Predicting Human Behaviour with Recurrent Neural Networks


Abstract
1. Introduction
2. Related Work
3. Actions, Activities and Behaviours
- Actions are temporally short and conscious muscular movements made by the users (e.g., taking a cup, opening the fridge, etc.).
- Activities are temporally longer but finite and are composed of several actions (e.g., preparing dinner, taking a shower, watching a movie, etc.).
- Behaviours describe how the user performs these activities at different times. We have identified two types of behaviours. The intra-activity behaviours describe how a single activity is performed by a user at different times (e.g., while the user is preparing dinner, sometimes they may gather all the ingredients before starting, while on other occasions, the user may take them as they are needed). The inter-activity behaviours describe how the user chains different activities (e.g., on Mondays after having breakfast, the user leaves the house to go to work, but in the weekends they go to the main room).
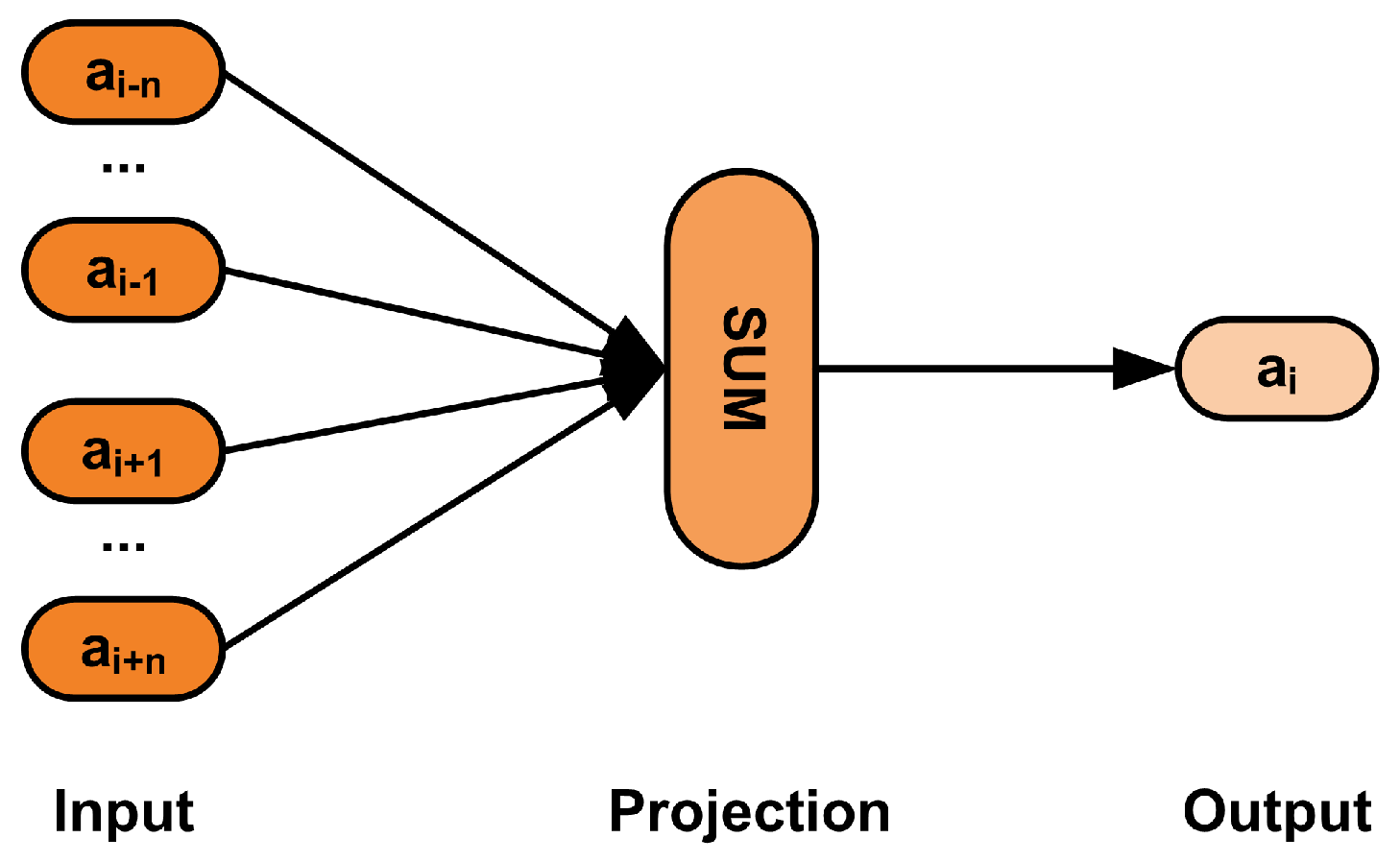
3.1. Semantic Embeddings for Action Representation
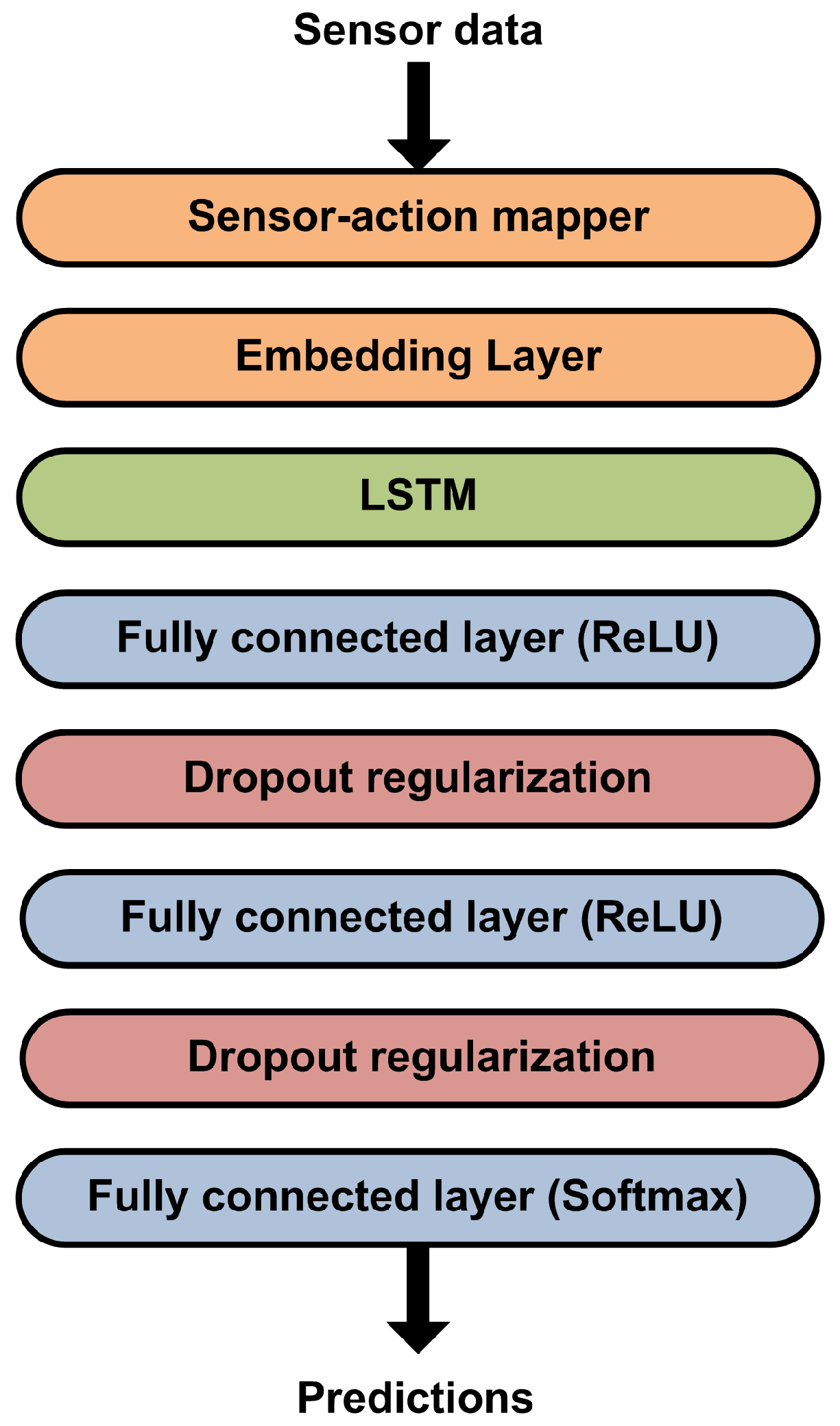
3.2. LSTM-Based Network for Behaviour Modelling
4. Evaluation
4.1. Experimental Setup
- Architecture experiments: we evaluated different architectures, varying the number of LSTMs and fully connected dense layers.
- Sequence length experiments: we evaluated the effects of altering the input action sequence length.
- Time experiments: we evaluated the effects of taking into account the timestamps of the input actions.
4.2. Metrics
4.3. Results and Discussion
5. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- United Nations. World Urbanization Prospects: The 2014 Revision, Highlights; Department of Economic and Social Affairs, Population Division, United Nations: New York, NY, USA, 2014. [Google Scholar]
- Caragliu, A.; Del Bo, C.; Nijkamp, P. Smart cities in Europe. J. Urban Technol. 2011, 18, 65–82. [Google Scholar] [CrossRef]
- Shapiro, J.M. Smart cities: Quality of life, productivity, and the growth effects of human capital. Rev. Econ. Stat. 2006, 88, 324–335. [Google Scholar] [CrossRef]
- Forman, D.E.; Berman, A.D.; McCabe, C.H.; Baim, D.S.; Wei, J.Y. PTCA in the Elderly: The “Young-Old” versus the “Old-Old”. J. Am. Geriatr. Soc. 1992, 40, 19–22. [Google Scholar] [CrossRef] [PubMed]
- Rashidi, P.; Mihailidis, A. A survey on ambient-assisted living tools for older adults. IEEE J. Biomed. Health Inform. 2013, 17, 579–590. [Google Scholar] [CrossRef] [PubMed]
- Azkune, G.; Almeida, A.; L López-de-Ipiña, D.; Chen, L. Extending knowledge-driven activity models through data-driven learning techniques. Expert Syst. Appl. 2015, 42, 3115–3128. [Google Scholar] [CrossRef]
- Azkune, G.; Almeida, A.; López-de-Ipiña, D.; Chen, L. Combining users’ activity survey and simulators to evaluate human activity recognition systems. Sensors 2015, 15, 8192–8213. [Google Scholar] [CrossRef] [PubMed]
- Bilbao, A.; Almeida, A.; López-de-Ipiña, D. Promotion of active ageing combining sensor and social network data. J. Biomed. Inform. 2016, 64, 108–115. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Weinland, D.; Ronfard, R.; Boyer, E. A survey of vision-based methods for action representation, segmentation and recognition. Comput. Vis. Image Underst. 2011, 115, 224–241. [Google Scholar] [CrossRef]
- Chen, L.; Hoey, J.; Nugent, C.D.; Cook, D.J.; Yu, Z. Sensor-based activity recognition. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2012, 42, 790–808. [Google Scholar] [CrossRef]
- Yilmaz, A.; Javed, O.; Shah, M. Object tracking: A survey. ACM Comput. Surv. (CSUR) 2006, 38, 13. [Google Scholar] [CrossRef]
- Bao, L.; Intille, S.S. Activity recognition from user-annotated acceleration data. In Proceedings of the International Conference on Pervasive Computing, Linz and Vienna, Austria, 21–23 April 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 1–17. [Google Scholar]
- Van Kasteren, T.; Noulas, A.; Englebienne, G.; Kröse, B. Accurate activity recognition in a home setting. In Proceedings of the 10th International Conference on Ubiquitous Computing, Seoul, Korea, 21–24 September 2008; ACM: New York, NY, USA, 2008; pp. 1–9. [Google Scholar]
- Oliver, N.; Garg, A.; Horvitz, E. Layered representations for learning and inferring office activity from multiple sensory channels. Comput. Vis. Image Underst. 2004, 96, 163–180. [Google Scholar] [CrossRef]
- Fatima, I.; Fahim, M.; Lee, Y.K.; Lee, S. A unified framework for activity recognition-based behavior analysis and action prediction in smart homes. Sensors 2013, 13, 2682–2699. [Google Scholar] [CrossRef] [PubMed]
- Ordóñez, F.J.; Iglesias, J.A.; De Toledo, P.; Ledezma, A.; Sanchis, A. Online activity recognition using evolving classifiers. Expert Syst. Appl. 2013, 40, 1248–1255. [Google Scholar] [CrossRef]
- Rashidi, P.; Cook, D.J. COM: A method for mining and monitoring human activity patterns in home-based health monitoring systems. ACM Trans. Intell. Syst. Technol. (TIST) 2013, 4, 64. [Google Scholar] [CrossRef]
- Chen, L.; Nugent, C.D.; Mulvenna, M.; Finlay, D.; Hong, X.; Poland, M. A logical framework for behaviour reasoning and assistance in a smart home. Int. J. Assist. Robot. Mechatron. 2008, 9, 20–34. [Google Scholar]
- Riboni, D.; Bettini, C. COSAR: Hybrid reasoning for context-aware activity recognition. Pers. Ubiquitous Comput. 2011, 15, 271–289. [Google Scholar] [CrossRef]
- Chen, L.; Nugent, C.D.; Wang, H. A knowledge-driven approach to activity recognition in smart homes. IEEE Trans. Knowl. Data Eng. 2012, 24, 961–974. [Google Scholar] [CrossRef]
- Aloulou, H.; Mokhtari, M.; Tiberghien, T.; Biswas, J.; Yap, P. An adaptable and flexible framework for assistive living of cognitively impaired people. IEEE J. Biomed. Health Inform. 2014, 18, 353–360. [Google Scholar] [CrossRef] [PubMed]
- Das, S.K.; Cook, D.J.; Battacharya, A.; Heierman, E.O.; Lin, T.Y. The role of prediction algorithms in the MavHome smart home architecture. IEEE Wirel. Commun. 2002, 9, 77–84. [Google Scholar] [CrossRef]
- Cook, D.J.; Youngblood, M.; Heierman, E.O.; Gopalratnam, K.; Rao, S.; Litvin, A.; Khawaja, F. MavHome: An agent-based smart home. In Proceedings of the First IEEE International Conference on Pervasive Computing and Communications, (PerCom 2003), Fort Worth, TX, USA, 26 March 2003; IEEE: Piscataway, NJ, USA, 2003; pp. 521–524. [Google Scholar]
- Cook, D.J.; Das, S.K. How smart are our environments? An updated look at the state of the art. Pervasive Mobile Comput. 2007, 3, 53–73. [Google Scholar] [CrossRef]
- Kurian, C.P.; Kuriachan, S.; Bhat, J.; Aithal, R.S. An adaptive neuro-fuzzy model for the prediction and control of light in integrated lighting schemes. Light. Res. Technol. 2005, 37, 343–351. [Google Scholar] [CrossRef]
- Morel, N.; Bauer, M.; El-Khoury, M.; Krauss, J. Neurobat, a predictive and adaptive heating control system using artificial neural networks. Int. J. Sol. Energy 2001, 21, 161–201. [Google Scholar] [CrossRef]
- Dounis, A.I.; Caraiscos, C. Advanced control systems engineering for energy and comfort management in a building environment—A review. Renew. Sustain. Energy Rev. 2009, 13, 1246–1261. [Google Scholar] [CrossRef]
- Chaaraoui, A.A.; Climent-Pérez, P.; Flórez-Revuelta, F. A review on vision techniques applied to human behaviour analysis for ambient-assisted living. Expert Syst. Appl. 2012, 39, 10873–10888. [Google Scholar] [CrossRef]
- Schank, R.C. Dynamic Memory: A Theory of Reminding and Learning in Computers and People; Cambridge University Press: Cambridge, UK, 1983. [Google Scholar]
- Schank, R.C.; Abelson, R.P. Scripts, Plans, Goals and Understanding, an Inquiry into Human Knowledge Structures; Lawrence Erlbaum Associates: Mahwah, NJ, USA, 1977. [Google Scholar]
- Hoey, J.; Poupart, P.; von Bertoldi, A.; Craig, T.; Boutilier, C.; Mihailidis, A. Automated handwashing assistance for persons with dementia using video and a partially observable Markov decision process. Comput. Vis. Image Underst. 2010, 114, 503–519. [Google Scholar] [CrossRef]
- Krüger, F.; Nyolt, M.; Yordanova, K.; Hein, A.; Kirste, T. Computational state space models for activity and intention recognition. A feasibility study. PLoS ONE 2014, 9, e109381. [Google Scholar] [CrossRef] [PubMed]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2013; pp. 3111–3119. [Google Scholar]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Jauvin, C. A neural probabilistic language model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge Graph Embedding by Translating on Hyperplanes. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, Hilton, QC, Canada, 27–31 July 2014; pp. 1112–1119. [Google Scholar]
- Dos Santos, C.N.; Gatti, M. Deep Convolutional Neural Networks for Sentiment Analysis of Short Texts. In Proceedings of the COLING, the 25th International Conference on Computational Linguistics: Technical Papers, Dublin, Ireland, 23–29 August 2014; pp. 69–78. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. 2014. arXiv:1408.5882. arXiv.org e-Print archive. Available online: https://arxiv.org/abs/1408.5882 (accessed on 15 December 2017).
- Lipton, Z.C.; Berkowitz, J.; Elkan, C. A Critical Review of Recurrent Neural Networks for Sequence Learning. 2015. arXiv:1506.00019. arXiv.org e-Print archive. Available online: https://arxiv.org/abs/1506.00019 (accessed on 15 December 2017).
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, PMLR, Ft. Lauderdale, FL, USA, 11–13 April 2011; Volome 15, No. 106. p. 275. [Google Scholar]
- Srivastava, N.; Hinton, G.E.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Dropout | LSTM # | LSTM Size | Dense # | Dense Size | Sequence Length | Coding |
|---|---|---|---|---|---|---|---|
| A1 | 0.4 | 1 (Standard) | 512 | 1 | 1024 | 5 | Embedding |
| A2 | 0.8 | 1 (Standard) | 512 | 1 | 1024 | 5 | Embedding |
| A3 | 0.8 | 1 (Standard) | 512 | 2 | 1024 | 5 | Embedding |
| A4 | 0.8 | 2 (Standard) | 512 | 2 | 1024 | 5 | Embedding |
| A5 | 0.2 | 1 (Standard) | 512 | 5 | 50 | 5 | Embedding |
| A6 | 0.8 | 1 (Bidirectional) | 512 | 2 | 1024 | 5 | Embedding |
| A7 | 0.8 | 1 (Standard) | 512 | 2 | 1024 | 5 | One-hot vector |
| A8 | 0.8 | 1 (Standard) | 512 | 1 | 1024 | 5 | One-hot vector |
| A9 | 0.8 | 2 (Standard) | 512 | 2 | 1024 | 5 | One-hot vector |
| ID | Sequence Length |
|---|---|
| S1 | 3 |
| S2 | 1 |
| S3 | 4 |
| S4 | 6 |
| S5 | 10 |
| S6 | 30 |
| ID | acc_at_1 | acc_at_2 | acc_at_3 | acc_at_4 | acc_at_5 |
|---|---|---|---|---|---|
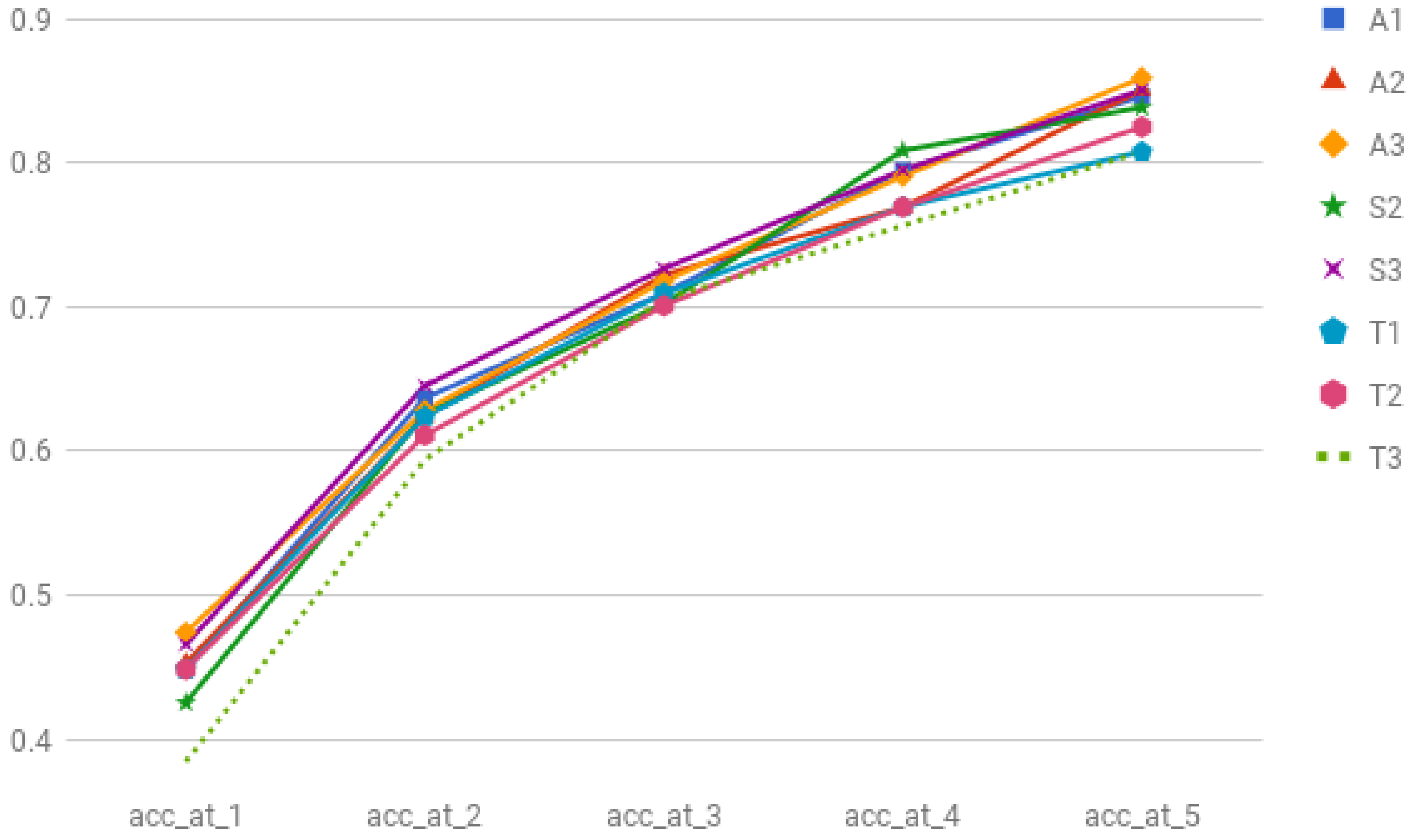
| A1 | 0.4487 | 0.6367 | 0.7094 | 0.7948 | 0.8461 |
| A2 | 0.4530 | 0.6239 | 0.7222 | 0.7692 | 0.8504 |
| A3 | 0.4744 | 0.6282 | 0.7179 | 0.7905 | 0.8589 |
| A4 | 0.4444 | 0.5940 | 0.6965 | 0.7735 | 0.8247 |
| A5 | 0.4402 | 0.5982 | 0.7136 | 0.7820 | 0.8418 |
| A6 | 0.4487 | 0.6068 | 0.7136 | 0.7905 | 0.8376 |
| A7 | 0.4572 | 0.6153 | 0.7094 | 0.7820 | 0.8376 |
| A8 | 0.4529 | 0.5811 | 0.7051 | 0.7735 | 0.8376 |
| A9 | 0.4102 | 0.5940 | 0.7008 | 0.7777 | 0.8247 |
| ID | acc_at_1 | acc_at_2 | acc_at_3 | acc_at_4 | acc_at_5 |
|---|---|---|---|---|---|
| A3 | 0.4744 | 0.6282 | 0.7179 | 0.7905 | 0.8589 |
| S1 | 0.4553 | 0.5957 | 0.7021 | 0.8 | 0.8553 |
| S2 | 0.4255 | 0.6255 | 0.7021 | 0.8085 | 0.8382 |
| S3 | 0.4658 | 0.6452 | 0.7264 | 0.7948 | 0.8504 |
| S4 | 0.4700 | 0.6196 | 0.6965 | 0.7692 | 0.8461 |
| S5 | 0.4592 | 0.6351 | 0.7210 | 0.7896 | 0.8369 |
| S6 | 0.4192 | 0.5589 | 0.6593 | 0.7554 | 0.8122 |
| ID | acc_at_1 | acc_at_2 | acc_at_3 | acc_at_4 | acc_at_5 |
|---|---|---|---|---|---|
| A3 | 0.4744 | 0.6282 | 0.7179 | 0.7905 | 0.8589 |
| T1 | 0.4487 | 0.6239 | 0.7094 | 0.7692 | 0.8076 |
| T2 | 0.4487 | 0.6111 | 0.7008 | 0.7692 | 0.8247 |
| T3 | 0.3846 | 0.5940 | 0.7051 | 0.7564 | 0.8076 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Almeida, A.; Azkune, G. Predicting Human Behaviour with Recurrent Neural Networks. Appl. Sci. 2018, 8, 305. https://doi.org/10.3390/app8020305
Almeida A, Azkune G. Predicting Human Behaviour with Recurrent Neural Networks. Applied Sciences. 2018; 8(2):305. https://doi.org/10.3390/app8020305
Chicago/Turabian StyleAlmeida, Aitor, and Gorka Azkune. 2018. "Predicting Human Behaviour with Recurrent Neural Networks" Applied Sciences 8, no. 2: 305. https://doi.org/10.3390/app8020305
APA StyleAlmeida, A., & Azkune, G. (2018). Predicting Human Behaviour with Recurrent Neural Networks. Applied Sciences, 8(2), 305. https://doi.org/10.3390/app8020305