
Short Text Classification Based on Enhanced Word Embedding and Hybrid Neural Networks


Abstract
1. Introduction
- An enhanced word embedding model based on pretrained Word2Vec is proposed. By incorporating Category Distribution Weight (CDW) into the refinement of TF-IDF, higher weights are assigned to category-specific terms. The TF-IDF-CDW-weighted Word2Vec embeddings, combined with POS features, allow the embedding vectors to emphasize key terms while minimizing the impact of noise.
- A hybrid model is designed by combining a GCNN with two BiLSTM networks. The GCNN captures local semantic patterns through multiscale gated convolutions. The BiLSTM layer captures global contextual dependencies, and a residual connection mechanism is incorporated to preserve the integrity of semantic representations. Finally, an attention mechanism dynamically adjusts the weights of the dual channels, enhancing classification performance.
- Experiments on the THUCNews and TNews datasets demonstrate that our model achieves accuracies of 91.85% and 87.70%, respectively, consistently outperforming several baseline models, thereby validating the effectiveness of both the enhanced embedding strategy and the hybrid neural architecture.
2. Related Work
2.1. Text Representation
2.2. Text Classification
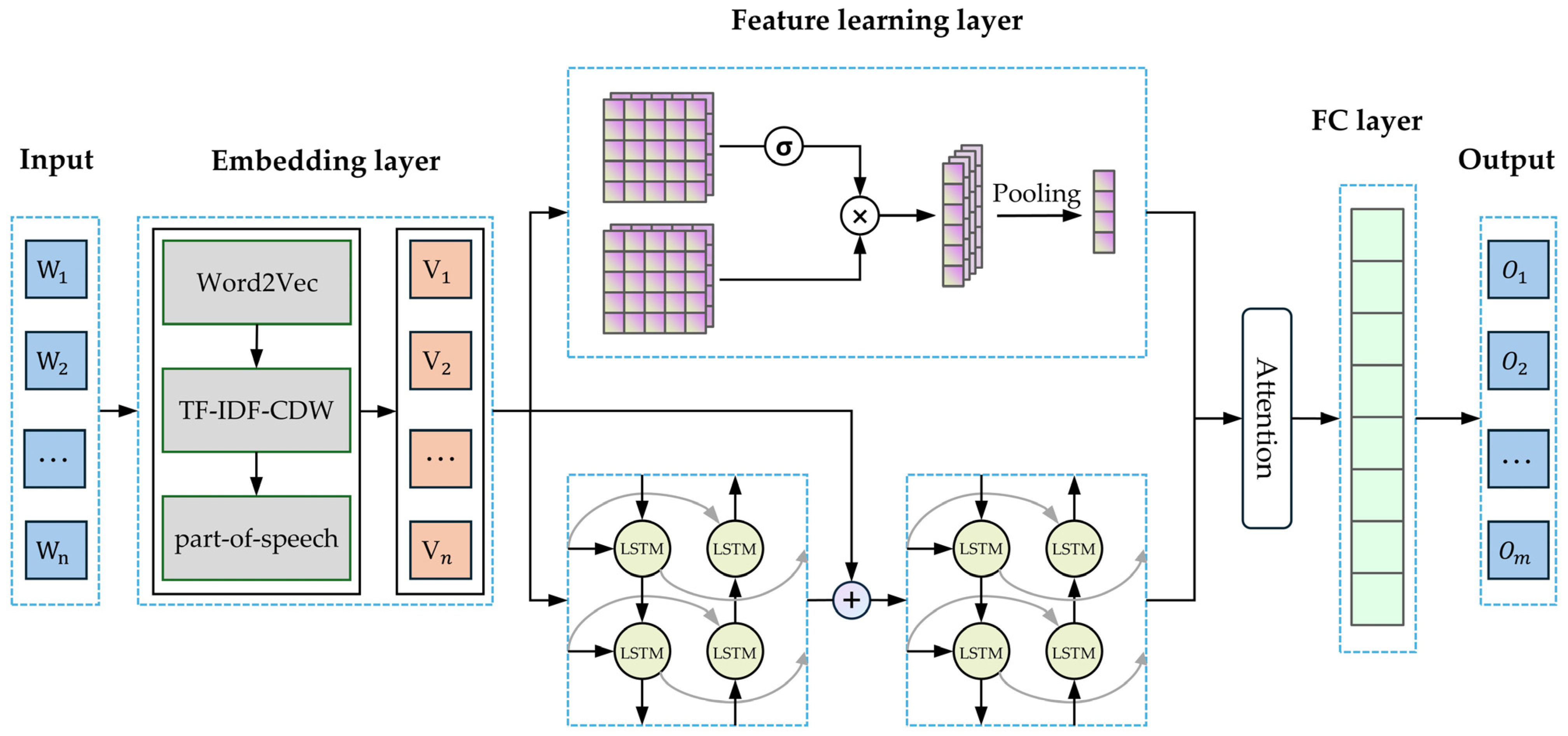
3. Methodology
3.1. Enhanced Word Embedding Based on Word2Vec
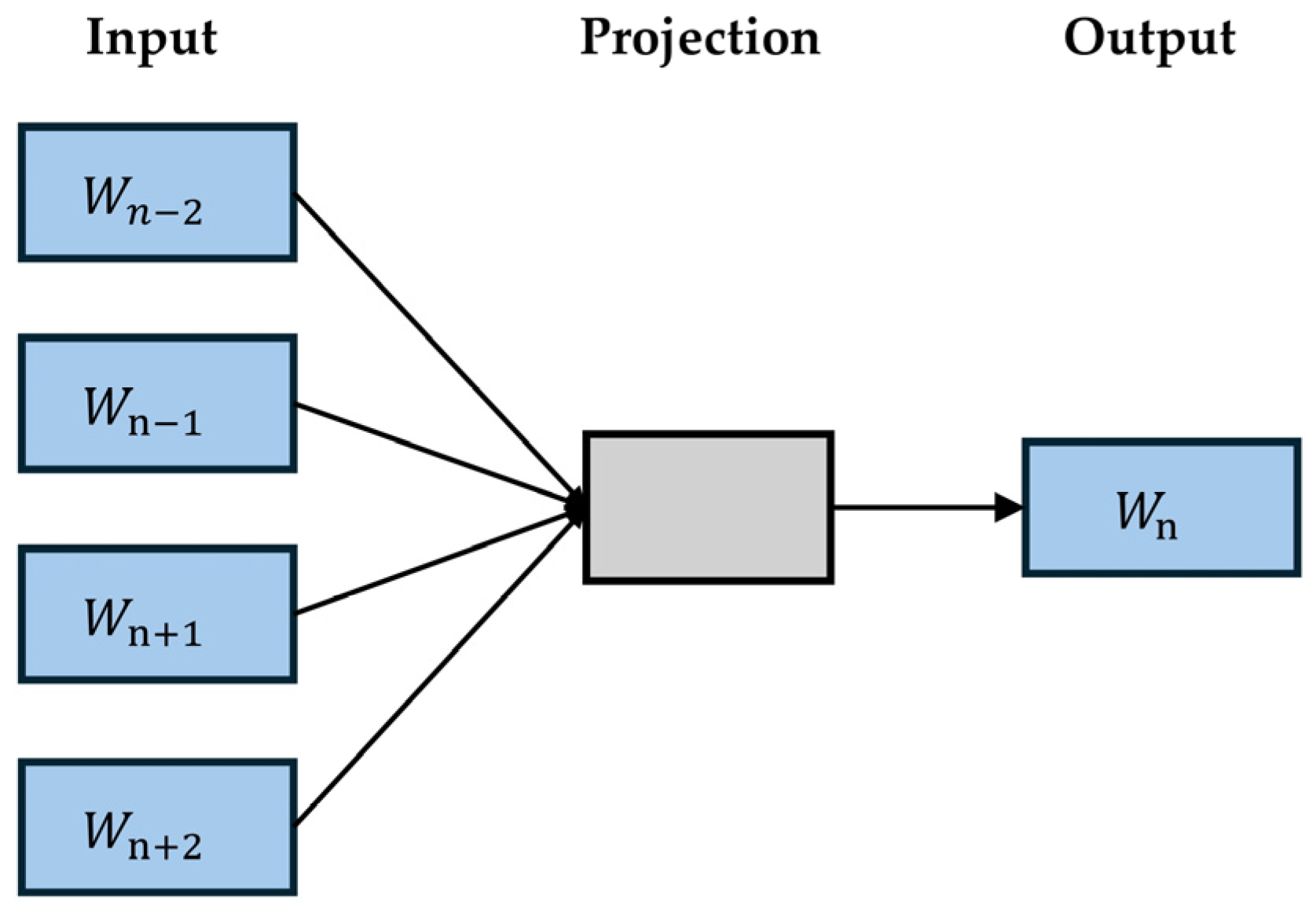
3.1.1. Word2Vec
3.1.2. TF-IDF-CDW
3.1.3. Part-of-Speech Encoding
3.1.4. Embedding Vector Generation
3.2. Hybrid Neural Network Based on a GCNN and Two-Layer BiLSTM
3.2.1. Gated Convolutional Neural Network
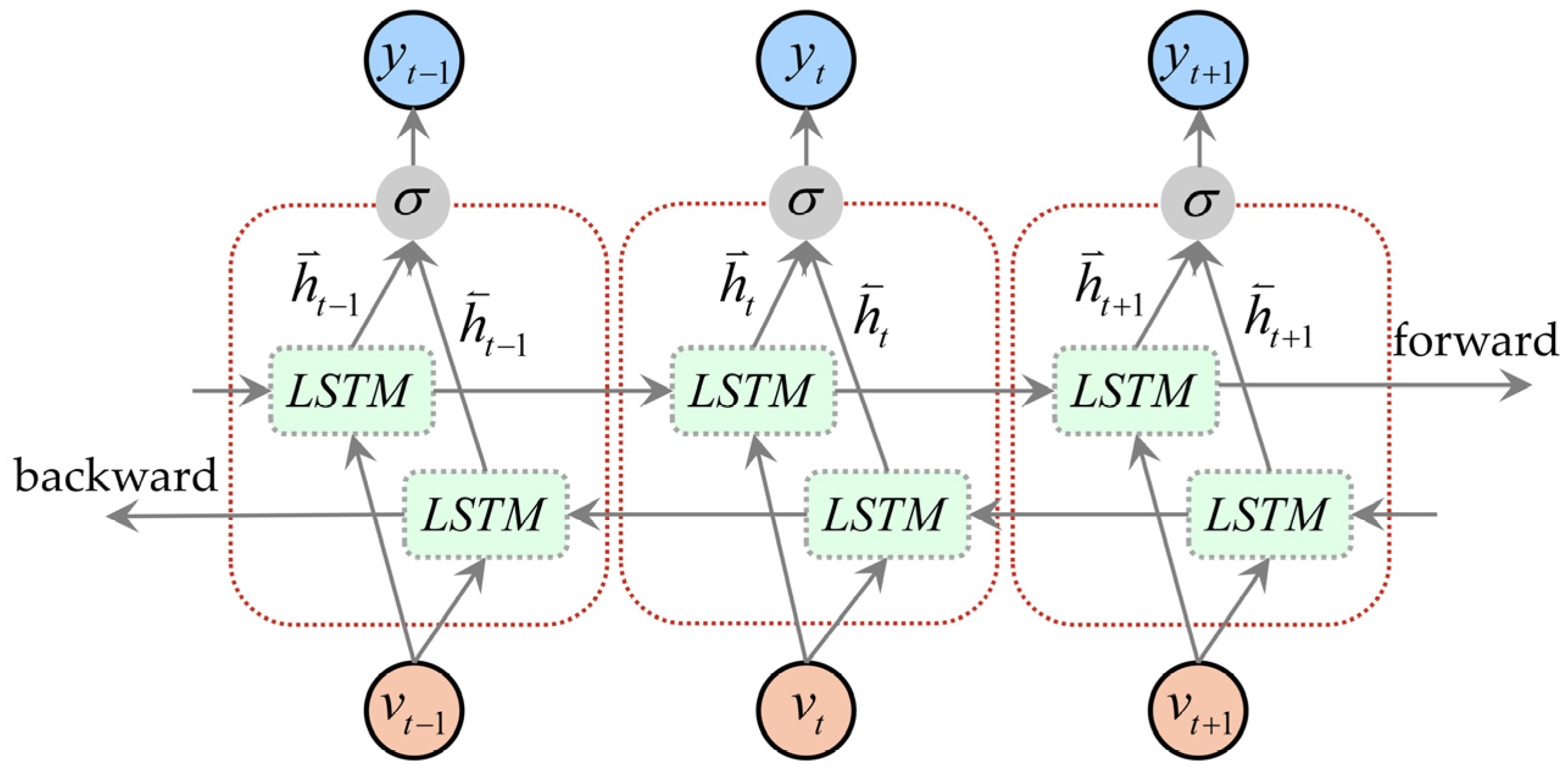
3.2.2. Two-Layer BiLSTM with Residual Connections
3.2.3. Fully Connected Layer
4. Experiment
4.1. Datasets and Preprocessing
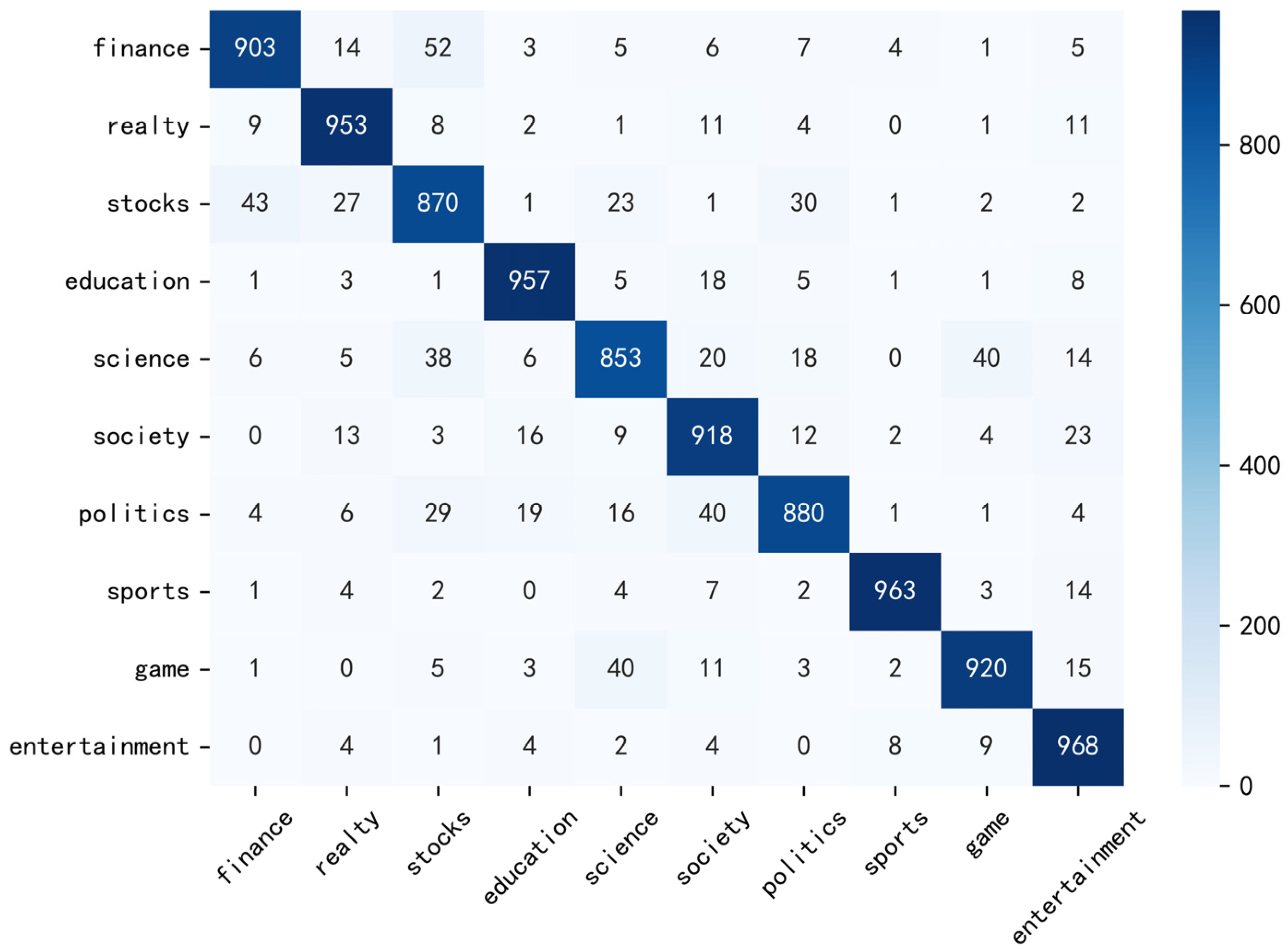
- THUCNews [43]: This dataset was sourced from news headlines published on the Sina News platform. To ensure uniform input length, samples with character lengths between 10 and 30 were selected, resulting in a dataset of 100,000 entries evenly distributed across 10 categories.
- TNews [44]: This dataset, collected from the Toutiao news app, was also filtered using the same length criterion. A total of 130,000 samples were selected, evenly covering 13 categories.
4.2. Experimental Environment and Hyperparameter Settings
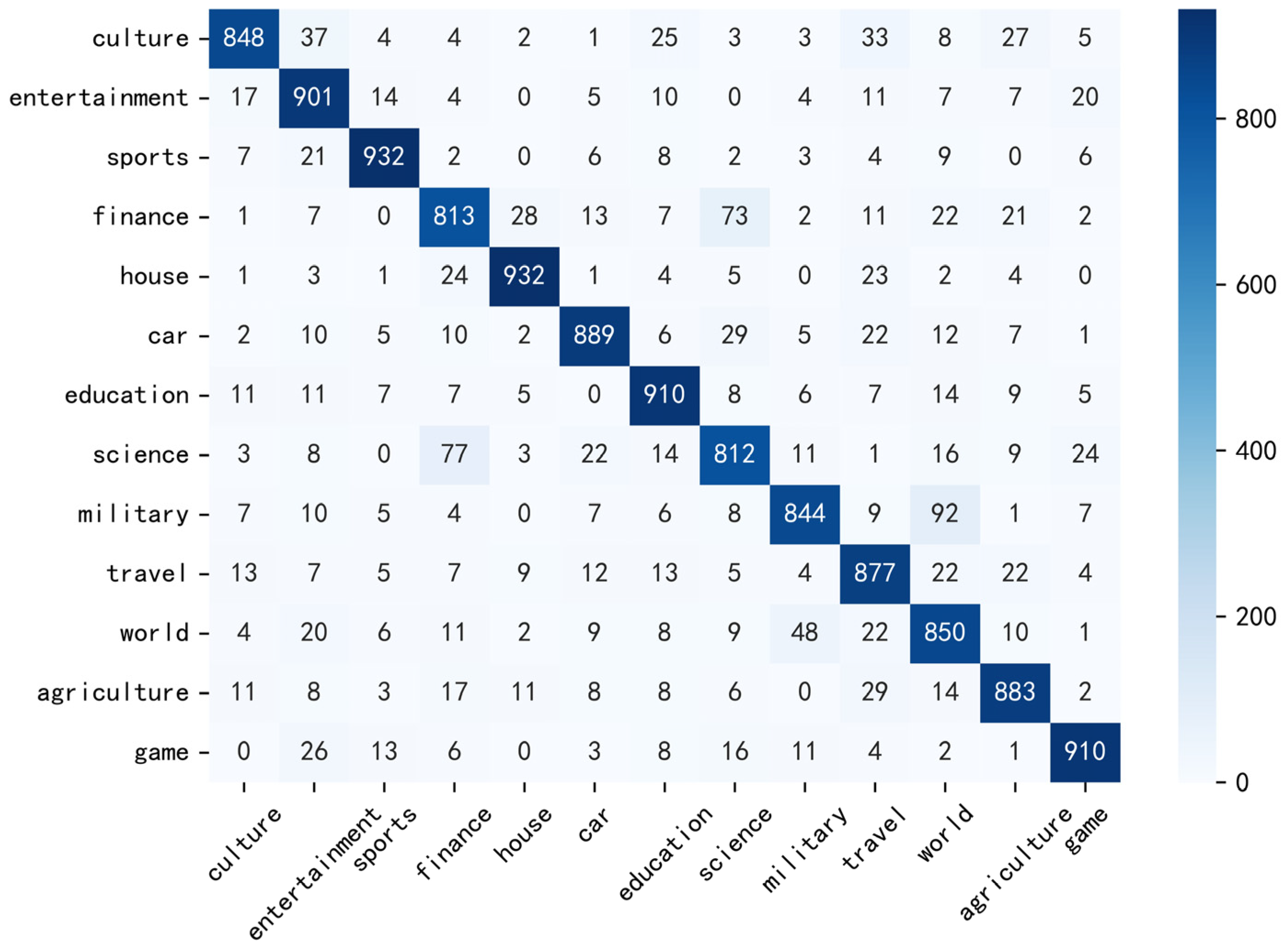
4.3. Experimental and Result Analysis
4.3.1. Comparative Experiments on News Datasets
- Our model outperforms other baseline models in terms of both accuracy and F1 score. The experimental results validate that word representations enriched with Term Frequency and POS features provide more-comprehensive semantic cues, and the hybrid model based on a GCNN and BiLSTM can learn more-comprehensive semantic information.
- The hybrid models CNN-BiLSTM and CNN-BiGRU-Attention outperform other single-architecture models on both datasets. CNN-BiGRU-Attention achieves an accuracy of 91.38% for THUCNews, 1.75% higher than the TextCNN model. CNN-BiLSTM attains an accuracy of 87.22% for TNews, which is 2.05% higher than BiLSTM-Attention. This verifies that the hybrid model’s ability to simultaneously capture local features and contextual information can improve classification performance.
- The GCNN achieves higher accuracy and F1 scores than TextCNN across both datasets, confirming that the introduction of a gating mechanism in the convolutional layers is more effective for extracting key features.
4.3.2. Comparative Experiments of Different Embedding Methods
4.3.3. Cross-Domain Performance on Medical Dataset
4.4. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Duarte, J.M.; Berton, L. A Review of Semi-Supervised Learning for Text Classification. Artif. Intell. Rev. 2023, 56, 9401–9469. [Google Scholar] [CrossRef]
- Wang, K.; Ding, Y.; Han, S.C. Graph Neural Networks for Text Classification: A Survey. Artif. Intell. Rev. 2024, 57, 190. [Google Scholar] [CrossRef]
- Huang, Y.; Liu, Q.; Peng, H.; Wang, J.; Yang, Q.; Orellana-Martín, D. Sentiment Classification Using Bidirectional LSTM-SNP Model and Attention Mechanism. Expert Syst. Appl. 2023, 221, 119730. [Google Scholar] [CrossRef]
- Bountakas, P.; Xenakis, C. HELPHED: Hybrid Ensemble Learning PHishing Email Detection. J. Netw. Comput. Appl. 2023, 210, 103545. [Google Scholar] [CrossRef]
- Zhou, Z.; Zhou, X.; Qian, L. Online Public Opinion Analysis on Infrastructure Megaprojects: Toward an Analytical Framework. J. Manag. Eng. 2021, 37, 04020105. [Google Scholar] [CrossRef]
- Xiao, L.; Li, Q.; Ma, Q.; Shen, J.; Yang, Y.; Li, D. Text Classification Algorithm of Tourist Attractions Subcategories with Modified TF-IDF and Word2Vec. PLoS ONE 2024, 19, e0305095. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP); Moschitti, A., Pang, B., Daelemans, W., Eds.; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 1746–1751. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Yao, L.; Mao, C.; Luo, Y. Graph Convolutional Networks for Text Classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 7370–7377. [Google Scholar] [CrossRef]
- Pavan Kumar, M.R.; Jayagopal, P. Context-Sensitive Lexicon for Imbalanced Text Sentiment Classification Using Bidirectional LSTM. J. Intell. Manuf. 2023, 34, 2123–2132. [Google Scholar] [CrossRef]
- Zhang, X.; Wu, Z.; Liu, K.; Zhao, Z.; Wang, J.; Wu, C. Text Sentiment Classification Based on BERT Embedding and Sliced Multi-Head Self-Attention Bi-GRU. Sensors 2023, 23, 1481. [Google Scholar] [CrossRef]
- Wang, Y.; Hou, Y.; Che, W.; Liu, T. From Static to Dynamic Word Representations: A Survey. Int. J. Mach. Learn. Cybern. 2020, 11, 1611–1630. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP); Moschitti, A., Pang, B., Daelemans, W., Eds.; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 1532–1543. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized Word Representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers); Walker, M., Ji, H., Stent, A., Eds.; Association for Computational Linguistics: New Orleans, LA, USA, 2018; pp. 2227–2237. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 4171–4186. [Google Scholar]
- Onan, A. Hierarchical Graph-Based Text Classification Framework with Contextual Node Embedding and BERT-Based Dynamic Fusion. J. King Saud Univ.-Comput. Inf. Sci. 2023, 35, 101610. [Google Scholar] [CrossRef]
- Zheng, J.; Wang, Y.; Wang, G.; Xia, J.; Huang, Y.; Zhao, G.; Zhang, Y.; Li, S. Using Context-to-Vector with Graph Retrofitting to Improve Word Embeddings. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Muresan, S., Nakov, P., Villavicencio, A., Eds.; Association for Computational Linguistics: Dublin, Ireland, 2022; pp. 8154–8163. [Google Scholar]
- Sun, X.; Liu, Z.; Huo, X. Six-Granularity Based Chinese Short Text Classification. IEEE Access 2023, 11, 35841–35852. [Google Scholar] [CrossRef]
- Li, H.; Li, X.; Yang, P.; Zhou, Z.; Cheng, L.; Hong, D. Avionics Fault Classification Based on Improved Word2Vec Word Embedding. In Proceedings of the Third International Symposium on Computer Applications and Information Systems (ISCAIS 2024), Wuhan, China, 22–24 March 2024; Volume 13210, pp. 842–849. [Google Scholar]
- Zhang, T.; Cui, W.; Liu, X.; Jiang, L.; Li, J. Research on Topic Evolution Path Recognition Based on LDA2vec Symmetry Model. Symmetry 2023, 15, 820. [Google Scholar] [CrossRef]
- Wang, J.; Zhao, C.; He, S.; Gu, Y.; Alfarraj, O.; Abugabah, A. LogUAD: Log Unsupervised Anomaly Detection Based on Word2Vec. Comput. Syst. Sci. Eng. 2022, 41, 1207. [Google Scholar] [CrossRef]
- George, M.; Murugesan, R. Improving Sentiment Analysis of Financial News Headlines Using Hybrid Word2Vec-TFIDF Feature Extraction Technique. Procedia Comput. Sci. 2024, 244, 1–8. [Google Scholar] [CrossRef]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep Learning--Based Text Classification: A Comprehensive Review. ACM Comput. Surv. 2022, 54, 1–40. [Google Scholar] [CrossRef]
- Li, Q.; Peng, H.; Li, J.; Xia, C.; Yang, R.; Sun, L.; Yu, P.S.; He, L. A Survey on Text Classification: From Traditional to Deep Learning. ACM Trans. Intell. Syst. Technol. 2022, 13, 1–41. [Google Scholar] [CrossRef]
- Johnson, R.; Zhang, T. Deep Pyramid Convolutional Neural Networks for Text Categorization. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Vancouver, BC, Canada, 2017; pp. 562–570. [Google Scholar]
- Tan, C.; Ren, Y.; Wang, C. An Adaptive Convolution with Label Embedding for Text Classification. Appl. Intell. 2023, 53, 804–812. [Google Scholar] [CrossRef]
- Soni, S.; Chouhan, S.S.; Rathore, S.S. TextConvoNet: A Convolutional Neural Network Based Architecture for Text Classification. Appl. Intell. 2023, 53, 14249–14268. [Google Scholar] [CrossRef] [PubMed]
- Khataei Maragheh, H.; Gharehchopogh, F.S.; Majidzadeh, K.; Sangar, A.B. A New Hybrid Based on Long Short-Term Memory Network with Spotted Hyena Optimization Algorithm for Multi-Label Text Classification. Mathematics 2022, 10, 488. [Google Scholar] [CrossRef]
- Dou, G.; Zhao, K.; Guo, M.; Mou, J. Memristor-based LSTM newtwork for text classification. Fractals 2023, 31, 2340040. [Google Scholar] [CrossRef]
- Zulqarnain, M.; Ghazali, R.; Aamir, M.; Hassim, Y.M.M. An Efficient Two-State GRU Based on Feature Attention Mechanism for Sentiment Analysis. Multimed. Tools Appl. 2024, 83, 3085–3110. [Google Scholar] [CrossRef]
- Prabhakar, S.K.; Rajaguru, H.; Won, D.-O. Performance Analysis of Hybrid Deep Learning Models with Attention Mechanism Positioning and Focal Loss for Text Classification. Sci. Program. 2021, 2021, 2420254. [Google Scholar] [CrossRef]
- Duan, L.; You, Q.; Wu, X.; Sun, J. Multilabel Text Classification Algorithm Based on Fusion of Two-Stream Transformer. Electronics 2022, 11, 2138. [Google Scholar] [CrossRef]
- Wu, D.; Wang, Z.; Zhao, W. XLNet-CNN-GRU Dual-Channel Aspect-Level Review Text Sentiment Classification Method. Multimed. Tools Appl. 2024, 83, 5871–5892. [Google Scholar] [CrossRef]
- Zeng, F.; Chen, N.; Yang, D.; Meng, Z. Simplified-Boosting Ensemble Convolutional Network for Text Classification. Neural Process. Lett. 2022, 54, 4971–4986. [Google Scholar] [CrossRef]
- Chen, Z.; Li, S.; Ye, L.; Zhang, H. Multi-Label Classification of Legal Text Based on Label Embedding and Capsule Network. Appl. Intell. 2023, 53, 6873–6886. [Google Scholar] [CrossRef]
- Sun, G.; Cheng, Y.; Zhang, Z.; Tong, X.; Chai, T. Text Classification with Improved Word Embedding and Adaptive Segmentation. Expert Syst. Appl. 2024, 238, 121852. [Google Scholar] [CrossRef]
- Salton, G.; Buckley, C. Term-Weighting Approaches in Automatic Text Retrieval. Inf. Process. Manag. 1988, 24, 513–523. [Google Scholar] [CrossRef]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language Modeling with Gated Convolutional Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 933–941. [Google Scholar]
- Zhou, P.; Qi, Z.; Zheng, S.; Xu, J.; Bao, H.; Xu, B. Text Classification Improved by Integrating Bidirectional LSTM with Two-Dimensional Max Pooling. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers; Matsumoto, Y., Prasad, R., Eds.; The COLING 2016 Organizing Committee: Osaka, Japan, 2016; pp. 3485–3495. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- THUCNews. Available online: https://github.com/thunlp/THUCTC (accessed on 3 March 2025).
- TNews. Available online: https://github.com/aceimnorstuvwxz/toutiao-text-classfication-dataset (accessed on 3 March 2025).
- Zhou, P.; Shi, W.; Tian, J.; Qi, Z.; Li, B.; Hao, H.; Xu, B. Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers); Association for Computational Linguistics: Berlin, Germany, 2016; pp. 207–212. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of Tricks for Efficient Text Classification. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers; Association for Computational Linguistics: Valencia, Spain, 2017; pp. 427–431. [Google Scholar]
- Mutabazi, E.; Ni, J.; Tang, G.; Cao, W. An Improved Model for Medical Forum Question Classification Based on CNN and BiLSTM. Appl. Sci. 2023, 13, 8623. [Google Scholar] [CrossRef]
- Li, X.; Zhang, Y.; Jin, J.; Sun, F.; Li, N.; Liang, S. A Model of Integrating Convolution and BiGRU Dual-Channel Mechanism for Chinese Medical Text Classifications. PLoS ONE 2023, 18, e0282824. [Google Scholar] [CrossRef]
- Chinese Medical Dialogue Data. Available online: https://github.com/Toyhom/Chinese-medical-dialogue-data (accessed on 24 April 2025).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Description | Main Advantages |
|---|---|---|
| Word2Vec [7] | Generates low-dimensional, dense word vectors based on contextual window information. | Embedding vectors provide rich semantic representations. |
| BERT [16] | Generates context-sensitive word vectors using a deep bidirectional Transformer network architecture. | Dynamically adapts embeddings based on context. |
| Context-to-Vec [18] | Enhances Word2Vec embeddings by integrating contextual information and refining it through graph-based topology, while improving semantic representations with synonym knowledge. | Addresses the limitations of static embeddings in semantic representation and context handling, significantly enhancing semantic expressiveness. |
| SGCSTC [19] | Fuses multiple granularities of information, such as word-jieba, word-jieba-radical, word-ngram, word-ngram-radical, and character embeddings. | Enriches the semantic representation of the text and alleviates the context sparsity issue in short texts. |
| LDA2Vec [21] | Combines Word2Vec with topic models to optimize domain-specific semantic representations through topic probabilities. | Improves word embedding by combining the strengths of LDA and Word2Vec. |
| Word2Vec-TFIDF [22] | Calculates the importance of each word using TF-IDF, then adjusts Word2Vec embeddings by applying these weights. | Retains the powerful semantic representation capability of Word2Vec while enhancing the distinguishability of words in specific contexts. |
| This paper | Quantifies the category distinction of words by using the improved TF-IDF-CDW weighting, dynamically adjusting Word2Vec embeddings, and incorporating part-of-speech encoding. | Enhances the semantic weight of key terms by considering category distribution and part-of-speech and assigning higher weights to category-specific words. |
| Dataset | Categories | Train | Validate | Test |
|---|---|---|---|---|
| THUCNews | 10 | 80,000 | 10,000 | 10,000 |
| TNews | 13 | 104,000 | 13,000 | 13,000 |
| Environment Component | Configuration |
|---|---|
| operating system | Windows 10 |
| CPU | Intel Core i7-13620H |
| GPU | RTX 4060 |
| RAM | 32 GB |
| programming language | Python 3.10.8 |
| framework | PyTorch 2.3.1 |
| Parameter | Value |
|---|---|
| Word2Vec embedding dimension | 300 |
| POS embedding dimension | 10 |
| convolution kernel widths | {2,3} |
| number of convolution kernels | 128 |
| BiLSTM hidden units | 128 |
| maximum sequence length | 16 |
| batch size | 64 |
| number of epochs | 10 |
| Model | THUCNews | TNews | ||
|---|---|---|---|---|
| Accuracy (%) | F1-Score (%) | Accuracy (%) | F1-Score (%) | |
| TextCNN | 89.63 | 89.60 | 85.96 | 85.99 |
| BiLSTM-Attention | 90.21 | 90.23 | 85.17 | 85.09 |
| GCNN | 90.48 | 90.51 | 86.12 | 86.05 |
| DPCNN | 90.69 | 90.80 | 86.47 | 86.49 |
| FastText | 90.84 | 90.83 | 86.75 | 86.59 |
| CNN-BiLSTM | 91.26 | 91.34 | 87.22 | 87.23 |
| CNN-BiGRU-Attention | 91.38 | 91.36 | 87.15 | 87.06 |
| Our model | 91.85 | 91.84 | 87.70 | 87.72 |
| Model | Accuracy (%) | F1-Score (%) | Training Time (s) | Inference Time (s) | Model Size (MB) |
|---|---|---|---|---|---|
| DPCNN | 90.69 | 90.80 | 313 | 3.32 | 48 |
| BERT | 92.03 | 91.99 | 1413 | 19.52 | 394 |
| Our model | 91.85 | 91.84 | 348 | 3.66 | 49 |
| Model | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|
| TextCNN | 85.55 | 85.75 | 85.55 | 85.63 |
| BiLSTM-Attention | 85.78 | 85.68 | 85.78 | 85.71 |
| GCNN | 86.35 | 86.27 | 86.35 | 86.28 |
| DPCNN | 86.87 | 86.86 | 86.87 | 86.72 |
| FastText | 87.07 | 87.05 | 87.07 | 87.05 |
| CNN-BiLSTM | 87.82 | 87.71 | 87.82 | 87.74 |
| CNN-BiGRU-Attention | 87.73 | 87.82 | 87.73 | 87.72 |
| Our model | 88.22 | 88.35 | 88.22 | 88.27 |
| Model Variation | THUCNews | TNews | ||
|---|---|---|---|---|
| Accuracy (%) | Decreased (%) | Accuracy (%) | Decreased (%) | |
| Remove the TF-IDF-CDW | 91.56 | 0.29 | 87.29 | 0.41 |
| Remove the POS encoding | 91.71 | 0.14 | 87.52 | 0.18 |
| Only keep Word2Vec | 91.52 | 0.33 | 87.20 | 0.50 |
| Remove the GCNN layer | 90.51 | 1.34 | 85.66 | 2.04 |
| Remove the BiLSTM layer | 90.82 | 1.03 | 86.22 | 1.58 |
| Our model | 91.85 | - | 87.70 | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Xie, Z.; Wang, H. Short Text Classification Based on Enhanced Word Embedding and Hybrid Neural Networks. Appl. Sci. 2025, 15, 5102. https://doi.org/10.3390/app15095102
Li C, Xie Z, Wang H. Short Text Classification Based on Enhanced Word Embedding and Hybrid Neural Networks. Applied Sciences. 2025; 15(9):5102. https://doi.org/10.3390/app15095102
Chicago/Turabian StyleLi, Cunhe, Zian Xie, and Haotian Wang. 2025. "Short Text Classification Based on Enhanced Word Embedding and Hybrid Neural Networks" Applied Sciences 15, no. 9: 5102. https://doi.org/10.3390/app15095102
APA StyleLi, C., Xie, Z., & Wang, H. (2025). Short Text Classification Based on Enhanced Word Embedding and Hybrid Neural Networks. Applied Sciences, 15(9), 5102. https://doi.org/10.3390/app15095102