1. Introduction
To promote sustainable economic and social development, energy sources such as solar energy and wind power need to be leveraged to counteract the rapidly growing energy consumption and deteriorating environment caused by climate change. To promote increased solar energy utilization, photovoltaic (PV) power generation has been rapidly developed worldwide [
1]. PV power generation is affected by solar radiation, temperature and other factors. It also has strong intermittency and volatility. Grid access by large-scale distributed PV power introduces significant obstacles to the planning, operation, scheduling and control of power systems. Accurate PV power prediction not only provides the basis for grid dispatch decision-making behavior, but also provides support for multiple power source space-time complementarity and coordinated control; this reduces pre-existing rotating reserve capacity and operating costs, which ensures the safety and stability of the system and promotes the optimal operation of the power grid [
2].
According to the timescale, PV power forecasting can be divided into long-term, short-term, and ultra-short-term forecasts [
3]. A medium-long-term forecast (i.e., with a prediction scale of several months) can provide support for power grid planning; Short-term prediction (i.e., with a prediction scale of one to four days in advance) can assist the dispatching department in formulating generator set start-stop plans. Super short-term forecast (i.e., with a prediction scale of 15 min in advance) can achieve a real-time rolling correction of the output plan curve and can provide early warning information to the dispatcher. The shorter the time scale, the more favorable the management of preventative situations and emergencies. Most of the existing literature describes short-term forecasting research with an hourly cycle. There are few reports on the ultra-short-term prediction of PV power generation [
4,
5,
6]. In addition, in the previous research, PV power prediction methods mainly include the following: physical methods, statistical methods, machine learning methods, and hybrid integration methods.
(1) In physical methods, numerical weather prediction (NWP) is the most widely used method, which involves more input data such as solar radiation, temperature, and other meteorological information.
(2) As for the statistical approaches, their main purpose is to establish a long-term PV output prediction model. In literature [
7,
8,
9,
10], the auto-regressive, auto-regressive moving average, auto-regressive integral moving average and Kalman filtering model of short-term PV prediction are respectively established based on the time series, and obtain good prediction results. The above model is mainly based on a linear model, which only requires historical PV data and does not require more meteorological factors. In addition, the time series methods can only capture linear relationships and require stationary input data or stationary differencing data.
(3) Along with the rapid update of computer hardware and the development of data mining, prediction methods based on machine learning have been successfully applied in many fields. Machine learning models that have been widely applied in PV output prediction models are nonlinear regression models such as the Deep Neural Network (DNN), the Recurrent Neural Network (RNN), the Convolutional Neural Network (CNN), the Deep Belief Network (DBN) and so forth. Literature [
11,
12] establishes output prediction models based on the neural network, which can consider multiple input influencing factors at the same time. The only drawback is that the network structure and parameter settings will have a great impact on the performance of the models, which limits the application of neural networks. Literature [
13,
14] has analyzed various factors affecting PV power and established support vector machine (SVM) prediction models facing PV prediction. The results show that the SVM adopts the principle of structural risk minimization to replace the principle of empirical risk minimization of traditional neural networks; thus, it has a better generalization ability. To effectively enhance the reliability and accuracy of PV prediction results, related literature proposes the use of intelligent optimization algorithms to estimate model parameters; some examples of intelligent optimization algorithms include the gray wolf algorithm, the similar day analysis method and the particle swarm algorithm [
15,
16,
17]. The example analysis illustrates the effectiveness of the optimization algorithm.
(4) In recent years, decomposition-refactoring prediction models based on signal analysis methods have attracted more and more attention from scholars. Relevant research shows that using signal analysis methods to preprocess data on PV power series can reduce the influence of non-stationary meteorological external factors on the prediction results and improve prediction accuracy. The decomposition methods of PV power output data mainly include wavelet analysis and wavelet packet transform [
18,
19], empirical mode decomposition (EMD) [
20], ensemble empirical mode decomposition (EEMD) [
21] and local mean decomposition (LMD) [
22]. Among them, wavelet analysis has good time-frequency localization characteristics, but the decomposition effect depends on the choice of basic function and the self-adaptability is poor [
23]. EMD has strong self-adaptability, but there are problems such as end-effects and over-enveloping [
24]. LMD has fewer iterations and lighter end-effects. However, judging the condition of purely FM signals requires trial and error. If the sliding span is not properly selected, the function will not converge, resulting in excessive smoothness, which affects algorithmic accuracy [
25]. EEMD is the improved EMD method; the analysis of the signal is made via a noise-assisted, weakened influence of modal aliasing. However, this method has a large amount of computation and more modal components than the true value [
26]. Variational mode decomposition (VMD) is a relatively new signal decomposition method. Compared to the recursive screening mode of EMD, EEMD, and LMD, by controlling the modal center frequency K, the VMD transforms the estimation of the sequence signal modality into a non-recursive variational modal problem to be solved, which can well express and separate the weak detail signal and the approximate signal in the signal. It is essentially a set of adaptive Wiener filters with a mature theoretical basis. In addition, the non-recursive method adopted does not transmit errors, and solves the modal aliasing phenomenon of EMD, EEDM and other methods appeared in the background of bad noise, and effectively weakens the degree of end-effect [
27]. Literature [
28] used this method for fault diagnoses and achieved good results.
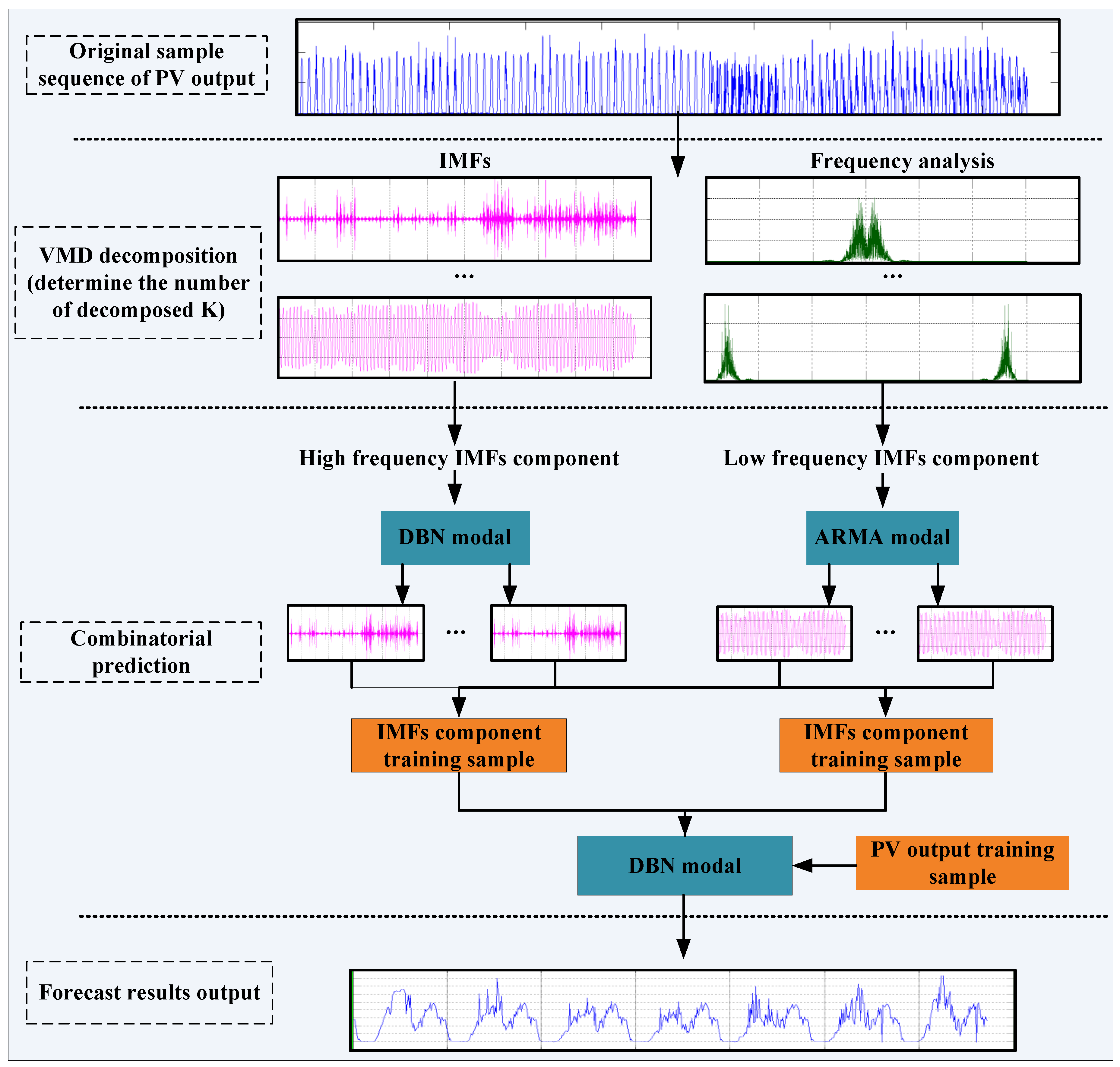
Through the above literature research, we find that the previous prediction methods using traditional neural network models and single machine learning models cannot meet the performance requirements of local solar irradiance prediction scenarios with complex fluctuations. To further improve the prediction accuracy of PV output, this work proposes a new and innovative hybrid prediction method that can improve prediction performance. This method is a hybrid of variational mode decomposition (VMD), the deep belief network (DBN), and the auto-regressive moving average model (ARMA); it combines these prediction techniques adaptively. Different from the traditional PV output prediction model, the key features of the VMD-ARMA-DBN prediction model are the perfect combination of the following parts: (1) VMD-based solar radiation sequence decomposition; (2) ARMA-based low-frequency component sequence prediction model; and (3) DBN-based high-frequency component sequence prediction model. The original photovoltaic output sequences are decomposed into multiple controllable subsequences of different frequencies by using the VMD methods. Then, based on the frequency characteristics of each subsequence, the subsequence prediction is performed by using the advantages of ARMA and DBN, respectively. Finally, the subsequences are reorganized, and the final PV output prediction value is obtained. The main contributions of this article are as follows:
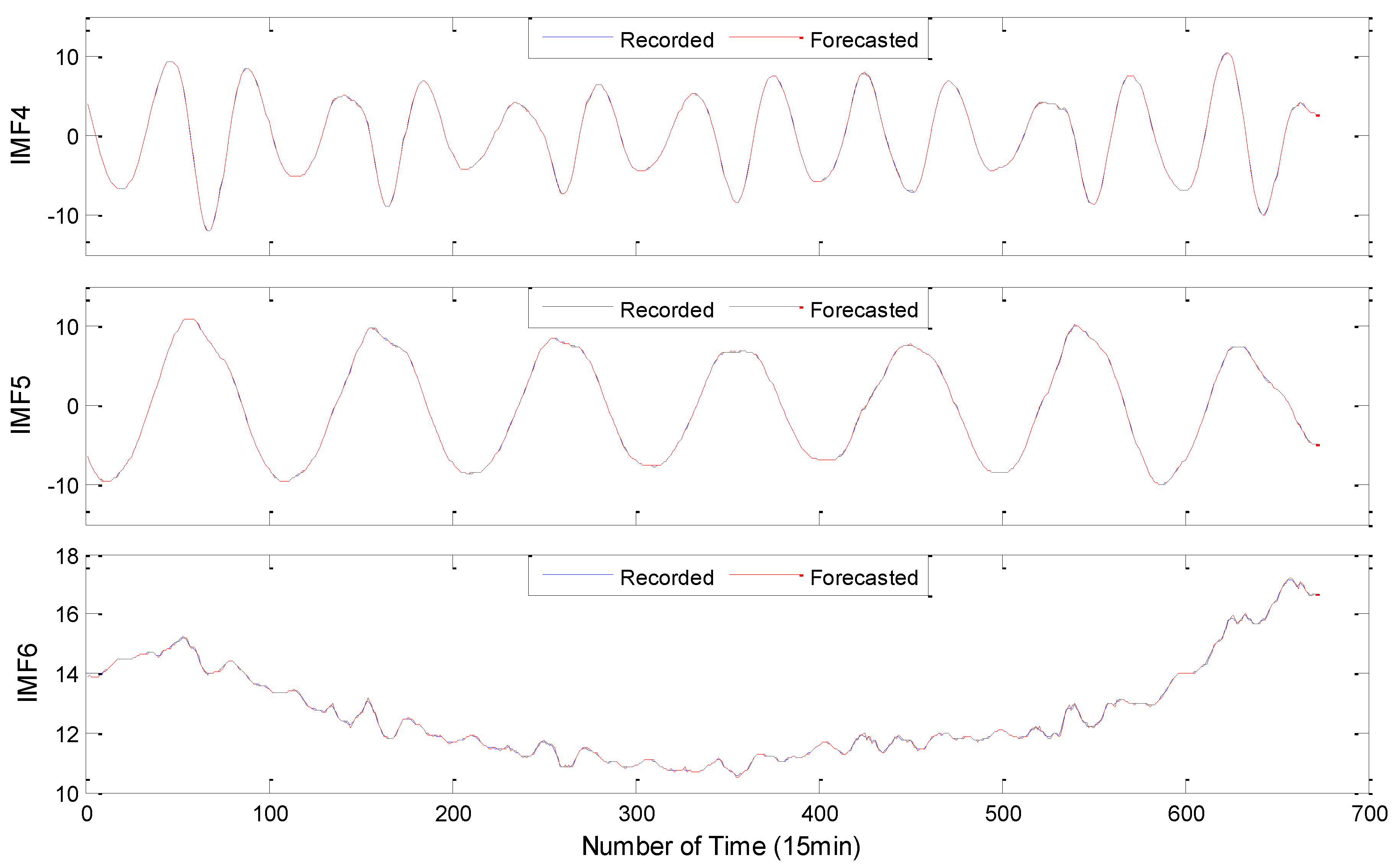
(1) To reduce the complexity and non-stationarity of the PV output data series, the VMD decomposition is used for the first time to preprocess the PV data sequence and decompose it into a series of IMF component sequences with good characteristics, achieving an effective extraction of advanced nonlinear features and hidden structures in PV output data sequences.
(2) An innovative method for predicting PV output based on VMD-DBM-ARMA is proposed. According to the characteristics of the IMF component sequence decomposed by the VMD, DBN and ARMA models are used to improve predictions of the high- and low-frequency component sequences, respectively. Based on this, the DBN is used for feature extraction and structural learning of the prediction results of each component sequence. Finally, the PV output predictive value is obtained.
(3) Taking the actual measured data of a PV power plant in China-Yunnan for application, the short-term PV output predictions of ARMA, DBN, EMD-ARMA-DBN, EEMD-ARMA-DBN, and VMD-ARMA-DBN were conducted and three prediction precisions were introduced, respectively. The evaluation indicators perform a statistical analysis on the prediction effect of each model. The results show that the proposed method can guarantee the stability of the prediction error and further improve the PV prediction accuracy.
The remainder of this paper is organized as follows:
Section 2 describes our proposed approach: A Hybrid Forecasting Method for Solar Output Power Based on VMD-DBN-ARMA; experimental results are presented in
Section 3; and the experimental comparison and conclusion are given in
Section 4 and
Section 5, respectively.
4. Discussions and Comparison
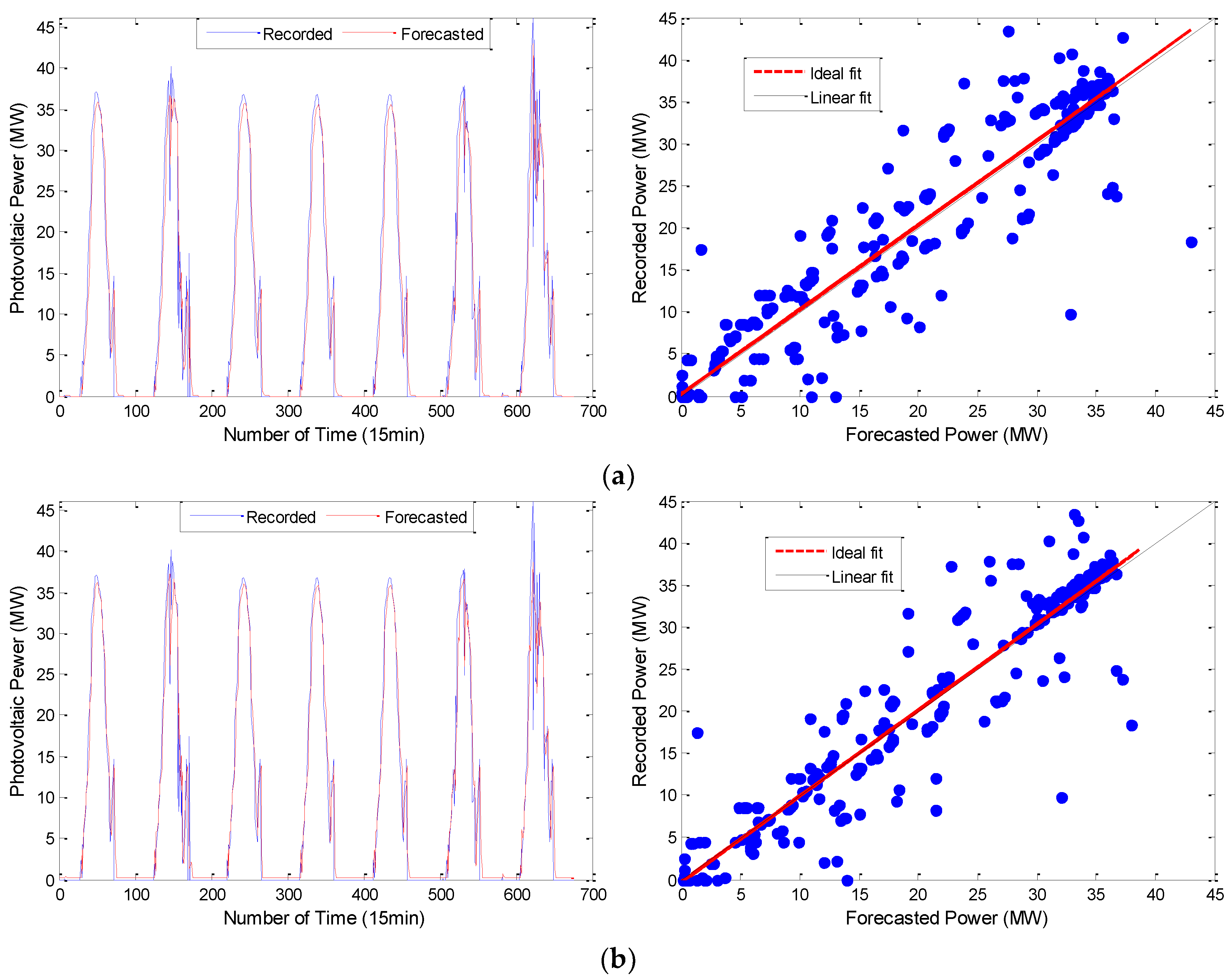
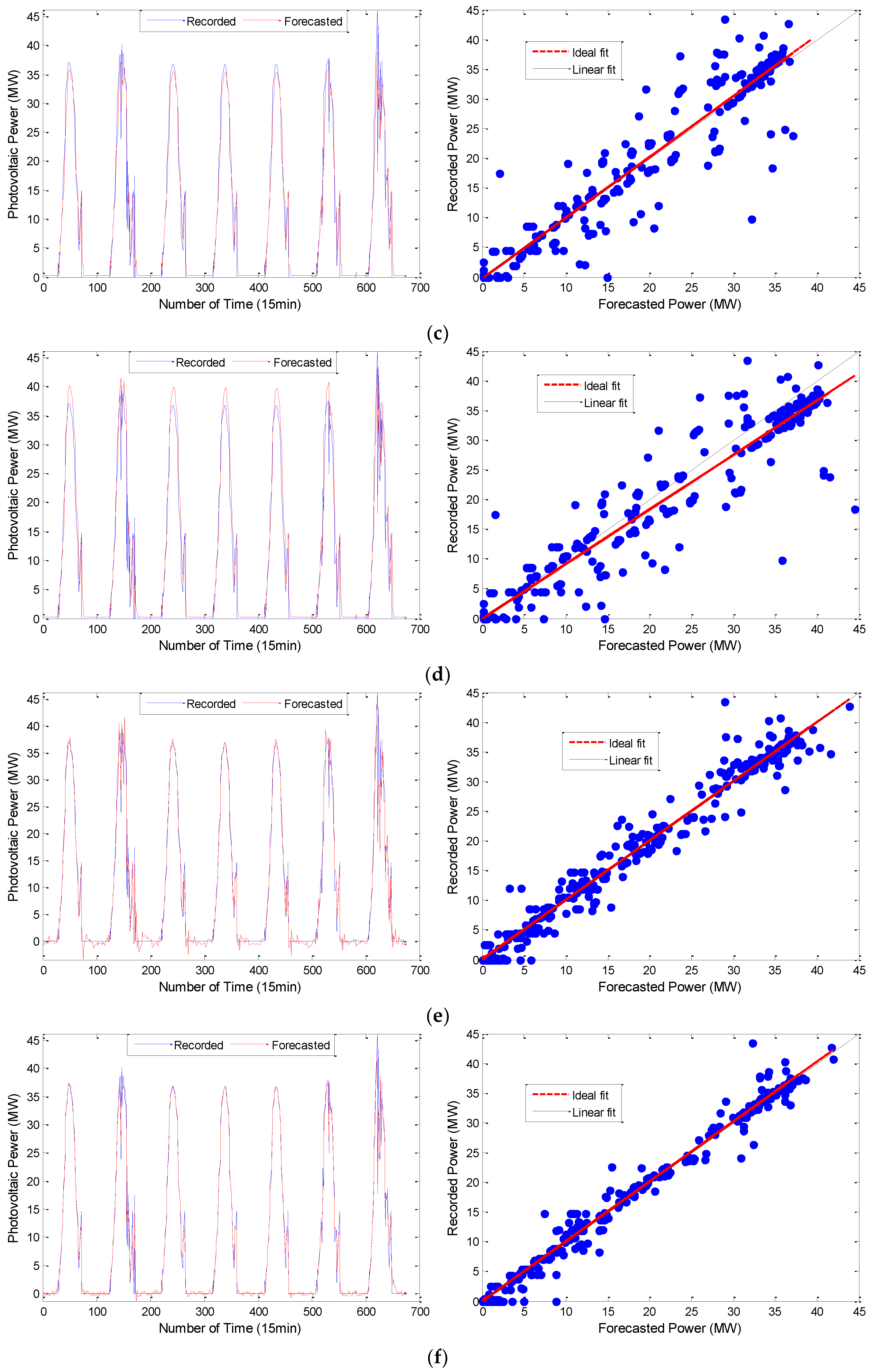
To test the prediction effect of the model proposed in this paper, we compared the results of the following prediction models: (1) the single prediction models (ARMA, DBN) used in this paper; (2) the common neural network prediction model, RNN and Gradient Boost Decision Tree (GBDT) in literature [
46,
47], used on a representative basis; (3) the combined prediction model, Discrete Wavelet Transformation (DWT) in literature [
48] and traditional EMD and EEMD are used on a representative basis. The prediction results for each model are shown in
Figure 11.
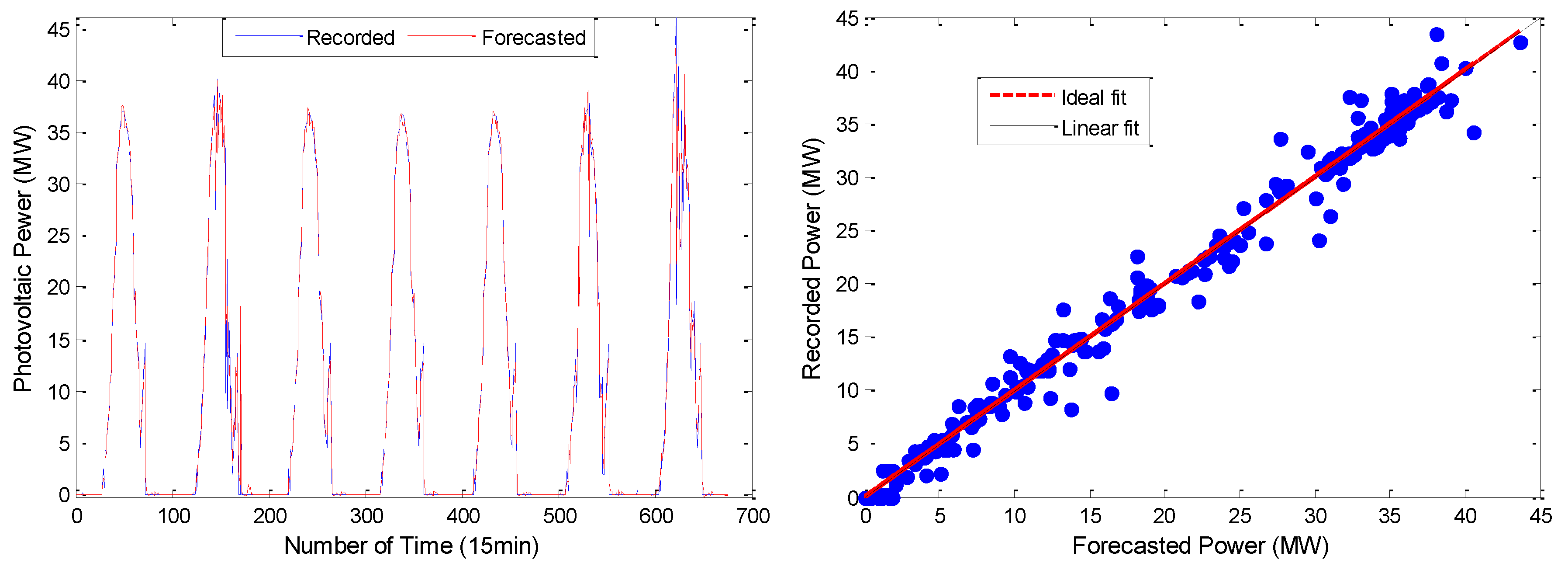
From the simulation results shown in
Figure 10 and
Figure 11, the VMD-ARMA-DBN combined models have a better tracking and fitting ability for the PV output curve. Compared to the single models, the combined model prediction accuracy (after using the modal decomposition technique) shows different degrees of improvement.
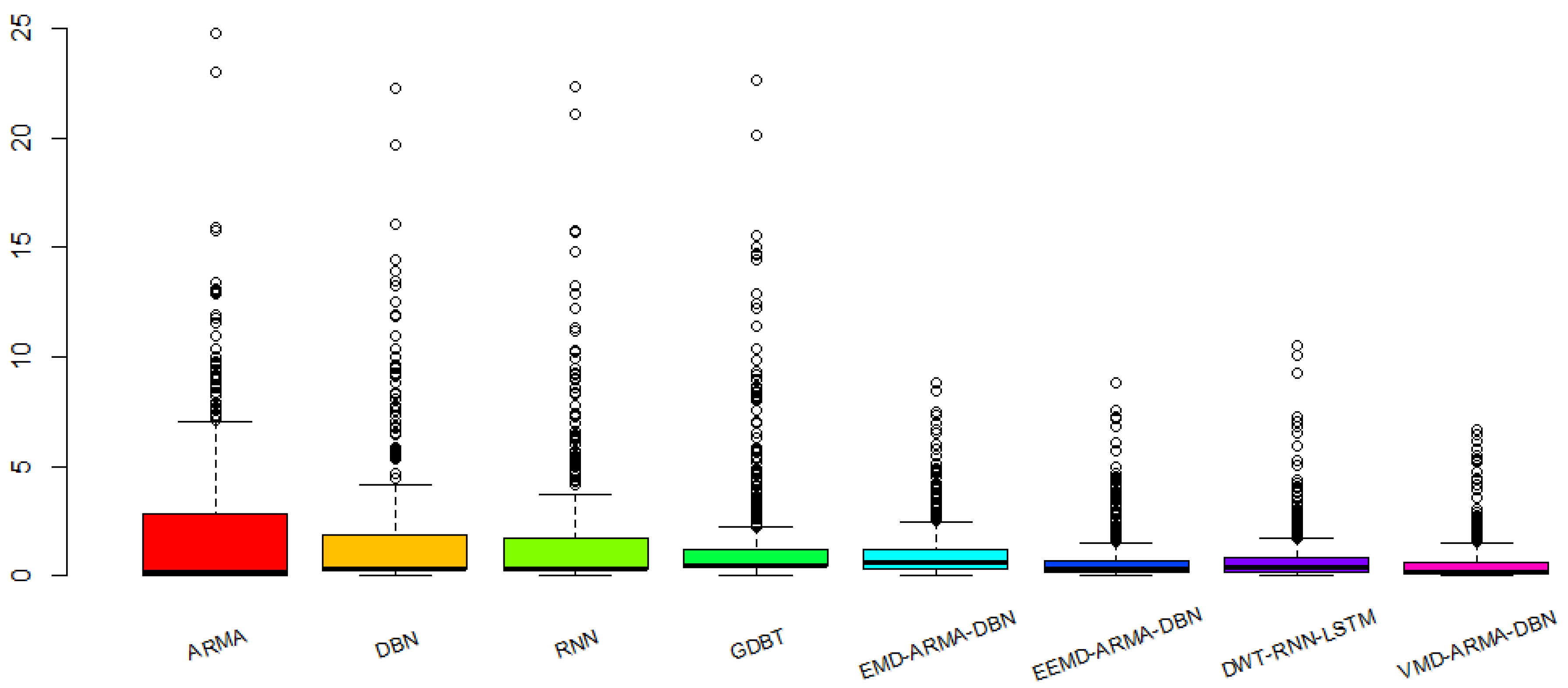
Figure 12 is a bar graph demonstrating the absolute error of prediction in each model.
From the perspective of the absolute error distribution of the prediction results, the stability of the prediction accuracy for the single models is poor, and the error distribution interval is large. Among them, the absolute error distribution interval of each model is [0, 24.7821], [0.0051, 22.2464], [0.0082, 22.3289], [0.0363, 22.6686], [0.0005, 8.8306], [0.0018, 8.7955], [0.0008, 10.5322], and [0.0017, 6.6526], respectively, and the prediction error median is 0.1692, 0.2791, 0.2708, 0.4523, 0.5926, 0.3078, 0.0351, and 0.1414, respectively. The absolute error distribution of the VMD-ARMA-DBN model is more concentrated and the median of the error is the smallest, which is the most ideal of the eight groups of prediction models. In summary, the VMD-based multi-frequency combined forecasting model presented in this paper is superior to other models. To compare the prediction effects of each model more intuitively, we used quantitative evaluation indicators.
Table 6 shows the evaluation results for each model.
First, it can be concluded from
Figure 12 and
Table 6 that, compared with the single prediction models containing ARMA, DBN, RNN, and GBDT, the introduction of the modal decomposition method has a great influence on the accuracy of the prediction results. The modal decomposition method is used to effectively decompose the original PV output, and the prediction method is selected according to the characteristics of different modal vectors, which can make the prediction result more accurate and stable, and the result can be anticipated. The PV system power output has high volatility, variability, and randomness; through modal decomposition it can effectively eliminate the unrelated noise components to make each component easier to predict. In the single prediction models, the error of the ARMA prediction model is the largest, which is not suitable for effectively tracking the undecomposed solar PV output; DBN, RNN and GBDT belong to machine learning, and the prediction error is essentially the same. However, the parameters of the RNN prediction model are more difficult to choose and more easily fall into the local optimum, and GBDT is easy to over-fit for complex models. However, combined prediction methods can effectively avoid these problems.
Second, the proposed VMD-ARMA-DBN model prediction results are always better than those of other combined prediction models (such as EMD, EEMD, and DWT). This is mainly because different decomposition methods have different ways of controlling the modal number, affecting the size of the prediction error. The center frequency of the VMD modal decomposition is controllable, which can effectively avoid modal aliasing compared with other modal decomposition models. The original sequences are decomposed according to the frequency components, and different prediction models are used for fitting purposes. According to the prediction results in
Table 6, this kind of combined prediction method significantly improves the prediction accuracy.
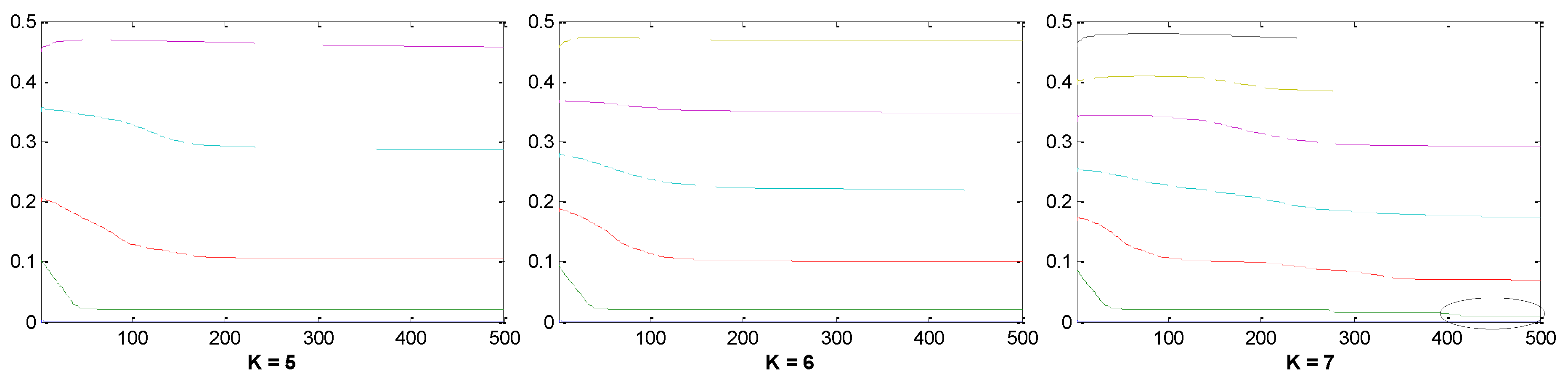
Finally, it should be noted that the prediction results of the VMD-ARMA-DBN models are different under different modal center frequencies K. Specifically, when K is too large, it is easy to cause excessive frequency decomposition, which increases the degree of complexity of the model prediction; when K is too small, it will cause modal overlapping, and the single frequency components cannot be effectively predicted, so only the appropriate K can be used to make an effective prediction. Moreover, this will be an important problem that must be overcome in the next research stage.
5. Conclusions
The short-term prediction accuracy of the nonlinear PV power time series in this work proposes a multi-frequency combined prediction model based on VMD mode decomposition. Specifically, the following was observed:
(1) For the first time, this paper introduces the VMD method into PV power plant output forecasting, decomposes the unstable PV output sequence, and conducts in-depth research on the characteristics of VMD. When traditional decomposition methods deal with sequences that contain both trend and wave terms, accurately extracting the shortcomings of the trend items is impossible. A combination method based on VMD-ARMA-DBN is proposed, which not only reflects the development trend of the size of PV output, but also decomposes the fluctuation series into a set of less complex and some strong periodical parameters, which greatly reduced the difficulty of prediction.
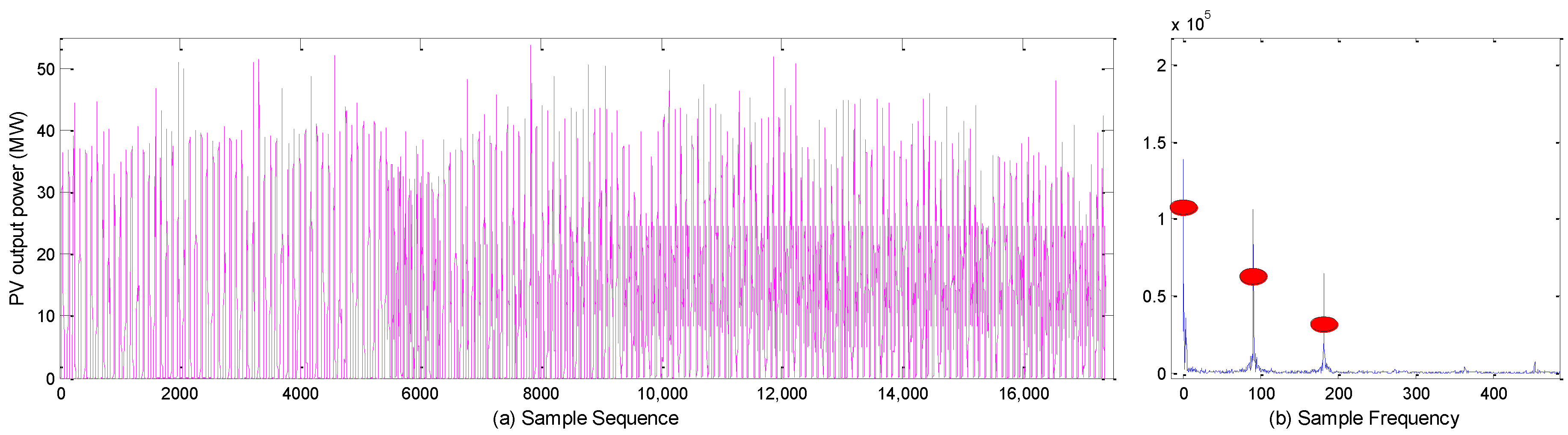
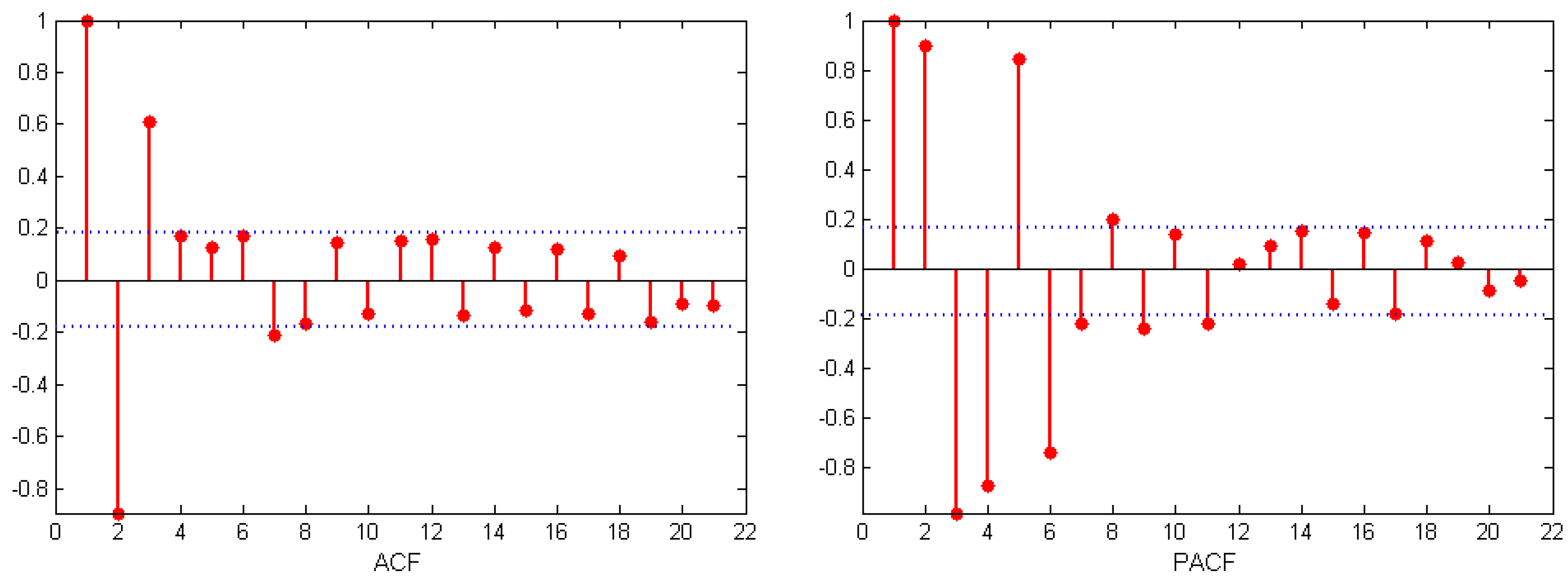
(2) If the VMD cannot restore the original sequence completely, and cannot determine the number of decomposition layers automatically, we propose a method to determine the number of VMD decomposition layers via a spectrum analysis, which can restore the original sequence to a large extent and ensure the stability of the component. First, according to the spectrum diagram of the sample data, we determined the number of modal components. If the overlapping phenomenon occurred in the center frequency iteration curve, the number of decompositions was selected and divided into high- and low-frequency components according to the characteristics of the different components. ARMA and DBN were used to simulate and predict high-frequency and low-frequency components. Then, the predictive value of each component was determined using DBN. Each one had a strong nonlinear mapping ability, and high self-learning ability and self-adaptive capability. The sample data of each component was taken as input, and the actual PV sample value was used as an output to train the model. Then, the predicted value of each component was used as input for the prediction. Finally, the PV output predicted value was obtained.
(3) To test the prediction effect of the VMD combinatorial model, the normalized absolute mean error, normalized root-mean-square error, and the Hill inequality coefficient were used to compare the single prediction models with the combined prediction models. The simulation results show that the different decomposition methods have been improved to varying degrees in terms of forecast accuracy. Thus, the VMD-ARMA-DBN model proposed in this work offers better accuracy and stability than the single prediction methods and the combined prediction models.
In the prediction process, we found that although the VMD improved the phenomenon of modal aliasing and false components, it was not eliminated. In addition, the DBN’s component--RBM needs to be further improved. The weight and offset of each layer of RBM are initialized during training. Therefore, even if the number of hidden layer nodes is compared and selected, the optimal model cannot be obtained, and the final prediction result will show diversification; that is, the same model yields different results, and to obtain optimal results, it is necessary to train the model multiple times, which makes the workload cumbersome. The above deficiencies inevitably increase the errors in the prediction process of each component and affect the final prediction results.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}