Improving Convolutional Neural Networks’ Accuracy in Noisy Environments Using k-Nearest Neighbors




Abstract
1. Introduction
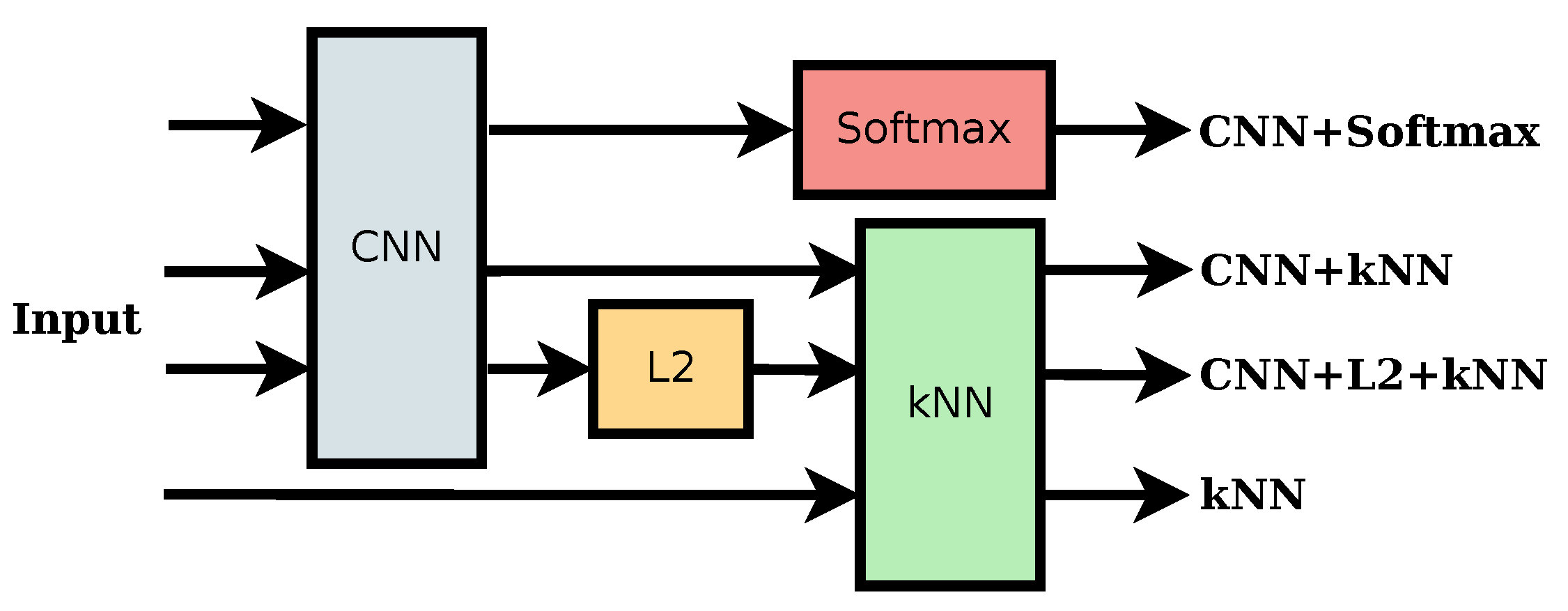
2. Materials and Methods
- Use of the CNN softmax layer.
- Use of the last hidden CNN layer (before the softmax) to get the neural codes, which are fed to a kNN that compares them to the training set prototypes using Euclidean distance in order to get the most likely class.
- Similar to the previous configuration, but normalizing with the neural codes before the kNN.
- Using directly the kNN on the raw data without any representation learning.
- Landsat is a dataset from the UCI repository [22]. It comprises windows in the four spectral bands depicting images of satellites. Each window is labeled as regards the information of the central pixel of the window.
- Handwritten Online Musical Symbol (HOMUS) [23] depicts binary images of isolated handwritten music symbols collected from 100 different musicians.
- NIST Special Database 19 (NIST) of the National Institute of Standards and Technology [24] consists of a huge dataset of isolated characters. For this work, a subset of the upper case characters was selected.
3. Experiments
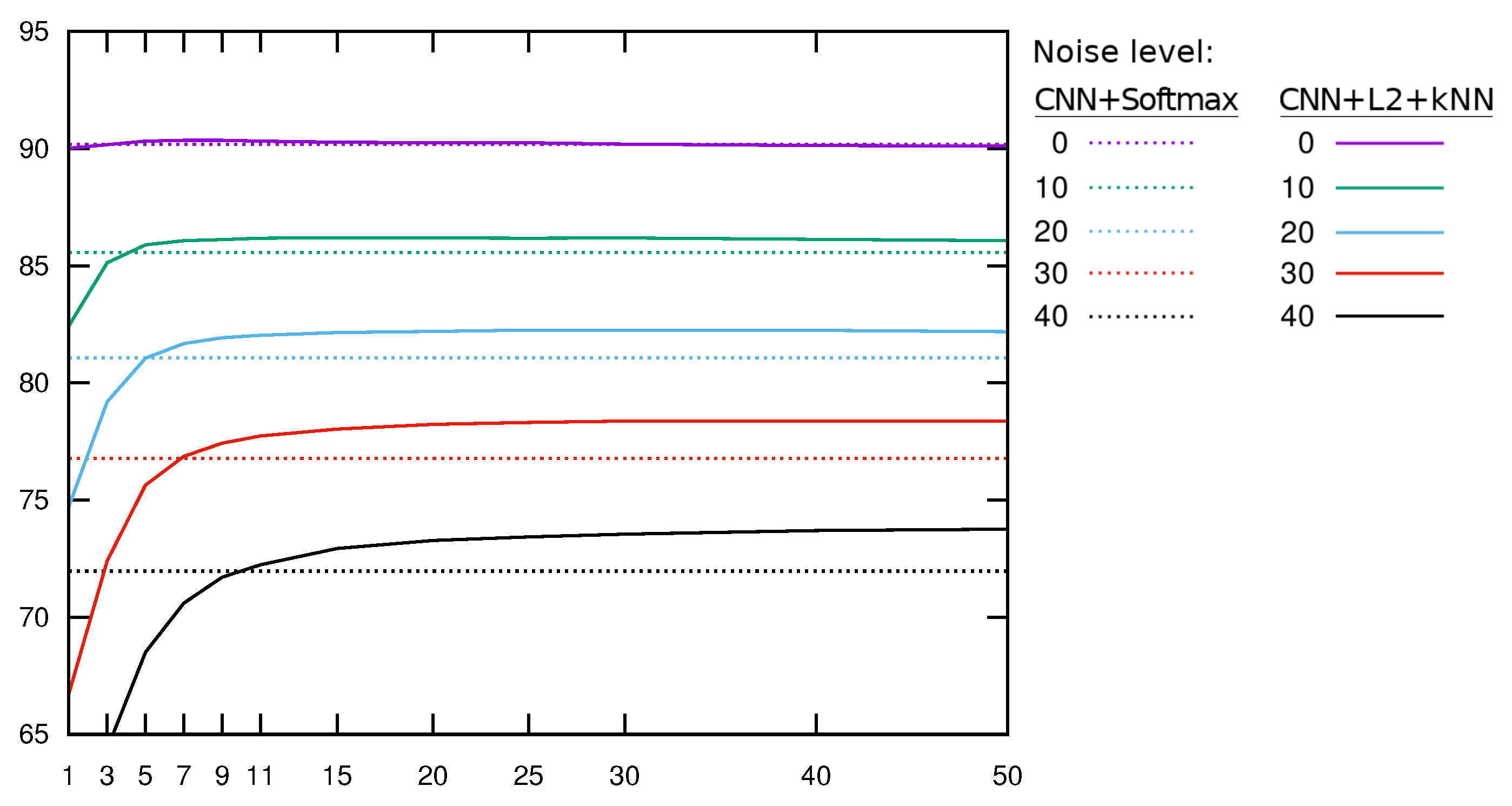
3.1. Statistical Significance Tests
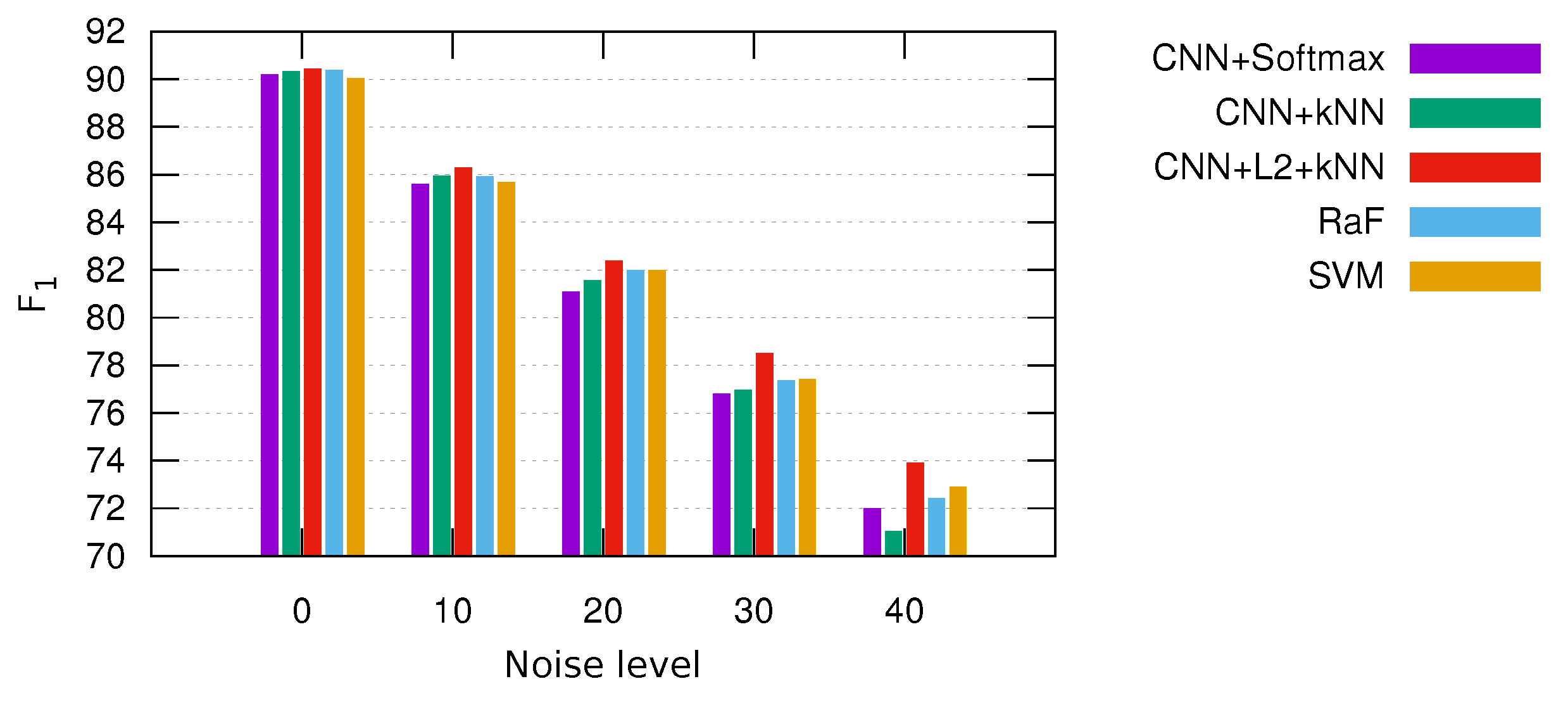
3.2. Comparison with Other Classifiers
- Support Vector Machine (SVM) [36]: This learns a hyperplane that tries to maximize the distance to the nearest samples (support vectors) of each class. It makes use of kernel functions to handle non-linear decision boundaries. In our case, a radial basis function (or Gaussian) kernel is considered. Typically, SVM also considers a parameter that measures the cost of learning a non-optimal hyperplane, which is usually referred to as parameter c. During preliminary experiments, we tuned this parameter in the range .
- Random Forest (RaF) [37]: This builds an ensemble classifier by generating several random decision trees at the training stage. The final output is taken by combining the individual decisions of each tree. The number of random trees has been established experimenting in the range .
4. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Jindal, I.; Nokleby, M.; Chen, X. Learning Deep Networks from Noisy Labels with Dropout Regularization. arXiv, 2017; arXiv:1705.03419. [Google Scholar]
- Zhu, X.; Wu, X. Class Noise vs. Attribute Noise: A Quantitative Study. Artif. Intell. Rev. 2004, 22, 177–210. [Google Scholar] [CrossRef]
- Benoît Frénay, M.V. Classification in the Presence of Label Noise: A Survey. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 845–869. [Google Scholar] [CrossRef] [PubMed]
- Bekker, A.J.; Goldberger, J. Training deep neural-networks based on unreliable labels. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2016), Shanghai, China, 20–25 March 2016; pp. 2682–2686. [Google Scholar] [CrossRef]
- Sukhbaatar, S.; Bruna, J.; Paluri, M.; Bourdev, L.; Fergus, R. Training Convolutional Networks with Noisy Labels. arXiv, 2014; arXiv:1406.2080. [Google Scholar]
- Reed, S.; Lee, H.; Anguelov, D.; Szegedy, C.; Erhan, D.; Rabinovich, A. Training Deep Neural Networks on Noisy Labels with Bootstrapping. arXiv, 2014; arXiv:1412.6596. [Google Scholar]
- Patrini, G.; Rozza, A.; Krishna Menon, A.; Nock, R.; Qu, L. Making Deep Neural Networks Robust to Label Noise: A Loss Correction Approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Azizpour, H.; Razavian, A.S.; Sullivan, J. Factors of Transferability for a Generic ConvNet Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1790–1802. [Google Scholar] [CrossRef] [PubMed]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Montreal, QC, USA, 8–13 December 2014; pp. 3320–3328. [Google Scholar]
- Babenko, A.; Slesarev, A.; Chigorin, A.; Lempitsky, V. Neural Codes for Image Retrieval. In Computer Vision–ECCV 2014, Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Part I; Springer International Publishing: Cham, Switzerland, 2014; pp. 584–599. [Google Scholar]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the Devil in the Details: Delving Deep into Convolutional Nets. arXiv, 2014; arXiv:1405.3531. [Google Scholar]
- Sharif Razavian, A.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN Features Off-the-Shelf: An Astounding Baseline for Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Columbus, OH, USA, 24–27 June 2014. [Google Scholar]
- Huang, F.; LeCun, Y. Large-scale learning with SVM and convolutional nets for generic object categorization. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2006), New York, NY, USA, 17–22 June 2006; Volume 1, pp. 284–291. [Google Scholar] [CrossRef]
- Jarrett, K.; Kavukcouglu, K.; Ranzato, M.; LeCun, Y. What is the Best Multi-Stage Architecture for Object Recognition? In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Kyoto, Japan, 29 September–2 October 2009; Volume 12. [Google Scholar]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G. Recent Advances in Convolutional Neural Networks. arXiv, 2015; arXiv:1512.07108. [Google Scholar]
- Kontschieder, P.; Fiterau, M.; Criminisi, A.; Rota Bulo, S. Deep Neural Decision Forests. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015. [Google Scholar]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Zheng, L.; Zhao, Y.; Wang, S.; Wang, J.; Tian, Q. Good Practice in CNN Feature Transfer. arXiv, 2016; arXiv:1604.00133. [Google Scholar]
- Hull, J.J. A database for handwritten text recognition research. IEEE Trans. Pattern Anal. Mach. Intell. 1994, 16, 550–554. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Dheeru, D.; Karra Taniskidou, E. UCI Machine Learning Repository; School of Information and Computer Sciences, University of of California: Irvine, CA, USA, 2017. [Google Scholar]
- Calvo-Zaragoza, J.; Oncina, J. Recognition of Pen-Based Music Notation: The HOMUS Dataset. In Proceedings of the International Conference on Pattern Recognition (ICPR), Stockholm, Sweden, 24–28 August 2014. [Google Scholar] [CrossRef]
- Wilkinson, R.A.; Geist, J.; Janet, S.; Grother, P.J.; Burges, C.J.; Creecy, R.; Hammond, B.; Hull, J.J.; Larsen, N.O.; Vogl, T.P.; et al. The First Census Optical Character Recognition System Conference; Technical Report; US Department of Commerce: Gaithersburg, MD, USA, 1992. [CrossRef]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features From Tiny Images; Technical Report; University of Toronto: Toronto, ON, USA, 2009. [Google Scholar]
- Torralba, A.; Fergus, R.; Freeman, W.T. 80 million tiny images: A large data set for nonparametric object and scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1958–1970. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Bottou, L. Large-scale machine learning with stochastic gradient descent. In Proceedings of the 19th International Symposium on Computational Statistics, Paris, France, 22–27 August 2010; Springer: New York, NY, USA, 2010; pp. 177–186. [Google Scholar]
- Zeiler, M.D. ADADELTA: An Adaptive Learning Rate Method. arXiv, 2012; arXiv:1212.5701. [Google Scholar]
- Natarajan, N.; Dhillon, I.; Ravikumar, P.; Tewari, A. Learning with noisy labels. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 1196–1204. [Google Scholar]
- Johnson, J.; Douze, M.; Jégou, H. Billion-scale similarity search with GPUs. arXiv, 2017; arXiv:1702.08734. [Google Scholar]
- Gallego, A.J.; Calvo-Zaragoza, J.; Valero-Mas, J.J.; Rico-Juan, J.R. Clustering-based k-nearest neighbor classification for large-scale data with neural codes representation. Pattern Recognit. 2018, 74, 531–543. [Google Scholar] [CrossRef]
- Malkov, Y.A.; Yashunin, D.A. Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs. arXiv, 2016; arXiv:1603.09320. [Google Scholar]
- Demsar, J. Statistical Comparisons of Classifiers over Multiple Data Sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Vapnik, V.N. Statistical Learning Theory, 1st ed.; Wiley: New York, NY, USA, 1998. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Ren, W.; Yu, Y.; Zhang, J.; Huang, K. Learning Convolutional NonLinear Features for K Nearest Neighbor Image Classification. In Proceedings of the IEEE International Conference on Pattern Recognition (ICPR), Stockholm, Sweden, 24–28 August 2014. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Instances | Classes | Shape |
|---|---|---|---|
| USPS | 9298 | 10 | |
| MNIST | 70,000 | 10 | |
| Landsat | 6435 | 6 | |
| HOMUS | 15,200 | 32 | |
| NIST | 44,951 | 26 | |
| CIFAR10 | 60,000 | 10 | |
| CIFAR100 | 60,000 | 100 |
| Dataset | Layer 1 | Layer 2 | Layer 3 | Layer 4 | Layer 5 | Layer 6 | Layer 7 |
|---|---|---|---|---|---|---|---|
| USPS | Conv () | Conv () MaxPool () Drop (0.25) | FC (128) Drop (0.5) | ||||
| MNIST | Conv () | Conv () MaxPool () Drop (0.25) | FC (128) Drop (0.5) | ||||
| Landsat | Conv () UpSamp () Drop (0.3) | Conv () UpSamp () Drop (0.3) | Conv () MaxPool () UpSamp () Drop (0.3) | FC (256) Drop (0.3) | FC (128) Drop (0.3) | ||
| HOMUS | Conv () MaxPool () Drop (0.2) | Conv () MaxPool () Drop (0.2) | Conv () Drop (0.2) | Conv () Drop (0.2) | FC (512) Drop (0.1) | FC (256) Drop (0.1) | FC (128) Drop (0.1) |
| NIST | Conv () MaxPool () Drop (0.2) | Conv () MaxPool () Drop (0.2) | Conv () Drop (0.2) | Conv () Drop (0.2) | FC (512) Drop (0.1) | FC (256) Drop (0.1) | FC (128) Drop (0.1) |
| CIFAR10 | VGG16 [27] | ||||||
| CIFAR100 | ResNet50 [28] scaling input images to | ||||||
| Dataset | Method | Noise (%) | ||||
|---|---|---|---|---|---|---|
| 0 | 10 | 20 | 30 | 40 | ||
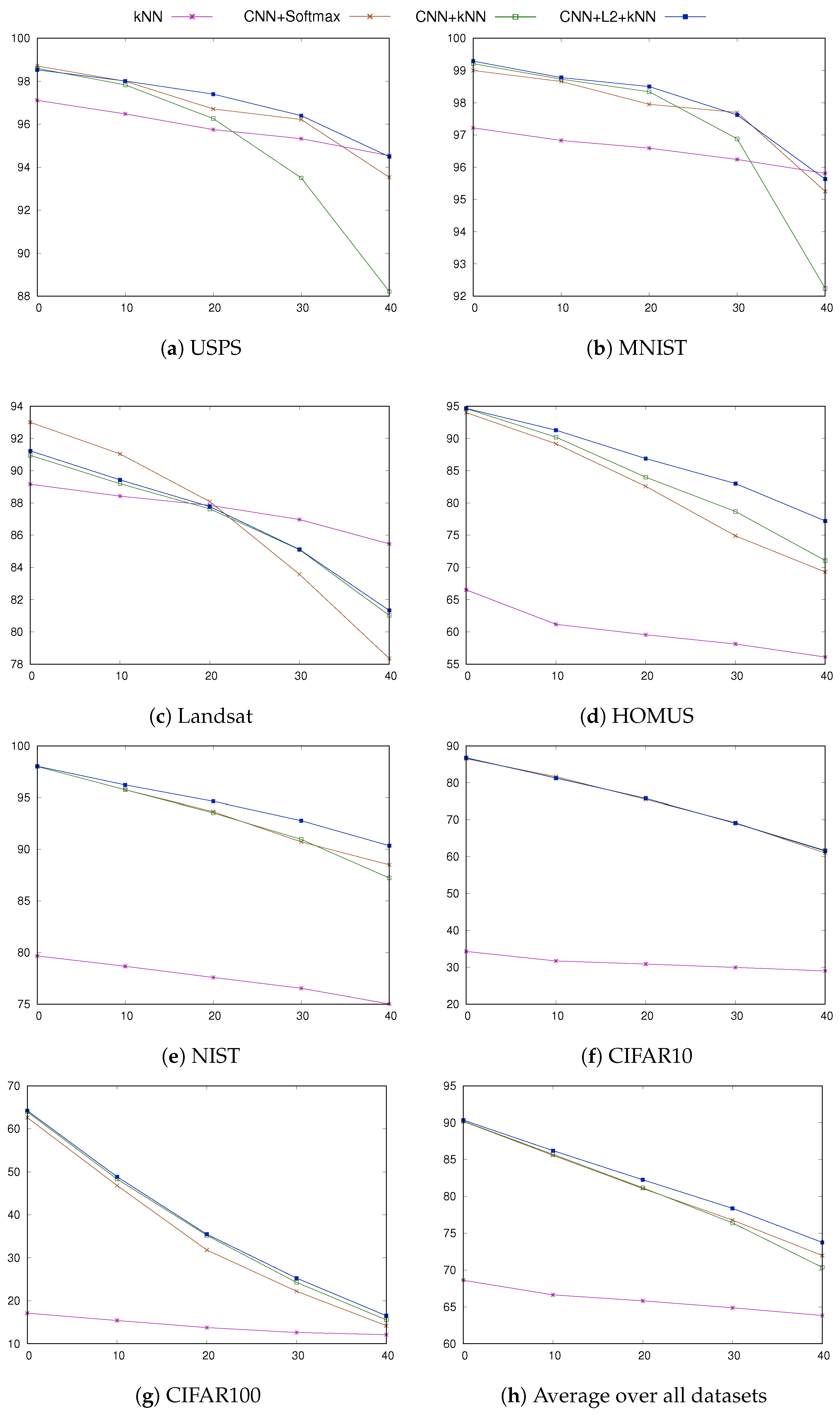
| USPS | kNN | 97.11 (1) | 96.48 (5) | 95.75 (9) | 95.33 (15) | 94.54 (15) |
| CNN + softmax | 98.71 | 98.00 | 96.71 | 96.22 | 93.53 | |
| CNN + kNN | 98.60 (5) | 97.83 (9) | 96.26 (11) | 93.50 (11) | 88.22 (20) | |
| CNN + + kNN | 98.53 (3) | 98.01 (7) | 97.40 (11) | 96.40 (25) | 94.49 (40) | |
| MNIST | kNN | 97.22 (1) | 96.83 (7) | 96.59 (9) | 96.24 (15) | 95.81 (20) |
| CNN + softmax | 99.00 | 98.66 | 97.95 | 97.70 | 95.25 | |
| CNN + kNN | 99.21 (5) | 98.73 (15) | 98.34 (20) | 96.88 (40) | 92.24 (50) | |
| CNN + + kNN | 99.29 (3) | 98.78 (11) | 98.50 (11) | 97.62 (30) | 95.63 (50) | |
| Landsat | kNN | 89.16 (3) | 88.42 (7) | 87.85 (9) | 86.97 (20) | 85.46 (20) |
| CNN + softmax | 93.00 | 91.04 | 88.08 | 83.57 | 78.35 | |
| CNN + kNN | 90.95 (7) | 89.19 (11) | 87.63 (20) | 85.10 (30) | 81.02 (50) | |
| CNN + + kNN | 91.23 (1) | 89.43 (15) | 87.77 (25) | 85.11 (40) | 81.33 (50) | |
| HOMUS | kNN | 66.52 (1) | 61.17 (7) | 59.56 (7) | 58.12 (9) | 56.1 (15) |
| CNN + softmax | 94.00 | 89.18 | 82.57 | 74.90 | 69.28 | |
| CNN + kNN | 94.63 (3) | 90.20 (9) | 83.99 (7) | 78.67 (9) | 71.07 (9) | |
| CNN + + kNN | 94.66 (1) | 91.28 (7) | 86.88 (15) | 83.01 (25) | 77.20 (15) | |
| NIST | kNN | 79.67 (5) | 78.66 (5) | 77.58 (7) | 76.53 (9) | 75.01 (15) |
| CNN + softmax | 98.00 | 95.75 | 93.64 | 90.72 | 88.5 | |
| CNN + kNN | 98.00 (1) | 95.75 (50) | 93.52 (50) | 90.96 (50) | 87.22 (50) | |
| CNN + + kNN | 98.03 (1) | 96.22 (40) | 94.64 (50) | 92.77 (50) | 90.35 (50) | |
| CIFAR10 | kNN | 34.28 (1) | 31.7 (9) | 30.87 (9) | 29.95 (15) | 29 (30) |
| CNN + softmax | 86.50 | 81.66 | 75.49 | 69.22 | 61.00 | |
| CNN + kNN | 86.70 (5) | 81.30 (5) | 75.77 (20) | 69.07 (30) | 61.69 (15) | |
| CNN + + kNN | 86.79 (7) | 81.26 (7) | 75.78 (5) | 69.04 (20) | 61.54 (7) | |
| CIFAR100 | kNN | 17.11 (1) | 15.41 (1) | 13.76 (1) | 12.62 (11) | 12.11 (20) |
| CNN + softmax | 62.60 | 46.80 | 31.80 | 22.20 | 14.20 | |
| CNN + kNN | 63.93 (25) | 48.30 (50) | 35.21 (50) | 24.28 (50) | 15.56 (50) | |
| CNN + + kNN | 64.23 (11) | 48.85 (20) | 35.46 (40) | 25.27 (50) | 16.51 (50) | |
| Average | kNN | 68.62 | 66.63 | 65.83 | 64.88 | 63.83 |
| CNN + softmax | 90.17 | 85.56 | 81.06 | 76.77 | 71.97 | |
| CNN + kNN | 90.20 | 85.70 | 81.16 | 76.39 | 70.37 | |
| CNN + + kNN | 90.35 | 86.20 | 82.25 | 78.37 | 73.76 | |
| Noise | Test | |||
|---|---|---|---|---|
| CNN + softmax > kNN | CNN + kNN > CNN + softmax | CNN + + kNN > CNN + softmax | CNN + + kNN > CNN + kNN | |
| 0 | ✓ | ✓ | ||
| 10 | ✓ | ✓ | ✓ | |
| 20 | ✓ | ✗ | ✓ | ✓ |
| 30 | ✓ | ✗ | ✓ | ✓ |
| 40 | ✓ | ✗ | ✓ | ✓ |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gallego, A.-J.; Pertusa, A.; Calvo-Zaragoza, J. Improving Convolutional Neural Networks’ Accuracy in Noisy Environments Using k-Nearest Neighbors. Appl. Sci. 2018, 8, 2086. https://doi.org/10.3390/app8112086
Gallego A-J, Pertusa A, Calvo-Zaragoza J. Improving Convolutional Neural Networks’ Accuracy in Noisy Environments Using k-Nearest Neighbors. Applied Sciences. 2018; 8(11):2086. https://doi.org/10.3390/app8112086
Chicago/Turabian StyleGallego, Antonio-Javier, Antonio Pertusa, and Jorge Calvo-Zaragoza. 2018. "Improving Convolutional Neural Networks’ Accuracy in Noisy Environments Using k-Nearest Neighbors" Applied Sciences 8, no. 11: 2086. https://doi.org/10.3390/app8112086
APA StyleGallego, A.-J., Pertusa, A., & Calvo-Zaragoza, J. (2018). Improving Convolutional Neural Networks’ Accuracy in Noisy Environments Using k-Nearest Neighbors. Applied Sciences, 8(11), 2086. https://doi.org/10.3390/app8112086