
SMILE: Segmentation-Based Centroid Matching for Image Rectification via Aligning Epipolar Lines


Abstract
1. Introduction
- Stereo image alignment without a checkerboard: we propose a novel stereo image alignment method that does not require calibration patterns such as checkerboards, enabling more flexible and practical image alignment.
- Object-based epipolar alignment: without prior camera calibration, we utilize object detection and segmentation to identify object pairs and effectively align epipolar lines horizontally based on the centroids of the detected objects.
- Performance evaluation in unstructured capture environments: The image dataset used in this study differs from typical stereo capture environments, as it consists of images taken manually, resulting in irregular Y-coordinate variations. The effectiveness of our approach is verified through various evaluation metrics, including Fundamental Matrix analysis, Y-Disparity, X-Disparity Entropy, SSIM, Feature Matching Accuracy, and Area-based Correlation. Additionally, our method successfully generates disparity maps even for image pairs where disparity map generation was previously unsuccessful, demonstrating its effectiveness.
2. Related Work
2.1. Camera Calibration
2.2. Image Rectification
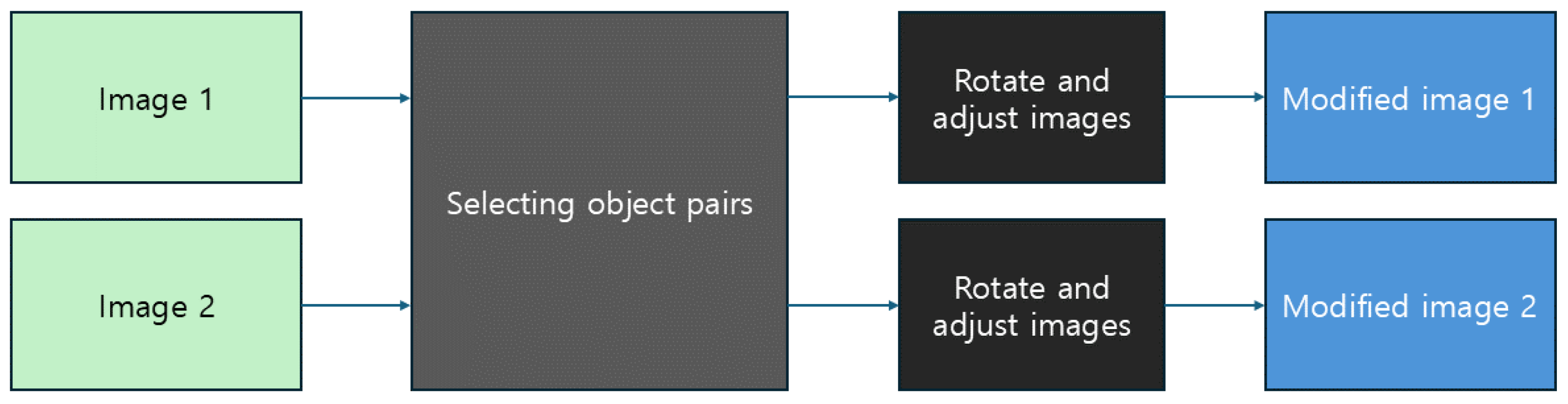
3. Methodology
3.1. Selecting Object Pairs
- The class order of the selected object pair (A, B) in Image 1 must match the class order of the selected object pair (A′, B′) in Image 2. (The classes should match exactly: A = A′, B = B′.)
- The selected object pairs in both images must have the same class and be located in roughly similar positions.
- Among the object pairs that meet the above conditions, the pair that requires the smallest rotation angle to align the centroid coordinates is selected.
| Algorithm 1 Object selection |
Input: Two images and Output: Best matching object pairs
|
3.2. Image Rotation and Adjustment
| Algorithm 2 Image rotation and alignment |
Input: Images , and best matching object pairs Output: Rotated and padded images
|
4. Experiments
4.1. Experimental Environment
4.2. Experimental Procedure and Evaluation Metrics
4.3. Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Scharstein, D.; Szeliski, R. A taxonomy and evaluation of dense two-frame stereo correspondence algorithms. Int. J. Comput. Vis. 2002, 47, 7–42. [Google Scholar] [CrossRef]
- Cao, X.; Foroosh, H. Camera calibration without metric information using 1D objects. In Proceedings of the 2004 International Conference on Image Processing, Singapore, 24–27 October 2004; ICIP’04. IEEE: New York, NY, USA, 2004; Volume 2, pp. 1349–1352. [Google Scholar]
- Zhang, Z. Camera calibration with one-dimensional objects. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 892–899. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef]
- Fusiello, A. Tutorial on Rectification of Stereo Images; University of Udine: Udine, Italy, 1998; Available online: https://www.researchgate.net/publication/2841773_Tutorial_on_Rectification_of_Stereo_Images (accessed on 15 April 2025).
- Li, S.; Cai, Q.; Wu, Y. Segmenting Epipolar Line. In Proceedings of the 2020 13th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Shenyang, China, 17–19 October 2020; IEEE: New York, NY, USA, 2020; pp. 355–359. [Google Scholar]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Hou, X.; Koch, C.; Rehg, J.M.; Yuille, A.L. The secrets of salient object segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 280–287. [Google Scholar]
- Gao, M.; Zheng, F.; Yu, J.J.; Shan, C.; Ding, G.; Han, J. Deep learning for video object segmentation: A review. Artif. Intell. Rev. 2023, 56, 457–531. [Google Scholar] [CrossRef]
- Claus, D.; Fitzgibbon, A.W. A rational function lens distortion model for general cameras. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; IEEE: New York, NY, USA, 2005; Volume 1, pp. 213–219. [Google Scholar]
- Tang, Z.; Von Gioi, R.G.; Monasse, P.; Morel, J.M. A precision analysis of camera distortion models. IEEE Trans. Image Process. 2017, 26, 2694–2704. [Google Scholar] [CrossRef] [PubMed]
- Drap, P.; Lefèvre, J. An exact formula for calculating inverse radial lens distortions. Sensors 2016, 16, 807. [Google Scholar] [CrossRef] [PubMed]
- Fitzgibbon, A.W. Simultaneous linear estimation of multiple view geometry and lens distortion. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; CVPR 2001. IEEE: New York, NY, USA, 2001; Volume 1, pp. I-125–I-132. [Google Scholar]
- Kim, J.; Bae, H.; Lee, S.G. Image distortion and rectification calibration algorithms and validation technique for a stereo camera. Electronics 2021, 10, 339. [Google Scholar] [CrossRef]
- Qi, W.; Li, F.; Zhenzhong, L. Review on camera calibration. In Proceedings of the 2010 Chinese Control and Decision Conference, Xuzhou, China, 26–28 May 2010; IEEE: New York, NY, USA, 2010; pp. 3354–3358. [Google Scholar]
- Gao, Z.; Zhu, M.; Yu, J. A novel camera calibration pattern robust to incomplete pattern projection. IEEE Sens. J. 2021, 21, 10051–10060. [Google Scholar] [CrossRef]
- Tsai, R. A versatile camera calibration technique for high-accuracy 3D machine vision metrology using off-the-shelf TV cameras and lenses. IEEE J. Robot. Autom. 1987, 3, 323–344. [Google Scholar] [CrossRef]
- Heikkila, J.; Silvén, O. A four-step camera calibration procedure with implicit image correction. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Juan, PR, USA, 17–19 June 1997; IEEE: New York, NY, USA, 1997; pp. 1106–1112. [Google Scholar]
- Jin, L.; Zhang, J.; Hold-Geoffroy, Y.; Wang, O.; Blackburn-Matzen, K.; Sticha, M.; Fouhey, D.F. Perspective fields for single image camera calibration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 17307–17316. [Google Scholar]
- Song, X.; Kang, H.; Moteki, A.; Suzuki, G.; Kobayashi, Y.; Tan, Z. MSCC: Multi-Scale Transformers for Camera Calibration. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2024; pp. 3262–3271. [Google Scholar]
- Yuan, K.; Guo, Z.; Wang, Z.J. RGGNet: Tolerance aware LiDAR-camera online calibration with geometric deep learning and generative model. IEEE Robot. Autom. Lett. 2020, 5, 6956–6963. [Google Scholar] [CrossRef]
- Pritts, J.; Chum, O.; Matas, J. Detection, rectification and segmentation of coplanar repeated patterns. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2973–2980. [Google Scholar]
- Papadimitriou, D.V.; Dennis, T.J. Epipolar line estimation and rectification for stereo image pairs. IEEE Trans. Image Process. 1996, 5, 672–676. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A survey of convolutional neural networks: Analysis, applications, and prospects. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 6999–7019. [Google Scholar] [CrossRef] [PubMed]
- Yang, S.; Lin, C.; Liao, K.; Zhang, C.; Zhao, Y. Progressively complementary network for fisheye image rectification using appearance flow. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6348–6357. [Google Scholar]
- Wang, Y.; Lu, Y.; Lu, G. Stereo rectification based on epipolar constrained neural network. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual Event, 6–11 June 2021; IEEE: New York, NY, USA, 2021; pp. 2105–2109. [Google Scholar]
- Liao, Z.; Zhou, W.; Li, H. DaFIR: Distortion-aware Representation Learning for Fisheye Image Rectification. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 7123–7135. [Google Scholar] [CrossRef]
- Hosono, M.; Simo-Serra, E.; Sonoda, T. Self-supervised deep fisheye image rectification approach using coordinate relations. In Proceedings of the 2021 17th International Conference on Machine Vision and Applications (MVA), Nagoya, Japan, 22–25 May 2023; IEEE: New York, NY, USA, 2021; pp. 1–5. [Google Scholar]
- Feng, H.; Liu, S.; Deng, J.; Zhou, W.; Li, H. Deep unrestricted document image rectification. IEEE Trans. Multimed. 2023, 26, 6142–6154. [Google Scholar] [CrossRef]
- Fan, J.; Zhang, J.; Tao, D. Sir: Self-supervised image rectification via seeing the same scene from multiple different lenses. IEEE Trans. Image Process. 2023, 32, 865–877. [Google Scholar] [CrossRef] [PubMed]
- Chao, C.H.; Hsu, P.L.; Lee, H.Y.; Wang, Y.C.F. Self-supervised deep learning for fisheye image rectification. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; IEEE: New York, NY, USA, 2020; pp. 2248–2252. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. Yolov9: Learning what you want to learn using programmable gradient information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Strengths | Limitations |
|---|---|---|
| Traditional Camera Calibration | Accurate estimation of intrinsic/extrinsic parameters using precise patterns | Requires calibration patterns |
| SIFT/SURF | Robust to rotation and scale changes | High computational cost (especially SIFT), not suitable for real time |
| Lightweight feature extractors (e.g., ORB) | Low computational cost, suitable for real-time applications | Lower accuracy and precision compared to SIFT/SURF |
| Deep-learning-based keypoint detection | High performance under various conditions | Requires large-scale training datasets |
| Original | Rectified | ||||
|---|---|---|---|---|---|
| A-1 | A-2 | ||||
| −0.0000 | 0.0000 | −0.0005 | −0.0000 | 0.0000 | −0.0014 |
| −0.0000 | 0.0000 | −0.0135 | −0.0000 | 0.0000 | −0.0096 |
| −0.0003 | 0.0113 | 1.0000 | 0.0009 | 0.0083 | 1.0000 |
| B-1 | B-2 | ||||
| 0.0000 | 0.0003 | −0.1526 | 0.0000 | 0.0000 | −0.0003 |
| −0.0004 | 0.0000 | 1.4253 | −0.0000 | 0.0000 | 0.0203 |
| 0.1797 | −1.4280 | 1.0000 | −0.0009 | −0.0220 | 1.0000 |
| C-1 | C-2 | ||||
| −0.0000 | 0.0006 | 0.0887 | −0.0000 | 0.0000 | 0.0011 |
| −0.0005 | 0.0000 | −2.5343 | −0.0000 | −0.0000 | −0.0373 |
| −0.1114 | 2.4634 | 1.0000 | −0.0019 | 0.0373 | 1.0000 |
| D-1 | D-2 | ||||
| 0.0000 | 0.0000 | −0.0007 | 0.0000 | −0.0000 | 0.0080 |
| −0.0000 | −0.0000 | 0.1133 | 0.0000 | −0.0000 | −0.0448 |
| −0.0004 | −0.1128 | 1.0000 | −0.0085 | 0.0446 | 1.0000 |
| E-1 | E-2 | ||||
| 0.0000 | 0.0000 | −0.0011 | 0.0000 | −0.0000 | 0.0138 |
| −0.0000 | −0.0000 | 0.0085 | −0.0000 | 0.0000 | −0.1716 |
| −0.0002 | −0.0091 | 1.0000 | −0.0015 | 0.1808 | 1.0000 |
| F-1 | F-2 | ||||
| 0.0000 | 0.0002 | −0.1414 | −0.0000 | −0.0000 | 0.0025 |
| −0.0002 | 0.0000 | 0.0004 | 0.0000 | 0.0000 | −0.0160 |
| 0.1346 | −0.0046 | 1.0000 | −0.0028 | 0.0150 | 1.0000 |
| G-1 | G-2 | ||||
| 0.0000 | 0.0000 | −0.0187 | −0.0000 | −0.0000 | 0.0071 |
| −0.0000 | −0.0000 | 0.0766 | 0.0000 | 0.0000 | −0.0313 |
| 0.0166 | −0.0757 | 1.0000 | −0.0057 | 0.0305 | 1.0000 |
| Metric | Original | Proposed |
|---|---|---|
| Y-disparity mean | 34.61 | 24.79 |
| Y-disparity Std | 46.19 | 56.32 |
| X-disparity entropy | 1.31 | 1.31 |
| SSIM | 0.4210 | 0.4412 |
| Feature matching accuracy | 0.2650 | 0.2599 |
| Area-based correlation | 0.3616 | 0.3847 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, J.; Lee, D. SMILE: Segmentation-Based Centroid Matching for Image Rectification via Aligning Epipolar Lines. Appl. Sci. 2025, 15, 4962. https://doi.org/10.3390/app15094962
Choi J, Lee D. SMILE: Segmentation-Based Centroid Matching for Image Rectification via Aligning Epipolar Lines. Applied Sciences. 2025; 15(9):4962. https://doi.org/10.3390/app15094962
Chicago/Turabian StyleChoi, Junewoo, and Deokwoo Lee. 2025. "SMILE: Segmentation-Based Centroid Matching for Image Rectification via Aligning Epipolar Lines" Applied Sciences 15, no. 9: 4962. https://doi.org/10.3390/app15094962
APA StyleChoi, J., & Lee, D. (2025). SMILE: Segmentation-Based Centroid Matching for Image Rectification via Aligning Epipolar Lines. Applied Sciences, 15(9), 4962. https://doi.org/10.3390/app15094962