Transfer Incremental Learning Using Data Augmentation

 , ,
, ,
Abstract
:1. Introduction
- An ability to learn data using one (or a few) example(s) at a time, in any order, without requiring to reconsider or store previous ones.
- An ability to sustain a classification accuracy comparable to state-of-art methods while traversing successive incremental learning stages, thus avoiding catastrophic forgetting.
- Low computation and memory footprints, during training and classifying phases, that should remain sublinear in both of number of examples and their dimension.
- Perform incremental learning following the above-mentioned definition,
- Approach state-of-the-art performances on vision datasets,
- Reduce memory usage and computation time by several order of magnitude compared to other incremental approaches.
2. Related Work
3. Proposed Method
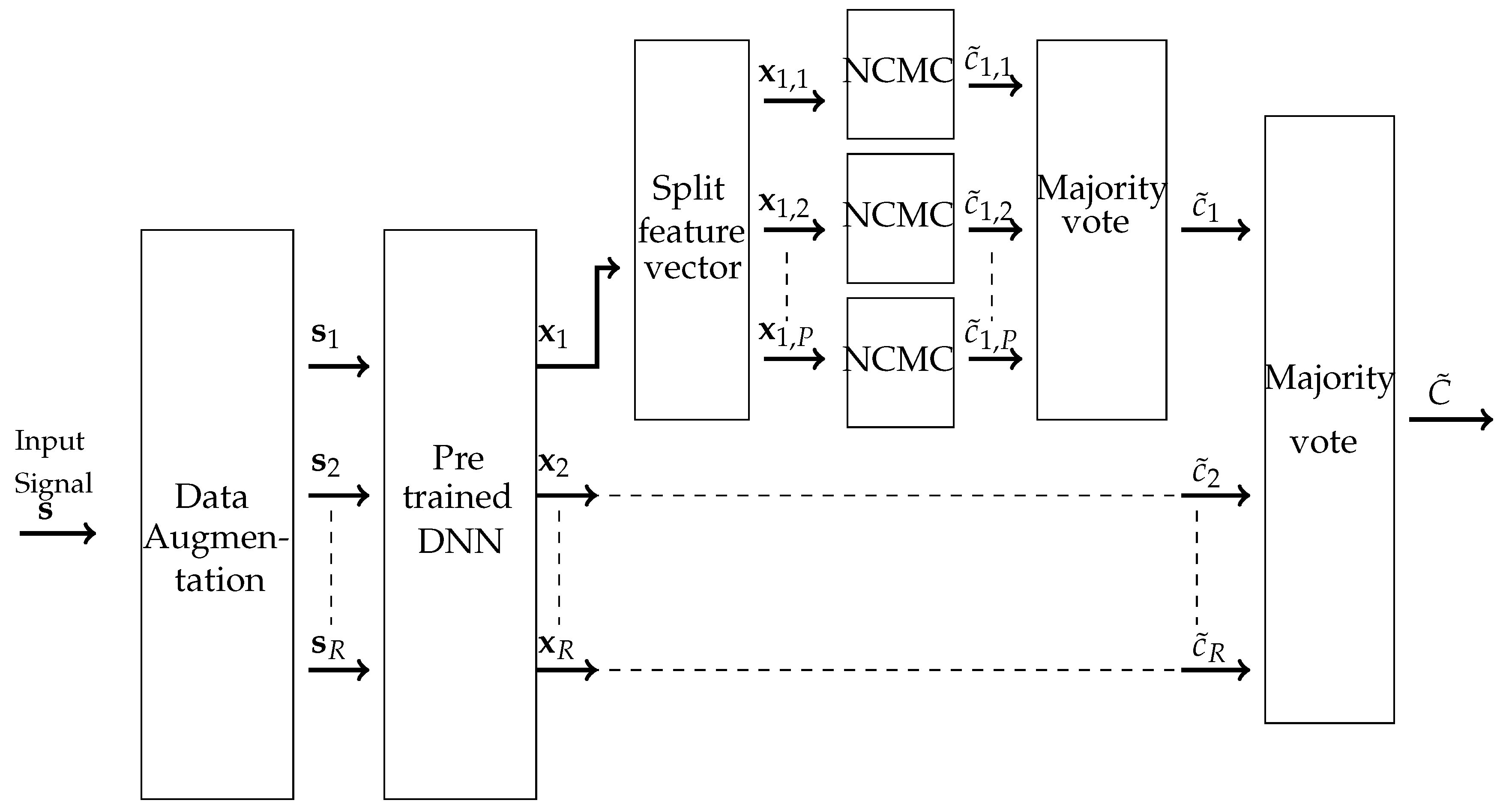
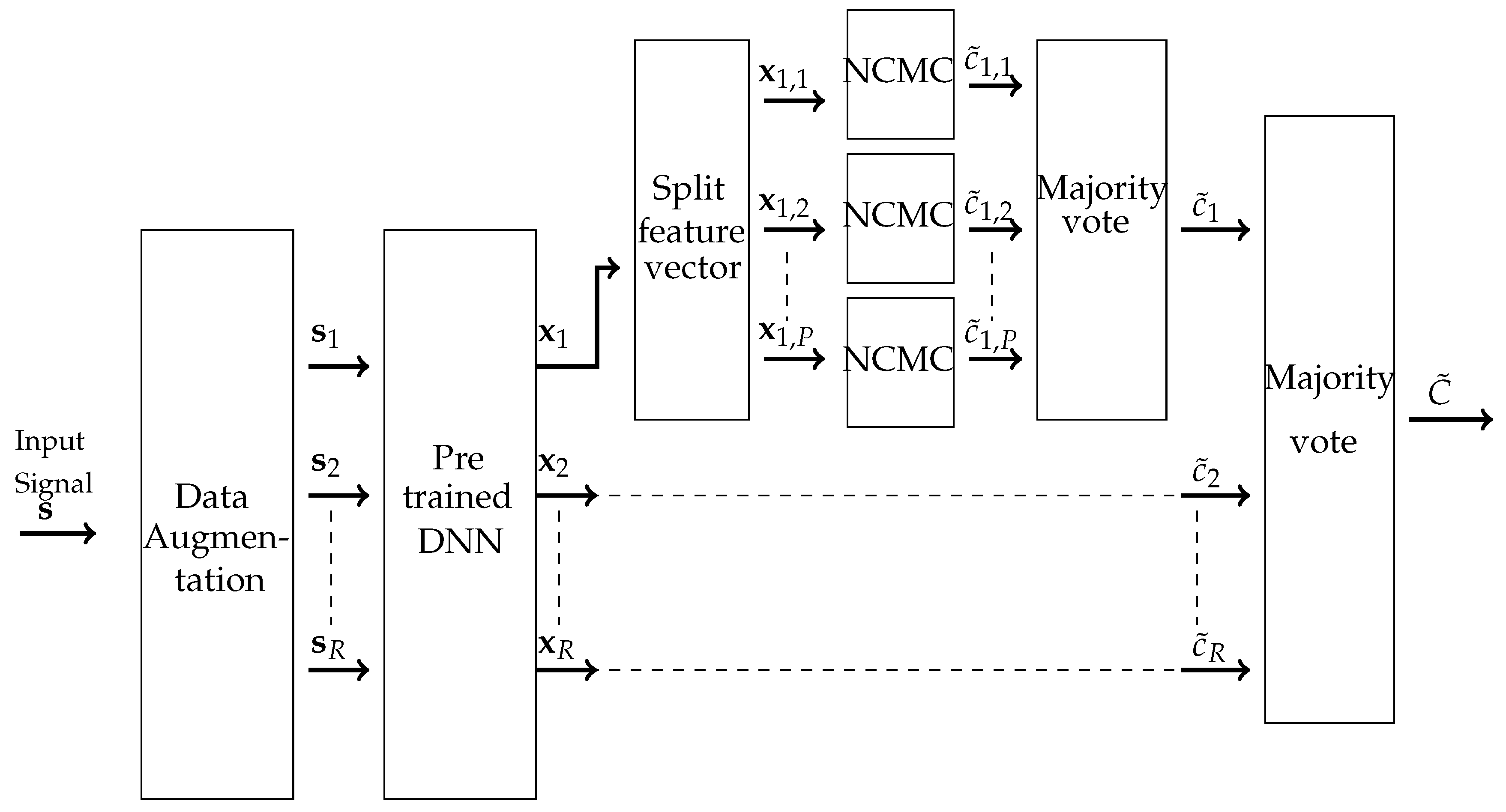
3.1. Overview of the Proposed Method
3.2. Details of the Proposed Method
3.2.1. Pre-Trained Deep Neural Networks
3.2.2. Projection to Low Dimensional Subspaces
| Algorithm 1 Incremental Learning of Anchor Subvectors |
| Input: streaming feature vector |
| for to P do |
| for to k do |
| end for |
| end for |
3.2.3. Aggregation of Subspaces Weak Classifiers
| Algorithm 2 Predicting the Class of a Test Input Signal |
| Input: input signal |
| Compute the feature vector associated with |
| Initialize the vote vector as the 0 vector with dimension C |
| for to P do |
| end for |
| Output: class attributed to |
3.2.4. Data Augmentation
3.2.5. Remarks
- (a)
- The learning procedure performs learning one example at a time,
- (b)
- The learning procedure is computationally light as it only requires performing of the order of d operations where d is the dimension of feature vectors,
- (c)
- The learning procedure has a small memory footprint, as it only stores averages of feature vectors,
- (d)
- The learning procedure is such that adding new examples can only increase robustness of the method, so that there is no catastrophic forgetting,
- (e)
- During prediction stage, memory usage is of the order of and thus is independent on the number of examples and grows linearly with the number of classes,
- (f)
- During prediction stage, computations are of the order of elementary operations.
4. Experiments
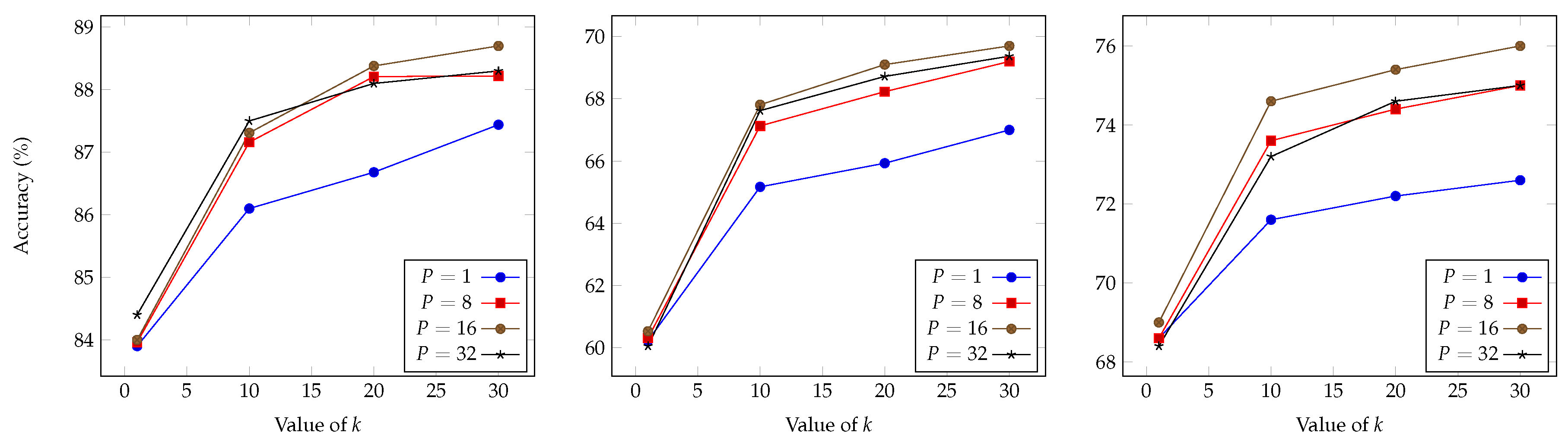
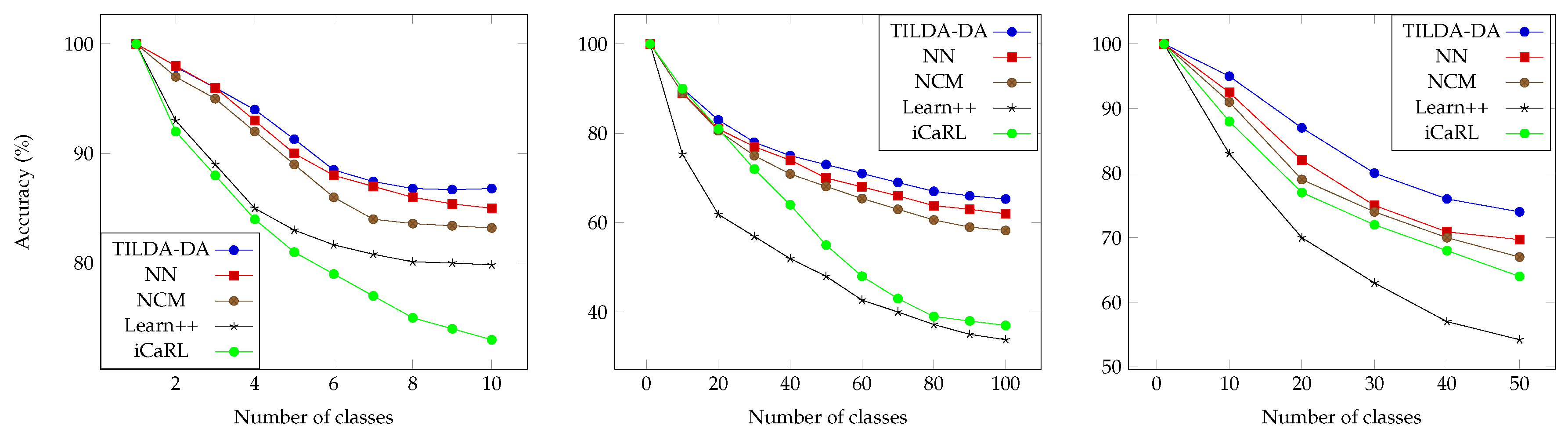
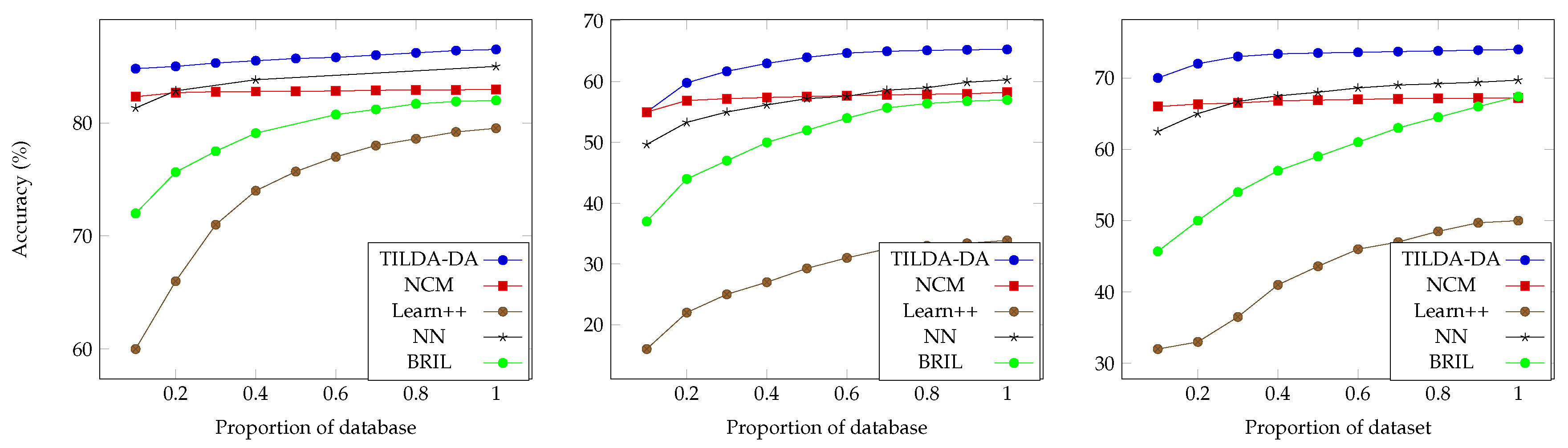
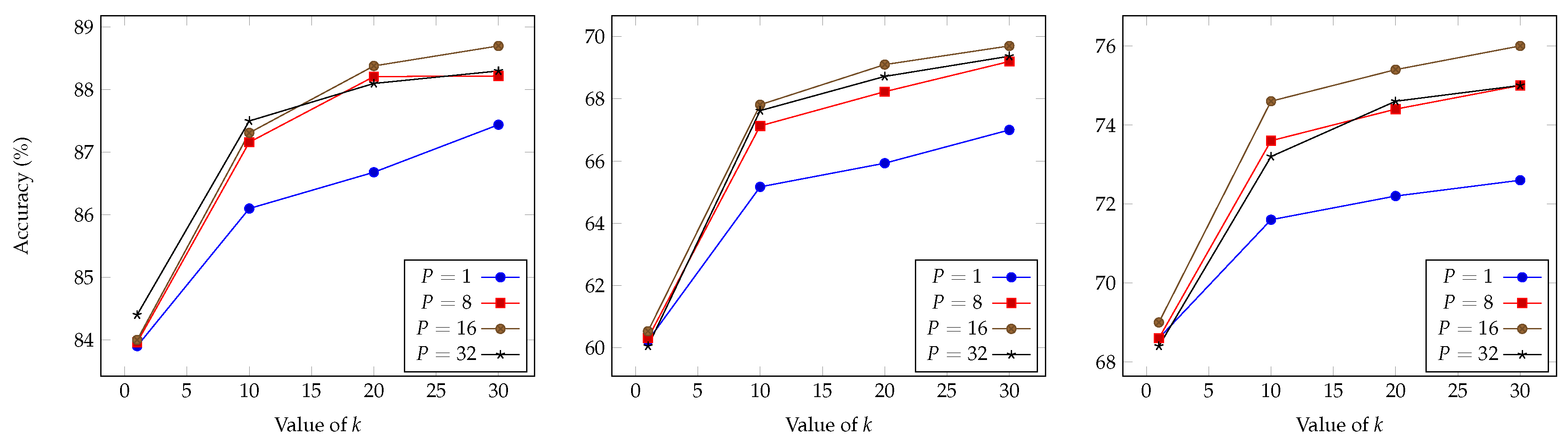
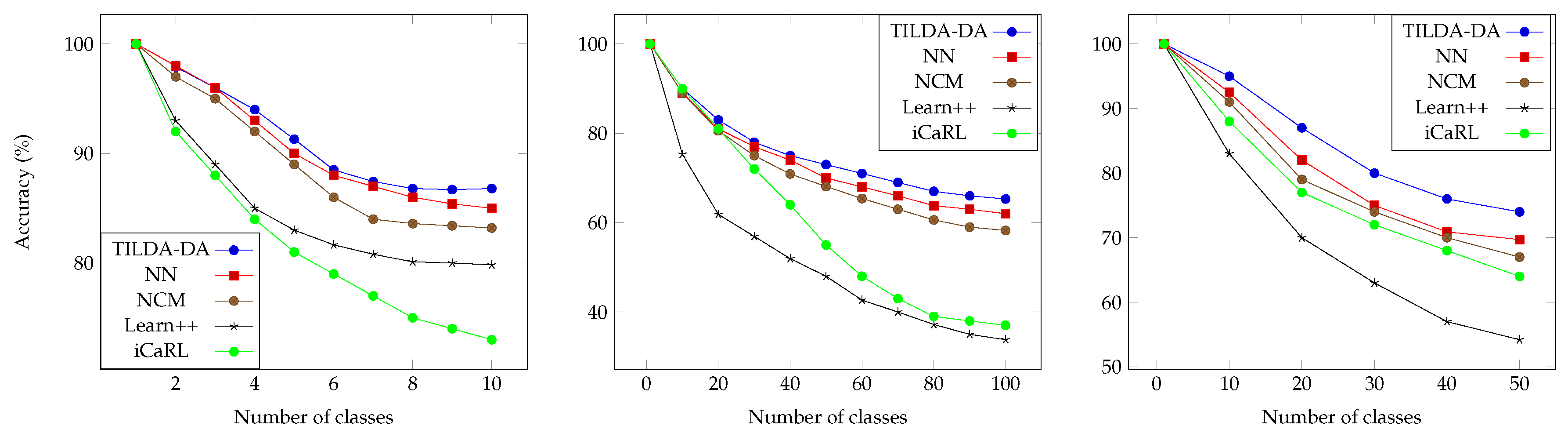
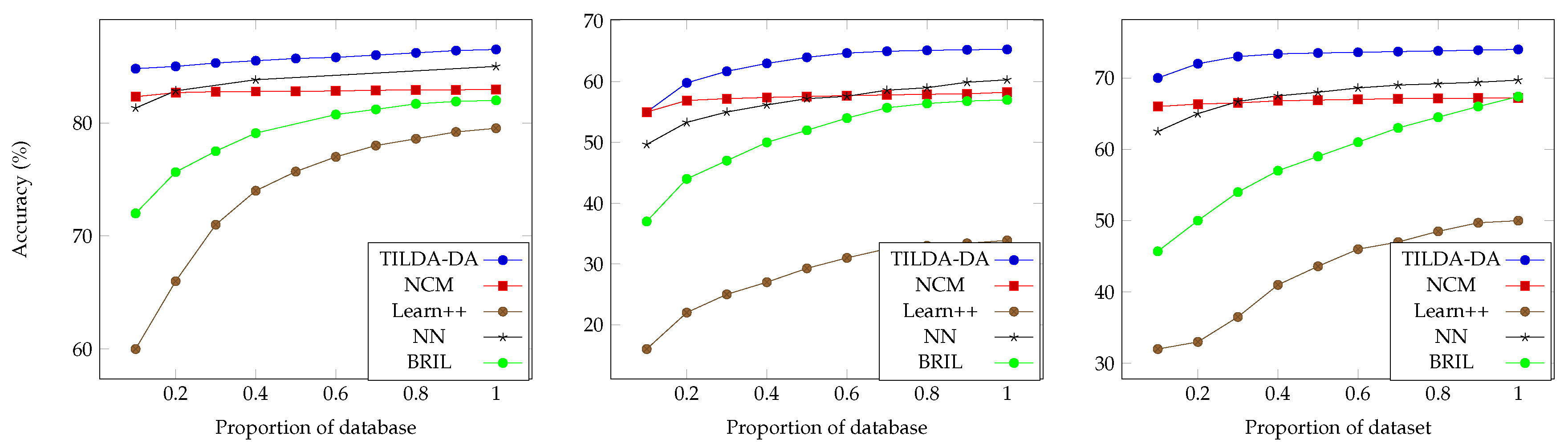
4.1. Benchmark Protocol
4.2. Results
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Bengio, Y.; Louradour, J.; Collobert, R.; Weston, J. Curriculum learning. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; ACM: New York, NY, USA, 2009; pp. 41–48. [Google Scholar]
- Kasabov, N. Evolving Connectionist Systems: Methods and Applications in Bioinformatics, Brain Study and Intelligent Machines; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- French, R.M. Catastrophic forgetting in connectionist networks. Trends Cogn. Sci. 1999, 3, 128–135. [Google Scholar] [CrossRef]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv, 2016; arXiv:1602.07360. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. arXiv, 2015; arXiv:1512.00567. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv, 2013; arXiv:1312.6199. [Google Scholar]
- Rebuffi, S.A.; Kolesnikov, A.; Sperl, G.; Lampert, C.H. iCaRL: Incremental Classifier and Representation Learning. In Proceedings of the 2017 Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Schlimmer, J.C.; Fisher, D. A case study of incremental concept induction. In Proceedings of the 5th National Conference on Artificial Intelligence, AAAI 1986, Philadelphia, PA, USA, 14–15 August 1986; pp. 496–501. [Google Scholar]
- Thrun, S. Is learning the n-th thing any easier than learning the first? In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 1996; pp. 640–646. [Google Scholar]
- Zhou, Z.H.; Chen, Z.Q. Hybrid decision tree. Knowl.-Based Syst. 2002, 15, 515–528. [Google Scholar] [CrossRef]
- Syed, N.A.; Huan, S.; Kah, L.; Sung, K. Incremental Learning with Support Vector Machines; CiteSeerX: University Park, PA, USA, 1999. [Google Scholar]
- Poggio, T.; Cauwenberghs, G. Incremental and decremental support vector machine learning. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2001; Volume 13, p. 409. [Google Scholar]
- Zheng, J.; Shen, F.; Fan, H.; Zhao, J. An online incremental learning support vector machine for large-scale data. Neural Comput. Appl. 2013, 22, 1023–1035. [Google Scholar] [CrossRef]
- Polikar, R.; Upda, L.; Upda, S.S.; Honavar, V. Learn++: An incremental learning algorithm for supervised neural networks. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2001, 31, 497–508. [Google Scholar] [CrossRef]
- Muhlbaier, M.D.; Topalis, A.; Polikar, R. Learn++. NC: Combining Ensemble of Classifiers with Dynamically Weighted Consult-and-Vote for Efficient Incremental Learning of New Classes. IEEE Trans. Neural Netw. 2009, 20, 152–168. [Google Scholar] [CrossRef] [PubMed]
- Pentina, A.; Sharmanska, V.; Lampert, C.H. Curriculum learning of multiple tasks. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5492–5500. [Google Scholar]
- Mensink, T.; Verbeek, J.; Perronnin, F.; Csurka, G. Distance-based image classification: Generalizing to new classes at near-zero cost. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2624–2637. [Google Scholar] [CrossRef] [PubMed]
- Mensink, T.; Verbeek, J.; Perronnin, F.; Csurka, G. Metric learning for large scale image classification: Generalizing to new classes at near-zero cost. In Proceedings of the Computer Vision–ECCV 2012, Florence, Italy, 7–13 October 2012; pp. 488–501. [Google Scholar]
- Ristin, M.; Guillaumin, M.; Gall, J.; Van Gool, L. Incremental learning of NCM forests for large-scale image classification. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3654–3661. [Google Scholar]
- Hacene, G.B.; Gripon, V.; Farrugia, N.; Arzel, M.; Jezequel, M. Budget restricted incremental learning with pre-trained convolutional neural networks and binary associative memories. In Proceedings of the 2017 IEEE International Workshop on Signal Processing Systems (SiPS), Lorient, France, 3–5 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Kuzborskij, I.; Orabona, F.; Caputo, B. From n to n + 1: Multiclass transfer incremental learning. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3358–3365. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2012; pp. 1097–1105. [Google Scholar]
- Oquab, M.; Bottou, L.; Laptev, I.; Sivic, J. Learning and Transferring Mid-Level Image Representations using Convolutional Neural Networks. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Hong, S.; You, T.; Kwak, S.; Han, B. Online Tracking by Learning Discriminative Saliency Map with Convolutional Neural Network. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 597–606. [Google Scholar]
- Ciresan, D.; Meier, U.; Gambardella, L.; Schmidhuber, J. Deep Big Simple Neural Nets Excel on Handwritten Digit Recognition. arXiv, 2010; arXiv:1003.0358. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| TILDA | TILDA-DA | TILDA-NCM | TILDA-P | |
|---|---|---|---|---|
| CIFAR100 | ||||
| CIFAR10 | ||||
| ImageNet50 | ||||
| ILSVRC 2012 |
| Only CI | Both CI and EI | Only EI | ||||||
|---|---|---|---|---|---|---|---|---|
| Learn++ | iCaRL | TILDA | TILDA-DA | NN | NCM | BRIL | Learn++ | |
| Acc (CIFAR100) | ||||||||
| M (CIFAR100) | ||||||||
| Acc (CIFAR10) | ||||||||
| M (CIFAR10) | ||||||||
| Acc (ImageNet50) | ||||||||
| M (ImageNet50) | ||||||||
| TILDA | TILDA-DA | TMLP | TSVM | |
|---|---|---|---|---|
| Acc (CIFAR100) | ||||
| Acc (CIFAR10) | ||||
| Acc (ImageNet50) |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Boukli Hacene, G.; Gripon, V.; Farrugia, N.; Arzel, M.; Jezequel, M. Transfer Incremental Learning Using Data Augmentation. Appl. Sci. 2018, 8, 2512. https://doi.org/10.3390/app8122512
Boukli Hacene G, Gripon V, Farrugia N, Arzel M, Jezequel M. Transfer Incremental Learning Using Data Augmentation. Applied Sciences. 2018; 8(12):2512. https://doi.org/10.3390/app8122512
Chicago/Turabian StyleBoukli Hacene, Ghouthi, Vincent Gripon, Nicolas Farrugia, Matthieu Arzel, and Michel Jezequel. 2018. "Transfer Incremental Learning Using Data Augmentation" Applied Sciences 8, no. 12: 2512. https://doi.org/10.3390/app8122512
APA StyleBoukli Hacene, G., Gripon, V., Farrugia, N., Arzel, M., & Jezequel, M. (2018). Transfer Incremental Learning Using Data Augmentation. Applied Sciences, 8(12), 2512. https://doi.org/10.3390/app8122512