1. Introduction
Software has become increasingly important over time. Previously, software was used to read data from memory using a programming language or to perform certain operations and present results. However, through software development that utilizes the strengths of various programming languages, software has been assigned roles ranging from simple tasks to entire systems. Furthermore, software is now used in various fields, including artificial intelligence (AI), to develop autonomous systems.
This increasing reliance on software underscores the severity of software failures. Regardless of whether an error or fault occurs in a small part of the software or involves the entire system, it can cause problems that differ considerably from previous software failures. Previously, software failures were caused by code errors or bugs, owing to the relatively simple architecture of earlier software. In contrast, modern software performs a wide variety of functions and has a complex structure. Therefore, many different failure scenarios have emerged. Software faults and failures caused by code errors, bugs, external shocks, compatibility issues, and technical errors can cause major social and economic problems. Two examples illustrate the damage caused by software failure.
Lime launched an electric-scooter service in October 2018 in Auckland, New Zealand. By February 2019, the company had received 155 reports on incidents involving scooter braking. By conducting independent investigations, the company found that the electric brakes suddenly engaged when travelling downhill at full speed, locking the scooter’s front wheel. This problem affected over 110 people and caused approximately $350,000 in damages. In another case, Vyaire Medical Ventilators with software version 6.0.1600.0, distributed in February 2021, experienced an error when the device stopped if the data communication port was set to a specific channel. Because this could result in severe injuries that could lead to death, the U.S. Food and Drug Administration (FDA) ordered a recall, and Vyaire Medical addressed the issue using a software patch. Software failures and faults occur in various forms, including operational problems when software is placed in an environment different from that used for development, and the resulting socioeconomic losses are significant. In particular, the characteristics of certain application fields can directly impact human life, thereby necessitating rigorous research into software reliability to prevent and mitigate software failures.
Software reliability evaluates the extent to which the software can be used without failure. Various methods have been studied to improve software reliability, such as error inflow, failure rate, and curve-fitting models [
1,
2,
3,
4].
Figure 1 shows an introduction to the different methodologies for software reliability modelling.
Among these, software reliability models that assume that software failures follow a nonhomogeneous Poisson process (NHPP) with a nonconstant mean at each point in time are being actively studied. In 1979, an NHPP software reliability model was developed based on the Goel (GO) model, assuming that the occurrence of failures increases exponentially over time [
5]. Other NHPP software reliability models were developed according to the form of failure, including a software reliability model in which the cumulative failure of software follows an S-shape or occurs in a U-shape [
6,
7,
8].
Recently, software reliability models based on the assumption of Weibull distribution or bathtub-shaped shapes have been proposed. In addition, various studies on software failure occurrences or incomplete debugging entail different efforts, focusing on the testing phase rather than the form of failure [
9,
10,
11,
12,
13,
14,
15].
Because software is used in various fields and its structure has become very complex, software failure cases have become more diverse, such as when a software failure is caused by the dependent effects of other failures [
16,
17] or the difference between the actual and developed operating environments [
18,
19,
20,
21,
22]. Therefore, research on software reliability models that consider various assumptions, such as dependent failures and operating environment uncertainties, has been continuously conducted. Recent studies have assumed that software test environments are not consistent or ideal and include uncertain factors such as test effort, test coverage, and differences in hardware and software configurations [
23,
24]. In addition, studies have been conducted to improve reliability through the relationship with the hardware to which it is applied, rather than by applying it in the isolation of software failures [
25].
In this study, we extended the NHPP software reliability model to failures arising from complex software, thereby proposing an NHPP software reliability model that considers both operating environment uncertainty and dependent failure occurrence. Previously, proposed software reliability models were based on a single assumption. However, because software failures can be caused by various factors, we propose a software reliability model that includes the assumptions of dependent failure occurrence. This describes when failures affect each other, as well as the operating environment uncertainty caused by the difference between the development and operating environments. In addition, the software reliability was evaluated using various methods to determine the goodness of fit. However, because various criteria have different characteristics, evaluating excellence using only a few values is infeasible [
26,
27,
28]. Therefore, we use a multi-criteria decision-making method (
) for a comprehensive evaluation, demonstrating the effectiveness of the proposed model through the new
, which reflects the size of the criteria for all models to be compared.
In summary, the contributions of this study are as follows:
This study proposes an NHPP software reliability model that considers both the uncertainty of the operating environment and dependent faults.
This study demonstrates the superiority of the proposed model through using the maximum value to approach comprehensive assessment and multi-faceted interpretation.
The remainder of this paper is organized as follows:
Section 2 introduces the general NHPP software reliability model and the new NHPP software that considers dependent failures and operating environment uncertainties.
Section 3 introduces the criteria and
s used for model comparison and proposes a new
.
Section 4 presents the data and fit, along with numerical example results. Finally,
Section 5 concludes the study.
5. Conclusions
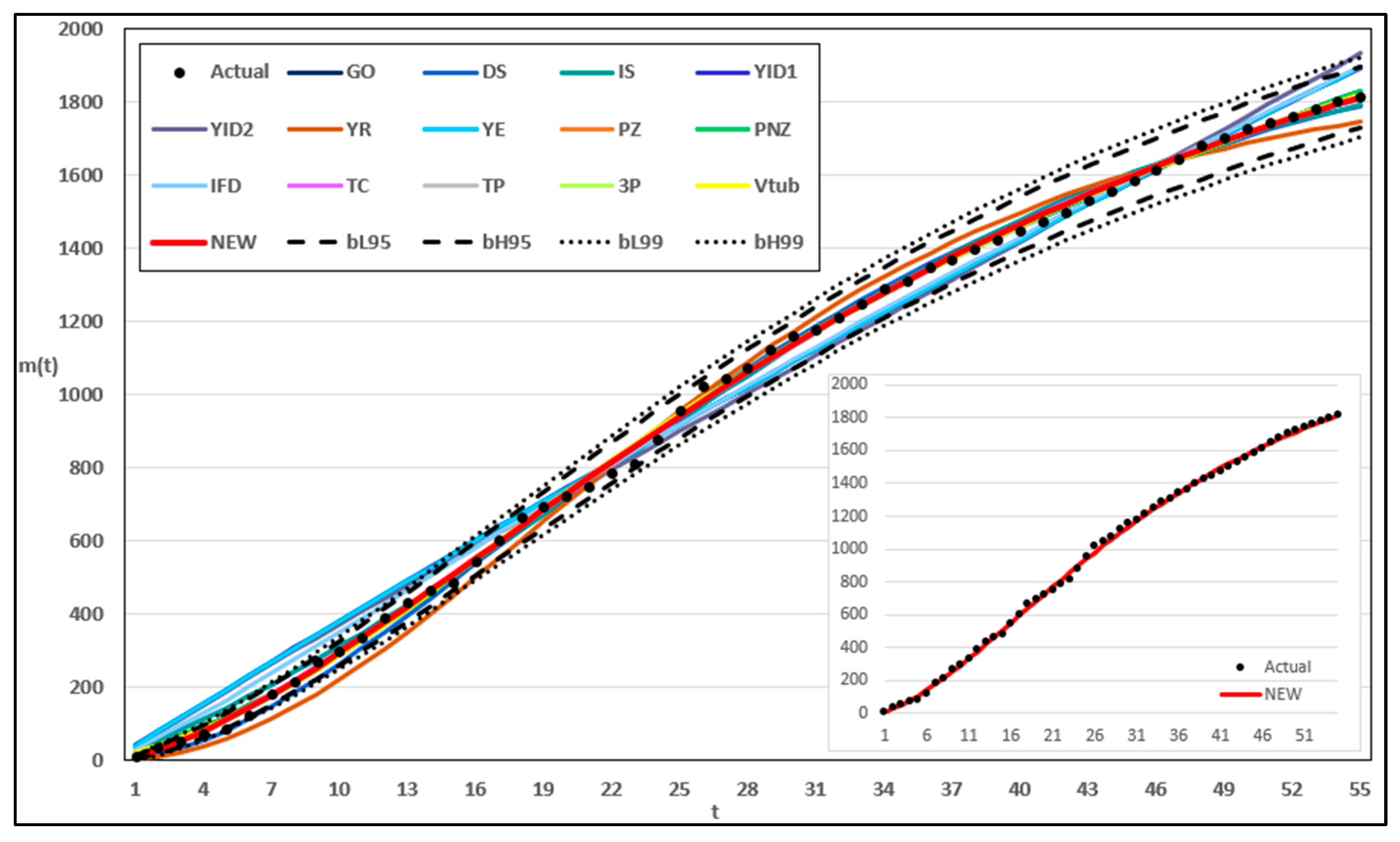
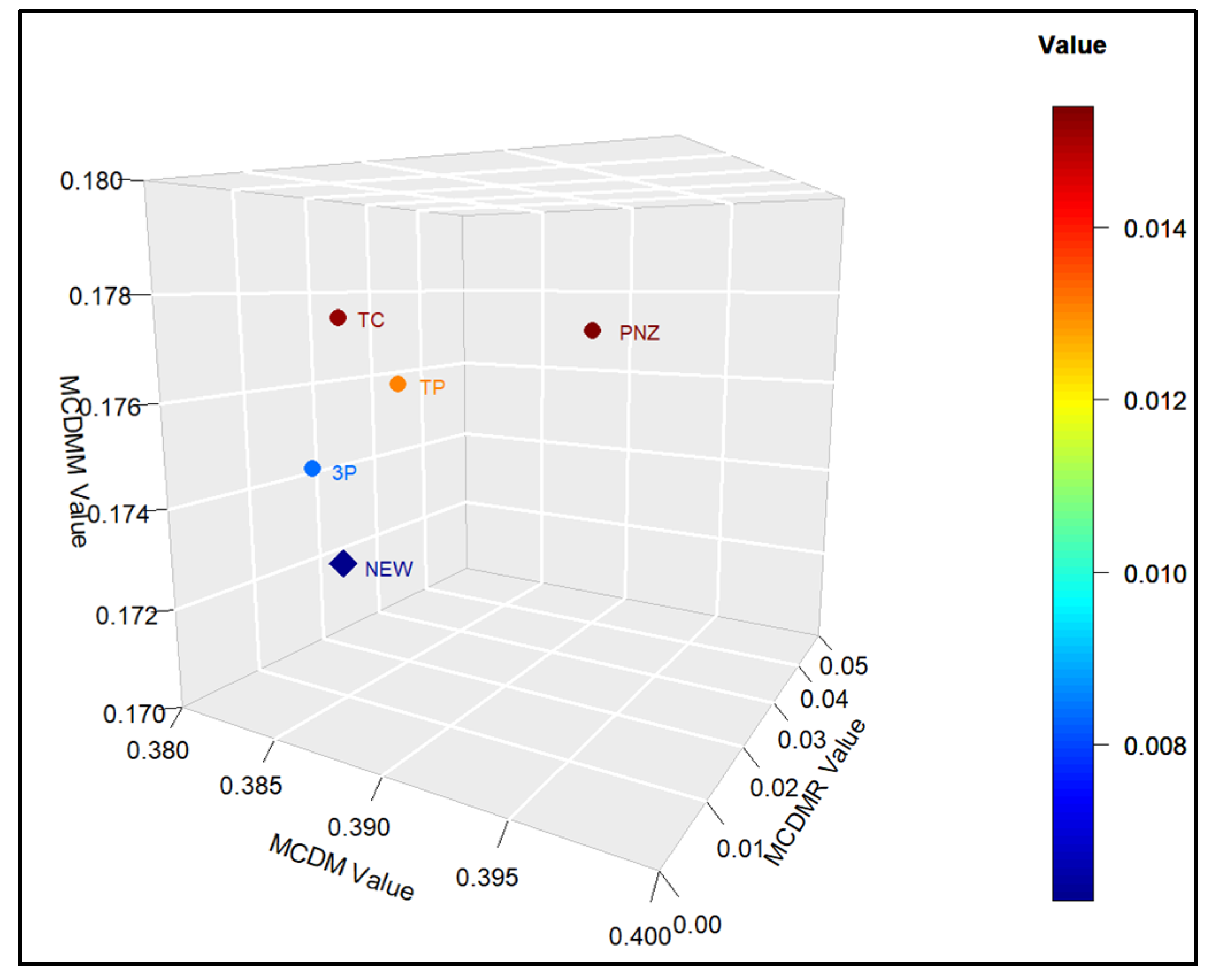
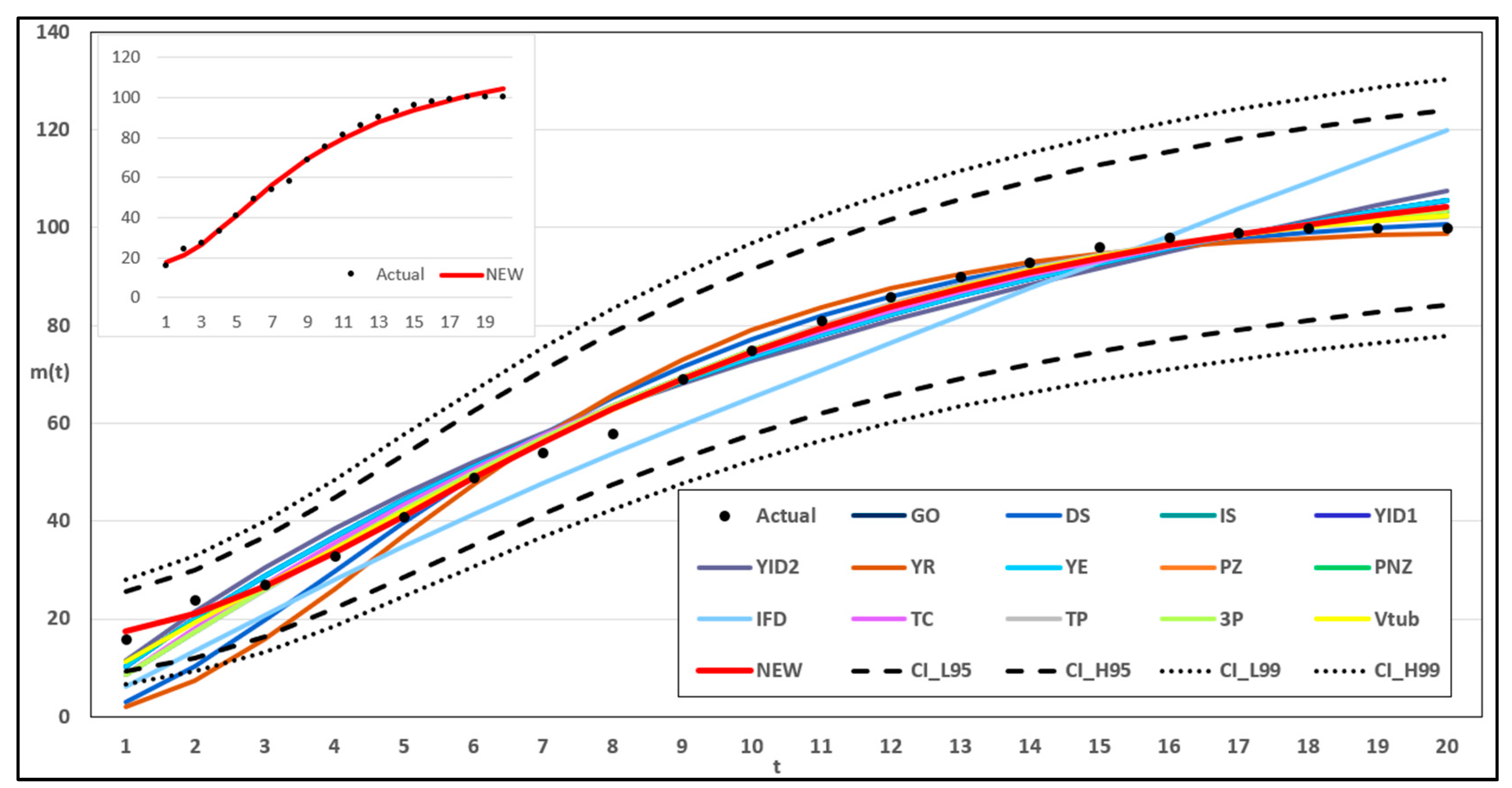
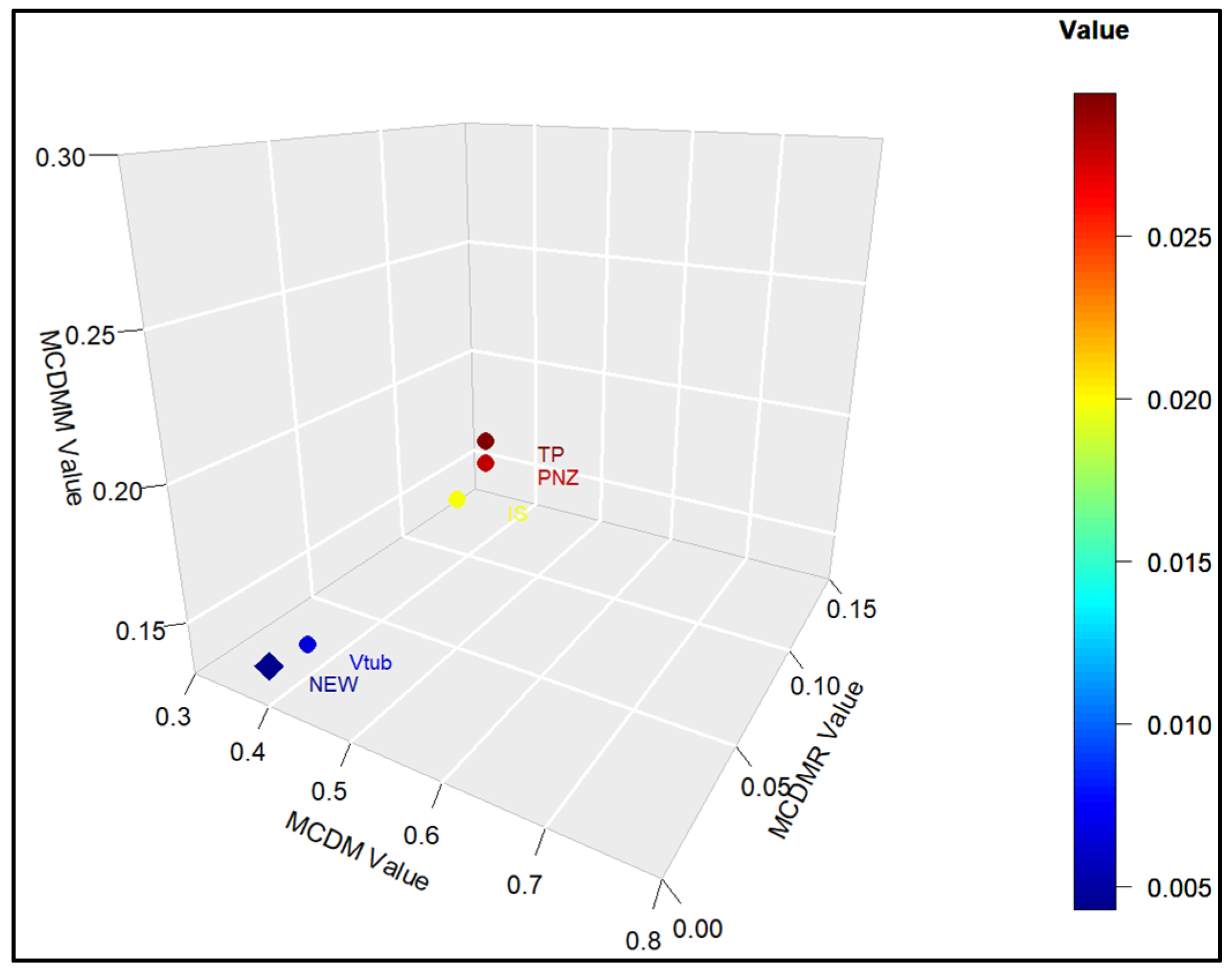
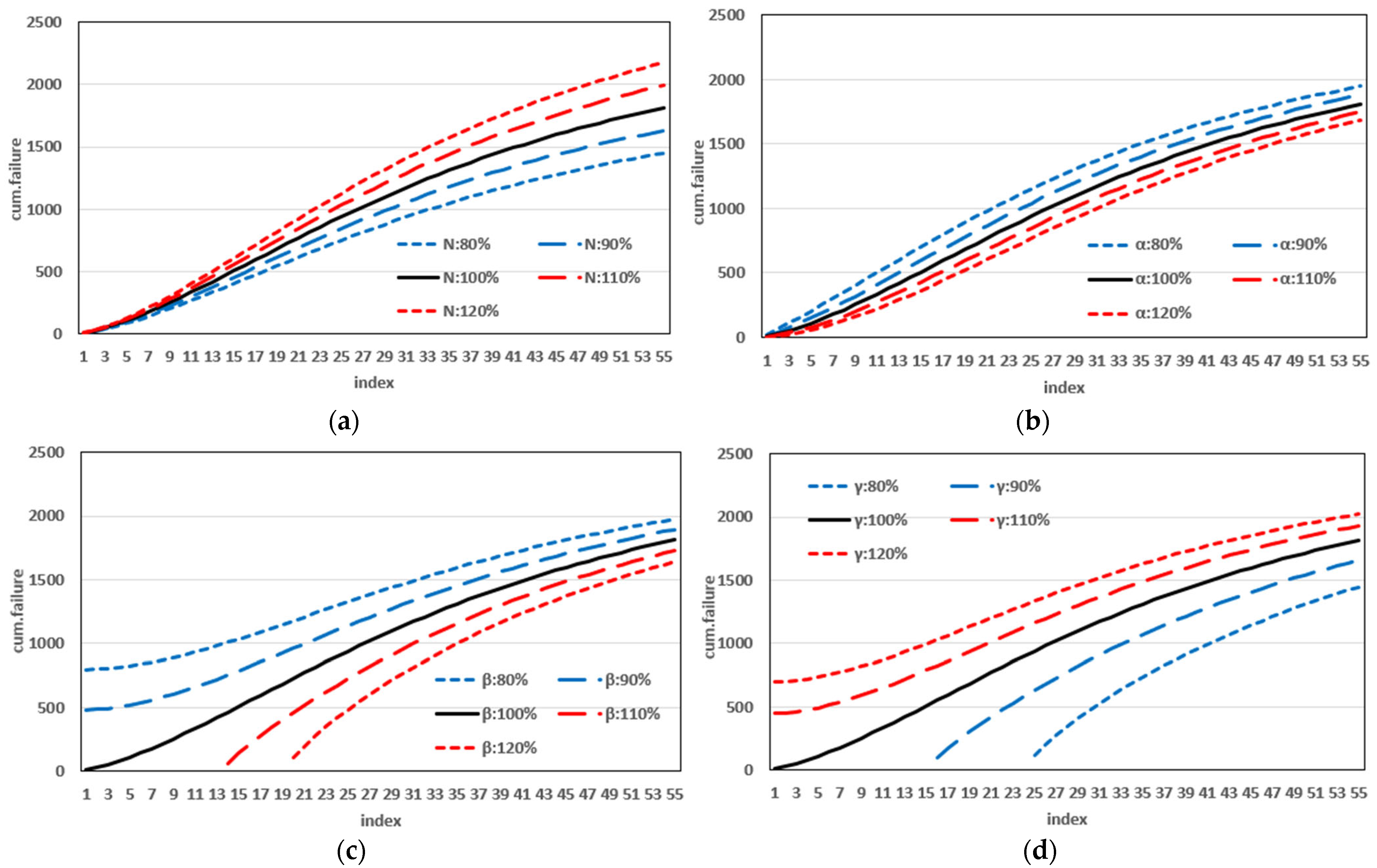
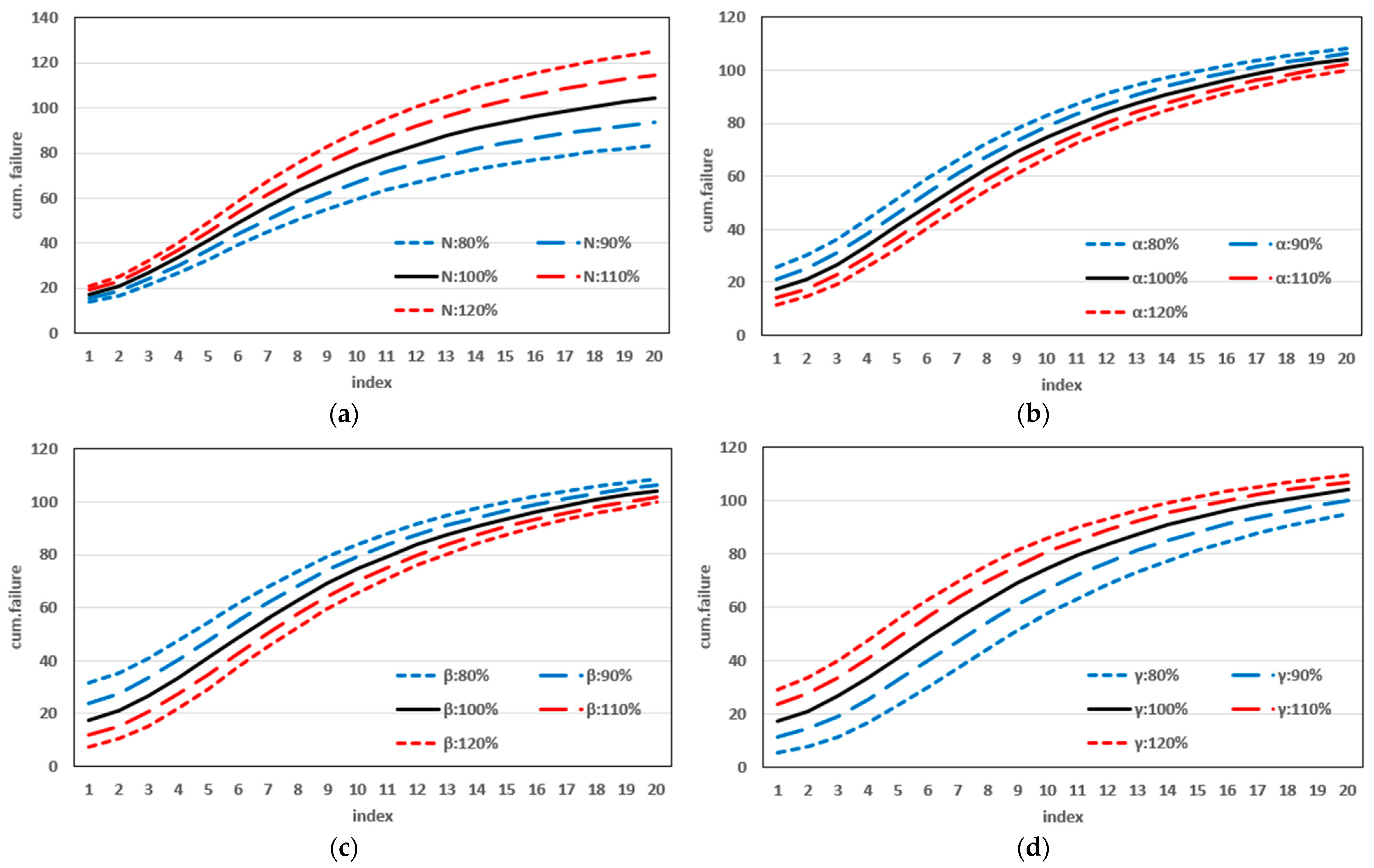
This study introduced a new type of NHPP software reliability model that simultaneously assumes uncertainty in the operating environment and dependent failure occurrence. Unlike previous studies, this study extends the range of failures that can occur in complex and diverse software by presenting a model that can predict the probability of occurrence in various environments. In addition, to demonstrate the effectiveness of the developed software reliability model, an using the maximum value, which can be interpreted in various manners. This method evaluates the effectiveness of a model through a comprehensive interpretation because when assessing the effectiveness of a model based on each criterion, it is particularly useful when multiple models perform well across individual criteria. In an analysis with 15 models across two datasets, it was showed that in Dataset 1, the proposed model performed best on all criteria, and in Dataset 2, the existing showed the third-best result, whereas the newly proposed showed the best result. Therefore, the , which improves the existing method, can increase the level of comparison by considering both quantitative and qualitative evaluations. The sensitivity analysis was conducted to compare the changes in the mean value function due to changes in the parameters for the two datasets. The changes for showed a trend of increasing variation as the value increases, showed a relatively small variation compared to other parameters, and showed a trend of decreasing variation as the value increases. The changes in the mean value function , that is, the impact on software failure prediction owing to changes in the parameters included in the model, varied per parameter and showed changes with common characteristics.
With the development of the software industry, the complexity and diversity of software have led to various software failures. Research on assumptions such as dependent failures and operating environment uncertainties is underway to predict these failures. Further research should be conducted based on additional assumptions to extend these studies. This study proposes a model with multiple assumptions, and there is a possibility of errors when these assumptions are changed. Therefore, additional research is required on generalizable software reliability models to predict software failure.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}