Deep Learning for Audio Event Detection and Tagging on Low-Resource Datasets


Abstract
1. Introduction
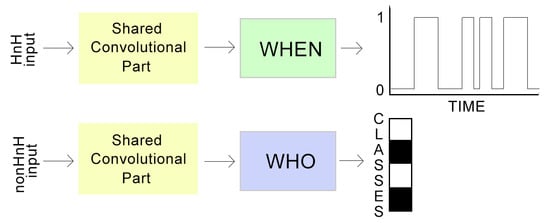
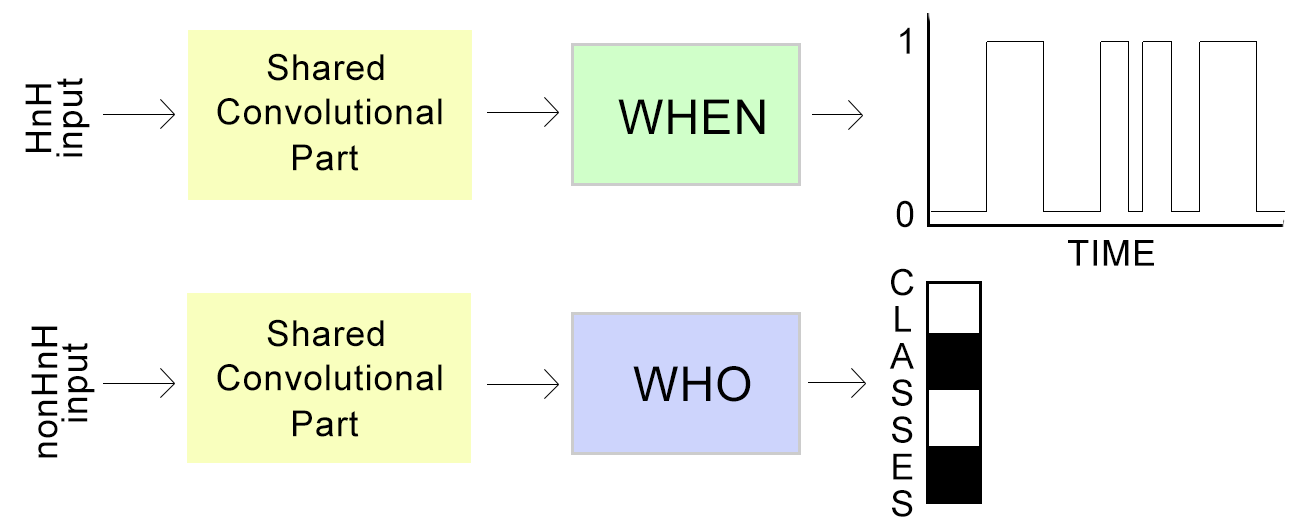
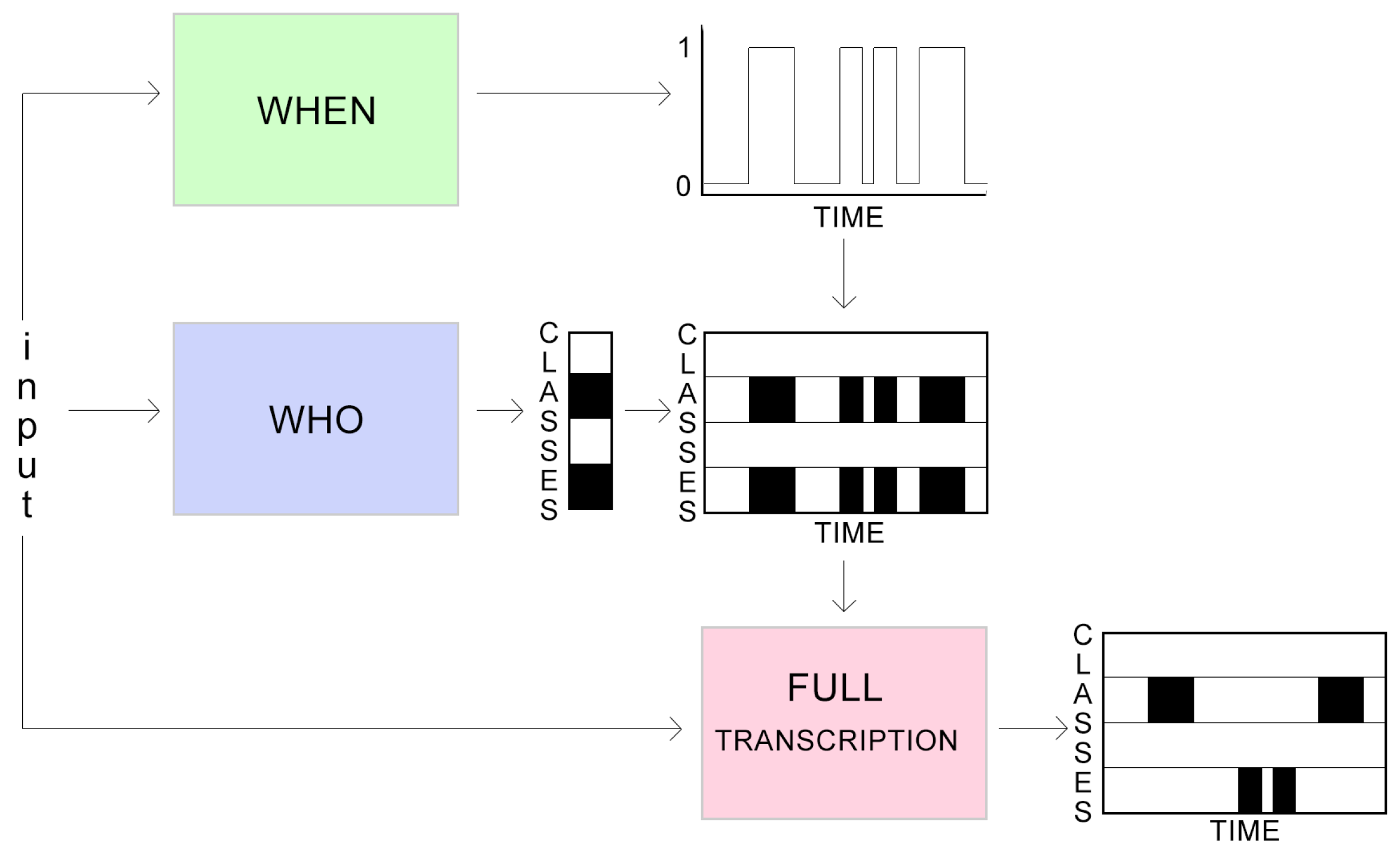
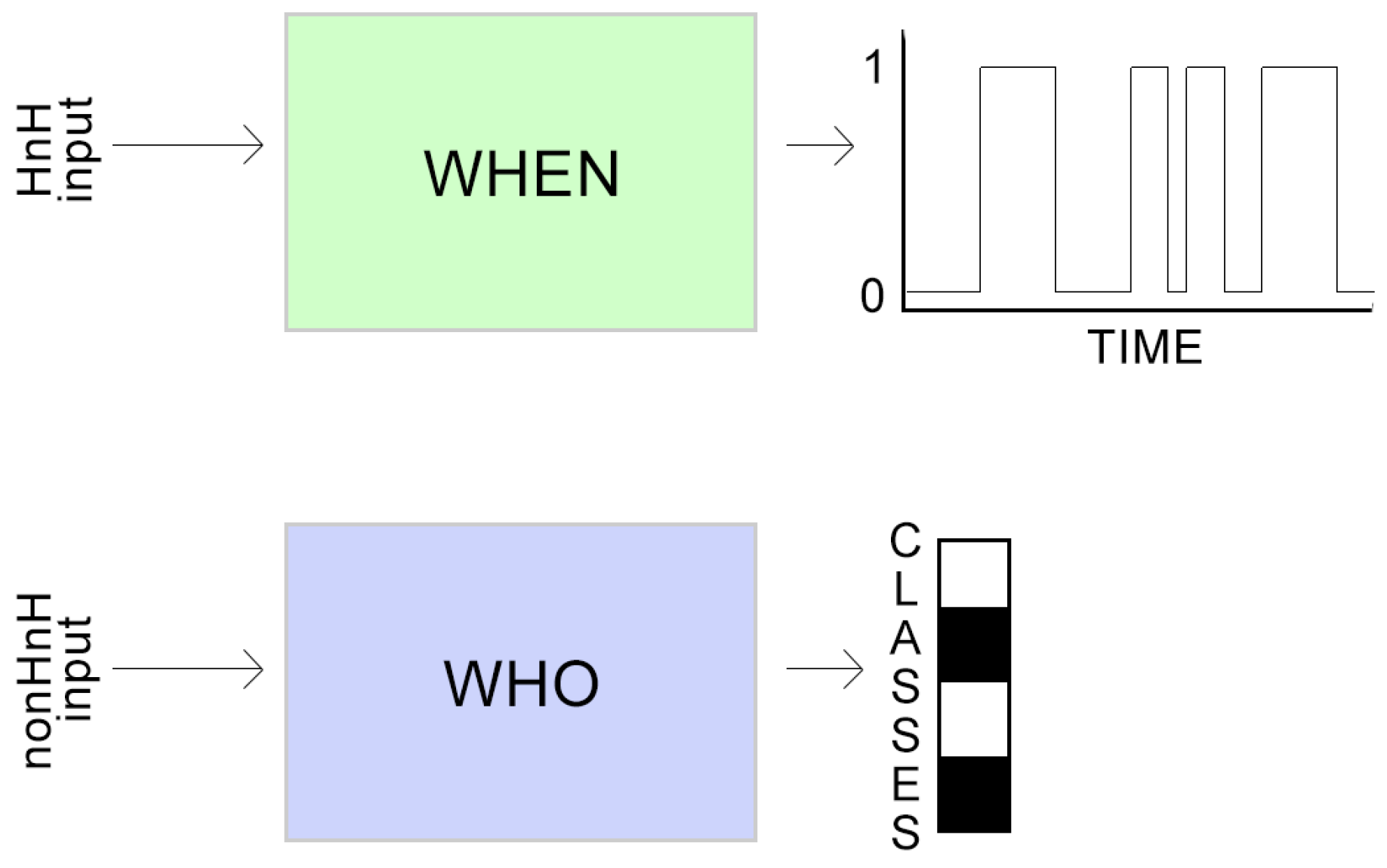
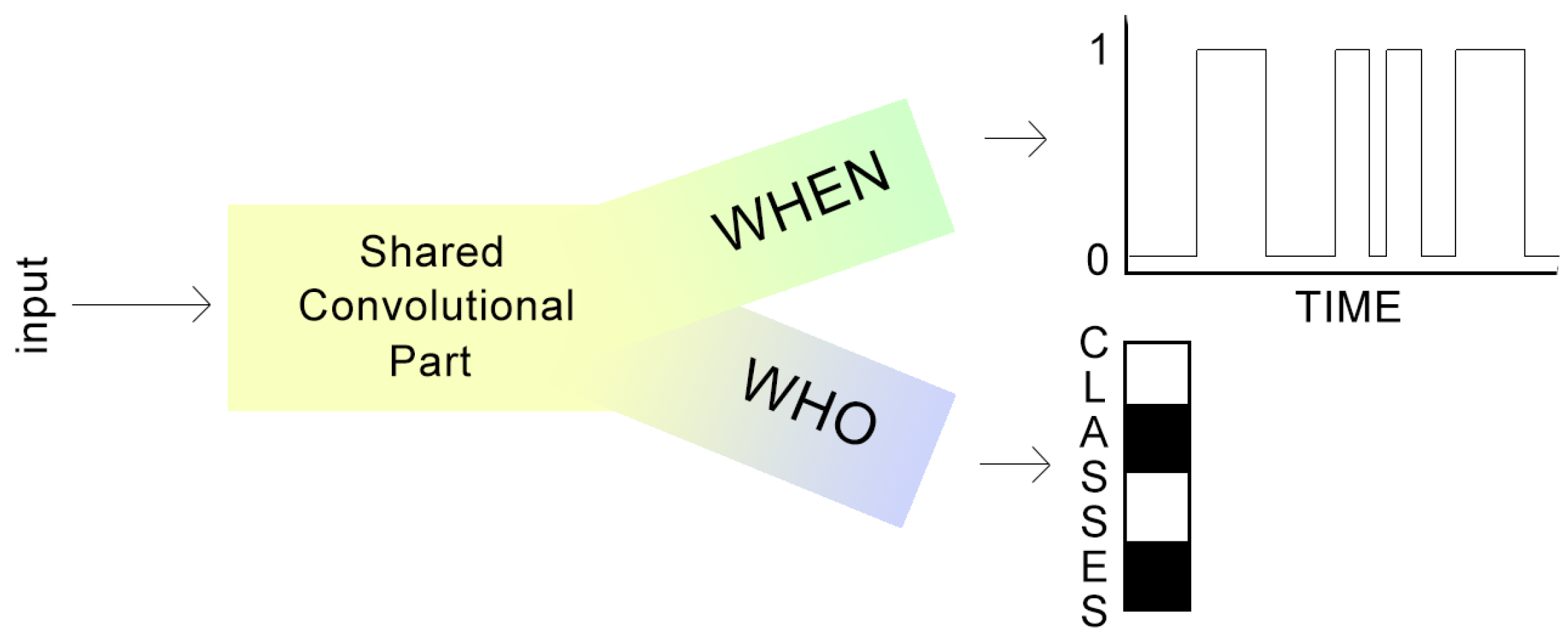
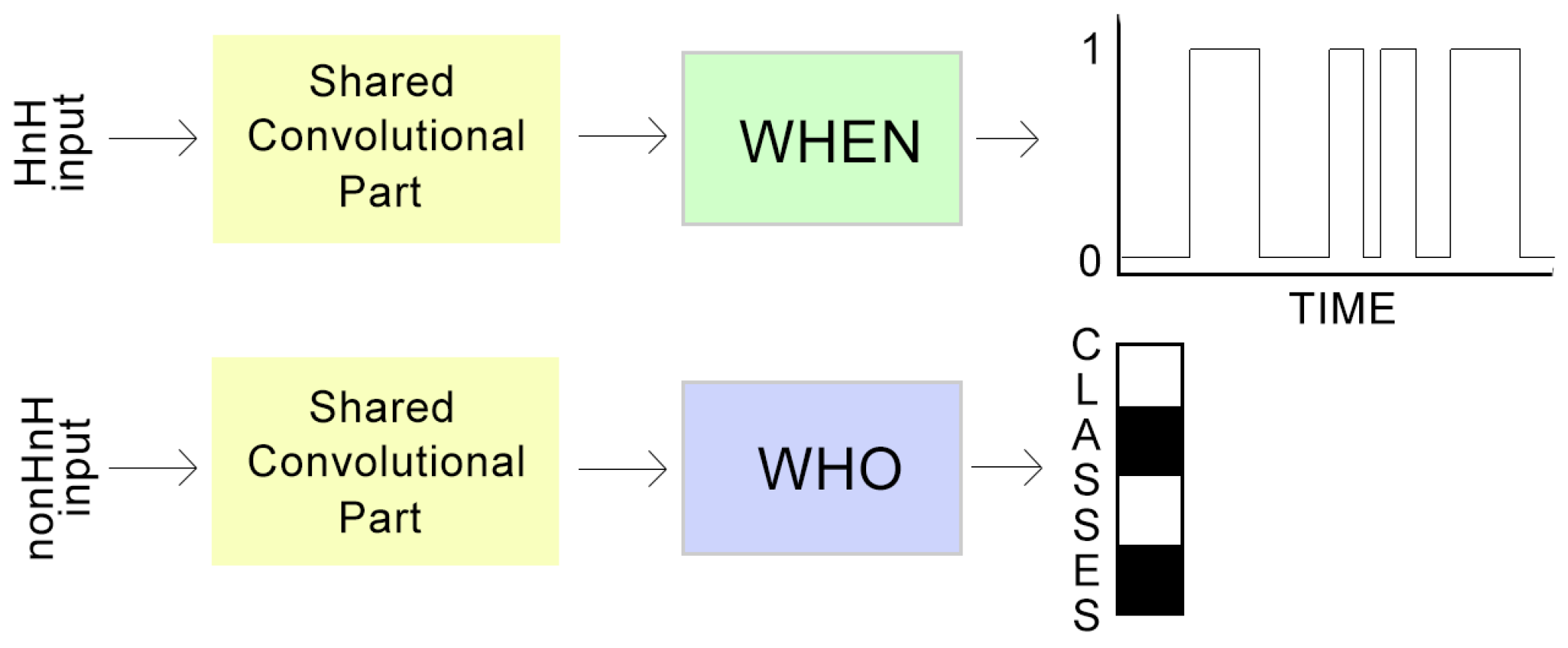
2. Task Factorisation
2.1. Input Features
2.2. Audio Event Detection (WHEN)
2.2.1. Neural Network Architecture
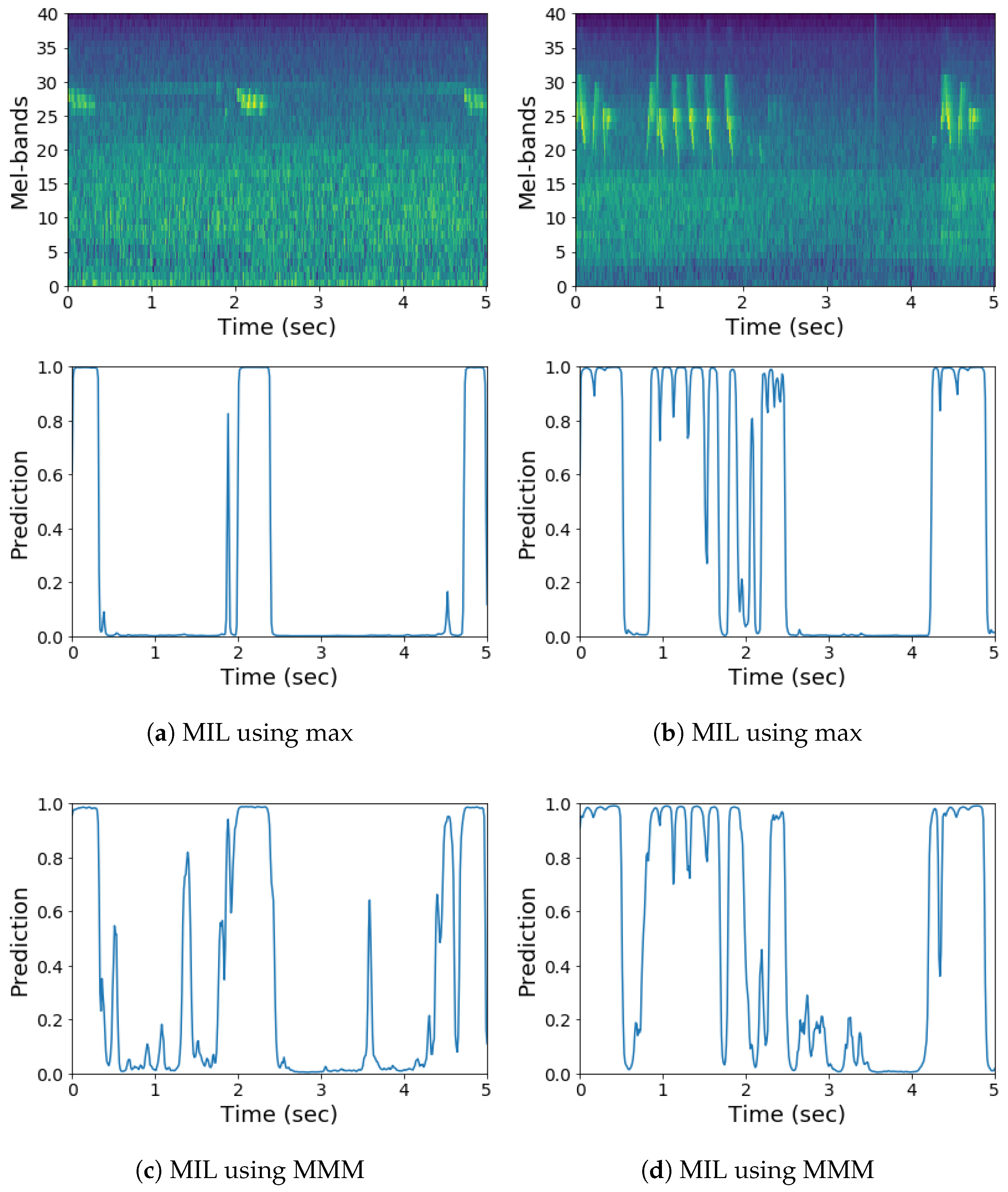
2.2.2. Multi Instance Learning
2.2.3. Half and Half Training
2.3. Audio Tagging (WHO)
Neural Network Architecture
3. Training Methods
3.1. Separate Training
3.2. Joint Training
3.3. Tied Weights Training
4. Evaluation
Results
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| MIL | Multi instance learning |
| GRUs | Gated recurrent units |
| ReLU | Rectified linear unit |
| MMM | Max mean min |
| HnH | Half and half |
| nonHnH | Non half and half |
| MTL | Multi-task learning |
| NIPS4B | Neural Information Processing Scaled for Bioacoustics |
| ROC | Receiver operating characteristic |
| AUC | Area under the curve |
References
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Choi, K.; Fazekas, G.; Sandler, M.B. Automatic Tagging Using Deep Convolutional Neural Networks. In Proceedings of the 17th International Society for Music Information Retrieval Conference (ISMIR), New York, NY, USA, 7–11 August 2016; pp. 805–811. [Google Scholar]
- Xu, Y.; Huang, Q.; Wang, W.; Foster, P.; Sigtia, S.; Jackson, P.J.B.; Plumbley, M.D. Unsupervised Feature Learning Based on Deep Models for Environmental Audio Tagging. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 1230–1241. [Google Scholar] [CrossRef]
- Xu, Y.; Kong, Q.; Huang, Q.; Wang, W.; Plumbley, M.D. Convolutional gated recurrent neural network incorporating spatial features for audio tagging. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 3461–3466. [Google Scholar]
- Adavanne, S.; Drossos, K.; Çakir, E.; Virtanen, T. Stacked convolutional and recurrent neural networks for bird audio detection. In Proceedings of the 2017 25th European Signal Processing Conference (EUSIPCO), Kos, Greece, 28 August–2 September 2017; pp. 1729–1733. [Google Scholar] [CrossRef]
- Pons, J.; Nieto, O.; Prockup, M.; Schmidt, E.M.; Ehmann, A.F.; Serra, X. End-to-end learning for music audio tagging at scale. Presented at the Workshop Machine Learning for Audio Signal Processing at NIPS (ML4Audio), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Cakir, E.; Heittola, T.; Huttunen, H.; Virtanen, T. Polyphonic sound event detection using multi label deep neural networks. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; pp. 1–7. [Google Scholar] [CrossRef]
- Parascandolo, G.; Huttunen, H.; Virtanen, T. Recurrent neural networks for polyphonic sound event detection in real life recordings. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 6440–6444. [Google Scholar] [CrossRef]
- Lee, D.; Lee, S.; Han, Y.; Lee, K. Ensemble of Convolutional Neural Networks for Weakly-supervised Sound Event Detection Using Multiple Scale Input. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2017 Workshop (DCASE 2017), Munich, Germany, 16–17 November 2017; pp. 74–79. [Google Scholar]
- Adavanne, S.; Virtanen, T. Sound Event Detection Using Weakly Labeled Dataset with Stacked Convolutional and Recurrent Neural Network. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2017 Workshop (DCASE 2017), Munich, Germany, 16–17 November 2017; pp. 12–16. [Google Scholar]
- Briggs, F.; Lakshminarayanan, B.; Neal, L.; Fern, X.; Raich, R.; Hadley, S.J.K.; Hadley, A.S.; Betts, M.G. Acoustic classification of multiple simultaneous bird species: A multi-instance multi-label approach. J. Acoust. Soc. Am. 2014, 131, 4640–4650. [Google Scholar] [CrossRef] [PubMed]
- Ruiz-Muñoz, J.F.; Orozco-Alzate, M.; Castellanos-Dominguez, G. Multiple Instance Learning-based Birdsong Classification Using Unsupervised Recording Segmentation. In Proceedings of the 24th International Conference on Artificial Intelligence (IJCAI’15), Buenos Aires, Argentina, 25–31 July 2015; pp. 2632–2638. [Google Scholar]
- Fanioudakis, L.; Potamitis, I. Deep Networks tag the location of bird vocalisations on audio spectrograms. arXiv, 2017; arXiv:1711.04347. [Google Scholar]
- Schlüter, J. Learning to Pinpoint Singing Voice from Weakly Labeled Examples. In Proceedings of the 17th International Society for Music Information Retrieval Conference (ISMIR 2016), New York, NY, USA, 7–11 August 2016. [Google Scholar]
- Kong, Q.; Xu, Y.; Wang, W.; Plumbley, M.D. A joint detection-classification model for audio tagging of weakly labelled data. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 641–645. [Google Scholar] [CrossRef]
- Hershey, S.; Chaudhuri, S.; Ellis, D.P.W.; Gemmeke, J.F.; Jansen, A.; Moore, R.C.; Plakal, M.; Platt, D.; Saurous, R.A.; Seybold, B.; et al. CNN architectures for large-scale audio classification. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 131–135. [Google Scholar] [CrossRef]
- Kumar, A.; Raj, B. Audio Event Detection Using Weakly Labeled Data. In Proceedings of the 2016 ACM on Multimedia Conference (MM’16), Amsterdam, The Netherlands, 15–19 October 2016; ACM: New York, NY, USA, 2016; pp. 1038–1047. [Google Scholar] [CrossRef]
- Kumar, A.; Raj, B. Deep CNN Framework for Audio Event Recognition using Weakly Labeled Web Data. arXiv, 2017; arXiv:1707.02530. [Google Scholar]
- Yu, D.; Deng, L. Automatic Speech Recognition; Springer: Berlin, Germany, 2016. [Google Scholar]
- Anguera, X.; Bozonnet, S.; Evans, N.; Fredouille, C.; Friedland, G.; Vinyals, O. Speaker Diarization: A Review of Recent Research. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 356–370. [Google Scholar] [CrossRef]
- Garcia-Romero, D.; Snyder, D.; Sell, G.; Povey, D.; McCree, A. Speaker diarization using deep neural network embeddings. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 4930–4934. [Google Scholar] [CrossRef]
- Tirumala, S.S.; Shahamiri, S.R. A Review on Deep Learning Approaches in Speaker Identification. In Proceedings of the 8th International Conference on Signal Processing Systems (ICSPS 2016), Auckland, New Zealand, 21–24 November 2016; ACM: New York, NY, USA, 2016; pp. 142–147. [Google Scholar] [CrossRef]
- Dietterich, T.G.; Lathrop, R.H.; Lozano-Pérez, T. Solving the multiple instance problem with axis-parallel rectangles. Artif. Intell. 1997, 89, 31–71. [Google Scholar] [CrossRef]
- Zhou, Z.H.; Zhang, M.L. Neural Networks for Multi-Instance Learning; Technical Report, AI Lab; Computer Science and Technology Department, Nanjing University: Nanjing, China, August 2002. [Google Scholar]
- Amar, R.; Dooly, D.R.; Goldman, S.A.; Zhang, Q. Multiple-Instance Learning of Real-Valued Data. In Proceedings of the Eighteenth International Conference on Machine Learning (ICML ’01), Williamstown, MA, USA, 28 June–1 July 2001; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2001; pp. 3–10. [Google Scholar]
- Liu, D.; Zhou, Y.; Sun, X.; Zha, Z.; Zeng, W. Adaptive Pooling in Multi-instance Learning for Web Video Annotation. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017; pp. 318–327. [Google Scholar] [CrossRef]
- Wang, Y.; Li, J.; Metze, F. Comparing the Max and Noisy-Or Pooling Functions in Multiple Instance Learning for Weakly Supervised Sequence Learning Tasks. arXiv, 2018; arXiv:1804.01146. [Google Scholar]
- Caruana, R. Multitask Learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Zhang, M.L.; Zhou, Z.H. A Review on Multi-Label Learning Algorithms. IEEE Trans. Knowl. Data Eng. 2014, 26, 1819–1837. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, Q. An overview of multi-task learning. Natl. Sci. Rev. 2018, 5, 30–43. [Google Scholar] [CrossRef]
- Neural Information Processing Scaled for Bioacoustics (NIPS4B) 2013 Bird Song Competition. Available online: http://sabiod.univ-tln.fr/nips4b/challenge1.html (accessed on 15 August 2018).
- Transcriptions for the NIPS4B 2013 Bird Song Competition Training Set. Available online: https://figshare.com/articles/Transcriptions_of_NIPS4B_2013_Bird_Challenge_Training_Dataset/6798548 (accessed on 15 August 2018).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Lasseck, M. Bird song classification in field recordings: Winning solution for NIPS4B 2013 competition. In Proceedings of the International Symposium Neural Information Scaled for Bioacoustics, Lake Tahoe, NV, USA, 10 December 2013; pp. 176–181. [Google Scholar]
- Duong, L.; Cohn, T.; Bird, S.; Cook, P. Low Resource Dependency Parsing: Cross-lingual Parameter Sharing in a Neural Network Parser. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 27–29 July 2015. [Google Scholar]
- Misra, I.; Shrivastava, A.; Gupta, A.; Hebert, M. Cross-Stitch Networks for Multi-task Learning. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Vegas, NV, USA, 27–30 June 2016; pp. 3994–4003. [Google Scholar] [CrossRef]
- Yang, Y.; Hospedales, T. Trace Norm Regularised Deep Multi-Task Learning. In Proceedings of the 5th International Conference on Learning Representations Workshop, Toulon, France, 24–26 April 2017. [Google Scholar]
- Ruder, S.; Bingel, J.; Augenstein, I.; Søgaard, A. Sluice networks: Learning what to share between loosely related tasks. arXiv, 2017; arXiv:1705.08142v2. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Size | #Fmaps | Activation | l2_regularisation |
|---|---|---|---|---|
| Convolution 2D | 3 × 3 | 64 | Linear | 0.001 |
| Batch Normalisation | - | - | - | - |
| Activation | - | - | ReLU | - |
| Convolution 2D | 3 × 3 | 64 | Linear | 0.001 |
| Batch Normalisation | - | - | - | - |
| Activation | - | - | ReLU | - |
| Max Pooling | 1 × 5 | - | - | - |
| Convolution 2D | 3 × 3 | 64 | Linear | 0.001 |
| Batch Normalisation | - | - | - | - |
| Activation | - | - | ReLU | - |
| Convolution 2D | 3 × 3 | 64 | Linear | 0.001 |
| Batch Normalisation | - | - | - | - |
| Activation | - | - | ReLU | - |
| Max Pooling | 1 × 4 | - | - | - |
| Convolution 2D | 3 × 3 | 64 | Linear | 0.001 |
| Batch Normalisation | - | - | - | - |
| Activation | - | - | ReLU | - |
| Convolution 2D | 3 × 3 | 64 | Linear | 0.001 |
| Batch Normalisation | - | - | - | - |
| Activation | - | - | ReLU | - |
| Max Pooling | 1 × 2 | - | - | - |
| Reshape | - | - | - | - |
| Bidirectional GRU | 64 | - | tanh | 0.01 |
| Bidirectional GRU | 64 | - | tanh | 0.01 |
| Time Distributed Dense | 64 | - | ReLU | 0.01 |
| Time Distributed Dense | 1 | - | Sigmoid | 0.01 |
| Flatten | - | - | - | - |
| Trainable parameters: | 320,623 |
| Layer | Size | #Fmaps | Activation | l2_regularisation |
|---|---|---|---|---|
| Convolution 2D | 3 × 3 | 64 | Linear | 0.001 |
| Batch Normalisation | - | - | - | - |
| Activation | - | - | ReLU | - |
| Convolution 2D | 3 × 3 | 64 | Linear | 0.001 |
| Batch Normalisation | - | - | - | - |
| Activation | - | - | ReLU | - |
| Max Pooling | 1 × 5 | - | - | - |
| Convolution 2D | 3 × 3 | 64 | Linear | 0.001 |
| Batch Normalisation | - | - | - | - |
| Activation | - | - | ReLU | - |
| Convolution 2D | 3 × 3 | 64 | Linear | 0.001 |
| Batch Normalisation | - | - | - | - |
| Activation | - | - | ReLU | - |
| Max Pooling | 1 × 4 | - | - | - |
| Convolution 2D | 3 × 3 | 64 | Linear | 0.001 |
| Batch Normalisation | - | - | - | - |
| Activation | - | - | ReLU | - |
| Convolution 2D | 3 × 3 | 64 | Linear | 0.001 |
| Batch Normalisation | - | - | - | - |
| Activation | - | - | ReLU | - |
| Max Pooling | 1 × 2 | - | - | - |
| Global Average Pooling 2D | - | - | - | - |
| Dense | #labels | - | Sigmoid | 0.001 |
| Trainable parameters: | 191,319 |
| Training | Input Type | WHEN | WHO |
|---|---|---|---|
| Method | WHEN | WHO | AUC | AUC |
| Separate | HnH | nonHnH | 0.90 | 0.94 |
| Joint [WHEN: 0.5; WHO: 0.5] | HnH | 0.89 | 0.52 |
| Joint [WHEN: 0.5; WHO: 0.5] | nonHnH | 0.47 | 0.57 |
| Joint [WHEN: 0.5; WHO: 5.0] | HnH | 0.90 | 0.50 |
| Joint [WHEN: 0.5; WHO: 5.0] | nonHnH | 0.82 | 0.75 |
| Tied Weights | HnH | nonHnH | 0.87 | 0.77 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Morfi, V.; Stowell, D. Deep Learning for Audio Event Detection and Tagging on Low-Resource Datasets. Appl. Sci. 2018, 8, 1397. https://doi.org/10.3390/app8081397
Morfi V, Stowell D. Deep Learning for Audio Event Detection and Tagging on Low-Resource Datasets. Applied Sciences. 2018; 8(8):1397. https://doi.org/10.3390/app8081397
Chicago/Turabian StyleMorfi, Veronica, and Dan Stowell. 2018. "Deep Learning for Audio Event Detection and Tagging on Low-Resource Datasets" Applied Sciences 8, no. 8: 1397. https://doi.org/10.3390/app8081397
APA StyleMorfi, V., & Stowell, D. (2018). Deep Learning for Audio Event Detection and Tagging on Low-Resource Datasets. Applied Sciences, 8(8), 1397. https://doi.org/10.3390/app8081397