A Hybrid Metaheuristic for Multi-Objective Scientific Workflow Scheduling in a Cloud Environment

Abstract
:1. Introduction
2. Related Work
3. Problem Description for the Proposed Methodology
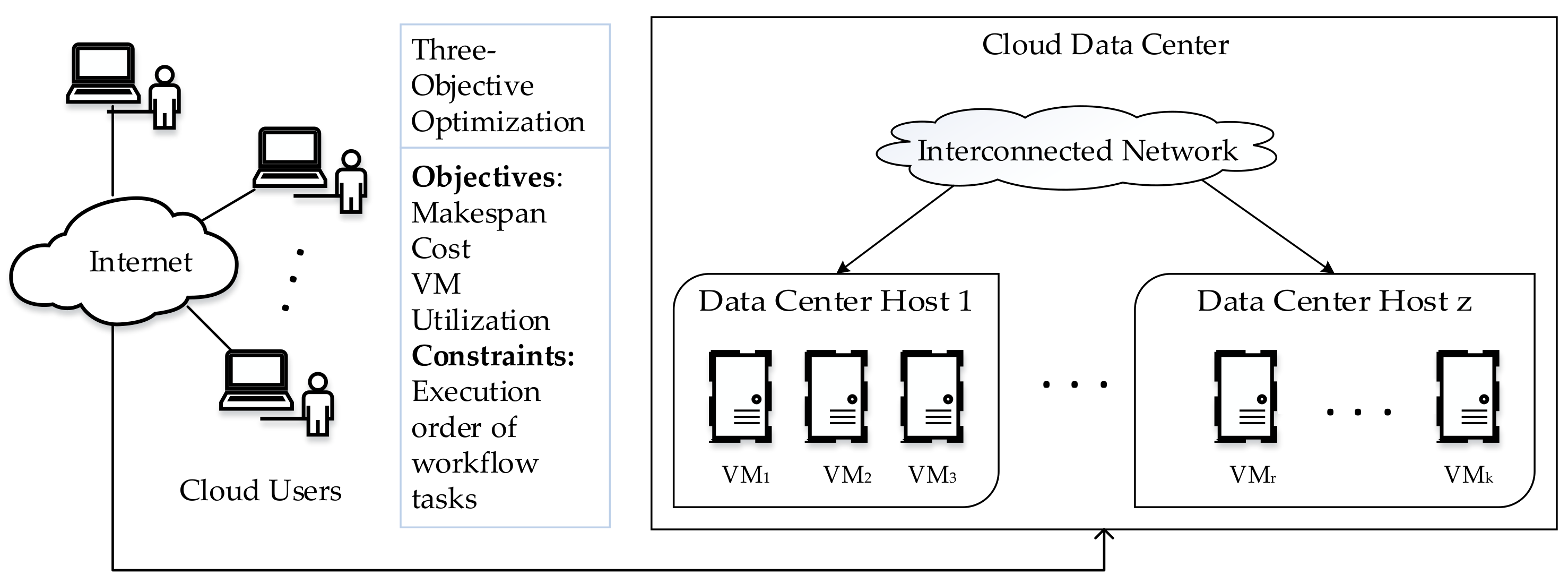
3.1. System Model
3.2. Assumptions
- (1)
- The workflow application is assumed to be executed in a single cloud data center, so that one possible source of execution delay, storage cost, and data transmission cost between data centers is eliminated.
- (2)
- An on-demand pricing model is considered, where any partial utilization of the leased VM is charged as a full time period.
- (3)
- The communication time for the tasks executed on the same VM is assumed to be zero.
- (4)
- The scheduling of tasks is considered to be non-preemptive, which means that a task cannot be interrupted while being executed until it has completed its execution.
- (5)
- Each task can be assigned to a single VM, and a VM can process several tasks.
- (6)
- Multi-tenant scenarios are not considered, i.e., each VM can only run one task at a time.
- (7)
- The processing capacity of a VM is provided either from the IaaS provider or can be calculated based on the work reported by Ostermann et al. (2010) [33]. The estimation times are scaled by the processing capacity of VM instances, i.e., 1 s of each task in a workflow runs for 1 s on a VM instance with one Elastic Compute Unit (ECU). Note that an ECU is the central processing unit (CPU) performance unit defined by Amazon. The processing capacity of an ECU (based on Xeon@1.1 GHz performing 4 flops per Hz) was estimated at 4.4 GFLOPS (Giga Floating Point Operations Per Second) [33].
- (8)
- When a VM is leased, a boot time of 97 seconds for proper initialization is considered based on the measurements reported by Mao and Humphrey (2011) [34] for the Amazon EC2 cloud.
- (9)
3.3. Multi-Objective Optimization
3.4. Problem Formulation
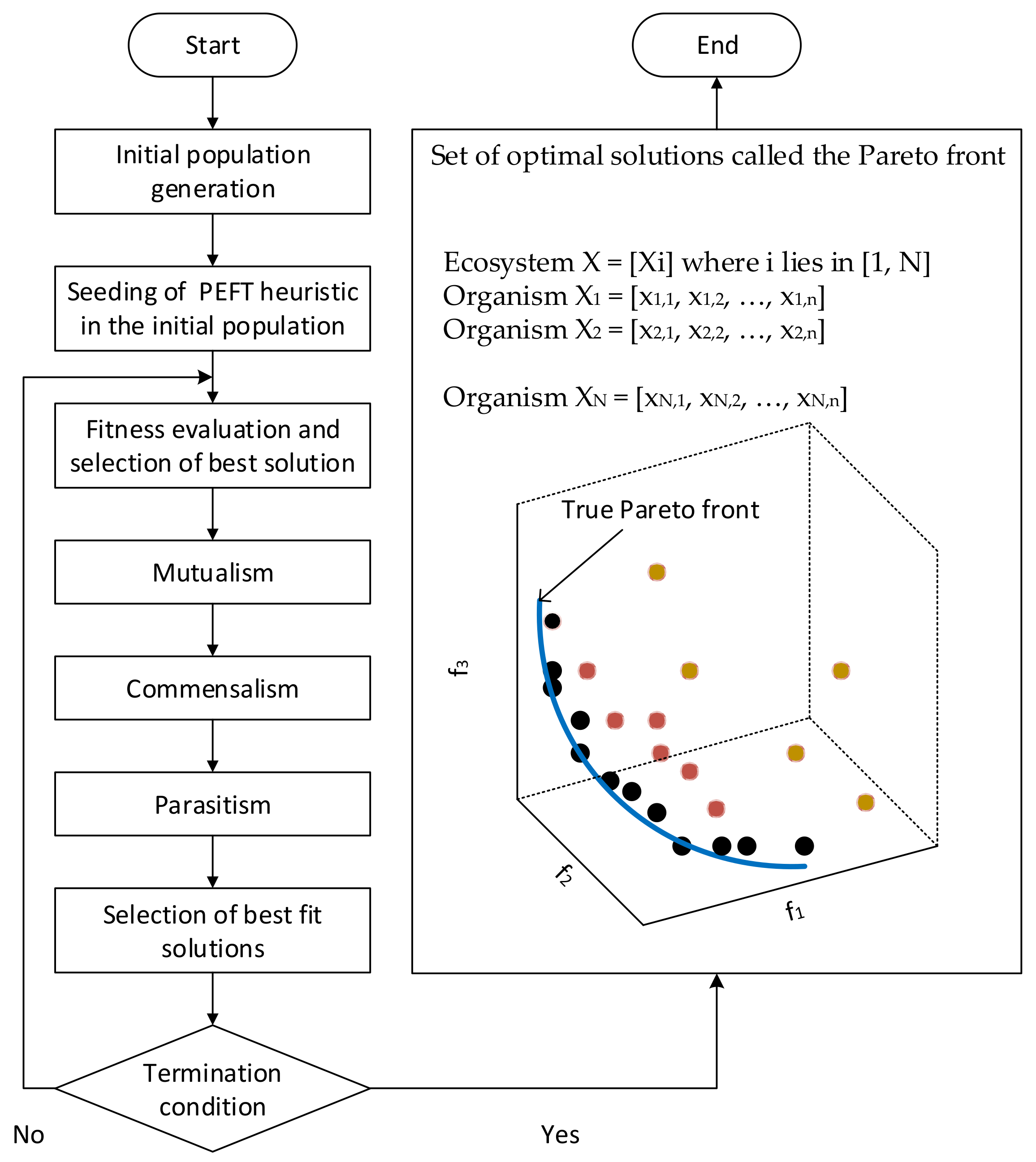
4. Proposed Work
4.1. Initialization
4.2. Fitness Evaluation
4.3. Optimization
4.3.1. Mutualism
4.3.2. Commensalism
4.3.3. Parasitism
4.4. Selection of Best Fit Solutions
4.5. Termination Condition
| Algorithm 1. Hybrid Bio-inspired Metaheuristic for Multi-objective Optimization (HBMMO) for Scientific Workflow Scheduling in the Cloud. | |
| Input: | Workflow and set of VMs |
| Output: | Pareto optimal set of solutions |
| 1 | //Initialization phase (Section 4.1) |
| 2 | Initialize parameters |
| 3 | Initialize population with randomly generated solutions where each solution satisfies all constraints |
| 4 | Replace one of the organism by mapping generated by PEFT algorithm |
| 5 | Initialize |
| 6 | while termination criteria not fulfilled do |
| 7 | //Fitness evaluation phase (Section 4.2) |
| 8 | Evaluate the fitness of each organism //according to Equation (3) |
| 9 | Select the best solution as |
| 10 | //Optimization phase (Section 4.3) |
| 11 | //Apply Mutualism (Section 4.3.1) |
| 12 | Randomly select where |
| 13 | Update organisms and //according to Equations (19)–(20) |
| 14 | //Commensalism (Section 4.3.2) |
| 15 | Update //according to Equation (22) |
| 16 | //Parasitism (Section 4.3.3) |
| 17 | Randomly select where |
| 18 | Create a parasite vector () |
| 19 | if fitness of is better than then |
| 20 | accept to replace |
| 21 | else reject and keep |
| 22 | end if |
| 23 | //Selection of best fit solution phase (Section 4.4) |
| 24 | Generate the combined population |
| 25 | Calculate normalized fitness values for each objective //according to Equation (26) |
| 26 | Apply the non-dominated sort to find the solutions in fronts , where is min s.t. |
| 27 | for each front do |
| 28 | for each objective function do |
| 29 | for each // size of |
| 30 | Evaluate crowding distance of //according to Equation (27) |
| 31 | Sort according to crowding distance in descending order |
| 32 | end for |
| 33 | Calculate total crowding distance value for every front |
| 34 | end for |
| 35 | end for |
| 36 | Store the best solution as Pareto set in each generation |
| 37 | end while |
5. Performance Evaluation
5.1. Experimental Setup
5.2. Evaluation Metrics
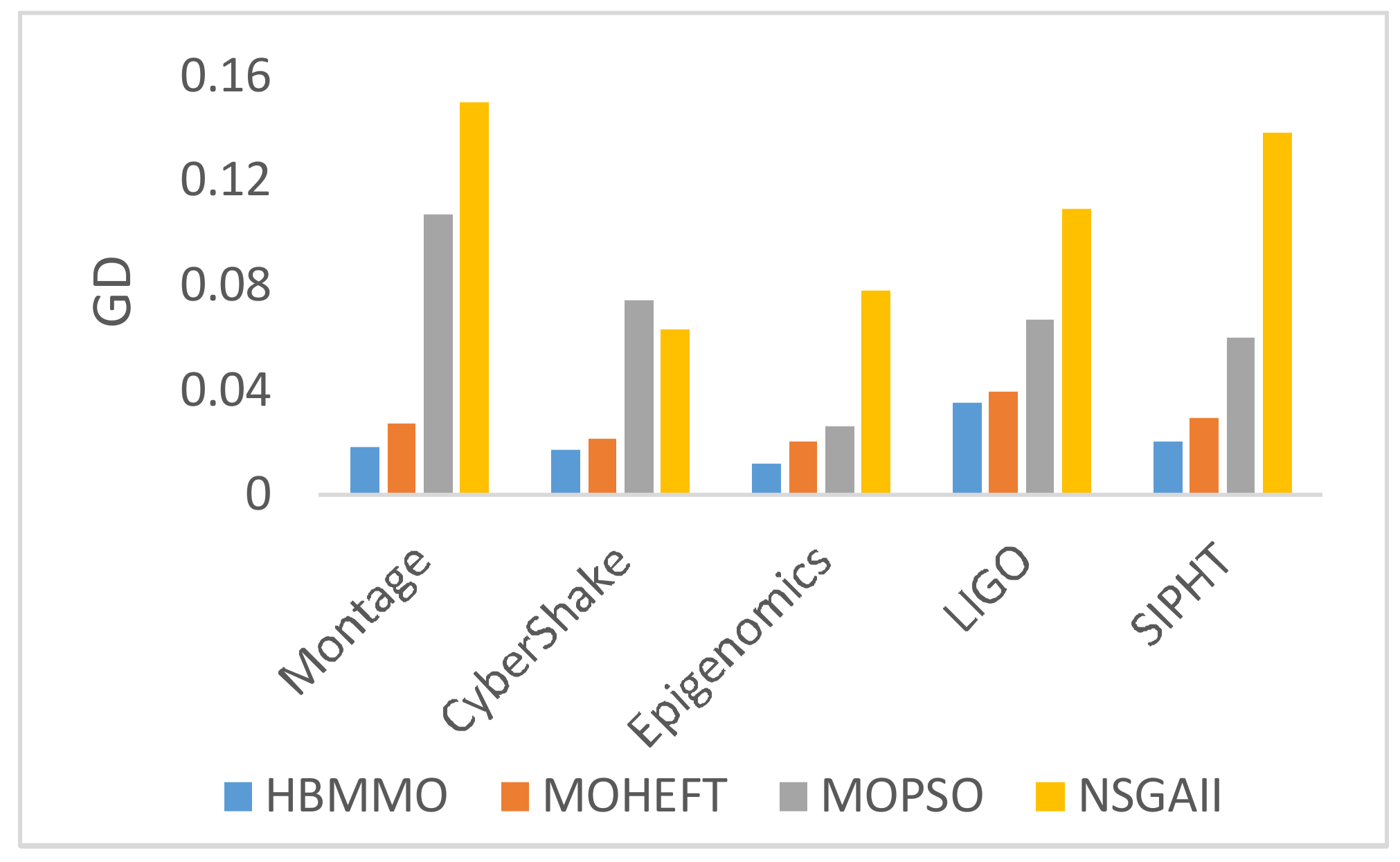
5.2.1. Inverted Generational Distance ()
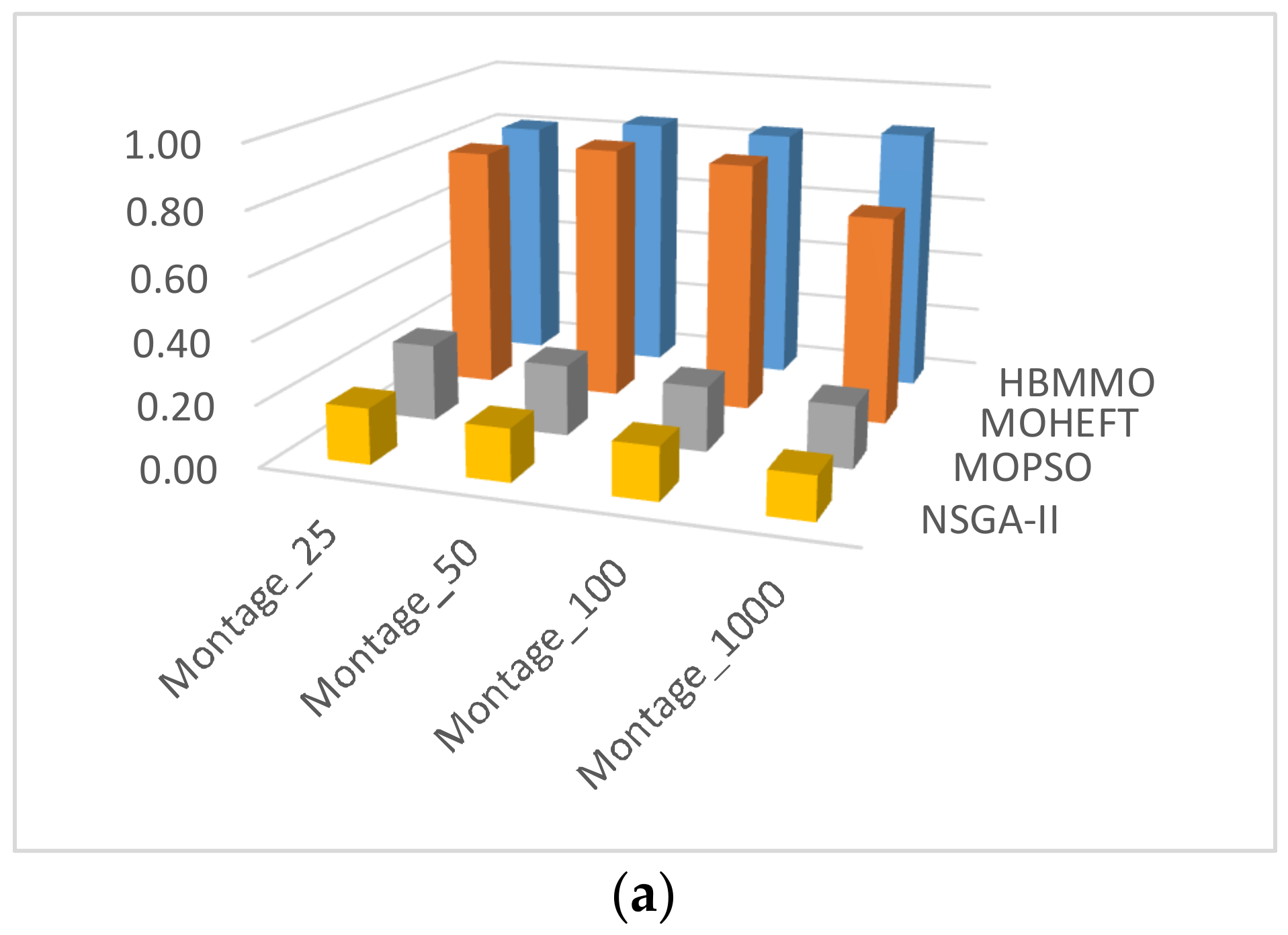
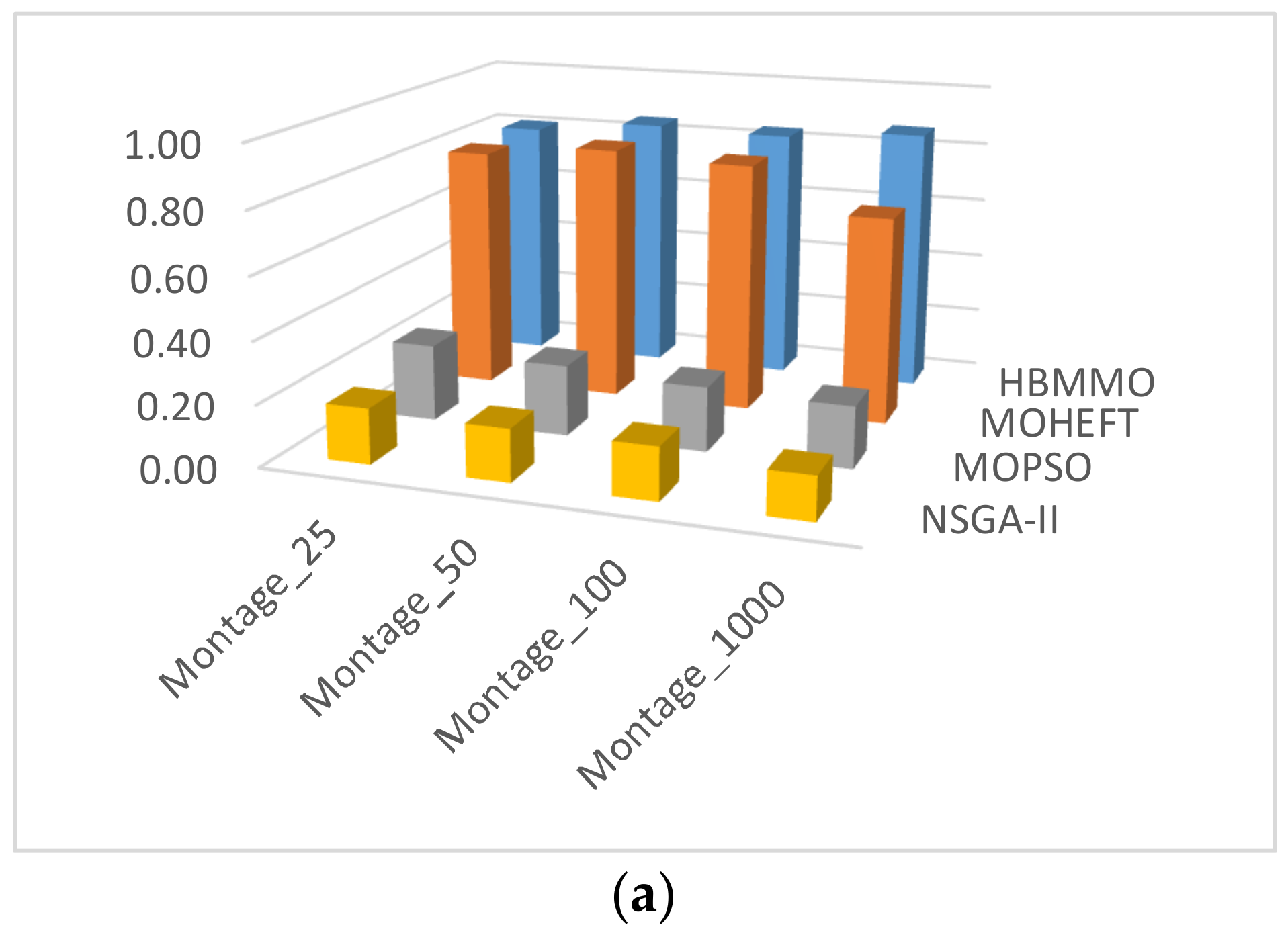
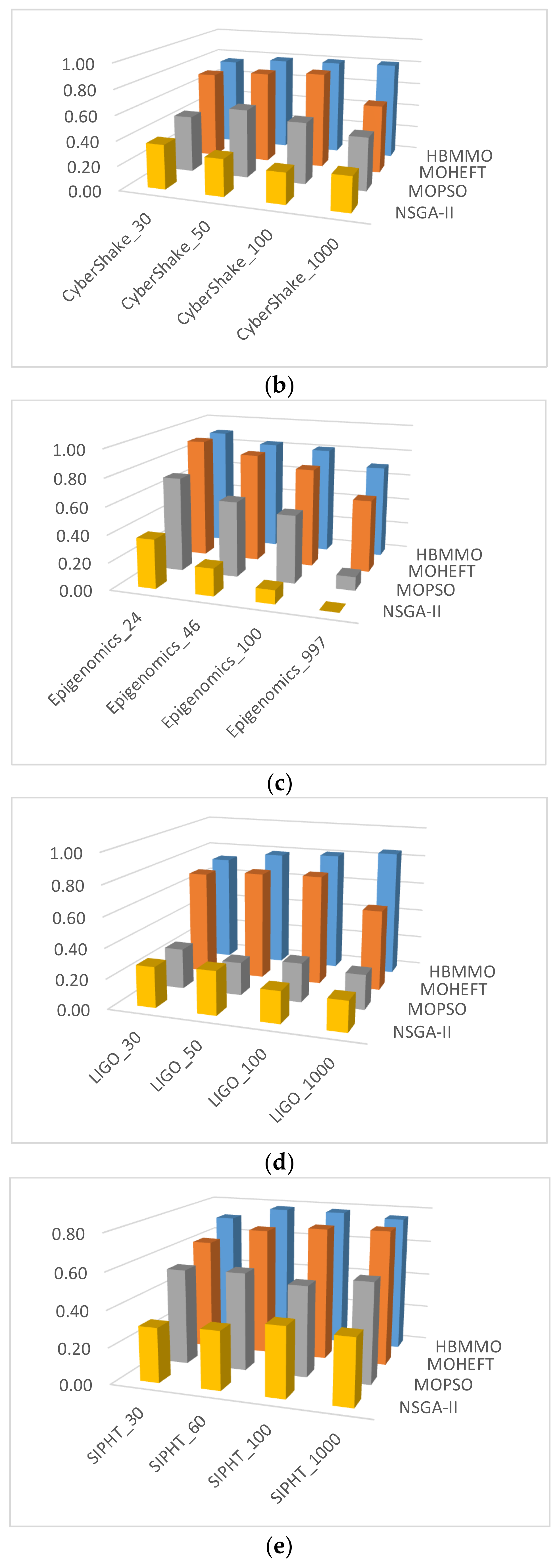
5.2.2. Hypervolume ()
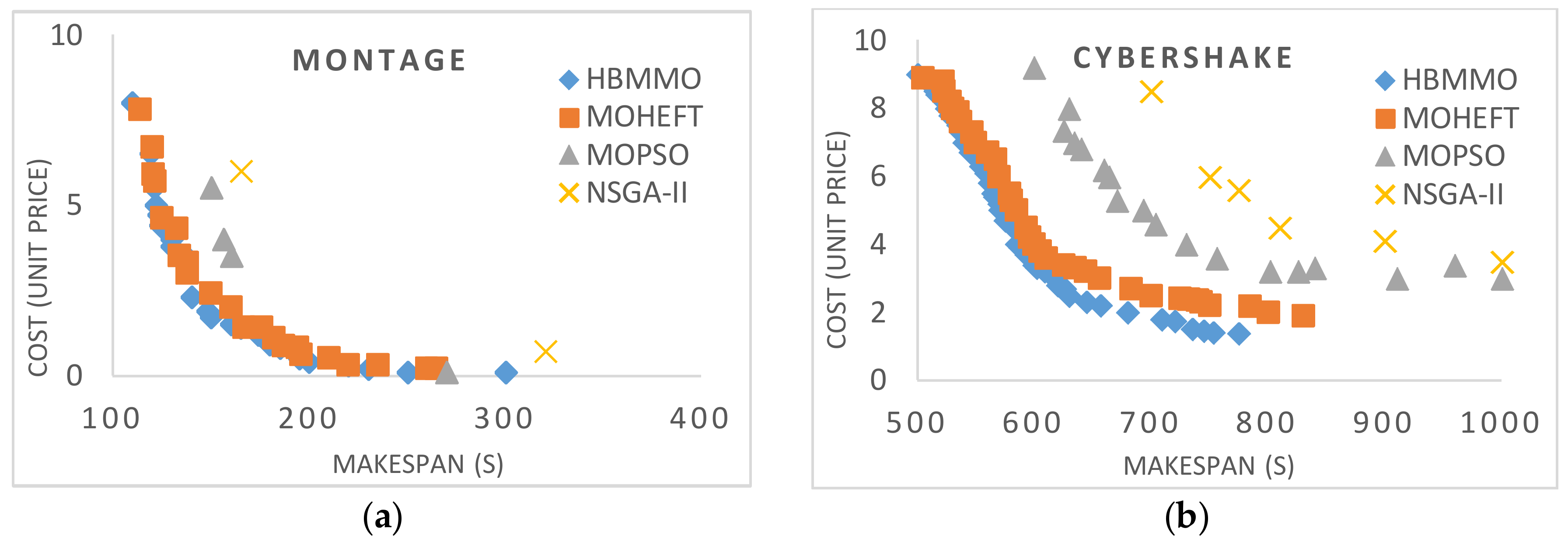
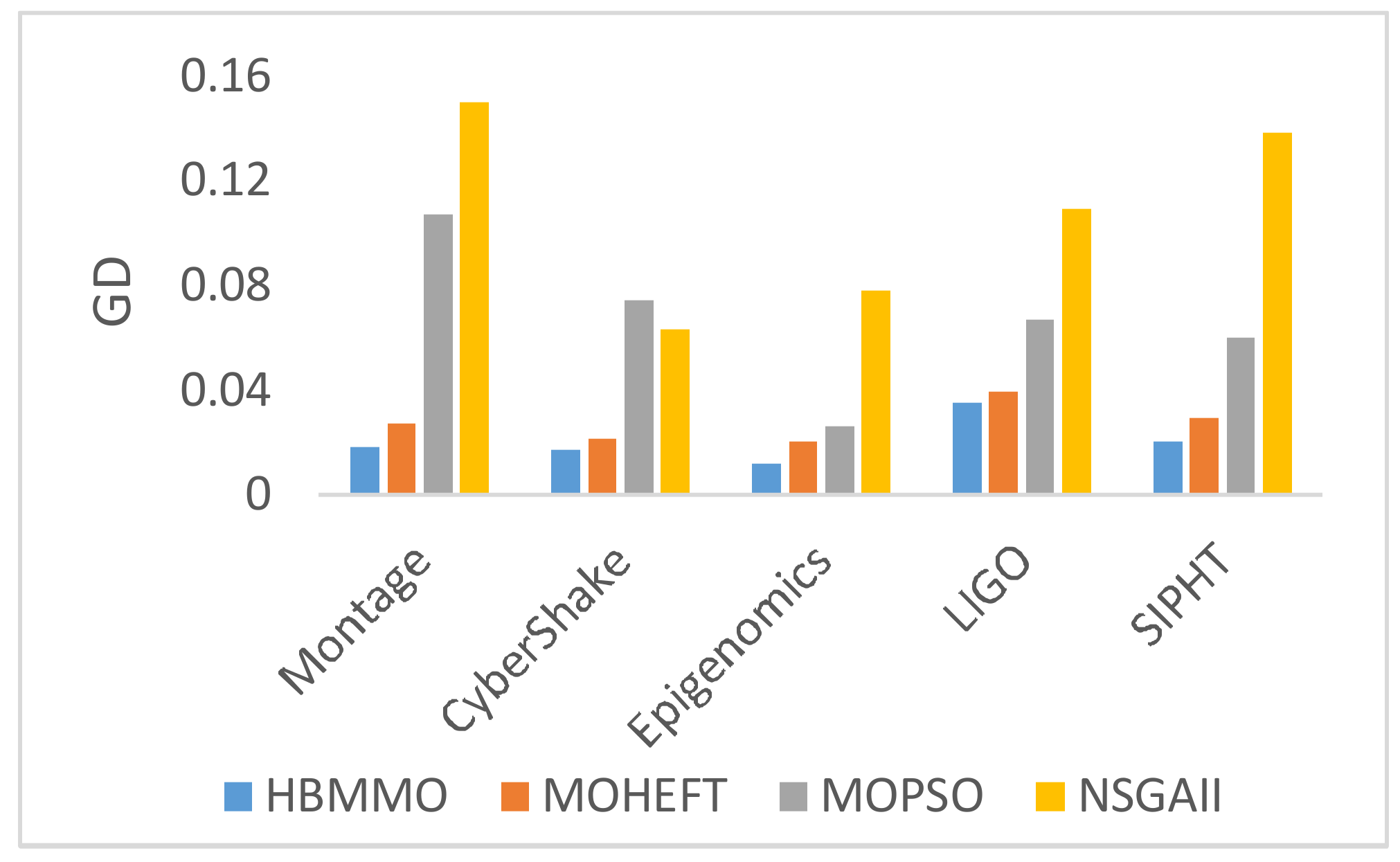
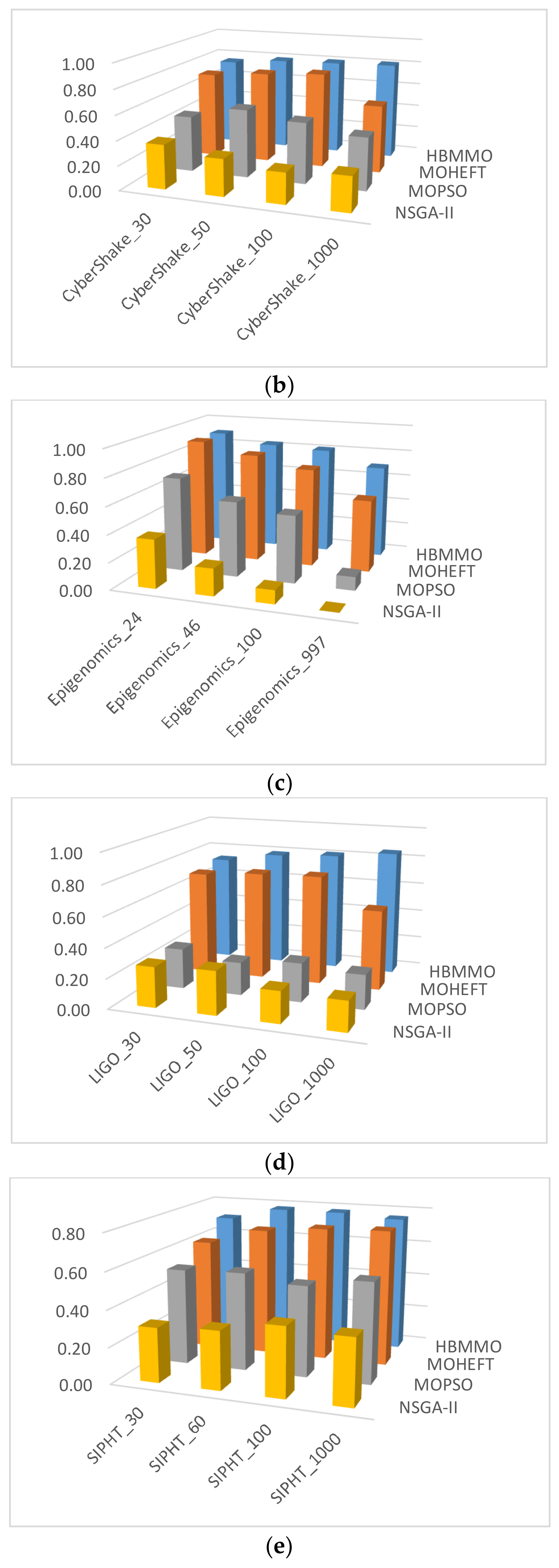
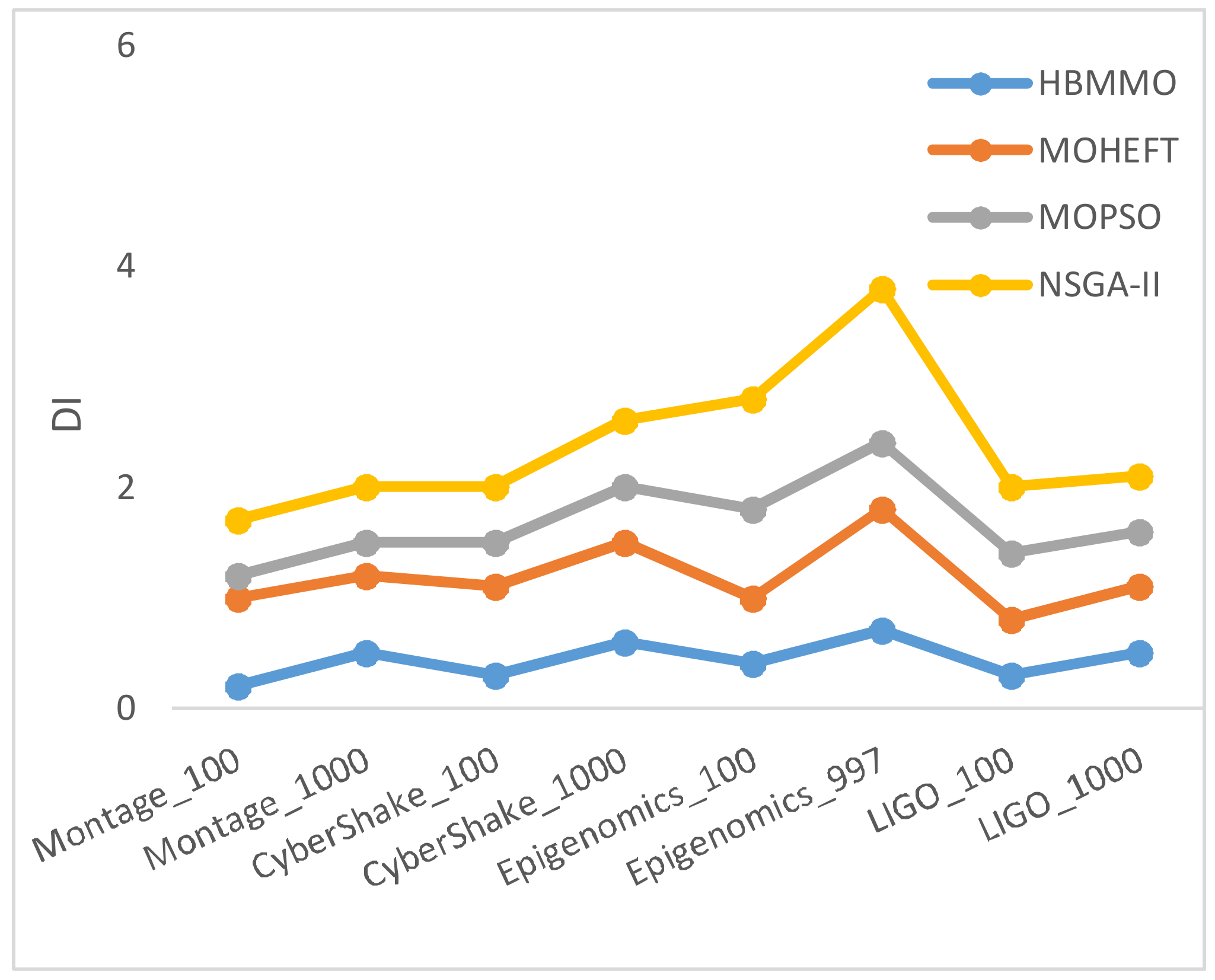
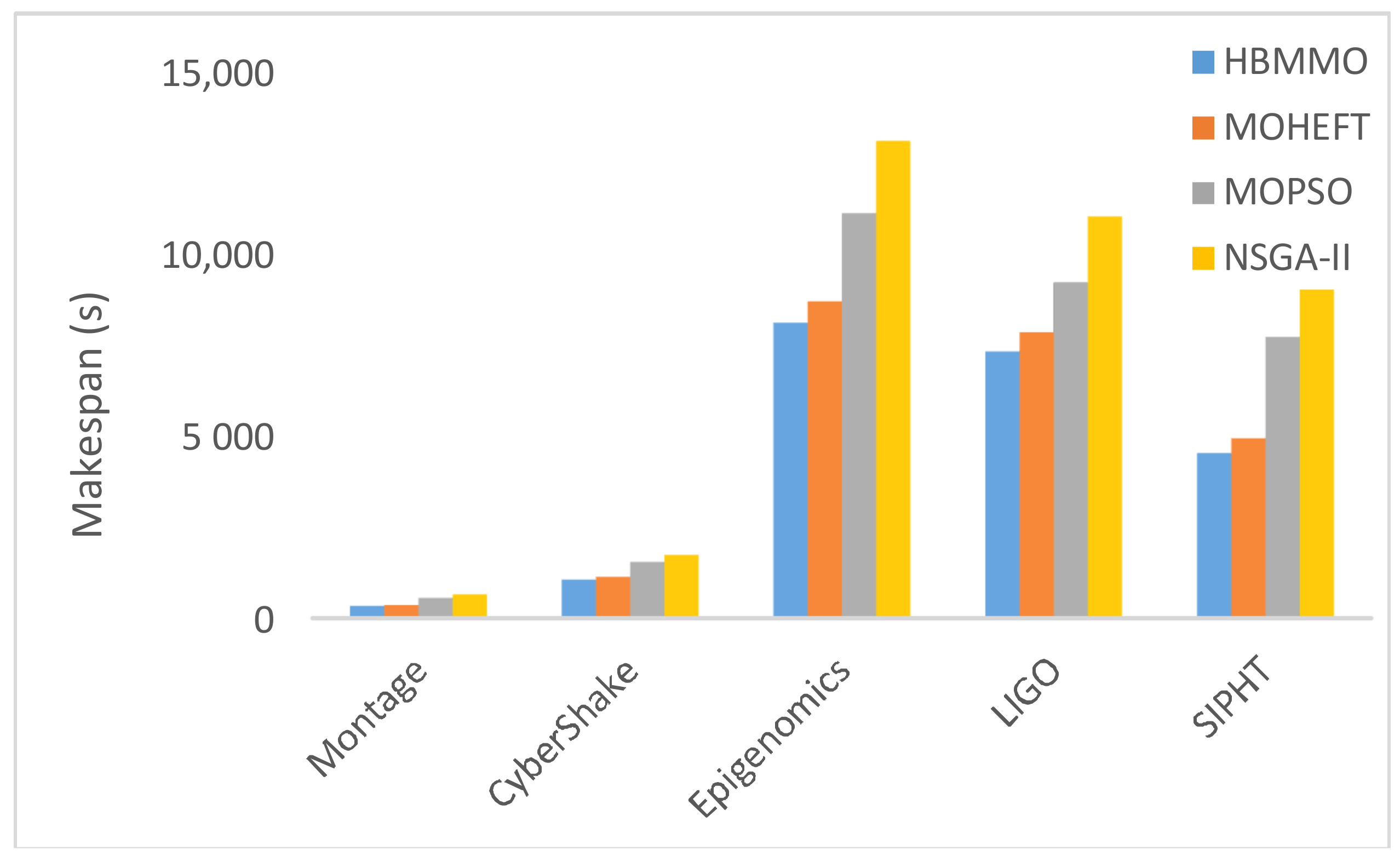
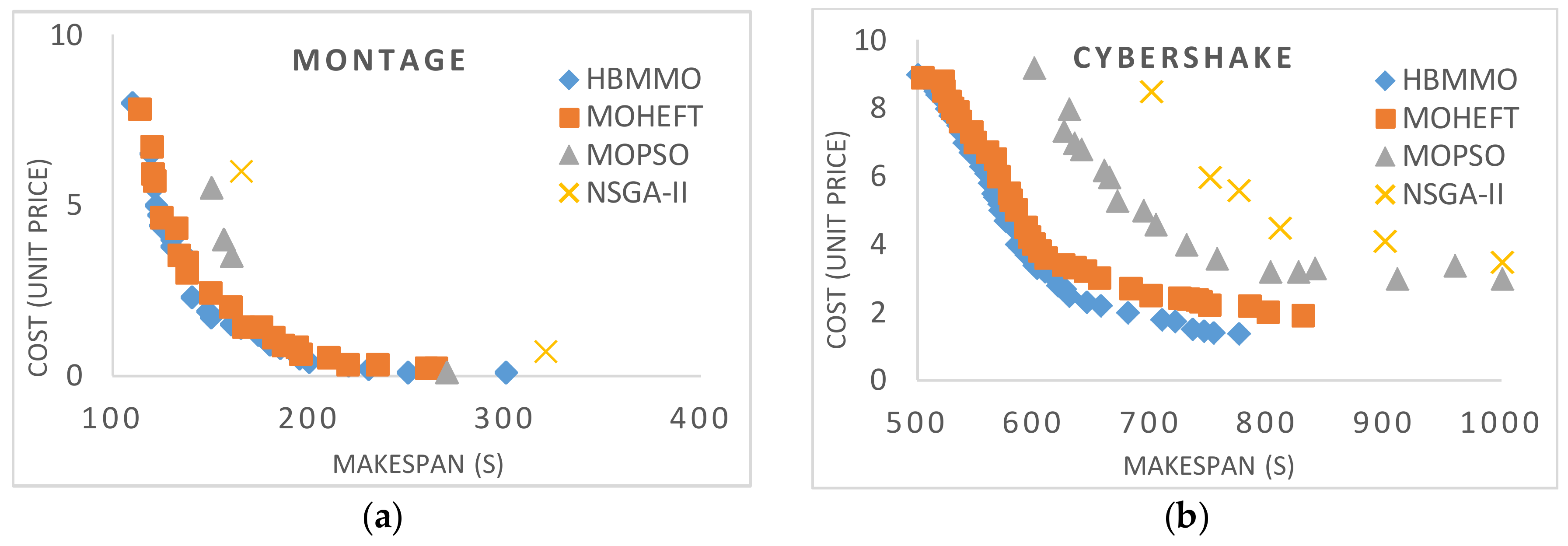
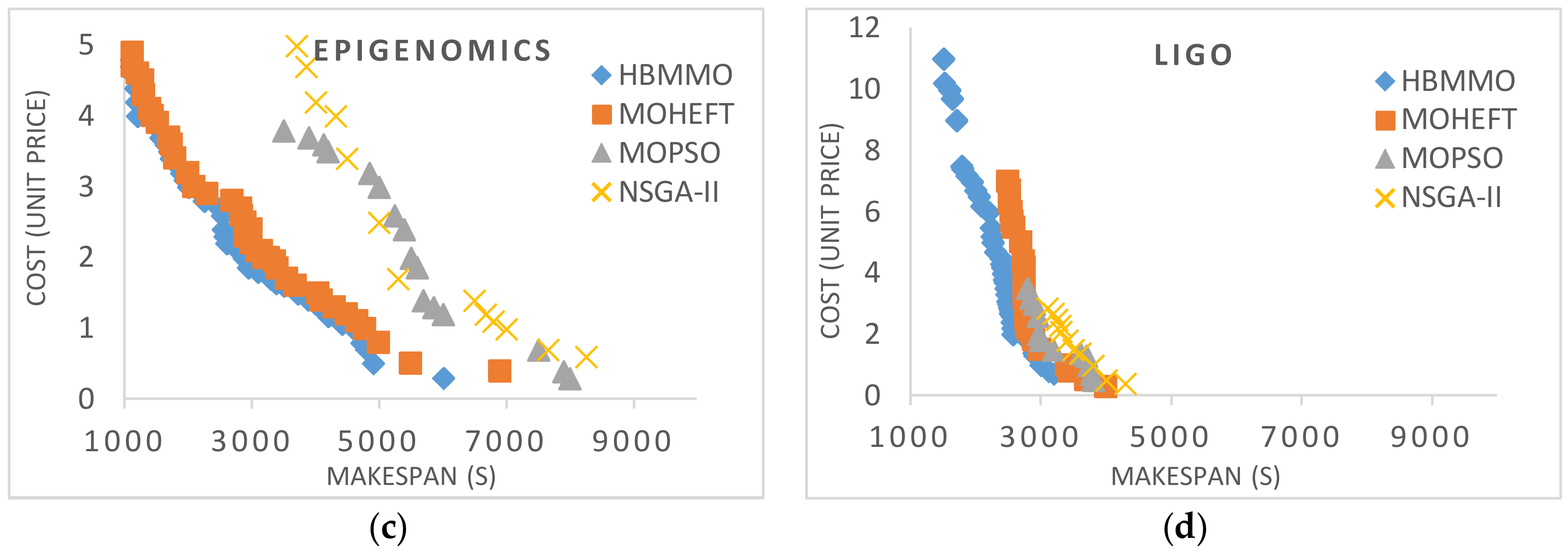
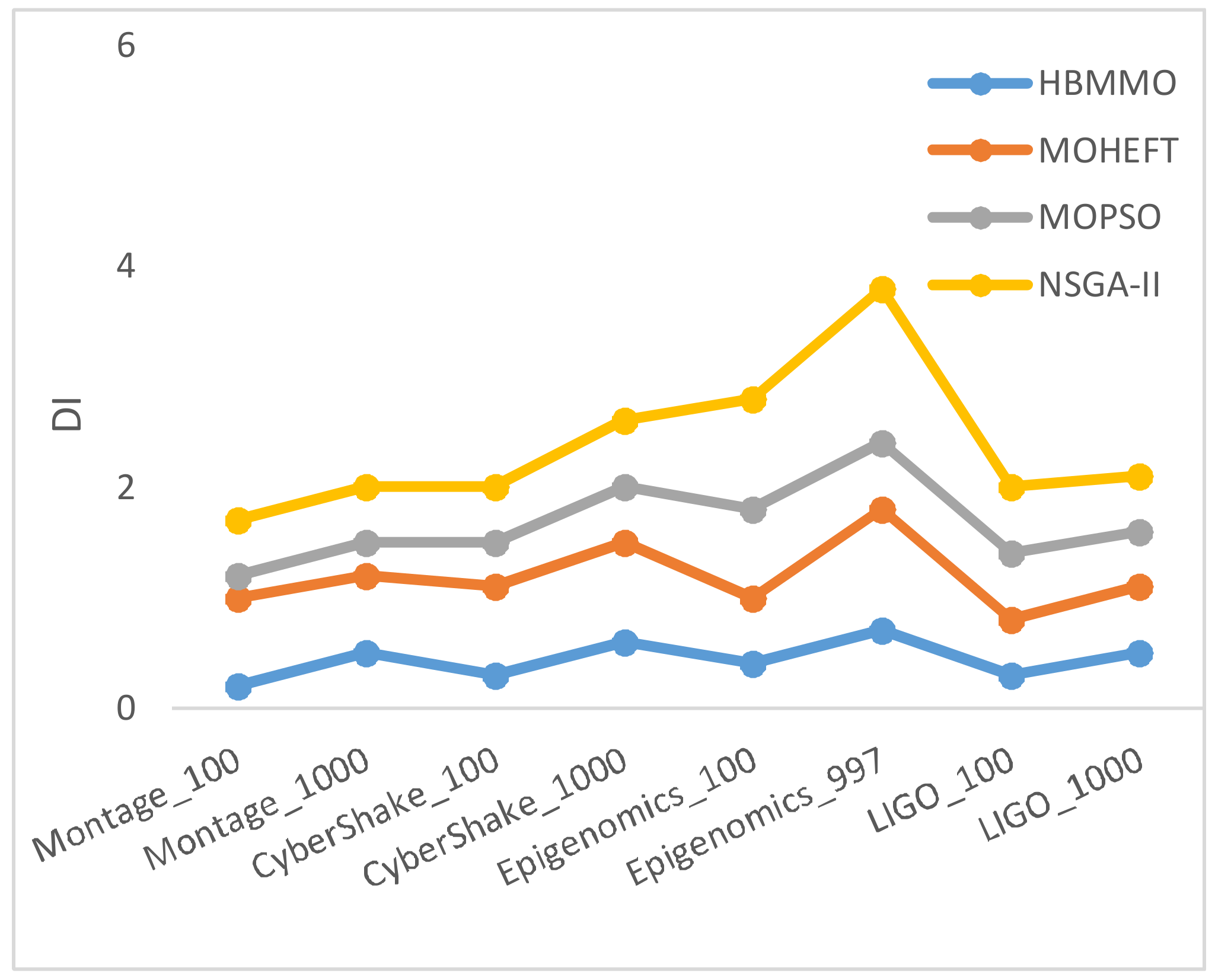
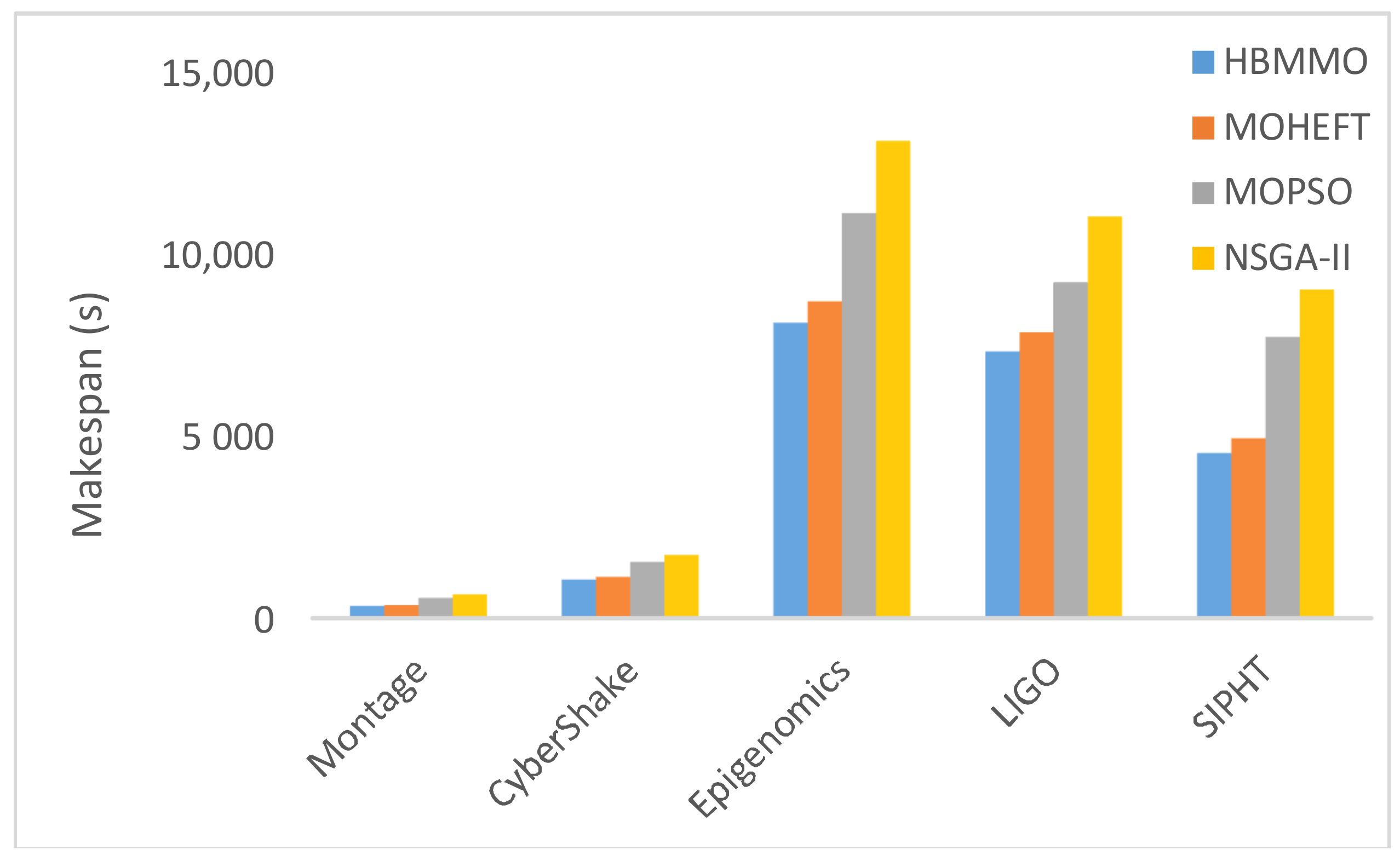
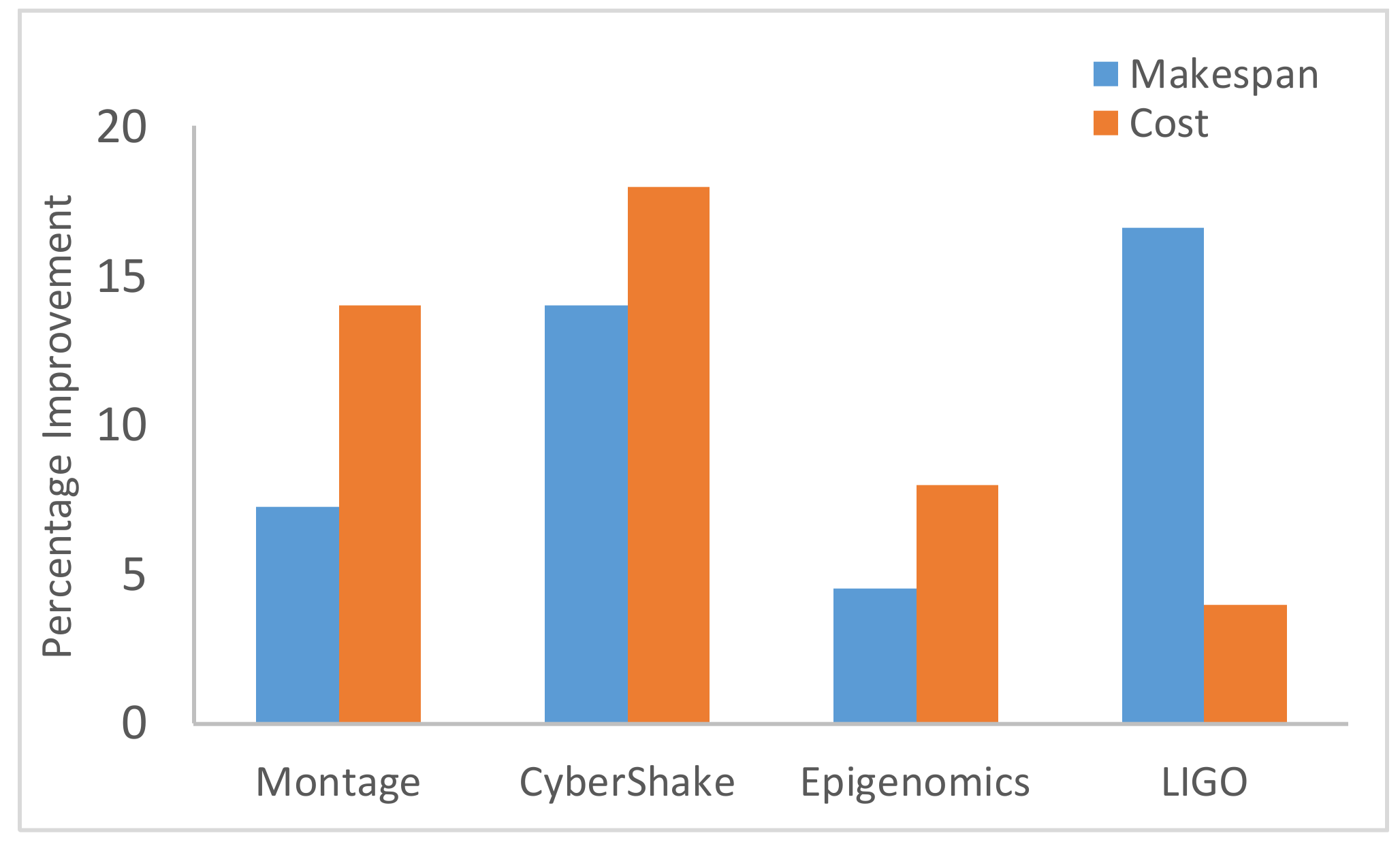
5.3. Simaulation Results
5.4. Analysis of Variance (ANOVA) Test
6. Conclusions and Future Work
Author Contributions
Conflicts of Interest
References
- Ostrowski, K.; Birman, K.; Doley, D. Extensible architecture for high-performance, scalable, reliable publish-subscribe eventing and notification. Int. J. Web Serv. Res. 2007, 4, 18–58. [Google Scholar] [CrossRef]
- Zhu, Z.M.; Zhang, G.X.; Li, M.Q.; Liu, X.H. Evolutionary multi-objective workflow scheduling in cloud. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 1344–1357. [Google Scholar] [CrossRef]
- Durillo, J.J.; Prodan, R. Multi-objective workflow scheduling in Amazon EC2. Clust. Comput. 2014, 17, 169–189. [Google Scholar] [CrossRef]
- Coello, C.A.C. Evolutionary multi-objective optimization: A historical view of the field. IEEE Comput. Intell. Mag. 2006, 1, 28–36. [Google Scholar] [CrossRef]
- Arabnejad, H.; Barbosa, J.G. List scheduling algorithm for heterogeneous systems by an optimistic cost table. IEEE Comput. Intell. Mag. 2014, 25, 682–694. [Google Scholar] [CrossRef]
- Choudhary, A.; Gupta, I.; Singh, V.; Jana, P.K. A GSA based hybrid algorithm for bi-objective workflow scheduling in cloud computing. Future Gener. Comput. Syst. 2018. [Google Scholar] [CrossRef]
- Fard, H.M.; Prodan, R.; Fahringer, T. Multi-objective list scheduling of workflow applications in distributed computing infrastructures. J. Parallel Distrib. Comput. 2014, 74, 2152–2165. [Google Scholar] [CrossRef]
- Cheng, M.Y.; Prayogo, D. Symbiotic Organisms Search: A new metaheuristic optimization algorithm. Comput. Struct. 2014, 139, 98–112. [Google Scholar] [CrossRef]
- Abdullahi, M.; Ngadi, M.A.; Abdulhamid, S.M. Symbiotic Organism Search optimization based task scheduling in cloud computing environment. Future Gener. Comput. Syst. 2016, 56, 640–650. [Google Scholar] [CrossRef]
- Topcuoglu, H.; Hariri, S.; Wu, M.Y. Performance-effective and low-complexity task scheduling for heterogeneous computing. IEEE Trans. Parall. Distrib. Syst. 2002, 13, 260–274. [Google Scholar] [CrossRef]
- Beloglazov, A.; Abawajy, J.; Buyya, R. Energy-aware resource allocation heuristics for efficient management of data centers for cloud computing. Future Gener. Comput. Syst. 2012, 28, 755–768. [Google Scholar] [CrossRef]
- Frincu, M.E. Scheduling highly available applications on cloud environments. Future Gener. Comput. Syst. 2014, 32, 138–153. [Google Scholar] [CrossRef]
- Yao, G.S.; Ding, Y.S.; Jin, Y.C.; Hao, K.R. Endocrine-based coevolutionary multi-swarm for multi-objective workflow scheduling in a cloud system. Soft Comput. 2017, 21, 4309–4322. [Google Scholar] [CrossRef]
- Nasonov, D.; Visheratin, A.; Butakov, N.; Shindyapina, N.; Melnik, M.; Boukhanovsky, A. Hybrid evolutionary workflow scheduling algorithm for dynamic heterogeneous distributed computational environment. J. Appl. Logic 2017, 24, 50–61. [Google Scholar] [CrossRef]
- Anwar, N.; Deng, H. Elastic scheduling of scientific workflows under deadline constraints in cloud computing environments. Future Internet 2018, 10, 5. [Google Scholar] [CrossRef]
- Madni, S.H.H.; Latiff, M.S.A.; Coulibaly, Y.; Abdulhamid, S.M. An appraisal of meta-heuristic resource allocation techniques for IaaS cloud. Indian J. Sci. Technol. 2016, 9. [Google Scholar] [CrossRef]
- Singh, P.; Dutta, M.; Aggarwal, N. A review of task scheduling based on meta-heuristics approach in cloud computing. Knowl. Inf. Syst. 2017, 52, 1–51. [Google Scholar] [CrossRef]
- Domanal, S.; Guddeti, R.M.; Buyya, R. A hybrid bio-inspired algorithm for scheduling and resource management in cloud environment. IEEE Serv. Comput. 2017, PP, 99. [Google Scholar] [CrossRef]
- Pooranian, Z.; Shojafar, M.; Abawajy, J.H.; Abraham, A. An efficient meta-heuristic algorithm for grid computing. J. Comb. Optim. 2015, 30, 413–434. [Google Scholar] [CrossRef]
- Abdullahi, M.; Ngadi, M.A. Hybrid symbiotic organisms search optimization algorithm for scheduling of tasks on cloud computing environment. PLoS ONE 2016, 11, e0158229. [Google Scholar] [CrossRef]
- Zhang, F.; Cao, J.W.; Li, K.Q.; Khan, S.U.; Hwang, K. Multi-objective scheduling of many tasks in cloud platforms. Future Gener. Comput. Syst. 2014, 37, 309–320. [Google Scholar] [CrossRef]
- Su, S.; Li, J.; Huang, Q.J.; Huang, X.; Shuang, K.; Wang, J. Cost-efficient task scheduling for executing large programs in the cloud. Parallel Comput. 2013, 39, 177–188. [Google Scholar] [CrossRef]
- Xu, H.; Yang, B.; Qi, W.; Ahene, E. A multi-objective optimization approach to workflow scheduling in clouds considering fault recovery. KSII Trans. Internet Inf. Syst. 2016, 10. [Google Scholar] [CrossRef]
- Casas, I.; Taheri, J.; Ranjan, R.; Wang, L.Z.; Zomaya, A.Y. A balanced scheduler with data reuse and replication for scientific workflows in cloud computing systems. Future Gener. Comput. Syst. 2016, 74, 168–178. [Google Scholar] [CrossRef]
- Hu, H.Z.; Tian, S.L.; Guo, Q.; Ouyang, A.J. An adaptive hybrid PSO multi-objective optimization algorithm for constrained optimization problems. Int. J. Pattern Recognit. Artif. Intell. 2015, 29, 1559009. [Google Scholar] [CrossRef]
- Ouyang, A.J.; Li, K.L.; Fei, X.W.; Zhou, X.; Duan, M.X. A novel hybrid multi-objective population migration algorithm. Int. J. Pattern Recognit. Artif. Intell. 2015, 29, 1559001. [Google Scholar] [CrossRef]
- Panda, A.; Pani, S. A Symbiotic Organisms Search algorithm with adaptive penalty function to solve multi-objective constrained optimization problems. Appl. Soft Comput. 2016, 46, 344–360. [Google Scholar] [CrossRef]
- Verma, A.; Kaushal, S. A hybrid multi-objective Particle Swarm Optimization for scientific workflow scheduling. Parallel Comput. 2017, 62, 1–19. [Google Scholar] [CrossRef]
- Ye, X.; Li, J.; Liu, S.; Liang, J.; Jin, Y. A hybrid instance-intensive workflow scheduling method in private cloud environment. Nat. Comput. 2017, 1–12. [Google Scholar] [CrossRef]
- Goulart, F.; Campelo, F. Preference-guided evolutionary algorithms for many-objective optimization. Inf. Sci. 2016, 329, 236–255. [Google Scholar] [CrossRef]
- Zhu, Z.X.; Xiao, J.; He, S.; Ji, Z.; Sun, Y.W. A multi-objective memetic algorithm based on locality-sensitive hashing for one-to-many-to-one dynamic pickup-and-delivery problem. Inf. Sci. 2016, 329, 73–89. [Google Scholar] [CrossRef]
- Deb, K.; Jain, H. An evolutionary many-objective optimization algorithm using reference-point-based non-dominated sorting approach, Part I: Solving problems with box constraints. IEEE Trans. Evol. Comput. 2014, 18, 577–601. [Google Scholar] [CrossRef]
- Ostermann, S.; Iosup, A.; Yigibasi, N.; Prodan, R.; Fahringer, T.; Epema, D. A performance analysis of EC2 cloud computing services for scientific computing. In Cloud Computing. CloudComp 2009; Lecture Notes of the Institute for Computer Sciences, Social-Informatics and Telecommunications Engineering; Springer: Berlin/Heidelberg, Germany, 2010; Volume 34. [Google Scholar] [CrossRef]
- Mao, M.; Humphrey, M. Auto-scaling to minimize cost and meet application deadlines in cloud workflows. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, Seatle, WA, USA, 12–18 November 2011. [Google Scholar] [CrossRef]
- Singh, V.; Gupta, I.; Jana, P.K. A novel cost-efficient approach for deadline-constrained workflow scheduling by dynamic provisioning of resources. Future Gener. Comput. Syst. 2018, 79, 95–110. [Google Scholar] [CrossRef]
- Rodriguez, M.A.; Buyya, R. Budget-driven scheduling of scientific workflows in IaaS clouds with fine-grained billing periods. ACM Trans. Auton. Adapt. Syst. 2017, 12, 5. [Google Scholar] [CrossRef]
- Schad, J.; Dittrich, J.; Quiane-Ruiz, J.A. Runtime measurements in the cloud: Observing, analyzing, and reducing variance. Proc. VLDB Endow. 2010, 3, 460–471. [Google Scholar] [CrossRef]
- Schad, J. Understanding and Managing the Performance Variation and Data Growth in Cloud Computing. Doctoral Thesis, Saarland University, Saarbruken, Germany, May 2015. [Google Scholar]
- Ezugwu, A.E.; Adewumi, A.O. Soft sets based symbiotic organisms search algorithm for resource discovery in cloud computing environment. Future Gener. Comput. Syst. 2017, 76, 33–55. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Calheiros, R.N.; Ranjan, R.; Beloglazov, A.; de Rose, C.A.F.; Buyya, R. CloudSim: A toolkit for modeling and simulation of cloud computing environments and evaluation of resource provisioning algorithms. Softw. Pract. Exp. 2011, 41, 23–50. [Google Scholar] [CrossRef]
- Chen, W.; Deelman, E. WorkflowSim: A toolkit for simulating scientific workflows in distributed environments. In Proceedings of the 2012 IEEE 8th International Conference on E-Science (e-Science), Chicago, IL, USA, 8–12 October 2012; pp. 1–12. [Google Scholar] [CrossRef]
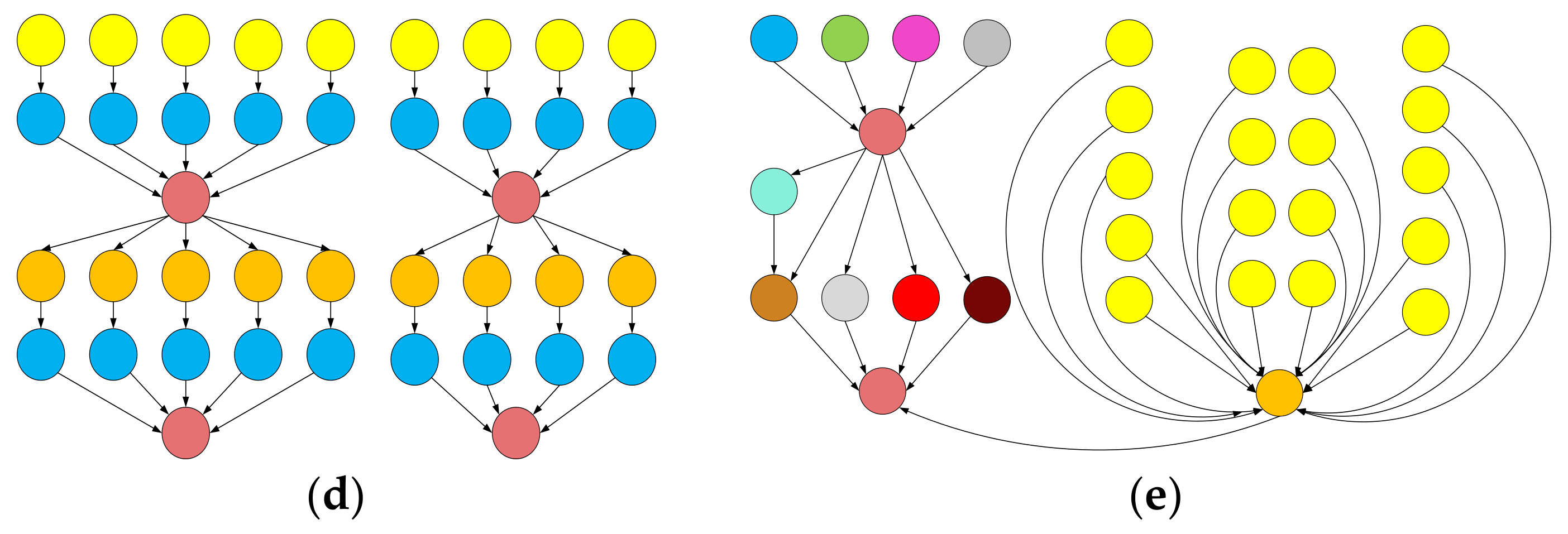
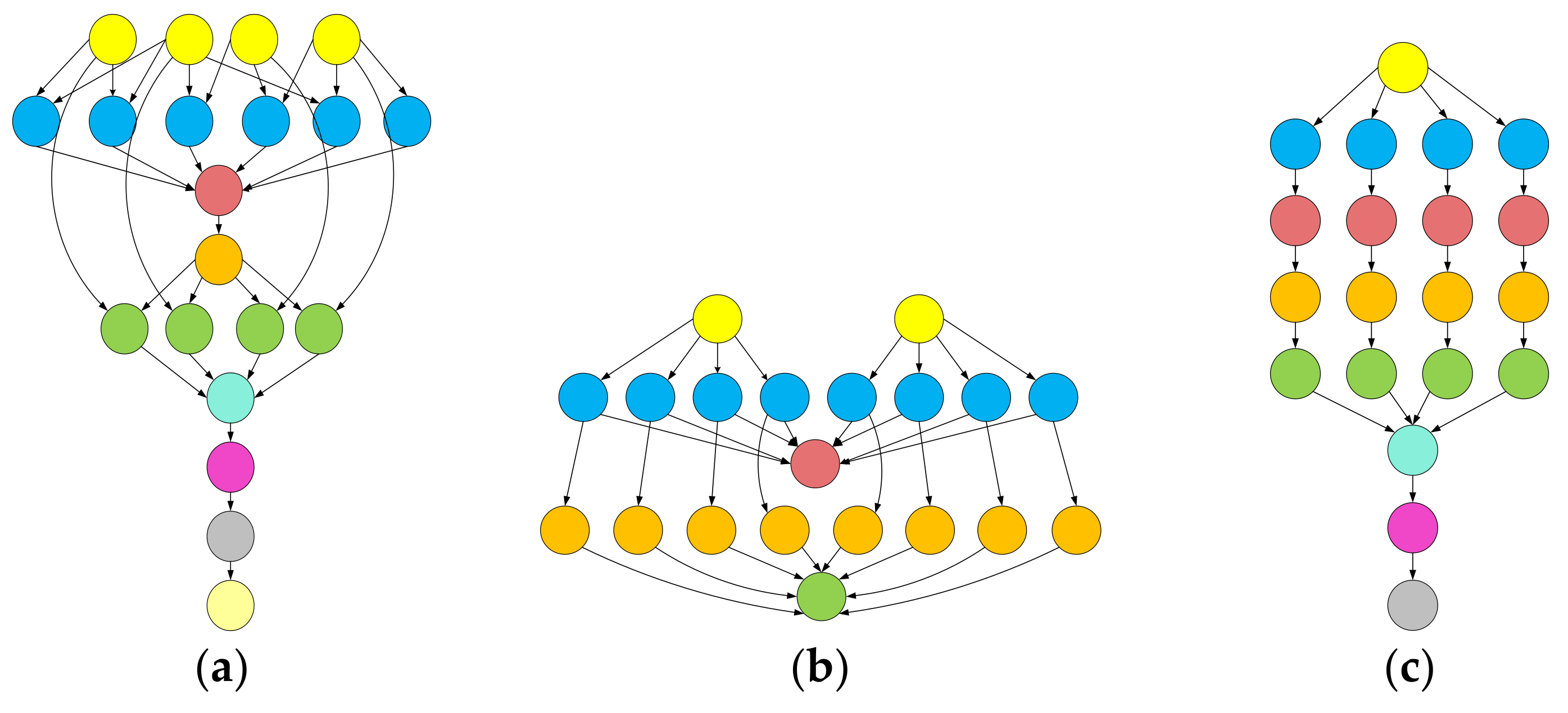
- Juve, G.; Chervenak, A.; Deelman, E.; Bharathi, S.; Mehta, G.; Vahi, K. Characterizing and profiling scientific workflows. Future Gener. Comput. Syst. 2013, 29, 682–692. [Google Scholar] [CrossRef]
- Deelman, E.; Vahi, K.; Juve, G.; Rynge, M.; Callaghan, S.; Maechling, P.J.; Mayani, R.; Chen, W.; da Silva, R.F.; Livny, M.; et al. Pegasus, a workflow management system for science automation. Future Gener. Comput. Syst. 2015, 46, 17–35. [Google Scholar] [CrossRef]
- Zitzler, E.; Thiele, L.; Laumanns, M.; Fonseca, C.M.; da Fonseca, V.G. Performance assessment of multiobjective optimizers: An analysis and review. IEEE Trans. Evol. Comput. 2003, 7, 117–132. [Google Scholar] [CrossRef]
- Coello, C.A.C.; Pulido, G.T.; Lechuga, M.S. Handling multiple objectives with Particle Swarm Optimization. IEEE Trans. Evol. Comput. 2004, 8, 256–279. [Google Scholar] [CrossRef]
- Muller, K.E.; Fetterman, B.A. Regression and ANOVA: An Integrated Approach Using SAS Software; SAS Institute: Cary, NC, USA, 2002. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| Set of tasks of the workflow, represented by vertices of the Directed Acyclic Graph (DAG) | |
| Set of Virtual Machines (VMs) | |
| Number of tasks in a given workflow | |
| Number of available VMs | |
| th task, | |
| th VM, | |
| Entry task of the given workflow | |
| Exit task of the given workflow | |
| Predecessors (or parents set) of | |
| Successors (or children set) | |
| Ecosystem (i.e., population) size, or in other words, the number of organisms (i.e., candidate solutions) in the ecosystem | |
| An ecosystem representing several candidate solutions | |
| th organism of representing a candidate solution corresponding to allocation of the whole workflow tasks over the available VMs | |
| Best organism known so far | |
| An integer representing the VM allocated to the task such that | |
| Number of objective functions | |
| Fitness function, including | |
| Makespan | |
| Cost | |
| Degree of imbalance of VMs | |
| Normalized fitness evaluation function of the solution across the objectives | |
| Binary variable, if task is executed on VM , ; otherwise | |
| Workload (i.e., service length) of task measured by Millions of Instructions (MI) | |
| Central Processing Unit (CPU) computing capacity of VM measured by Millions of Instruction Per Second (MIPS) | |
| Data transfer size from task to | |
| Bandwidth of VM | |
| Start time of task executed on VM | |
| Execution time of task running on VM | |
| Communication time between task and ; if the tasks are executed on same VM, | |
| Finish time of task executed on VM | |
| Available time of VM for the execution of task | |
| Finish time of last task | |
| Cost per interval unit of VM type | |
| Billing interval of VM type | |
| Execution cost of task on VM | |
| Data transfer cost per time unit for VM | |
| VM performance variability | |
| Execution makespan of workflow | |
| Degree of imbalance among VMs | |
| Utilization rate of VM |
| Task ID | |||||||||||
| VM ID | 1 | 3 | 2 | 2 | 4 | 1 | 3 | 1 | 3 | 4 | 2 |
| Parameter | Value |
|---|---|
| Number of tasks | (20–1000) |
| Number of VMs | 8 |
| MIPS | 500–1500 |
| RAM | (512–2048) MB |
| Bandwidth | 1 MBps |
| Number of processors | 2 |
| Population size | 100 |
| Maximum iterations | 500 |
| Number of simulation runs | 50 |
| Workflow | Number of Nodes | Number of Edges | Mean Data Size (MB) |
|---|---|---|---|
| Montage_25 | 25 | 95 | 3.43 |
| Montage_50 | 50 | 206 | 3.36 |
| Montage_100 | 100 | 433 | 3.23 |
| Montage_1000 | 1000 | 4485 | 3.21 |
| CyberShake_30 | 30 | 112 | 747.48 |
| CyberShake_50 | 50 | 188 | 864.74 |
| CyberShake_100 | 100 | 380 | 849.60 |
| CyberShake_100 | 1000 | 3988 | 102.29 |
| Epigenomics_24 | 24 | 75 | 116.20 |
| Epigenomics_46 | 46 | 148 | 104.81 |
| Epigenomics_100 | 100 | 322 | 395.10 |
| Epigenomics_997 | 997 | 3228 | 388.59 |
| LIGO_30 | 30 | 95 | 9.00 |
| LIGO_50 | 50 | 160 | 9.16 |
| LIGO_100 | 100 | 319 | 8.93 |
| LIGO_1000 | 1000 | 3246 | 8.90 |
| SIPHT_30 | 30 | 91 | 7.73 |
| SIPHT_60 | 60 | 198 | 6.95 |
| SIPHT_100 | 100 | 335 | 6.27 |
| SIPHT_1000 | 1000 | 3528 | 5.91 |
| Workflow | Source of Variation | SS | df | MS | F |
|---|---|---|---|---|---|
| Montage_1000 | Between groups | 5.20 × 10−7 | 2 | 2.6 × 10−7 | 9.3 × 103 |
| Within groups | 7.50 × 10−10 | 27 | 2.8 × 10−11 | ||
| Total | 5.2 × 10−7 | 29 | |||
| CyberShake_1000 | Between groups | 2.9 × 10−12 | 2 | 1.45 × 10−11 | 2.3 × 104 |
| Within groups | 1.7 × 10−14 | 27 | 6.3 × 10−16 | ||
| Total | 2.9 × 10−12 | 29 | |||
| Epigenomics_997 | Between groups | 1.3 × 10−12 | 2 | 6.5 × 10−13 | 1.5 × 103 |
| Within groups | 1.2 × 10−14 | 27 | 4.4 × 10−16 | ||
| Total | 1.3 × 10−12 | 29 | |||
| LIGO_1000 | Between groups | 6.5 × 10−11 | 2 | 3.2 × 10−11 | 1.8 × 103 |
| Within groups | 4.9 × 10−13 | 27 | 1.8 × 10−14 | ||
| Total | 6.5 × 10−11 | 29 | |||
| SIPHT_1000 | Between groups | 2.1 × 10−10 | 2 | 1.05 × 10−10 | 1.2 × 103 |
| Within groups | 2.4 × 10−12 | 27 | 8.9 × 10−14 | ||
| Total | 2.1 × 10−10 | 29 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Anwar, N.; Deng, H. A Hybrid Metaheuristic for Multi-Objective Scientific Workflow Scheduling in a Cloud Environment. Appl. Sci. 2018, 8, 538. https://doi.org/10.3390/app8040538
Anwar N, Deng H. A Hybrid Metaheuristic for Multi-Objective Scientific Workflow Scheduling in a Cloud Environment. Applied Sciences. 2018; 8(4):538. https://doi.org/10.3390/app8040538
Chicago/Turabian StyleAnwar, Nazia, and Huifang Deng. 2018. "A Hybrid Metaheuristic for Multi-Objective Scientific Workflow Scheduling in a Cloud Environment" Applied Sciences 8, no. 4: 538. https://doi.org/10.3390/app8040538
APA StyleAnwar, N., & Deng, H. (2018). A Hybrid Metaheuristic for Multi-Objective Scientific Workflow Scheduling in a Cloud Environment. Applied Sciences, 8(4), 538. https://doi.org/10.3390/app8040538