An Emotion-Aware Personalized Music Recommendation System Using a Convolutional Neural Networks Approach



Abstract
1. Introduction
2. Related Works
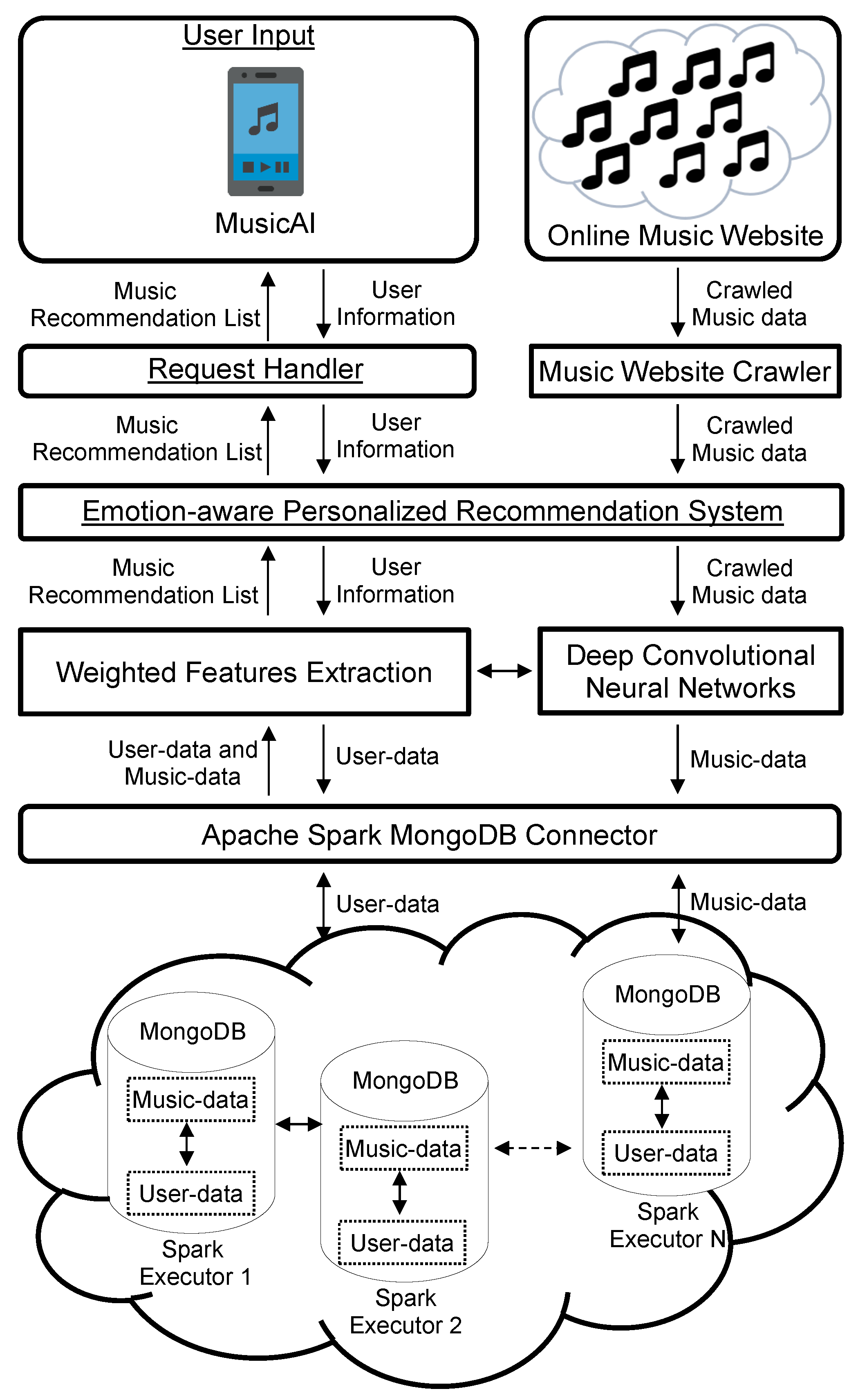
3. Emotion-Aware PMRS
- User input: This is the front-end layer of the EPMRS system architecture. This layer keeps track of the user’s data. The user’s data contains the user’s music listening data, the user’s current emotion, the user’s login data, the time of the day, the geographical location, the user’s click stream, the user’s rating for the song, the ambience, etc. This user’s data are given as input data to the request handler layer for further processing. This layer accepts the recommended songs list generated from the EPMRS layer from the request handler layer. The recommended songs’ list is displayed to the user as part of the music recommendations.
- Request handler: This layer acts as a middle layer between user input and the EPMRS layer. The user’s data obtained from the user input layer is the input data to the EPMRS layer for providing music recommendations with respect to the user. This layer gets the recommended songs from the EPMRS layer and sends it to the user input layer.
- EPMRS: This layer is the core layer where the EPMRS is deployed. This layer is a cloud-based distributed storage and processing layer. In order to store a huge amount of user behaviors on large scale music (e.g., more than one million songs data), we use the Docker technology to provide cloud environment to the EPMRS. Each Docker container is an Apache spark node containing mongoDB as the database. The Apache spark with mongoDB provides the distributed data storage and processing in this layer. Along with users’ data, this layer is also responsible for storing the music data. The music data is collected from the music website crawlers. We use Apache Nutch based music website crawlers to crawl the music data from the online music websites. The music data contains the metadata and the audio signal of the songs. The music data and the user’s data are stored as part of the distributed storage in the EPMRS. After processing the user’s data and the music data, the EPMRS generates the recommended songs list to the user. This recommended songs list is given as input to the request handler layer.
4. EPMRS Mathematical Model
4.1. Dataset
4.2. Weighted Feature Extraction
4.3. Deep CNN
- Rectified linear units (RLUs) are used as an alternative to the sigmoid function. The usage of RLUs in DCNN contributes to faster convergence. The RLUs minimizes the vanishing gradient problem, which is a common problem in traditional multi layer neural networks.
- In order to increase the speed of the EPMRS, we execute the DCNN approach in a parallel fashion on the GPU. We used the Keras library [24] to execute the DCNN on the GPU in a parallel fashion.
5. Experimental Results
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| CB | content based |
| CF | collaborative filtering |
| CSMRS | content similarity music recommendation sys |
| DCNN | deep convolutional neural networks |
| EPMRS | emotion-aware personalized music recommendation system |
| GRU | gated recurrent units |
| LSTM | long short term memory |
| PMRS | personalized music recommendation system |
| PMRSE | personalized music recommendation system based on electroencephalography feedback |
| RNN | recurrent neural networks |
| SVM | support vector machine |
| WFE | weighted feature extraction |
References
- Hyung, Z.; Park, J.S.; Lee, K. Utilizing context-relevant keywords extracted from a large collection of user-generated documents for music discovery. Inf. Process. Manag. 2017, 53, 1185–1200. [Google Scholar] [CrossRef]
- Pazzani, M.J.; Billsus, D. Content based recommendation systems. In The Adaptive Web: Methods and Strategies of Web Personalization; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2007; pp. 325–341. [Google Scholar]
- Schafer, J.B.; Frankowski, D.; Herlocker, J.; Sen, S. Collaborative filtering recommender systems. In The Adaptive Web: Methods and Strategies of Web Personalization; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2007; pp. 291–324. [Google Scholar]
- Burke, R. Hybrid web recommender systems. In The Adaptive Web: Methods and Strategies of Web Personalization; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2007; pp. 377–408. [Google Scholar]
- Aljanaki, A.; Wiering, F.; Veltkamp, R.C. Studying emotion induced by music through a crowdsourcing game. Inf. Process. Manag. 2016, 52, 115–128. [Google Scholar] [CrossRef]
- Shan, M.K.; Kuo, F.F.; Chiang, M.F.; Lee, S.Y. Emotion-based music recommendation by affinity discovery from film music. Expert Syst. Appl. 2009, 36, 7666–7674. [Google Scholar] [CrossRef]
- Bogdanov, D.; Wack, N.; Gómez, E.; Gulati, S.; Herrera, P.; Mayor, O.; Roma, G.; Salamon, J.; Zapata, J.; Serra, X. ESSENTIA: An open-source library for sound and music analysis. In Proceedings of the 21st ACM International Conference on Multimedia, Barcelona, Spain, 21 Octobor 2013; pp. 855–858. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Hsu, C.W.; Lin, C.J. A comparison of methods for multiclass support vector machines. IEEE Trans. Neural Netw. 2002, 13, 415–425. [Google Scholar] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: Lessons learned from the 2015 mscoco image captioning challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 652–663. [Google Scholar] [CrossRef] [PubMed]
- Oord, A.V.; Dieleman, S.; Schrauwen, B. Deep content-based music recommendation. In Proceedings of the 26th Neural Information Processing Systems, Lake Tahoe, CA, USA, 5–10 December 2013; pp. 2643–2651. [Google Scholar]
- Salamon, J.; Bello, J.P. Deep convolutional neural networks and data augmentation for environmental sound classification. IEEE Signal Process. Lett. 2017, 24, 279–283. [Google Scholar] [CrossRef]
- Bertin-Mahieux, T.; Ellis, D.P.; Whitman, B.; Lamere, P. The million song dataset. ISMIR 2011, 2, 10. [Google Scholar]
- Fan, R.E.; Chang, K.W.; Hsieh, C.J.; Wang, X.R.; Lin, C.J. LIBLINEAR: A library for large linear classification. J. Mach. Learn. Res. 2008, 9, 1871–1874. [Google Scholar]
- Schedl, M.; Pohle, T.; Knees, P.; Widmer, G. Exploring the music similarity space on the web. ACM Trans. Inf. Syst. 2011, 29, 1–24. [Google Scholar] [CrossRef]
- Humphrey, E.J.; Bello, J.P.; LeCun, Y. Moving beyond feature design: Deep architectures and automatic feature learning in music informatics. In Proceedings of the 13th International Society for Music Information Retrieval Conference, Porto, Portugal, 8 October 2012; pp. 403–408. [Google Scholar]
- McFee, B.; Lanckriet, G.R. Learning multi-modal similarity. J. Mach. Learn. Res. 2011, 12, 491–523. [Google Scholar]
- Haupt, J. Last.fm: People-powered online radio. Music Ref. Serv. Q. 2009, 12, 23–24. [Google Scholar] [CrossRef]
- Ignatov, D.I.; Nikolenko, S.I.; Abaev, T.; Poelmans, J. Online recommender system for radio station hosting based on information fusion and adaptive tag-aware profiling. Expert Syst. Appl. 2016, 55, 546–558. [Google Scholar] [CrossRef]
- Tan, Y.K.; Xu, X.; Liu, Y. Improved recurrent neural networks for session-based recommendations. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016; pp. 17–22. [Google Scholar]
- Hu, Y.; Koren, Y.; Volinsky, C. Collaborative filtering for implicit feedback datasets. In Proceedings of the 8th IEEE International Conference Data Mining, Pisa, Italy, 15–19 December 2008; pp. 263–272. [Google Scholar]
- Wu, H.C.; Luk, R.W.P.; Wong, K.F.; Kwok, K.L. Interpreting TF-IDF term weights as making relevance decisions. Proc. ACM Trans. Inf. Syst. 2008, 26, 13:1–13:37. [Google Scholar] [CrossRef]
- Erickson, B.J.; Korfiatis, P.; Akkus, Z.; Kline, T.; Philbrick, K. Toolkits and libraries for deep learning. J. Digit. Imag. 2017, 30, 400–405. [Google Scholar] [CrossRef] [PubMed]
- McFee, B.; Barrington, L.; Lanckriet, G. Learning content similarity for music recommendation. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 2207–2218. [Google Scholar] [CrossRef]
- Chang, H.Y.; Huang, S.C.; Wu, J.H. A personalized music recommendation system based on electroencephalography feedback. Multimed. Tools Appl. 2017, 76, 19523–19542. [Google Scholar] [CrossRef]
- Jaganmohan. MusicRecommendation: Content Based Recommendation System. GitHub. Available online: https://github.com/jaganmohan/MusicRecommendation/ (accessed on 1 April 2018).
- Anandbhoraskar. Music Classification. GitHub. Available online: https://github.com/anandbhoraskar/musicClassification/ (accessed on 16 June 2018).
- Junorecords. Available online: https://www.juno.co.uk/ (accessed on 1 November 2017).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Genre | EPMRS | CSMRS | PMRSE |
|---|---|---|---|
| Breakbeat | 74.96 | 60.66 | 52.33 |
| Dancehall | 94.56 | 80.44 | 73.15 |
| Downtempo | 76.52 | 61.91 | 50.98 |
| Drum and bass | 85.56 | 80.43 | 75.32 |
| Funky house | 79.55 | 82.45 | 74.53 |
| Hip Hop | 84.56 | 81.12 | 78.84 |
| Minimal house | 69.32 | 73.56 | 62.37 |
| Rock | 95.36 | 90.56 | 68.04 |
| Trance | 85.28 | 75.89 | 65.74 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdul, A.; Chen, J.; Liao, H.-Y.; Chang, S.-H. An Emotion-Aware Personalized Music Recommendation System Using a Convolutional Neural Networks Approach. Appl. Sci. 2018, 8, 1103. https://doi.org/10.3390/app8071103
Abdul A, Chen J, Liao H-Y, Chang S-H. An Emotion-Aware Personalized Music Recommendation System Using a Convolutional Neural Networks Approach. Applied Sciences. 2018; 8(7):1103. https://doi.org/10.3390/app8071103
Chicago/Turabian StyleAbdul, Ashu, Jenhui Chen, Hua-Yuan Liao, and Shun-Hao Chang. 2018. "An Emotion-Aware Personalized Music Recommendation System Using a Convolutional Neural Networks Approach" Applied Sciences 8, no. 7: 1103. https://doi.org/10.3390/app8071103
APA StyleAbdul, A., Chen, J., Liao, H.-Y., & Chang, S.-H. (2018). An Emotion-Aware Personalized Music Recommendation System Using a Convolutional Neural Networks Approach. Applied Sciences, 8(7), 1103. https://doi.org/10.3390/app8071103