
AI-Powered System to Facilitate Personalized Adaptive Learning in Digital Transformation



Abstract
Featured Application
Abstract
1. Introduction
2. Related Work
2.1. The Deployment of LLMs in Domain-Specific Applications
2.2. Structured Knowledge Base with RAG
2.3. Knowledge-Driven AI Agents for Helping Personalized Adaptive Learning
2.4. The Impact of Our Approach on Personalized Adaptive Learning in Digital Transformation
3. Materials and Methods
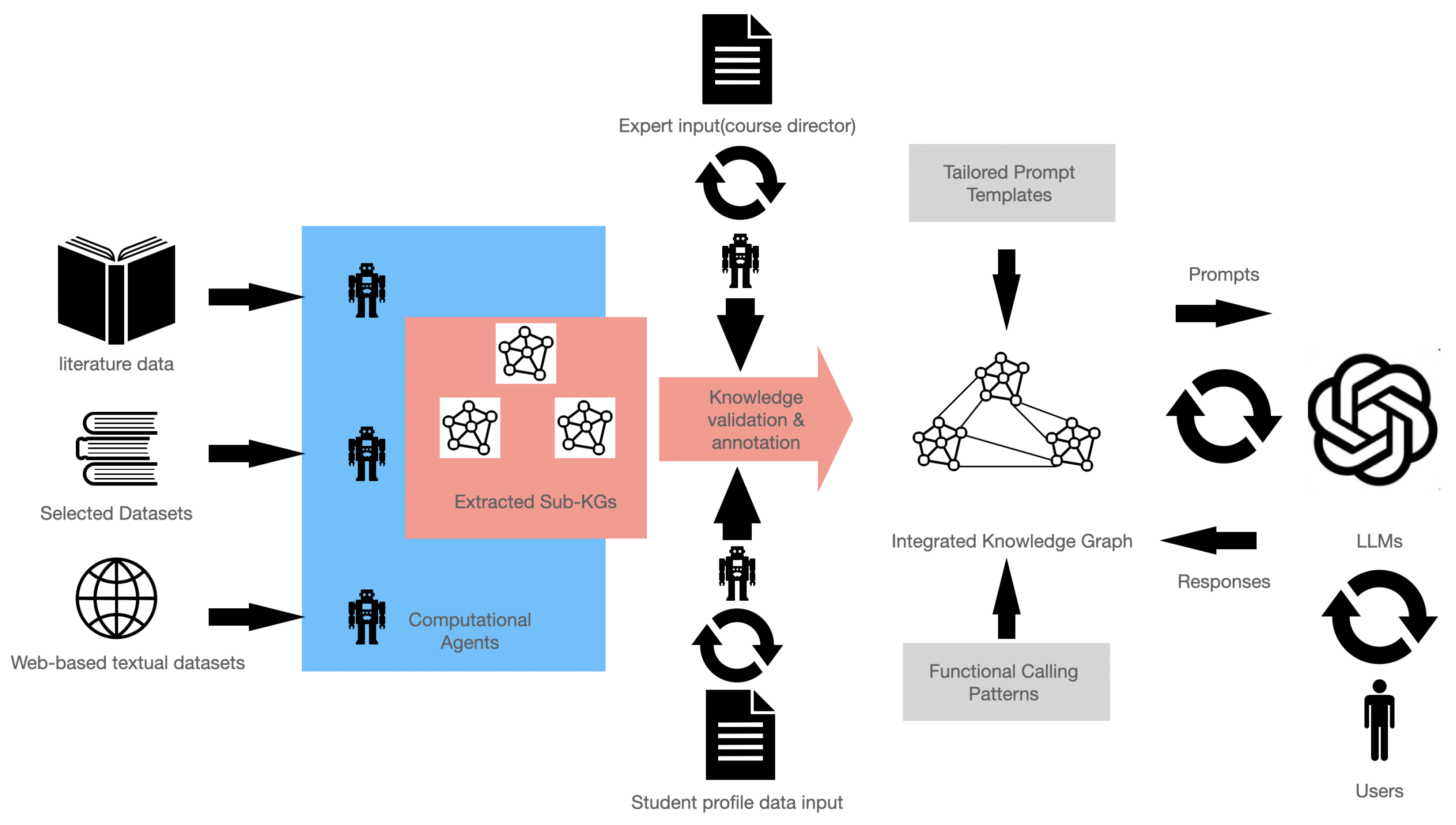
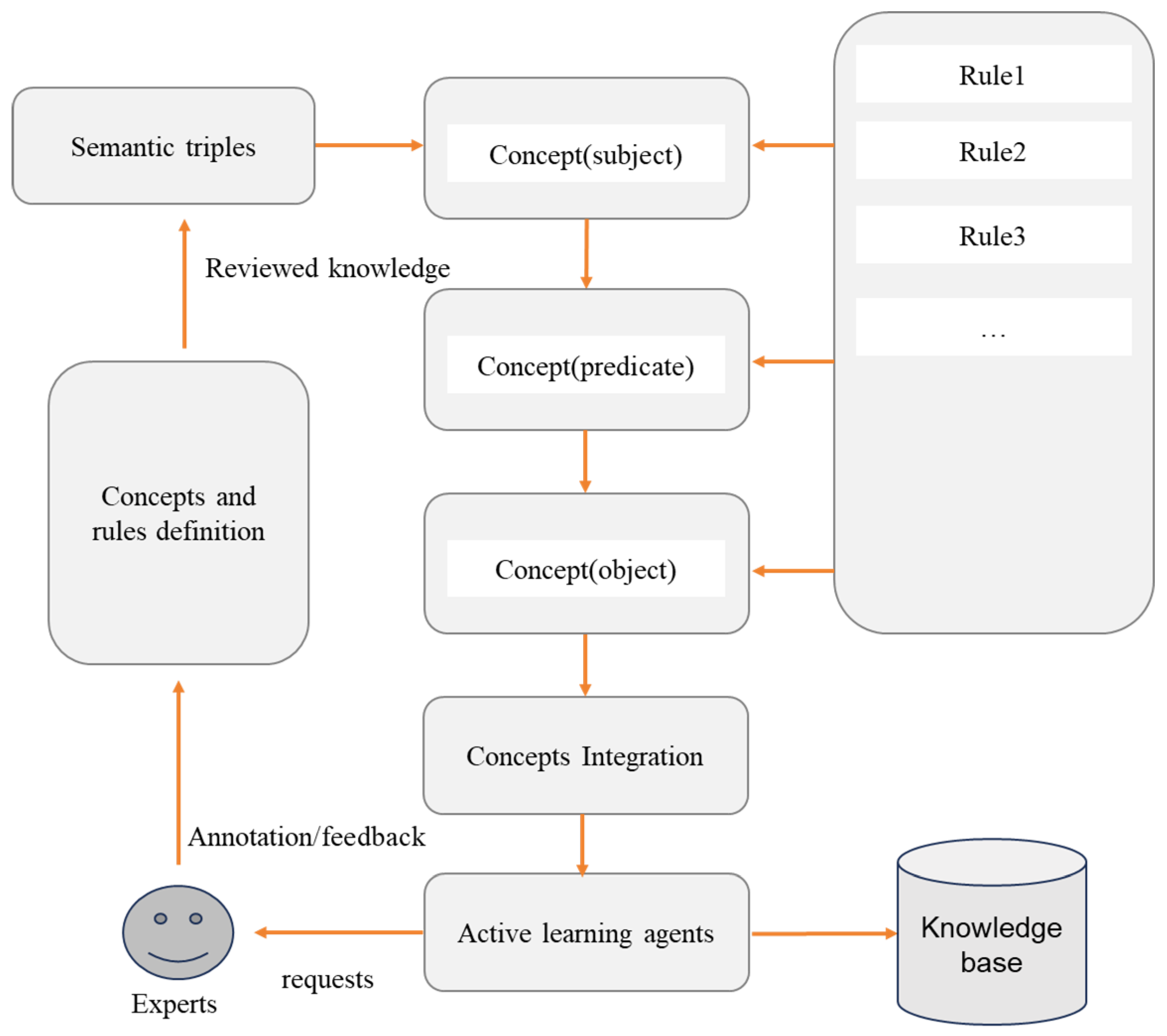
3.1. Knowledge Engineering Facilitated by Context Awareness Agents Empowered with LLMs
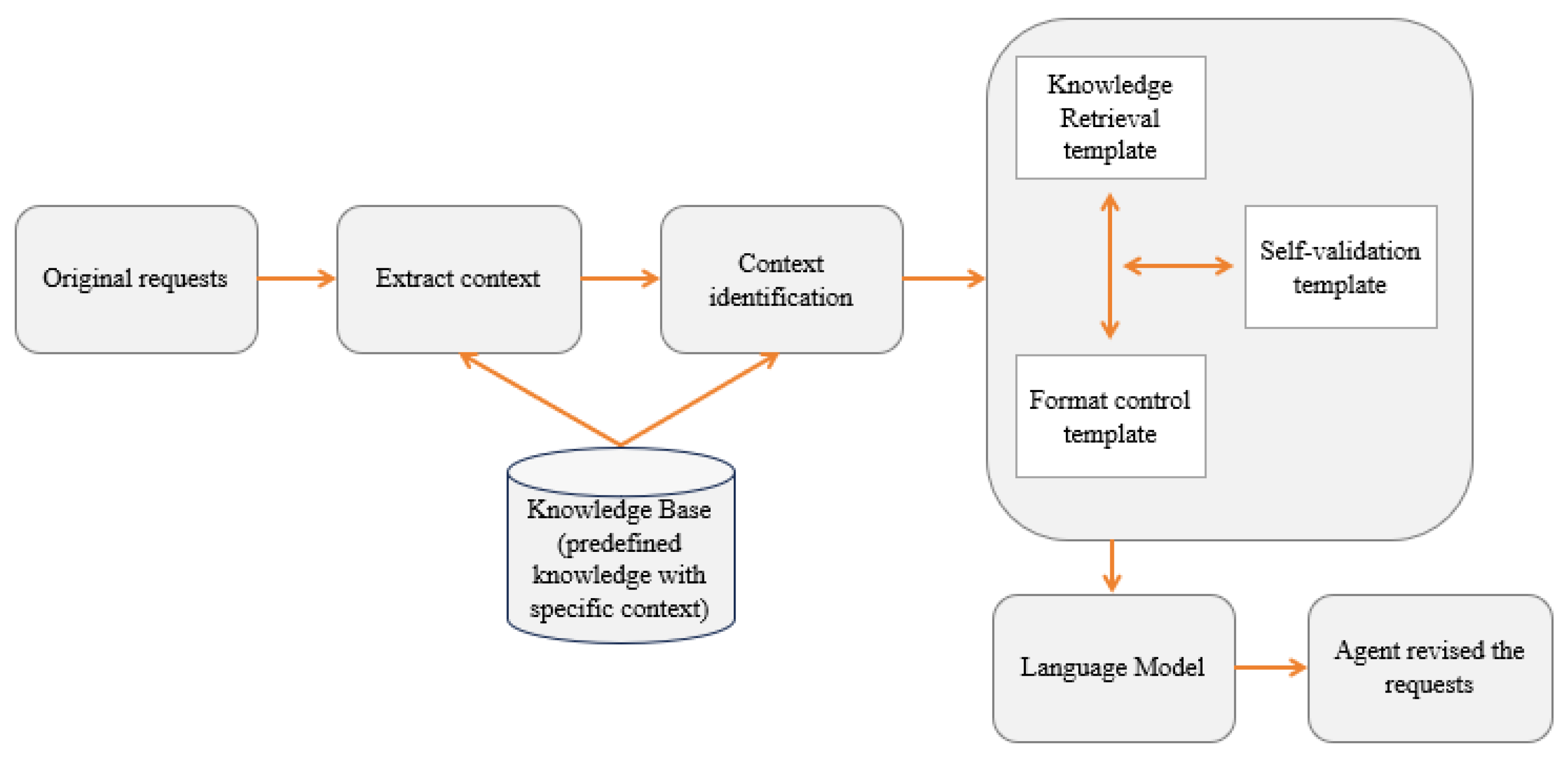
3.2. RAG with Context-Based Knowledge Retrieval
| Algorithm 1 Example pseudocode in RAG pipeline | |
| 1: | Input: Retrieved knowledge X, Parameter synthesized prompt |
| 2: | Output: Processed results R |
| 3: | for each do |
| 4: | Update agent |
| 5: | Running agent |
| 6: | if then |
| 7: | Store new knowledge if there is any |
| 8: | |
| 9: | Release y |
| 10: | else |
| 11: | while Check do |
| 12: | Invoke corresponding functions F or agents Z |
| 13: | |
| 14: | end while |
| 15: | Release y |
| 16: | end if |
| 17: | Store r into R |
| 18: | end for |
| 19: | for each do |
| 20: | Integrate with r |
| 21: | Update |
| 22: | end for |
| 23: | return R |
- Contextual information matching: The first step in the process is to capture and encode the user’s context. Contextual information may include explicit user inputs (for example, search requests), implicit signals (e.g., user profiles), and external environmental factors (e.g., location or time). This contextual data are transformed into a few concept keywords using an encoder, such as in a pre-trained language model. These keywords represent the user’s intent and needs in a compact, semantic format.
- Knowledge retrieval from the knowledge base: The concept keywords are used to search for relevant knowledge from the knowledge base. These sources may include the following:
- –
- KGs: Structured representations of domain-specific knowledge, such as product attributes, expert reviews, or user-generated content.
- –
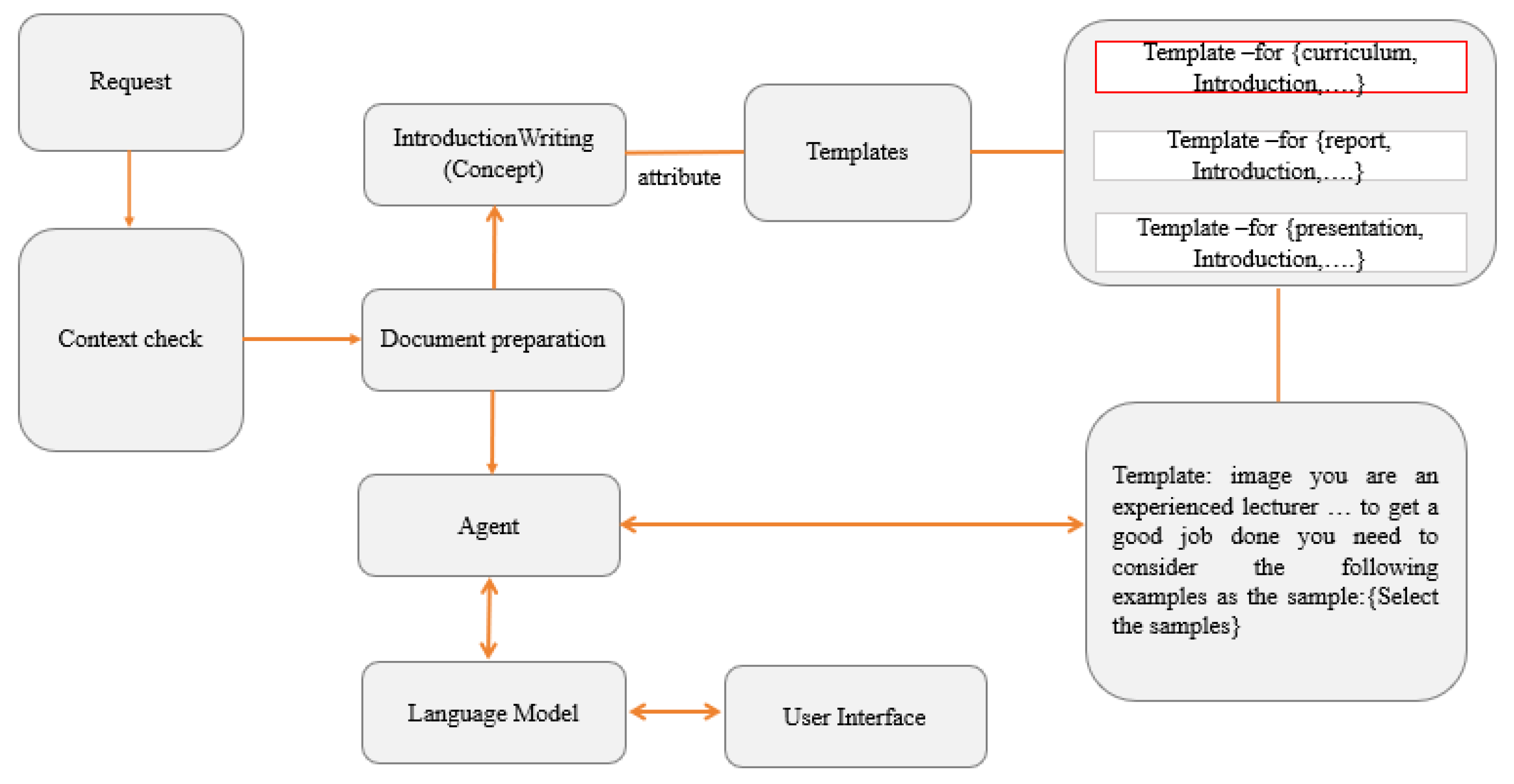
- Document repositories: Collections of relevant textual data, such as articles, manuals, or FAQs. The system employs similarity-based ranking techniques (cosine similarity) to fetch the most relevant knowledge nodes. Figure 5 shows an example of the use of customized knowledge to recommend better instruction examples in curriculum development. In this example, the system can find the predefined prompt template from the knowledge base based on the user’s requests and use that prompt to request that the LLMs give more specific responses.
- Context-aware prompt and contextual adaptation: The retrieved information is added to the given prompt template along with the original user request for synthesis of the input prompt for LLMs. This step ensures that its responses are informed by the most up-to-date and relevant knowledge.
- Personalized recommendation generation: The LLMs generate responses in a natural language format, enriched with context-specific explanations. The user can define their favorite styles in the relevant prompt templates to personalize the format of the output. Using RAG, the system can achieve better contextual awareness, accuracy, and user satisfaction.
4. Results and Discussion
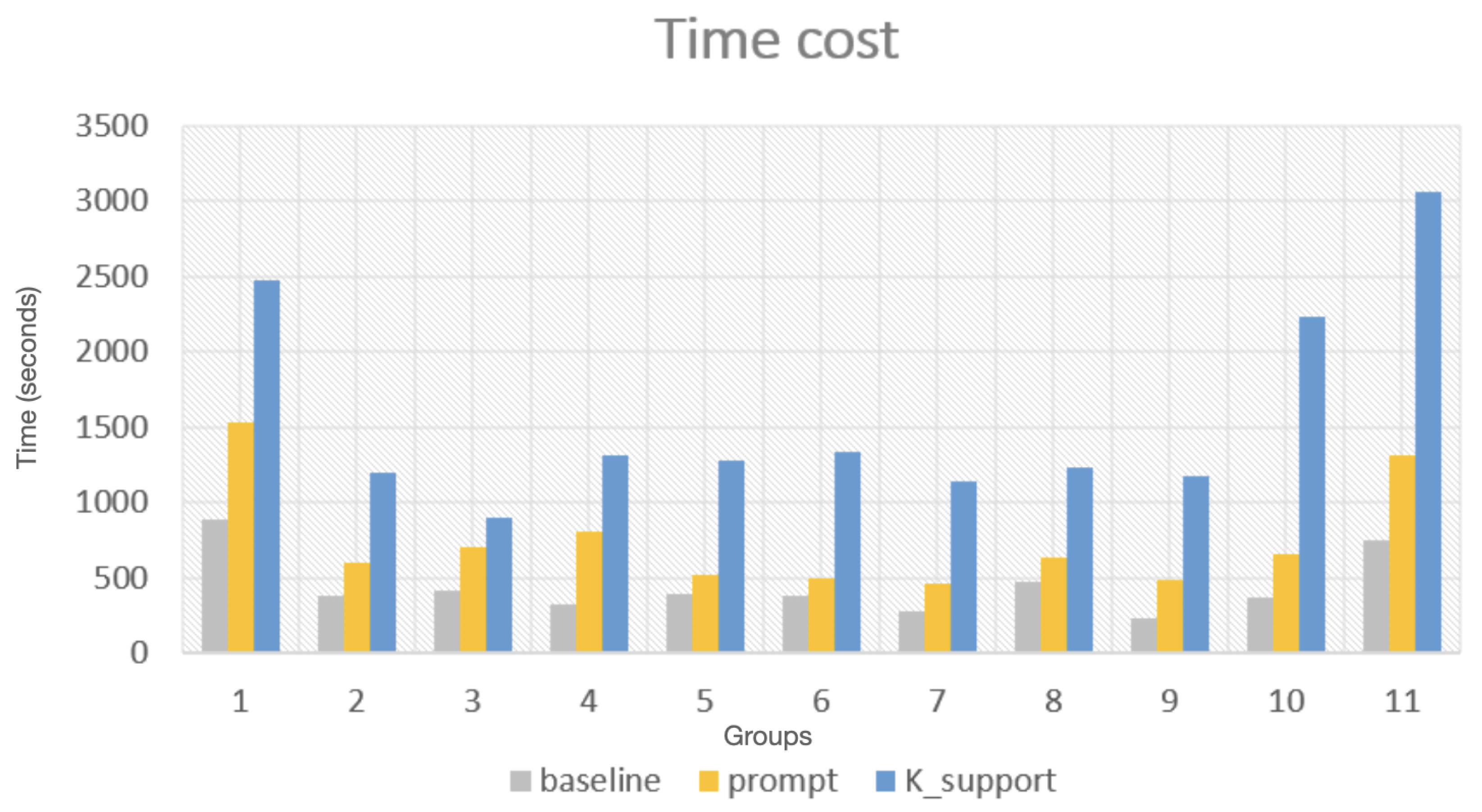
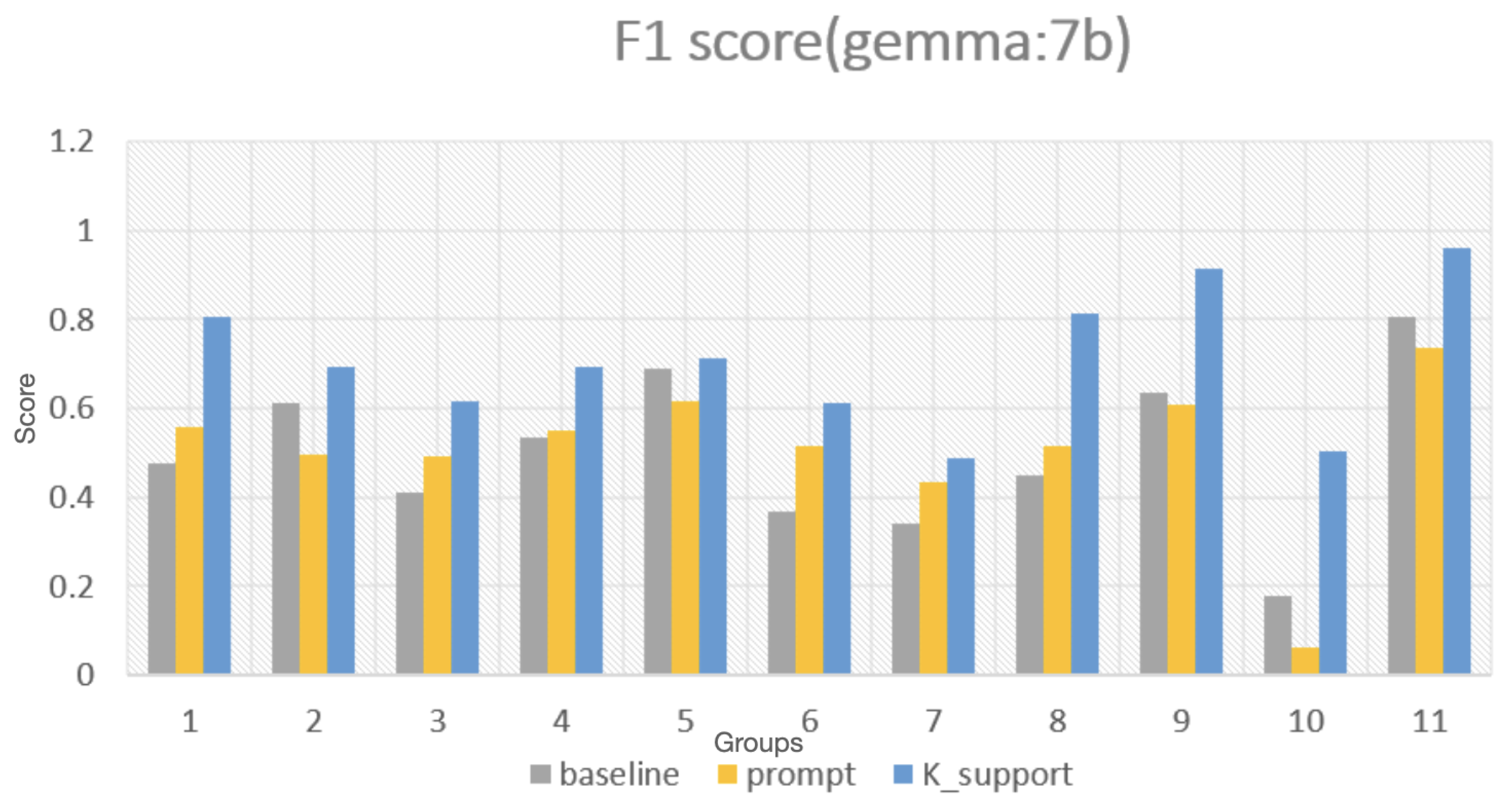
4.1. Test on the Performance of LLMs with Knowledge Support
Improvement with Domain-Specific Knowledge Support
4.2. Test with Customized Knowledge Update
- Data Preparation: Anonymized resume data available online were downloaded and used to simulate student registration processes to initiate the program.
- Personal Knowledge Extraction: The resume and personal information of each student were entered into the system to provide a basic dataset for personalized recommendations.
- Profile and Customized Knowledge Update: The system was tasked with retrieving the most suitable user profile knowledge and relevant domain-specific knowledge (i.e., description of the course module) from the knowledge base. This data were used to prepare a customized learning plan tailored to the individual’s background and interests. All domain-specific knowledge was extracted from relevant literature documents and stored in the system knowledge base. The user could ask the system to extend this customized knowledge by updating more files or inputs at any time.
- Knowledge Integration and Recommendation: Based on domain-specific knowledge and the student profile, the system was requested to generate advice and compile a report detailing possible suggestions for the student.
- Interactive Guidance: Finally, the system interacted with the students to address specific questions and provide contextual guidance based on the generated learning plan.
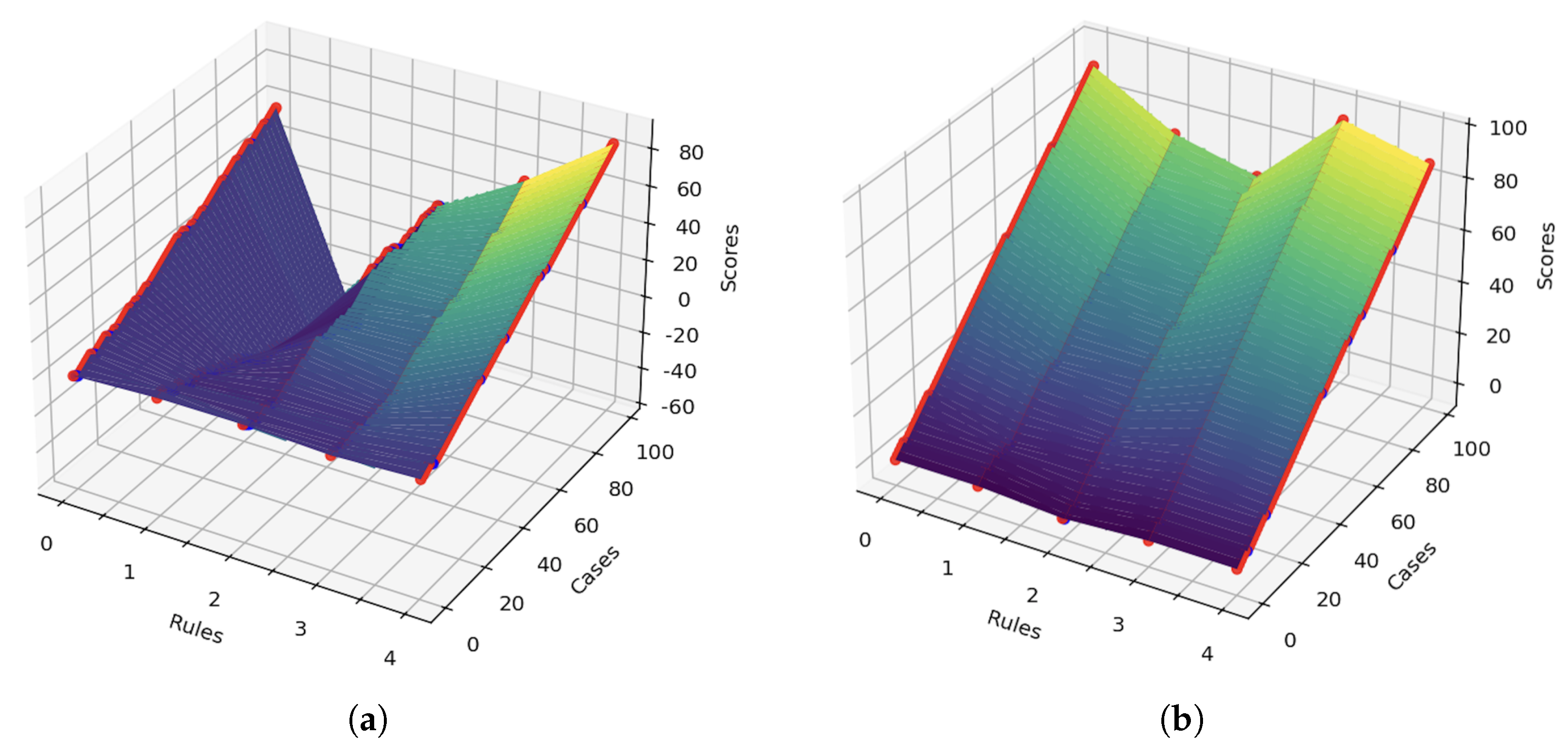
- Rule0: The suggestion should include a recommended reading list.
- –
- Importance: A reading list provides tangible, actionable resources to start learning, and bridges the gap between wanting to study and knowing where to begin. As the curriculum designers suggested, a good reading list is the primary part of a pre-study guide, preventing the guide from remaining vague or overly theoretical.
- –
- Related aspects:
- *
- Aligns resources with the course’s depth and complexity.
- *
- Sets expectations about content difficulty.
- Rule1: The suggestion should explain the prerequisites for studying the course.
- –
- Importance: Prerequisites prevent students from jumping into material they are not ready for. Such a suggestion protects learners from frustration by making sure they are adequately prepared. The instructors hope to use this information to better guide students in self-assessment and to be fully prepared before starting the course.
- –
- Related aspects:
- *
- Guide students to fill knowledge gaps first if needed.
- *
- Supports scaffolded learning, where new knowledge builds on existing understanding.
- Rule2: The suggestion should be of proper length.
- –
- Importance: Length affects clarity and usability. If the suggestion is too short, it might be incomplete or vague. Otherwise, it could overwhelm the reader or bury key points.
- –
- Related aspects:
- *
- Efficient communication.
- *
- Easy to digest.
- *
- Focused on essentials, without filler.
- Rule3: The suggestion should include some custom advice for the applicants.
- –
- Importance: Generic advice may not resonate or be useful for all learners. To provide adaptive learning, the system needs to be able to understand the personal characteristics of each student and provide them with customized advice.
- –
- Related aspects:
- *
- Makes learners feel seen and supported.
- *
- Can address things like learning style, time management, or career goals based on the student’s context.
- *
- Make learning suggestions that are appropriate for the student’s context.
- Rule4: The suggestion should consider the particular information on the personal profile of the given applicants.
- –
- Importance: This ensures that personalization in adaptive learning is based on the particular profiles of the students. This rule aims to examine the knowledge integration between domain-specific knowledge and personal profile knowledge. All features need to be extracted from the correct real user profile and seamlessly adapted to the background of the chosen courses.
- –
- Related aspects:
- *
- Personalized feature extraction
- *
- Knowledge integration
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. The List of Tested Subjects in the Experiments
Appendix A.1. List of Tested Subjects with Different LLMs Across Different Domains

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
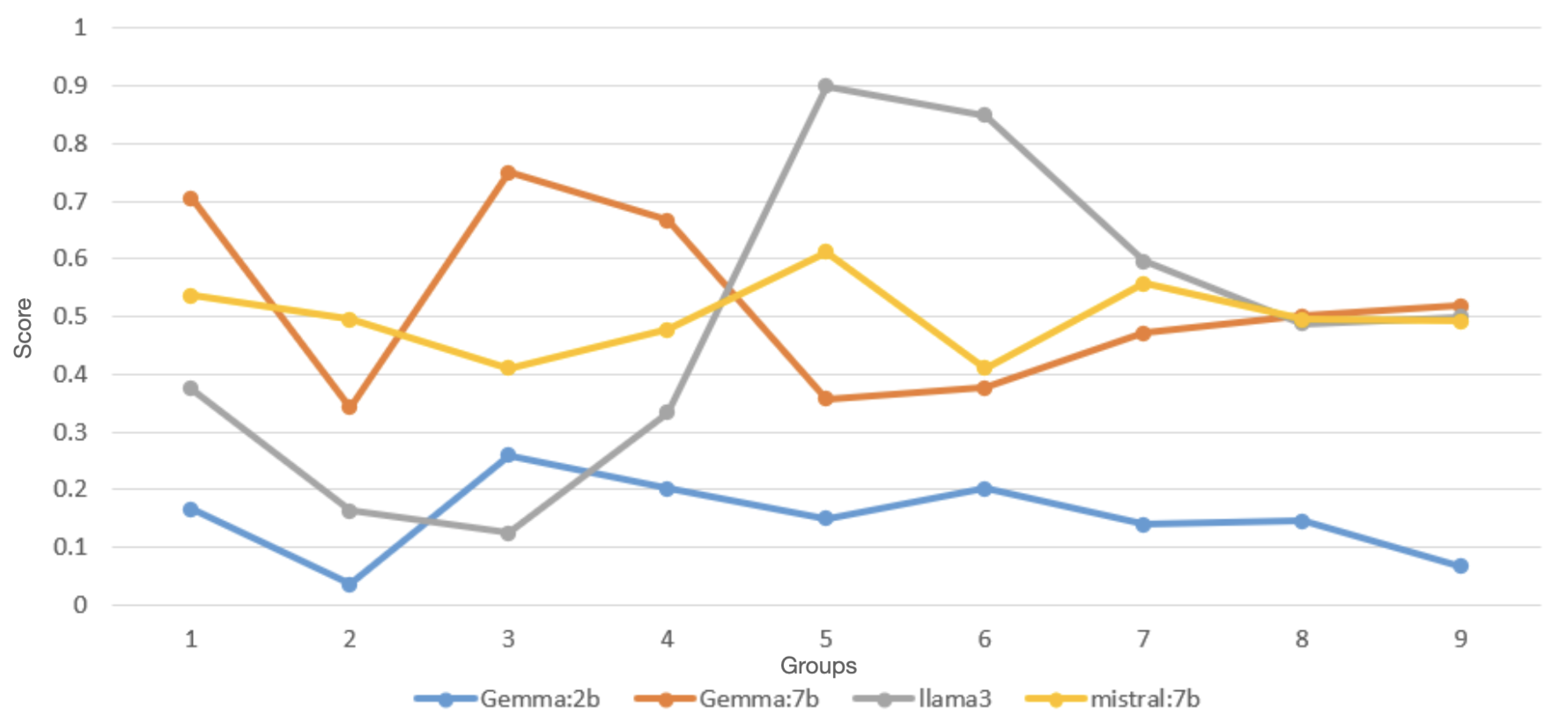
| Subject | Gemma:7b | Mistral:7b | Llama3 | Gemma:2b |
|---|---|---|---|---|
| Politics | 0.71 | 0.53 | 0.38 | 0.17 |
| Chemistry | 0.34 | 0.49 | 0.17 | 0.05 |
| Astronomy | 0.75 | 0.42 | 0.12 | 0.28 |
| History | 0.69 | 0.48 | 0.34 | 0.2 |
| Computer security | 0.36 | 0.62 | 0.89 | 0.15 |
| Global facts | 0.37 | 0.41 | 0.86 | 0.21 |
| Clinical knowledge | 0.47 | 0.56 | 0.59 | 0.14 |
| Geography | 0.50 | 0.50 | 0.49 | 0.15 |
| Medicine | 0.53 | 0.49 | 0.5 | 0.08 |
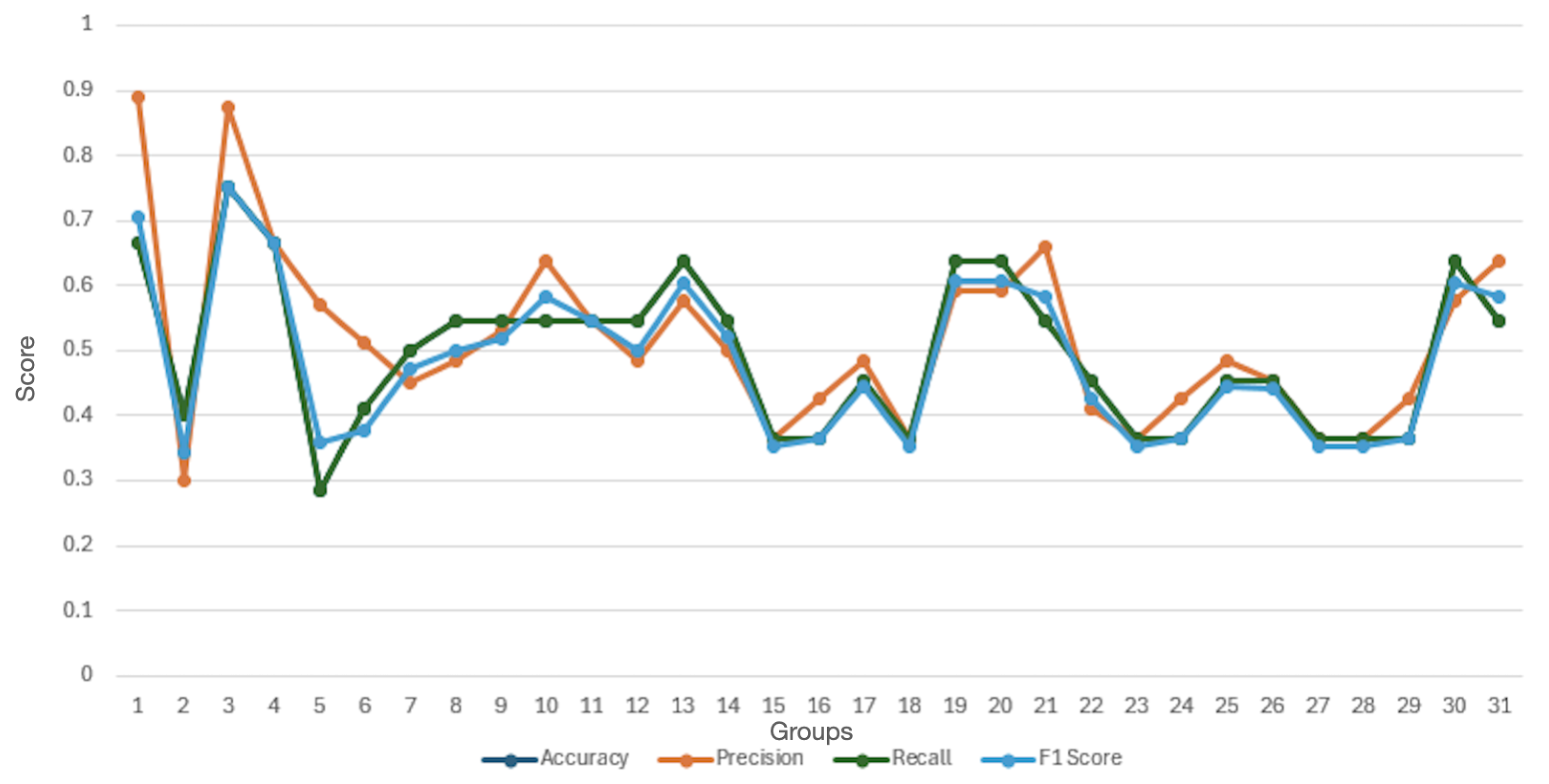
Appendix A.2. List of Tested Subjects with Gemma:7b Across Different Domains
| Subject | F1 Score |
|---|---|
| Politics | 0.71 |
| Chemistry | 0.34 |
| Astronomy | 0.75 |
| History | 0.69 |
| Computer security | 0.36 |
| Global facts | 0.37 |
| Clinical knowledge | 0.47 |
| Geography | 0.50 |
| Medicine | 0.53 |
| Microeconomics | 0.57 |
| Moral disputes | 0.55 |
| Algebra | 0.51 |
| Business ethics | 0.61 |
| Miscellaneous | 0.52 |
| Philosophy | 0.34 |
| Psychology | 0.35 |
| Biology | 0.45 |
| Statistics | 0.34 |
| International law | 0.62 |
| Moral disputes | 0.62 |
| Human aging | 0.59 |
| Anatomy | 0.41 |
| Electrical engineering | 0.35 |
| Logical fallacies | 0.36 |
| Mathematics | 0.47 |
| Human sexuality | 0.46 |
| Virology | 0.35 |
| Accounting | 0.36 |
| Nutrition | 0.37 |
| Moral scenarios | 0.61 |
| Religions | 0.58 |
References
- Xing, M.; Zhang, R.; Xue, H.; Chen, Q.; Yang, F.; Xiao, Z. Understanding the weakness of large language model agents within a complex android environment. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Barcelona, Spain, 25–29 August 2024; pp. 6061–6072. [Google Scholar]
- Uchida, S. Using early LLMs for corpus linguistics: Examining ChatGPT’s potential and limitations. Appl. Corpus Linguist. 2024, 4, 100089. [Google Scholar] [CrossRef]
- Fan, W.; Ding, Y.; Ning, L.; Wang, S.; Li, H.; Yin, D.; Chua, T.S.; Li, Q. A survey on rag meeting llms: Towards retrieval-augmented large language models. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Barcelona, Spain, 25–29 August 2024; pp. 6491–6501. [Google Scholar]
- Wang, H.; Li, Y.F. Large Language Model Empowered by Domain-Specific Knowledge Base for Industrial Equipment Operation and Maintenance. In Proceedings of the 2023 5th International Conference on System Reliability and Safety Engineering (SRSE), Beijing, China, 20–23 October 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 474–479. [Google Scholar]
- Wu, J.; Yang, S.; Zhan, R.; Yuan, Y.; Chao, L.S.; Wong, D.F. A survey on LLM-generated text detection: Necessity, methods, and future directions. Comput. Linguist. 2025, 51, 275–338. [Google Scholar] [CrossRef]
- Hofer, M.; Obraczka, D.; Saeedi, A.; Köpcke, H.; Rahm, E. Construction of Knowledge Graphs: Current State and Challenges. Information 2024, 15, 509. [Google Scholar] [CrossRef]
- Yildirim, I.; Paul, L. From task structures to world models: What do LLMs know? Trends Cogn. Sci. 2024, 28, 404–415. [Google Scholar] [CrossRef]
- Yang, J.; Jin, H.; Tang, R.; Han, X.; Feng, Q.; Jiang, H.; Zhong, S.; Yin, B.; Hu, X. Harnessing the power of llms in practice: A survey on chatgpt and beyond. ACM Trans. Knowl. Discov. Data 2024, 18, 1–32. [Google Scholar] [CrossRef]
- Deng, J.; Zubair, A.; Park, Y.J. Limitations of large language models in medical applications. Postgrad. Med J. 2023, 99, 1298–1299. [Google Scholar] [CrossRef] [PubMed]
- Asher, N.; Bhar, S.; Chaturvedi, A.; Hunter, J.; Paul, S. Limits for Learning with Language Models. In Proceedings of the 12th Joint Conference on Lexical and Computational Semantics (*SEM 2023), Toronto, ON, Canada, 13–14 July 2023. [Google Scholar]
- Pal, S.; Bhattacharya, M.; Lee, S.S.; Chakraborty, C. A domain-specific next-generation large language model (LLM) or ChatGPT is required for biomedical engineering and research. Ann. Biomed. Eng. 2024, 52, 451–454. [Google Scholar] [CrossRef]
- Chen, Z.; Lin, M.; Wang, Z.; Zang, M.; Bai, Y. PreparedLLM: Effective pre-pretraining framework for domain-specific large language models. Big Earth Data 2024, 8, 649–672. [Google Scholar] [CrossRef]
- Li, Y.; Ma, S.; Wang, X.; Huang, S.; Jiang, C.; Zheng, H.T.; Xie, P.; Huang, F.; Jiang, Y. EcomGPT: Instruction-tuning Large Language Model with Chain-of-Task Tasks for E-commerce. arXiv 2023, arXiv:2308.06966. [Google Scholar] [CrossRef]
- Wu, S.; Irsoy, O.; Lu, S.; Dabravolski, V.; Dredze, M.; Gehrmann, S.; Kambadur, P.; Rosenberg, D.; Mann, G. Bloomberggpt: A large language model for finance. arXiv 2023, arXiv:2303.17564. [Google Scholar]
- Nguyen, H.T. A Brief Report on LawGPT 1.0: A Virtual Legal Assistant Based on GPT-3. arXiv 2023, arXiv:2302.05729. [Google Scholar]
- Luo, R.; Sun, L.; Xia, Y.; Qin, T.; Zhang, S.; Poon, H.; Liu, T.Y. BioGPT: Generative pre-trained transformer for biomedical text generation and mining. Briefings Bioinform. 2022, 23, bbac409. [Google Scholar] [CrossRef]
- Venigalla, A.; Frankle, J.; Carbin, M. Biomedlm: A domain-specific large language model for biomedical text. MosaicML 2022, 23, 2. [Google Scholar]
- Deng, C.; Zhang, T.; He, Z.; Chen, Q.; Shi, Y.; Zhou, L.; Fu, L.; Zhang, W.; Wang, X.; Zhou, C.; et al. Learning A Foundation Language Model for Geoscience Knowledge Understanding and Utilization. arXiv 2023, arXiv:2306.05064. [Google Scholar]
- Bi, Z.; Zhang, N.; Xue, Y.; Ou, Y.; Ji, D.; Zheng, G.; Chen, H. Oceangpt: A large language model for ocean science tasks. arXiv 2023, arXiv:2310.02031. [Google Scholar]
- Soman, S.; HG, R. Observations on LLMs for telecom domain: Capabilities and limitations. In Proceedings of the Third International Conference on AI-ML Systems, Bangalore, India, 25–28 October 2023; pp. 1–5. [Google Scholar]
- Pan, S.; Luo, L.; Wang, Y.; Chen, C.; Wang, J.; Wu, X. Unifying large language models and knowledge graphs: A roadmap. IEEE Trans. Knowl. Data Eng. 2024, 36, 3580–3599. [Google Scholar] [CrossRef]
- Siriwardhana, S.; Weerasekera, R.; Wen, E.; Kaluarachchi, T.; Rana, R.; Nanayakkara, S. Improving the domain adaptation of retrieval augmented generation (RAG) models for open domain question answering. Trans. Assoc. Comput. Linguist. 2023, 11, 1–17. [Google Scholar] [CrossRef]
- Amarnath, N.S.; Nagarajan, R. An Intelligent Retrieval Augmented Generation Chatbot for Contextually-Aware Conversations to Guide High School Students. In Proceedings of the 2024 4th International Conference on Sustainable Expert Systems (ICSES), Kaski, Nepal, 15–17 October 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1393–1398. [Google Scholar]
- Ko, H.T.; Liu, Y.K.; Tsai, Y.C.; Suen, S. Enhancing Python Learning Through Retrieval-Augmented Generation: A Theoretical and Applied Innovation in Generative AI Education. In Proceedings of the International Conference on Innovative Technologies and Learning, Tartu, Estonia, 14–16 August 2024; Springer: Cham, Switzerland, 2024; pp. 164–173. [Google Scholar]
- Long, C.; Liu, Y.; Ouyang, C.; Yu, Y. Bailicai: A Domain-Optimized Retrieval-Augmented Generation Framework for Medical Applications. arXiv 2024, arXiv:2407.21055. [Google Scholar]
- Li, Y.; Zhao, J.; Li, M.; Dang, Y.; Yu, E.; Li, J.; Sun, Z.; Hussein, U.; Wen, J.; Abdelhameed, A.M.; et al. RefAI: A GPT-powered retrieval-augmented generative tool for biomedical literature recommendation and summarization. J. Am. Med. Inform. Assoc. 2024, 31, 2030–2039. [Google Scholar] [CrossRef]
- Xu, Z.; Cruz, M.J.; Guevara, M.; Wang, T.; Deshpande, M.; Wang, X.; Li, Z. Retrieval-augmented generation with knowledge graphs for customer service question answering. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, Washington, DC, USA, 14–18 July 2024; pp. 2905–2909. [Google Scholar]
- Halgin, F.; Mohammedand, A.T. Intelligent patent processing: Leveraging retrieval-augmented generation for enhanced consultant services. In Proceedings of the International Symposium on Digital Transformation, Växjö, Sweden, 11–13 September 2024. [Google Scholar]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.t.; Rocktäschel, T.; et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Adv. Neural Inf. Process. Syst. 2020, 33, 9459–9474. [Google Scholar]
- Perković, G.; Drobnjak, A.; Botički, I. Hallucinations in LLMs: Understanding and Addressing Challenges. In Proceedings of the 2024 47th MIPRO ICT and Electronics Convention (MIPRO), Opatija, Croatia, 20–24 May 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 2084–2088. [Google Scholar]
- Ayala, O.; Bechard, P. Reducing hallucination in structured outputs via Retrieval-Augmented Generation. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 6: Industry Track), Mexico City, Mexico, 16–21 June 2024; pp. 228–238. [Google Scholar]
- Peng, C.; Xia, F.; Naseriparsa, M.; Osborne, F. Knowledge graphs: Opportunities and challenges. Artif. Intell. Rev. 2023, 56, 13071–13102. [Google Scholar] [CrossRef]
- Song, Y.; Li, W.; Dai, G.; Shang, X. Advancements in Complex Knowledge Graph Question Answering: A Survey. Electronics 2023, 12, 4395. [Google Scholar] [CrossRef]
- Edge, D.; Trinh, H.; Cheng, N.; Bradley, J.; Chao, A.; Mody, A.; Truitt, S.; Larson, J. From local to global: A graph rag approach to query-focused summarization. arXiv 2024, arXiv:2404.16130. [Google Scholar]
- Meyer, L.P.; Stadler, C.; Frey, J.; Radtke, N.; Junghanns, K.; Meissner, R.; Dziwis, G.; Bulert, K.; Martin, M. Llm-assisted knowledge graph engineering: Experiments with chatgpt. In Proceedings of the Working Conference on Artificial Intelligence Development for a Resilient and Sustainable Tomorrow, Leipzig, Germany, 20–29 June 2023; Springer Fachmedien Wiesbaden: Wiesbaden, Germany, 2023; pp. 103–115. [Google Scholar]
- Zhu, Y.; Wang, X.; Chen, J.; Qiao, S.; Ou, Y.; Yao, Y.; Deng, S.; Chen, H.; Zhang, N. Llms for knowledge graph construction and reasoning: Recent capabilities and future opportunities. World Wide Web 2024, 27, 58. [Google Scholar] [CrossRef]
- Peng, H.; Ma, S.; Spector, J.M. Personalized adaptive learning: An emerging pedagogical approach enabled by a smart learning environment. Smart Learn. Environ. 2019, 6, 1–14. [Google Scholar] [CrossRef]
- Fariani, R.I.; Junus, K.; Santoso, H.B. A systematic literature review on personalised learning in the higher education context. Technol. Knowl. Learn. 2023, 28, 449–476. [Google Scholar] [CrossRef]
- Chen, D.L.; Aaltonen, K.; Lampela, H.; Kujala, J. The Design and Implementation of an Educational Chatbot with Personalized Adaptive Learning Features for Project Management Training. Technol. Knowl. Learn. 2024, 1–26. [Google Scholar] [CrossRef]
- Shin, D.; Shim, Y.; Yu, H.; Lee, S.; Kim, B.; Choi, Y. Saint+: Integrating temporal features for ednet correctness prediction. In Proceedings of the LAK21: 11th International Learning Analytics and Knowledge Conference, Irvine, CA, USA, 12–16 April 2021; pp. 490–496. [Google Scholar]
- Mejeh, M.; Sarbach, L. Co-design: From Understanding to Prototyping an Adaptive Learning Technology to Enhance Self-regulated Learning. Technol. Knowl. Learn. 2024, 1–26. [Google Scholar] [CrossRef]
- Lozano, E.A.; Sánchez-Torres, C.E.; López-Nava, I.H.; Favela, J. An open framework for nonverbal communication in human-robot interaction. In Proceedings of the International Conference on Ubiquitous Computing and Ambient Intelligence, Riviera Maya, Mexico, 28–29 November 2023; Springer: Cham, Switzerland, 2023; pp. 21–32. [Google Scholar]
- Favela, J.; Cruz-Sandoval, D.; Rocha, M.M.d.; Muchaluat-Saade, D.C. Social Robots for Healthcare and Education in Latin America. Commun. ACM 2024, 67, 70–71. [Google Scholar] [CrossRef]
- Ruan, S.; Nie, A.; Steenbergen, W.; He, J.; Zhang, J.; Guo, M.; Liu, Y.; Dang Nguyen, K.; Wang, C.Y.; Ying, R.; et al. Reinforcement learning tutor better supported lower performers in a math task. Mach. Learn. 2024, 113, 3023–3048. [Google Scholar] [CrossRef]
- Kulshreshtha, D.; Shayan, M.; Belfer, R.; Reddy, S.; Serban, I.V.; Kochmar, E. Few-shot question generation for personalized feedback in intelligent tutoring systems. In PAIS 2022; IOS Press: Amsterdam, The Netherlands, 2022; pp. 17–30. [Google Scholar]
- El Fazazi, H.; Elgarej, M.; Qbadou, M.; Mansouri, K. Design of an adaptive e-learning system based on multi-agent approach and reinforcement learning. Eng. Technol. Appl. Sci. Res. 2021, 11, 6637–6644. [Google Scholar] [CrossRef]
- Yekollu, R.K.; Bhimraj Ghuge, T.; Sunil Biradar, S.; Haldikar, S.V.; Farook Mohideen Abdul Kader, O. AI-driven personalized learning paths: Enhancing education through adaptive systems. In Proceedings of the International Conference on Smart data intelligence, Trichy, India, 2–3 February 2024; Springer: Singapore, 2024; pp. 507–517. [Google Scholar]
- Amin, S.; Uddin, M.I.; Alarood, A.A.; Mashwani, W.K.; Alzahrani, A.O.; Alzahrani, H.A. An adaptable and personalized framework for top-N course recommendations in online learning. Sci. Rep. 2024, 14, 10382. [Google Scholar] [CrossRef]
- Bilyalova, A.; Salimova, D.; Zelenina, T. Digital transformation in education. In Proceedings of the Integrated Science in Digital Age: ICIS 2019, Munich, Germany, 15–18 December 2019; Springer: Cham, Switzerland, 2020; pp. 265–276. [Google Scholar]
- Mukul, E.; Büyüközkan, G. Digital transformation in education: A systematic review of education 4.0. Technol. Forecast. Soc. Chang. 2023, 194, 122664. [Google Scholar] [CrossRef]
- Tomás, B.S. Extrinsic and Intrinsic Personalization in the Digital Transformation of Education. J. Ethics High. Educ. 2024, 5, 1–34. [Google Scholar]
- Cantú-Ortiz, F.J.; Galeano Sánchez, N.; Garrido, L.; Terashima-Marin, H.; Brena, R.F. An artificial intelligence educational strategy for the digital transformation. Int. J. Interact. Des. Manuf. 2020, 14, 1195–1209. [Google Scholar] [CrossRef]
- Sun, Q.; Abdourazakou, Y.; Norman, T.J. LearnSmart, adaptive teaching, and student learning effectiveness: An empirical investigation. J. Educ. Bus. 2017, 92, 36–43. [Google Scholar] [CrossRef]
- Martin, F.; Chen, Y.; Moore, R.L.; Westine, C.D. Systematic review of adaptive learning research designs, context, strategies, and technologies from 2009 to 2018. Educ. Technol. Res. Dev. 2020, 68, 1903–1929. [Google Scholar] [CrossRef]
- Xiaoyu, Z.; Tobias, T. Exploring the efficacy of adaptive learning technologies in online education: A longitudinal analysis of student engagement and performance. Int. J. Sci. Eng. Appl. 2023, 12, 28–31. [Google Scholar]
- Hagendorff, T. Deception abilities emerged in large language models. Proc. Natl. Acad. Sci. USA 2024, 121, e2317967121. [Google Scholar] [CrossRef]
- Oruganti, S.; Nirenburg, S.; English, J.; McShane, M. Automating Knowledge Acquisition for Content-Centric Cognitive Agents Using LLMs. In Proceedings of the AAAI Symposium Series, Arlington, VA, USA, 25–27 October 2023; Volume 2, pp. 379–385. [Google Scholar]
- Yao, Y.; González-Vélez, H.; Croitoru, M. Explanatory Dialogues with Active Learning for Rule-based Expertise. In Proceedings of the RuleML+ RR (Companion), Bucharest, Romania, 16–18 September 2024. [Google Scholar]
- Shekhar, S.; Favier, A.; Alami, R.; Croitoru, M. A Knowledge Rich Task Planning Framework for Human-Robot Collaboration. In Proceedings of the International Conference on Innovative Techniques and Applications of Artificial Intelligence, Cambridge, UK, 12–14 December 2023; Springer: Cham, Switzerland, 2023; pp. 259–265. [Google Scholar]
- Dong, Q.; Li, L.; Dai, D.; Zheng, C.; Ma, J.; Li, R.; Xia, H.; Xu, J.; Wu, Z.; Chang, B.; et al. A survey on in-context learning. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Miami, FL, USA, 12–16 November 2024; pp. 1107–1128. [Google Scholar]
- Team, G.; Mesnard, T.; Hardin, C.; Dadashi, R.; Bhupatiraju, S.; Pathak, S.; Sifre, L.; Rivière, M.; Kale, M.S.; Love, J.; et al. Gemma: Open models based on gemini research and technology. arXiv 2024, arXiv:2403.08295. [Google Scholar]
- Meta, A. Llama 3. 2024. Available online: https://llama.meta.com/llama3/ (accessed on 1 November 2024).
- Jiang, A.Q.; Sablayrolles, A.; Mensch, A.; Bamford, C.; Chaplot, D.S.; Casas, D.d.l.; Bressand, F.; Lengyel, G.; Lample, G.; Saulnier, L.; et al. Mistral 7B. arXiv 2023, arXiv:2310.06825. [Google Scholar]
- Hendrycks, D.; Burns, C.; Basart, S.; Zou, A.; Mazeika, M.; Song, D.; Steinhardt, J. Measuring massive multitask language understanding. arXiv 2020, arXiv:2009.03300. [Google Scholar]
- Goutte, C.; Gaussier, E. A probabilistic interpretation of precision, recall and F-score, with implication for evaluation. In Proceedings of the European Conference on Information Retrieval, Santiago de Compostela, Spain, 21–23 March 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 345–359. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019. [Google Scholar]
- Bhawal, S. Resume Dataset. Data Set. 2021. Available online: https://www.kaggle.com/datasets/snehaanbhawal/resume-dataset (accessed on 27 April 2025).
- Grattafiori, A.; Dubey, A.; Jauhri, A.; Pandey, A.; Kadian, A.; Al-Dahle, A.; Letman, A.; Mathur, A.; Schelten, A.; Vaughan, A.; et al. The llama 3 herd of models. arXiv 2024, arXiv:2407.21783. [Google Scholar]

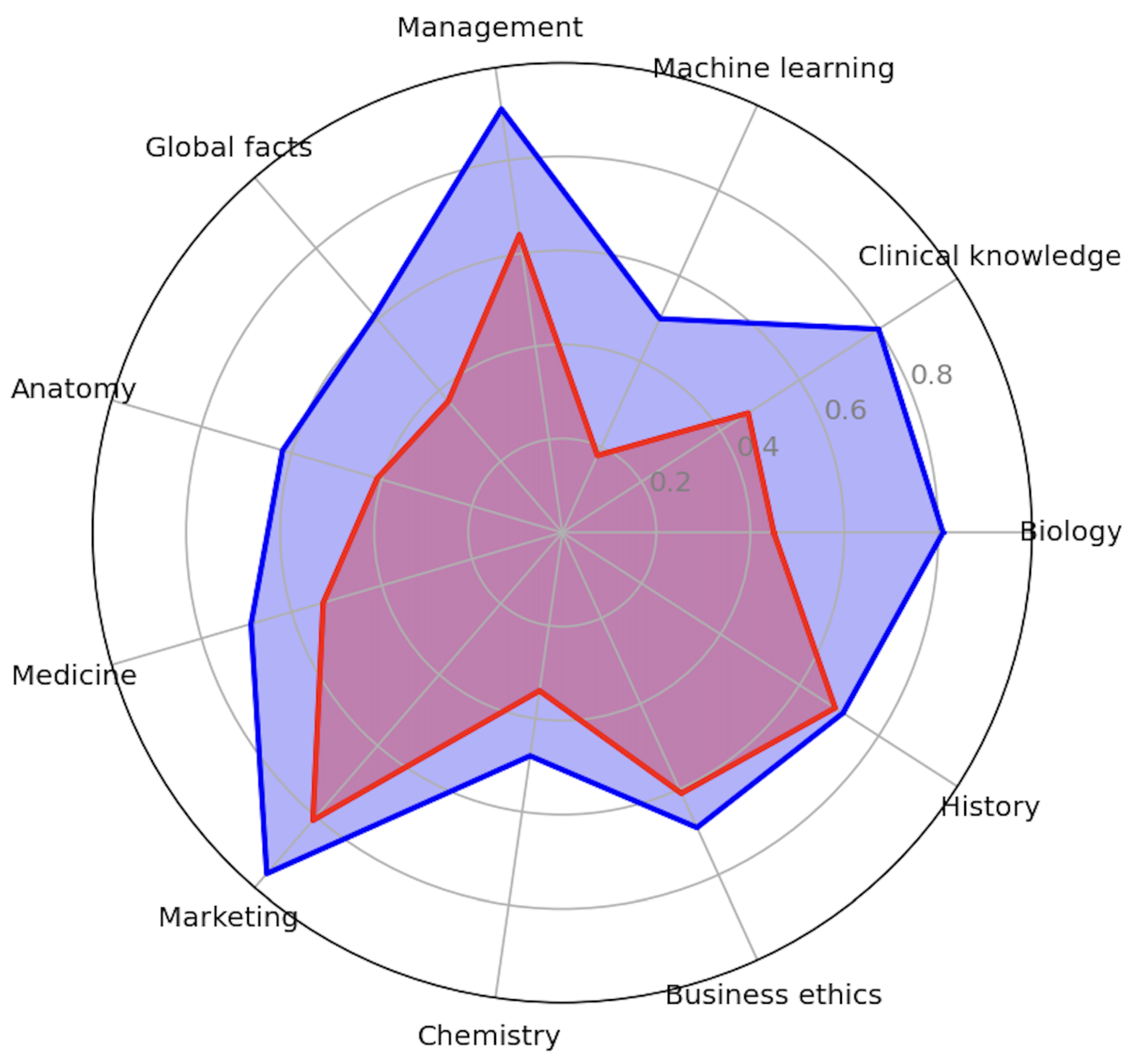

| Domains | Performance | Distance | Improvement % |
|---|---|---|---|
| Biology | 0.81 | 0.36 | 44% |
| Clinical knowledge | 0.80 | 0.33 | 40% |
| Machine learning | 0.50 | 0.32 | 64% |
| Management | 0.91 | 0.27 | 30% |
| Global facts | 0.61 | 0.24 | 39% |
| Anatomy | 0.62 | 0.21 | 33% |
| Medicine | 0.69 | 0.16 | 22% |
| Marketing | 0.96 | 0.15 | 16% |
| Chemistry | 0.48 | 0.14 | 30% |
| Business ethics | 0.69 | 0.08 | 12% |
| History | 0.71 | 0.02 | 3% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, Y.; González-Vélez, H. AI-Powered System to Facilitate Personalized Adaptive Learning in Digital Transformation. Appl. Sci. 2025, 15, 4989. https://doi.org/10.3390/app15094989
Yao Y, González-Vélez H. AI-Powered System to Facilitate Personalized Adaptive Learning in Digital Transformation. Applied Sciences. 2025; 15(9):4989. https://doi.org/10.3390/app15094989
Chicago/Turabian StyleYao, Yao, and Horacio González-Vélez. 2025. "AI-Powered System to Facilitate Personalized Adaptive Learning in Digital Transformation" Applied Sciences 15, no. 9: 4989. https://doi.org/10.3390/app15094989
APA StyleYao, Y., & González-Vélez, H. (2025). AI-Powered System to Facilitate Personalized Adaptive Learning in Digital Transformation. Applied Sciences, 15(9), 4989. https://doi.org/10.3390/app15094989