An Efficient Multiscale Scheme Using Local Zernike Moments for Face Recognition


Abstract
:1. Introduction
2. Local Zernike Moments Transformation
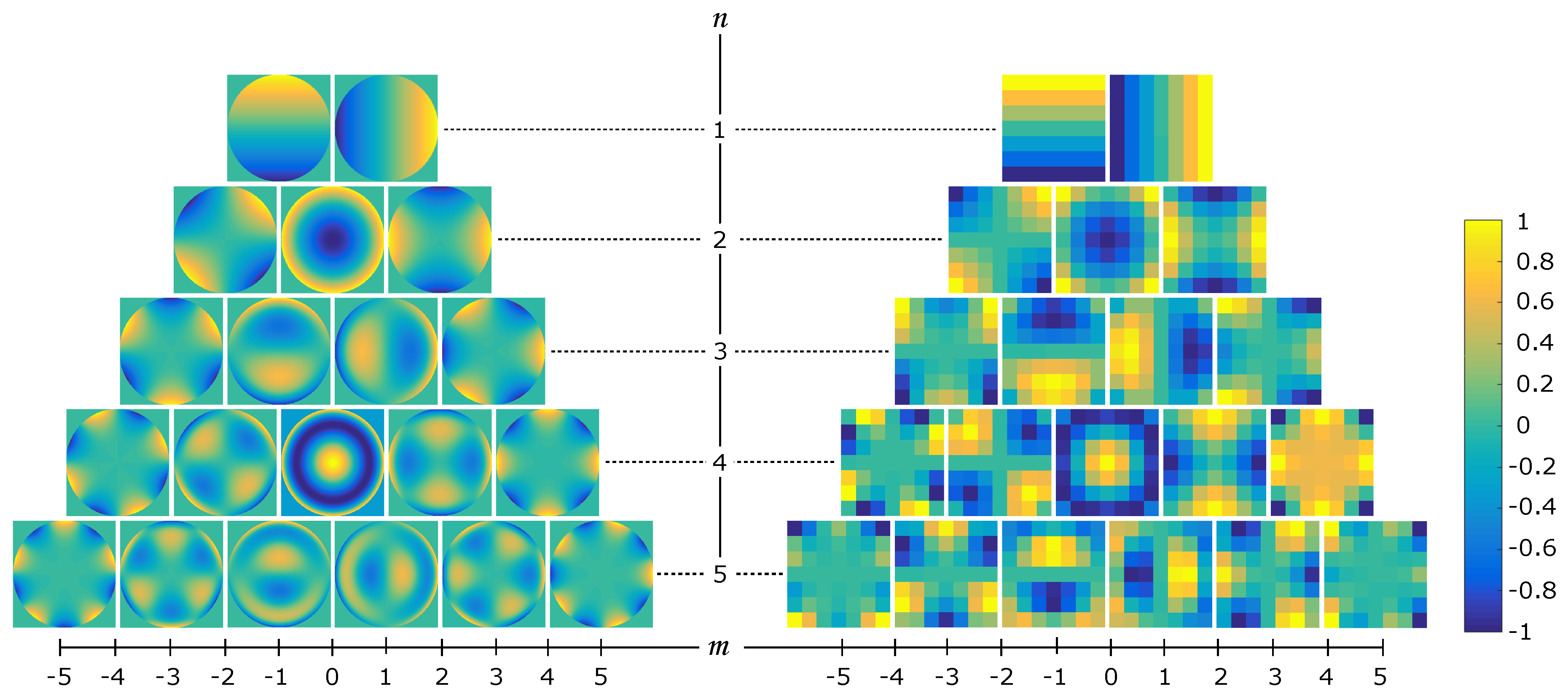
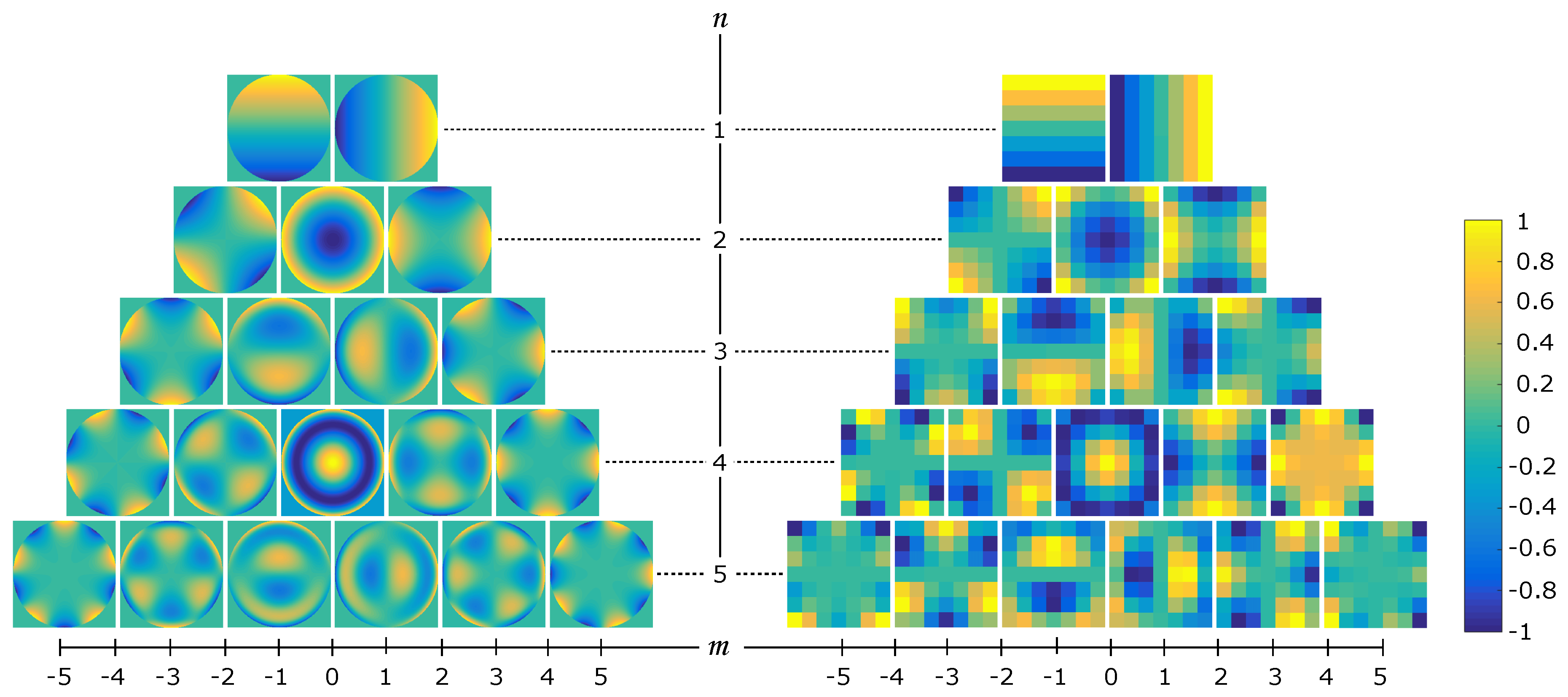
2.1. Zernike Moments
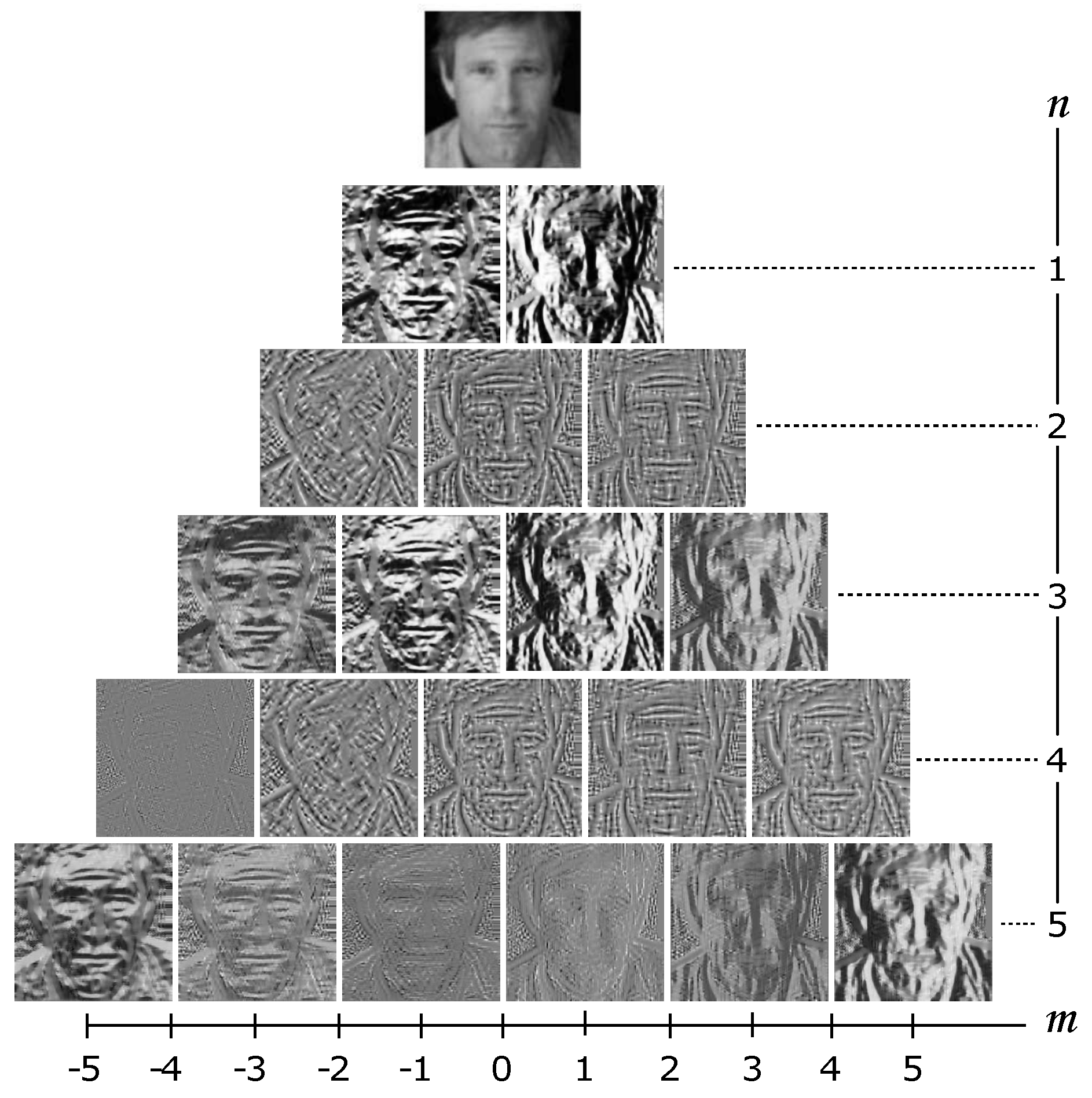
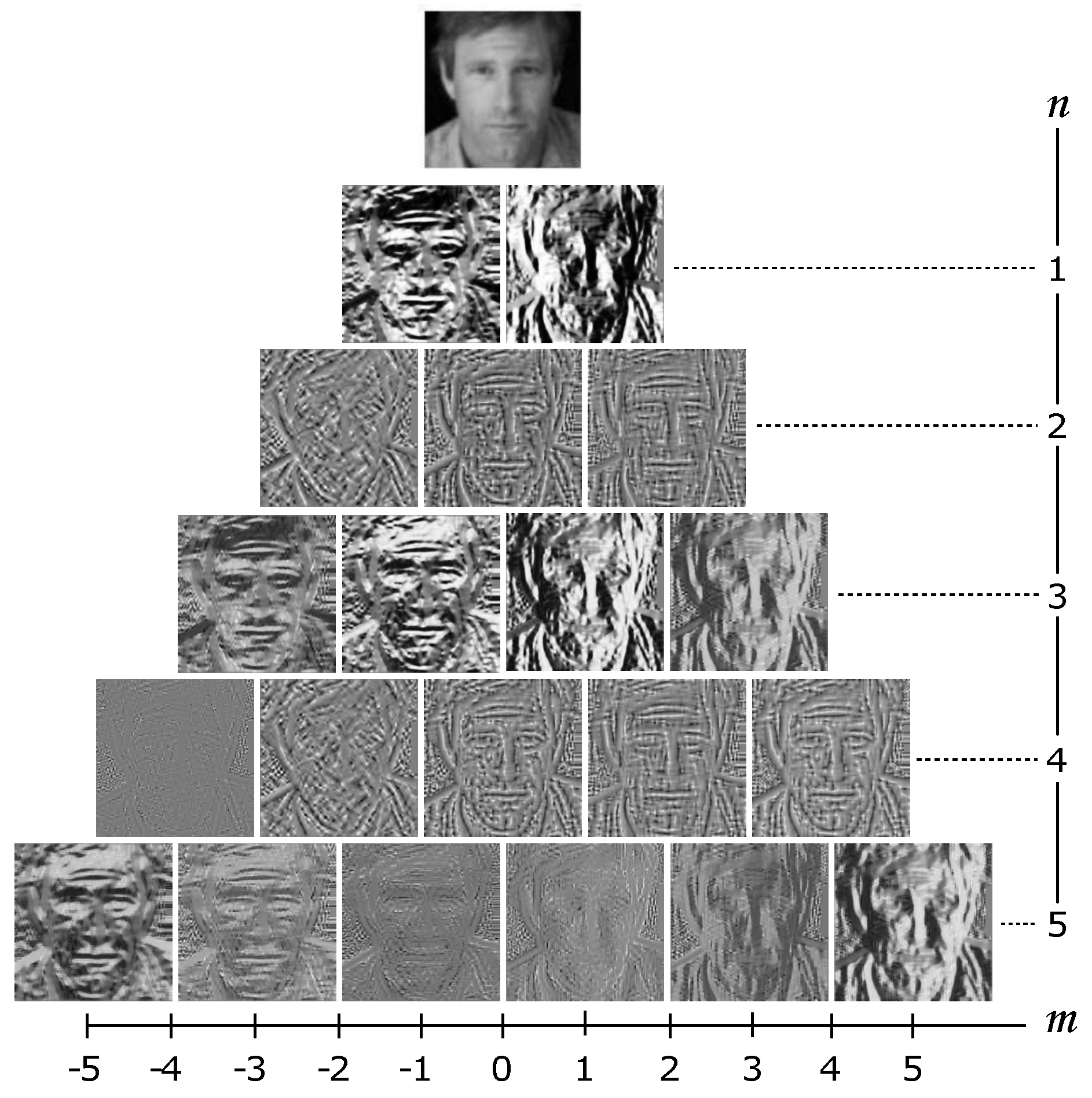
2.2. Local Zernike Moments
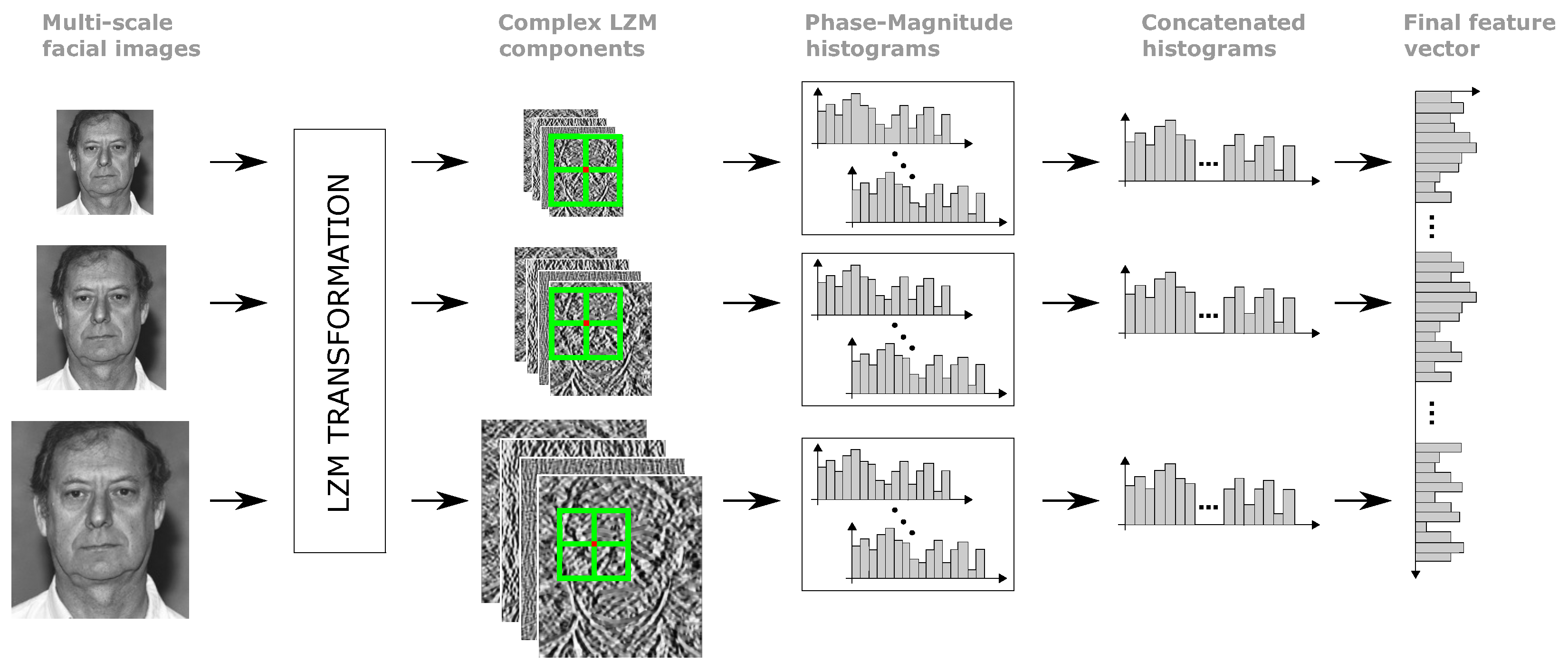
3. MS-LZM Face Recognition Scheme
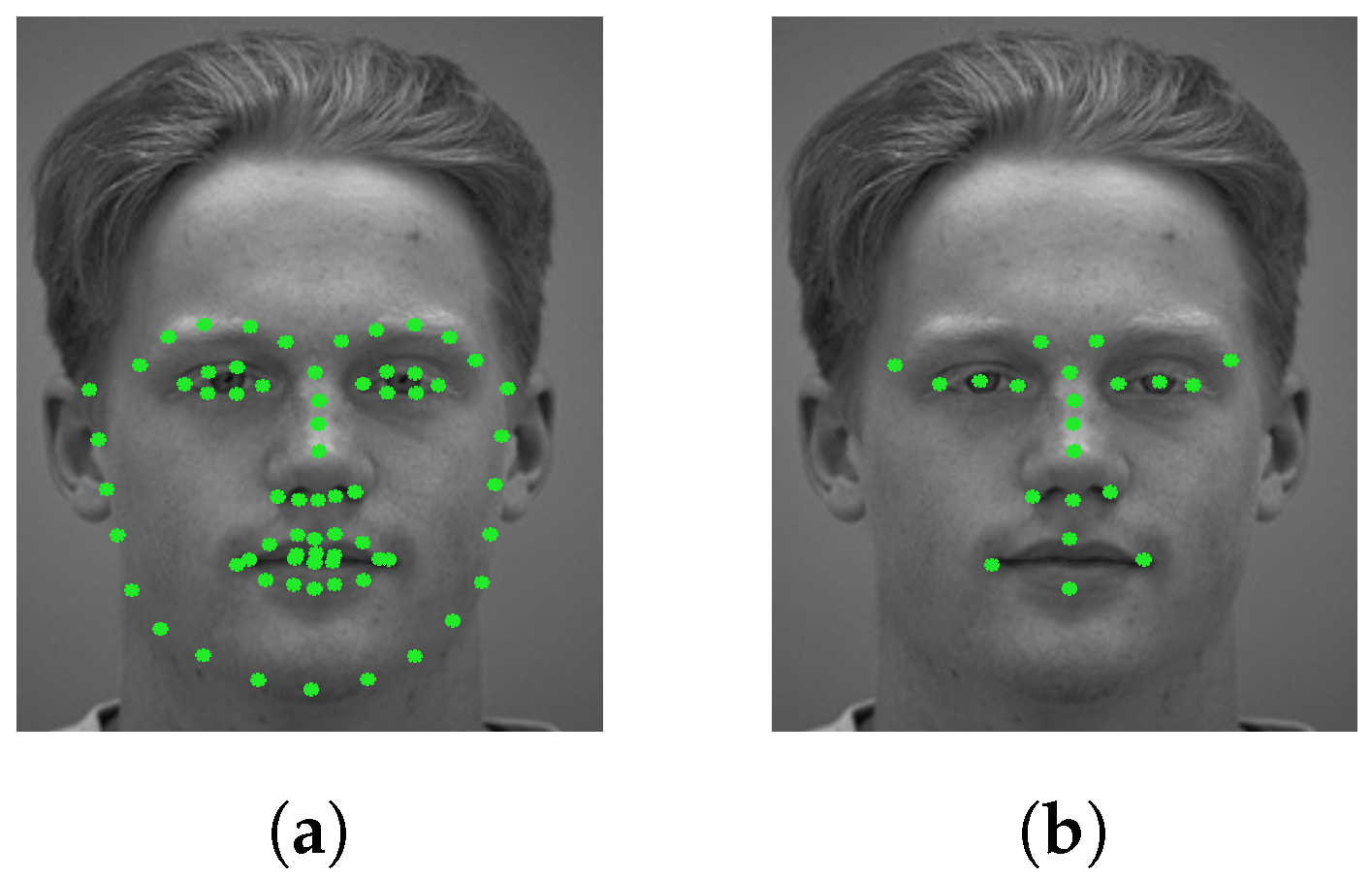
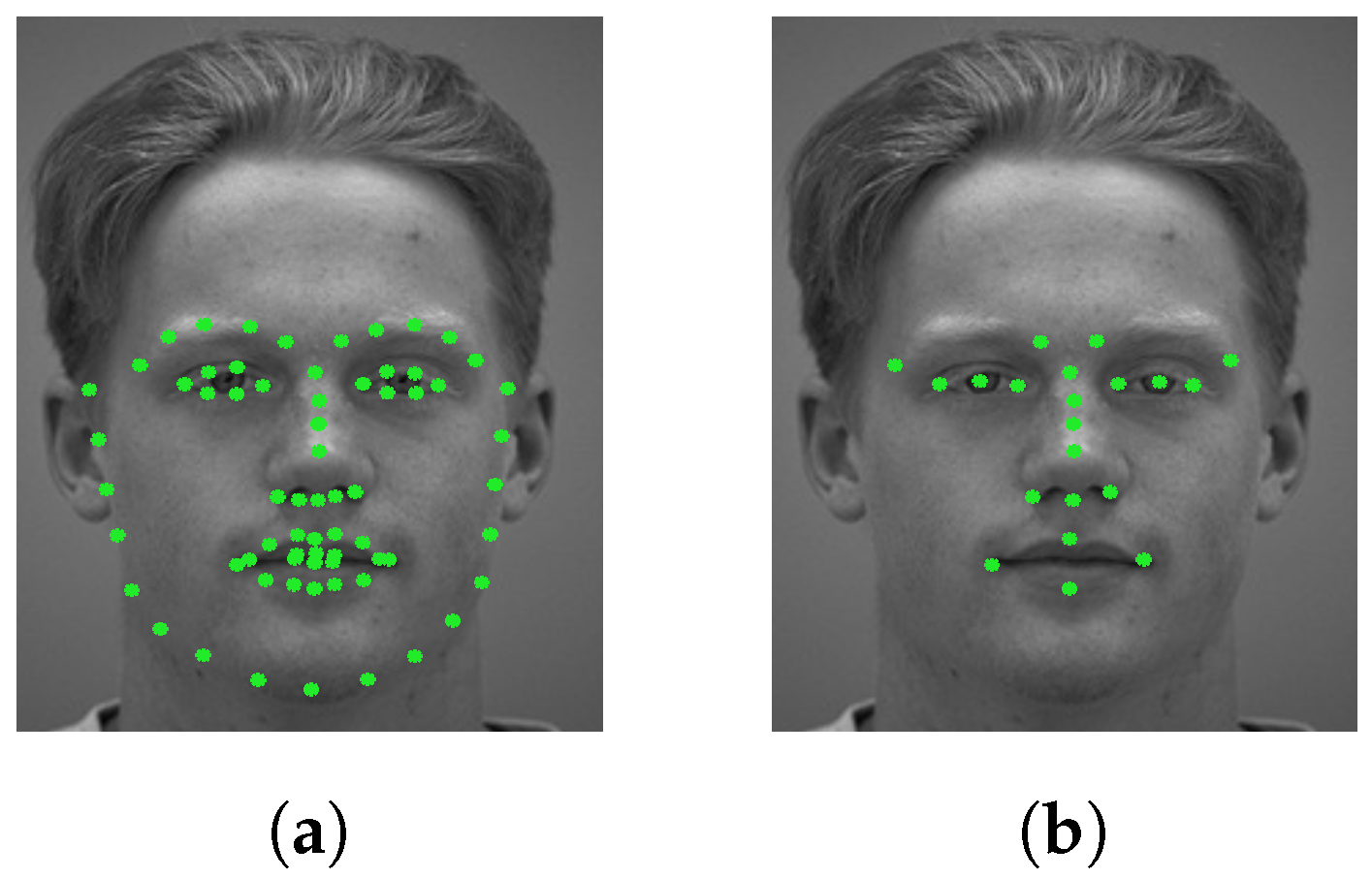
3.1. Multiscale Feature Extraction Around Facial Points
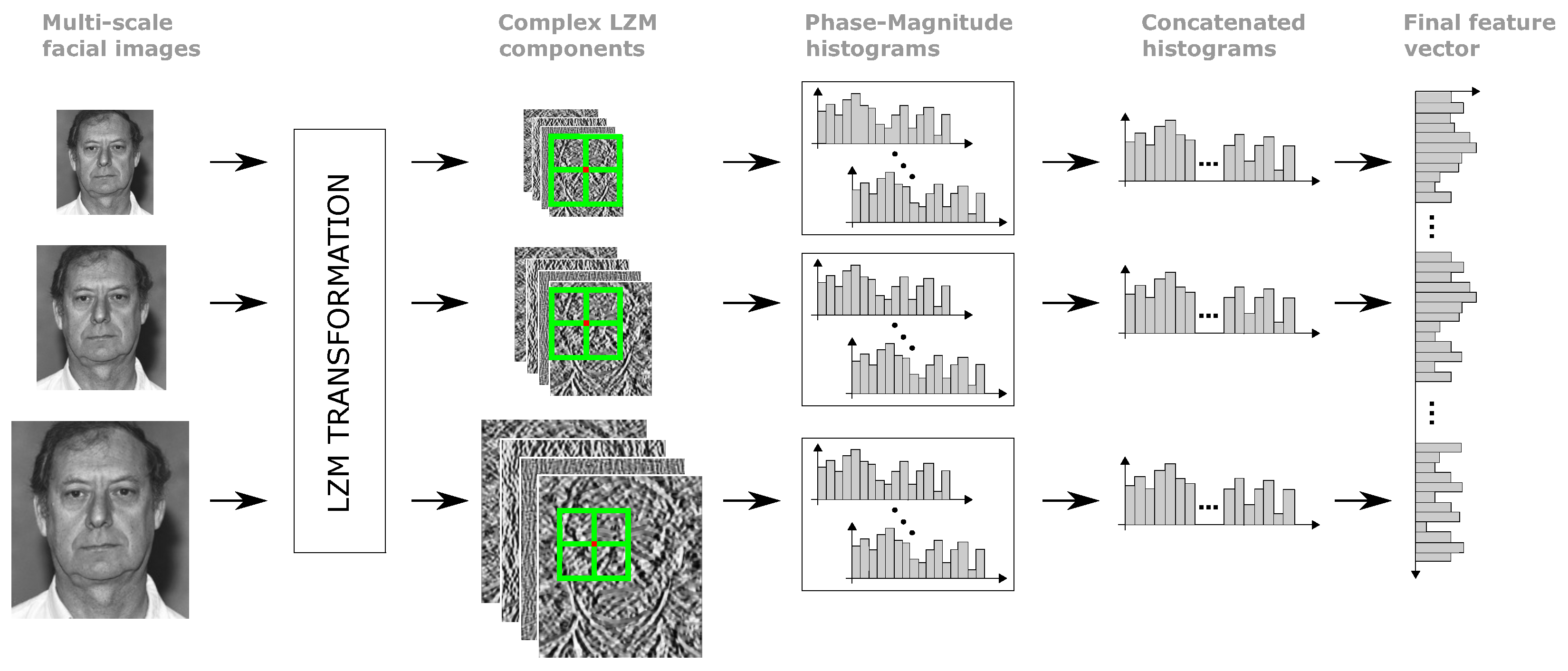
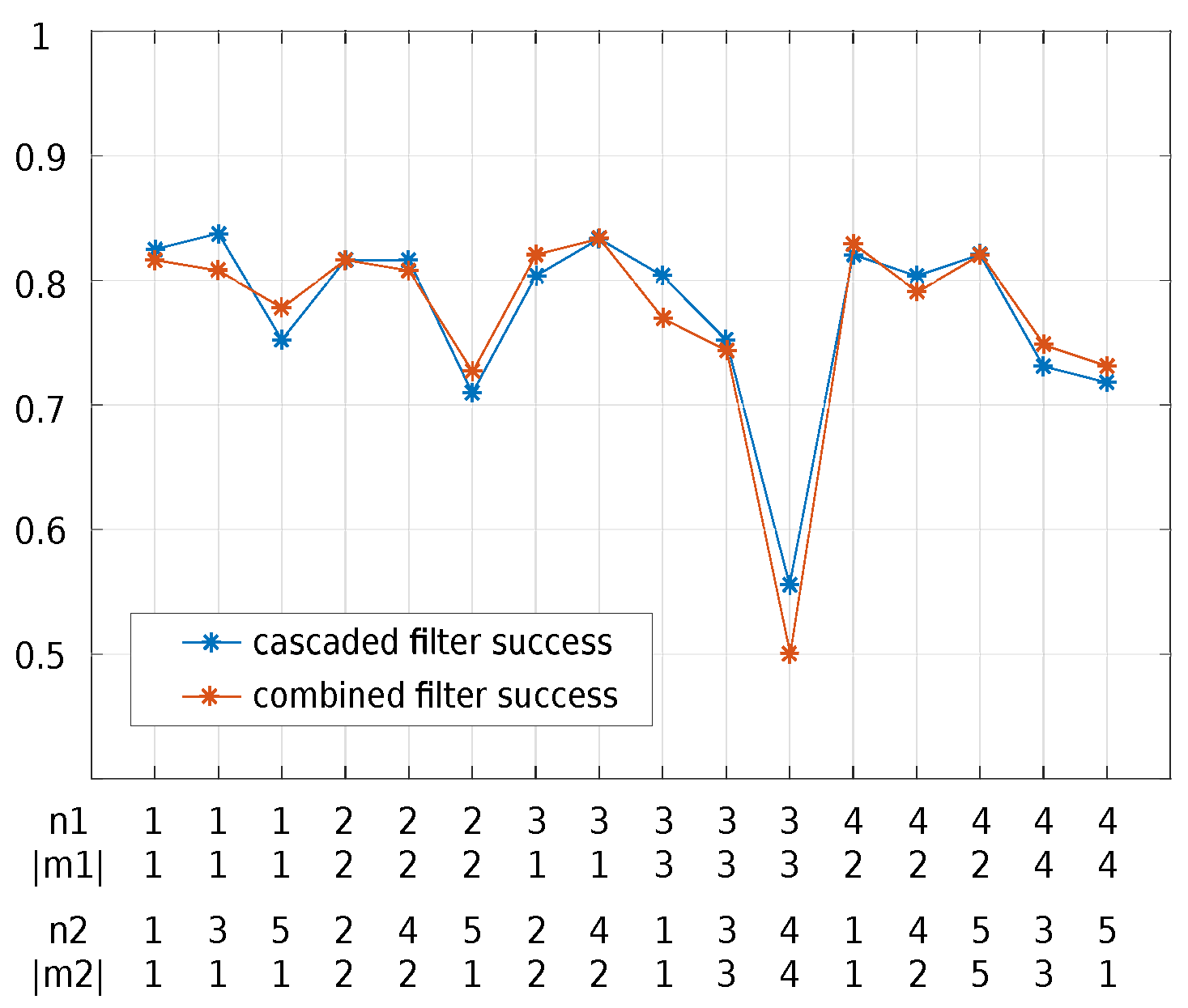
3.2. Cascaded LZM Transform
3.3. Dimensionality Reduction and Distance Calculation
4. Experimental Results
4.1. Experiments on FERET
4.2. Experiments on LFW
4.3. Experiments on SCface
4.4. Discussion
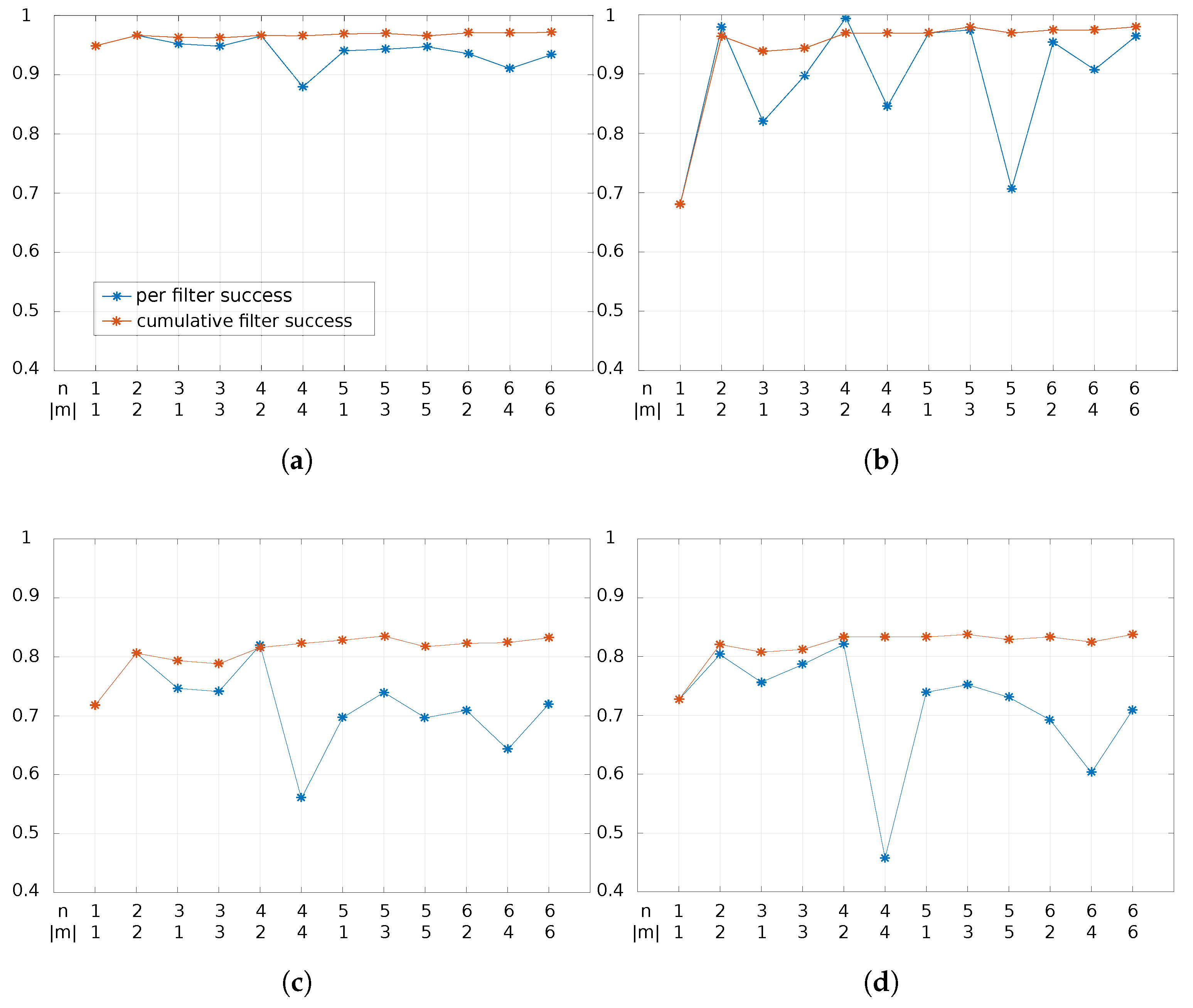
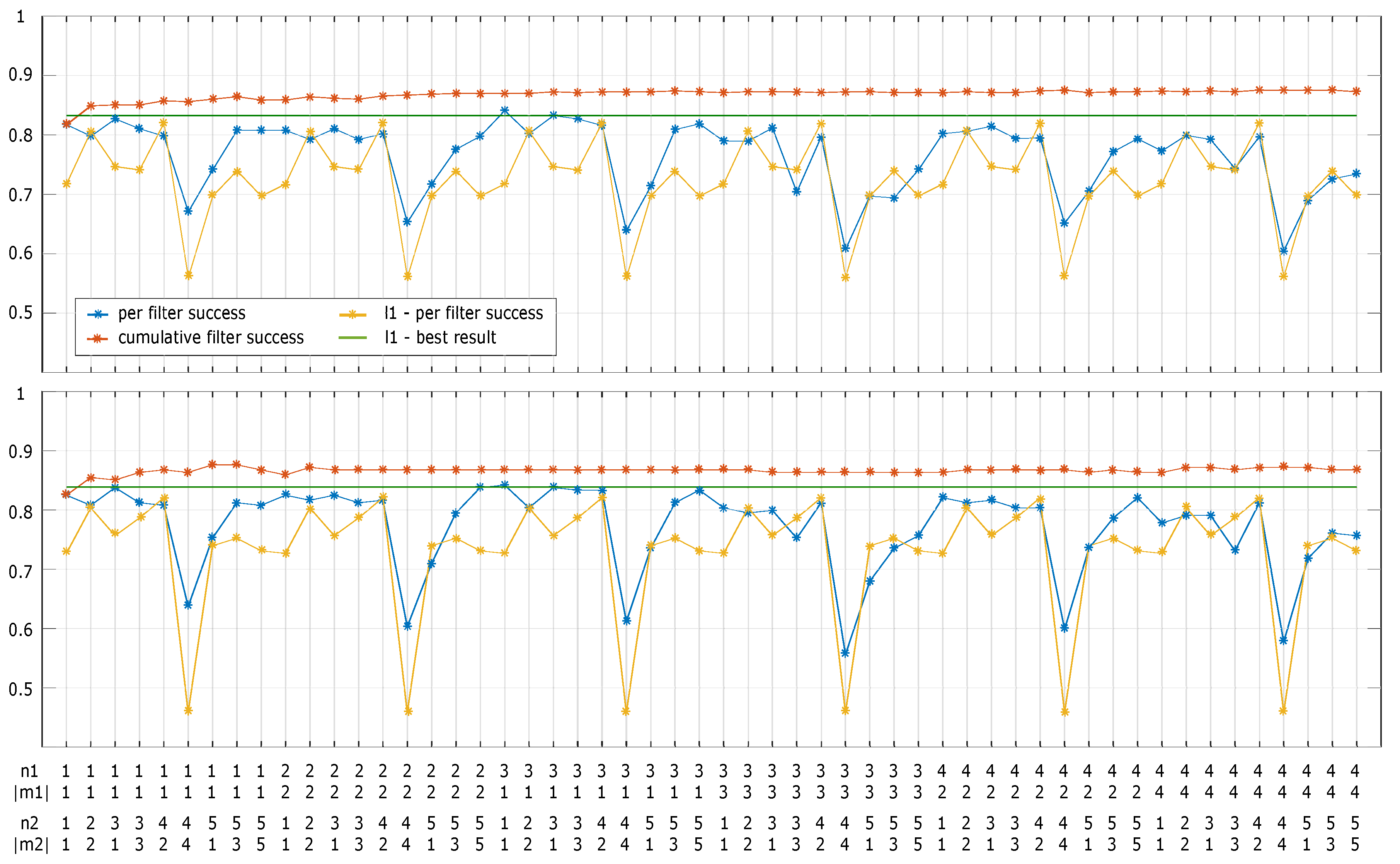
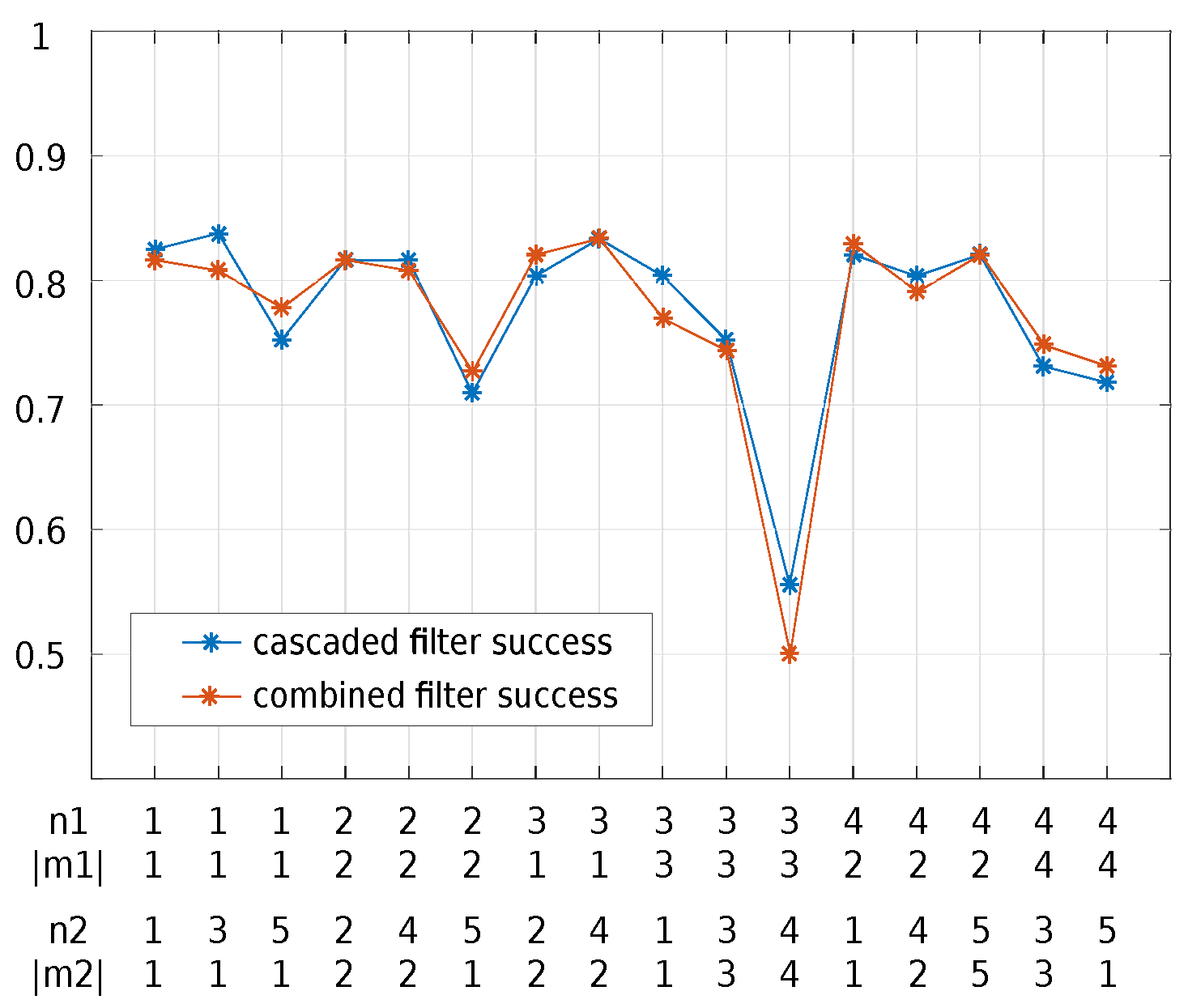
4.4.1. Results
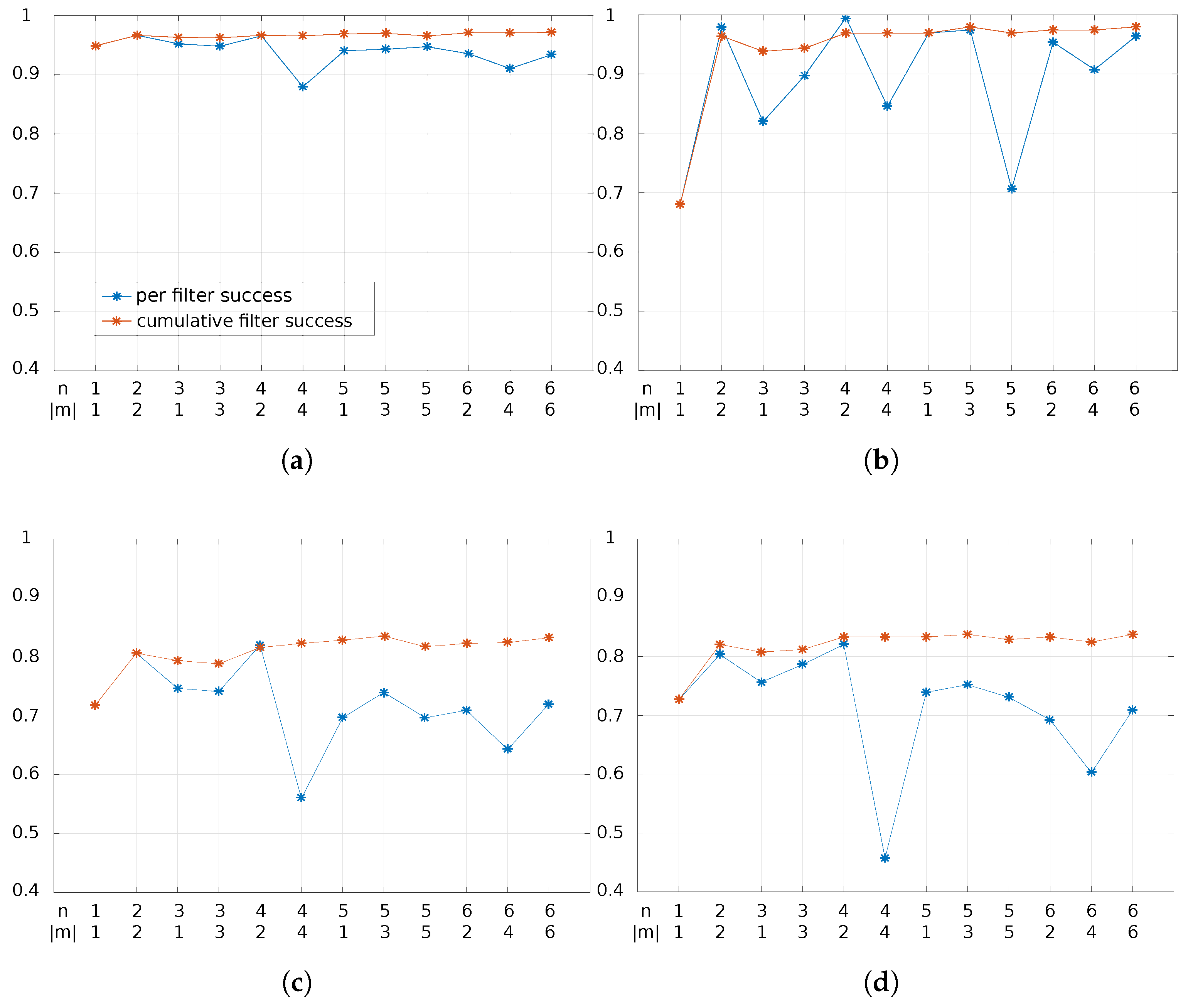
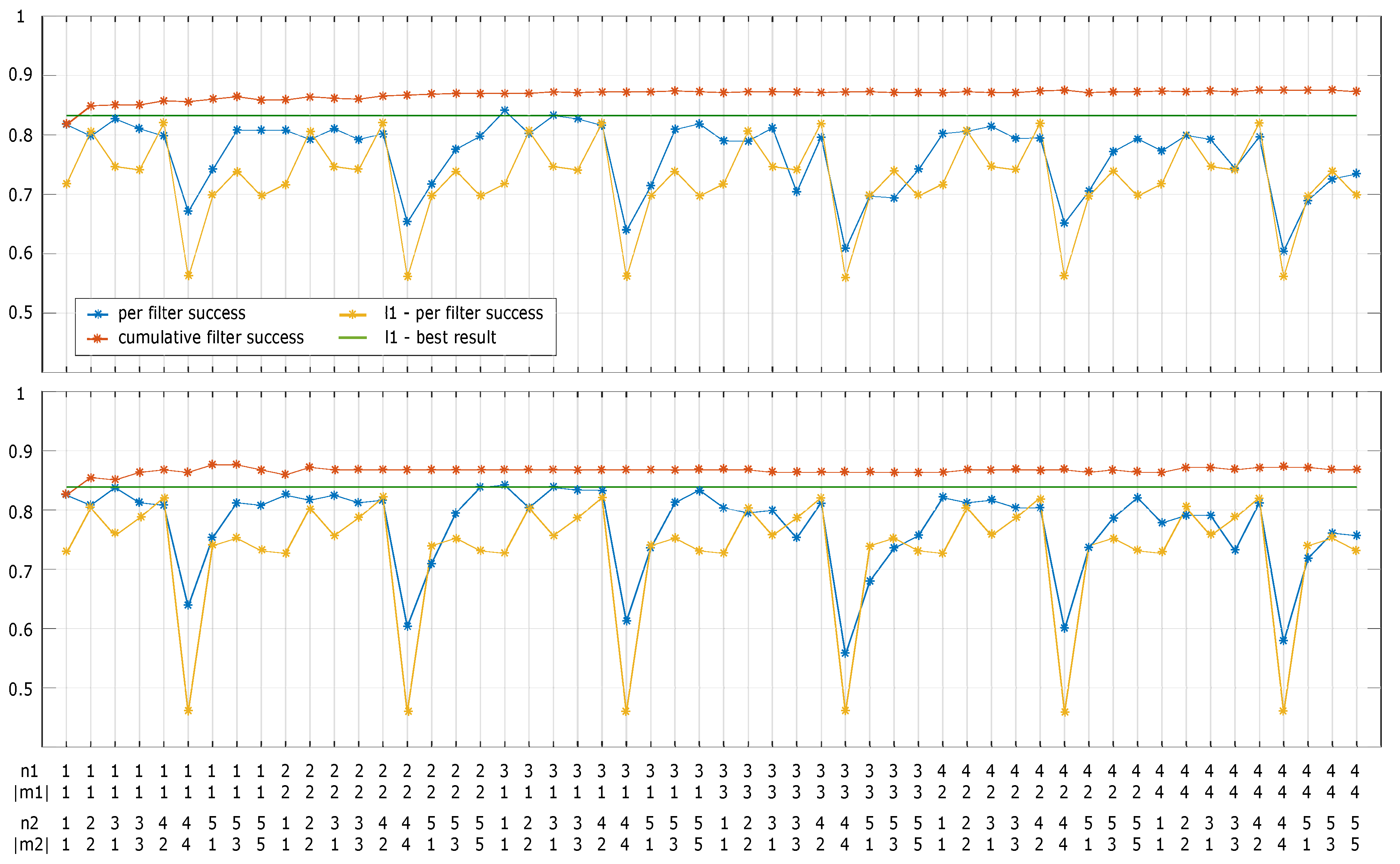
4.4.2. Parameters
- The number of scales used for extracting multi-scale features and the sizes of face images
- Moment degrees and filter sizes used in LZM transformations.
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Shnain, N.A.; Hussain, Z.M.; Lu, S.F. A feature-based structural measure: An image similarity measure for face recognition. Appl. Sci. 2017, 7, 786. [Google Scholar] [CrossRef]
- Ding, C.; Choi, J.; Tao, D.; Davis, L.S. Multi-directional multi-level dual-cross patterns for robust face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 518–531. [Google Scholar] [CrossRef] [PubMed]
- Barr, J.R.; Bowyer, K.W.; Flynn, P.J.; Biswas, S. Face recognition from video: A review. Int. J. Pattern Recognit. Artif. Intell. 2012, 26, 1266002. [Google Scholar] [CrossRef]
- Yi, D.; Lei, Z.; Li, S.Z. Shared representation learning for heterogenous face recognition. In Proceedings of the IEEE 2015 11th International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Ljubljana, Slovenia, 4–8 May 2015; Volume 1, pp. 1–7. [Google Scholar]
- Marcolin, F.; Vezzetti, E. Novel descriptors for geometrical 3D face analysis. Multimed. Tools Appl. 2017, 76, 13805–13834. [Google Scholar] [CrossRef]
- Moos, S.; Marcolin, F.; Tornincasa, S.; Vezzetti, E.; Violante, M.G.; Fracastoro, G.; Speranza, D.; Padula, F. Cleft lip pathology diagnosis and foetal landmark extraction via 3D geometrical analysis. Int. J. Interact. Des. Manuf. IJIDeM 2017, 11, 1–18. [Google Scholar] [CrossRef]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. Deepface: Closing the gap to human-level performance in face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 1701–1708. [Google Scholar]
- Masi, I.; Rawls, S.; Medioni, G.; Natarajan, P. Pose-aware face recognition in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4838–4846. [Google Scholar]
- Sarfraz, M.S.; Stiefelhagen, R. Deep Perceptual Mapping for Cross-Modal Face Recognition. Int. J. Comput. Vis. 2016, 122, 426–438. [Google Scholar] [CrossRef]
- Xi, M.; Chen, L.; Polajnar, D.; Tong, W. Local binary pattern network: A deep learning approach for face recognition. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3224–3228. [Google Scholar]
- Turk, M.; Pentland, A. Eigenfaces for recognition. J. Cognit. Neurosci. 1991, 3, 71–86. [Google Scholar] [CrossRef] [PubMed]
- Belhumeur, P.N.; Hespanha, J.P.; Kriegman, D.J. Eigenfaces vs. fisherfaces: Recognition using class specific linear projection. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 711–720. [Google Scholar] [CrossRef]
- Bartlett, M.S.; Movellan, J.R.; Sejnowski, T.J. Face recognition by independent component analysis. IEEE Trans. Neural Netw. 2002, 13, 1450–1464. [Google Scholar] [CrossRef] [PubMed]
- Bereta, M.; Pedrycz, W.; Reformat, M. Local descriptors and similarity measures for frontal face recognition: A comparative analysis. J. Vis. Commun. Image Represent. 2013, 24, 1213–1231. [Google Scholar] [CrossRef]
- Ahonen, T.; Hadid, A.; Pietikainen, M. Face description with local binary patterns: Application to face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 2037–2041. [Google Scholar] [CrossRef] [PubMed]
- Jin, H.; Liu, Q.; Lu, H.; Tong, X. Face detection using improved LBP under Bayesian framework. In Proceedings of the Third International Conference on Image and Graphics (ICIG’04), Hong Kong, China, 18–20 December 2004; pp. 306–309. [Google Scholar]
- Liao, S.; Zhu, X.; Lei, Z.; Zhang, L.; Li, S.Z. Learning multi-scale block local binary patterns for face recognition. In Proceedings of the International Conference on Biometrics, Seoul, Korea, 27–29 August 2007; Springer: Berlin, Germany, 2007; pp. 828–837. [Google Scholar]
- Wolf, L.; Hassner, T.; Taigman, Y. Effective unconstrained face recognition by combining multiple descriptors and learned background statistics. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1978–1990. [Google Scholar] [CrossRef] [PubMed]
- Guo, Z.; Zhang, L.; Zhang, D. A completed modeling of local binary pattern operator for texture classification. IEEE Trans. Image Process. 2010, 19, 1657–1663. [Google Scholar] [PubMed]
- Tan, X.; Triggs, B. Enhanced local texture feature sets for face recognition under difficult lighting conditions. IEEE Trans. Image Process. 2010, 19, 1635–1650. [Google Scholar] [PubMed]
- Zhang, B.; Gao, Y.; Zhao, S.; Liu, J. Local derivative pattern versus local binary pattern: face recognition with high-order local pattern descriptor. IEEE Trans. Image Process. 2010, 19, 533–544. [Google Scholar] [CrossRef] [PubMed]
- Daugman, J.G. Uncertainty relation for resolution in space, spatial frequency, and orientation optimized by two-dimensional visual cortical filters. JOSA A 1985, 2, 1160–1169. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2005), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Vu, N.S.; Caplier, A. Enhanced patterns of oriented edge magnitudes for face recognition and image matching. IEEE Trans. Image Process. 2012, 21, 1352–1365. [Google Scholar] [PubMed]
- Ul Hussain, S.; Triggs, B. Visual recognition using local quantized patterns. In Proceedings of the Computer Vision (ECCV 2012), Florence, Italy, 7–13 October 2012; Springer: Berlin, Germany, 2012; pp. 716–729. [Google Scholar]
- Teague, M.R. Image analysis via the general theory of moments. JOSA 1980, 70, 920–930. [Google Scholar] [CrossRef]
- Zhai, H.L.; Di Hu, F.; Huang, X.Y.; Chen, J.H. The application of digital image recognition to the analysis of two-dimensional fingerprints. Anal. Chim. Acta 2010, 657, 131–135. [Google Scholar] [CrossRef] [PubMed]
- Kan, C.; Srinath, M.D. Invariant character recognition with Zernike and orthogonal Fourier–Mellin moments. Pattern Recognit. 2002, 35, 143–154. [Google Scholar] [CrossRef]
- Tan, C.W.; Kumar, A. Accurate iris recognition at a distance using stabilized iris encoding and Zernike moments phase features. IEEE Trans. Image Process. 2014, 23, 3962–3974. [Google Scholar] [CrossRef] [PubMed]
- Foon, N.H.; Pang, Y.H.; Jin, A.T.B.; Ling, D.N.C. An efficient method for human face recognition using wavelet transform and Zernike moments. In Proceedings of the IEEE International Conference on Computer Graphics, Imaging and Visualization (CGIV 2004), Penang, Malaysia, 2 July 2004; pp. 65–69. [Google Scholar]
- Laine, A.; Fan, J. Texture classification by wavelet packet signatures. IEEE Trans. Pattern Anal. Mach. Intell. 1993, 15, 1186–1191. [Google Scholar] [CrossRef]
- Ouanan, H.; Ouanan, M.; Aksasse, B. Gabor-zernike features based face recognition scheme. Int. J. Imaging Robot 2015, 16, 118–131. [Google Scholar]
- Fathi, A.; Alirezazadeh, P.; Abdali-Mohammadi, F. A new Global-Gabor-Zernike feature descriptor and its application to face recognition. J. Vis. Commun. Image Represent. 2016, 38, 65–72. [Google Scholar] [CrossRef]
- Majeed, S. Face recognition using fusion of Local Binary Pattern and Zernike moments. In Proceedings of the IEEE International Conference on Power Electronics, Intelligent Control and Energy Systems (ICPEICES), Delhi, India, 4–6 July 2016; pp. 1–5. [Google Scholar]
- Singh, C.; Walia, E.; Mittal, N. Fusion of Zernike Moments and SIFT Features for Improved Face Recognition. In Proceedings of the International Conference on Recent Advances and Future Trends in Information Technology, Punjab, India, 21–23 March 2012; pp. 26–31. [Google Scholar]
- Huang, R.; Du, M.; Me, D. A human face recognition approach based on spatially weighted pseudo-Zernike moments. In Proceedings of the IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence) (IJCNN 2008), Hong Kong, China, 1–8 June 2008; pp. 1604–1608. [Google Scholar]
- Kanan, H.R.; Faez, K.; Gao, Y. Face recognition using adaptively weighted patch PZM array from a single exemplar image per person. Pattern Recognit. 2008, 41, 3799–3812. [Google Scholar] [CrossRef]
- Sarıyanidi, E.; Dağlı, V.; Tek, S.C.; Tunc, B.; Gökmen, M. Local Zernike Moments: A new representation for face recognition. In Proceedings of the IEEE 2012 19th IEEE International Conference on Image Processing (ICIP), Orlando, FL, USA, 30 September–3 October 2012; pp. 585–588. [Google Scholar]
- Alasag, T.; Gokmen, M. Face recognition in low resolution images by using local Zernike moments. In Proceedings of the International Conference on Machine Vision and Machine Learning, Beijing, China, 21–26 June 2014; pp. 1–7. [Google Scholar]
- Kahraman, S.E.; Gokmen, M. Face pair matching with Local Zernike Moments and L2-Norm metric learning. In Proceedings of the 2014 22nd IEEE Signal Processing and Communications Applications Conference (SIU), Trabzon, Turkey, 23–25 April 2014; pp. 1524–1527. [Google Scholar]
- Basaran, E.; Gokmen, M. An Efficient Face Recognition Scheme Using Local Zernike Moments (LZM) Patterns. In Proceedings of the Asian Conference on Computer Vision, Singapore, 1–2 November 2014; Springer: Berlin, Germany, 2014; pp. 710–724. [Google Scholar]
- Sun, X.; Fu, X.; Shao, Z.; Shang, Y.; Ding, H. Local Zernike Moment and Multiscale Patch-Based LPQ for Face Recognition. In Proceedings of 2016 Chinese Intelligent Systems Conference; Springer: Berlin, Germany, 2016; pp. 19–27. [Google Scholar]
- Sariyanidi, E.; Gunes, H.; Gökmen, M.; Cavallaro, A. Local Zernike Moment Representation for Facial Affect Recognition. In Proceedings of the British Machine Vision Conference, Bristol, 9–13 September 2013. [Google Scholar]
- Gazioğlu, B.S.A.; Gökmen, M. Facial Expression Recognition from Still Images. In Proceedings of the International Conference on Augmented Cognition, Vancouver, BC, Canada, 9–14 July 2017; Springer: Berlin, Germany, 2017; pp. 413–428. [Google Scholar]
- Nguyen, H.T.; Caplier, A. Local patterns of gradients for face recognition. IEEE Trans. Inf. Forensics Secur. 2015, 10, 1739–1751. [Google Scholar] [CrossRef]
- Xie, S.; Shan, S.; Chen, X.; Chen, J. Fusing local patterns of gabor magnitude and phase for face recognition. IEEE Trans. Image Process. 2010, 19, 1349–1361. [Google Scholar] [PubMed]
- Chen, D.; Cao, X.; Wen, F.; Sun, J. Blessing of dimensionality: High-dimensional feature and its efficient compression for face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3025–3032. [Google Scholar]
- Zhu, X.; Lei, Z.; Yan, J.; Yi, D.; Li, S.Z. High-fidelity pose and expression normalization for face recognition in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 787–796. [Google Scholar]
- Su, Y.; Shan, S.; Chen, X.; Gao, W. Hierarchical ensemble of global and local classifiers for face recognition. IEEE Trans. Image Process. 2009, 18, 1885–1896. [Google Scholar] [CrossRef] [PubMed]
- Deng, W.; Hu, J.; Guo, J. Gabor-eigen-whiten-cosine: A robust scheme for face recognition. In Proceedings of the International Workshop on Analysis and Modeling of Faces and Gestures, Beijing, China, 16 October 2005; Springer: Berlin, Germany, 2005; pp. 336–349. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Başaran, E.; Gökmen, M. Face recognition with Local Zernike Moments features around landmarks. In Proceedings of the IEEE 2016 24th Signal Processing and Communication Application Conference (SIU), Zonguldak, Turkey, 16–19 May 2016; pp. 2089–2092. [Google Scholar]
- Phillips, P.J.; Moon, H.; Rizvi, S.A.; Rauss, P.J. The FERET evaluation methodology for face-recognition algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1090–1104. [Google Scholar] [CrossRef]
- Huang, G.B.; Ramesh, M.; Berg, T.; Learned-Miller, E. Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments; Technical Report 07-49; University of Massachusetts: Amherst, MA, USA, 2007. [Google Scholar]
- Grgic, M.; Delac, K.; Grgic, S. SCface–surveillance cameras face database. Multimed. Tools Appl. 2011, 51, 863–879. [Google Scholar] [CrossRef]
- Chong, C.W.; Raveendran, P.; Mukundan, R. A comparative analysis of algorithms for fast computation of Zernike moments. Pattern Recognit. 2003, 36, 731–742. [Google Scholar] [CrossRef]
- King, D.E. Dlib-ml: A Machine Learning Toolkit. J. Mach. Learn. Res. 2009, 10, 1755–1758. [Google Scholar]
- Kazemi, V.; Sullivan, J. One millisecond face alignment with an ensemble of regression trees. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 1867–1874. [Google Scholar]
- Julesz, B. Textons, the elements of texture perception, and their interactions. Nature 1981, 290, 91–97. [Google Scholar] [CrossRef] [PubMed]
- Howard, I.P.; Rogers, B.J. Binocular Vision and Stereopsis; Oxford University Press: Oxford, MS, USA, 1995. [Google Scholar]
- Pentland, A. Experiments with Eigenfaces; M.I.T. Media Lab Vision and Modeling Group Technical Report; Vision and Modeling Group, Media Laboratory, Massachusetts Institute of Technology: Cambridge, MA, USA, 1992. [Google Scholar]
- Moon, H.; Phillips, P.J. Computational and performance aspects of PCA-based face-recognition algorithms. Perception 2001, 30, 303–321. [Google Scholar] [CrossRef] [PubMed]
- Cament, L.A.; Castillo, L.E.; Perez, J.P.; Galdames, F.J.; Perez, C.A. Fusion of local normalization and Gabor entropy weighted features for face identification. Pattern Recognit. 2014, 47, 568–577. [Google Scholar] [CrossRef]
- Vu, N.S. Exploring patterns of gradient orientations and magnitudes for face recognition. IEEE Trans. Inf. Forensics Secur. 2013, 8, 295–304. [Google Scholar] [CrossRef]
- Chai, Z.; Sun, Z.; Mendez-Vazquez, H.; He, R.; Tan, T. Gabor ordinal measures for face recognition. IEEE Trans. Inf. Forensics Secur. 2014, 9, 14–26. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M.J. Robust real-time face detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Sharma, G.; Jurie, F. Local higher-order statistics (LHS) describing images with statistics of local non-binarized pixel patterns. Comput. Vis. Image Underst. 2016, 142, 13–22. [Google Scholar] [CrossRef]
- Arashloo, S.R.; Kittler, J. Efficient processing of MRFs for unconstrained-pose face recognition. In Proceedings of the 2013 IEEE Sixth International Conference on Biometrics: Theory, Applications and Systems (BTAS), Arlington, VA, USA, 29 September–2 October 2013; pp. 1–8. [Google Scholar]
- Ylioinas, J.; Kannala, J.; Hadid, A.; Pietikäinen, M. Face recognition using smoothed high-dimensional representation. In Proceedings of the Scandinavian Conference on Image Analysis, Copenhagen, Denmark, 15–17 June 2015; Springer: Berlin, Germany, 2015; pp. 516–529. [Google Scholar]
- Yi, D.; Lei, Z.; Li, S.Z. Towards pose robust face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3539–3545. [Google Scholar]
- Juefei-Xu, F.; Luu, K.; Savvides, M. Spartans: Single-sample periocular-based alignment-robust recognition technique applied to non-frontal scenarios. IEEE Trans. Image Process. 2015, 24, 4780–4795. [Google Scholar] [CrossRef] [PubMed]
- Arashloo, S.R.; Kittler, J. Class-specific kernel fusion of multiple descriptors for face verification using multiscale binarised statistical image features. IEEE Trans. Inf. Forensics Secur. 2014, 9, 2100–2109. [Google Scholar] [CrossRef]
- Chan, C.H.; Kittler, J.; Messer, K. Multi-scale local binary pattern histograms for face recognition. In Proceedings of the International Conference on Biometrics, Seoul, Korea, 27–29 August 2007; Springer: Berlin, Germany, 2007; pp. 809–818. [Google Scholar]
- Tahir, M.A.; Chan, C.H.; Kittler, J.; Bouridane, A. Face recognition using multi-scale local phase quantisation and linear regression classifier. In Proceedings of the IEEE 2011 18th IEEE International Conference on Image Processing (ICIP), Brussels, Belgium, 11–14 September 2011; pp. 765–768. [Google Scholar]
- Kannala, J.; Rahtu, E. Bsif: Binarized statistical image features. In Proceedings of the IEEE 2012 21st International Conference on Pattern Recognition (ICPR), Tsukuba, Japan, 11–15 November 2012; pp. 1363–1366. [Google Scholar]
- Peng, Y.; Gökberk, B.; Spreeuwers, L.; Veldhuis, R. An evaluation of super-resolution for face recognition. In Proceedings of the 33rd WIC Symposium on Information Theory in the Benelux, Enschede, The Netherlands, 24–25 May 2012; pp. 36–43. [Google Scholar]
- Wilman, W.W.Z.; Yuen, P.C. Very low resolution face recognition problem. In Proceedings of the 2010 Fourth IEEE International Conference on Biometrics: Theory, Applications and Systems (BTAS), Arlington, VA, USA, 27–29 September 2010; pp. 1–6. [Google Scholar] [CrossRef]
- Nguyen, H.T.; Caplier, A. Elliptical local binary patterns for face recognition. In Proceedings of the Asian Conference on Computer Vision, Daejeon, Korea, 5–6 November 2012; Springer: Berlin, Germany, 2012; pp. 85–96. [Google Scholar]
- Khotanzad, A.; Hong, Y.H. Rotation invariant image recognition using features selected via a systematic method. Pattern Recognit. 1990, 23, 1089–1101. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Fb | Fc | Dup1 | Dup2 | Avg |
|---|---|---|---|---|---|
| LMEGW//LN + LGXP [64] | 99.9 | 100 | 94.7 | 91.9 | 97.5 |
| s-POEM + POD + WPCA [65] | 99.7 | 100 | 94.9 | 94.0 | 97.7 |
| GOM [66] | 99.9 | 100 | 95.7 | 93.1 | 97.9 |
| LMEGW//LN + LGBP [64] | 99.9 | 100 | 95.6 | 93.6 | 98.0 |
| Basaran et al. [42] | 99.8 | 100 | 96.0 | 94.9 | 98.2 |
| MDML-DCPs + WPCA [2] | 99.8 | 100 | 96.1 | 95.7 | 98.3 |
| Basaran et al. [53] | 99.8 | 100 | 97.5 | 96.6 | 98.8 |
| LPOG + WPCA [46] | 99.8 | 100 | 97.4 | 97.0 | 98.8 |
| MS-LZM | 99.7 | 100 | 98.1 | 97.9 | 99.1 |
| Method | AUC |
|---|---|
| LHS [68] | 0.8107 |
| MRF-MLBP [69] | 0.8994 |
| SA-BSIF + WPCA [70] | 0.9318 |
| LBPNet [10] | 0.9404 |
| Pose Adaptive Filter (PAF) [71] | 0.9405 |
| Spartans [72] | 0.9428 |
| MRF-Fusion-CSKDA [73] | 0.9894 |
| MS-LZM | 0.9515 |
| Probe | PCA [56] | SR [77] | DSR [78] | ELBP [79] | LPOG [46] | MS-LZM |
|---|---|---|---|---|---|---|
| cam1_1 | 2.3 | N/A | N/A | 43.1 | 69.2 | 72.3 |
| cam1_2 | 7.7 | 56.2 | 73.1 | 75.4 | ||
| cam1_3 | 5.4 | 45.4 | 47.7 | 42.3 | ||
| cam2_1 | 3.1 | 36.9 | 57.7 | 62.3 | ||
| cam2_2 | 7.7 | 50.8 | 66.2 | 74.6 | ||
| cam2_3 | 3.9 | 42.3 | 48.5 | 43.1 | ||
| cam3_1 | 1.5 | 34.6 | 49.2 | 53.9 | ||
| cam3_2 | 3.9 | 46.9 | 63.1 | 80.8 | ||
| cam3_3 | 7.7 | 51.5 | 54.6 | 54.6 | ||
| cam4_1 | 0.7 | 32.3 | 43.9 | 69.2 | ||
| cam4_2 | 3.9 | 50.0 | 75.4 | 82.3 | ||
| cam4_3 | 8.5 | 50.8 | 58.5 | 56.9 | ||
| cam5_1 | 1.5 | 36.2 | 53.9 | 64.6 | ||
| cam5_2 | 7.7 | 32.3 | 52.3 | 64.6 | ||
| cam5_3 | 5.4 | 31.5 | 38.5 | 36.2 | ||
| Average | 4.7 | 16.4 | 20.2 | 42.7 | 56.8 | 62.2 |
| Probe | PCA [56] | ELBP [79] | LPOG [46] | MS-LZM |
|---|---|---|---|---|
| cam6_1 | 1.5 | 9.2 | 13.1 | 21.5 |
| cam6_2 | 3.1 | 15.4 | 23.9 | 38.5 |
| cam6_3 | 3.9 | 25.4 | 31.5 | 33.1 |
| cam7_1 | 0.7 | 13.1 | 17.7 | 27.7 |
| cam7_2 | 5.4 | 13.1 | 20.0 | 34.6 |
| cam7_3 | 4.6 | 13.9 | 19.2 | 25.4 |
| Average | 3.2 | 15.0 | 20.9 | 30.1 |
| Dataset | n1 | n2 | k1 | k2 | #Scales | Time |
|---|---|---|---|---|---|---|
| FERET | 4 | 4 | 5 | 5 | 5 | 0.82 s |
| LFW | 4 | 4 | 7 | 7 | 5 | 0.95 s |
| SCface-Vis | 4 | 4 | 7 | 7 | 3 | 0.39 s |
| SCface-IR | 1 | 4 | 7 | 7 | 3 | 0.10 s |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Basaran, E.; Gökmen, M.; Kamasak, M.E. An Efficient Multiscale Scheme Using Local Zernike Moments for Face Recognition. Appl. Sci. 2018, 8, 827. https://doi.org/10.3390/app8050827
Basaran E, Gökmen M, Kamasak ME. An Efficient Multiscale Scheme Using Local Zernike Moments for Face Recognition. Applied Sciences. 2018; 8(5):827. https://doi.org/10.3390/app8050827
Chicago/Turabian StyleBasaran, Emrah, Muhittin Gökmen, and Mustafa E. Kamasak. 2018. "An Efficient Multiscale Scheme Using Local Zernike Moments for Face Recognition" Applied Sciences 8, no. 5: 827. https://doi.org/10.3390/app8050827
APA StyleBasaran, E., Gökmen, M., & Kamasak, M. E. (2018). An Efficient Multiscale Scheme Using Local Zernike Moments for Face Recognition. Applied Sciences, 8(5), 827. https://doi.org/10.3390/app8050827