
Development of Height Indicators using Omnidirectional Images and Global Appearance Descriptors





Abstract
:1. Introduction
2. Omnidirectional Imaging and Global Appearance Descriptors
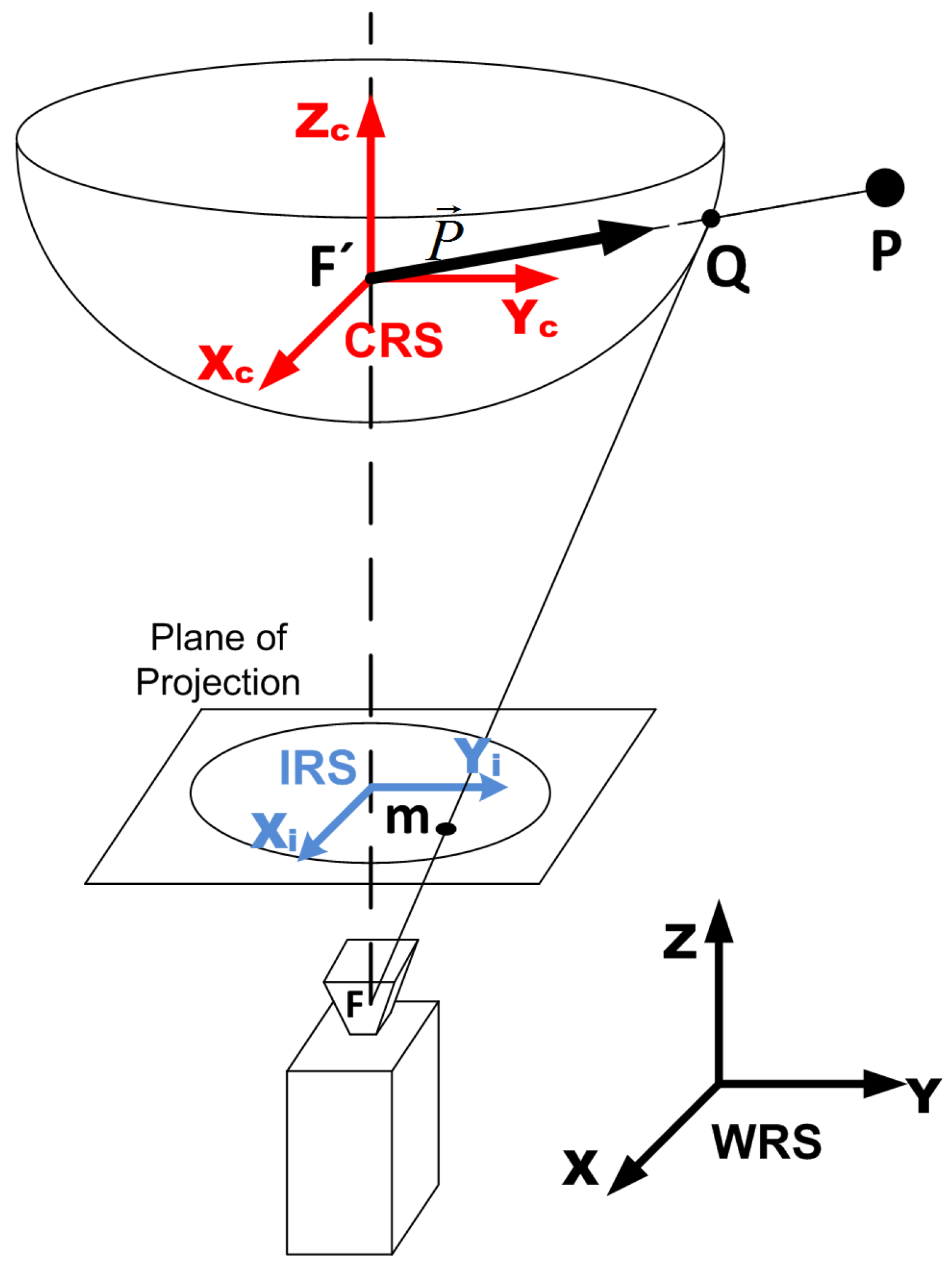
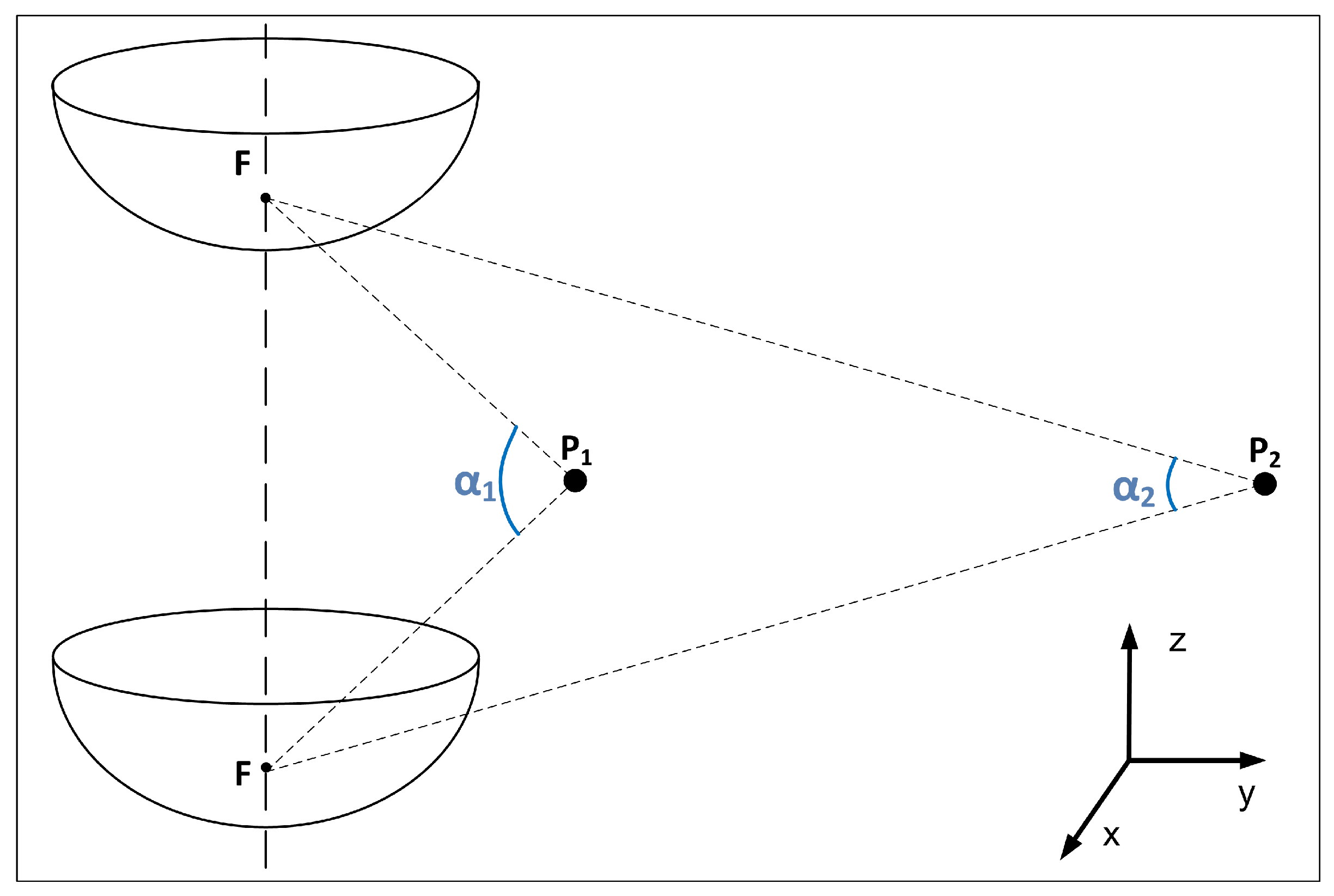
2.1. Catadioptric Vision Sensors
2.2. Global Appearance Descriptors
2.2.1. Fourier Signature
2.2.2. Two-dimensional Discrete Fourier Transform
2.2.3. Spherical Fourier Transform
3. Development of Height Indicators Using Global Appearance Descriptors
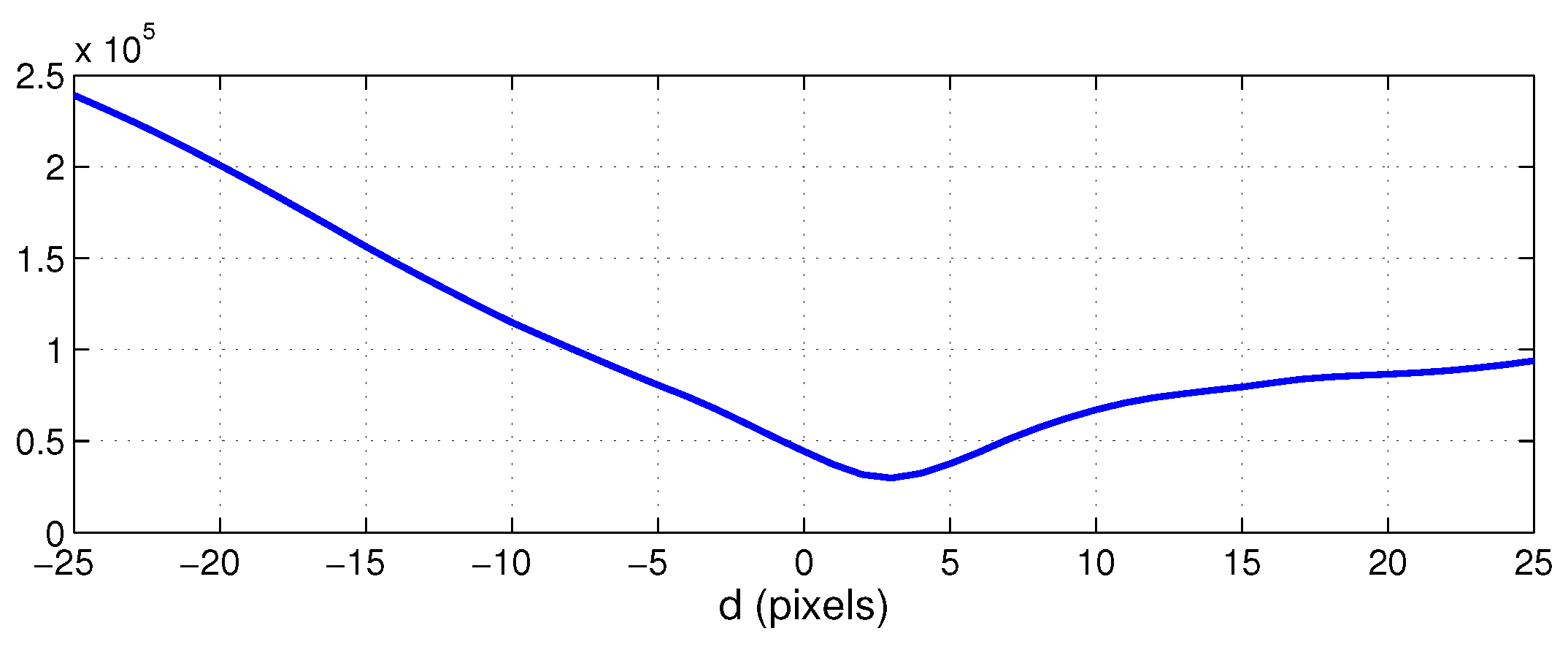
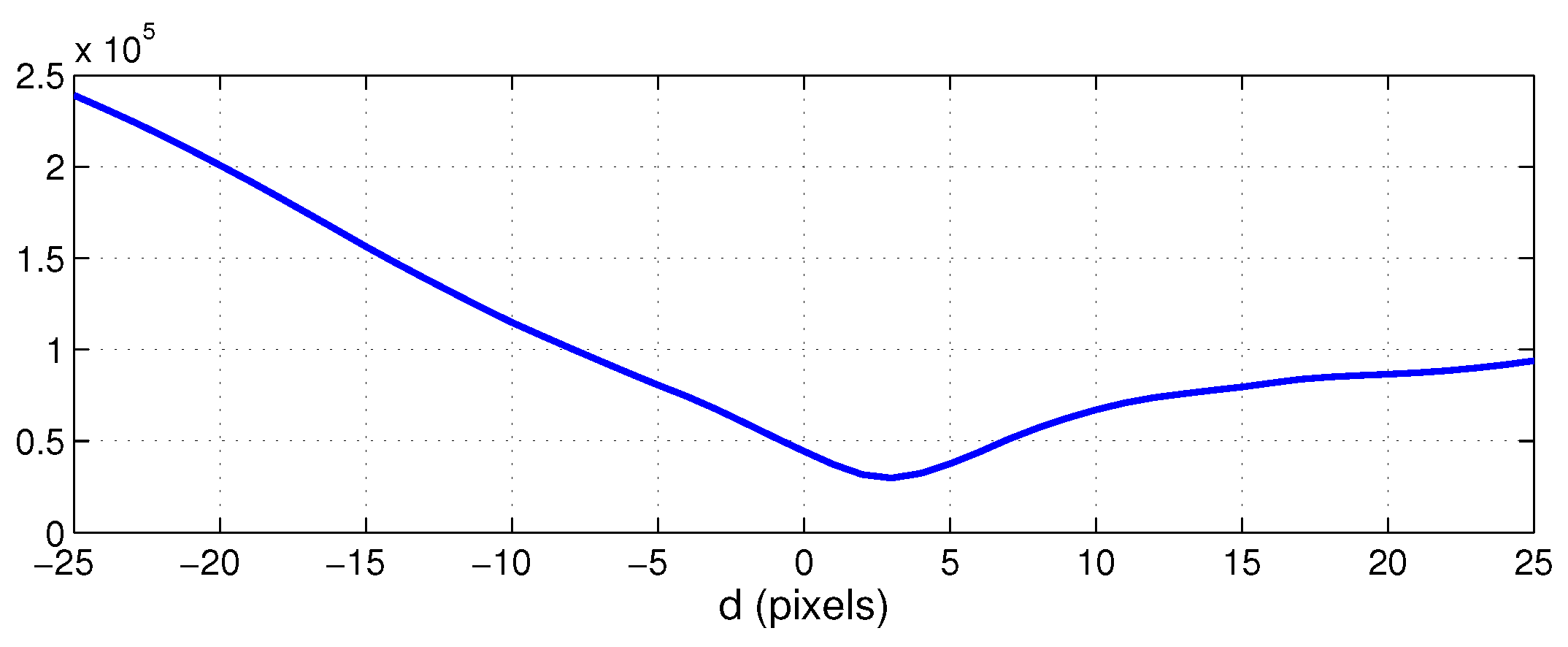
3.1. Method 1: Central Cell Correlation of Panoramic Images
3.2. Method 2: 2D-DFT Vertical Phase
3.3. Method 3: Multiscale Analysis of the Orthographic View
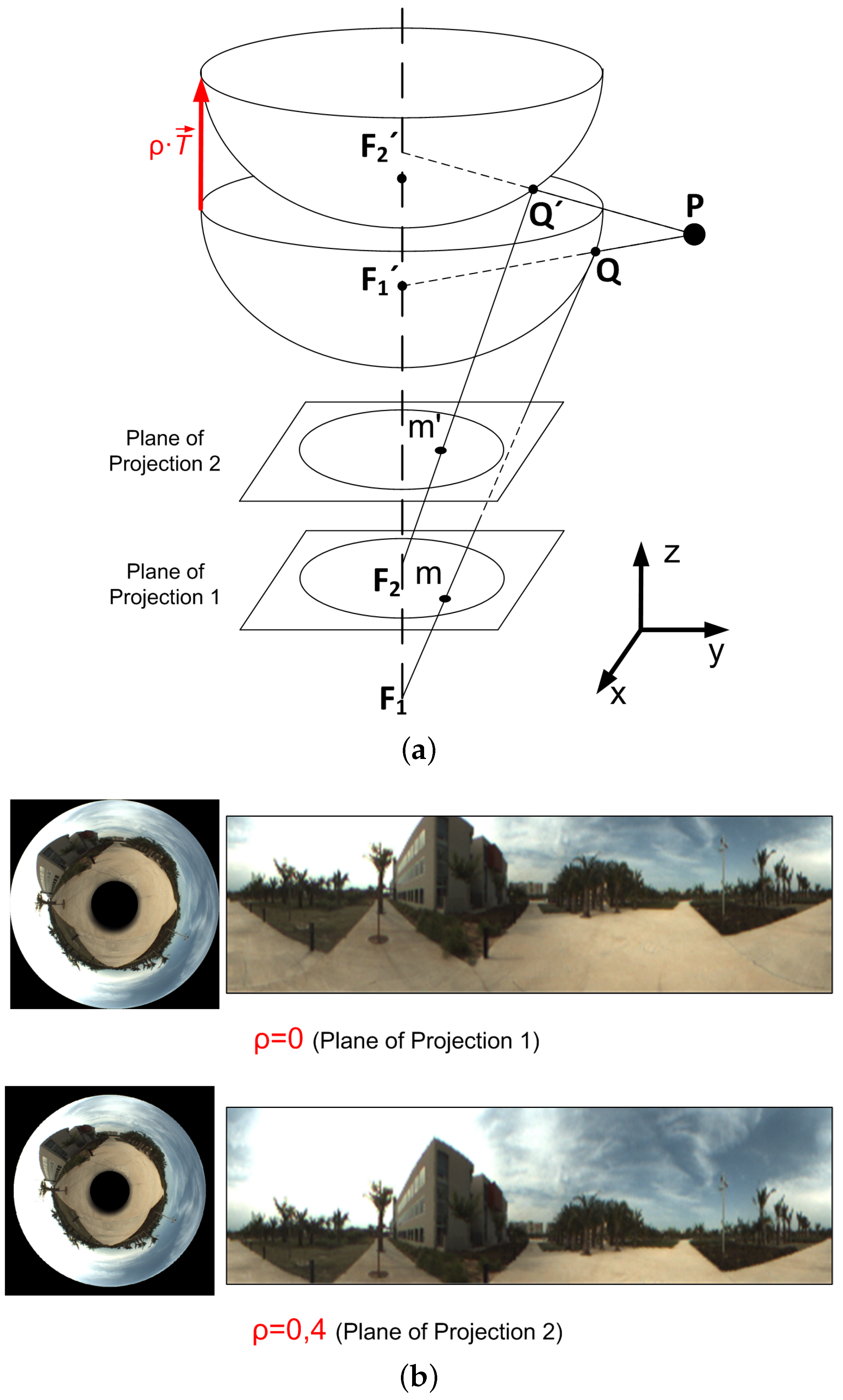
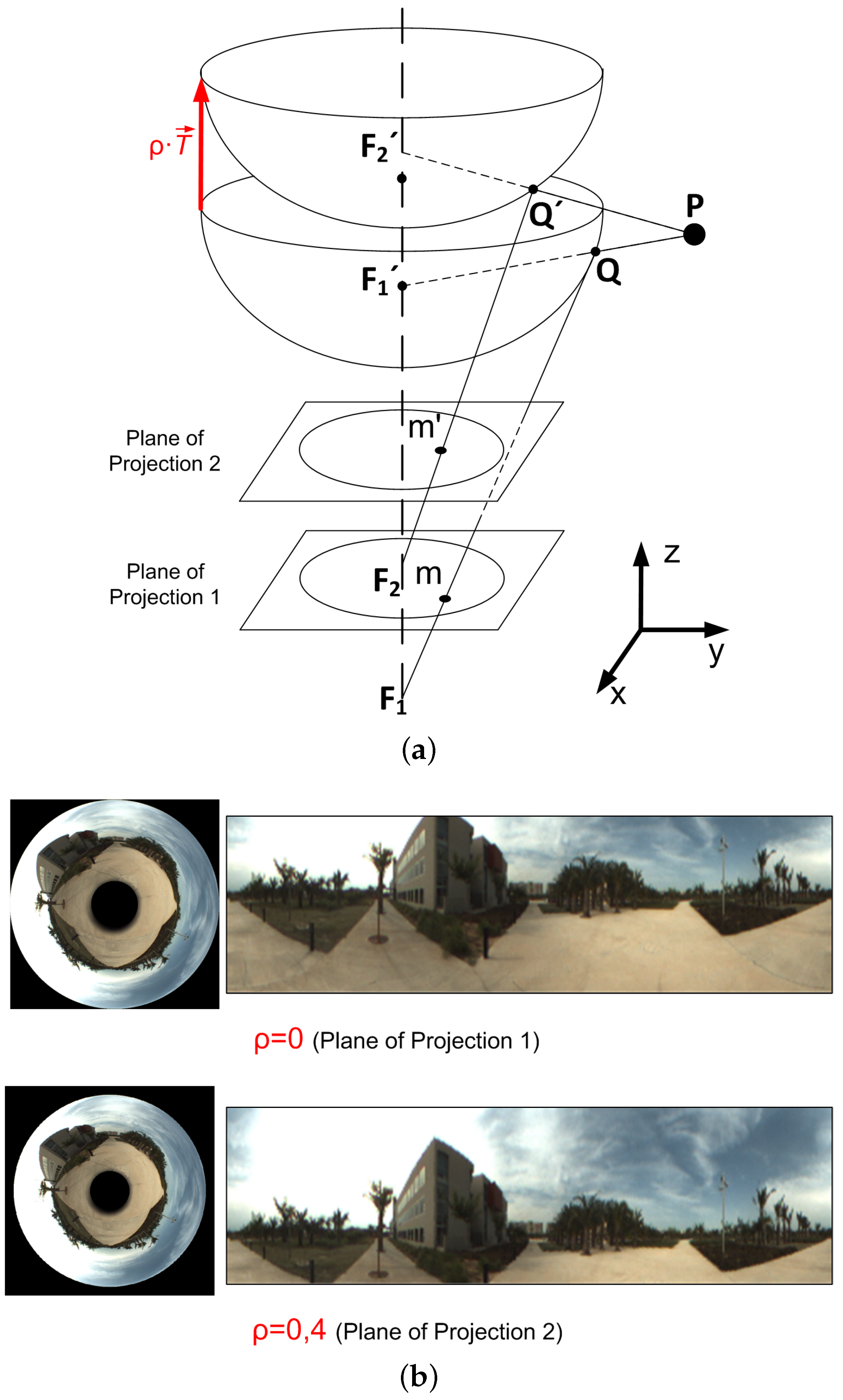
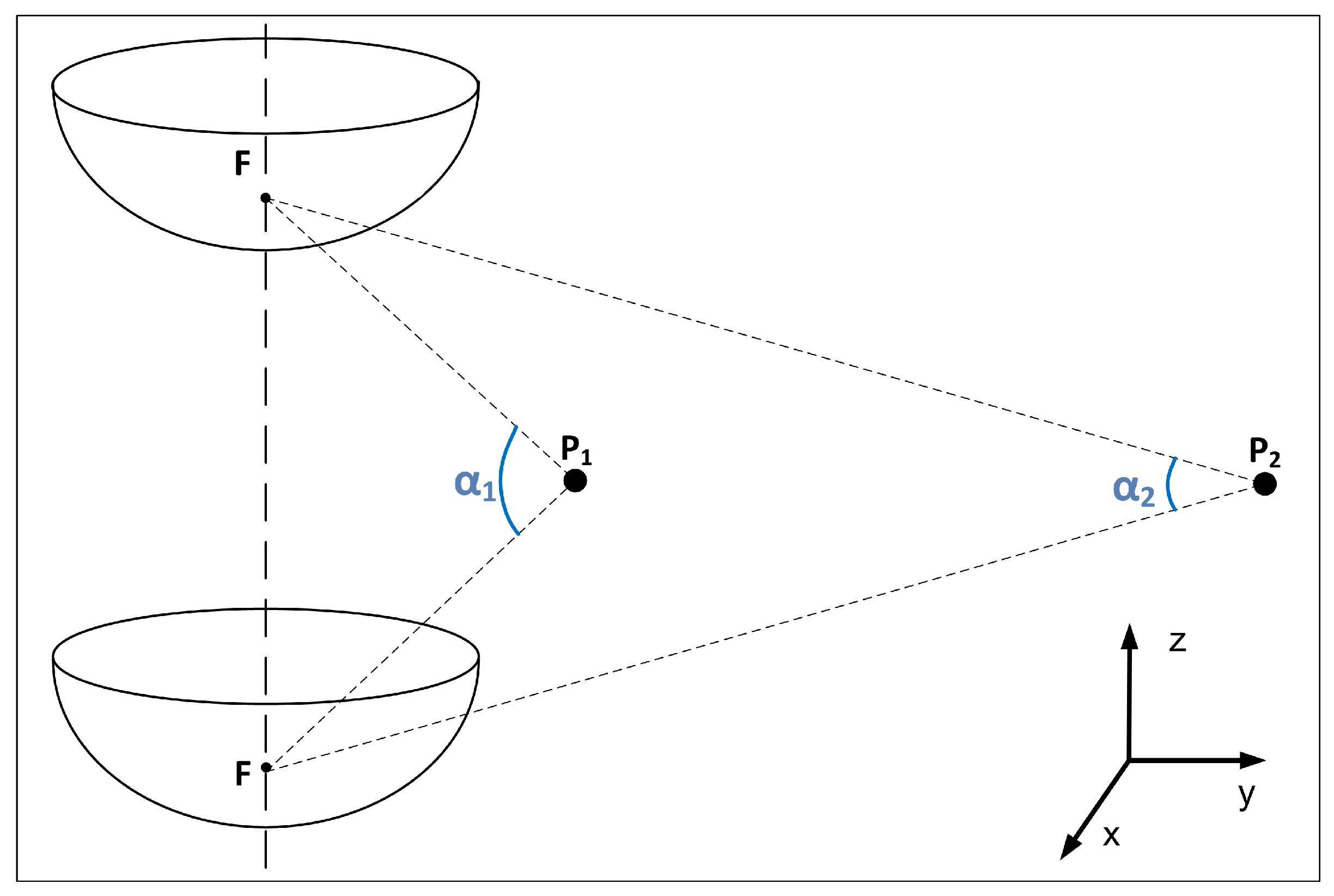
3.4. Method 4: Change of the Camera Reference System (CRS)
3.5. Method 5: Matching of SURF Features
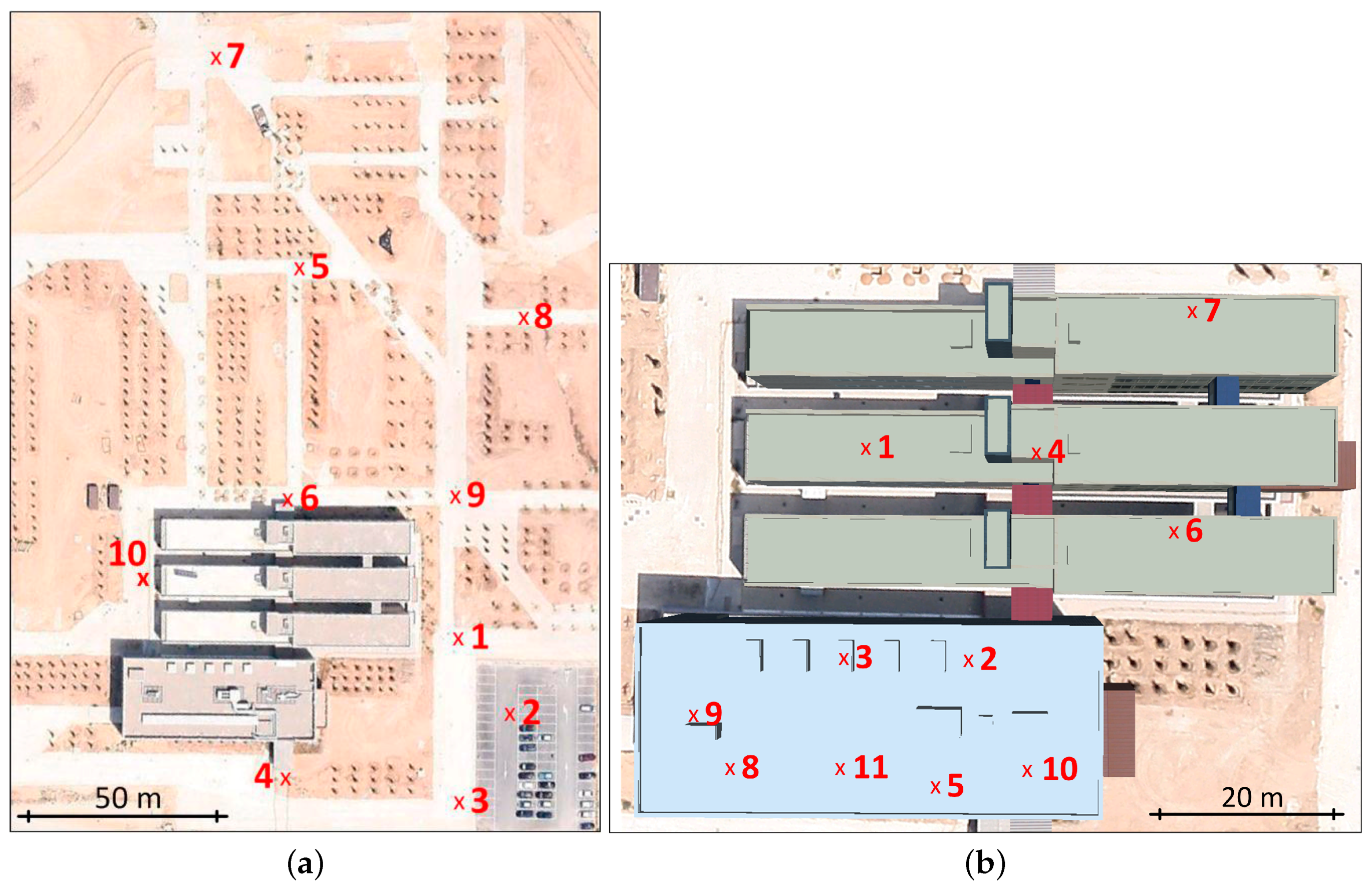
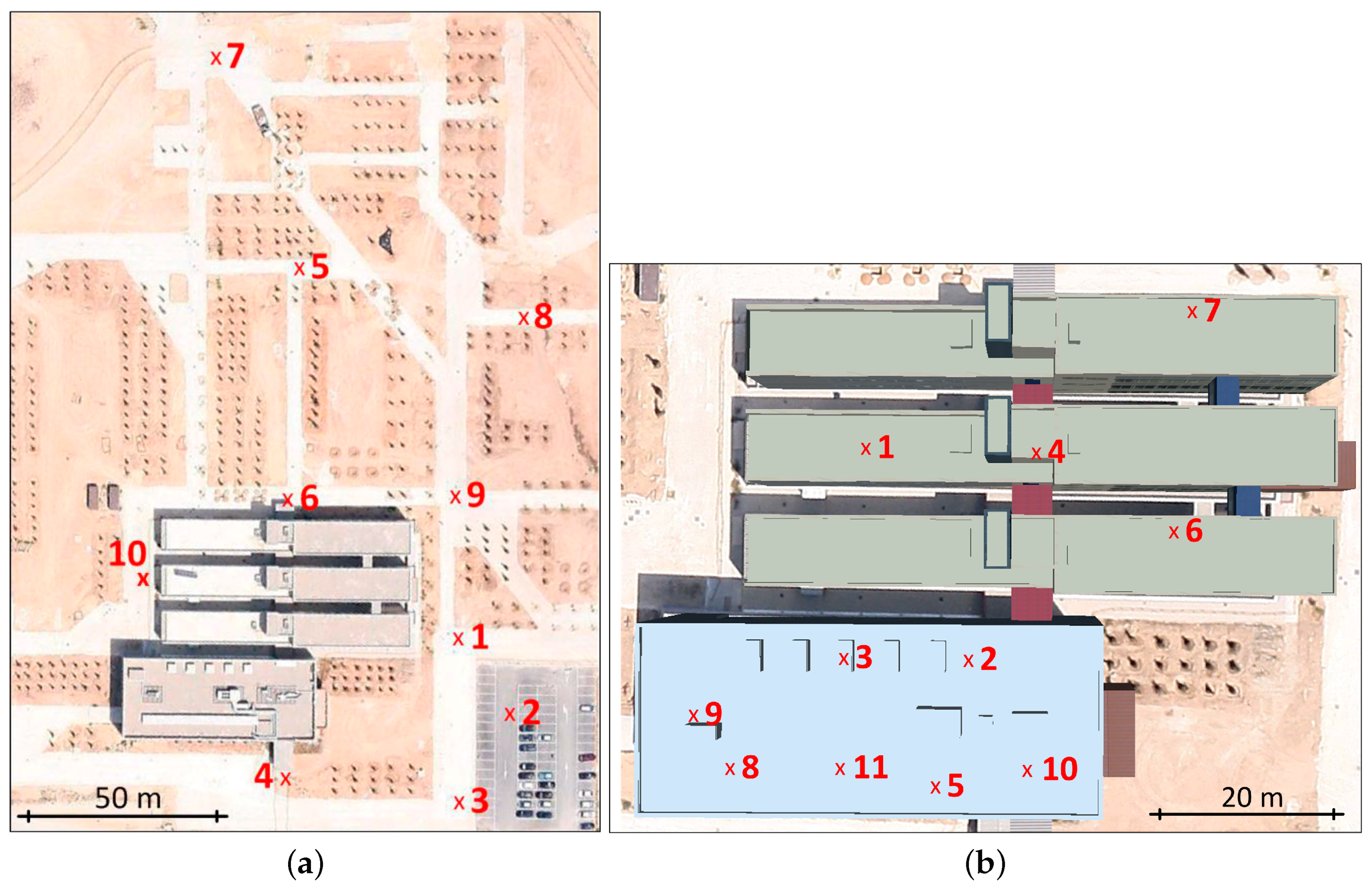
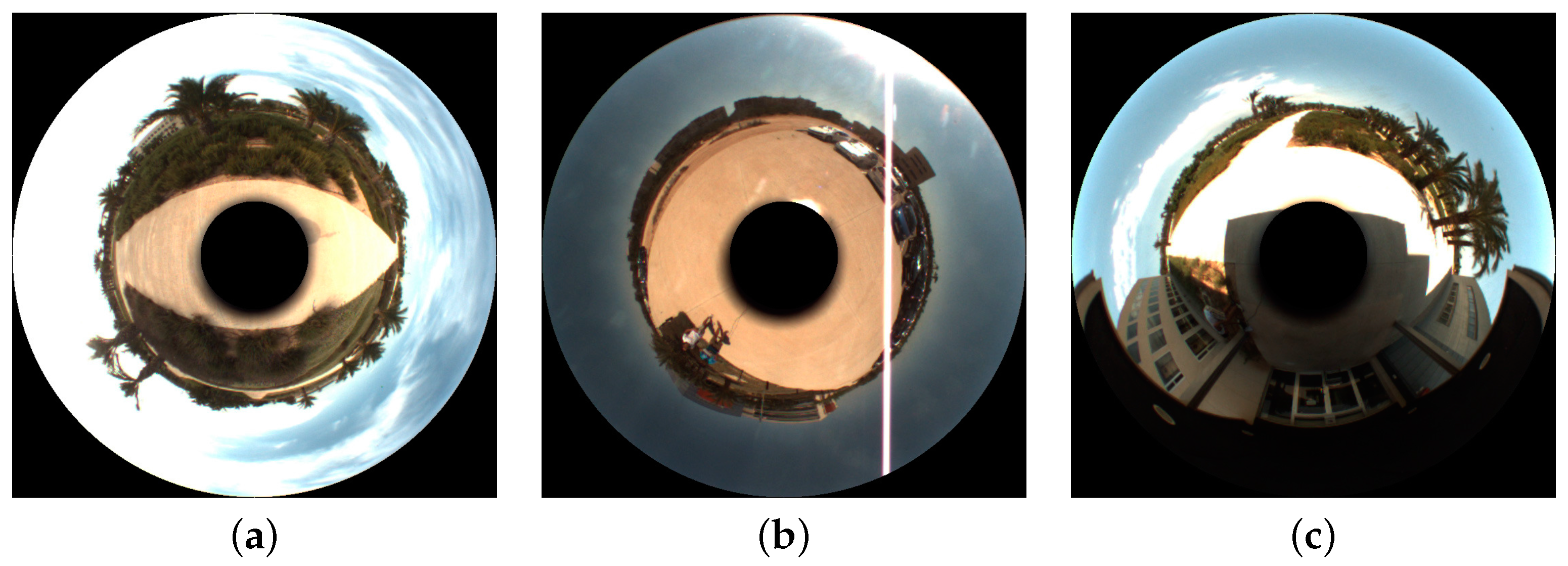
4. Sets of Images
5. Experiments and Results
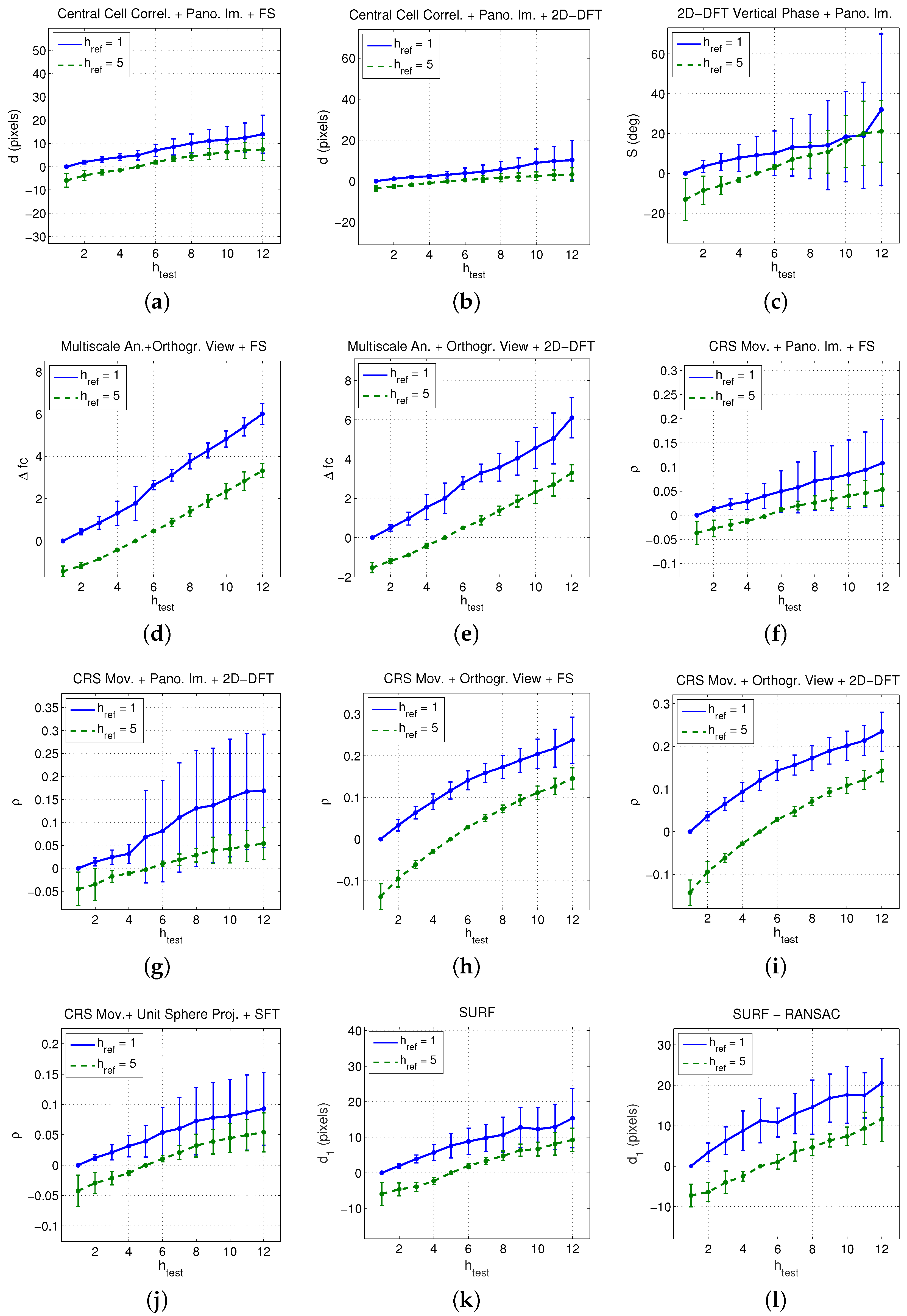
5.1. Configuration of the Experiments
- (c1)
- The bottom image of each set ( in Table 2) is considered to be the reference image, and the rest of images of each set are considered as test images. Since each test image presents a different altitude with respect to the reference image in each set, this situation allows us to analyse the linearity of the estimated relative altitude versus the actual relative altitude.
- (c2)
- The image captured at (intermediate position, equivalent to cm according to Table 2) is considered to be the reference image, and the rest of images of each set are considered as test images. This permits studying the behaviour of the methods to estimate both positive and negative relative altitudes and analysing the symmetry of the behaviour.
- (c3)
- Different reference images and altitude gaps are considered. This permits assessing the behaviour of the algorithms independently on the image chosen as reference image and on the altitude gap. For each set of images, we carry out as many comparisons as possible considering different images as reference. For example, considering a gap , equivalent to 30 cm, we compare the first image with the third, the second with the fourth, and so on until carrying out all the experiments that the range of height permits. Table 4 shows the number of experiments for each height gap and data set in this condition. All these experiments are carried out both with positive and negative relative heights.
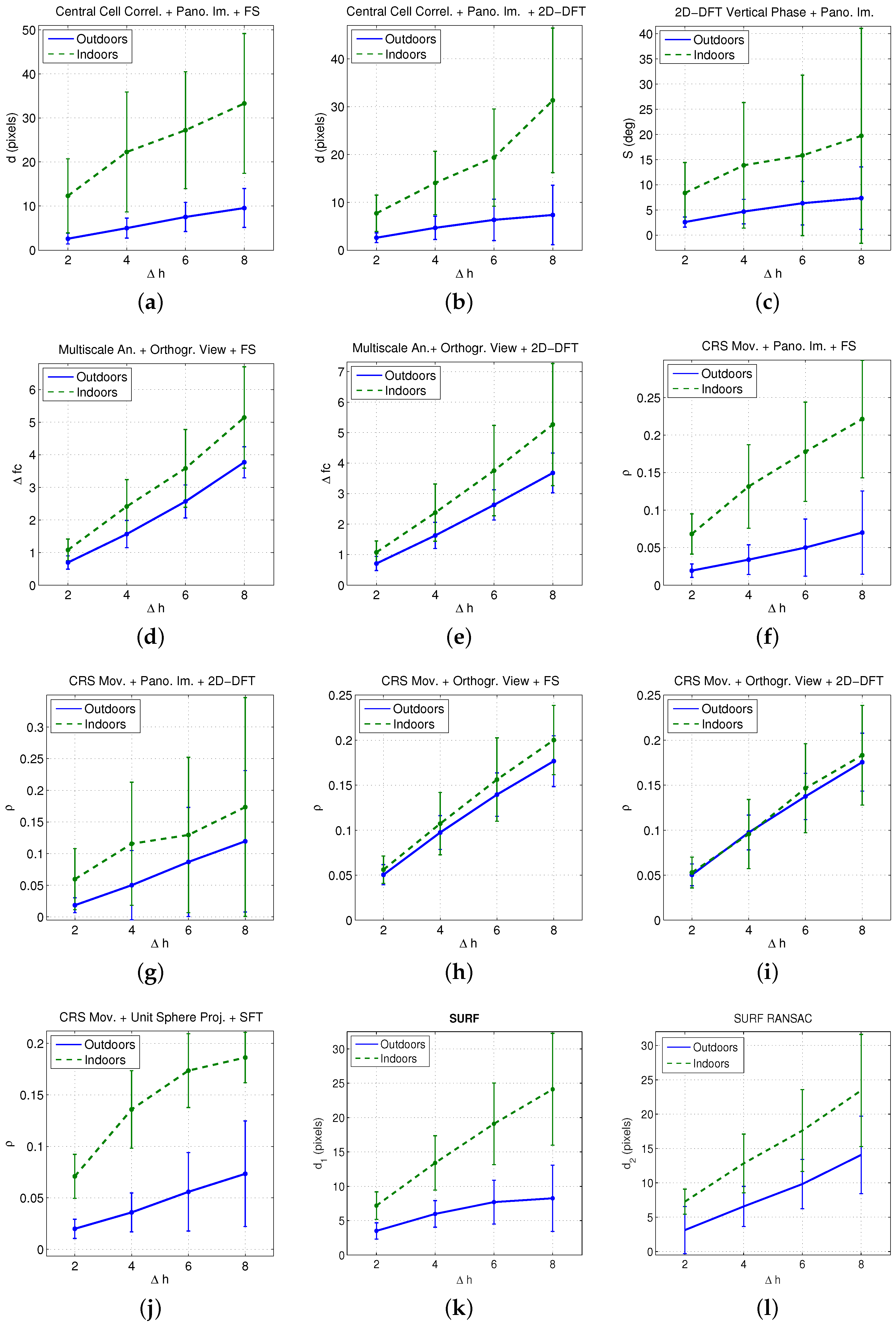
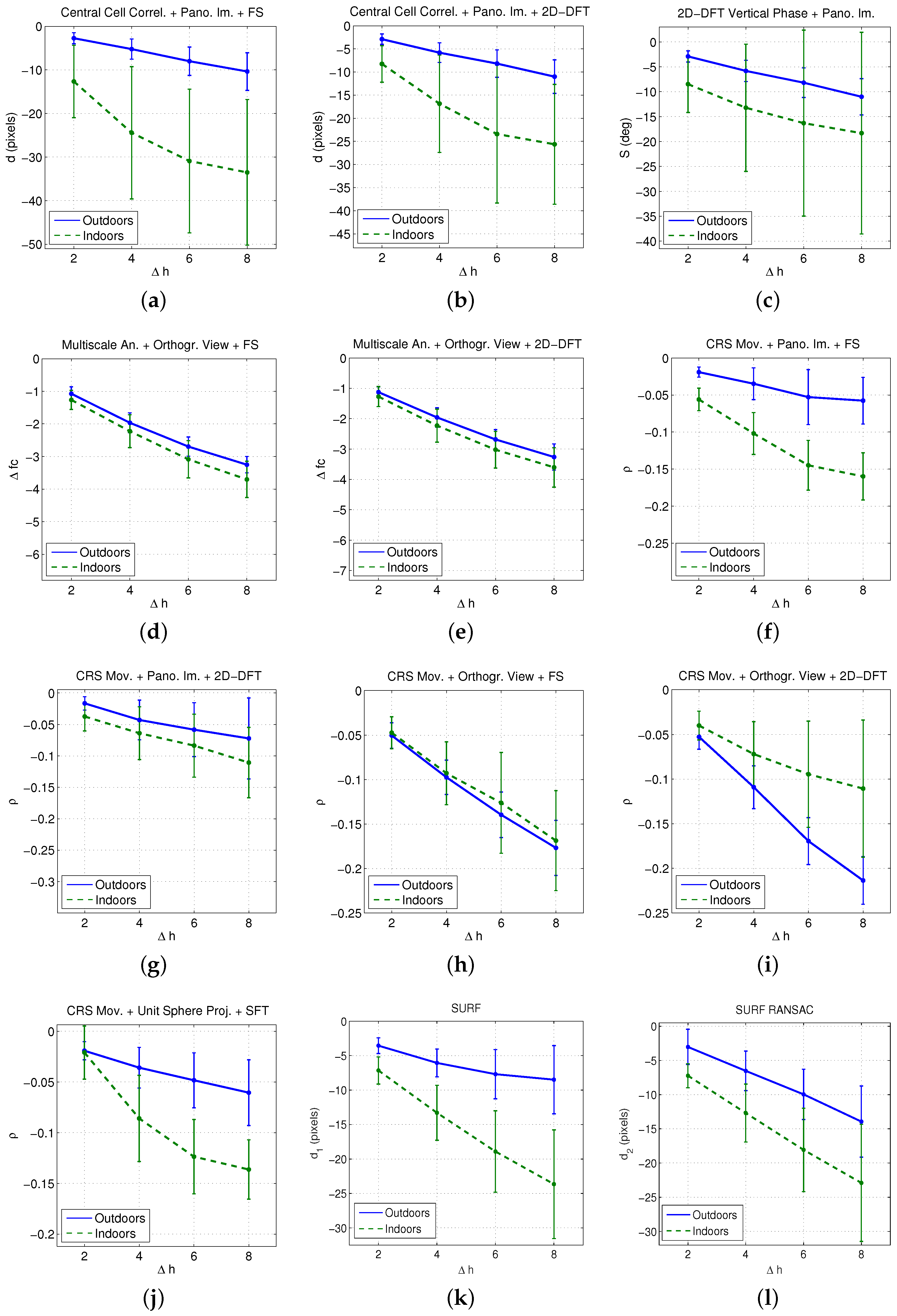
5.2. Results
6. Conclusions
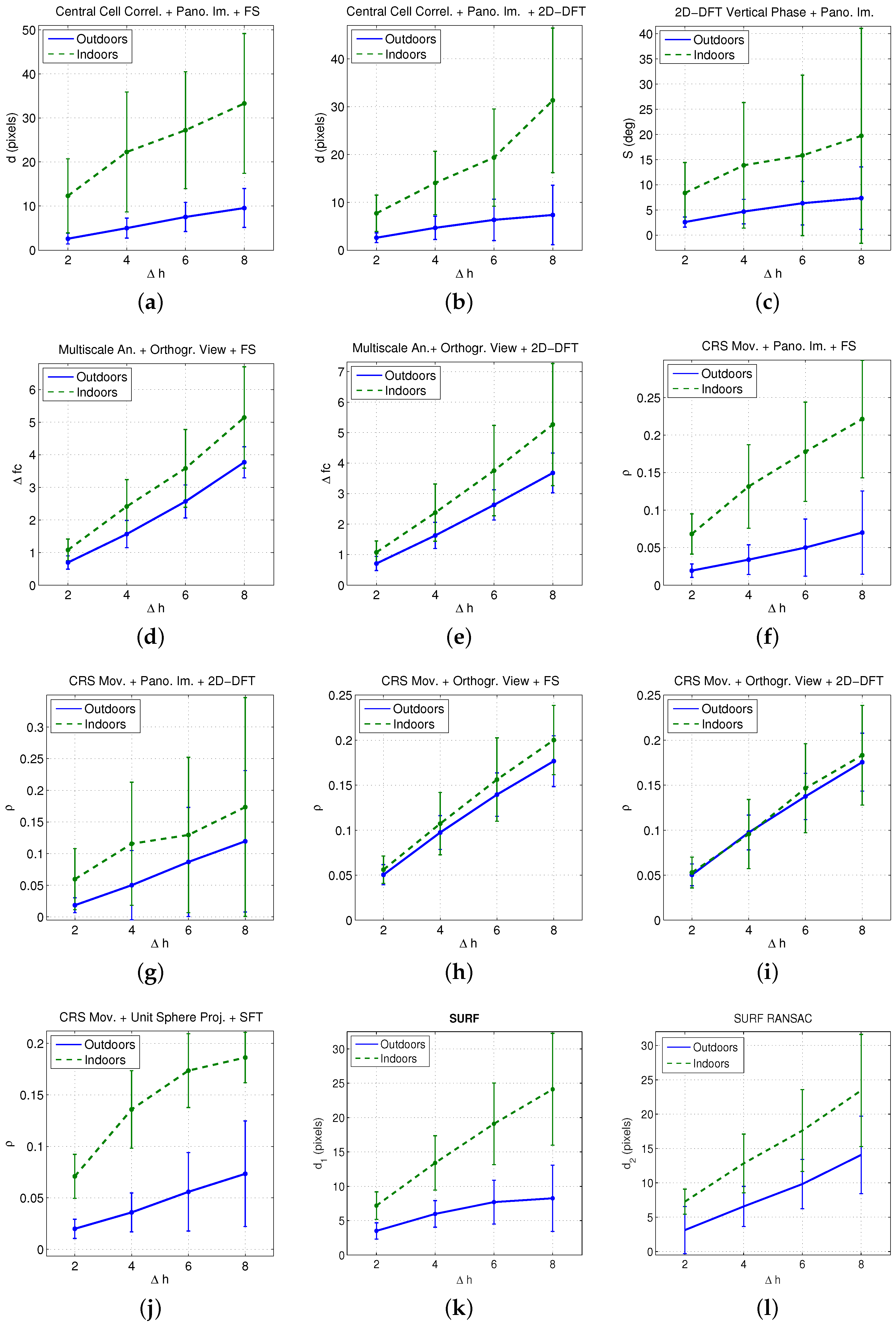
- All the methods proposed are able to detect the relative height between the capture points of two images captured along a vertical line, dealing successfully with little displacements in the floor plane and small changes in the orientation of the visual system produced during the capture.
- Some of the indicators present a quite linear tendency. In general, this linear tendency is clearer when using images captured outdoors.
- The sign of the indicators provides information about the direction of the vertical movement. Therefore, a negative sign indicates that the test image is below the reference image.
- In some cases, the results present a relatively high standard deviation, mainly when the height gap between the reference and the test images increases. In general, this effect is more clearly noticeable indoors.
- Techniques based on the orthographic projection of the omnidirectional images present the most linear behaviour and the lowest deviation, specially with the method based on the Camera Reference System (CRS) movement. This way, a larger working range can be obtained with this method.
- The different techniques rely on the movement of the scene objects to estimate the relative height. Since this movement is quantitatively higher indoors, the indicators obtained with this database present, in general, higher absolute values. As the orthographic projection mainly gathers the floor information, the methods based on this projection present less difference between indoor and outdoor scenes. Therefore, the magnitude of the indicators based on this projection is less dependent on the capture environment. This is an additional advantage of this kind of projection, specially when using the CRS method along with the FS.
- In the indoor environment, the slope of some indicators tends to decrease as the height increases. It happens mainly in the methods based on multiscale analysis and in CRS movement. Also, the effect is more pronounced when the reference image is , what means estimating higher height gaps. The effect shown in Figure 19 may have an influence on this behaviour: the objects in the scene experience movements with different magnitude as the height of the camera changes, and this effect will be more pronounced in the case of the higher height gaps, leading to a loss of linearity in these cases.
- When comparing to methods based on local features, only the global-appearance methods that make use of the panoramic image have shown relatively worse results (as they present a higher standard deviation in most cases). The other global appearance-methods prove to be an efficient alternative to local features both considering their computational cost, and the linearity and standard deviation of the results.
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| DOF | Degree of Freedom |
| WRS | World Reference System |
| CRS | Camera Reference System |
| IRS | Image Reference System |
| DFT | Discrete Fourier Transform |
| 2D-DFT | Two-Dimensional Discrete Fourier Transform |
| FS | Fourier Signature |
| SFT | Spherical Fourier Transform |
| VRM | Vertical Rotation Matrix |
References
- Fernández, L.; Payá, L.; Reinoso, O.; Jiménez, L. Appearance-based approach to hybrid metric-topological simultaneous localisation and mapping. IET Intell. Transp. Syst. 2014, 8, 688–699. [Google Scholar] [CrossRef]
- Saito, T.; Kuroda, Y. Mobile robot localization using multiple observations based on place recognition and GPS. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 1548–1553. [Google Scholar]
- Cherubini, A.; Chaumette, F. Visual navigation of a mobile robot with laser-based collision avoidance. Int. J. Robot. Res. 2013, 32, 189–205. [Google Scholar] [CrossRef]
- Fotiadis, E.P.; Garzon, M.; Barrientos, A. Human Detection from a Mobile Robot Using Fusion of Laser and Vision Information. Sensors 2013, 13, 11603–11635. [Google Scholar] [CrossRef] [PubMed]
- Yong-Guo, Z.; Wei, C.; Guang-Liang, L. The Navigation of Mobile Robot Based on Stereo Vision. In Proceedings of the 2012 Fifth International Conference on Intelligent Computation Technology and Automation (ICICTA), Zhangjiajie, Hunan, China, 12–14 January 2012; pp. 670–673. [Google Scholar]
- Sturm, P.; Ramalingam, S.; Tardif, J.P.; Gasparini, S.; Barreto, J. Camera Models and Fundamental Concepts Used in Geometric Computer Vision. Found. Trends Comput. Graph. Vis. 2011, 6, 1–183. [Google Scholar] [CrossRef]
- Liu, M.; Pradalier, C.; Siegwart, R. Visual Homing From Scale with an Uncalibrated Omnidirectional Camera. IEEE Trans. Robot. 2013, 29, 1353–1365. [Google Scholar] [CrossRef]
- Rituerto, A.; Murillo, A.; Guerrero, J. Semantic labeling for indoor topological mapping using a wearable catadioptric system. Robot. Auton. Syst. 2014, 62, 685–695. [Google Scholar] [CrossRef]
- Lowe, D. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Valgren, C.; Lilienthal, A.J. SIFT, SURF and seasons: Appearance-based long-term localization in outdoor environments. Robot. Auton. Syst. 2010, 58, 149–156, Selected papers from the 2007 European Conference on Mobile Robots (ECMR 2007). [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Alahi, A.; Ortiz, R.; Vandergheynst, P. FREAK: Fast Retina Keypoint. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 510–517. [Google Scholar]
- Oliva, A.; Torralba, A. Building the gist of a scene: The role of global image features in recognition; Progress in Brain Reasearch Volume 155; Elsevier: Amsterdam, The Netherlands, 2006. [Google Scholar]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; Volume 2, pp. 2169–2178. [Google Scholar]
- Leonardis, A.; Bischof, H. Robust Recognition Using Eigenimages. Comput. Vis. Image Underst. 2000, 78, 99–118. [Google Scholar] [CrossRef]
- Murillo, A.; Singh, G.; Kosecka, J.; Guerrero, J. Localization in Urban Environments Using a Panoramic Gist Descriptor. IEEE Trans. Robot. 2013, 29, 146–160. [Google Scholar] [CrossRef]
- Se, S.; Lowe, D.G.; Little, J.J. Vision-based global localization and mapping for mobile robots. IEEE Trans. Robot. 2005, 21, 364–375. [Google Scholar] [CrossRef]
- Choi, Y.W.; Kwon, K.K.; Lee, S.I.; Choi, J.W.; Lee, S.G. Multi-robot Mapping Using Omnidirectional-Vision SLAM Based on Fisheye Images. ETRI J. (Electron. Telecommun. Res. Inst.) 2014, 36, 913–923. [Google Scholar] [CrossRef]
- Caruso, D.; Engel, J.; Cremers, D. Large-Scale Direct SLAM for omnidirectional cameras. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems, Hamburg, Germany, 28 September–2 October 2015; IEEE: Hamburg, Germany, 2015; pp. 141–148. [Google Scholar]
- Bacca, B.; Salvi, J.; Cufí, X. Appearance-based mapping and localization for mobile robots using a feature stability histogram. Robot. Auton. Syst. 2011, 59, 840–857. [Google Scholar] [CrossRef]
- Kostavelis, I.; Charalampous, K.; Gasteratos, A.; Tsotsos, J.K. Robot navigation via spatial and temporal coherent semantic maps. Eng. Appl. Artif. Intell. 2015, 48, 173–187. [Google Scholar] [CrossRef]
- Dayoub, F.; Morris, T.; Upcroft, B.; Corke, P. Vision-only autonomous navigation using topometric maps. In Proceedings of the2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 1923–1929. [Google Scholar]
- Berenguer, Y.; Payá, L.; Ballesta, M.; Reinoso, O. Position Estimation and Local Mapping Using Omnidirectional Images and Global Appearance Descriptors. Sensors (Basel) 2015, 10, 26368–26395. [Google Scholar] [CrossRef] [PubMed]
- Gallegos, G.; Meilland, M.; Rives, P.; Comport, A.I. Appearance-based SLAM relying on a hybrid laser/omnidirectional sensor. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Taipei, Taiwan, 18–22 October 2010; pp. 3005–3010. [Google Scholar]
- Garcia-Fidalgo, E.; Ortiz, A. Vision-based topological mapping and localization methods: A survey. Robot. Auton. Syst. 2015, 64, 1–20. [Google Scholar] [CrossRef]
- Payá, L.; Amorós, F.; Fernández, L.; Reinoso, O. Performance of Global-Appearance Descriptors in Map Building and Localization Using Omnidirectional Vision. Sensors 2014, 14, 3033. [Google Scholar] [CrossRef] [PubMed]
- Chang, C.K.; Siagian, C.; Itti, L. Mobile robot vision navigation and localization using Gist and Saliency. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Taipei, Taiwan, 18–22 October 2010; pp. 4147–4154. [Google Scholar]
- Maohai, L.; Han, W.; Lining, S.; Zesu, C. Robust omnidirectional mobile robot topological navigation system using omnidirectional vision. Eng. Appl. Artif. Intell. 2013, 26, 1942–1952. [Google Scholar] [CrossRef]
- Hsia, K.H.; Lien, S.F.; Su, J.P. Height estimation via stereo vision system for unmanned helicopter autonomous landing. In Proceedings of the 2010 International Symposium on Computer, Communication, Control and Automation (3CA), Tainan, Taiwan, 5–7 May 2010; Volume 2, pp. 257–260. [Google Scholar]
- Mondragón, I.F.; Olivares-Méndez, M.A.; Campoy, P.; Martínez, C.; Mejias, L. Unmanned aerial vehicles UAVs attitude, height, motion estimation and control using visual systems. Auton. Robot. 2010, 29, 17–34. [Google Scholar] [CrossRef]
- Lee, K.Z. A Simple Calibration Approach to Single View Height Estimation. In Proceedings of the 2012 Ninth Conference on Computer and Robot Vision (CRV), Toronto, ON, Canada, 28–30 May 2012; pp. 161–166. [Google Scholar]
- Pan, C.; Hu, T.; Shen, L. BRISK based target localization for fixed-wing UAV’s vision-based autonomous landing. In Proceedings of the 2005 IEEE International Conference on Information and Automation, Lijiang, China, 18–22 April 2015; IEEE: Lijiang, China, 2015; pp. 2499–2503. [Google Scholar]
- Amorós, F.; Payá, L.; Reinoso, O.; Fernández, L.; Valiente, D. Towards Relative Altitude Estimation in Topological Navigation Tasks using the Global Appearance of Visual Information. In Proceedings of the International Conference on Computer Vision Theory and Applications, VISAPP 2014, Lisbon, Portugal, 5–8 January 2014; SciTePress—Science and Technology Publications: Setúbal, Portugal, 2014; Volume 1, pp. 194–201, ISBN 978-989-758-003-1. [Google Scholar]
- Payá, L.; Reinoso, O.; Berenguer, Y.; Úbeda, D. Using Omnidirectional Vision to Create a Model of the Environment: A Comparative Evaluation of Global-Appearance Descriptors. J. Sens. 2016, 2016. [Google Scholar] [CrossRef] [PubMed]
- Scaramuzza, D.; Martinelli, A.; Siegwart, R. A Flexible Technique for Accurate Omnidirectional Camera Calibration and Structure from Motion. In Proceedings of the IEEE International Conference on Computer Vision Systems, 2006 ICV ’06, New York, NY, USA, 4–7 January 2006; p. 45. [Google Scholar]
- Gaspar, J.; Winters, N.; Santos-Victor, J. Vision-based navigation and environmental representations with an omnidirectional camera. IEEE Trans. Robot. Autom. 2000, 16, 890–898. [Google Scholar] [CrossRef]
- Menegatti, E.; Maeda, T.; Ishiguro, H. Image-based memory for robot navigation using properties of omnidirectional images. Robot. Auton. Syst. 2004, 47, 251–267. [Google Scholar] [CrossRef]
- Driscoll, J.; Healy, D. Computing Fourier Transforms and Convolutions on the 2-Sphere. Adv. Appl. Math. 1994, 15, 202–250. [Google Scholar] [CrossRef]
- Makadia, A.; Sorgi, L.; Daniilidis, K. Rotation estimation from spherical images. In Proceedings of the 17th International Conference on Pattern Recognition, ICPR 2004, Cambridge, UK, 23–26 August 2004; Volume 3, pp. 590–593. [Google Scholar]
- Schairer, T.; Huhle, B.; Strasser, W. Increased accuracy orientation estimation from omnidirectional images using the spherical Fourier transform. In Proceedings of the 3DTV Conference: The True Vision-Capture, Transmission and Display of 3D Video, Potsdam, Germany, 4–6 May 2009; pp. 1–4. [Google Scholar]
- Huhle, B.; Schairer, T.; Schilling, A.; Strasser, W. Learning to localize with Gaussian process regression on omnidirectional image data. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Taipei, Taiwan, 18–22 October 2010; pp. 5208–5213. [Google Scholar]
- Schairer, T.; Huhle, B.; Vorst, P.; Schilling, A.; Strasser, W. Visual mapping with uncertainty for correspondence-free localization using Gaussian process regression. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), San Francisco, CA, USA, 25–30 September 2011; pp. 4229–4235. [Google Scholar]
- Amorós, F.; Payá, L.; Reinoso, O.; Mayol-Cuevas, W.; Calway, A. Global Appearance Applied to Visual Map Building and Path Estimation Using Multiscale Analysis. Math. Probl. Eng. 2014, 65. [Google Scholar] [CrossRef]
- Valiente, D.; Gil, A.; Fernández, L.; Reinoso, O. View-based SLAM using Omnidirectional Images. In Proceedings of the International Conference on Informatics in Control, Automation and Robotics, ICINCO 2012, Rome, Italy, 28–31 July 2012; pp. 48–57. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Gool, L. SURF: Speeded Up Robust Features. In Computer Vision at ECCV 2006; Leonardis, A., Bischof, H., Pinz, A., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2006; Volume 3951, pp. 404–417. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Se, S.; Lowe, D.; Little, J. Global localization using disctinctive visual features. In Proceedings of the 2002 IEEE/RSJ International Conference on Intelligent Robots and Systems, Lausanne, Switzerland, 30 September–4 October 2002; pp. 226–231. [Google Scholar]
- ARVC: Automation, Robotics and Computer Vision Research Group. Miguel Hernandez University. Set of Images for Altitude Estimation. Available online: http://arvc.umh.es/db/images/altitude/ (accessed on 10 April 2017).
- Eizoh Ltd. Wide 70 Hyperbolic Mirror. Available online: http://www.eizoh.co.jp/mirror/wide70.html (accessed on 10 April 2017).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Mirror Eizoh Wide 70 |
|---|---|
| Geometry | Hyberbolic |
| Maximum Diameter | 70 mm |
| Height | 35 mm |
| Angle of view above the horizon | 60 deg |
| Angle of view below the horizon | 60 deg |
| h | z (cm) | # Im. Outdoors | # Im. Indoors |
|---|---|---|---|
| 1 | 125 | 10 | 11 |
| 2 | 140 | 10 | 11 |
| 3 | 155 | 10 | 11 |
| 4 | 170 | 10 | 11 |
| 5 | 185 | 10 | 11 |
| 6 | 200 | 10 | 11 |
| 7 | 215 | 10 | 11 |
| 8 | 230 | 10 | 10 |
| 9 | 245 | 10 | 8 |
| 10 | 260 | 10 | 6 |
| 11 | 275 | 10 | 6 |
| 12 | 290 | 10 | 5 |
| TOTAL # IMAGES | 120 | 112 | |
| Height Estimation Method | Image Projection | Descriptor | Height Indicator |
|---|---|---|---|
| 1. Central Cell Correlation | Panoramic Image | FS | d (pixels) |
| 2D-DFT | d (pixels) | ||
| 2. 2D-DFT Vertical Phase | Panoramic image | 2D-DFT | S |
| 3. Multiscale Analysis | Orthographic View | FS | |
| 2D-DFT | |||
| 4. Camera Reference System Movement | Panoramic Image | FS | |
| 2D-DFT | |||
| Orthographic View | FS | ||
| 2D-DFT | |||
| Unit Sphere Projection | SFT | ||
| 5. Matching Local Features | Omnidirectional Scene | SURF | |
| SURF-RANSAC |
| () | # Experiments Outdoors | # Experiments Indoors | |
|---|---|---|---|
| 2 | 30 | 100 | 90 |
| 4 | 60 | 80 | 68 |
| 6 | 90 | 60 | 46 |
| 8 | 120 | 40 | 25 |
| Height Estimation Method | Image projection | Descriptor | (s) | (s) |
|---|---|---|---|---|
| 1. Central Cell Correlation | Panoramic Image | FS | 0.0450 | 0.0011 |
| Panoramic Image | 2D-DFT | 0.0709 | 0.0017 | |
| 2. 2D-DFT Vertical Phase | Panoramic Image | 2D-DFT | 0.0032 | 0.0662 |
| 3. Multiscale Analysis | Orthographic View | FS | 11.5117 | 0.1908 |
| 2D-DFT | 10.6323 | 0.1800 | ||
| 4. Camera Reference System Movement | Panoramic Image | FS | 11.8509 | 0.0405 |
| 2D-DFT | 11.3911 | 0.0385 | ||
| Orthographic View | FS | 11.6408 | 0.0273 | |
| 2D-DFT | 11.3409 | 0.0241 | ||
| Unit Sphere Proj. | SFT | 17.8813 | 0.2985 | |
| 5. Matching Local Features | Omnidirectional Scene | SURF | 0.0939 | 0.2354 |
| SURF-RANSAC | 0.0978 | 0.3810 |
| Height Estimation Method | Image Projection | Descriptor | (KB) | (KB) |
|---|---|---|---|---|
| 1. Central Cell Correlation | Panoramic Image | FS | 1312 | 32 |
| 2D-DFT | 328 | 8 | ||
| 2. 2D-DFT Vertical Phase | Panoramic Image | 2D-DFT | 8 | 8 |
| 3. Multiscale Analysis | Orthographic View | FS | 3904 | 64 |
| 2D-DFT | 488 | 8 | ||
| 4. Camera Reference System Movement | Panoramic Image | FS | 1296 | 16 |
| 2D-DFT | 162 | 8 | ||
| Orthographic View | FS | 2496 | 64 | |
| 2D-DFT | 312 | 8 | ||
| Unit Sphere Proj. | SFT | 1952 | 64 | |
| 5. Matching Local Features | Omnidirectional Scene | SURF | 99 | 99 |
| SURF-RANSAC | 99 | 99 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Amorós, F.; Payá, L.; Ballesta, M.; Reinoso, O. Development of Height Indicators using Omnidirectional Images and Global Appearance Descriptors. Appl. Sci. 2017, 7, 482. https://doi.org/10.3390/app7050482
Amorós F, Payá L, Ballesta M, Reinoso O. Development of Height Indicators using Omnidirectional Images and Global Appearance Descriptors. Applied Sciences. 2017; 7(5):482. https://doi.org/10.3390/app7050482
Chicago/Turabian StyleAmorós, Francisco, Luis Payá, Mónica Ballesta, and Oscar Reinoso. 2017. "Development of Height Indicators using Omnidirectional Images and Global Appearance Descriptors" Applied Sciences 7, no. 5: 482. https://doi.org/10.3390/app7050482
APA StyleAmorós, F., Payá, L., Ballesta, M., & Reinoso, O. (2017). Development of Height Indicators using Omnidirectional Images and Global Appearance Descriptors. Applied Sciences, 7(5), 482. https://doi.org/10.3390/app7050482