1. Introduction
Gears are one of the most critical components in many industrial machines. Health monitoring and fault diagnosis of gears are necessary to reduce breakdown time and increase productivity. Pitting is one of the most common gear faults and normally difficult to detect. An undetected gear pitting fault during the operation of the gears can lead to catastrophic failures of the machines.
In recent years, many gear pitting fault detection methods have been developed. Following the same way to classify machine fault diagnostic and prognostic methods by [
1,
2], gear pitting fault detection methods can be classified into two main categories, namely model-based methods and data-driven methods. The model-based techniques rely on accurate dynamic models of the systems, while the data-driven approaches use data to train fault detection models. Model-based approaches obtain the residuals between actual system and output. These residuals are then used as the indicator of the actual faults [
3,
4]. However, the model-based approaches require not only expertise in dynamic modeling, but also accurate condition parameters of the studied system. On the other hand, data-driven approaches do not require the knowledge of the target system and dynamic modeling expertise. In comparison with model-based techniques, data-driven approaches can design a fault detection system that can be easily applied when massive data is available. Data-driven techniques are appropriate when a comprehensive understanding of system operation is absent, or when it is sufficiently difficult to model the complicated system [
5].
Data-driven-based gear pitting fault detection methods in general relies on feature extraction by human experts and complicated signal processing techniques. For example, Reference [
6] used a zoomed phase map of continuous wavelet transform to detect minor damage such as gear fitting. References [
7,
8] used the mean frequency of a scalogram to get features for gear pitting fault detection. Reference [
9] extracted condition indicators from time-averaged vibration data for gear pitting damage detection. Reference [
10] used empirical mode decomposition (EMD) to extract features from vibration signals for gear pitting detection. Reference [
11] combined EMD and fast independent component analysis to extract features from stator current signals for gear pitting fault detection. Reference [
12,
13] applied spectral kurtosis to extract features for gear pitting fault detection. Reference [
14] extracted statistical parameters of vibration signals in the frequency domains as an input to artificial neural network for gear pitting fault classification. One challenge facing the abovementioned data-driven gear fault detection methods in the era of big data is that features extracted from vibration signals depend greatly on prior knowledge of complicated signal processing and diagnosis expertise. Besides, features are selected per the specific fault detection problems and may not be appropriate for different fault detection problems. An approach that can automatically and effectively self-learns gear fault features from the big vibration data and effectively detect the gear fault is necessary to address the challenge.
As a data-driven approach, sparse coding is a class of unsupervised methods for learning sets of overcomplete bases to represent data efficiently. Unlike principal component analysis (PCA) that learn a complete set of basis vectors efficiently, sparse coding learns an overcomplete basis. This gives sparse coding the advantage of generating basis vectors that are able to better capture structures and patterns inherent in the input data. Recently, sparse coding-based methods have been developed for machinery fault diagnosis [
15,
16,
17,
18]. However, these methods used manually constructed overcomplete dictionaries that cannot guarantee to match the structures in the analyzed data. Sparse coding with dictionary learning is viewed as an adaptive feature extraction method for machinery fault diagnosis [
19]. Study reported in Reference [
19] developed a feature extraction approach for machinery fault diagnosis using sparse coding with dictionary learning. In their approach, the dictionary is learned through solving a joint optimization problem alternatively: one for the dictionary and one for the sparse coefficients. One limitation with this approach is that solving the joint optimization problem alternatively for massive data is NP-complete [
20] and therefore is not efficient for automation.
In this paper, a new method is proposed. The proposed approach combines the advantages of sparse coding with dictionary learning in feature extraction and the self-learning power of the deep sparse autoencoder for dictionary learning. Autoencoder is an unsupervised machine learning technique and a deep autoencoder is a stacked autoencoder network with multiple hidden layers. To the knowledge of the authors, no attempt to combine sparse coding with dictionary learning and deep sparse autoencoder for gear pitting fault detection has been reported in the literature.
2. The Methodology
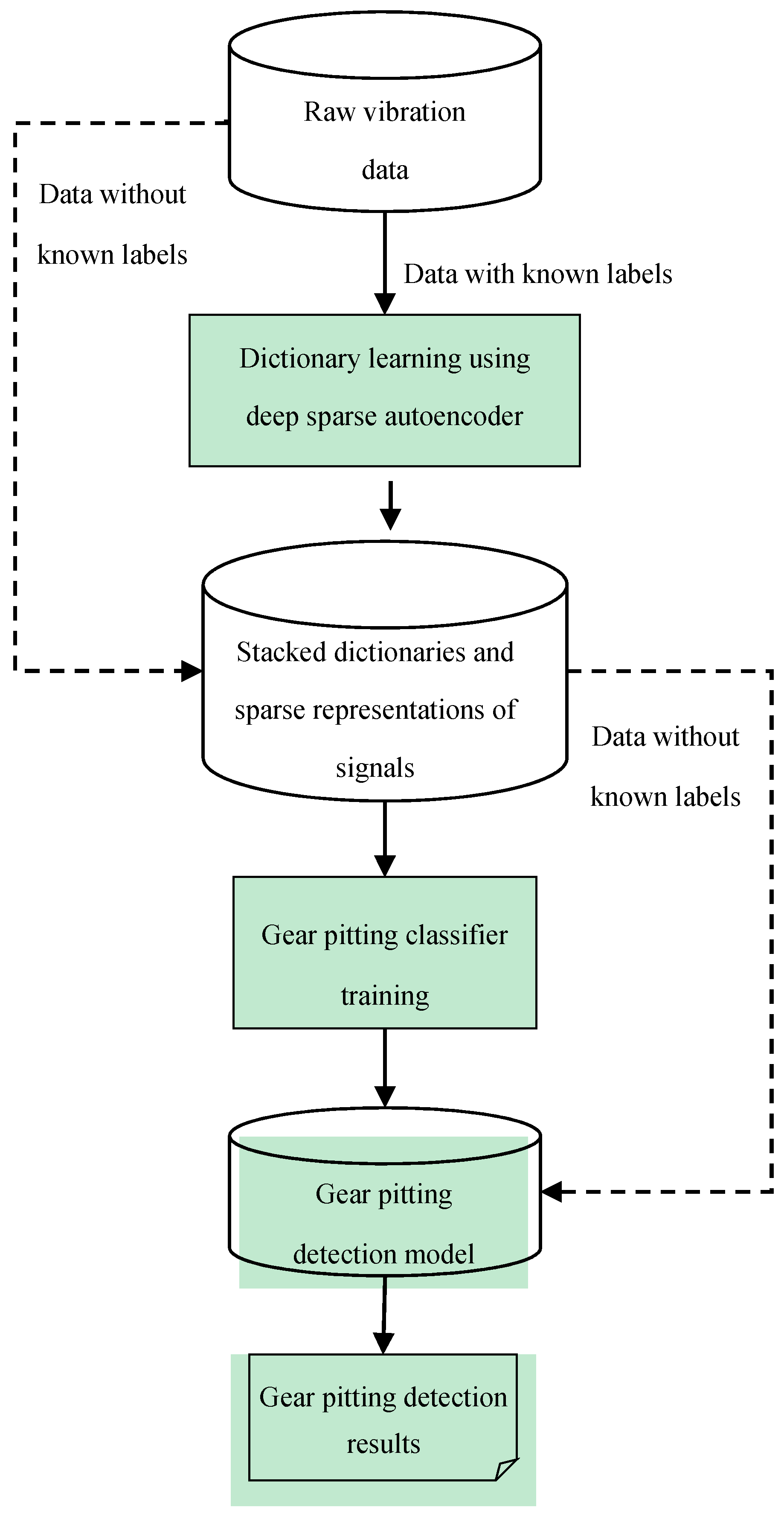
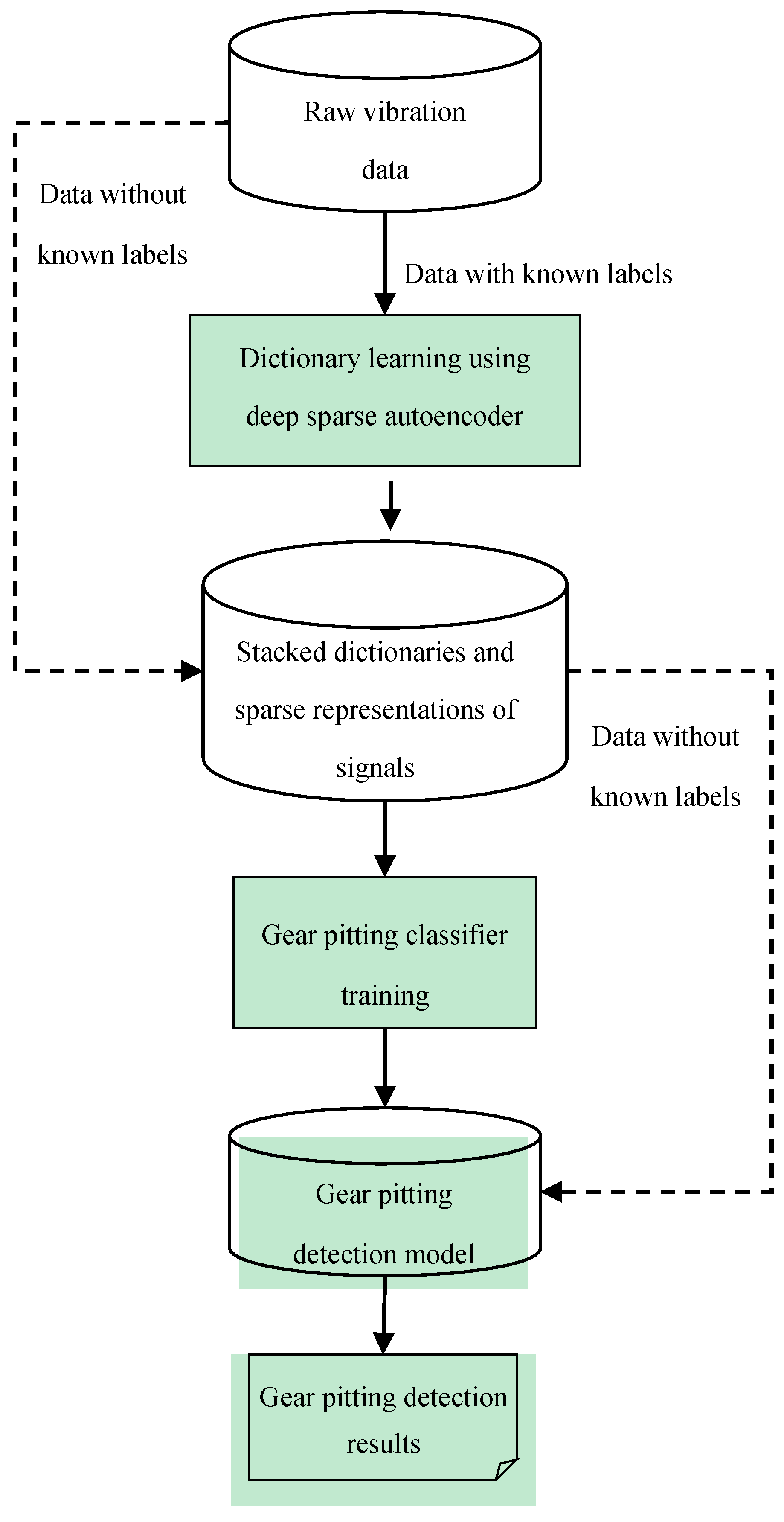
The general procedure of the presented method is shown in
Figure 1 below. As shown in
Figure 1, the presented method is composed of three main steps. Firstly, the dictionary and the corresponding representation of raw data will be obtained through unsupervised learning by the deep sparse autoencoder. Then, a simple backpropagation neural network constructed as the last hidden layer and the output layer is trained to classify the healthy and pitting gear condition using the learnt representation. With the learnt dictionary and trained classifier, the testing raw data are then imported into the network for pitting fault detection. It should be noted that the dictionary learning process is an unsupervised learning process. Thus, the representations regarded as features extracted from raw signals are learnt completely unsupervised without fine-tuning.
Section 2.1 and
Section 2.2 give a brief introduction on dictionary learning and autoencoder, respectively. Dictionary learning using deep sparse autoencoder for gear pitting detection is explained in
Section 2.3.
2.1. Dictionary Learning
In recent years, the application of dictionary learning has been popularized in various fields, including image and speech recognition [
21,
22,
23,
24,
25]. The study of dictionary learning application in vision can be traced back to the end of the last century [
26]. The goal of dictionary learning is to learn a basis for representation of the original input data. The expansion of dictionary learning based applications is benefited from the introduction of K-SVD [
27,
28]. K-SVD is an algorithm that decomposes the training data in matrix form into a dense basis and sparse coefficients. Given an input signal
, the basic dictionary learning formula can be expressed as:
where
represents the dictionary matrix to be learnt with dimension
n as number of data points in the input signal
and
as the number of atoms in the dictionary
D, each column of
D the basic function
also known as atoms in dictionary learning,
the representation coefficients of the input signal
, and
the approximation accuracy accessed by the
.
The goal of dictionary learning is to learn a basis which can represent the samples in a sparse presentation, meaning that
is required to be sparse. Thus, fundamental principle of dictionary learning with sparse representations is expressed as:
Subject to:
where function
is referred to as
that counts the nonzero entries of a vector, as a sparsity measurement, and
the approximation error tolerance.
As shown in Equation (2), solution of the
minimization is a NP hard problem [
20]. Thus, the orthogonal matching pursuit (OMP) [
29] is commonly used to solve approximation of
minimization. As mentioned previously, the popular used dictionary learning algorithm K-SVD was developed with employment of OMP as well. The K-SVD is constituted by two main procedures. In the first procedure, the dictionary matrix is firstly learnt and then it is used in the second procedure to represent the data sparsely. In the procedure of dictionary learning, K-SVD estimate the atoms one at a time according to the ranking update with efficient technique. Such strategy leads to the disadvantage of K-SVD as relatively low computing efficiency since the singular value decomposition (SVD) is required in each iteration.
The basic functions of dictionary matrix D can be either manually extracted or automatically learned from the input data. The manually extracted basic functions are simple and will lead to fast algorithms, however with poor performance on matching the structure in the analyzed data. An adaptive dictionary should be learned from input data through machine learning based methods, such that the basic functions can capture a maximal amount of structures of the data.
2.2. Autoencoder
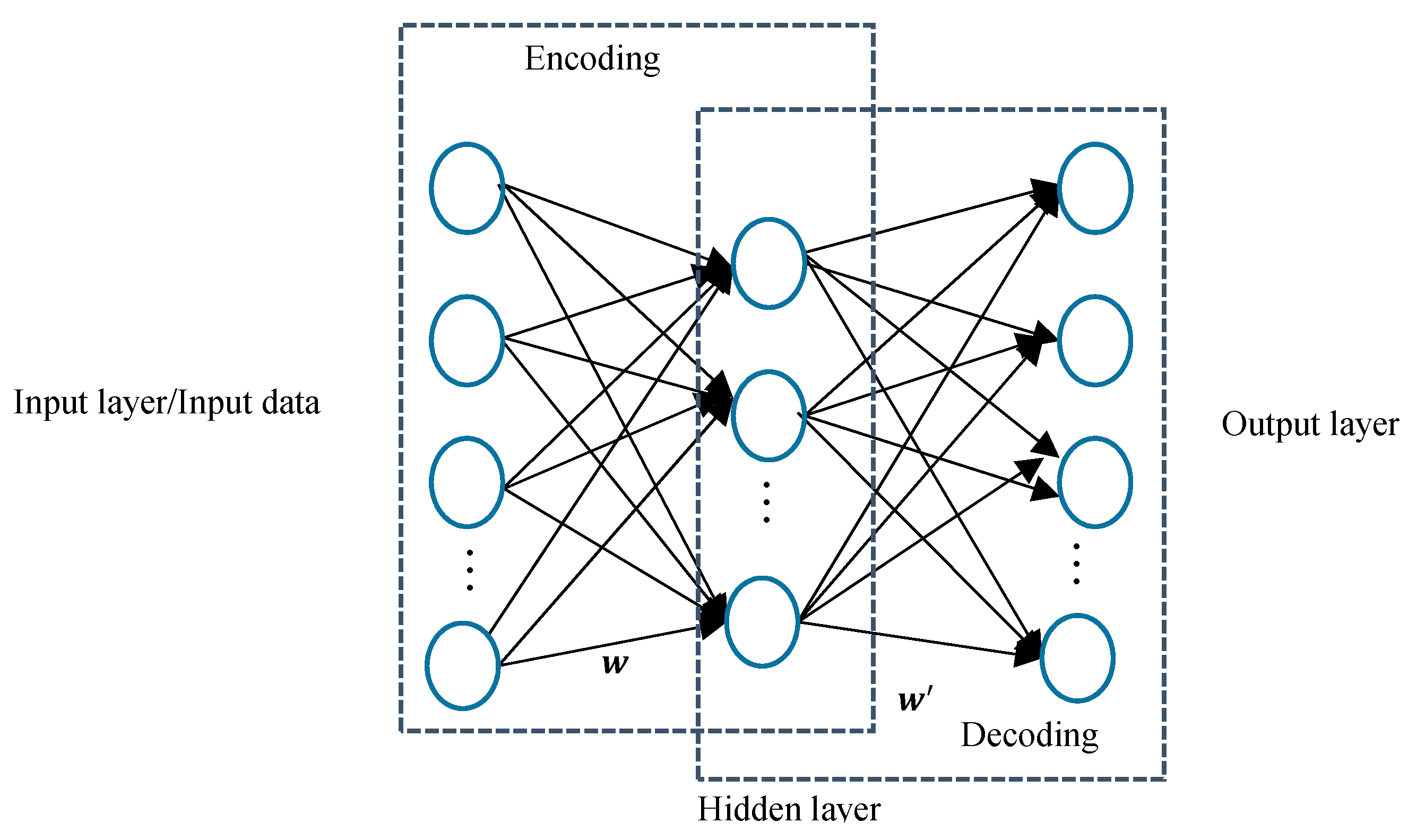
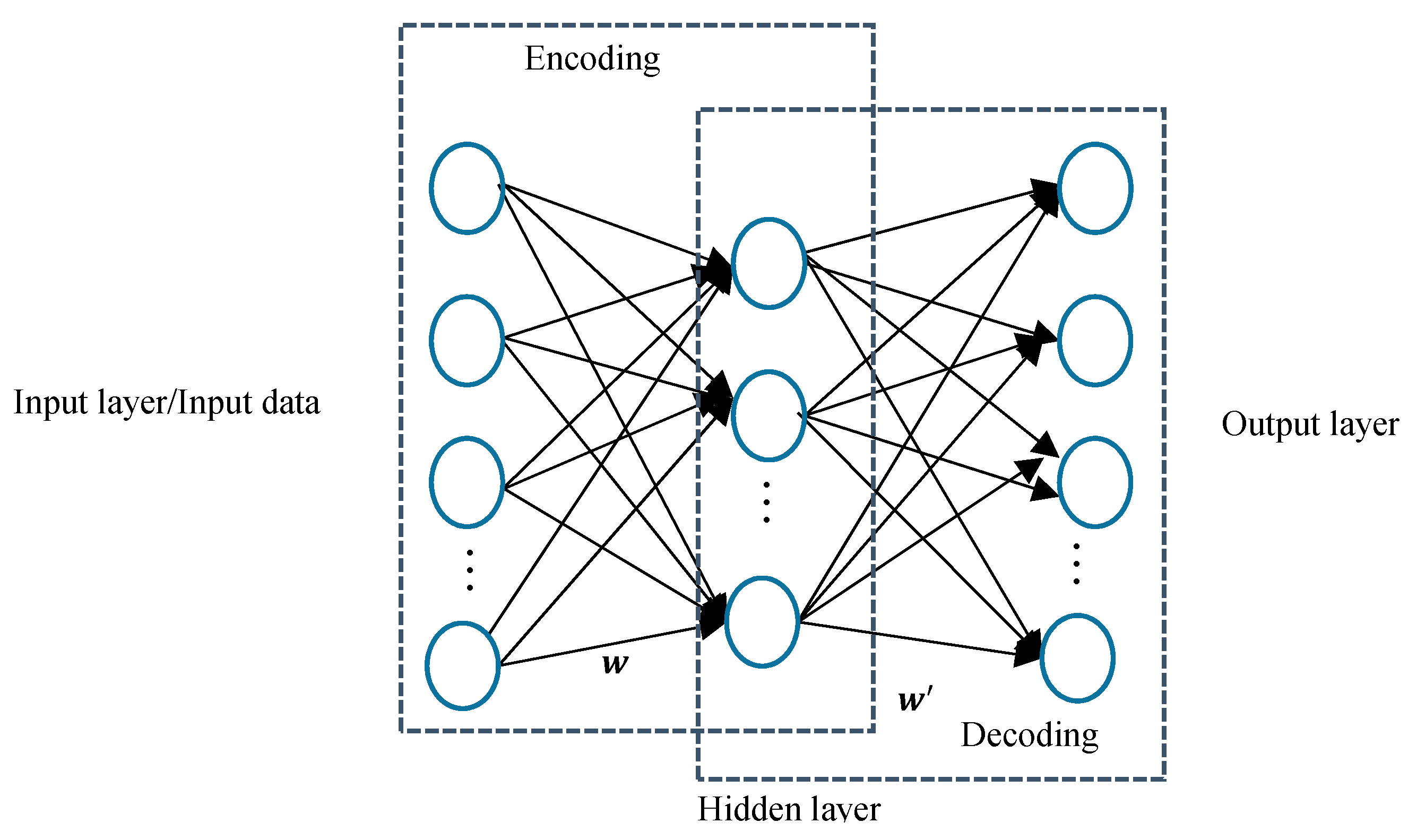
The structure of autoencoder is shown in
Figure 2. A typical autoencoder contains two parts, namely the encoding and decoding part. As shown in
Figure 2, the encoding part maps the input data to the latent expression in the hidden layer, and then the decoding part reconstructed the latent expression to the original data as output. In an autoencoder, all the neurons in the input layer are connected to all the neurons in the hidden layer, and vice versa. With a given input data (bias term included) vector
, the latent expression in the hidden layer
can be written as:
where
represents the weights matrix between each neuron in the input layer and the one in the hidden layer,
the non-linear activation function used to smooth the output of the hidden layer. Commonly, the activation function is selected as sigmoid or tanh function.
The decoding portion reverse the maps the latent expression to the data space as:
where
represents the reconstructed data mapped from the latent expression in the hidden layer,
the weight matrix between hidden layer and the output layer, and
the activation function to smooth the output layer results. Likewise,
is usually selected as sigmoid or tanh function.
The objective in the autoencoder training procedure is to obtain the set of encoding weights
and decoding weights
such that the error between the original input data and the reconstructed data is minimized. The learning objective can be written as:
The smooth and continuously differentiable activation function in the Equation (5) guarantees that even as a non-convex problem in Equation (6), the smooth results leads it can be solved by gradient descent techniques.
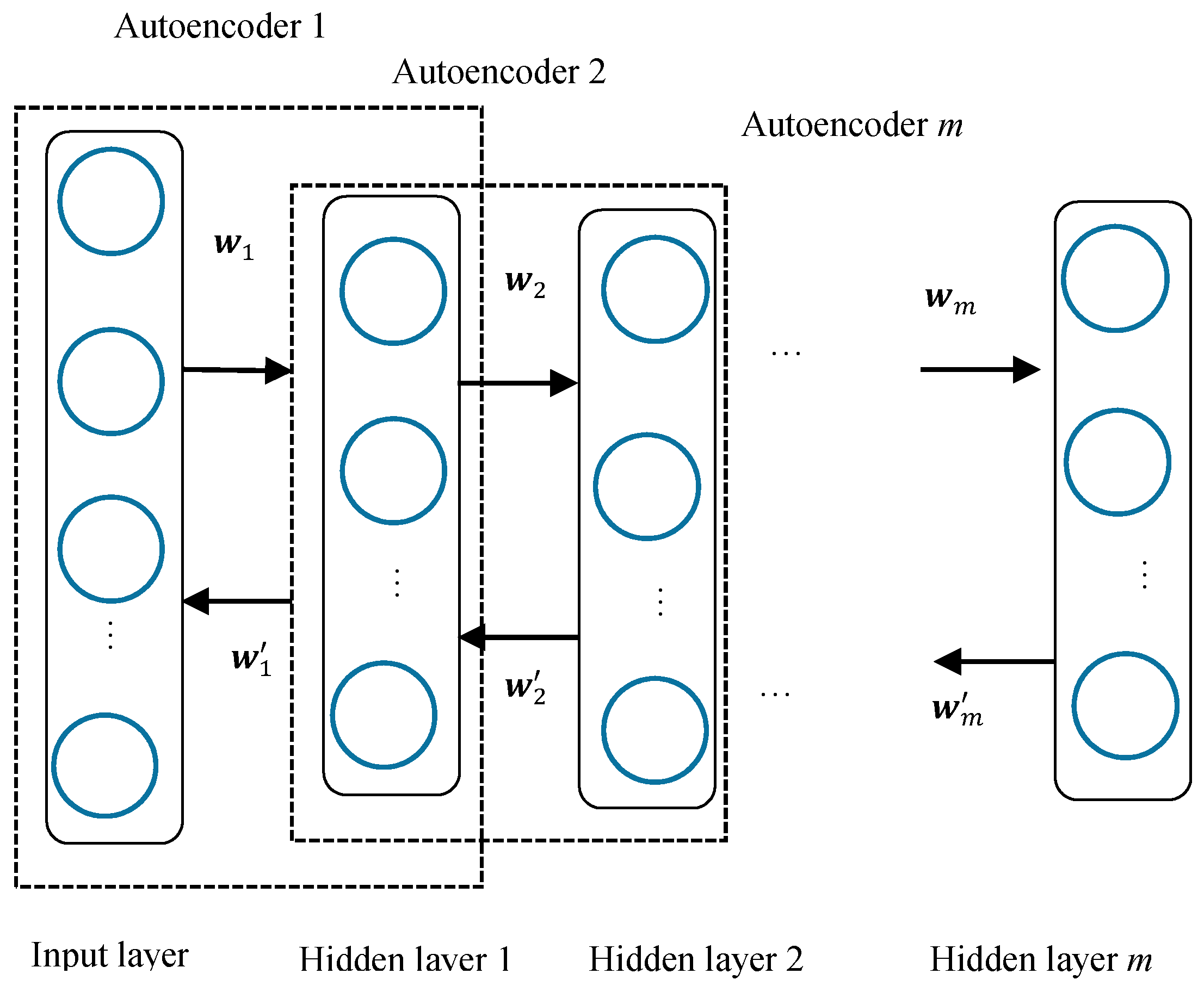
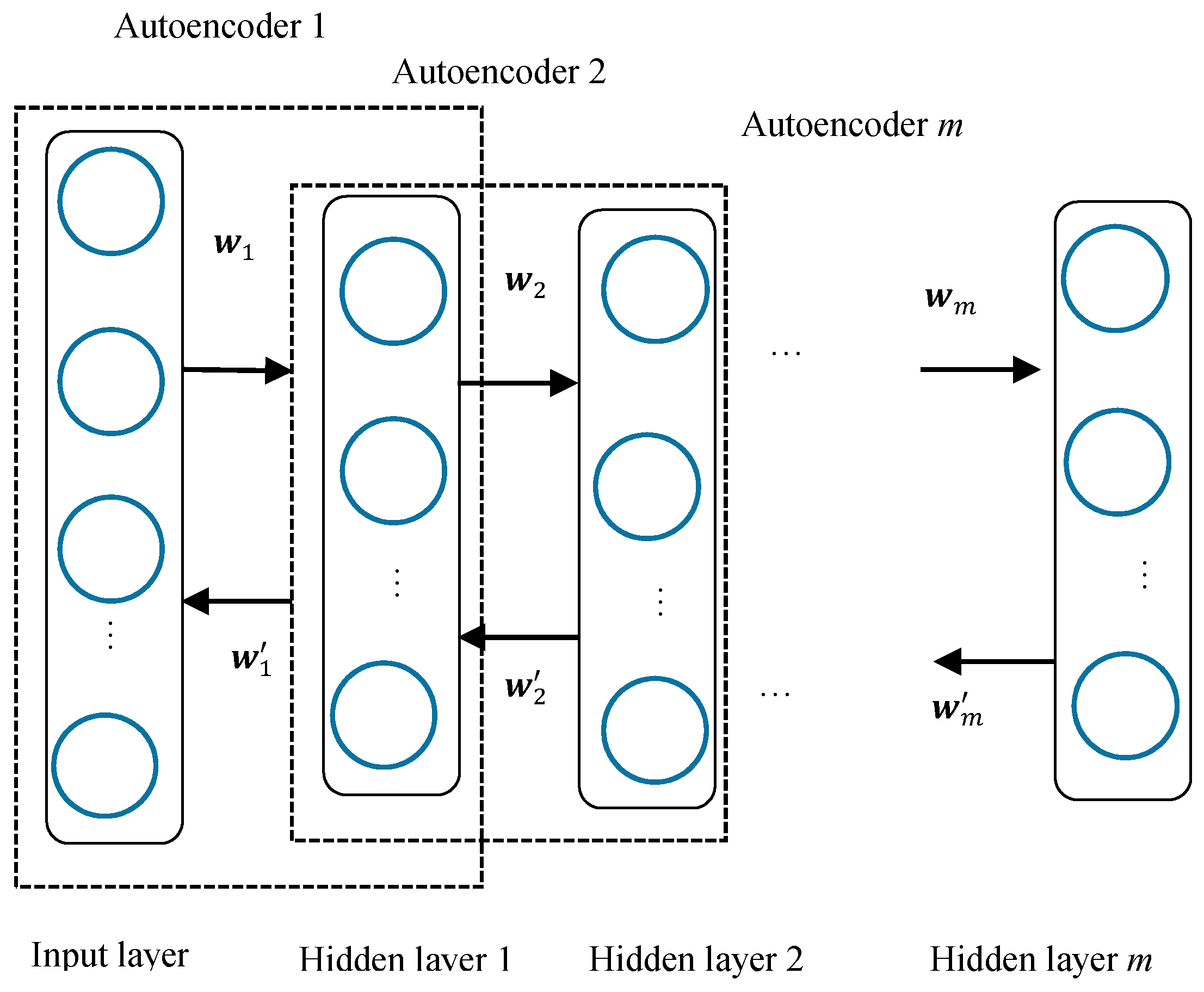
Furthermore, multiple autoencoders can be stacked to construct a deep structure. The deep autoencoder structure is illustrated in
Figure 3.
For the deep autoencoders shown in
Figure 3, the overall cost function can be expressed based on Equation (6) as:
where
, and
where
and
(
) represent the encoding and decoding weight matrix of the
ith autoencoder in the network respectively,
and
the encoding and decoding activation function of the
ith autoencoder. The computational complexity of massive amount of parameters (weight matrix) in Equation (7) results in computation challenge and over fitting phenomena. Thus, searching for the appropriate solution is commonly accomplished through the layer-wise learning behavior.
2.3. Dictionary Learning Using Deep Sparse Autoencoder
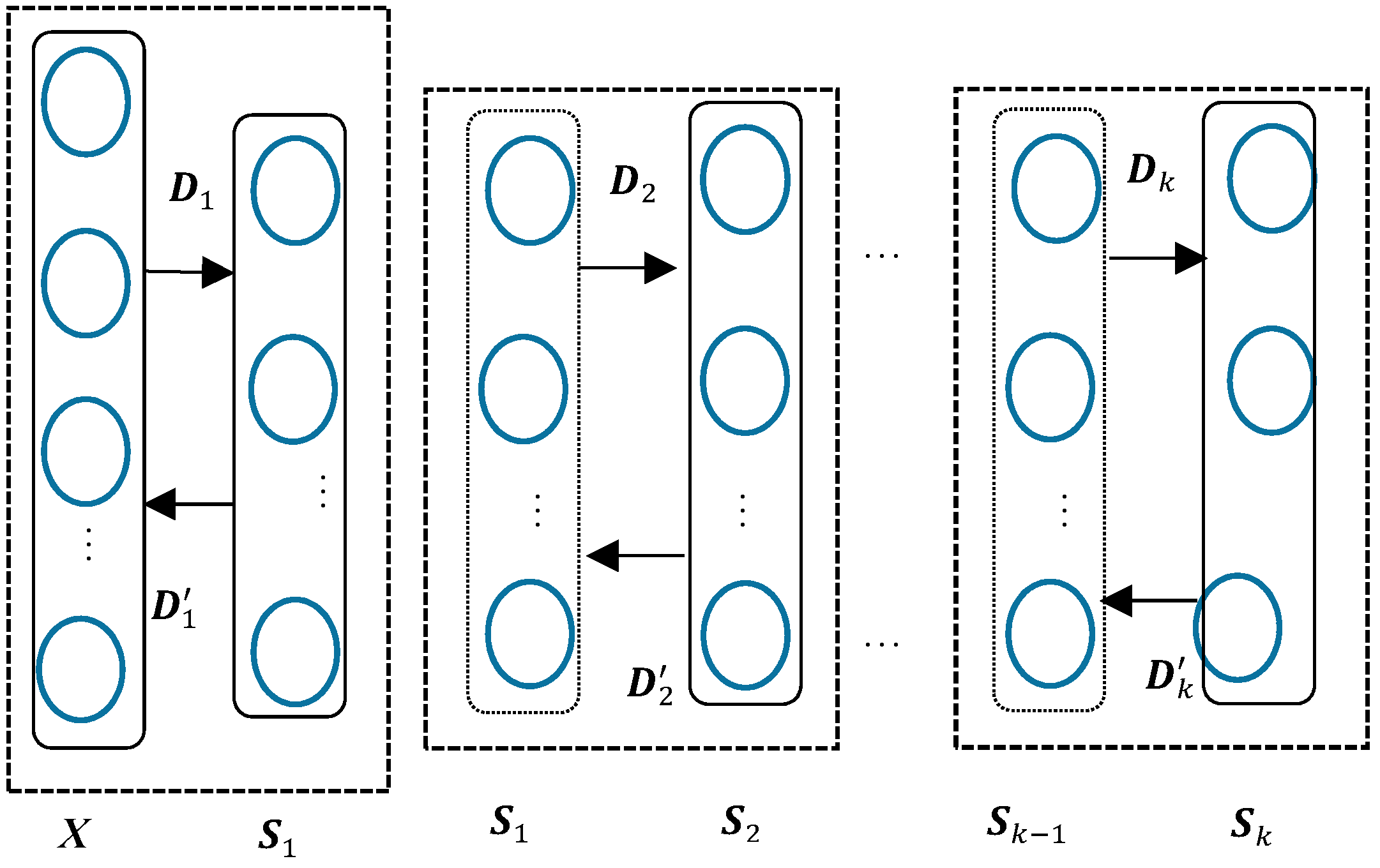
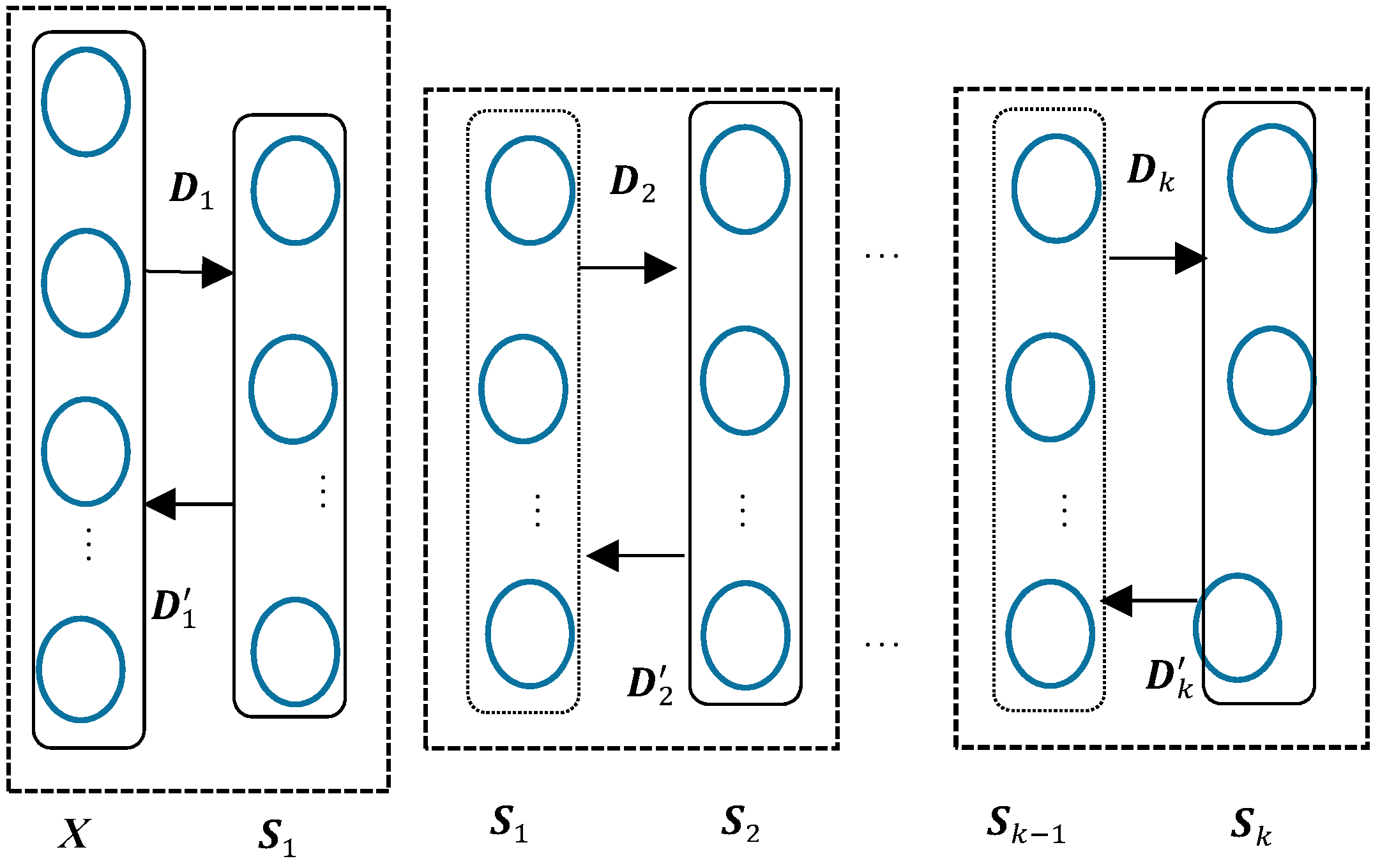
Based on the previously reviewed dictionary learning and stacked autoencoder models, a deep sparse autoencoder based dictionary learning is presented in this section. Like the structure of a deep autoencoder, the deep sparse autoencoder based dictionary learning can be illustrated as
Figure 4 below.
As shown in
Figure 4, each dash block represents a shallow/single dictionary learning process.
The first dictionary learning process can be written as:
where
stands for the set of
input signals,
the signal vector with a length of
,
for
the first learnt dictionary, and
for
the first latent expression of
in
. Treating the deep autoencoder as a dictionary learning network, one can define
for
as the reconstruction weight from latent expression
to original input
. Like the expression in the autoencoder, the reconstructed input data
can be written as:
where
and
represent the encoding and decoding activation functions, respectively.
Substitute
in Equation (9) with Equation (8),
can be written as:
Here in this study, the activation function for both encoding and decoding processes are selected as sigmoid function. The cost function of dictionary learning using deep sparse autoencoder can be expressed as:
where
N represents the number of input vectors,
the parameter controlling the weight of the sparsity penalty term,
the sparsity parameter,
the average activation of the hidden unit
over the all
training samples. The sparsity penalty term is defined as Kullback-Leibler (KL) divergence, which is used to measure the difference between two distributions. It is defined as
when
, otherwise the KL divergence increases as
increases. In comparison with the similar
k-sparse autoencoder proposed in [
30], the advantages of the deep sparse autoencoder include: (1) The introduction of the sparsity penalty leads to the automatic determination of the sparsity rather than pre-defined as
k-sparsity. It enables the deep sparse autoencoder to extract the sparse features more accurately based on the characteristics of the data. (2) The dictionary is learnt in the encoding procedure. The encoding dictionary is different from the encoding weight matrix. (3) The deep sparse autoencoders does not require the fine-tuning process while the performance of
k-sparse autoencoders relies on the supervised fine-tuning process.
In the deep autoencoder, the output of a hidden layer in the previous autoencoder can be taken as the input to the next autoencoder. Let the first layer of the
kth autoencoder in the deep autoencoder be the
kth layer and the second layer as the (
k + 1)
th layer. Also, let
and
be the dictionary and reconstruction weight for the
kth layer in the deep autoencoder, the encoding procedure in the
kth autoencoder can be expressed as:
where
stands for the output of the
kth layer,
and
the input for the
kth and (
k + 1)
th layer, respectively.
Similarly, the decoding procedure in the
kth autoencoder can be expressed as:
Thus, the original input
can be expressed by the latent expression
in the (
k + 1)
th layer as:
where
represents the learnt dictionary in the
kth dictionary learning process,
the latent expression of
in
.
The stacked dictionaries will be learnt in a greedy layer by layer way. The greedy layer by layer learning guarantees the convergence at each layer.
3. Gear Test Experimental Setup and Data Collection
The gear pitting tests were performed on a single stage gearbox installed as an electronically closed transmission test rig. The gearbox test rig includes two 45 kW Siemens servo motors. One of the motors can act as the driving motor while the other can be configured as the load motor. The configuration of the driving mode is flexible. Compared with traditional open loop test rig, the electrically closed test rig is economically more efficient, and can virtually be configured with arbitrary load and speed specifications within the rated power. The overall gearbox test rig, excluding the control system, is showed in
Figure 5.
The testing gearbox is a single stage gearbox with spur gears. The gearbox has a speed reduction of 1.8:1. The input driving gear has 40 teeth and the driven gear has 72 teeth. The 3-D geometric model of the gearbox is shown in
Figure 6.
Gear parameters are provided in
Table 1.
The pitting fault was simulated by using electrical discharge machine to erode gear tooth face. The pitting location is on one of the teeth on the output driven gear with 72 teeth. Approximately, the gear tooth face was eroded with a depth of 0.5 mm. One row of pitting faults was created along the tooth width. The simulated pitting fault is shown in
Figure 7.
A tri-axial accelerometer was attached on the gearbox case close to the bearing house on the output end as shown in
Figure 8.
Both healthy and pitted gearboxes under various operating condition were run and the vibration signals collected. The tested operation conditions are listed in
Table 2. The vibration signals were collected with a sampling rate of 20.48 KHz.
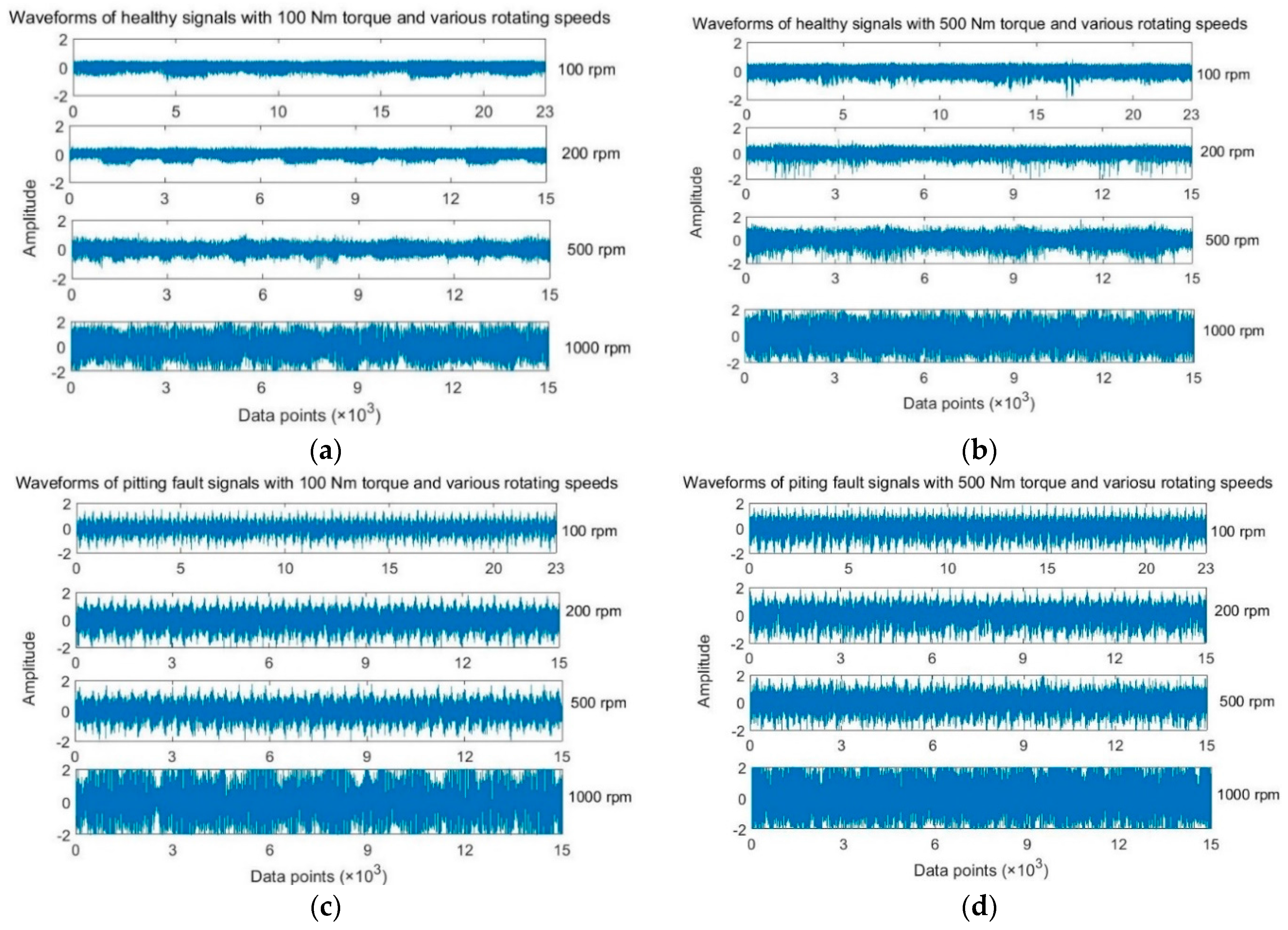
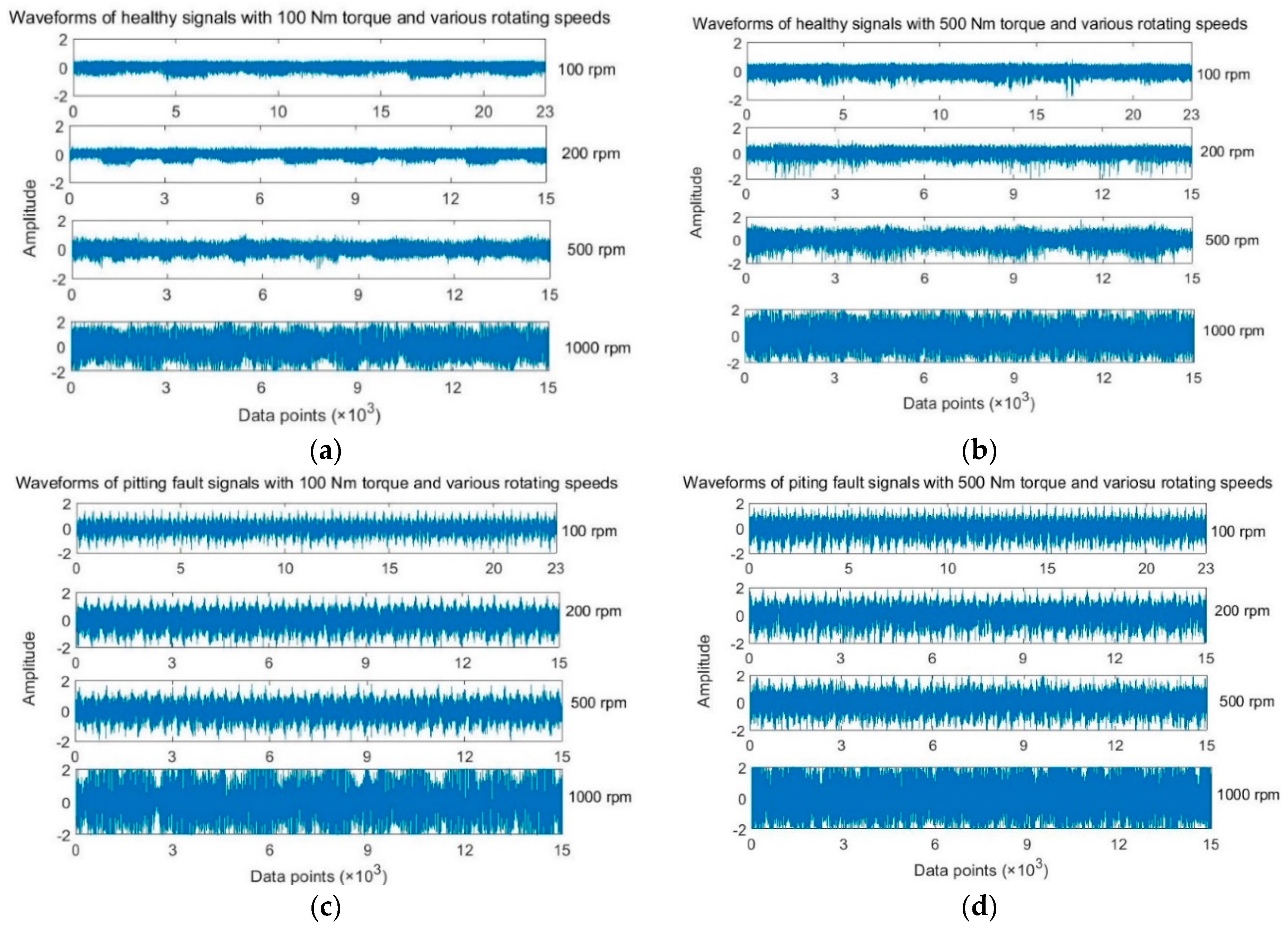
Figure 9 shows the raw vibration signals collected for normal gear and pitting gear at loading conditions of 100 Nm and 500 Nm.
4. The Validation Results
The proposed deep sparse autoencoder structure was implemented to accomplish the greedy deep dictionary learning. The vibration signals along the
z vertical direction were used in this study since they contain the richest vibration information among the three monitored directions. At first, the gear pitting detection was carried on using signals with light loading as the training data and signals with heavy loadings as the testing data, respectively. Loadings of 100 Nm torque and 500 Nm torque were used as light loading condition and heavy loading condition, respectively. Signals at rotating speeds of 100, 200, 500 and 1000 rpm were used for validation tests. To study the influence of different rotating speeds on the pitting gear fault detection performance of the deep sparse autoencoder, 100 and 1000 rpm were selected as low and high speed for independent validations. The length of the samples was decided to ensure that at least one revolution of the output driven gear was included. Therefore, there were 23,000 data points in each sample for signals at 100 rpm and 15,000 data points for signals at a speed of at least 200 rpm. Thus, 26 samples of signals at 100 rpm were generated for healthy gear and pitting gear, respectively. Hence, there were 52 samples in the training dataset and 52 samples in the testing dataset. Similarly, 40 samples of signals at 1000 rpm were generated for each gear condition, with 80 samples in the training dataset and 80 samples in the testing dataset. The structure of the deep sparse autoencoder was designed separately for signals at 100 rpm and signals at the speed of over 100 rpm as: one input layer (23,000 neurons for signals at 100 rpm and 15,000 neurons for signals at the speed over 100 rpm), four hidden layers (1000-500-200-50 neurons), and one output layer (2 neurons). Particularly, following the suggestions in [
31], the sparsity parameter in each sparse autoencoder was set as
= 3 and
. The sparse representations of the original signals were imported into classifier for pitting gear fault detection. The last hidden layers of 50 neurons and the output layer of 2 neurons were constructed as a simple backpropagation neural network as a classifier for gear pitting detection. The two neurons in the output layer were setup for classifying the input signals as either gear pitting fault or normal gear. The training parameters of the back propagation neural network classifier were set as: training epoch was 100, learning rate was 0.05 and the momentum was 0.05. For each gear condition, the models were executed 5 times to get average detection accuracy. The detection results are shown in
Table 3.
The detection results in
Table 3 show a good adaptive learning performance of the presented method. The testing accuracy is high as 98.88% overall, which is slightly lower than the training accuracy. It can be explained as that signals at light loading condition contain less fault significant information. Furthermore, the same designed deep sparse autoencoder structure was experimented with heavy loading training data and light loading testing data. The detection results are shown in
Table 4.
It can be observed from
Table 4 that in comparison with results shown in
Table 3, the testing accuracy is slightly higher than the training accuracy. The better adaptive feature extraction and fault detection results are benefited from that the signals with heavy loading condition contain more fault significant information. The results in
Table 3 and
Table 4 show marginal influence of the rotating shaft speeds on the pitting fault detection performance.
Moreover, the signals with stable loading and mixed rotating speed were also tested in the study. The detailed description of each dataset used in the validation is provided in
Table 5. The detection results are presented in
Table 6 and
Table 7.
Still, 100 and 500 Nm torque loadings were selected as the light loading and heavy loading condition. For each loading condition, 52 samples and 80 samples were generated for both healthy and pitting gear condition at 100 rpm and at the speeds over 100 rpm, respectively. In comparison with the results in
Table 3 and
Table 4, even though the detection accuracies in
Table 6 and
Table 7 for both cases (trained with light loading samples and tested with heavy loading samples, and vice versa) are slightly lower, the accuracies obtained by the deep sparse autoencoders are satisfactorily as high as 97.13% and 99.89%. The satisfactory detection results show the good performance without the effects of various rotating speeds of the deep sparse autoencoders. Furthermore, it shows the capability of the deep sparse autoencoders in automatically extracting the adaptive features from the raw vibration signals. The validation results have shown the good robustness of the deep sparse autoencoders on gear pitting detection without much influence of working conditions, including loadings and rotating speeds.
To make a comparison, a typical autoencoder based deep neural network (DNN) presented in [
32] was selected to detect the gear pitting fault using the same data. The DNN was designed with a similar structure like the deep sparse autoencoder, namely one input layer (23,000 neurons and 15,000 neurons), four hidden layers (1000-500-200-50 neurons), and one output layer (2 neurons). Like the deep sparse autoencoder, the last hidden layer and the output layer of the DNN was designed as a back propagation neural network classifier. Since the autoencoder based neural network normally requires supervised fine-tuning process for better classification, the designed DNN was tested without and with supervised fine-tuning. The detection results of the DNN are provided in
Table 8 and
Table 9.
In comparing the results obtained by the DNN in
Table 8 and
Table 9 with those obtained by the deep sparse autoencoder, one can see that the deep sparse autoencoder gives a better performance than the DNN based approach for gear pitting fault detection. In both cases, the detection accuracies obtained by the DNN are much lower than those of the deep sparse autoencoder. In comparison with the DNN, the presented method is more robust in automatically extracting the adaptive features for gear pitting detection. In addition, the presented method does not require the supervised fine-tuning process. Such advantage will increase the computational efficiency and enhance the robustness of the gear pitting fault detection in dealing with massive data.
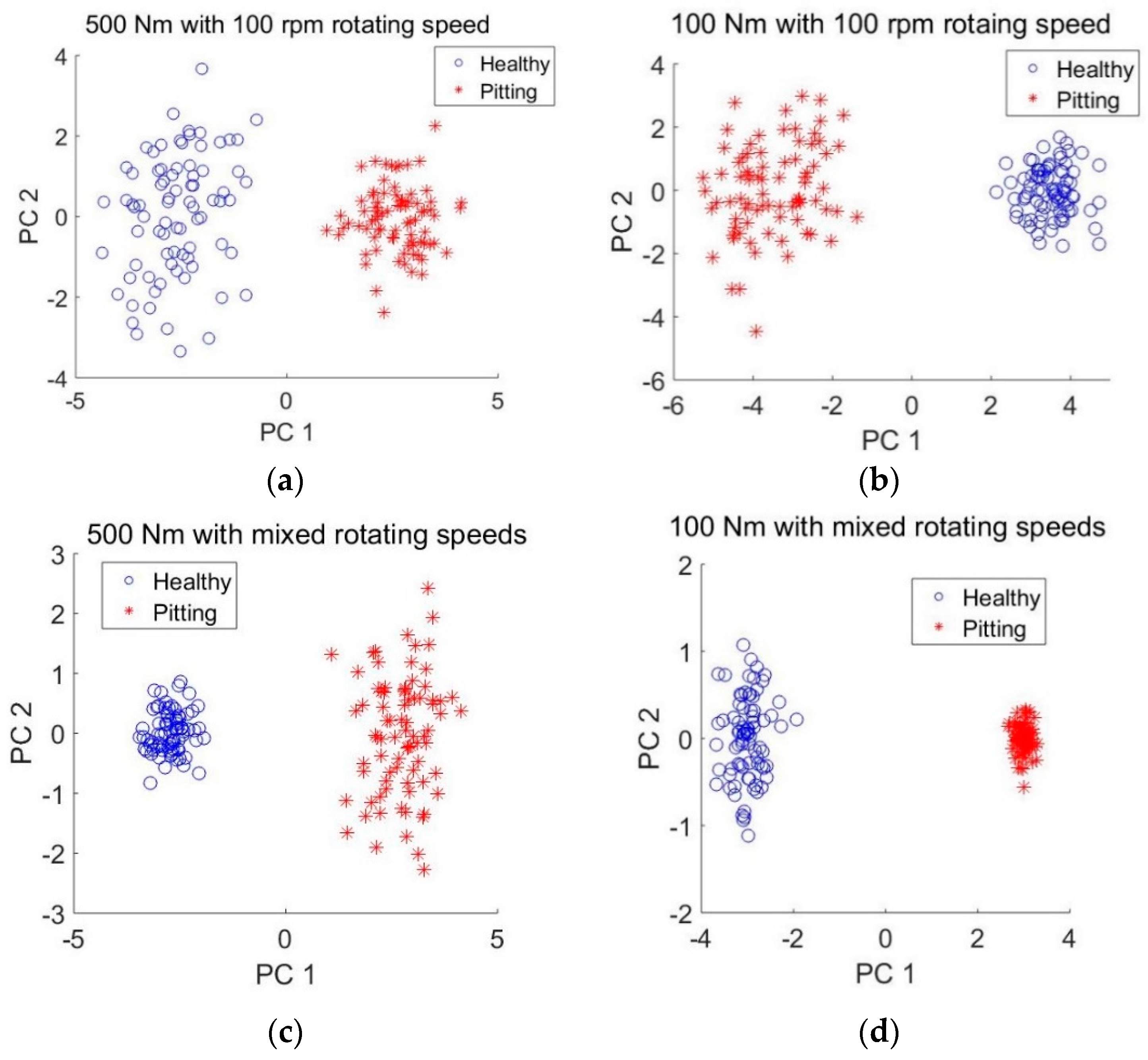
To verify the ability of the presented method for automatically adaptive features extraction, using a similar approach in [
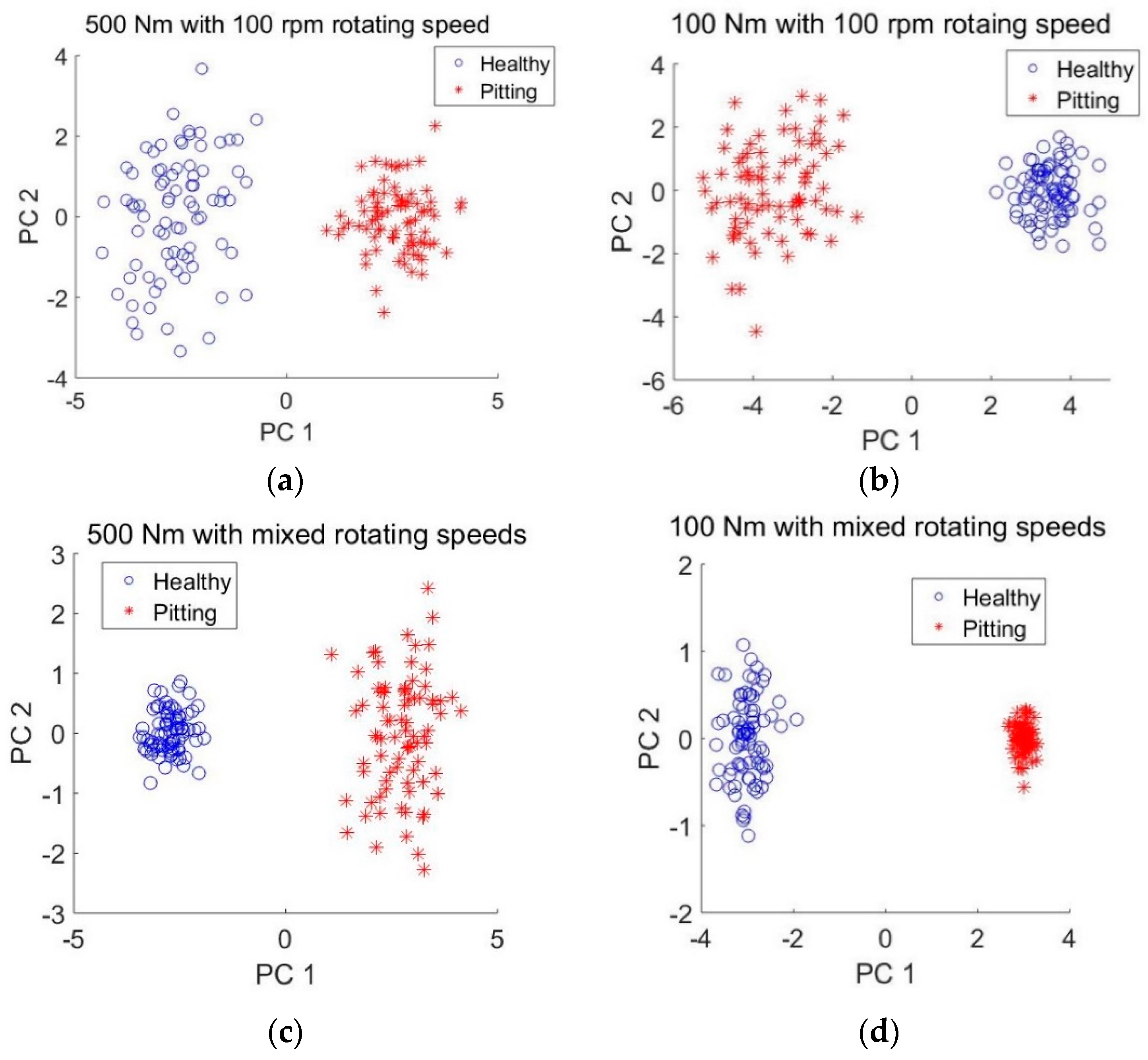
33], the principal component analysis (PCA) was employed to visualize the extracted features. The values of neurons in the last hidden layer were regarded as pitting fault features since they were used for pitting detection in the output layer. Therefore, 50 features were obtained by the deep sparse autoencoders. The first two principle components were used for the visualization since they carried out more than 90% information in the feature domain. Since pitting gear detection results at rotating speed of 1000 rpm is slightly more accurate than that at 100 rpm, only features obtained using signals at 100 rpm were plotted for observation. The scatter plot of principle components of the features automatically extracted from datasets A, B, E and F are presented in
Figure 10.
It can be observed from
Figure 10 that the features of the same health condition are grouped in the corresponding clusters which are clearly separated from each other. In comparison with
Figure 10a,c,
Figure 10b,d show a better clustering performance and more clear separation boundary between the healthy and pitting gear conditions. This could be due to the fact that the features of heaving loading conditions in A and E are extracted using the deep sparse autoencoders trained with data of light loading conditions. The fault features of light conditions are normally less significant than those of heavy loading conditions.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}