Chained Anomaly Detection Models for Federated Learning: An Intrusion Detection Case Study

 ,
,
Abstract
1. Introduction
2. Related Work
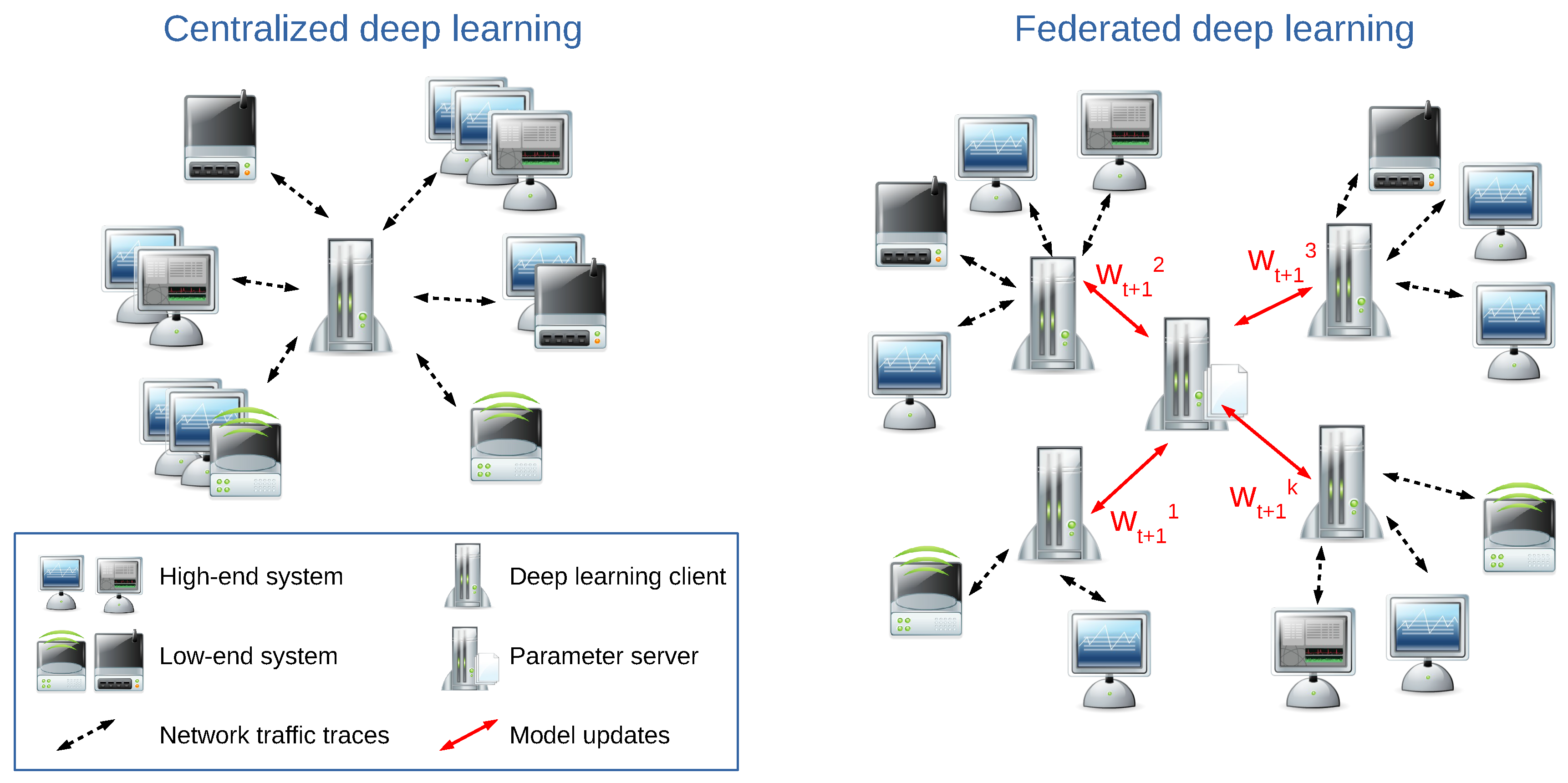
2.1. Federated Machine Learning and Deep Learning
2.2. Intrusion Detection and Response Systems
2.3. Machine Learning in Adversarial Settings
2.4. Machine Learning and Blockchains
2.5. Bridging the Gap
3. Accountable Federated Learning for Anomaly Detection
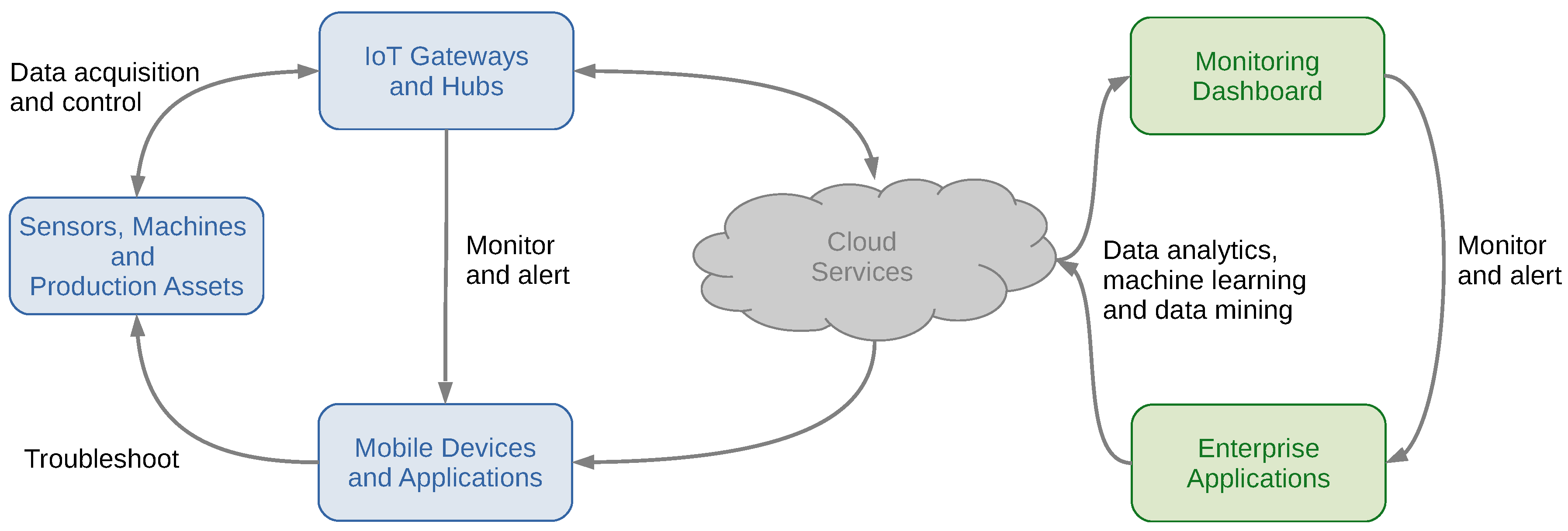
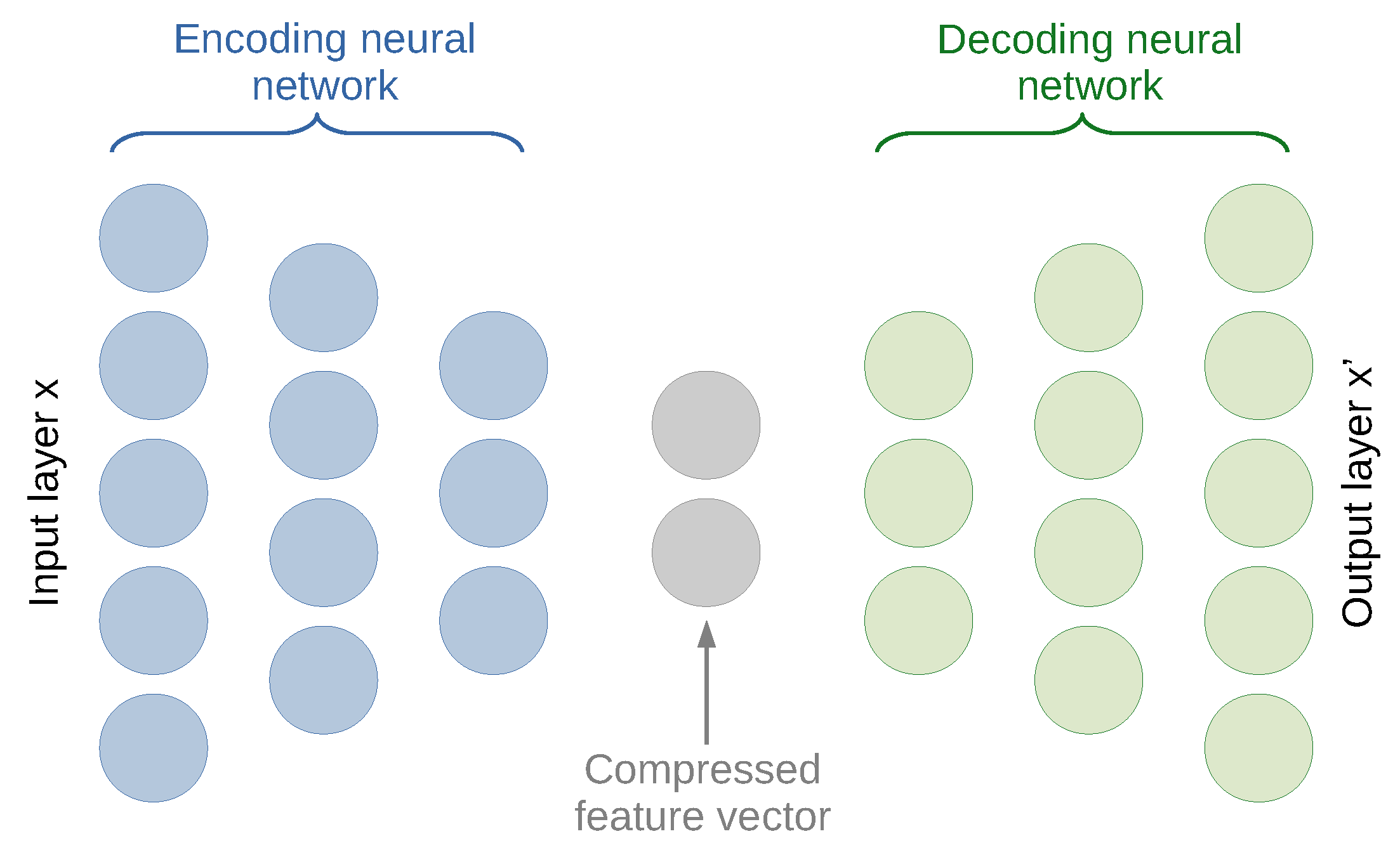
3.1. Intrusion Detection with a (Deep) Neural Network-Based Anomaly Detection
- two symmetrical encoding and decoding parts each with three dense layers;
- the total amount of five dense layers including three hidden layers;
- the number of neurons per layer 50 → 25 → 10 → 25 → 50;
- the total amount of learnable weights (25 × 50) + (10 × 25) + (25 × 10) + (50 × 25) = 3000;
- a rectified linear unit (ReLU) as the activation function;
- the Adam stochastic gradient descent (SGD) optimization algorithm;
- the learning rate of 0.05;
- norm (or the mean squared error) as the loss function;
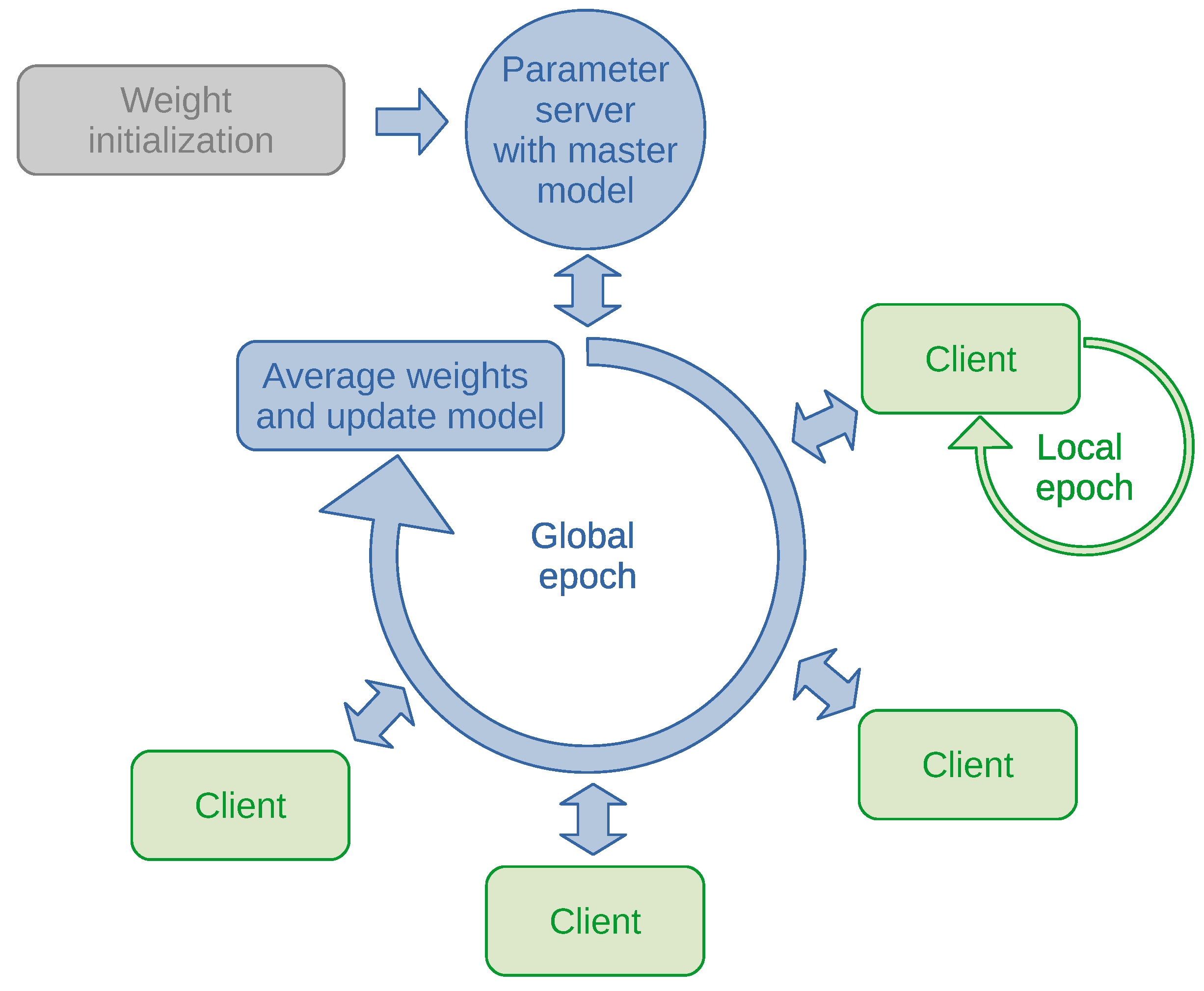
3.2. Anomaly Detection through Federated Learning
| Algorithm 1. C is the global batch size; B is the local batch size; the K clients are indexed by k; E is the number of local epochs; and is the learning rate (adapted from [37]). |
|
3.3. Federated Learning in an Adversarial Setting
- A monitored node is compromised and provides malicious network flow features such that the connected deep learning client optimizes its local model based on erroneous traffic data.
- A deep learning client is compromised and provides malicious weight updates to the parameter server and/or does not adopt new model updates broadcast by the parameter server.
- The parameter server is compromised and provides malicious neural network model updates back to the deep learning clients.
3.4. Auditing the Anomaly Models and Weight Updates on the Blockchain
- host01:~$ multichain-util create ids
- host01:~$ multichaind ids -daemon
- host01:~$ multichain-cli ids grant 1anp8AquvvPi87LP5BQ3HPAKNDRnwKbb99fLTu connect
- host02:~$ multichaind ids@192.168.100.24:6469 -daemon
- host01:~$ multichain-cli ids create stream anomaly false
- host01:~$ multichain-cli ids publish anomaly init ’{"json":{"nb_layers": 5, ...}}’
- host01:~$ multichain-cli ids grant 1anp8AquvvPi87LP5BQ3HPAKNDRnwKbb99fLTu send
- host01:~$ multichain-cli ids grant 1anp8AquvvPi87LP5BQ3HPAKNDRnwKbb99fLTu anomaly.write
- host01:~$ multichain-cli ids subscribe anomaly
- host01:~$ multichain-cli ids liststreamitems anomaly # all items
- host01:~$ multichain-cli ids liststreamkeyitems anomaly init # items with the key ’init’
- host02:~$ multichain-cli ids publish anomaly host02_1 ’{"json":{"deltaweights": [ 0.1, -0.23, ... ]}}’
- host01:~$ multichain-cli ids grant 1anp8AquvvPi87LP5BQ3HPAKNDRnwKbb99fLTu mine
host01:~$ multichain-cli ids liststreamkeyitems anomaly host02_1
{"method":"liststreamkeyitems","params":["anomaly","host02_1"],"id":"85490301-1541081528","chain_name":"ids"}
[
{
"publishers" : [
"1anp8AquvvPi87LP5BQ3HPAKNDRnwKbb99fLTu"
],
"keys" : [
"host02_1"
],
"offchain" : false,
"available" : true,
"data" : {
"json" : {
"deltaweights" : [ 0.1, -0.23, ... ]
}
},
"confirmations" : 52,
"blocktime" : 1541079108,
"txid" : "6631960d2e75dcae7839653979c1d9872d1a01958fb3b93bf76d22a50ffd9298"
}
]
4. Evaluation
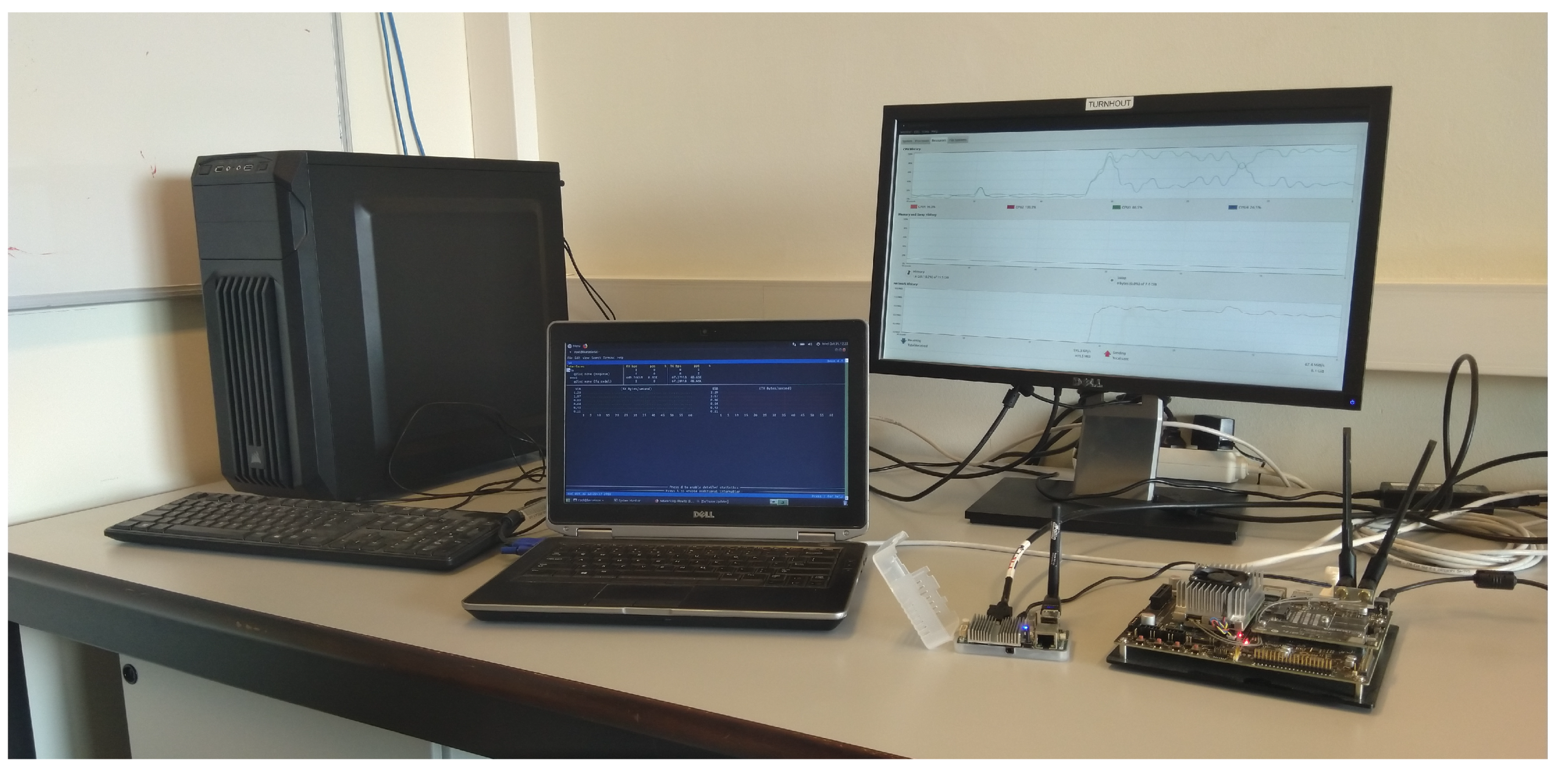
4.1. Experimental Setup
- 18 desktop nodes with an Intel i5-2400 CPU at 3.10 GHz and 4 GB of memory
- 1 laptop with an Intel i5-3320M CPU at 2.60 GHz and 16 GB of memory
- An NVIDIA Jetson TX2 with a Quad ARM A57 processor, 8 GB of memory and 256 CUDA cores
- An ODROID U3 mini-board with a Quad Cortex-A9 processor and 2 GB of memory
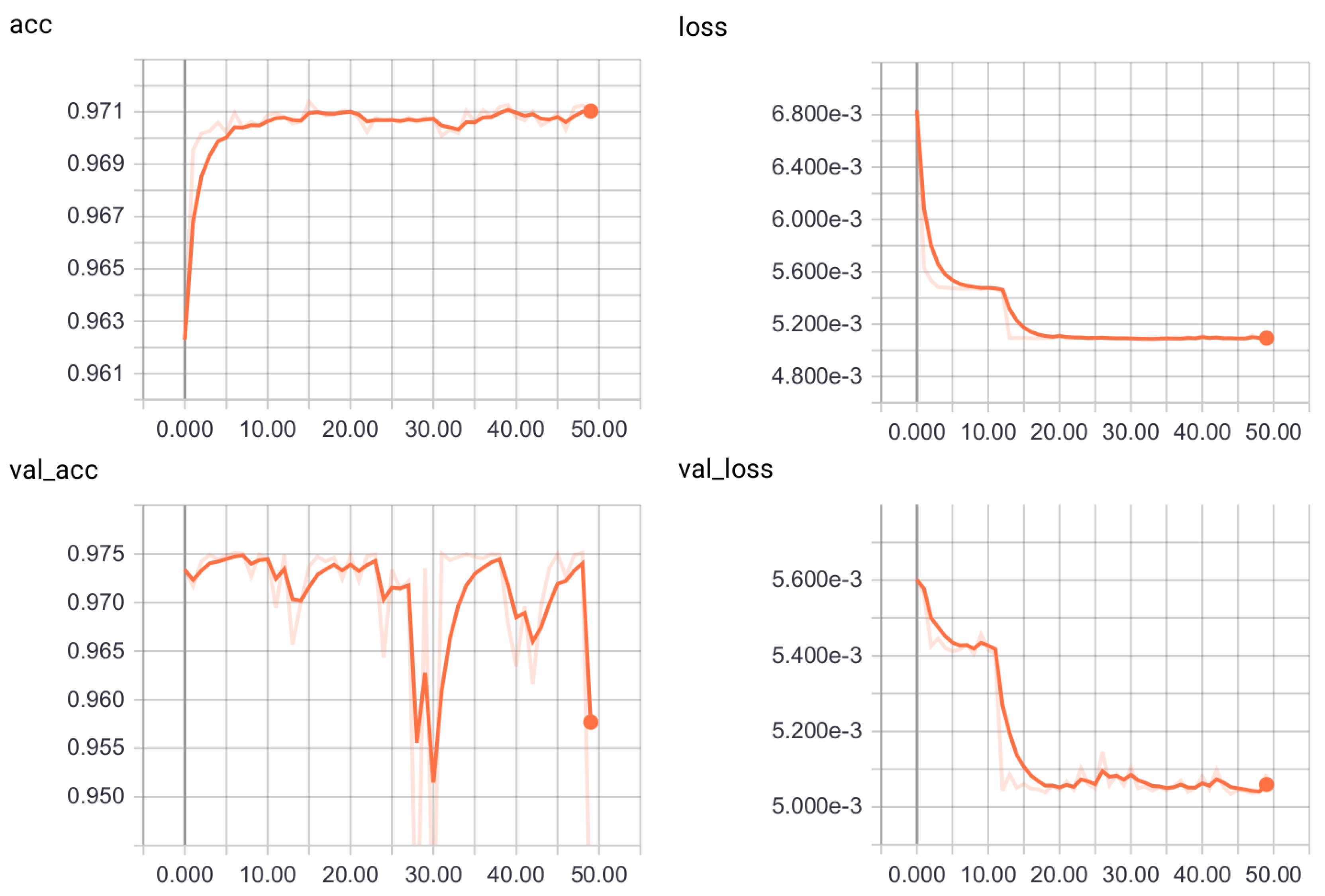
4.2. Centralized Learning
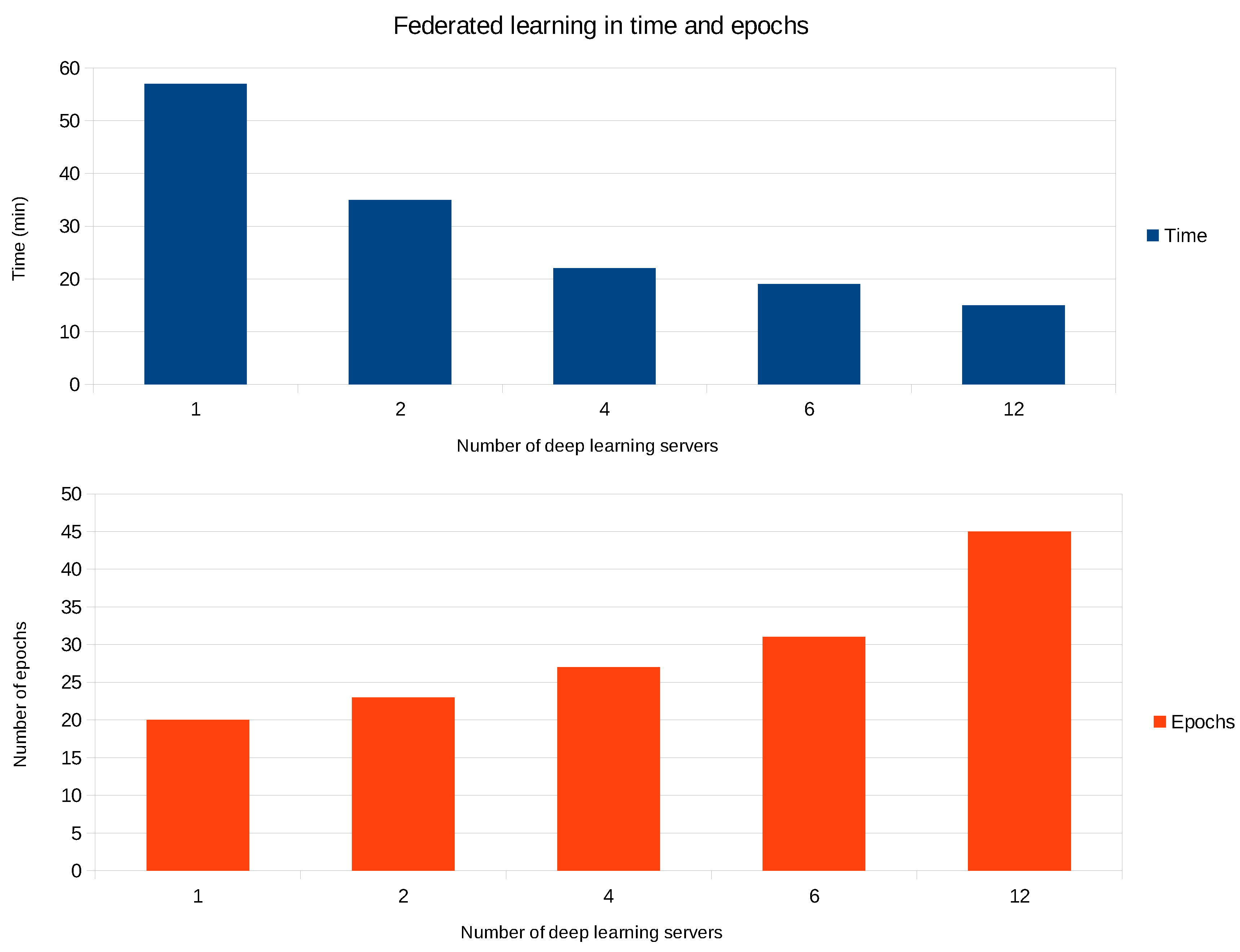
4.3. Federated Learning With Varying the Number of Deep Learning Clients
4.4. Federated Learning with Blockchain Support
- A parameter server receives the weight updates directly from the deep learning servers and immediately processes them.
- A parameter server only processes those weight updates that have been stored and validated on the blockchain.
4.5. Auditing the Federated Learning Process
- Creating two streams, one for local weight updates and another one for averaged model updates.
- Granting deep learning clients to write only to the first stream and read only from the second.
4.6. Discussion, Limitations, and Validity Threats
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Sadeghi, A.R.; Wachsmann, C.; Waidner, M. Security and Privacy Challenges in Industrial Internet of Things. In Proceedings of the 2015 52nd ACM/EDAC/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 8–12 June 2015; ACM: New York, NY, USA, 2015; pp. 54:1–54:6. [Google Scholar] [CrossRef]
- Preuveneers, D.; Zudor, E.I. The intelligent industry of the future: A survey on emerging trends, research challenges and opportunities in Industry 4.0. JAISE 2017, 9, 287–298. [Google Scholar] [CrossRef]
- Verma, R.M.; Kantarcioglu, M.; Marchette, D.J.; Leiss, E.L.; Solorio, T. Security Analytics: Essential Data Analytics Knowledge for Cybersecurity Professionals and Students. IEEE Secur. Privacy 2015, 13, 60–65. [Google Scholar] [CrossRef]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly Detection: A Survey. Acm Comput. Surv. 2009, 41, 15:1–15:58. [Google Scholar] [CrossRef]
- Verma, R. Security Analytics: Adapting Data Science for Security Challenges. In Proceedings of the Fourth ACM International Workshop on Security and Privacy Analytics, Tempe, AZ, USA, 19–21 March 2018; ACM: New York, NY, USA, 2018; pp. 40–41. [Google Scholar] [CrossRef]
- Konecný, J.; McMahan, H.B.; Yu, F.X.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated Learning: Strategies for Improving Communication Efficiency. arXiv, 2016; arXiv:1610.05492. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; Singh, A., Zhu, X.J., Eds.; Volume 54, pp. 1273–1282. [Google Scholar]
- Du, M.; Li, F.; Zheng, G.; Srikumar, V. DeepLog: Anomaly Detection and Diagnosis from System Logs Through Deep Learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; ACM: New York, NY, USA, 2017; pp. 1285–1298. [Google Scholar] [CrossRef]
- Hitaj, B.; Ateniese, G.; Perez-Cruz, F. Deep Models Under the GAN: Information Leakage from Collaborative Deep Learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; ACM: New York, NY, USA, 2017; pp. 603–618. [Google Scholar] [CrossRef]
- Sundaram, A. An Introduction to Intrusion Detection. XRDS 1996, 2, 3–7. [Google Scholar] [CrossRef]
- Inayat, Z.; Gani, A.; Anuar, N.B.; Khan, M.K.; Anwar, S. Intrusion response systems: Foundations, design, and challenges. J. Netw. Comput. Appl. 2016, 53–74. [Google Scholar] [CrossRef]
- Karim, I.; Vien, Q.T.; Le, T.A.; Mapp, G. A Comparative Experimental Design and Performance Analysis of Snort-Based Intrusion Detection System in Practical Computer Networks. Computers 2017, 1, 6. [Google Scholar] [CrossRef]
- Lunt, T.F. A Survey of Intrusion Detection Techniques. Comput. Secur. 1993, 12, 405–418. [Google Scholar] [CrossRef]
- Mitchell, R.; Chen, I.R. A Survey of Intrusion Detection Techniques for Cyber-physical Systems. ACM Comput. Surv. 2014, 46, 55:1–55:29. [Google Scholar] [CrossRef]
- Vasilomanolakis, E.; Karuppayah, S.; Mühlhäuser, M.; Fischer, M. Taxonomy and Survey of Collaborative Intrusion Detection. ACM Comput. Surv. 2015, 47, 55:1–55:33. [Google Scholar] [CrossRef]
- Zarpelo, B.B.; Miani, R.S.; Kawakani, C.T.; de Alvarenga, S.C. A Survey of Intrusion Detection in Internet of Things. J. Netw. Comput. Appl. 2017, 84, 25–37. [Google Scholar] [CrossRef]
- Rubinstein, B.I.; Nelson, B.; Huang, L.; Joseph, A.D.; Lau, S.h.; Rao, S.; Taft, N.; Tygar, J.D. ANTIDOTE: Understanding and Defending Against Poisoning of Anomaly Detectors. In Proceedings of the 9th ACM SIGCOMM Conference on Internet Measurement, Chicago, IL, USA, 4–6 November 2009; ACM: New York, NY, USA, 2009; pp. 1–14. [Google Scholar] [CrossRef]
- Biggio, B.; Nelson, B.; Laskov, P. Poisoning Attacks Against Support Vector Machines. In Proceedings of the 29th International Coference on International Conference on Machine Learning, Edinburgh, UK, 26 June–1 July 2012; pp. 1467–1474. [Google Scholar]
- Chen, S.; Xue, M.; Fan, L.; Hao, S.; Xu, L.; Zhu, H.; Li, B. Automated poisoning attacks and defenses in malware detection systems: An adversarial machine learning approach. Comput. Secur. 2018, 73, 326–344. [Google Scholar] [CrossRef]
- Wang, Z. Deep Learning-Based Intrusion Detection With Adversaries. IEEE Access 2018, 6, 38367–38384. [Google Scholar] [CrossRef]
- Huang, C.H.; Lee, T.H.; Chang, L.H.; Lin, J.R.; Horng, G. Adversarial Attacks on SDN-Based Deep Learning IDS System. In Mobile and Wireless Technology 2018; Kim, K.J., Kim, H., Eds.; Springer: Singapore, 2019; pp. 181–191. [Google Scholar]
- Madan, I.; Saluja, S.; Zhao, A. Automated Bitcoin Trading via Machine Learning Algorithms. 2014. Available online: http://cs229.stanford.edu/proj2014/Isaac%20Madan,%20Shaurya%20Saluja,%20Aojia%20Zhao,Automated%20Bitcoin%20Trading%20via%20Machine%20Learning%20Algorithms.pdf (accessed on 22 November 2018).
- Bikowski, K. Application of Machine Learning Algorithms for Bitcoin Automated Trading. In Machine Intelligence and Big Data in Industry; Springer: Cham, Switzerland, 2016; pp. 161–168. [Google Scholar]
- Chen, W.; Zheng, Z.; Cui, J.; Ngai, E.; Zheng, P.; Zhou, Y. Detecting Ponzi Schemes on Ethereum: Towards Healthier Blockchain Technology. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1409–1418. [Google Scholar] [CrossRef]
- Bogner, A. Seeing is Understanding: Anomaly Detection in Blockchains with Visualized Features. In Proceedings of the 2017 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2017 ACM International Symposium on Wearable Computers, Maui, HI, USA, 11–15 September 2017; ACM: New York, NY, USA, 2017; pp. 5–8. [Google Scholar] [CrossRef]
- Meng, W.; Tischhauser, E.W.; Wang, Q.; Wang, Y.; Han, J. When Intrusion Detection Meets Blockchain Technology: A Review. IEEE Access 2018, 6, 10179–10188. [Google Scholar] [CrossRef]
- Weng, J.; Weng, J.; Zhang, J.; Li, M.; Zhang, Y.; Luo, W. DeepChain: Auditable and Privacy-Preserving Deep Learning with Blockchain-Based Incentive. Cryptology ePrint Archive, Report 2018/679. 2018. Available online: https://www.semanticscholar.org/paper/DeepChain%3A-Auditable-and-Privacy-Preserving-Deep-Weng-Weng/07f229cc6e5b80fc8ffbbb3e4db85142466f55a9 (accessed on 16 December 2018).
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward Generating a New Intrusion Detection Dataset and Intrusion Traffic Characterization. In Proceedings of the 4th International Conference on Information Systems Security and Privacy, Funchal, Portugal, 22–24 January 2018; pp. 108–116. [Google Scholar] [CrossRef]
- Chalapathy, R.; Menon, A.K.; Chawla, S. Anomaly Detection using One-Class Neural Networks. arXiv, 2018; arXiv:1802.06360. [Google Scholar]
- Ruff, L.; Vandermeulen, R.; Goernitz, N.; Deecke, L.; Siddiqui, S.A.; Binder, A.; Müller, E.; Kloft, M. Deep One-Class Classification. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Dy, J., Krause, A., Eds.; PMLR: Stockholmsmässan, Stockholm, Sweden, 2018; Volume 80, pp. 4393–4402. [Google Scholar]
- Ayesh, A.S.D.D.A. Intelligent intrusion detection systems using artificial neural networks. ICT Express 2018, 4, 95–99. [Google Scholar] [CrossRef]
- Ryan, J.; Lin, M.J.; Miikkulainen, R. Intrusion Detection with Neural Networks. In Proceedings of the 1997 Conference on Advances in Neural Information Processing Systems 10; MIT Press: Cambridge, MA, USA, 1998; pp. 943–949. [Google Scholar]
- Hodo, E.; Bellekens, X.; Hamilton, A.; Dubouilh, P.; Iorkyase, E.; Tachtatzis, C.; Atkinson, R. Threat analysis of IoT networks using artificial neural network intrusion detection system. In Proceedings of the 2016 International Symposium on Networks, Computers and Communications (ISNCC), Hammamet, Tunisia, 11–13 May 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Baldi, P. Autoencoders, Unsupervised Learning and Deep Architectures. In Proceedings of the 2011 International Conference on Unsupervised and Transfer Learning Workshop, Washington, DC, USA, 2 July 2011; Volume 27, pp. 37–50. [Google Scholar]
- Min, E.; Long, J.; Liu, Q.; Cui, J.; Cai, Z.; Ma, J. SU-IDS: A Semi-supervised and Unsupervised Framework for Network Intrusion Detection. In Cloud Computing and Security; Sun, X., Pan, Z., Bertino, E., Eds.; Springer: Cham, Switzerland, 2018; pp. 322–334. [Google Scholar]
- Radford, B.J.; Richardson, B.D.; Davis, S.E. Sequence Aggregation Rules for Anomaly Detection in Computer Network Traffic. arXiv, 2018; arXiv:1805.03735. [Google Scholar]
- McMahan, H.B.; Moore, E.; Ramage, D.; y Arcas, B.A. Federated Learning of Deep Networks using Model Averaging. arXiv, 2018; arXiv:1602.05629. [Google Scholar]
- Jagielski, M.; Oprea, A.; Biggio, B.; Liu, C.; Nita-Rotaru, C.; Li, B. Manipulating Machine Learning: Poisoning Attacks and Countermeasures for Regression Learning. In Proceedings of the 2018 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 21–23 May 2018; pp. 19–35. [Google Scholar] [CrossRef]
- Wang, Y.; Chaudhuri, K. Data Poisoning Attacks against Online Learning. arXiv, 2018; arXiv:1808.08994. [Google Scholar]
- Steinhardt, J.; Koh, P.W.; Liang, P. Certified Defenses for Data Poisoning Attacks. arXiv, 2017; arXiv:1706.0369. [Google Scholar]
- Greenspan, G. Multichain Private Blockchain—White Paper. 2017. Available online: https://arxiv.org/pdf/1706.03691.pdf (accessed on 16 December 2018).
- Deeplearning4j: Open-Source, Distributed Deep Learning for the JVM. 2014. Available online: https://deeplearning4j.org (accessed on 22 November 2018).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
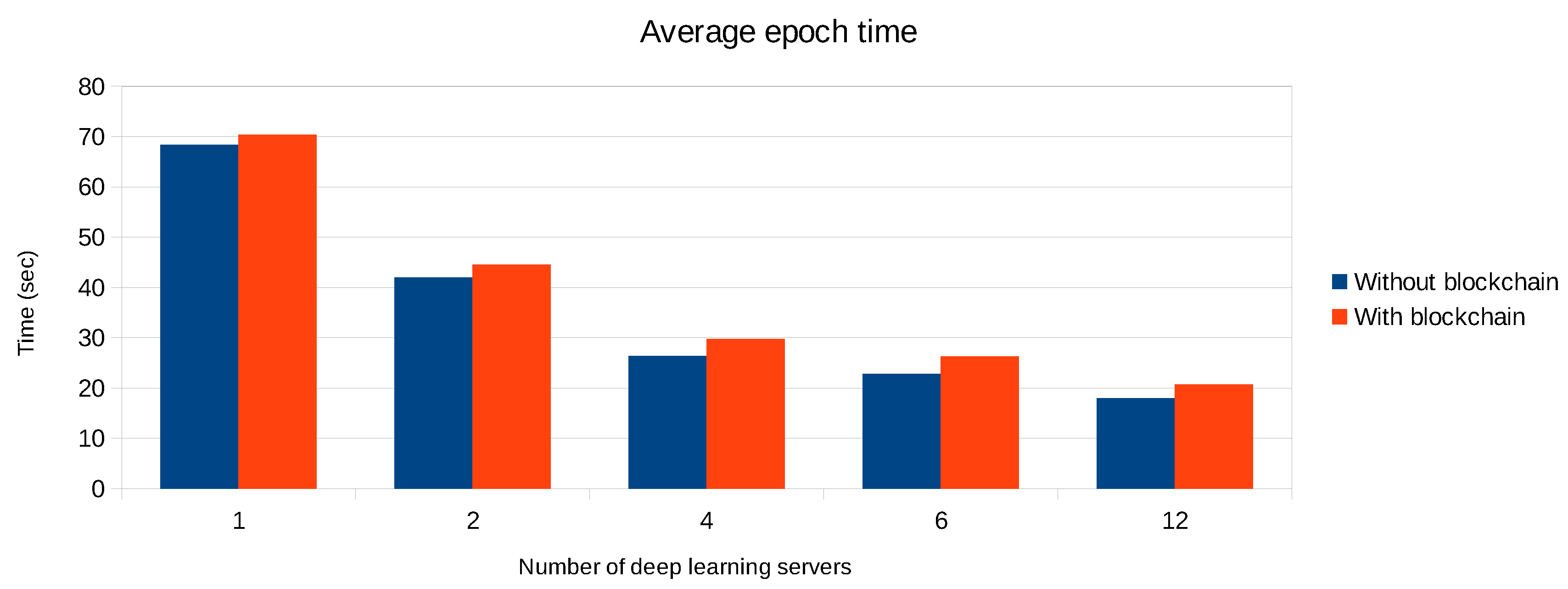{kind=link}
| Destination Port | Flow Duration | Total FwdPackets | Total Backward Packets |
| Total Length of Fwd Packets | Total Length of BwdPackets | Fwd Packet Length Max | Fwd Packet Length Min |
| Fwd Packet Length Mean | Fwd Packet Length Std | Bwd Packet Length Max | Bwd Packet Length Min |
| Bwd Packet Length Mean | Bwd Packet Length Std | Flow Bytes/s | Flow Packets/s |
| Flow IATMean | Flow IAT Std | Flow IAT Max | Flow IAT Min |
| Fwd IAT Total | Fwd IAT Mean | Fwd IAT Std | Fwd IAT Max |
| Fwd IAT Min | Bwd IAT Total | Bwd IAT Mean | Bwd IAT Std |
| Bwd IAT Max | Bwd IAT Min | Fwd PSHFlags | Bwd PSH Flags |
| Fwd URGFlags | Bwd URG Flags | Fwd Header Length | Bwd Header Length |
| Fwd Packets/s | Bwd Packets/s | Min Packet Length | Max Packet Length |
| Packet Length Mean | Packet Length Std | Packet Length Variance | FINFlag Count |
| SYNFlag Count | RSTFlag Count | PSH Flag Count | ACK Flag Count |
| URG Flag Count | CWEFlag Count | ECEFlag Count | Down/Up Ratio |
| Average Packet Size | Avg Fwd Segment Size | Avg Bwd Segment Size | Fwd Header Length |
| Fwd Avg Bytes/Bulk | Fwd Avg Packets/Bulk | Fwd Avg Bulk Rate | Bwd Avg Bytes/Bulk |
| Bwd Avg Packets/Bulk | Bwd Avg Bulk Rate | Subflow Fwd Packets | Subflow Fwd Bytes |
| Subflow Bwd Packets | Subflow Bwd Bytes | Init_Win_bytes_forward | Init_Win_bytes_backward |
| act_data_pkt_fwd | min_seg_size_forward | Active Mean | Active Std |
| Active Max | Active Min | Idle Mean | Idle Std |
| Idle Max | Idle Min |
| Reconstruction Error | |
|---|---|
| count | 105,984.0 |
| mean | 4.988194 × 10 |
| std | 9.683384 × 10 |
| min | 4.865089 × 10 |
| 25% | 4.711496 × 10 |
| 50% | 1.177916 × 10 |
| 75% | 4.335404 × 10 |
| max | 1.791145 × 10 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Preuveneers, D.; Rimmer, V.; Tsingenopoulos, I.; Spooren, J.; Joosen, W.; Ilie-Zudor, E. Chained Anomaly Detection Models for Federated Learning: An Intrusion Detection Case Study. Appl. Sci. 2018, 8, 2663. https://doi.org/10.3390/app8122663
Preuveneers D, Rimmer V, Tsingenopoulos I, Spooren J, Joosen W, Ilie-Zudor E. Chained Anomaly Detection Models for Federated Learning: An Intrusion Detection Case Study. Applied Sciences. 2018; 8(12):2663. https://doi.org/10.3390/app8122663
Chicago/Turabian StylePreuveneers, Davy, Vera Rimmer, Ilias Tsingenopoulos, Jan Spooren, Wouter Joosen, and Elisabeth Ilie-Zudor. 2018. "Chained Anomaly Detection Models for Federated Learning: An Intrusion Detection Case Study" Applied Sciences 8, no. 12: 2663. https://doi.org/10.3390/app8122663
APA StylePreuveneers, D., Rimmer, V., Tsingenopoulos, I., Spooren, J., Joosen, W., & Ilie-Zudor, E. (2018). Chained Anomaly Detection Models for Federated Learning: An Intrusion Detection Case Study. Applied Sciences, 8(12), 2663. https://doi.org/10.3390/app8122663