
Cooling Load Forecasting Method for Central Air Conditioning Systems in Manufacturing Plants Based on iTransformer-BiLSTM


Abstract
1. Introduction
2. Materials and Methods
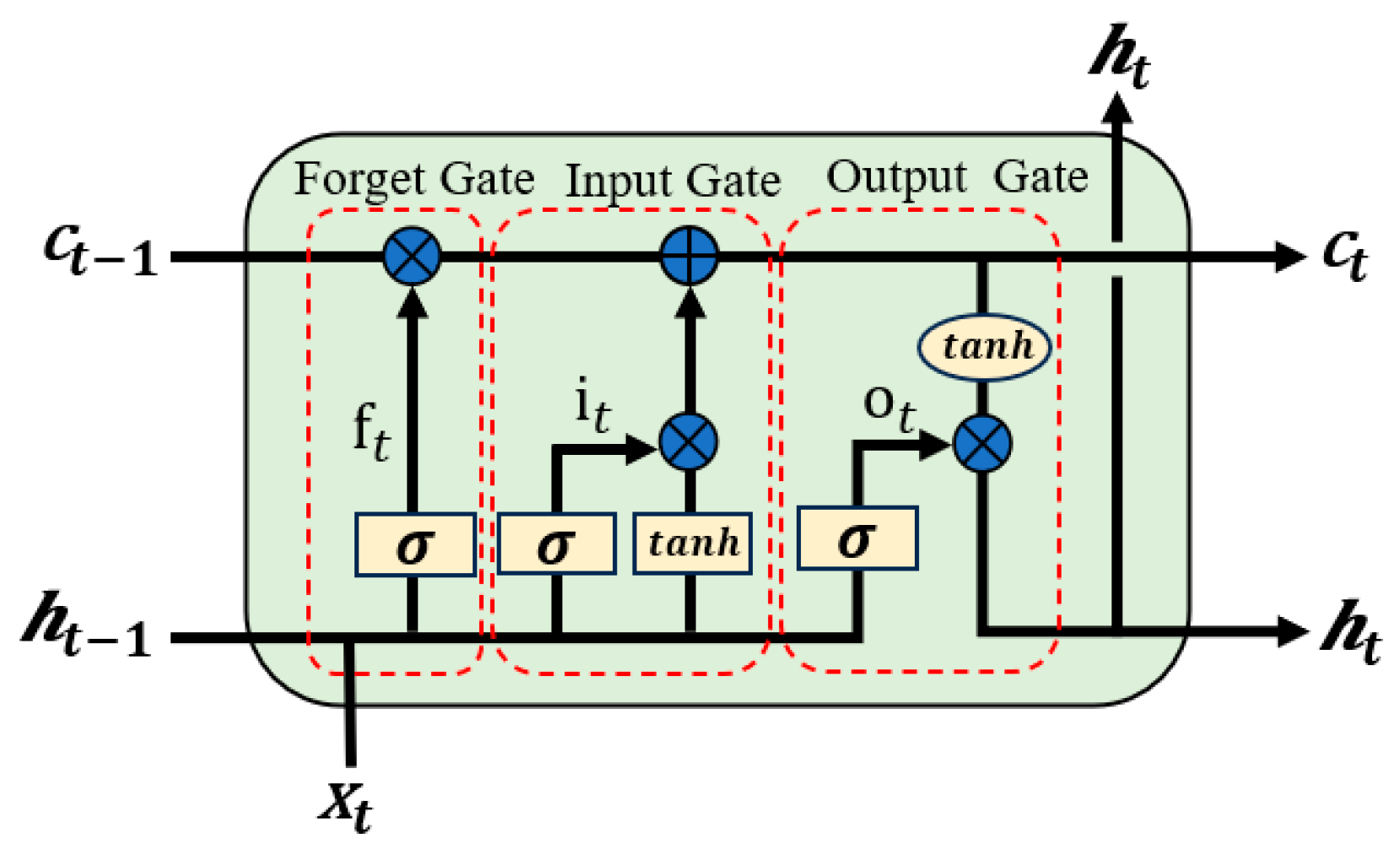
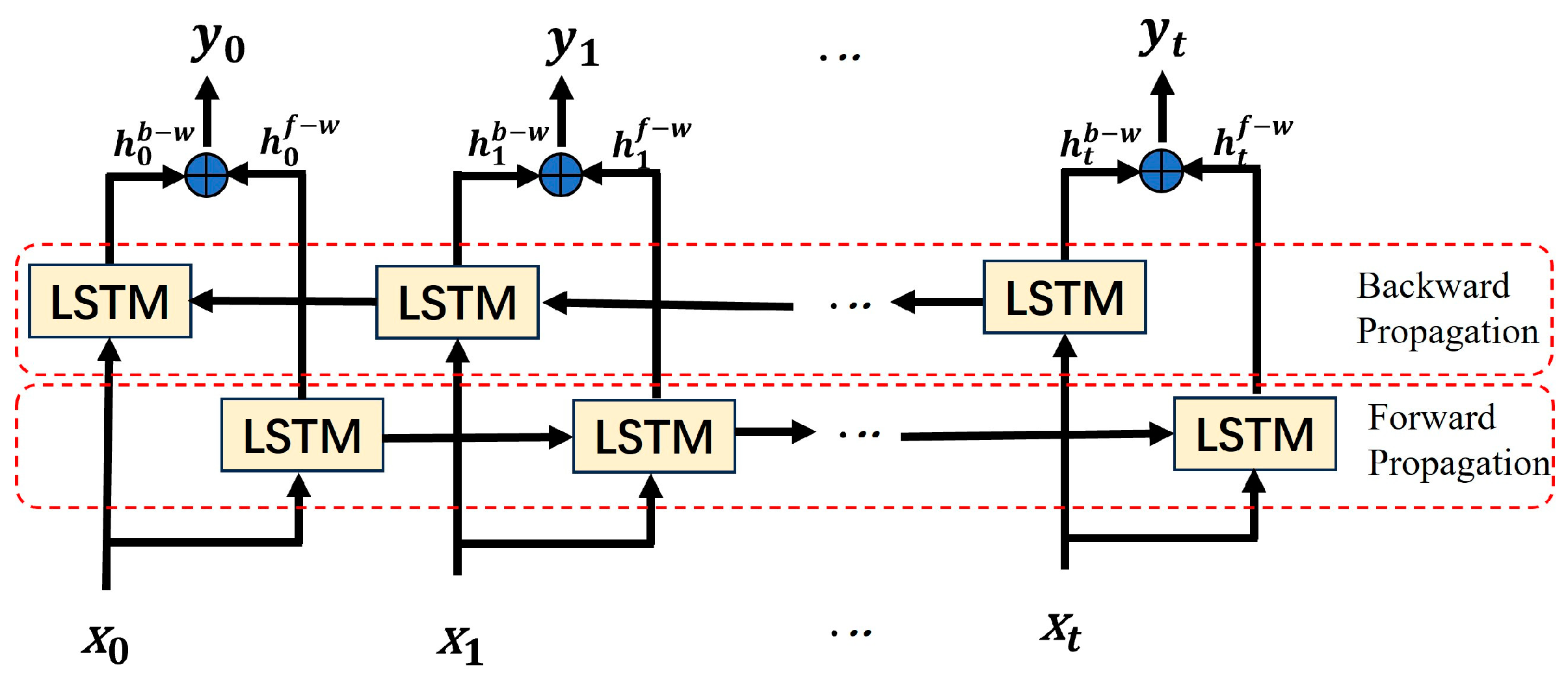
2.1. Bidirectional Long Short-Term Memory Network (BiLSTM) Model
2.2. iTransformer Model
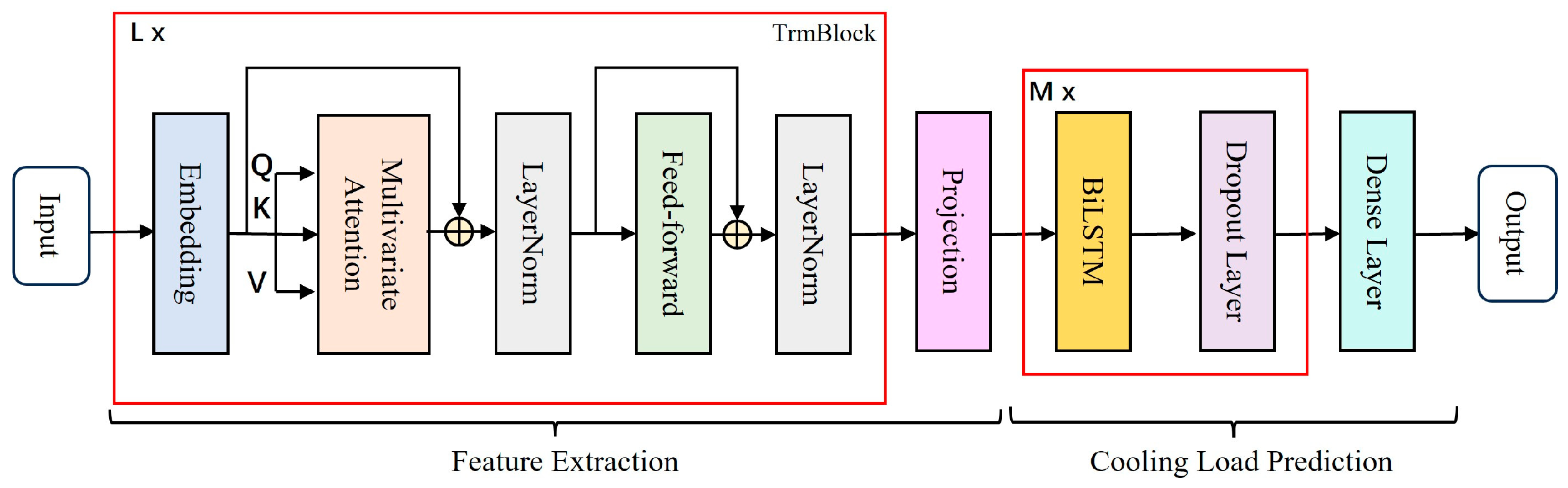
2.3. iTransformer-BiLSTM Prediction Method
3. Case Analysis
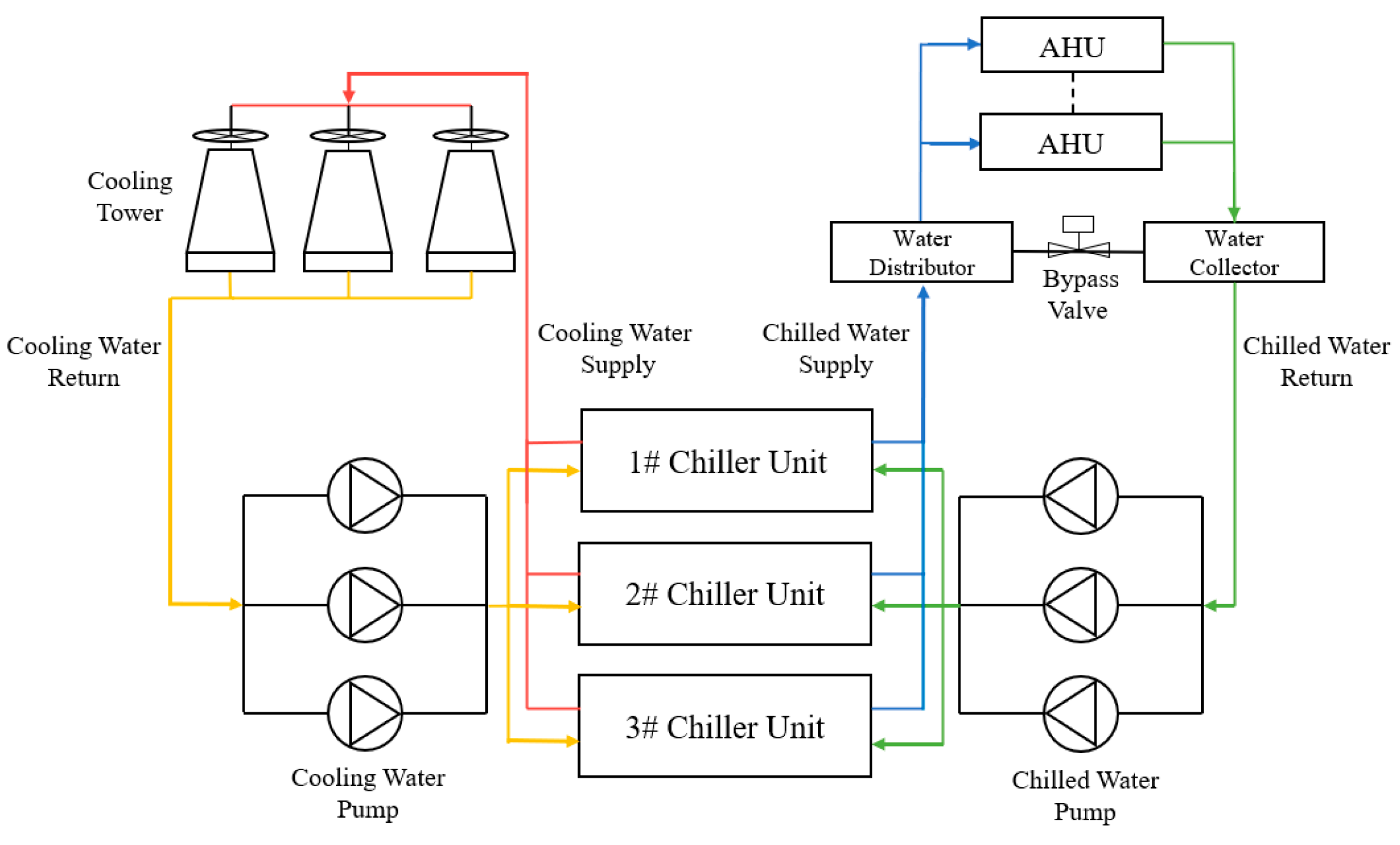
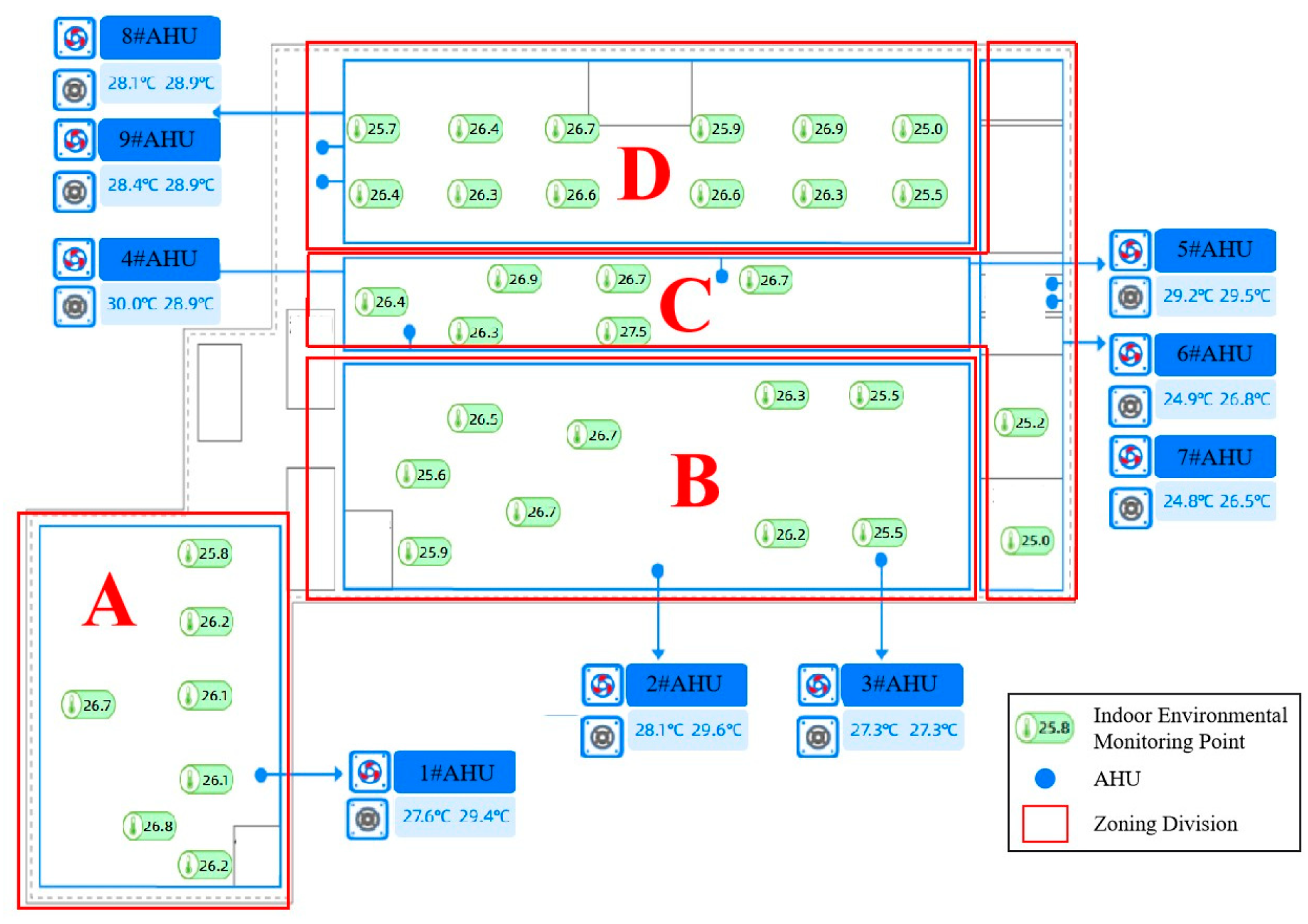
3.1. Research Object
3.2. Data Preprocessing
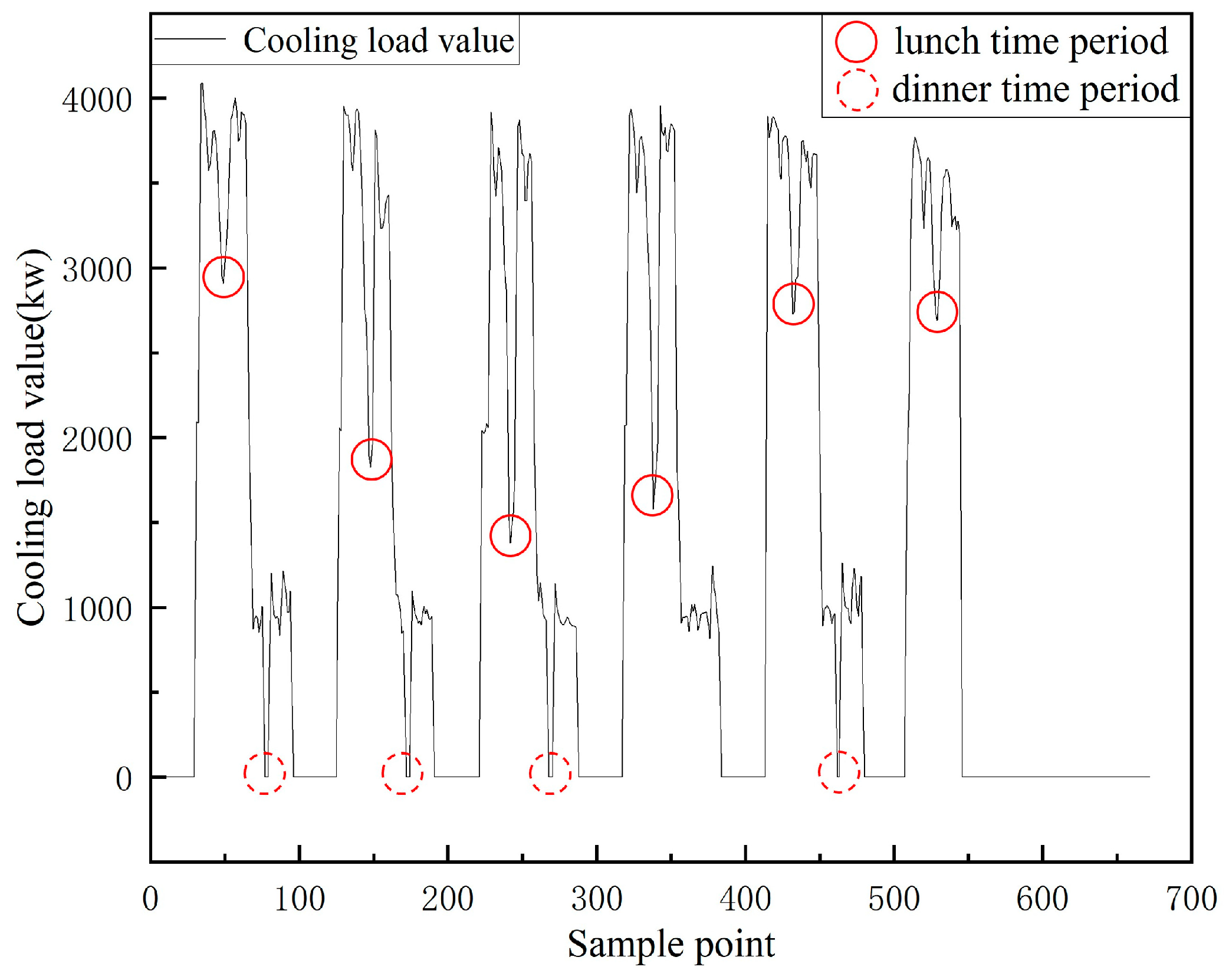
3.3. Analysis of Cooling Load Characteristics and Influencing Factors
3.4. Evaluation and Analysis of Model Prediction Results
3.4.1. Model Evaluation Metrics
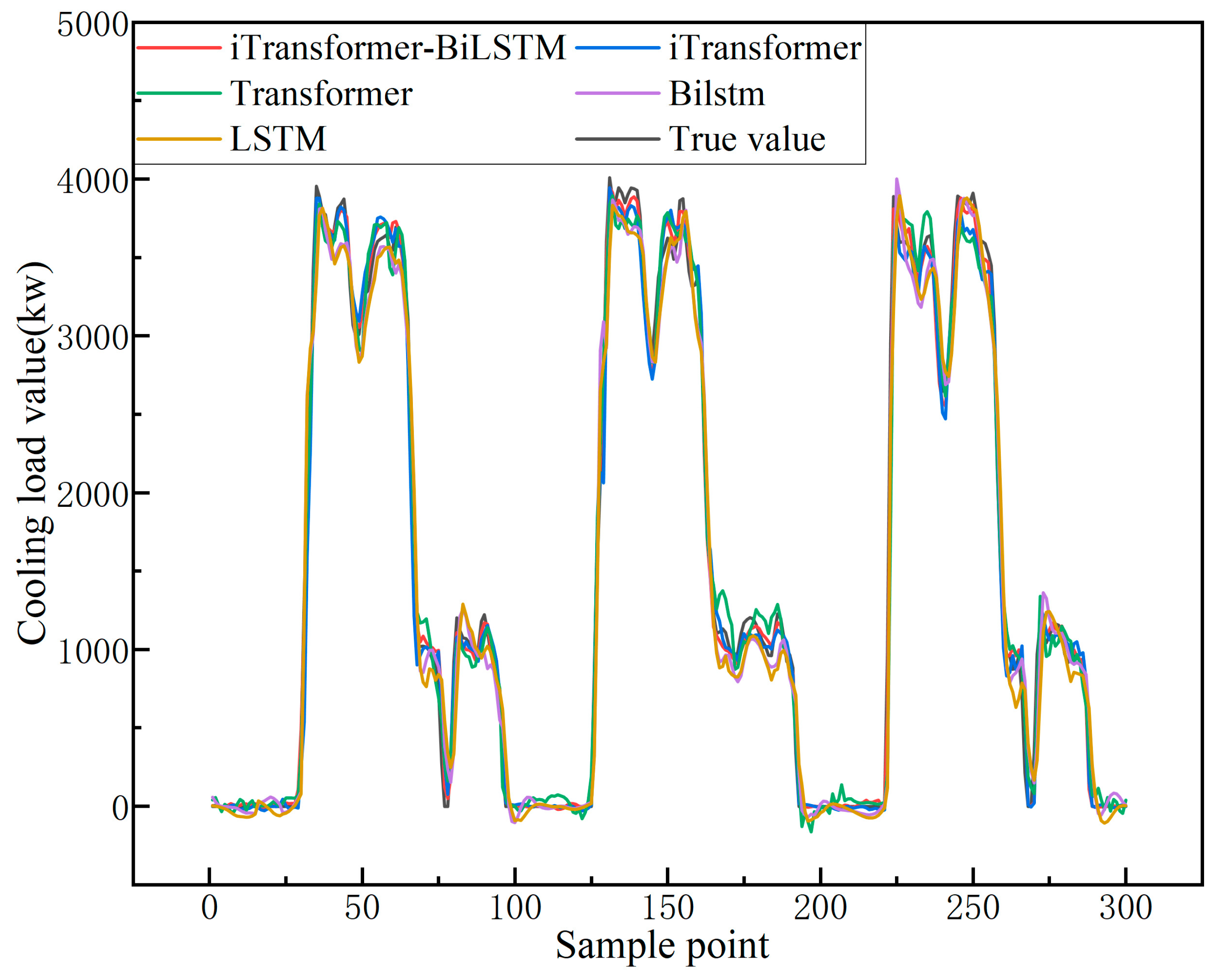
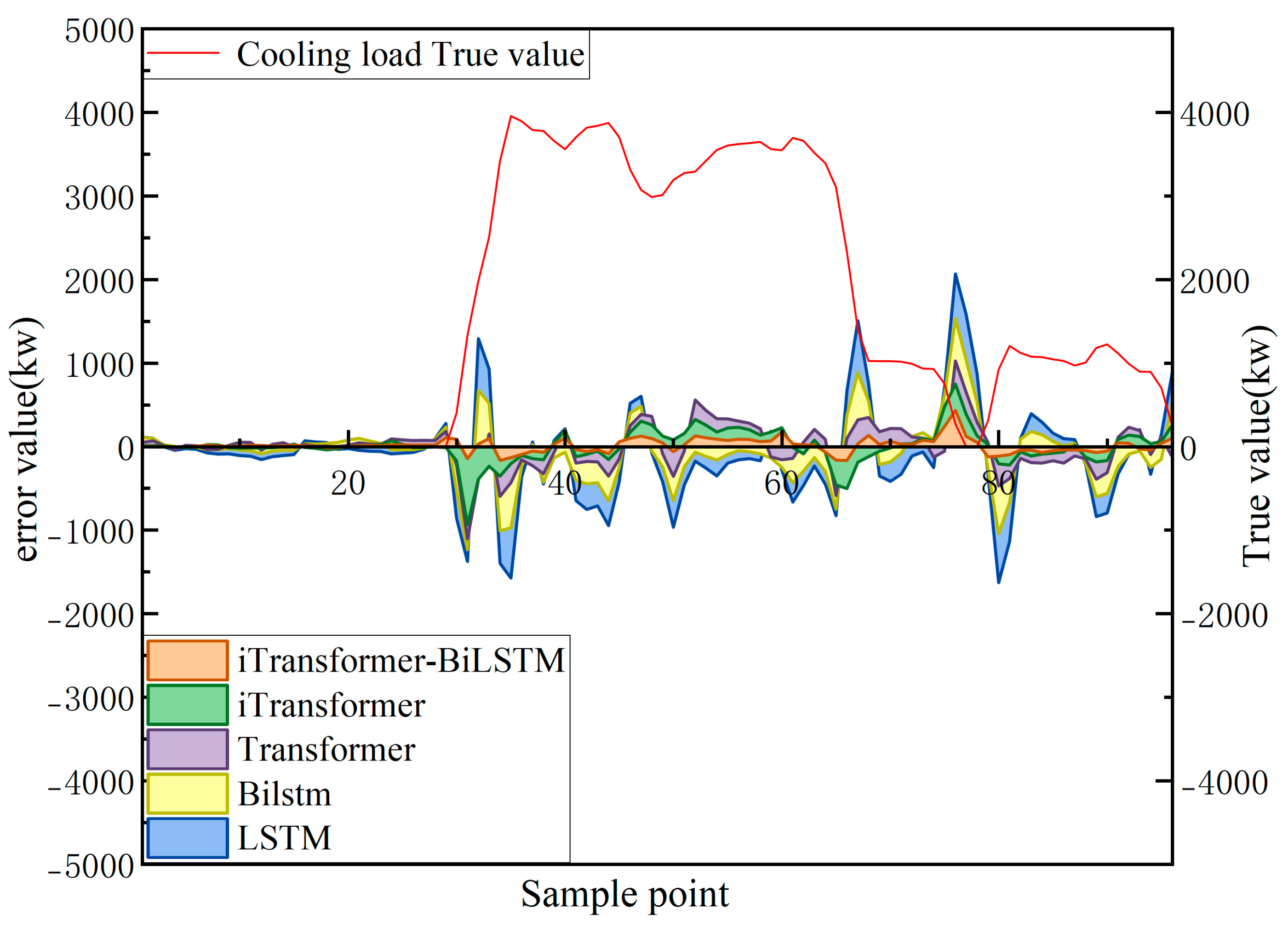
3.4.2. Comparative Analysis of Single Model
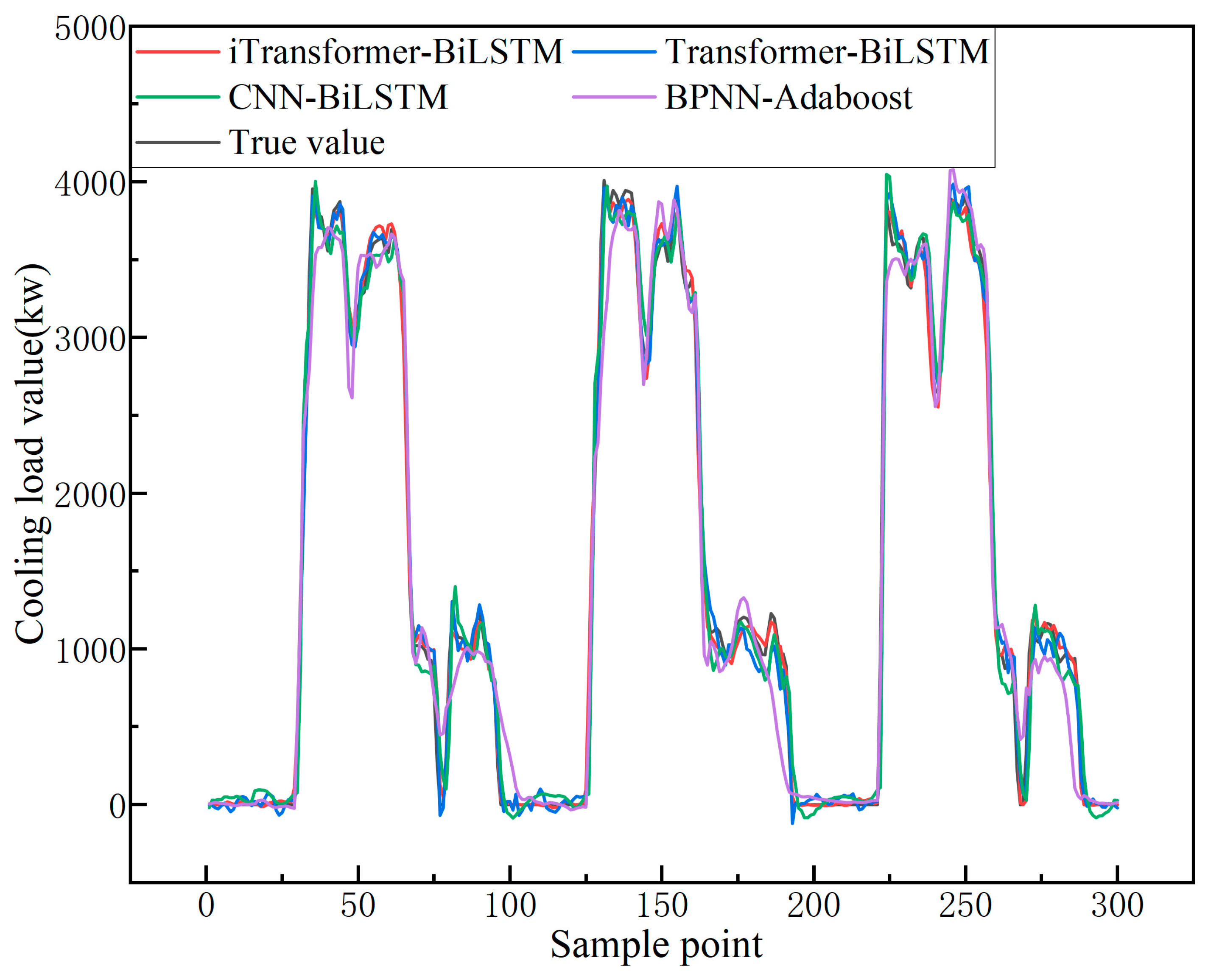
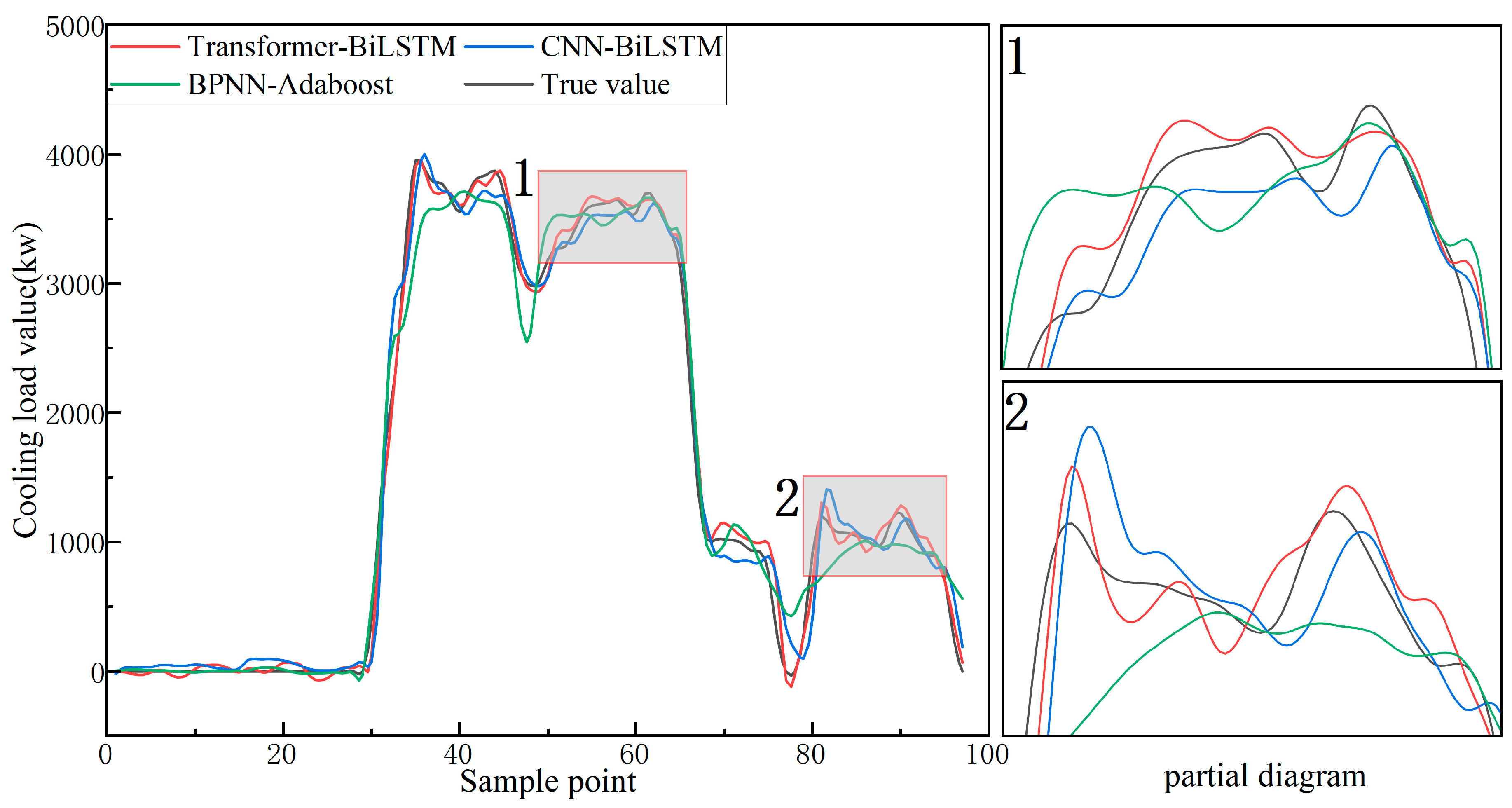
3.4.3. Comparative Analysis with Other Combined Models
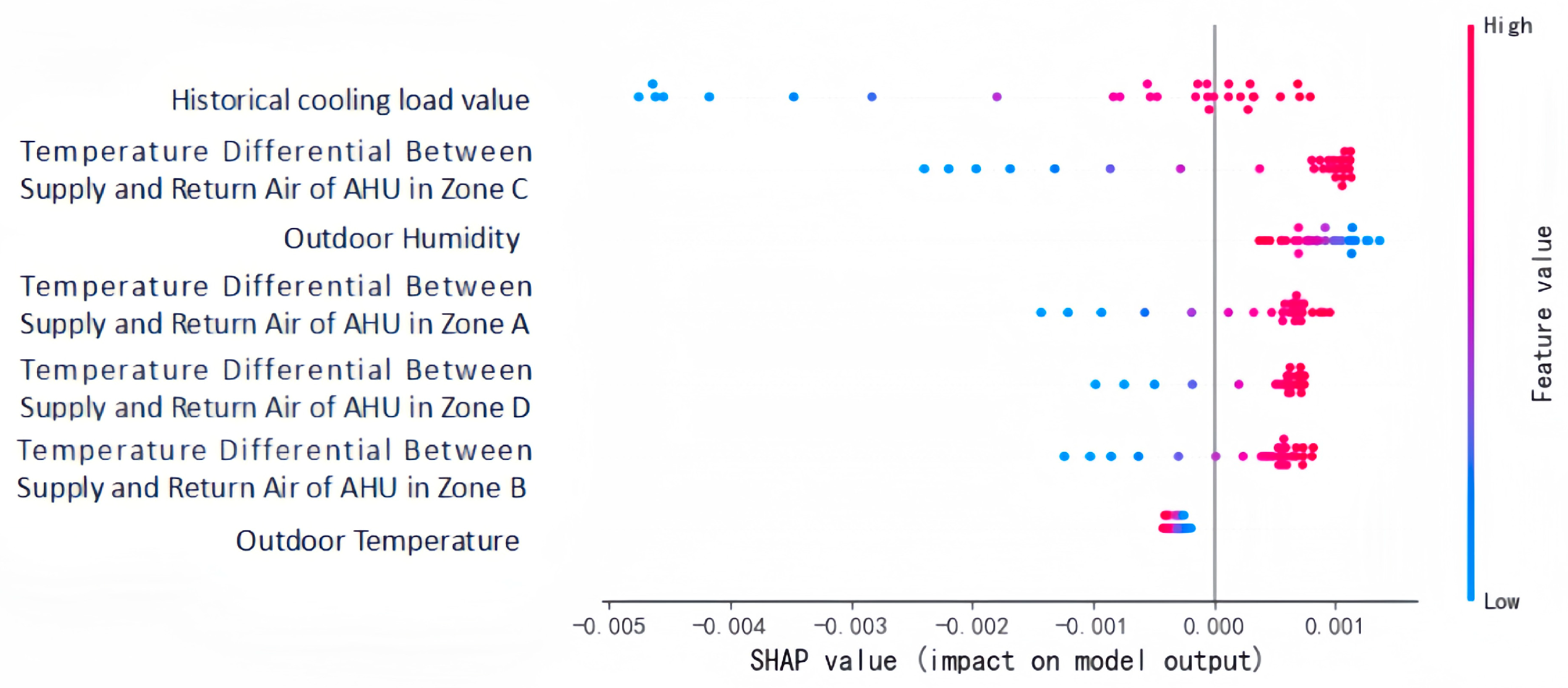
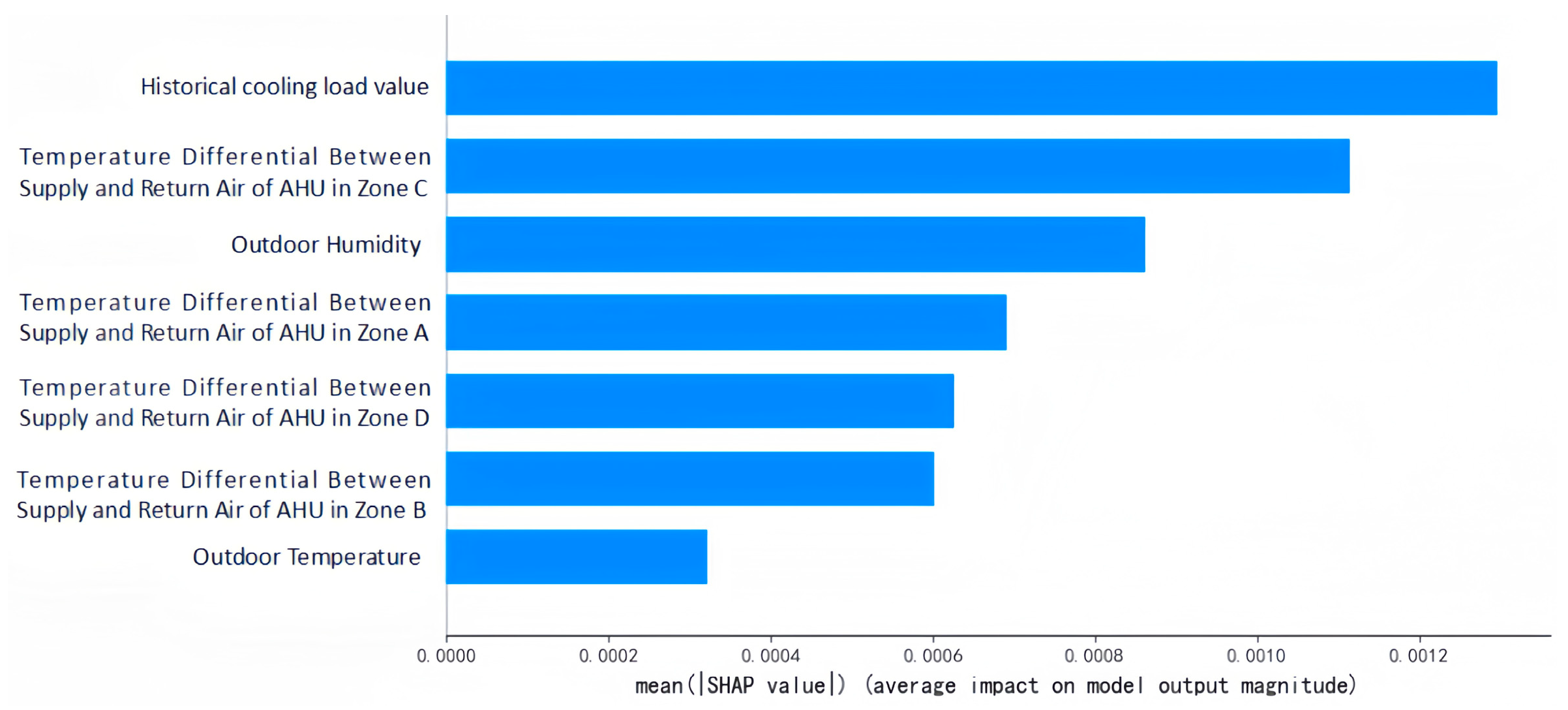
3.4.4. Model Input Variable Sensitivity Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sun, L.; Hu, Z.; Mae, M.; Imaizumi, T. Deep transfer learning strategy based on TimesBlock-CDAN for predicting thermal environment and air conditioner energy consumption in residential buildings. Appl. Energy 2025, 381, 125188. [Google Scholar] [CrossRef]
- Liu, J.; Zhai, Z.; Zhang, Y.; Wang, Y.; Ding, Y. Comparison of energy consumption prediction models for air conditioning at different time scales for large public buildings. J. Build. Eng. 2024, 96, 110423. [Google Scholar] [CrossRef]
- Cen, J.; Zeng, L.; Liu, X.; Wang, F.; Deng, S.; Yu, Z.; Zhang, G.; Wang, W. Research on energy-saving optimization method for central air conditioning system based on multi-strategy improved sparrow search algorithm. Int. J. Refrig. 2024, 160, 263–274. [Google Scholar] [CrossRef]
- Zhang, Q.; Tian, Z.; Ma, Z.; Li, G.; Lu, Y.; Niu, J. Development of the heating load prediction model for the residentia building of district heating based on model calibration. Energy 2020, 205, 117949. [Google Scholar] [CrossRef]
- He, N.; Qian, C.; Liu, L.; Cheng, F. Air conditioning load prediction based on hybrid data decomposition and non-parametric fusion model. J. Build. Eng. 2023, 80, 108095. [Google Scholar] [CrossRef]
- Roy, D.; Chakraborty, T.; Basu, D.; Bhattacharjee, B. Feasibility and performance of ground source heat pump systems for commercial applications in tropical and subtropical climates. Renew. Energy 2020, 152, 467–483. [Google Scholar] [CrossRef]
- Cao, J.; Liu, J.; Man, X. A united WRF/TRNSYS method for estimating the heating/cooling load for the thousand-meter scale megatall buildings. Appl. Therm. Eng. 2017, 114, 196–210. [Google Scholar] [CrossRef]
- Sangwan, P.; Mehdizadeh-Rad, H.; Ng, A.W.M.; Tariq, M.A.U.R.; Nnachi, R.C. Performance Evaluation of Phase Change Materials to Reduce the Cooling Load of Buildings in a Tropical Climate. Sustainability 2022, 14, 3171. [Google Scholar] [CrossRef]
- Tao, Y.; Yan, H.; Gao, H.; Sun, Y.; Li, G. Applicaion of SVR optimized by modified simulated anneaing (MSA-SVR) air conditioning load prediction mode. J. Ind. Inf. Integr. 2019, 15, 247–251. [Google Scholar]
- Cheng, R.; Yu, J.; Zhang, M.; Feng, C.; Zhang, W. Short-term hybrid forecasting model of ice storage air-conditioning based on improved SVR. J. Build. Eng. 2022, 50, 104194. [Google Scholar] [CrossRef]
- Fan, C.; Liao, Y.; Zhou, G.; Zhou, X.; Ding, Y. Improving cooling load prediction reliability for HVAC system using Monte-Carlo simulation to deal with uncertainties in input variables. Energy Build. 2020, 226, 110372. [Google Scholar] [CrossRef]
- Wang, Z.; Hong, T.; Piette, M.A. Building thermal load prediction through shallow machine learning and deep learning. Appl. Energy 2020, 263, 114683. [Google Scholar] [CrossRef]
- Ahmad, T.; Chen, H.; Shair, J.; Xu, C. Deployment of data-mining short and medium-term horizon cooling load forecasting models for building energy optimization and management. Int. J. Refrig. 2019, 98, 399–409. [Google Scholar] [CrossRef]
- Kwok, S.S.K.; Lee, E.W.M. A study of the importance of occupancy to building cooling load in prediction by intelligent approach. Energy Convers. Manag. 2011, 52, 2555–2564. [Google Scholar] [CrossRef]
- Chao, W.H.; Dong, W. Prediction on hourly cooling load of buildings based on neural networks. Int. J. Smart Home 2015, 9, 35–52. [Google Scholar]
- He, N.; Liu, L.; Qian, C.; Zhang, L.; Yang, Z.; Li, S. A closed-loop data-fusion framework for air conditioning load prediction based on LBF. Energy Rep. 2022, 8, 7724–7734. [Google Scholar] [CrossRef]
- Sajjad, M.; Khan, Z.A.; Ullah, A.; Hussain, T.; Ullah, W.; Lee, M.Y.; Baik, S.W. A novel CNN-GRU-based hybrid approach for short-term residential load forecasting. IEEE Access 2020, 8, 143759–143768. [Google Scholar] [CrossRef]
- Chen, J.; Ding, L.; Zhang, K.; Hou, C.; Lai, Z. Deep Learning Based Air Conditioning Set Temperature Prediction with Meteorological Data. In Proceedings of the 2023 IEEE Sustainable Power and Energy Conference (iSPEC), Chongqing, China, 28–30 November 2023; pp. 1–6. [Google Scholar]
- Zhang, J.; Zhao, L. Efficient greenhouse gas prediction using IoT data streams and a CNN-BiLSTM-KAN model. Alex. Eng. J. 2025, 123, 261–270. [Google Scholar] [CrossRef]
- Kavitha, R.J.; Thiagarajan, C.; Priya, P.I.; Anand, A.V.; Al-Ammar, E.A.; Santhamoorthy, M.; Chandramohan, P. Improved Harris Hawks Optimization with Hybrid Deep Learning Based Heating and Cooling Load Prediction on residential buildings. Chemosphere 2022, 309, 136525. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Yuan, P.; Zhao, W.; Zhao, Y. Intelligent prediction algorithm of ship roll and pitch motion based on SSA-optimized BiLSTM network. Ocean Eng. 2025, 320, 120331. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systerms, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: New York, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Yu, D.; Liu, T.; Wang, K.; Li, K.; Mercangöz, M.; Zhao, J.; Lei, Y.; Zhao, R. Transformer based day-ahead cooling load forecasting of hub airport air-conditioning systems with thermal energy storage. Energy Build. 2024, 308, 114008. [Google Scholar] [CrossRef]
- Zou, Y.; Chen, Y.; Xu, Y.; Zhang, H.; Zhang, S. Short-term freeway traffic speed multistep prediction using an iTransformer model. Phys. A Stat. Mech. Its Appl. 2024, 655, 130185. [Google Scholar] [CrossRef]
- Ren, D.; Hu, Q.; Zhang, T. EKLT: Kolmogorov-Arnold attention-driven LSTM with Transformer model for river water level prediction. J. Hydrol. 2025, 649, 132430. [Google Scholar] [CrossRef]
- Li, W.; Liu, C.; Xu, Y.; Niu, C.; Li, R.; Li, M.; Hu, C.; Tian, L. An interpretable hybrid deep learning model for flood forecasting based on Transformer and LSTM. J. Hydrol. Reg. Stud. 2024, 54, 101873. [Google Scholar] [CrossRef]
- Kow, P.Y.; Liou, J.Y.; Yang, M.T.; Lee, M.H.; Chang, L.C.; Chang, F.J. Advancing climate-resilient flood mitigation: Utilizing transformer-LSTM for water level forecasting at pumping stations. Sci. Total Environ. 2024, 927, 172246. [Google Scholar] [CrossRef]
- Zhai, C.; He, X.; Cao, Z.; Abdou-Tankari, M.; Wang, Y.; Zhang, M. Photovoltaic power forecasting based on VMD-SSA-Transformer: Multidimensional analysis of dataset length, weather mutation and forecast accuracy. Energy 2025, 324, 135971. [Google Scholar] [CrossRef]
- Wang, S.; Shi, J.; Yang, W.; Yin, Q. High and low frequency wind power prediction based on Transformer and BiGRU-Attention. Energy 2024, 288, 129753. [Google Scholar] [CrossRef]
- Xue, H.; Wang, S.; Xia, M.; Guo, S. G-Trans: A hierarchical approach to vessel trajectory prediction with GRU-based transformer. Ocean Eng. 2024, 300, 117431. [Google Scholar] [CrossRef]
- Lin, S.; Jiang, Y.; Hong, F.; Xu, L.; Huang, H.; Wang, B. HDFormer: A transformer-based model for fishing vessel trajectory prediction via multi-source data fusion. Ocean Eng. 2025, 320, 120309. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 19–21 May 2021; Volume 35, pp. 11106–11115. [Google Scholar]
- Liu, Y.; Hu, T.; Zhang, H.; Wu, H.; Wang, S.; Ma, L.; Long, M. itransformer: Inverted transformers are effective for time series forecasting. arXiv 2023, arXiv:2310.06625. [Google Scholar]
- Lai, T.C.; Xu, K.K.; Zhu, C.J.; Xu, K.K. A One-step Prediction Method of Building Cooling Load Based on Improved CNN-GRU. Mech. Electr. Eng. Technol. 2024, 53, 119–122. (In Chinese) [Google Scholar]
- Ma, L.; Huang, Y.; Zhao, T. A synchronous prediction method for hourly energy consumption of abnormal monitoring branch based on the data-driven. Energy Build. 2022, 260, 111940. [Google Scholar] [CrossRef]
- Fu, T. Short-term gas load forecasting based on BPAdaboost model. Sci. Technol. Bull. 2013, 29, 55–57. (In Chinese) [Google Scholar]
- Luo, S.; Wang, B.; Gao, Q.; Wang, Y.; Pang, X. Stacking integration algorithm based on CNN-BiLSTM-Attention with XGBoost for short-term electricity load forecasting. Energy Rep. 2024, 12, 2676–2689. [Google Scholar] [CrossRef]
- Su, Z.; Zheng, G.; Wang, G.; Hu, M.; Kong, L. An IDBO-optimized CNN-BiLSTM model for load forecasting in regional integrated energy systems. Comput. Electr. Eng. 2025, 123, 110013. [Google Scholar] [CrossRef]
- Zhao, M.; Guo, G.; Fan, L.; Han, L.; Yu, Q.; Wang, Z. Short-term natural gas load forecasting analysis based on VMD-Transformer-BiLSTM. Appl. Integr. Circuits 2025, 42, 400–402. (In Chinese) [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Influencing Factor | Specific Content |
|---|---|
| Building structure | The physical structure of the building, such as the material properties of the enclosure and the insulation performance of wall materials, etc. |
| Internal heat source | The internal heat sources of the workshop (such as the operation of production equipment, lighting systems, etc.), the number of employees, and their activity intensity. |
| Outdoor meteorological parameters | Environmental factors such as outdoor temperature, humidity, ground air pressure, wind speed, and solar radiation intensity. |
| Feature Name | Correlation Coefficient | Feature Name | Correlation Coefficient |
|---|---|---|---|
| Day of the Week | 0.110 | Average Supply Air Temperature in Zone C | −0.846 |
| Temperature Differential Between Supply and Return Air of AHU in Zone D | 0.880 | Average Supply Air Temperature in Zone B | −0.789 |
| Temperature Differential Between Supply and Return Air of AHU in Zone C | 0.921 | Average Supply Air Temperature in Zone A | −0.788 |
| Temperature Differential Between Supply and Return Air of AHU in Zone B | 0.894 | Average Temperature in Zone D | −0.307 |
| Temperature Differential Between Supply and Return Air of AHU in Zone A | 0.886 | Average Temperature in Zone C | −0.574 |
| Average Return Air Temperature of AHU in Zone D | −0.141 | Average Temperature in Zone B | −0.361 |
| Average Return Air Temperature of AHU in Zone C | −0.044 | Average Temperature in Zone A | −0.379 |
| Average Return Air Temperature of AHU in Zone B | 0.203 | Outdoor Temperature | 0.463 |
| Average Return Air Temperature of AHU in Zone A | 0.149 | Wet Bulb Temperature | 0.114 |
| Average Supply Air Temperature in Zone D | −0.797 | Outdoor Humidity | −0.336 |
| Model | Parameter Settings | |
|---|---|---|
| iTransformer-BiLSTM | iTransformer | Number of encoder layers: 2, number of multi-head attention heads: 4, number of channels: 128. |
| BiLSTM | Number of BiLSTM layers: 2, number of hidden units per layer: 64/32, Dropout rate: 0.05. | |
| other | Epoch: 256, learning rate: 0.002, optimizer: Adam, loss function: RMSE. |
| Model | RMSE | MAE | SMAPE (%) |
|---|---|---|---|
| iTransformer-BiLSTM | 93.963 | 62.788 | 4.936 |
| iTransformer | 135.271 | 81.733 | 5.953 |
| Transformer | 153.629 | 111.194 | 6.703 |
| BiLSTM | 196.028 | 134.015 | 8.799 |
| LSTM | 205.868 | 141.610 | 9.348 |
| Model | Main Parameter Settings |
|---|---|
| BPNN-Adaboost | Number of weak classifiers: 5, BPNN network layers: 2, Neurons per layer: 64/32 |
| CNN-BiLSTM | CNN layers: 2, Kernel size: 2 × 2, Pooling layer size: 2 × 2, Channels: 128, BiLSTM settings: Same as the proposed main mode |
| Transformer-BiLSTM | Encoder layers: 2, Attention heads: 4, Channels: 128, BiLSTM settings: Same as the proposed main model |
| Model | RMSE | MAE | SMAPE (%) |
|---|---|---|---|
| iTransforme-BiLSTM | 93.963 | 62.788 | 4.936 |
| Transformer-BiLSTM | 114.517 | 82.310 | 6.020 |
| CNN-BiLSTM | 174.387 | 116.031 | 8.574 |
| BPNN-Adaboost | 225.960 | 145.096 | 10.916 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, X.; Zhou, X.; Yan, J.; Huang, X. Cooling Load Forecasting Method for Central Air Conditioning Systems in Manufacturing Plants Based on iTransformer-BiLSTM. Appl. Sci. 2025, 15, 5214. https://doi.org/10.3390/app15095214
Huang X, Zhou X, Yan J, Huang X. Cooling Load Forecasting Method for Central Air Conditioning Systems in Manufacturing Plants Based on iTransformer-BiLSTM. Applied Sciences. 2025; 15(9):5214. https://doi.org/10.3390/app15095214
Chicago/Turabian StyleHuang, Xiaofeng, Xuan Zhou, Junwei Yan, and Xiaofei Huang. 2025. "Cooling Load Forecasting Method for Central Air Conditioning Systems in Manufacturing Plants Based on iTransformer-BiLSTM" Applied Sciences 15, no. 9: 5214. https://doi.org/10.3390/app15095214
APA StyleHuang, X., Zhou, X., Yan, J., & Huang, X. (2025). Cooling Load Forecasting Method for Central Air Conditioning Systems in Manufacturing Plants Based on iTransformer-BiLSTM. Applied Sciences, 15(9), 5214. https://doi.org/10.3390/app15095214