Large-Scale Fine-Grained Bird Recognition Based on a Triplet Network and Bilinear Model

Abstract
:1. Introduction
2. Background
2.1. Dataset and Evaluation Metric
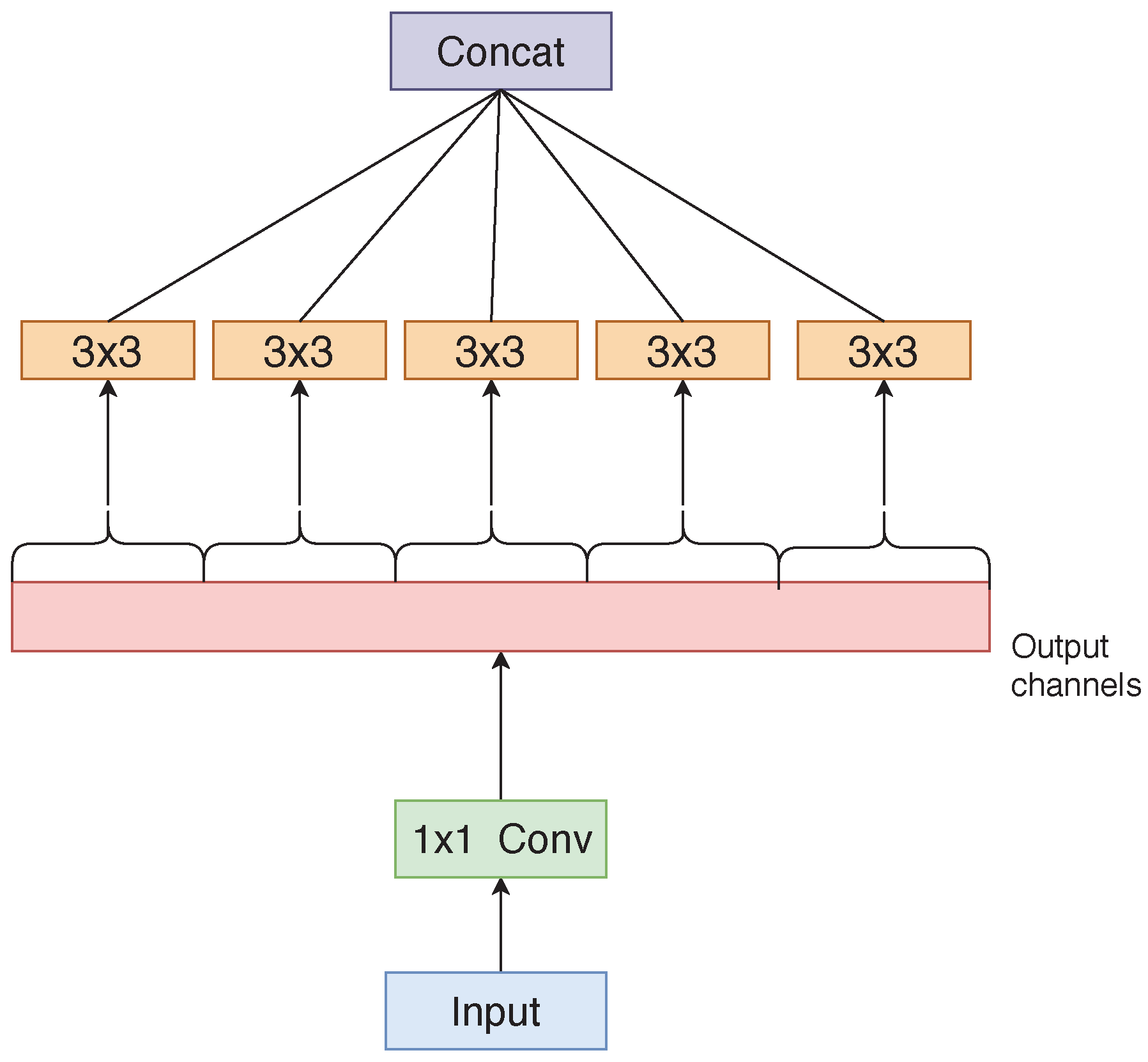
2.2. Xception
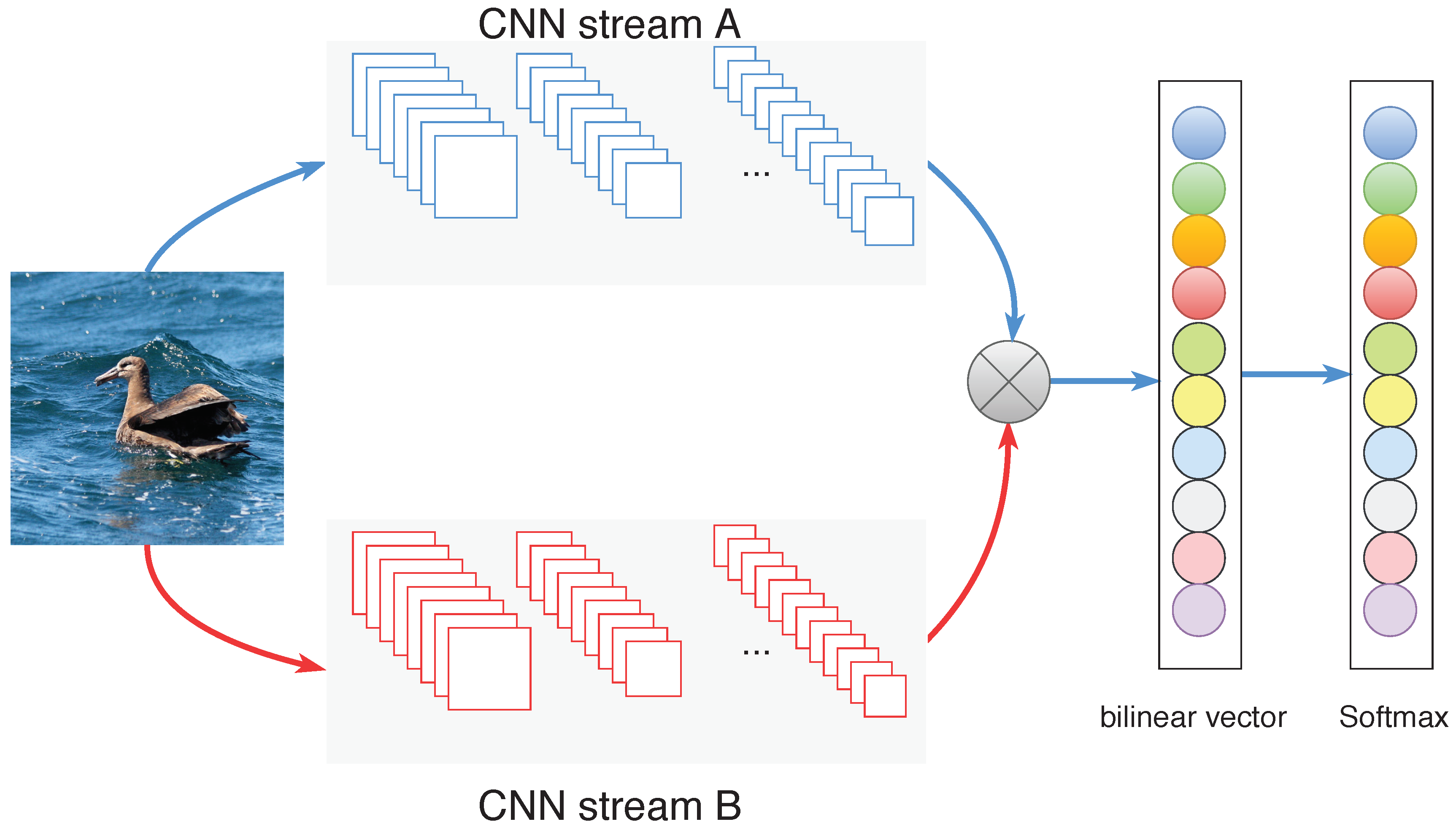
2.3. Fully Shared Bilinear Model
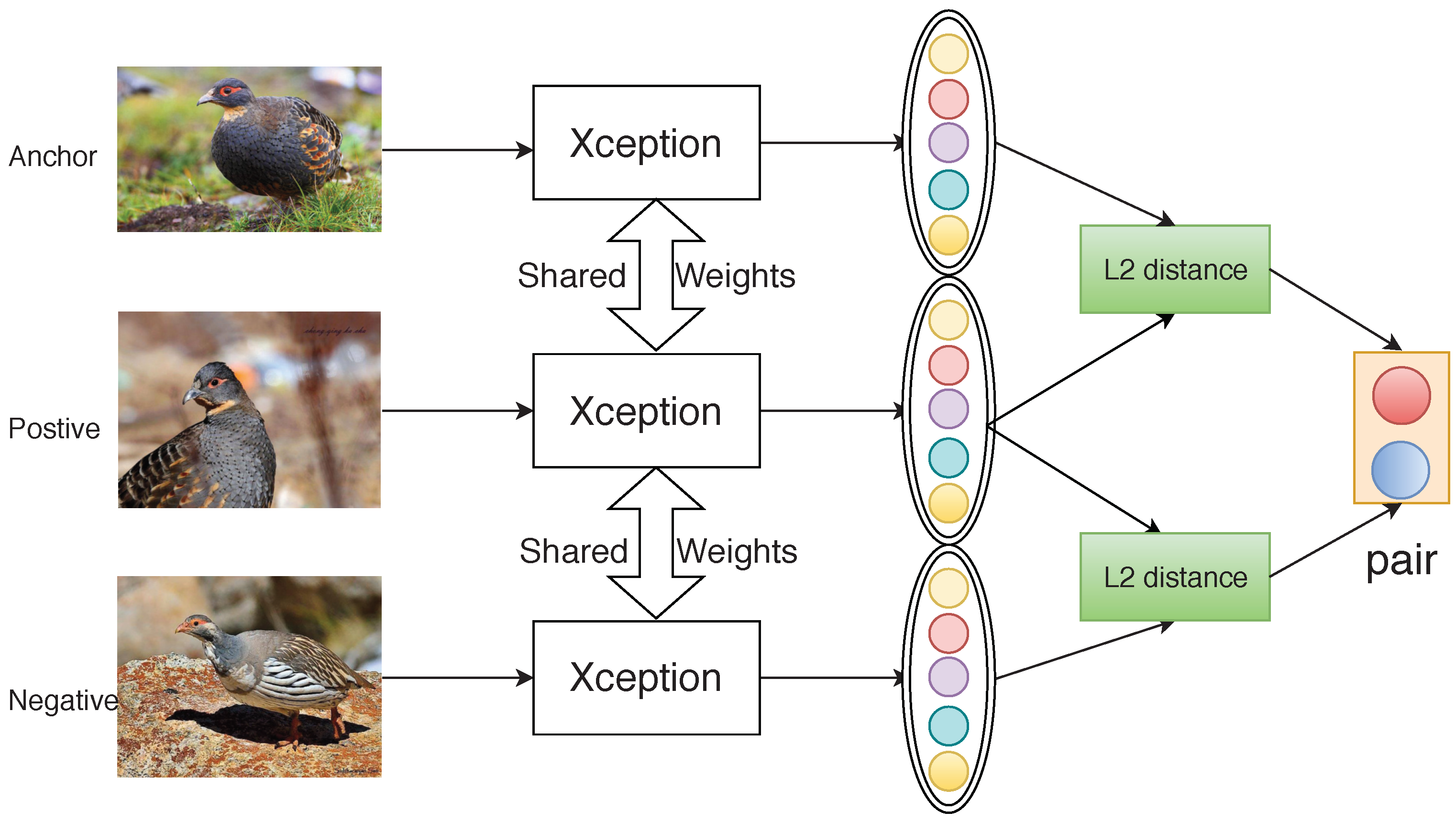
2.4. Triplet Networks
3. Methods
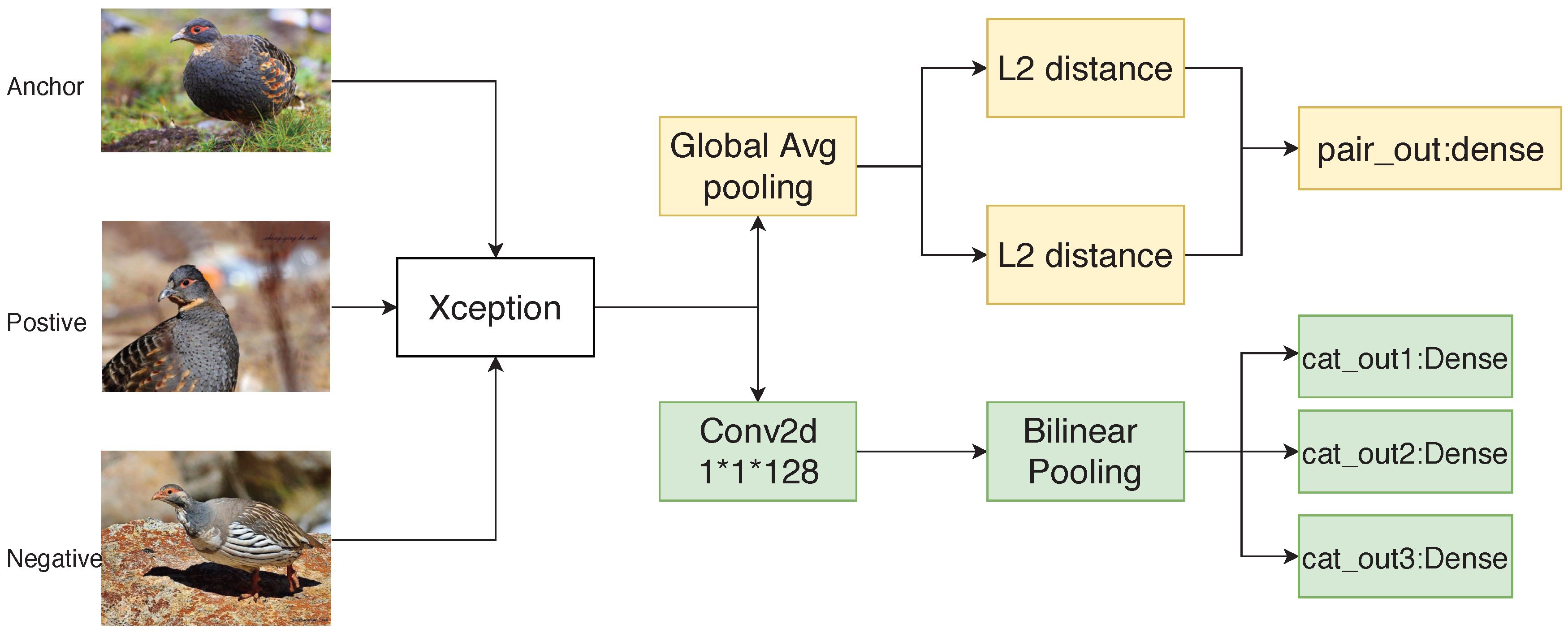
3.1. The Architecture
3.2. Train and Test
3.3. Loss Function
4. Results
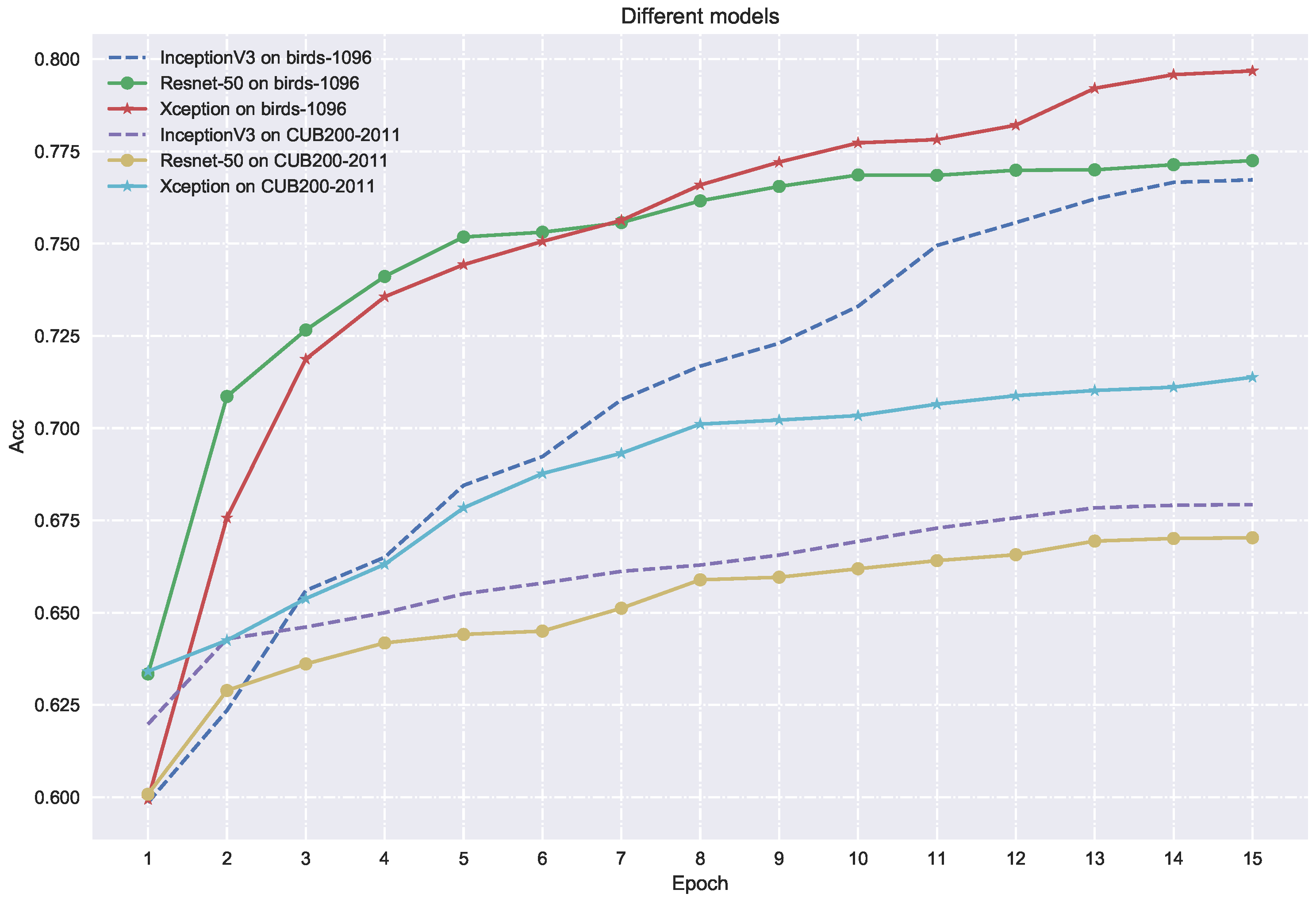
4.1. Comparisons with Other Models
4.2. System Accuracy
5. Discussion
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Bosch, A.; Zisserman, A.; Muñoz, X. Scene Classification Using a Hybrid Generative/Discriminative Approach. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 712–727. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, J.; Rehg, J.M. CENTRIST: A Visual Descriptor for Scene Categorization. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1489–1501. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gehler, P.; Nowozin, S. On feature combination for multiclass object classification. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 221–228. [Google Scholar] [CrossRef]
- Jarrett, K.; Kavukcuoglu, K.; Ranzato, M.; LeCun, Y. What is the best multi-stage architecture for object recognition? In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2146–2153. [Google Scholar] [CrossRef]
- Wah, C.; Branson, S.; Welinder, P.; Perona, P.; Belongie, S. The Caltech-UCSD Birds200-2011 Dataset; California Institute of Technology: Pasadena, CA, USA, 2011. [Google Scholar]
- Khosla, A.; Jayadevaprakash, N.; Yao, B.; Li, F.-F. Novel Dataset for Fine-Grained Image Categorization. In Proceedings of the First Workshop on Fine-Grained Visual Categorization, IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011. [Google Scholar]
- Nilsback, M.; Zisserman, A. Automated Flower Classification over a Large Number of Classes. In Proceedings of the 2008 Sixth Indian Conference on Computer Vision, Graphics Image Processing, Bhubaneswar, India, 16–19 December 2008; pp. 722–729. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef] [PubMed]
- Zhang, N.; Donahue, J.; Girshick, R.; Darrell, T. Part-Based R-CNNs for Fine-Grained Category Detection. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 834–849. [Google Scholar]
- Branson, S.; Horn, G.V.; Belongie, S.J.; Perona, P. Bird Species Categorization Using Pose Normalized Deep Convolutional Nets. arXiv, 2014; arXiv:1406.2952. [Google Scholar]
- Xiao, T.; Xu, Y.; Yang, K.; Zhang, J.; Peng, Y.; Zhang, Z. The application of two-level attention models in deep convolutional neural network for fine-grained image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, 7–12 June 2015; pp. 842–850. [Google Scholar] [CrossRef]
- Simon, M.; Rodner, E. Neural Activation Constellations: Unsupervised Part Model Discovery with Convolutional Networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, 7–13 December 2015; pp. 1143–1151. [Google Scholar] [CrossRef]
- Chen, Y.; Li, J.; Xiao, H.; Jin, X.; Yan, S.; Feng, J. Dual Path Networks. arXiv, 2017; arXiv:1707.01629. [Google Scholar]
- Lin, T.; Roy Chowdhury, A.; Maji, S. Bilinear CNN Models for Fine-Grained Visual Recognition. In Proceedings of the 2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, 7–13 December 2015; pp. 1449–1457. [Google Scholar] [CrossRef]
- Zhao, B.; Wu, X.; Feng, J.; Peng, Q.; Yan, S. Diversified Visual Attention Networks for Fine-Grained Object Classification. IEEE Trans. Multimedia 2017, 19, 1245–1256. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Xiong, H.; Zhou, W.; Lin, W.; Tian, Q. Picking Deep Filter Responses for Fine-Grained Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 1134–1142. [Google Scholar] [CrossRef]
- Zhang, Y.; Wei, X.; Wu, J.; Cai, J.; Lu, J.; Nguyen, V.A.; Do, M.N. Weakly Supervised Fine-Grained Categorization With Part-Based Image Representation. IEEE Trans. Image Process. 2016, 25, 1713–1725. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. arXiv, 2015; arXiv:1512.00567. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv, 2015; arXiv:1512.03385. [Google Scholar]
- Bengio, Y. Deep Learning of Representations for Unsupervised and Transfer Learning. In Proceedings of the ICML Workshop on Unsupervised and Transfer Learning, Bellevue, WA, USA, 27 June 2012; pp. 17–36. [Google Scholar]
- Lin, T.; Roy Chowdhury, A.; Maji, S. Bilinear CNN Models for Fine-grained Visual Recognition. arXiv, 2015; arXiv:1504.07889. [Google Scholar]
- Zheng, G.; Tan, M.; Yu, J.; Wu, Q.; Fan, J. Fine-grained image recognition via weakly supervised click data guided bilinear CNN model. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo, ICME 2017, Hong Kong, China, 10–14 July 2017; pp. 661–666. [Google Scholar] [CrossRef]
- Hadsell, R.; Chopra, S.; LeCun, Y. Learning a Similarity Metric Discriminatively, with Application to Face Verification. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 539–546. [Google Scholar] [CrossRef]
- Norouzi, M.; Fleet, D.J.; Salakhutdinov, R. Hamming Distance Metric Learning. In Advances in Neural Information Processing Systems 25, Proceedings of the 26th Annual Conference on Neural Information Processing Systems 2012, Lake Tahoe, NV, USA, 3–6 December 2012; MIT Press Ltd.: Cambridge, MA, USA, 2012; pp. 1070–1078. [Google Scholar]
- Hoffer, E.; Ailon, N. Deep metric learning using Triplet network. arXiv, 2014; arXiv:1412.6622. [Google Scholar]
- Lu, R.; Wu, K.; Duan, Z.; Zhang, C. Deep ranking: Triplet MatchNet for music metric learning. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2017, New Orleans, LA, USA, 5–9 March 2017; pp. 121–125. [Google Scholar] [CrossRef]
- Lin, M.; Chen, Q.; Yan, S. Network In Network. arXiv, 2013; arXiv:1312.4400. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, À.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar] [CrossRef]
- Lin, T.; Maji, S. Improved Bilinear Pooling with CNNs. arXiv, 2017; arXiv:1707.06772. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.S.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, AISTATS 2010, Chia Laguna Resort, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv, 2014; arXiv:1412.6980. [Google Scholar]
- Mandt, S.; Hoffman, M.D.; Blei, D.M. Stochastic Gradient Descent as Approximate Bayesian Inference. arXiv, 2017; arXiv:1704.04289. [Google Scholar]
- Shore, J.E.; Johnson, R.W. Axiomatic derivation of the principle of maximum entropy and the principle of minimum cross-entropy. IEEE Trans. Inf. Theory 1980, 26, 26–37. [Google Scholar] [CrossRef] [Green Version]
- Selvaraju, R.R.; Das, A.; Vedantam, R.; Cogswell, M.; Parikh, D.; Batra, D. Grad-CAM: Why did you say that? Visual Explanations from Deep Networks via Gradient-based Localization. arXiv, 2016; arXiv:1610.02391. [Google Scholar]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps. arXiv, 2013; arXiv:1312.6034. [Google Scholar]
- Chattopadhyay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-CAM++: Generalized Gradient-based Visual Explanations for Deep Convolutional Networks. arXiv, 2017; arXiv:1710.11063. [Google Scholar]
- Fu, J.; Zheng, H.; Mei, T. Look Closer to See Better: Recurrent Attention Convolutional Neural Network for Fine-Grained Image Recognition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4476–4484. [Google Scholar] [CrossRef]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial Transformer Networks. arXiv, 2015; arXiv:1506.02025. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Dataset | Acc |
|---|---|---|
| Inception-v3 | Birds-1096 | 76.73% |
| Resnet-50 | Birds-1096 | 77.25% |
| Xception | Birds-1096 | 79.68% |
| Inception-v3 | CUB200-2011 | 67.93% |
| Resnet-50 | CUB200-2011 | 67.03% |
| Xception | CUB200-2011 | 71.38% |
| Model | Dataset | Acc |
|---|---|---|
| Our model (Xception+Bilinear+Triplet) | Birds-1096 | 88.91% |
| Our model (Xception+Bilinear+Triplet) | CUB200-2011 | 85.58% |
| Xception+Bilinear | Birds-1096 | 86.91% |
| Xception+Bilinear | CUB200-2011 | 83.65% |
| Xception+Bilinear | CUB200-2011 | 83.65% |
| Xception | Birds-1096 | 79.68% |
| Xception | CUB200-2011 | 71.38% |
| RA-CNN (scale 1+2+3) | CUB200-2011 | 85.30% |
| ST-CNN (Incaption net) | CUB200-2011 | 84.10% |
| FDFR | CUB200-2011 | 82.60% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Z.; Luo, Z.; Li, J.; Wang, K.; Shi, B. Large-Scale Fine-Grained Bird Recognition Based on a Triplet Network and Bilinear Model. Appl. Sci. 2018, 8, 1906. https://doi.org/10.3390/app8101906
Zhao Z, Luo Z, Li J, Wang K, Shi B. Large-Scale Fine-Grained Bird Recognition Based on a Triplet Network and Bilinear Model. Applied Sciences. 2018; 8(10):1906. https://doi.org/10.3390/app8101906
Chicago/Turabian StyleZhao, Zhicheng, Ze Luo, Jian Li, Kaihua Wang, and Bingying Shi. 2018. "Large-Scale Fine-Grained Bird Recognition Based on a Triplet Network and Bilinear Model" Applied Sciences 8, no. 10: 1906. https://doi.org/10.3390/app8101906
APA StyleZhao, Z., Luo, Z., Li, J., Wang, K., & Shi, B. (2018). Large-Scale Fine-Grained Bird Recognition Based on a Triplet Network and Bilinear Model. Applied Sciences, 8(10), 1906. https://doi.org/10.3390/app8101906