Interference-Aware Cooperative Anti-Jamming Distributed Channel Selection in UAV Communication Networks


Abstract
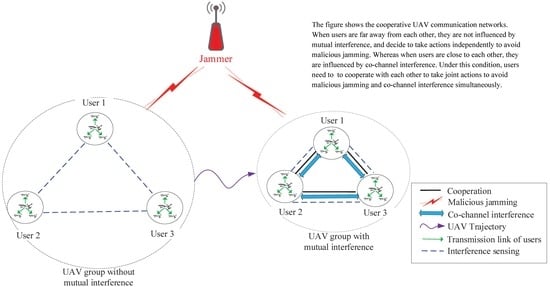
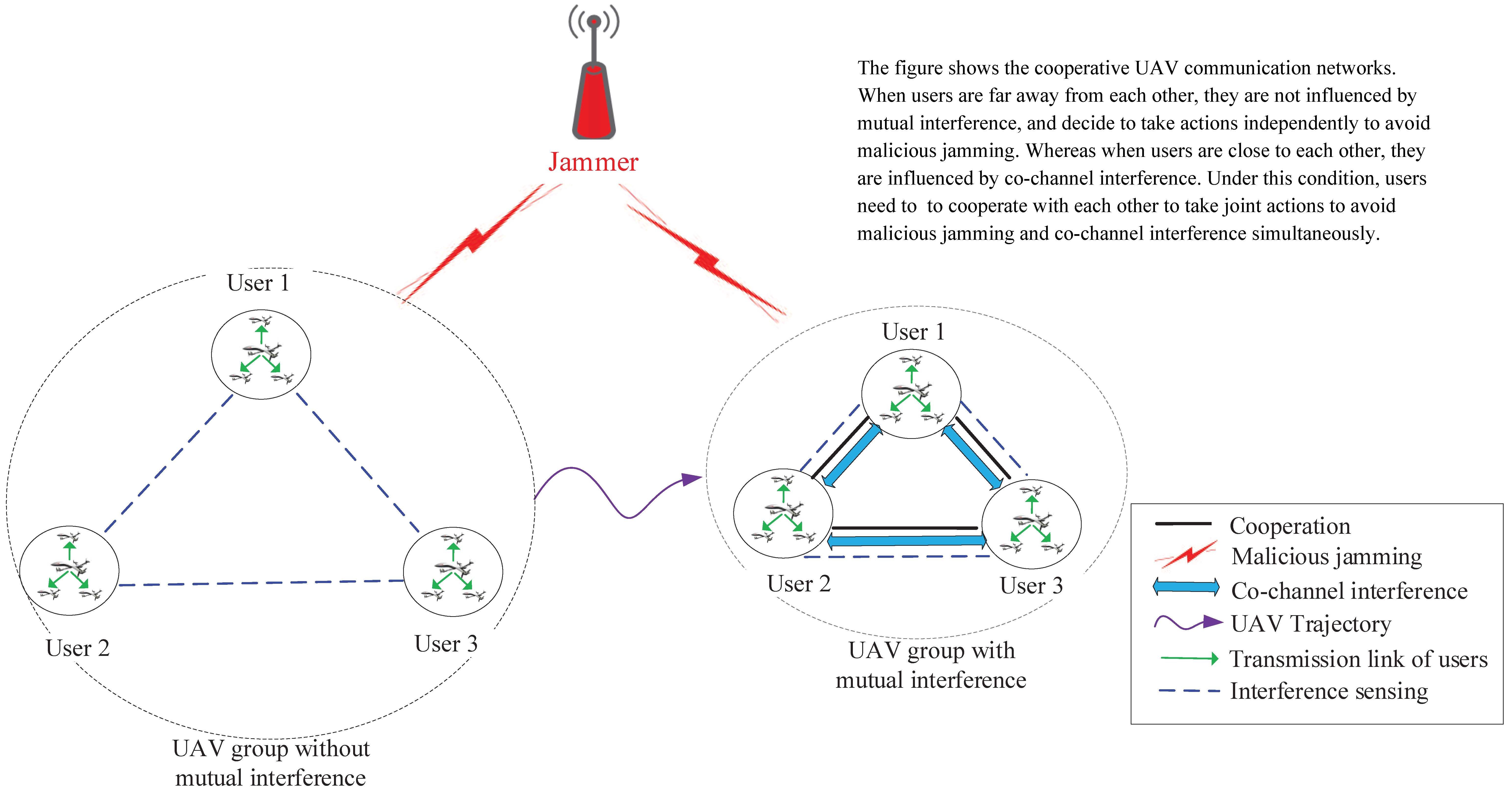
1. Introduction
- A cooperative anti-jamming mechanism is designed for UAV communication networks, where UAVs cooperate via joint Q table sharing. Considering the influence of co-channel interference, an MDP and a Markov game are formulated, respectively.
- An interference-aware cooperative anti-jamming distributed channel selection algorithm (ICADCSA) is designed for the anti-jamming selection problem. Without the influence of co-channel interference, an independent Q-learning method is adopted, while under the influence of co-channel interference, a multi-agent Q-learning method is employed.
- Simulation results exhibit the performance of the proposed ICADCSA, which can avoid the malicious jamming and co-channel interference effectively. Moreover, the influence of channel switching cost and cooperation cost are investigated.
2. System Model and Problem Formulation
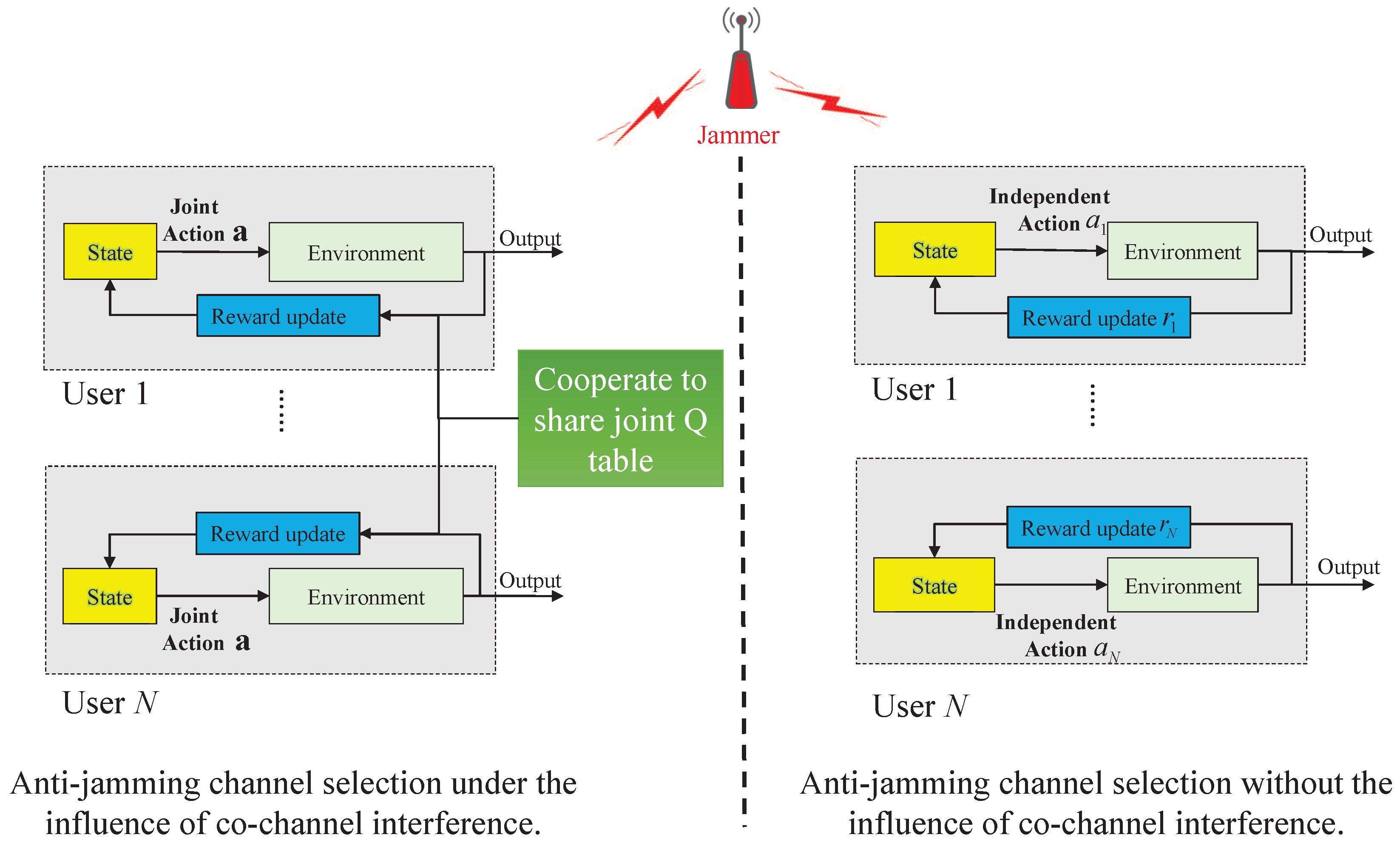
3. Interference-Aware Cooperative Anti-Jamming Mechanism in the UAV Group
3.1. Markov Decision Process
- is the discrete set of user n’s environment. is the environment state of user n at time t. , and represent user n’s transmission channel and jamming channel, respectively. In this case, user n’s state is not influenced by other users.
- is the channel strategy set of user n; denotes the channel selection strategy under the state of t moment; similarly, user n’s strategy is not influenced by others.
- The reward function of user n is , which satisfies . Specifically, for every state , user n can obtain a reward with action .
- The state transition function satisfies . Moreover, it also meets the Markov property, shown as:
3.2. Single Q-Learning
3.3. Markov Game
- is the discrete state set. In the cooperative anti-jamming issue, represents all users’ states and the jammer’s state. Users’ states are correlative.
- Denote as the channel selection set of user n, and is the joint action set of all users in the UAV group. The action space is .
- is the state transition function, and the state space is , which satisfies . Specifically, is the joint channel selection strategy, and s is the current state. is the coming state after all users take joint action under state s. The state transition function satisfies the Markov property, as well.
- are the reward functions of each user, and they satisfy . For UAVs in the group, no matter what joint actions are being taken, each one can obtain an immediate reward.
3.4. Multi-Agent Q-Learning
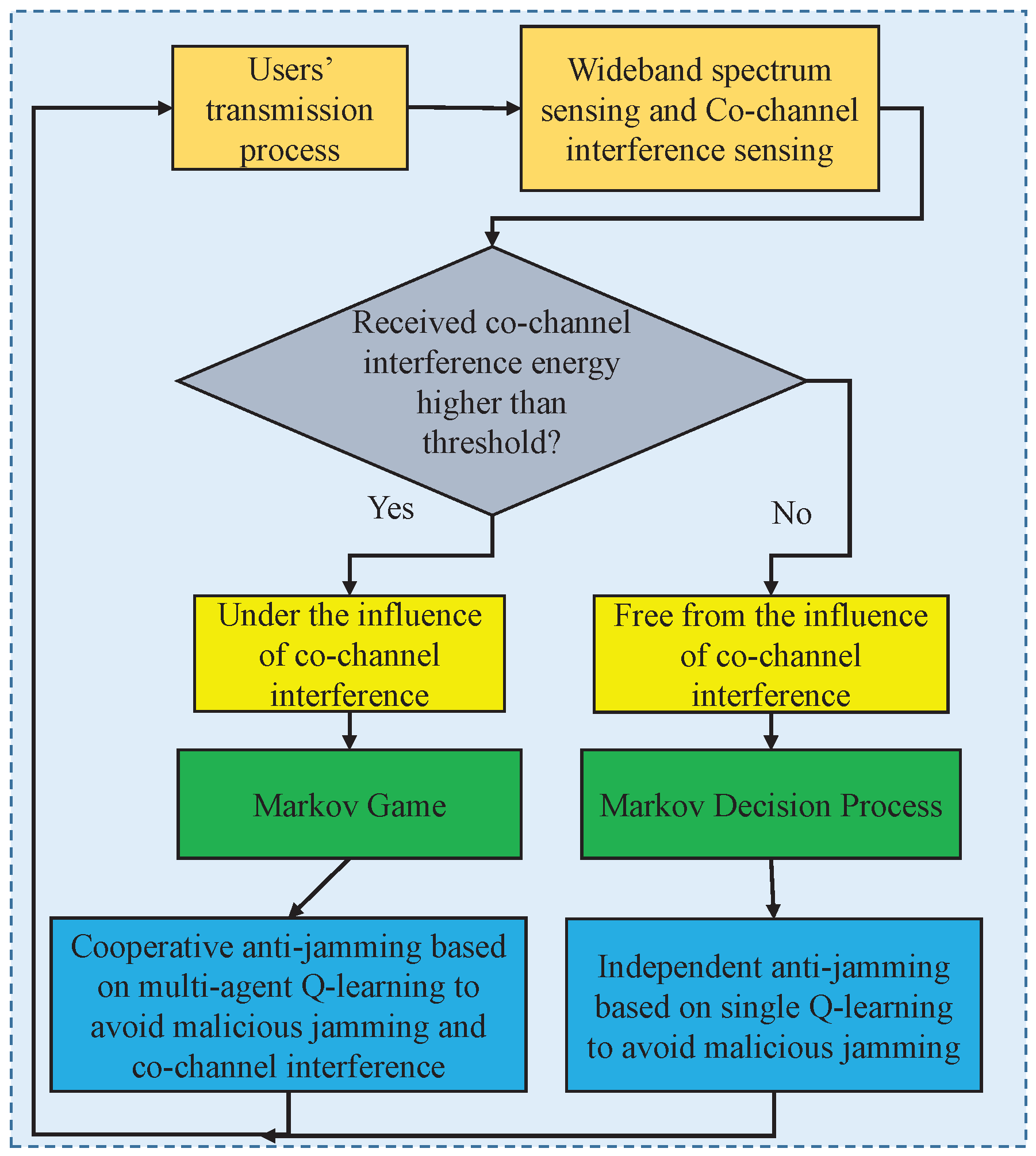
4. Interference-Aware Cooperative Anti-Jamming Distributed Channel Selection Algorithm
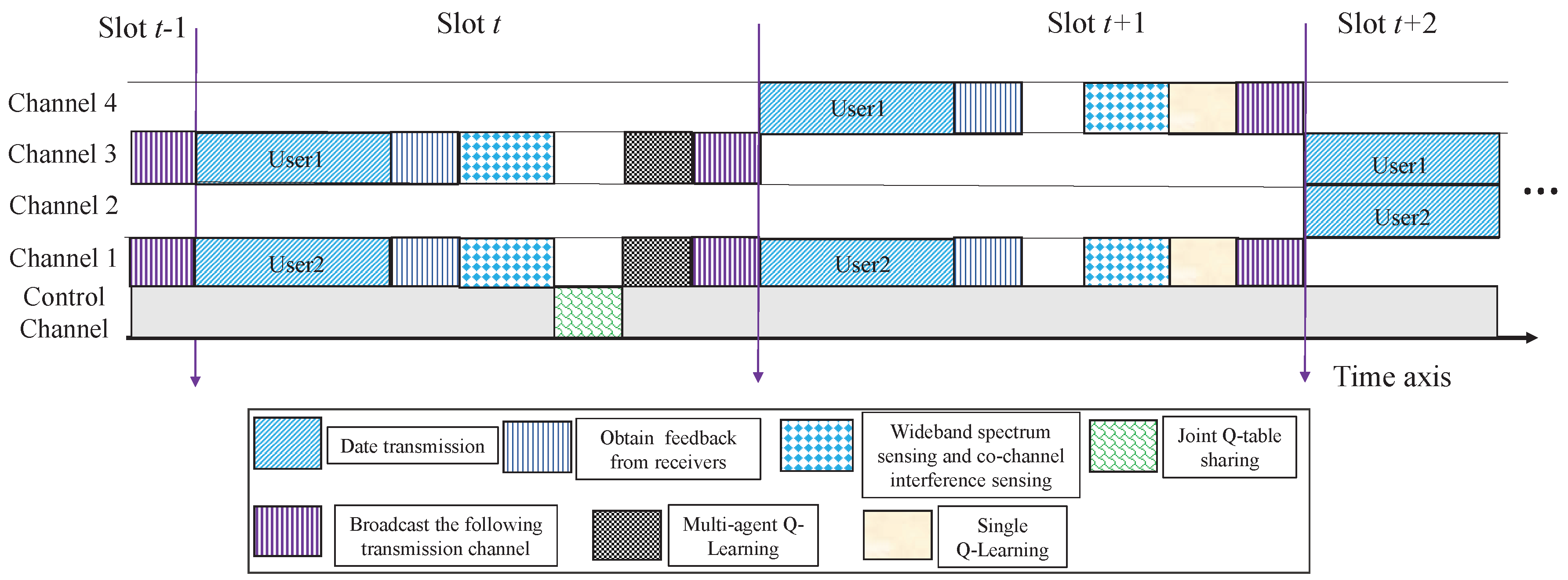
4.1. Algorithm Description
| Algorithm 1: Interference-aware cooperative anti-jamming distributed channel selection algorithm. |
| Initialization: |
| Initialize the starting time, ending time and relative learning parameters of the simulation. |
| Initialize every user n’s joint action Q table and single Q table . |
| Set the initial locations and states of all users. |
| Repeat Iterations: |
| Each user senses and observes the current environment state and then makes a judgment about the co-channel interference according to co-channel interference sensing. |
| If users are under the influence of co-channel interference, go to multi-agent Q-learning. |
Multi-agent Q-learning:
|
| Otherwise, go to single Q-learning. |
Single Q-learning:
|
| End |
| Jump out of the repeat process when the algorithm reaches the maximal iterations. |
4.2. Complexity Analysis
4.3. A Discussion on the Quick Decision for UAVs
5. Simulation Results and Discussions
5.1. Simulation Setting
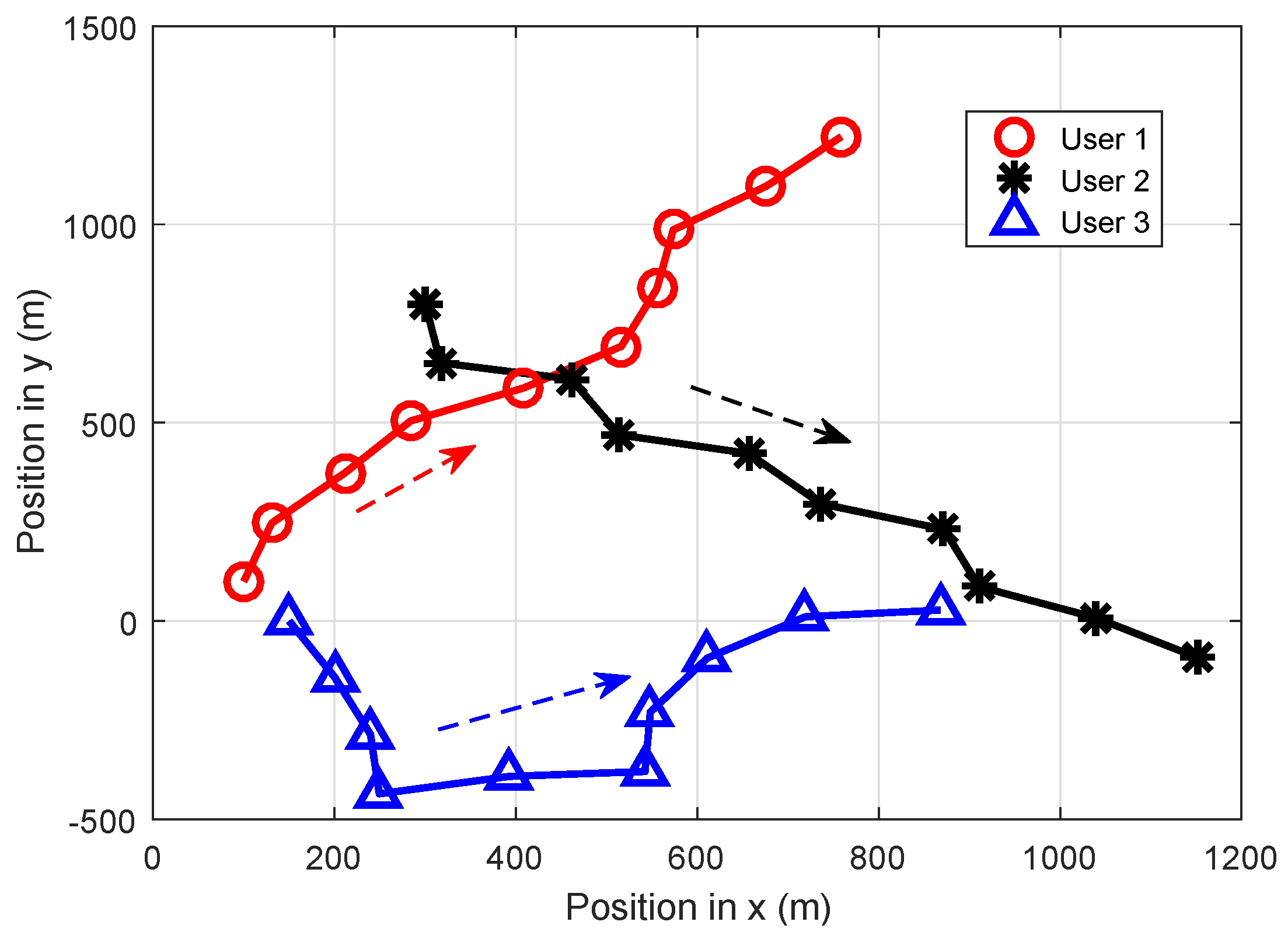
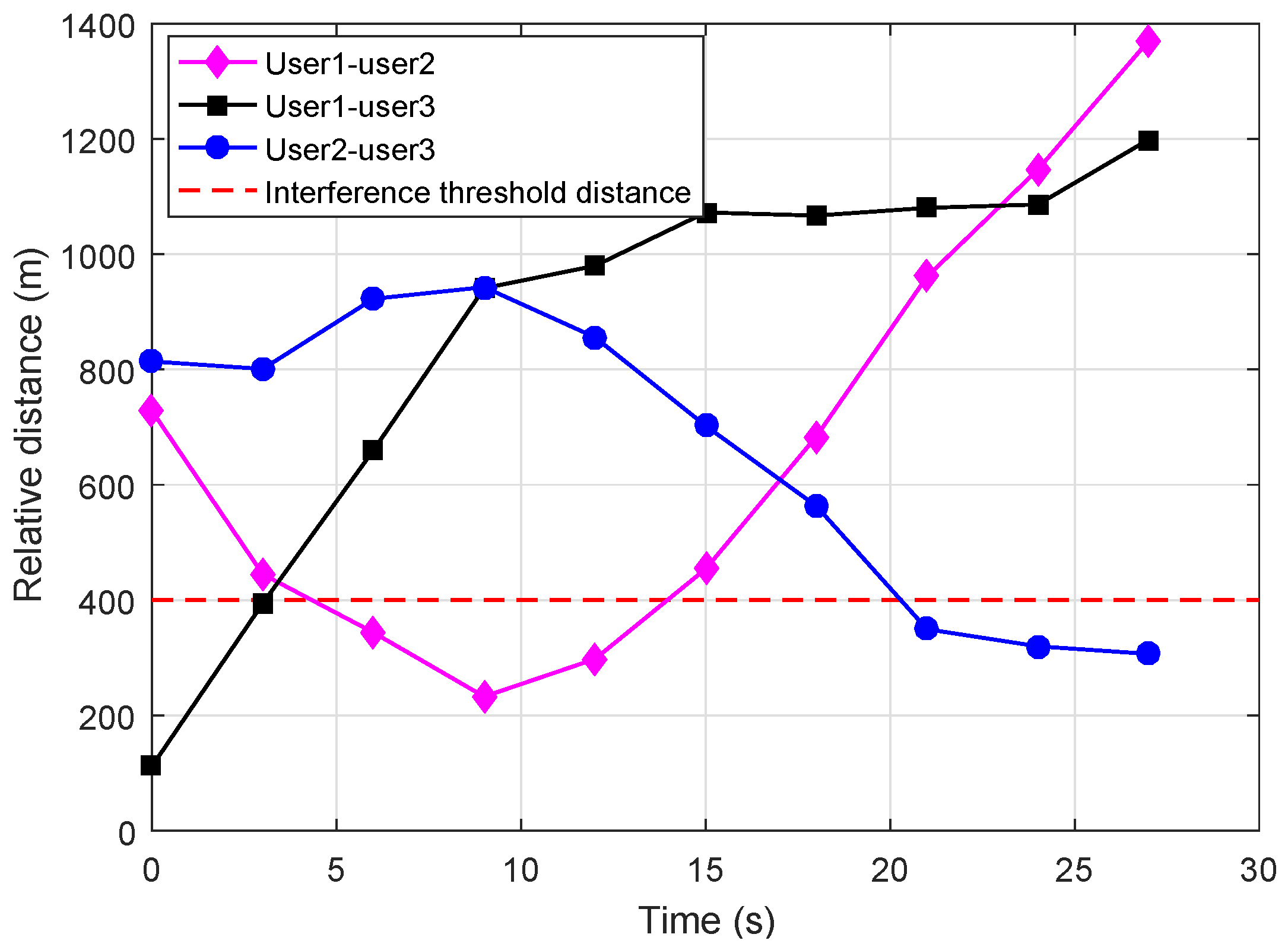
5.2. Channel Selection Strategies of Users and the Jammer
5.3. Performance Analysis of Users
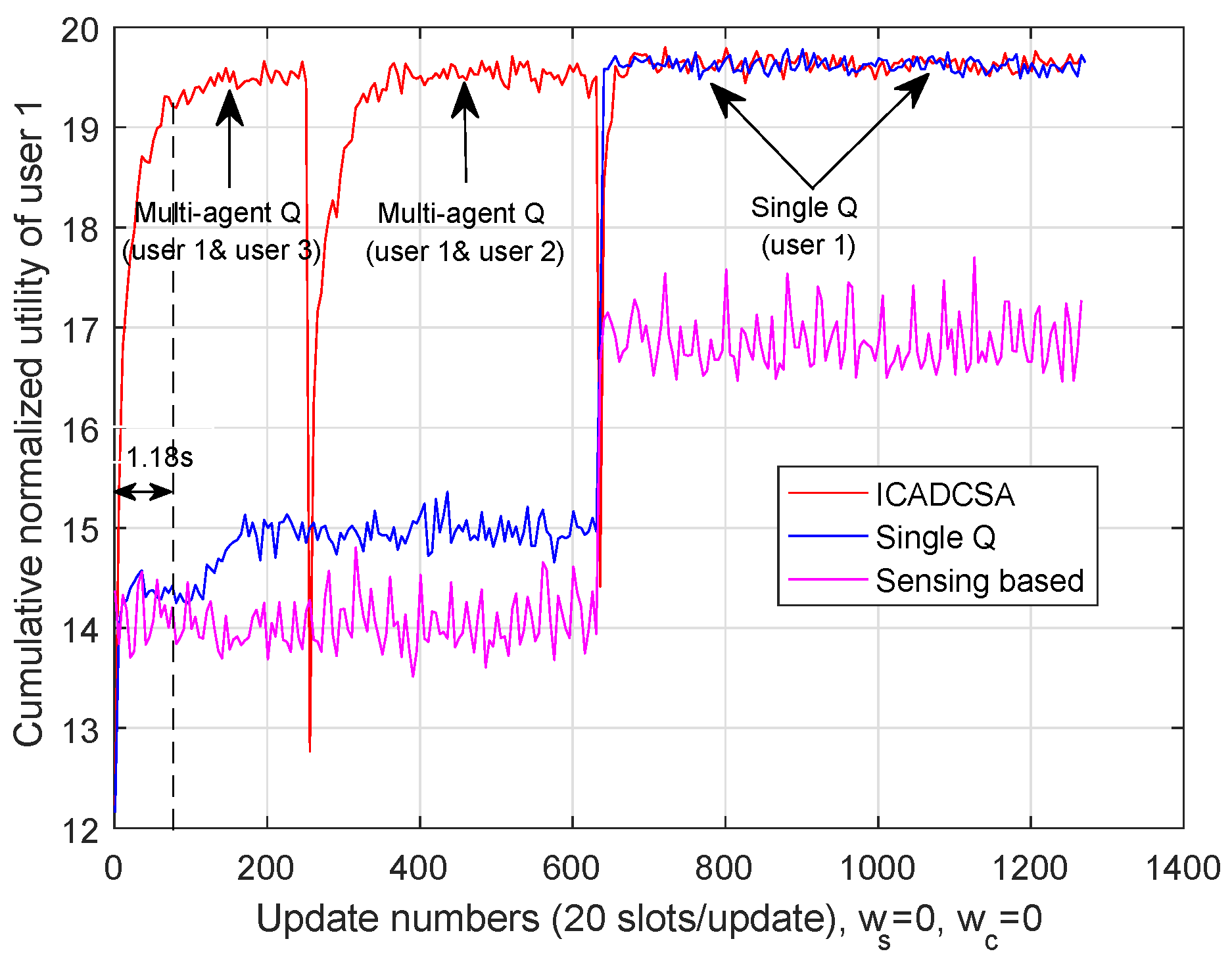
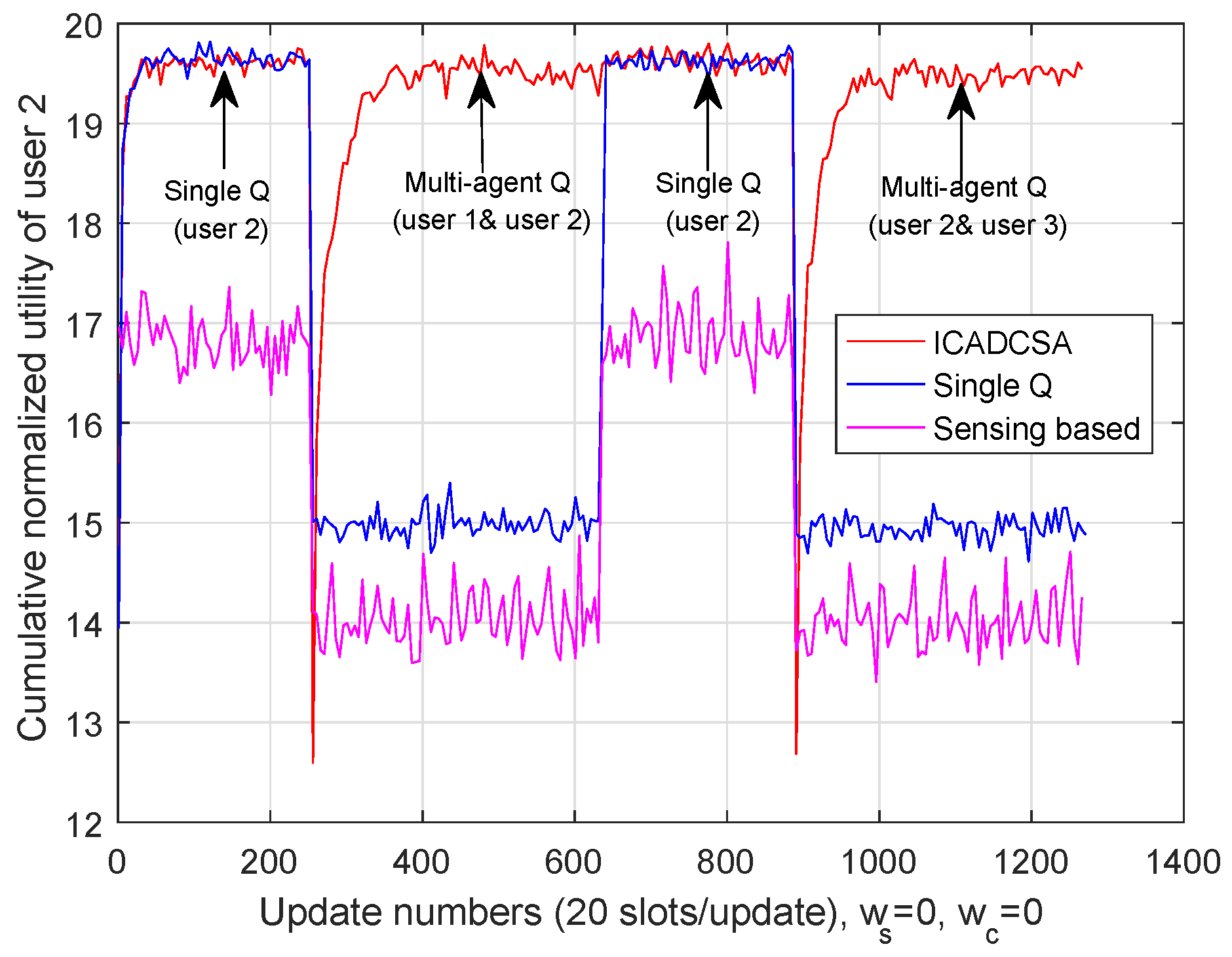
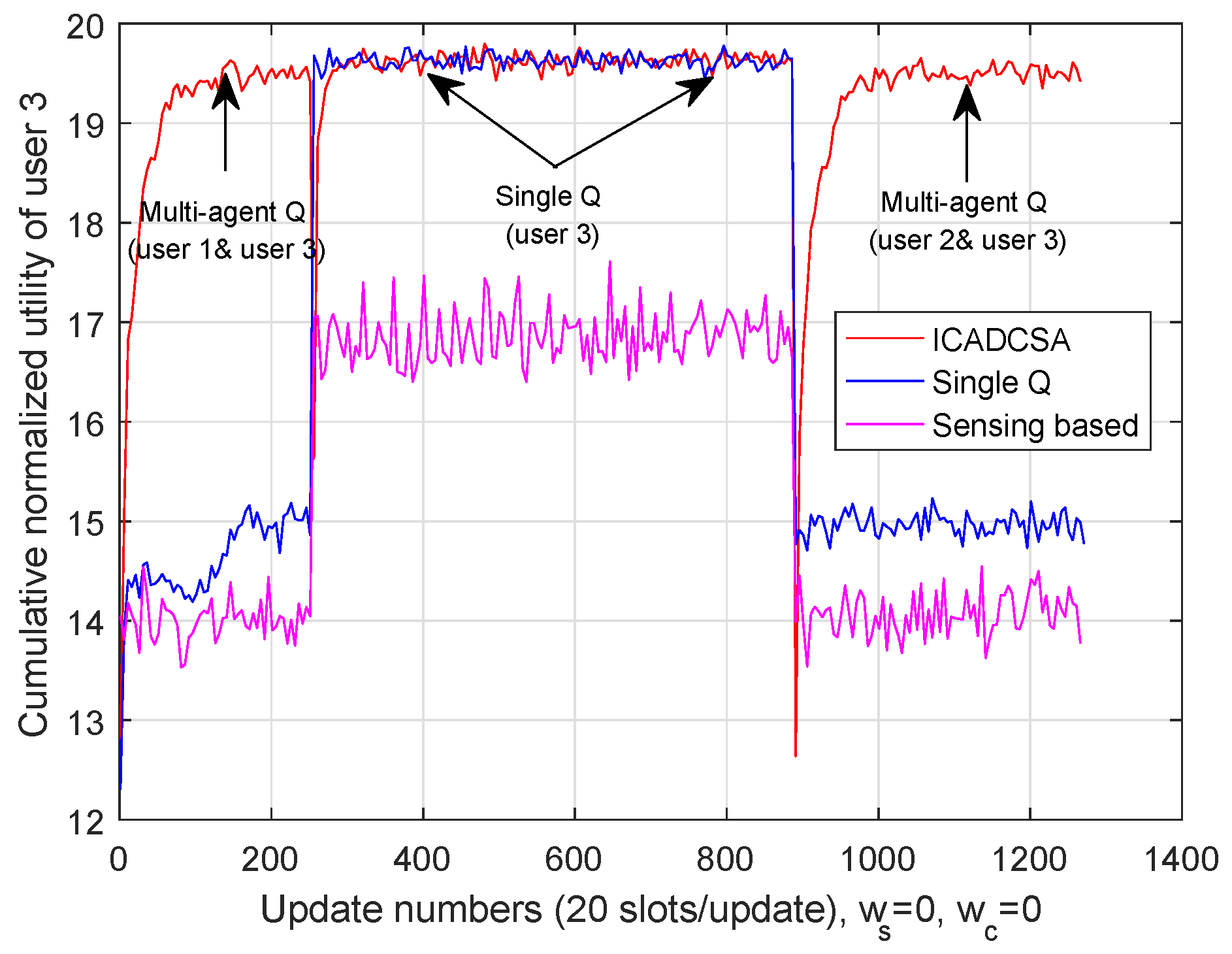
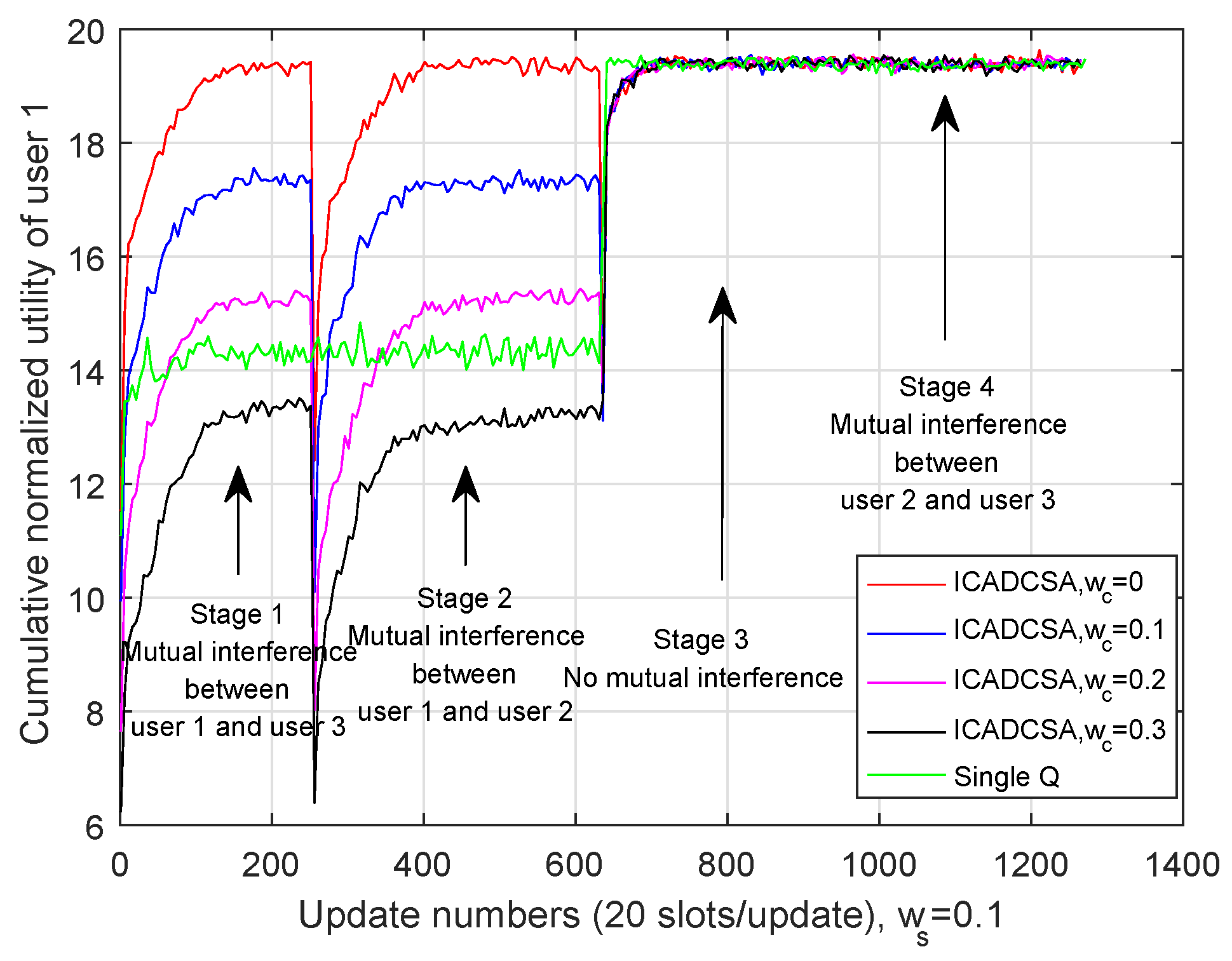
5.3.1. Performance Analysis without Cost
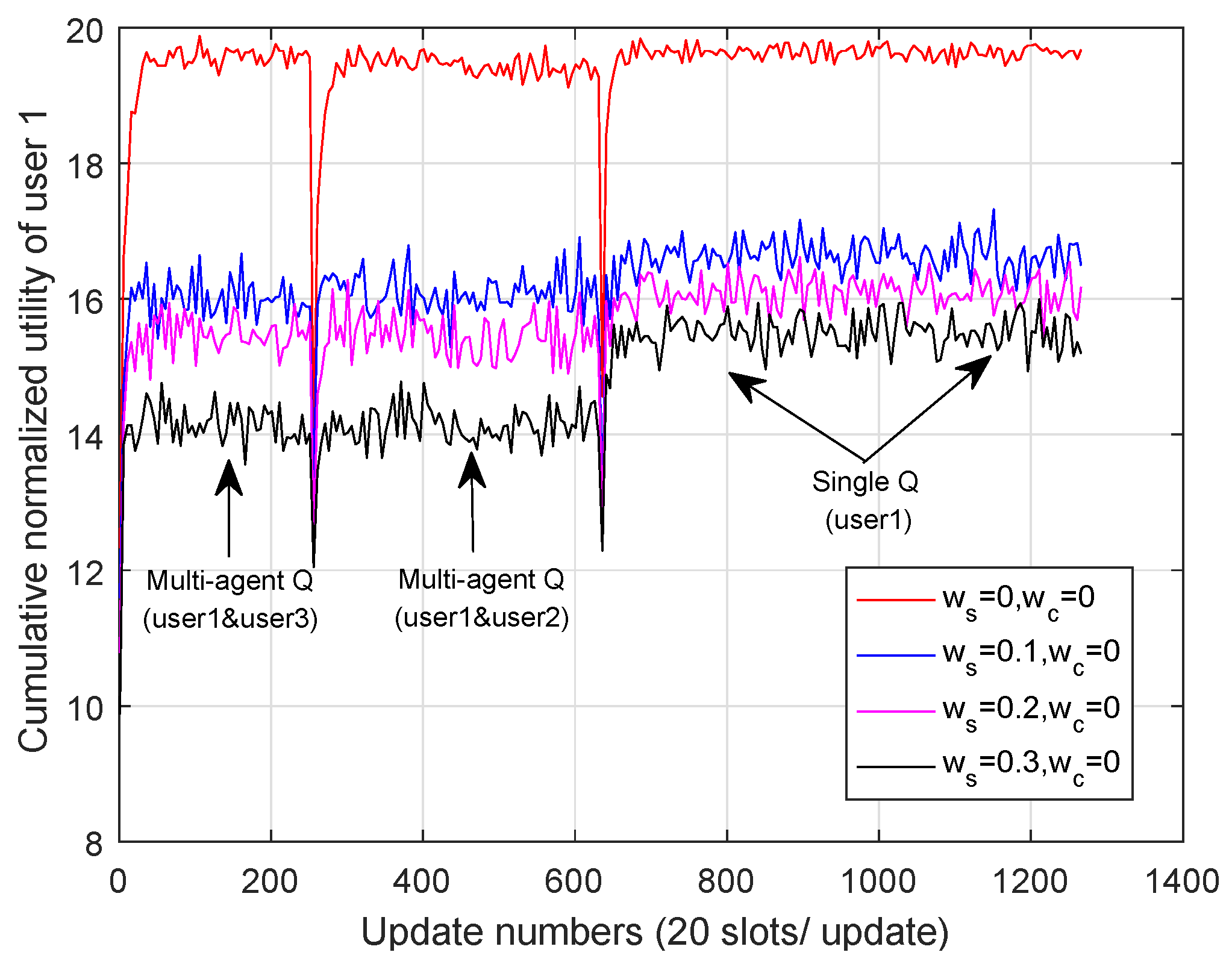
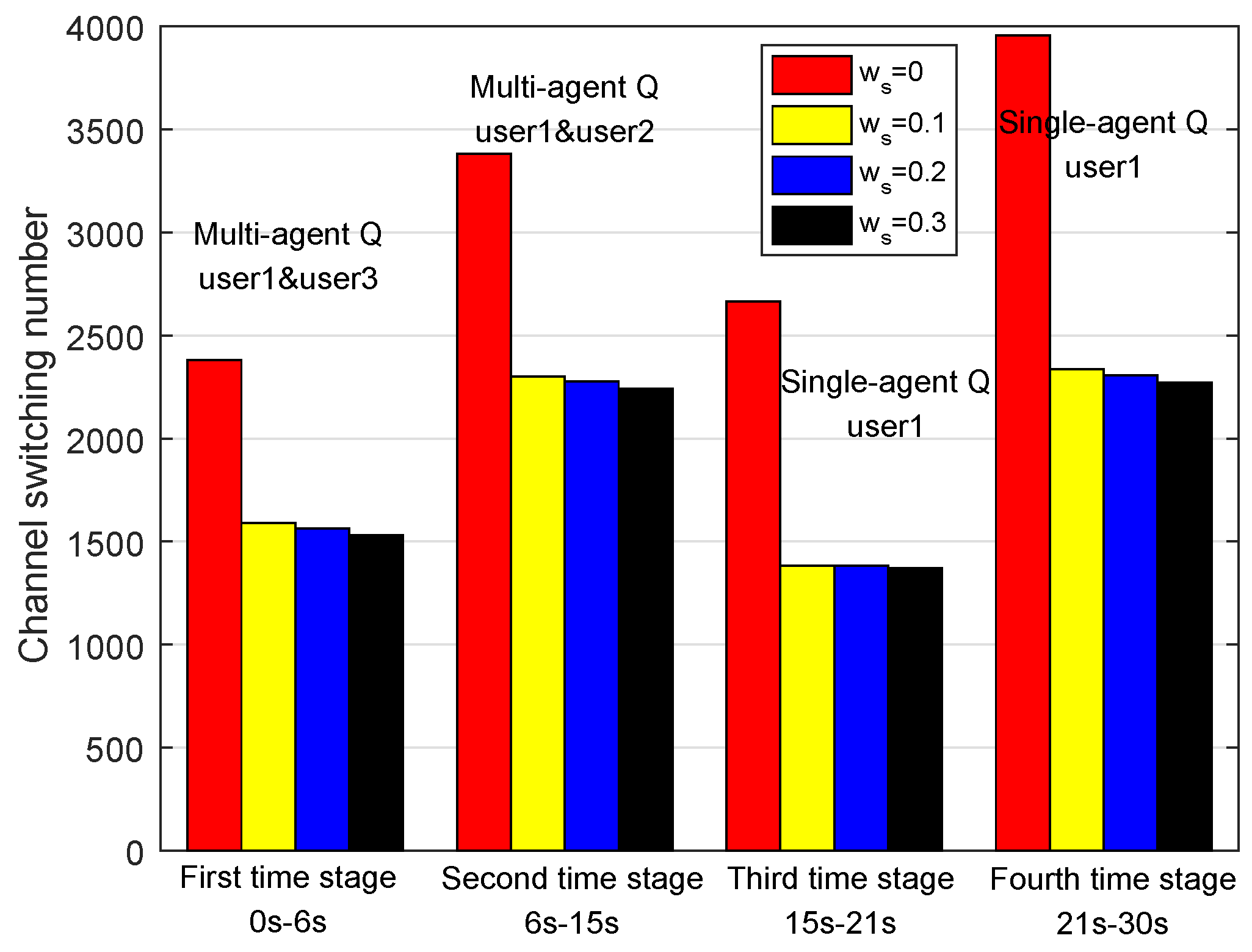
5.3.2. Performance Analysis with Cost
5.3.3. Quick Decision under the Dynamic Environment
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gupta, L.; Jain, R.; Vaszkun, G. Survey of important issues in UAV communication networks. IEEE Commun. Surv. Tutor. 2016, 18, 1123–1152. [Google Scholar] [CrossRef]
- Liu, D.; Xu, Y.; Wang, J.; Xu, Y.; Anpalagan, A.; Wu, Q.; Wang, H.; Shen, L. Self-organizing relay selection in UAV communication networks: A matching game perspective. arXiv, 2018; arXiv:1805.09257. [Google Scholar]
- Zou, Y.; Zhu, J.; Wang, X.; Hanzo, L. A survey on wireless security: Technical challenges, recent advances, and future trends. Proc. IEEE 2016, 104, 1727–1765. [Google Scholar] [CrossRef]
- Chen, C.; Song, M.; Xin, C.; Backens, J. A game-theoretical anti-jamming scheme for cognitive radio networks. IEEE Netw. 2013, 27, 22–27. [Google Scholar] [CrossRef]
- Zhang, L.; Guan, Z.; Melodia, T. United against the enemy: Anti-jamming based on cross-layer cooperation in wireless networks. IEEE Trans. Wirel. Commun. 2016, 15, 5733–5747. [Google Scholar] [CrossRef]
- Zhu, H.; Fang, C.; Liu, Y.; Chen, C.; Li, M.; Shen, X.S. You can jam but you cannot hide: Defending against jamming attacks for geo-location database driven spectrum sharing. IEEE J. Sel. Areas Commun. 2016, 34, 2723–2737. [Google Scholar] [CrossRef]
- Akyildiz, I.F.; Lee, W.Y.; Vuran, M.C.; Mohanty, S. Next generation/dynamic spectrum access/cognitive radio wireless networks: A survey. Comput. Netw. 2016, 50, 2127–2159. [Google Scholar] [CrossRef]
- Xu, Y.; Wang, J.; Wu, Q.; Anpalagan, A.; Yao, Y.D. Opportunistic spectrum access in unknown dynamic environment: A game-theoretic stochastic learning solution. IEEE Trans. Wirel. Commun. 2012, 11, 1380–1391. [Google Scholar] [CrossRef]
- Wu, Q.; Xu, Y.; Wang, J.; Shen, L.; Zheng, J.; Anpalagan, A. Distributed channel selection in time-varying radio environment: Interference mitigation game with uncoupled stochastic learning. IEEE Trans. Veh. Technol. 2013, 62, 4524–4538. [Google Scholar]
- Niyato, D.; Saad, W. Game Theory in Wireless and Communication Networks; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Xu, Y.; Wang, J.; Wu, Q.; Du, Z.; Shen, L.; Anpalagan, A. A game-theoretic perspective on self-organizing optimization for cognitive small cells. IEEE Commun. Mag. 2015, 53, 100–108. [Google Scholar] [CrossRef]
- Sun, Y.; Wang, J.; Sun, F.; Zhang, J. Energy-aware joint user scheduling and power control for two-tier femtocell networks: A hierarchical game approach. IEEE Syst. J. 2017, 12, 2533–2544. [Google Scholar] [CrossRef]
- Jia, L.; Xu, Y.; Sun, Y.; Feng, S.; Anpalagan, A. Stackelberg game approaches for anti-jamming defence in wireless networks. arXiv, 2018; arXiv:1805.12308. [Google Scholar]
- Yang, D.; Xue, G.; Zhang, J.; Richa, A.; Fang, X. Coping with a smart jammer in wireless networks: A stackelberg game approach. IEEE Trans. Wirel. Commun. 2013, 12, 4038–4047. [Google Scholar] [CrossRef]
- Li, Y.; Xiao, L.; Liu, J.; Tang, Y. Power control stackelberg game in cooperative anti-jamming communications. In Proceedings of the 2014 5th International Conference on Game Theory for Networks, Beijing, China, 25–27 November 2014; pp. 1–6. [Google Scholar]
- Xiao, L.; Chen, T.; Liu, J.; Dai, H. Anti-jamming transmission stackelberg game with observation errors. IEEE Commun. Lett. 2015, 19, 949–952. [Google Scholar] [CrossRef]
- Yao, F.; Jia, L.; Sun, Y.; Xu, Y.; Feng, S.; Zhu, Y. A hierarchical learning approach to anti-jamming channel selection strategies. Wirel. Netw. 2017, 1–13. [Google Scholar] [CrossRef]
- Xu, Y.; Wang, J.; Wu, Q.; Zheng, J.; Shen, L.; Anpalagan, A. Dynamic spectrum access in time-varying environment: Distributed learning beyond expectation optimization. IEEE Trans. Commun. 2017, 65, 5305–5318. [Google Scholar] [CrossRef]
- Xiao, L.; Lu, X.; Xu, D.; Tang, Y.; Wang, L.; Zhuang, W. UAV relay in VANETs against smart jamming with reinforcement learning. IEEE Trans. Veh. Technol. 2018, 67, 4087–4097. [Google Scholar] [CrossRef]
- Chen, J.; Xu, Y.; Wu, Q. Distributed channel selection for multicluster FANET based on real-time trajectory: A Potential game approach. IEEE Trans. Veh. Technol. 2018. submitted. [Google Scholar]
- Hu, Q.; Yue, W. Markov Decision Processes with Their Applications; Springer: New York, NY, USA, 2007. [Google Scholar]
- Puterman, M.L. Markov Decision Processes: Discrete Stochastic Dynamic Programming; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- Watkins, C.J.C.H.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Slimeni, F.; Chtourou, Z.; Scheers, B.; Le Nir, V.; Attia, R. Cooperative Q-learning based channel selection for cognitive radio networks. Wirel. Netw. 2018, 1–11. [Google Scholar] [CrossRef]
- Kong, L.; Xu, Y.; Zhang, Y. A reinforcement learning approach for dynamic spectrum anti-jamming in fading environment. In Proceedings of the 2018 18th IEEE International Conference on Communication Technology (ICCT 2018), Chongqing, China, 8–11 October 2018; pp. 1–7. [Google Scholar]
- Liu, X.; Xu, Y.; Jia, L.; Wu, Q.; Anpalagan, A. Anti-jamming communications using spectrum waterfall: A deep reinforcement learning approach. IEEE Commun. Lett. 2018, 22, 998–1001. [Google Scholar] [CrossRef]
- Busoniu, L.; Babuska, R.; De Schutter, B. A comprehensive survey of multi-agent reinforcement learning. IEEE Trans. Syst. Man Cybern. 2008, 38, 156–172. [Google Scholar] [CrossRef]
- Aref, M.A.; Jayaweera, S.K.; Machuzak, S. Multi-agent reinforcement learning based cognitive anti-jamming. In Proceedings of the 2017 IEEE Wireless Communications and Networking Conference (WCNC), San Francisco, CA, USA, 19–22 March 2017; pp. 1–6. [Google Scholar]
- Aref, M.A.; Jayaweera, S.K. A novel cognitive anti-jamming stochastic game. In Proceedings of the Cognitive Communications for Aerospace Applications Workshop 2017, Cleveland, OH, USA, 27–28 June 2017; pp. 1–4. [Google Scholar]
- Aref, M.A.; Jayaweera, S.K. A cognitive anti-jamming and interference-avoidance stochastic game. In Proceedings of the 2017 IEEE 16th International Conference on Cognitive Informatics & Cognitive Computing (ICCI*CC), Oxford, UK, 26–28 July 2017; pp. 520–527. [Google Scholar]
- Yao, F.; Jia, L. A collaborative multi-agent reinforcement learning anti-jamming algorithm in wireless networks. arXiv, 2018; arXiv:1809.04374. [Google Scholar]
- Xu, Y.; Ren, G.; Chen, J.; Luo, Y.; Jia, L.; Liu, X.; Yang, Y.; Xu, Y. A one-leader multi-follower Bayesian-Stackelberg game for anti-jamming transmission in UAV communication networks. IEEE Access 2018, 6, 21697–21709. [Google Scholar] [CrossRef]
- Cao, L.; Zheng, H. Distributed rule-regulated spectrum sharing. IEEE J. Sel. Areas Commun. 2008, 26, 130–145. [Google Scholar] [CrossRef]
- Vlassis, N. A concise introduction to multi-agent systems and distributed artificial intelligence. Synth. Lect. Artif. Intell. Mach. Learn. 2007, 1, 1–71. [Google Scholar] [CrossRef]
- Xu, Y.; Wu, Q.; Shen, L.; Wang, J.; Anpalagan, A. Opportunistic spectrum access with spatial reuse: Graphical game and uncoupled learning solutions. IEEE Trans. Wirel. Commun. 2013, 12, 4814–4826. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Computation | |
| Storage Size | |
| Information Sharing |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Y.; Ren, G.; Chen, J.; Zhang, X.; Jia, L.; Kong, L. Interference-Aware Cooperative Anti-Jamming Distributed Channel Selection in UAV Communication Networks. Appl. Sci. 2018, 8, 1911. https://doi.org/10.3390/app8101911
Xu Y, Ren G, Chen J, Zhang X, Jia L, Kong L. Interference-Aware Cooperative Anti-Jamming Distributed Channel Selection in UAV Communication Networks. Applied Sciences. 2018; 8(10):1911. https://doi.org/10.3390/app8101911
Chicago/Turabian StyleXu, Yifan, Guochun Ren, Jin Chen, Xiaobo Zhang, Luliang Jia, and Lijun Kong. 2018. "Interference-Aware Cooperative Anti-Jamming Distributed Channel Selection in UAV Communication Networks" Applied Sciences 8, no. 10: 1911. https://doi.org/10.3390/app8101911
APA StyleXu, Y., Ren, G., Chen, J., Zhang, X., Jia, L., & Kong, L. (2018). Interference-Aware Cooperative Anti-Jamming Distributed Channel Selection in UAV Communication Networks. Applied Sciences, 8(10), 1911. https://doi.org/10.3390/app8101911