Classification of Architectural Heritage Images Using Deep Learning Techniques

 ,
, 
Abstract
1. Introduction
1.1. Digital Documentation
1.2. Image Classification
1.3. Contributions
2. Materials and Methods
2.1. Dataset Created for These Tests
2.2. Deep Learning
2.2.1. Convolutional Neural Networks (CNNs)
2.2.2. Stochastic Gradient Descent
2.2.3. Useful Properties of CNNs
2.3. Application of CNNs to the Classification of Images of Architectural Heritage
2.3.1. Train from Scratch or Full Training
2.3.2. Fine-Tuning
2.3.3. Hyperparameter Optimization
3. Results
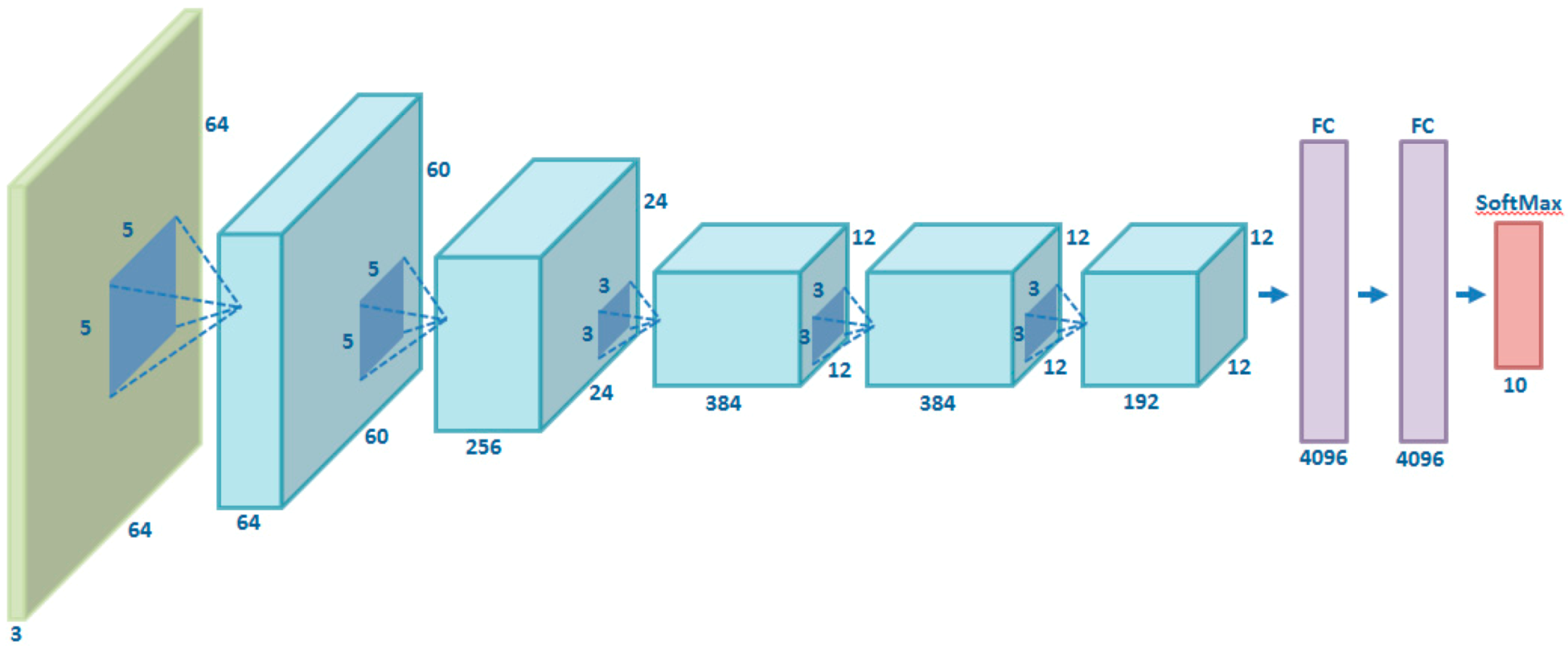
3.1. Convolutional Neural Networks (AlexNet, Inception V3)
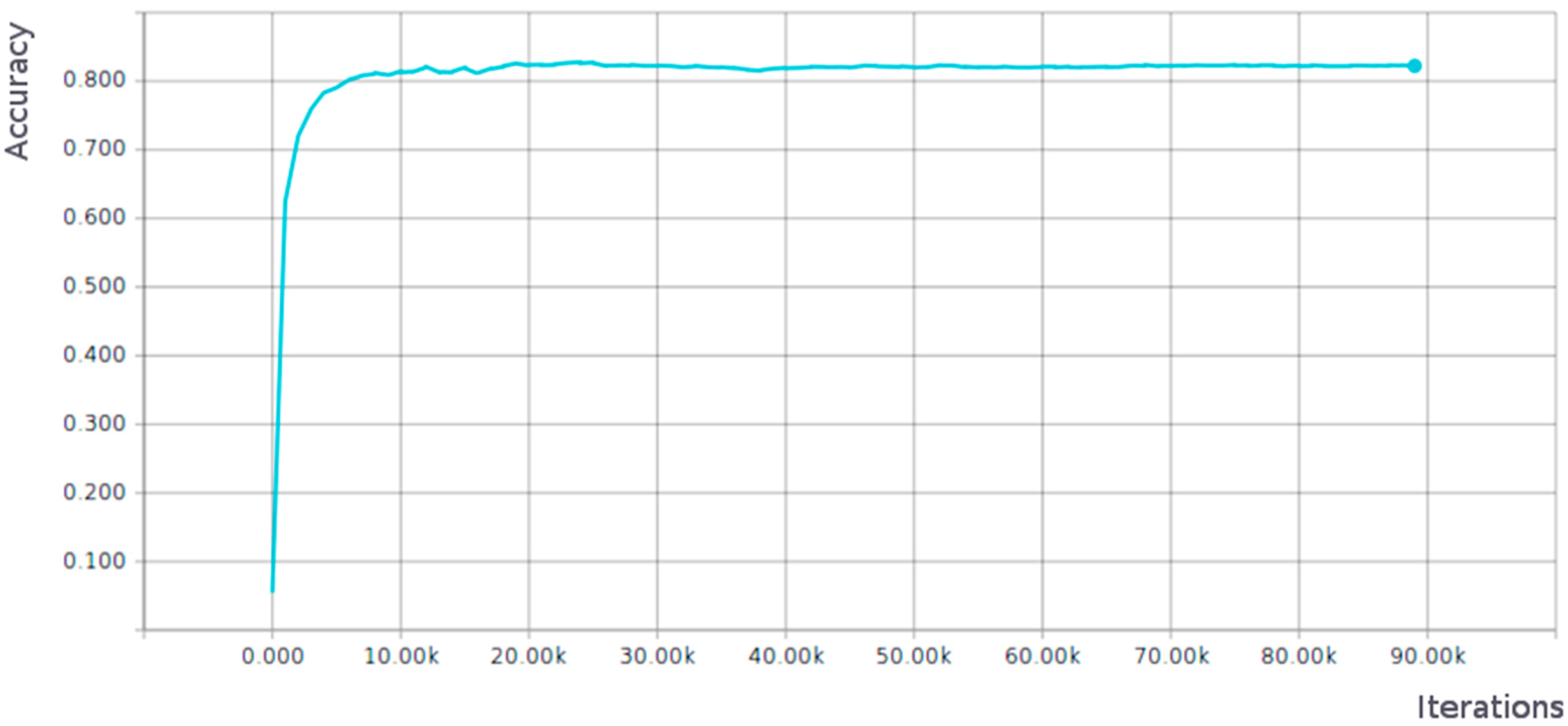
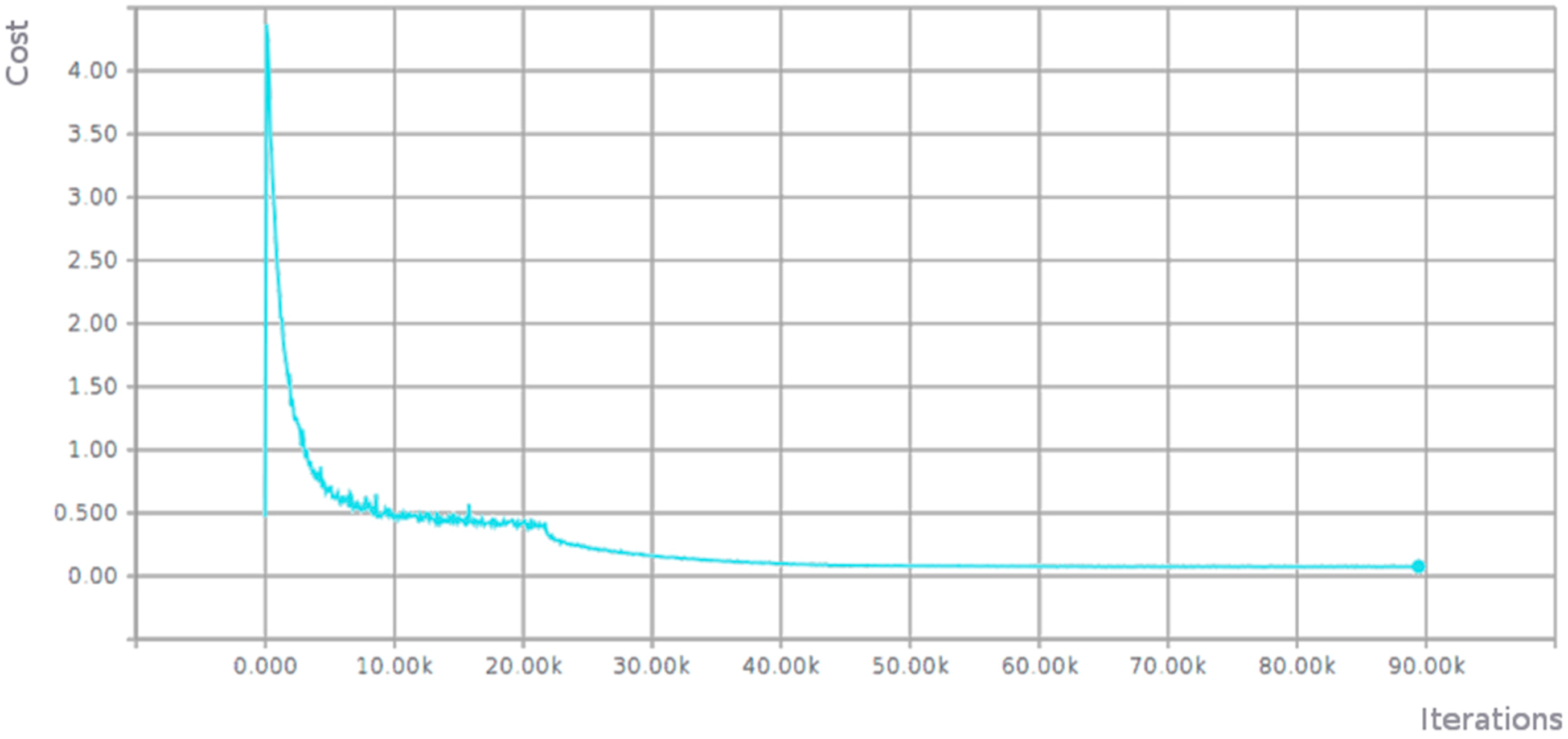
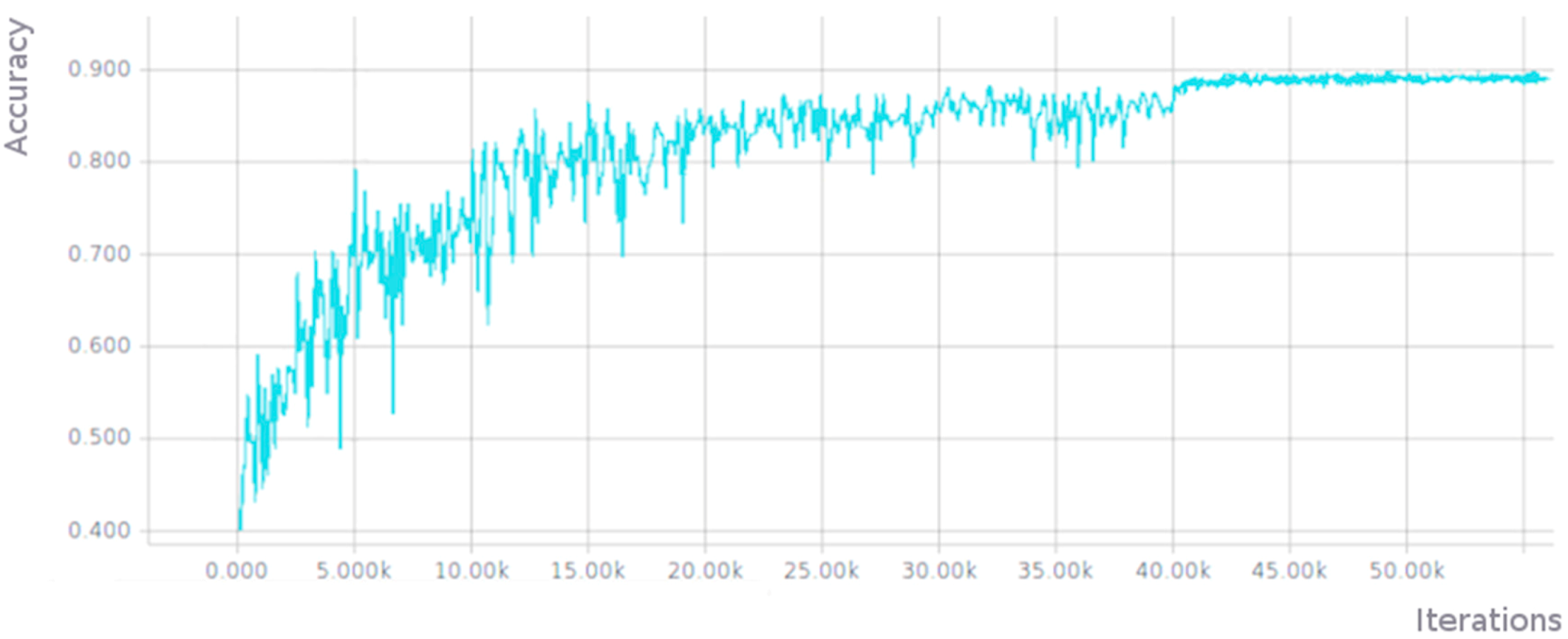
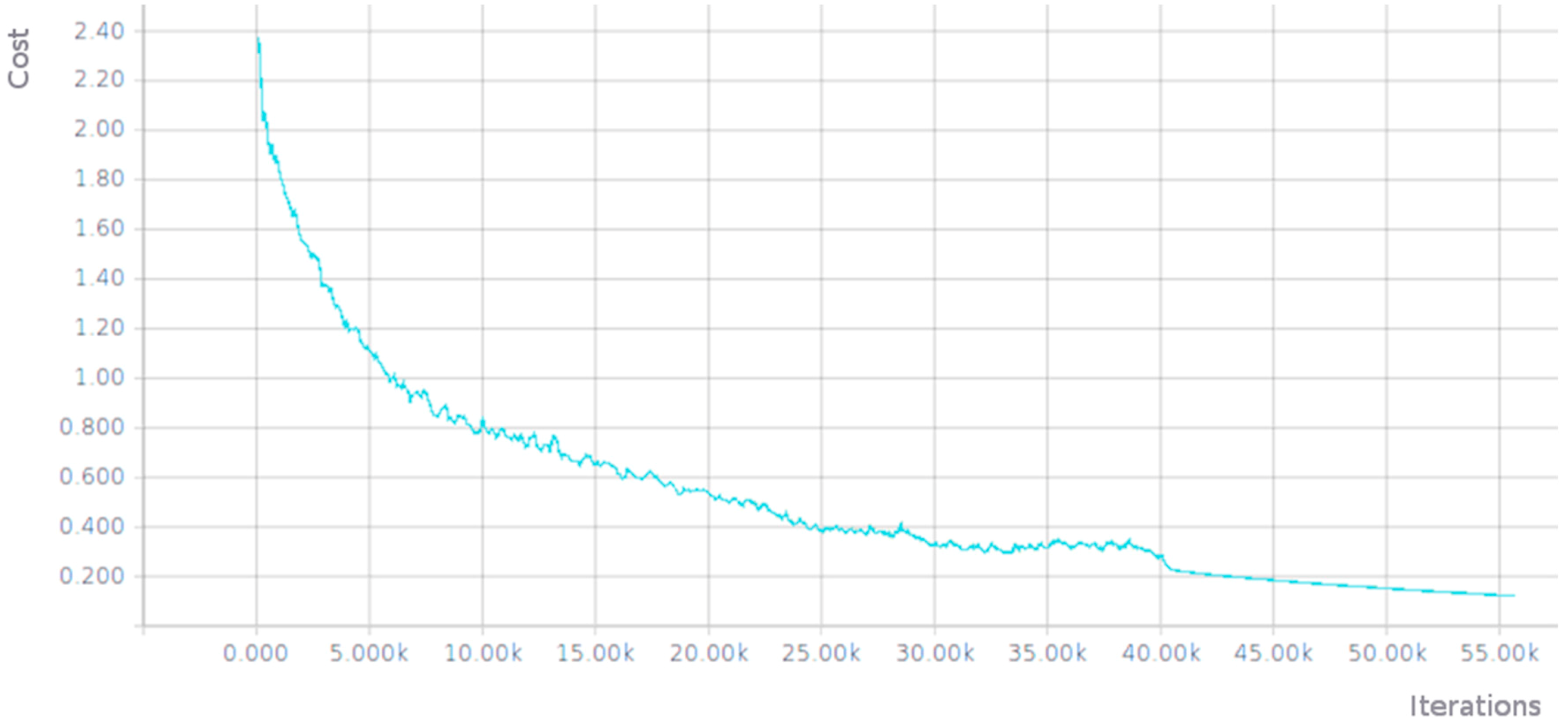
3.1.1. Full Training of AlexNet Network
3.1.2. Fine-Tuning of an Inception V3 Network
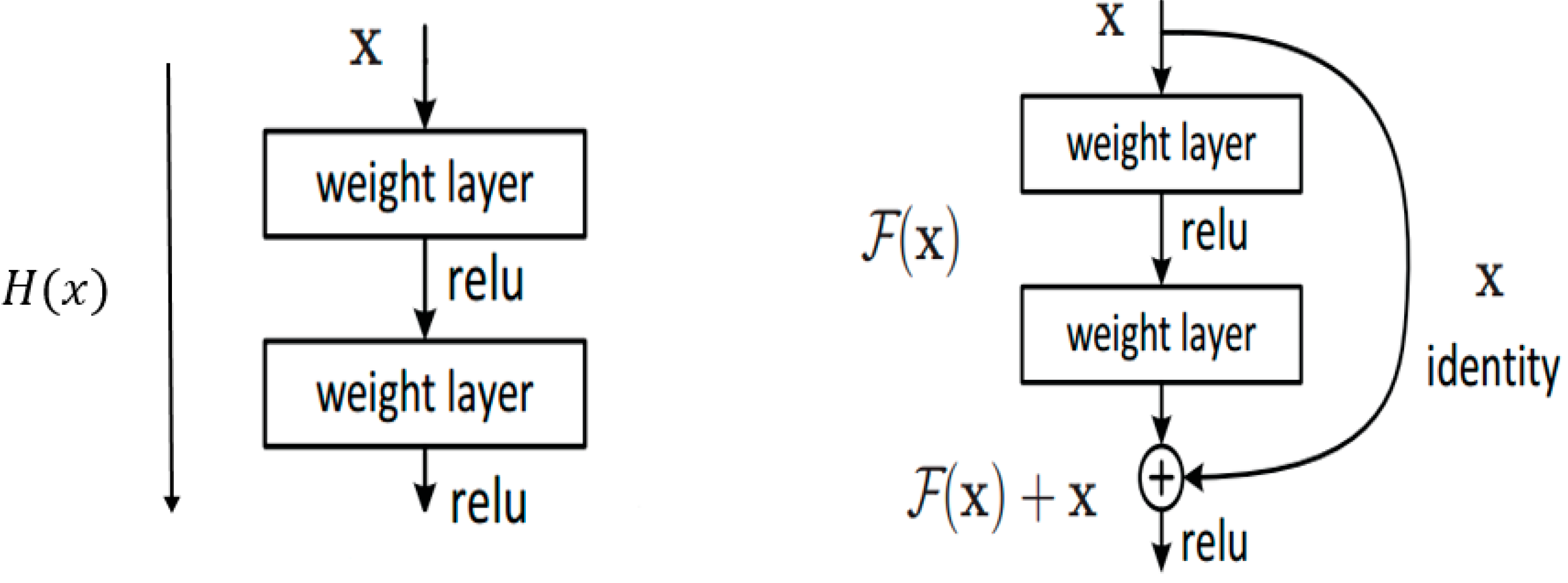
3.2. Residual Networks (ResNet and Inception-ResNet-v2)
3.2.1. Full Training of a Residual Network (ResNet)
3.2.2. Fine Tuning a Residual Network (Inception-ResNet-v2)
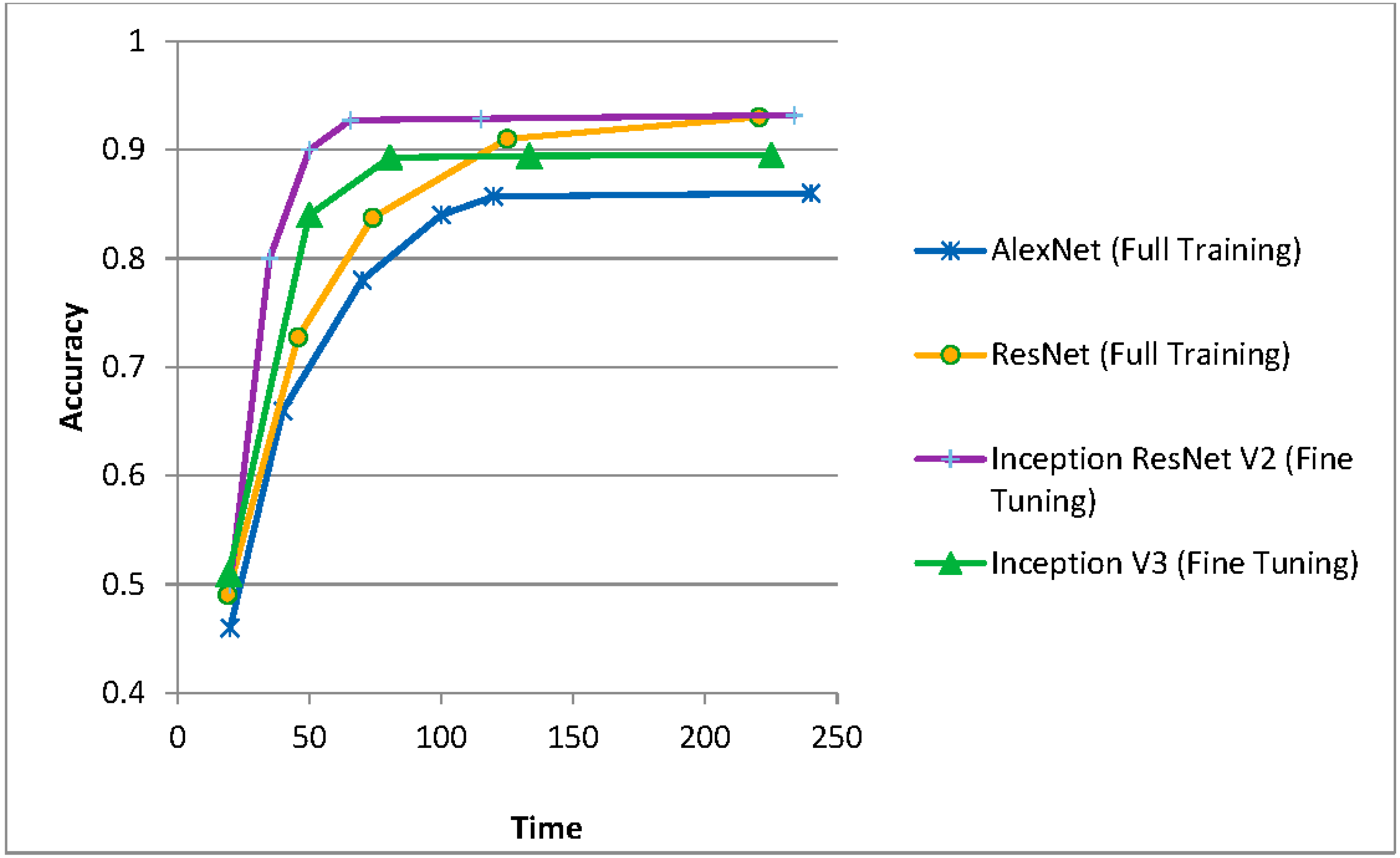
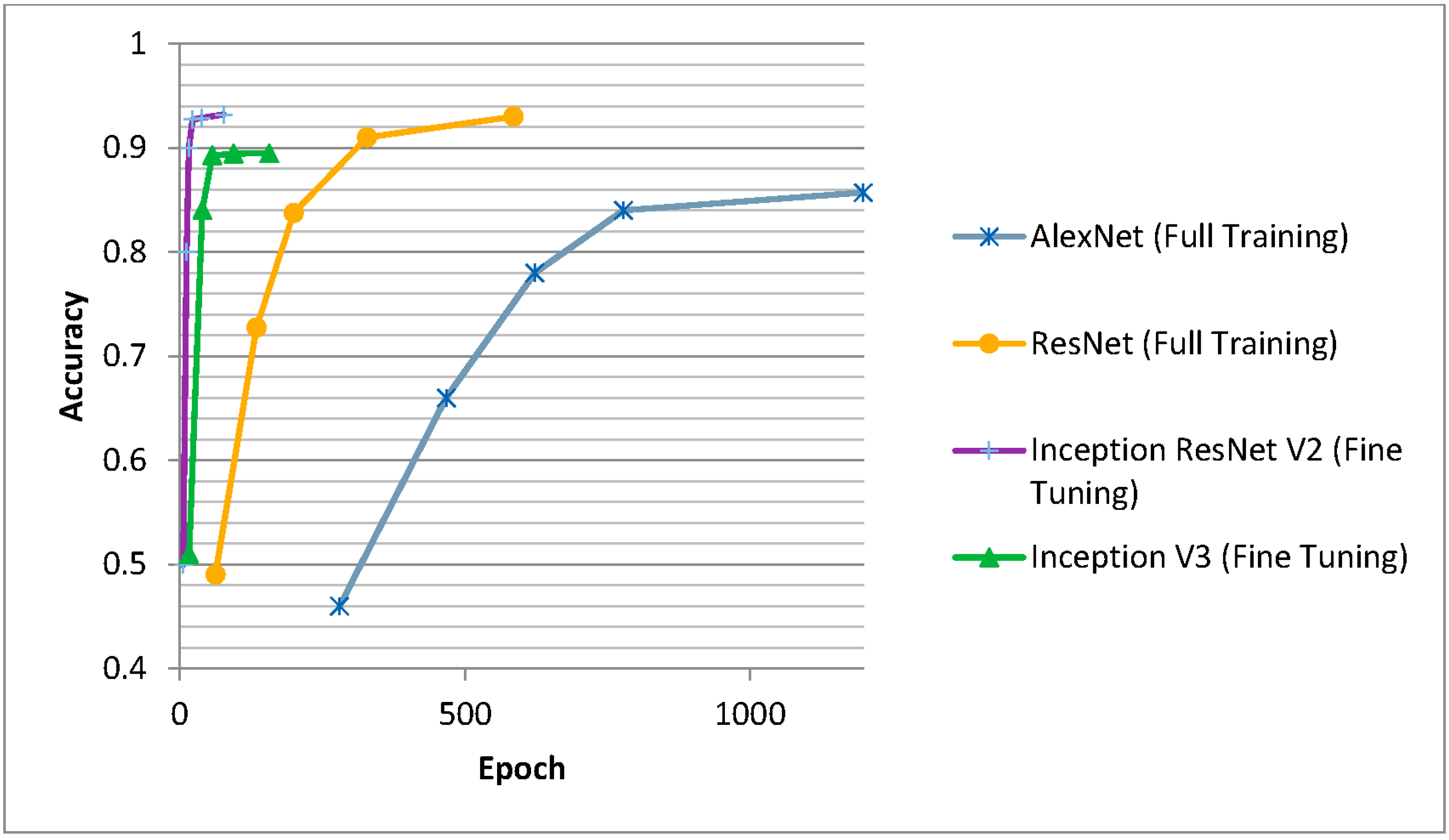
3.3. Comparison of the Results
3.3.1. Failures Detected Using CNNs in Image Classification
3.3.2. Comparison with Other Methods
4. Discussion
5. Conclusions
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Letellier, R.; Schmid, W.; LeBlanc, F. Recording, Documentation, and Information Management for the Conservation of Heritage Places: Guiding Principles; Routledge: London, UK; New York, NY, USA, 2007. [Google Scholar]
- Remondino, F. Heritage Recording and 3D Modeling with Photogrammetry. Remote Sens. 2011, 3, 1104–1138. [Google Scholar] [CrossRef]
- CIPA Heritage Documentation. Available online: http://cipa.icomos.org/ (accessed on 25 September 2017).
- ICOMOS, International Council on Monuments & Sites. Available online: http://www.icomos.org/ (accessed on 25 September 2017).
- ISPRS, International Society of Photogrammetry and Remote Sensing. Available online: http://www.isprs.org/ (accessed on 25 September 2017).
- Beck, L. Digital Documentation in the Conservation of Cultural Heritage: Finding the Practical in best Practice. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2013, XL-5/W2, 85–90. [Google Scholar] [CrossRef]
- Hassani, F.; Moser, M.; Rampold, R.; Wu, C. Documentation of cultural heritage; techniques, potentials, and constraints. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, XL-5/W7, 207–214. [Google Scholar] [CrossRef]
- López, F.J.; Lerones, P.M.; Llamas, J.; Gómez-García-Bermejo, J.; Zalama, E. A framework for using point cloud data of heritage buildings towards geometry modeling in a BIM context: A case study on Santa Maria la Real de Mave Church. Int. J. Archit. Heritage 2017, 11. [Google Scholar] [CrossRef]
- Apollonio, F.I.; Giovannini, E.C. A paradata documentation methodology for the Uncertainty Visualization in digital reconstruction of CH artifacts. SCIRES-IT 2015, 5, 1–24. [Google Scholar]
- Di Giulio, R.; Maietti, F.; Piaia, E.; Medici, M.; Ferrari, F.; Turillazzi, B. Integrated Data Capturing Requirements for 3d Semantic Modelling of Cultural Heritage: The INCEPTION Protocol. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, XLII-2/W3, 251–257. [Google Scholar] [CrossRef]
- Oses, N.; Dornaika, F.; Moujahid, A. Image-based delineation and classification of built heritage masonry. Remote Sens. 2014, 6, 1863–1889. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-Based Convolutional Networks for Accurate Object Detection and Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 142–158. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Cireşan, D.; Meier, U.; Schmidhuber, J. Multi-column deep neural networks for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. arXiv, 2015; arXiv:1512.03385. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Toshev, A.; Erhan, D. Deep neural networks for object detection. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 2553–2561. [Google Scholar]
- Mnih, V.; Hinton, G. Learning to Label Aerial Images from Noisy Data. In Proceedings of the 29th International Conference on Machine Learning (ICML-12), Edinburgh, UK, 27 June–3 July 2012; pp. 567–574. [Google Scholar]
- Gao, F.; Huang, T.; Wang, J.; Sun, J.; Hussain, A.; Yang, E. Dual-Branch Deep Convolution Neural Network for Polarimetric SAR Image Classification. Appl. Sci. 2017, 7, 447. [Google Scholar] [CrossRef]
- Tajbakhsh, N.; Shin, J.; Gurudu, S.; Hurst, R.; Kendall, C.; Gotway, M.; Liang, J. Convolutional Neural Networks for Medical Image Analysis: Full Training or Fine Tuning? IEEE Trans. Med. Imaging 2016, 35, 1299–1312. [Google Scholar] [CrossRef] [PubMed]
- Gao, Y.; Lee, H.J. Local Tiled Deep Networks for Recognition of Vehicle Make and Model. Sensors 2016, 16, 226. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Min, X.; Sun, S.; Lin, W.; Tang, Z. DeepGait: A Learning Deep Convolutional Representation for View-Invariant Gait Recognition Using Joint Bayesian. Appl. Sci. 2017, 7, 210. [Google Scholar] [CrossRef]
- Pedraza, A.; Bueno, G.; Deniz, O.; Cristóbal, G.; Blanco, S.; Borrego-Ramos, M. Automated Diatom Classification (Part B): A Deep Learning Approach. Appl. Sci. 2017, 7, 460. [Google Scholar] [CrossRef]
- Liu, L.; Wang, H.; Wu, C. A machine learning method for the large-scale evaluation of urban visual environment. arXiv, 2016; arXiv:1608.03396. [Google Scholar]
- Sa, I.; Ge, Z.; Dayoub, F.; Upcroft, B.; Perez, T.; McCool, C. DeepFruits: A Fruit Detection System Using Deep Neural Networks. Sensors 2016, 16, 1222. [Google Scholar] [CrossRef] [PubMed]
- Chu, W.-T.; Tsai, M.-H. Visual pattern discovery for architecture image classification and product image search. In Proceedings of the 2nd ACM International Conference on Multimedia Retrieval, Hong Kong, China, 5–8 June 2012. [Google Scholar]
- Goel, A.; Juneja, M.; Jawahar, C.V. Are buildings only instances?: Exploration in architectural style categories. In Proceedings of the Eighth Indian Conference on Computer Vision, Graphics and Image Processing, Mumbai, India, 16–19 December 2012. [Google Scholar]
- Mathias, M.; Martinovic, A.; Weissenberg, J.; Haegler, S.; Van Gool, L. Automatic Architectural Style Recognition. In Proceedings of the 4th ISPRS International Workshop 3D-ARCH 2011, Trento, Italy, 2–4 March 2011; Volume XXXVIII-5/W16, pp. 171–176. [Google Scholar]
- Shalunts, G.; Haxhimusa, Y.; Sablatni, R. Architectural Style Classification of Building Facade Windows. In Advances in Visual Computing 6939; Springer: Las Vegas, NV, USA, 2011; pp. 280–289. [Google Scholar]
- Zhang, L.; Song, M.; Liu, X.; Sun, L.; Chen, C.; Bu, J. Recognizing architecture styles by hierarchical sparse coding of blocklets. Inf. Sci. 2014, 254, 141–154. [Google Scholar] [CrossRef]
- Xu, Z.; Tao, D.; Zhang, Y.; Wu, J.; Tsoi, A.C. Architectural Style Classification Using Multinomial Latent Logistic Regression. In Computer Vision—ECCV 2014; Springer: Cham, Switzerland, 2014; Volume 8689, pp. 600–615. [Google Scholar]
- Llamas, J.; Lerones, P.; Zalama, E.; Gómez García -Bermejo, J. Applying Deep Learning Techniques to Cultural Heritage Images within the INCEPTION Project. In EuroMed 2016: Digital Heritage. Progress in Cultural Heritage: Documentation, Preservation, and Protection. Part I, Nicosia, Cyprus, 31 October–5 November 2016; Springer: Cham, Switzerland, 2016; Volume 10059, pp. 25–32. [Google Scholar]
- Lu, Y. Food Image Recognition by Using Convolutional Neural Networks (CNNs). arXiv, 2016; arXiv:1612.00983. [Google Scholar]
- Yanai, K.; Kawano, Y. Food image recognition using deep convolutional network with pre-training and fine-tuning. In Proceedings of the IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Turin, Italy, 29 June–3 July 2015; pp. 1–6. [Google Scholar]
- Datahub. Available online: https://datahub.io (accessed on 25 September 2017).
- Liang, H.; Li, Q. Hyperspectral Imagery Classification Using Sparse Representations of Convolutional Neural Network Features. Remote Sens. 2016, 8, 99. [Google Scholar] [CrossRef]
- Bengio, Y. Deep Learning of Representations for Unsupervised and Transfer Learning. In Proceedings of the ICML Workshop on Unsupervised and Transfer Learning, Bellevue, WA, USA, 2 July 2011; Volume 27, pp. 17–36. [Google Scholar]
- YFCC100m. In: Yahoo Flickr Creative Commons 100 Million Dataset. Available online: http://www.yfcc100m.org/ (accessed on 25 September 2017).
- Getty Art & Architecture Thesaurus (AAT). Available online: http://www.getty.edu/research/tools/vocabularies/aat/about.html (accessed on 25 September 2017).
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- ImageNet. Available online: http://www.image-net.org (accessed on 25 September 2017).
- MIT Places. Available online: http://places.csail.mit.edu/ (accessed on 25 September 2017).
- Werbos, P. Applications of advances in nonlinear sensitivity analysis. In Proceedings of the 10th IFIP Conference, New York, NY, USA, 31 August–4 September 1981; pp. 762–770. [Google Scholar]
- Rumelhart, D.; Hinton, G.; Williams, R. Learning internal representations by error propagation. Parallel Distrib. Process. 1986, 1, 318–362. [Google Scholar]
- Dundar, A.; Jin, J.; Culurciello, E. Convolutional Clustering for Unsupervised Learning. arXiv, 2015; arXiv:1511.06241. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-scale machine learning on heterogeneous systems. arXiv, 2016; arXiv:1603.04467. [Google Scholar]
- Bengio, Y. Practical recommendations for gradient-based training of deep architectures. arXiv, 2012; arXiv:1206.5533. [Google Scholar]
- Bottou, L. Stochastic Gradient Descent Tricks. In Neural Networks, Tricks of the Trade, Reloaded 7700; Springer: Berlin/Heidelberg, Germany, 2012; pp. 430–445. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Berg, A.C. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. arXiv, 2015; arXiv:1512.00567. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. arXiv, 2016; arXiv:1602.07261. [Google Scholar]
- Canziani, A.; Paszke, A.; Culurciello, E. An Analysis of Deep Neural Network Models for Practical Applications. arXiv, 2016; arXiv:1605.07678. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Examples |
|---|---|
| Altar (829 images) |  |
| Apse (514 images) |  |
| Bell tower (1059 images) |  |
| Column (1919 images) |  |
| Dome (inner) (616 images) |  |
| Dome (outer) (1177 images) |  |
| Flying buttress (407 images) |  |
| Gargoyle (and Chimera) (1571 images) |  |
| Stained glass (1033 images) |  |
| Vault (1110 images) |  |
| Momentum | Initial Learning Rate | Learning Rate Decay Factor | Moving Average Decay | Number of Epochs Per Decay | Weight Decay | Batch Size |
|---|---|---|---|---|---|---|
| 0.9 | 0.1 | 0.1 | 0.9999 | 350 | 0.0005 | 128 |
| Momentum | Initial Learning Rate | Decay | Number of Epochs Per Decay | Weight Decay Rate | End Learning Rate | Batch Size |
|---|---|---|---|---|---|---|
| 0.9 | 0.01 | 0.94 | 2 | 0.00004 | 0.0001 | 32 |
| Momentum | Initial Learning Rate | Learning Rate Decay Factor | Number of Epochs Per Decay | Weight Decay Rate | End Learning Rate | Batch Size |
|---|---|---|---|---|---|---|
| 0.9 | 0.1 | 1/10 every 15,000 iter | 2 | 0.0002 | 0.0001 | 128 |
| Momentum | Initial Learning Rate | Decay | Number of Epochs Per Decay | Weight Decay Rate | End Learning Rate | Batch Size |
|---|---|---|---|---|---|---|
| 0.9 | 0.01 | 0.94. | 2 | 0.00004 | 0.0001 | 32 |
| Algorithm | Image Size | Accuracy | Epoch |
|---|---|---|---|
| AlexNet (Full Training) | 32 × 32 | 0.823 | 1400 |
| AlexNet (Full Training) | 64 × 64 | 0.857 | 1198 |
| ResNet (Full Training) | 32 × 32 | 0.896 | 949 |
| ResNet (Full Training) | 64 × 64 | 0.93 | 585 |
| Inception V3 (Fine Tuning) | 64 × 64 | 0.8943 | 93 |
| Inception V3 (Fine Tuning) | 128 × 128 | 0.9155 | 88 |
| Inception-ResNet-v2 (Fine Tuning) | 64 × 64 | 0.9103 | 82 |
| Inception-ResNet-v2 (Fine Tuning) | 128 × 128 | 0.9319 | 77 |
| Category | Altar | Apse | Bell Tower | Column | Dome (Inner) | Dome (Outer) | Flying Buttress | Gargoyle | Stained Glass | Vault | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Altar | 0.935 | 0.000 | 0.014 | 0.005 | 0.000 | 0.000 | 0.000 | 0.006 | 0.000 | 0.030 |  |
| Apse | 0.000 | 0.906 | 0.036 | 0.005 | 0.000 | 0.009 | 0.045 | 0.003 | 0.000 | 0.000 | |
| Bell tower | 0.000 | 0.000 | 0.886 | 0.003 | 0.000 | 0.013 | 0.000 | 0.036 | 0.000 | 0.000 | |
| Column | 0.028 | 0.000 | 0.014 | 0.965 | 0.000 | 0.004 | 0.015 | 0.022 | 0.000 | 0.030 | |
| Dome (inner) | 0.000 | 0.000 | 0.000 | 0.000 | 0.992 | 0.009 | 0.000 | 0.006 | 0.000 | 0.013 | |
| Dome (outer) | 0.000 | 0.063 | 0.032 | 0.000 | 0.000 | 0.964 | 0.000 | 0.022 | 0.000 | 0.000 | |
| Flying buttress | 0.000 | 0.031 | 0.018 | 0.013 | 0.000 | 0.000 | 0.896 | 0.025 | 0.000 | 0.004 | |
| Gargoyle | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.045 | 0.866 | 0.000 | 0.004 | |
| Stained glass | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.003 | 0.995 | 0.009 | |
| Vault | 0.037 | 0.000 | 0.000 | 0.008 | 0.008 | 0.000 | 0.000 | 0.011 | 0.005 | 0.909 |
| Measure | Altar | Apse | Bell Tower | Column | Dome (Inner) | Dome (Outer) | Flying Buttress | Gargoyle | Stained Glass | Vault |
|---|---|---|---|---|---|---|---|---|---|---|
| Recall (Sensitivity) | 0.878 | 0.845 | 0.920 | 0.940 | 0.944 | 0.911 | 0.732 | 0.987 | 0.986 | 0.941 |
| Precision | 0.935 | 0.906 | 0.886 | 0.965 | 0.992 | 0.964 | 0.896 | 0.866 | 0.995 | 0.909 |
| Specificity | 0.996 | 0.995 | 0.986 | 0.992 | 0.999 | 0.995 | 0.996 | 0.972 | 0.999 | 0.988 |
| Balanced accuracy | 0.937 | 0.920 | 0.953 | 0.966 | 0.972 | 0.953 | 0.864 | 0.979 | 0.992 | 0.965 |
| F1 score | 0.906 | 0.874 | 0.903 | 0.953 | 0.967 | 0.937 | 0.805 | 0.923 | 0.990 | 0.925 |
| Category | Altar | Apse | Bell Tower | Column | Dome (Inner) | Dome (Outer) | Flying Buttress | Gargoyle | Stained Glass | Vault | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Altar | 0.824 | 0.000 | 0.006 | 0.015 | 0.000 | 0.000 | 0.014 | 0.000 | 0.007 | 0.019 |  |
| Apse | 0.013 | 0.707 | 0.018 | 0.000 | 0.000 | 0.015 | 0.014 | 0.004 | 0.000 | 0.000 | |
| Bell tower | 0.000 | 0.086 | 0.888 | 0.021 | 0.000 | 0.036 | 0.000 | 0.024 | 0.000 | 0.000 | |
| Column | 0.044 | 0.086 | 0.018 | 0.944 | 0.000 | 0.007 | 0.014 | 0.028 | 0.007 | 0.006 | |
| Dome (inner) | 0.013 | 0.000 | 0.000 | 0.000 | 0.952 | 0.000 | 0.000 | 0.012 | 0.000 | 0.025 | |
| Dome (outer) | 0.000 | 0.052 | 0.047 | 0.000 | 0.000 | 0.942 | 0.000 | 0.004 | 0.000 | 0.006 | |
| Flying buttress | 0.006 | 0.000 | 0.012 | 0.005 | 0.000 | 0.000 | 0.914 | 0.008 | 0.000 | 0.000 | |
| Gargoyle | 0.006 | 0.034 | 0.012 | 0.010 | 0.000 | 0.000 | 0.043 | 0.920 | 0.000 | 0.000 | |
| Stained glass | 0.019 | 0.017 | 0.000 | 0.005 | 0.048 | 0.000 | 0.000 | 0.000 | 0.986 | 0.012 | |
| Vault | 0.075 | 0.017 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.932 |
| Measure | Altar | Apse | Bell Tower | Column | Dome (Inner) | Dome (Outer) | Flying Buttress | Gargoyle | Stained Glass | Vault |
|---|---|---|---|---|---|---|---|---|---|---|
| Recall (Sensitivity) | 0.936 | 0.820 | 0.882 | 0.876 | 0.870 | 0.908 | 0.914 | 0.958 | 0.933 | 0.920 |
| Precision | 0.824 | 0.707 | 0.888 | 0.944 | 0.952 | 0.942 | 0.914 | 0.920 | 0.986 | 0.932 |
| Specificity | 0.978 | 0.987 | 0.985 | 0.991 | 0.998 | 0.994 | 0.996 | 0.983 | 0.998 | 0.991 |
| Balanced accuracy | 0.957 | 0.904 | 0.933 | 0.933 | 0.934 | 0.951 | 0.955 | 0.971 | 0.966 | 0.956 |
| F1 score | 0.876 | 0.759 | 0.885 | 0.909 | 0.909 | 0.925 | 0.914 | 0.939 | 0.959 | 0.926 |
 |  |  |  |  |
| Bell tower: 78.22% | Bell tower: 76.94% | Gargoyle: 57.11% | Dome (inner): 70.72% | Apse: 63.61% |
| Dome (outer): 19.39% | Dome (outer): 21.99% | Column: 33.95% | Vault: 27.02% | Column: 36.15% |
| Apse: 2.36% | Gargoyle: 0.71% | Flying buttress: 6.83% | Stained glass: 2.24% | Bell tower: 0.21% |
| Correct Category | Images Incorrectly Classified (and the Corresponding Wrong Categories) | |||
|---|---|---|---|---|
| Altar |  Column |  Stained glass |  Vault | |
| Apse |  Dome (outer) |  Flying buttress |  Altar |  Bell tower |
| Bell tower |  Gargoyle |  Column |  Apse |  Dome(outer) |
| Column |  Altar |  Flying buttress |  Gargoyle |  Stained glass |
| Dome (inner) |  Vault |  Altar | ||
| Dome (outer) |  Bell tower |  Apse | ||
| Flying buttress |  Bell tower |  Gargoyle |  Altar | |
| Gargoyle |  Flying buttress |  Column |  Bell tower | |
| Stained glass |  Altar |  Column | ||
| Vault |  Altar |  Apse | ||
| Algorithm | Image Size | Accuracy | Epoch |
|---|---|---|---|
| MLLR + SP | Different sizes (typically 800 × 600) | 0.4621 | |
| DPM (Deformable part-based model)-LSVM | Different sizes (typically 800 × 600) | 0.3769 | |
| OB (Object bank)-Part | Different sizes (typically 800 × 600) | 0.4541 | |
| SP (Spatial pyramid) | Different sizes (typically 800 × 600) | 0.4452 | |
| Inception V3 (Fine Tuning) | 64 × 64 | 0.5567 | 65 |
| Inception-ResNet-v2 (Fine Tuning) | 64 × 64 | 0.5433 | 116 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Llamas, J.; M. Lerones, P.; Medina, R.; Zalama, E.; Gómez-García-Bermejo, J. Classification of Architectural Heritage Images Using Deep Learning Techniques. Appl. Sci. 2017, 7, 992. https://doi.org/10.3390/app7100992
Llamas J, M. Lerones P, Medina R, Zalama E, Gómez-García-Bermejo J. Classification of Architectural Heritage Images Using Deep Learning Techniques. Applied Sciences. 2017; 7(10):992. https://doi.org/10.3390/app7100992
Chicago/Turabian StyleLlamas, Jose, Pedro M. Lerones, Roberto Medina, Eduardo Zalama, and Jaime Gómez-García-Bermejo. 2017. "Classification of Architectural Heritage Images Using Deep Learning Techniques" Applied Sciences 7, no. 10: 992. https://doi.org/10.3390/app7100992
APA StyleLlamas, J., M. Lerones, P., Medina, R., Zalama, E., & Gómez-García-Bermejo, J. (2017). Classification of Architectural Heritage Images Using Deep Learning Techniques. Applied Sciences, 7(10), 992. https://doi.org/10.3390/app7100992