.16 | 90.19 | 84.31 |
| Avg-DOW | 74.65 | 89.67 | 81.47 |
| L1-AvgSOW | - | - | - |
| L2-AvgSOW | 79.81 | 90.32 | 84.74 |
| L1-AvgDOW | 93.85 | 94.58 | 94.21 |
| L2-AvgDOW | 75.55 | 92.12 | 83.02 |
| L1-SOW | 95.80 | 94.19 | 94.99 |
| L2-SOW | 80.33 | 93.80 | 86.54 |
| L1-DOW | 95.25 | 93.29 | 94.26 |
| L2-DOW | 75.26 | 90.70 | 82.27 |
| Method | Precision | Recall | F1 Scores |
|---|---|---|---|
| SOW | 77.04 | 75.90 | 76.40 |
| DOW | 76.26 | 74.83 | 75.54 |
| SOW⊕DOW | 75.09 | 76.31 | 75.70 |
| Method | Precision | Recall | F1 Scores |
|---|---|---|---|
| SOW | 90.27 | 89.80 | 90.03 |
| DOW | 93.14 | 92.90 | 93.02 |
| SOW⊕DOW | 89.28 | 91.35 | 90.30 |
| Method | Category | Precision | Recall | F1 Scores |
|---|---|---|---|---|
| SOW | Un-Normalized | 77.04 | 75.90 | 76.40 |
| SOW⊕DOW | Un-Normalized | 75.09 | 76.31 | 75.70 |
| DOW | Un-Normalized | 76.26 | 74.83 | 75.54 |
| L1-DOW | Normalized | 77.46 | 73.08 | 75.20 |
| L1-SOW | Normalized | 77.41 | 72.40 | 74.82 |
| L1-AvgDOW | Normalized | 75.20 | 73.88 | 74.54 |
| L1-AvgSOW | Normalized | 74.62 | 73.21 | 73.91 |
| L2-SOW | Normalized | 69.65 | 78.46 | 73.79 |
| L2-DOW | Normalized | 67.88 | 77.65 | 72.44 |
| L2-AvgDOW | Normalized | 65.74 | 80.08 | 72.20 |
| Avg-SUM | Normalized | 66.66 | 77.79 | 71.80 |
| L2-AvgSOW | Normalized | 65.82 | 77.52 | 71.19 |
| Avg-DOW | Normalized | 62.88 | 79.81 | 70.34 |
| Method | Category | Precision | Recall | F1 Scores |
|---|---|---|---|---|
| L1-SOW | Normalized | 95.80 | 94.19 | 94.99 |
| L1-DOW | Normalized | 95.25 | 93.29 | 94.26 |
| L1-AvgDOW | Normalized | 93.85 | 94.58 | 94.21 |
| DOW | Un-Normalized | 93.14 | 92.90 | 93.02 |
| SOW⊕DOW | Un-Normalized | 89.28 | 91.35 | 90.30 |
| SOW | Un-Normalized | 90.27 | 89.80 | 90.03 |
| L2-SOW | Normalized | 80.33 | 93.80 | 86.54 |
| L2-AvgSOW | Normalized | 79.81 | 90.32 | 84.74 |
| Avg-SUM | Normalized | 79.16 | 90.19 | 84.31 |
| L2-AvgDOW | Normalized | 75.55 | 92.12 | 83.02 |
| L2-DOW | Normalized | 75.26 | 90.70 | 82.27 |
| L2-AvgSOW | Normalized | 74.65 | 89.67 | 81.47 |
| Sentence | Predicted Category | Actual Category |
|---|---|---|
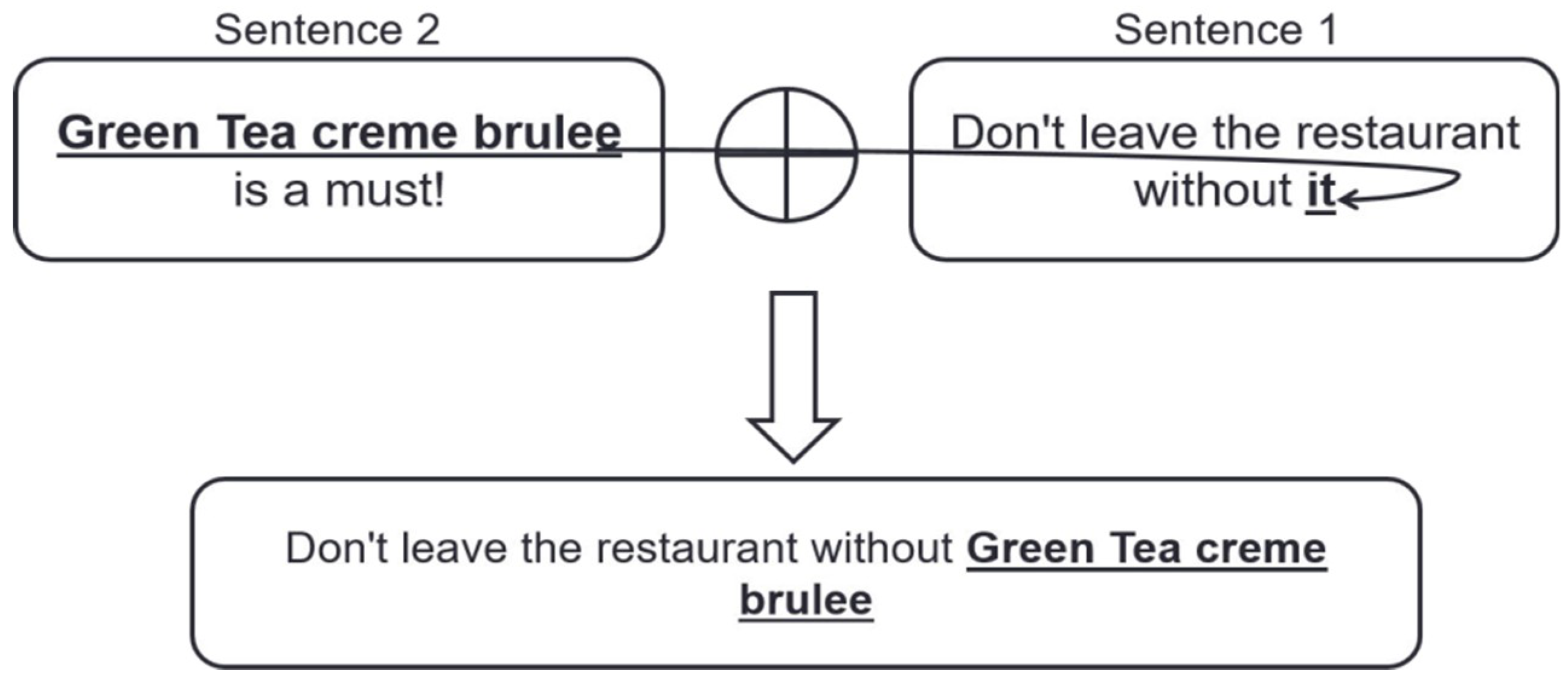
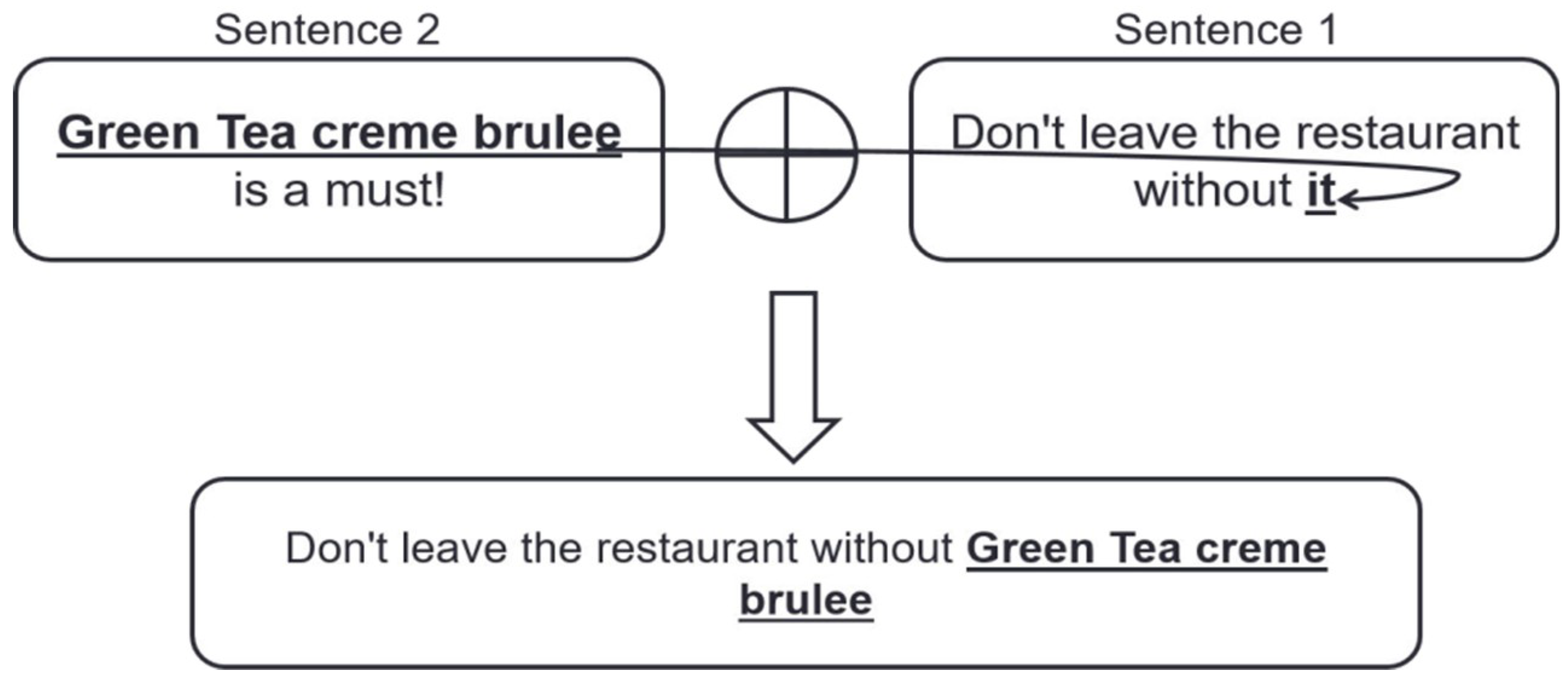
| Don’t leave the restaurant without it. | [“RESTAURANT#GENERAL”] | [“FOOD#QUALITY”] |
| It was absolutely amazing. | [“FOOD#QUALITY”] | [“RESTAURANT#GENERAL”] |
| It’s *very* reasonably priced, esp. for the quality of the food. | [“FOOD#PRICES”, “FOOD#QUALITY”, “RESTAURANT#PRICES”] | [“FOOD#PRICES”, “FOOD#QUALITY”] |
| AMAZING | [“FOOD#QUALITY”, “RESTAURANT#GENERAL”] | [“RESTAURANT#GENERAL”] |
| Sentence | Predicted Category | Actual Category |
|---|---|---|
| It is the not worth going at all and spend your money there!!! | [“RESTAURANT#GENERAL”, “RESTAURANT#PRICES”] | [“RESTAURANT#GENERAL”] |
| Mama Mia—I live in the neighborhood and feel lucky to live by such a great pizza place. | [“AMBIENCE#GENERAL”, “RESTAURANT#GENERAL”] | [“RESTAURANT#GENERAL”] |
| Its worth the wait, especially since they’ll give you a call when the table is ready. | [“SERVICE#GENERAL”] | [“RESTAURANT#GENERAL”, “SERVICES#GENERAL”] |
| I liked the atmosphere very much but the food was not worth the price. | [“AMBIENCE#GENERAL”, “FOOD#QUALITY”, “RESTAURANT#PRICES”] | [“AMBIENCE#GENERAL”, “FOOD#PRICES”, “FOOD#QUALITY”] |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dilawar, N.; Majeed, H.; Beg, M.O.; Ejaz, N.; Muhammad, K.; Mehmood, I.; Nam, Y. Understanding Citizen Issues through Reviews: A Step towards Data Informed Planning in Smart Cities. Appl. Sci. 2018, 8, 1589. https://doi.org/10.3390/app8091589
Dilawar N, Majeed H, Beg MO, Ejaz N, Muhammad K, Mehmood I, Nam Y. Understanding Citizen Issues through Reviews: A Step towards Data Informed Planning in Smart Cities. Applied Sciences. 2018; 8(9):1589. https://doi.org/10.3390/app8091589
Chicago/Turabian StyleDilawar, Noman, Hammad Majeed, Mirza Omer Beg, Naveed Ejaz, Khan Muhammad, Irfan Mehmood, and Yunyoung Nam. 2018. "Understanding Citizen Issues through Reviews: A Step towards Data Informed Planning in Smart Cities" Applied Sciences 8, no. 9: 1589. https://doi.org/10.3390/app8091589
APA StyleDilawar, N., Majeed, H., Beg, M. O., Ejaz, N., Muhammad, K., Mehmood, I., & Nam, Y. (2018). Understanding Citizen Issues through Reviews: A Step towards Data Informed Planning in Smart Cities. Applied Sciences, 8(9), 1589. https://doi.org/10.3390/app8091589