Hybrid Genetic Simulated Annealing Algorithm for Improved Flow Shop Scheduling with Makespan Criterion


Abstract
1. Introduction
- (1)
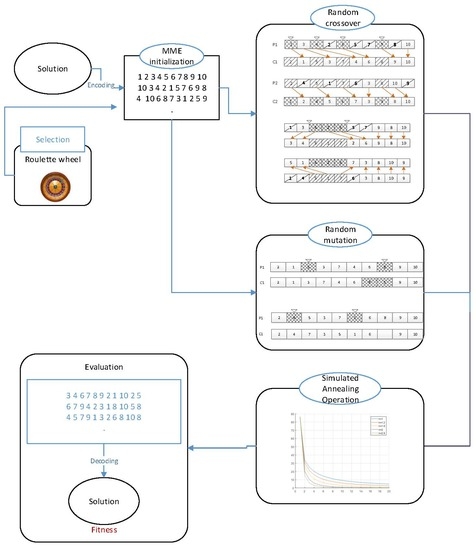
- We propose the novel HGSA algorithm to solve FSSPs. It is characterized by an operational coding in GA and a hormone regulation mechanism in the simulated annealing part of the algorithm. The MME [28] algorithm, combined with the NEH [5] and MinMax (MM) [29] heuristic algorithms, is used for initialization of the population. We use location-based intersection and two-point intersection for crossover operations with either one of these two being randomly selected. In the mutation process, twors mutation or inversion mutation [30] is randomly employed to mutate the population. After the crossover and mutation operation is completed, the best individuals are retained, and the simulated annealing operation is performed on these solutions.
- (2)
- Using the widely adopted Taillard benchmark FSSPs, we conducted extensive experiments and showed that our HGSA algorithm achieved better results than the baseline algorithms to which it was compared in our study. We showed that our HGSA algorithm’s high performance for FSSPs is based on its hybrid search strategy, twors/inversion mutation, location-based/two-point crossovers, and their combination with the MME heuristic algorithm for population initialization.
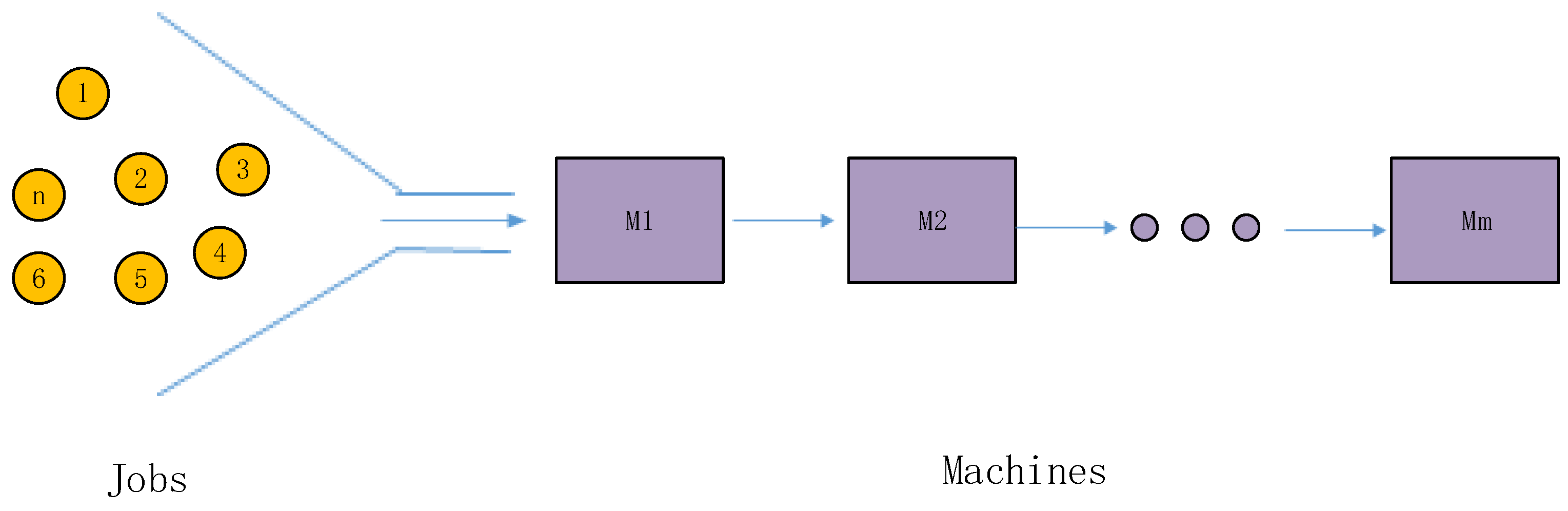
2. Flow Shop Scheduling Problem Description
3. Hybrid Genetic Simulated Annealing Algorithm
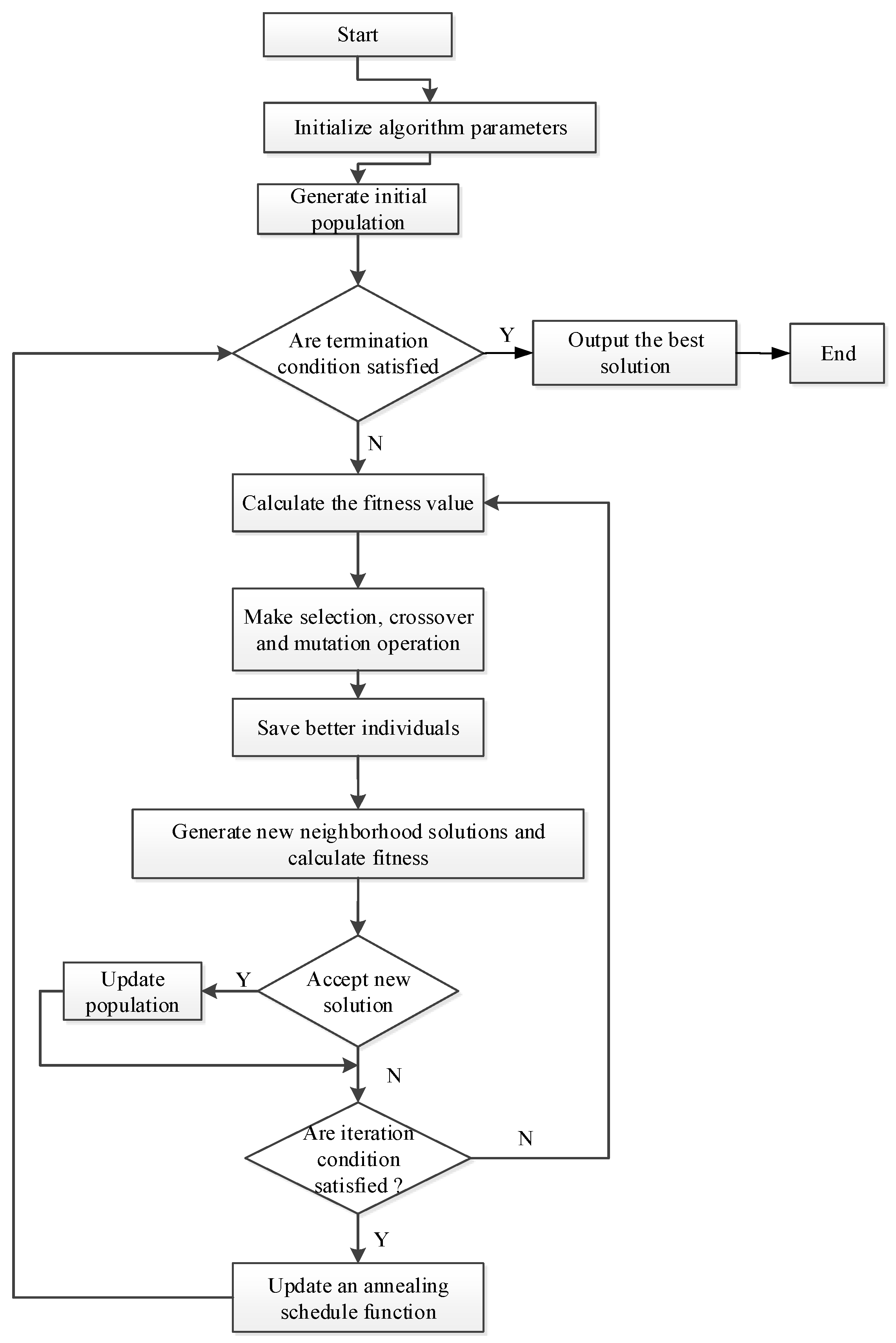
3.1. Overview of the HGSA Algorithm
| HGSA {Hybrid Genetic Simulated Annealing Algorithm} Initialize population by MME while (not stop condition) do Step 1: Select the population Step 2: Crossover operation If(random==0) location-based Crossover else two-point Crossover Step 3: Mutation operation If(random==0) Insertion Mutation else Reverse order Mutation Step 4: Simulated annealing opearation end_while |
3.2. Encoding Representation
3.3. Initial Population
3.4. Crossover Operation
3.4.1. Location-Based Crossover
3.4.2. Two-Point Crossover
3.5. Mutation Operation
3.5.1. Twors Mutation
3.5.2. Inversion Mutation
3.6. Simulated Annealing Operation
3.6.1. Neighborhood Structure
3.6.2. Initial Temperature
3.6.3. Annealing Rate
3.6.4. The Terminating Condition
3.7. Benchmark Selected
3.8. Computational Complexity
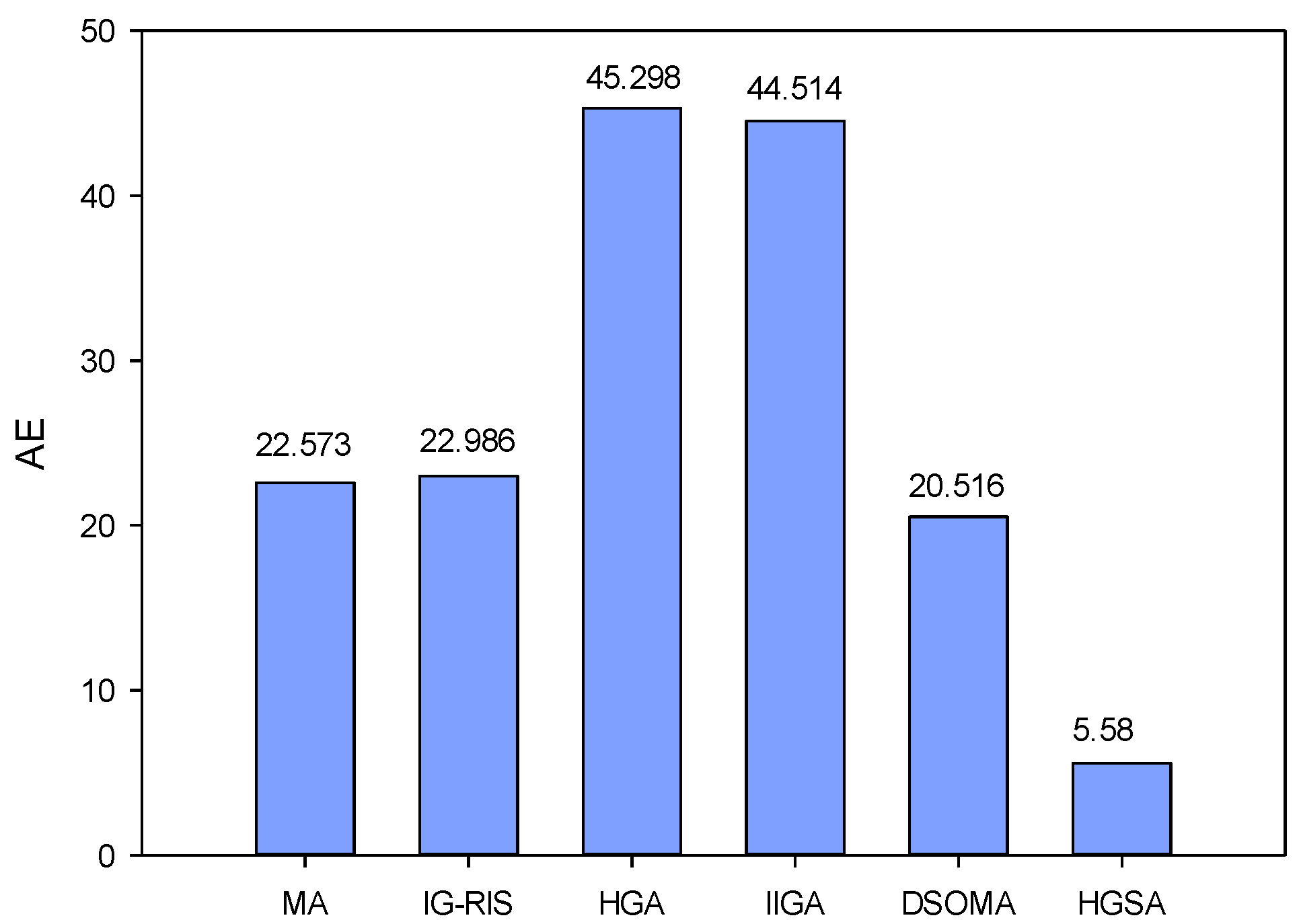
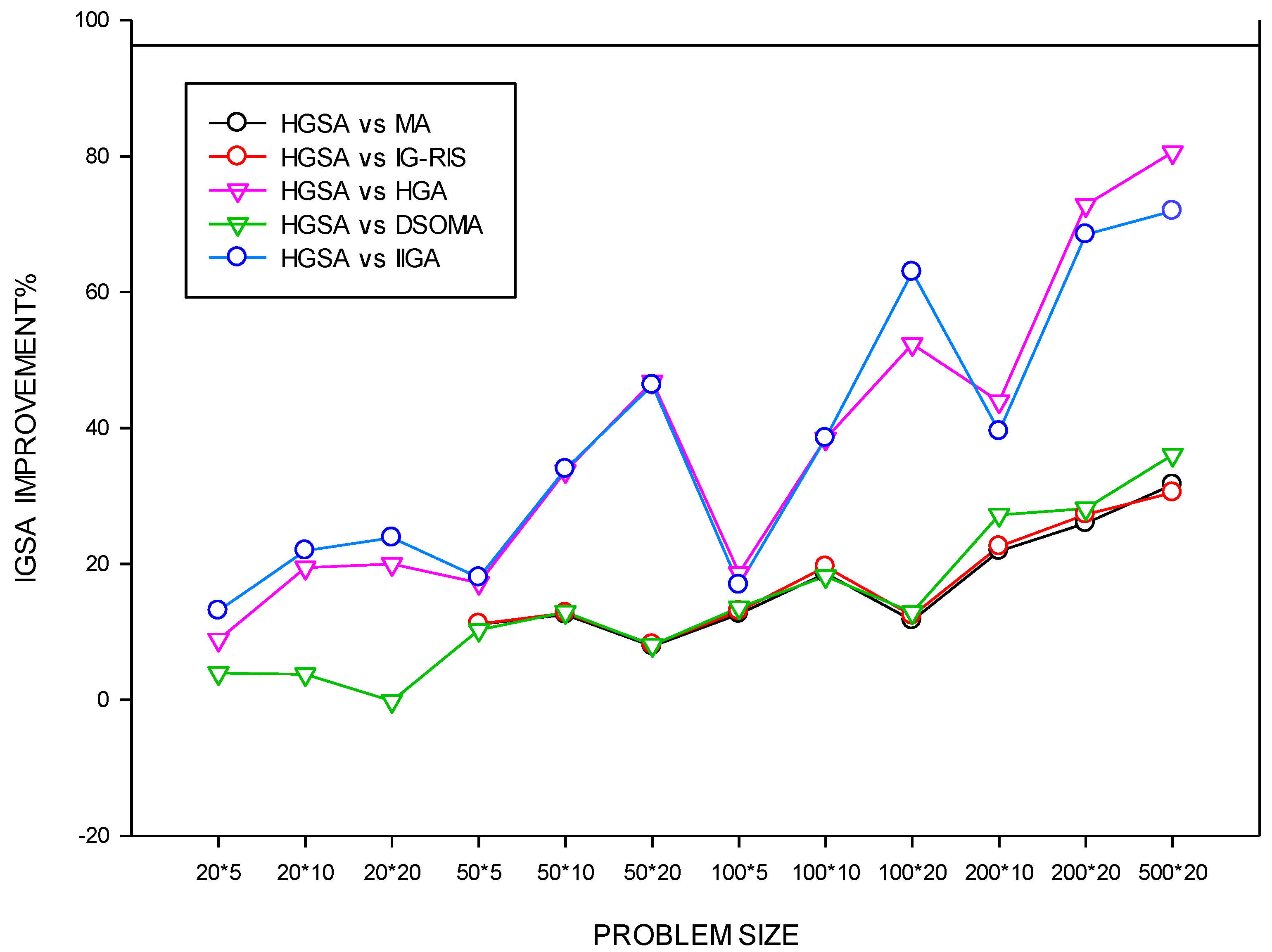
4. Experimental Results and Analysis
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Johnson, S.M. Optimal two- and three-stage production schedules with setup times included. Naval Res. Logist. Q. 2010, 1, 61–68. [Google Scholar] [CrossRef]
- Hong, Z.Y.; Pang, H.L. Study on a constructive heuristic algorithm based on compromise policy for Blocking flow-shop scheduling. Syst. Eng. Theory Pract. 2008, 28, 114–118. [Google Scholar]
- Ignall, E.; Schrage, L. Application of the Branch and Bound Technique to Some Flow-Shop Scheduling Problems. Oper. Res. 1965, 13, 400–412. [Google Scholar] [CrossRef]
- Bansal, S.P. Minimizing the Sum of Completion Times of n Jobs over m Machines in a Flowshop A Branch and Bound Approach. AIIE Trans. 1977, 9, 306–311. [Google Scholar] [CrossRef]
- Nawaz, M.E.E.E., Jr.; Ham, I. A heuristic algorithm for the m -machine, n -job flow-shop sequencing problem. Omega 1983, 11, 91–95. [Google Scholar] [CrossRef]
- Cui, Q.; Xiuli, W.U.; Jianjun, Y.U. Improved genetic algorithm variable neighborhood search for solving hybrid flow shop scheduling problem. Comput. Integr. Manuf. Syst. 2017, 23, 1917–1927. [Google Scholar]
- Marichelvam, M.K.; Prabaharan, T.; Yang, X.S. Improved cuckoo search algorithm for hybrid flow shop scheduling problems to minimize makespan. Appl. Soft Comput. 2014, 19, 93–101. [Google Scholar] [CrossRef]
- Burdett, R.L.; Kozan, E. A sequencing approach for creating new train timetables. OR Spectr. 2010, 32, 163–193. [Google Scholar] [CrossRef]
- Rathinam, B. Rule based heuristic approach for minimizing total flow time in permutation flow shop scheduling. Teh. Vjesn. 2015, 22, 25–32. [Google Scholar] [CrossRef]
- Govindan, K.; Balasundaram, R.; Baskar, N.; Asokan, P. A Hybrid Approach for Minimizing Makespan In Permutation Flowshop Scheduling. J. Syst. Sci. Syst. Eng. 2017, 26, 50–76. [Google Scholar] [CrossRef]
- Han, Y.Y.; Gong, D.; Sun, X. A discrete artificial bee colony algorithm incorporating differential evolution for the flow-shop scheduling problem with blocking. Eng. Optim. 2015, 47, 927–946. [Google Scholar] [CrossRef]
- Pan, C.H.; Huang, H.C. A hybrid genetic algorithm for no-wait job shop scheduling problems. Expert Syst. Appl. 2009, 36, 5800–5806. [Google Scholar] [CrossRef]
- Gao, K.; Pan, Q.; Suganthan, P.N.; Li, J. Effective heuristics for the no-wait flow shop scheduling problem with;total flow time minimization. Int. J. Adv. Manuf. Technol. 2013, 66, 1563–1572. [Google Scholar] [CrossRef]
- Bertolissi, E. Heuristic algorithm for scheduling in the no-wait flow-shop. J. Mater. Process. Technol. 2000, 107, 459–465. [Google Scholar] [CrossRef]
- Nowicki, E.; Smutnicki, C. A fast tabu search algorithm for the permutation flow-shop problem. Eur. J. Oper. Res. 1996, 91, 160–175. [Google Scholar] [CrossRef]
- Sayoti, F.; Ri, M.E. Golden Ball Algorithm for solving Flow Shop Scheduling Problem. Ijimai 2016, 4, 15–18. [Google Scholar] [CrossRef]
- Kasihmuddin, M.S.B.M.; Mansor, M.A.B.; Sathasivam, S. Genetic Algorithm for Restricted Maximum k-Satisfiability in the Hopfield Network. Int. J. Interact. Multimedia Artif. Intell. 2016, 4, 52. [Google Scholar]
- Tseng, L.; Lin, Y. A hybrid genetic algorithm for no-wait flowshop scheduling problem. Int. J. Prod. Econ. 2010, 128, 144–152. [Google Scholar] [CrossRef]
- Ding, J.Y.; Song, S.; Gupta, J.N.; Zhang, R.; Chiong, R.; Wu, C. An improved iterated greedy algorithm with a Tabu-based reconstruction strategy for the no-wait flowshop scheduling problem. Appl. Soft Comput. 2015, 30, 604–613. [Google Scholar] [CrossRef]
- Tasgetiren, M.F.; Kizilay, D.; Pan, Q.K.; Suganthan, P.N. Iterated greedy algorithms for the blocking flowshop scheduling problem with makespan criterion. Comput. Oper. Res. 2017, 77, 111–126. [Google Scholar] [CrossRef]
- Pan, Q.K.; Wang, L.; Sang, H.Y.; Li, J.Q.; Liu, M. A High Performing Memetic Algorithm for the Flowshop Scheduling Problem with Blocking. IEEE Trans. Autom. Sci. Eng. 2013, 10, 741–756. [Google Scholar]
- Davendra, D.; Bialicdavendra, M. Scheduling flow shops with blocking using a discrete self-organising migrating algorithm. Int. J. Prod. Res. 2013, 51, 2200–2218. [Google Scholar] [CrossRef]
- Eddaly, M.; Jarboui, B.; Siarry, P. Combinatorial particle swarm optimization for solving blocking flowshop scheduling problem. J. Comput. Des. Eng. 2016, 3, 295–311. [Google Scholar] [CrossRef]
- Burdett, R.L.; Kozan, E. Evolutionary algorithms for flowshop sequencing with non-unique jobs. Int. Trans. Oper. Res. 2000, 7, 401–418. [Google Scholar] [CrossRef]
- Yin, H.L. Genetic Algorithm Nested with Simulated Annealing for Big Job Shop Scheduling Problems. In Proceedings of the 2013 9th International Conference on Computational Intelligence and Security (CIS), Emei Moutain, China, 14–15 December 2013. [Google Scholar]
- Andresen, M.; BräSel, H.; MöRig, M.; Tusch, J.; Werner, F.; Willenius, P. Simulated annealing and genetic algorithms for minimizing mean flow time in an open shop. Math. Comput. Model. 2008, 48, 1279–1293. [Google Scholar] [CrossRef]
- Dai, M.; Tang, D.; Giret, A.; Salido, M.A.; Li, W.D. Energy-efficient scheduling for a flexible flow shop using an improved genetic-simulated annealing algorithm. Robot. Comput.-Integr. Manuf. 2013, 29, 418–429. [Google Scholar] [CrossRef]
- Ronconi, D.P. A note on constructive heuristics for the flowshop problem with blocking. Int. J. Prod. Econ. 2004, 87, 39–48. [Google Scholar] [CrossRef]
- Merz, P.; Freisleben, B. Memetic Algorithms for the Traveling Salesman Problem. Complex Syst. 1997, 13, 297–345. [Google Scholar]
- Abdoun, O.; Abouchabaka, J.; Tajani, C. Analyzing the Performance of Mutation Operators to Solve the Travelling Salesman Problem. Int. J. Emerg. Sci. 2012, 2, 61–77. [Google Scholar]
- Koulamas, C.; Kyparisis, G.J. The three-stage assembly flowshop scheduling problem. Comput. Oper. Res. 2001, 28, 689–704. [Google Scholar] [CrossRef]
- Chang, P.; Hsieh, J.; Lin, S. The development of gradual-priority weighting approach for the multi-objective flowshop scheduling problem. Int. J. Prod. Econ. 2002, 79, 171–183. [Google Scholar] [CrossRef]
- Fink, A.; Vos, S. Solving the continuous flow-shop scheduling problem by metaheuristics. Eur. J. Oper. Res. 2003, 151, 400–414. [Google Scholar] [CrossRef]
- Wang, J.; Xia, Z.Q. Flow-shop scheduling with a learning effect. J. Oper. Res. Soc. 2005, 56, 1325–1330. [Google Scholar] [CrossRef]
- Agarwal, A.; Colak, S.; Eryarsoy, E. Improvement heuristic for the flow-shop scheduling problem: An adaptive-learning approach. Eur. J. Oper. Res. 2006, 169, 801–815. [Google Scholar] [CrossRef]
- Rajendran, C.; Ziegler, H. Ant-colony algorithms for permutation flowshop scheduling to minimize makespan/total flowtime of jobs. Eur. J. Oper. Res. 2007, 155, 426–438. [Google Scholar] [CrossRef]
- Yagmahan, B.; Yenisey, M.M. Ant colony optimization for multi-objective flow shop scheduling problem. Comput. Ind. Eng. 2008, 54, 411–420. [Google Scholar] [CrossRef]
- Zhang, G.; Shao, X.; Li, P.; Gao, L. An effective hybrid particle swarm optimization algorithm for multi-objective flexible job-shop scheduling problem. Comput. Ind. Eng. 2009, 56, 1309–1318. [Google Scholar] [CrossRef]
- Sayadi, M.K.; Ramezanian, R.; Ghaffarinasab, N. A discrete firefly meta-heuristic with local search for makespan minimization in permutation flow shop scheduling problems. Int. J. Ind. Eng. Comput. 2010, 1, 1–10. [Google Scholar] [CrossRef]
- Pan, Q.K.; Tasgetiren, M.F.; Suganthan, P.N.; Chua, T.J. A discrete artificial bee colony algorithm for the lot-streaming flow shop scheduling problem. China Mech. Eng. 2011, 181, 2455–2468. [Google Scholar] [CrossRef]
- Deng, G.; Gu, X. A hybrid discrete differential evolution algorithm for the no-idle permutation flow shop scheduling problem with makespan criterion. Comput. Oper. Res. 2012, 39, 2152–2160. [Google Scholar] [CrossRef]
- Li, X.; Yin, M. A hybrid cuckoo search via Lévy flights for the permutation flow shop scheduling problem. Int. J. Prod. Res. 2013, 51, 4732–4754. [Google Scholar] [CrossRef]
- Xie, Z.; Zhang, C.; Shao, X.; Lin, W.; Zhu, H. An effective hybrid teaching–learning-based optimization algorithm for permutation flow shop scheduling problem. Adv. Eng. Softw. 2014, 77, 35–47. [Google Scholar] [CrossRef]
- Lin, Q.; Gao, L.; Li, X.; Zhang, C. A hybrid backtracking search algorithm for permutation flow-shop scheduling problem minimizing makespan and energy consumption. Comput. Ind. Eng. 2015, 85, 437–446. [Google Scholar] [CrossRef]
- Lin, J.; Zhang, S. An effective hybrid biogeography-based optimization algorithm for the distributed assembly permutation flow-shop scheduling problem. Comput. Ind. Eng. 2016, 97, 128–136. [Google Scholar] [CrossRef]
- Deng, J.; Wang, L.; Wang, S.Y.; Zheng, X.L. A competitive memetic algorithm for the distributed two-stage assembly flow-shop scheduling problem. Int. J. Prod. Res. 2017, 54, 3561–3577. [Google Scholar] [CrossRef]
- Chen, P.; Wen, W.; Li, R.; Li, X. A hybrid backtracking search algorithm for permutation flow-shop scheduling problem minimizing makespan and energy consumption. In Proceedings of the 2017 IEEE International Conference on Industrial Engineering and Engineering Management (IEEM), Singapore, 10–13 December 2017. [Google Scholar]
- Bewoor, L.; Prakash, V.C.; Sapkal, S. Evolutionary Hybrid Particle Swarm Optimization Algorithm for Solving NP-Hard No-Wait Flow Shop Scheduling Problems. Algorithms 2017, 10, 121. [Google Scholar] [CrossRef]
- Sun, Z.; Gu, X. Hybrid Algorithm Based on an Estimation of Distribution Algorithm and Cuckoo Search for the No Idle Permutation Flow Shop Scheduling Problem with the Total Tardiness Criterion Minimization. Sustainability 2017, 9, 953. [Google Scholar]
- Meng, T.; Pan, Q.K.; Li, J.Q.; Sang, H.Y. An improved migrating birds optimization for an integrated lot-streaming flow shop scheduling problem. Swarm Evol. Comput. 2018, 38, 64–78. [Google Scholar] [CrossRef]
- Yahyaoui, A.; Fnaiech, N.; Fnaiech, F. A Suitable Initialization Procedure for Speeding a Neural Network Job-Shop Scheduling. IEEE Trans. Ind. Electron. 2011, 58, 1052–1060. [Google Scholar] [CrossRef]
- Liu, S.Q.; Kozan, E. Scheduling a flow shop with combined buffer conditions. Int. J. Prod. Econ. 2009, 117, 371–380. [Google Scholar] [CrossRef]
- Tao, S.; Wang, S. An algorithm for weighted sub-graph matching based on gradient flows. Inf. Sci. 2016, 340–341, 104–121. [Google Scholar] [CrossRef]
- Ku, L. An Adaptive Variable Neighbourhood Search Algorithm for the Hybrid Flowshop Scheduling Problem. Syst. Eng. 2015, 11, 121–129. [Google Scholar]
- Dai, M.; Tang, D.; Zheng, K.; Cai, Q. An Improved Genetic-Simulated Annealing Algorithm Based on a Hormone Modulation Mechanism for a Flexible Flow-Shop Scheduling Problem. Adv. Mech. Eng. 2013, 5, 124903. [Google Scholar] [CrossRef]
- Taillard, E. Benchmarks for basic scheduling problems. Eur. J. Oper. Res. 1993, 64, 278–285. [Google Scholar] [CrossRef]
- Salido, M.A.; Escamilla, J.; Giret, A.; Barber, F. A genetic algorithm for energy-efficiency in job-shop scheduling. Int. J. Adv. Manuf. Technol. 2016, 85, 1303–1314. [Google Scholar] [CrossRef]
- Rajkumar, R.; Shahabudeen, P. An improved genetic algorithm for the flowshop scheduling problem. Int. J. Prod. Res. 2009, 47, 233–249. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author, Year, and Reference | Algorithm | Optimization Criteria | Benchmarks | Summary |
|---|---|---|---|---|
| Koulamas (2001) [31] | Heuristics with ratio performance guarantees (HRPG) | Makespan |
| |
| Chang et al. (2002) [32] | Gradual-priority weighting (GPW) | Makespan, total flowtime, total tardiness |
| |
| Andreas et al. (2003) [33] | Metaheuristics | Total flowtime | Taillard |
|
| Wang et al. (2005) [34] | Polynomial algorithm | Makespan, total flowtime |
| |
| Agarwal (2006) [35] | Improvement heuristic approach (IHA) | Taillard, Carlier, Heller |
| |
| Rajendran (2007) [36] | Proposed ant colony algorithms | Makespan, total flowtime | Taillard |
|
| Yagmahan et al. (2008) [37] | Ant colony optimization (ACO) | Makespan, total flow time, total machine idle time | Reeves |
|
| Zhang et al. (2009) [38] | Hybrid particle swam optimization (PSO) algorithm | Makespan, maximal machine workload |
| |
| Sayadi et al. (2010) [39] | Firefly metaheuristic (FMH) | Makespan | Demirkol |
|
| Pan et al. (2011) [40] | Discrete artificial bee colony (DABC) algorithm | Total weighted earliness and tardiness penalties |
| |
| Deng et al. (2012) [41] | Hybrid discrete differential evolution (HDDE) algorithm | Makespan | Ruiz |
|
| Li et al. (2013) [42] | Cuckoo search (CS)-based memetic algorithm (HCS) | Makespan, total flow time | Car, Rec |
|
| Xie et al. (2014) [43] | Hybrid teaching–learning-based optimization (HTLBO) algorithm | Makespan, maximum lateness | Carlier’s, Reeves Yamada’s |
|
| Lin et al. (2015) [44] | Hybrid backtracking search algorithm (HBSA) | Makespan | Civicioglu |
|
| Lin et al. (2016) [45] | Hybrid biogeography-based optimization (HBBO) algorithm | Makespan | Hatami |
|
| Deng et al. (2017) [46] | Competitive memetic algorithm (CMA) | Makespan, total tardiness | Taillard |
|
| Peng et al. (2017) [47] | Hybrid backtracking search (HBSA) | Makespan, energy consumption | Car |
|
| Bewoor et al. (2017) [48] | Hybrid particle swarm optimization (PHPSO) algorithm | Total flow time | Taillard |
|
| Sun et al. (2017) [49] | Hybrid estimation of the distribution algorithm and cuckoo search (HEDA_CS) | Total Tardiness | Ruiz |
|
| Meng et al. (2018) [50] | Improved migrating birds optimization (IMMBO) | Makespan | Randomly generated |
|
| Parameter | Meaning |
|---|---|
| J = {1, 2, …, n} | Set of n jobs |
| M = {11, 2, …, m} | Set of m machines |
| pij | The processing time when job i is processed on machine tool j |
| Sij | The starting time when job i is processed on machine tool j |
| Cij | The finishing time when job i is processed on machine tool j |
| π = {π1, π2, …, πn} | A sequence of jobs |
| Π | Set of all jobs’ sequences |
| Cmax(π) | Makespan of one job’s sequence π |
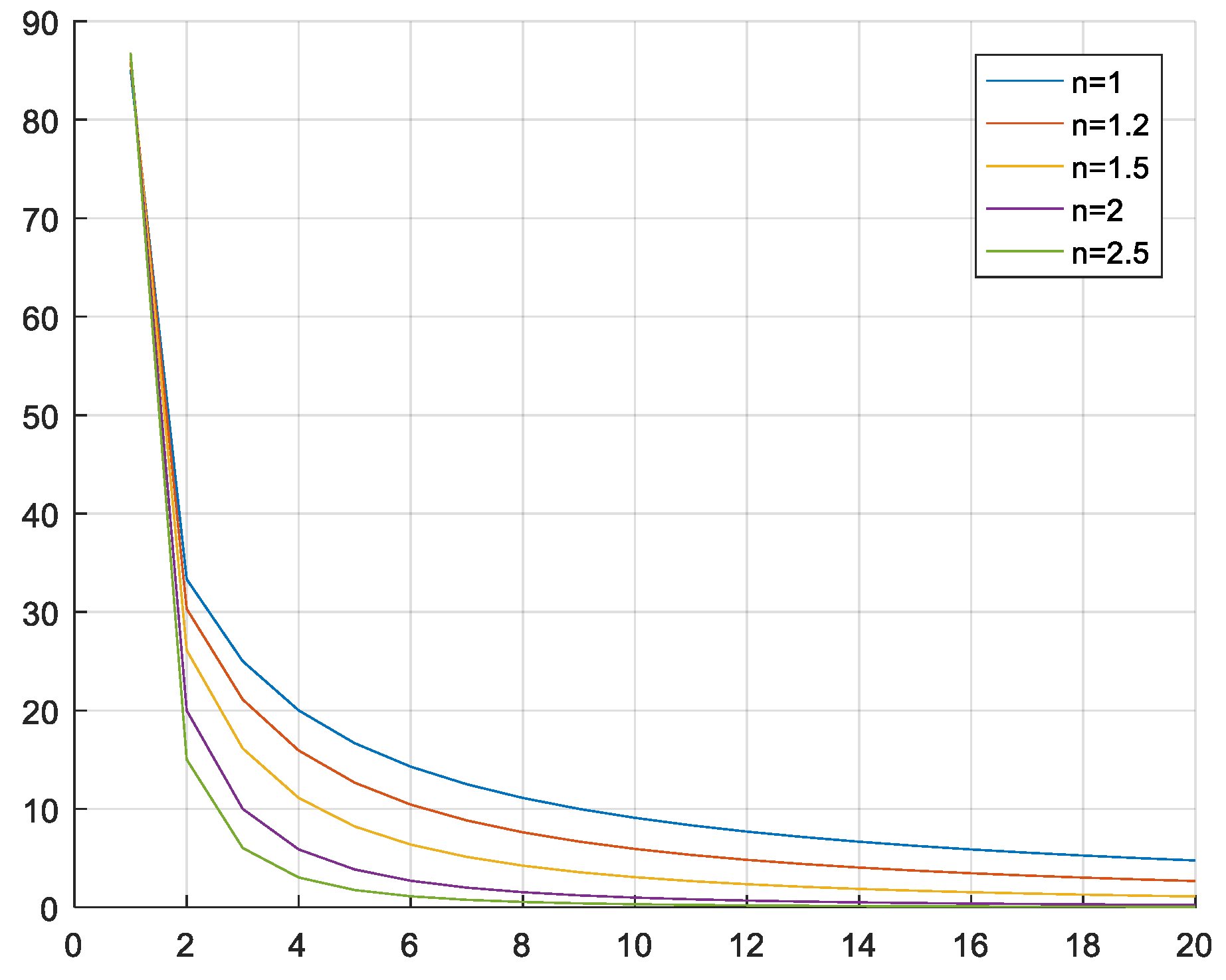
| Problem Size | Function Factor (n) | ARPD% |
|---|---|---|
| 200 × 20 | 1.0 | 9.21 |
| 1.2 | 7.82 | |
| 1.5 | 5.16 | |
| 2.0 | 8.34 | |
| 2.5 | 11.06 | |
| 500 × 20 | 1.0 | 6.28 |
| 1.2 | 5.49 | |
| 1.5 | 3.29 | |
| 2.0 | 7.13 | |
| 2.5 | 9.56 |
| Problem Size | Instance | Upper Bound | MA | IG-RIS | HGA | IIGA | DSOMA | HGSA |
|---|---|---|---|---|---|---|---|---|
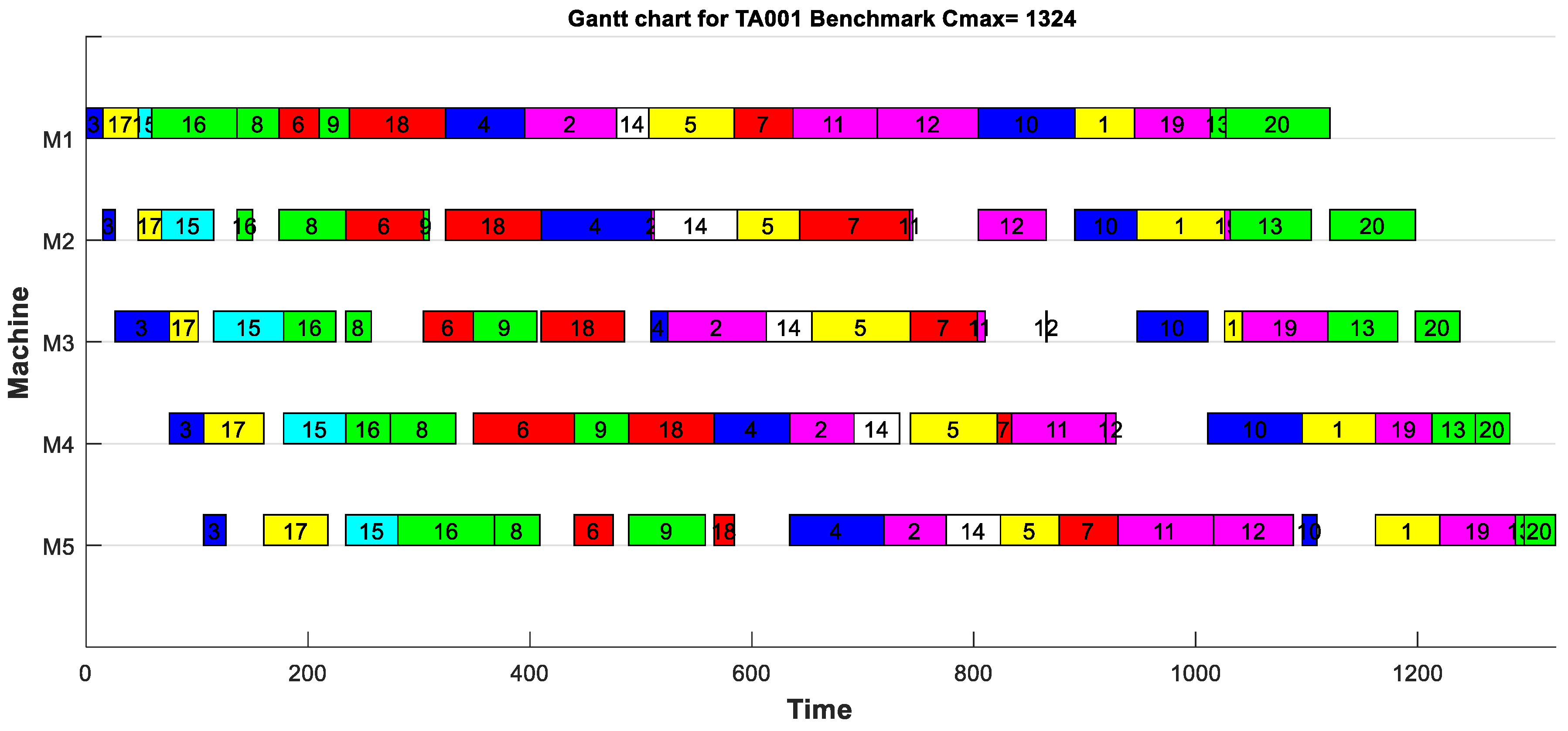
| 20 × 5 | Ta001 | 1278 | - | - | 1449 | 1486 | 1374 | 1324 |
| Ta002 | 1359 | - | - | 1460 | 1528 | 1408 | 1442 | |
| Ta003 | 1081 | - | - | 1386 | 1460 | 1280 | 1098 | |
| Ta004 | 1293 | - | - | 1521 | 1588 | 1448 | 1469 | |
| Ta005 | 1235 | - | - | 1403 | 1449 | 1341 | 1291 | |
| Ta006 | 1195 | - | - | 1430 | 1481 | 1363 | 1391 | |
| Ta007 | 1239 | - | - | 1461 | 1483 | 1381 | 1299 | |
| Ta008 | 1206 | - | - | 1433 | 1482 | 1379 | 1292 | |
| Ta009 | 1230 | - | - | 1398 | 1469 | 1373 | 1306 | |
| Ta010 | 1108 | - | - | 1324 | 1377 | 1283 | 1233 | |
| 20 × 10 | Ta011 | 1582 | - | - | 1955 | 2011 | 1698 | 1713 |
| Ta012 | 1659 | - | - | 2123 | 2166 | 1833 | 1718 | |
| Ta013 | 1496 | - | - | 1912 | 1940 | 1676 | 1555 | |
| Ta014 | 1377 | - | - | 1782 | 1811 | 1546 | 1516 | |
| Ta015 | 1419 | - | - | 1933 | 1933 | 1617 | 1573 | |
| Ta016 | 1397 | - | - | 1827 | 1892 | 1590 | 1457 | |
| Ta017 | 1484 | - | - | 1944 | 1963 | 1622 | 1622 | |
| Ta018 | 1538 | - | - | 2006 | 2057 | 1731 | 1749 | |
| Ta019 | 1593 | - | - | 1908 | 1973 | 1747 | 1624 | |
| Ta020 | 1591 | - | - | 2001 | 2051 | 1782 | 1722 | |
| 20 × 20 | Ta021 | 2297 | - | - | 2912 | 2973 | 2436 | 2331 |
| Ta022 | 2099 | - | - | 2780 | 2582 | 2234 | 2280 | |
| Ta023 | 2326 | - | - | 2922 | 3013 | 2479 | 2480 | |
| Ta024 | 2223 | - | - | 2967 | 3001 | 2348 | 2362 | |
| Ta025 | 2291 | - | - | 2953 | 3003 | 2435 | 2507 | |
| Ta026 | 2226 | - | - | 2908 | 2988 | 2383 | 2375 | |
| Ta027 | 2273 | - | - | 2970 | 3052 | 2390 | 2341 | |
| Ta028 | 2200 | - | - | 2763 | 2839 | 2328 | 2279 | |
| Ta029 | 2237 | - | - | 2972 | 3009 | 2363 | 2410 | |
| Ta030 | 2178 | - | - | 2919 | 2979 | 2323 | 2401 | |
| 50 × 5 | Ta031 | 2724 | 3000 | 3002 | 3127 | 3161 | 3033 | 2731 |
| Ta032 | 2834 | 3199 | 3201 | 3438 | 3432 | 3045 | 2934 | |
| Ta033 | 2621 | 3011 | 3011 | 3182 | 3211 | 3036 | 2638 | |
| Ta034 | 2751 | 3128 | 3128 | 3289 | 3339 | 3011 | 2785 | |
| Ta035 | 2863 | 3162 | 3166 | 3315 | 3356 | 3128 | 2864 | |
| Ta036 | 2829 | 3166 | 3169 | 3324 | 3347 | 3166 | 2907 | |
| Ta037 | 2725 | 3013 | 3013 | 3183 | 3231 | 3021 | 2764 | |
| Ta038 | 2683 | 3067 | 3073 | 3243 | 3235 | 3063 | 2706 | |
| Ta039 | 2552 | 2908 | 2908 | 3059 | 3072 | 2908 | 2610 | |
| Ta040 | 2782 | 3111 | 3120 | 3301 | 3317 | 3120 | 2784 | |
| 50 × 10 | Ta041 | 2991 | 3638 | 3638 | 4251 | 4274 | 3638 | 3198 |
| Ta042 | 2867 | 3486 | 3507 | 4139 | 4177 | 3511 | 3020 | |
| Ta043 | 2839 | 3483 | 3488 | 4083 | 4099 | 3492 | 3055 | |
| Ta044 | 3063 | 3656 | 3656 | 4480 | 4399 | 3672 | 3124 | |
| Ta045 | 2976 | 3629 | 3629 | 4316 | 4322 | 3633 | 3129 | |
| Ta046 | 3006 | 3596 | 3621 | 4282 | 4289 | 3621 | 3293 | |
| Ta047 | 3093 | 3692 | 3696 | 4376 | 4420 | 3704 | 3232 | |
| Ta048 | 3037 | 3562 | 3572 | 4304 | 4318 | 3572 | 3390 | |
| Ta049 | 2897 | 3527 | 3532 | 4162 | 4155 | 3541 | 3237 | |
| Ta050 | 3065 | 3622 | 3624 | 4232 | 4283 | 3624 | 3251 | |
| 50 × 20 | Ta051 | 3850 | 4479 | 4500 | 6138 | 6129 | 4511 | 4105 |
| Ta052 | 3704 | 4276 | 4276 | 5721 | 5725 | 4288 | 3992 | |
| Ta053 | 3640 | 4261 | 4289 | 5847 | 5862 | 4289 | 3900 | |
| Ta054 | 3720 | 4366 | 4377 | 5781 | 5788 | 4378 | 3921 | |
| Ta055 | 3610 | 4261 | 4268 | 5891 | 5886 | 4271 | 4020 | |
| Ta056 | 3681 | 4280 | 4280 | 5875 | 5863 | 4202 | 3971 | |
| Ta057 | 3704 | 4304 | 4308 | 5937 | 5962 | 4315 | 4093 | |
| Ta058 | 3691 | 4317 | 4326 | 5919 | 5926 | 4326 | 4090 | |
| Ta059 | 3743 | 4315 | 4316 | 5839 | 5876 | 4329 | 4107 | |
| Ta060 | 3756 | 4413 | 4428 | 5935 | 5958 | 4422 | 4113 | |
| 100 × 5 | Ta061 | 5493 | 6143 | 6151 | 6492 | 6397 | 6151 | 5536 |
| Ta062 | 5268 | 6022 | 6022 | 6353 | 6234 | 6064 | 5302 | |
| Ta063 | 5175 | 5927 | 5927 | 6148 | 6121 | 6003 | 5221 | |
| Ta064 | 5014 | 5756 | 5772 | 6080 | 6026 | 5786 | 5044 | |
| Ta065 | 5250 | 5957 | 5960 | 6254 | 6200 | 6021 | 5358 | |
| Ta066 | 5135 | 5812 | 5852 | 6177 | 6074 | 5869 | 5197 | |
| Ta067 | 5246 | 5989 | 6004 | 6257 | 6274 | 6004 | 5414 | |
| Ta068 | 5094 | 5856 | 5915 | 6225 | 6130 | 5924 | 5130 | |
| Ta069 | 5448 | 6066 | 6123 | 6443 | 6370 | 6154 | 5546 | |
| Ta070 | 5322 | 6142 | 6159 | 6441 | 6381 | 6186 | 5480 | |
| 100 × 10 | Ta071 | 5770 | 7016 | 7042 | 8115 | 8077 | 7042 | 5964 |
| Ta072 | 5349 | 6740 | 6791 | 7986 | 7880 | 6813 | 5596 | |
| Ta073 | 5676 | 6878 | 6936 | 8057 | 8028 | 6943 | 5796 | |
| Ta074 | 5781 | 7116 | 7187 | 8327 | 8348 | 7198 | 5928 | |
| Ta075 | 5467 | 6810 | 6810 | 7991 | 7859 | 6815 | 5748 | |
| Ta076 | 5303 | 6614 | 6666 | 7823 | 7801 | 6685 | 5446 | |
| Ta077 | 5595 | 6783 | 6801 | 7915 | 7866 | 6827 | 5679 | |
| Ta078 | 5617 | 6790 | 6874 | 7379 | 7913 | 6874 | 5723 | |
| Ta079 | 5871 | 6981 | 7055 | 8226 | 8161 | 6092 | 5934 | |
| Ta080 | 5845 | 6814 | 6965 | 8186 | 8114 | 6990 | 5998 | |
| 100 × 20 | Ta081 | 6202 | 7796 | 7844 | 10,745 | 10,700 | 7854 | 6395 |
| Ta082 | 6183 | 7845 | 7894 | 10,655 | 10,594 | 7910 | 6433 | |
| Ta083 | 6271 | 7794 | 7794 | 10,672 | 10,611 | 7825 | 6689 | |
| Ta084 | 6269 | 7797 | 7899 | 10,630 | 10,607 | 7902 | 6419 | |
| Ta085 | 6314 | 7817 | 7901 | 10,548 | 10,539 | 7901 | 6536 | |
| Ta086 | 6364 | 7826 | 7888 | 10,700 | 10,690 | 7921 | 6527 | |
| Ta087 | 6268 | 7923 | 7930 | 10,827 | 10,825 | 8051 | 6542 | |
| Ta088 | 6401 | 7984 | 8022 | 10,863 | 10,839 | 8025 | 6712 | |
| Ta089 | 6275 | 7877 | 7969 | 10,751 | 10,723 | 7969 | 6760 | |
| Ta090 | 6434 | 7913 | 7933 | 10,794 | 10,798 | 8036 | 6621 | |
| 200 × 10 | Ta091 | 10,862 | 13,348 | 13,406 | 15,739 | 15,319 | 13,507 | 11,120 |
| Ta092 | 10,480 | 13,242 | 13,313 | 15,534 | 15,085 | 16,458 | 10,658 | |
| Ta093 | 10,922 | 13,318 | 13,416 | 15,755 | 15,376 | 13,521 | 11,224 | |
| Ta094 | 10,889 | 13,290 | 13,344 | 15,842 | 15,200 | 13,686 | 11,075 | |
| Ta095 | 10,524 | 13,247 | 13,360 | 15,692 | 15,209 | 13,547 | 10,793 | |
| Ta096 | 10,326 | 13,079 | 13,192 | 15,622 | 15,109 | 13,247 | 10,467 | |
| Ta097 | 10,854 | 13,517 | 13,598 | 15,877 | 15,395 | 13,910 | 11,394 | |
| Ta098 | 10,730 | 13,483 | 13,504 | 15,733 | 15,237 | 13,830 | 11,011 | |
| Ta099 | 10,438 | 13,277 | 13,310 | 15,573 | 15,100 | 13,410 | 10,725 | |
| Ta100 | 10,657 | 13,325 | 13,439 | 15,803 | 15,340 | 13,744 | 10,786 | |
| 200 × 20 | Ta101 | 11,195 | 14,912 | 14,912 | 20,148 | 19,681 | 15,027 | 11,642 |
| Ta102 | 11,203 | 14,876 | 15,002 | 20,539 | 20,096 | 15,211 | 11,683 | |
| Ta103 | 11,281 | 15,057 | 15,186 | 20,511 | 19,913 | 15,247 | 11,930 | |
| Ta104 | 11,275 | 14,975 | 15,082 | 20,461 | 19,928 | 15,174 | 11,791 | |
| Ta105 | 11,259 | 14,733 | 14,970 | 20,339 | 19,843 | 15,047 | 11,728 | |
| Ta106 | 11,176 | 14,861 | 15,101 | 20,501 | 19,942 | 15,212 | 11,690 | |
| Ta107 | 11,360 | 14,988 | 15,099 | 20,680 | 20,112 | 15,168 | 11,958 | |
| Ta108 | 11,334 | 14,926 | 15,141 | 20,614 | 20,056 | 15,247 | 11,730 | |
| Ta109 | 11,192 | 14,885 | 15,034 | 20,300 | 19,918 | 15,136 | 12,138 | |
| Ta110 | 11,288 | 14,921 | 15,122 | 20,437 | 19,935 | 15,243 | 12,084 | |
| 500 × 20 | Ta111 | 26,059 | 35,677 | 35,372 | 49,095 | 46,689 | 37,064 | 26,859 |
| Ta112 | 26,520 | 35,953 | 35,743 | 49,461 | 47,275 | 37,419 | 27,220 | |
| Ta113 | 26,371 | 35,732 | 35,452 | 48,777 | 46,544 | 37,059 | 27,511 | |
| Ta114 | 26,456 | 36,084 | 35,687 | 49,283 | 46,899 | 37,014 | 26,912 | |
| Ta115 | 26,334 | 35,774 | 35,417 | 48,950 | 46,741 | 36,894 | 26,930 | |
| Ta116 | 26,477 | 35,948 | 35,747 | 49,533 | 46,941 | 37,372 | 27,354 | |
| Ta117 | 26,389 | 35,631 | 35,395 | 48,943 | 46,509 | 36,698 | 26,888 | |
| Ta118 | 26,560 | 35,943 | 35,568 | 49,277 | 46,873 | 36,944 | 27,229 | |
| Ta119 | 26,005 | 35,658 | 35,304 | 49,207 | 46,743 | 36,862 | 28,103 | |
| Ta120 | 26,457 | 36,016 | 35,643 | 49,092 | 46,847 | 37,098 | 27,290 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, H.; Li, S.; Jiang, H.; Hu, J.; Hu, J. Hybrid Genetic Simulated Annealing Algorithm for Improved Flow Shop Scheduling with Makespan Criterion. Appl. Sci. 2018, 8, 2621. https://doi.org/10.3390/app8122621
Wei H, Li S, Jiang H, Hu J, Hu J. Hybrid Genetic Simulated Annealing Algorithm for Improved Flow Shop Scheduling with Makespan Criterion. Applied Sciences. 2018; 8(12):2621. https://doi.org/10.3390/app8122621
Chicago/Turabian StyleWei, Hongjing, Shaobo Li, Houmin Jiang, Jie Hu, and Jianjun Hu. 2018. "Hybrid Genetic Simulated Annealing Algorithm for Improved Flow Shop Scheduling with Makespan Criterion" Applied Sciences 8, no. 12: 2621. https://doi.org/10.3390/app8122621
APA StyleWei, H., Li, S., Jiang, H., Hu, J., & Hu, J. (2018). Hybrid Genetic Simulated Annealing Algorithm for Improved Flow Shop Scheduling with Makespan Criterion. Applied Sciences, 8(12), 2621. https://doi.org/10.3390/app8122621