The proposed RNN model was implemented in Python using the open source TensorFlow deep learning framework developed by Google [
34]. TensorFlow has automatic differentiation and parameter sharing capabilities, which allows a wide range of architectures to be easily defined and executed [
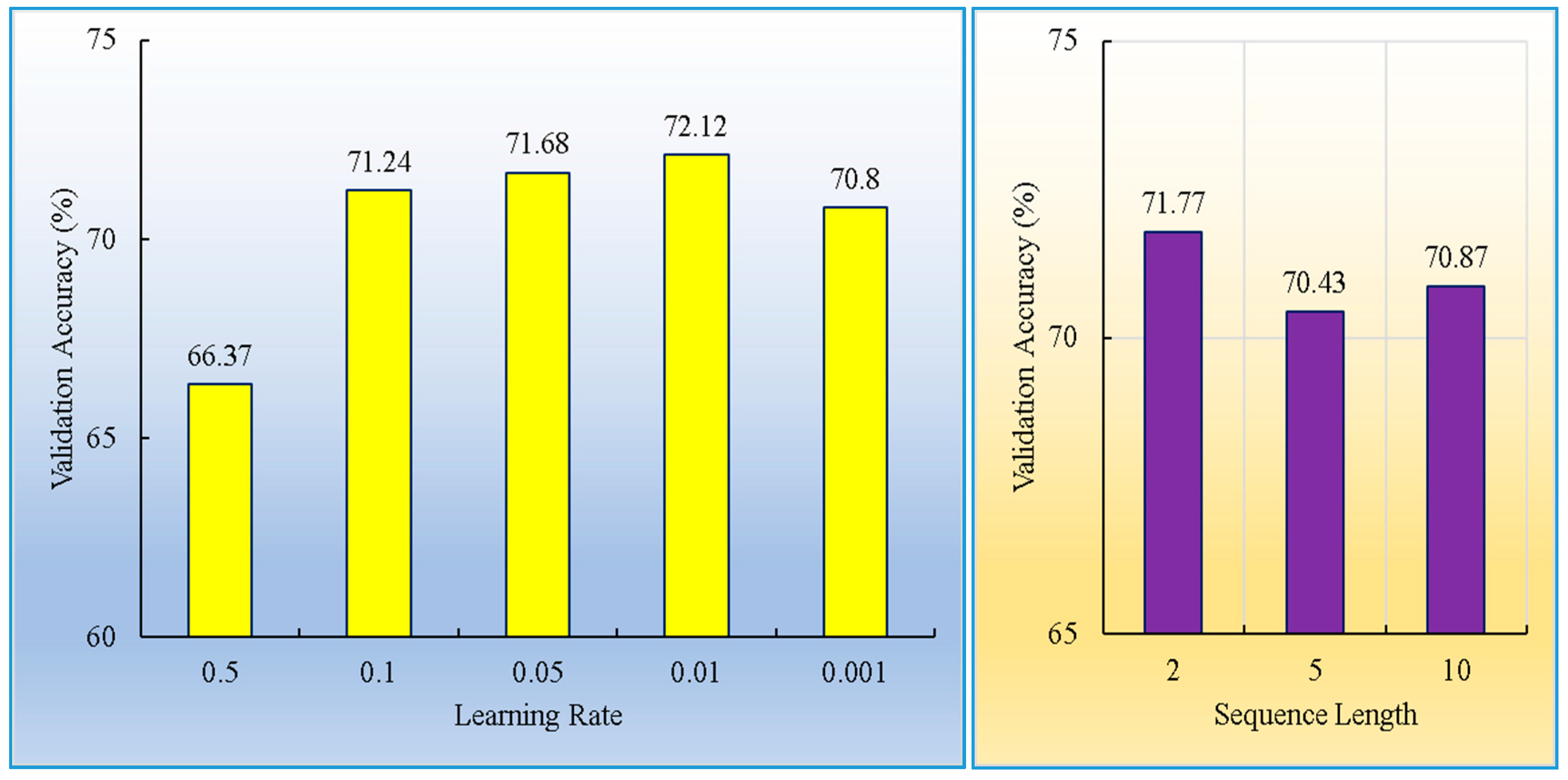
34]. The proposed network was trained with 791 samples and validated with 339 samples using the Tensorflow framework. The SGD optimization algorithm was applied, with a batch size of 32 and a learning rate of 0.01.
4.1. Data
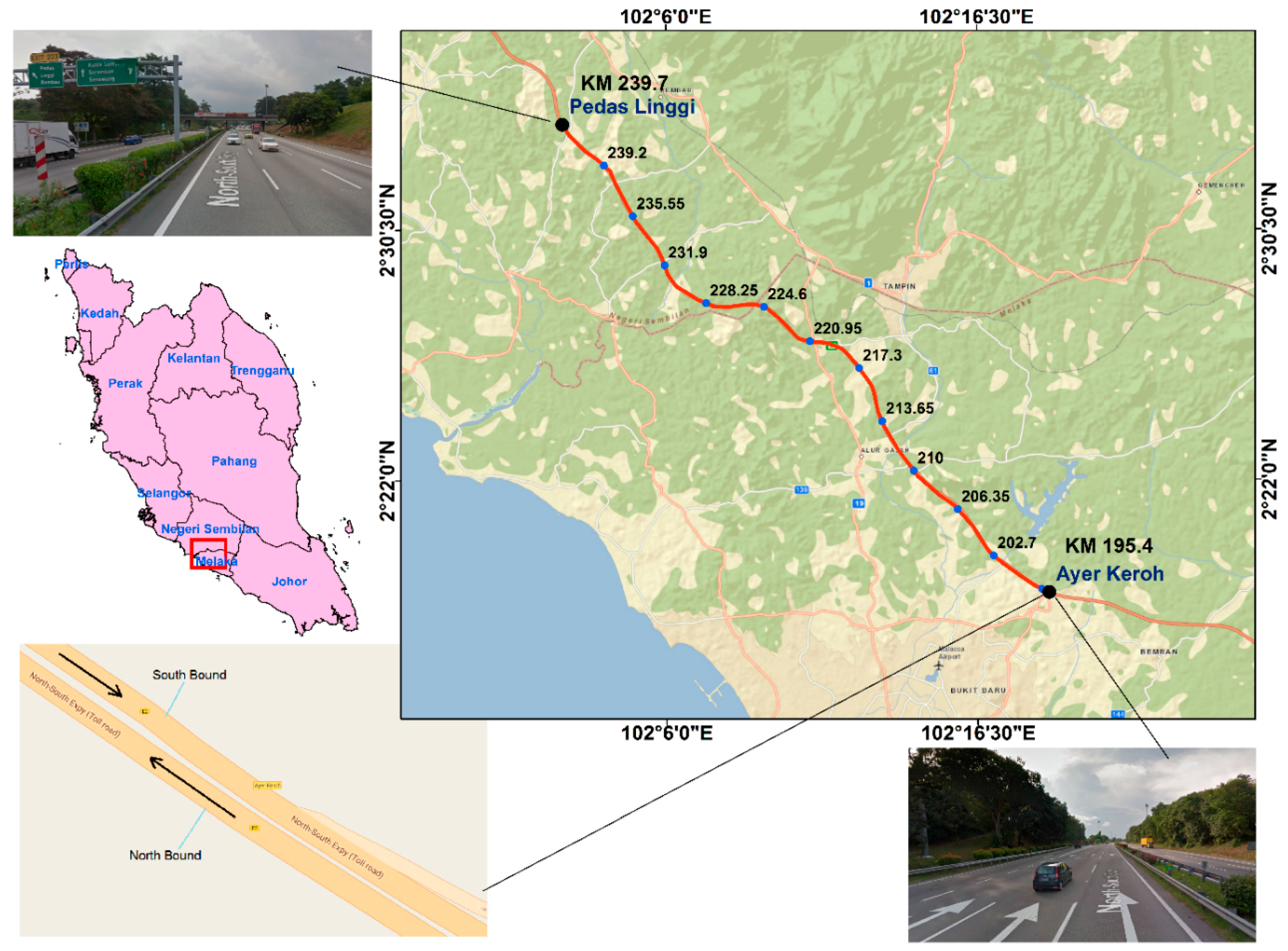
The traffic accident data for the period 2009–2015 from the North-South Expressway (NSE, Petaling Jaya, Malaysia), Malaysia were used in this study. The NSE is the longest expressway (772 km) operated by Projek Lebuhraya Usaha Sama (PLUS) Berhad (the largest expressway operator in Malaysia, Petaling Jaya, Malaysia) and links many major cities and towns in Peninsular Malaysia. The data were obtained from the PLUS accident databases. The files used in this study were accident frequency and accident severity files in the form of an Excel spreadsheet. The accident frequency file contains the positional and descriptive accident location and the number of accidents in each road segment of 100 m. The accident records were separated according to the road bound (south, north). In contrast, the accident severity file contains the general accident characteristics such as accident time, road surface and lighting conditions, collision type, and the reported accident cause. To link the two files, the unique identity field (accident number) was used.
According to the vehicle type information in the accident data, three scenarios were found: (1) single-vehicle with object accidents, (2) two-vehicle accidents, (3) and multiple vehicle accidents (mostly three vehicles). Training a deep learning model requires many samples to capture the data structure and to avoid model overfitting. Therefore, the analysis in this study did not focus just on a single scenario, but instead, all scenarios were included in training the proposed RNN model. In total, 1130 accident records were reported during 2009–2015. Of these, 740 (approximately 65.4%) resulted in drivers damaging property only. On the other hand, 172 (15.2%) drivers were involved in possible/evident injury, and 218 (19.4%) in disabling injury.
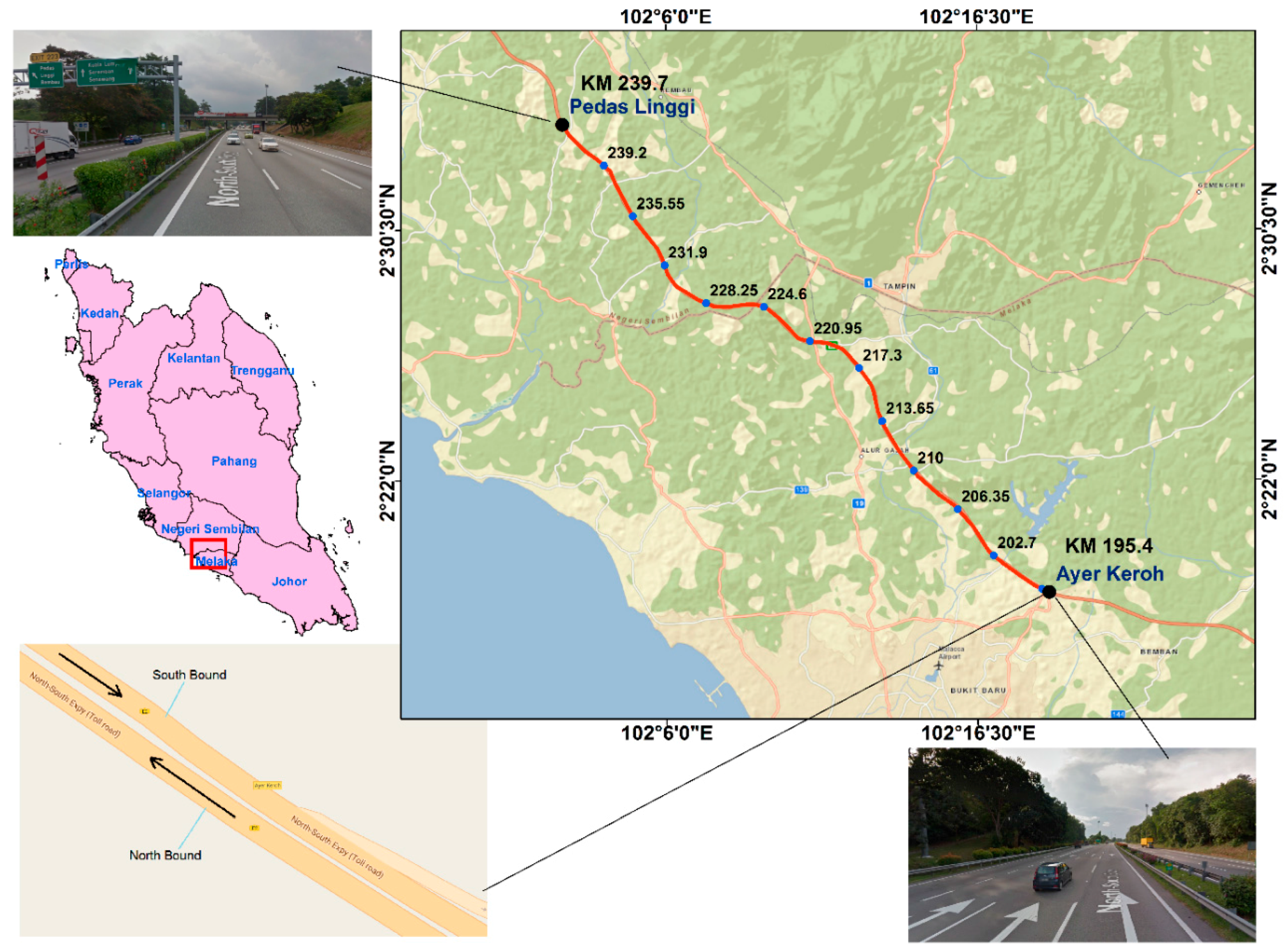
The section of the NSE used in this study has a length of 15 km running from Ayer Keroh (210 km) to Pedas Linggi (225 km) (
Figure 3). The accident severity data showed that the last section (220–225) of the NSE experienced several accidents resulting in serious injury (82) than the other sections (
Table 2). Most accidents have occurred on the main route and southbound of the expressway. During the accident events, the actual accident causes were documented. The data showed that lost control, brake failure, and obstacles were the main accident causes on the NSE. With respect to lighting and surface conditions, most accidents occurred in daylight conditions and with a dry road surface. The main collision types in the accident records were out of control and rear collision. In addition, the accident time factor showed that 91.68% of the accidents occurred during the daytime. Additionally, the data also revealed that two-car accidents, single heavy car with an object and motorcycle with an object were the most recorded crashes on the NSE.
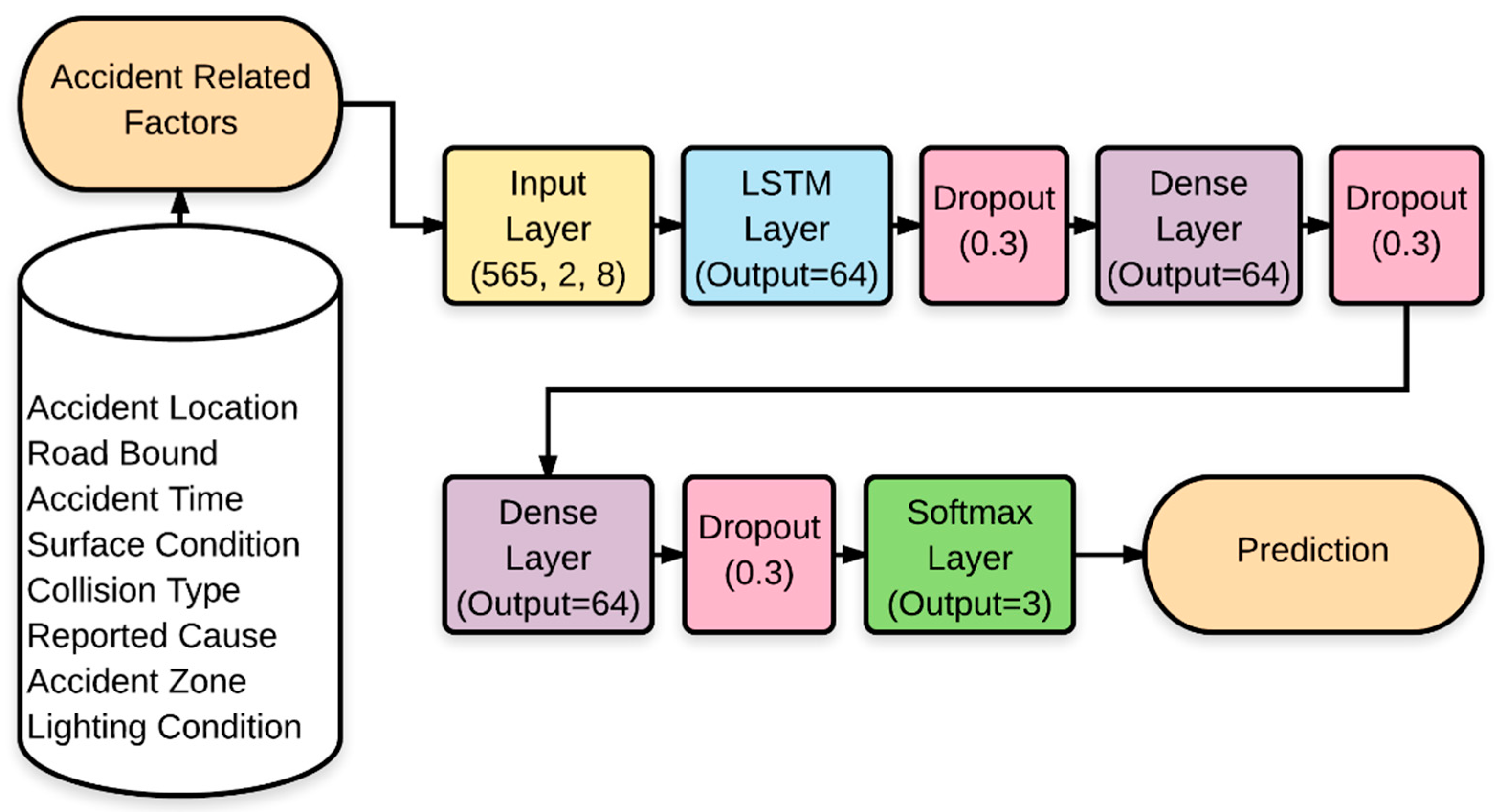
Before feeding the accident data into the recurrent neural network, the data must be preprocessed. The steps included were: removing missing data, data transformation, and detection of highly correlated factors. Some data were missing in the accident records; therefore, the complete raw data in which a missing data is found was removed. The data transformation included one-hot encoding for the categorical factors. In addition, correlation between predictors was assessed to detect any multicollinearity problem. First, the multiple
R2 was calculated for each factor. Second, the Variance Inflation Factor (
VIF) was calculated from the multiple
R2 for each factor (
Table 3). The highest correlation of 0.27 was found between lighting condition factor and surface condition factor. However, the highest multiple
R2 and
VIF were found to be 0.135 and 1.156 for surface condition factor. There was no multicollinearity found among the factors if
VIF = 1.0, however when the value exceeded 1.0, then moderate multicollinearity was found. In both cases, no high correlation was found during the model training and testing phase. Therefore, none of the factors was removed.
4.6. Extraction Factor Contribution in the RNN Model
To compute the contribution of each factor in predicting the severity of traffic accidents, the profile method [
39,
40] was used. This technique examines the evolution of each factor with a scale of values, while the remaining factors keep their values fixed. Each factor
takes 11 values resulting from the division of the range, between its minimum and maximum value, into 10 equal intervals. All factors except one were initially fixed at their minimum value and then were fixed successively at their first quartile, median, third quartile and maximum values. Five values of the response variable were obtained for each 11 value and adopted by
, and the median of those five values was calculated. Finally, a curve with the profile of variation was obtained for every factor.
Table 7 shows the calculated weight of each factor by the profile method implemented in Python. The results indicate that the road bound and accident time have a significant effect on injury severity; the drivers had a greater risk of injuries during daytime along the southbound lanes of the NSE. Also, dry surface conditions were found to be more dangerous than a wet surface, as far as driver injury severity is concerned. During rainy times (surface is wet), drivers decrease their speed due to traffic jams, hence decreasing the severity level of driver injury. Lighting conditions, such as dark with and without street lights, increase the potential of possible injury and fatality, whereas daylight reduces the severity level of driver injury. The negative weight of the accident location factor indicates that severe accidents are most likely to happen in the section 220–225 km of the expressway. When vehicle types such as cars and motorcycles are involved in crashes, drivers are more prone to possible injury and fatality than for heavy vehicles and buses. Fatigue and speeding can give the driver a greater chance of experiencing a severe injury than other causes reported in the dataset. Accidents at the entry and exit ramps, toll plaza, and main route are more dangerous than accidents in other zones. Collision type also plays a significant role in increasing or decreasing the severity level of an accident. The analysis in this paper shows that collisions such as out of control and rear collisions increase the injury severity, whereas right angle side collision and sideswipe decrease the injury severity on the NSE.
4.7. Comparative Experiment
In this experiment, the proposed RNN model was compared with the traditional MLP model and the BLR approach. The advantages of MLP networks over Radial Basis Function (RBF) networks are that MLP networks are compact, less sensitive to including unnecessary inputs, and more effective for modeling data with categorical inputs.
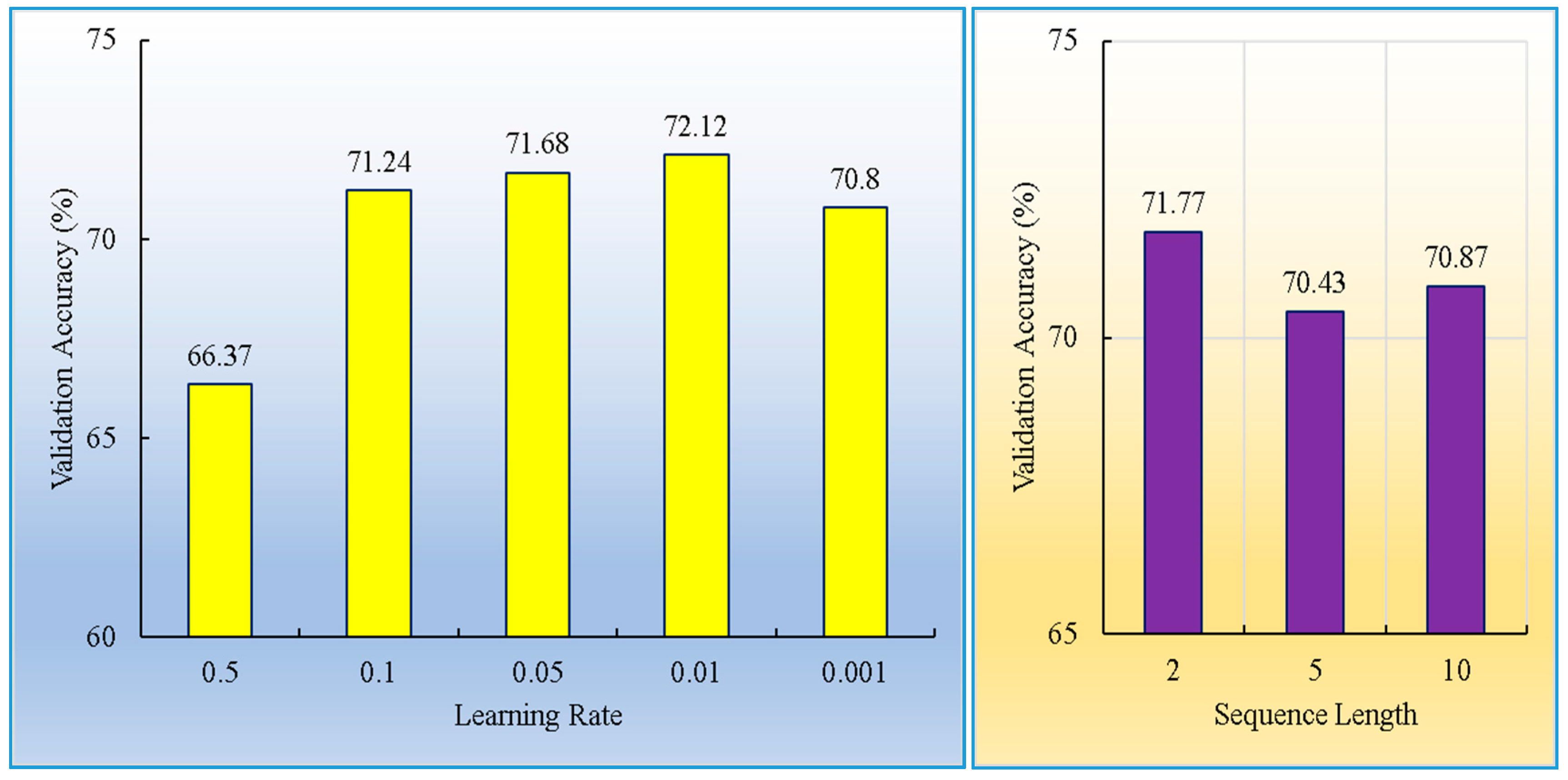
The Grid Search algorithm was used to search the space of MLP network architectures and configurations. The number of units in the hidden layer, activation functions and the learning rate were optimized. The search space of the number of hidden units was 4 to 64 units. Five activation functions were tested such as Gaussian, Identity, Sigmoid, Softmax, and Exponential for the hidden and output layers. In addition, five values of learning rate (0.5, 0.1, 0.05, 0.01, and 0.001) were evaluated. The suboptimal network was then determined according to the best validation accuracy. The suboptimal network is the one that best represents the relationship between the input and output variables. In total, 100 network architectures with different combinations of selected parameters and network configurations were executed, and the validation accuracy on 20% of the data was computed for each created model. Then, the best network was retained. The best network had eight (8) hidden units with identity activation function, a Softmax activation in the output layer, and a learning rate of 0.01. The training and validation performance of the network was 68.90% and 65.48% respectively.
On the other hand, the BLR [
41] and the computation of Markov chain Monte Carlo (MCMC) simulations were implemented in OpenBUGS software. BUGS modeling language (Bayesian Inference using Gibbs Sampling) is an effective and simplified platform to allow the computation using MCMC algorithms for all sorts of Bayesian models including BLR applied. The simulation of the posterior distribution of beta (
) allowed estimating the mean, standard deviation, and quartiles of the parameters of each explanatory variable. In the simulation stage, two MCMC chains were used to ensure convergence. The initial 100,000 iterations were discarded as burn-ins to achieve convergence and a further 20,000 iterations for each chain were performed and kept to calculate the posterior estimates of interested parameters.
In developing the Bayesian model, monitoring convergence is important because it ensures that the posterior distribution was achieved at the beginning of sampling of parameters. Convergence of multiple chains is assessed using the Brooks-Gelman-Rubin (BGR) statistic [
42]. A value of less than 1.2 BGR statistic indicates convergence [
42]. Convergence is also assessed by visual inspection of the MCMC trace plots for the model parameters and by monitoring the ratios of the Monte Carlo errors with respect to the corresponding standard deviation. The estimates of these ratios should be less than 0.05. In addition, MC error less than 0.05 also indicates that convergence may have been achieved [
43]. The results of BLR showed training and validation accuracies of 70.30% and 58.30% respectively. In addition, the model had an average MC error of 0.047, Brooks-Gelman-Rubin (BGR) of 0.98, and model fitting performance (Deviance Information Criterion-DIC) of 322.
The comparative analysis showed that the proposed RNN model outperformed both MLP and BLR in terms of training and validation accuracies (
Table 8). The BLR model performed better than MLP on the training dataset; however, its accuracy on the validation dataset was less than the MLP model. The MLP model uses only local contexts and therefore does not capture the spatial and temporal correlations in the dataset. The hidden units of the RNN model contain historical information from previous states, hence increasing the information about the data structure, which may be the main reason for its high validation accuracy over the other two methods. Building BLR models is more difficult than NN models, because they require expert domain knowledge and effective feature engineering processes. The NN model automatically captures the underlying structure of the dataset and extracts different levels of features abstractions. However, building deep learning models with various modules (e.g., fully connected networks, LSTM, convolutional layers) can be a challenging task. In addition, the BLR models are less prone to over-fitting of the training dataset than NN models, because they involve simpler relationships between the outcome and the explanatory variables. Complex networks with more hidden units and many modules often tend to over-fit more, because they detect almost any possible interaction so that the model becomes too specific to the training dataset. Therefore, optimization of network structures is very critical to avoid over-fitting and build practical prediction models. In computing the importance of an explanatory factor, the BLR models could easily calculate the factor importance and the confidence intervals of the predicted probabilities. In contrast, NN methods, which are not built primarily for statistical use, cannot easily calculate the factor importance or generate confidence intervals of the predicted probabilities unless extensive computations were done.
In addition, based on the estimated weight of each accident related factor, the factors could be ranked by scaling the weights into the range of 1–100 and then giving them a rank from 1 to 9 as shown in
Table 9. The three methods (MLP, BLR, and RNN) did not agree on the factors’ ranking. For example, the RNN model ranked accident time as the most influential factor in injury severity, whereas accident time was ranked 2 and 7 by the BLR and MLP models, respectively. Both the RNN and BLR models agreed on several factors’ ranking i.e., accident location (6), accident reported cause (5), and collision type (8). The correlation (
R2) between the RNN and BLR ranks was 0.72. In contrast, RNN and MLP did not agree on the ranking of the factors and their ranking correlation was the lowest (0.38).
4.9. Applicability and Limitations of the Proposed Method
The proposed RNN model is a promising traffic accident forecasting tool that has several applications in practice. First, identifying the most risky road sections (i.e., site ranking) is a daily practice of transportation agencies in many cities around the world. Accident prediction models, such as the one we proposed in this research, are often an effective solution for identifying risky road sections and helping to conduct investigations into methods for improving the safety performance of the road systems. Second, the RNN model is able to explain the underlying relationships between several accidents’ related factors, such as accident time and collision type, and the injury severity outcomes. Information about the effects of accident factors on the injury severity outcomes provides huge amount of information to the transportation agencies and stakeholders. Finally, estimating the expected number of traffic accidents in a road section can help road designers to optimize the geometric alignments of the roads based on the accident scenarios.
However, the proposed RNN model has some constraints and limitations. The major limitation of the model is that the input factors are prerequisite and if any of them is missing, the output probabilities cannot be accurately estimated. Another constraint of the model is the sequence length of the RNN model, which mainly depends on the number of accident records in the training dataset. To handle this limitation, the future works should develop RNN models that operate on input sequences of variable lengths via Tensorflow dynamic calculation.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}