
Survey of Dense Video Captioning: Techniques, Resources, and Future Perspectives


Abstract
1. Introduction
- (1)
- A comprehensive survey of the state-of-the-art techniques for Dense Video Captioning, categorizing and analyzing the existing methodologies.
- (2)
- An in-depth review of the most widely used datasets for DVC, highlighting their strengths and limitations.
- (3)
- A detailed discussion of the evaluation metrics and protocols commonly employed in DVC research, including challenges and opportunities for future developments.
- (4)
- Identification of emerging trends and future directions in DVC research, providing valuable insights for researchers and practitioners in the field.
2. Fundamentals of Dense Video Captioning
2.1. Definition and Objectives of DVC
2.2. Key Subprocesses
2.3. Challenges in DVC
3. Techniques for Dense Video Captioning
3.1. Encoder-Decoder Based Approaches
3.1.1. Basic Encoder-Decoder Models
3.1.2. Multimodal Fusion Encoder-Decoder Models
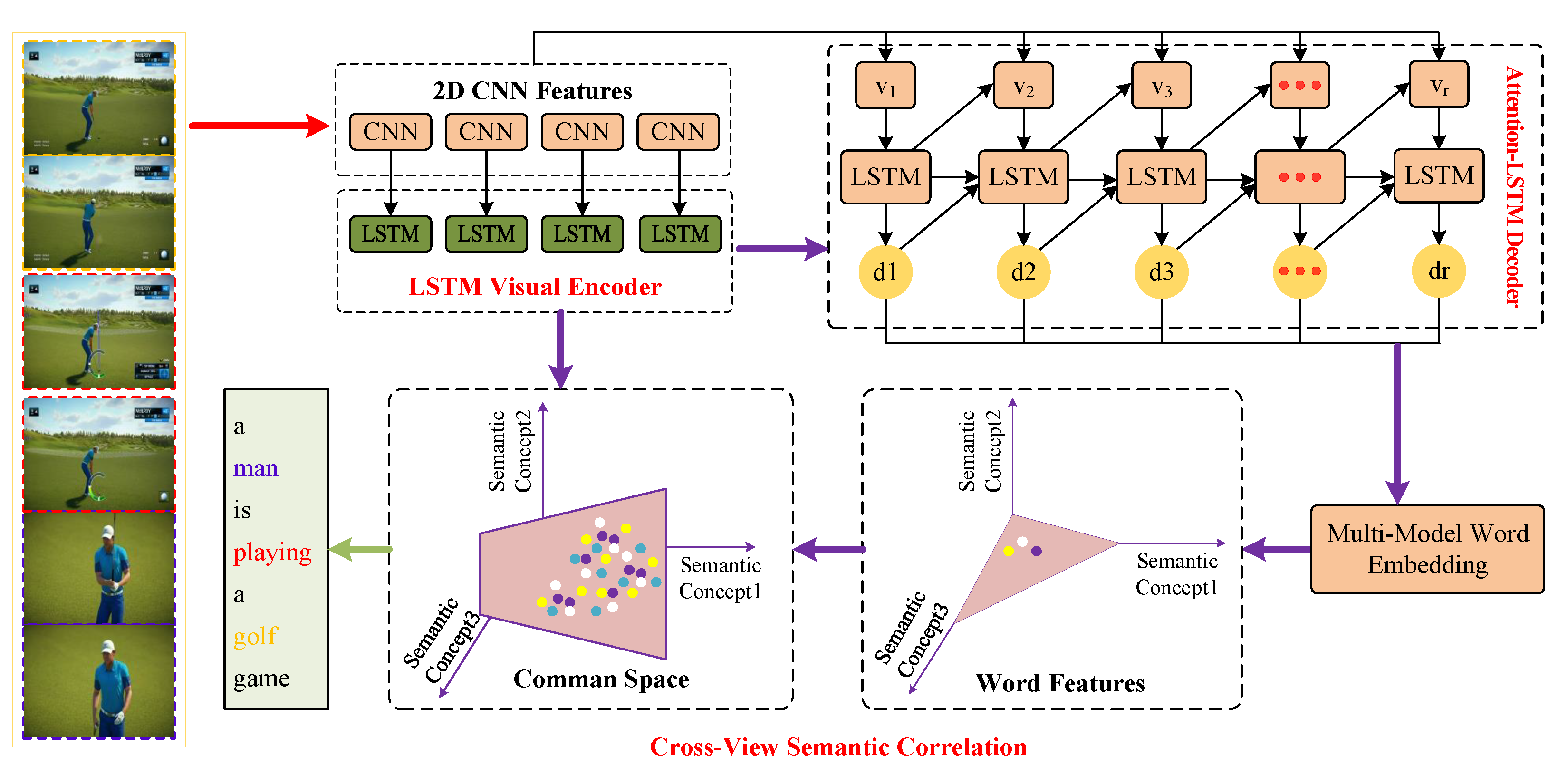
3.1.3. Attention-Based Encoder-Decoder Models
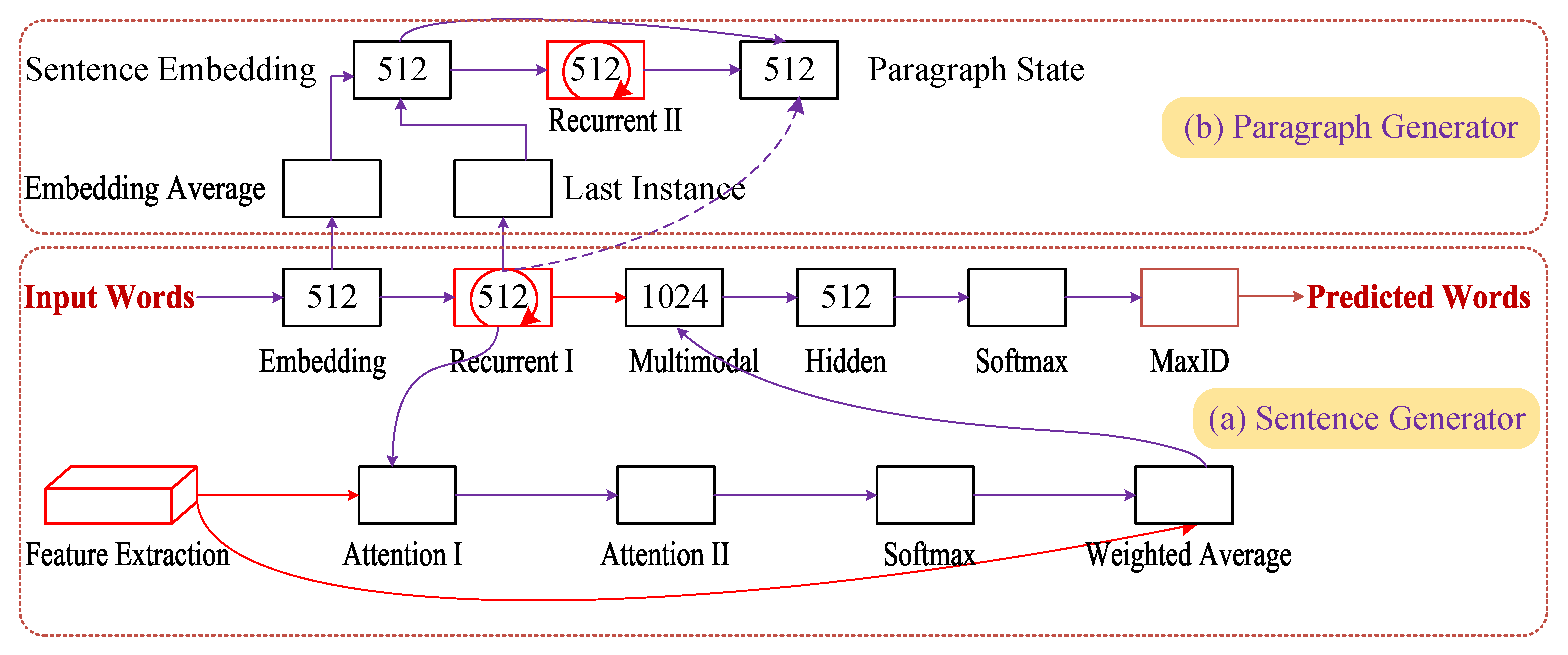
3.1.4. Hierarchical Encoder-Decoder Models
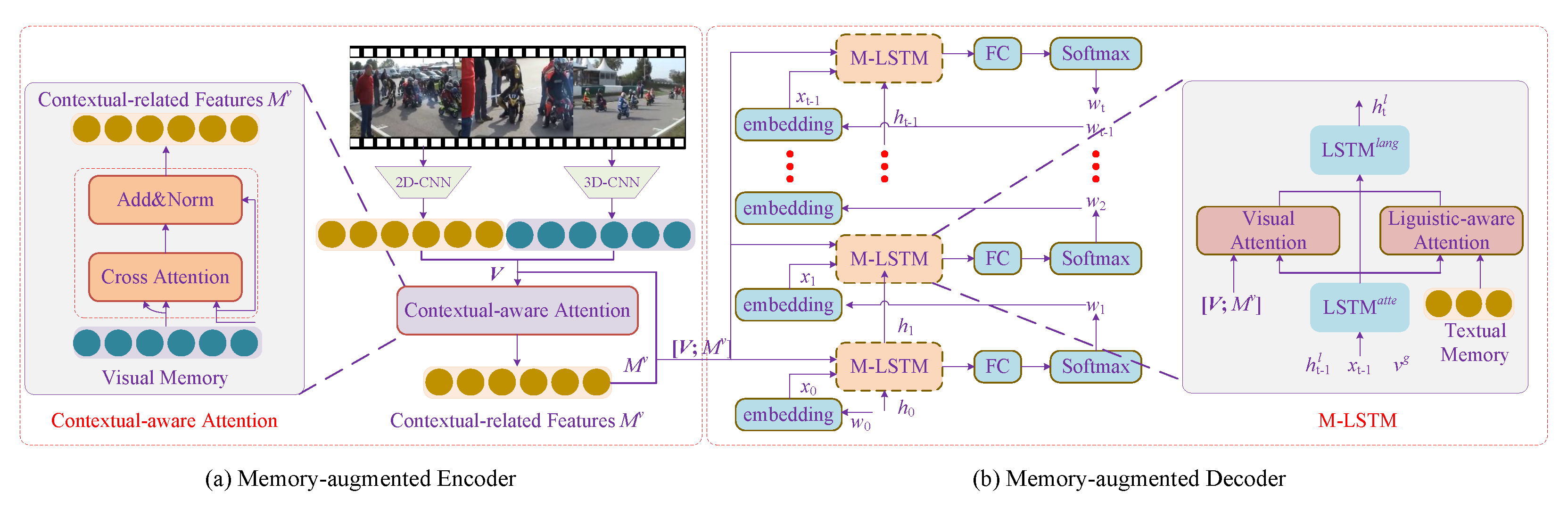
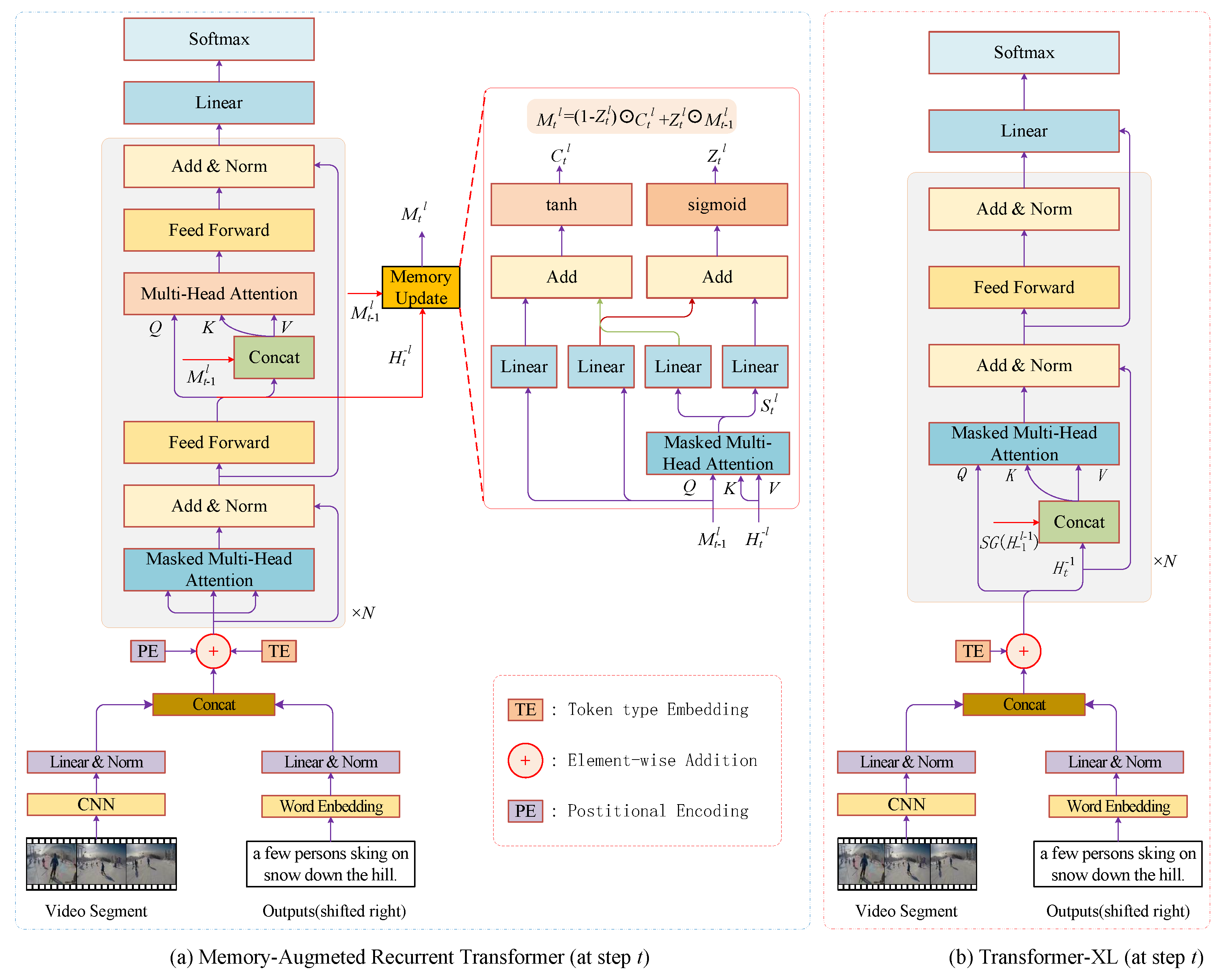
3.1.5. Memory-Augmented Encoder-Decoder Models
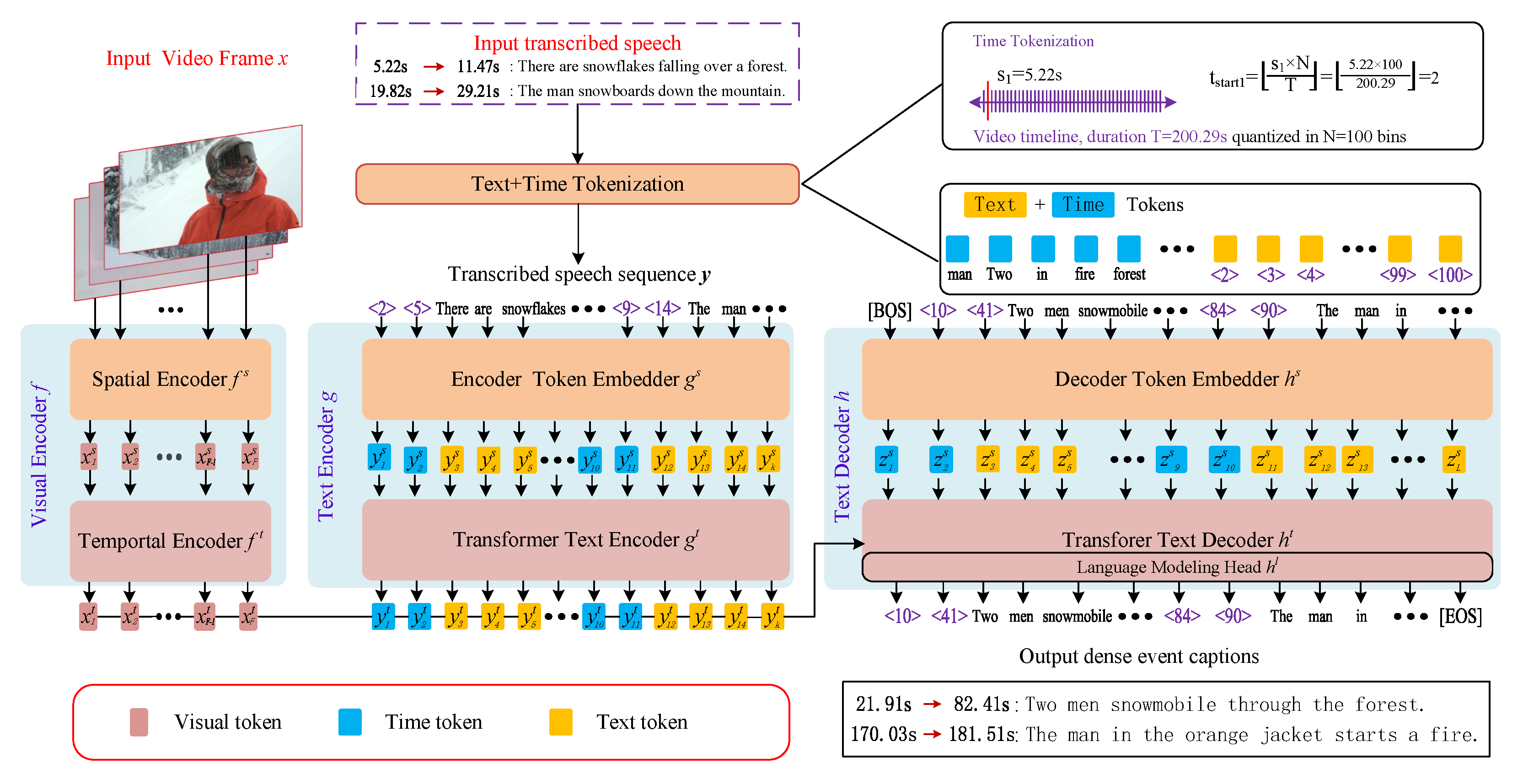
3.1.6. Transformer-Based Encoder-Decoder Models
3.2. Discussion-Encoder-Decoder Based APPROACHES
3.3. Transformer-Based Approaches
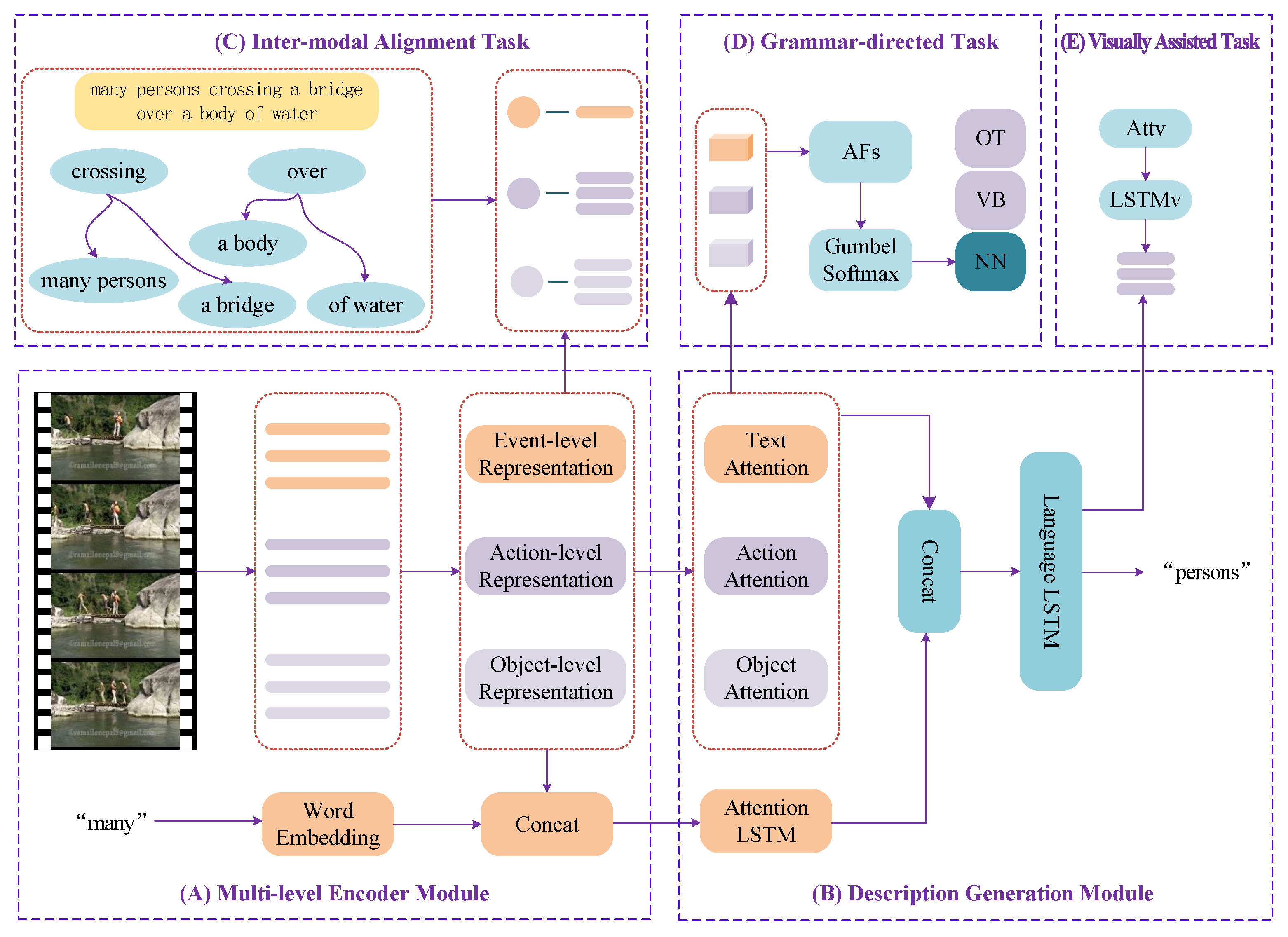
3.3.1. Knowledge-Enhanced Transformer Models
3.3.2. Sparse Attention-Based Transformer Models
3.3.3. Hierarchical Transformer Models
3.3.4. Single-Stream Transformer Models
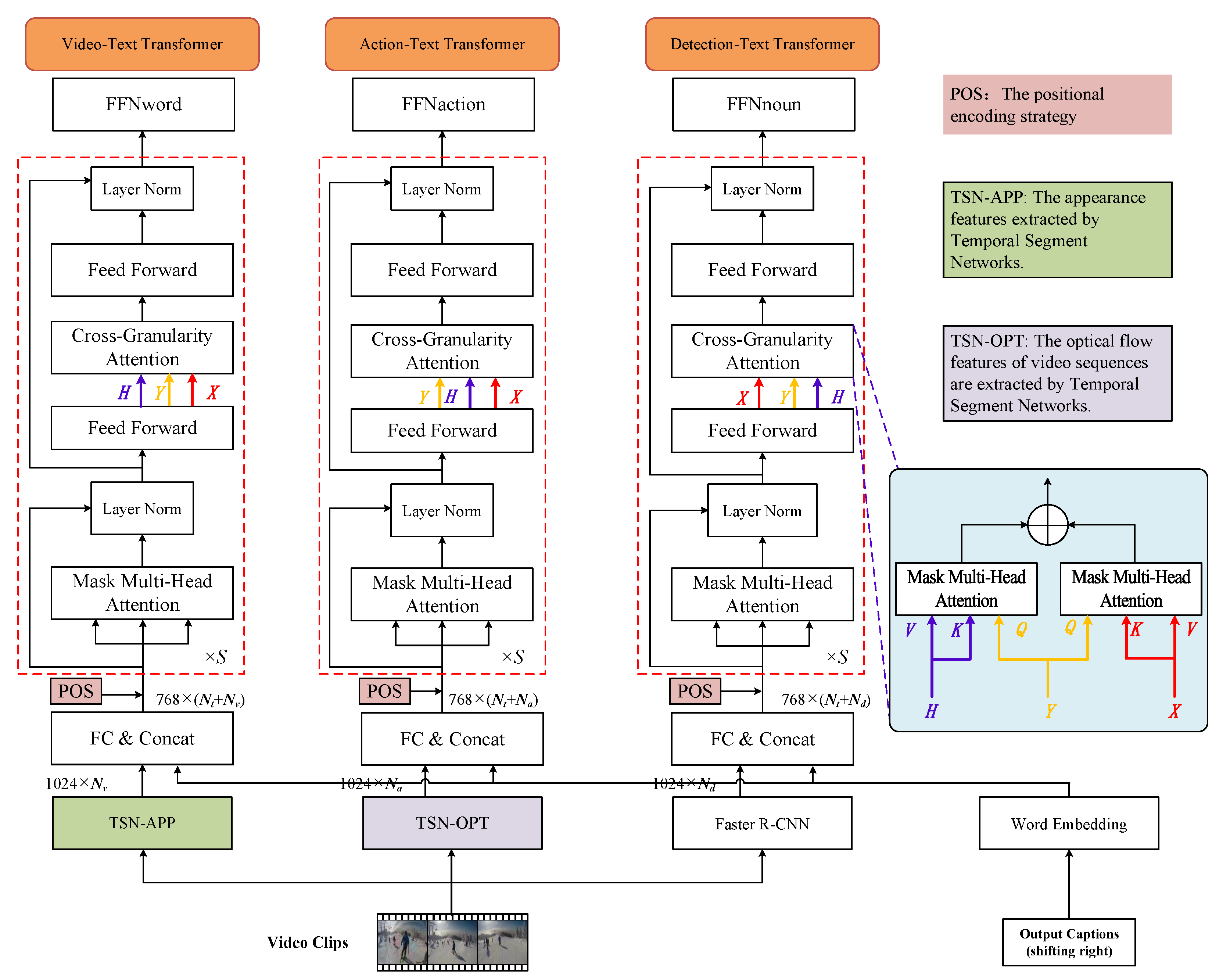
3.3.5. Multi-Stream Transformer Models
3.4. Discussion-Transformer Based APPROACHES
3.5. Attention-Based Approaches
3.5.1. Spatial Attention Models
3.5.2. Temporal Attention Models
3.5.3. Semantic Attention Models
3.5.4. Multi-Modal Attention Models
3.6. Discussion-Attention Based Models
4. Datasets for Dense Video Captioning
4.1. Detailed Descriptions
- (1)
- MSVDMSVD [49] (Microsoft Video Description) is a pioneering and widely adopted dataset for video captioning tasks. It features short video clips accompanied by descriptive sentences. Each video clip in MSVD is annotated with a single sentence description, providing a concise summary of the clip’s content. The MSVD dataset comprises over 1970 video clips, offering a substantial collection for research and development in video captioning.
- (2)
- TACoSTACoS [50] (Textually Annotated Cooking Scenes) is a multimodal corpus containing high-quality videos of cooking activities aligned with multiple natural language descriptions. This facilitates grounding action descriptions in visual information. The corpus provides sentence-level alignments between textual descriptions and video segments, alongside annotations indicating similarity between action descriptions. TACoS comprises 127 videos with 2540 textual descriptions, resulting in 2206 aligned descriptions after filtering. It contains 146,771 words and 11,796 unique sentences.
- (3)
- MPII-MDMPII-MD [51] is a dataset sourced from movies for video description. It aims to facilitate research on generating multi-sentence descriptions for videos. Each video is annotated with multiple temporally localized sentences that cover key events and details. The dataset contains 94 movies, amounting to 68,000 clips with 68.300 multi-sentence descriptions.
- (4)
- TGIFTGIF [52] (Tumblr GIF) is a large-scale dataset designed for animated GIF description, containing 100,000 GIFs collected from Tumblr and 120,000 natural language descriptions sourced via crowdsourcing. Each GIF is accompanied by multiple sentences to capture its visual content. High-quality annotations are ensured through syntactic and semantic validation, ensuring strong visual-textual associations. Workers were selected based on language proficiency and performance. The dataset is split into 90K training, 10K validation, and 10K test GIFs, providing ample data for model training and evaluation.
- (5)
- MSR-VTTMSR-VTT [7] (Microsoft Research Video to Text) is a diverse video dataset tailored for various video-to-text generation tasks, including video captioning and dense video captioning. It spans 20 broad categories, offering a rich variety of video content. Annotations for MSR-VTT are provided by 1327 AMT workers, ensuring each video clip is accompanied by multiple captions that offer comprehensive coverage of various aspects of the video content, enhancing the understanding of video semantics. MSR-VTT comprises 10,000 video clips sourced from 7180 videos, with an average of 20 captions per video.
- (6)
- CharadesCharades is a large-scale video dataset designed for activity understanding and video description tasks [53]. It contains videos of people performing daily activities in various indoor scenes. The annotations for Charades include action labels, temporal intervals, and natural language descriptions, collected through Amazon Mechanical Turk to provide comprehensive coverage of video content. Charades comprises 9848 videos, recorded by 267 people in 15 different indoor scenes. Each video is annotated with multiple action classes and descriptions.
- (7)
- VTWVTW (Video Titles in the Wild) is a large-scale dataset of user-generated videos automatically crawled from online communities [54]. It contains 18,100 videos with an average duration of 1.5 min, each associated with a concise title produced by an editor. Each video is annotated with a single title sentence describing the most salient event, accompanied by 1–3 longer description sentences. Highlight moments corresponding to the titles are manually labeled in a subset. The dataset spans 213.2 h in total, making it a challenging benchmark for video title generation tasks.
- (8)
- ActivityNet CaptionsActivityNet Captions [2] is a large-scale dataset for dense video captioning, featuring over 20,000 videos segmented into multiple temporal intervals. With 100K descriptions totaling 849 h, each averaging 13.48 words and capturing 36 s of video content, it comprehensively annotates activities within each interval. Annotations in the dataset include multiple temporally localized sentences per video, averaging 3.65 per clip, which collectively cover 94.6% of video content with 10% overlap, ideal for studying concurrent events. Covering over 849 video hours, the dataset encompasses 20K videos and generates 100k sentences. Both sentence length and count per video follow normal distributions, indicative of varying video durations.
- (9)
- YouCook2YouCook2 [4] is a comprehensive cooking video dataset, featuring 2000 YouTube videos across 89 recipes from diverse cuisines. It covers a wide range of cooking styles, ingredients, and utensils, primarily used for video summarization, recipe generation, and dense video captioning tasks. YouCook2 includes temporal boundaries of cooking steps and ingredients, along with textual descriptions for each step. These annotations provide detailed, step-by-step insights into the cooking process. Comprising 2000 cooking videos, YouCook2 offers a substantial dataset for research and development in cooking-related video analysis.
- (10)
- BDD-XThe BDD-X [55] dataset is a large-scale video dataset designed for explaining self-driving vehicle behaviors. It contains over 77 h of driving videos with human-annotated descriptions and explanations of vehicle actions. Each video clip is annotated with action descriptions and justifications. Annotators view the videos from a driving instructor’s perspective, describing what the driver is doing and why. The dataset comprises 6984 videos, split into training (5588), validation (698), and test sets (698). Over 26,000 actions are annotated across 8.4 million frames.
- (11)
- VideoStoryVideoStory [56] is a novel dataset tailored for multi-sentence video description. It comprises 20k videos sourced from social media, spanning diverse topics and engaging narratives. Each video is annotated with multiple paragraphs, containing 123k sentences temporally aligned to video segments. On average, each video has 4.67 annotated sentences. The dataset encompasses 396 h of video content, divided into training (17,098 videos), validation (999 videos), test (1011 videos), and blind test sets (1039 videos).
- (12)
- M-VADM-VAD [57] (Montreal Video Annotation Dataset) is a large-scale movie description dataset consisting of video clips from various movies. It aims to support research on video captioning and related tasks. Each video clip is paired with a textual description. Annotations include face tracks associated with characters mentioned in the captions. The dataset contains over 92 movies, resulting in a substantial number of video clips and textual descriptions, providing rich material for video captioning research.
- (13)
- VATEXVATEX [58] (Video and Text) is a large-scale dataset comprising 41,269 video clips, each approximately 10 s long, sourced from the Kinetics-600 dataset. Each video clip in VATEX is annotated with 10 English and 10 Chinese descriptions, providing rich linguistic information across two languages. VATEX boasts a total of 41,269 video clips, making it a substantial resource for video description tasks.
- (14)
- TVCTVC [59] (TV Show Caption) is a large-scale multimodal video caption dataset built upon the TVR dataset. It requires systems to gather information from both video and subtitles to generate relevant descriptions. Each annotated moment in TVR has additional descriptions collected to form the TVC dataset, totaling 262,000 descriptions for 108 [53] moments. Descriptions may focus on video, subtitles, or both. The dataset includes 174,350 training descriptions, 43,580 validation descriptions, and 21,780 public test descriptions, split across numerous videos and moments.
- (15)
- ViTTThe ViTT [21] (Video Timeline Tags) dataset comprises 8000 untrimmed instructional videos, tailored for tasks that involve video content analysis and tagging. It aims to address the uniformity issue in YouCook2 videos by sampling videos with cooking/recipe labels from YouTube-8M. Each video in ViTT is annotated with 7.1 temporally-localized short tags, offering detailed insights into various aspects of the video content. Annotators have identified each step and assigned descriptive yet concise tags. The ViTT dataset boasts 8000 videos, with an average duration of 250 s per video. It contains a vast array of unique tags and token types, making it a comprehensive resource for video analysis tasks.
- (16)
- VC_NBA_2022VC_NBA_2022 [60] is a specialized basketball video dataset designed for knowledge-guided entity-aware video captioning tasks. This dataset is intended to support the generation of text descriptions that include specific entity names and fine-grained actions, particularly tailored for basketball live text broadcasts. VC_NBA_2022 provides annotations beyond conventional video captions. It leverages a multimodal basketball game knowledge graph (KG_NBA_2022) to offer additional context and knowledge, such as player images and names. Each video segment is annotated with detailed captions covering 9 types of fine-grained shooting events and incorporating player-related information from the knowledge graph. The dataset contains 3977 basketball game videos, with 3162 clips used for training and 786 clips for testing. Each video has one text description and associated candidate player information (images and names). The dataset is constructed to focus on shot and rebound events, which are the most prevalent in basketball games.
- (17)
- WTSWTS [61] (Woven Traffic Safety Dataset) is a specialized video dataset designed for fine-grained spatial-temporal understanding tasks in traffic scenarios, particularly focusing on pedestrian-centric events. Comprehensive textual descriptions and unique 3D Gaze data are provided for each video event, capturing detailed behaviors of both vehicles and pedestrians across diverse traffic situations. The dataset contains over 1.2k video events, with rich annotations that enable in-depth analysis and understanding of traffic dynamics.
4.2. Characteristics and Limitations of Each Dataset
- (1)
- MSVDMSVD is an early and well-established dataset that features short video clips accompanied by concise descriptions. However, its size and diversity are somewhat limited, and the single sentence descriptions may not fully capture all aspects of the video content.
- (2)
- TACoSTACoS is a multimodal corpus that offers video-text alignments along with diverse cooking actions and fine-grained sentence-level annotations. Nevertheless, it is restricted to the cooking domain and thus may lack the diversity needed for broader actions.
- (3)
- MPII-MDMPII-MD centers on movie descriptions and contains 94 videos paired with 68k sentences, providing multi-sentence annotations aligned with video clips. But this dataset is confined to movie-related content and lacks the diversity of topics typically found in social media videos.
- (4)
- TGIFTGIF consists of 100K animated GIFs coupled with 120K natural language descriptions, showcasing rich motion information and cohesive visual stories. Yet, due to the nature of animated GIFs, it lacks audio and long-form narratives, which limits its complexity compared to full videos.
- (5)
- MSR-VTTMSR-VTT boasts diverse video content spanning various topics, with multiple captions per video segment to offer a comprehensive understanding. However, the annotations may occasionally be redundant or overlapping, and the quality of captions can vary, potentially affecting model training.
- (6)
- CharadesCharades, comprising 9,848 annotated videos of daily activities involving 267 people, covers 157 action classes and facilitates research in action recognition and video description. Nonetheless, the dataset’s focus on home environments restricts diversity in backgrounds and activities, possibly impacting generalization.
- (7)
- VTWThe VTW dataset holds 18,100 automatically crawled user-generated videos with diverse titles, presenting a challenging benchmark for video title generation. However, the temporal location and extent of highlights in most videos are unknown, posing challenges for highlight-sensitive methods.
- (8)
- ActivityNet CaptionsActivityNet Captions is a large-scale dataset characterized by diverse video content, fine-grained temporal annotations, and rich textual descriptions. The complexity of the videos might make it difficult for models to accurately capture all details, and some annotations may exhibit varying levels of granularity.
- (9)
- YouCook2YouCook2 zeroes in on cooking activities, making it highly domain-specific with detailed step-by-step annotations. Compared to general-purpose datasets, it has limited diversity in video content, and its annotations are biased towards cooking terminology.
- (10)
- BDD-XBDD-X contains over 77 h of driving videos with 26k human-annotated descriptions and explanations, covering diverse driving scenarios and conditions. However, it is important to note that the annotations are rationalizations from observers rather than capturing drivers’ internal thought processes.
- (11)
- VideoStoryVideoStory comprises 20k social media videos paired with 123k multi-sentence descriptions, spanning a variety of topics and demonstrating temporal consistency. But there’s a possibility that its representativeness might be limited as it tends to focus on engaging content when it comes to all social media videos.
- (12)
- M-VADThe M-VAD dataset holds 92 movies with detailed descriptions that cover different genres. It zeroes in on captions for movie clips, which makes it quite suitable for video captioning research. Nevertheless, it lacks character visual annotations as well as proper names in the captions, thereby restricting its application in tasks that require naming capabilities.
- (13)
- VATEXVATEX shines in its focus on a broad range of video activities, rendering it versatile for various video understanding tasks. It offers detailed and diverse annotations that touch upon multiple aspects of the video content. Yet, despite being extensive, it may not be deeply specialized in one particular domain like some other datasets. Moreover, while comprehensive, its annotations might not be finely tuned to the specific terminology or nuances of highly specialized fields.
- (14)
- TVCTVC stands out as a large-scale dataset equipped with multimodal descriptions and embraces diverse context types such as video, subtitle, or both, along with rich human interactions. However, the annotations within this dataset may vary in their level of detail, and some descriptions could be more centered around one modality.
- (15)
- ViTTViTT centers on text-to-video retrieval tasks, making it immensely valuable for video-text understanding and alignment. It provides detailed annotations that link textual descriptions to corresponding video segments. Still, when compared to general-purpose video datasets, its focus is narrower, concentrating on specific types of videos pertinent to the text-to-video retrieval task. Additionally, the annotations might lean towards the terminology and context commonly seen in text-video pairing scenarios.
- (16)
- VC_NBA_2022The VC_NBA_2022 dataset presents a specialized collection of basketball game videos, covering a multitude of in-game events. It delivers detailed and specific annotations for shooting incidents along with player-centric details, offering an exhaustive comprehension of basketball game situations. Nonetheless, the dataset’s annotations could occasionally be skewed towards certain aspects of the game, perhaps overlooking other vital elements. Furthermore, the quality and consistency of these annotations can fluctuate, which might influence the efficacy of model training.
- (17)
- WTSWTS has a distinct focus on traffic safety scenarios, making it highly pertinent to studies involving pedestrian and vehicle interactions. It includes thorough annotations comprising textual descriptions and 3D gaze data for in-depth analysis. Although, in contrast to general-purpose video datasets, it has a more confined scope concerning video content as it concentrates solely on traffic safety circumstances. Furthermore, its annotations may exhibit bias towards traffic-related terminology and specific facets of pedestrian and vehicle behavior.
4.3. Data Preprocessing and Augmentation Techniques
5. Evaluation Protocols and Metrics
5.1. Key Metrics
5.1.1. BLEU
5.1.2. METEOR
- (1)
- Word AlignmentThe initial step involves aligning words between the machine-generated and reference translations using exact matching, stemming (Porter stemmer), and synonymy matching (WordNet). This alignment is carried out in stages, each focusing on a different matching criterion.
- (2)
- Precision and Recall CalculationOnce aligned METEOR calculates Precision (P) as the ratio of correctly matched unigrams in the translation to the total unigrams, and Recall (R) as the ratio of correctly matched unigrams to the total in the reference.
- (3)
- F-measure CalculationMETEOR then computes the harmonic mean (F-measure) of Precision (P) and Recall (R), with more weight given to Recall (R).
- (4)
- Penalty for FragmentationTo penalize translations with poor ordering or gaps, METEOR calculates a fragmentation Penalty based on the number of chunks formed by adjacent matched unigrams in the translation and reference.where and are parameters that control the Penalty.
- (5)
- Final METEOR Score
5.1.3. CIDEr
- (1)
- TF-IDF Weightingwhere is the frequency of n-gram in reference caption , is the vocabulary of all n-grams, is the total number of images, and q is a constant typically set to the average length of reference captions.
- (2)
- Cosine Similarity for n-grams of Length nwhere is the candidate caption, is the set of reference captions, and and are the TF-IDF vectors for the n-grams of length n in the candidate and reference captions, respectively.
- (3)
- Combined CIDEr Scorewhere N is the maximum n-gram length (typically 4), and are the weights for different n-gram lengths (typically set to for uniform weights).
5.1.4. ROUGE-L
- (1)
- LCS CalculationFor two sequences X and Y, let denote the length of their longest common subsequence.
- (2)
- Recall and PrecisionRecall () is determined by the ratio of the length of the longest common subsequence (LCS) to the length of the reference sequence. Precision (), on the other hand, is calculated as the ratio of the length of the LCS to the length of the candidate sequence.
- (3)
- F-MeasureThe F-measure () is the harmonic mean of Recall () and Precision ().where is a parameter that controls the relative importance of Recall and Precision. In ROUGE evaluations, is often set to a very large value (e.g., ), effectively making equal to .
5.1.5. SODA
- (1)
- Optimal Matching Using Dynamic ProgrammingSODA uses dynamic programming to find the best match between generated and reference captions, maximizing their IoU score sum while considering temporal order. The IoU between a generated caption p and a reference caption g is defined as:where and represent the start and end times of the event proposals corresponding to the captions.Given a set of reference captions G and generated captions P, SODA finds the optimal matching by solving:where S holds the maximum score of optimal matching between the first i generated captions and the first j reference captions, and C is the cost matrix based on IoU scores.
- (2)
- F-measure for Evaluating Video Story DescriptionTo penalize redundant captions and ensure the generated captions cover all relevant events, SODA computes Precision and Recall based on the optimal matching and derives F-measure scores:where represents an evaluation metric like METEOR.
5.1.6. SPICE
5.1.7. WMD
5.2. Challenges in Evaluation and Benchmarking
- (1)
- Diversity of Video ContentVideos contain a wide range of events, contexts, and interactions, making it difficult to create a comprehensive set of reference captions that capture all possible descriptions. This diversity can lead to inconsistencies in evaluation results.
- (2)
- Semantic SimilarityCurrent metrics rely heavily on n-gram matching and may not accurately capture the semantic similarity between captions. This can result in models being penalized for generating captions that are semantically correct but differ in wording from the references.
- (3)
- Temporal LocalizationDVC involves not only generating accurate captions but also locating the events in the video. Evaluating the temporal localization of events is challenging, as it requires precise annotations and may not be fully captured by existing metrics.
5.3. Discussion on the Interpretability and Fairness of Evaluation Metrics
- (1)
- InterpretabilityMetrics should provide clear insights into the strengths and weaknesses of the models. For example, a low BLEU score may indicate a lack of n-gram overlap, while a high CIDEr score may suggest good consensus with reference captions. However, it is important to interpret these scores in the context of the specific task and dataset.
- (2)
- FairnessEvaluation metrics should be fair and unbiased, reflecting the true performance of the models. This requires careful selection of reference captions and consideration of the diversity of video content. Metrics should also be robust to variations in annotation quality and consistency.
5.4. Benchmark Results
5.4.1. MSVD Dataset: Method Performance Overview

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| NO | Method | Method’s Category | BLEU-4 | METEOR | CIDEr | ROUGE-L | Year |
|---|---|---|---|---|---|---|---|
| 1 | ASGNet [81] | Encoder-decoder | 55.2 | 36.6 | 101.8 | 74.3 | 2025 |
| 2 | CroCaps [82] | Encoder-decoder | 58.2 | 39.79 | 112.29 | 77.41 | 2025 |
| 3 | KG-VCN [77] | Encoder-decoder | 64.9 | 39.7 | 107.1 | 77.2 | 2025 |
| 4 | PKG [83] | Encoder-decoder | 60.1 | 39.3 | 107.2 | 76.2 | 2025 |
| 5 | ATMNet [78] | Encoder-decoder | 58.8 | 41.1 | 121.9 | 78.2 | 2025 |
| 6 | Howtocaption [76] | Encoder-decoder | 70.4 | 46.4 | 154.2 | 83.2 | 2024 |
| 7 | MAN [28] | Encoder-decoder | 59.7 | 37.3 | 101.5 | 74.3 | 2024 |
| 8 | GSEN [84] | Encoder-decoder | 58.8 | 37.6 | 102.5 | 75.2 | 2024 |
| 9 | EDS [85] | Encoder-decoder | 59.6 | 39.5 | 110.2 | 76.2 | 2024 |
| 10 | SATLF [86] | Encoder-decoder | 60.9 | 40.8 | 110.9 | 77.5 | 2024 |
| 11 | GLG [87] | Encoder-decoder | 63.6 | 42.4 | 107.8 | 80.8 | 2024 |
| 12 | CMGNet [88] | Encoder-decoder | 54.2 | 36.9 | 96.2 | 74.5 | 2024 |
| 13 | ViT/L14 [89] | Encoder-decoder | 60.1 | 41.4 | 121.5 | 78.2 | 2023 |
| 14 | CARE [90] | Encoder-decoder | 56.3 | 39.11 | 106.9 | 75.6 | 2023 |
| 15 | VCRN [91] | Encoder-decoder | 59.1 | 37.4 | 100.8 | 74.6 | 2023 |
| 16 | RSFD [92] | Encoder-decoder | 51.2 | 35.7 | 96.7 | 72.9 | 2023 |
| 17 | vc-HRNAT [26] | Encoder-decoder | 57.7 | 36.8 | 98.1 | 74.1 | 2022 |
| 18 | SemSynAN [93] | Encoder-decoder | 64.4 | 41.9 | 111.5 | 79.5 | 2021 |
| 19 | TTA [94] | Encoder-decoder | 51.8 | 35.5 | 87.7 | 72.4 | 2021 |
| 20 | AVSSN [93] | Encoder-decoder | 62.3 | 39.2 | 107.7 | 76.8 | 2021 |
| 21 | RMN [80] | Encoder-decoder | 54.6 | 36.5 | 94.4 | 73.4 | 2020 |
| 22 | SAAT [95] | Encoder-decoder | 46.5 | 33.5 | 81.0 | 69.4 | 2020 |
| 23 | VNS-GRU [79] | Encoder-decoder | 66.5 | 42.1 | 121.5 | 79.7 | 2020 |
| 24 | JSRL-VCT [96] | Encoder-decoder | 52.8 | 36.1 | 87.8 | 71.8 | 2019 |
| 25 | GFN-POS [27] | Encoder-decoder | 53.9 | 34.9 | 91.0 | 72.1 | 2019 |
| 26 | DCM [97] | Encoder-decoder | 53.3 | 35.6 | 83.1 | 71.2 | 2019 |
| 27 | CEMSA [33] | Transformer | 60.9 | 40.5 | 117.9 | 77.9 | 2024 |
| 28 | SnapCap [42] | Transformer | 51.7 | 36.5 | 94.7 | 73.5 | 2024 |
| 29 | COST [41] | Transformer | 56.3 | 37.2 | 99.2 | 74.3 | 2023 |
| 30 | TextKG [32] | Transformer | 60.8 | 38.5 | 105.2 | 75.1 | 2023 |
| 31 | UAT-FEGs [35] | Transformer | 56.5 | 36.4 | 92.8 | 72.8 | 2022 |
| 32 | HMN [36] | Transformer | 59.2 | 37.7 | 104.0 | 75.1 | 2022 |
| 33 | O2NA [98] | Transformer | 55.4 | 37.4 | 96.4 | 74.5 | 2021 |
| 34 | STGN [99] | Transformer | 52.2 | 36.9 | 93.0 | 73.9 | 2020 |
| 35 | SBAT [34] | Transformer | 53.1 | 35.3 | 89.5 | 72.3 | 2020 |
| 36 | TVT [38] | Transformer | 53.21 | 35.23 | 86.76 | 72.01 | 2018 |
| 37 | STAN [45] | Attention | 40.0 | 40.2 | 72.1 | 55.2 | 2025 |
| 38 | IVRC [100] | Attention | 58.8 | 40.3 | 116.0 | 77.4 | 2024 |
| 39 | MesNet [101] | Attention | 54.0 | 36.3 | 100.1 | 73.6 | 2023 |
| 40 | ADL [47] | Attention | 54.1 | 35.7 | 81.6 | 70.4 | 2022 |
| 41 | STAG [102] | Attention | 58.6 | 37.1 | 91.5 | 73.0 | 2022 |
| 42 | SemSynAN [103] | Attention | 64.4 | 41.9 | 111.5 | 79.5 | 2021 |
| 43 | T-DL [104] | Attention | 55.1 | 36.4 | 85.7 | 72.2 | 2021 |
| 44 | SGN [105] | Attention | 52.8 | 35.5 | 94.3 | 72.9 | 2021 |
| 45 | ORG-TRL [106] | Attention | 54.3 | 36.4 | 95.2 | 73.9 | 2020 |
| 46 | MAM-RNN [107] | Attention | 41.3 | 32.2 | 53.9 | 68.8 | 2017 |
5.4.2. MSR-VTT Dataset: Method Performance Overview
5.4.3. VATEX Dataset: Method Performance Overview
5.4.4. ActivityNet Captions Dataset: Method Performance Overview
| NO | Method | Method’s Category | BLEU-4 | METEOR | CIDEr | ROUGE-L | Year |
|---|---|---|---|---|---|---|---|
| 1 | COST [41] | Encoder-decoder | 11.88 | 15.70 | 29.64 | - | 2023 |
| 2 | MPP-net [119] | Encoder-decoder | 12.75 | 16.01 | 29.35 | - | 2023 |
| 3 | VSJM-Net [22] | Encoder-decoder | 3.97 | 12.89 | 26.52 | 25.37 | 2022 |
| 4 | VC-FF [113] | Encoder-decoder | 2.76 | 7.02 | 26.55 | 18.16 | 2021 |
| 5 | JSRL-VCT [96] | Encoder-decoder | 1.9 | 11.30 | 44.20 | 22.40 | 2019 |
| 6 | TextKG [32] | Transformer | 11.3 | 16.5 | 26.6 | 6.3 | 2023 |
| 7 | Vltint [120] | Transformer | 14.93 | 18.16 | 33.07 | 36.86 | 2023 |
| 8 | SART [114] | Transformer | 11.35 | 16.21 | 28.35 | 7.18 | 2022 |
| 9 | BMT-V+sm [115] | Transformer | 2.55 | 8.65 | 13.48 | 13.62 | 2021 |
| 10 | COOT [37] | Transformer | 17.43 | 15.99 | 28.19 | 31.45 | 2020 |
| 11 | MART [39] | Transformer | 10.85 | 15.99 | 28.19 | 6.64 | 2020 |
| 12 | EC-SL [116] | Attention | 1.33 | 7.49 | 21.21 | 13.02 | 2021 |
| 13 | WS-DEC [117] | Attention | 1.27 | 6.30 | 18.77 | 12.55 | 2018 |
| 14 | Bi-SST [118] | Attention | 2.30 | 9.60 | 12.68 | 19.10 | 2018 |
5.4.5. YouCook2 Dataset: Method Performance Overview
| NO | Method | Method’s Category | BLEU-4 | METEOR | CIDEr | ROUGE-L | Year |
|---|---|---|---|---|---|---|---|
| 1 | Howtocaption [76] | Encoder-decoder | 8.8 | 15.9 | 116.4 | 37.3 | 2024 |
| 2 | COTE [122] | Encoder-decoder | 12.14 | 19.77 | 1.22 | 43.26 | 2024 |
| 3 | COST [41] | Encoder-decoder | 8.65 | 15.62 | 1.05 | 36.5 | 2023 |
| 4 | VSJM-Net [22] | Encoder-decoder | 1.09 | 4.31 | 9.07 | 10.51 | 2022 |
| 5 | MV-GPT [108] | Encoder-decoder | 21.26 | 26.36 | 2.14 | 48.58 | 2022 |
| 6 | E2vidD6-MASSvid-BiD [21] | Encoder-decoder | 12.04 | 18.32 | 1.23 | 39.03 | 2020 |
| 7 | UniVL [121] | Encoder-decoder | 17.35 | 22.35 | 1.81 | 46.52 | 2020 |
| 8 | TextKG [32] | Transformer | 14.0 | 22.1 | 75.9 | - | 2023 |
| 9 | SART [114] | Transformer | 11.43 | 19.91 | 57.66 | 8.58 | 2022 |
| 10 | MART [39] | Transformer | 11.30 | 19.85 | 57.24 | 6.69 | 2020 |
| 11 | COOT [37] | Transformer | 17.97 | 19.85 | 57.24 | 37.94 | 2020 |
| 12 | Videobert+S3D [124] | Transformer | 4.33 | 11.94 | 0.55 | 28.8 | 2019 |
| 13 | ActBERT [123] | Attention | 5.41 | 13.30 | 0.65 | 30.56 | 2020 |
| 14 | Bi-SST [118] | Attention | 2.30 | 9.60 | 12.68 | 19.10 | 2018 |
5.4.6. VITT Dataset: Method Performance Overview
| NO | Method | Method’s Category | BLEU-4 | METEOR | CIDEr | ROUGE-L | SODA | Year |
|---|---|---|---|---|---|---|---|---|
| 1 | AIEM [126] | Encoder-decoder | - | 44.9 | 11.3 | - | 11.8 | 2025 |
| 2 | Streaming_Vid2Seq [129] | Encoder-decoder | - | 5.8 | 25.2 | - | 10.0 | 2024 |
| 3 | Vid2Seq [31] | Encoder-decoder | - | 8.5 | 43.5 | - | 13.5 | 2023 |
| 4 | VidChapters-7M [125] | Encoder-decoder | - | 9.6 | 50.9 | - | 15.1 | 2023 |
| 5 | SimpleConcat_WikiHow_T5 [127] | Encoder-decoder | 1.34 | 7.97 | 0.25 | 9.21 | - | 2022 |
| 6 | FAD [128] | Transformer | - | 18.9 | 37.2 | - | 10.2 | 2024 |
5.4.7. Eight Datasets: Method Performance Overview
| NO | Method | Method’s Category | Dataset | BLEU-4 | METEOR | CIDEr | ROUGE-L | Year |
|---|---|---|---|---|---|---|---|---|
| 1 | KEANetT [130] | Encoder-decoder | VC_NBA_2022 | 32.4 | 28.0 | 138.5 | 54.9 | 2025 |
| 2 | Instance-VideoLLM [61] | Attention | WTS | 0.121 | 0.409 | 0.389 | 0.417 | 2025 |
| 3 | UCF-SST-NLP [131] | Attention | WTS | 0.2005 | 0.4115 | 0.5573 | 0.4416 | 2024 |
| 4 | TrafficVLM(VC) [142] | Encoder-decoder | WTS | 0.419 | 0.493 | 0.609 | 0.589 | 2024 |
| 5 | TrafficVLM(PC) [142] | Encoder-decoder | WTS | 0.316 | 0.378 | 0.61 | 0.438 | 2024 |
| 6 | CityLLaVA [132] | Encoder-decoder | WTS | 0.289 | 0.484 | 1.044 | 0.481 | 2024 |
| 7 | Video-LLaMA [133] | Encoder-decoder | WTS | 0.045 | 0.247 | 0.210 | 0.226 | 2023 |
| 8 | Video-ChatGPT [134] | Encoder-decoder | WTS | 0.072 | 0.267 | 0.282 | 0.266 | 2023 |
| 9 | +VSE [143] | Transformer | BDD-X | 21.82 | 25.42 | 162.12 | 42.47 | 2024 |
| 10 | MVVC [144] | Transformer | BDD-X | 17.5 | 20.7 | 107.0 | 44.4 | 2024 |
| 11 | ADAPT [145] | Transformer | BDD-X | 11.4 | 15.2 | 102.6 | 32.0 | 2023 |
| 12 | CMGNet [88] | Encoder-decoder | TGIF | 16.2 | 18.4 | 53.7 | 43.7 | 2024 |
| 13 | SAAT [95] | Encoder-decoder | TGIF | 15.3 | 18.1 | 49.6 | 42.3 | 2020 |
| 14 | RMN [80] | Encoder-decoder | TGIF | 15.6 | 18.1 | 50.1 | 42.6 | 2020 |
| 15 | COTE [122] | Encoder-decoder | TVC | 12.20 | 17.56 | 45.81 | 33.24 | 2024 |
| 16 | MMT [59] | Transformer | TVC | 10.87 | 16.91 | 45.38 | 32.81 | 2020 |
| 17 | HERO [135] | Transformer | TVC | 12.35 | 17.64 | 49.98 | 34.16 | 2020 |
| 18 | HRL [25] | Encoder-decoder | Charades | 18.8 | 19.5 | 23.2 | 41.4 | 2018 |
| 19 | LSCEC [136] | Encoder-decoder | TACoS | 47.6 | 0.352 | 1.774 | 0.725 | 2021 |
| 20 | JEDDi-Net [137] | Encoder-decoder | TACoS | 18.1 | 23.85 | 103.98 | 50.85 | 2018 |
| 21 | ResBRNN [138] | Encoder-decoder | VideoStory | 15.6 | 20.1 | 103.6 | 29.9 | 2019 |
| 22 | m-RNN [139] | Encoder-decoder | VideoStory | 11.8 | 18.0 | 81.3 | 28.5 | 2015 |
| 23 | Boundary-aware [140] | Encoder-decoder | MPII-MD | 0.8 | 7.0 | 10.8 | 16.7 | 2017 |
| 24 | VL-LSTM [141] | Encoder-decoder | MPII-MD | 0.80 | 7.03 | 9.98 | 16.02 | 2015 |
| 25 | SMT [51] | Encoder-decoder | MPII-MD | 0.47 | 5.59 | 13.21 | 8.14 | 2015 |
6. Emerging Trends and Future Directions
6.1. Current Research Trends in DVC
6.2. Open Challenges and Limitations
6.3. Potential Future Directions
- (1)
- Improved Event Recognition and Localization AlgorithmsTo address the limitations of current event recognition and localization algorithms, researchers are exploring novel approaches such as contrastive learning and self-supervised learning. These methods can leverage unlabeled video data to learn more discriminative features, improving the performance of event detection and localization. Additionally, integrating temporal context and semantic information can further enhance the accuracy of event recognition.
- (2)
- Enhanced Multimodal Integration and Cross-Media UnderstandingMultimodal integration is key to improving the descriptive capabilities of DVC systems. Future research should focus on developing more sophisticated multimodal fusion techniques that can effectively combine visual, audio, and language features. Moreover, cross-media understanding, which involves linking video content to related text, audio, and other media, holds promise for advancing DVC applications in various domains.
- (3)
- More Efficient and Interpretable ModelsAs DVC systems become more complex, the need for efficient and interpretable models becomes increasingly important. Researchers are exploring various techniques to reduce the computational complexity of DVC models, such as model pruning, quantization, and knowledge distillation. Additionally, developing interpretable models that can provide insights into the decision-making process of DVC systems will enhance their trustworthiness and usability.
- (4)
- Applications in Video Retrieval, Accessibility, and Content AnalysisDVC has a wide range of applications, including video retrieval, accessibility, and content analysis. In video retrieval, DVC can improve the accuracy and efficiency of search results by generating descriptive text for each video segment. For accessibility, DVC can help visually impaired individuals better understand video content by providing detailed descriptions of events and actions. In content analysis, DVC can provide valuable insights into video data, facilitating tasks such as automatic annotation, classification, and summarization.
7. Conclusions
7.1. Summary of the Review’s Key Findings
7.2. Contributions and Implications for the Field of DVC
7.3. Final Thoughts and Recommendations for Future Research
- (1)
- Exploration of Novel Model ArchitecturesResearchers should continue to investigate new model architectures that can more effectively capture the temporal and spatial dynamics of video content. This may involve the development of more advanced attention mechanisms, the integration of graph neural networks for modeling relationships between objects and events, or the utilization of reinforcement learning to optimize caption generation.
- (2)
- Enhancement of Multimodal Fusion TechniquesAs multimodal information becomes increasingly crucial for DVC, researchers should focus on refining fusion techniques that can harness the complementary strengths of visual, auditory, and textual cues. This may entail employing more sophisticated feature extraction methods, developing better alignment strategies for multimodal features, or exploring innovative ways to combine predictions from different modalities.
- (3)
- Creation of Diverse and High-Quality DatasetsTo bolster the development and evaluation of DVC models, researchers should endeavor to create diverse and high-quality datasets that span a wide range of video genres, languages, and cultural contexts. Additionally, there is a need for datasets that incorporate more challenging and realistic scenarios to test the robustness and scalability of DVC models.
- (4)
- Development of Temporal-Specific Evaluation MetricsGiven the limitations of current NLP-based metrics in assessing temporal event localization, future research should prioritize the creation of evaluation metrics specifically designed for dense video captioning. These metrics should focus on temporal Precision (P) and Recall (R), event alignment accuracy, and the ability to capture temporal dependencies. Potential approaches may include developing metrics that evaluate the temporal coherence of generated captions, measuring the alignment between predicted and ground-truth event boundaries, or incorporating temporal consistency as a key criterion. Such advancements would provide a more comprehensive and relevant framework for evaluating the performance of dense video captioning systems in real-world applications.
- (5)
- Exploration of Applications and Use CasesLastly, researchers should explore the potential applications and use cases of DVC technology to demonstrate its value and drive adoption in real-world scenarios. This may involve collaborating with industry partners to develop prototypes and pilot projects, conducting user studies to grasp the needs and preferences of end-users, or exploring new ways to integrate DVC technology into existing systems and platforms.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rafiq, G.; Rafiq, M.; Choi, G.S. Video description: A comprehensive survey of deep learning approaches. Artif. Intell. Rev. 2023, 56, 13293–13372. [Google Scholar] [CrossRef]
- Krishna, R.; Hata, K.; Ren, F.; Fei-Fei, L.; Niebles, J.C. Dense-captioning events in videos. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 706–715. [Google Scholar] [CrossRef]
- Li, Y.; Yao, T.; Pan, Y.; Chao, H.; Mei, T. Jointly localizing and describing events for dense video captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition alt, Lake City, UT, USA, 18–23 June 2018; pp. 7492–7500. [Google Scholar] [CrossRef]
- Zhou, L.; Xu, C.; Corso, J. Towards automatic learning of procedures from web instructional videos. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar] [CrossRef]
- Rafiq, M.; Rafiq, G.; Choi, G.S. Video description: Datasets & evaluation metrics. IEEE Access 2021, 9, 121665–121685. [Google Scholar] [CrossRef]
- Hou, R.; Chen, C.; Shah, M. Tube convolutional neural network (t-cnn) for action detection in videos. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5822–5831. [Google Scholar] [CrossRef]
- Xu, J.; Mei, T.; Yao, T.; Rui, Y. Msr-vtt: A large video description dataset for bridging video and language. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5288–5296. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.-J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar] [CrossRef]
- Lavie, A.; Agarwal, A. Meteor: An automatic metric for MT evaluation with high levels of correlation with human judgments. In Proceedings of the Second Workshop on Statistical Machine Translation, Prague, Czech Republic, 23 June 2007; pp. 228–231. [Google Scholar]
- Vedantam, R.; Lawrence Zitnick, C.; Parikh, D. Cider: Consensus-based image description evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4566–4575. [Google Scholar] [CrossRef]
- Chin-Yew, L. Rouge: A package for automatic evaluation of summaries. In Proceedings of the Workshop on Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004; pp. 74–81. Available online: https://aclanthology.org/W04-1013/ (accessed on 21 March 2025).
- Fujita, S.; Hirao, T.; Kamigaito, H.; Okumura, M.; Nagata, M. SODA: Story oriented dense video captioning evaluation framework. In Proceedings of the European Conference on Computer Vision, Virtual, Online, UK, 23–28 August 2020; pp. 517–531. [Google Scholar] [CrossRef]
- Anderson, P.; Fernando, B.; Johnson, M.; Gould, S. Spice: Semantic propositional image caption evaluation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 382–398. [Google Scholar] [CrossRef]
- Kusner, M.; Sun, Y.; Kolkin, N.; Weinberger, K. From word embeddings to document distances. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 957–966. Available online: https://proceedings.mlr.press/v37/kusnerb15 (accessed on 21 March 2025).
- Aafaq, N.; Mian, A.; Liu, W.; Gilani, S.Z.; Shah, M. Video description: A survey of methods, datasets, and evaluation metrics. ACM Comput. Surv. 2019, 52, 1–37. [Google Scholar] [CrossRef]
- Yan, C.; Tu, Y.; Wang, X.; Zhang, Y.; Hao, X.; Zhang, Y.; Dai, Q. Spatial-temporal attention mechanism for video captioning. IEEE Trans. Multimed. 2019, 22, 229–241. [Google Scholar] [CrossRef]
- Wang, T.; Zhang, R.; Lu, Z.; Zheng, F.; Cheng, R.; Luo, P. End-to-end dense video captioning with parallel decoding. In Proceedings of the IEEE International Conference on Computer Vision, Online, Canada, 11–17 October 2021; pp. 6847–6857. [Google Scholar] [CrossRef]
- Venugopalan, S.; Xu, H.; Donahue, J.; Rohrbach, M.; Mooney, R.; Saenko, K. Translating videos to natural language using deep recurrent neural networks. arXiv 2014, arXiv:1412.4729. [Google Scholar] [CrossRef]
- Yao, L.; Torabi, A.; Cho, K.; Ballas, N.; Pal, C.; Larochelle, H.; Courville, A. Describing videos by exploiting temporal structure. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4507–4515. [Google Scholar] [CrossRef]
- Hori, C.; Hori, T.; Lee, T.-Y.; Zhang, Z.; Harsham, B.; Hershey, J.R.; Marks, T.K.; Sumi, K. Attention-based multimodal fusion for video description. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4193–4202. [Google Scholar] [CrossRef]
- Huang, G.; Pang, B.; Zhu, Z.; Rivera, C.; Soricut, R. Multimodal pretraining for dense video captioning. arXiv 2020, arXiv:2011.11760. [Google Scholar] [CrossRef]
- Aafaq, N.; Mian, A.; Akhtar, N.; Liu, W.; Shah, M. Dense video captioning with early linguistic information fusion. IEEE Trans. Multimed. 2022, 25, 2309–2322. [Google Scholar] [CrossRef]
- Yu, H.; Wang, J.; Huang, Z.; Yang, Y.; Xu, W. Video paragraph captioning using hierarchical recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 4584–4593. [Google Scholar] [CrossRef]
- Pan, Y.; Mei, T.; Yao, T.; Li, H.; Rui, Y. Jointly modeling embedding and translation to bridge video and language. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, USA, 26–30 June 2016; pp. 4594–4602. [Google Scholar] [CrossRef]
- Wang, X.; Chen, W.; Wu, J.; Wang, Y.-F.; Wang, W.Y. Video captioning via hierarchical reinforcement learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4213–4222. [Google Scholar] [CrossRef]
- Gao, L.; Lei, Y.; Zeng, P.; Song, J.; Wang, M.; Shen, H.T. Hierarchical representation network with auxiliary tasks for video captioning and video question answering. IEEE Trans. Image Process. 2021, 31, 202–215. [Google Scholar] [CrossRef]
- Wang, B.; Ma, L.; Zhang, W.; Jiang, W.; Wang, J.; Liu, W. Controllable video captioning with POS sequence guidance based on gated fusion network. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27–2 November 2019; pp. 2641–2650. [Google Scholar] [CrossRef]
- Jing, S.; Zhang, H.; Zeng, P.; Gao, L.; Song, J.; Shen, H.T. Memory-based augmentation network for video captioning. IEEE Trans. Multimed. 2023, 26, 2367–2379. [Google Scholar] [CrossRef]
- Yang, X.; Tang, K.; Zhang, H.; Cai, J. Auto-encoding scene graphs for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 10685–10694. [Google Scholar] [CrossRef]
- Zhou, L.; Zhou, Y.; Corso, J.J.; Socher, R.; Xiong, C. End-to-end dense video captioning with masked transformer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8739–8748. [Google Scholar] [CrossRef]
- Yang, A.; Nagrani, A.; Seo, P.H.; Miech, A.; Pont-Tuset, J.; Laptev, I.; Sivic, J.; Schmid, C. Vid2seq: Large-scale pretraining of a visual language model for dense video captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 10714–10726. [Google Scholar] [CrossRef]
- Gu, X.; Chen, G.; Wang, Y.; Zhang, L.; Luo, T.; Wen, L. Text with knowledge graph augmented transformer for video captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 18941–18951. [Google Scholar] [CrossRef]
- Zhang, B.; Gao, J.; Yuan, Y. Center-enhanced video captioning model with multimodal semantic alignment. Neural Netw. 2024, 180, 106744. [Google Scholar] [CrossRef]
- Jin, T.; Huang, S.; Chen, M.; Li, Y.; Zhang, Z. SBAT: Video captioning with sparse boundary-aware transformer. arXiv 2020, arXiv:2007.11888. [Google Scholar] [CrossRef]
- Im, H.; Choi, Y.-S. UAT: Universal attention transformer for video captioning. Sensors 2022, 22, 4817. [Google Scholar] [CrossRef]
- Ye, H.; Li, G.; Qi, Y.; Wang, S.; Huang, Q.; Yang, M.-H. Hierarchical modular network for video captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 17939–17948. [Google Scholar] [CrossRef]
- Ging, S.; Zolfaghari, M.; Pirsiavash, H.; Brox, T. Coot: Cooperative hierarchical transformer for video-text representation learning. Adv. Neural Inf. Process. Syst. 2020, 33, 22605–22618. [Google Scholar] [CrossRef]
- Chen, M.; Li, Y.; Zhang, Z.; Huang, S. TVT: Two-view transformer network for video captioning. In Proceedings of the Asian Conference on Machine Learning, Beijing, China, 14–16 November 2018; pp. 847–862. Available online: https://proceedings.mlr.press/v95/chen18b (accessed on 21 March 2025).
- Lei, J.; Wang, L.; Shen, Y.; Yu, D.; Berg, T.L.; Bansal, M. Mart: Memory-augmented recurrent transformer for coherent video paragraph captioning. arXiv 2020, arXiv:2005.05402. [Google Scholar] [CrossRef]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.; Le, Q.V.; Salakhutdinov, R. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv 2019, arXiv:1901.02860. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, L.; Fan, H.; Luo, T. Collaborative three-stream transformers for video captioning. Comput. Vis. Image Underst. 2023, 235, 103799. [Google Scholar] [CrossRef]
- Sun, J.; Su, Y.; Zhang, H.; Cheng, Z.; Zeng, Z.; Wang, Z.; Chen, B.; Yuan, X. SnapCap: Efficient Snapshot Compressive Video Captioning. arXiv 2024, arXiv:2401.04903. [Google Scholar] [CrossRef]
- Tu, Y.; Zhang, X.; Liu, B.; Yan, C. Video description with spatial-temporal attention. In Proceedings of the ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 1014–1022. [Google Scholar] [CrossRef]
- Gao, L.; Guo, Z.; Zhang, H.; Xu, X.; Shen, H.T. Video captioning with attention-based LSTM and semantic consistency. IEEE Trans. Multimed. 2017, 19, 2045–2055. [Google Scholar] [CrossRef]
- Yousif, A.J.; Al-Jammas, M.H. Semantic-based temporal attention network for Arabic Video Captioning. Nat. Lang. Process. J. 2025, 10, 100122. [Google Scholar] [CrossRef]
- Guo, Z.; Gao, L.; Song, J.; Xu, X.; Shao, J.; Shen, H.T. Attention-based LSTM with semantic consistency for videos captioning. In Proceedings of the ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 357–361. [Google Scholar] [CrossRef]
- Ji, W.; Wang, R.; Tian, Y.; Wang, X. An attention based dual learning approach for video captioning. Appl. Soft Comput. 2022, 117, 108332. [Google Scholar] [CrossRef]
- Lin, K.; Gan, Z.; Wang, L. Multi-modal feature fusion with feature attention for VATEX captioning challenge 2020. arXiv 2020, arXiv:2006.03315. [Google Scholar] [CrossRef]
- Chen, D.; Dolan, W.B. Collecting highly parallel data for paraphrase evaluation. In Proceedings of the Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 190–200. Available online: https://aclanthology.org/P11-1020/ (accessed on 21 March 2025).
- Regneri, M.; Rohrbach, M.; Wetzel, D.; Thater, S.; Schiele, B.; Pinkal, M. Grounding action descriptions in videos. Trans. Assoc. Comput. Linguist. 2013, 1, 25–36. [Google Scholar] [CrossRef]
- Rohrbach, A.; Rohrbach, M.; Tandon, N.; Schiele, B. A dataset for movie description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3202–3212. [Google Scholar] [CrossRef]
- Li, Y.; Song, Y.; Cao, L.; Tetreault, J.; Goldberg, L.; Jaimes, A.; Luo, J. TGIF: A new dataset and benchmark on animated GIF description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4641–4650. [Google Scholar] [CrossRef]
- Sigurdsson, G.A.; Varol, G.; Wang, X.; Farhadi, A.; Laptev, I.; Gupta, A. Hollywood in homes: Crowdsourcing data collection for activity understanding. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 510–526. [Google Scholar] [CrossRef]
- Zeng, K.-H.; Chen, T.-H.; Niebles, J.C.; Sun, M. Title generation for user generated videos. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 609–625. [Google Scholar] [CrossRef]
- Kim, J.; Rohrbach, A.; Darrell, T.; Canny, J.; Akata, Z. Textual explanations for self-driving vehicles. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 563–578. [Google Scholar] [CrossRef]
- Gella, S.; Lewis, M.; Rohrbach, M. A dataset for telling the stories of social media videos. In Proceedings of the Conference on Empirical Methods in Natural Language, Brussels, Belgium, 31 October–4 November 2018; pp. 968–974. [Google Scholar] [CrossRef]
- Pini, S.; Cornia, M.; Bolelli, F.; Baraldi, L.; Cucchiara, R. M-VAD names: A dataset for video captioning with naming. Multimed. Tools Appl. 2019, 78, 14007–14027. [Google Scholar] [CrossRef]
- Wang, X.; Wu, J.; Chen, J.; Li, L.; Wang, Y.-F.; Wang, W.Y. Vatex: A large-scale, high-quality multilingual dataset for video-and-language research. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4581–4591. [Google Scholar] [CrossRef]
- Lei, J.; Yu, L.; Berg, T.L.; Bansal, M. TVR: A large-scale dataset for video-subtitle moment retrieval. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 447–463. [Google Scholar] [CrossRef]
- Xi, Z.; Shi, G.; Wu, L.; Li, X.; Yan, J.; Wang, L.; Liu, Z. Knowledge Graph Supported Benchmark and Video Captioning for Basketball. arXiv 2024, arXiv:2401.13888. [Google Scholar] [CrossRef]
- Kong, Q.; Kawana, Y.; Saini, R.; Kumar, A.; Pan, J.; Gu, T.; Ozao, Y.; Opra, B.; Sato, Y.; Kobori, N. Wts: A pedestrian-centric traffic video dataset for fine-grained spatial-temporal understanding. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; pp. 1–18. [Google Scholar] [CrossRef]
- Yang, T.; Jia, J.; Wang, B.; Cheng, Y.; Li, Y.; Hao, D.; Cao, X.; Chen, Q.; Li, H.; Jiang, P.; et al. Spatiotemporal Fine-grained Video Description for Short Videos. In Proceedings of the ACM International Conference on Multimedia, Melbourne, Australia, 28–31 October 2024; pp. 3945–3954. [Google Scholar] [CrossRef]
- Zhang, G.; Ren, J.; Gu, J.; Tresp, V. Multi-event video-text retrieval. In Proceedings of the IEEE International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 22113–22123. [Google Scholar] [CrossRef]
- Shen, X.; Li, D.; Zhou, J.; Qin, Z.; He, B.; Han, X.; Li, A.; Dai, Y.; Kong, L.; Wang, M.; et al. Fine-grained audible video description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 10585–10596. [Google Scholar] [CrossRef]
- Islam, M.M.; Ho, N.; Yang, X.; Nagarajan, T.; Torresani, L.; Bertasius, G. Video ReCap: Recursive Captioning of Hour-Long Videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 18198–18208. [Google Scholar] [CrossRef]
- Kim, M.; Kim, H.B.; Moon, J.; Choi, J.; Kim, S.T. Do You Remember? Dense Video Captioning with Cross-Modal Memory Retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 13894–13904. [Google Scholar] [CrossRef]
- Ohkawa, T.; Yagi, T.; Nishimura, T.; Furuta, R.; Hashimoto, A.; Ushiku, Y.; Sato, Y. Exo2EgoDVC: Dense Video Captioning of Egocentric Procedural Activities Using Web Instructional Videos. arXiv 2023, arXiv:2311.16444. [Google Scholar] [CrossRef]
- Wu, J.; Wang, J.; Yang, Z.; Gan, Z.; Liu, Z.; Yuan, J.; Wang, L. Grit: A generative region-to-text transformer for object understanding. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; pp. 207–224. [Google Scholar] [CrossRef]
- Liu, C.; Hu, C.; Liu, Q.; Aggarwal, J.K. Video event description in scene context. Neurocomputing 2013, 119, 82–93. [Google Scholar] [CrossRef]
- Zhou, X.; Arnab, A.; Sun, C.; Schmid, C. Dense Video Object Captioning from Disjoint Supervision. arXiv 2023, arXiv:2306.11729. [Google Scholar] [CrossRef]
- Xiao, J.; Wu, Y.; Chen, Y.; Wang, S.; Wang, Z.; Ma, J. LSTFE-net: Long short-term feature enhancement network for video small object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 14613–14622. [Google Scholar] [CrossRef]
- Gao, H.; Xu, H.; Cai, Q.-Z.; Wang, R.; Yu, F.; Darrell, T. Disentangling propagation and generation for video prediction. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9006–9015. [Google Scholar] [CrossRef]
- Ramanathan, V.; Liang, P.; Fei-Fei, L. Video event understanding using natural language descriptions. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 905–912. [Google Scholar] [CrossRef]
- Whitehead, S.; Ji, H.; Bansal, M.; Chang, S.-F.; Voss, C. Incorporating background knowledge into video description generation. In Proceedings of the Conference on Empirical Methods in Natural Language, Brussels, Belgium, 31 October–4 November 2018; pp. 3992–4001. [Google Scholar] [CrossRef]
- Guadarrama, S.; Krishnamoorthy, N.; Malkarnenkar, G.; Venugopalan, S.; Mooney, R.; Darrell, T.; Saenko, K. Youtube2text: Recognizing and describing arbitrary activities using semantic hierarchies and zero-shot recognition. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2712–2719. [Google Scholar] [CrossRef]
- Shvetsova, N.; Kukleva, A.; Hong, X.; Rupprecht, C.; Schiele, B.; Kuehne, H. Howtocaption: Prompting llms to transform video annotations at scale. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; pp. 1–18. [Google Scholar] [CrossRef]
- Yuan, F.; Gu, S.; Zhang, X.; Fang, Z. Fully exploring object relation interaction and hidden state attention for video captioning. Pattern Recognit. 2025, 159, 111138. [Google Scholar] [CrossRef]
- Xu, T.; Zhang, Y.; Song, X.; Feng, Z.-H.; Wu, X.-J. ATMNet: Adaptive Two-Stage Modular Network for Accurate Video Captioning. IEEE Trans. Syst. Man, Cybern. Syst. 2025, 55, 2821–2833. [Google Scholar] [CrossRef]
- Chen, H.; Li, J.; Hu, X. Delving deeper into the decoder for video captioning. In ECAI 2020; IOS Press: Amsterdam, The Netherlands, 2020; pp. 1079–1086. [Google Scholar] [CrossRef]
- Tan, G.; Liu, D.; Wang, M.; Zha, Z.-J. Learning to discretely compose reasoning module networks for video captioning. arXiv 2020, arXiv:2007.09049. [Google Scholar] [CrossRef]
- Liu, Y.; Zhu, H.; Wu, Z.; Du, S.; Wu, S.; Shi, J. Adaptive semantic guidance network for video captioning. Comput. Vis. Image Underst. 2025, 251, 104255. [Google Scholar] [CrossRef]
- Xu, W.; Xu, Y.; Miao, Z.; Cen, Y.-G.; Wan, L.; Ma, X. CroCaps: A CLIP-assisted cross-domain video captioner. Expert Syst. Appl. 2024, 268, 126296. [Google Scholar] [CrossRef]
- Li, P.; Wang, T.; Zhao, X.; Xu, X.; Song, M. Pseudo-labeling with keyword refining for few-supervised video captioning. Pattern Recognit. 2025, 159, 111176. [Google Scholar] [CrossRef]
- Luo, X.; Luo, X.; Wang, D.; Liu, J.; Wan, B.; Zhao, L. Global semantic enhancement network for video captioning. Pattern Recognit. 2024, 145, 109906. [Google Scholar] [CrossRef]
- Lou, Y.; Zhang, W.; Song, X.; Hua, Y.; Wu, X.-J. EDS: Exploring deeper into semantics for video captioning. Pattern Recognit. Lett. 2024, 186, 133–140. [Google Scholar] [CrossRef]
- Ma, Y.; Zhu, Z.; Qi, Y.; Beheshti, A.; Li, Y.; Qing, L.; Li, G. Style-aware two-stage learning framework for video captioning. Knowl.-Based Syst. 2024, 301, 112258. [Google Scholar] [CrossRef]
- Zhao, H.; Chen, Z.; Yang, Y. Multi-scale features with temporal information guidance for video captioning. Eng. Appl. Artif. Intell. 2024, 137, 109102. [Google Scholar] [CrossRef]
- Rao, Q.; Yu, X.; Li, G.; Zhu, L. CMGNet: Collaborative multi-modal graph network for video captioning. Comput. Vis. Image Underst. 2024, 238, 103864. [Google Scholar] [CrossRef]
- Shen, Y.; Gu, X.; Xu, K.; Fan, H.; Wen, L.; Zhang, L. Accurate and fast compressed video captioning. In Proceedings of the IEEE International Conference on Computer Vision, Paris, France, 23–28 October 2023; pp. 15558–15567. [Google Scholar] [CrossRef]
- Yang, B.; Cao, M.; Zou, Y. Concept-aware video captioning: Describing videos with effective prior information. IEEE Trans. Image Process. 2023, 32, 5366–5378. [Google Scholar] [CrossRef]
- Zeng, P.; Zhang, H.; Gao, L.; Li, X.; Qian, J.; Shen, H.T. Visual commonsense-aware representation network for video captioning. IEEE Trans. Neural Netw. Learn. Syst. 2023, 36, 1092–1103. [Google Scholar] [CrossRef]
- Zhong, X.; Li, Z.; Chen, S.; Jiang, K.; Chen, C.; Ye, M. Refined semantic enhancement towards frequency diffusion for video captioning. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington DC, USA, 7–14 February 2023; Volume 37, pp. 3724–3732. [Google Scholar] [CrossRef]
- Perez-Martin, J.; Bustos, B.; P’erez, J. Improving video captioning with temporal composition of a visual-syntactic embedding. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 3039–3049. [Google Scholar] [CrossRef]
- Tu, Y.; Zhou, C.; Guo, J.; Gao, S.; Yu, Z. Enhancing the alignment between target words and corresponding frames for video captioning. Pattern Recognit. 2021, 111, 107702. [Google Scholar] [CrossRef]
- Zheng, Q.; Wang, C.; Tao, D. Syntax-aware action targeting for video captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13096–13105. [Google Scholar] [CrossRef]
- Hou, J.; Wu, X.; Zhao, W.; Luo, J.; Jia, Y. Joint syntax representation learning and visual cue translation for video captioning. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8918–8927. [Google Scholar] [CrossRef]
- Xiao, H.; Shi, J. Diverse video captioning through latent variable expansion. Pattern Recognit. Lett. 2022, 160, 19–25. [Google Scholar] [CrossRef]
- Liu, F.; Ren, X.; Wu, X.; Yang, B.; Ge, S.; Zou, Y.; Sun, X. O2NA: An object-oriented non-autoregressive approach for controllable video captioning. arXiv 2021, arXiv:2108.02359. [Google Scholar] [CrossRef]
- Pan, B.; Cai, H.; Huang, D.-A.; Lee, K.-H.; Gaidon, A.; Adeli, E.; Niebles, J.C. Spatio-temporal graph for video captioning with knowledge distillation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10870–10879. [Google Scholar] [CrossRef]
- Tian, M.; Li, G.; Qi, Y.; Wang, S.; Sheng, Q.Z.; Huang, Q. Rethink video retrieval representation for video captioning. Pattern Recognit. 2024, 156, 110744. [Google Scholar] [CrossRef]
- Niu, T.-Z.; Dong, S.-S.; Chen, Z.-D.; Luo, X.; Huang, Z.; Guo, S.; Xu, X.-S. A multi-layer memory sharing network for video captioning. Pattern Recognit. 2023, 136, 109202. [Google Scholar] [CrossRef]
- Xue, P.; Zhou, B. Exploring the Spatio-Temporal Aware Graph for video captioning. IET Comput. Vis. 2022, 16, 456–467. [Google Scholar] [CrossRef]
- Perez-Martin, J.; Bustos, B.; P’erez, J. Attentive visual semantic specialized network for video captioning. In Proceedings of the 2020 25th International Conference on Pattern Recognition, Milan, Italy, 10–15 January 2021; pp. 5767–5774. [Google Scholar] [CrossRef]
- Peng, Y.; Wang, C.; Pei, Y.; Li, Y. Video captioning with global and local text attention. Vis. Comput. 2022, 38, 4267–4278. [Google Scholar] [CrossRef]
- Ryu, H.; Kang, S.; Kang, H.; Yoo, C.D. Semantic grouping network for video captioning. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 2514–2522. [Google Scholar] [CrossRef]
- Zhang, Z.; Shi, Y.; Yuan, C.; Li, B.; Wang, P.; Hu, W.; Zha, Z.-J. Object relational graph with teacher-recommended learning for video captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13278–13288. [Google Scholar] [CrossRef]
- Li, X.; Zhao, B.; Lu, X. MAM-RNN: Multi-level attention model based RNN for video captioning. In Proceedings of the International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; Volume 2017, pp. 2208–2214. [Google Scholar] [CrossRef]
- Seo, P.H.; Nagrani, A.; Arnab, A.; Schmid, C. End-to-end generative pretraining for multimodal video captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 17959–17968. [Google Scholar] [CrossRef]
- Tang, M.; Wang, Z.; Liu, Z.; Rao, F.; Li, D.; Li, X. Clip4caption: Clip for video caption. In Proceedings of the ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021; pp. 4858–4862. [Google Scholar] [CrossRef]
- Chen, H.; Lin, K.; Maye, A.; Li, J.; Hu, X. A semantics-assisted video captioning model trained with scheduled sampling. Front. Robot. AI 2020, 7, 475767. [Google Scholar] [CrossRef]
- Zhang, Z.; Qi, Z.; Yuan, C.; Shan, Y.; Li, B.; Deng, Y.; Hu, W. Open-book video captioning with retrieve-copy-generate network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 9837–9846. [Google Scholar] [CrossRef]
- Zhu, X.; Guo, L.; Yao, P.; Lu, S.; Liu, W.; Liu, J. Vatex video captioning challenge 2020: Multi-view features and hybrid reward strategies for video captioning. arXiv 2019, arXiv:1910.11102. [Google Scholar] [CrossRef]
- Hosseinzadeh, M.; Wang, Y. Video captioning of future frames. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 980–989. [Google Scholar] [CrossRef]
- Man, X.; Ouyang, D.; Li, X.; Song, J.; Shao, J. Scenario-aware recurrent transformer for goal-directed video captioning. ACM Trans. Multimed. Comput. Commun. Appl. 2022, 18, 1–17. [Google Scholar] [CrossRef]
- Estevam, V.; Laroca, R.; Pedrini, H.; Menotti, D. Dense video captioning using unsupervised semantic information. J. Vis. Commun. Image Represent. 2024, 107, 104385. [Google Scholar] [CrossRef]
- Chen, S.; Jiang, Y.-G. Towards bridging event captioner and sentence localizer for weakly supervised dense event captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 8425–8435. [Google Scholar] [CrossRef]
- Duan, X.; Huang, W.; Gan, C.; Wang, J.; Zhu, W.; Huang, J. Weakly supervised dense event captioning in videos. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 3029–3039. [Google Scholar] [CrossRef]
- Wang, J.; Jiang, W.; Ma, L.; Liu, W.; Xu, Y. Bidirectional attentive fusion with context gating for dense video captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7190–7198. [Google Scholar] [CrossRef]
- Wei, Y.; Yuan, S.; Chen, M.; Shen, X.; Wang, L.; Shen, L.; Yan, Z. MPP-net: Multi-perspective perception network for dense video captioning. Neurocomputing 2023, 552, 126523. [Google Scholar] [CrossRef]
- Yamazaki, K.; Vo, K.; Truong, Q.S.; Raj, B.; Le, N. Vltint: Visual-linguistic transformer-in-transformer for coherent video paragraph captioning. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington DC, USA, 7–14 February 2023; Volume 37, pp. 3081–3090. [Google Scholar] [CrossRef]
- Luo, H.; Ji, L.; Shi, B.; Huang, H.; Duan, N.; Li, T.; Li, J.; Bharti, T.; Zhou, M. Univl: A unified video and language pre-training model for multimodal understanding and generation. arXiv 2020, arXiv:2002.06353. [Google Scholar] [CrossRef]
- Zeng, Y.; Wang, Y.; Liao, D.; Li, G.; Xu, J.; Man, H.; Liu, B.; Xu, X. Contrastive topic-enhanced network for video captioning. Expert Syst. Appl. 2024, 237, 121601. [Google Scholar] [CrossRef]
- Zhu, L.; Yang, Y. Actbert: Learning global-local video-text representations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8746–8755. [Google Scholar] [CrossRef]
- Sun, C.; Myers, A.; Vondrick, C.; Murphy, K.; Schmid, C. Videobert: A joint model for video and language representation learning. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7464–7473. [Google Scholar] [CrossRef]
- Yang, A.; Nagrani, A.; Laptev, I.; Sivic, J.; Schmid, C. Vidchapters-7m: Video chapters at scale. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 11–17 December 2023; pp. 49428–49444. [Google Scholar] [CrossRef]
- Kim, D.; Piergiovanni, A.J.; Angelova, A. Actions Inspire Every Moment: Online Action-Augmented Dense Video Captioning. 2024. Available online: https://openreview.net/forum?id=oO3oXJ19Pb (accessed on 21 March 2025).
- Zhu, W.; Pang, B.; Thapliyal, A.V.; Wang, W.Y.; Soricut, R. End-to-end dense video captioning as sequence generation. arXiv 2022, arXiv:2204.08121. [Google Scholar] [CrossRef]
- Piergiovanni, A.J.; Kim, D.; Ryoo, M.S.; Noble, I.; Angelova, A. Whats in a Video: Factorized Autoregressive Decoding for Online Dense Video Captioning. arXiv 2024, arXiv:2411.14688. [Google Scholar] [CrossRef]
- Zhou, X.; Arnab, A.; Buch, S.; Yan, S.; Myers, A.; Xiong, X.; Nagrani, A.; Schmid, C. Streaming dense video captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–20 June 2024; pp. 18243–18252. [Google Scholar] [CrossRef]
- Xi, Z.; Shi, G.; Li, X.; Yan, J.; Li, Z.; Wu, L.; Liu, Z.; Wang, L. A simple yet effective knowledge guided method for entity-aware video captioning on a basketball benchmark. Neurocomputing 2025, 619, 129177. [Google Scholar] [CrossRef]
- Shoman, M.; Wang, D.; Aboah, A.; Abdel-Aty, M. Enhancing traffic safety with parallel dense video captioning for end-to-end event analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 16–20 June 2024; pp. 7125–7133. [Google Scholar] [CrossRef]
- Duan, Z.; Cheng, H.; Xu, D.; Wu, X.; Zhang, X.; Ye, X.; Xie, Z. Cityllava: Efficient fine-tuning for vlms in city scenario. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 16–20 June 2024; pp. 7180–7189. [Google Scholar] [CrossRef]
- Zhang, H.; Li, X.; Bing, L. Video-llama: An instruction-tuned audio-visual language model for video understanding. arXiv 2023, arXiv:2306.02858. [Google Scholar] [CrossRef]
- Maaz, M.; Rasheed, H.; Khan, S.; Khan, F.S. Video-chatgpt: Towards detailed video understanding via large vision and language models. arXiv 2023, arXiv:2306.05424. [Google Scholar] [CrossRef]
- Li, L.; Chen, Y.-C.; Cheng, Y.; Gan, Z.; Yu, L.; Liu, J. Hero: Hierarchical encoder for video+ language omni-representation pre-training. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Online, 16–20 November 2020; pp. 2046–2065. [Google Scholar] [CrossRef]
- Mahmud, T.; Billah, M.; Hasan, M.; Roy-Chowdhury, A.K. Prediction and description of near-future activities in video. Comput. Vis. Image Underst. 2021, 210, 103230. [Google Scholar] [CrossRef]
- Xu, H.; Li, B.; Ramanishka, V.; Sigal, L.; Saenko, K. Joint event detection and description in continuous video streams. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision, Honolulu, HI, USA, 7–11 January 2019; pp. 396–405. [Google Scholar] [CrossRef]
- Li, J.; Wong, Y.; Zhao, Q.; Kankanhalli, M.S. Video storytelling: Textual summaries for events. IEEE Trans. Multimed. 2019, 22, 554–565. [Google Scholar] [CrossRef]
- Mao, J. Deep captioning with multimodal recurrent neural networks (m-rnn). arXiv 2014, arXiv:1412.6632. [Google Scholar] [CrossRef]
- Baraldi, L.; Grana, C.; Cucchiara, R. Hierarchical boundary-aware neural encoder for video captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1657–1666. [Google Scholar] [CrossRef]
- Rohrbach, A.; Rohrbach, M.; Schiele, B. The Long-Short Story of Movie Description. arXiv 2015, arXiv:1506.01698. [Google Scholar] [CrossRef]
- Dinh, Q.M.; Ho, M.K.; Dang, A.Q.; Tran, H.P. Trafficvlm: A controllable visual language model for traffic video captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 17–18 June 2024; pp. 7134–7143. [Google Scholar] [CrossRef]
- Chen, F.; Xu, C.; Jia, Q.; Wang, Y.; Liu, Y.; Zhang, H.; Wang, E. Egocentric Vehicle Dense Video Captioning. In Proceedings of the ACM International Conference on Multimedia, Melbourne, Australia, 28 October–1 November 2024; pp. 137–146. [Google Scholar] [CrossRef]
- Wu, S.; Gao, Y.; Yang, W.; Li, H.; Zhu, G. End-to-End Video Captioning Based on Multiview Semantic Alignment for Human–Machine Fusion. IEEE Trans. Autom. Sci. Eng. 2024, 22, 4682–4690. [Google Scholar] [CrossRef]
- Jin, B.; Liu, X.; Zheng, Y.; Li, P.; Zhao, H.; Zhang, T.; Zheng, Y.; Zhou, G.; Liu, J. Adapt: Action-aware driving caption transformer. In Proceedings of the IEEE International Conference on Robotics and Automation, Yokohama, Japan, 29 May–2 June 2023; pp. 7554–7561. [Google Scholar] [CrossRef]








| NO | Datasets | Domain | Type | Videos | Clips | Sentences | Captions Num | Caption Len | Year |
|---|---|---|---|---|---|---|---|---|---|
| 1 | MSVD [49] | Open | Scene | 1970 | 1970 | 70,028 | 85,550 | 7.14 | 2011 |
| 2 | TACoS [50] | Cooking | Scene | 127 | 7206 | 18,227 | 18,227 | 8.27 | 2013 |
| 3 | MPII-MD [51] | Movie | Scene | 94 | 68,337 | 68,375 | 68,375 | 11.05 | 2015 |
| 4 | TGIF [52] | Open | Scene | - | 125,781 | 125,781 | 125,781 | 11.28 | 2016 |
| 5 | MSR-VTT [7] | Open | Scene | 7180 | 10,000 | 200,000 | 200,000 | 9.27 | 2016 |
| 6 | Charades [53] | Daily | Scene | 9848 | - | 27,847 | 27,847 | - | 2016 |
| 7 | VTW [54] | Open | Scene | 18,100 | 18,100 | 44.603 | 44.603 | - | 2016 |
| 8 | ActivityNet Captions [2] | Open | Instance | 20,000 | 100,000 | 100,000 | 72,976 | 13.48 | 2017 |
| 9 | YouCook2 [4] | Cooking | Video | 2000 | 15,400 | 15,400 | 15,400 | 7.7 | 2018 |
| 10 | BDD-X [55] | Traffic | Scene | 6984 | 6984 | 26,228 | 26,228 | 14.5 | 2018 |
| 11 | VideoStory [56] | Social Media | Scene | 20,147 | 122,626 | 122,626 | 122,626 | 13.32 | 2018 |
| 12 | M-VAD [57] | Movie | Scene | 92 | 48,986 | 55,904 | 46,589 | 12.44 | 2019 |
| 13 | VATEX [58] | Open | Scene | 41,250 | 41,250 | 826,000 | 825,000 | 15.25 | 2019 |
| 14 | TVC [59] | TV show | Scene | 21,793 | 107,926 | 261,510 | 261,510 | 13.4 | 2020 |
| 15 | ViTT [21] | Cooking | Video | 8169 | 8169 | - | 5840 | 7.1 | 2020 |
| 16 | VC_NBA_2022 [60] | Basketball | Video | 3977 | 3948 | - | 3977 | - | 2022 |
| 17 | WTS [61] | Traffic | Instance | 6061 | 6061 | - | 49,860 | 58.7 | 2023 |
| NO | Metric Name | Designed for | Methodology | Limitation |
|---|---|---|---|---|
| 1 | BLEU [8] | Machine Translation | n-gram precision | Only consideration of precision and lack of recall measures. |
| 2 | METEOR [9] | Machine Translation | n-gram with synonym matching | METEOR’s synonymy is limited by WordNet and is complex to implement. |
| 3 | CIDEr [10] | Image Description Generation | Term frequency-inverse document summary weighted n-gram similarity | Fails to fully mimic human judgment. |
| 4 | ROUGE-L [11] | Document Summarization | n-gram recall | Fails to account for semantic similarity. |
| 5 | SODA [12] | Dense Video Captioning | F-measure using precision and recall | Ignores caption diversity. |
| 6 | SPICE [13] | Image Description Generation | Scene-graph synonym matching | Fails to capture the syntactic structure of a sentence. |
| 7 | WMD [14] | Document Similarity | Earth Mover’s Distance on word2vec | Fails to handle long documents. |
| NO | Method | Method’s Category | BLEU-4 | METEOR | CIDEr | ROUGE-L | Year |
|---|---|---|---|---|---|---|---|
| 1 | ASGNet [81] | Encoder-decoder | 43.4 | 29.6 | 52.6 | 62.5 | 2025 |
| 2 | CroCaps [82] | Encoder-decoder | 44.95 | 29.28 | 53.78 | 62.86 | 2025 |
| 3 | KG-VCN [77] | Encoder-decoder | 45.0 | 28.7 | 51.9 | 62.5 | 2025 |
| 4 | PKG [83] | Encoder-decoder | 44.8 | 30.5 | 53.5 | 63.4 | 2025 |
| 5 | ATMNet [78] | Encoder-decoder | 48.9 | 31.9 | 62.8 | 65.5 | 2025 |
| 6 | Howtocaption [76] | Encoder-decoder | 49.8 | 32.2 | 65.3 | 66.3 | 2024 |
| 7 | MAN [28] | Encoder-decoder | 41.3 | 28.0 | 49.8 | 61.4 | 2024 |
| 8 | GSEN [84] | Encoder-decoder | 42.9 | 28.4 | 51.0 | 61.7 | 2024 |
| 9 | EDS [85] | Encoder-decoder | 44.6 | 29.6 | 54.3 | 62.9 | 2024 |
| 10 | SATLF [86] | Encoder-decoder | 47.5 | 30.3 | 54.1 | 63.8 | 2024 |
| 11 | GLG [87] | Encoder-decoder | 49.1 | 31.9 | 63.6 | 66.1 | 2024 |
| 12 | CMGNet [88] | Encoder-decoder | 43.6 | 29.1 | 54.6 | 60.6 | 2024 |
| 13 | CARE [90] | Encoder-decoder | 46.9 | 30.9 | 59.2 | 64.3 | 2023 |
| 14 | ViT/L14 [89] | Encoder-decoder | 44.4 | 30.3 | 57.2 | 63.4 | 2023 |
| 15 | VCRN [91] | Encoder-decoder | 41.5 | 28.1 | 50.2 | 61.2 | 2023 |
| 16 | RSFD [92] | Encoder-decoder | 43.4 | 29.3 | 53.1 | 62.3 | 2023 |
| 17 | vc-HRNAT [26] | Encoder-decoder | 43.0 | 28.2 | 61.7 | 49.6 | 2022 |
| 18 | MV-GPT [108] | Encoder-decoder | 48.92 | 38.66 | 0.60 | 64.00 | 2022 |
| 19 | AVSSN [93] | Encoder-decoder | 45.5 | 31.4 | 50.6 | 64.3 | 2021 |
| 20 | TTA [94] | Encoder-decoder | 41.4 | 27.7 | 46.7 | 61.1 | 2021 |
| 21 | Clip4caption [109] | Encoder-decoder | 47.2 | 31.2 | 60.0 | 64.8 | 2021 |
| 22 | SemSynAN [93] | Encoder-decoder | 46.4 | 30.4 | 51.9 | 64.7 | 2021 |
| 23 | RMN [80] | Encoder-decoder | 42.5 | 28.4 | 49.6 | 61.6 | 2020 |
| 24 | SAAT [95] | Encoder-decoder | 40.5 | 28.2 | 49.1 | 60.9 | 2020 |
| 25 | VNS-GRU [79] | Encoder-decoder | 45.3 | 29.9 | 53.0 | 63.4 | 2020 |
| 26 | JSRL-VCT [96] | Encoder-decoder | 42.3 | 29.7 | 49.1 | 62.8 | 2019 |
| 27 | GFN-POS [27] | Encoder-decoder | 41.7 | 27.8 | 48.5 | 61.2 | 2019 |
| 28 | DCM [97] | Encoder-decoder | 28.7 | 43.4 | 61.6 | 47.2 | 2019 |
| 39 | SDN [110] | Encoder-decoder | 45.8 | 29.3 | 53.2 | 63.6 | 2019 |
| 30 | HRL [25] | Encoder-decoder | 41.3 | 28.7 | 48.0 | 61.7 | 2018 |
| 31 | CEMSA [33] | Transformer | 43.6 | 31.1 | 53.3 | 62.1 | 2024 |
| 32 | SnapCap [42] | Transformer | 42.2 | 29.1 | 52.2 | 62.0 | 2024 |
| 33 | TextKG [32] | Transformer | 46.6 | 30.5 | 60.8 | 64.8 | 2023 |
| 34 | HMN [36] | Transformer | 43.5 | 29.0 | 51.5 | 62.7 | 2022 |
| 35 | UAT-FEGs [35] | Transformer | 43.0 | 27.8 | 49.7 | 60.9 | 2022 |
| 36 | O2NA [98] | Transformer | 41.6 | 28.5 | 51.1 | 62.4 | 2021 |
| 37 | SBAT [34] | Transformer | 42.9 | 28.9 | 51.6 | 61.5 | 2020 |
| 38 | STGN [99] | Transformer | 40.5 | 28.3 | 47.1 | 60.9 | 2020 |
| 39 | TVT [38] | Transformer | 42.46 | 28.24 | 48.53 | 61.07 | 2018 |
| 40 | STAN [45] | Attention | 26.6 | 35.2 | 38.0 | 48.9 | 2025 |
| 41 | IVRC [100] | Attention | 43.7 | 30.2 | 57.1 | 63.0 | 2024 |
| 42 | MesNet [101] | Attention | 44.0 | 29.2 | 52.2 | 62.1 | 2023 |
| 43 | ADL [47] | Attention | 26.6 | 40.2 | 44.0 | 60.2 | 2022 |
| 44 | STAG [102] | Attention | 43.3 | 29.0 | 49.5 | 63.5 | 2022 |
| 45 | SemSynAN [103] | Attention | 46.4 | 30.4 | 51.9 | 64.7 | 2021 |
| 46 | T-DL [104] | Attention | 42.3 | 28.9 | 49.2 | 61.7 | 2021 |
| 47 | SGN [105] | Attention | 40.8 | 28.3 | 49.5 | 60.8 | 2021 |
| 48 | ORG-TRL [106] | Attention | 43.6 | 28.8 | 50.9 | 62.1 | 2020 |
| NO | Method | Method’s Category | BLEU-4 | METEOR | CIDEr | ROUGE-L | Year |
|---|---|---|---|---|---|---|---|
| 1 | PKG [83] | Encoder-decoder | 34.3 | 23.5 | 53.3 | 49.5 | 2025 |
| 2 | KG-VCN [77] | Encoder-decoder | 33.3 | 22.9 | 53.3 | 49.5 | 2025 |
| 3 | SATLF [86] | Encoder-decoder | 34.3 | 24.2 | 59.0 | 50.8 | 2024 |
| 4 | MAN [28] | Encoder-decoder | 32.7 | 22.4 | 48.9 | 49.1 | 2024 |
| 5 | CARE [90] | Encoder-decoder | 37.5 | 25.1 | 63.1 | 52.4 | 2023 |
| 6 | VCRN [91] | Encoder-decoder | 32.4 | 22.4 | 49.9 | 48.9 | 2023 |
| 7 | ViT/L14 [89] | Encoder-decoder | 35.8 | 25.3 | 64.8 | 52.0 | 2023 |
| 8 | vc-HRNAT [26] | Encoder-decoder | 32.1 | 21.9 | 48.5 | 48.4 | 2022 |
| 9 | RCG [111] | Encoder-decoder | 33.9 | 23.7 | 57.5 | 50.2 | 2021 |
| 10 | VATEX-En [112] | Transformer | 40.7 | 25.8 | 81.4 | 53.7 | 2019 |
| 11 | VATEX-Ch [112] | Transformer | 32.6 | 32.1 | 59.5 | 56.5 | 2019 |
| 12 | IVRC [100] | Attention | 32.8 | 24.0 | 57.4 | 50.3 | 2024 |
| 13 | ORG-TRL [106] | Attention | 32.1 | 22.2 | 49.7 | 48.9 | 2020 |
| 14 | FAtt(VATEX-En) [48] | Attention | 39.2 | 25.0 | 76.0 | 52.7 | 2020 |
| 15 | FAtt(VATEX-Ch) [48] | Attention | 33.1 | 30.3 | 50.4 | 49.7 | 2020 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Song, R. Survey of Dense Video Captioning: Techniques, Resources, and Future Perspectives. Appl. Sci. 2025, 15, 4990. https://doi.org/10.3390/app15094990
Liu Z, Song R. Survey of Dense Video Captioning: Techniques, Resources, and Future Perspectives. Applied Sciences. 2025; 15(9):4990. https://doi.org/10.3390/app15094990
Chicago/Turabian StyleLiu, Zhandong, and Ruixia Song. 2025. "Survey of Dense Video Captioning: Techniques, Resources, and Future Perspectives" Applied Sciences 15, no. 9: 4990. https://doi.org/10.3390/app15094990
APA StyleLiu, Z., & Song, R. (2025). Survey of Dense Video Captioning: Techniques, Resources, and Future Perspectives. Applied Sciences, 15(9), 4990. https://doi.org/10.3390/app15094990