1. Introduction
Accurate disease diagnosis remains the crucial first step before initiating any treatment. In this context, medical imaging plays a pivotal role in clinical analysis. In recent years, however, the percentage of utilization of imaging examinations, such as MRI and CT scans, has continued to rise [
1]. This has contributed to the increased need for faster and more accurate image analysis tools.
Medical imaging is primarily regarded as a technique for visualizing functional and structural features of the human body through modalities such as x-rays and magnetic resonance imaging. Moreover, the integration of imaging technologies within healthcare networks has significantly enhanced the quality and efficiency of medical services, driven by advances in computer science and imaging engineering.
The interpretation of medical images remains a time-consuming and expertise-demanding task, prone to variability and potential errors, especially in resource-constrained environments [
2]. To address these challenges, the automatic generation of captions for radiology images has emerged as a promising solution. In this work, caption generation refers to the automatic assignment of multiple medical concept labels (UMLS CUIs) to radiology images, rather than the generation of full natural language sentences. The task is addressed as a multilabel classification problem. Automatically generating descriptive labels can assist radiologists by speeding up analysis and reducing diagnostic errors.
A deep learning-based system capable of automatically generating labels for radiology images is proposed, leveraging transfer learning strategies. Pre-trained models on large datasets such as ImageNet are fine-tuned on the specialized ImageCLEF medical caption detection dataset [
3], enabling adaptation to the medical imaging domain.
Advanced deep learning methodologies have been extensively applied to classification tasks within the medical domain [
4]. Convolutional Neural Networks (CNNs), pretrained on large-scale datasets such as ImageNet, are frequently employed as image encoders for medical imaging applications. However, ImageNet primarily comprises images from general visual scenes, which differ significantly from medical images in both content and texture. Consequently, finetuning CNN models is often required to optimize performance when adapting to the medical imaging domain. In [
5], a refined version of the Inception V3 CNN architecture was developed to classify skin lesions as benign or malignant, achieving diagnostic accuracy comparable to that of experienced dermatologists. These results demonstrate that CNNs originally trained on non-medical datasets can be effectively repurposed for medical imaging tasks, provided that domain-specific refinements are appropriately implemented.
These labels explain radiology images in detail, and each image may be associated with multiple labels, making it a multilabel classification problem.
1.1. Medical Imaging Modalities
Radiologists specialize in the diagnosis and treatment of diseases by utilizing a range of imaging modalities, including x-rays, angiography, computed tomography (CT), magnetic resonance imaging (MRI), positron emission tomography (PET), nuclear medicine, and sonography. Each modality differs fundamentally in the technique used to acquire medical images.
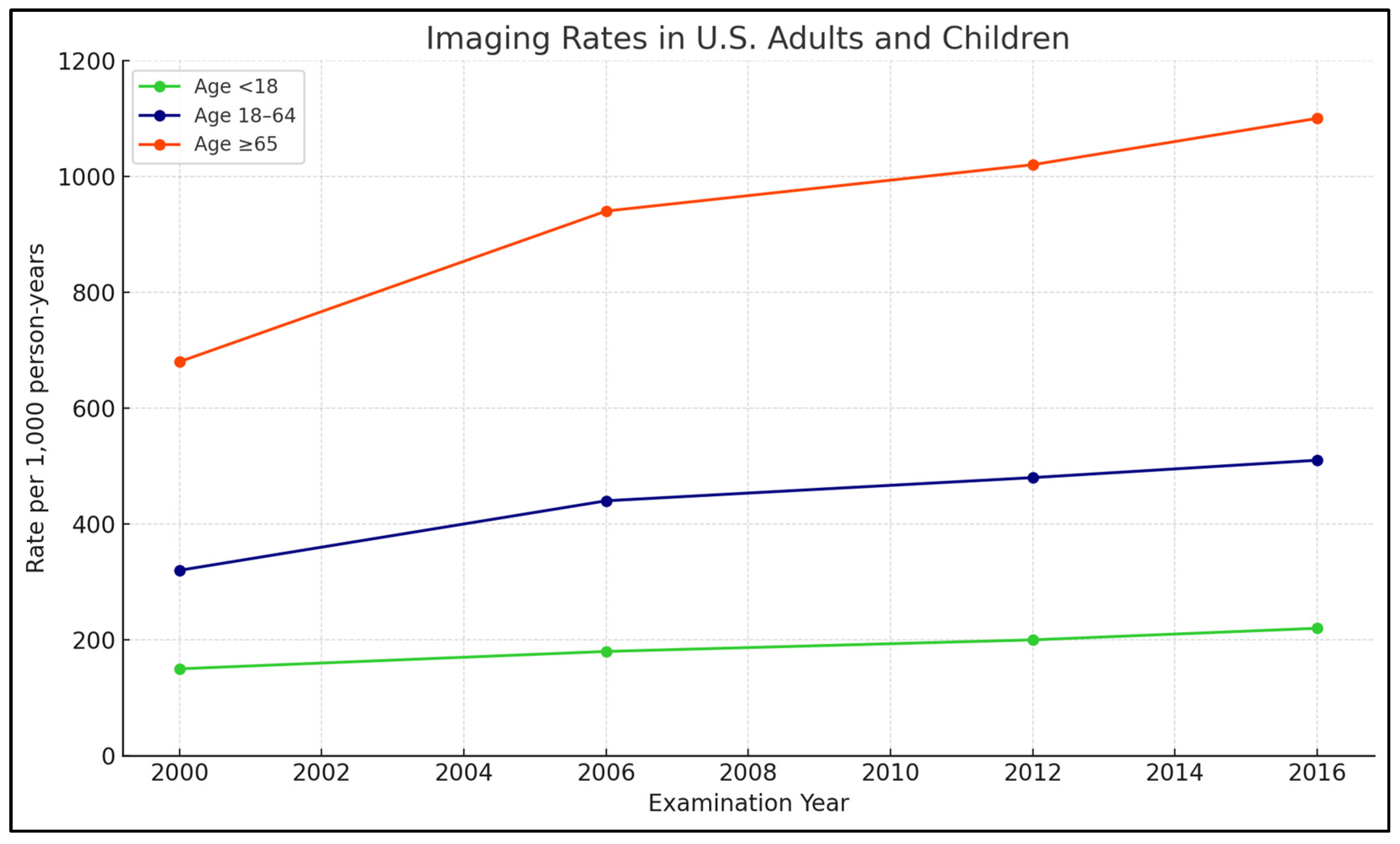
Technologies, utilization rates for MRI, CT, and other modalities have continued to climb in both Ontario, Canada, and the United States, based on a study of over 135 million imaging examinations conducted by Kaiser Permanente, UC San Francisco, and UC Davis. This trend has raised concerns about potential overuse of medical imaging.
A study published on 3 September 2019, in the American Medical Association Journal, provided the first comprehensive analysis of imaging trends across diverse populations. Although the early 2000s saw a modest decline in imaging utilization, a subsequent rise in MRI and CT usage has been observed, particularly among adult outpatient groups, with pediatric CT utilization showing a decline in recent years.
Figure 1 illustrates the trends in the use of medical imaging technologies within the U.S. healthcare system.
1.2. Problem Statement
The diagnostic process for medical images can benefit significantly from natural language processing (NLP) and computer vision methodologies, particularly with the recent advancements in deep learning. Concept annotation has become a common approach to predict multiple medical concepts associated with radiology images, as shown in recent works [
6,
7,
8]. This constitutes a fundamental step toward the broader goal of full caption generation. Automatic labeling methods can reduce diagnostic errors and operational costs in medical departments (1). A primary objective of automated caption generation systems is to assist radiologists by reducing the time required for image analysis and minimizing potential diagnostic inaccuracies (2).
1.3. Research Objective
The objective of this research is to improve the efficiency of radiological image analysis.
The developed system labels radiology images with descriptive medical concepts, supporting radiologists in the preparation of diagnostic reports. Automating information extraction from medical images facilitates faster comprehension, reduces human error, and contributes to improved clinical decision-making processes.
Healthcare institutions could adopt such systems to enhance disease diagnosis and classification tasks.
Future work may involve leveraging the detected medical concepts to generate full, coherent textual captions using natural language processing (NLP) models, thereby completing the full image captioning pipeline.
1.4. On the Automatic Generation of Medical Imaging Information
Medical imaging, including radiography and pathology imaging, constitutes an essential component of diagnostic and therapeutic workflows in clinical settings.
A multi-task learning framework was introduced, capable of simultaneously predicting image tags and generating descriptive reports. This framework incorporates a co-attention mechanism designed to jointly capture visual and semantic information, thereby enhancing the precision in identifying and describing anomalous regions. Additionally, a hierarchical Long Short-Term Memory (LSTM) architecture was developed to effectively model long-range semantic dependencies and to generate high-quality, coherent textual reports.
The performance of the proposed methods was validated on two prominent medical datasets: IU X-Ray [
9] and PEIR Gross [
10] datasets. The evaluation employed the BLEU (Bilingual Evaluation Understudy) metric, where “n” denotes the n-gram window size used for comparison between generated and reference texts.
The IU X-Ray dataset comprises radiology images accompanied by structured reports organized into four sections: Contrast, Indication, Impression, and Findings. Conversely, the PEIR Gross dataset contains 7443 gross pathology images, each associated with a single descriptive caption sourced from 21 sub-categories of the PEIR (Pathology Education Instructional Resource) library, designed for medical education.
The experimental results are summarized in
Table 1, indicating the BLEU-n scores achieved on both datasets.
1.5. Report Generation of Automatic Radiology Founded on Multi-View Imagery Medical and Fusion Concepts Enrichment
A novel medicinal imaging report age group prototype concentrating on radiology is projected. To be exact, the contributions of the future outline are x-ray pictures of the chest area from dissimilar views (forward and adjacent), founded on which radioscopy intelligences are produced consequently. Radiology info contains material radiotherapists’ summaries and is significant for additional analysis and follow-up endorsements [
11].
The extensively utilized chest x-ray radiology report dataset (IU-RR) from Indiana University serves as an effective resource for this task. Radiology reports typically consist of coherent narratives composed of multiple sentences or short passages summarizing diagnostic findings. Addressing the specific challenges of report generation, the encoder and decoder components of the architecture are enhanced in the following ways: firstly, a multi-task framework is proposed that jointly performs chest x-ray image classification and report generation. This framework has proven effective as the encoder learns to capture features pertinent to radiology-specific report generation. Given the limited size of the IU-RR dataset, encoder pre-training becomes essential to achieve robust performance.
Dissimilar from preceding revisions maximizing ImageNet, which is composed of universal-purpose object acknowledgment, they pre-train with chest x-ray imageries that are large-scale from the similar field, specifically [
12], to apprehend field precise imagery topographies for decoding the best.
Furthermore, initial approaches generally treated frontal and lateral chest x-ray views as independent modalities, overlooking their complementary diagnostic information. Studies demonstrate that lateral views provide essential information that frontal views alone may miss. Instead of simple feature concatenation or aggregation (e.g., mean, sum), a more structured and context-aware fusion of multi-view features is proposed.
Additionally, it is probable to produce unpredictable consequences for similar patients founded on images from dissimilar opinions. They suggest manufacturing multi-view info by applying a sentence-level courtesy archetypal, forcing the encoder to extract dependable topographies with loss of cross-view reliability (CVC). The decoder uses ranked LSTM (sentence- and word-level LSTM) to produce radioscopy bits of intelligence from the decoder side.
This integrated approach, by maintaining cross-view consistency and applying hierarchical sequence modeling, significantly enhances the quality and clinical relevance of the generated radiology reports.
1.6. The KERP Framework
The generation of comprehensive and semantically coherent descriptions for medical images poses significant challenges. This process requires bridging the gap between visual perception and linguistic representation, incorporating domain-specific medical knowledge, and ensuring the production of accurate and clinically meaningful descriptions. Addressing these complexities, a novel knowledge-driven approach named Encode, Retrieve, and Paraphrase (KERP) has been proposed. This method integrates traditional data-driven retrieval mechanisms with modern knowledge-based modeling to facilitate the generation of precise and context-aware medical reports [
13].
The KERP framework decomposes the task of medical report generation into two sequential phases: initially, the creation of a structured graph representing medical abnormalities detected in the visual input, followed by the generation of corresponding natural language descriptions. Specifically, the Encode module transforms extracted visual features into an organized abnormality graph by leveraging prior medical knowledge. Subsequently, the Retrieve module accesses relevant textual templates associated with the abnormalities identified in the graph. Finally, the Paraphrase module refines the retrieved templates into customized, case-specific medical narratives.
The essential of KERP is a projected generic application unit—Chart Transformer (GTR) that animatedly converts high-level semantics between graph-structured statistics of multiple domains such as knowledge charts, pictures, and arrangements. The Chart Transformer provides a versatile mechanism for dynamically translating between different semantic spaces, enabling effective interaction between visual, graphical, and textual representations.
The effectiveness of the KERP approach was validated on two benchmark datasets: IU X-Ray and CX-CHR. The IU X-Ray dataset contains chest radiographs paired with detailed radiology reports, while CX-CHR comprises a private collection of chest x-rays with corresponding clinical descriptions. This research [
14] uses BLEU-n to evaluate the performance of abnormality and disease arrangement.
Table 2 shows experimental results [
10].
The empirical findings demonstrate that KERP achieves state-of-the-art results on both datasets, with substantial improvements observed in terms of abnormality prediction accuracy, dynamic knowledge graph construction, and the generation of contextually accurate textual descriptions. The fundamental difference between our research and this is that it only focuses on using the chest x-ray. In contrast, there is a large diversity in the dataset we are maximizing in our research.
Therefore, while KERP represents a notable advancement in the automatic generation of radiological reports from chest x-rays, the broader and more diverse scope addressed in the current study introduces additional challenges that necessitate further methodological innovations.
1.7. Profound Learning for Ultrasound Imagery Caption Generation Founded on Object Detection
Significant advancements in image captioning have been achieved through deep learning methods applied to natural imagery. Nonetheless, there remains a notable lack of effective techniques specifically designed for the detailed analysis and automatic interpretation of disease-related content in ultrasound imaging. Ultrasound images, characterized by grayscale representations with low resolution and significant noise, present unique challenges, including indistinct boundaries between anatomical structures and interference between various pathological conditions. Furthermore, in clinical practice, although certain regions of the sonographic image may contain the primary diagnostic information, the entire image is essential for anatomical orientation and artifact assessment during interpretation. Similar challenges are also encountered in nuclear medicine imaging, where low spatial resolution and high noise levels complicate the identification and interpretation of pathological features.
These complexities render the direct analysis of ultrasound images particularly demanding. Historically, efforts within medical imaging understanding have predominantly centered on classification, detection, segmentation, and concept recognition tasks [
6]. To address these specific challenges, a novel approach for ultrasound image caption generation based on part detection was proposed. This method simultaneously identifies and encodes key focus areas within ultrasound images and subsequently utilizes a Long Short-Term Memory (LSTM) network to decode the encoded features into coherent textual descriptions, accurately conveying the pathological content identified within the focus regions.
The investigational outcomes show that the technique can precisely detect the focus area’s site and recovers scores of BLEU-1 and BLEU-2 with fewer parameters and shorter running time. The major distinction between the present research and the aforementioned study lies in the imaging modalities considered. Whereas the referenced work exclusively targets caption generation for ultrasound images, the current study extends its methodology to support multiple imaging modalities, thereby encompassing a broader range of diagnostic scenarios.
Experimental results reported by Zeng et al. demonstrated that the Faster RCNN model achieved a BLEU-1 score of 0.63, a BLEU-2 score of 0.55, and a BLEU-3 score of 0.47 [
15]. These outcomes highlight the effectiveness of integrating part detection with sequential decoding mechanisms, significantly enhancing the precision and clinical relevance of captions generated from ultrasound imagery.
1.8. ImageCLEF Caption Detection Task
The Cross-Language Evaluation Forum (CLEF) serves as an international platform dedicated to advancing research in cross-linguistic information retrieval [
16]. Its objective is to assess the progress achieved in multilingual data access and to promote solutions addressing the unique challenges associated with multilingual and cross-modal information retrieval. Within this framework, ImageCLEF was initiated in 2003 as part of the CLEF initiative, focusing specifically on supporting the evaluation of systems designed for the automatic annotation of images with concepts, multimodal information retrieval based on both textual and visual content, and multilingual retrieval of annotated images.
ImageCLEF has consistently attracted participation from both academic institutions and industry researchers across diverse fields including visual information retrieval, computer vision, natural language processing, and medical informatics. The 2017 ImageCLEF campaign introduced several new evaluation tasks, among which the automatic generation of medical image captions was featured for the first time [
17,
18]. Each year, the dataset provided for these tasks has been updated to reflect evolving research needs and technological advancements.
1.8.1. ImageCLEF Caption Detection Task 2017
The ImageCLEF 2017 Caption Detection task was divided into two subtasks: concept detection and caption prediction. Participants first identified relevant UMLS concepts in biomedical images and then generated intelligible captions based on these concepts and image features. Capturing concept interactions was crucial to reconstruct the original captions beyond simply detecting individual visual elements.
The training set contained 164,614 biomedical images extracted from PubMed Central, with corresponding UMLS concepts for concept detection and image–caption pairs for caption prediction. Validation and test sets included 10,000 images each. Evaluation metrics were the F1-score for concept detection and the BLEU score for caption prediction. Performance summaries are shown in
Table 3,
Table 4,
Table 5 and
Table 6:
Sadid A. Hassan et al. [
19] achieved the best results in the caption prediction task using an encoder–decoder architecture combining CNNs for feature extraction and RNNs with attention mechanisms for caption generation. They fine-tuned VGG19 on the ImageCLEF dataset and trained the model using stochastic gradient descent with the Adam optimizer and dropout regularization.
For concept detection, Asma Ben Abacha et al. [
20] employed multilabel classification with CNNs and Binary Relevance-Decision Trees (BR-DTs), using GoogleNet for feature extraction. They also explored various visual descriptors such as CEDD and FCTH [
17], finding that CEDD yielded the best performance in their experiments.
Leonidas Valavanis and Spyridon Stathopoulos [
21] proposed a probabilistic k-nearest neighbor (PKNN) approach, combining bag-of-visual-words (BoVW) and Quantized Bag of Colors (QBoC) models, achieving second-best performance without external resources. Dense SIFT features and late fusion techniques were used to enhance retrieval and prediction performance.
Overall, the 2017 task demonstrated the effectiveness of deep learning, information retrieval, and ensemble methods for biomedical image captioning.
1.8.2. ImageCLEF Caption Detection Task 2018
The 2018 ImageCLEF Caption Detection task, a continuation of the 2017 edition [
22], focused on clinical descriptions to limit dataset diversity. External data usage was restricted, and the challenge emphasized identifying general topics from biomedical images based on large-scale training data. The task maintained two subtasks: concept detection, requiring automatic extraction of UMLS CUIs, and caption prediction, generating descriptive captions (
Table 7 and
Table 8):
Several methods were developed for concept detection. One approach applied a traditional bag-of-visual-words model using ORB descriptors, with keypoints clustered via k-means (k = 4096) using FAISS [
23]. Generative Adversarial Networks (GANs) [
24] and their hybrid autoencoding variants [
25] were also explored to learn latent visual features. Open-source tools like LIRE were used to index images, combined with Latent Dirichlet Allocation (LDA) for concept grouping.
In total, fifteen runs were submitted [
26]. ImageSem achieved the best performance, reaching an F1-score of 0.0928 in concept detection and a BLEU-Score of 0.2501 in caption prediction. Their method, based on image retrieval and transfer learning, highlighted challenges in fully capturing biomedical image semantics.
1.8.3. ImageCLEF Caption Detection Task 2019
The ImageCLEF 2019 Caption Detection task [
27], third in the series after 2017 and 2018, focused solely on radiology images mined from PubMed Central to reduce label noise. A single subtask required detecting UMLS concepts from images. The training set included 56,629 images, with 14,157 for validation. Teams mainly applied deep learning approaches such as CNNs, RNNs (especially LSTM), adversarial autoencoders, and transfer learning models. The evaluation used F1-scores averaged across 10,000 test images (
Table 9).
AUEB NLP’s top-ranked systems combined CNN image encoders with retrieval and multilabel classification approaches. Their best model adapted CheXNet [
3] using DenseNet-121, extending it to predict 5528 concepts by replacing the original output layer, applying sigmoidal activation, and optimizing thresholding at 0.16 [
28]. Another system combined CheXNet probabilities with k-NN retrieval scores, and a VGG-19 based model ranked fifth.
Jing Xu et al. [
29] proposed a hybrid CNN-LSTM framework with attention mechanisms. Features were extracted using a fine-tuned ResNet-101 encoder, followed by an LSTM decoder using attention to dynamically focus on image regions during concept prediction. Their method ranked second overall.
ImageCLEF 2019 confirmed the effectiveness of combining transfer learning, retrieval, and attention-based models for biomedical concept detection.
3. Experiments and Results
3.1. Dataset Exploration
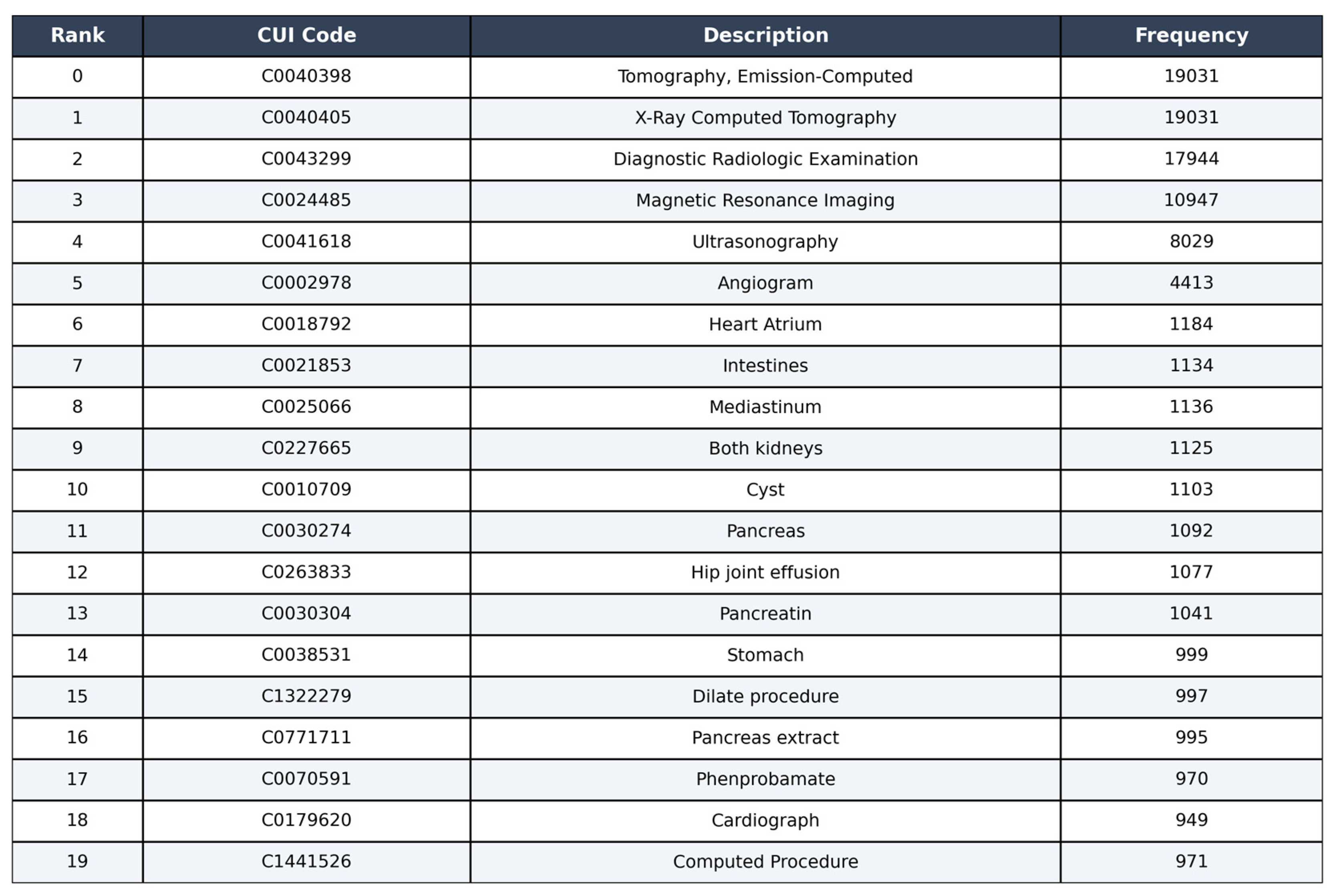
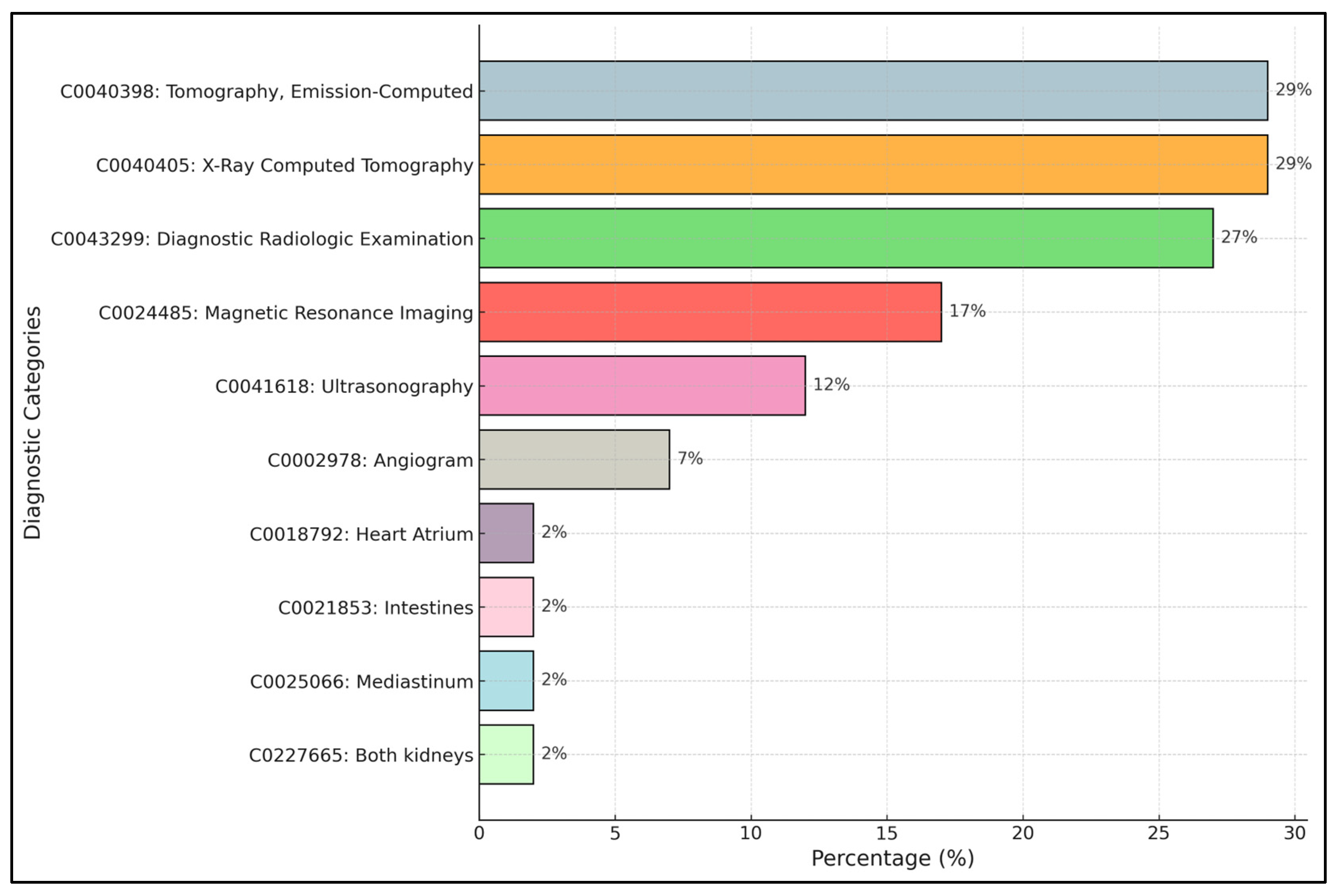
Figure 5 shows the distribution of concepts in the ImageCLEF dataset, the top 10 most frequent concepts.
The most frequent categories are “Tomography, Emission-Computed” (29%) corresponding to nuclear medicine imaging techniques such as PET and SPECT, and “X-Ray Computed Tomography” (29%), followed closely by “Diagnostic Radiologic Examination” (27%). These three categories dominate the dataset, indicating a strong prevalence of cross-sectional imaging techniques (CT and general diagnostic radiology). Other significant concepts include “Magnetic Resonance Imaging” (17%) and “Ultrasonography” (12%), confirming the relevance of MRI and ultrasound imaging within the dataset. Less frequent categories, such as “Angiogram” (7%), “Heart Atrium” (2%), “Intestines” (2%), “Mediastinum” (2%), and “Both Kidneys” (2%), represent more specific anatomical or procedural concepts.
This distribution highlights the imbalance present in the dataset, with a few dominant concepts and many rare ones, which needs to be addressed carefully in the model training and evaluation phases.
3.2. Experimental Outcomes of Deep Learning Algorithms
Table 11 presents the experimental results obtained from different deep learning models under various settings. The ImageCLEF dataset, consisting of 3047 concepts, was used throughout the experiments. The initial experiments involved training a DenseNet121 model with transfer learning, utilizing ImageNet pre-trained weights and setting the number of epochs to 10. Training on a CPU-based system required approximately 15 days and achieved an F1-score of 0.33. Subsequently, DenseNet121 was trained without transfer learning under the same epoch setting on a GPU-based system, which took approximately one month to complete and yielded an F1-score of 0.21. Experiments were also conducted with a ResNet101 model using transfer learning (ImageNet pre-trained weights) and three epochs. Training on a CPU-based system required about seven days, resulting in an F1-score of 0.21. When ResNet101 was trained without transfer learning on a GPU-based system (three epochs), training lasted about 20 days, and the F1-score obtained was 0.17.
Finally, the VGG19 model was trained on the dataset without transfer learning, achieving an F1-score of 0.265. Based on these results, DenseNet121 with transfer learning was selected as the optimal approach, as models with fewer layers or without transfer learning consistently yielded lower performance.
Table 12 shows the experimental outcomes of different profound learning versions with alternative settings. We initially used the ImageCLEF dataset of 3047 concepts. However, we did not obtain any meaningful results, so we reduced the number of concepts to 20. We started with training the base prototype of DenseNet121 with the transfer learning concepts, i.e., weights of ImageNet pre-trained on DenseNet121 and settings epochs equal to 3. It took almost three days to train the prototype on a CPU-founded system. This gave us an F1-score of 0.89.
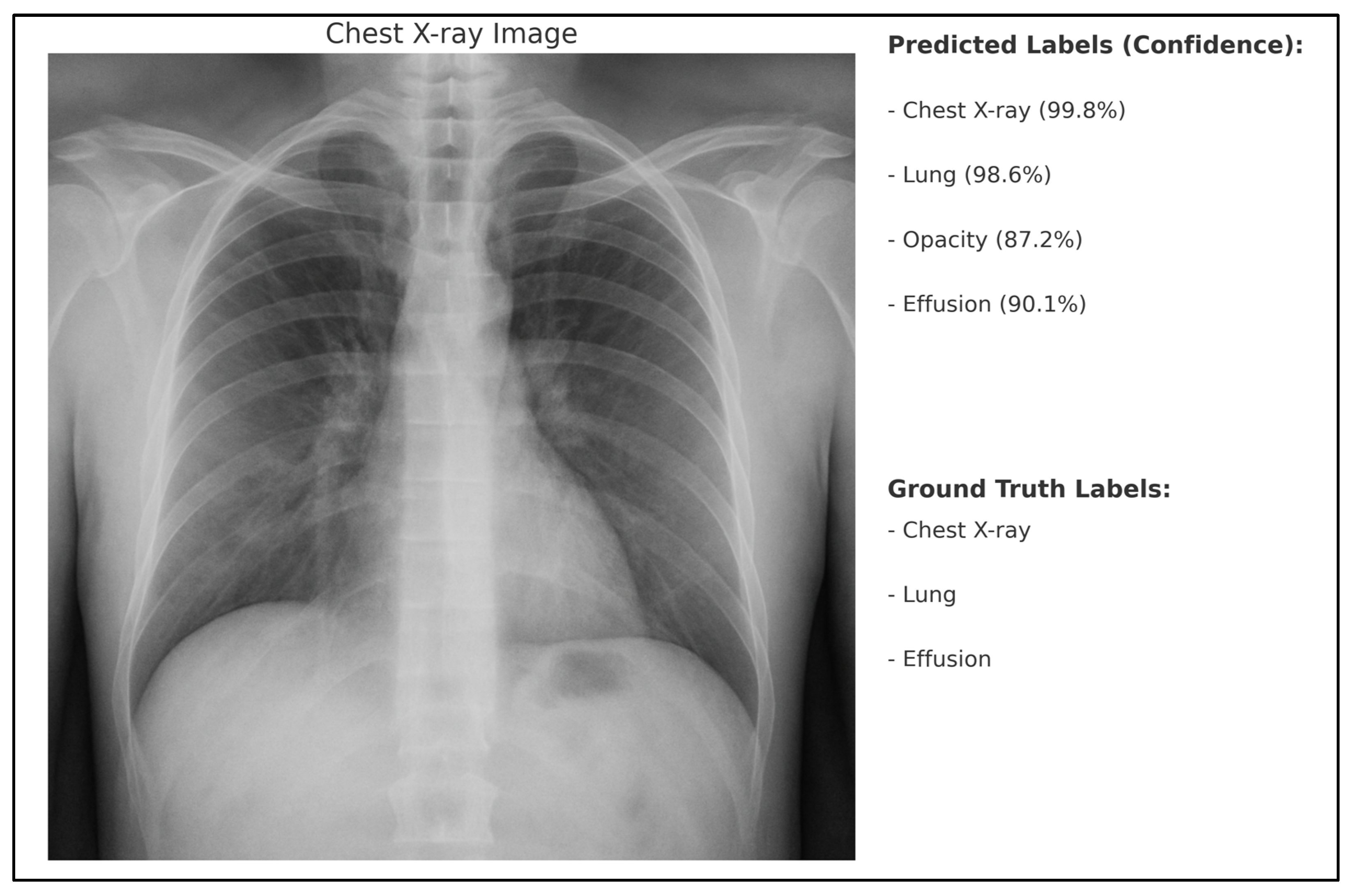
To better illustrate the model’s behavior in predicting medical concepts from radiological images, we provide an example in
Figure 6. The ground truth labels for the image are also shown for comparison. As can be seen, the model correctly identifies the major anatomical structures (“Chest X-ray”, “Lung”, “Effusion”) with high confidence, and additionally predicts the concept “Opacity”, which was not annotated in the ground truth but is a plausible finding in chest radiographs.
This significant improvement in classification performance when focusing on the 20 most frequent concepts is mainly attributed to the higher frequency of these classes, which alleviates the few-shot learning problem. Although some label noise may be present in the dataset, it was not identified as the primary limitation in this study. The main challenge encountered was the scarcity of examples for many rare classes. The ResNet101 model was subsequently trained using transfer learning, employing ImageNet pre-trained weights and setting the number of epochs to 3. Training on a CPU-based system required approximately three days and resulted in an F1-score of 0.88.
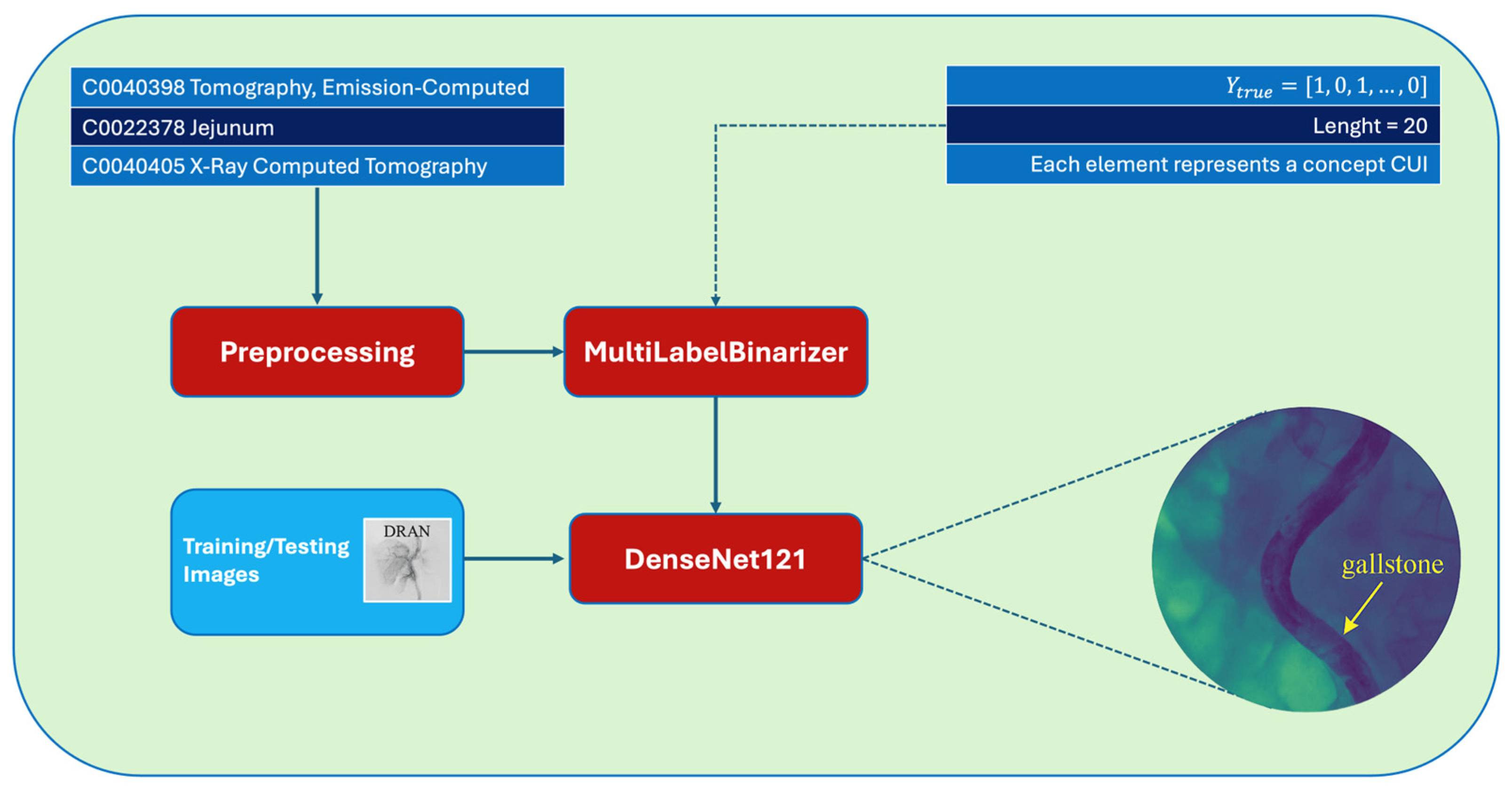
The modality-wise F1-score of the DenseNet121 model was calculated, starting with the DRAN images corresponding to the angiogram modality. However, no meaningful results were obtained. Due to time constraints, this process was discontinued, as generating new CSV files proved to be complex and time-consuming. In this analysis, the modality-wise F1-score refers to the evaluation across seven modalities present in the training, validation, and testing datasets. The goal was to assess the model’s learning performance for each individual modality.
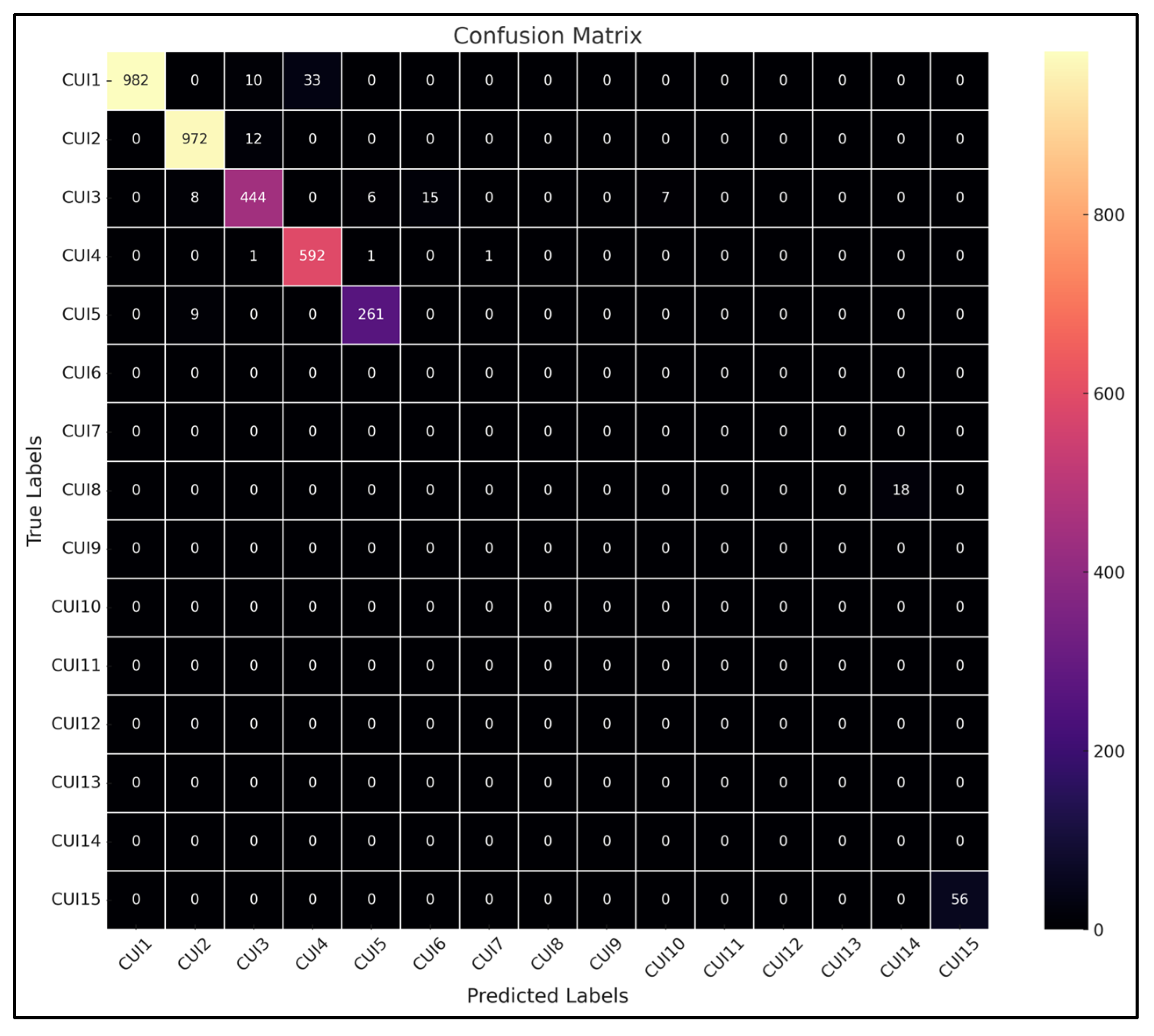
Figure 7 shows the confusion matrix of the testing phase. We generated multiple testing subsets, and there was one that we have selected from DRXR that means mostly x-ray images. This confusion matrix is the result of that testing subset. Here in the confusion matrix, as we can see, label CUI2 has a high value assigned to it, and CUI2 stands for X-Ray Computed Tomography as all images belong to this specific modality, so it has high value. This result is obtained by training the prototype on DenseNet121.
Although the global F1-score achieved by the DenseNet121 model remains high,
Figure 8 clearly highlights a strong class imbalance. Most of the correct predictions are concentrated in a few dominant concepts (such as CUI1 and CUI2), while several other classes are underrepresented or not predicted at all. To provide a more balanced evaluation of the model’s performance, we also calculated the Macro-F1-score, which was 78% for DenseNet121 and 77% for ResNet101. These values better reflect the impact of class imbalance on model performance.
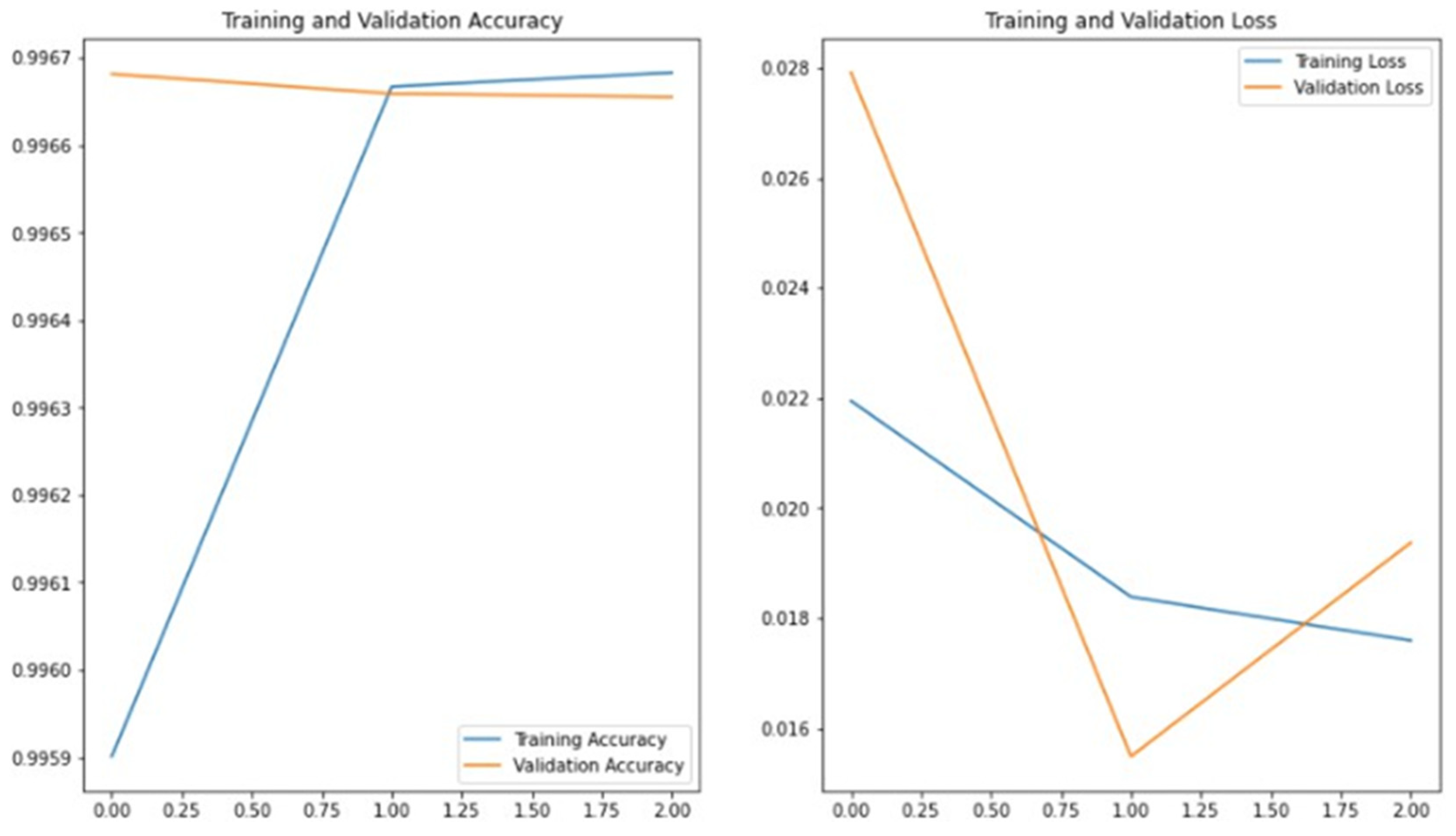
Figure 8 presents the training and validation accuracy and loss curves obtained during the training of DenseNet121 on the ImageCLEF dataset. The graph indicates that reasonable accuracy could not be achieved without applying transfer learning. Increasing the number of epochs from 10 to 20 did not produce a significant improvement in the results. This analysis highlights the importance of transfer learning in the context of this study.
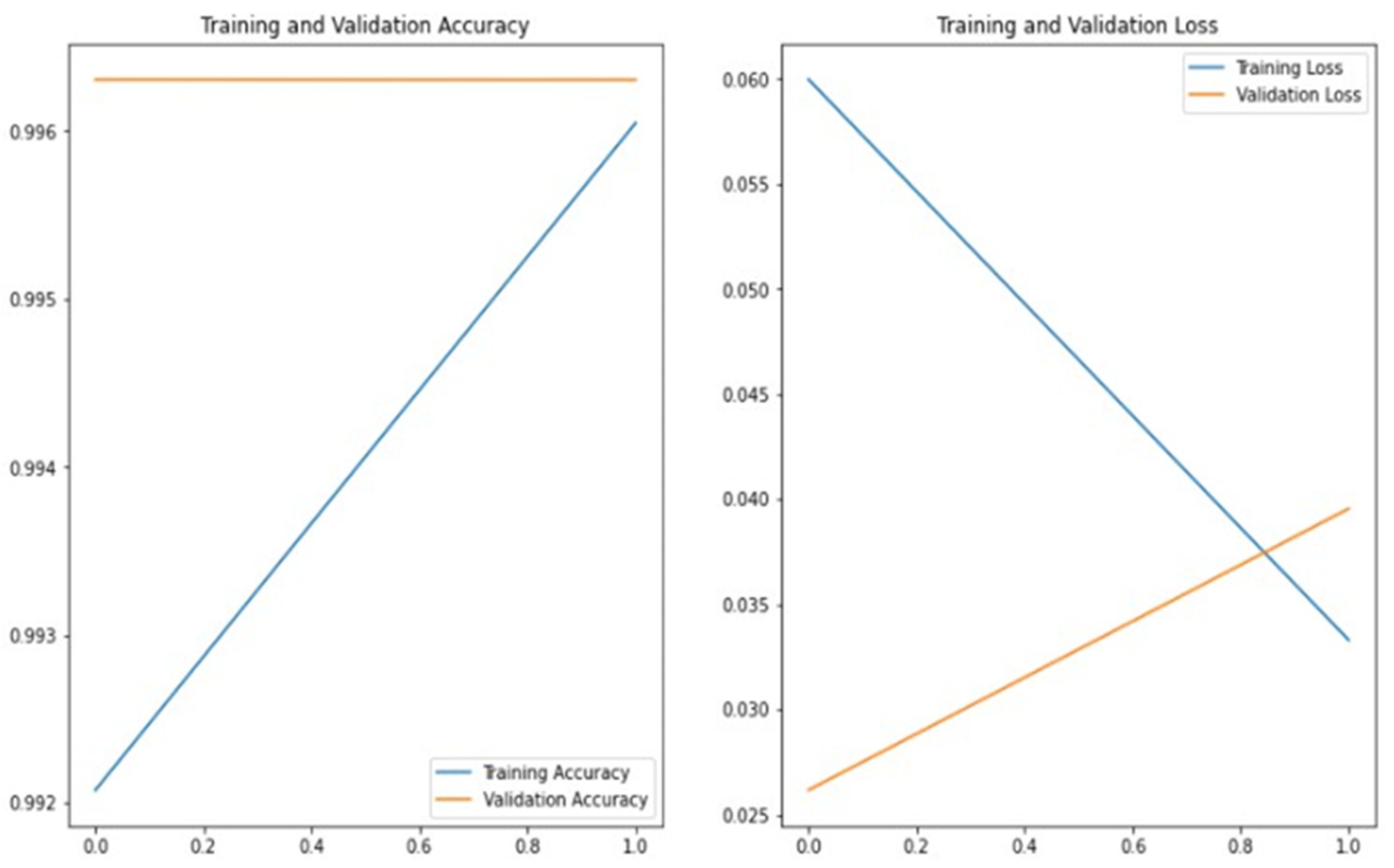
Figure 9 presents the training and validation accuracy and loss curves obtained during the training of ResNet101 on the ImageCLEF dataset. The graph demonstrates that good accuracy can be achieved by applying transfer learning. This analysis further highlights the importance of transfer learning for this study. In this experiment, the number of epochs was set to 2 to control the increase in time complexity associated with a higher number of epochs.
Figure 10 shows the training and validation accuracy and loss graph when VGG19 was trained on the ImageCLEF dataset. This graph shows that maximizing transfer learning can achieve good accuracy but also that this prototype is overfitting. Here we set the number of epochs to 1 because the time complexity also increases by increasing the number of epochs.
Although the models achieved reasonable accuracy, it is important to note that the training processes were limited to a very small number of epochs (2 for ResNet101 and 1 for VGG19) mainly due to time complexity constraints.
As a result, the training and validation curves shown in
Figure 9 and
Figure 10 do not fully represent complete convergence.
In future developments, we plan to extend the number of training epochs and adjust the early stopping criteria to allow a more complete model convergence and performance stabilization.
3.3. Comparison with Baseline Models
To provide clearer context for the obtained results, the performance of the deep learning models was compared with the official baseline performance reported in the ImageCLEFmed 2020 leaderboard. The comparison includes precision, recall, F1-score, and standard deviation across the models. The results are summarized in
Table 13.
As shown in
Table 13, the proposed DenseNet121 model using transfer learning achieved a significant improvement compared to the official ImageCLEF baseline, particularly in terms of F1-score (89.0% vs. 37.0%). Moreover, precision and recall values were consistently higher across all evaluated models. In contrast, the VGG19 model trained without transfer learning on the full set of 3047 concepts achieved lower performance, with an F1-score of 27.0%. The relatively low standard deviations confirm the stability and robustness of the training process.
4. Conclusions
DenseNet121 outperformed the other deep learning and machine learning models evaluated. Caption detection on radiology images was conducted using deep learning models, achieving a highest F1-score of 0.89. The proposed model demonstrated superior performance compared to previously published datasets and examples from recent years. Although direct comparison is limited due to differences in experimental setups, the results are generally comparable to those reported in the literature. Efforts were also made to optimize outcomes by minimizing time complexity and reducing resource consumption. We tried to achieve good outcomes on a CPU-founded system.
4.1. Future Directions
The concepts, also called CUIs, were successfully detected to accurately label the radiology images. The future direction to this work is categorized into two main types as given below.
Future research could focus on training separate models for each imaging modality represented in the dataset. Given the high diversity among modalities, such as x-ray, MRI, and CT scans, specialized models may capture modality-specific features more effectively than a unified model. After training, the outputs from each modality-specific model could be combined through ensemble learning strategies to improve overall classification performance. This approach could also help identify which models perform best for each modality type, providing deeper insights into how modality characteristics affect learning outcomes and guiding the development of more targeted diagnostic tools.
In this study, we reduced the number of concepts to the 20 most frequent ones to address extreme class imbalance and ensure a stable experimental framework. However, future work will focus on expanding the classification task to include a broader and more diverse set of UMLS concepts. This will allow for a more realistic evaluation of model performance in clinical applications. Considering the severe imbalance and the few-shot learning challenges associated with rare medical concepts, future directions also involve exploring advanced learning strategies such as few-shot learning, meta-learning techniques, and specialized data augmentation methods tailored for multilabel classification problems.
4.2. Limitations
Although the proposed system achieved strong performance in the automatic generation of radiology image captions, several limitations must be acknowledged regarding its potential clinical application. First, the model was developed and evaluated exclusively on the ImageCLEF2020 dataset, which, despite its diversity, may not fully capture the variability of real-world clinical radiology images from different institutions, imaging devices, and patient populations. Furthermore, to address the challenges of class imbalance and computational complexity, the analysis was restricted to the 20 most frequent medical concepts. While this strategy significantly improved the model’s F1-score, it limited the ability to detect rare but clinically critical findings, potentially reducing its applicability in comprehensive diagnostic workflows. Another important limitation is the interpretability of the system. Deep learning models such as DenseNet121 operate as black-box systems, making it difficult to provide transparent explanations for each prediction. This may reduce clinical trust and acceptance, especially in contexts requiring high accountability. Moreover, despite achieving good performance metrics, even small errors in automatic labeling could propagate into clinical reports and introduce diagnostic risks if not properly supervised by expert radiologists. Finally, although efforts were made to optimize computational efficiency, real-time deployment in clinical environments may require substantial GPU resources, which may not always be available. Future research will focus on expanding the range of detectable concepts, validating the system of external clinical datasets, improving interpretability mechanisms, and evaluating its integration into clinical practice through user-centered studies.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}