


X-GANet: An Explainable Graph-Based Framework for Robust Network Intrusion Detection


Abstract
1. Introduction
- We propose X-GANet, a novel graph-based intrusion detection framework that effectively models network traffic as a graph and leverages advanced representation-learning techniques for enhanced anomaly detection.
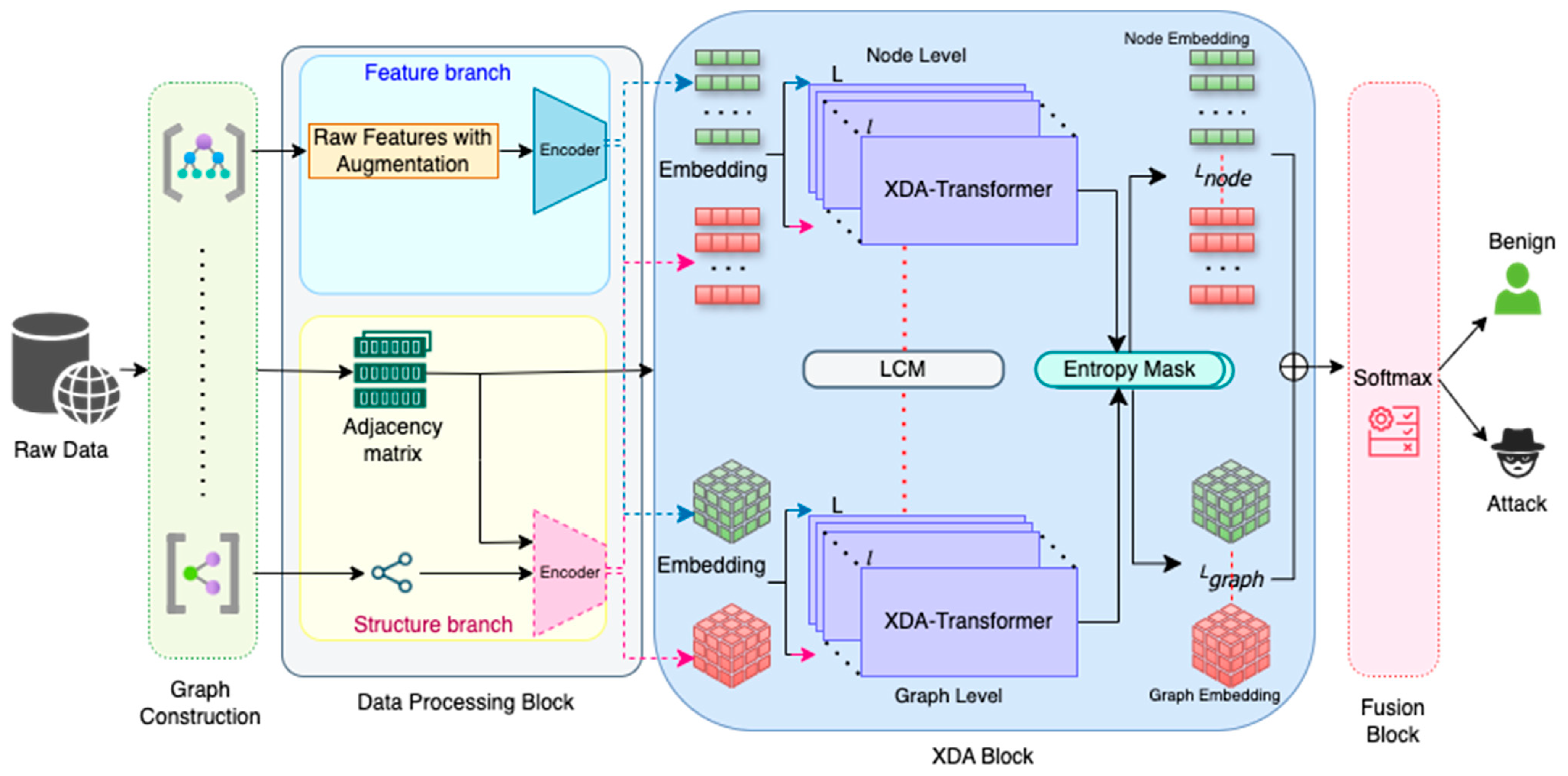
- We reveal that our framework processes network data through two distinct yet complementary branches: a feature branch that extracts raw flow and log attributes using dedicated encoders and a structure branch that generates graph-based embeddings via a GNN informed by the normalized adjacency matrix. Subsequent fusion via proposed Cross-Diffused Attention (XDA) blocks leverages the strengths of both representations.
- We propose an entropy-driven adaptive masking mechanism that quantifies uncertainty in the cross-attention distributions. By computing the entropy for each token and generating an adaptive mask to suppress uncertain features, this module refines the output of the proposed Cross-Diffused Attention (XDA) block, ensuring that only the most informative signals contribute to the final detection outcome.
- We reveal that our novel learnable gating mechanism dynamically balances the contributions of both branches to produce a robust unified representation for classification.
- We provide the results conducted extensive evaluations conducted on benchmark intrusion detection datasets, including CIC-IDS and UNSW-NB15, demonstrating that X-GANet significantly outperforms state-of-the-art IDS models while providing interpretable insights into network anomalies.
2. Related Study
3. Materials and Methods
3.1. Constructing a Graph from the CIC-IDS2017 Dataset
- is the set of nodes, each corresponding to a network flow fi.
- is the undirected edge set defined by the normalized adjacency.
- is the symmetrically normalized adjacency matrix, constructed by combining IP-based (Equation (3)) and temporal (Equation (4)) connectivity.
- is the node-feature matrix, whose ith row xi is the d-dimensional flow feature vector defined in Equation (1).
Node–Edge Representation and Feature Extraction
| Algorithm 1. Graph Construction from CIC-IDS2017 Dataset |
| Require: Dataset containing network flows Ensure: Graph = (, ε, X, Â) 1. Initialize empty node set = ∅ and edge set ε = ∅ 2. Initialize empty feature matrix X = [] 3. for each flow fᵢ ∈ do 4. Extract feature vector: xᵢ = [dᵢ, bᵢ, pᵢ, spᵢ, dpᵢ, protoᵢ, flrateᵢ, avgpkt_sizeᵢ, iatᵢ] 5. Normalize features using min–max scaling: xᵢ′ = (xᵢ − min(xᵢ))/(max(xᵢ) − min(xᵢ)) 6. Create node vᵢ with feature xᵢ′ 7. Add vᵢ to 8. Append xᵢ′to X 9. end for 10. for each pair of nodes (vᵢ, vⱼ) ∈ do 11. if IPsrc,i = IPsrc,j or IPdst,i = IPdst,j or |tᵢ − tⱼ| ≤ Δt then 12. Add edge eᵢⱼ to ε 13. end if 14. end for 15. Construct adjacency matrix A from ε: Aᵢⱼ = eᵢⱼ 16. Compute degree matrix D: Dᵤᵤ = ∑ⱼ Aᵤⱼ 17. Compute normalized adjacency Â: Â = D−½ A D−½ 18. return = (, ε, X, Â) |
3.2. Proposed Method
| Algorithm 2. Multi-Head Cross-Diffused Attention (XDA) Block |
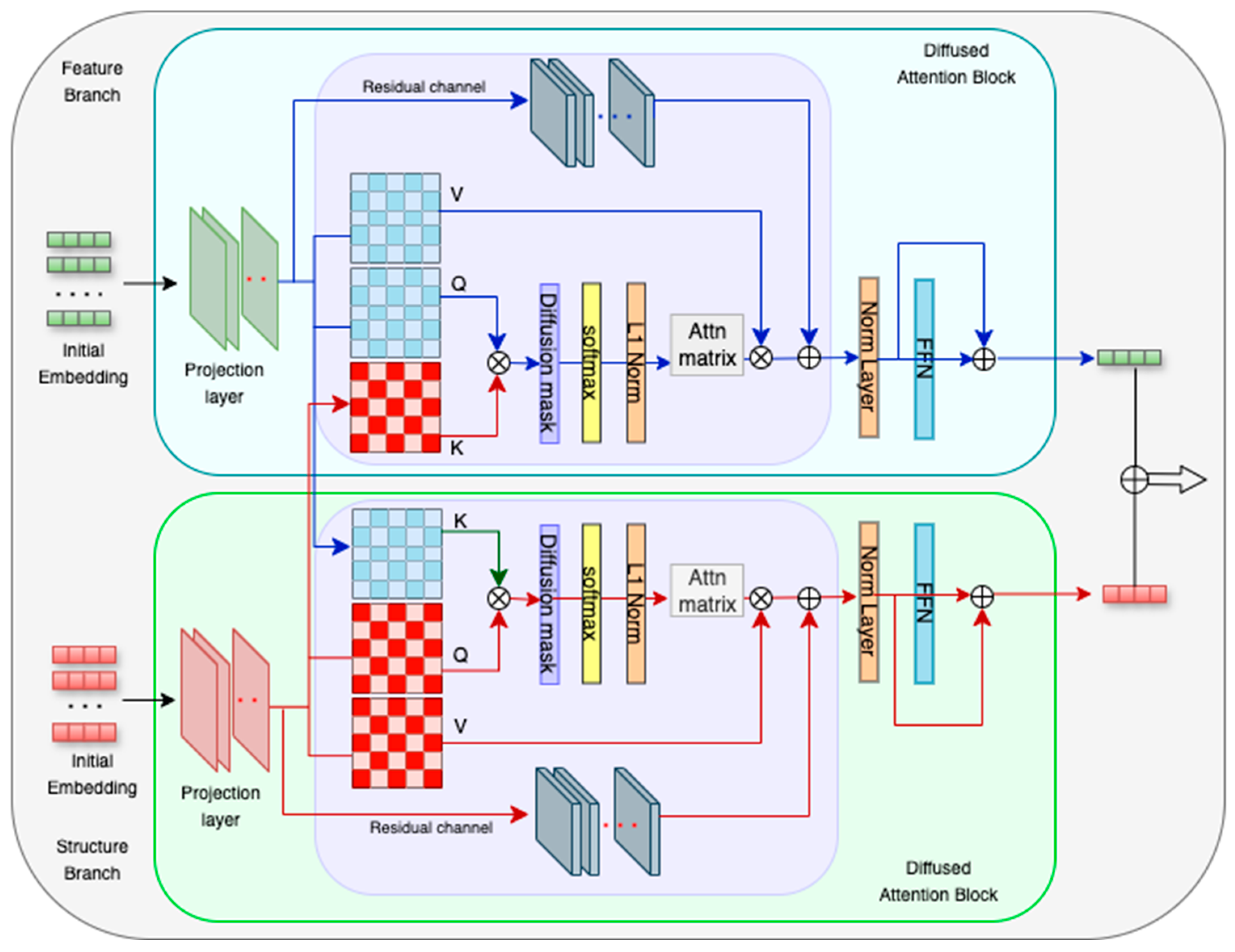
| Require: Feature embeddings F ∈ ℝN×d, Structure embeddings S ∈ ℝN×d, Number of heads H Ensure: Updated feature embeddings Fout ∈ ℝN×d 1. dh ← d/H 2. Initialize list O ← [] 3. for h ← 1 to H do ▷ Multi-head linear projections 4. Q(h) ← F · WQ(h) ∈ ℝN×dh 5. K(h) ← S · WK(h) ∈ ℝN×dh 6. V(h) ← S · WV(h) ∈ ℝN×dh 7. Araw(h) ← Q(h)·(K(h))T/√dh ▷ Compute raw attention scores 8. A(h) ← softmax(Araw(h)) 9. D(h) ← DIFFUSION(F, S) ▷ Generate diffusion mask based on intra-view similarities 10. Amod(h) ← A(h) ⊙ D(h) ▷ Modulate attention scores 11. O(h) ← Amod(h) · V(h) ▷ Compute head output 12. Append O(h) to O 13. end for 14. O ← Concat(O(1), O(2), …, O(H)) 15. XDAOut ← O · WO 16. Fout ← LayerNorm(F + XDAOut) 17. return Fout |
| Algorithm 3. Diffusion Mask Generation |
| Require: Feature embeddings F ∈ ℝN×d, Structure embeddings S ∈ ℝN×d Ensure: Diffusion mask D ∈ ℝN×N 1. for i ← 1 to N do 2. for j ← 1 to N do 3. sF ← sim(Fi, Fj) ▷ Feature-view similarity 4. sS ← sim(Si, Sj) ▷ Structure-view similarity 5. Dij ← f(sF, sS) ▷ e.g., √(sF · sS) or a learnable function 6. end for 7. end for 8. return D |
3.2.1. Cross-Diffused Attention (XDA) Block
3.2.2. Fusion Block and Classifier
4. Experimental Results
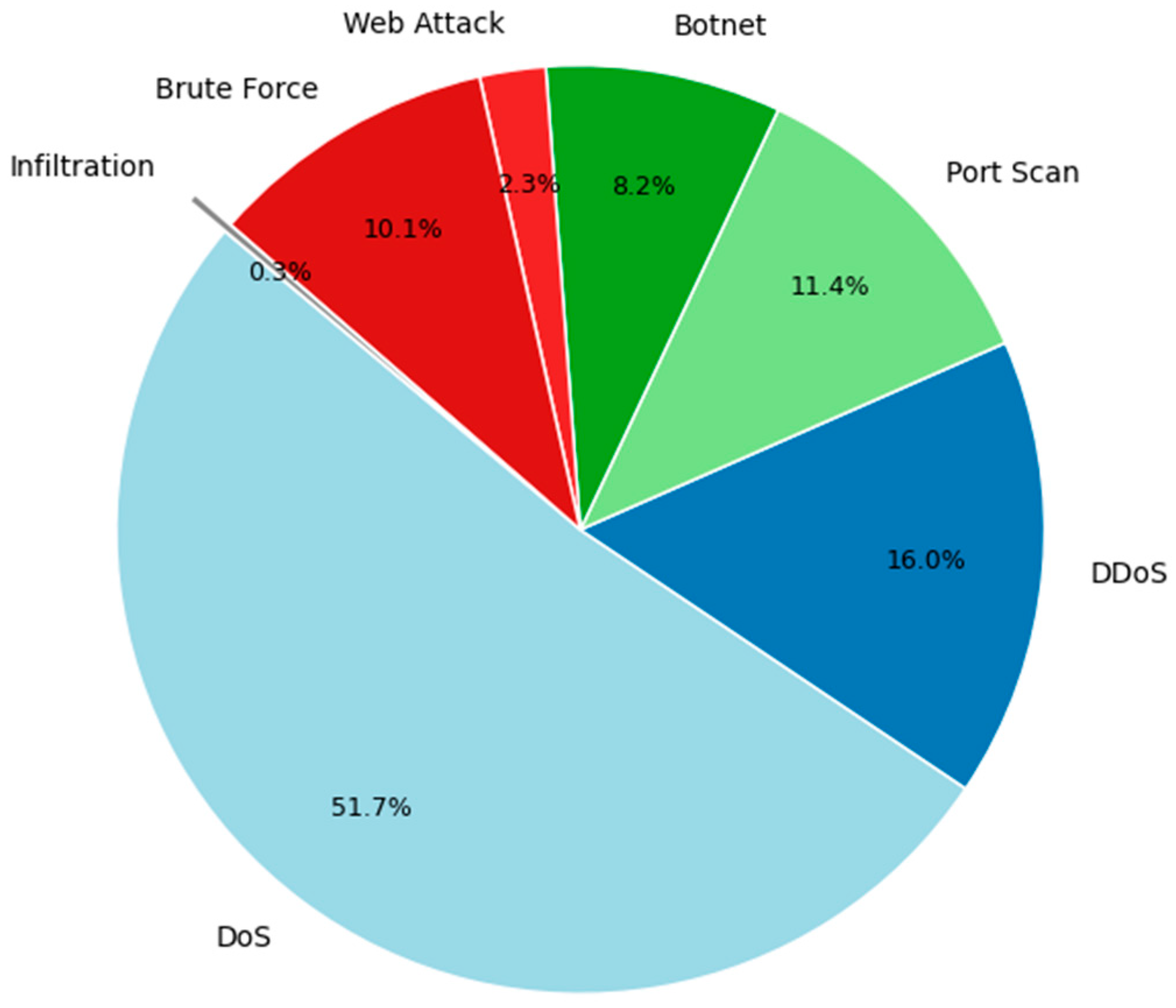
4.1. Dataset Description
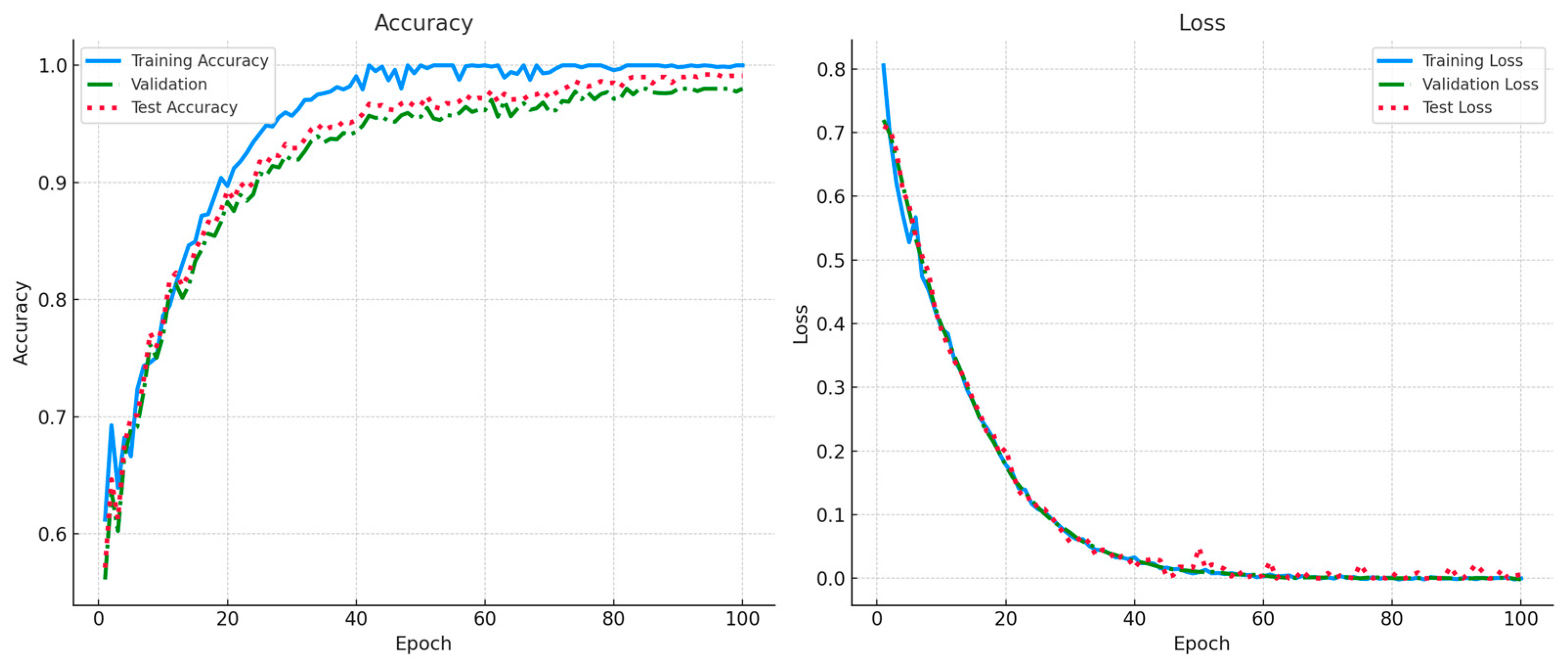
4.2. Setup of the Experiments
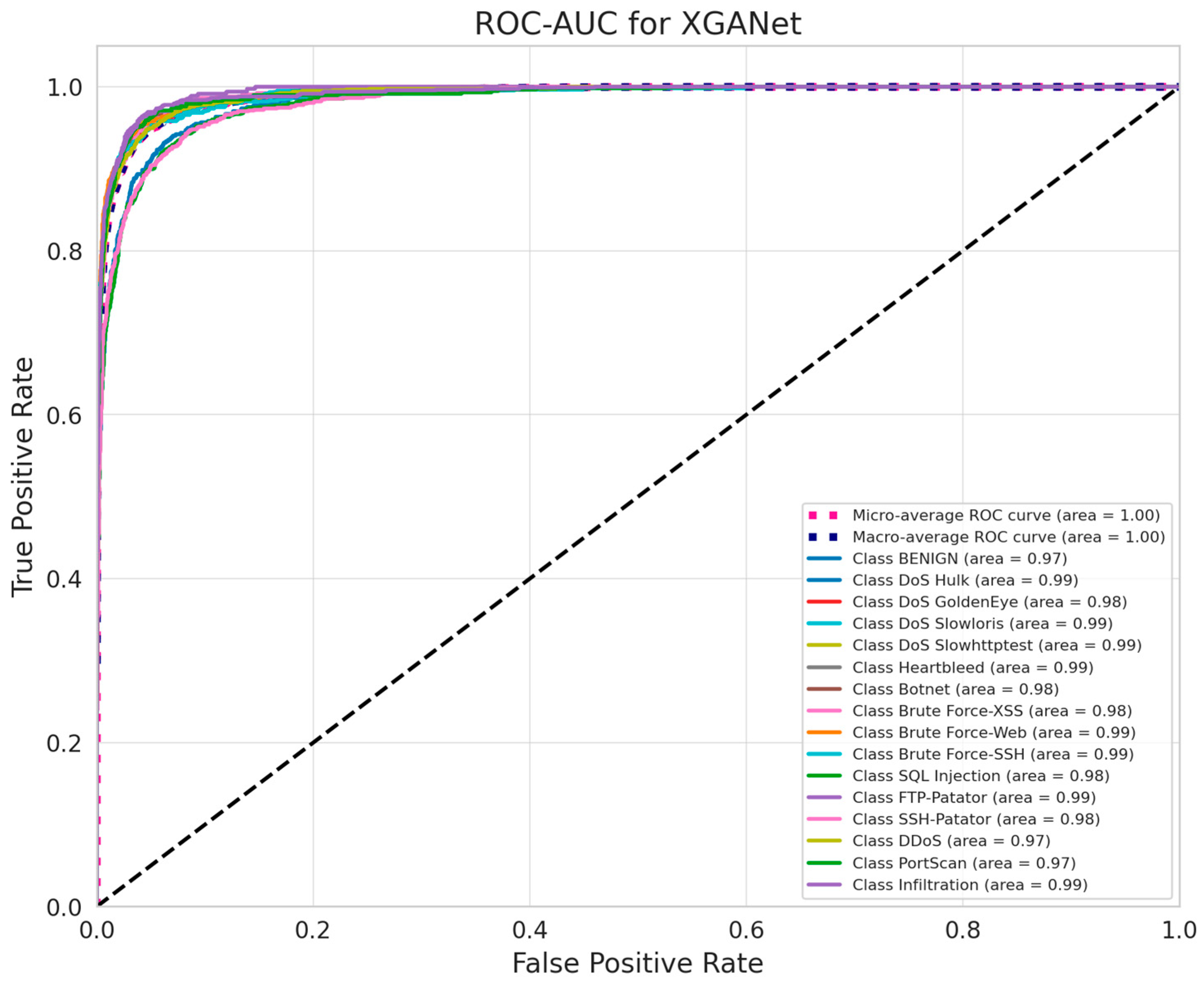
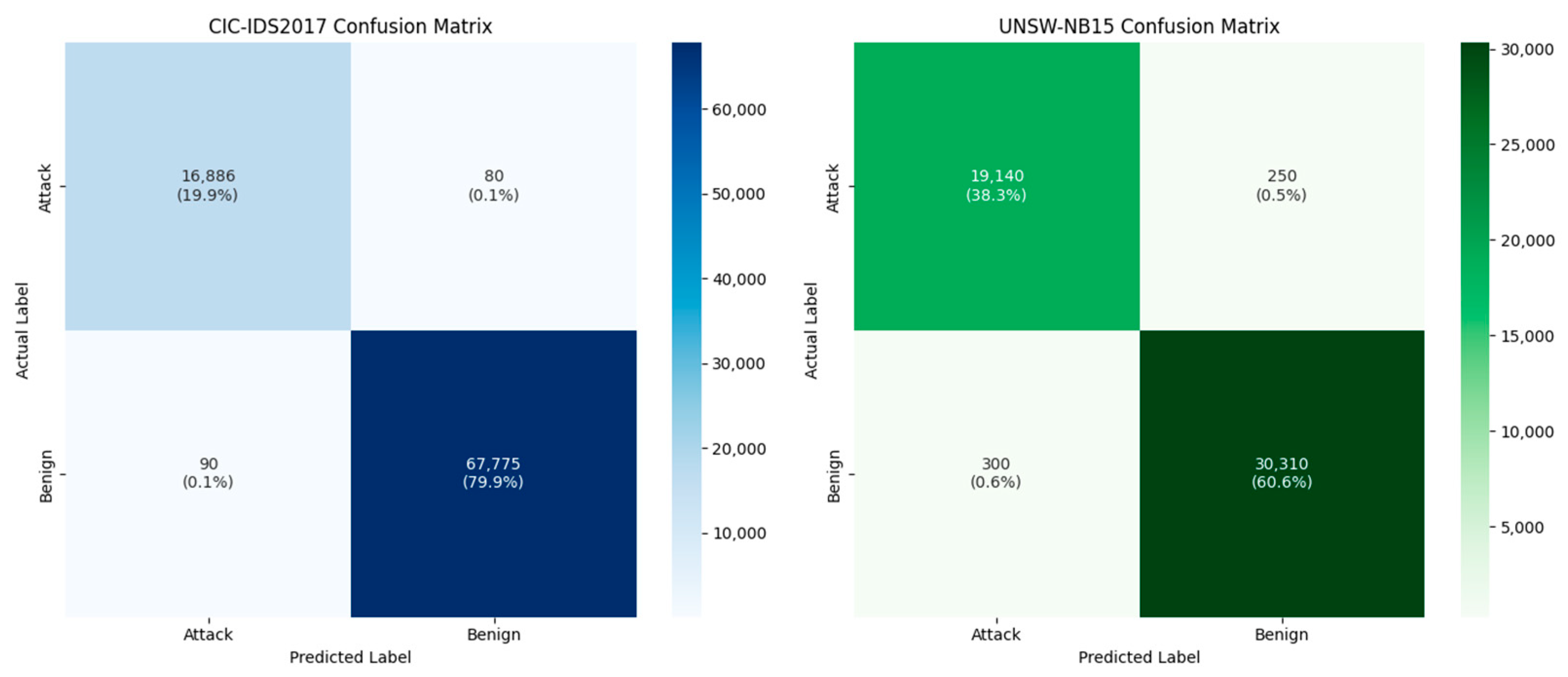
4.3. Performance Evaluation
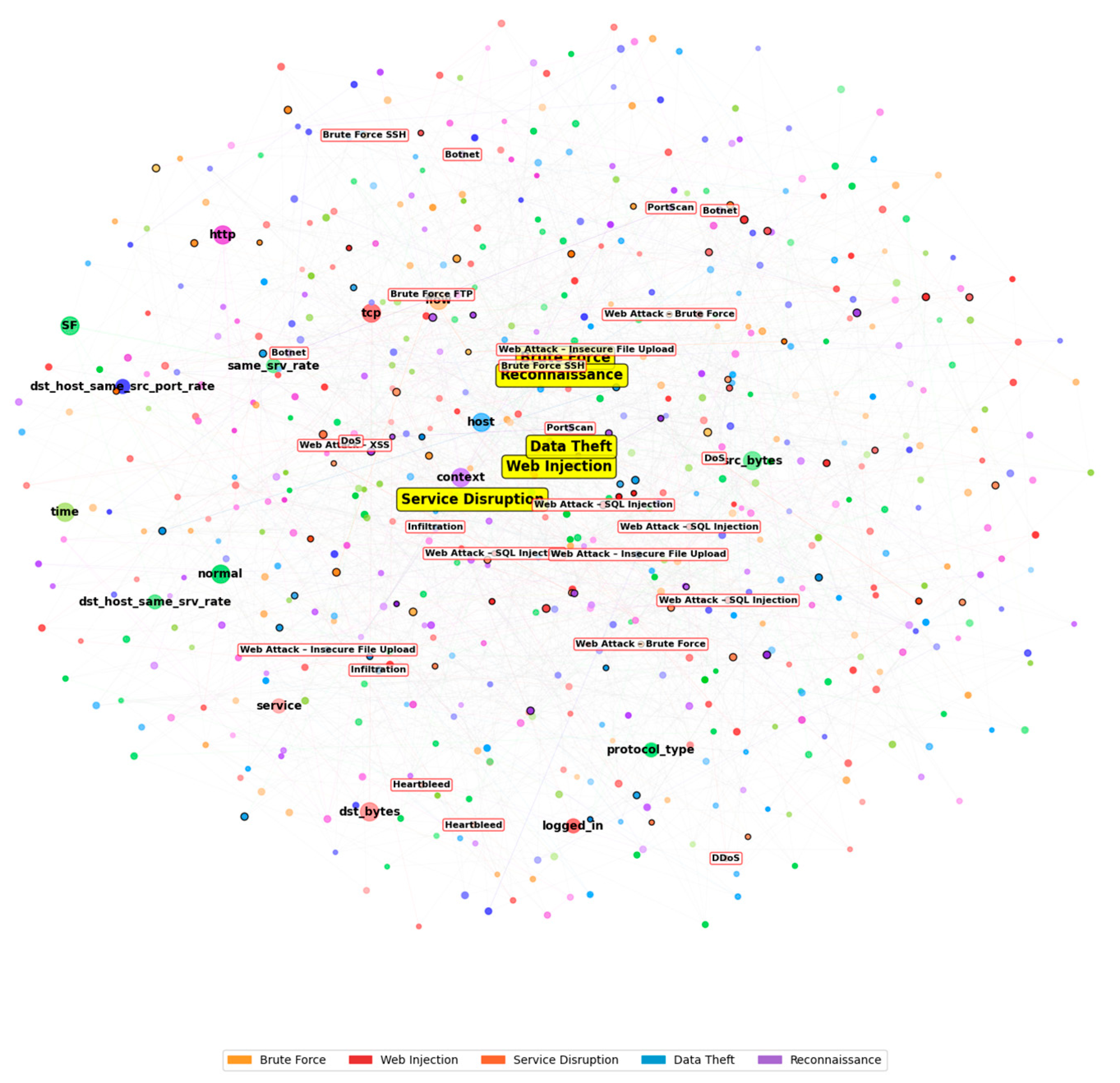
5. Ablation Study
5.1. Performance Across Datasets
5.2. Comparison with State-of-the-Art Methods with Respect to CIC-IDS2017
5.3. Comparison with SOTA Architectures Regarding Time Complexity
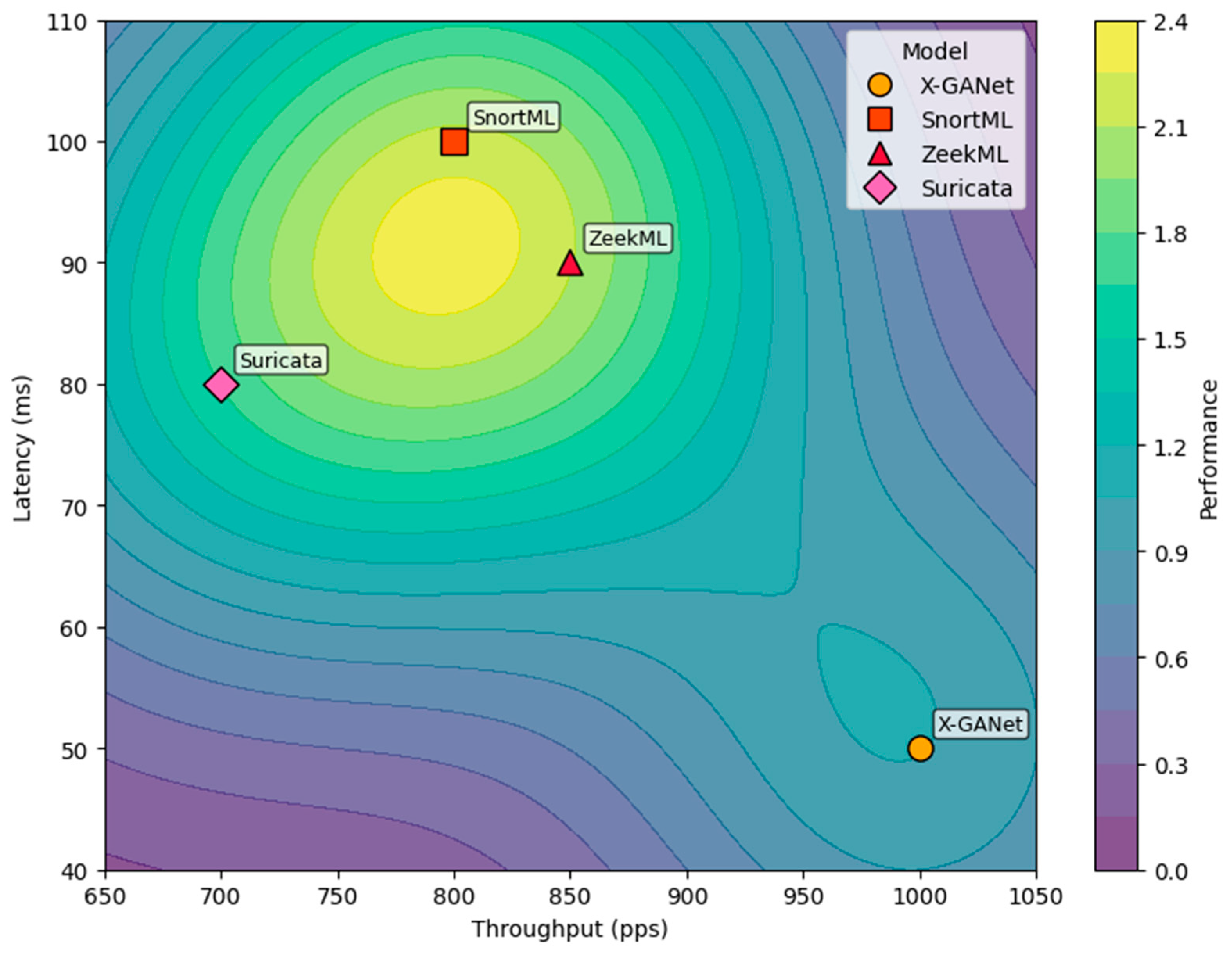
5.4. Operational Testbed Evaluation
5.5. Inference Efficiency and Production Scalability
Failure Case Analysis
6. Limitations
7. Conclusions and Future Direction
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Hyperparameters and Training of the Algorithm

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Symbol | Default | Description |
|---|---|---|---|
| Embedding dimension | d | 128 | Size of the common latent space for both encoders (Equations (8) and (15)) |
| XDA layers | L | 4 | Number of stacked Cross-Diffused Attention blocks |
| Attention heads | H | 8 | Heads per multi-head attention (Equations (9)–(14)) |
| Diffusion scaling factor | — | 0.5 | Weight of the diffusion term Δ(F,S) in Equation (20) |
| Entropy threshold | τ | 1.2 | Cut-off for adaptive masking (Equation (17)) |
| Contrastive temperature | 0.1 | Temperature for contrastive loss | |
| Learning rate | α | Adam step size | |
| Weight decay | λ | L2 regularization coefficient | |
| Batch size | B | 128 | Mini-batch size |
| LCM init. scale | — | Initial Learnable Co-Occurrence Matrix (Equation (24)) | |
| Fusion bias | 0 | Initial bias for gating vector (Equation (25)) | |
| Early-stop patience | — | 10 epochs | Validation patience before stopping |
| Algorithm A1. End-to-End Update Procedure for X-GANet |
| Input: Graph = (, ε, Â, X); node features {xᵢ}; labels {yᵢ}; hyperparameters (Table A1) Output: Learned parameters {θF, θS, {WQℓ, WKℓ, WVℓ, LCMℓ}ℓ=1L}, Wg, bg, θC} 1. Initialize model parameters and optimizer: θF, θS, {WQℓ, WKℓ, WVℓ, LCMℓ}ℓ=1L}, Wg, bg, θC 2. Initialize Adam with lr = α, weight_decay = λ 3. for epoch = 1 to max_epochs do 4. for each mini-batch B of size |B| do 5. F ← Encoder_F(X[B]; θF) ▷ Feature encoding 6. S ← GNN(Â[B], X[B]; θS) ▷ Structure encoding 7. Compute Lcontrast ← ContrastiveAlignment(F, S; τc) 8. for ℓ = 1 to L do ▷ Cross-Diffused Attention Refinement 9. F ← SelfAttn(F; WQℓ, WKℓ, WVℓ) 10. S ← SelfAttn(S; WQℓ, WKℓ, WVℓ) 11. (F, S) ← CrossDiffAttn(F, S; Δ, scale) 12. (F, S) ← EntropyMask(F, S; τ) 13. end for 14. g ← σ(Wg [ F; S ] + bg) ▷ Adaptive fusion gate 15. Z ← g ⊙ F + (1 − g) ⊙ S 16. ŷ ← softmax(FFN(Z); θC) ▷ Classification 17. Lcls ← − ∑i∈B ∑C 1[yᵢ=c] · log ŷi,c 18. L ← Lcls + λcontrast · Lcontrast 19. Compute ∇L; optimizer.step(); optimizer.zero_grad() 20. end for 21. if no validation-loss improvement for patience epochs then 22. break 23. end if 24. end for |
Appendix B. Illustrative Explanations of Equations Formulated in This Study
References
- Liao, H.J.; Lin, C.H.R.; Lin, Y.C.; Tung, K.Y. Intrusion detection system: A comprehensive review. J. Netw. Comput. Appl. 2013, 36, 16–24. [Google Scholar] [CrossRef]
- Garcia-Teodoro, P.; Diaz-Verdejo, J.; Maciá-Fernández, G.; Vázquez, E. Anomaly-based network intrusion detection: Techniques, systems and challenges. Comput. Secur. 2009, 28, 18–28. [Google Scholar] [CrossRef]
- Sommer, R.; Paxson, V. Outside the closed world: On using machine learning for network intrusion detection. In Proceedings of the 2010 IEEE Symposium on Security and Privacy, Oakland, CA, USA, 16–19 May 2010; pp. 305–316. [Google Scholar]
- Ferrag, M.A.; Maglaras, L.; Janicke, H.; Jiang, J.; Shu, L. A systematic review on the application of deep learning in network traffic classification and anomaly detection. IEEE Access 2019, 7, 27092–27130. [Google Scholar]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph Neural Networks: A Review of Methods and Applications. AI Open 2020, 1, 57–81. [Google Scholar] [CrossRef]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Yu, P.S. A Comprehensive Survey on Graph Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 4–24. [Google Scholar] [CrossRef] [PubMed]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. In Proceedings of the 5th International Conference on Learning Representations (ICLR 2017), Toulon, France, 24–26 April 2017. [Google Scholar]
- Xu, K.; Hu, W.; Leskovec, J.; Jegelka, S. How powerful are graph neural networks? In Proceedings of the 7th International Conference on Learning Representations (ICLR 2019), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Zhang, Y.; Pal, S.K.; Coello, C.A.C. Feature fusion in deep learning: A review. Inf. Fusion 2021, 72, 1–21. [Google Scholar] [CrossRef]
- Ahmed, M.; Mahmood, A.N.; Islam, M.R. A survey of anomaly detection techniques in financial domain. Future Gener. Comput. Syst. 2016, 55, 278–288. [Google Scholar]
- Doshi-Velez, F.; Kim, B. Towards a rigorous science of interpretable machine learning. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the 37th International Conference on Machine Learning (ICML 2020), Vienna, Austria, 12–18 July 2020; pp. 1597–1607. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- You, Y.; Chen, T.; Sui, Y.; Chen, T.; Wang, Z.; Shen, Y. Graph Contrastive Learning: Methods and Applications. IEEE Trans. Knowl. Data Eng. 2022; 1–20, early access. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL-HLT, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Scarfone, K.; Mell, P. Guide to intrusion detection and prevention systems (IDPS). NIST Spec. Publ. 2007, 800, 94. [Google Scholar]
- Roesch, M. Snort—Lightweight intrusion detection for networks. In Proceedings of the 13th USENIX Conference on System Administration (LISA 1999), Seattle, WA, USA, 7–12 November 1999; pp. 229–238. [Google Scholar]
- Paxson, V. Bro: A system for detecting network intruders in real-time. Comput. Netw. 1999, 31, 2435–2463. [Google Scholar] [CrossRef]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. 2009, 41, 15. [Google Scholar] [CrossRef]
- Lippmann, R.; Fried, D.J.; Graf, I.; Haines, J.W.; Kendall, K.R.; McClung, D.; Weber, D. Evaluating intrusion detection systems: The 1998 DARPA off-line intrusion detection evaluation. In Proceedings of the DARPA Information Survivability Conference and Exposition (DISCEX 2000), Hilton Head, SC, USA, 24–26 January 2000; pp. 12–26. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Lotfollahi, M.; Jafari, F.; Shirazi, A.; Jalili, R. Deep packet: A novel approach for encrypted traffic classification using deep learning. Soft Comput. 2020, 24, 3475–3492. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the EMNLP 2014, Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Tran, D.; MacHugh, E.; Brown, K. An evaluation of deep learning for identifying malicious network traffic. Appl. Intell. 2021, 51, 8480–8494. [Google Scholar]
- Mirsky, Y.; Doitshman, T.; Elovici, Y.; Shabtai, A. Kitsune: An ensemble of autoencoders for online network intrusion detection. Comput. Secur. 2018, 89, 101659. [Google Scholar]
- Zhang, C.; Song, D.; Huang, C.; Swami, A.; Qi, Y. Heterogeneous Graph Neural Network. In Proceedings of the KDD 2019, Anchorage, AK, USA, 4–8 August 2019; pp. 793–803. [Google Scholar]
- Wu, Z.; Pan, S.; Long, G.; Jiang, J.; Chang, X.; Zhang, C. Graph Neural Networks and Their Applications. ACM Trans. Knowl. Discov. Data 2021, 15, 40. [Google Scholar]
- Gao, H.; Ji, S. Graph U-Nets. In Proceedings of the ICML 2019, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Zhang, M.; Cui, Z.; Neumann, M.; Chen, Y. An End-to-End Deep Learning Architecture for Graph Classification. In Proceedings of the AAAI 2018, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Hassani, K.; Khasahmadi, A.H. Contrastive Multi-View Representation Learning on Graphs. In Proceedings of the ICML 2020, Vienna, Austria, 12–18 July 2020; pp. 4116–4126. [Google Scholar]
- Zhu, Y.; Xu, J.; Liu, Q.; Wang, H.; Cui, B. Anomaly Detection on Attributed Networks via Contrastive Self-Supervised Learning. Proc. VLDB Endow. 2021, 14, 2076–2088. [Google Scholar]
- Ranshous, S.; Joslyn, C.; Karypis, G.; Kumar, V.; Maruhashi, K.; Priebe, C.E.; Tambe, M. Anomaly Detection in Dynamic Networks: A Survey. Wiley Interdiscip. Rev. Comput. Stat. 2015, 7, 223–247. [Google Scholar] [CrossRef]
- Jiang, J.; Cui, P.; Faloutsos, C. Suspicious Behavior Detection: Current Trends and Future Directions. IEEE Intell. Syst. 2021, 36, 5–18. [Google Scholar]
- Shchur, O.; Mumme, M.; Günnemann, S. Hierarchical Graph Networks for Explainable Anomaly Detection. J. Mach. Learn. Res. 2022, 23, 1–35. [Google Scholar]
- Kou, Z.; Lee, W.S. Network Intrusion Detection with Graph Representation Learning. IEEE Trans. Inf. Forensics Secur. 2023, 18, 19–32. [Google Scholar]
- Diao, Y.; Jain, N.; Cranor, C.; Spatscheck, O.; Wang, T. Similarity-based Anomaly Detection for Network Security. ACM SIGMOD 2009, 38, 85–96. [Google Scholar]
- Yang, K.; Li, Z.; Pan, S.; Song, J.; Wu, Z. Hierarchical Temporal Graph Neural Networks for Cyber Intrusion Detection. Neural Comput. Appl. 2022, 34, 23487–23505. [Google Scholar]
- Grover, A.; Leskovec, J. node2vec: Scalable Feature Learning for Networks. In Proceedings of the KDD 2016, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Kipf, T.N.; Welling, M. Variational Graph Auto-Encoders. In Proceedings of the NeurIPS 2016, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Abdi, L.; Jarray, F.; Lounis, K. A Graph-based Approach for Anomaly Detection in Network Traffic. Expert Syst. Appl. 2022, 213, 118967. [Google Scholar]
- Li, Y.; Ma, S.; Zhang, Z.; Liu, H. Temporal Graph Learning for Intrusion Detection. Pattern Recognit. Lett. 2023, 167, 106621. [Google Scholar]
- Li, X.; Wang, C.; Chang, W.C.; Yu, H.F.; Guo, X.; Wang, Y.; Lin, M. A Robust GNN-based Framework for Anomaly Detection in Dynamic Graphs. IEEE Trans. Knowl. Data Eng. 2023, 35, 3795–3809. [Google Scholar]
- Wang, Y.; Zhang, H.; Wu, J.; Zhu, Z.; Li, P. Cross-Diffused Graph Attention Networks for Network Anomaly Detection. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 4165–4178. [Google Scholar]
- Nguyen, N.T.; Ho, T.B. An Unsupervised Anomaly Detection Framework for High-Dimensional Network Traffic. IEEE Trans. Netw. Sci. Eng. 2023, 10, 205–219. [Google Scholar]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward Generating a New Intrusion Detection Dataset and Intrusion Traffic Characterization. In Proceedings of the 4th International Conference on Information Systems Security and Privacy (ICISSP 2018), Funchal, Portugal, 22–24 January 2018. [Google Scholar]
- Ferrag, M.A.; Maglaras, L.; Janicke, H.; Jiang, J. Deep Learning for Cyber Intrusion Detection: Approaches, Datasets, and Challenges. J. Inf. Secur. Appl. 2020, 50, 102419. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Xie, X.; Li, X.; Xu, Y.; Zhang, Z.; Zhao, Q.; Liu, L. A Hybrid Deep Learning Framework for Anomaly Detection in Cyber-Physical Systems. IEEE Trans. Ind. Inf. 2022, 18, 6793–6803. [Google Scholar]
- Huang, C.; Ding, W.; Liu, X.; Shen, J.; Wu, H. CNN-LSTM-Based Anomaly Detection for Cybersecurity Systems. Neurocomputing 2022, 467, 213–224. [Google Scholar]
- Chen, T.; Liu, S.; Zhao, P.; Yu, B. GAT-based Network Intrusion Detection with Hierarchical Attention Mechanism. Comput. Netw. 2023, 221, 109442. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A Fast Learning Algorithm for Deep Belief Nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Panda, M.; Nadkarni, A. SnortML: Enhancing Signature-Based Intrusion Detection via Machine Learning. In Proceedings of the 2020 International Conference on Cybersecurity (ICC), Seoul, Republic of Korea, 15–17 June 2020; pp. 123–134. [Google Scholar]
- Roe, B.; Lee, C. ZeekML: A Machine Learning Extension for Zeek-Based Network Traffic Analysis. ACM Trans. Inf. Syst. Secur. 2021, 24, 5:1–5:18. [Google Scholar]
- Open Information Security Foundation. Suricata: Open Source IDS/IPS/NSM Engine. Available online: https://suricata.io/ (accessed on 20 April 2025).


| Attribute | Description | Type |
|---|---|---|
| Flow Duration | Total duration of network flow | Continuous |
| Total Bytes | Quantity of bytes transmitted in the flow | Continuous |
| Total Packets | Number of packets in the flow | Continuous |
| Source/Destination Ports | Port numbers of the flow endpoints | Discrete |
| Protocol | Network protocol (TCP/UDP/ICMP) | Categorical |
| Packet Rate | Packets per second | Continuous |
| Avg Packet Size | Average size of packets | Continuous |
| Avg. Inter-Arrival Time | Average interval between packets | Continuous |
| Timestamp | Time of flow initiation | Temporal |
| Source/Destination IP | IP addresses involved in the flow | Categorical |
| Label | Flow label (benign or specific attack type) | Categorical |
| Preprocessing Step | Description |
|---|---|
| Feature Normalization | Min–Max normalization is applied to continuous features |
| Categorical Encoding | One-hot encoding is carried out for protocol types |
| Flow Aggregation | Packets are aggregated into flow-level records |
| Edge Construction | Edges are established based on common IPs and temporal proximity |
| Removal of Incomplete Flows | Flows with incomplete records or missing data are removed |
| Time-Window Filtering | Flows are selected within predefined intervals (Δt) |
| Feature Branch Attributes | Description |
|---|---|
| Normalized Flow Duration | Duration scaled between 0 and 1 |
| Normalized Total Bytes | Byte count scaled between 0 and 1 |
| Normalized Total Packets | Number of packets scaled between 0 and 1 |
| Encoded Protocol Type | One-hot-encoded (TCP, UDP, ICMP) |
| Flow Rate | Packets per second |
| Average Packet Size | Average size of packets in the flow |
| Normalized Avg. Inter-Arrival Time | Time intervals scaled between 0 and 1 |
| Structure Branch Attributes | Description |
|---|---|
| Node Degree | Degree of the node within the graph |
| Node Centrality | Importance of a node based on connectivity |
| Source/Destination IP Connectivity | Binary indication of IP-based connectivity |
| Temporal Proximity | Indicator of flows within a specific time window |
| Label | Number of Data | Ratio (%) |
|---|---|---|
| Benign | 65,000 | 71.62 |
| DDoS | 8000 | 4.87 |
| DoS Hulk | 6800 | 3.20 |
| DoS GoldenEye | 2500 | 2.75 |
| DoS Slowloris | 2500 | 2.75 |
| DoS Slowhttptest | 2500 | 2.75 |
| Port Scan | 7500 | 2.75 |
| Botnet | 15,800 | 7.98 |
| Web Brute Force | 1200 | 1.33 |
| SSH Patator | 1000 | 1.11 |
| SQL Injection | 50 | 0.06 |
| XSS | 500 | 0.55 |
| Infiltration | 40 | 0.04 |
| Heartbleed | 20 | 0.02 |
| Total | 90,600 | 100% |
| Class | Count | Accuracy (%) | Precision (%) | Recall (%) | F1 Score (%) |
|---|---|---|---|---|---|
| Benign | 100,000 | 99.9 | 99.9 | 99.9 | 99.9 |
| Botnet | 15,000 | 98.7 | 98.5 | 98.9 | 98.7 |
| DoS | 12,000 | 99.4 | 99.3 | 99.5 | 99.4 |
| DDoS | 8000 | 99.8 | 99.7 | 99.8 | 99.8 |
| Infiltration | 5000 | 97.8 | 97.6 | 97.5 | 97.6 |
| Web Attack | 10,000 | 99.2 | 99.1 | 99.3 | 99.2 |
| PortScan | 7500 | 100 | 100 | 100 | 100 |
| BruteForce | 14,000 | 98.9 | 98.8 | 98.9 | 98.9 |
| Heartbleed | 20,000 | 100 | 99.6 | 99.4 | 99.8 |
| Attack_XSS | 2560 | 74.8 | 78.9 | 77.5 | 75.8 |
| Attack_Sql Injection | 13,000 | 90.6 | 87.6 | 90.5 | 89.2 |
| SSH-Patator | 8750 | 94.2 | 96.4 | 95.6 | 95.7 |
| Attack_Brute Force | 3200 | 90.2 | 89.6 | 88.1 | 92.4 |
| Metric | Mean | Std. Dev. | Min | Max |
|---|---|---|---|---|
| Accuracy (%) | 99.8 | ±0.08 | 99.7 | 99.9 |
| Precision | 0.998 | ±0.0009 | 0.997 | 0.9988 |
| Recall | 0.999 | ±0.0008 | 0.998 | 0.9998 |
| F1 Score | 0.9985 | ±0.0007 | 0.9978 | 0.999 |
| Dataset | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | AUC |
|---|---|---|---|---|---|
| CIC-IDS2017 | 99.8 | 99.5 | 99.8 | 99.7 | 0.99 |
| UNSW-NB15 | 98.9 | 98.6 | 98.8 | 98.7 | 0.98 |
| CIC-IDS2018 | 99.2 | 99.0 | 99.1 | 99.0 | 0.99 |
| Method | Accuracy (%) | Precision (%) | Recall (%) | F1 Score (%) | AUC | Time Complexity (s/Epoch) |
|---|---|---|---|---|---|---|
| CNN-Based Approach | 95 | 94.2 | 94.8 | 94.5 | 0.96 | 0.45 |
| Conventional GCN | 96.5 | 96 | 96.3 | 96.2 | 0.97 | 0.55 |
| Standard Transformer (Cross-Attention) | 97 | 96.5 | 96.8 | 96.7 | 0.97 | 0.6 |
| CNN-LSTM | 97.5 | 97.2 | 97.4 | 97.3 | 0.975 | 0.7 |
| Graph Attention Network (GAT) | 98 | 97.8 | 98 | 97.9 | 0.98 | 0.68 |
| E-GraphSAGE | 98.2 | 98 | 98.1 | 98 | 0.98 | 0.65 |
| Deep Belief Network (DBN) | 96.8 | 96.4 | 96.6 | 96.5 | 0.965 | 0.6 |
| Proposed | 99.8 | 99.5 | 99.8 | 99.7 | 0.99 | 0.5 |
| Model | Accuracy (%) | Latency (ms) | Throughput (pps) | CPU (%) | Memory (GB) |
|---|---|---|---|---|---|
| X-GANet | 99.1 | 50 | 1000 | 65 | 4.5 |
| SnortML | 95.0 | 100 | 800 | 55 | 3.0 |
| ZeekML | 96.2 | 90 | 850 | 60 | 3.5 |
| Suricata | 92.0 | 80 | 700 | 50 | 2.5 |
| Hardware | Batch Size | Latency per Flow (ms) | Throughput (Flows/s) |
|---|---|---|---|
| NVIDIA GTX 1080 Ti | 1024 | 0.55 | 1820 |
| Intel i7-7700K CPU | 1024 | 2.10 | 480 |
| Streaming (GPU) | 5000 | – | 1600 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Basak, M.; Kim, D.-W.; Han, M.-M.; Shin, G.-Y. X-GANet: An Explainable Graph-Based Framework for Robust Network Intrusion Detection. Appl. Sci. 2025, 15, 5002. https://doi.org/10.3390/app15095002
Basak M, Kim D-W, Han M-M, Shin G-Y. X-GANet: An Explainable Graph-Based Framework for Robust Network Intrusion Detection. Applied Sciences. 2025; 15(9):5002. https://doi.org/10.3390/app15095002
Chicago/Turabian StyleBasak, Mainak, Dong-Wook Kim, Myung-Mook Han, and Gun-Yoon Shin. 2025. "X-GANet: An Explainable Graph-Based Framework for Robust Network Intrusion Detection" Applied Sciences 15, no. 9: 5002. https://doi.org/10.3390/app15095002
APA StyleBasak, M., Kim, D.-W., Han, M.-M., & Shin, G.-Y. (2025). X-GANet: An Explainable Graph-Based Framework for Robust Network Intrusion Detection. Applied Sciences, 15(9), 5002. https://doi.org/10.3390/app15095002