Salient Region Detection Using Diffusion Process with Nonlocal Connections


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
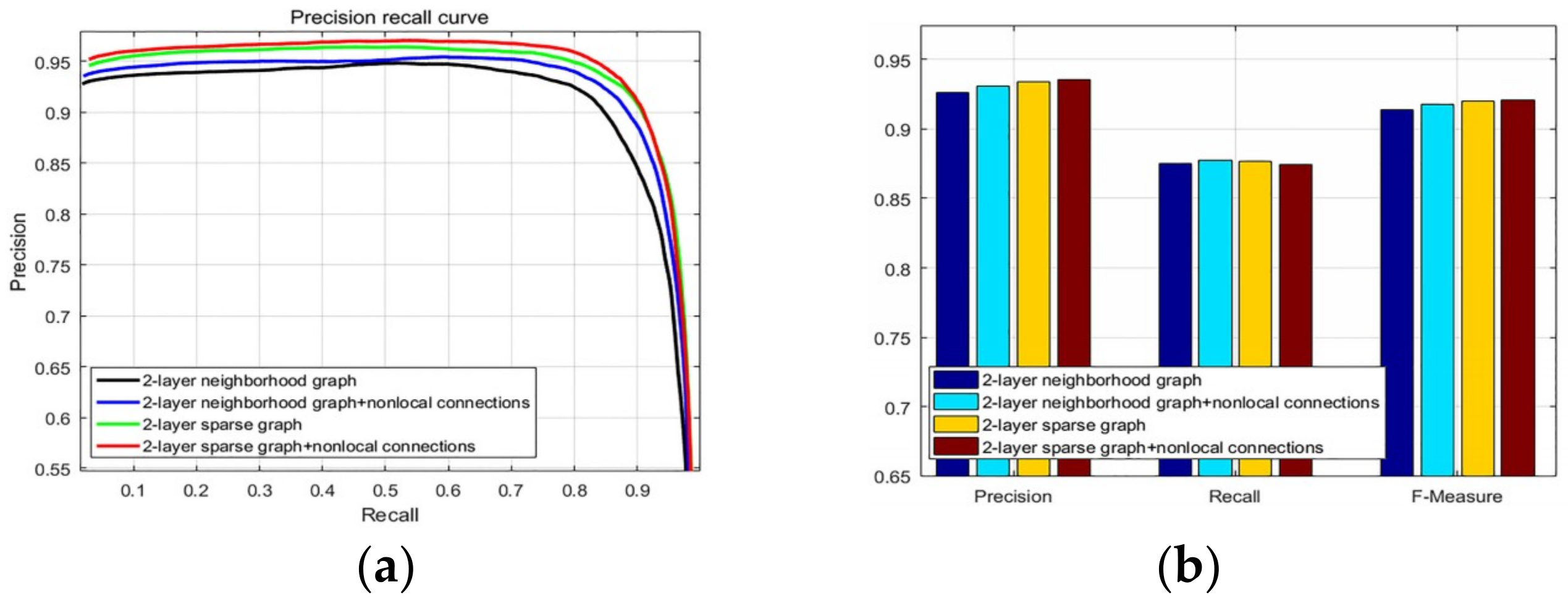
- The nonlocal intrinsic relevance is exploited into the 2-layer sparse graph, and with the saliency information based on different feature cues, we construct the new foreground and background biased diffusion matrix.
- A saliency-biased Gaussian model is presented to overcome the defect of the center-biased model.
- To preferably highlight the salient regions and excavate the multi-scale saliency information, we design a single-layer updating and multi-layer integrating algorithm.
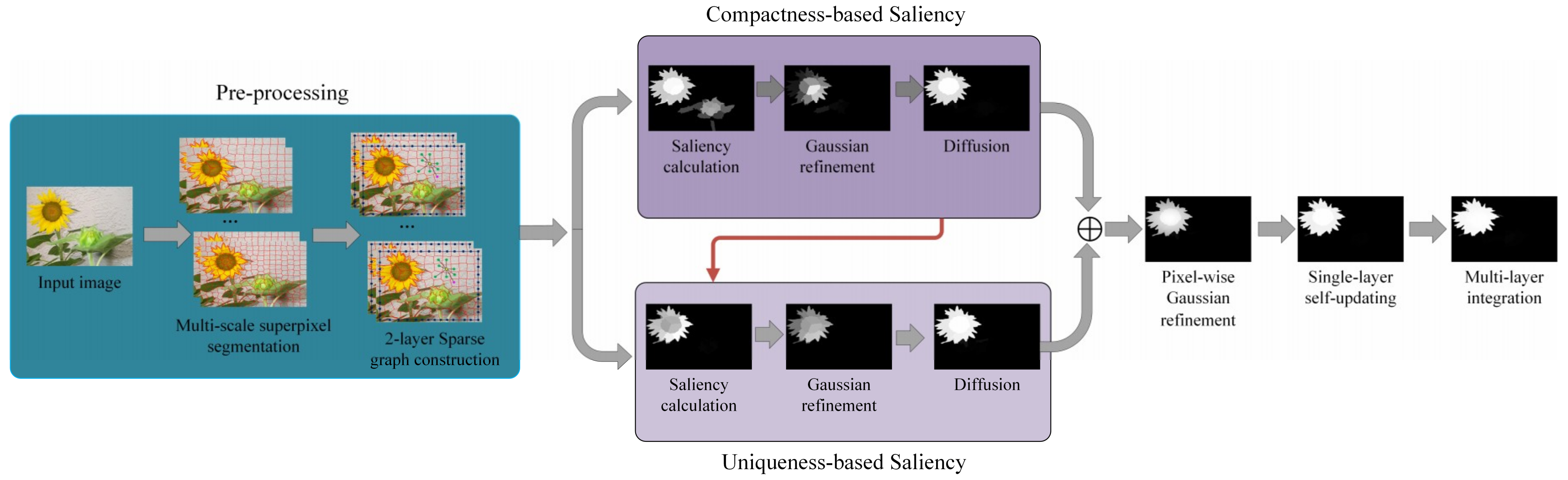
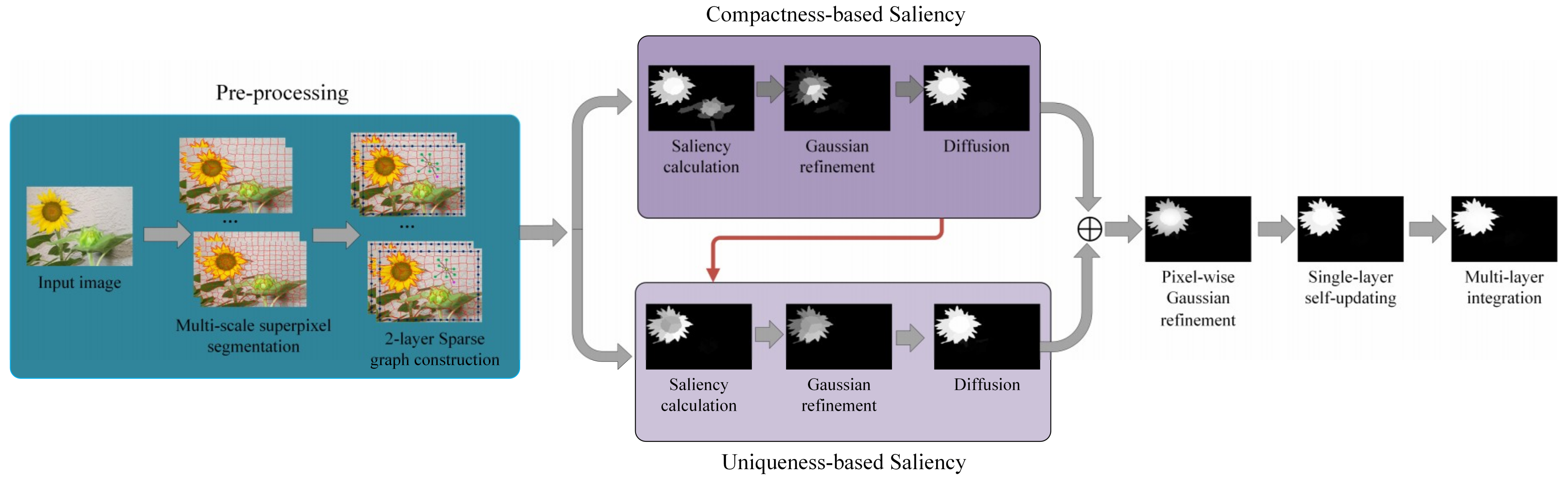
2. Proposed Approach
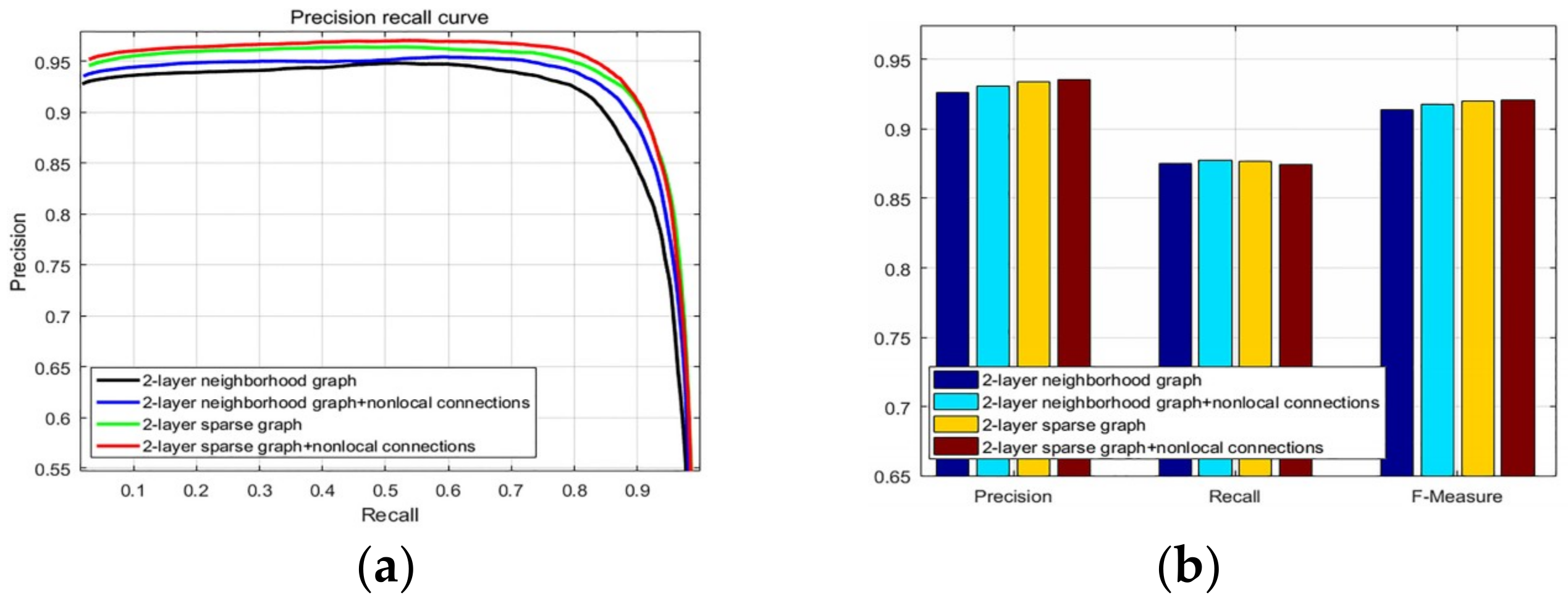
2.1. 2-Layer Sparse Graph Construction
2.2. Compactness-Based Saliency Map
2.2.1. Compactness Calculation
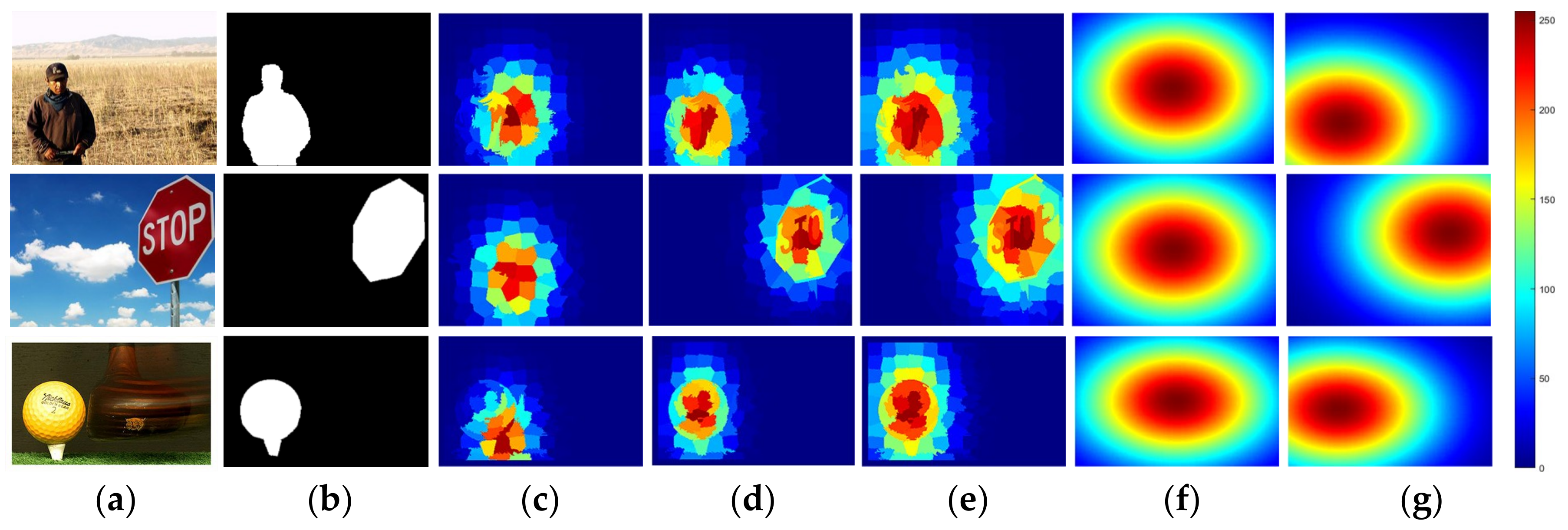
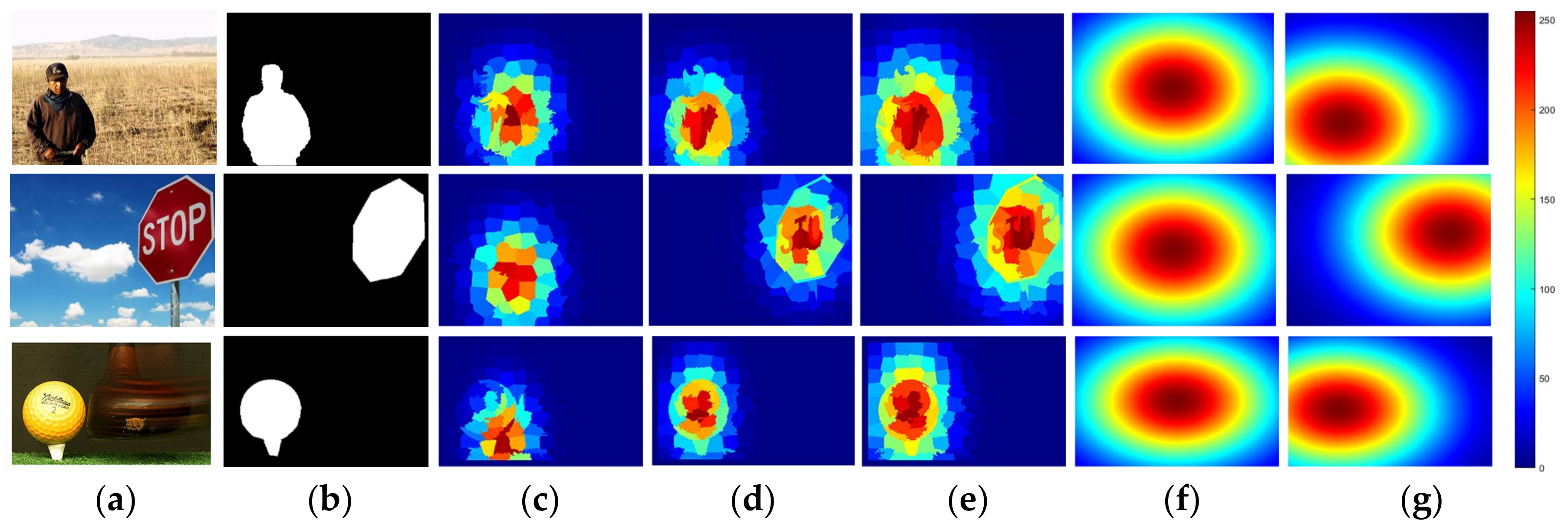
2.2.2. Compactness-Biased Gaussian Model
2.2.3. Diffusion Process with Nonlocal Connections
2.3. Uniqueness-Based Saliency Map
2.3.1. Uniqueness Calculation
2.3.2. Uniqueness-Biased Gaussian Model
2.3.3. Diffusion Process
2.4. Combination and Pixel-Wise Gaussian Refinement
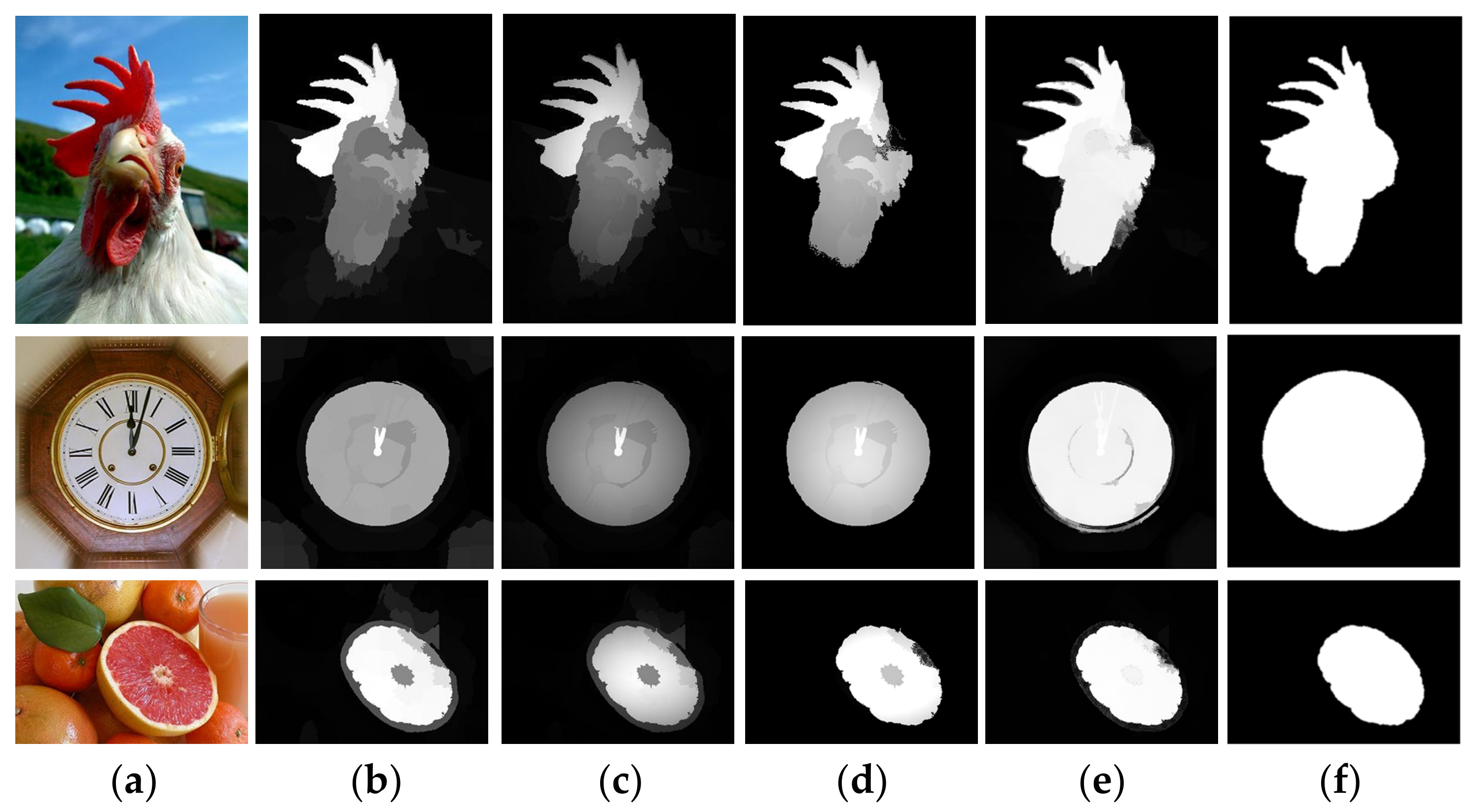
2.5. Single-Layer Updating and Multi-Layer Integration
2.5.1. Single-Layer Updating
2.5.2. Multi-Layer Integration
3. Experiment
3.1. Experimental Setup
3.2. Evaluation Criteria
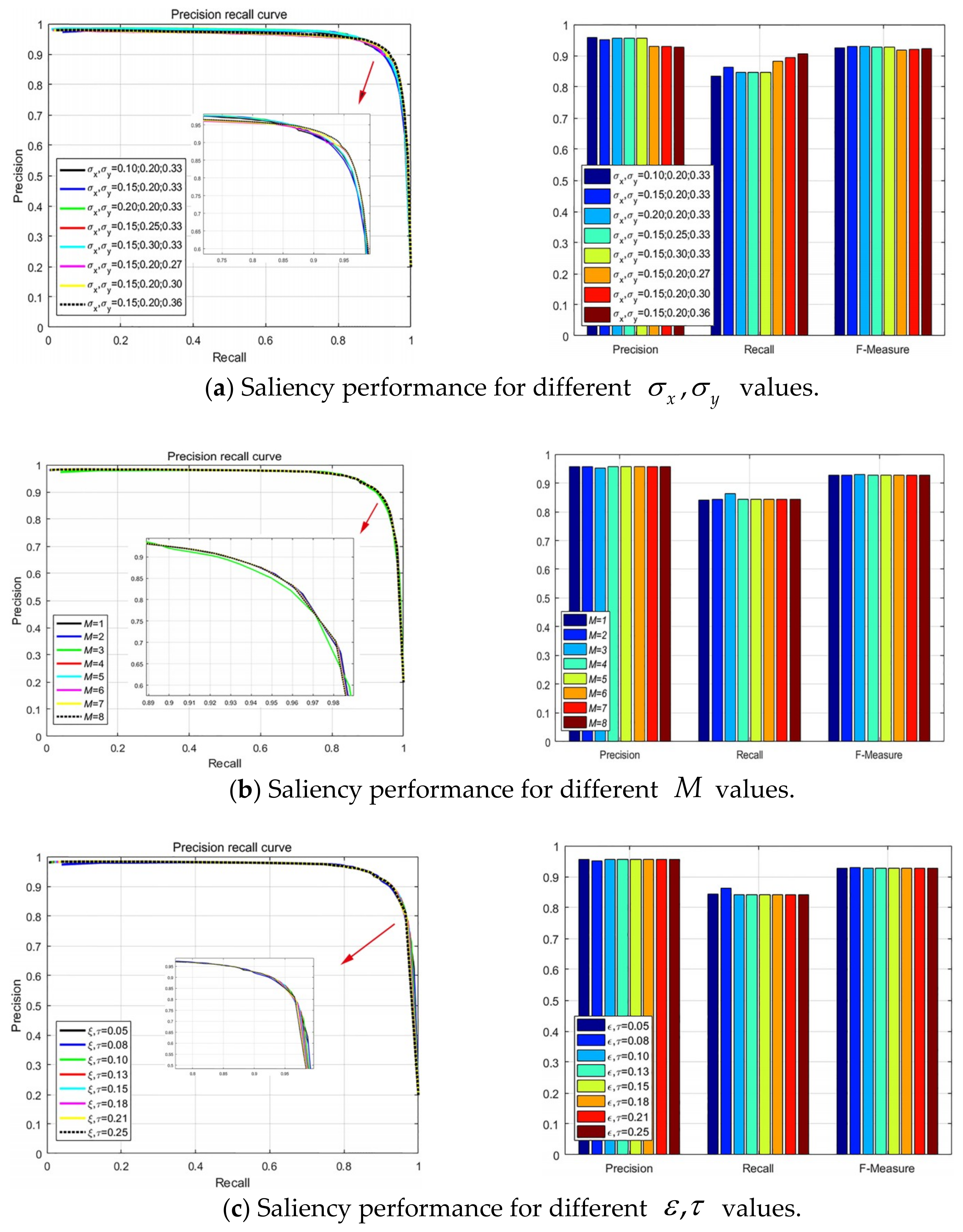
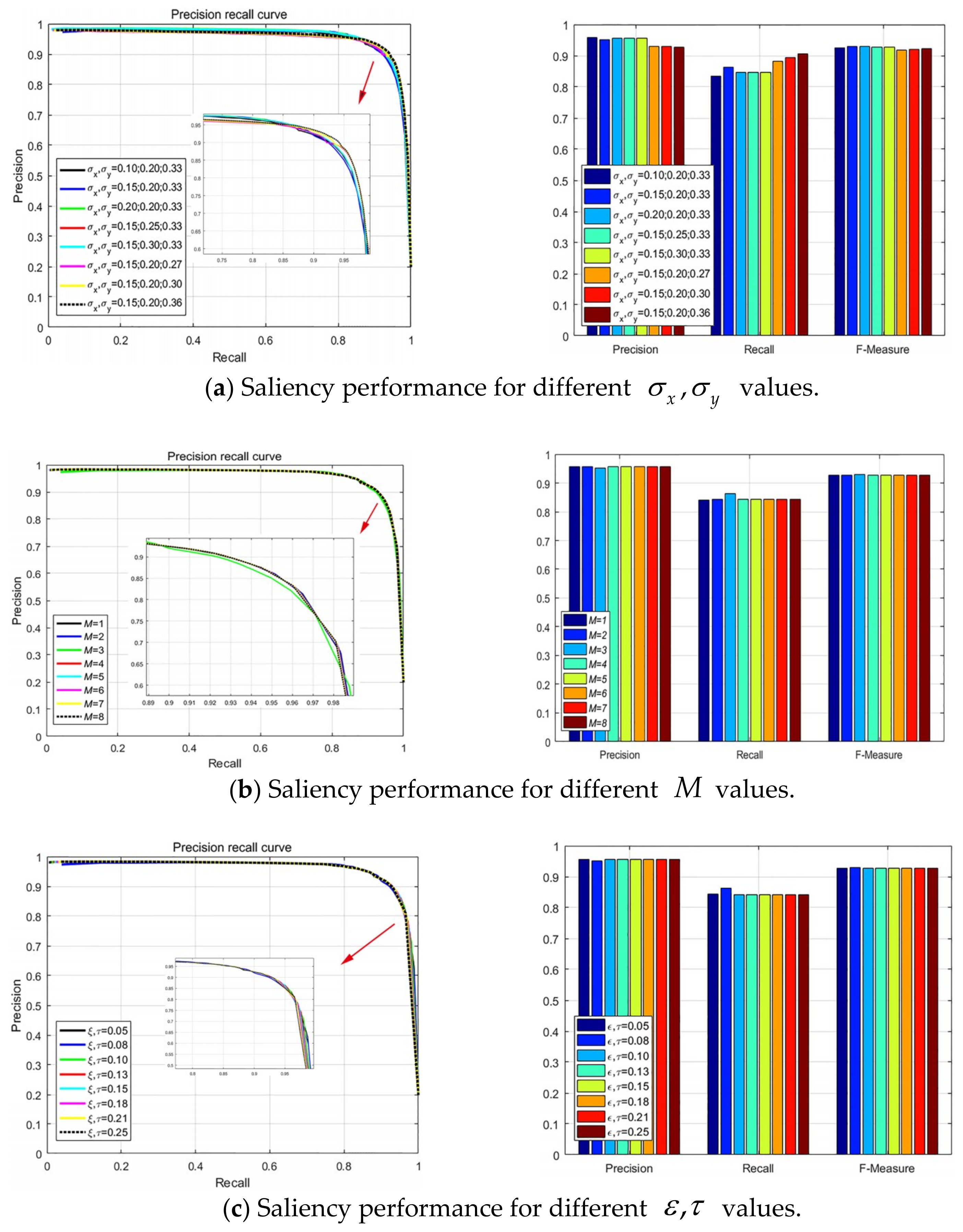
3.3. Parameter Analysis
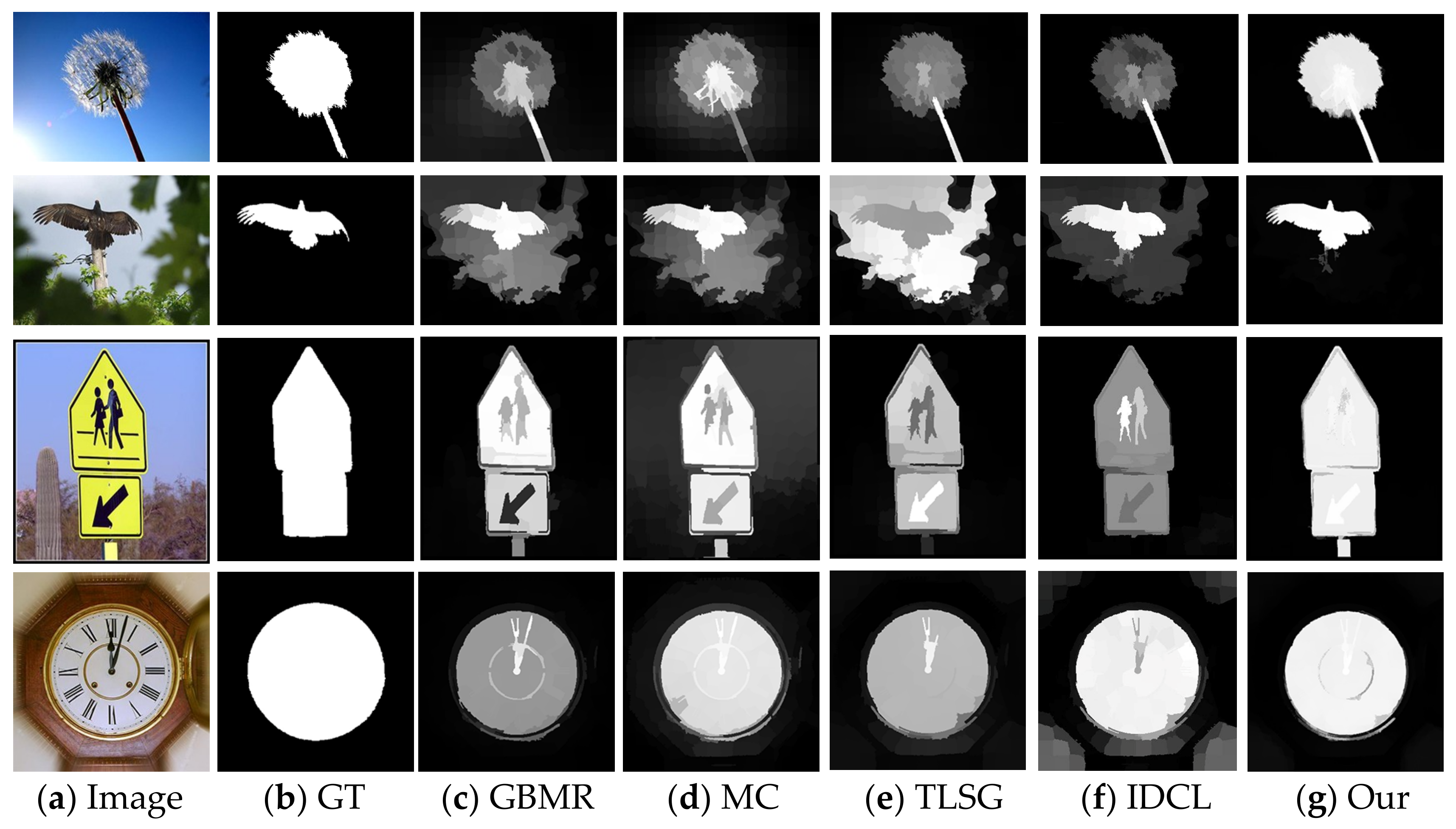
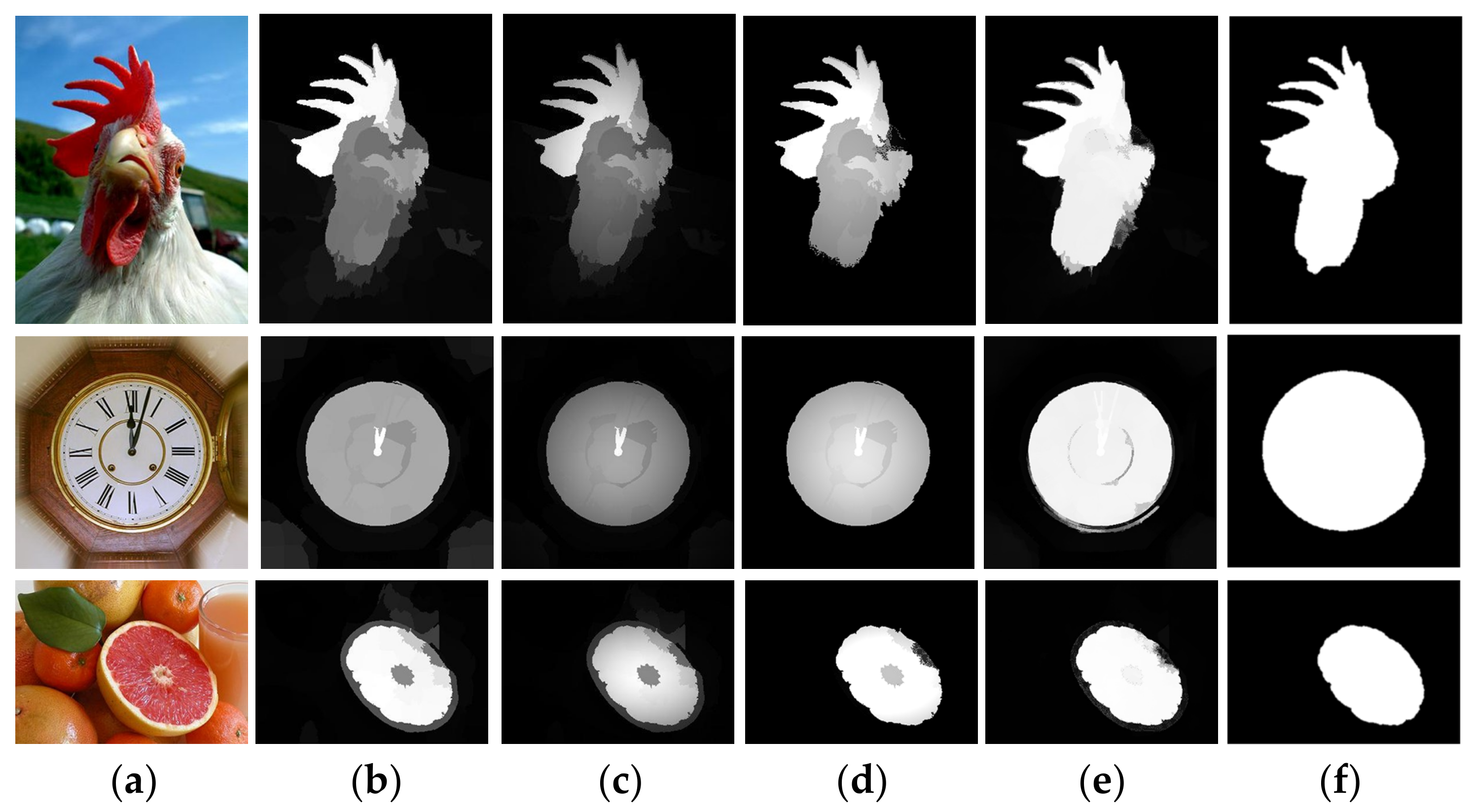
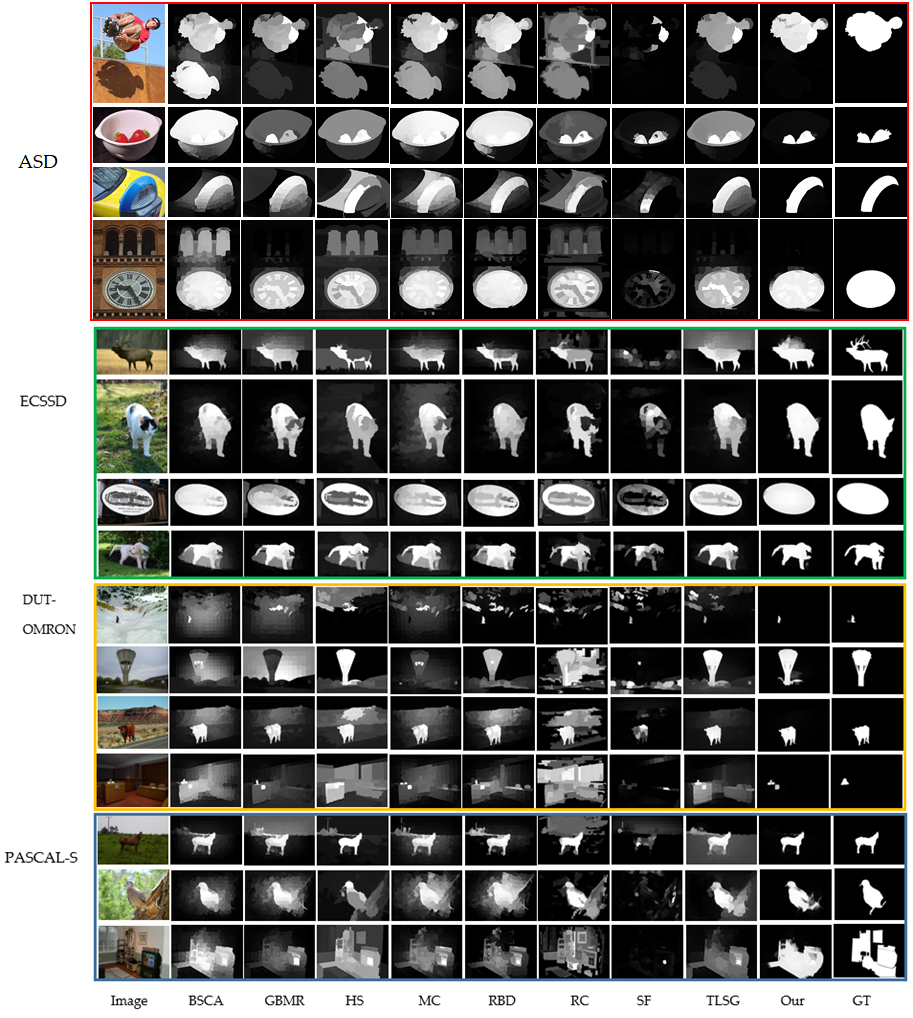
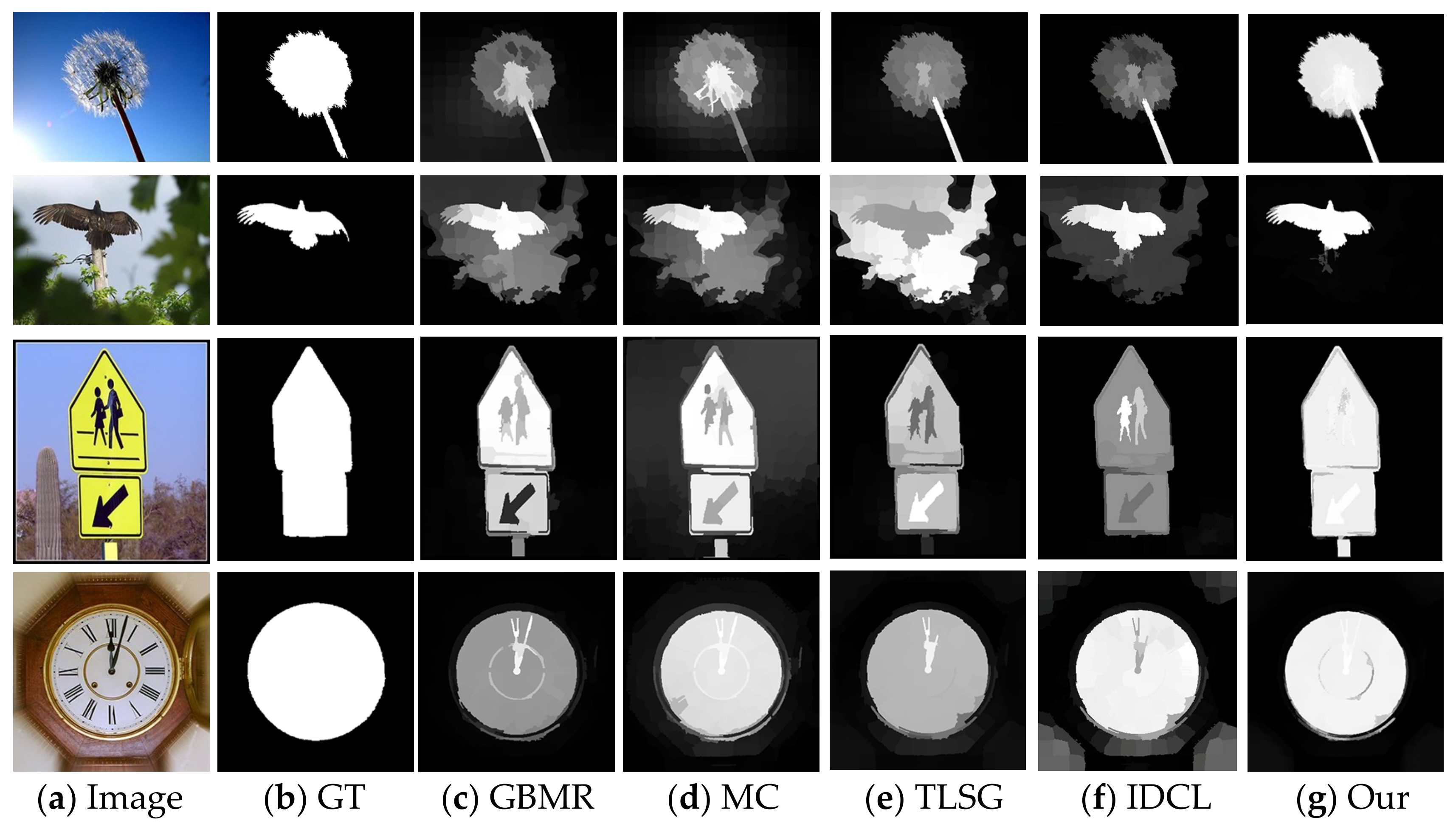
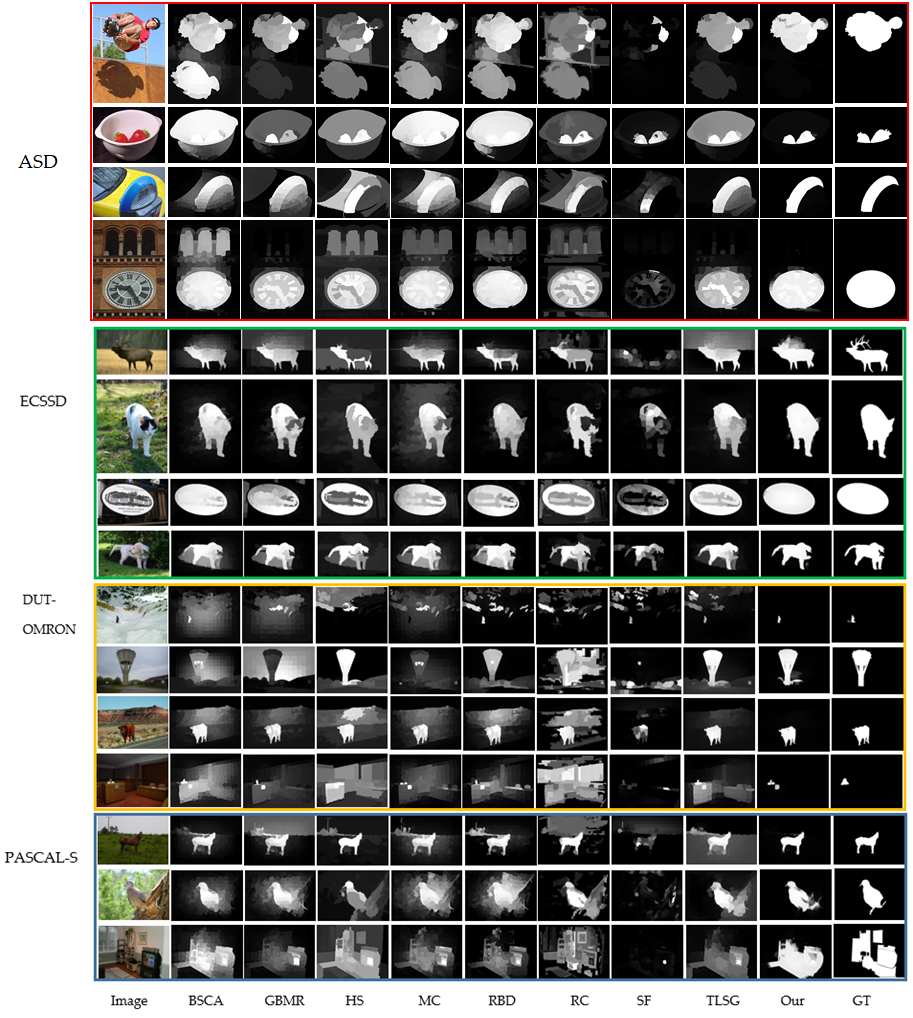
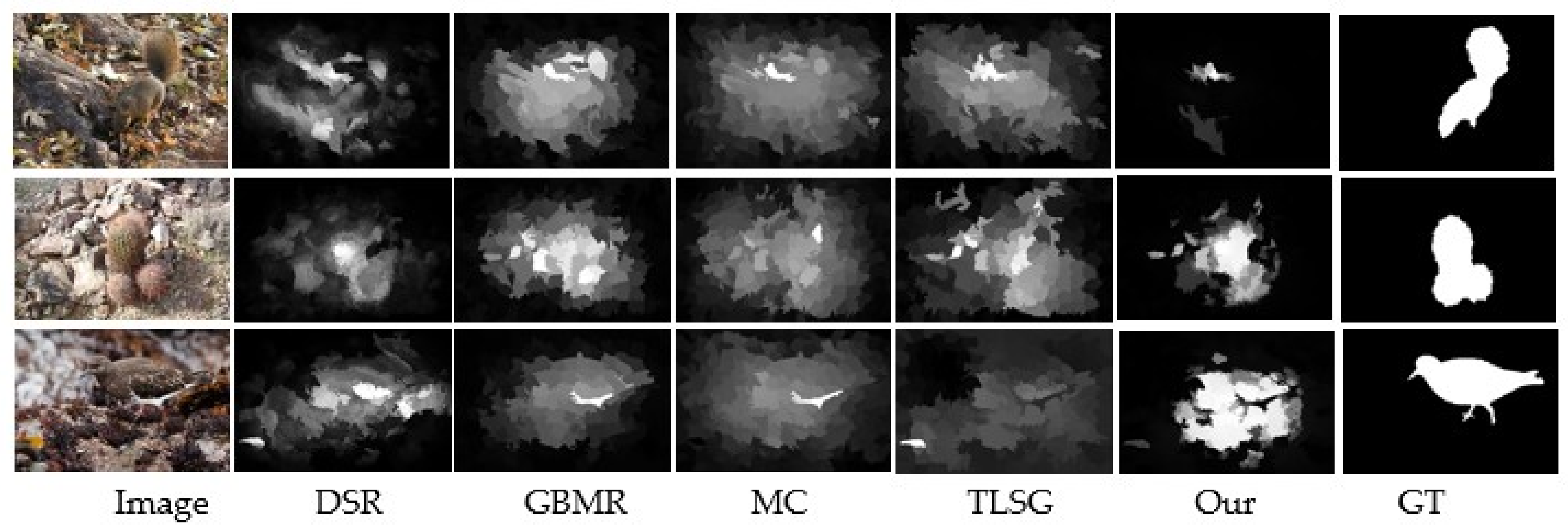
3.4. Visual Comparisons
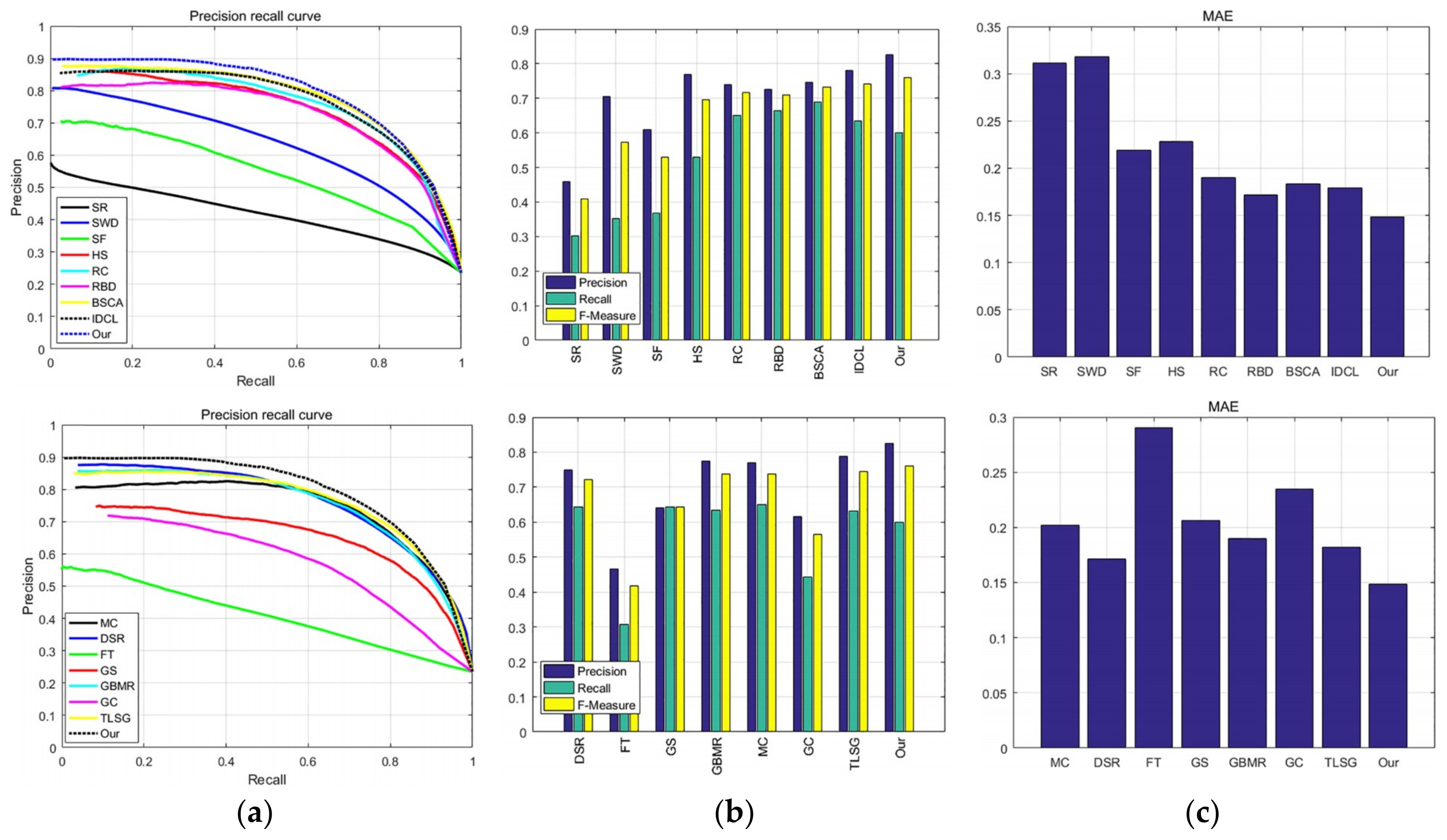
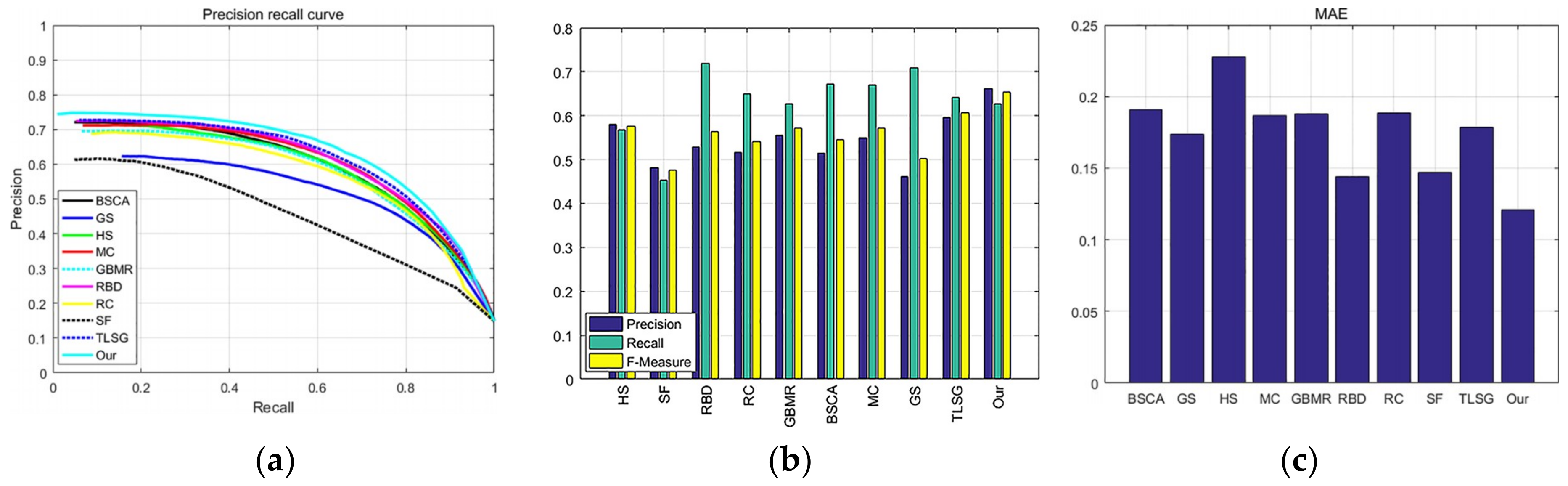
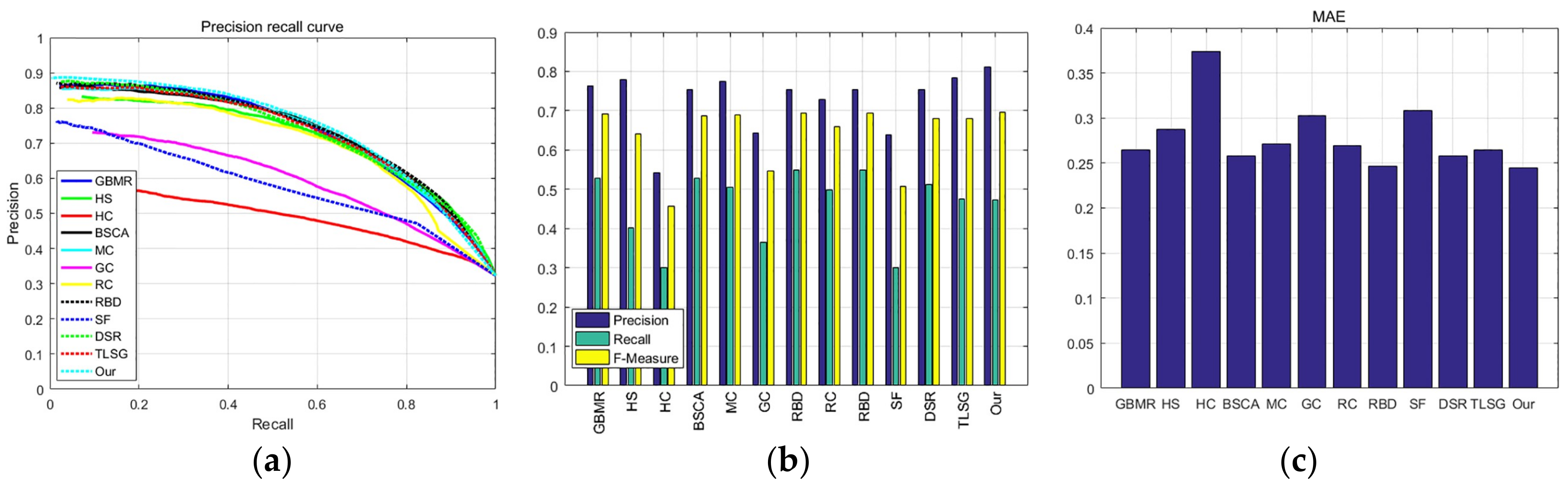
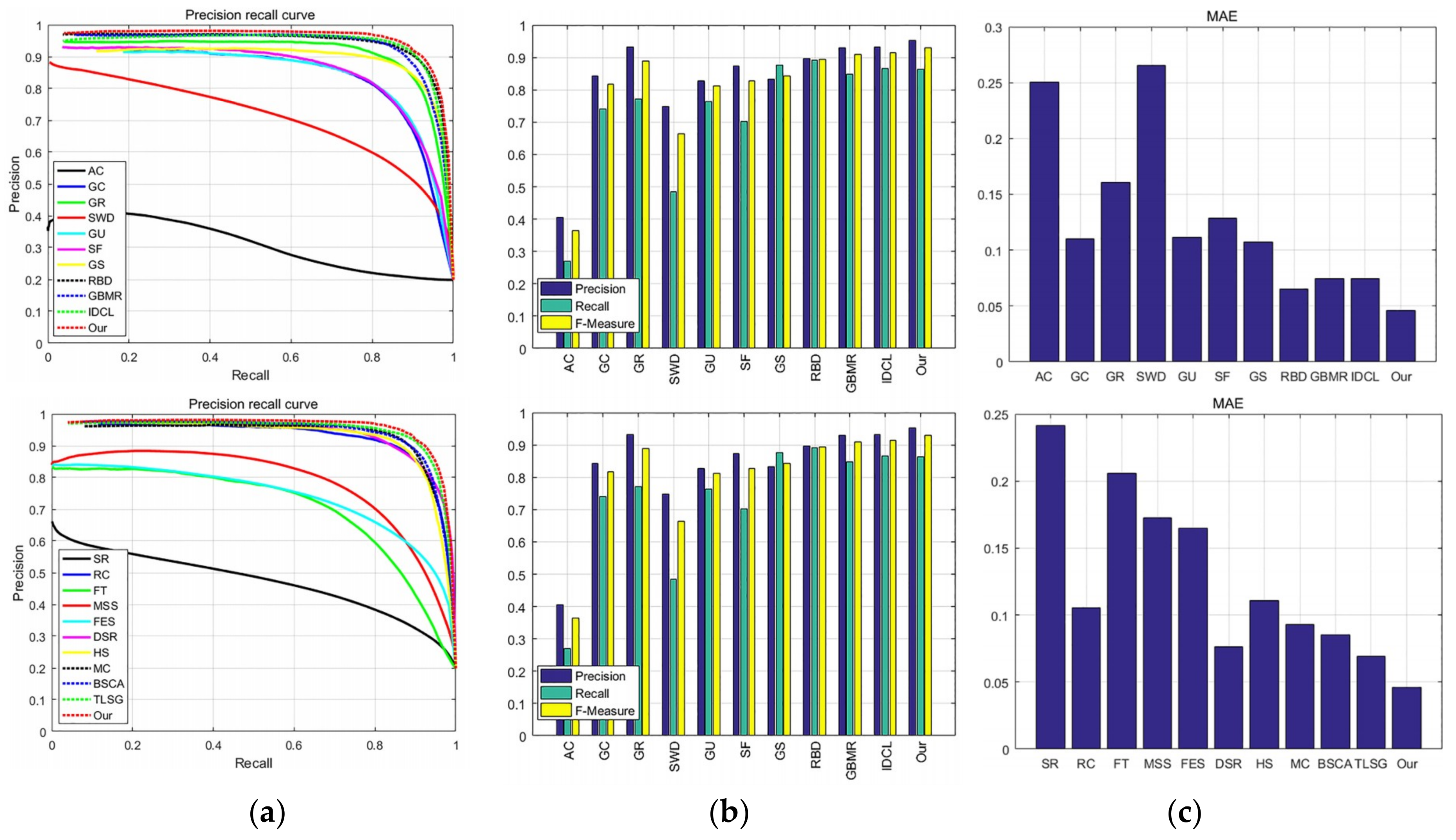
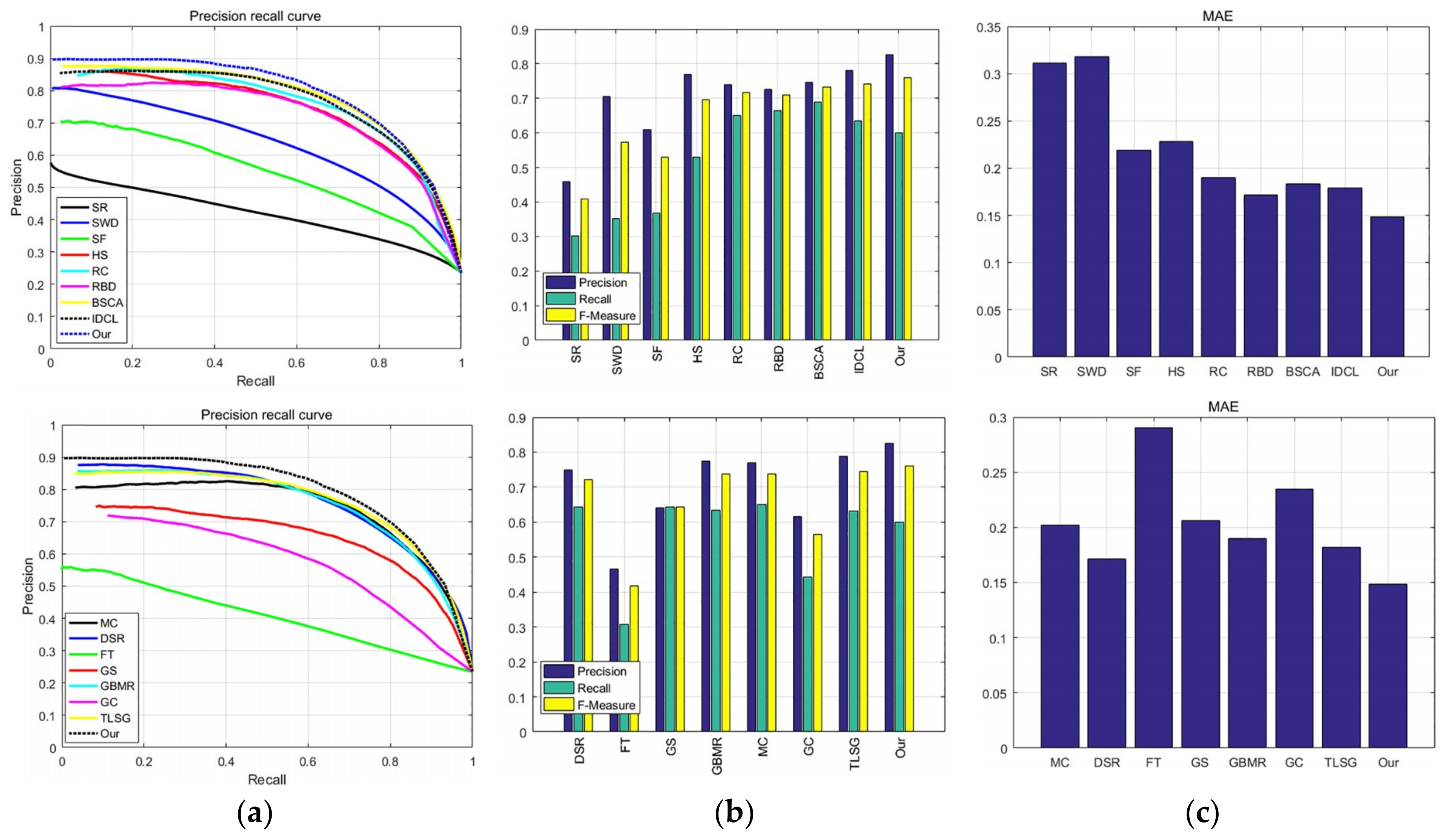
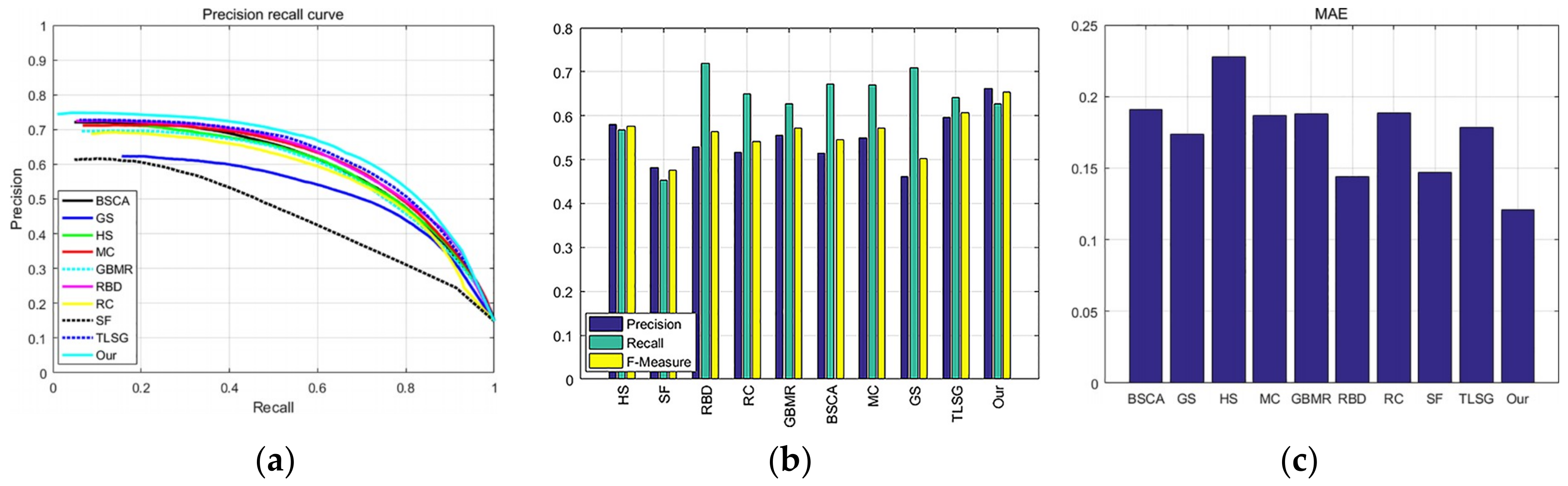
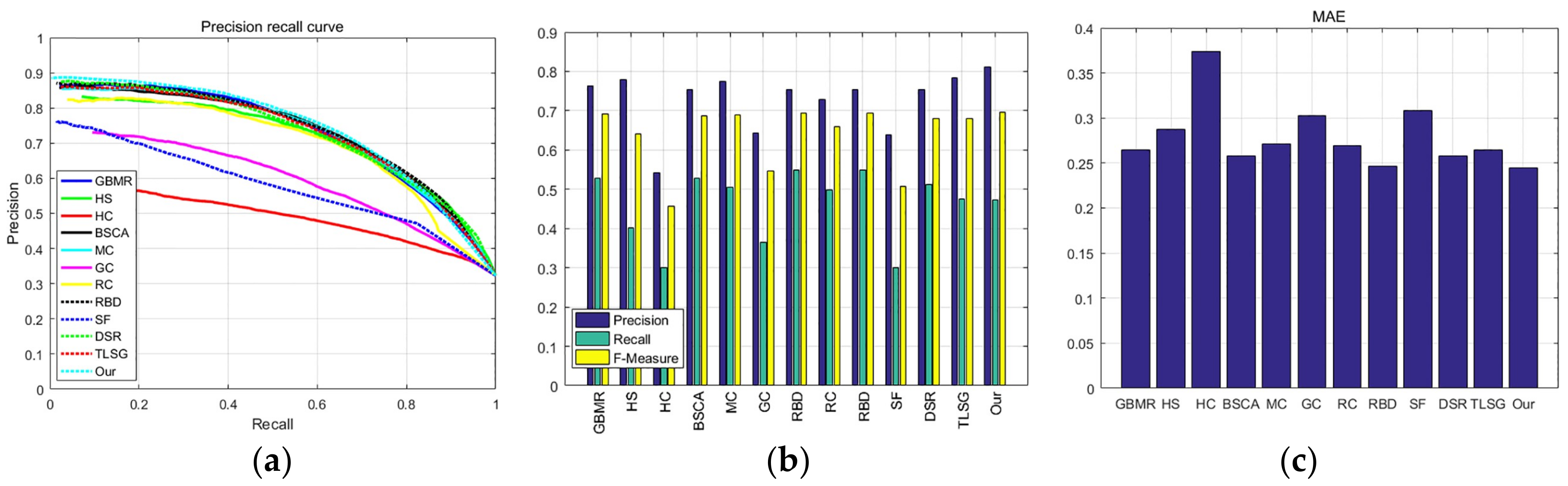
3.5. Quantitative Comparison
3.5.1. ASD
3.5.2. ECSSD
3.5.3. DUT-OMRON
3.5.4. PASCAL-S
4. Failure Cases
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Chang, K.Y.; Liu, T.L.; Lai, S.H. From co-saliency to co-segmentation: An efficient and fully unsupervised energy minimization model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 2129–2136. [Google Scholar]
- Alexe, B.; Deselaers, T.; Ferrari, V. Measuring the Objectness of Image Windows. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2189–2202. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Walther, D.; Rutishauser, U.; Koch, C.; Perona, P. Selective visual attention enables learning and recognition of multiple objects in cluttered scenes. Comput. Vis. Image Underst. 2005, 100, 41–63. [Google Scholar] [CrossRef] [Green Version]
- Guo, C.; Zhang, L. A novel multiresolution spatiotemporal saliency detection model and its applications in image and video compression. Oncogene 1988, 3, 523. [Google Scholar]
- Alexe, B.; Deselaers, T.; Ferrari, V. What is an object? In Proceedings of the Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 73–80. [Google Scholar]
- Yang, J.; Yang, M.H. Top-down visual saliency via joint CRF and dictionary learning. In Proceedings of the Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2296–2303. [Google Scholar]
- Cheng, M.M.; Zhang, G.X.; Mitra, N.J.; Huang, X. Global contrast based salient region detection. In Proceedings of the Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 409–416. [Google Scholar]
- Hornung, A.; Pritch, Y.; Krahenbuhl, P.; Perazzi, F. Saliency filters: Contrast based filtering for salient region detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 733–740. [Google Scholar]
- Zhou, L.; Yang, Z.; Yuan, Q.; Zhou, Z.; Hu, D. Salient Region Detection via Integrating Diffusion-Based Compactness and Local Contrast. IEEE Trans. Image Process. 2015, 24, 3308–3320. [Google Scholar] [CrossRef] [PubMed]
- Wei, Y.; Wen, F.; Zhu, W.; Sun, J. Geodesic Saliency Using Background Priors. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 29–42. [Google Scholar]
- Zhu, W.; Liang, S.; Wei, Y.; Sun, J. Saliency Optimization from Robust Background Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2814–2821. [Google Scholar]
- Li, X.; Lu, H.; Zhang, L.; Xiang, R.; Yang, M.H. Saliency Detection via Dense and Sparse Reconstruction. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2976–2983. [Google Scholar]
- Hou, X.; Zhang, L. Saliency Detection: A Spectral Residual Approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 18–23 June 2007; pp. 1–8. [Google Scholar]
- Achanta, R.; Estrada, F.; Wils, P.; Sstrunk, S. Salient region detection and segmentation. ICVS 2008, 5008, 66–75. [Google Scholar]
- Achanta, R.; Hemami, S.; Estrada, F.; Susstrunk, S. Frequency-tuned salient region detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2009, Miami, FL, USA, 20–25 June 2009; pp. 1597–1604. [Google Scholar]
- Zhou, L.; Yang, Z.; Zhou, Z.; Hu, D. Salient Region Detection using Diffusion Process on a 2-Layer Sparse Graph. IEEE Trans Image Process. 2017, 26, 5882–5894. [Google Scholar] [CrossRef] [PubMed]
- Schölkopf, B.; Platt, J.; Hofmann, T. Graph-Based Visual Saliency. Proc Neural Inf. Process. Syst. 2006, 19, 545–552. [Google Scholar]
- Liu, T.; Sun, J.; Zheng, N.N.; Tang, X.; Shum, H.Y. Learning to Detect A Salient Object. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Chang, K.Y.; Liu, T.L.; Chen, H.T.; Lai, S.H. Fusing generic objectness and visual saliency for salient object detection. In Proceedings of the International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 914–921. [Google Scholar]
- Ren, Z.; Hu, Y.; Chia, L.T.; Rajan, D. Improved saliency detection based on superpixel clustering and saliency propagation. In Proceedings of the ACM International Conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 1099–1102. [Google Scholar]
- Mai, L.; Niu, Y.; Liu, F. Saliency Aggregation: A Data-Driven Approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1131–1138. [Google Scholar]
- Gopalakrishnan, V.; Hu, Y.; Rajan, D. Random walks on graphs for salient object detection in images. IEEE Trans Image Process. 2010, 19, 3232–3242. [Google Scholar] [CrossRef] [PubMed]
- Yang, C.; Zhang, L.; Lu, H.; Xiang, R.; Yang, M.H. Saliency Detection via Graph-Based Manifold Ranking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3166–3173. [Google Scholar]
- Jiang, B.; Zhang, L.; Lu, H.; Yang, C.; Yang, M.-H. Saliency Detection via Absorbing Markov Chain. IEEE Int. Conf. Comput. Vis. 2013. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Ai, J.; Jiang, B.; Lu, H.; Li, X. Saliency Detection via Absorbing Markov Chain with Learnt Transition Probability. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1665–1672. [Google Scholar]
- Lu, S.; Mahadevan, V.; Vasconcelos, N. Learning Optimal Seeds for Diffusion-Based Salient Object Detection. In Proceedings of the Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2790–2797. [Google Scholar]
- Sun, J.; Lu, H.; Liu, X. Saliency Region Detection Based on Markov Absorption Probabilities. IEEE Trans. Image Process. 2015, 24, 1639–1649. [Google Scholar] [CrossRef] [PubMed]
- Jiang, P.; Vasconcelos, N.; Peng, J. Generic Promotion of Diffusion-Based Salient Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 217–225. [Google Scholar]
- Li, C.; Yuan, Y.; Cai, W.; Xia, Y. Robust saliency detection via regularized random walks ranking. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2015), Boston, MA, USA, 7–12 June 2015; pp. 2710–2717. [Google Scholar]
- Qin, Y.; Lu, H.; Xu, Y.; Wang, H. Saliency detection via Cellular Automata. In Proceedings of the Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 110–119. [Google Scholar]
- Li, H.; Lu, H.; Lin, Z.; Shen, X.; Price, B. Inner and inter label propagation: Salient object detection in the wild. IEEE Trans Image Process. 2015, 24, 3176–3186. [Google Scholar] [CrossRef] [PubMed]
- Gong, C.; Tao, D.; Liu, W.; Maybank, S.J.; Fang, M.; Fu, K.; Yang, J. Saliency propagation from simple to difficult. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2531–2539. [Google Scholar]
- Qiu, Y.; Sun, X.; She, M.F. Saliency detection using hierarchical manifold learning. Neurocomputing 2015, 168, 538–549. [Google Scholar] [CrossRef]
- Xiang, D.; Wang, Z. Salient Object Detection via Saliency Spread; Springer International Publishing: New York, NY, USA, 2014; pp. 457–472. [Google Scholar]
- Zhou, L.; Yang, S.; Yang, Y.; Yang, Z. Geodesic distance and compactness prior based salient region detection. In Proceedings of the International Conference on Image and Vision Computing, Palmerston North, New Zealand, 21–22 November 2016; pp. 1–5. [Google Scholar]
- Wang, Z.; Xiang, D.; Hou, S.; Wu, F. Background-Driven Salient Object Detection. IEEE Trans. Multimedia 2017. [Google Scholar] [CrossRef]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC Superpixels Compared to State-of-the-Art Superpixel Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shen, X.; Wu, Y. A unified approach to salient object detection via low rank matrix recovery. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 853–860. [Google Scholar]
- Duan, L.; Wu, C.; Miao, J.; Qing, L.; Fu, Y. Visual saliency detection by spatially weighted dissimilarity. In Proceedings of the Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 473–480. [Google Scholar]
- Otsu, N. Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Yan, Q.; Xu, L.; Shi, J.; Jia, J. Hierarchical Saliency Detection. In Proceedings of the Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1155–1162. [Google Scholar]
- Li, Y.; Hou, X.; Koch, C.; Rehg, J.M.; Yuille, A.L. The Secrets of Salient Object Segmentation. In Proceedings of the Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 280–287. [Google Scholar]
- Cheng, M.M.; Warrell, J.; Lin, W.Y.; Zheng, S.; Vineet, V.; Crook, N. Efficient Salient Region Detection with Soft Image Abstraction. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1529–1536. [Google Scholar]
- Yang, C.; Zhang, L.; Lu, H. Graph-Regularized Saliency Detection With Convex-Hull-Based Center Prior. IEEE Signal Process. Lett. 2013, 20, 637–640. [Google Scholar] [CrossRef]
- Achanta, R.; Süsstrunk, S. Saliency detection using maximum symmetric surround. In Proceedings of the IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010; pp. 2653–2656. [Google Scholar]
- Tavakoli, H.R.; Rahtu, E. Fast and efficient saliency detection using sparse sampling and kernel density estimation. In Proceedings of the Scandinavian Conference on Image Analysis, Ystad, Sweden, 23–27 May 2011; pp. 666–675. [Google Scholar]
- Borji, A.; Cheng, M.M.; Jiang, H.; Li, J. Salient Object Detection: A Benchmark. IEEE Trans. Image Process. 2015, 24, 5706–5722. [Google Scholar] [CrossRef] [Green Version]
- Shuai, J.; Qing, L.; Miao, J.; Ma, Z.; Chen, X. Salient region detection via texture-suppressed background contrast. In Proceedings of the IEEE International Conference on Image Processing, Melbourne, Australia, 15–18 September 2013; pp. 2470–2474. [Google Scholar]
- Yan, X.; Wang, Y.; Song, Q.; Dai, K. Salient object detection via boosting object-level distinctiveness and saliency refinement. J. Vis. Commun. Image Represent. 2017. [Google Scholar] [CrossRef]





© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, H.; Han, G.; Liu, P.; Wu, Y. Salient Region Detection Using Diffusion Process with Nonlocal Connections. Appl. Sci. 2018, 8, 2526. https://doi.org/10.3390/app8122526
Luo H, Han G, Liu P, Wu Y. Salient Region Detection Using Diffusion Process with Nonlocal Connections. Applied Sciences. 2018; 8(12):2526. https://doi.org/10.3390/app8122526
Chicago/Turabian StyleLuo, Huiyuan, Guangliang Han, Peixun Liu, and Yanfeng Wu. 2018. "Salient Region Detection Using Diffusion Process with Nonlocal Connections" Applied Sciences 8, no. 12: 2526. https://doi.org/10.3390/app8122526
APA StyleLuo, H., Han, G., Liu, P., & Wu, Y. (2018). Salient Region Detection Using Diffusion Process with Nonlocal Connections. Applied Sciences, 8(12), 2526. https://doi.org/10.3390/app8122526