An Efficient Retrieval Technique for Trademarks Based on the Fuzzy Inference System


Abstract
:1. Introduction
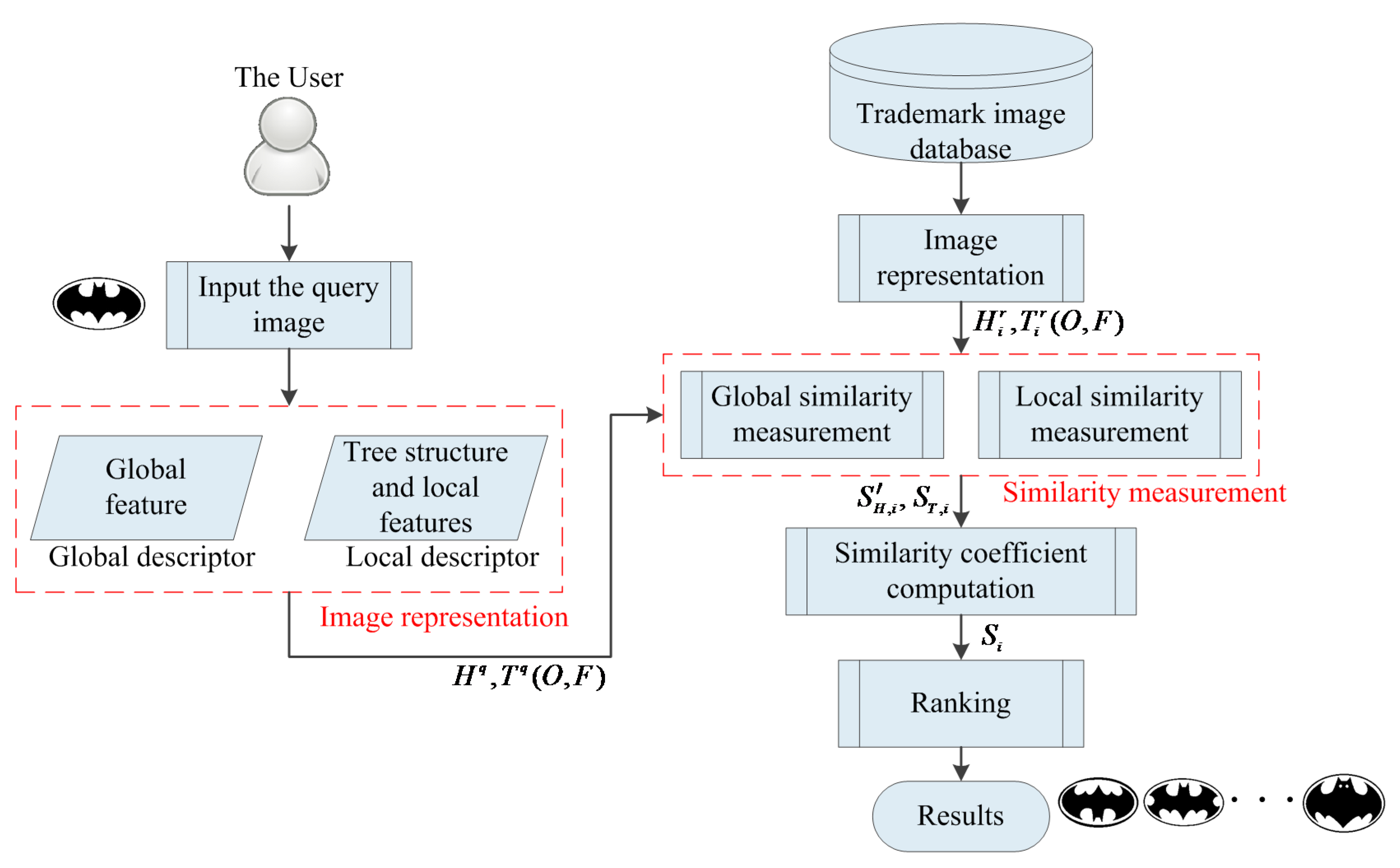
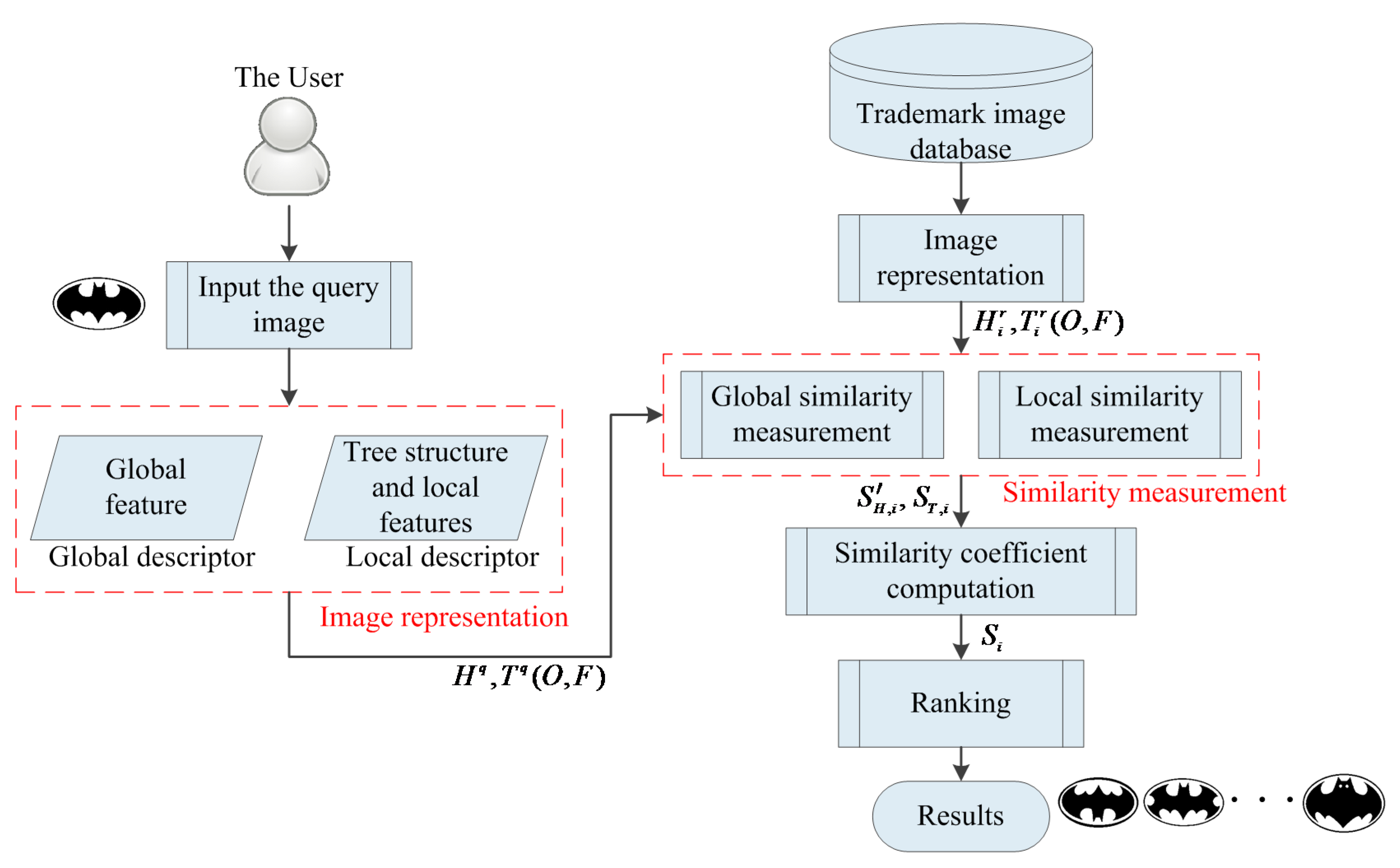
2. Architecture of the Proposed Technique
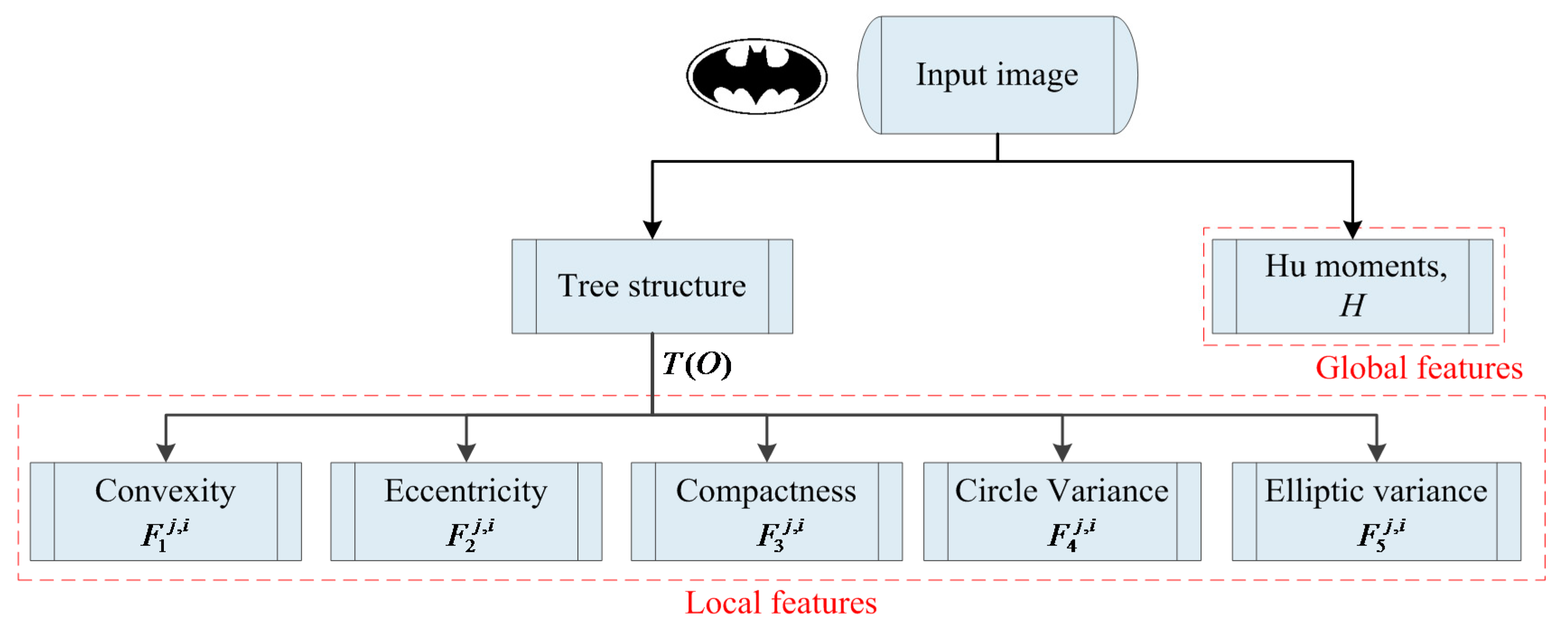
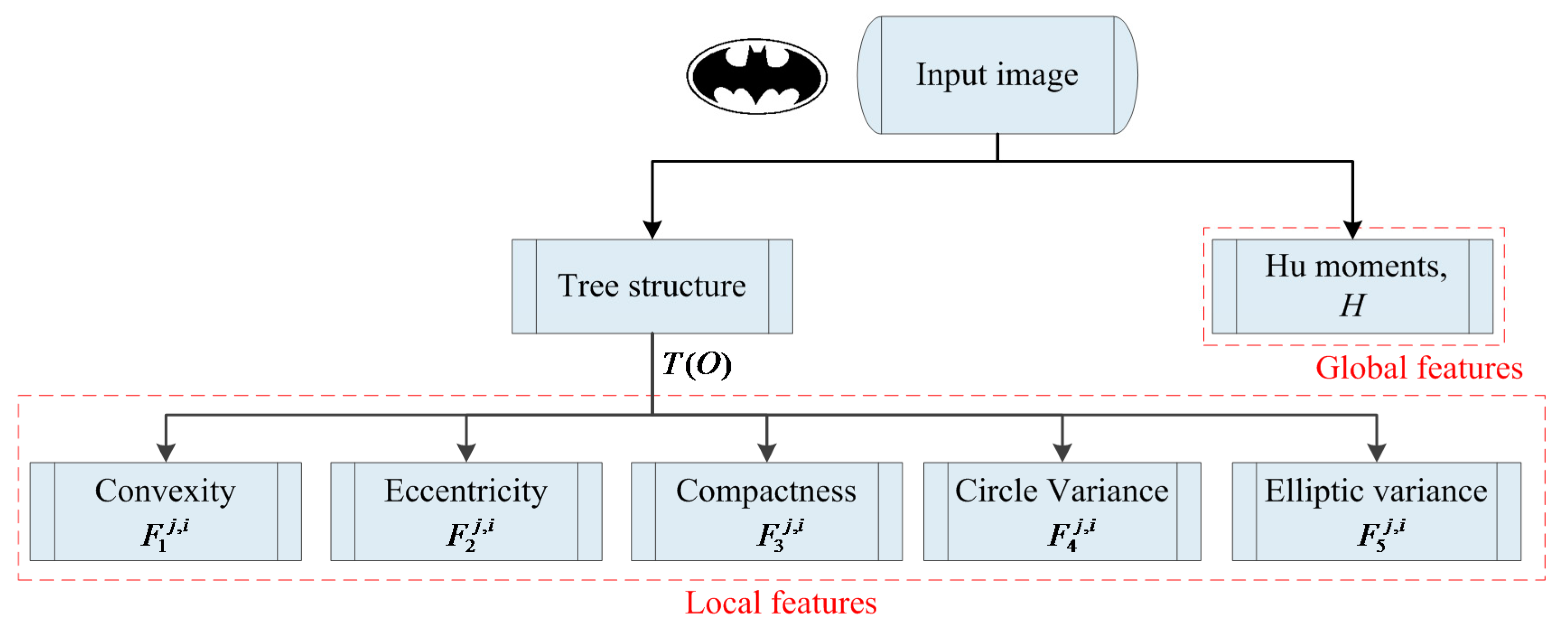
3. Image Representation
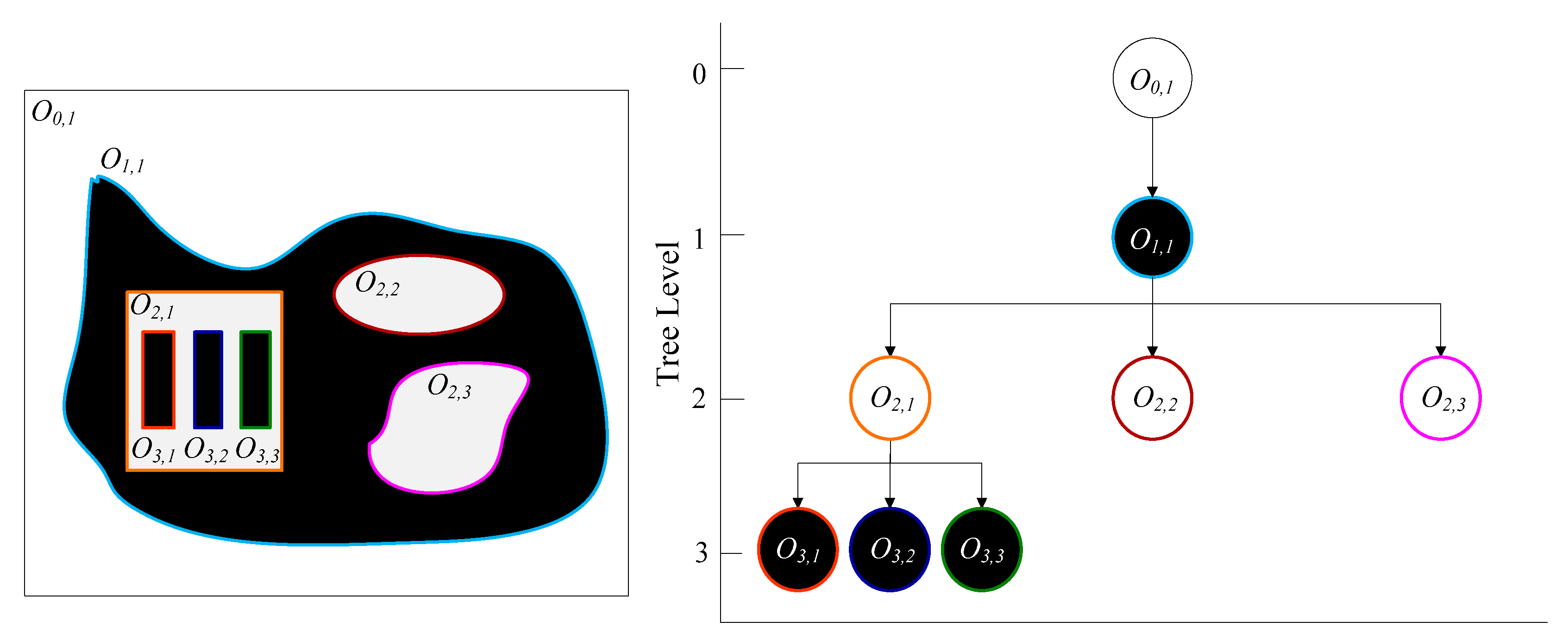
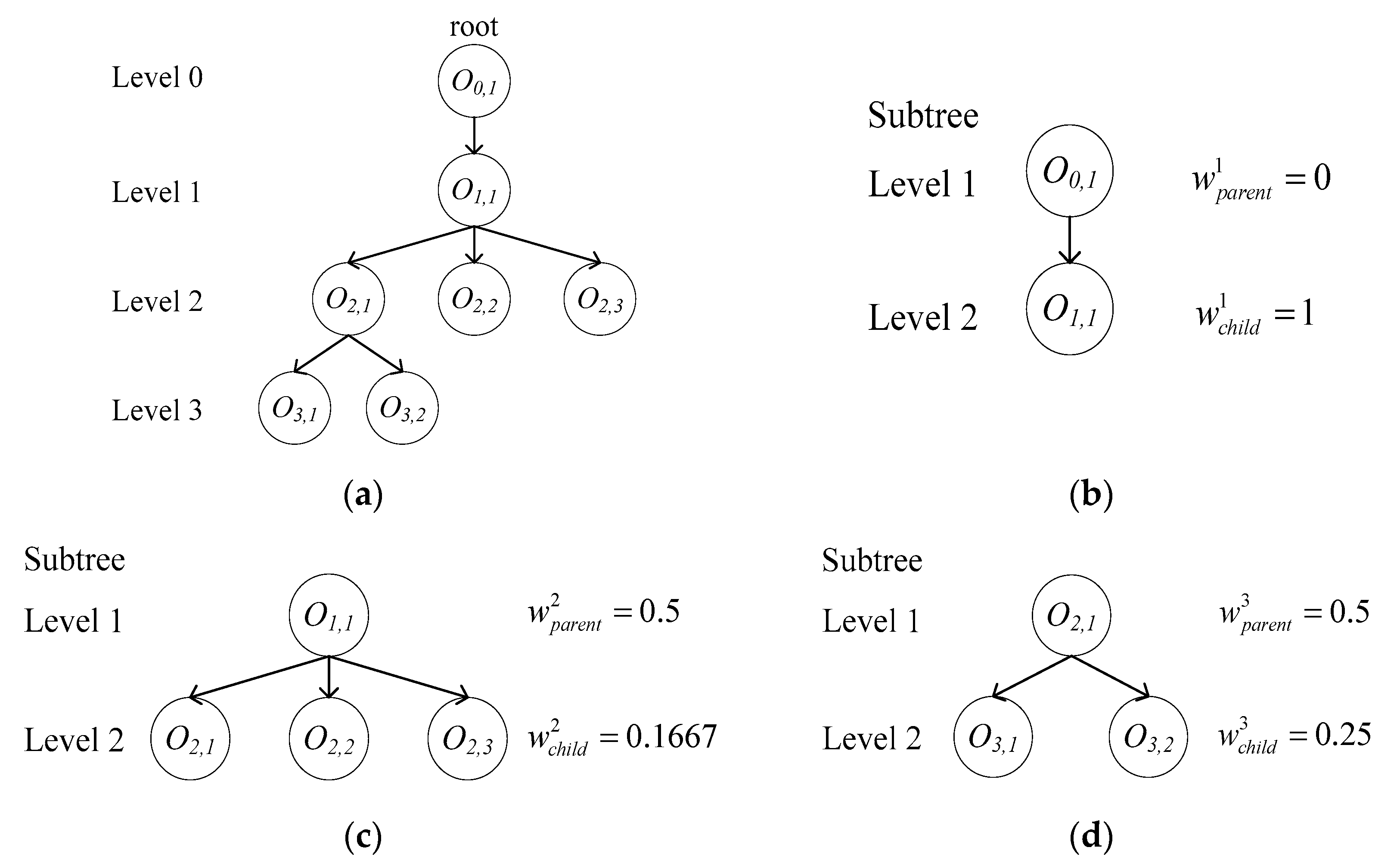
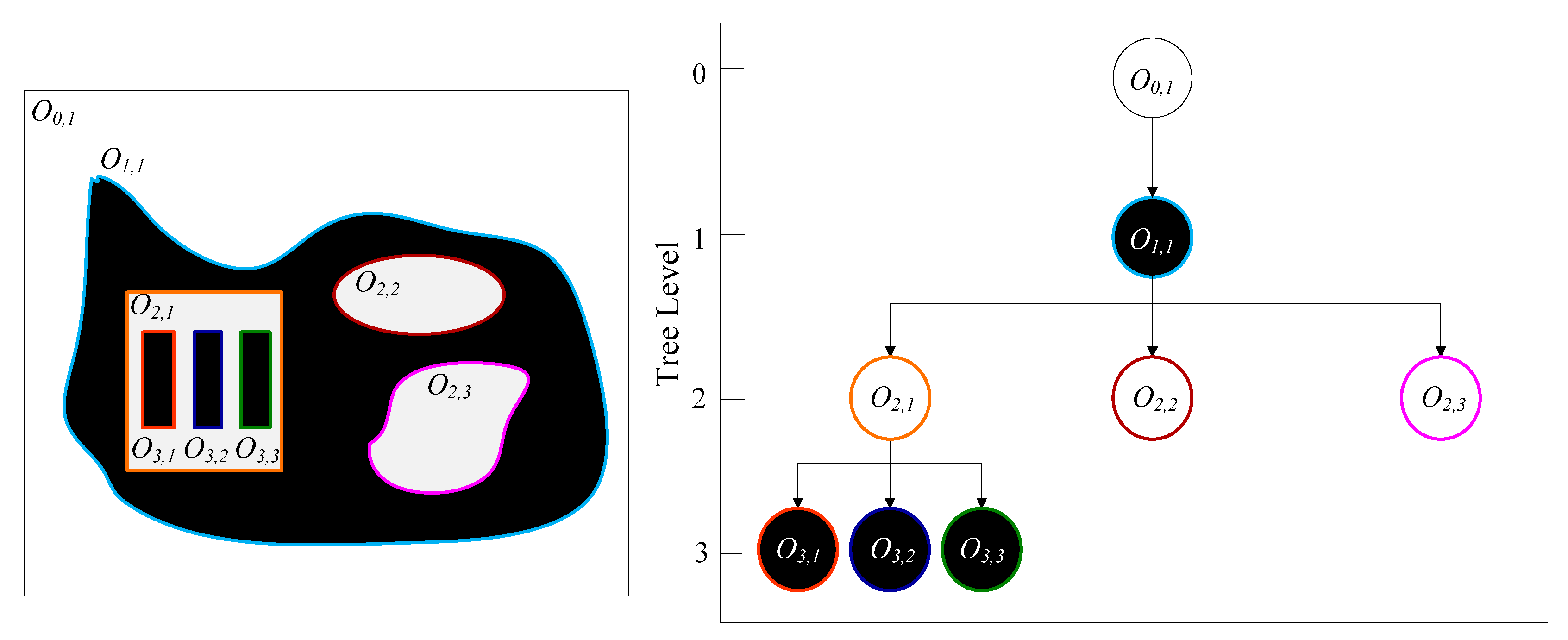
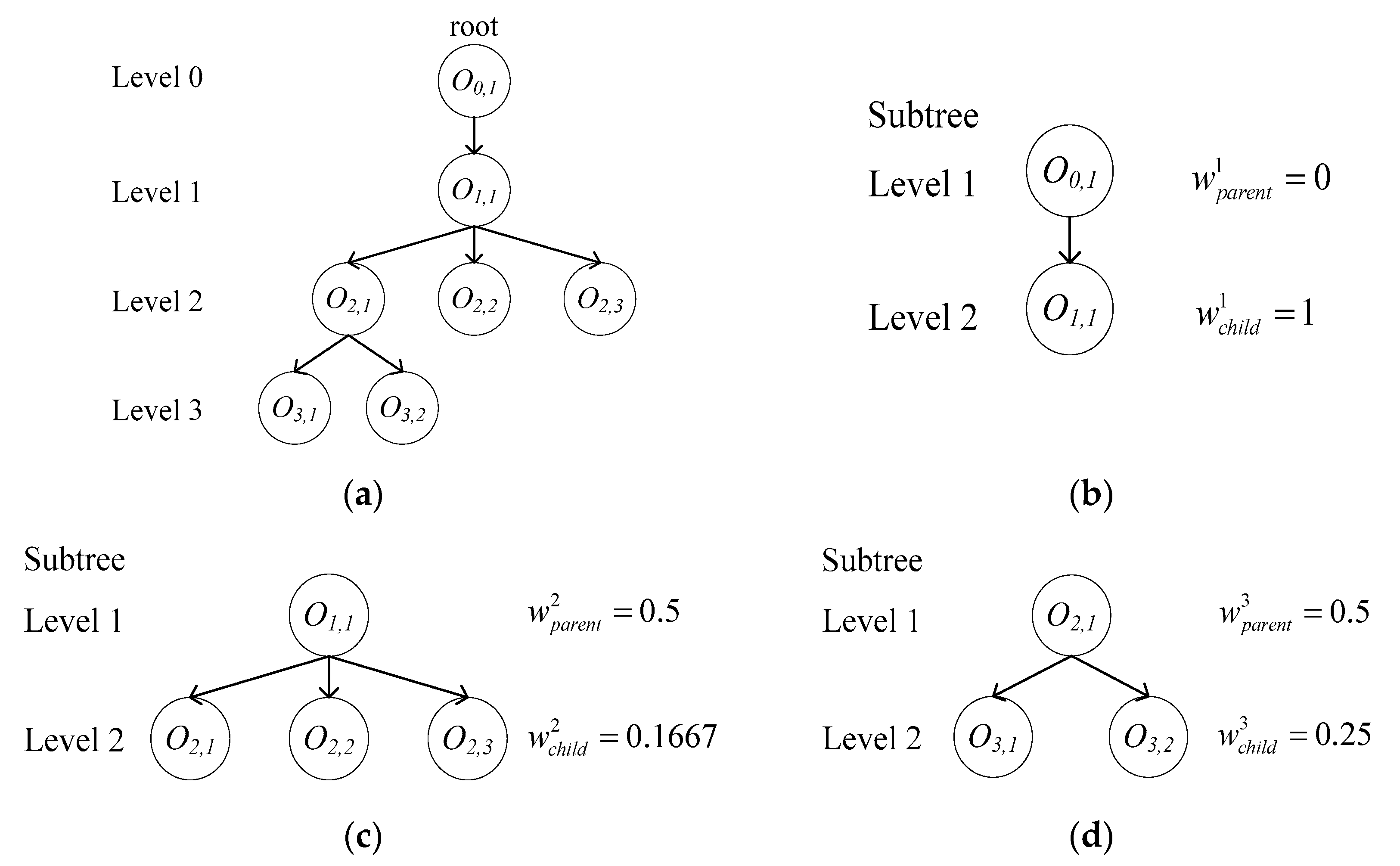
3.1. Tree Representation
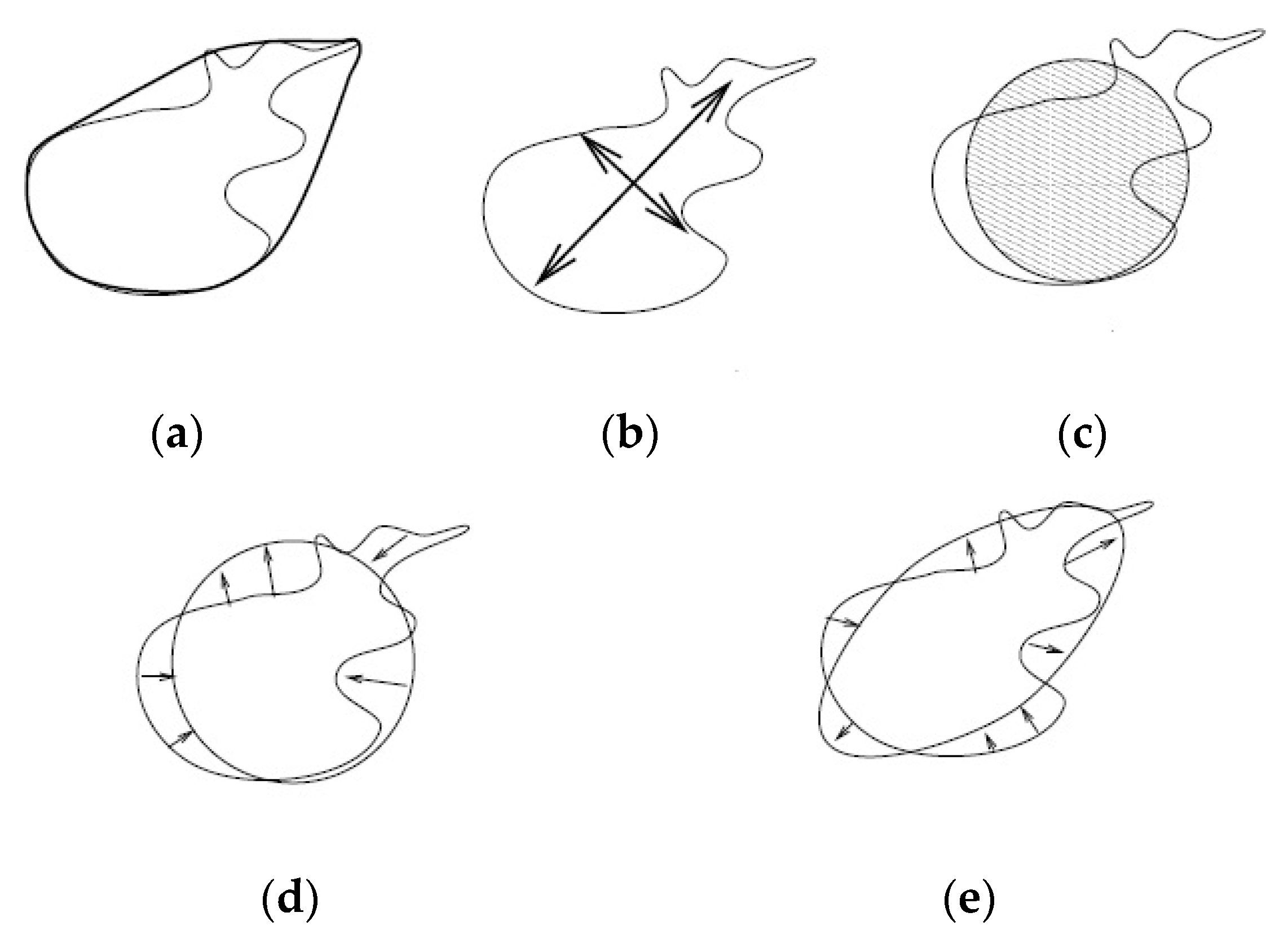
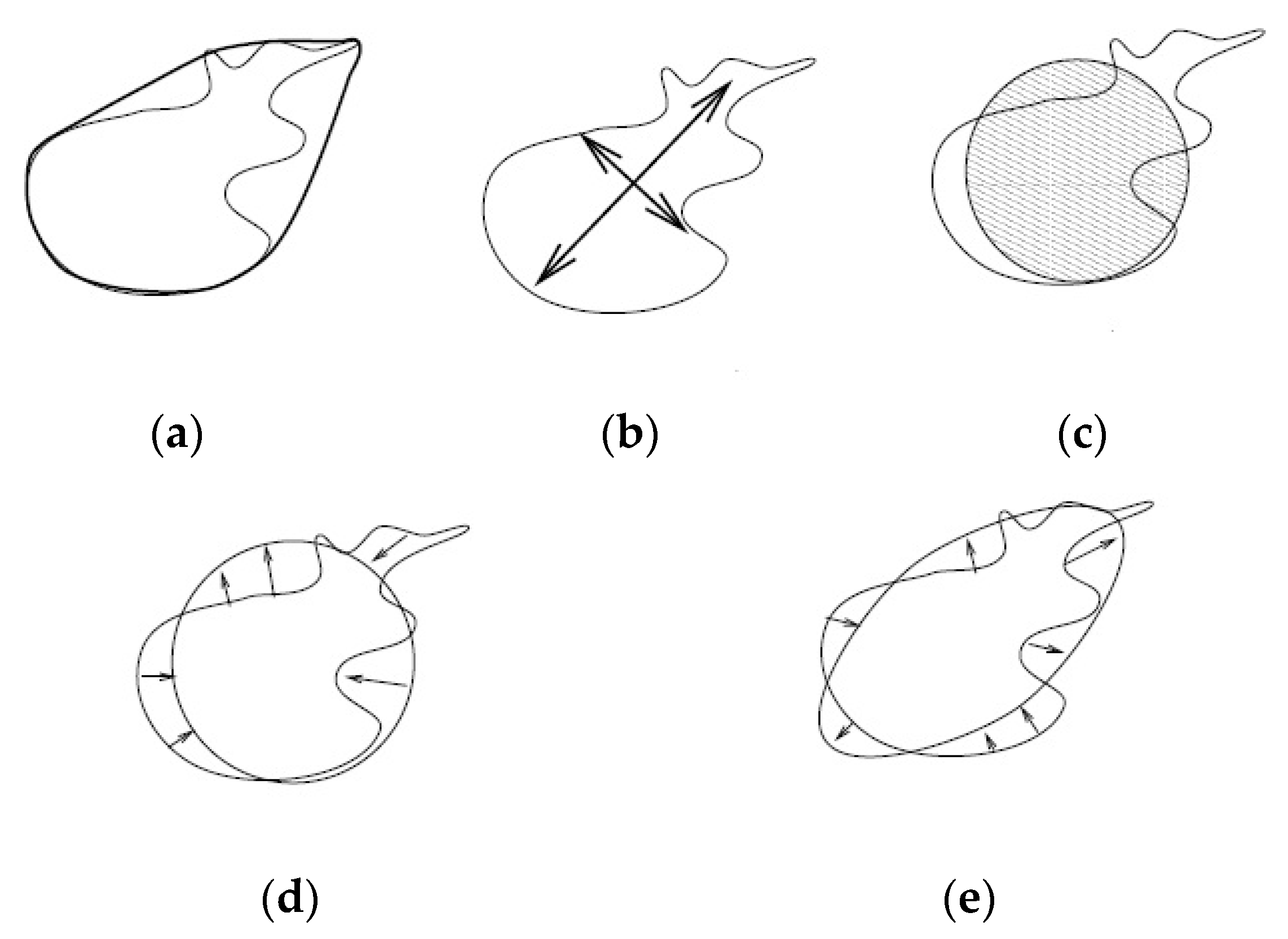
3.2. Feature Extraction
4. Similarity Measurement
4.1. Global Similarity Measurement
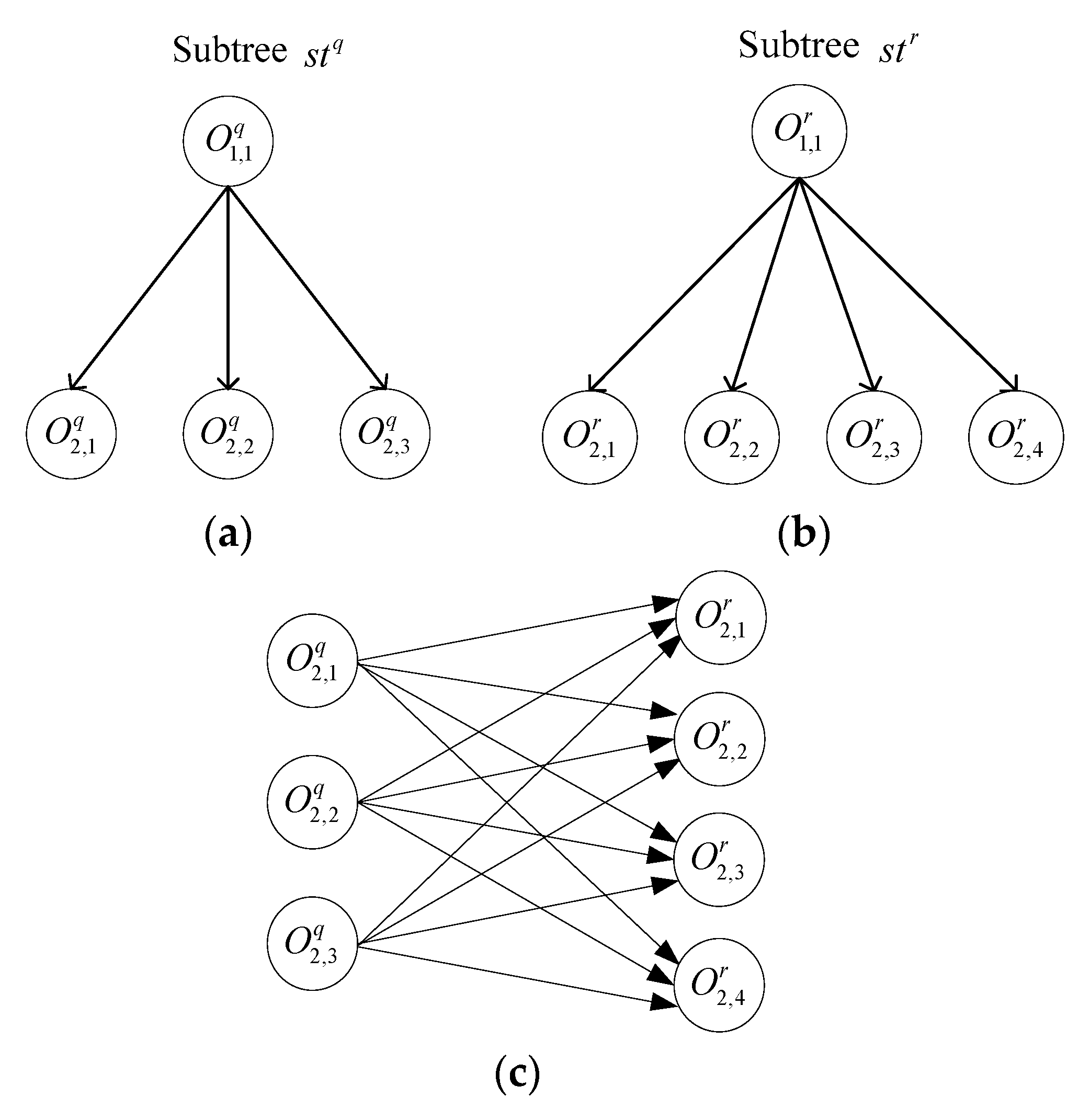
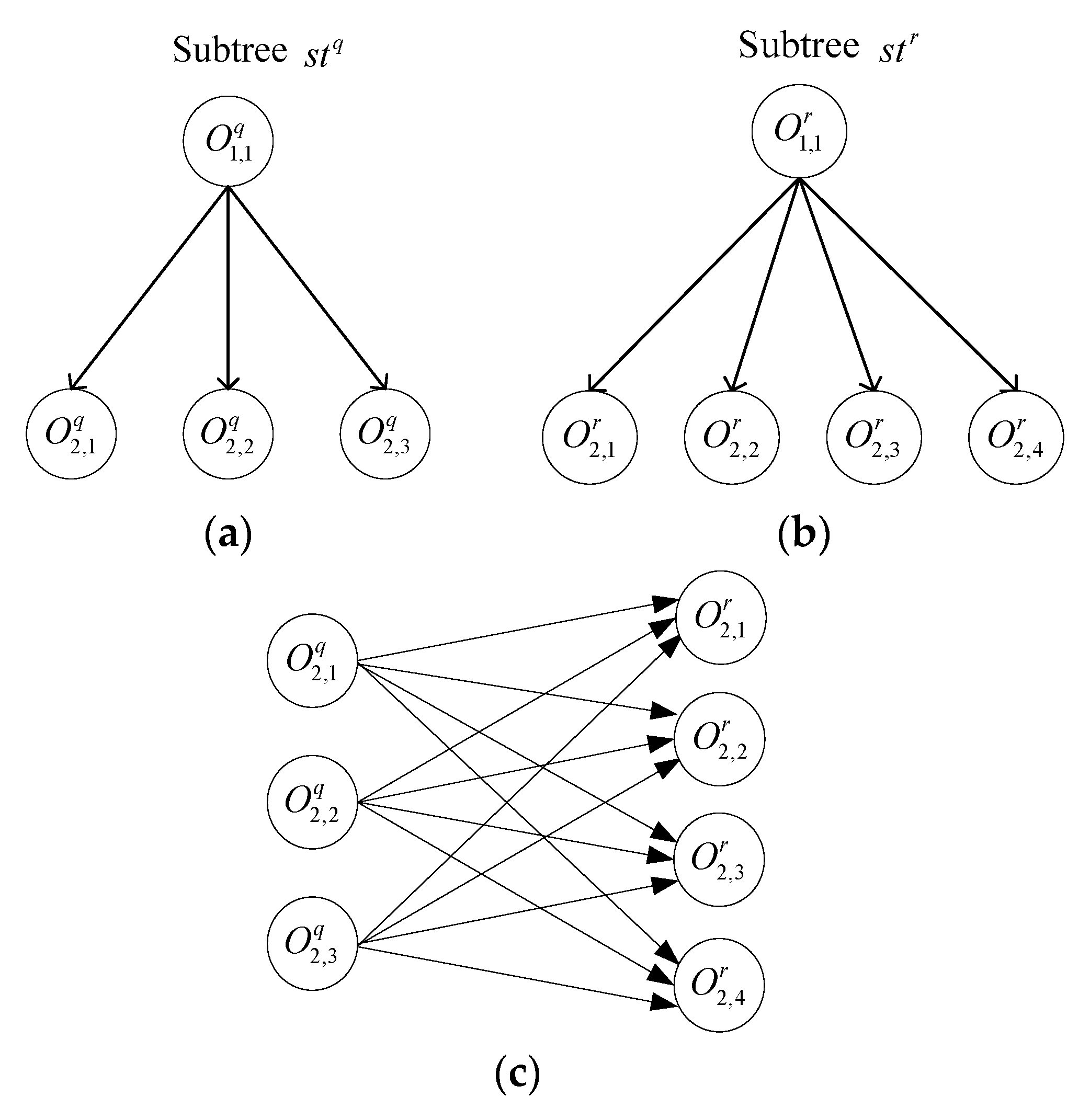
4.2. Local Similarity Measurement
4.2.1. Node Similarity Measurement
- Fuzzification:The first step is to transform the input crisp values such as either ‘0’ or ‘1’ into grades of membership for the linguistic terms of fuzzy sets. The membership function is used to associate a grade with each linguistic term. Selecting a proper membership function is an application dependent problem. Some of most commonly used prototype membership functions are cone, exponential, and triangular functions. Two factors are considered when selecting the membership function for our system: the retrieval accuracy and the computational burden for evaluating a membership function. We chose the triangular function as the membership function since it has good expressiveness and high computational efficiency in the literature [30,33], as shown in Figure 5. The input and output linguistic terms of this paper are = {‘not similar’, ‘similar’} and = {‘not similar’, ‘similar’, ‘very similar’}, respectively. To satisfy the requirement of the membership function in the FIS, the input crisp values must be transformed into similarity values, . The designed formula based on the Manhattan distance is defined as:where, , and and are the f-th local geometric features of the query and retrieved image, respectively.Using Equation (17), the five features of a node described in Section 3, namely, (1) convexity, (2) eccentricity, (3) compactness, (4) circle variance, and (5) elliptic variance are transformed to the similarity crisp values, . The similarity crisp values are further converted into grades of membership for the linguistic terms of fuzzy sets.
- Fuzzy inference engine:The fuzzy inference engine employs fuzzy IF-THEN rules to express input-output relationships and models the qualitative inputs and reasoning process for creating the output. The law to design or build a set of fuzzy rules is based on a human being’s knowledge or experience, which depends on each different actual application. The IF part is mainly used to capture knowledge using the elastic conditions, and the THEN part can be utilized to give the conclusion in linguistic variable form. This IF-THEN rule is widely used by the fuzzy inference system to compute the degree to which the input data matches the condition of a rule. In this paper, there are five input variables and two linguistic terms, so we have possible rules. One of the fuzzy IF-THEN rules is represented by:where and is the number of fuzzy rules. In addition, and are denoted as the linguistic terms for the grade of membership, and , in the L-th rule, respectively. Here we demonstrate the three fuzzy IF-THEN rules in our rule base as the following:The output results are then aggregated using the Mamdani-type inference [33], a MAX-MIN compositional operator. There are two steps in the MAX-MIN compositional operator. In the first step, we use the minimum inference engine to integrate the fuzzy sets in the rule , such that:where calculates the membership value of its operand. Then, the second step integrates the overall fuzzy set by standard union:
- Defuzzification:After the reasoning results, the fuzzy output is still a linguistic variable, and this linguistic variable needs to be converted into a crisp variable via the defuzzification process. Two commonly used methods of defuzzification are the center of area (COA) method and middle of maximum method (MOM). In this paper, the COA was used based on its better results; the formula of the COA is expressed as:where and are the tree nodes of the query image and the retrieved image, respectively, is the number of quantization levels of the output, and is the amount of output at the quantization level . Following the defuzzification process, the center of gravity of the fuzzy set can be obtained. By using the FIS, the similarity between two nodes, and , can be estimated by the core function, , based on their five feature distances.
4.2.2. Weighting Subtree Similarity Measurement
5. Experimental Results and Discussion
5.1. Experiment Setup
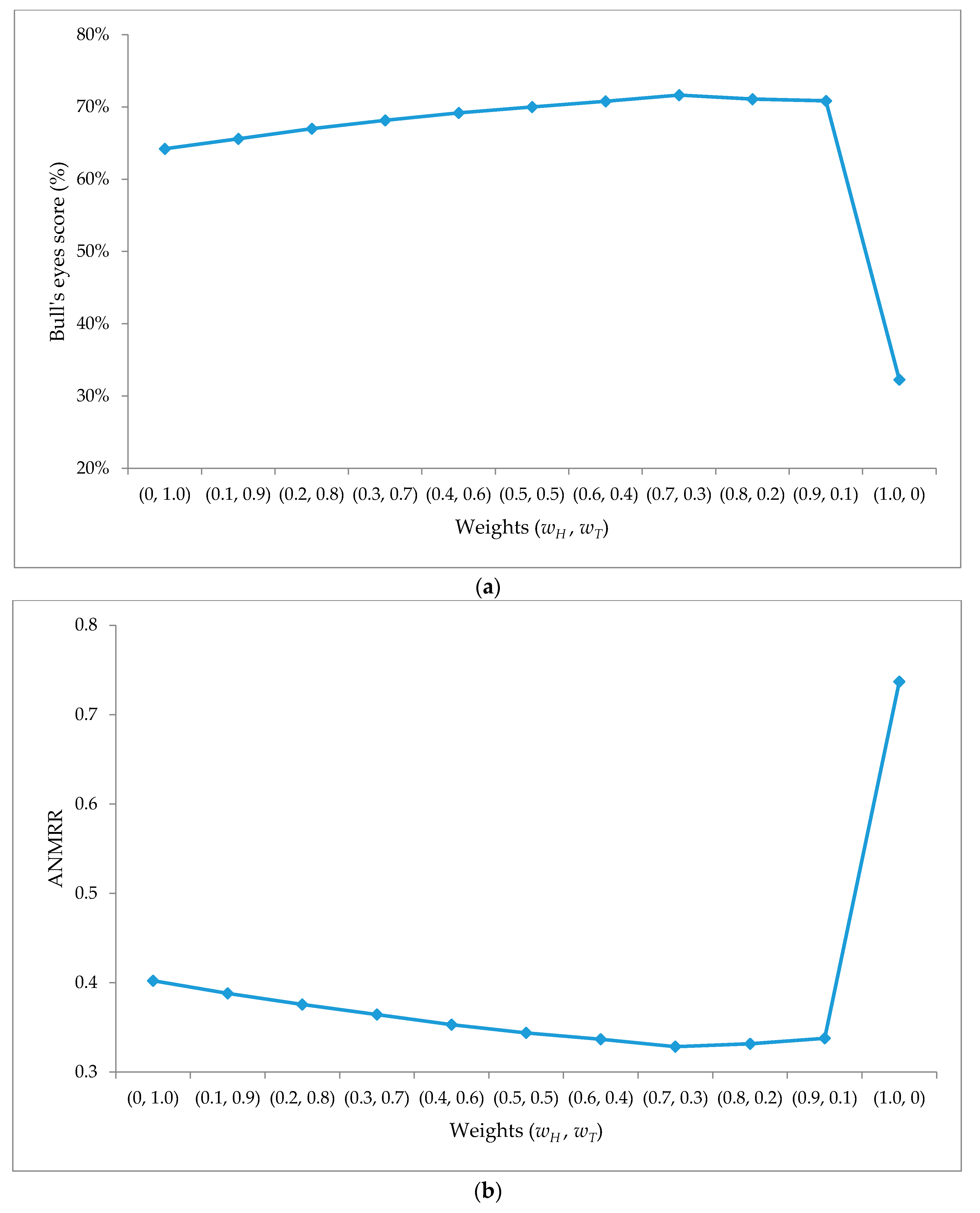
5.2. Analysis for Parameters Setting
5.3. Analysis for the Effect of Fuzzy Inference System
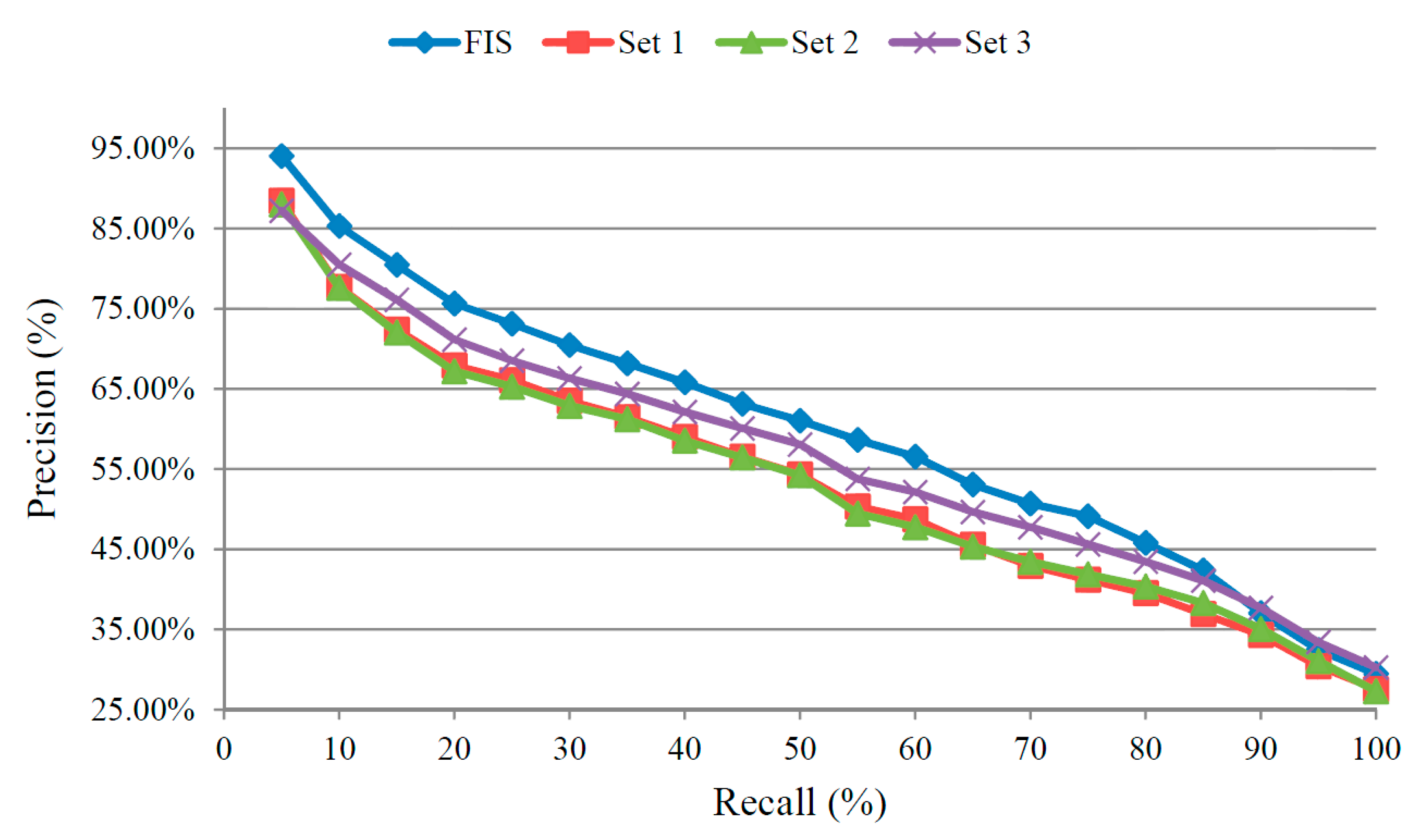
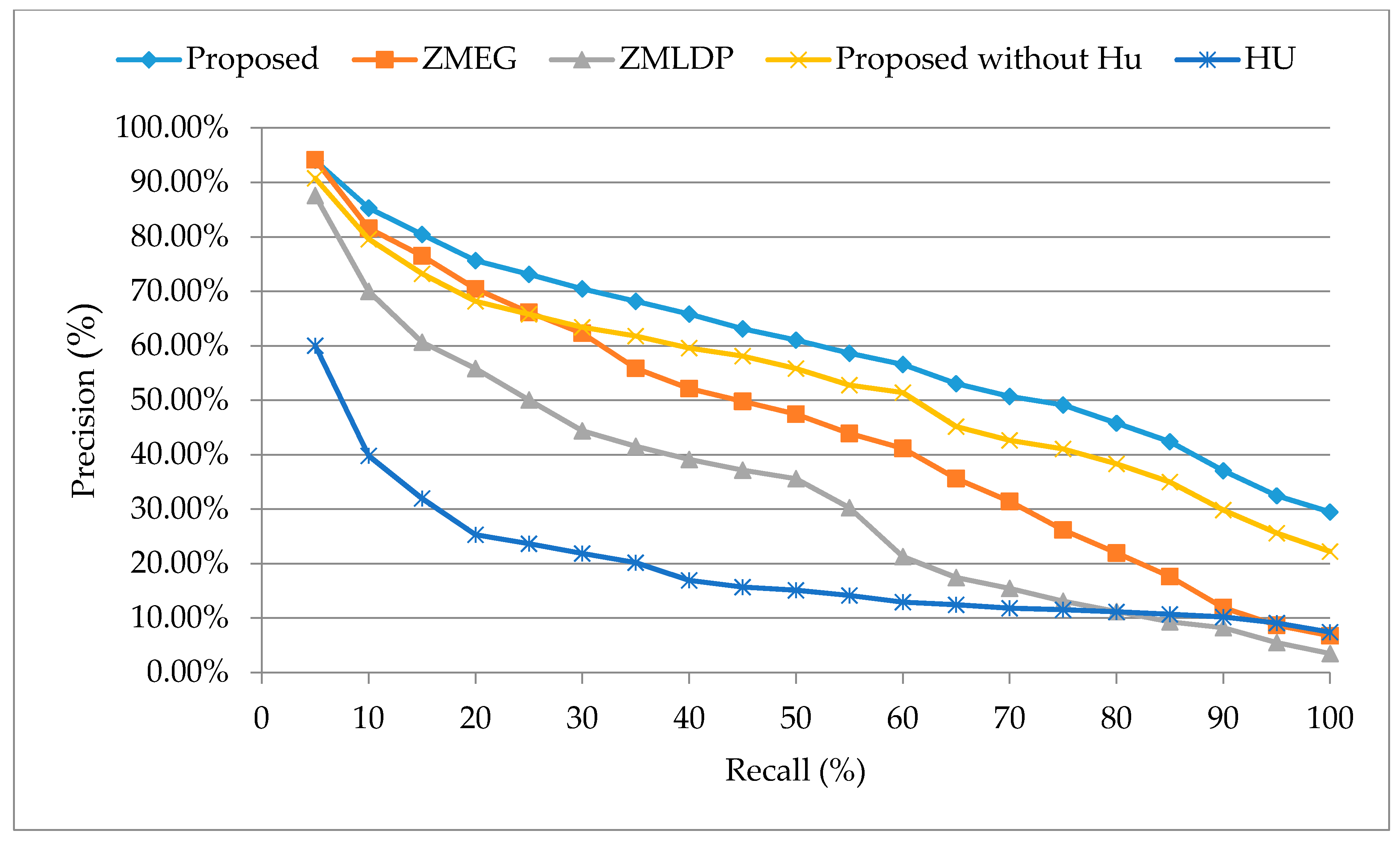
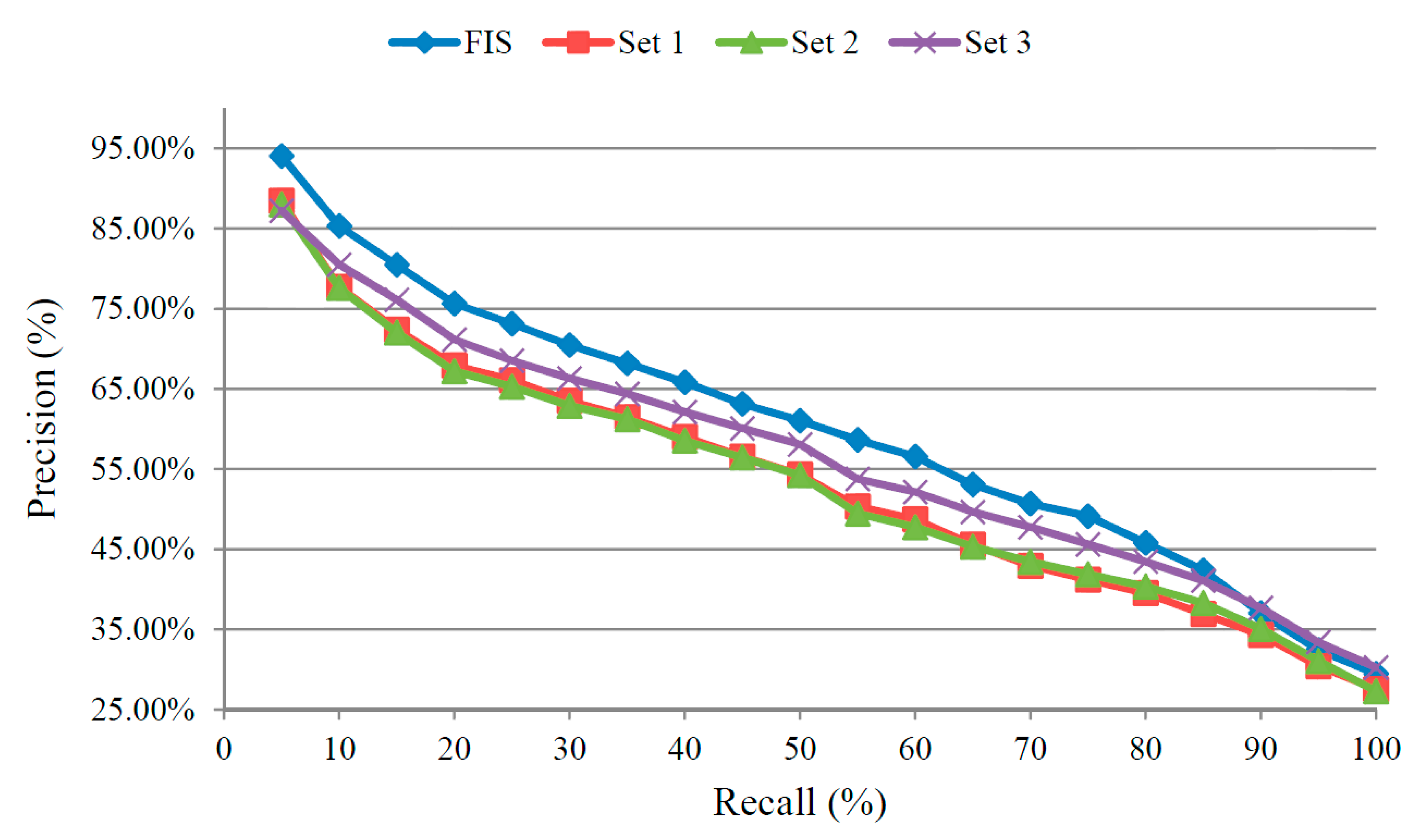
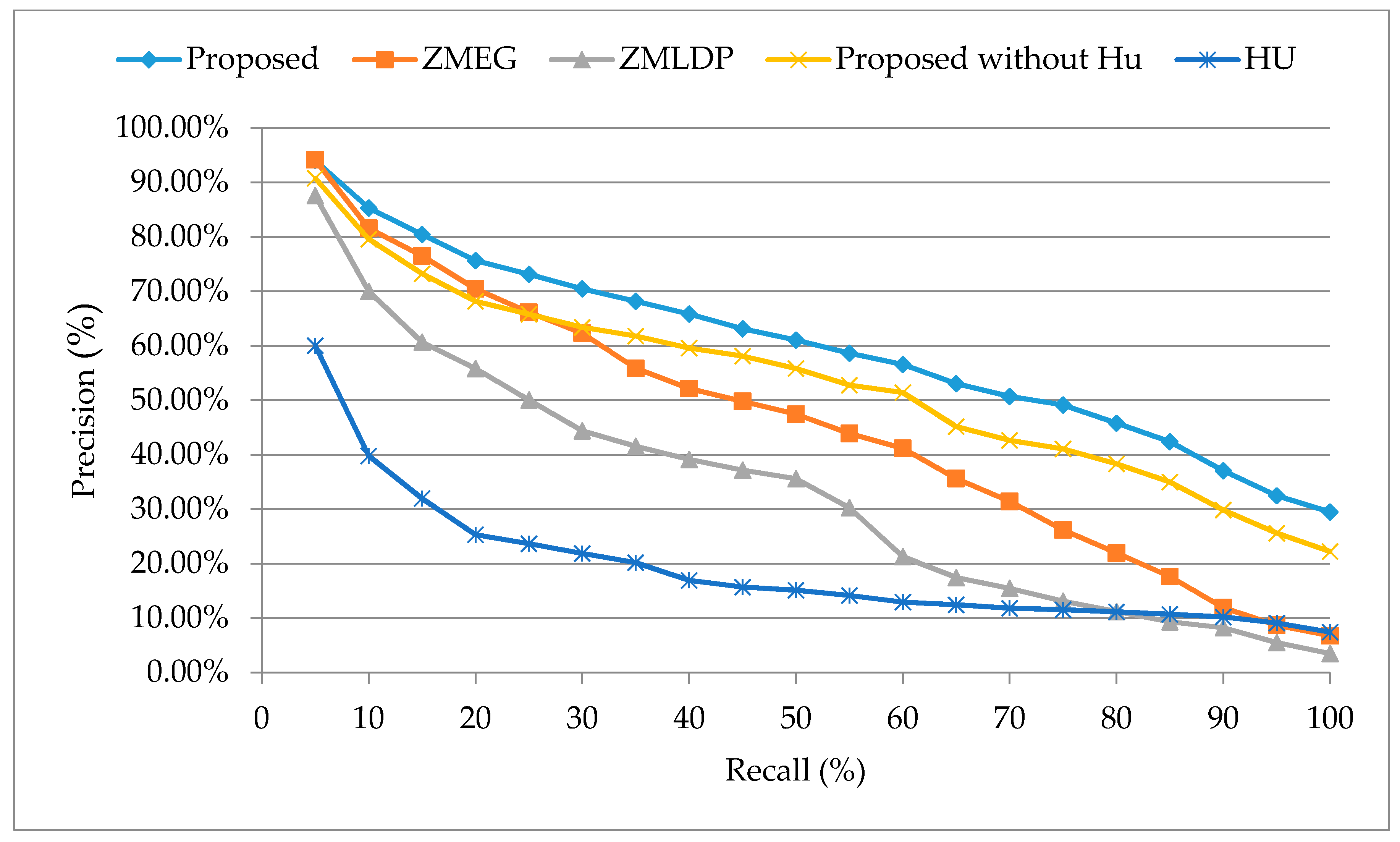
5.4. Performance of the Precision-Recall Rates
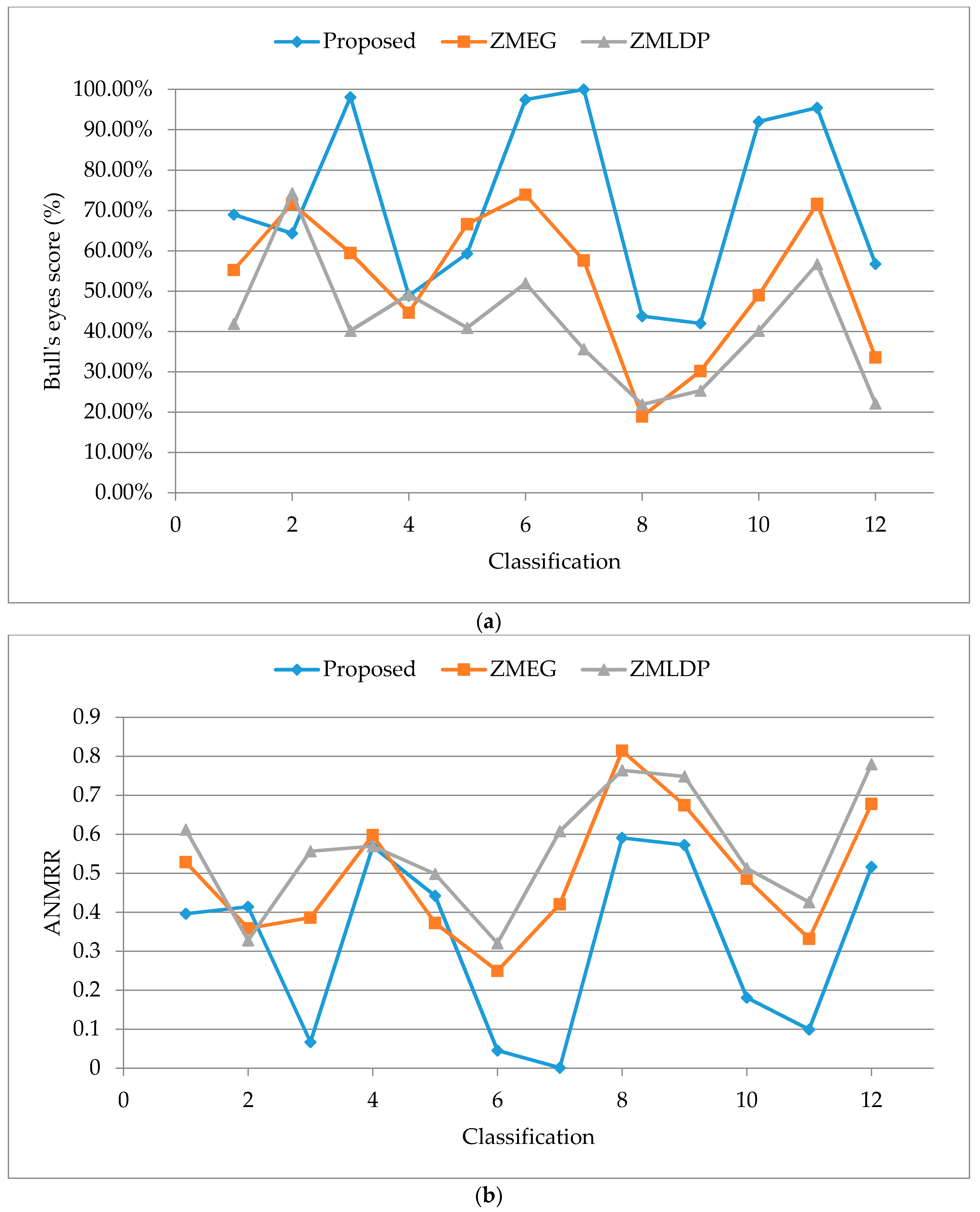
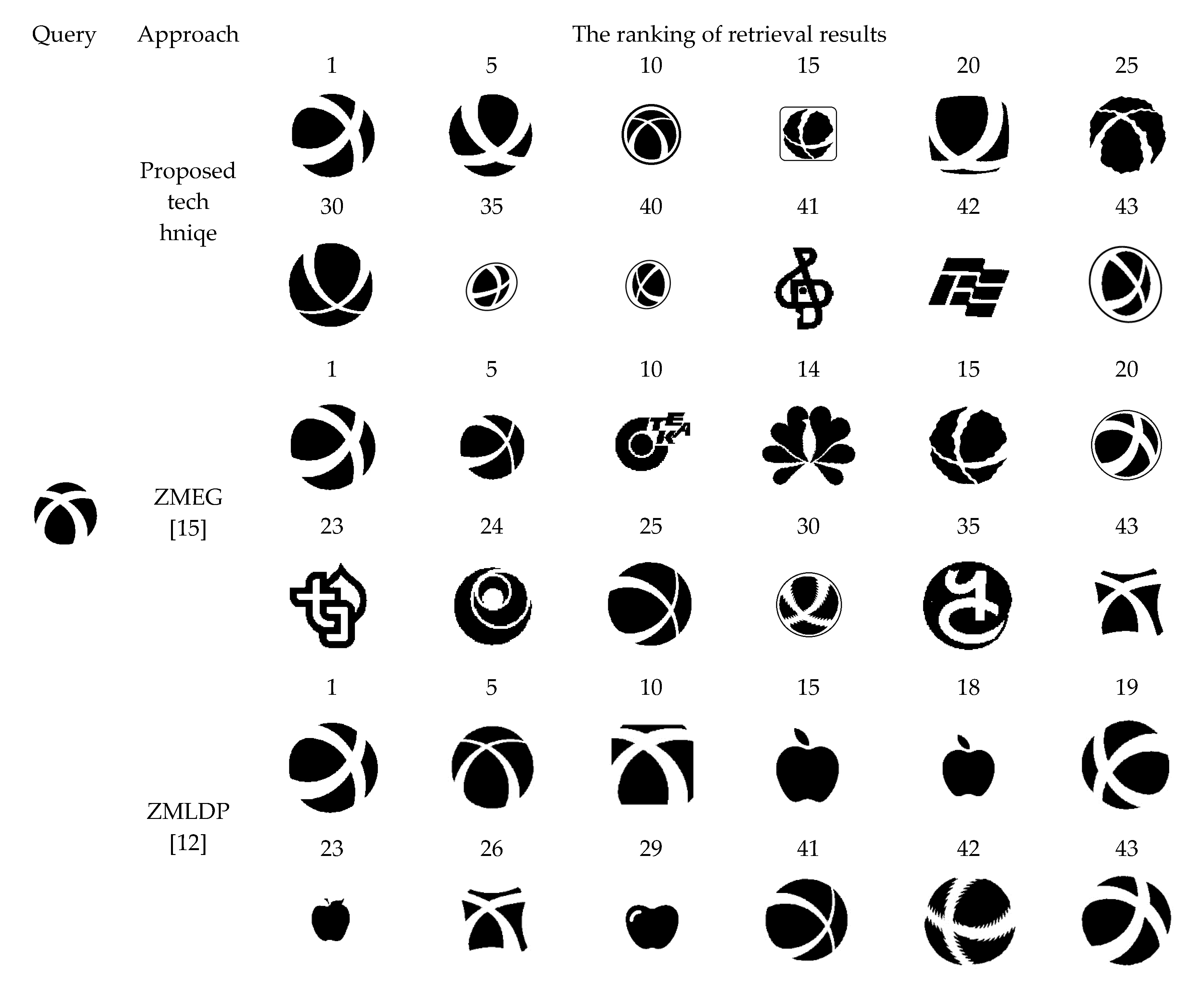
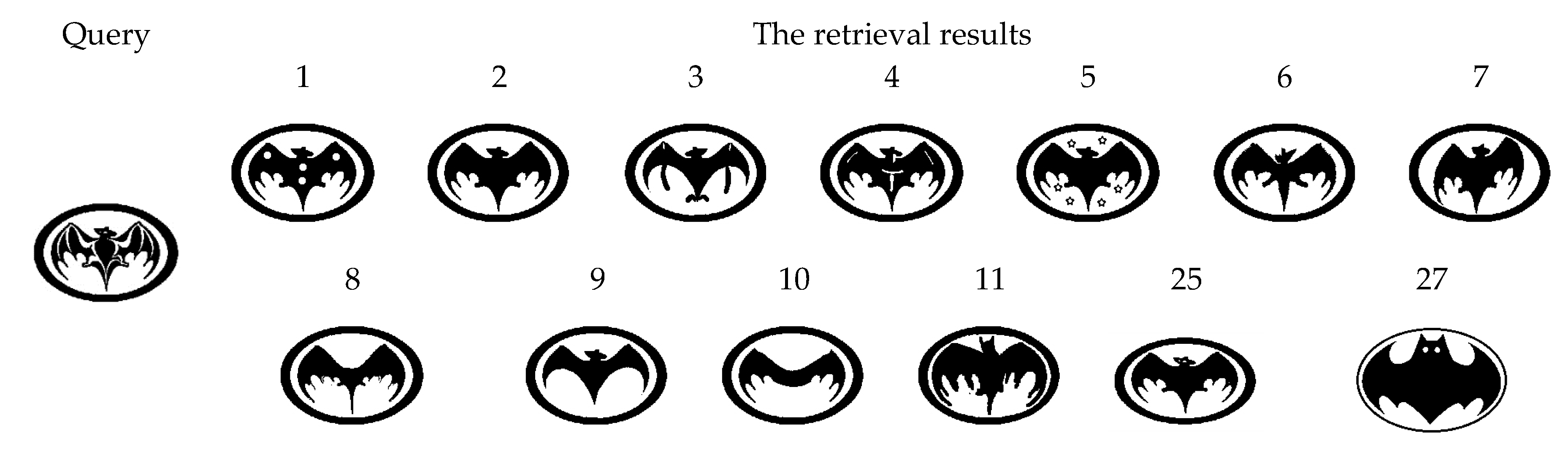
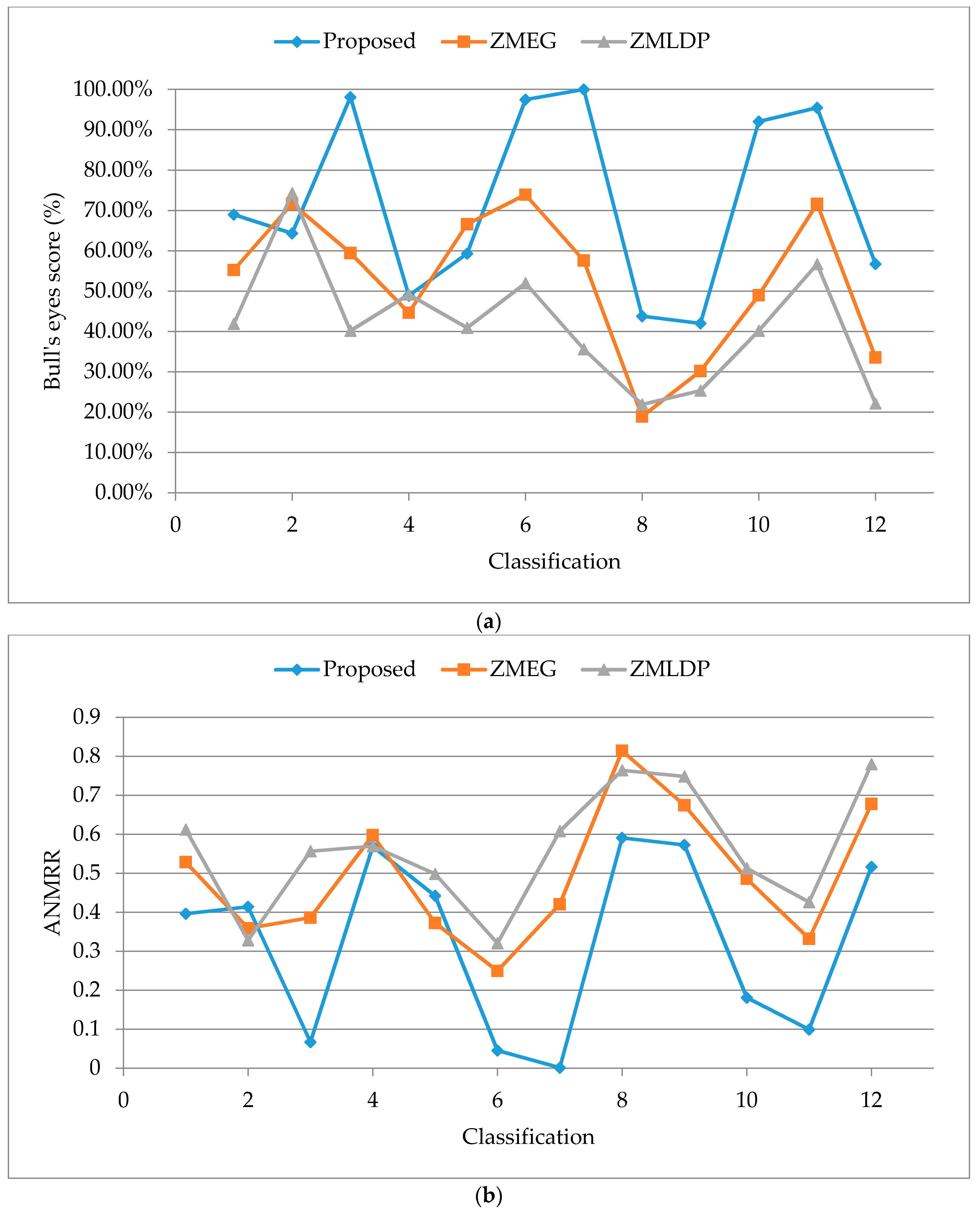
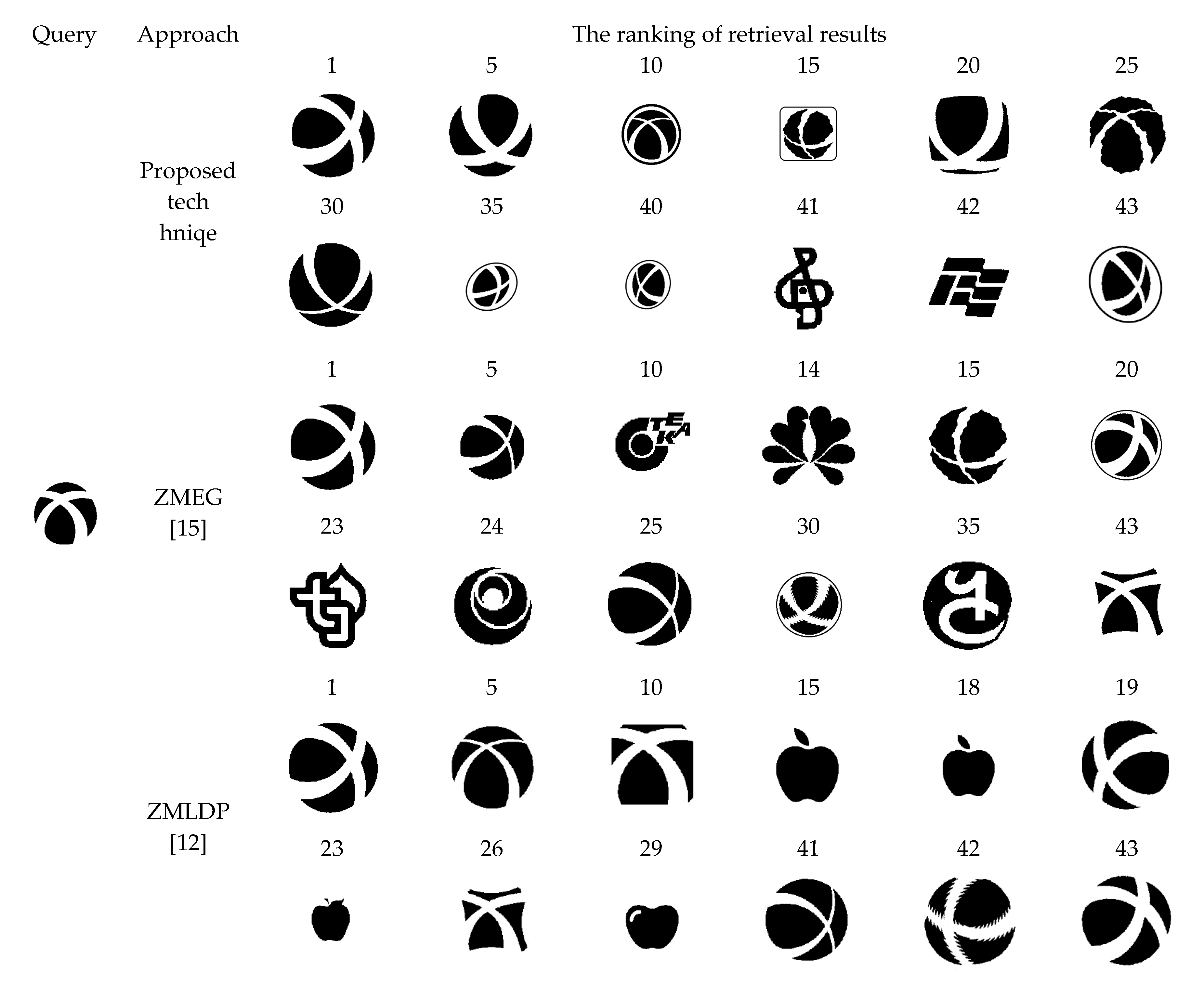
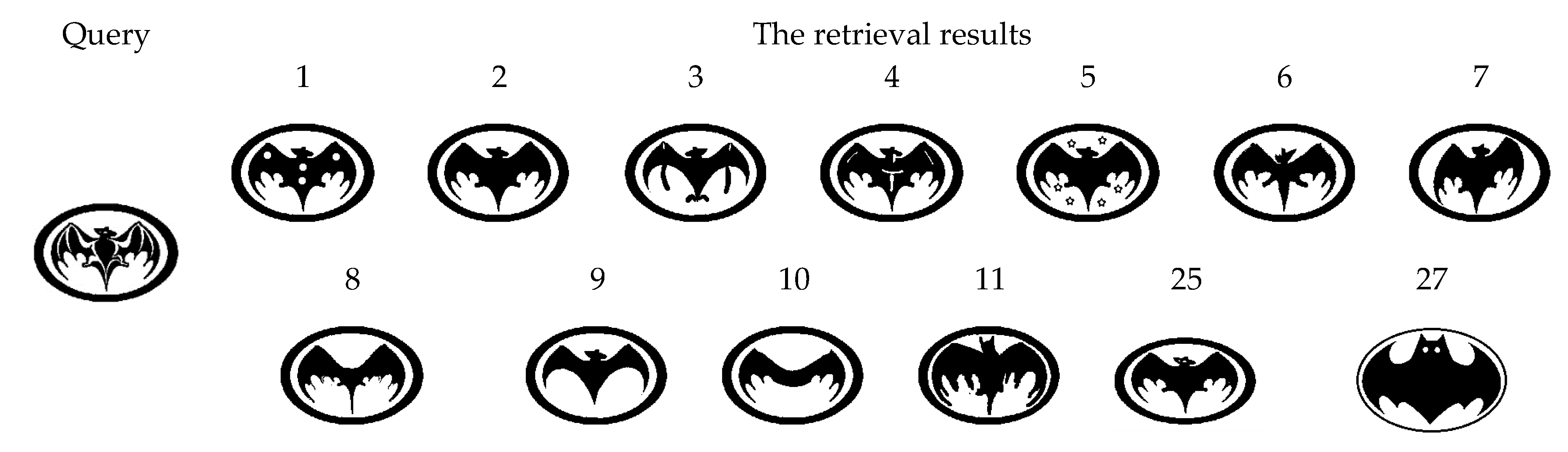
5.5. Performance of Bull’s Eye Score and the Retrieval Ranking
5.6. Performance of Efficiency
5.7. Discussion
6. Conclusions
Author Contributions
Conflicts of Interest
References
- Dharani, T.; Aroquiaraj, I.L. A survey on content based image retrieval. In Proceedings of the 2013 International Conference on Pattern Recognition, Informatics and Mobile Engineering, Salem, India, 21–22 February 2013; pp. 485–490. [Google Scholar]
- Rafiee, G.; Dlay, S.S.; Woo, W.L. A review of content-based image retrieval. In Proceedings of the 2010 7th International Symposium on Communication Systems, Networks & Digital Signal Processing (CSNDSP 2010), Newcastle upon Tyne, UK, 21–23 July 2010; pp. 775–779. [Google Scholar]
- Smeulders, A.W.M.; Worring, M.; Santini, S.; Gupta, A.; Jain, R. Content-based image retrieval at the end of the early years. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1349–1380. [Google Scholar] [CrossRef]
- Rui, Y.; Huang, T.S.; Chang, S.F. Image retrieval: Current techniques, promising directions, and open issues. J. Vis. Commun. Image Represent. 1999, 10, 39–62. [Google Scholar] [CrossRef]
- Kesidis, A.; Karatzas, D. Logo and trademark recognition. In Handbook of Document Image Processing and Recognition; Doermann, D., Tombre, K., Eds.; Springer: London, UK, 2014; pp. 591–646. [Google Scholar]
- Schietse, J.; Eakins, J.P.; Veltkamp, R.C. Practice and challenges in trademark image retrieval. In Proceedings of the 6th ACM International Conference on Image and Video Retrieval, Amsterdam, The Netherlands, 9–11 July 2007; pp. 518–524. [Google Scholar]
- Singh, P.; Gupta, V.; Hrisheekesha, P. A review on shape based descriptors for image retrieval. Int. J. Comput. Appl. 2015, 125, 27–32. [Google Scholar] [CrossRef]
- Yang, M.; Kpalma, K.; Ronsin, J. A survey of shape feature extraction techniques. In Pattern Recognition; Peng-Yeng, Y., Ed.; InTech: Rijeka, Croatia, 2008; pp. 43–90. [Google Scholar]
- Amanatiadis, A.; Kaburlasos, V.G.; Gasteratos, A.; Papadakis, S.E. Evaluation of shape descriptors for shape-based image retrieval. IET Image Process. 2011, 5, 493–499. [Google Scholar] [CrossRef]
- Niu, D.; Bremer, P.-T.; Lindstrom, P.; Hamann, B.; Zhou, Y.; Zhang, C. Two-dimensional shape retrieval using the distribution of extrema of laplacian eigenfunctions. Vis. Comput. 2017, 33, 607–624. [Google Scholar] [CrossRef]
- Hong, Z.; Jiang, Q. Hybrid content-based trademark retrieval using region and contour features. In Proceedings of the 22nd International Conference on Advanced Information Networking and Applications-Workshops (AINA Workshops 2008), Okinawa, Japan, 25–28 March 2008; pp. 1163–1168. [Google Scholar]
- Goyal, A.; Walia, E. Variants of dense descriptors and zernike moments as features for accurate shape-based image retrieval. Signal Image Video Process. 2014, 8, 1273–1289. [Google Scholar] [CrossRef]
- Li, L.; Wang, D.; Cui, G. Trademark image retrieval using region zernike moments. In Proceedings of the 2008 Second International Symposium on Intelligent Information Technology Application, Shanghai, China, 20–22 December 2008; pp. 301–305. [Google Scholar]
- Zhang, D.; Lu, G. A comparative study of fourier descriptors for shape representation and retrieval. In Proceedings of the 5th Asian Conference on Computer Vision, Melbourne, Australia, 23–25 January 2002; pp. 23–25. [Google Scholar]
- Anuar, F.M.; Setchi, R.; Lai, Y.-K. Trademark image retrieval using an integrated shape descriptor. Expert Syst. Appl. 2013, 40, 105–121. [Google Scholar] [CrossRef]
- Alajlan, N.; El Rube, I.; Kamel, M.S.; Freeman, G. Shape retrieval using triangle-area representation and dynamic space warping. Pattern Recogn. 2007, 40, 1911–1920. [Google Scholar] [CrossRef]
- Juneja, K.; Verma, A.; Goel, S.; Goel, S. A survey on recent image indexing and retrieval techniques for low-level feature extraction in cbir systems. In Proceedings of the 2015 IEEE International Conference on Computational Intelligence & Communication Technology (CICT), Ghaziabad, India, 13–14 February 2015; pp. 67–72. [Google Scholar]
- Eakins, J.P.; Riley, K.J.; Edwards, J.D. Shape feature matching for trademark image retrieval. In Image and Video Retrieval, Proceedings of the Second International Conference, CIVR 2003 Urbana, Champaign, IL, USA, 24–25 July 2003; Bakker, E.M., Lew, M.S., Huang, T.S., Sebe, N., Zhou, X.S., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; pp. 28–38. [Google Scholar]
- Qi, H.; Li, K.; Shen, Y.; Qu, W. An effective solution for trademark image retrieval by combining shape description and feature matching. Pattern Recogn. 2010, 43, 2017–2027. [Google Scholar] [CrossRef]
- Wei, C.H.; Li, Y.; Chau, W.Y.; Li, C.T. Trademark image retrieval using synthetic features for describing global shape and interior structure. Pattern Recogn. 2009, 42, 386–394. [Google Scholar] [CrossRef]
- Alajlan, N.; Kamel, M.S.; Freeman, G.H. Geometry-based image retrieval in binary image databases. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1003–1013. [Google Scholar] [CrossRef] [PubMed]
- Liu, D.; Wang, S.; Liu, Y.; Zeng, F.; Wu, J.; Li, W. Tree representation and feature fusion based method for multi-object binary image retrieval. J. Inf. Comput. Sci. 2013, 10, 1055–1064. [Google Scholar] [CrossRef]
- Jain, S. A machine learning approach: Svm for image classification in cbir. Int. J. Appl. Innov. Eng. Manag. 2013, 2, 446–452. [Google Scholar]
- Tursun, O.; Aker, C.; Kalkan, S. A large-scale dataset and benchmark for similar trademark retrieval. arXiv, 2017; arXiv:1701.05766. [Google Scholar]
- Shanmugapriya, N.; Nallusamy, R. A new content based image retrieval system using gmm and relevance feedback. J. Comput. Sci. 2014, 10, 330–340. [Google Scholar] [CrossRef]
- Ionescu, M.; Ralescu, A. Fuzzy hamming distance in a content-based image retrieval system. In Proceedings of the 2004 IEEE International Conference on Fuzzy Systems (IEEE Cat. No.04CH37542), Budapest, Hungary, 25–29 July 2004; Volume 1723, pp. 1721–1726. [Google Scholar]
- Chiu, C.Y.; Lin, H.C.; Yang, S.N. A fuzzy logic cbir system. In Proceedings of the 12th IEEE International Conference on Fuzzy Systems, 2003 (FUZZ ’03), St. Louis, MO, USA, 25–28 May 2003; Volume 1172, pp. 1171–1176. [Google Scholar]
- Lakdashti, A.; Moin, M.S.; Badie, K. Irtf: Image retrieval through fuzzy modeling. In Proceedings of the 2008 IEEE International Conference on Communications, Beijing, China, 19–23 May 2008; pp. 490–494. [Google Scholar]
- Adel, A.E.; Ejbali, R.; Zaied, M.; Amar, C.B. A new system for image retrieval using beta wavelet network for descriptors extraction and fuzzy decision support. In Proceedings of the 2014 6th International Conference of Soft Computing and Pattern Recognition (SoCPaR), Tunis, Tunisia, 11–14 August 2014; pp. 232–236. [Google Scholar]
- Saini, A.; Gupta, Y.; Saxena, A.K. Fuzzy based approach to develop hybrid ranking function for efficient information retrieval. In Advances in Intelligent Informatics; El-Alfy, E.-S.M., Thampi, S.M., Takagi, H., Piramuthu, S., Hanne, T., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 471–479. [Google Scholar]
- Chen, C.S.; Yeh, C.W.; Yin, P.Y. A novel fourier descriptor based image alignment algorithm for automatic optical inspection. J. Vis. Commun. Image Represent. 2009, 20, 178–189. [Google Scholar] [CrossRef]
- Wang, X.; Xie, K. Application of the fuzzy logic in content-based image retrieval. J. Comput. Sci. Technol. 2005, 5, 19–24. [Google Scholar]
- Iancu, I. A mamdani type fuzzy logic controller. In Fuzzy Logic: Controls, Concepts, Theories and Applications; InTech: Rijeka, Croatia, 2012; pp. 325–350. [Google Scholar]
- Balázs, K.; Kóczy, L.T.; Botzheim, J. Comparison of fuzzy rule-based learning and inference systems. In Proceedings of the 9th International Symposium of Hungarian Researchers on Computational Intelligence and Informatics, Budapest, Hungary, 6–8 November 2008; pp. 61–75. [Google Scholar]
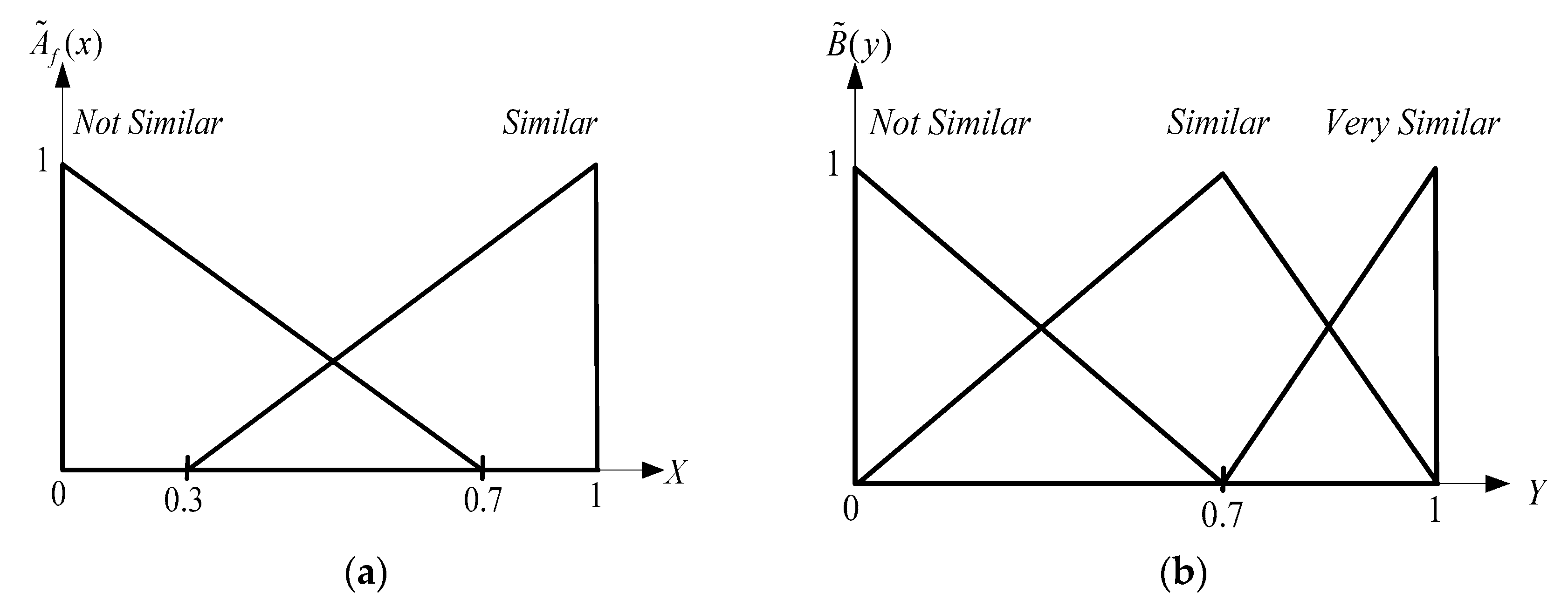




{kind=link}
{kind=link}
{kind=link}
{kind=link}
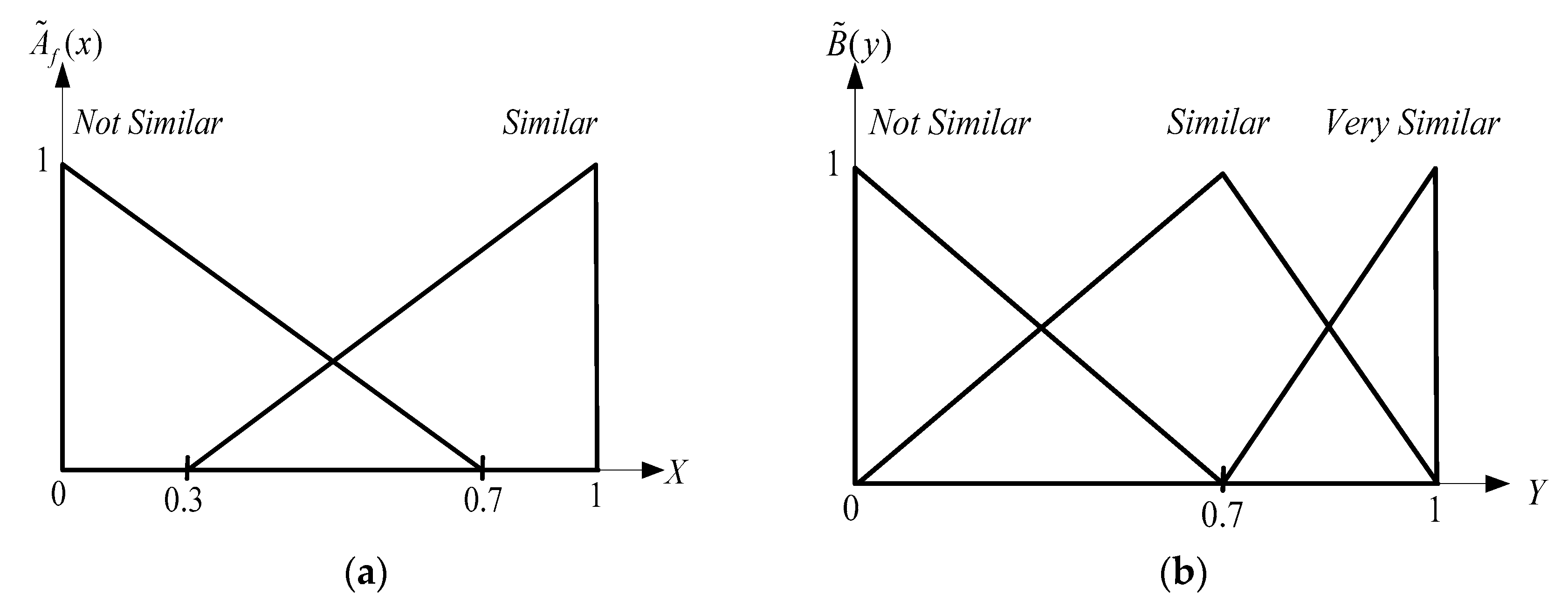{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, C.-S.; Weng, C.-M. An Efficient Retrieval Technique for Trademarks Based on the Fuzzy Inference System. Appl. Sci. 2017, 7, 849. https://doi.org/10.3390/app7080849
Chen C-S, Weng C-M. An Efficient Retrieval Technique for Trademarks Based on the Fuzzy Inference System. Applied Sciences. 2017; 7(8):849. https://doi.org/10.3390/app7080849
Chicago/Turabian StyleChen, Chin-Sheng, and Chi-Min Weng. 2017. "An Efficient Retrieval Technique for Trademarks Based on the Fuzzy Inference System" Applied Sciences 7, no. 8: 849. https://doi.org/10.3390/app7080849
APA StyleChen, C.-S., & Weng, C.-M. (2017). An Efficient Retrieval Technique for Trademarks Based on the Fuzzy Inference System. Applied Sciences, 7(8), 849. https://doi.org/10.3390/app7080849