This section presents the application of the preceding algorithms to acoustic source localization and separation problems through numerical simulation. These algorithms were compared for three example problems, with the aid of a uniform linear array (ULA) and a random array. In addition, an inverse solution involved in sound field analysis (SFA) and sound field synthesis (SFS) in spatial audio was investigated. Microphone data are synthetic and generated by the model of Equation (1).
3.1. Uniform Linear Array
In the numerical simulation shown in
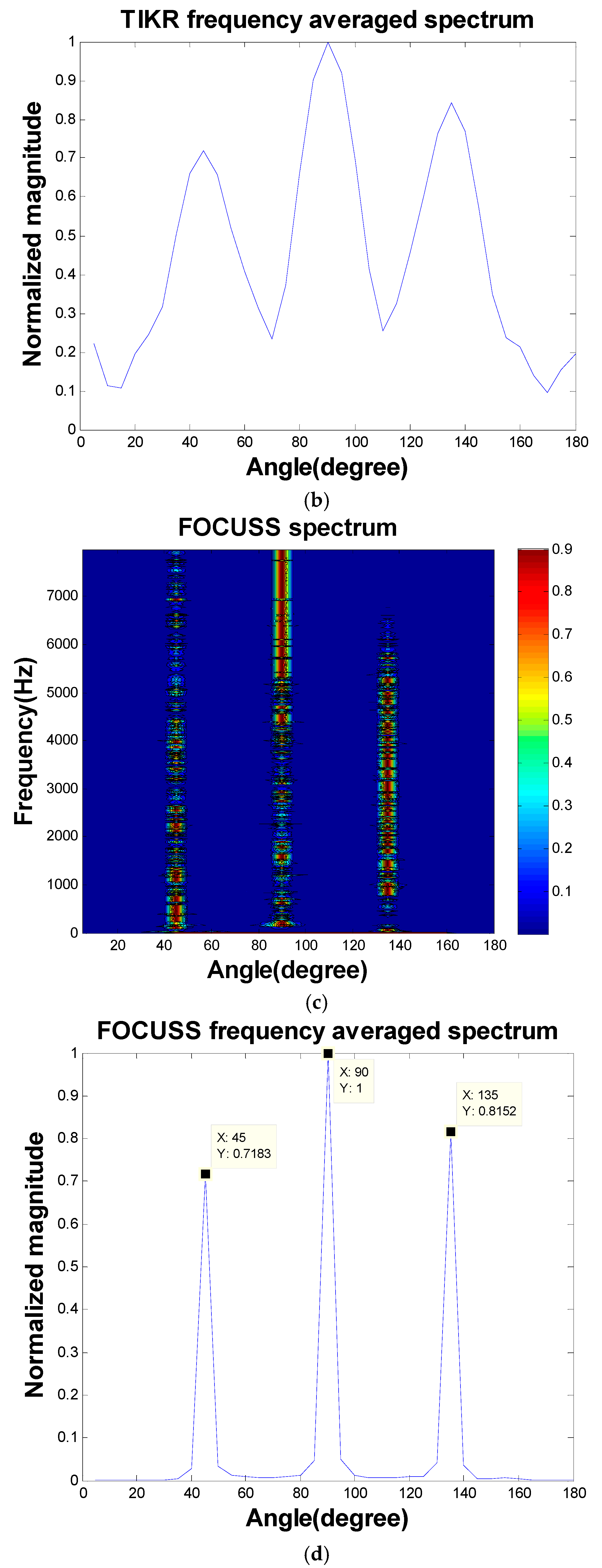
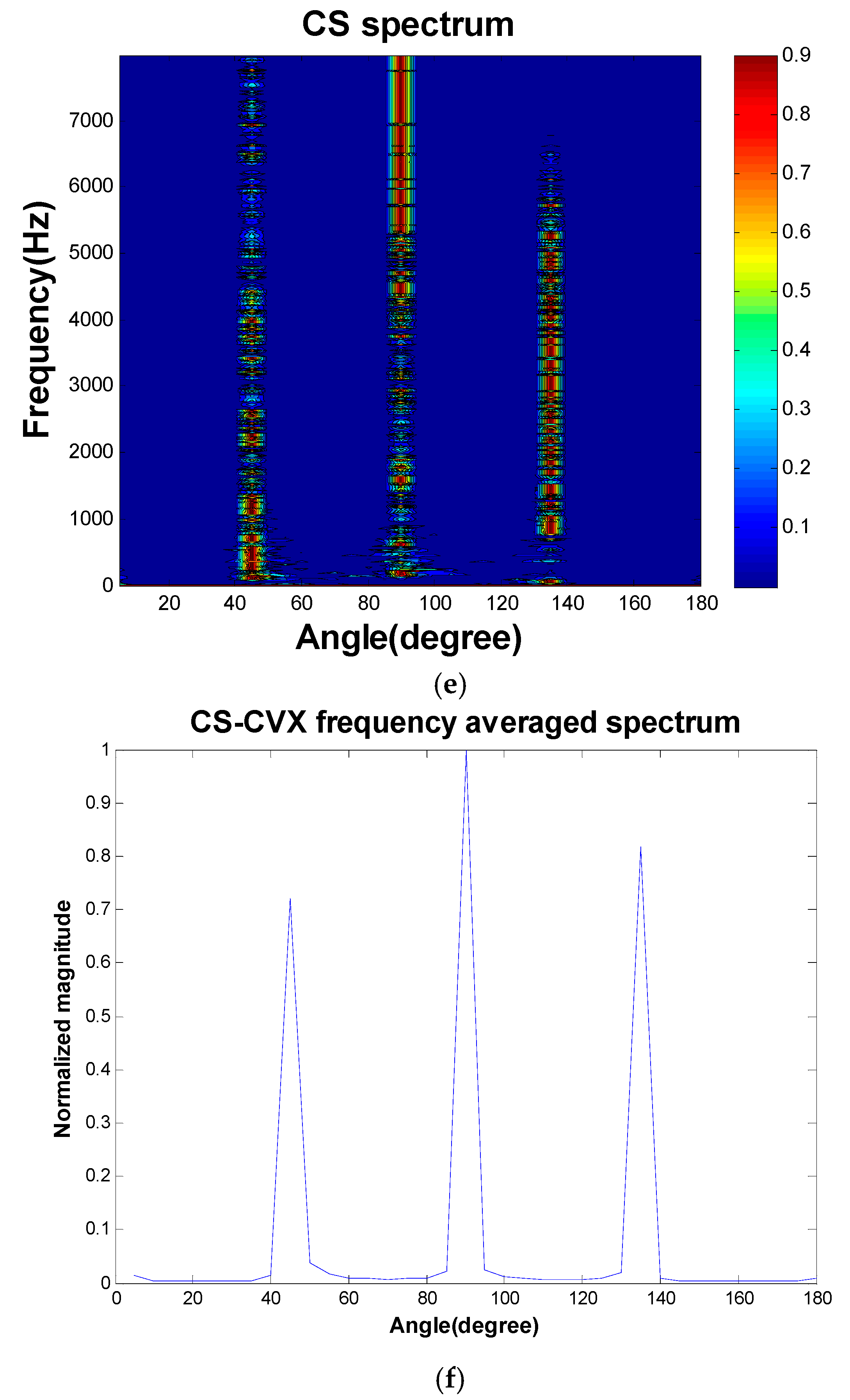
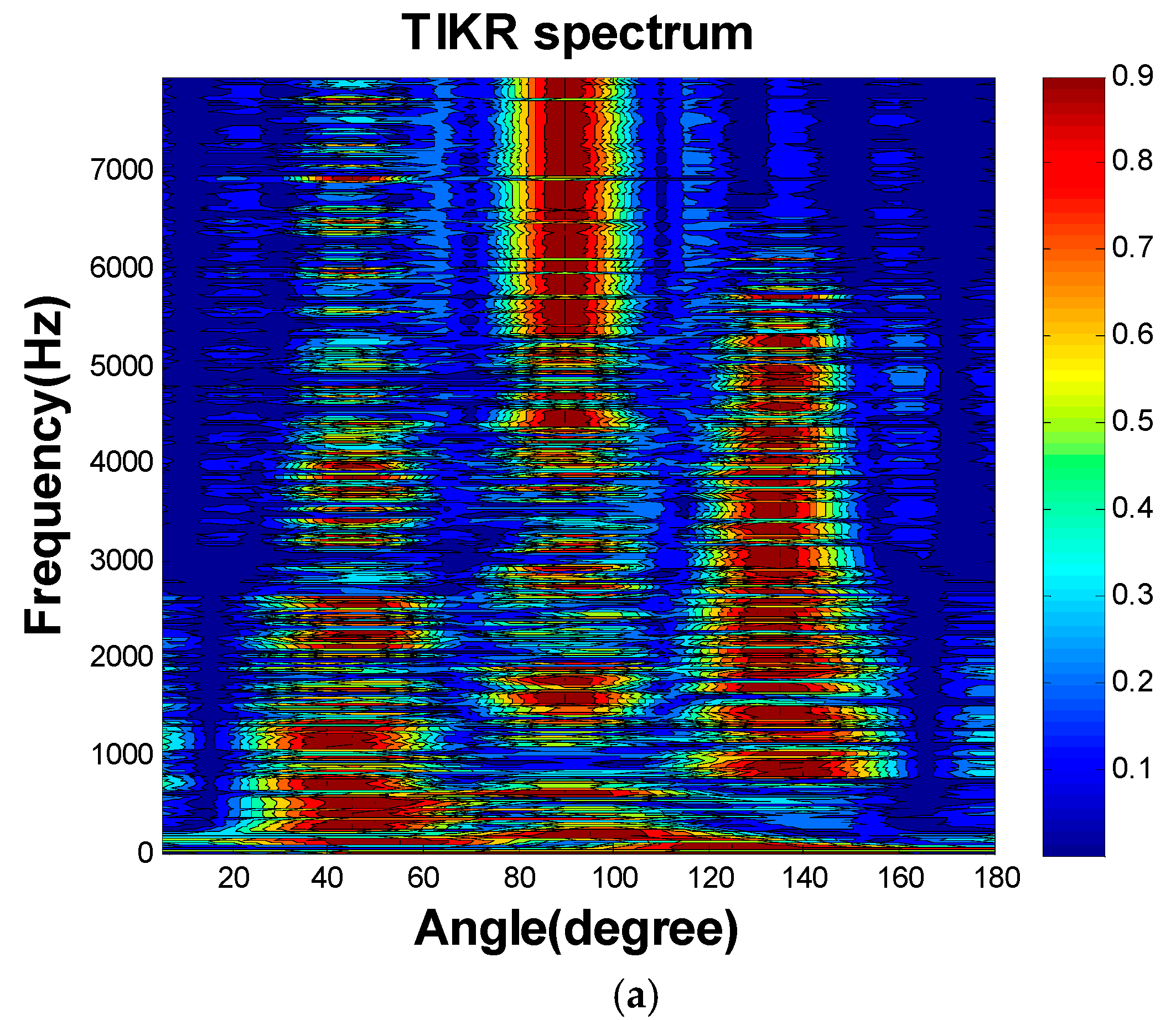
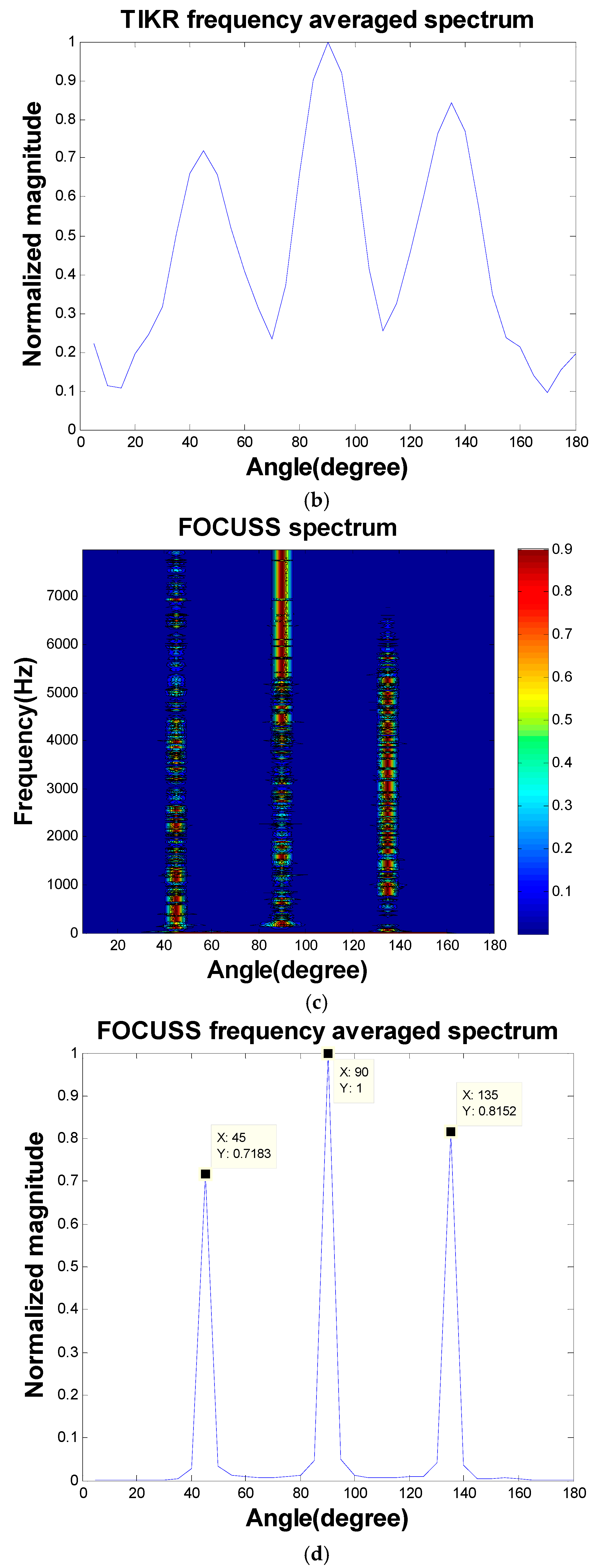
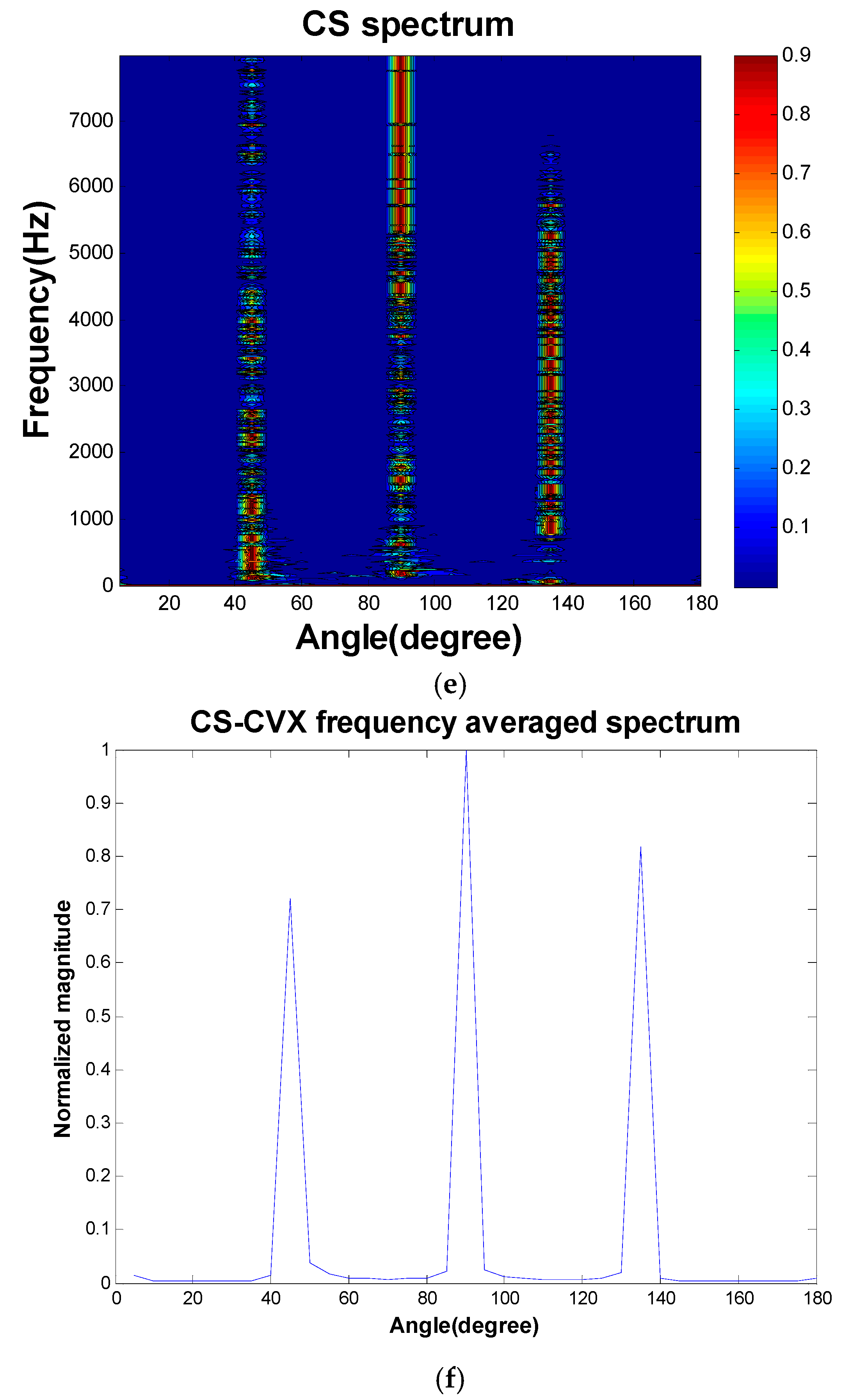
Figure 4, 10-microphone ULA was utilized to separate the signals emitted by three sources. The sources were located at the far field such that the plane wave assumption was valid. The spacing between adjacent microphones was 10 cm. This simulated underdetermined system contained 36 sources as our dictionary. We separated the signals and localized the signals in one stage. TIKR, FOCUSS, and CS-CVX algorithms were used to solve these inverse problems.
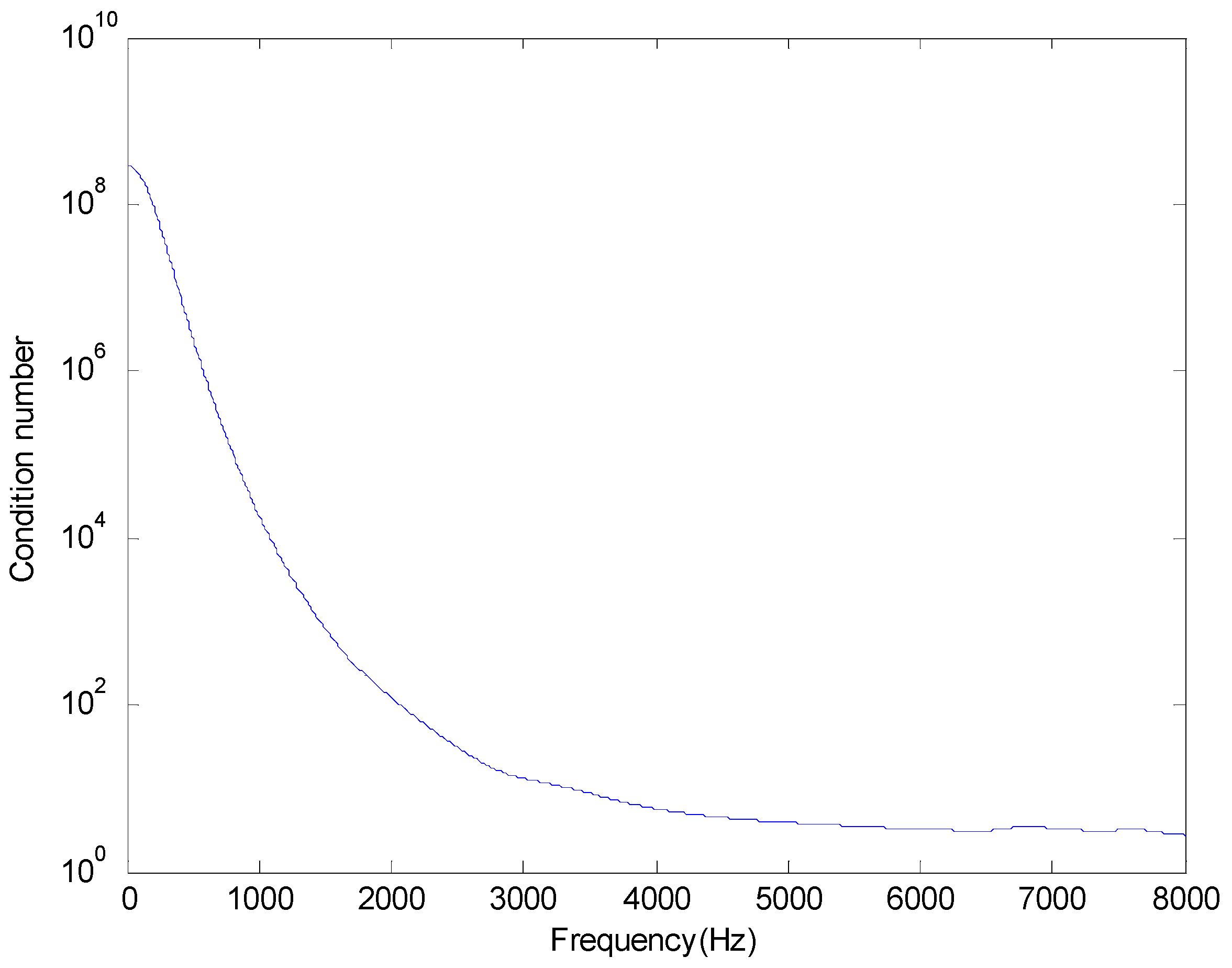
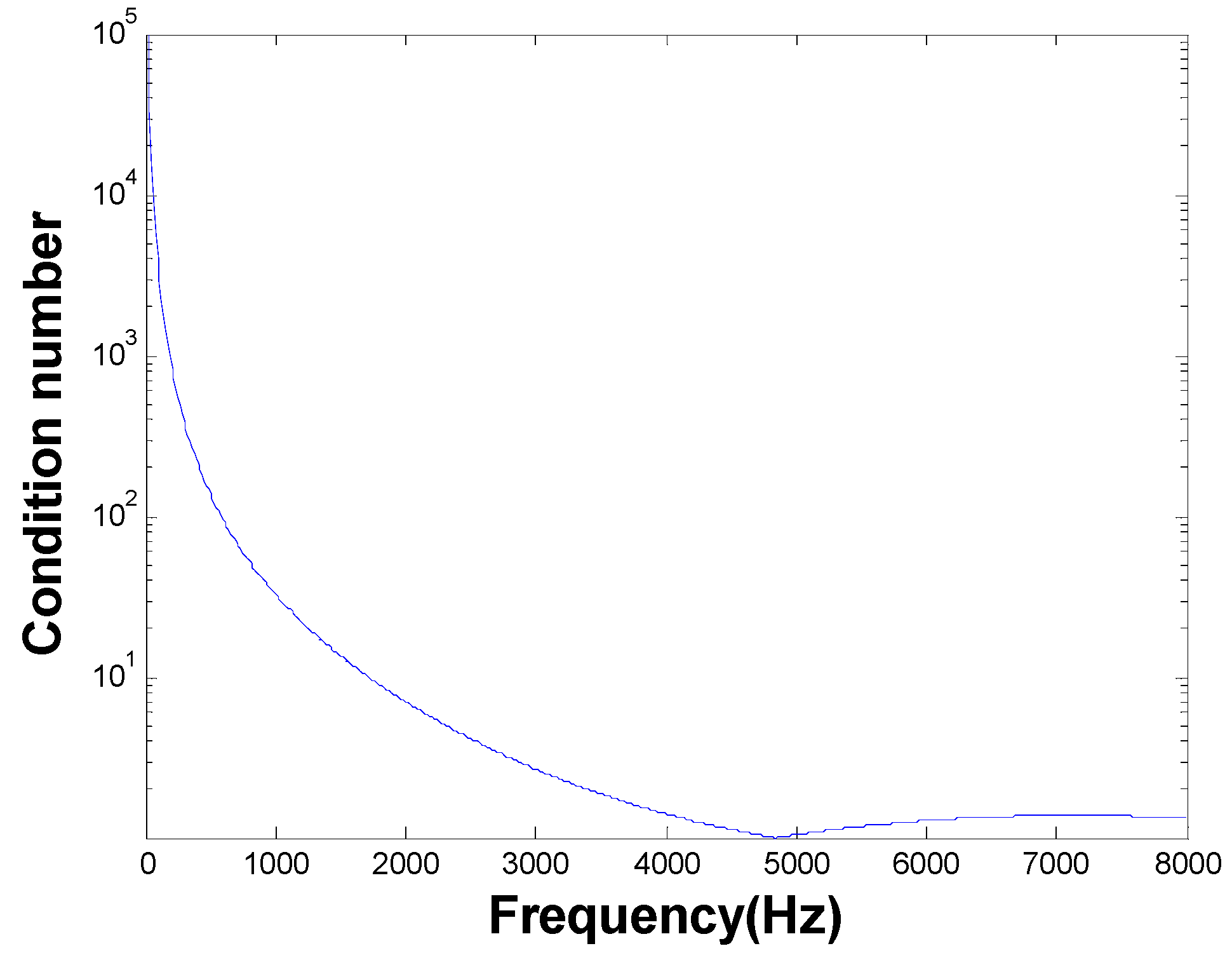
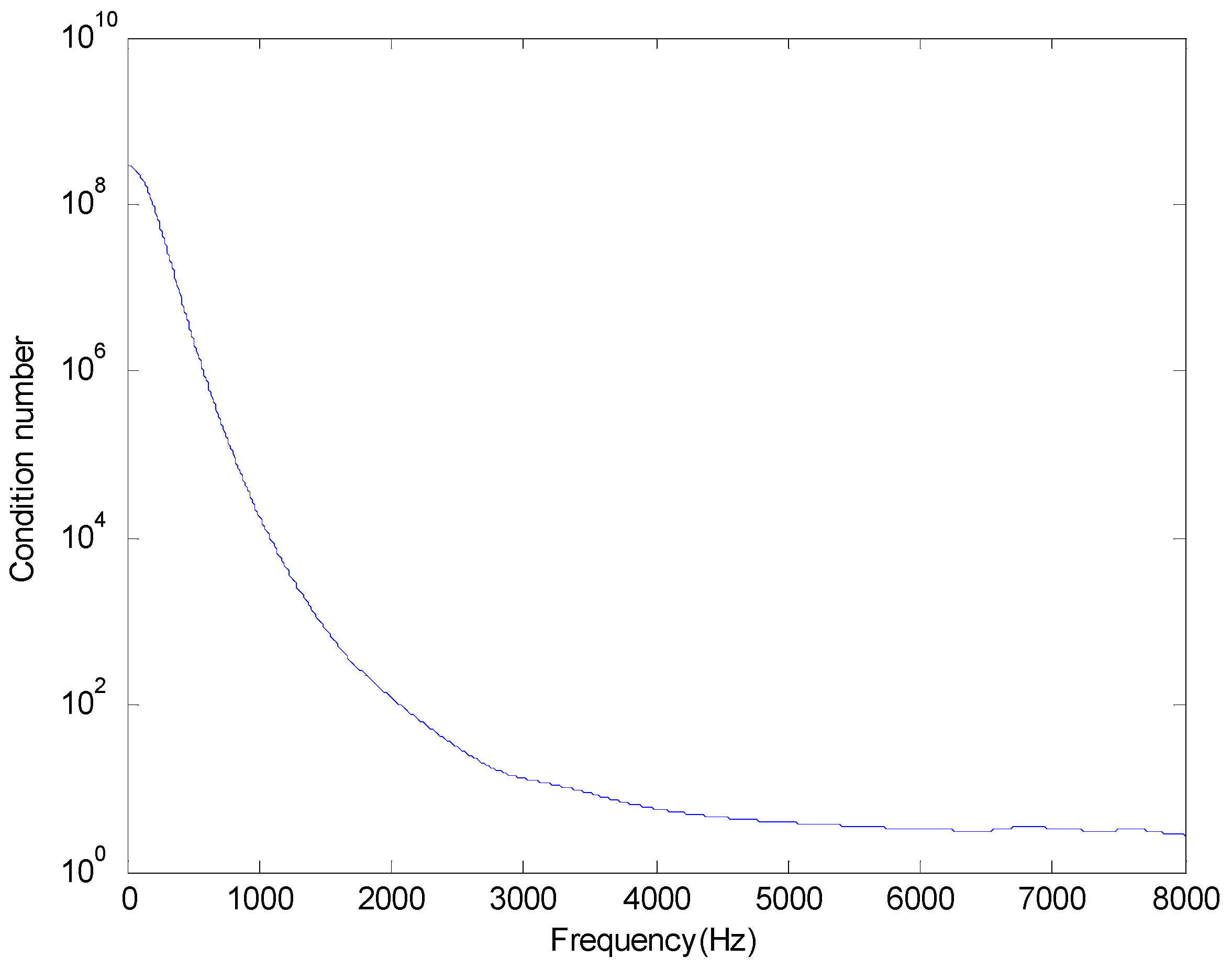
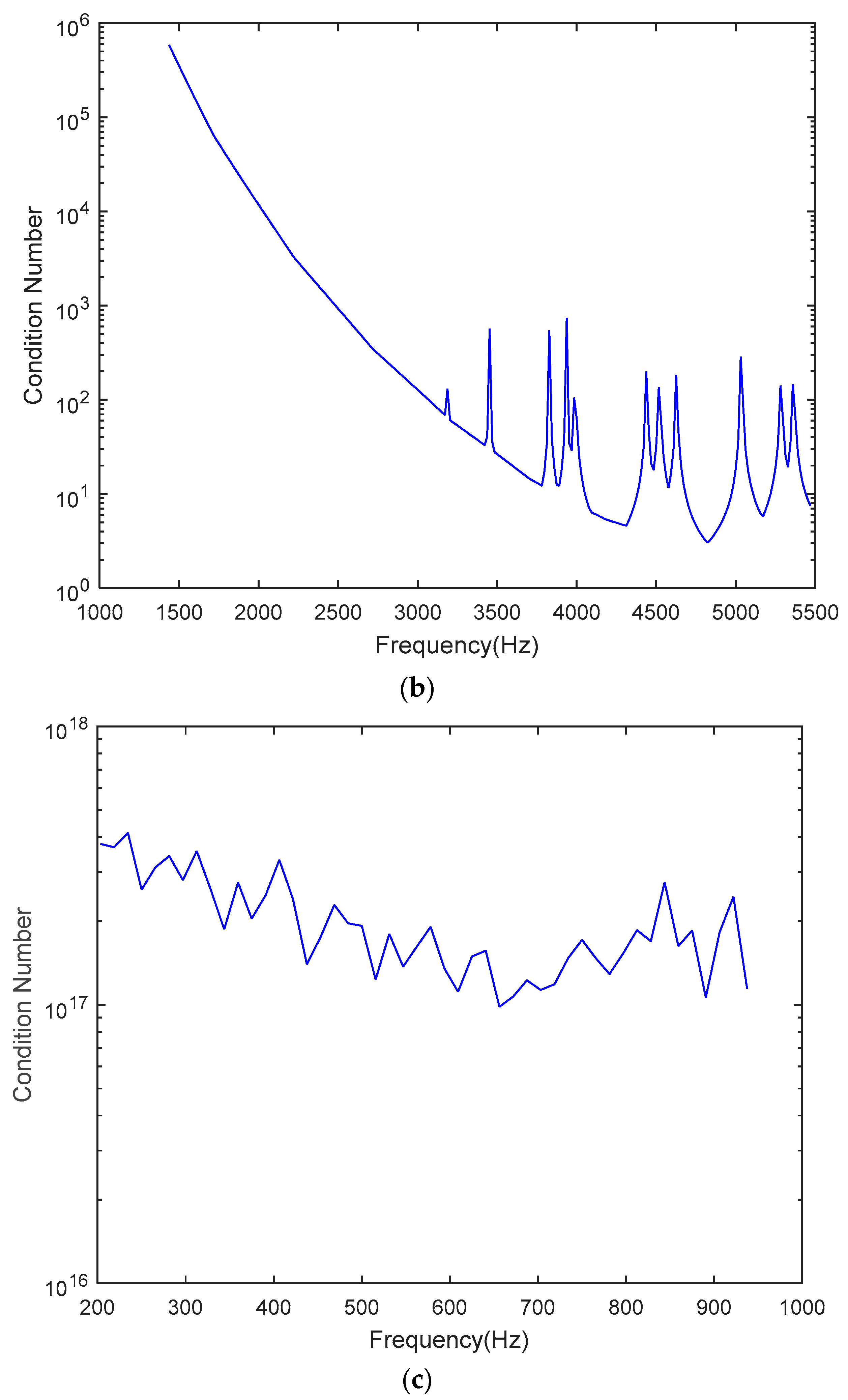
Figure 5 shows the condition numbers of different frequencies. The problem is ill-conditioned at low frequencies. Source localization results are shown in
Figure 6.
The separation results obtained using TIKR, FOCUSS, and CS-CVX are summarized in
Table 1. PESQ is an objective test measure for speech quality evaluation. It is a full-reference algorithm and analyzes the speech signal sample-by-sample after a temporal alignment of corresponding excerpts of reference and test signal. The mean opinion score (MOS) is calculated on the basis of PESQ ranging from 1 to 5; MOS signifies the difference in speech quality between the clean and the separated signals, which is affected by separation performance and signal distortion. The segmental SNR (segSNR) is defined as
The segSNR correlates with the effect of noise reduction. The FOCUSS-PINV algorithm was observed to achieve the highest score in PESQ and segSNR (
Table 1), although it required more computation time than TIKR and FOCUSS-TIKR.
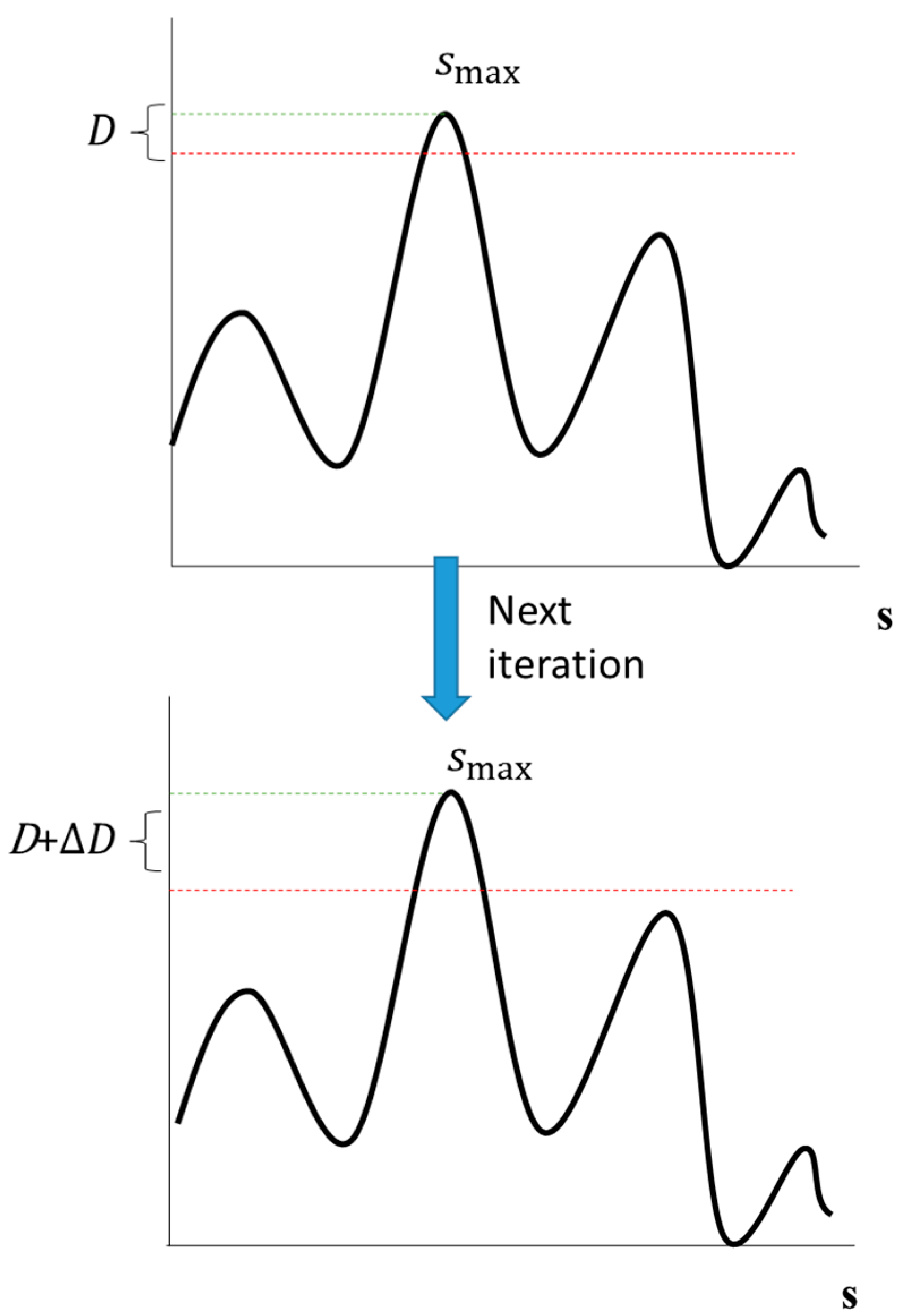
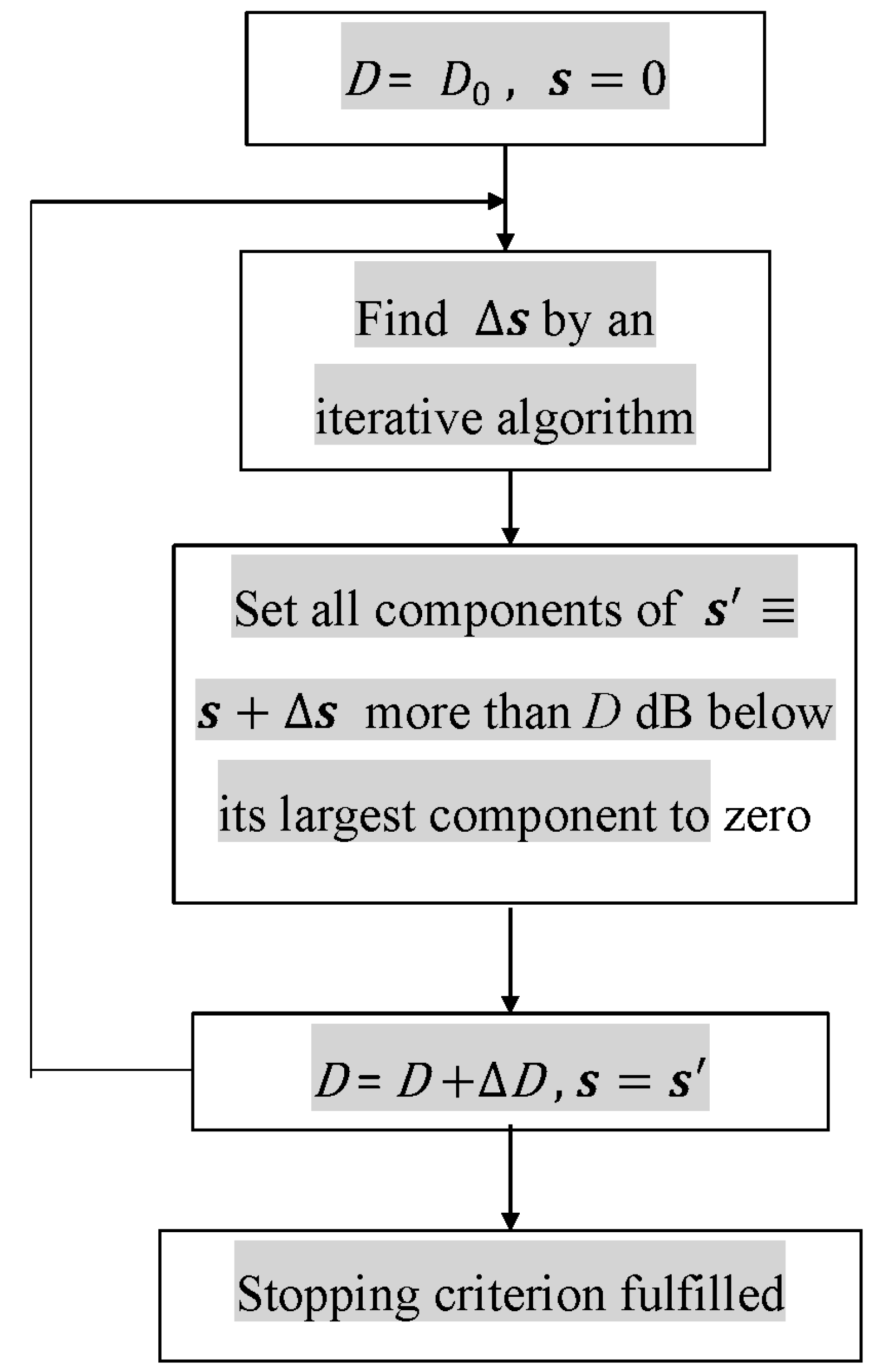
In our previous simulation, we simulated microphones that had no noise; therefore, our regularization parameter was very close to zero. In the current simulation, our microphones did have white noise with a magnitude equal to the magnitude of the microphone signals divided by 100. Therefore, the potential loss of SNR was 40 dB.
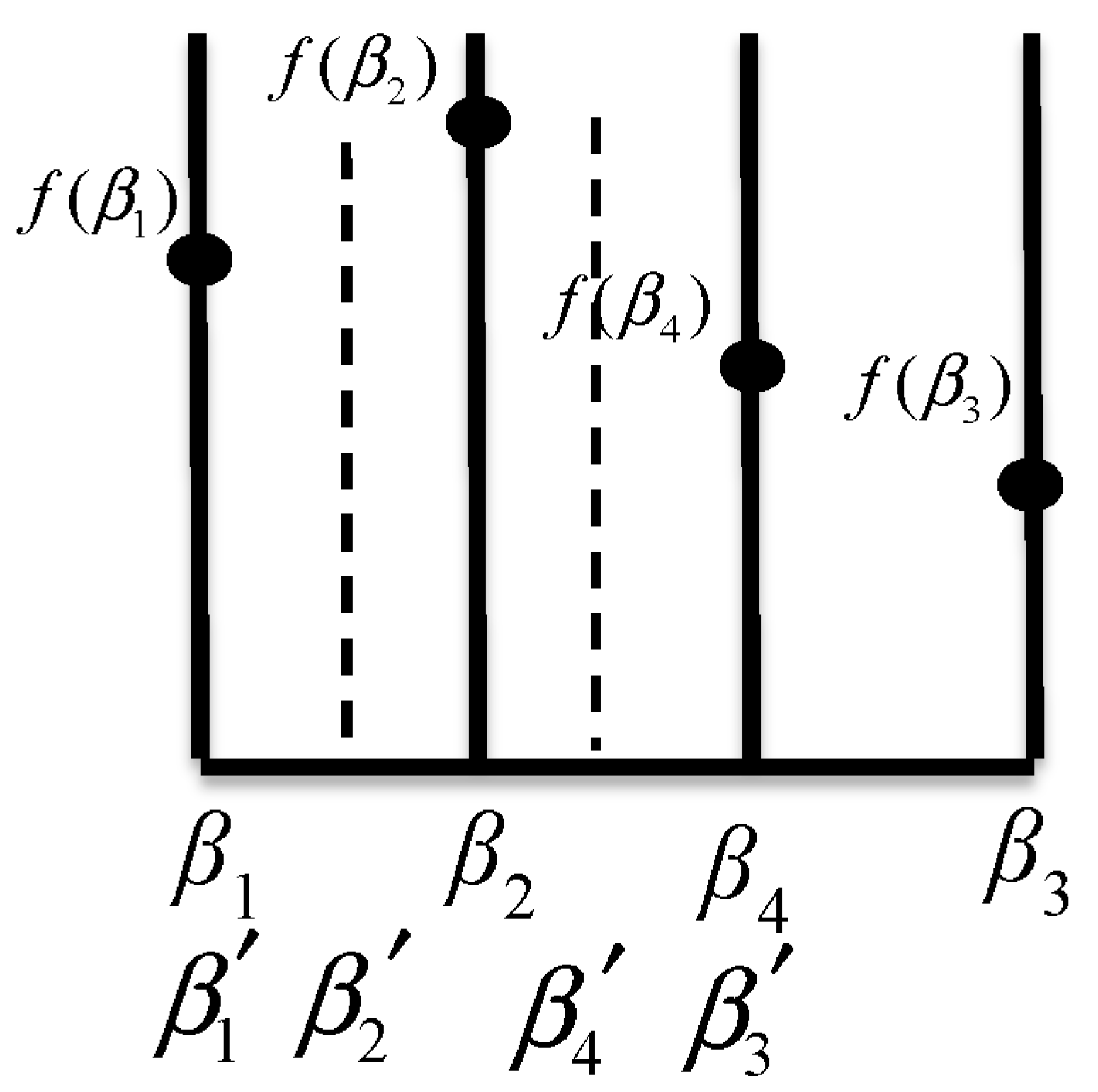
The regularization parameter is chosen by the maximal singular
value dividing 100 in 100 Hz. In our case, the maximal singular value was equal to 5.32. Next, a coarse search was performed by varying
β in orders of 10 and using the GSS algorithm to find the optimal regularization parameter. In this case, the optimal regularization parameter was 0.0174, and the FOCUSS-PINV of the robustness to the noise was very ineffective because PINV artifacts caused discontinuities in regularization. CS-CVX was sensitive to the noise, and the segSNR and PESQ achieved lower scores than FOCUSS-TIKR did, as listed in
Table 2 and
Table 3 (20dB). Therefore, noise was present, and FOCUSS-TIKR was the best choice in this case. It outperformed PESQ and segSNR.
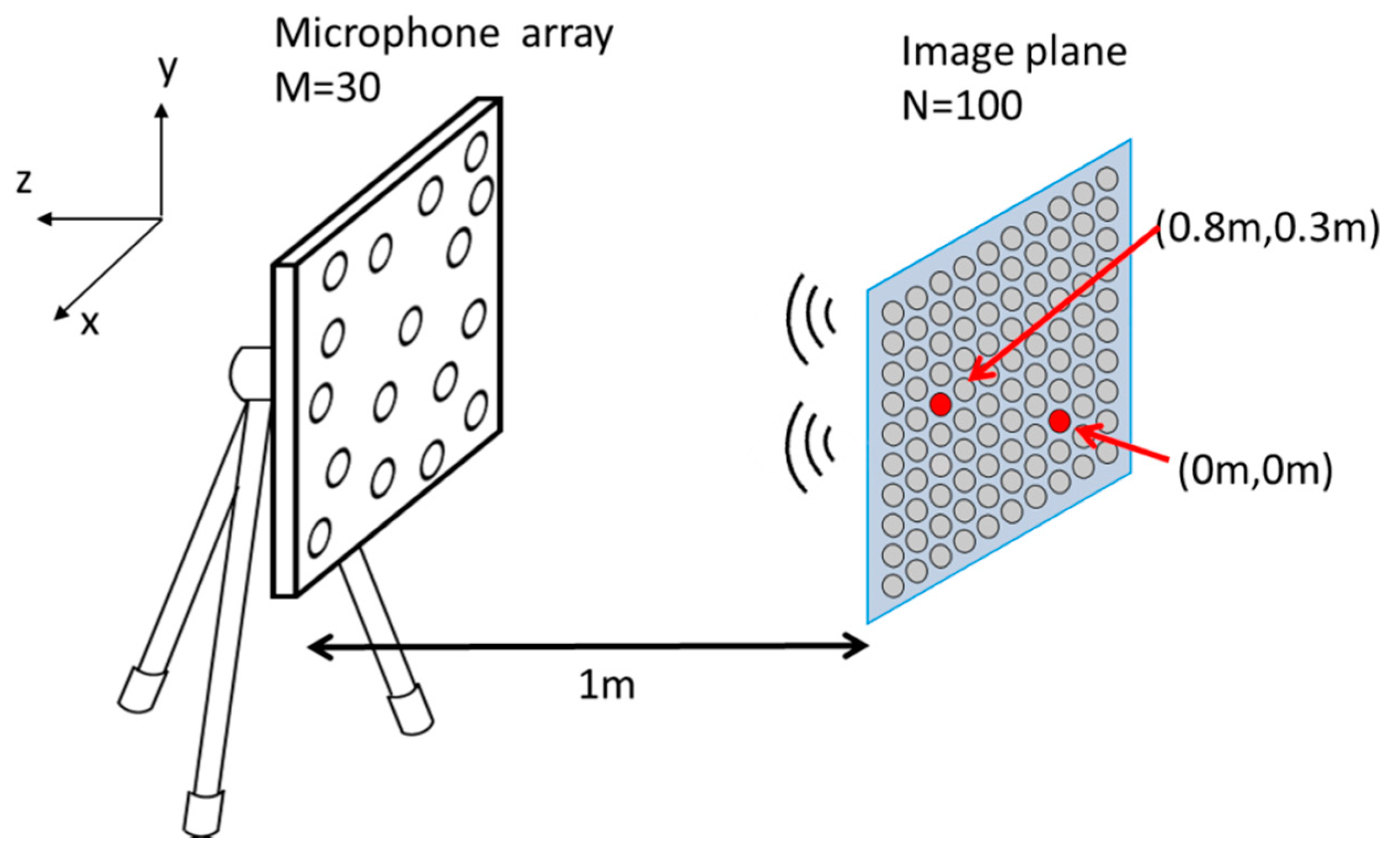
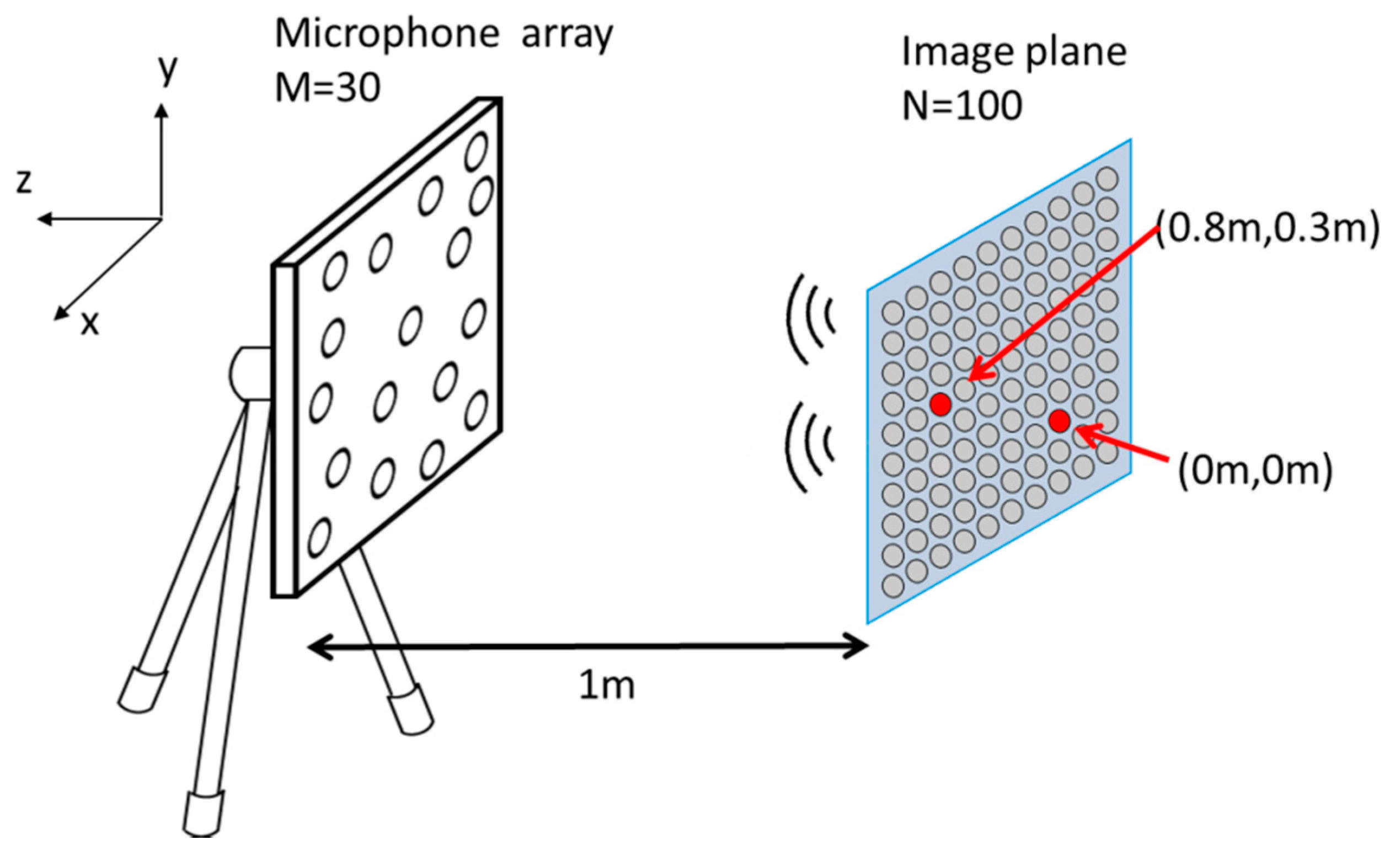
3.2. Random Array
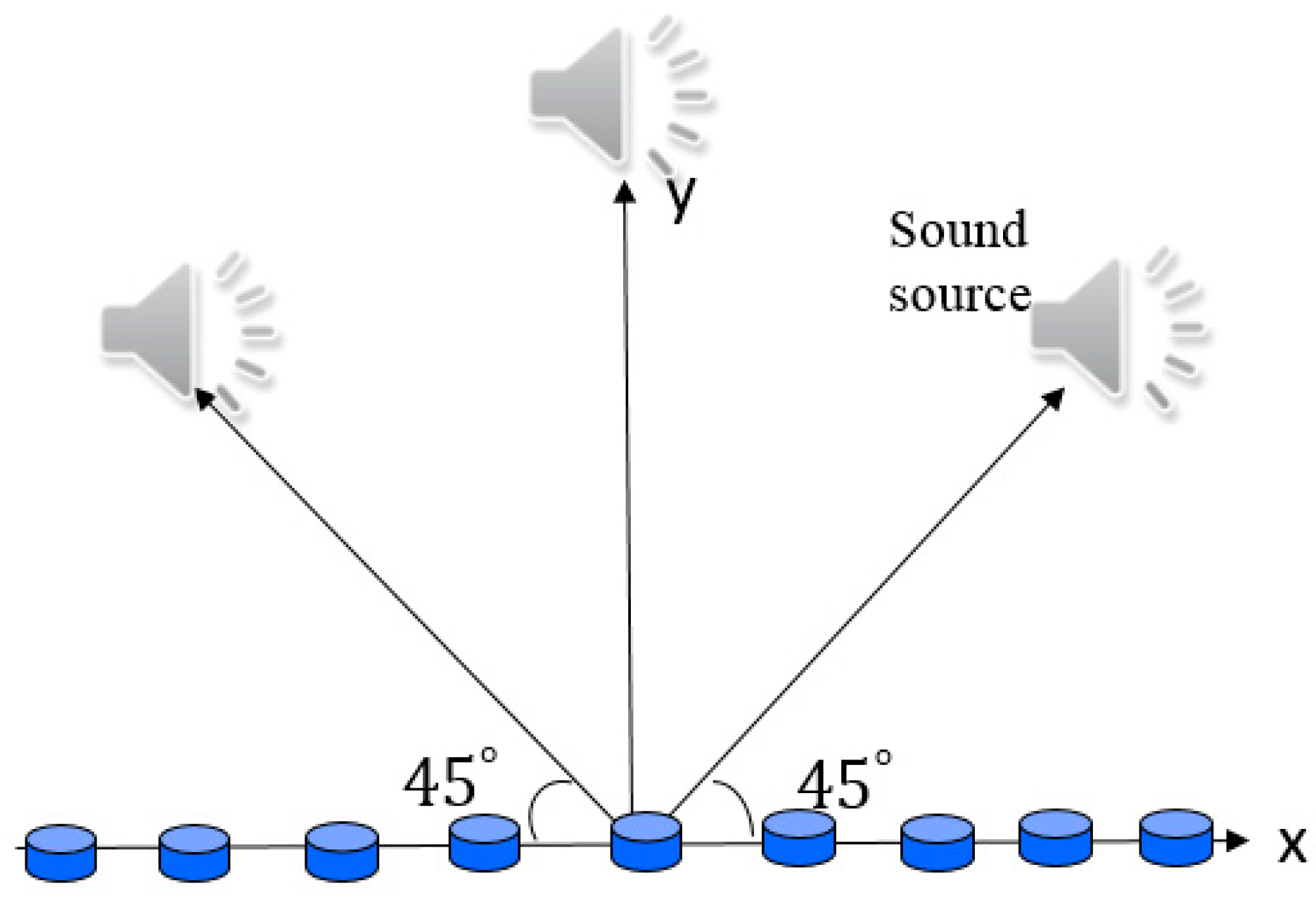
A simulation was conducted for localization and separation of two point sources located at (0, 0, −1 m) and (0.8, 0.3, −1 m), both of which were emitting clean speech signals, as illustrated in
Figure 7. A 30-element random array with aperture dimension 0.48 m × 0.4 m situated at
z = 0 was utilized to capture the signals emitted by these two sources. To set up the propagation matrix, 100 (10 × 10) equivalent sources were distributed on the image plane located 1 m away from the array.
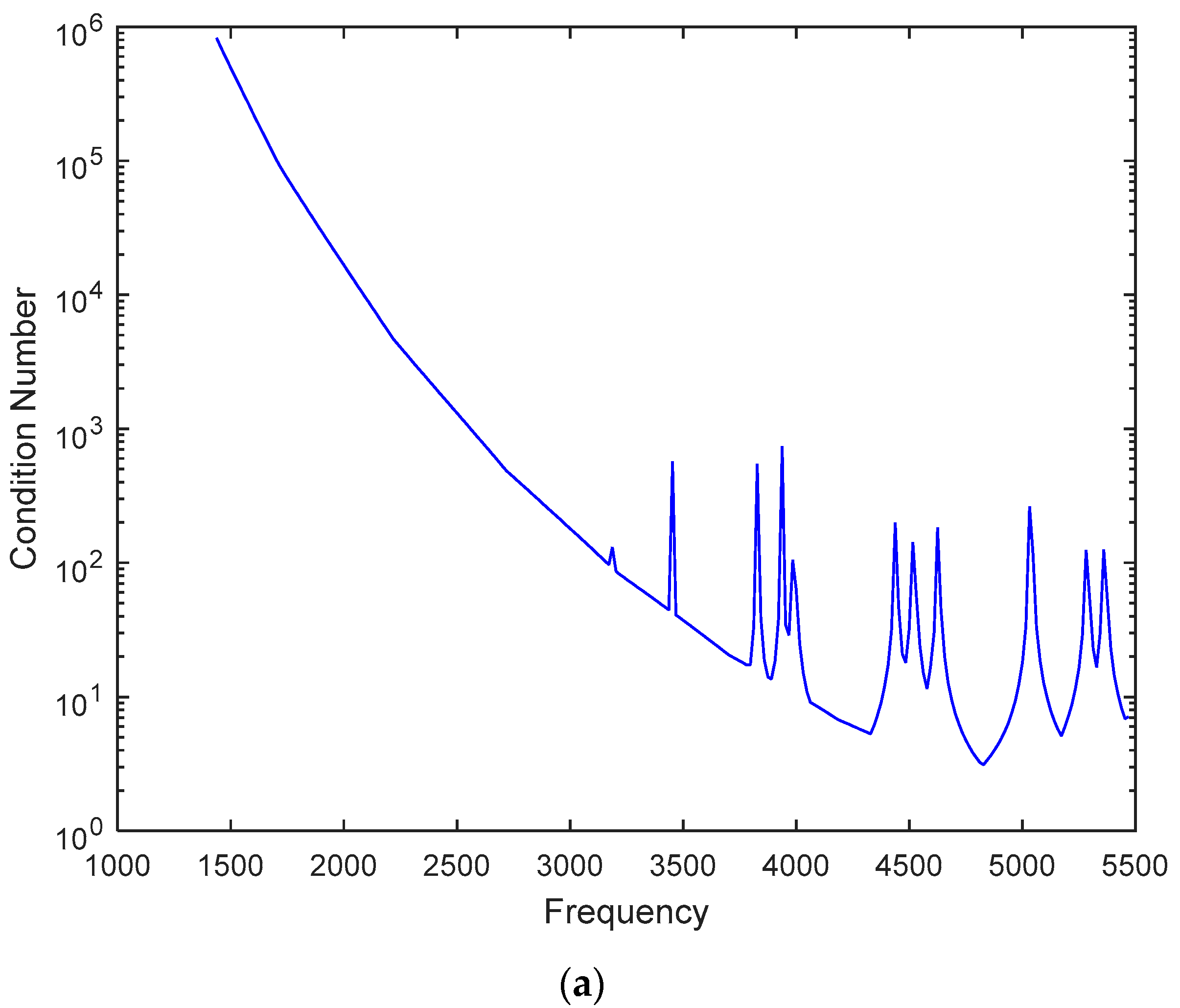
Figure 8 shows the condition numbers of different frequencies. The problem is ill-conditioned at low frequencies.
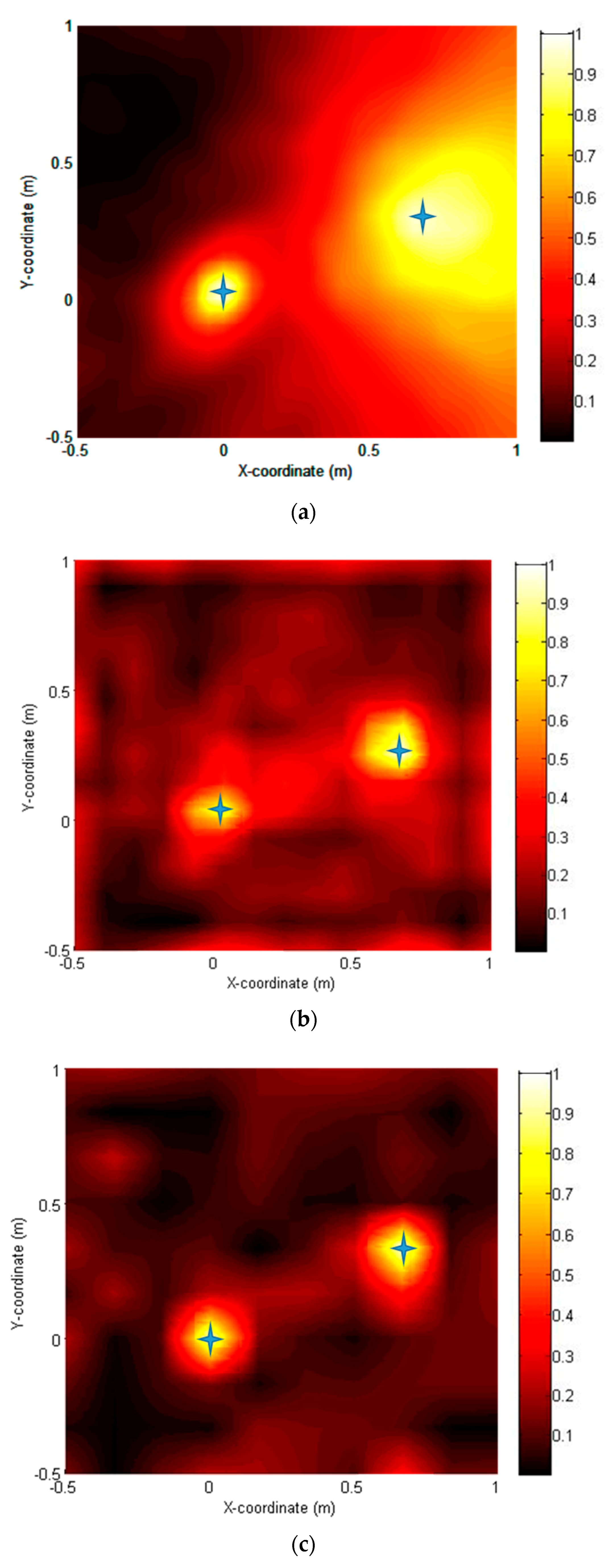
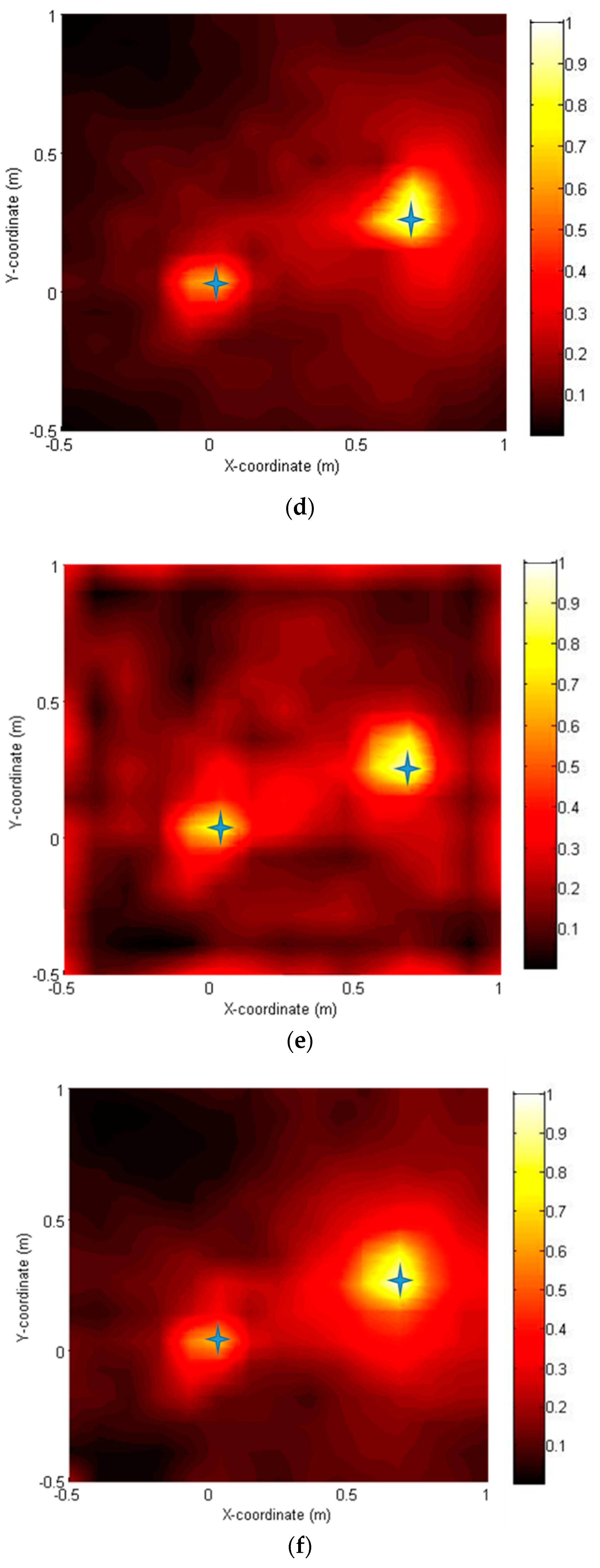
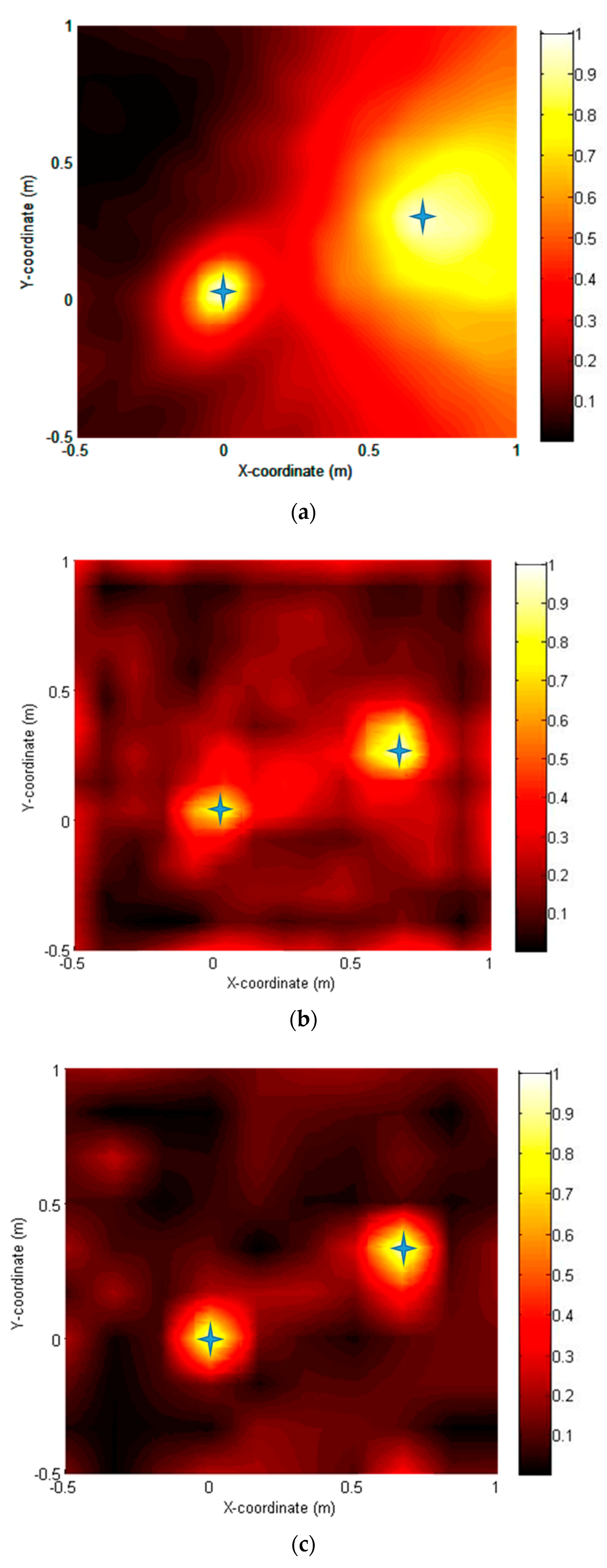
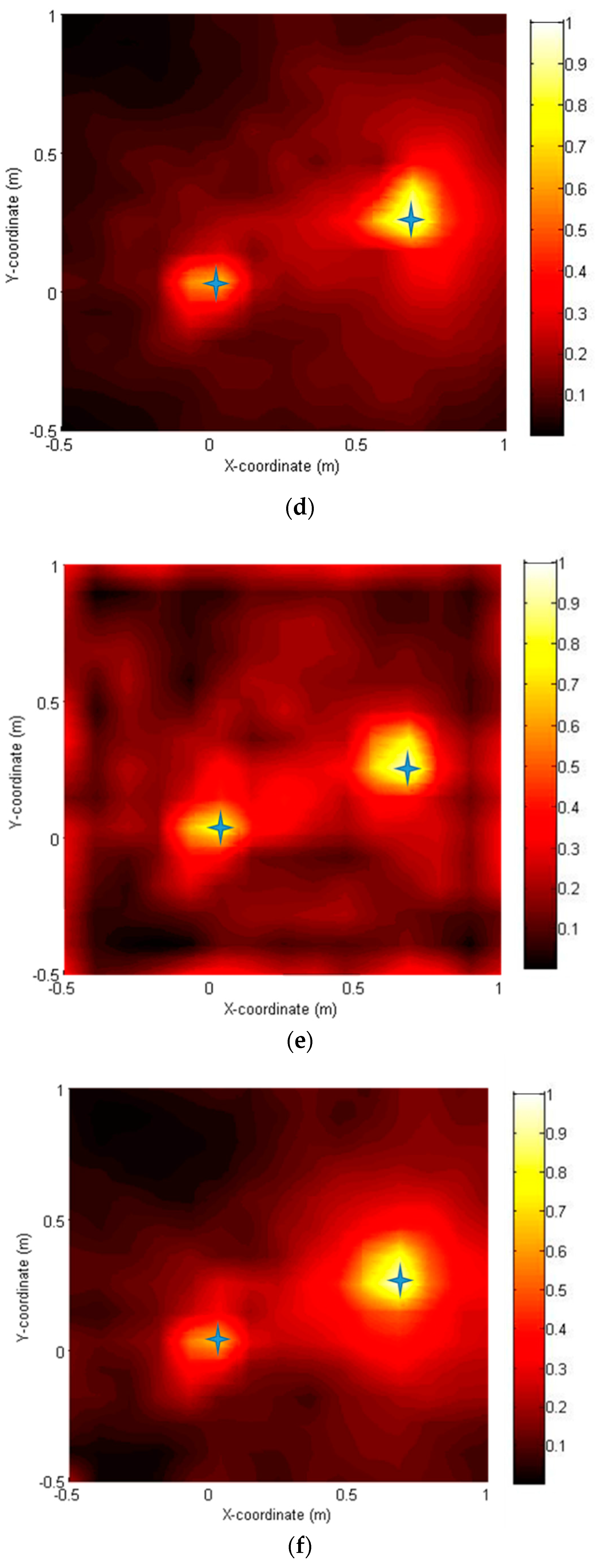
Figure 9a–f show the source localization results obtained using six approaches. Two sources were correctly located on the noise map with varying degrees of resolution by all methods. A conventional method delay and sum (DAS) method (a) gave the poorest resolution, whereas the CS-CVX method provided the highest resolution. The SD method (d) and CG method (f) were acceptable but did not perform quite as well as the CS-CVX method. The NT method (e) yielded accurate source locations with a slightly increased sidelobe level, but it was the most computationally efficient (
Table 2).
Table 4 presents a comparison of the separation results obtained using five methods. CS-CVX displayed the highest scores for PESQ and segSNR, despite being extremely time-consuming. Iterative CS approaches were determined to be far more computationally efficient than the CS-CVX method. The CG method attained the highest PESQ, but the lowest segSNR. This suggests that the favorable separation performance of the CG method comes at the price of signal distortion. The SD and NT methods demonstrated acceptable PESQ and high segSNR. Although signals were not perfectly separated by using these two methods, the incurred distortion was minor. In general, methods present a trade-off between separation performance and signal distortion.
Table 5 shows the separation results with additive noise (SNR = 28 dB). All the methods were observed to suffer from the interference of noise; consequently, the values of PESQ and segSNR were notably low. However, all the methods were determined to be robust to noise. The present study also considered mismatches between equivalent sources (dictionaries) and real sources.
Table 6 shows the separation results of the NT method with different levels of mismatch. Mismatch means that the real source is not precisely on the deployed source location (dictionary). Extreme mismatch means the real source is exactly on the center of four nearest the deployed source location. More descriptions are added to the revised manuscript. Unless the source was just at the center of the near dictionaries, the separation performance was high and not influenced by noise.
3.3. SFA and SFS
Depending on the sparsity of the sound sources, the SFA stage can be implemented in several manners [
35,
36,
37,
38]. For the sparse-source scenario, a two-stage algorithm is utilized; the source bearings are estimated using the minimum power distortionless response (MPDR) [
7] and the associated amplitudes of plane waves are estimated using the TIKR algorithm. For the nonsparse-source scenario, a one-stage algorithm based on the CS-CVX algorithm or the FOCUSS algorithm is employed.
The SFS stage is carried out using a loudspeaker array to reconstruct the sound field with the source bearing and amplitude obtained in the SFA stage. Pressure matching was employed for the SFS purpose in this study by sampling a large number of virtual control points in the interior area surrounded by the loudspeakers. The pressure matching procedure can be described as the following optimization problem:
where
is the amplitude vector of the
Pth primary plane-wave component,
denotes the amplitude vector of the input signals to the
L secondary loudspeaker sources,
denotes the room response matrix, and
is the steering vector for the
dth primary plane-wave component to the
nth control point,
.
is the steering matrix from the plane-wave components obtained in the preceding SFA stage to the control points. Therefore, the optimal solution can be written as
where “#” symbolizes some type of inverse operation on the matrix
. In this study, TIKR was utilized to calculate the input signal amplitudes to the secondary sources. GSS can be used to find the optimal regularization parameter.
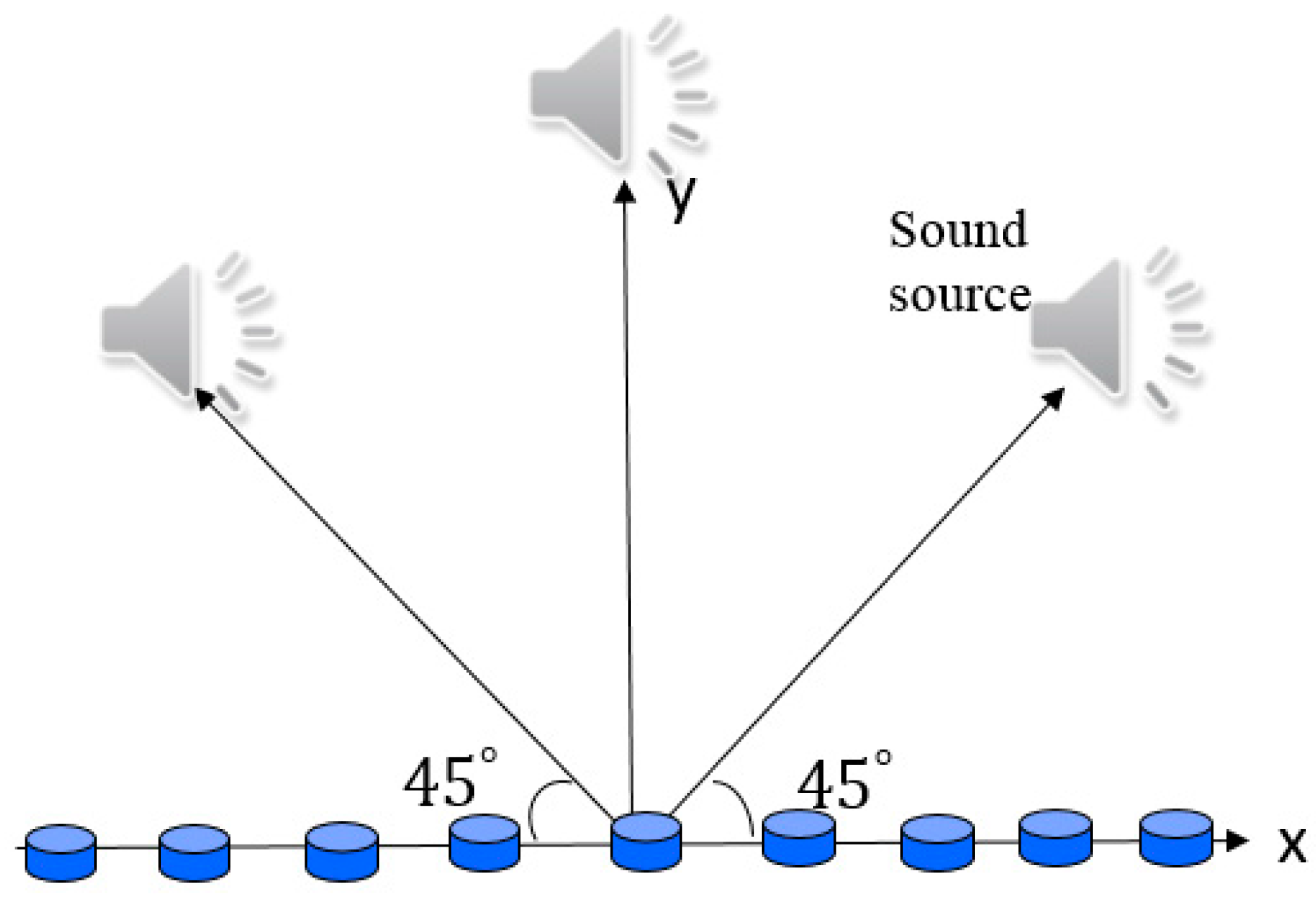
Experiments were conducted to validate the proposed audio analysis and synthesis system. In the SFA stage, a 24-element circular microphone array with a radius of 12 cm was utilized to capture and parameterize the sound field in an anechoic chamber (the recording room), as illustrated in
Figure 10. In the SFS stage, a rectangular, 32-loudspeaker array was employed to reproduce in a live room (the reproduction room) the sound field previously encoded in the SFA stage. The walls of the room were lined with acoustically reflective boards (
Figure 11).
To process microphone output and loudspeaker input signals, multichannel analog-to-digital converters (M-32 AD) and digital-to-analog converters (M-32 DA) (RME, Haimhausen, Germany) were used with a sampling frequency of 16 kHz.
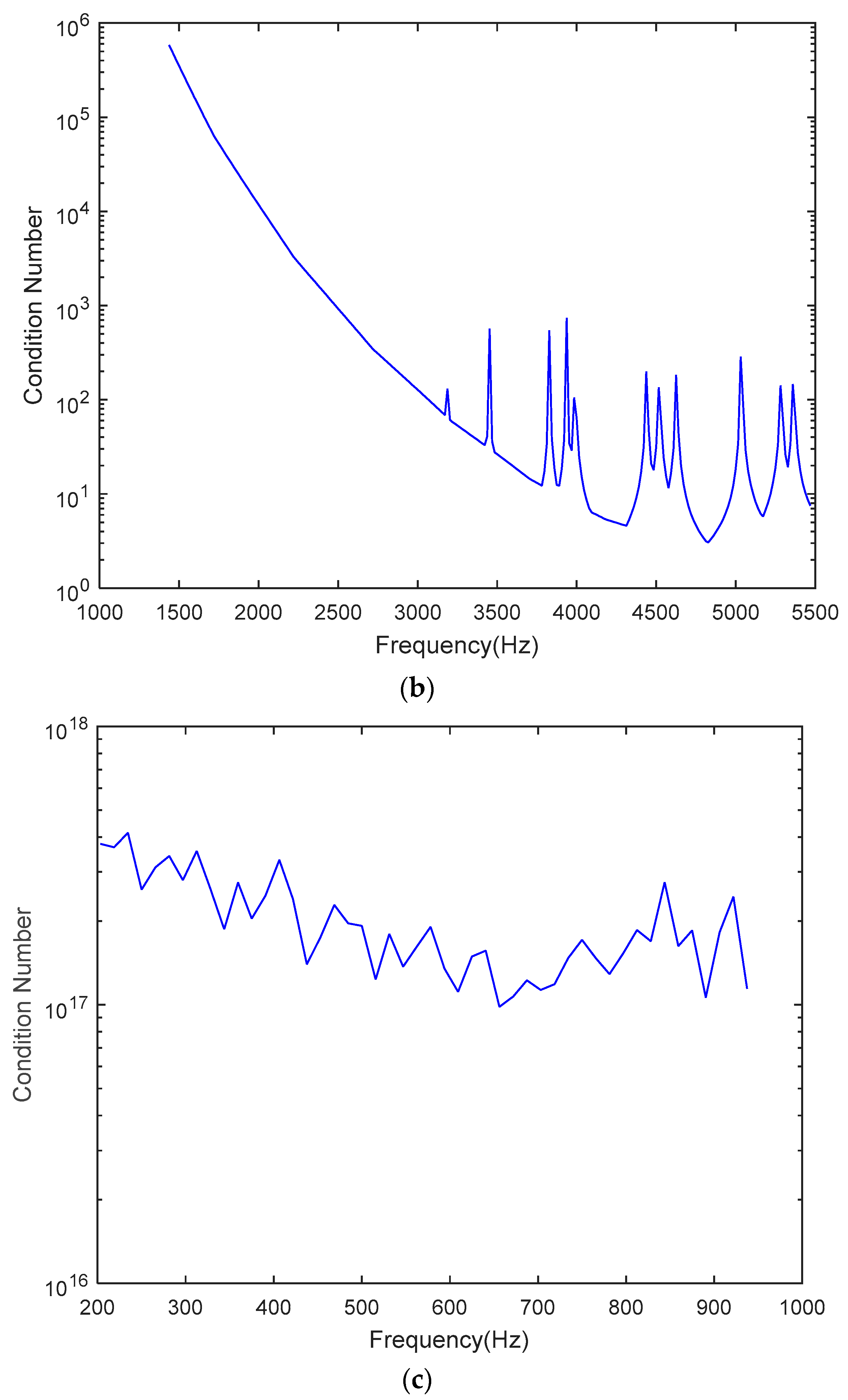
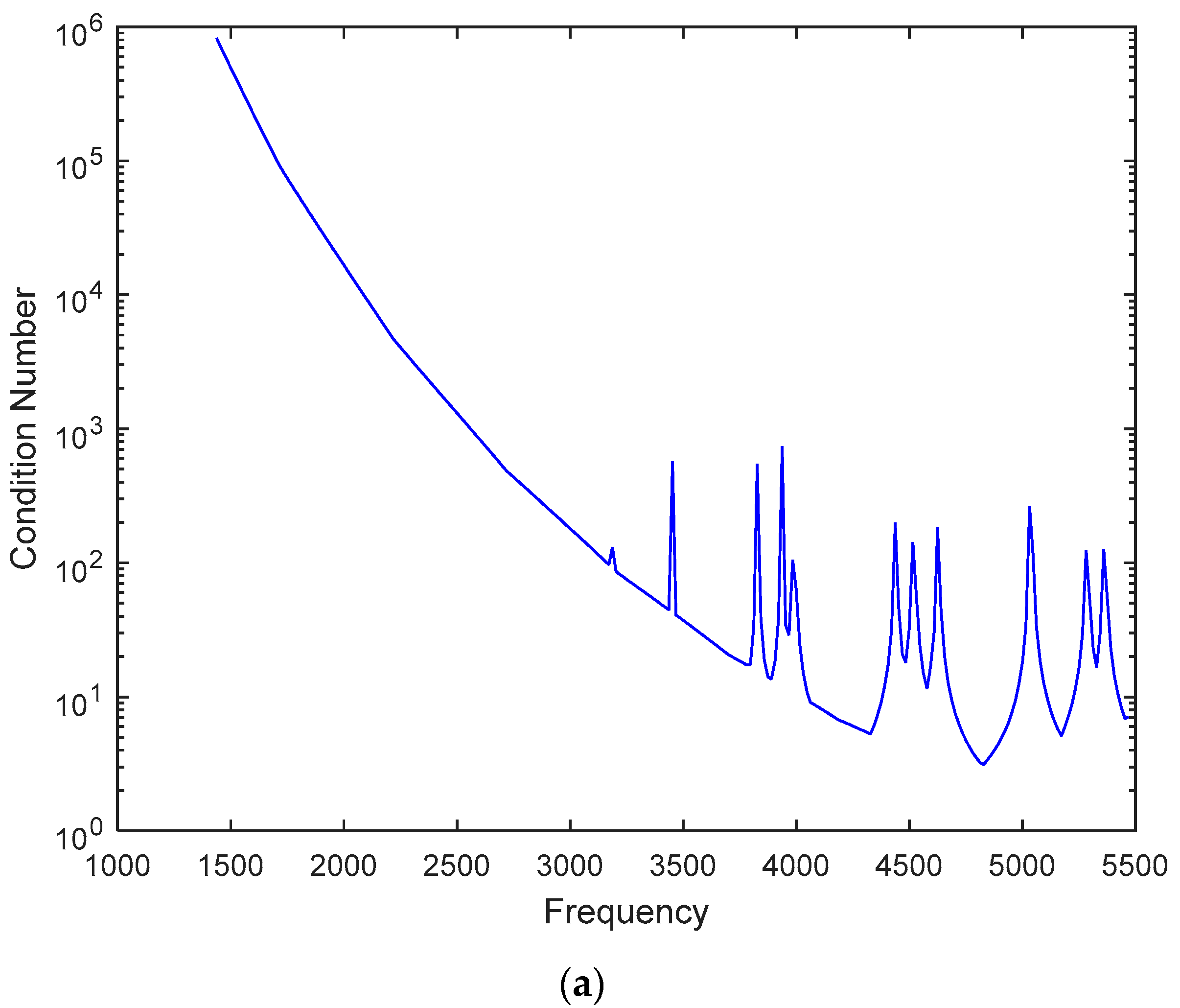
An audio codec system involves three inverse problems, namely the SFA stage, room response modeling, and the SFS stage. The condition numbers are plotted against the frequencies of three steering matrices in
Figure 12a–c.
Figure 12c indicates that the ill-posedness encountered in the room response modeling procedures must be addressed, with the aid of appropriate regularization methods. Large regularization parameters can increase the robustness of the inverse problem. In this study, we set the regularization parameter to 10.
In the SFA experiment, loudspeaker sources positioned at the angles
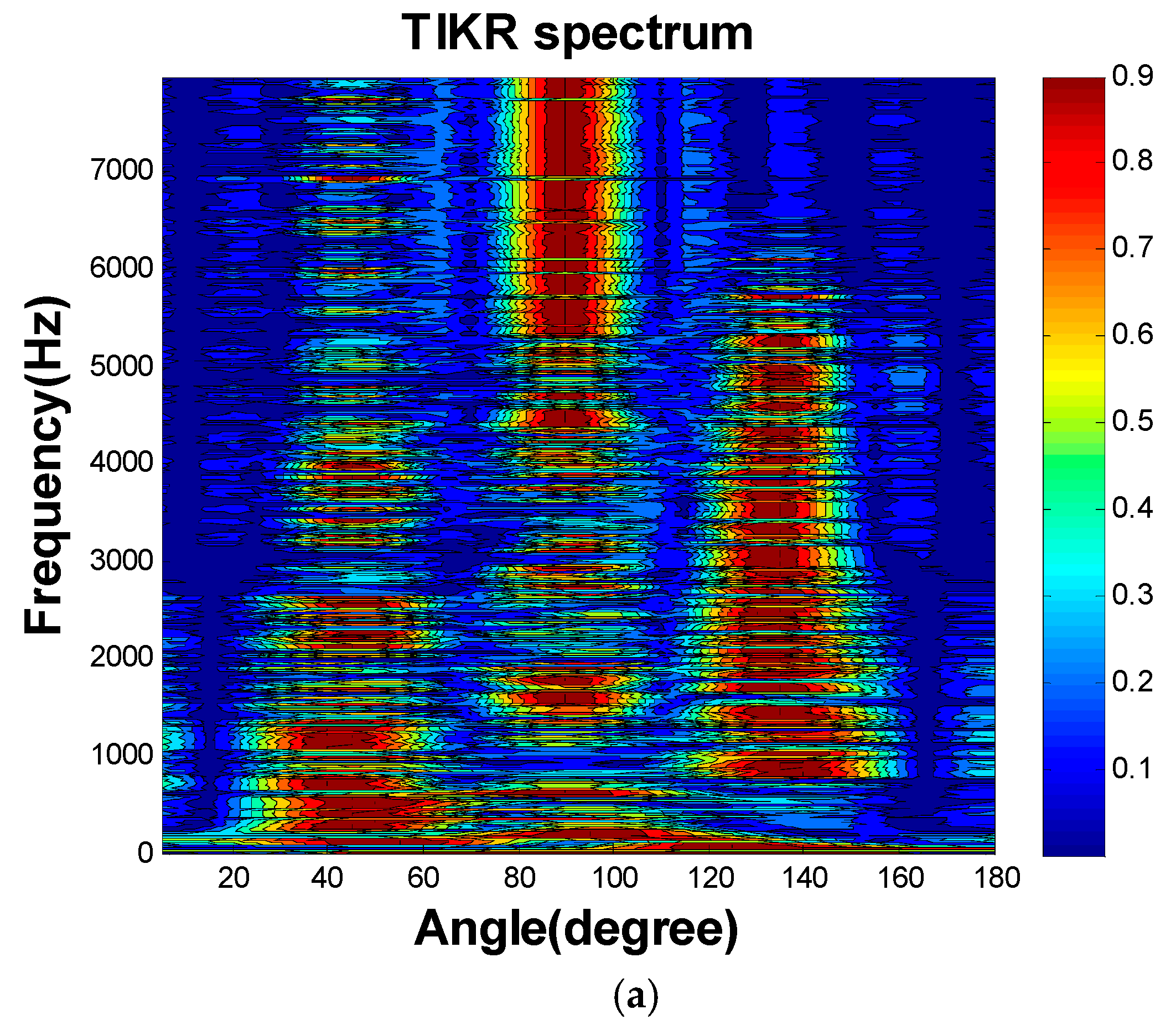
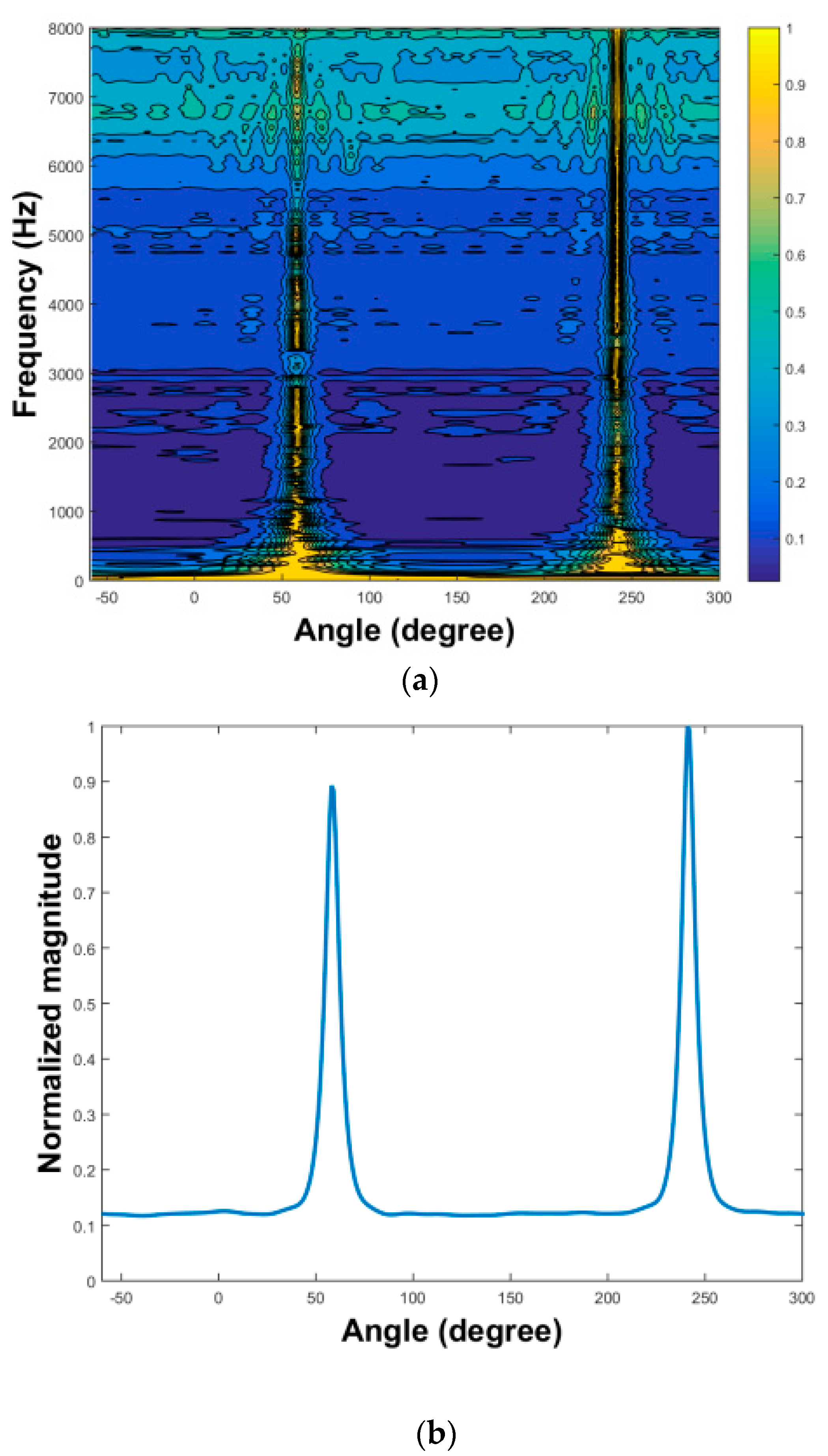
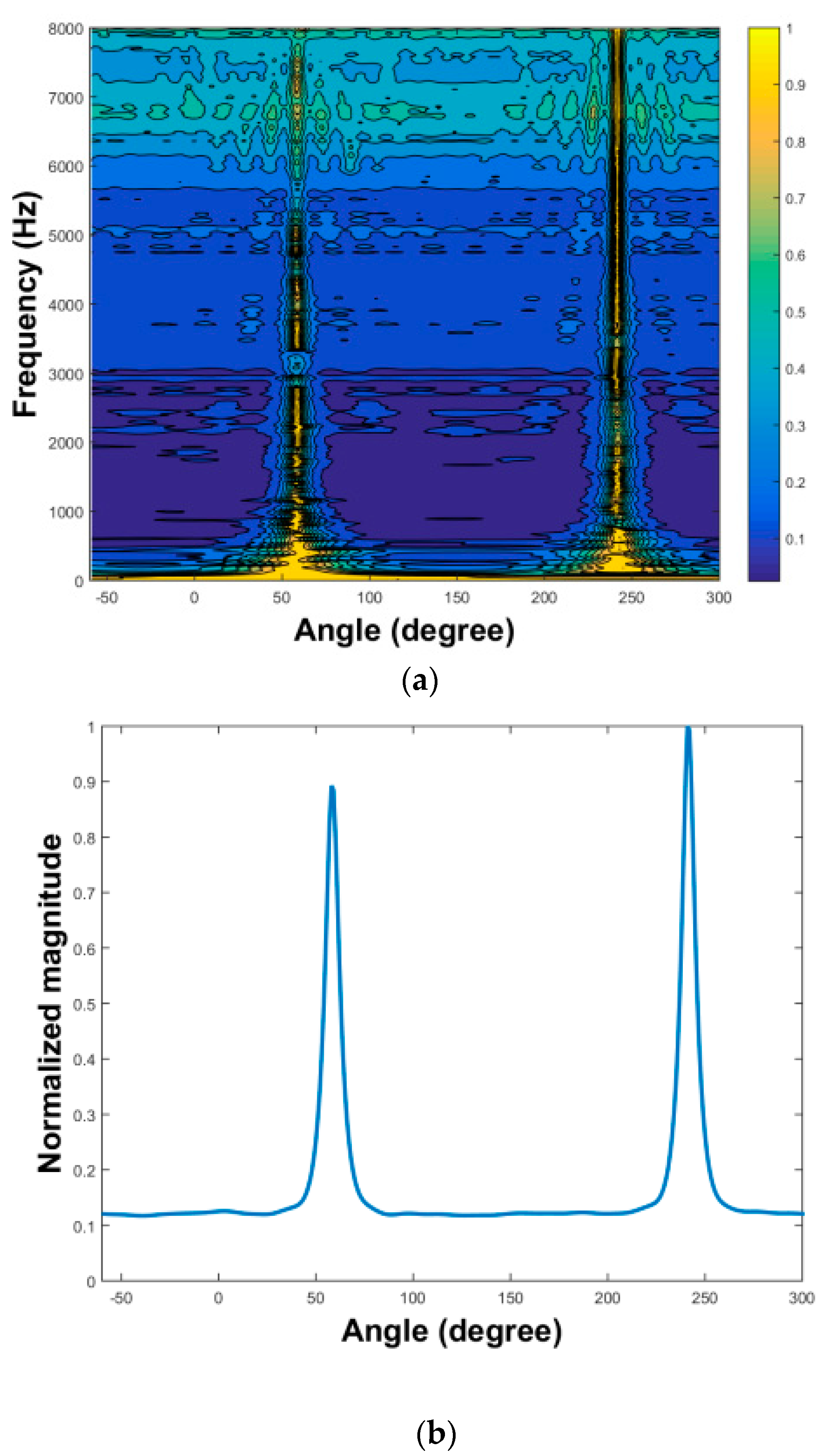
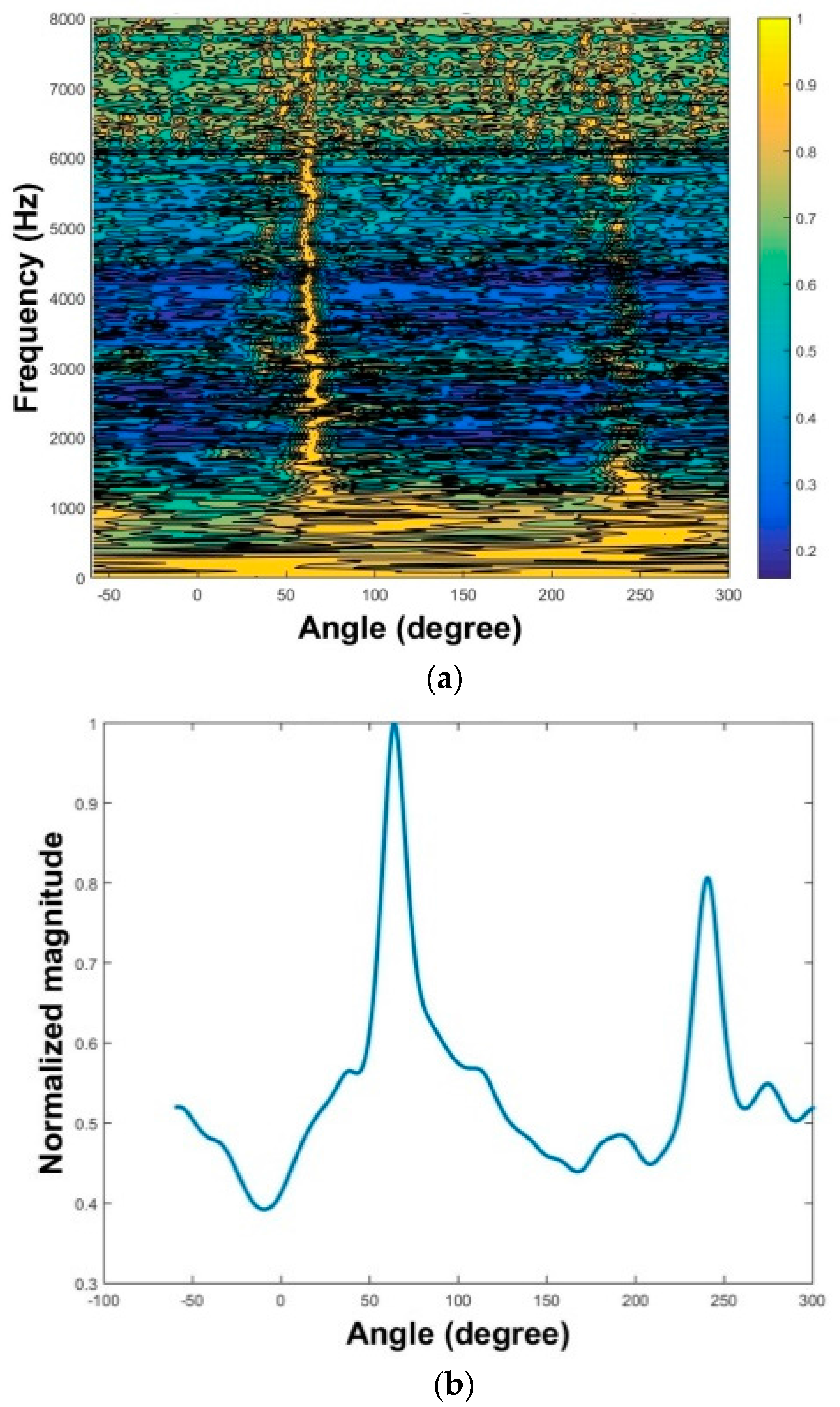
played two 10-s speech clips. After recording the source by CMA, we used three algorithms to extract the source signals. First, we applied the two-stage MPDR and TIKR algorithms. The MPDR spectrum is plotted as a function of angle and frequency in
Figure 13a. The resulting frequency-averaged and normalized MPDR spectrum is illustrated in
Figure 13b, which peaks at the angles
as desired. The results show that the source was accurately localized using MPDR. Next, the source signals were extracted using the TIKR algorithm. We also applied one-stage CS algorithms and one-stage FOCUSS algorithms, which located sources and separated their amplitudes in a single calculation.
The signals extracted using different methods were evaluated by using the MOS of the PESQ test. Results confirmed that the TIKR performed well in signal separation with satisfactory audio quality. The results are summarized in
Table 7.
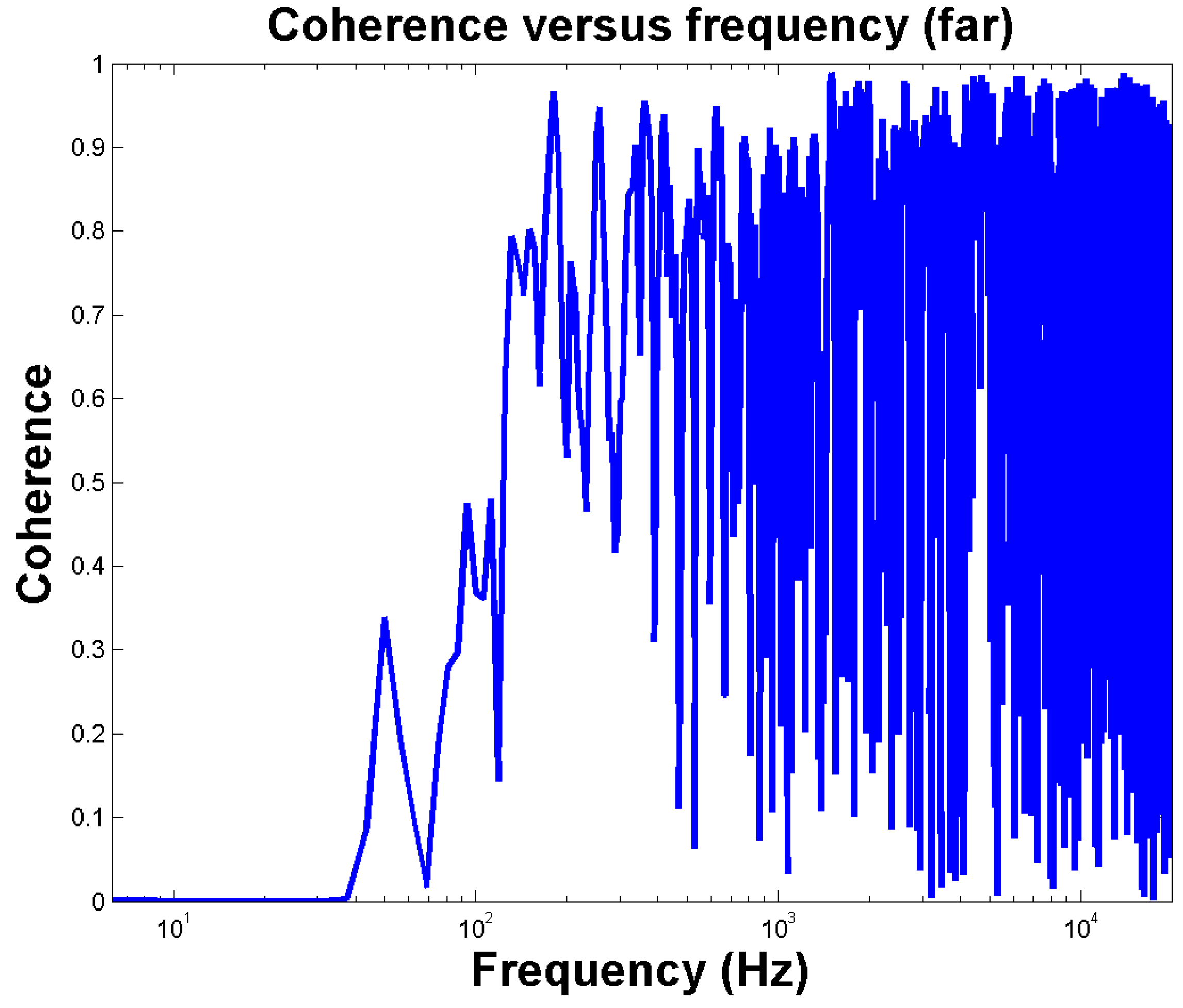
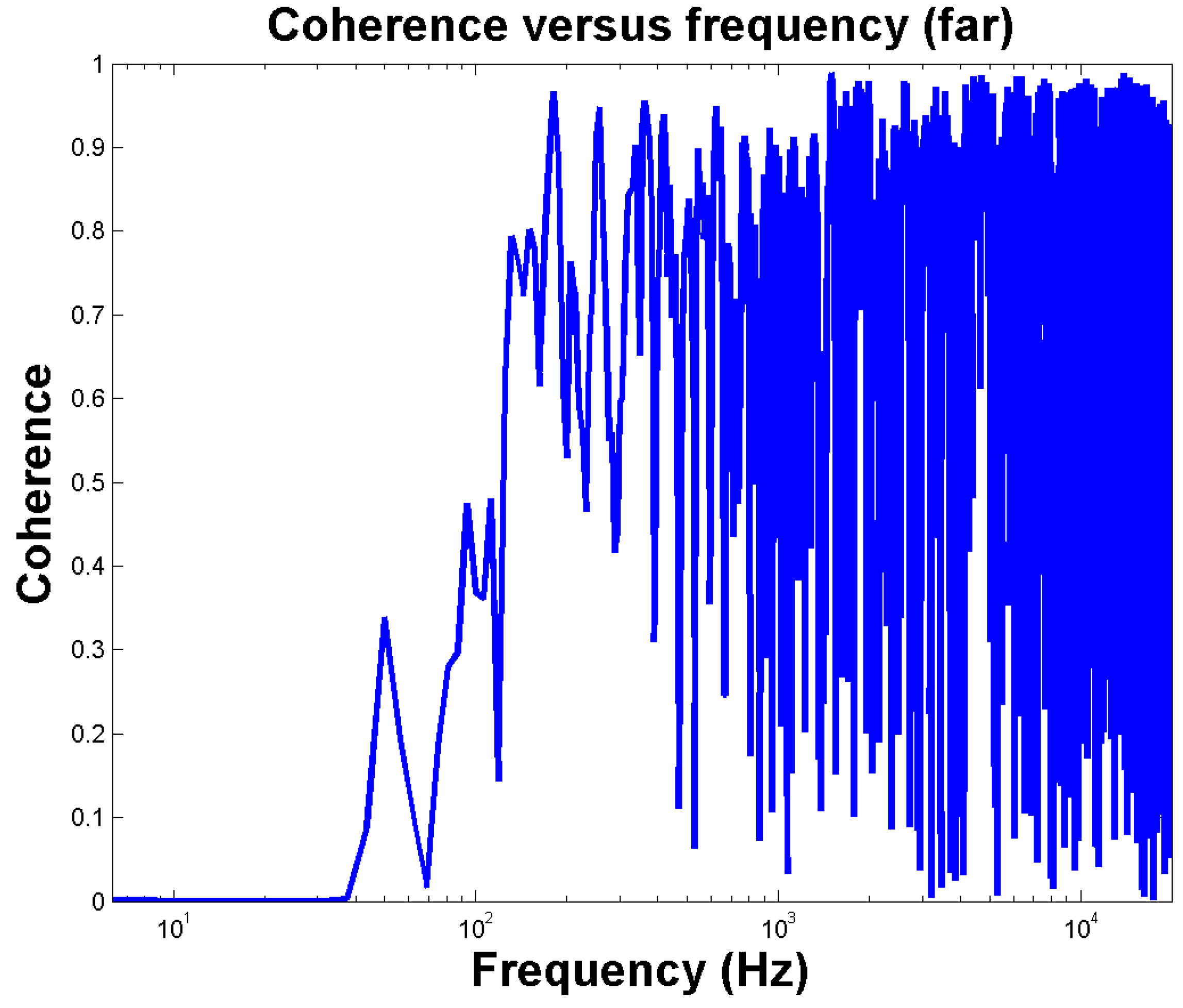
One sample coherence function between one loudspeaker and one microphone is shown in
Figure 14, indicating the signal quality to be poor below 200 Hz. Therefore, band-limited processing was applied for all frequencies up to 200 Hz in the SFS stage. In this frequency range, pressure matching was used on the basis of the room response model.
The SFS stage was conducted for three different methods. The coherence between the loudspeaker and the microphone was poor below 200 Hz; therefore, the signals below 200 Hz were not processed. Method 1, band-limited processing, was applied from 200 Hz to the spatial aliasing frequency, 952 Hz, in the SFS stage. In this frequency range, pressure matching was performed on the basis of the room response model. Below 200 Hz, unprocessed audio signals were fed directly to the loudspeakers. Above 952 Hz, a simple vector panning [
39] approach was adopted. The optimal regularization parameter
β achieving the highest MOS in room response modeling was calculated using GSS [
21] as
β = 0.0008634.
In the second method, instead of a vector panning method, we used DAS to process signals above 952 Hz. In the third method, we used pressure matching to obtain signals above 200 Hz. The use of different regularization parameters in pressure matching results in different levels of localization performance and audio quality.
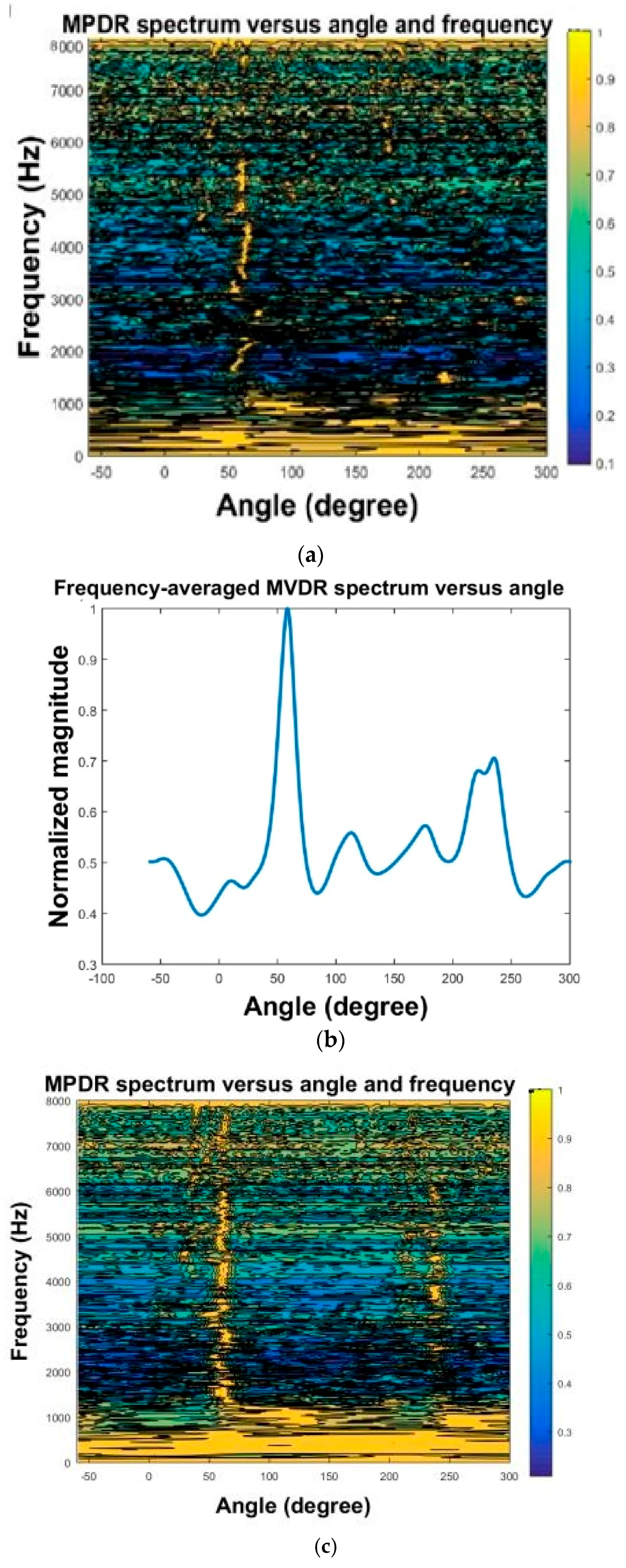
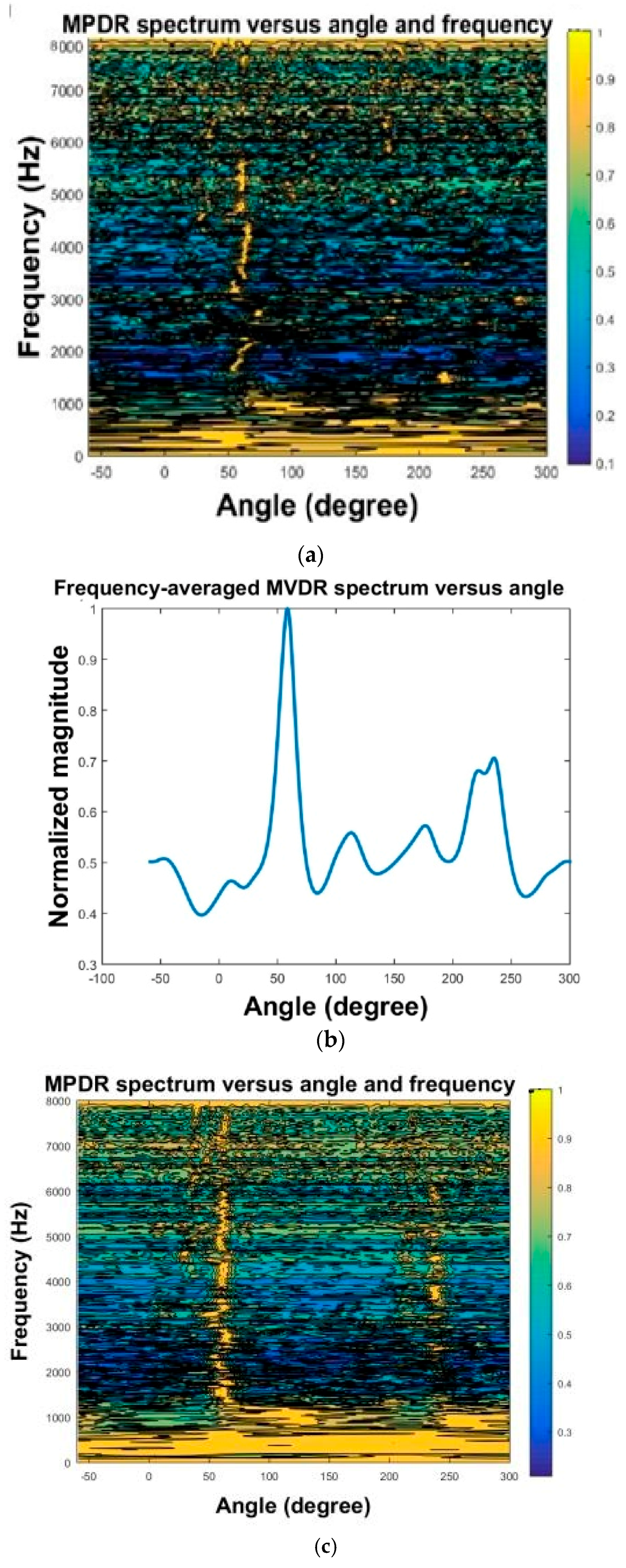
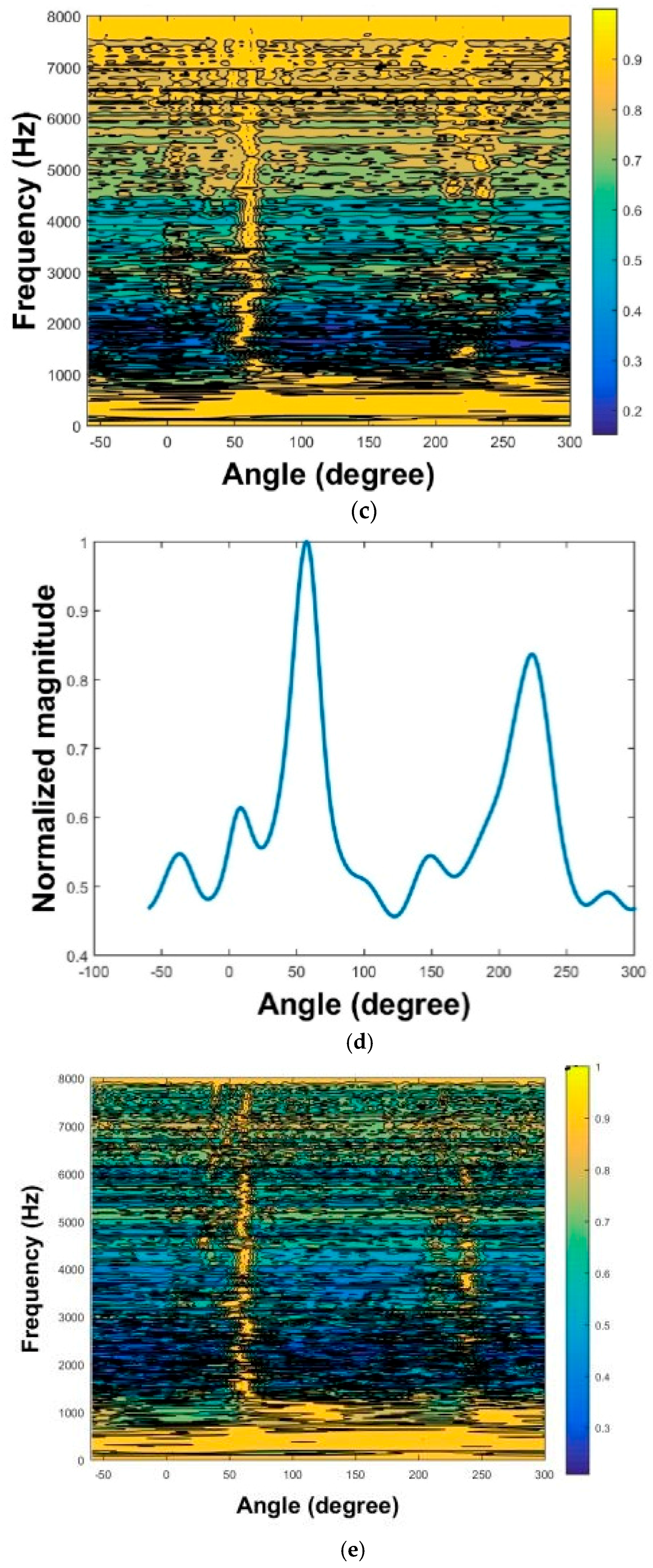
Figure 15a,c shows the MPDR spectrum and the normalized MPDR spectrum obtained using the third method for
β = 0.01 and
β = 10, respectively. Low values of the regularization parameter
β yielded higher localization performance than high values did. These two signals were compared with the clean signal through the PESQ test. The results showed that the high
β ensured satisfactory voice quality, whereas the low
β impaired voice quality.
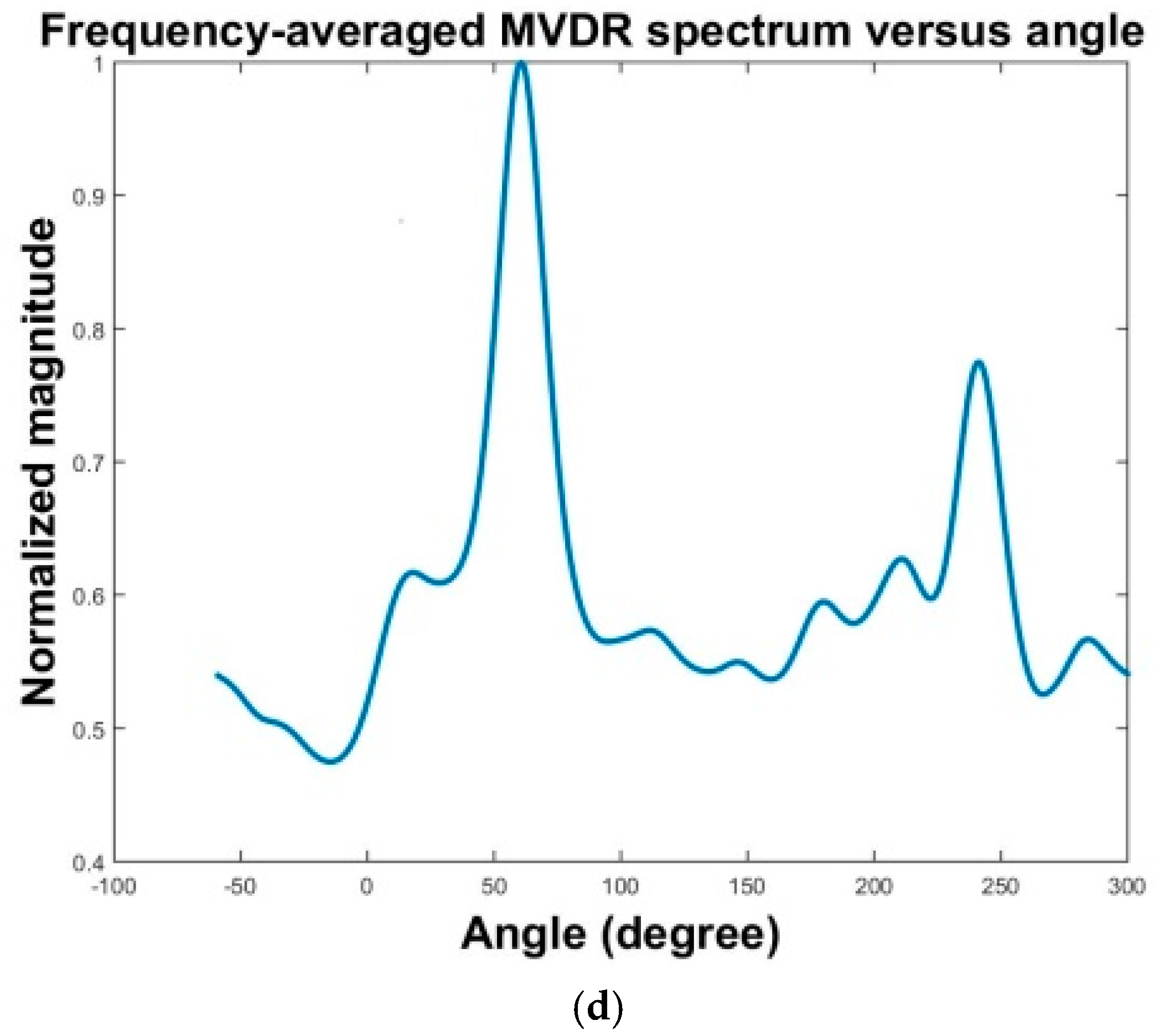
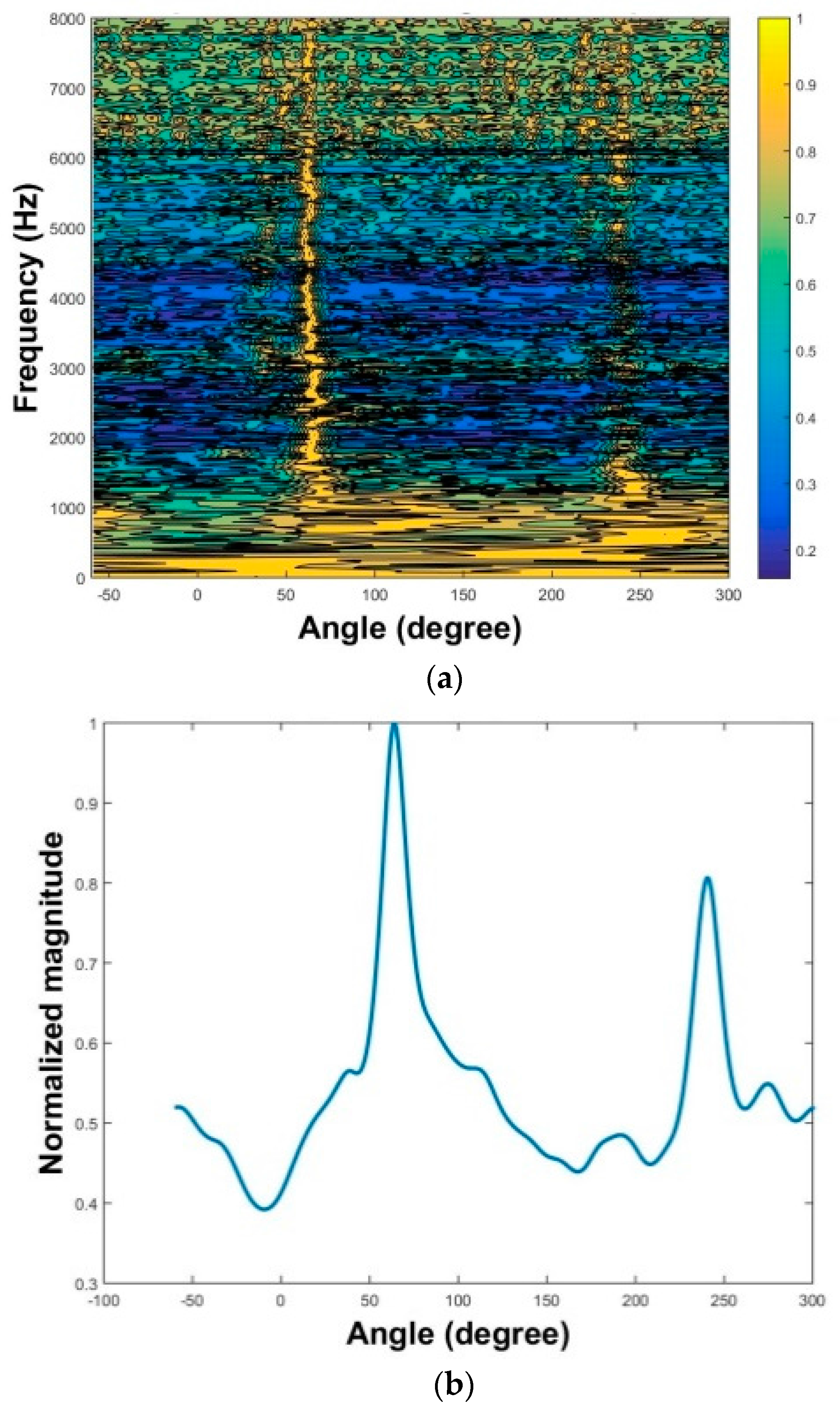
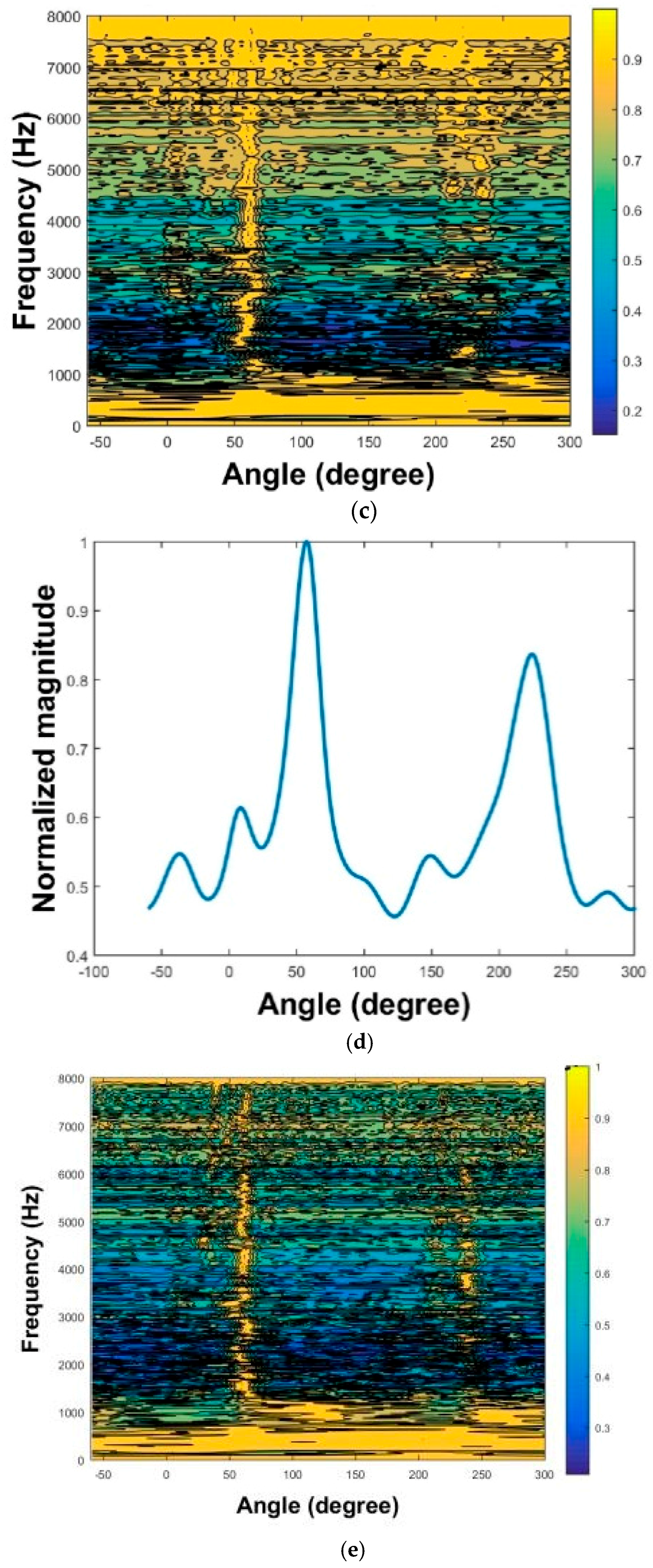
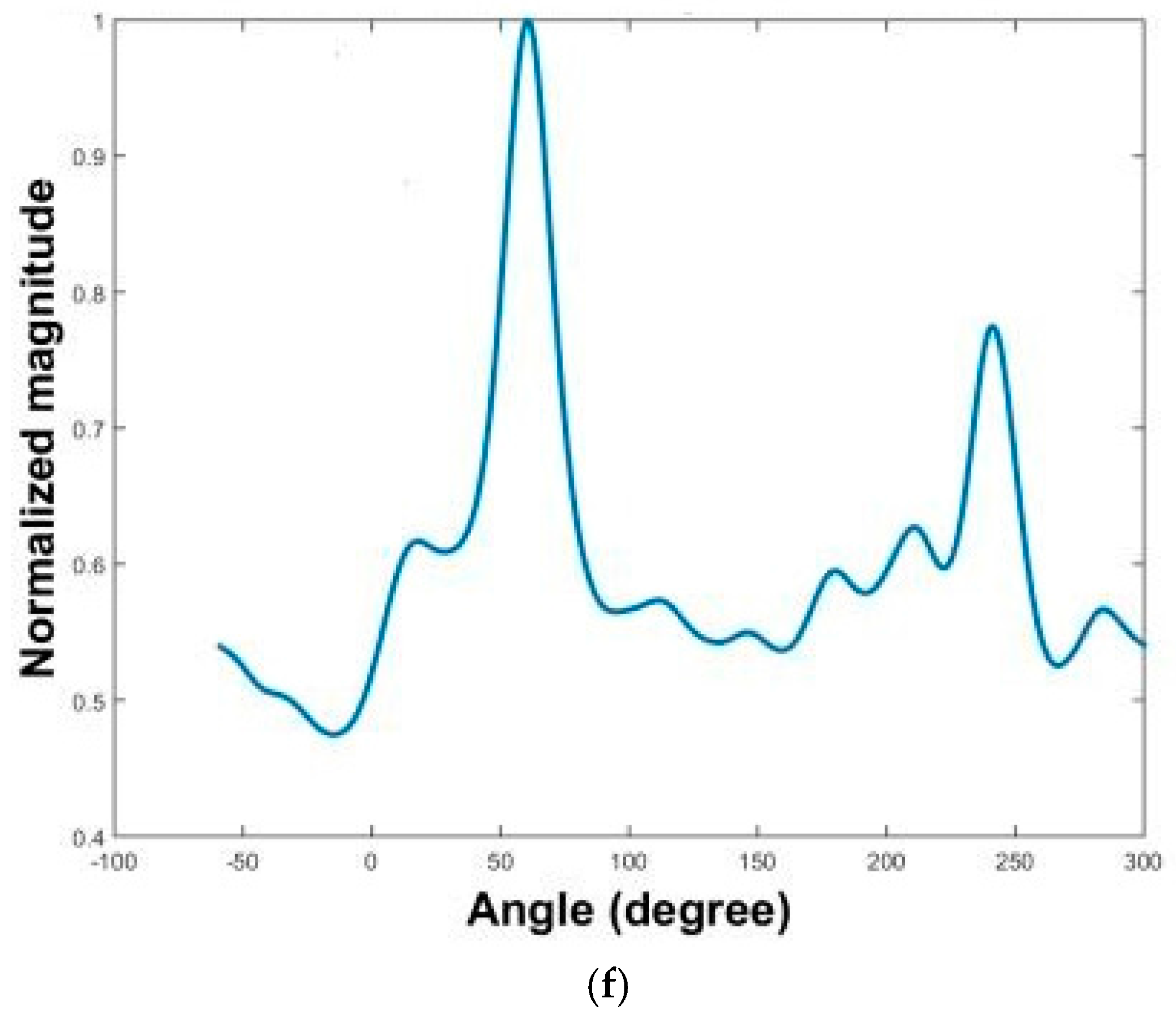
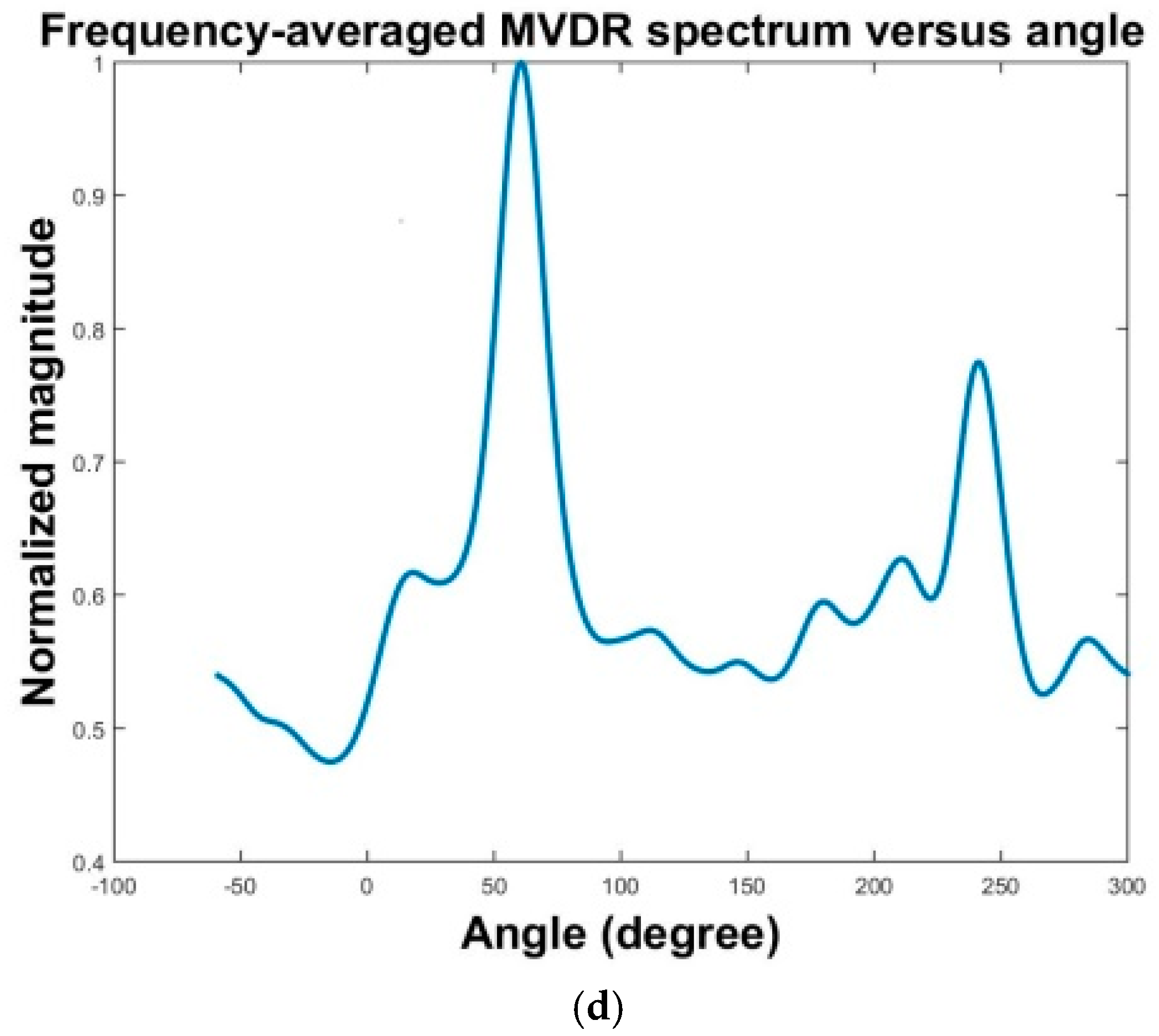
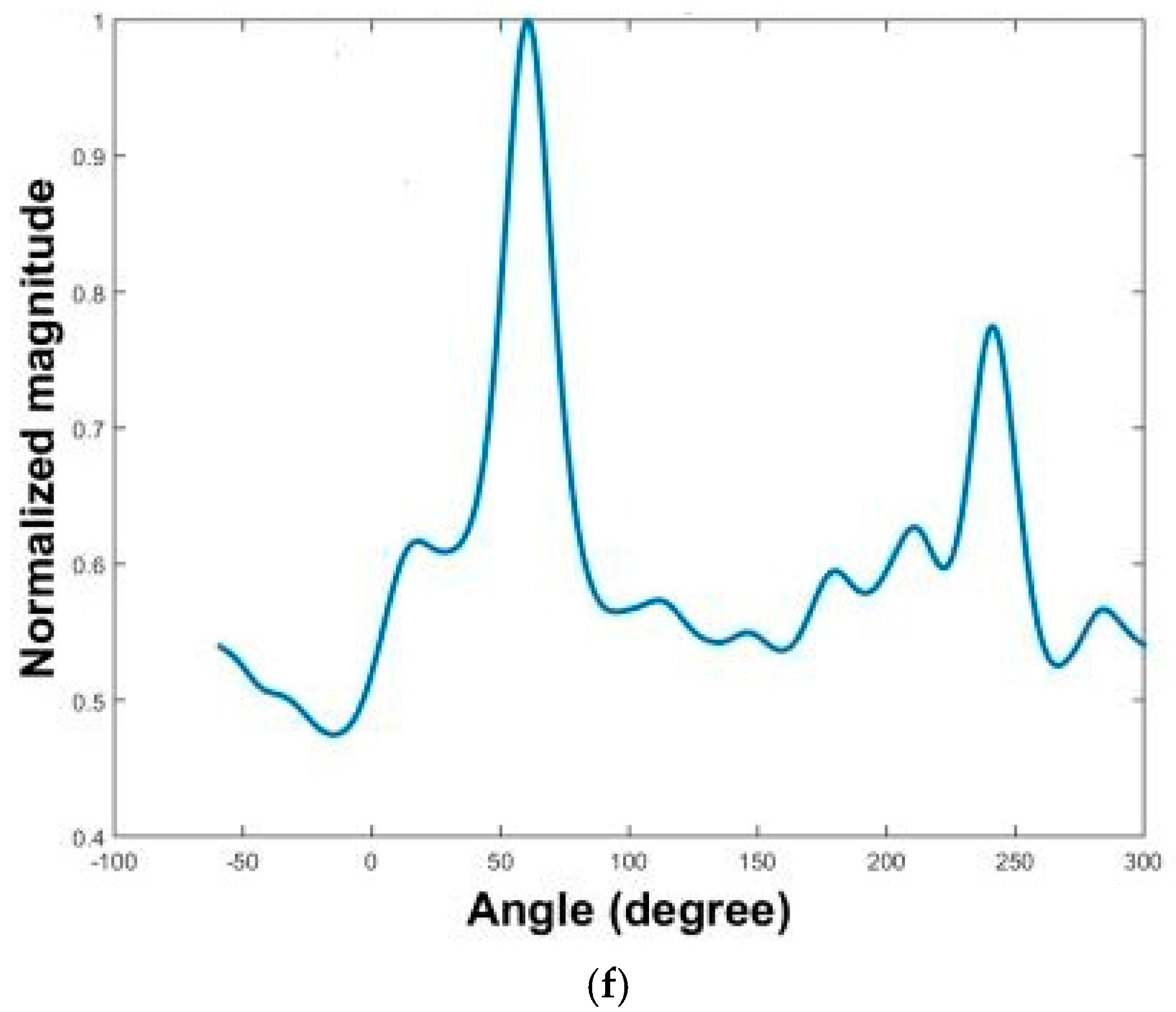
The results of three localization methods are presented in
Figure 16a–f. The MPDR spectra are plotted as functions of angle and frequency in
Figure 16a,c,f. The resulting frequency-averaged and normalized MPDR spectra are shown in
Figure 16b,d,f.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}