Machine Learning Approaches for Outdoor Air Quality Modelling: A Systematic Review



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Method
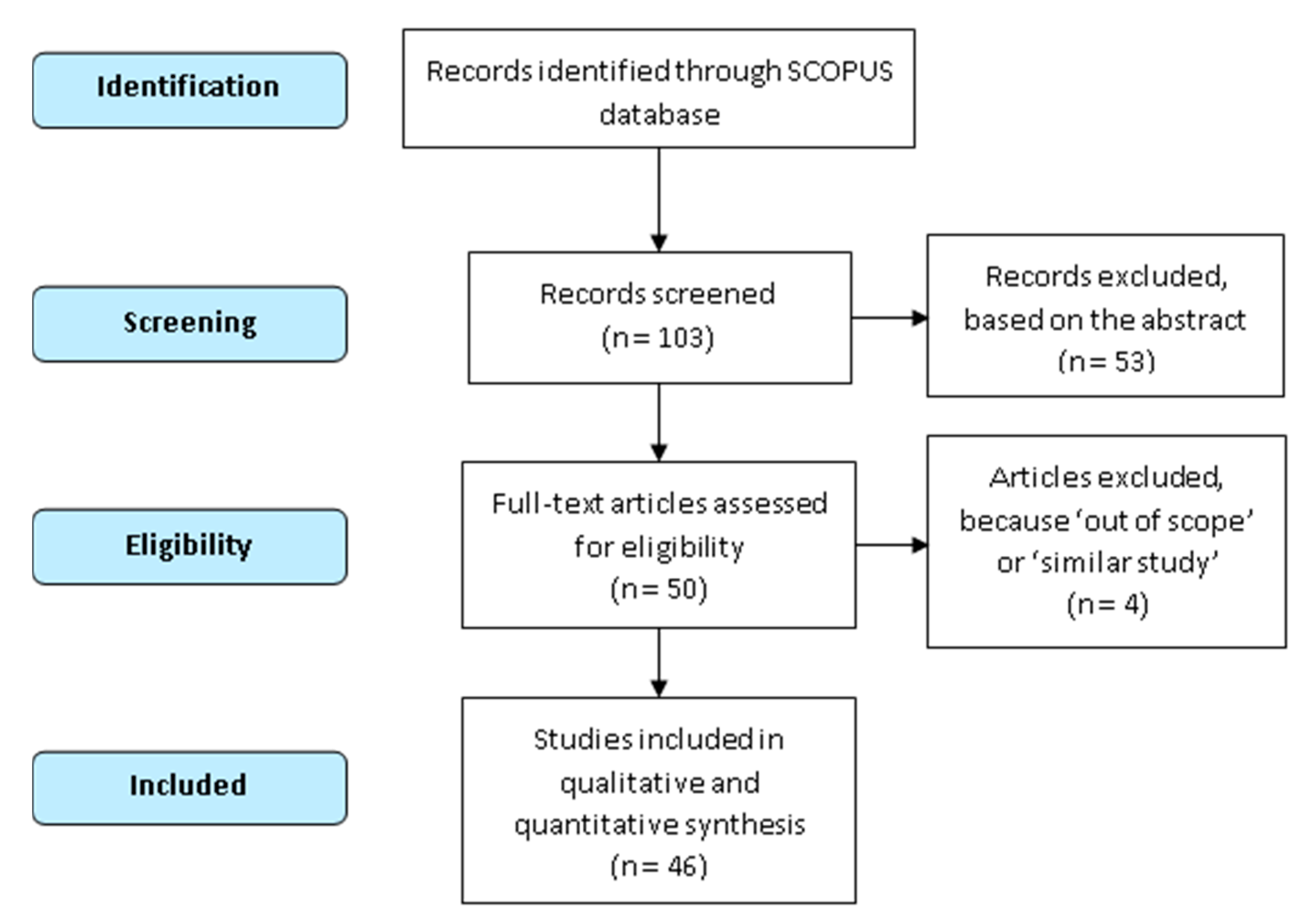
2.1. Search Strategy
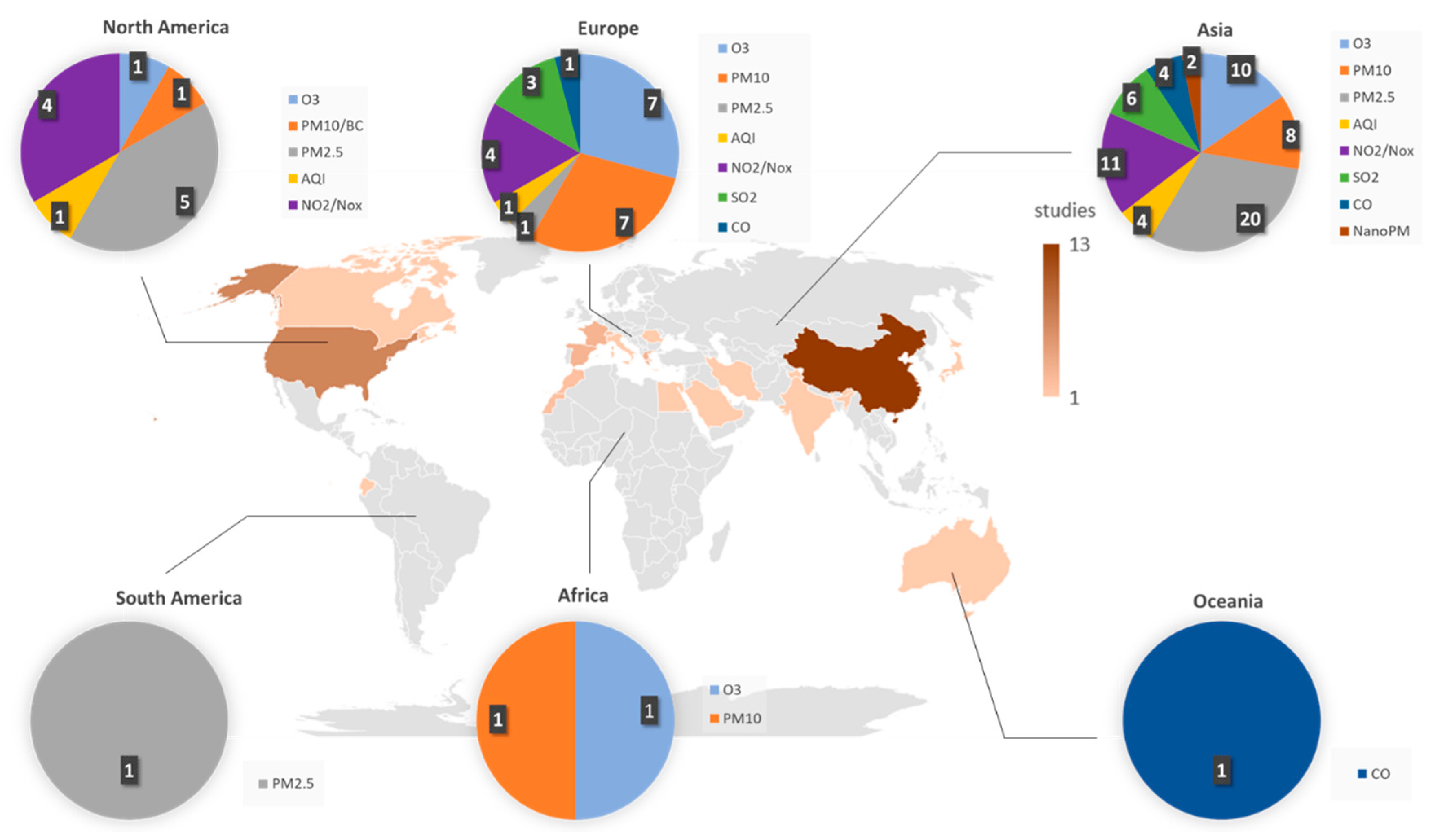
2.2. Analyzed Parameters
2.3. Synthesis of Results
3. Results and Discussion
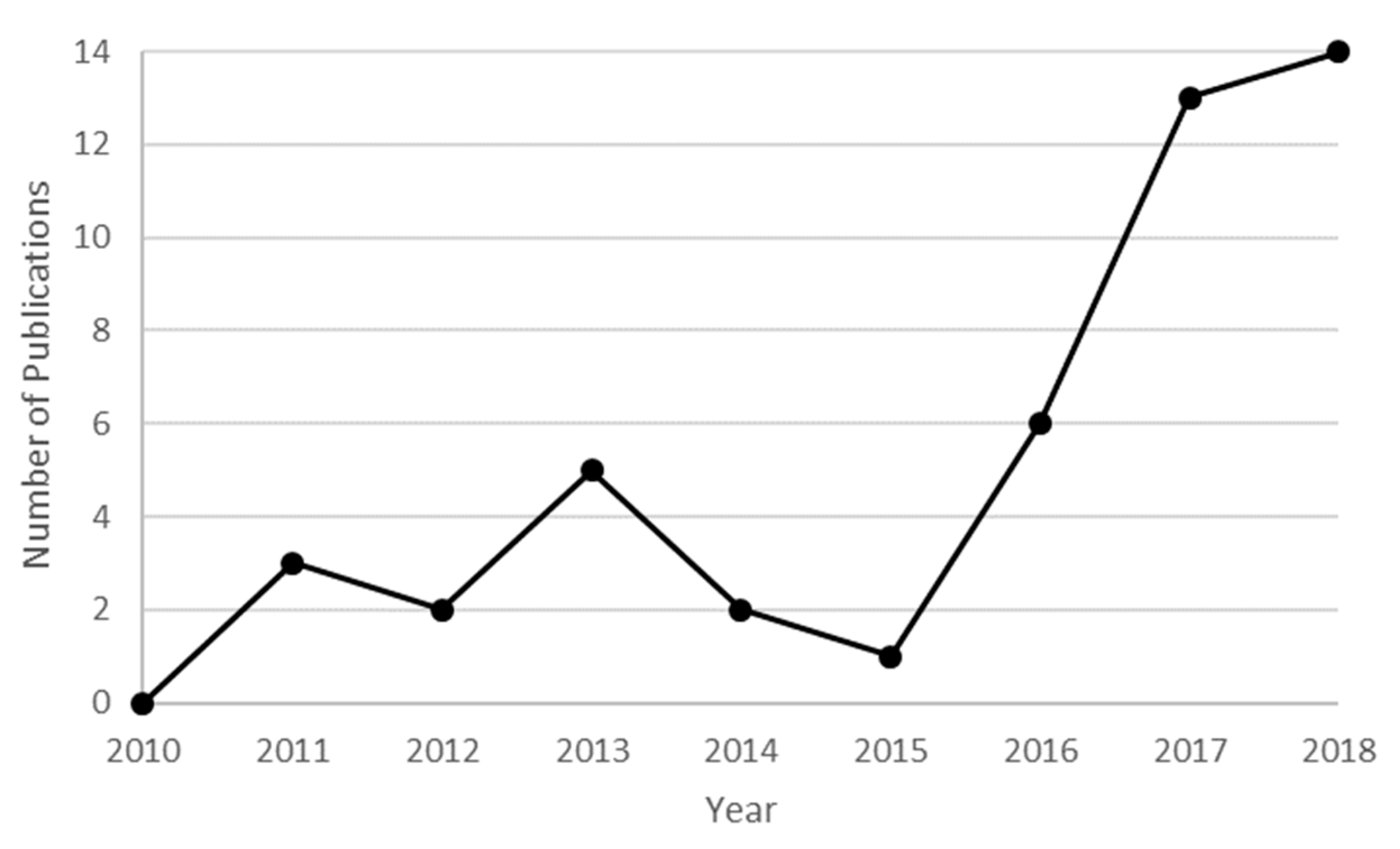
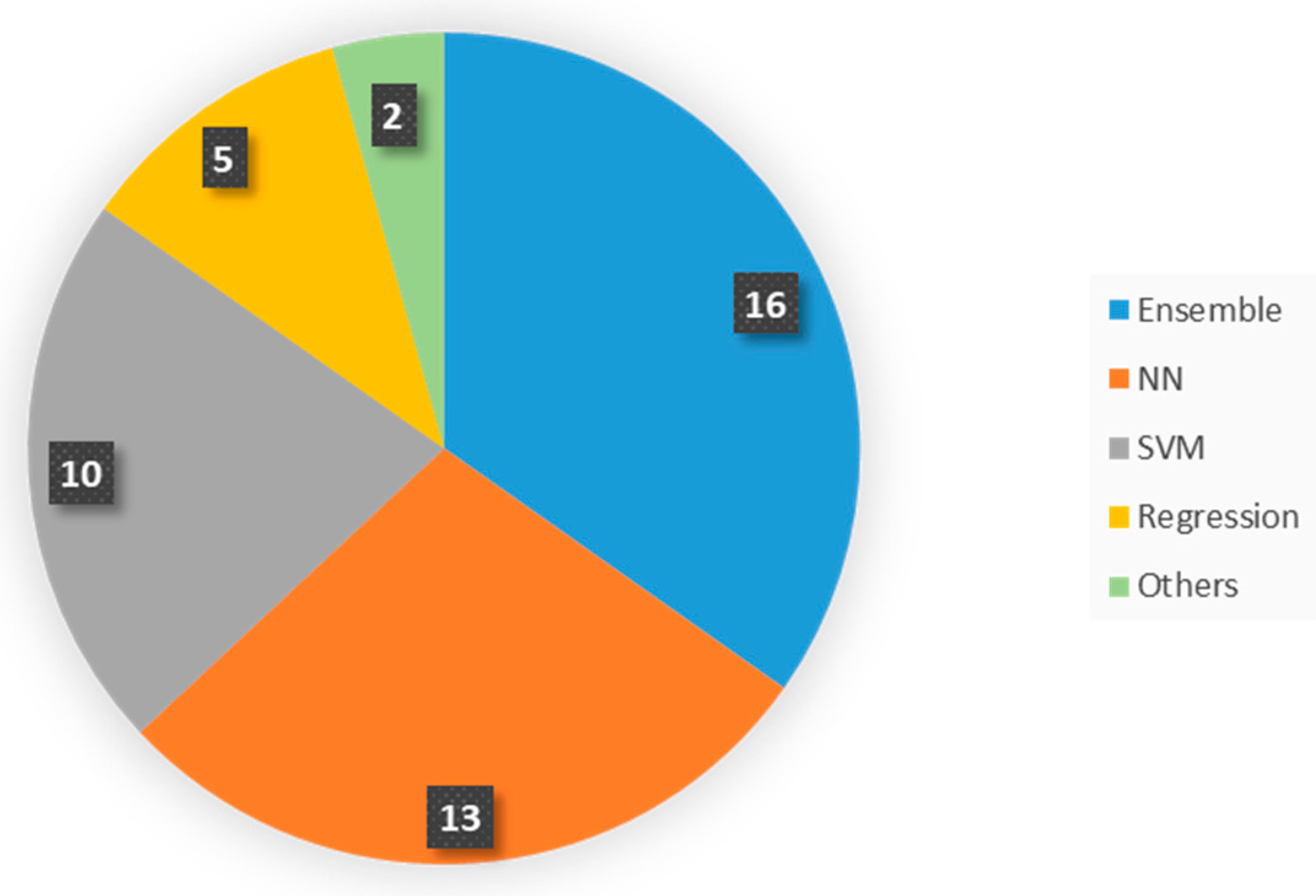
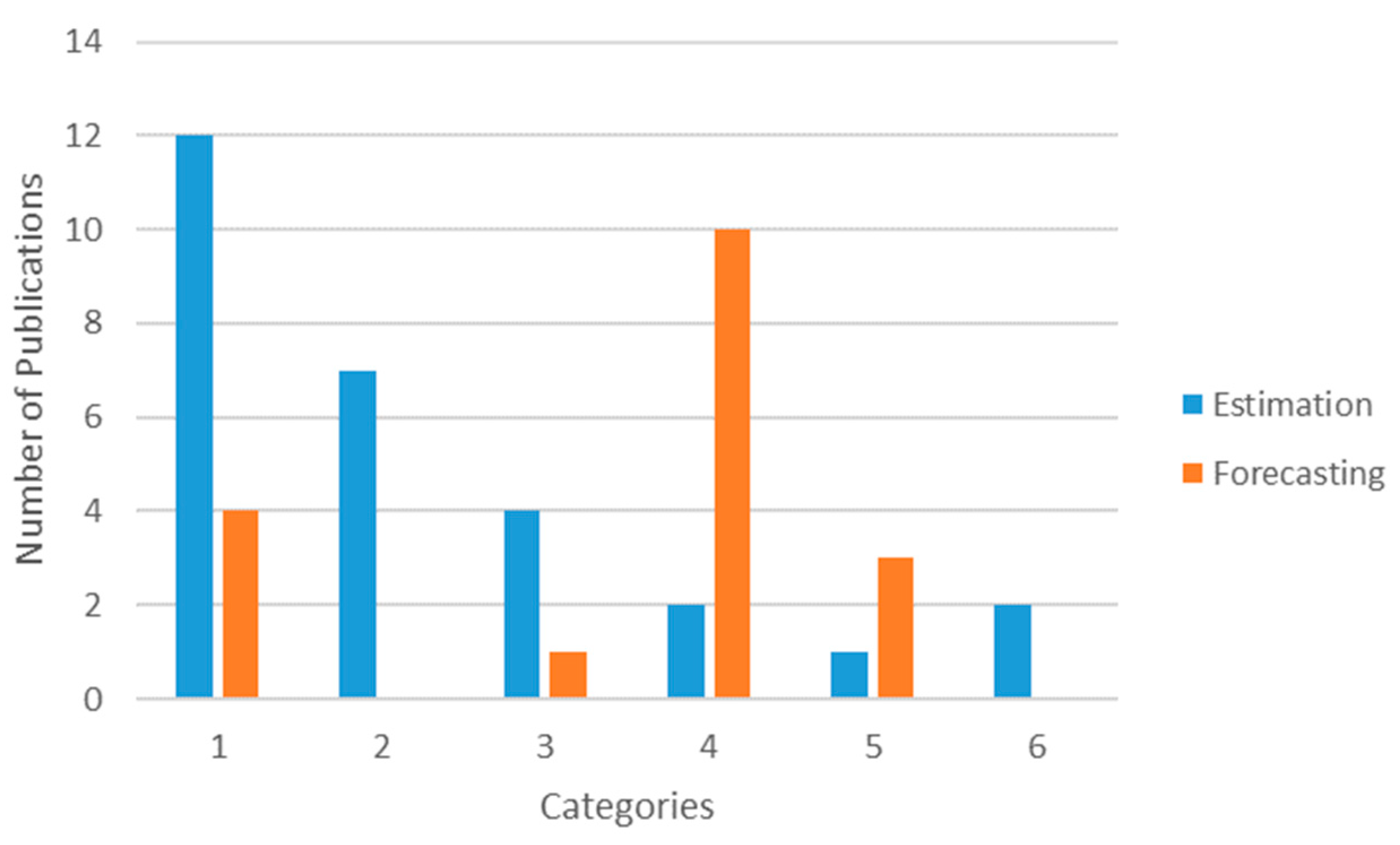
3.1. General Description
3.2. Detailed Description
3.2.1. Category 1: Identifying Relevant Predictors and Understanding the Non-Linear Relationship with Air Pollution
3.2.2. Category 2: Image-Based Monitoring and Tackling Low Spatial Resolution from Non-Specific/Low Resolution Sensors
3.2.3. Category 3: Considering Land Use and Spatial Heterogeneity/Dependence
3.2.4. Category 4: Hybrid Models and Extreme/Deep Learning
3.2.5. Category 5: Towards an Application System
3.2.6. Category 6: Nanoparticles as a New Challenge
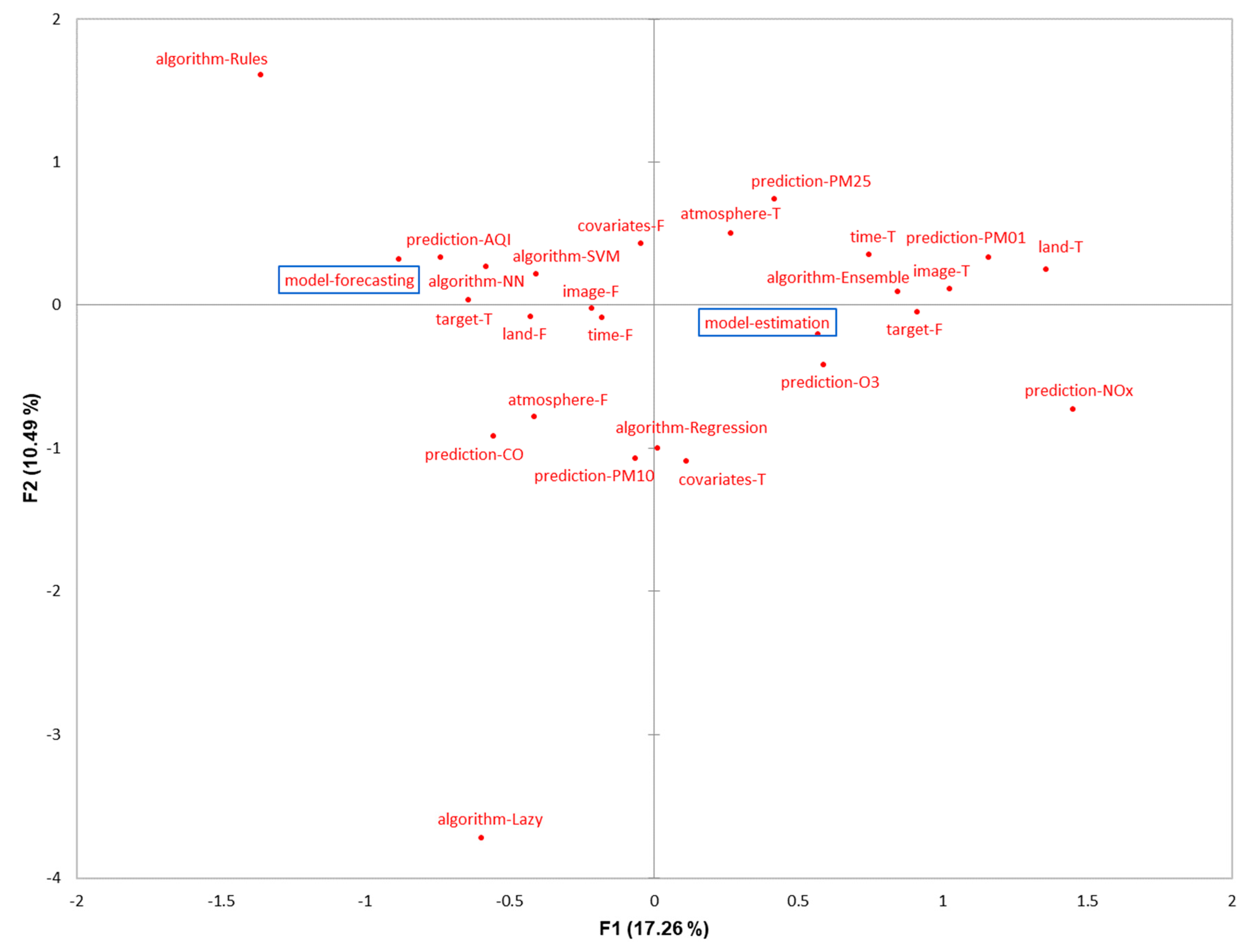
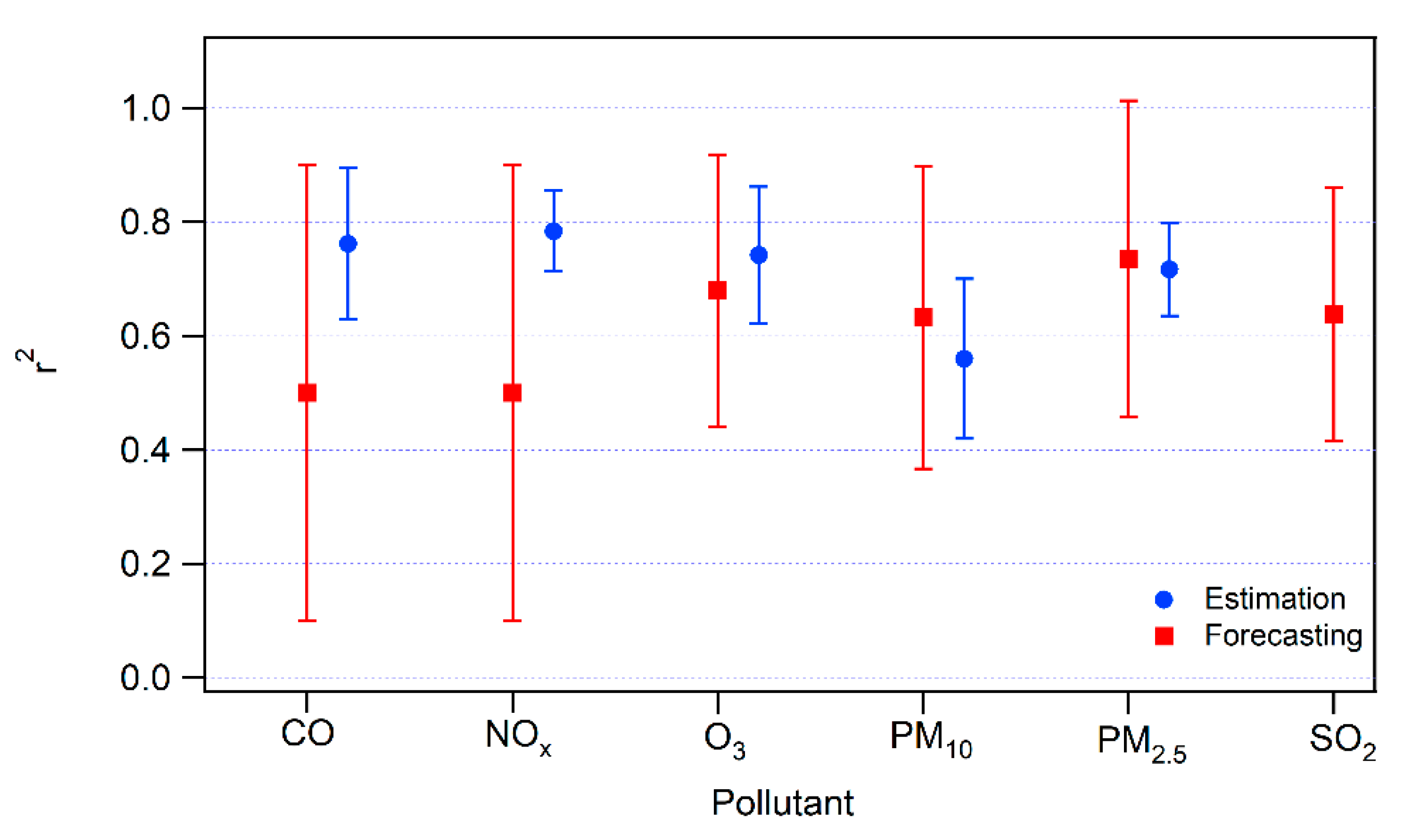
3.3. Synthesis
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
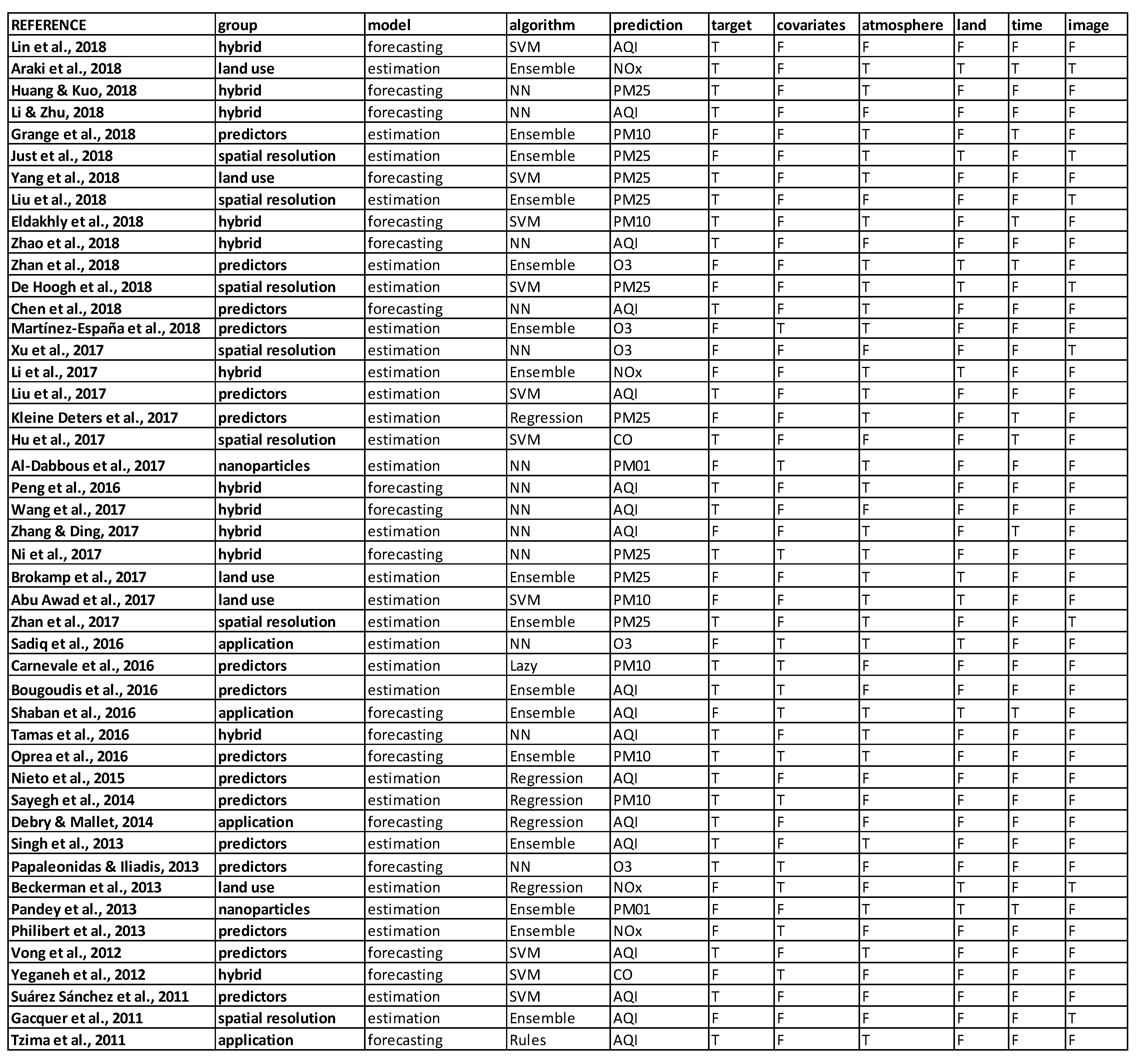
Appendix A

References
- WHO. 7 Million Premature Deaths Annually Linked to Air Pollution Page 1 of 2 WHO|7 Million Premature Deaths Annually Linked to Air Pollution Page 2 of 2. Available online: http://www.who.int/mediacentre/news/releases/2014/air-pollution/en/#.WqBfue47NRQ.mendeley (accessed on 7 March 2018).
- Limb, M. Half of wealthy and 98% of poorer cities breach air quality guidelines. BMJ 2016, 353. [Google Scholar] [CrossRef] [PubMed]
- WHO. Air Pollution Levels Rising in Many of the World’s Poorest Cities. Available online: http://www.who.int/mediacentre/news/releases/2016/air-pollution-rising/en/#.WhOPG9ANlBk.mendeley (accessed on 21 November 2017).
- Daly, A.; Zannetti, P. Air pollution modeling—An overview. Ambient Air Pollut. 2007, I, 15–28. [Google Scholar]
- Met Office. Numerical Atmospheric-Dispersion Modelling Environment (NAME) Model. Available online: http://www-cast.ch.cam.ac.uk/cast_pics/WP_NAME.pdf (accessed on 5 December 2018).
- Cohen, A.J.; Brauer, M.; Burnett, R.; Anderson, H.R.; Frostad, J.; Estep, K.; Balakrishnan, K.; Brunekreef, B.; Dandona, L.; Dandona, R.; et al. Estimates and 25-year trends of the global burden of disease attributable to ambient air pollution: An analysis of data from the Global Burden of Diseases Study 2015. Lancet 2017, 389, 1907–1918. [Google Scholar] [CrossRef]
- Kinney, P.L. Climate Change, Air Quality, and Human Health. Am J. Prev. Med. 2008, 35, 459–467. [Google Scholar] [CrossRef] [PubMed]
- Lelieveld, J.; Evans, J.S.; Fnais, M.; Giannadaki, D.; Pozzer, A. The contribution of outdoor air pollution sources to premature mortality on a global scale. Nature 2015, 525, 367. [Google Scholar] [CrossRef] [PubMed]
- Pannullo, F.; Lee, D.; Neal, L.; Dalvi, M.; Agnew, P.; O’Connor, F.M.; Mukhopadhyay, S.; Sahu, S.; Sarran, C. Quantifying the impact of current and future concentrations of air pollutants on respiratory disease risk in England. Environ. Health 2017, 16, 29. [Google Scholar] [CrossRef] [PubMed]
- Silva, R.A.; West, J.J.; Lamarque, J.-F.; Shindell, D.T.; Collins, W.J.; Faluvegi, G.; Folberth, G.A.; Horowitz, L.W.; Nagashima, T.; Naik, V.; et al. Future global mortality from changes in air pollution attributable to climate change. Nat. Clim. Chang. 2017, 7, 647–651. [Google Scholar] [CrossRef]
- Kim, D.; Stockwell, W.R. An online coupled meteorological and air quality modeling study of the effect of complex terrain on the regional transport and transformation of air pollutants over the Western United States. Atmos. Environ. 2008, 42, 4006–4021. [Google Scholar] [CrossRef]
- Grigoras, G.; Cuculeanu, V.; Ene, G.; Mocioaca, G.; Deneanu, A. Air pollution dispersion modeling in a polluted industrial area of complex terrain from Romania. Rom. Rep. Phys. 2012, 64, 173–186. [Google Scholar]
- Lagzi, I.; Mészáros, R.; Gelybó, G.; Leelőssy, Á. Theory and limitations of Gaussian models. In Atmospheric Chemistry; Eötvös Loránd University-ELTE: Budapest, Hungary, 2013. [Google Scholar]
- Lutman, E.R.; Jones, S.R.; Hill, R.A.; McDonald, P.; Lambers, B. Comparison between the predictions of a Gaussian plume model and a Lagrangian particle dispersion model for annual average calculations of long-range dispersion of radionuclides. J. Environ. Radioact. 2004, 75, 339–355. [Google Scholar] [CrossRef]
- Seigneur, C.; Moran, M. Chapter 8. Chemical-Transport Models. Available online: https://www.narsto.org/sites/narsto-dev.ornl.gov/files/Ch71.3MB.pdF (accessed on 6 December 2018).
- NCAR. Models. Available online: https://www2.acom.ucar.edu/bai/models (accessed on 12 May 2018).
- Ahmadov, R. WRF-Chem: Online vs Offline Atmospheric Chemistry Modeling. In ASP Colloquium; National Center for Atmospheric Research (NCAR): Boulder, CO, USA, 2016. [Google Scholar]
- Feng, X.; Li, Q.; Zhu, Y.; Hou, J.; Jin, L.; Wang, J. Artificial neural networks forecasting of PM2.5 pollution using air mass trajectory based geographic model and wavelet transformation. Atmos. Environ. 2015, 107, 118–128. [Google Scholar] [CrossRef]
- Jimenez, P.A.; Dudhia, J. On the Ability of the WRF Model to Reproduce the Surface Wind Direction over Complex Terrain. J. Appl. Meteorol. Climatol. 2013, 1610–1617. [Google Scholar] [CrossRef]
- Baklanov, A. Application of CFD Methods for Modelling in Air Pollution Problems: Possibilities and Gaps. Environ. Monit. Assess. 2000, 65, 181–189. [Google Scholar] [CrossRef]
- Chen, J.; Chen, H.; Wu, Z.; Hu, D.; Pan, J.Z. Forecasting smog-related health hazard based on social media and physical sensor. Inf. Syst. 2017, 64, 281–291. [Google Scholar] [CrossRef]
- Grange, S.K.; Carslaw, D.C.; Lewis, A.C.; Boleti, E.; Hueglin, C. Random forest meteorological normalisation models for Swiss PM10 trend analysis. Atmos. Chem. Phys. Discuss. 2018, 1–28. [Google Scholar] [CrossRef]
- Liu, B.-C.; Binaykia, A.; Chang, P.-C.; Tiwari, M.; Tsao, C.-C. Urban air quality forecasting based on multi- dimensional collaborative Support Vector Regression (SVR): A case study of Beijing-Tianjin-Shijiazhuang. PLoS ONE 2017, 12, e0179763. [Google Scholar] [CrossRef]
- Shimadera, H.; Kojima, T.; Kondo, A. Evaluation of Air Quality Model Performance for Simulating Long-Range Transport and Local Pollution of PM2.5 in Japan. Adv. Meteorol. 2016, 2016. [Google Scholar] [CrossRef]
- Ritter, M.; Müller, M.D.; Tsai, M.-Y.; Parlow, E. Air pollution modeling over very complex terrain: An evaluation of WRF-Chem over Switzerland for two 1-year periods. Atmos. Res. 2013, 132–133, 209–222. [Google Scholar] [CrossRef]
- Lee, M.; Brauer, M.; Wong, P.; Tang, R.; Tsui, T.H.; Choi, C.; Cheng, W.; Lai, P.-C.; Tian, L.; Thach, T.-Q.; et al. Land use regression modelling of air pollution in high density high rise cities: A case study in Hong Kong. Sci. Total Environ. 2017, 592, 306–315. [Google Scholar] [CrossRef]
- Nhung, N.T.T.; Amini, H.; Schindler, C.; Kutlar Joss, M.; Dien, T.M.; Probst-Hensch, N.; Perez, L.; Künzli, N. Short-term association between ambient air pollution and pneumonia in children: A systematic review and meta-analysis of time-series and case-crossover studies. Environ. Pollut. 2017, 230, 1000–1008. [Google Scholar] [CrossRef]
- Zafra, C.; Ángel, Y.; Torres, E. ARIMA analysis of the effect of land surface coverage on PM10 concentrations in a high-altitude megacity. Atmos. Pollut. Res. 2017, 8, 660–668. [Google Scholar] [CrossRef]
- Zhu, W.; Wang, J.; Zhang, W.; Sun, D. Short-term effects of air pollution on lower respiratory diseases and forecasting by the group method of data handling. Atmos. Environ. 2012, 51, 29–38. [Google Scholar] [CrossRef]
- Zhang, Y.; Bocquet, M.; Mallet, V.; Seigneur, C.; Baklanov, A. Real-time air quality forecasting, part I: History, techniques, and current status. Atmos. Environ. 2012, 60, 632–655. [Google Scholar] [CrossRef]
- Brokamp, C.; Jandarov, R.; Rao, M.B.; LeMasters, G.; Ryan, P. Exposure assessment models for elemental components of particulate matter in an urban environment: A comparison of regression and random forest approaches. Atmos. Environ. 2017, 151, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Adam-Poupart, A.; Brand, A.; Fournier, M.; Jerrett, M.; Smargiassi, A. Spatiotemporal modeling of ozone levels in Quebec (Canada): A comparison of kriging, land-use regression (LUR), and combined Bayesian maximum entropy-LUR approaches. Environ. Health Perspect. 2014, 122, 970–976. [Google Scholar] [CrossRef] [PubMed]
- Hoek, G.; Beelen, R.; de Hoogh, K.; Vienneau, D.; Gulliver, J.; Fischer, P.; Briggs, D. A review of land-use regression models to assess spatial variation of outdoor air pollution. Atmos. Environ. 2008, 42, 7561–7578. [Google Scholar] [CrossRef]
- Marshall, J.D.; Nethery, E.; Brauer, M. Within-urban variability in ambient air pollution: Comparison of estimation methods. Atmos. Environ. 2008, 42, 1359–1369. [Google Scholar] [CrossRef]
- Zhan, Y.; Luo, Y.; Deng, X.; Grieneisen, M.L.; Zhang, M.; Di, B. Spatiotemporal prediction of daily ambient ozone levels across China using random forest for human exposure assessment. Environ. Pollut. 2018, 233, 464–473. [Google Scholar] [CrossRef]
- Martínez-España, R.; Bueno-Crespo, A.; Timón, I.; Soto, J.; Muñoz, A.; Cecilia, J.M. Air-pollution prediction in smart cities through machine learning methods: A case of study in Murcia, Spain. J. Univ. Comput. Sci. 2018, 24, 261–276. [Google Scholar]
- Bougoudis, I.; Demertzis, K.; Iliadis, L. HISYCOL a hybrid computational intelligence system for combined machine learning: The case of air pollution modeling in Athens. Neural Comput. Appl. 2016, 27, 1191–1206. [Google Scholar] [CrossRef]
- Sayegh, A.S.; Munir, S.; Habeebullah, T.M. Comparing the Performance of Statistical Models for Predicting PM10 Concentrations. Aerosol Air Qual. Res. 2014, 10, 653–665. [Google Scholar] [CrossRef]
- Singh, K.P.; Gupta, S.; Rai, P. Identifying pollution sources and predicting urban air quality using ensemble learning methods. Atmos. Environ. 2013, 80, 426–437. [Google Scholar] [CrossRef]
- Philibert, A.; Loyce, C.; Makowski, D. Prediction of N2O emission from local information with Random Forest. Environ. Pollut. 2013, 177, 156–163. [Google Scholar] [CrossRef] [PubMed]
- Nieto, P.J.G.; Antón, J.C.Á.; Vilán, J.A.V.; García-Gonzalo, E. Air quality modeling in the Oviedo urban area (NW Spain) by using multivariate adaptive regression splines. Environ. Sci. Pollut. Res. 2015, 22, 6642–6659. [Google Scholar] [CrossRef] [PubMed]
- Kleine Deters, J.; Zalakeviciute, R.; Gonzalez, M.; Rybarczyk, Y. Modeling PM2.5 Urban Pollution Using Machine Learning and Selected Meteorological Parameters. J. Electr. Comput. Eng. 2017, 2017. [Google Scholar] [CrossRef]
- Carnevale, C.; Finzi, G.; Pederzoli, A.; Turrini, E.; Volta, M. Lazy Learning based surrogate models for air quality planning. Environ. Model. Softw. 2016, 83, 47–57. [Google Scholar] [CrossRef]
- Suárez Sánchez, A.; García Nieto, P.J.; Riesgo Fernández, P.; del Coz Díaz, J.J.; Iglesias-Rodríguez, F.J. Application of an SVM-based regression model to the air quality study at local scale in the Avilés urban area (Spain). Math. Comput. Model. 2011, 54, 1453–1466. [Google Scholar] [CrossRef]
- Vong, C.M.; Ip, W.F.; Wong, P.K.; Yang, J.Y. Short-term prediction of air pollution in Macau using support vector machines. J. Control Sci. Eng. 2012, 2012. [Google Scholar] [CrossRef]
- Chen, S.; Kan, G.; Li, J.; Liang, K.; Hong, Y. Investigating China’s urban air quality using big data, information theory, and machine learning. Pol. J. Environ. Stud. 2018, 27, 565–578. [Google Scholar] [CrossRef]
- Papaleonidas, A.; Iliadis, L. Neurocomputing techniques to dynamically forecast spatiotemporal air pollution data. Evol. Syst. 2013, 4, 221–233. [Google Scholar] [CrossRef]
- Oprea, M.; Dragomir, E.G.; Popescu, M.; Mihalache, S.F. Particulate Matter Air Pollutants Forecasting using Inductive Learning Approach. Rev. Chim. 2016, 67, 2075–2081. [Google Scholar]
- Liu, Y.; Cao, G.; Zhao, N.; Mulligan, K.; Ye, X. Improve ground-level PM2.5 concentration mapping using a random forests-based geostatistical approach. Environ. Pollut. 2018, 235, 272–282. [Google Scholar] [CrossRef] [PubMed]
- Just, A.; De Carli, M.; Shtein, A.; Dorman, M.; Lyapustin, A.; Kloog, I. Correcting Measurement Error in Satellite Aerosol Optical Depth with Machine Learning for Modeling PM2.5 in the Northeastern USA. Remote Sens. 2018, 10, 803. [Google Scholar] [CrossRef]
- Zhan, Y.; Luo, Y.; Deng, X.; Chen, H.; Grieneisen, M.L.; Shen, X.; Zhu, L.; Zhang, M. Spatiotemporal prediction of continuous daily PM2.5 concentrations across China using a spatially explicit machine learning algorithm. Atmos. Environ. 2017, 155, 129–139. [Google Scholar] [CrossRef]
- Xu, J.; Schussler, O.; Rodriguez, D.G.L.; Romahn, F.; Doicu, A. A Novel Ozone Profile Shape Retrieval Using Full-Physics Inverse Learning Machine (FP-ILM). IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 5442–5457. [Google Scholar] [CrossRef]
- De Hoogh, K.; Héritier, H.; Stafoggia, M.; Künzli, N.; Kloog, I. Modelling daily PM2.5 concentrations at high spatio-temporal resolution across Switzerland. Environ. Pollut. 2018, 233, 1147–1154. [Google Scholar] [CrossRef]
- Hu, K.; Rahman, A.; Bhrugubanda, H.; Sivaraman, V. HazeEst: Machine Learning Based Metropolitan Air Pollution Estimation from Fixed and Mobile Sensors. IEEE Sens. J. 2017, 17, 3517–3525. [Google Scholar] [CrossRef]
- Gacquer, D.; Delcroix, V.; Delmotte, F.; Piechowiak, S. Comparative study of supervised classification algorithms for the detection of atmospheric pollution. Eng. Appl. Artif. Intell. 2011, 24, 1070–1083. [Google Scholar] [CrossRef]
- Abu Awad, Y.; Koutrakis, P.; Coull, B.A.; Schwartz, J. A spatio-temporal prediction model based on support vector machine regression: Ambient Black Carbon in three New England States. Environ. Res. 2017, 159, 427–434. [Google Scholar] [CrossRef]
- Araki, S.; Shima, M.; Yamamoto, K. Spatiotemporal land use random forest model for estimating metropolitan NO2 exposure in Japan. Sci. Total Environ. 2018, 634, 1269–1277. [Google Scholar] [CrossRef]
- Beckerman, B.S.; Jerrett, M.; Martin, R.V.; van Donkelaar, A.; Ross, Z.; Burnett, R.T. Application of the deletion/substitution/addition algorithm to selecting land use regression models for interpolating air pollution measurements in California. Atmos. Environ. 2013, 77, 172–177. [Google Scholar] [CrossRef]
- Yang, W.; Deng, M.; Xu, F.; Wang, H. Prediction of hourly PM2.5 using a space-time support vector regression model. Atmos. Environ. 2018, 181, 12–19. [Google Scholar] [CrossRef]
- Li, L.; Lurmann, F.; Habre, R.; Urman, R.; Rappaport, E.; Ritz, B.; Chen, J.C.; Gilliland, F.D.; Wu, J. Constrained Mixed-Effect Models with Ensemble Learning for Prediction of Nitrogen Oxides Concentrations at High Spatiotemporal Resolution. Environ. Sci. Technol. 2017, 51, 9920–9929. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Ding, W. Prediction of air pollutants concentration based on an extreme learning machine: The case of Hong Kong. Int. J. Environ. Res. Public Health 2017, 14, 1–19. [Google Scholar] [CrossRef] [PubMed]
- Peng, H.; Lima, A.R.; Teakles, A.; Jin, J.; Cannon, A.J.; Hsieh, W.W. Evaluating hourly air quality forecasting in Canada with nonlinear updatable machine learning methods. Air Qual. Atmos. Health 2017, 10, 195–211. [Google Scholar] [CrossRef]
- Yeganeh, B.; Motlagh, M.S.P.; Rashidi, Y.; Kamalan, H. Prediction of CO concentrations based on a hybrid Partial Least Square and Support Vector Machine model. Atmos. Environ. 2012, 55, 357–365. [Google Scholar] [CrossRef]
- Tamas, W.; Notton, G.; Paoli, C.; Nivet, M.L.; Voyant, C. Hybridization of air quality forecasting models using machine learning and clustering: An original approach to detect pollutant peaks. Aerosol Air Qual. Res. 2016, 16, 405–416. [Google Scholar] [CrossRef]
- Ni, X.Y.; Huang, H.; Du, W.P. Relevance analysis and short-term prediction of PM2.5 concentrations in Beijing based on multi-source data. Atmos. Environ. 2017, 150, 146–161. [Google Scholar] [CrossRef]
- Li, C.; Zhu, Z. Research and application of a novel hybrid air quality early-warning system: A case study in China. Sci. Total Environ. 2018, 626, 1421–1438. [Google Scholar] [CrossRef]
- Eldakhly, N.M.; Aboul-Ela, M.; Abdalla, A. A Novel Approach of Weighted Support Vector Machine with Applied Chance Theory for Forecasting Air Pollution Phenomenon in Egypt. Int. J. Comput. Intell. Appl. 2018, 17, 1–29. [Google Scholar] [CrossRef]
- Wang, D.; Wei, S.; Luo, H.; Yue, C.; Grunder, O. A novel hybrid model for air quality index forecasting based on two-phase decomposition technique and modified extreme learning machine. Sci. Total Environ. 2017, 580, 719–733. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Zhang, R.; Wu, J.-L.; Chang, P.-C. A deep recurrent neural network for air quality classification. J. Inf. Hiding Multimed. Signal Process. 2018, 9, 346–354. [Google Scholar]
- Huang, C.J.; Kuo, P.H. A deep cnn-lstm model for particulate matter (PM2.5) forecasting in smart cities. Sensors 2018, 18. [Google Scholar] [CrossRef]
- Sadiq, A.; El Fazziki, A.; Ouarzazi, J.; Sadgal, M. Towards an agent based traffic regulation and recommendation system for the on-road air quality control. Springerplus 2016, 5. [Google Scholar] [CrossRef]
- Tzima, F.A.; Mitkas, P.A.; Voukantsis, D.; Karatzas, K. Sparse episode identification in environmental datasets: The case of air quality assessment. Expert Syst. Appl. 2011, 38, 5019–5027. [Google Scholar] [CrossRef]
- Debry, E.; Mallet, V. Ensemble forecasting with machine learning algorithms for ozone, nitrogendioxide and PM10 on the Prev’Air platform. Atmos. Environ. 2014, 91, 71–74. [Google Scholar] [CrossRef]
- Shaban, K.B.; Kadri, A.; Rezk, E. Urban Air Pollution Monitoring System with Forecasting Models. IEEE Sens. J. 2016, 16, 2598–2606. [Google Scholar] [CrossRef]
- United States Environmental Protection Agency. Particulate Matter (PM2.5) Trends. Available online: https://www.epa.gov/air-trends/particulate-matter-pm25-trends (accessed on 5 December 2018).
- European Environment Agency. Air Quality in Europe—2018 Report; European Environment Agency: Copenhagen, Denmark, 2018. [Google Scholar]
- European Environment Agency. Air Quality in Europe—2017 Report; European Environment Agency: Copenhagen, Denmark, 2017. [Google Scholar]
- Zalakeviciute, R.; Rybarczyk, Y.; López-Villada, J.; Diaz Suarez, M.V. Quantifying decade-long effects of fuel and traffic regulations on urban ambient PM2.5 pollution in a mid-size South American city. Atmos. Pollut. Res. 2017. [Google Scholar] [CrossRef]
- Miller, M.R.; Raftis, J.B.; Langrish, J.P.; McLean, S.G.; Samutrtai, P.; Connell, S.P.; Wilson, S.; Vesey, A.T.; Fokkens, P.H.B.; Boere, A.J.F.; et al. Inhaled Nanoparticles Accumulate at Sites of Vascular Disease. ACS Nano 2017, 11, 4542–4552. [Google Scholar] [CrossRef] [PubMed]
- Al–Dabbous, A.N.; Kumar, P.; Khan, A.R. Prediction of airborne nanoparticles at roadside location using a feed–forward artificial neural network. Atmos. Pollut. Res. 2017, 8, 446–454. [Google Scholar] [CrossRef]
- Pandey, G.; Zhang, B.; Jian, L. Predicting submicron air pollution indicators: A machine learning approach. Environ. Sci. Process. Impacts 2013, 15, 996–1005. [Google Scholar] [CrossRef] [PubMed]
- Prank, M.; Sofiev, M.; Tsyro, S.; Hendriks, C.; Semeena, V.; Francis, X.V.; Butler, T.; Van Der Gon, H.D.; Friedrich, R.; Hendricks, J.; et al. Evaluation of the performance of four chemical transport models in predicting the aerosol chemical composition in Europe in 2005. Atmos. Chem. Phys. 2016, 16, 6041–6070. [Google Scholar] [CrossRef]







© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rybarczyk, Y.; Zalakeviciute, R. Machine Learning Approaches for Outdoor Air Quality Modelling: A Systematic Review. Appl. Sci. 2018, 8, 2570. https://doi.org/10.3390/app8122570
Rybarczyk Y, Zalakeviciute R. Machine Learning Approaches for Outdoor Air Quality Modelling: A Systematic Review. Applied Sciences. 2018; 8(12):2570. https://doi.org/10.3390/app8122570
Chicago/Turabian StyleRybarczyk, Yves, and Rasa Zalakeviciute. 2018. "Machine Learning Approaches for Outdoor Air Quality Modelling: A Systematic Review" Applied Sciences 8, no. 12: 2570. https://doi.org/10.3390/app8122570
APA StyleRybarczyk, Y., & Zalakeviciute, R. (2018). Machine Learning Approaches for Outdoor Air Quality Modelling: A Systematic Review. Applied Sciences, 8(12), 2570. https://doi.org/10.3390/app8122570