
Causal Inference-Based Self-Supervised Cross-Domain Fundus Image Segmentation


Abstract
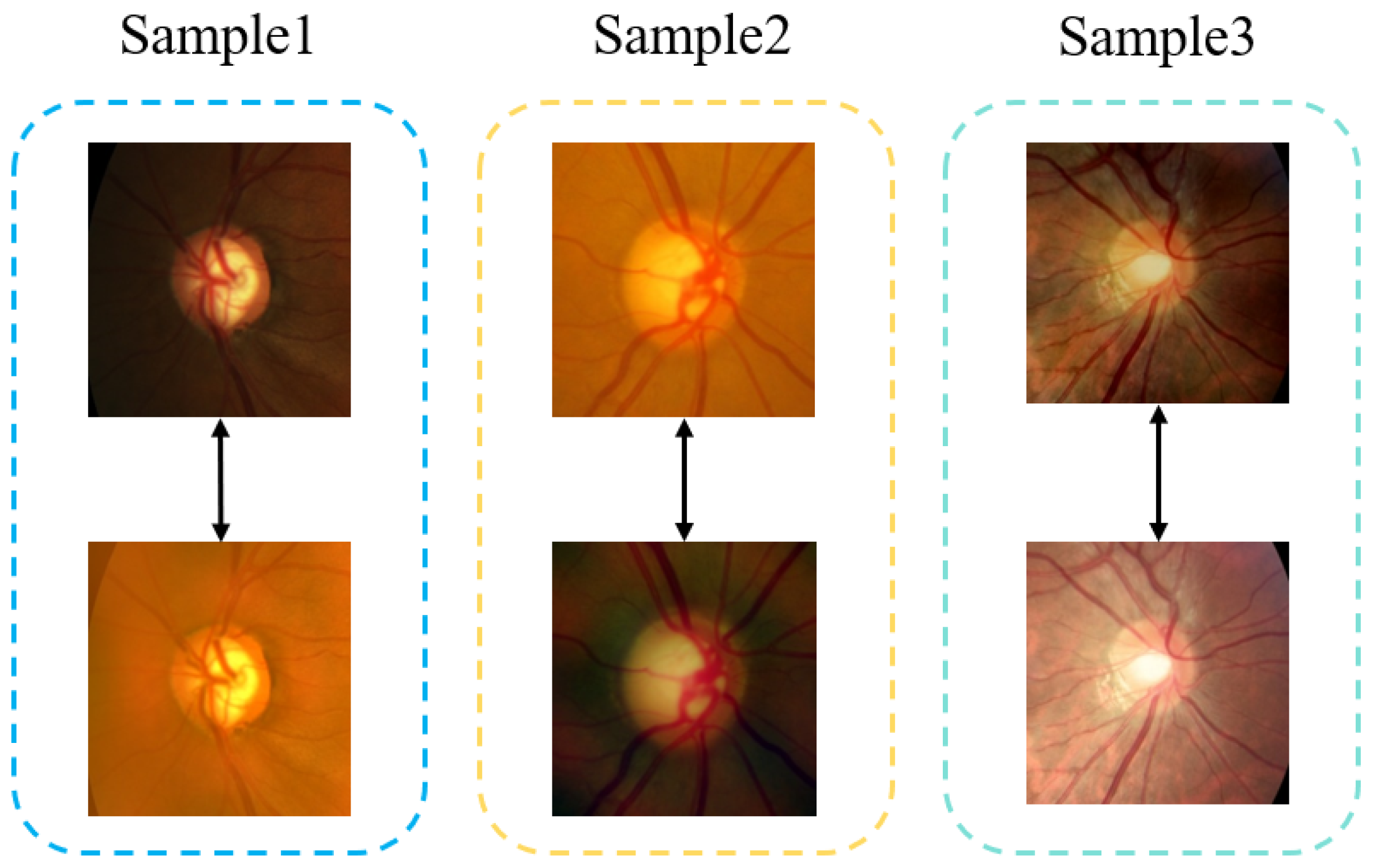
1. Introduction
- We propose a causal inference-based pseudo-label fusion module for self-supervised learning that effectively reduces domain style bias and imposes constraints on target domain images.
- We conduct extensive experiments on three publicly available datasets, and the results fully demonstrate the effectiveness of the proposed modules as well as a significant improvement in overall performance.
2. Related Works
3. Methods
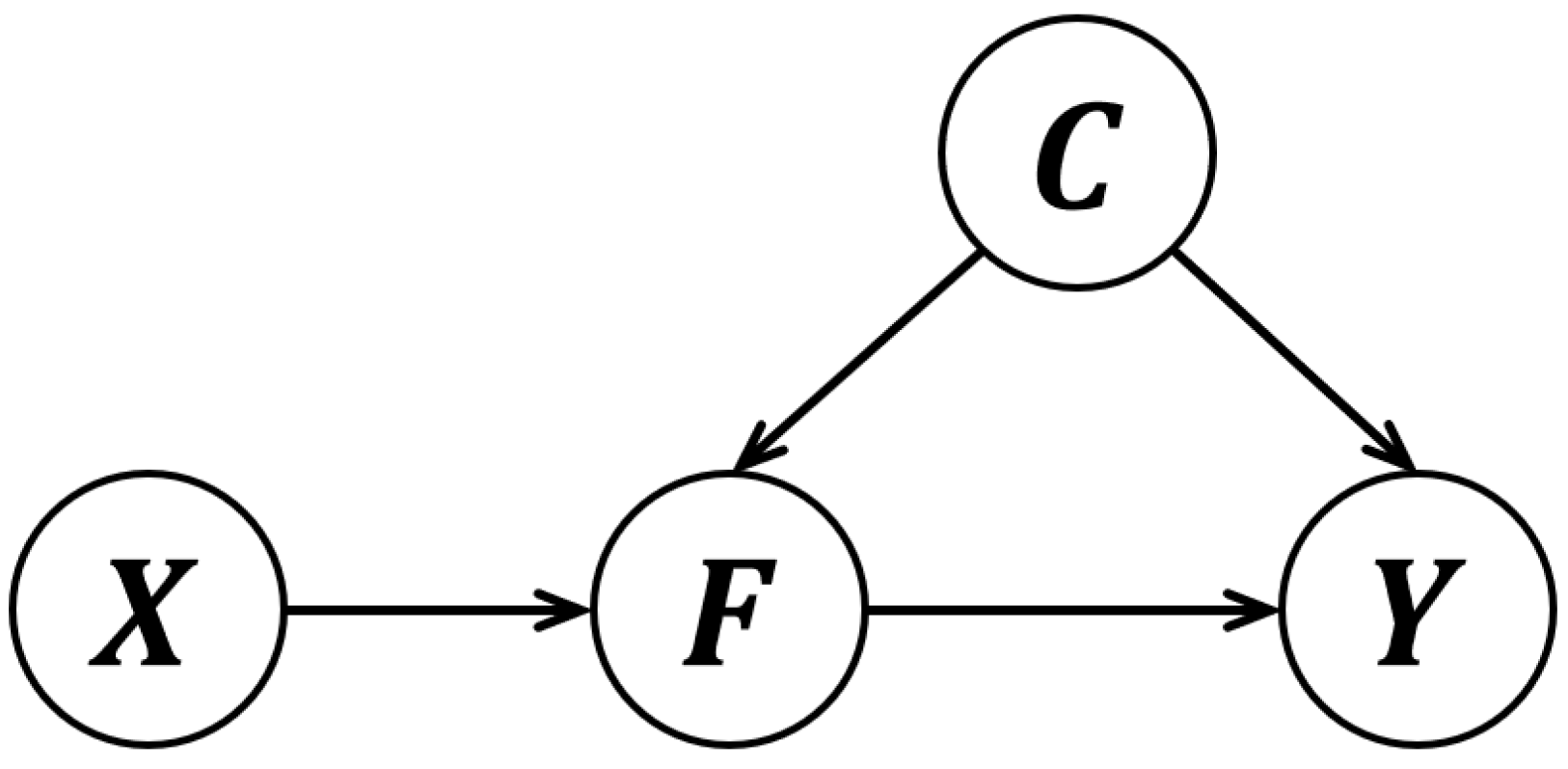
3.1. Causal Inference
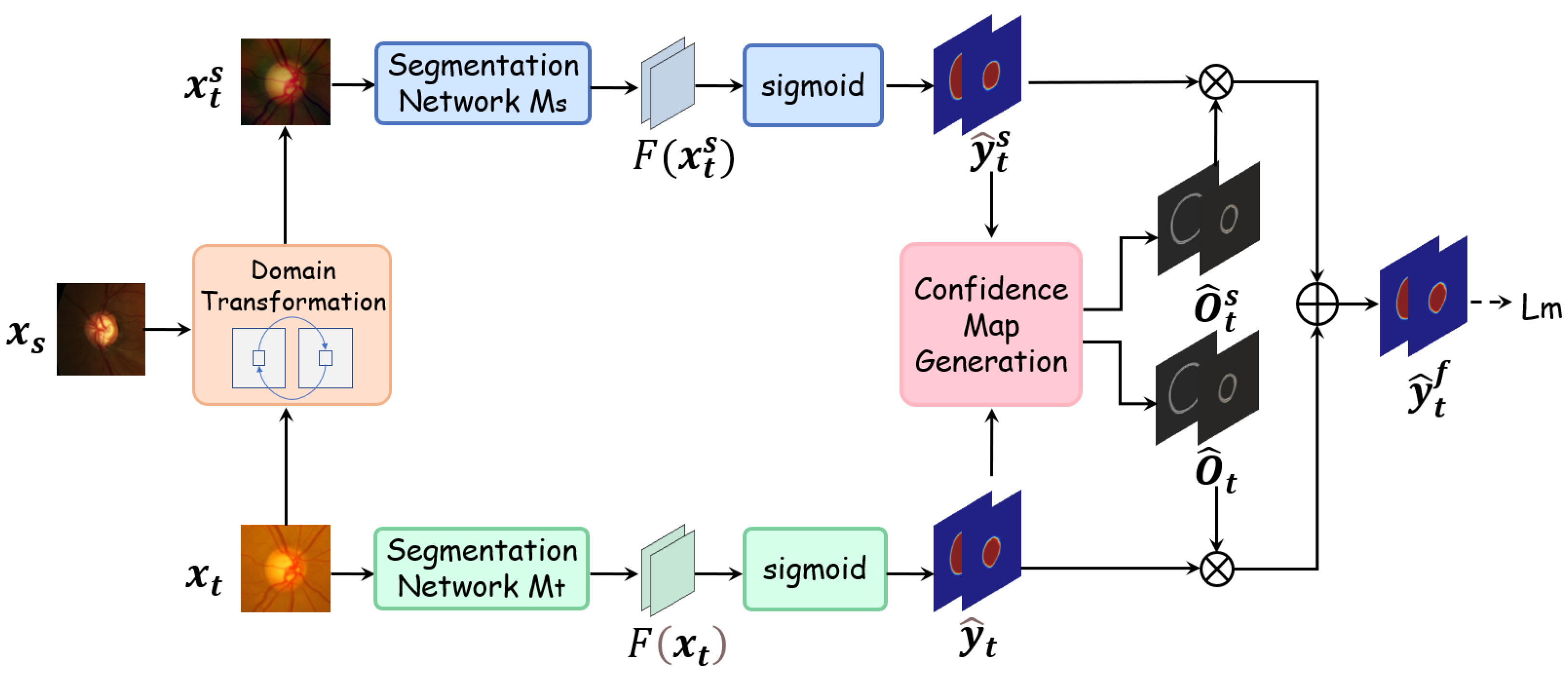
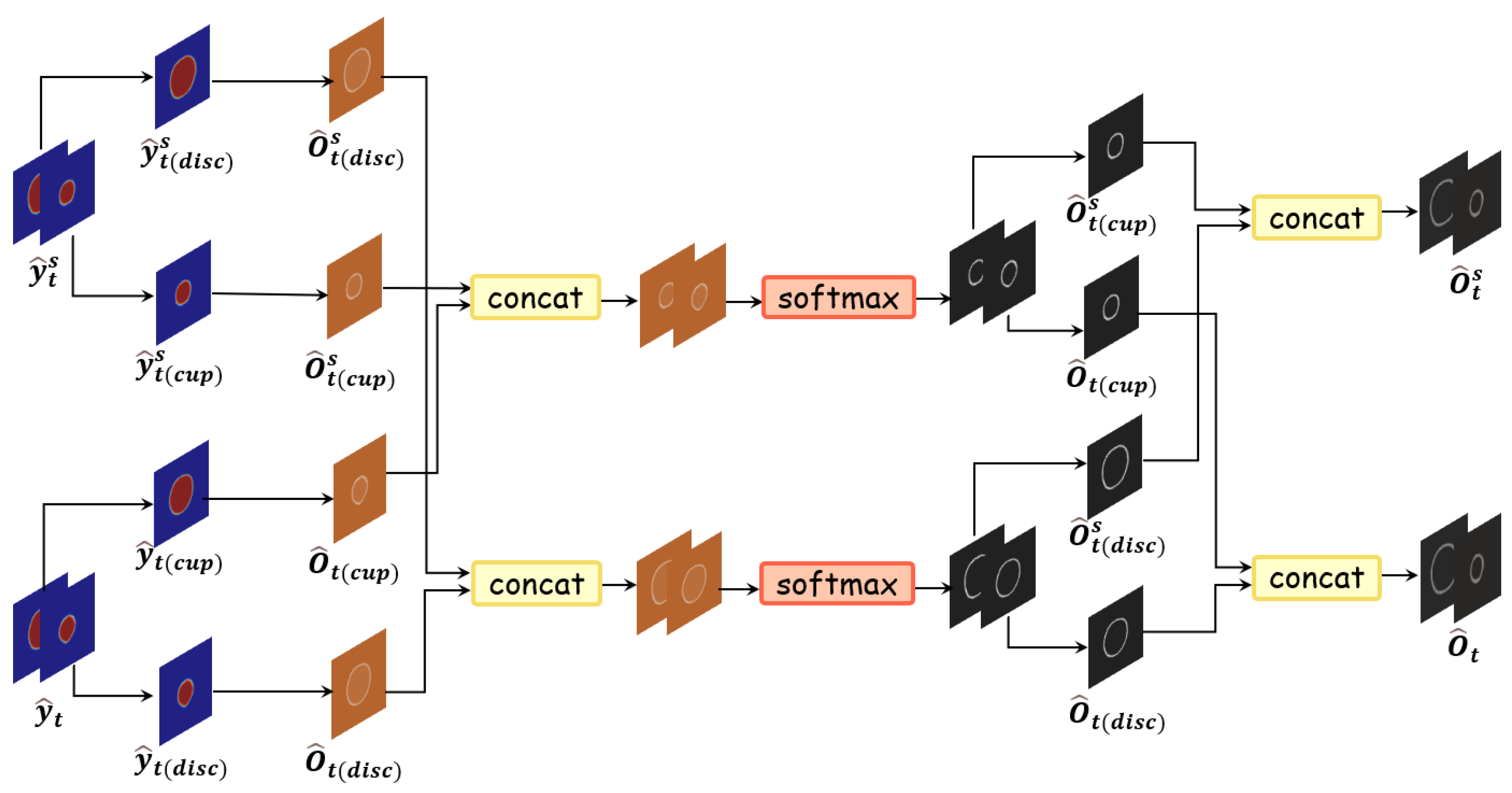
3.2. Causal Inference-Based Pseudo-Label Fusion Module
3.3. Source Domain Image Style Transfer and Adversarial Training Mechanism
3.4. Cross-Domain Contrastive Learning
3.5. Loss Function
4. Experiments
4.1. Datasets and Implementation Details
4.2. Performance Comparison with Prior Methods
4.2.1. Quantitative Analysis
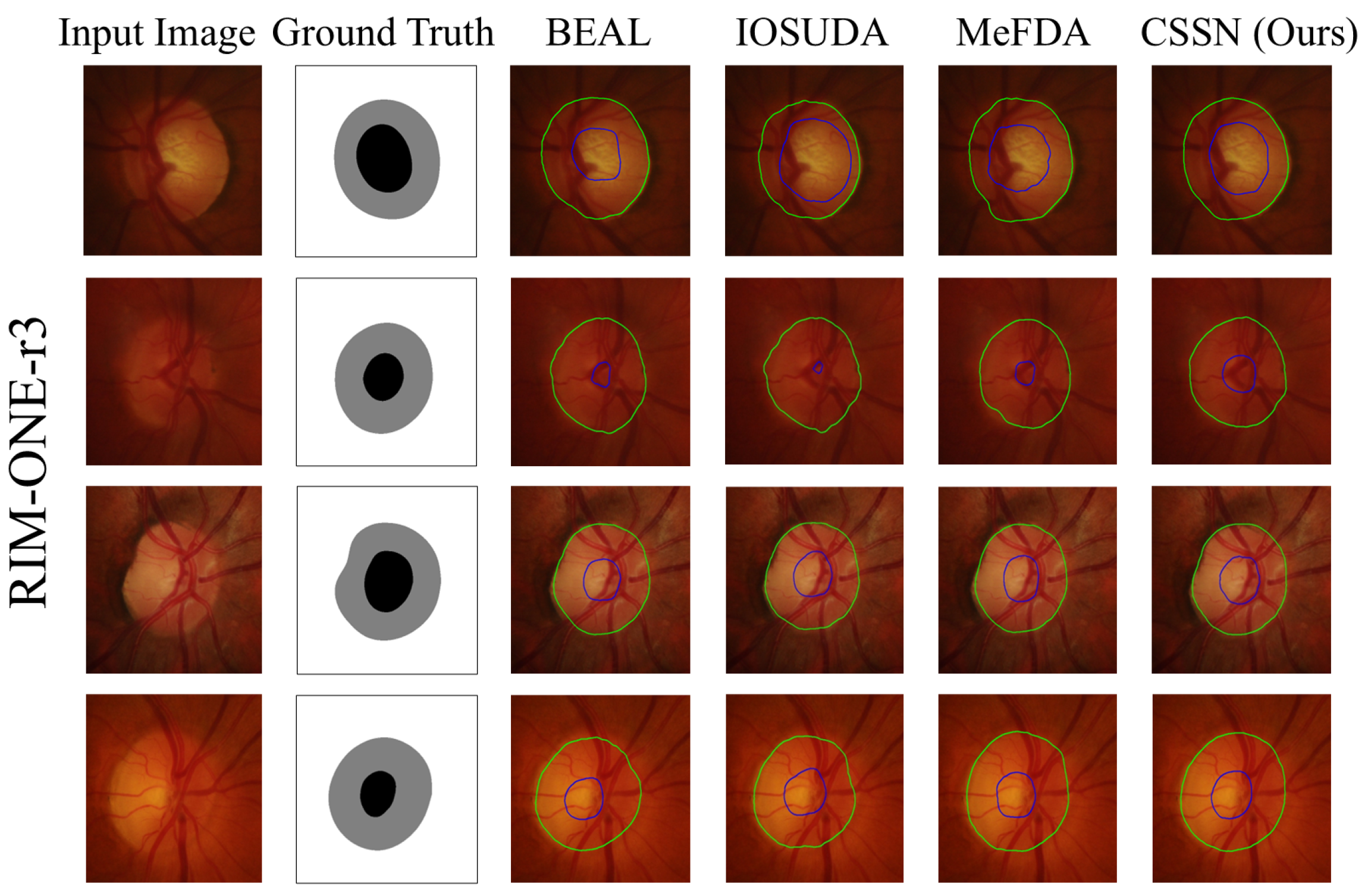
4.2.2. Qualitative Analysis
4.3. Discussion on Causal Inference-Based Pseudo-Label Fusion Module
4.3.1. Effectiveness of Pseudo-Label Fusion
4.3.2. Effectiveness of Confidence-Based Dynamic Fusion
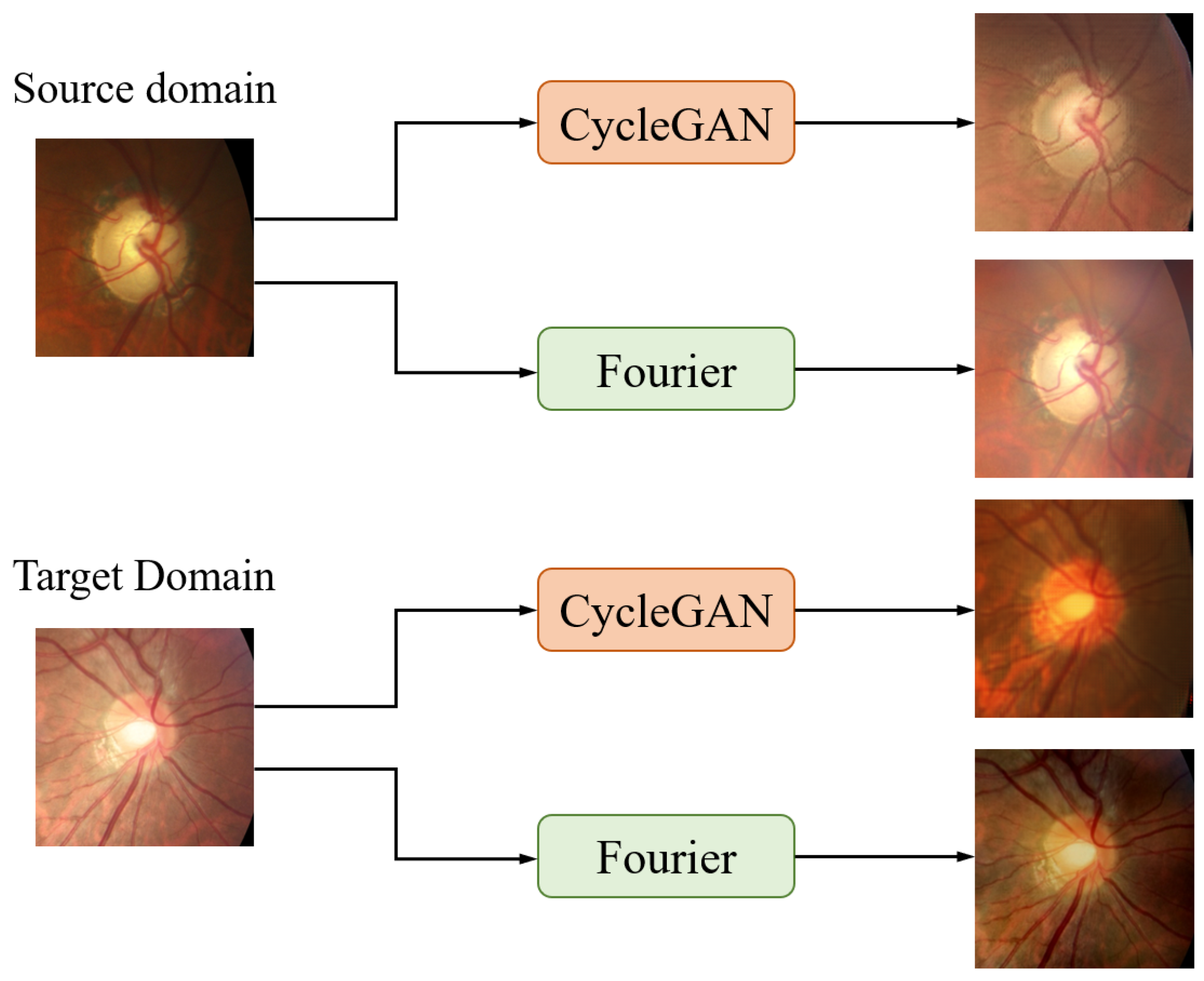
4.4. Discussion on Domain Transformation Methods
4.5. Loss Ablation Study
- Baseline Segmentation Loss (): The results obtained using only , which relies solely on the labeled source data, establish the baseline segmentation performance.
- Adversarial Loss (): By incorporating , we observed significant performance gains—especially on the RIM-one-R3 dataset, which exhibits a larger domain shift.
- Target Segmentation Loss (): Next, we incorporated the target segmentation loss , which is based on the pseudo-labels generated by our causal inference-based pseudo-label fusion module. The addition of resulted in substantial improvements across all three datasets, thereby demonstrating the reliability of the predicted pseudo-labels.
- Maximum Square Loss (): Incorporating the maximum square loss further improved segmentation performance by regularizing pseudo-label predictions and balancing high-confidence outputs.
- Cross-domain Contrastive Loss (): Finally, the cross-domain contrastive loss was introduced to constrain the features extracted from the original images and their style-transferred counterparts, ensuring consistency between the dual-path outputs.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tham, Y.-C.; Li, X.; Wong, T.Y.; Quigley, H.A.; Aung, T.; Cheng, C.-Y. Global Prevalence of Glaucoma and Projections of Glaucoma Burden Through 2040: A Systematic Review and Meta-Analysis. Ophthalmology 2014, 121, 2081–2090. [Google Scholar] [CrossRef]
- Mary, M.C.V.S.; Rajsingh, E.B.; Jacob, J.K.K.; Anandhi, D.; Amato, U.; Selvan, S.E. An Empirical Study on Optic Disc Segmentation Using an Active Contour Model. Biomed. Signal Process. Control 2015, 18, 19–29. [Google Scholar] [CrossRef]
- Gagan, J.H.; Shirsat, H.S.; Kamath, Y.S.; Kuzhuppilly, N.I.R.; Kumar, J.R.H. Automated Optic Disc Segmentation Using Basis Splines-Based Active Contour. IEEE Access 2022, 10, 88152–88163. [Google Scholar] [CrossRef]
- Gopalakrishnan, A.; Almazroa, A.; Raahemifar, K.; Lakshminarayanan, V. Optic Disc Segmentation Using Circular Hough Transform and Curve Fitting. In Proceedings of the 2015 2nd International Conference on Opto-Electronics and Applied Optics (IEM OPTRONIX), Vancouver, BC, Canada, 5–17 October 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1–4. [Google Scholar]
- Zhu, X.; Rangayyan, R.M. Detection of the Optic Disc in Images of the Retina Using the Hough Transform. In Proceedings of the 2008 30th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Vancouver, BC, Canada, 20–25 August 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 3546–3549. [Google Scholar]
- Welfer, D.; Scharcanski, J.; Kitamura, C.M.; Dal Pizzol, M.M.; Ludwig, L.W.B.; Marinho, D.R. Segmentation of the Optic Disk in Color Eye Fundus Images Using an Adaptive Morphological Approach. Comput. Biol. Med. 2010, 40, 124–137. [Google Scholar] [CrossRef]
- Morales, S.; Naranjo, V.; Angulo, J.; Alcañiz, M. Automatic Detection of Optic Disc Based on PCA and Mathematical Morphology. IEEE Trans. Med. Imaging 2013, 32, 786–796. [Google Scholar] [CrossRef]
- Lu, Z.; Chen, D. Weakly Supervised and Semi-Supervised Semantic Segmentation for Optic Disc of Fundus Image. Symmetry 2020, 12, 145. [Google Scholar] [CrossRef]
- Choukikar, P.; Patel, A.K.; Mishra, R.S. Segmenting the Optic Disc in Retinal Images Using Thresholding. Int. J. Comput. Appl. 2014, 94, 6–10. [Google Scholar] [CrossRef]
- Wang, S.; Yu, L.; Yang, X.; Fu, C.-W.; Heng, P.-A. Patch-based output space adversarial learning for joint optic disc and cup segmentation. IEEE Trans. Med. Imaging 2019, 38, 2485–2495. [Google Scholar] [CrossRef]
- Wang, S.; Yu, L.; Li, K.; Yang, X.; Fu, C.-W.; Heng, P.-A. Boundary and entropy-driven adversarial learning for fundus image segmentation. Int. J. Med. Image Comput. Comput.-Assist. Interv. 2019, 2019, 102–110. [Google Scholar]
- Chen, C.; Wang, G. IOSUDA: An Unsupervised Domain Adaptation with Input and Output Space Alignment for Joint Optic Disc and Cup Segmentation. Appl. Intell. 2021, 51, 3880–3898. [Google Scholar] [CrossRef]
- Kadambi, S.; Wang, Z.; Xing, E. WGAN Domain Adaptation for the Joint Optic Disc-and-Cup Segmentation in Fundus Images. Int. J. Comput. Assist. Radiol. Surg. 2020, 15, 1205–1213. [Google Scholar] [CrossRef]
- Xu, S.-P.; Li, T.-B.; Zhang, Z.-Q.; Song, D. Minimizing-Entropy and Fourier Consistency Network for Domain Adaptation on Optic Disc and Cup Segmentation. IEEE Access 2021, 9, 153985–153994. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. Adv. Neural Inf. Process. Syst. 2014, 27. Available online: https://proceedings.neurips.cc/paper_files/paper/2014/file/f033ed80deb0234979a61f95710dbe25-Paper.pdf (accessed on 25 January 2025).
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; March, M.; Lempitsky, V. Domain-Adversarial Training of Neural Networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Guan, Y.; Zhang, L.; Li, J.; Xu, X.; Yan, Y.; Zhang, L. A Lightweight Entropy–Curvature-Based Attention Mechanism for Meningioma Segmentation in MRI Images. Appl. Sci. 2025, 15, 3401. [Google Scholar] [CrossRef]
- Guo, B.; Cao, N.; Zhang, R.; Yang, P. SCENet: Small Kernel Convolution with Effective Receptive Field Network for Brain Tumor Segmentation. Appl. Sci. 2024, 14, 11365. [Google Scholar] [CrossRef]
- Zou, C.; Jeon, W.-S.; Ju, H.-R.; Rhee, S.-Y. A Dual-Headed Teacher–Student Framework with an Uncertainty-Guided Mechanism for Semi-Supervised Skin Lesion Segmentation. Electronics 2025, 14, 984. [Google Scholar] [CrossRef]
- Tang, Y.; Guo, Y.; Wang, H.; Song, T.; Lu, Y. Uncertainty-Aware Semi-Supervised Method for Pectoral Muscle Segmentation. Bioengineering 2025, 12, 36. [Google Scholar] [CrossRef]
- Fu, H.; Cheng, J.; Xu, Y.; Wong, D.W.K.; Liu, J.; Cao, X. Joint Optic Disc and Cup Segmentation Based on Multi-Label Deep Network and Polar Transformation. IEEE Trans. Med. Imaging 2018, 37, 1597–1605. [Google Scholar] [CrossRef]
- Liu, P.; Kong, B.; Li, Z.; Zhang, S.; Fang, R. CFEA: Collaborative Feature Ensembling Adaptation for Domain Adaptation in Unsupervised Optic Disc and Cup Segmentation. Int. J. Med. Image Comput. Comput.-Assist. Interv. 2019, 2019, 521–529. [Google Scholar]
- He, Y.; Kong, J.; Liu, D.; Li, J.; Zheng, C. Self-ensembling with mask-boundary domain adaptation for optic disc and cup segmentation. Eng. Appl. Artif. Intell. 2024, 129, 107635. [Google Scholar] [CrossRef]
- Chen, Y.; Ji, Y.; Wang, H.; Hao, X.; Yang, Y.; Ma, Y.; Yu, D. Causal Inference-Based Adversarial Domain Adaptation for Cross-Domain Industrial Intrusion Detection. IEEE Trans. Ind. Inform. 2024, 21, 970–979. [Google Scholar] [CrossRef]
- Schneider, M. A Review of Nonlinear FFT-Based Computational Homogenization Methods. Acta Mech. 2021, 232, 2051–2100. [Google Scholar] [CrossRef]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Springer: Cham, Switzerland, 2018; pp. 801–818. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 4510–4520. [Google Scholar]
- Chen, M.; Xue, H.; Cai, D. Domain Adaptation for Semantic Segmentation with Maximum Squares Loss. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 2090–2099. [Google Scholar]
- Peng, L.; Mo, Y.; Xu, J.; Shen, J.; Shi, X.; Li, X.; Shen, H.T.; Zhu, X. GRLC: Graph Representation Learning with Constraints. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 8609–8622. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; PMLR: New York, NY, USA, 2020; pp. 1597–1607. [Google Scholar]
- Orlando, J.I.; Fu, H.; Breda, J.B.; van Keer, K.; Bathula, D.R.; Diaz-Pinto, A.; Fang, R.; Heng, P.-A.; Kim, J.; Lee, J.; et al. REFUGE Challenge: A Unified Framework for Evaluating Automated Methods for Glaucoma Assessment from Fundus Photographs. Med. Image Anal. 2020, 59, 101570. [Google Scholar] [CrossRef]
- Sivaswamy, J.; Krishnadas, S.; Chakravarty, A.; Joshi, G.; Tabish, A.S. A Comprehensive Retinal Image Dataset for the Assessment of Glaucoma from the Optic Nerve Head Analysis. JSM Biomed. Imaging Data Pap. 2015, 2, 1004. [Google Scholar]
- Fumero, F.; Alayón, S.; Sanchez, J.L.; Sigut, J.; Gonzalez-Hernandez, M. RIM-ONE: An Open Retinal Image Database for Optic Nerve Evaluation. Int. J.-Comput.-Based Med. Syst. 2011, 2011, 1–6. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Zhang, Y.; Miao, S.; Mansi, T.; Liao, R. Task Driven Generative Modeling for Unsupervised Domain Adaptation: Application to X-Ray Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; Springer: Cham, Switzerland, 2018; pp. 599–607. [Google Scholar]
- Hoffman, J.; Wang, D.; Yu, F.; Darrell, T. FCNs in the Wild: Pixel-Level Adversarial and Constraint-Based Adaptation. arXiv 2016, arXiv:1612.02649. [Google Scholar]
- Javanmardi, M.; Tasdizen, T. Domain Adaptation for Biomedical Image Segmentation Using Adversarial Training. In Proceedings of the IEEE International Symposium on Biomedical Imaging (ISBI), Washington, DC, USA, 4–7 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 554–558. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2223–2232. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Domain | Dataset | Number (Train/Test) | Image Size |
|---|---|---|---|
| Source | REFUGE Train | 400/0 | |
| Target | Drishti-GS | 50/51 | |
| Target | RIM-ONE-r3 | 99/60 | |
| Target | REFUGE Validation/Test | 400/400 |
| Method | Drishti-GS | RIM-ONE-r3 | REFUGE Val | ||||||
|---|---|---|---|---|---|---|---|---|---|
| TD-GAN [35] | 0.747 | 0.924 | 0.117 | 0.728 | 0.853 | 0.118 | - | - | - |
| Hoffman et al. [36] | 0.851 | 0.959 | 0.093 | 0.755 | 0.852 | 0.109 | - | - | - |
| WGAN [13] | 0.840 | 0.954 | 0.106 | - | - | - | - | - | - |
| Javanmardi et al. [37] | 0.849 | 0.961 | 0.091 | 0.779 | 0.853 | 0.103 | - | - | - |
| OSAL-pixel [10] | 0.851 | 0.962 | 0.089 | 0.778 | 0.854 | 0.097 | 0.869 | 0.932 | 0.059 |
| pOSAL [10] | 0.858 | 0.965 | 0.082 | 0.787 | 0.865 | 0.089 | 0.875 | 0.946 | 0.051 |
| BEAL [11] | 0.862 | 0.961 | 0.084 | 0.810 | 0.898 | 0.090 | 0.852 | 0.948 | 0.055 |
| IOSUDA [12] | 0.775 | 0.940 | 0.091 | 0.723 | 0.907 | 0.095 | 0.829 | 0.954 | 0.057 |
| CFEA [22] | - | - | - | - | - | - | 0.863 | 0.942 | 0.052 |
| MeFDA [14] | 0.866 | 0.959 | 0.082 | 0.821 | 0.909 | 0.087 | 0.880 | 0.956 | 0.049 |
| OADA [23] | 0.873 | 0.965 | 0.085 | 0.816 | 0.904 | 0.094 | 0.885 | 0.952 | 0.044 |
| CSSN (Ours) | 0.876 | 0.971 | 0.081 | 0.818 | 0.922 | 0.083 | 0.885 | 0.958 | 0.049 |
| Dataset | Method | |||
|---|---|---|---|---|
| Drishti-GS | w/o pseudo-labels | 0.822 | 0.941 | 0.097 |
| Single-path pseudo-labels | 0.847 | 0.952 | 0.085 | |
| Causal Inference-based | 0.876 | 0.971 | 0.081 | |
| RIM-ONE-r3 | w/o pseudo-labels | 0.757 | 0.873 | 0.103 |
| Single-path pseudo-labels | 0.798 | 0.896 | 0.093 | |
| Causal Inference-based | 0.818 | 0.922 | 0.083 | |
| REFUGE Val | w/o pseudo-labels | 0.831 | 0.941 | 0.056 |
| Single-path pseudo-labels | 0.840 | 0.952 | 0.052 | |
| Causal Inference-based | 0.885 | 0.958 | 0.049 |
| Dataset | Method | |||
|---|---|---|---|---|
| Drishti-GS | Avg-pooling | 0.871 | 0.966 | 0.087 |
| Ours | 0.876 | 0.971 | 0.081 | |
| RIM-ONE-r3 | Avg-pooling | 0.816 | 0.918 | 0.087 |
| Ours | 0.818 | 0.922 | 0.083 | |
| REFUGE Val | Avg-pooling | 0.861 | 0.947 | 0.053 |
| Ours | 0.885 | 0.958 | 0.049 |
| Dataset | Method | |||
|---|---|---|---|---|
| Drishti-GS | CycleGAN | 0.853 | 0.942 | 0.089 |
| Fourier | 0.876 | 0.971 | 0.081 | |
| RIM-ONE-r3 | CycleGAN | 0.793 | 0.911 | 0.094 |
| Fourier | 0.818 | 0.922 | 0.083 | |
| REFUGE Val | CycleGAN | 0.861 | 0.923 | 0.056 |
| Fourier | 0.885 | 0.958 | 0.049 |
| Dataset | Method | |||
|---|---|---|---|---|
| Drishti-GS | 0.822 | 0.941 | 0.097 | |
| 0.829 | 0.939 | 0.093 | ||
| 0.867 | 0.958 | 0.084 | ||
| 0.869 | 0.961 | 0.084 | ||
| 0.876 | 0.971 | 0.081 | ||
| RIM-ONE-r3 | 0.757 | 0.873 | 0.103 | |
| 0.781 | 0.883 | 0.097 | ||
| 0.805 | 0.897 | 0.090 | ||
| 0.814 | 0.913 | 0.085 | ||
| 0.818 | 0.922 | 0.083 | ||
| REFUGE Val | 0.831 | 0.941 | 0.056 | |
| 0.849 | 0.951 | 0.055 | ||
| 0.871 | 0.953 | 0.054 | ||
| 0.873 | 0.959 | 0.049 | ||
| 0.885 | 0.958 | 0.049 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Q.; Zhang, Q.; Zhang, Z.; Liu, H.; Nie, W. Causal Inference-Based Self-Supervised Cross-Domain Fundus Image Segmentation. Appl. Sci. 2025, 15, 5074. https://doi.org/10.3390/app15095074
Li Q, Zhang Q, Zhang Z, Liu H, Nie W. Causal Inference-Based Self-Supervised Cross-Domain Fundus Image Segmentation. Applied Sciences. 2025; 15(9):5074. https://doi.org/10.3390/app15095074
Chicago/Turabian StyleLi, Qiang, Qiyi Zhang, Zheqi Zhang, Hengxin Liu, and Weizhi Nie. 2025. "Causal Inference-Based Self-Supervised Cross-Domain Fundus Image Segmentation" Applied Sciences 15, no. 9: 5074. https://doi.org/10.3390/app15095074
APA StyleLi, Q., Zhang, Q., Zhang, Z., Liu, H., & Nie, W. (2025). Causal Inference-Based Self-Supervised Cross-Domain Fundus Image Segmentation. Applied Sciences, 15(9), 5074. https://doi.org/10.3390/app15095074